
Apricot Stone Classification Using Image Analysis and Machine Learning

Abstract
:1. Introduction
2. Materials and Methods
2.1. Materials
2.2. Imaging Systems
2.3. Image Processing
2.4. Statistical Analysis
2.4.1. Classification of Apricot Stones Based on Cultivar
2.4.2. Evaluation of Classification Models
3. Results
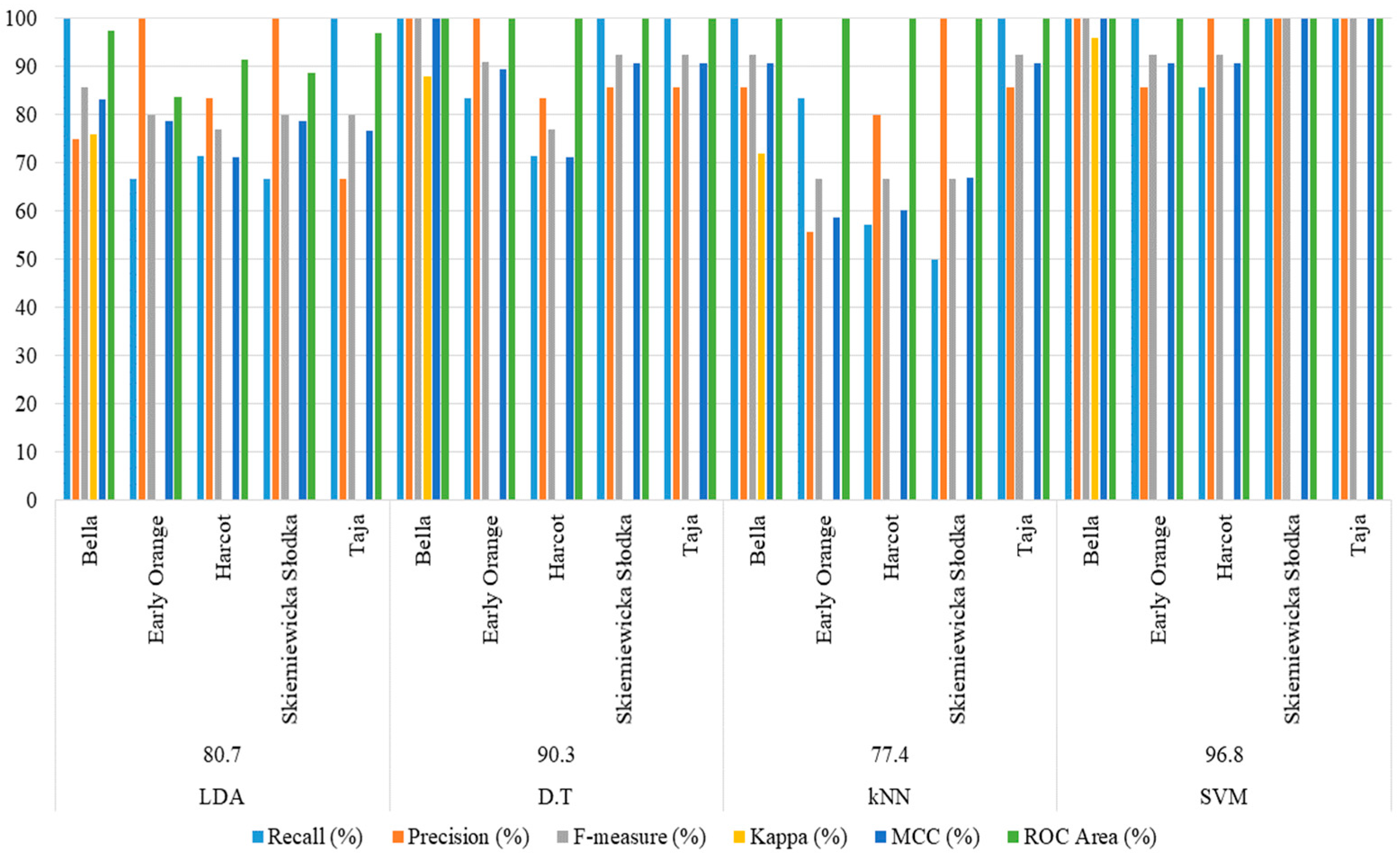
3.1. Classification Results Based on Features from All Colour Channels
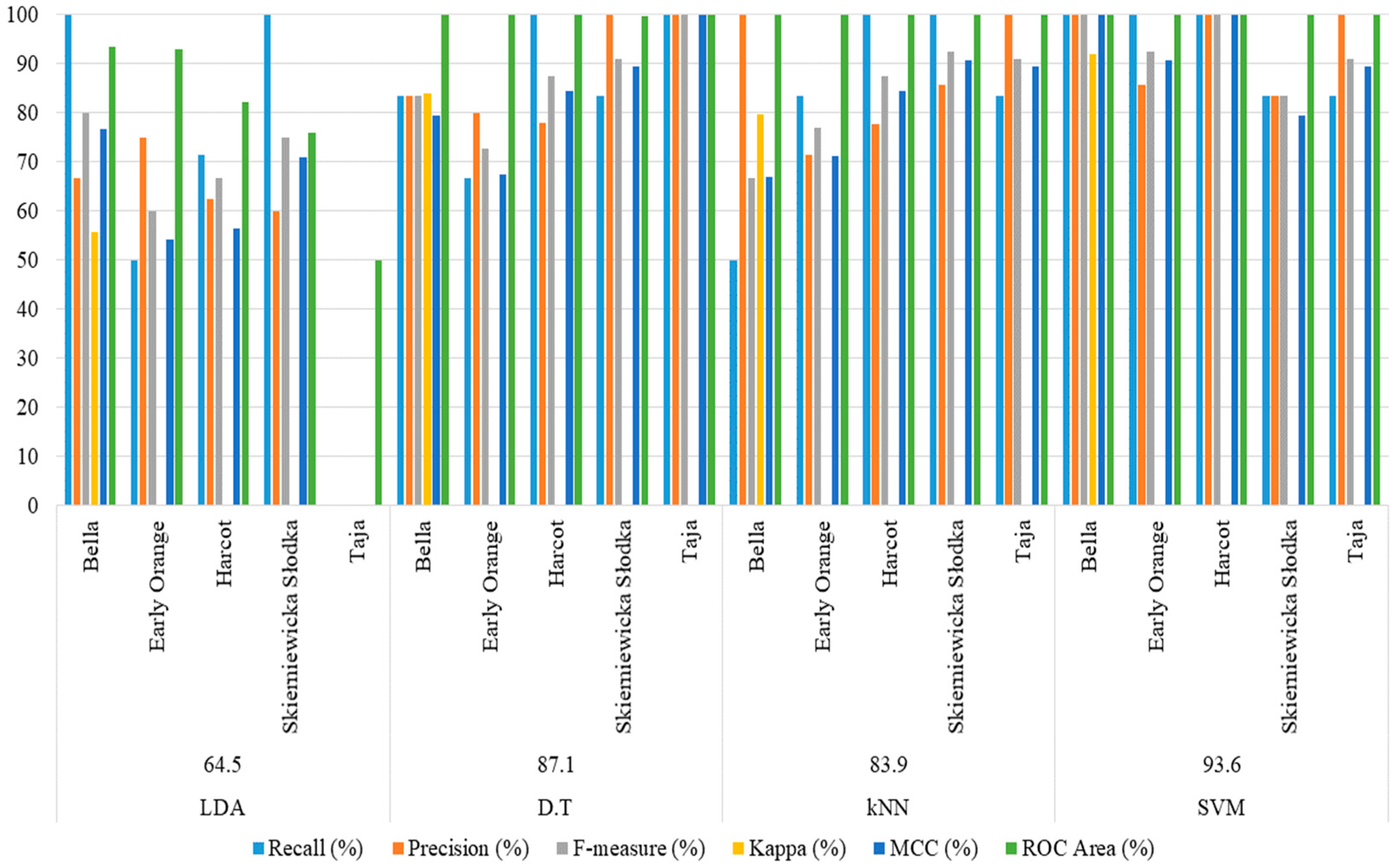
3.2. Classification Results Based on Features from Individual Colour Channels
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- FAOSTAT. Crop and Livestock Product: Apricot. Available online: https://www.fao.org/faostat/en/#data/QCL (accessed on 17 January 2022).
- Featherstone, S. Canning of fruit. In A Complete Course in Canning and Related Processes: Processing Procedures for Canned Food Products; Featherstone, S., Ed.; Woodhead Publishing: Sawston, UK, 2015; Volume 3, pp. 85–134. [Google Scholar]
- Moustafa, K.; Cross, J. Production, pomological and nutraceutical properties of apricot. J. Food Sci. Technol. 2019, 56, 12–23. [Google Scholar] [CrossRef]
- González-García, E.; Marina, M.L.; García, M.C. Apricot. In Valorization of Fruit Processing By-Products; Galanakis, C.M., Ed.; Academic Press: Cambridge, MA, USA, 2019; pp. 43–65. [Google Scholar]
- Özarslan, S.; Atelge, M.R.; Kaya, M.; Ünalan, S. A Novel Tea factory waste metal-free catalyst as promising supercapacitor electrode for hydrogen production and energy storage: A dual functional material. Fuel 2021, 305, 121578. [Google Scholar] [CrossRef]
- Akhone, M.A.; Bains, A.; Tosif, M.M.; Chawla, P.; Fogarasi, M.; Fogarasi, S. Apricot Kernel: Bioactivity, Characterization, Applications, and Health Attributes. Foods 2022, 11, 2184. [Google Scholar] [CrossRef]
- Xi, W.; Lei, Y. Apricot. In Nutritional Composition and Antioxidant Properties of Fruits and Vegetables; Jaiswal, A.K., Ed.; Academic Press: Cambridge, MA, USA, 2020; pp. 613–629. [Google Scholar]
- Gupta, S.; Chhajed, M.; Arora, S.; Thakur, G.; Gupta, R. Medicinal value of apricot: A review. Indian J. Pharm. Sci. 2018, 80, 790–794. [Google Scholar] [CrossRef]
- Karsavuran, N.; Charehsaz, M.; Celik, H.; Asma, B.M.; Yakıncı, C.; Aydın, A. Amygdalin in bitter and sweet seeds of apricots. Toxicol. Environ. Chem. 2014, 96, 1564–1570. [Google Scholar] [CrossRef]
- Ghorab, H.; Lammi, C.; Arnoldi, A.; Kabouche, Z.; Aiello, G. Proteomic analysis of sweet Algerian apricot kernels (Prunus armeniaca L.) by combinatorial peptide ligand libraries and LC–MS/MS. Food Chem. 2018, 239, 935–945. [Google Scholar] [CrossRef]
- Huang, C.; Tang, X.; Liu, Z.; Huang, W.; Ye, Y. Enzymes-dependent antioxidant activity of sweet apricot kernel protein hydrolysates. LWT 2022, 154, 112825. [Google Scholar] [CrossRef]
- de Souza, T.S.; Dias, F.F.; Oliveira, J.P.S.; de Moura Bell, J.M.; Koblitz, M.G.B. Biological properties of almond proteins produced by aqueous and enzyme-assisted aqueous extraction processes from almond cake. Sci. Rep. 2020, 10, 10873. [Google Scholar] [CrossRef] [PubMed]
- Akin, E.B.; Karabulut, I.; Topcu, A. Some compositional properties of main Malatya apricot (Prunus armeniaca L.) varieties. Food Chem. 2008, 107, 939–948. [Google Scholar] [CrossRef]
- Jakubowski, T.; Zdyb, H. Apricot breeding and research in Poland. Acta Hortic. 1995, 384, 251–254. [Google Scholar] [CrossRef]
- Licznar-Malanczuk, M.; Sosna, I. Evaluation of several apricot cultivars and clones in the Lower Silesia climatic condition. Part II: Vigor, health and mortality. J. Fruit Ornam. Plant Res. 2005, 13, 49–57. [Google Scholar]
- Farag, M.A.; Ramadan, N.S.; Shorbagi, M.; Farag, N.; Gad, H.A. Profiling of Primary Metabolites and Volatiles in Apricot (Prunus armeniaca L.) Seed Kernels and Fruits in the Context of Its Different Cultivars and Soil Type as Analyzed Using Chemometric Tools. Foods 2022, 11, 1339. [Google Scholar] [CrossRef] [PubMed]
- Pinder, A.C.; Godfrey, G. Food Process Monitoring Systems; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Sun, D.-W. Computer Vision Technology for Food Quality Evaluation; Academic Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Abdullah, M.Z. Image acquisition systems. In Computer Vision Technology for Food Quality Evaluation; Elsevier: Amsterdam, The Netherlands, 2016; pp. 3–43. [Google Scholar]
- Zou, X.; Zhao, J. Nondestructive Measurement in Food and Agro-Products; Springer: Dordrecht, The Netherlands, 2015. [Google Scholar]
- Patrício, D.I.; Rieder, R. Computer vision and artificial intelligence in precision agriculture for grain crops: A systematic review. Comput. Electron. Agric. 2018, 153, 69–81. [Google Scholar] [CrossRef] [Green Version]
- Jayas, D.; Paliwal, J.; Erkinbaev, C.; Ghosh, P.; Karunakaran, C. Wheat quality evaluation. In Computer Vision Technology for Food Quality Evaluation; Elsevier: Amsterdam, The Netherlands, 2016; pp. 385–412. [Google Scholar]
- Visen, N.; Paliwal, J.; Jayas, D.; White, N. Ae—Automation and emerging technologies: Specialist neural networks for cereal grain classification. Biosyst. Eng. 2002, 82, 151–159. [Google Scholar] [CrossRef]
- Sabanci, K.; Kayabasi, A.; Toktas, A. Computer vision-based method for classification of wheat grains using artificial neural network. J. Sci. Food Agric. 2017, 97, 2588–2593. [Google Scholar] [CrossRef]
- Sun, K.; Wang, Z.; Tu, K.; Wang, S.; Pan, L. Recognition of mould colony on unhulled paddy based on computer vision using conventional machine-learning and deep learning techniques. Sci. Rep. 2016, 6, 37994. [Google Scholar] [CrossRef] [Green Version]
- Qadri, S.; Furqan Qadri, S.; Razzaq, A.; Ul Rehman, M.; Ahmad, N.; Nawaz, S.A.; Saher, N.; Akhtar, N.; Khan, D.M. Classification of canola seed varieties based on multi-feature analysis using computer vision approach. Int. J. Food Prop. 2021, 24, 493–504. [Google Scholar] [CrossRef]
- Ogawa, Y. Quality evaluation of rice. In Computer Vision Technology for Food Quality Evaluation; Elsevier: Amsterdam, The Netherlands, 2016; pp. 413–437. [Google Scholar]
- Symons, S.J.; Shahin, M.A.; Xiong, Z.; Dai, Q.; Sun, D.-W. Quality evaluation of corn/maize. In Computer Vision Technology for Food Quality Evaluation; Elsevier: Amsterdam, The Netherlands, 2016; pp. 439–462. [Google Scholar]
- Ropelewska, E.; Mieszczakowska-Frąc, M.; Kruczyńska, D. The evaluation of the usefulness of textures from cross-section images obtained using a digital camera and a flatbed scanner for cultivar discrimination of quince (Cydonia oblonga Mill.). Food Control 2022, 131, 108447. [Google Scholar] [CrossRef]
- Szczypiński, P.M.; Strzelecki, M.; Materka, A.; Klepaczko, A. MaZda—A software package for image texture analysis. Comput. Methods Programs Biomed. 2009, 94, 66–76. [Google Scholar] [CrossRef] [PubMed]
- Bishop, C.M.; Nasrabadi, N.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4. [Google Scholar]
- Duda, R.O.; Hart, P.E. Pattern Classification; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Brereton, R.G. Chemometrics: Data Analysis for the Laboratory and Chemical Plant; John Wiley & Sons: Hoboken, NJ, USA, 2003. [Google Scholar]
- Abe, S. Support Vector Machines for Pattern Classification; Springer: Berlin/Heidelberg, Germany, 2005; Volume 2. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Practical machine learning tools and techniques. In Data Mining: Practical Machine Learning Tools and Techniques, 3rd ed.; Morgan Kaufmann/Elsevier: Burlington, NJ, USA, 2011. [Google Scholar]
- Ropelewska, E.; Piecko, J. Discrimination of tomato seeds belonging to different cultivars using machine learning. Eur. Food Res. Technol. 2022, 248, 685–705. [Google Scholar] [CrossRef]
- Ropelewska, E.; Szwejda-Grzybowska, J. A comparative analysis of the discrimination of pepper (Capsicum annuum L.) based on the cross-section and seed textures determined using image processing. J. Food Process Eng. 2021, 44, e13694. [Google Scholar] [CrossRef]
- Saito, T.; Rehmsmeier, M. The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PLoS ONE 2015, 10, e0118432. [Google Scholar] [CrossRef] [Green Version]
- Ropelewska, E. Diversity of plum stones based on image texture parameters and machine learning algorithms. Agronomy 2022, 12, 762. [Google Scholar] [CrossRef]
- Ropelewska, E.; Cai, X.; Zhang, Z.; Sabanci, K.; Aslan, M.F. Benchmarking Machine Learning Approaches to Evaluate the Cultivar Differentiation of Plum (Prunus domestica L.) Kernels. Agriculture 2022, 12, 285. [Google Scholar] [CrossRef]
- Sarigu, M.; Grillo, O.; Bianco, M.L.; Ucchesu, M.; d’Hallewin, G.; Loi, M.C.; Venora, G.; Bacchetta, G. Phenotypic identification of plum varieties (Prunus domestica L.) by endocarps morpho-colorimetric and textural descriptors. Comput. Electron. Agric. 2017, 136, 25–30. [Google Scholar] [CrossRef]
- Depypere, L.; Chaerle, P.; Mijnsbrugge, K.V.; Goetghebeur, P. Stony endocarp dimension and shape variation in Prunus section Prunus. Ann. Bot. 2007, 100, 1585–1597. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Frigau, L.; Antoch, J.; Bacchetta, G.; Sarigu, M.; Ucchesu, M.; Zaratin Alves, C.; Mola, F. A statistical approach to the morphological classification of Prunus sp. seeds. Plant Biosyst. Int. J. Deal. All Asp. Plant Biol. 2020, 154, 877–886. [Google Scholar] [CrossRef]
- Ropelewska, E.; Sabanci, K.; Aslan, M.F.; Azizi, A. A Novel Approach to the Authentication of Apricot Seed Cultivars Using Innovative Models Based on Image Texture Parameters. Horticulturae 2022, 8, 431. [Google Scholar] [CrossRef]
- Ropelewska, E.; Rutkowski, K.P. Differentiation of peach cultivars by image analysis based on the skin, flesh, stone and seed textures. Eur. Food Res. Technol. 2021, 247, 2371–2377. [Google Scholar] [CrossRef]
- Moretzsohn, F. Digital imaging: Flatbed scanners and digital cameras. In The Mollusks: A Guide to Their Study, Collection, and Preservation; Universal Publishers: Boca Raton, FL, USA, 2006; pp. 59–71. [Google Scholar]
- Blasco, J.; Garcia, E.M.; Sun, D.-W.; ZHENG, C. Vision Systems. In Optical Monitoring of Fresh and Processed Agricultural Crops; Zude, M., Ed.; CRC Press: Boca Raton, FL, USA, 2008; pp. 83–140. [Google Scholar]
- Gunduz, O.; Ceyhan, V.; Erol, E.; Ozkaraman, F. An Evaluation of farm Level Sustainability of Apricot Farms in Malatya Province of Turkey. J. Food Agric. Environ. 2011, 9, 700–705. [Google Scholar]
- Kousar, R.; Makhdum, M.S.A.; Abbas, A.; Nasir, J.; Naseer, M.A.u.R. Issues and Impacts of the Apricot Value Chain on the Upland Farmers in the Himalayan Range of Pakistan. Sustainability 2019, 11, 4482. [Google Scholar] [CrossRef] [Green Version]
- Karatas, N. Evaluation of Nutritional Content in Wild Apricot Fruits for Sustainable Apricot Production. Sustainability 2022, 14, 1063. [Google Scholar] [CrossRef]
- Rampáčková, E.; Göttingerová, M.; Gála, P.; Kiss, T.; Ercişli, S.; Nečas, T. Evaluation of Protein and Antioxidant Content in Apricot Kernels as a Sustainable Additional Source of Nutrition. Sustainability 2021, 13, 4742. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | All Features | Selected Features | ||
|---|---|---|---|---|
| Training (%) | Testing (%) | Training (%) | Testing (%) | |
| LDA-Linear | 97.85 | 87.10 | 97.85 | 77.42 |
| LDA-Diagonal | 87.10 | 83.87 | 98.92 | 90.30 |
| Quadratic Diagonal | 90.32 | 80.65 | 97.85 | 93.55 |
| Decision Trees | 96.77 | 90.32 | 98.92 | 90.32 |
| kNN | 97.85 | 77.42 | 98.92 | 87.10 |
| SVM | 97.85 | 96.77 | 97.85 | 96.77 |
| Algorithm | All Features | Selected Features | ||
|---|---|---|---|---|
| Training (%) | Testing (%) | Training (%) | Testing (%) | |
| LDA-Linear | 97.85 | 87.10 | 95.70 | 93.55 |
| LDA-Diagonal | 81.72 | 67.74 | 96.77 | 96.77 |
| Quadratic Diagonal | 69.89 | 64.52 | 98.92 | 100 |
| Decision Trees | 95.70 | 90.32 | 97.85 | 87.10 |
| kNN | 94.62 | 87.10 | 100 | 100 |
| SVM | 100 | 93.55 | 100 | 96.77 |
| Colour Channel L | Colour Channel a | Colour Channel b |
|---|---|---|
| LHMean LHPerc50 LHPerc90 LHPerc99 LHDomn01 LHDomn10 LS5SV3SumEntrp LS5SV5SumOfSqs LS5SZ5InvDfMom LS5SZ5Entropy LS5SN5AngScMom LS5SN5InvDfMom LS4RHRLNonUni | aHMean aHSkewness aHKurtosis aHPerc01 aHPerc10 aHPerc90 aHDomn01 aHDomn10 aSGMean aSGSkewness aSGNonZeros aS5SZ1SumOfSqs aS5SV3SumEntrp aS5SH5Contrast aS5SH5InvDfMom aS5SH5DifEntrp aS5SZ5InvDfMom aS5SN5AngScMom aS5SN5InvDfMom aS4RVGLevNonU aS4RZGLevNonU aATeta2 aASigma | bHMean bHSkewness bHPerc01 bHPerc10 bHPerc50 bHPerc90 bHDomn01 bHDomn10 bSGNonZeros bSGPerc01 bS5SV1DifVarnc bS5SZ3Entropy bS5SH5InvDfMom bS5SZ5Contrast bS5SN5InvDfMom |
| Colour Channel L | Colour Channel a | Colour Channel b |
|---|---|---|
| LHMean LHPerc10 LHPerc90 LHPerc99 LSGArea LSGNonZeros LS4RHShrtREmp LATeta1 LATeta2 LATeta4 | aHMean aHSkewness aHKurtosis aHPerc01 aHPerc10 aHPerc50 aHDomn01 aHMaxm10 aHDomn10 aSGSkewness aSGKurtosis aS5SZ1Correlat aS5SZ3DifEntrp aS4RHGLevNonU aS4RHLngREmph aS4RVRLNonUni aATeta2 aATeta4 | bHMean bHSkewness bHPerc01 bHPerc10 bHPerc90 bHPerc99 bSGArea bSGSkewness bSGKurtosis bATeta2 bATeta4 |
| Algorithm | Selected Features (L*) | Selected Features (a*) | Selected Features (b*) | |||
|---|---|---|---|---|---|---|
| Training (%) | Testing (%) | Training (%) | Testing (%) | Training (%) | Testing (%) | |
| LDA-Linear | 86.02 | 80.06 | 93.55 | 83.87 | 90.32 | 80.65 |
| LDA-Diagonal | 72.04 | 67.74 | 81.72 | 83.87 | 82.8 | 83.87 |
| Quadratic diagonal | 74.19 | 67.74 | 84.95 | 83.87 | 83.97 | 83.87 |
| Decision Trees | 79.57 | 64.52 | 89.25 | 67.74 | 90.32 | 87.10 |
| kNN | 92.47 | 67.74 | 94.62 | 71.97 | 93.55 | 83.87 |
| SVM | 86.02 | 80.65 | 96.77 | 80.65 | 93.55 | 87.10 |
| Algorithm | Selected Features (L*) | Selected Features (a*) | Selected Features (b*) | |||
|---|---|---|---|---|---|---|
| Training (%) | Testing (%) | Training (%) | Testing (%) | Training (%) | Testing (%) | |
| LDA-Linear | 92.47 | 83.87 | 96.77 | 80.65 | 89.25 | 77.42 |
| LDA-Diagonal | 86.02 | 87.10 | 86.02 | 80.65 | 82.80 | 80.65 |
| Quadratic diagonal | 88.17 | 87.10 | 91.40 | 90.32 | 84.95 | 80.65 |
| Decision Trees | 90.32 | 74.19 | 95.70 | 74.19 | 88.17 | 67.74 |
| kNN | 97.85 | 83.87 | 100 | 83.87 | 95.70 | 70.97 |
| SVM | 94.62 | 83.87 | 95.70 | 83.87 | 93.55 | 67.74 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ropelewska, E.; Rady, A.M.; Watson, N.J. Apricot Stone Classification Using Image Analysis and Machine Learning. Sustainability 2023, 15, 9259. https://doi.org/10.3390/su15129259
Ropelewska E, Rady AM, Watson NJ. Apricot Stone Classification Using Image Analysis and Machine Learning. Sustainability. 2023; 15(12):9259. https://doi.org/10.3390/su15129259
Chicago/Turabian StyleRopelewska, Ewa, Ahmed M. Rady, and Nicholas J. Watson. 2023. "Apricot Stone Classification Using Image Analysis and Machine Learning" Sustainability 15, no. 12: 9259. https://doi.org/10.3390/su15129259