

Short-Term Traffic Congestion Prediction Using Hybrid Deep Learning Technique
Abstract
:1. Introduction
- We proposed a hybrid Xception—support vector machine (XPSVM) classifier model to predict STTC every 5 min over 1 h.
- We propose the Xception classifier, which uses separable convolution, ReLU, and convolution techniques to predict feature congestion based on a traffic dataset.
- We propose an SVM classifier that uses maximum marginal separations to predict the output in a more accurate way using the weight regularization technique. We conducted in-depth tests using urban road congestion data to explore the reliability of the proposed model.
2. Literature Review
3. Materials and Methods
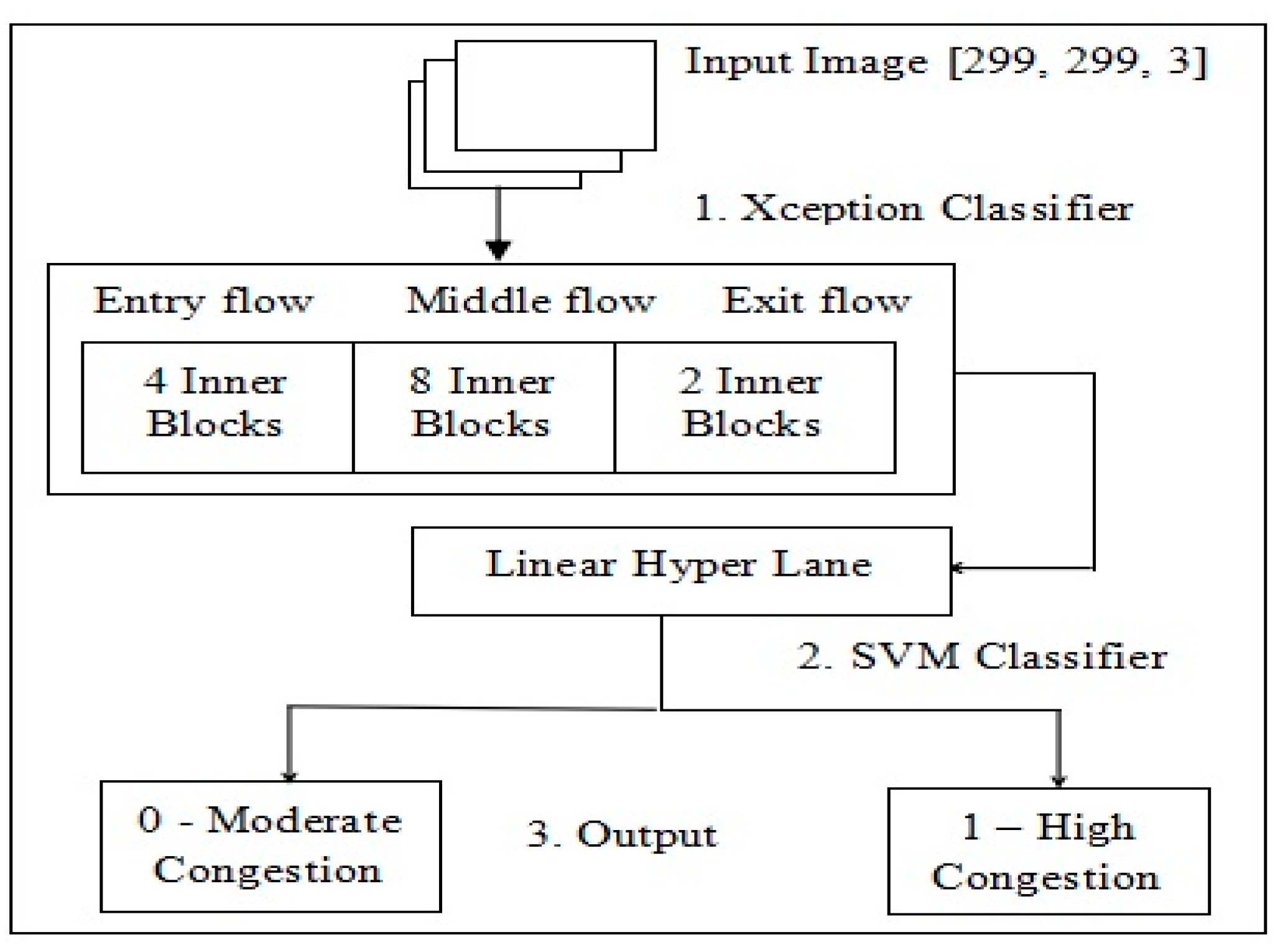
3.1. XPSVM Method
3.2. Xception Classifier
3.3. Support Vector Machine Classifier
- c—is a vector normal to the hyperplane,
- y—is the input vector, and
- d—is the offset.
3.3.1. Dot Product in SVM
- —is a vector
- —is a vector and
- a—is the decision boundary.
3.3.2. L2 Regularization
- C—is the regularized cost function,
- C0—is the unregularized cost function,
- γ—is the regularization parameter,
- n—is the number of features, and
- —is the weight.
3.3.3. Cost Function and Gradient Updates
- C—is the cost function,
- x—is the input vector,
- y—is the true class, and
- f(x)—is the output of SVM given input x.
4. Implementation
| Algorithm 1 Algorithm of XPSVM |
| (A) Xception: 1. Create imagedatagenerator to load image data from the train directory with batch size as 32 or 64, class mode as “categorial” and each image in 2D Array [299, 299]. 2. Similarly, create imagedatagenerator to load image data from test directory with batch size as 32 or 64, class mode as “categorial” and each image in 2D Array [299, 299]. 3. Create a sequential model with hidden layers as per the architecture of Xception or create the instance of in built trained Xception Model using keras (using this in-built model). 4. Disable already trained 14 blocks (layers) of Xception. 5. Pop out the default output layers of Xception model to add the custom output layers. 6. Add the fully connected (output) layers. 6.1 Add the flatten layer. 6.2. Add 3 dense layers with neuron as 200, 100, 50, and activation function as “relu”. NOTE: reason to choose only 3 dense. Sol: optimum number of output layers to the chosen image data is 3, which are tested using keras tuner frame work. (B) SVM: (Supervised Linear Regressor). 7. Add another dense layer with: 7.1 Neurons—2 because we have two classifications (moderate and high congestion). 7.2 Kernel regularizes—keras regularizes l2 with value as 0.001 (it can be customized, but 0.001 was giving best accuracy). 7.3 Activation functions—linear (reason: the problem statement is binary classification). 8. Compile the created XceptionSVM Model with: 8.1 Optimizer function—Adam 8.2 Loss function—categorical hinge (due to binary classification, we use loss function). 9. Train or fit the XceptionSVM model for 150 Epochs and capture the loss, accuracy values of each epoch of training, validation images. |
- Hardware: i7 Processor, 16 GB RAM, Graphics processing unit (GPU).
- Software: macOS Catalina, Python 3.10.5, API-Keras.
5. Experiments and Results Analysis
5.1. Data Description
5.2. Performance Evaluation or Validation
5.3. Results Analysis and Discussion
- The proposed model best fits to linear and nonlinear map images because of its optimizer, the SVM classifier, which uses the L2 regularization technique, which is not present in the compared algorithms, and it also outperforms other algorithms in terms of training speed, fewer parameters (less memory consumption), weight sharing, and error rates.
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Marfia, G.; Roccetti, M.; Amoroso, A. A new traffic congestion prediction model for advanced traveler information and management systems. Wirel. Commun. Mob. Comput. 2013, 13, 266–276. [Google Scholar] [CrossRef]
- Alisoltani, N.; Leclercq, L.; Zargayouna, M. Can dynamic ride-sharing reduce traffic congestion? Transp. Res. Part B Methodol. 2021, 145, 212–246. [Google Scholar] [CrossRef]
- Nguyen, D.B.; Dow, C.R.; Hwang, S.F. An efficient traffic congestion monitoring system on internet of vehicles. Wirel. Commun. Mob. Comput. 2018, 2018, 9136813. [Google Scholar] [CrossRef]
- Rempe, F.; Huber, G.; Bogenberger, K. Spatio-Temporal congestion patterns in urban traffic networks. Transp. Res. Procedia 2016, 15, 513–524. [Google Scholar] [CrossRef] [Green Version]
- Lee, W.H.; Tseng, S.S.; Shieh, J.L.; Chen, H.H. Discovering traffic bottlenecks in an urban network by spatiotemporal data mining on location-based services. IEEE Trans. Intell. Transp. Syst. 2011, 12, 1047–1056. [Google Scholar] [CrossRef]
- Tomtom Traffic Index. Available online: https://www.tomtom.com/traffic-index/ (accessed on 3 November 2022).
- World Health Organization. Global Status Report on Road Safety 2015; World Health Organization: Geneva, Switzerland, 2015. [Google Scholar]
- Practical Guide to Ensemble Learning. Available online: https://towardsdatascience.com/practical-guide-to-ensemble-learning-d34c74e022a0 (accessed on 14 September 2022).
- Ermagun, A.; Levinson, D. Spatiotemporal traffic forecasting: Review and proposed directions. Transp. Rev. 2018, 38, 786–814. [Google Scholar] [CrossRef]
- Smith, B.L.; Williams, B.M.; Oswald, R.K. Comparison of parametric and nonparametric models for traffic flow forecasting. Transp. Res. Part C Emerg. Technol. 2002, 10, 303–321. [Google Scholar] [CrossRef]
- Sukode, S.; Gite, S. Vehicle traffic congestion control & monitoring system in IoT. Int. J. Appl. Eng. Res. 2015, 10, 19513–19523. [Google Scholar]
- Gramaglia, M.; Calderon, M.; Bernardos, C.J. ABEONA monitored traffic: VANET assisted cooperative traffic congestion forecasting. IEEE Veh. Technol. Mag. 2014, 9, 50–57. [Google Scholar]
- Wen, F.; Zhang, G.; Sun, L.; Wang, X.; Xu, X. A hybrid temporal association rules mining method for traffic congestion prediction. Comput. Ind. Eng. 2019, 130, 779–787. [Google Scholar] [CrossRef]
- Ranjan, N.; Bhandari, S.; Zhao, H.P.; Kim, H.; Khan, P. City-wide traffic congestion prediction based on CNN, LSTM and transpose CNN. IEEE Access 2020, 8, 81606–81620. [Google Scholar] [CrossRef]
- Tseng, F.H.; Hsueh, J.H.; Tseng, C.W.; Yang, Y.T.; Chao, H.C.; Chou, L.D. Congestion prediction with big data for real-time highway traffic. IEEE Access 2018, 6, 57311–57323. [Google Scholar] [CrossRef]
- Zhang, S.; Yao, Y.; Hu, J.; Zhao, Y.; Li, S.; Hu, J. Deep auto encoder neural networks for short-term traffic congestion prediction of transportation networks. Sensors 2019, 19, 2229. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chakraborty, P.; Adu-Gyamfi, Y.O.; Poddar, S.; Ahsani, V.; Sharma, A.; Sarkar, S. Traffic congestion detection from camera images using deep convolution neural networks. Transp. Res. Rec. 2018, 2672, 222–231. [Google Scholar] [CrossRef] [Green Version]
- Nagy, A.M.; Simon, V. Improving traffic prediction using congestion propagation patterns in smart cities. Adv. Eng. Inform. 2021, 50, 101343. [Google Scholar] [CrossRef]
- Elfar, A.; Talebpour, A.; Mahmassani, H.S. Machine learning approach to short-term traffic congestion prediction in a connected environment. Transp. Res. Rec. 2018, 2672, 185–195. [Google Scholar] [CrossRef]
- Li, T.; Ni, A.; Zhang, C.; Xiao, G.; Gao, L. Short-term traffic congestion prediction with Conv—BiLSTM considering spatio-temporal features. IET Intell. Transp. Syst. 2020, 14, 1978–1986. [Google Scholar] [CrossRef]
- Chen, M.; Yu, X.; Liu, Y. PCNN: Deep convolutional networks for short-term traffic congestion prediction. IEEE Trans. Intell. Transp. Syst. 2018, 19, 3550–3559. [Google Scholar] [CrossRef] [Green Version]
- Ma, X.; Yu, H.; Wang, Y.; Wang, Y. Large-scale transportation network congestion evolution prediction using deep learning theory. PLoS ONE 2015, 10, e0119044. [Google Scholar] [CrossRef]
- Song, J.; Zhao, C.; Zhong, S.; Nielsen, T.A.S.; Prishchepov, A.V. Mapping spatio-temporal patterns and detecting the factors of traffic congestion with multi-source data fusion and mining techniques. Comput. Environ. Urban Syst. 2019, 77, 101364. [Google Scholar] [CrossRef]
- Gollapalli, M.; Musleh, D.; Ibrahim, N.; Khan, M.A.; Abbas, S.; Atta, A.; Khan, M.A.; Farooqui, M.; Iqbal, T.; Ahmed, M.S.; et al. A neuro-fuzzy approach to road traffic congestion prediction. Comput. Mater. Contin. 2022, 73, 295–310. [Google Scholar] [CrossRef]
- Liu, L.; Lian, M.; Lu, C.; Zhang, S.; Liu, R.; Xiong, N.N. TCSA: A Traffic Congestion Situation Assessment Scheme Based on Multi-Index Fuzzy Comprehensive Evaluation in 5G-IoV. Electronics 2022, 11, 1032. [Google Scholar] [CrossRef]
- Bokaba, T.; Doorsamy, W.; Paul, B.S. A Comparative Study of Ensemble Models for Predicting Road Traffic Congestion. Appl. Sci. 2022, 12, 1337. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Support Vector Machine—Introduction to Machine Learning Algorithms. Available online: https://towardsdatascience.com/support-vector-machine-introduction-to-machine-learning-algorithms-934a444fca47 (accessed on 14 September 2022).
- Everything you should know about Confusion Matrix for Machine Learning. Available online: https://www.analyticsvidhya.com/blog/2020/04/confusion-matrix-machine-learning/ (accessed on 14 September 2022).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Input Values | Best Parameter Values |
|---|---|---|
| Epochs | 10, 15, 20, 25, 30, 35, 40 | 25 |
| Hidden Layers | 14, 28, 42 | 14 |
| Neurons in hidden layer | 10, 15, 20, 25, 30 | 10 |
| Dense layers | 3, 6, 9, 12, 15 | 3 |
| 1st dense layer neurons | 200, 300, 400 | 200 |
| 2nd dense layer neurons | 100, 200, 300 | 100 |
| 3rd dense layer neurons | 50, 100, 150 | 50 |
| Dense layers activation functions | relu, sigmoid, softmax, softplus, tanh, exponential | Relu |
| Kernel regularizer | L1,L2 | L1 |
| L2 regularizer weights | 0.1, 0.01, 0.001 | 0.001 |
| Loss functions | categorical hinge, categorical, categorical cross entropy | categorical hinge |
| Optimizer | adam, adadelta, sgd, adamax, nadam | Adam |
| Parameters | Values |
|---|---|
| Input Parameters | 3D Array with Size as (299, 299, 3) |
| Epochs | 25 |
| Flatten layers | 1 |
| Separableconvolution layers | 34 |
| Convolution layers | 6 |
| Maxpooling layers | 4 |
| Dense layers (fully connected layer) | 3 |
| Neurons in each dense layer | 200, 100, 50 Successively |
| Loss function | categorical hinge marginal loss function |
| Activation function | relu activation |
| Optimizer | Adam |
| Parameters | Values |
|---|---|
| Input parameters | 3D array with size as (x, x, 50) where x is >=1 |
| Output parameters | 2 (high congestion and low congestion) |
| Epochs | 25 |
| Regularizer | L2 weight regularizer |
| Regularizer variable weight | 0.01 to 0.001 |
| Kernel function | linear because output variables are two |
| Marginal planes | two, one each for two output variables |
| Precision (%) | Recall (%) | F1 Score (%) | |
|---|---|---|---|
| Proposed Model | 98.21 | 98.8 | 98.5 |
| Xception | 96.4 | 97.6 | 97.5 |
| Inception | 95.82 | 97.2 | 96.5 |
| Resnet | 95.14 | 96.76 | 95.8 |
| Vgg16 | 94.06 | 96.04 | 95.02 |
| MobileNet | 93.7 | 95.8 | 97.7 |
| Algorithm | Training | Testing | ||
|---|---|---|---|---|
| Type 1 Error | Type 2 Error | Type 1 Error | Type 2 Error | |
| MobileNet | 6.3 | 4.2 | 5.5 | 3.3 |
| VGG16 | 5.9 | 3.9 | 4.8 | 2.9 |
| ResNet101 | 4.8 | 3.2 | 3.7 | 2.3 |
| InceptionV3 | 4.1 | 2.8 | 3.2 | 1.8 |
| Xception | 3.5 | 2.4 | 2.6 | 1.5 |
| Proposed model | 1.8 | 1.2 | 0.95 | 0.5 |
| Algorithm | Accuracy |
|---|---|
| Proposed Model | 97.16 |
| Xception | 94.01 |
| InceptionV3 | 93.04 |
| ResNet101 | 91.9 |
| VGG16 | 90.1 |
| MobileNet | 89.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Anjaneyulu, M.; Kubendiran, M. Short-Term Traffic Congestion Prediction Using Hybrid Deep Learning Technique. Sustainability 2023, 15, 74. https://doi.org/10.3390/su15010074
Anjaneyulu M, Kubendiran M. Short-Term Traffic Congestion Prediction Using Hybrid Deep Learning Technique. Sustainability. 2023; 15(1):74. https://doi.org/10.3390/su15010074
Chicago/Turabian StyleAnjaneyulu, Mohandu, and Mohan Kubendiran. 2023. "Short-Term Traffic Congestion Prediction Using Hybrid Deep Learning Technique" Sustainability 15, no. 1: 74. https://doi.org/10.3390/su15010074