
Predicting Determinants of Lifelong Learning Intention Using Gradient Boosting Machine (GBM) with Grid Search



Abstract
:1. Introduction
2. Methods
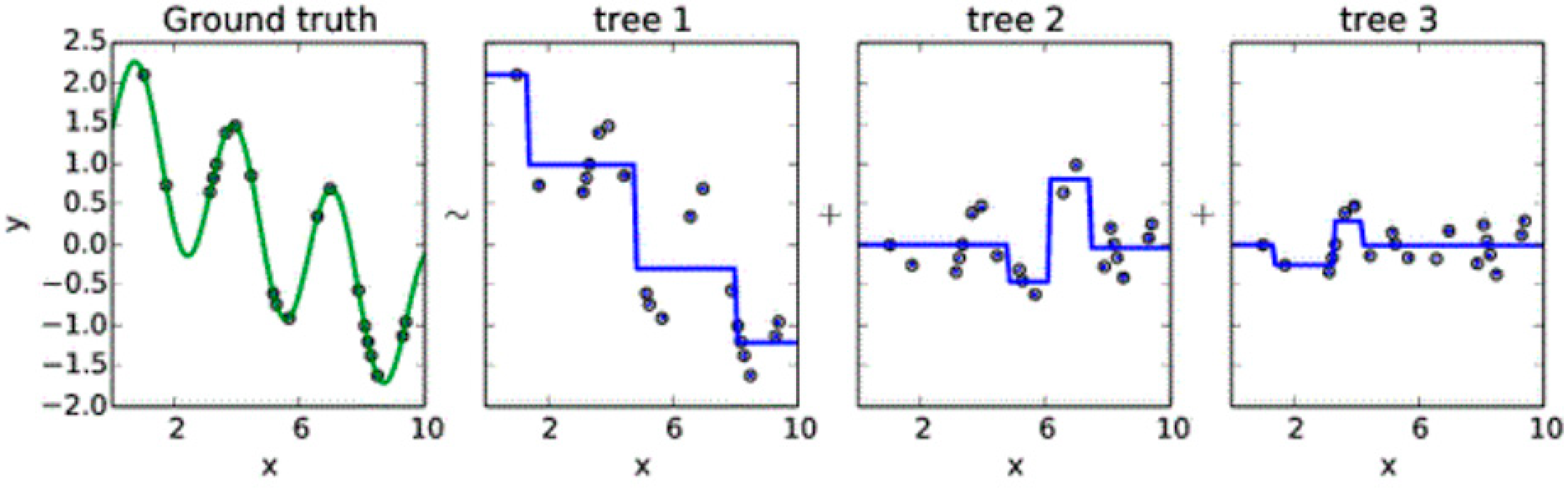
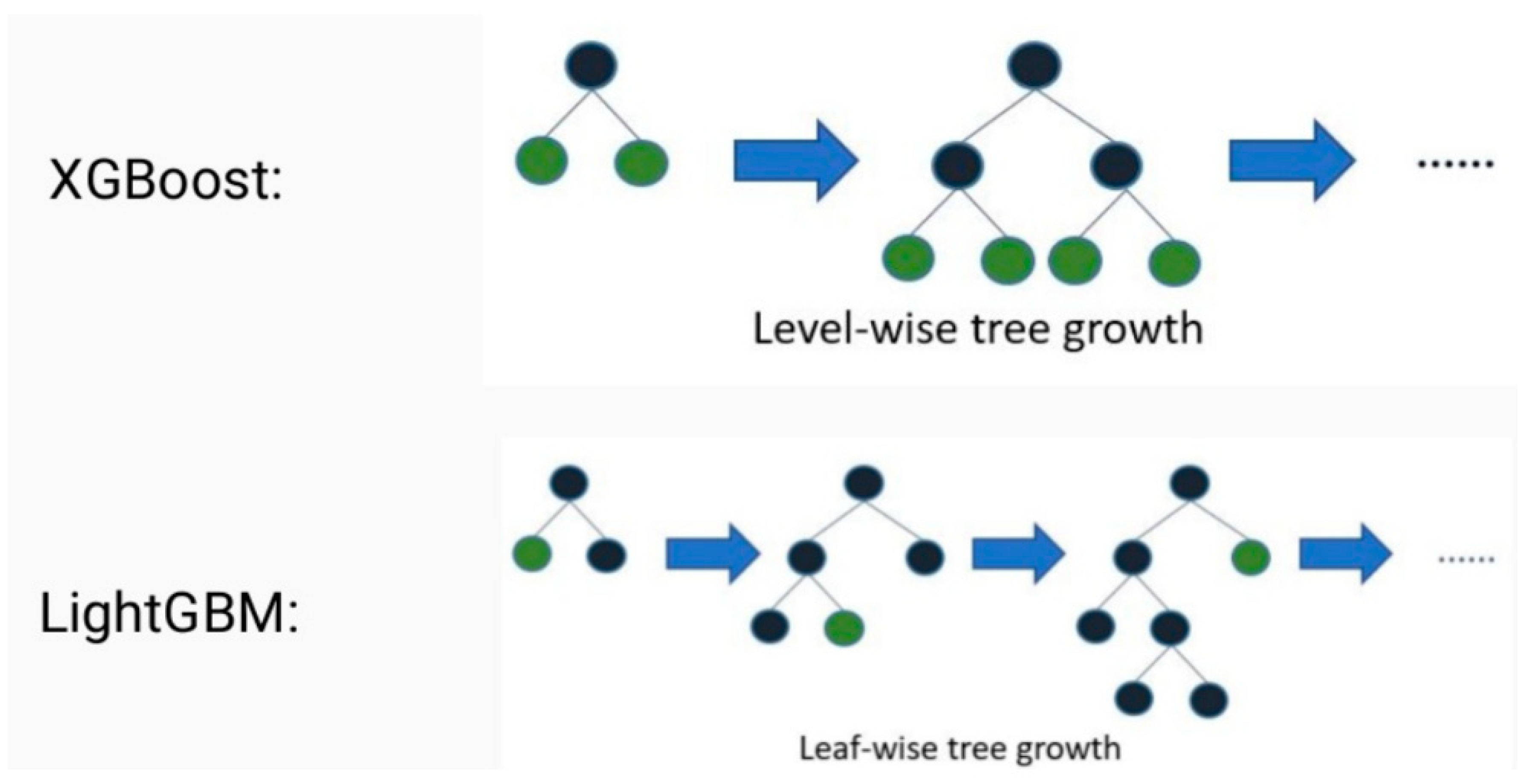
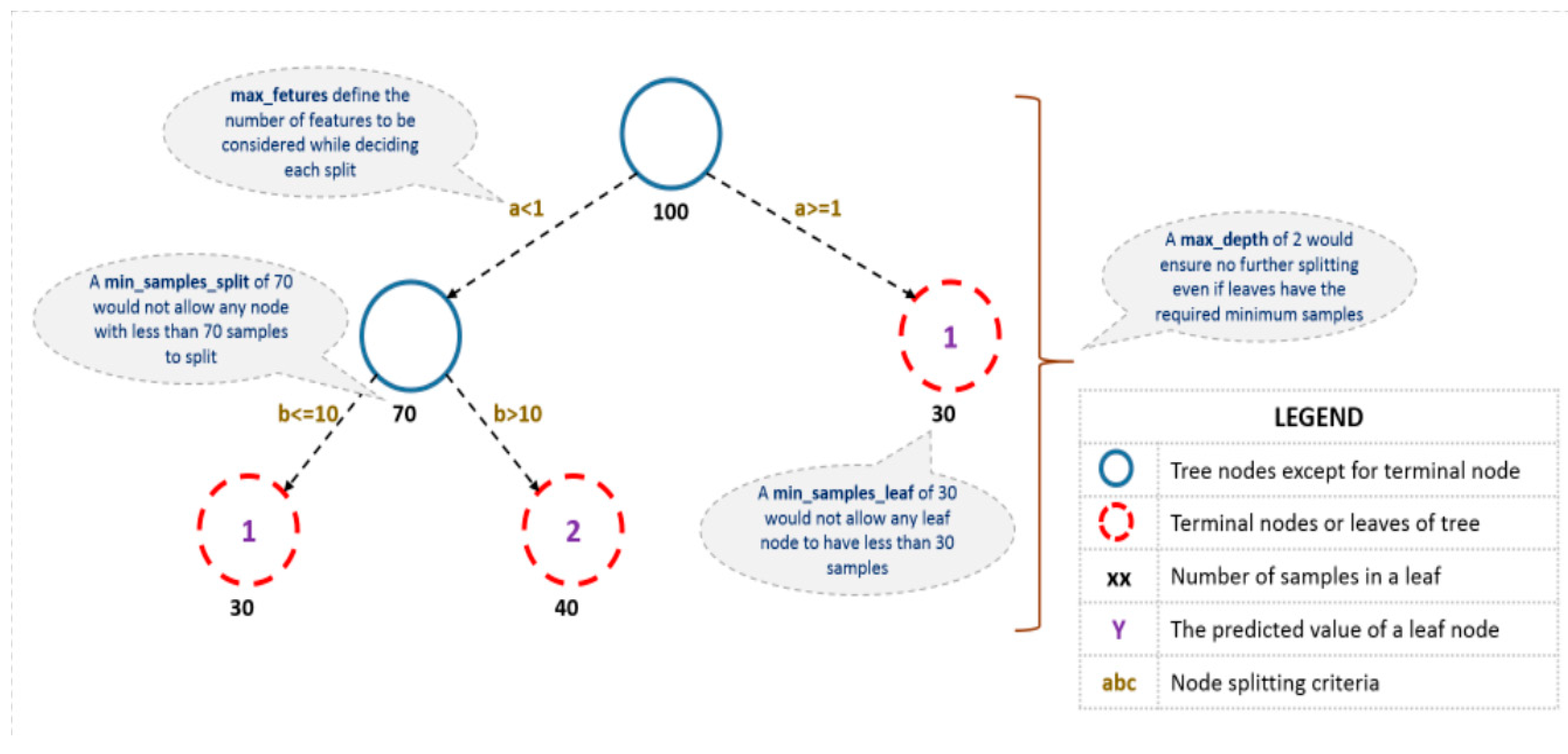
2.1. Boosting-Based Machine Learning
2.2. Proposed Method
3. Results
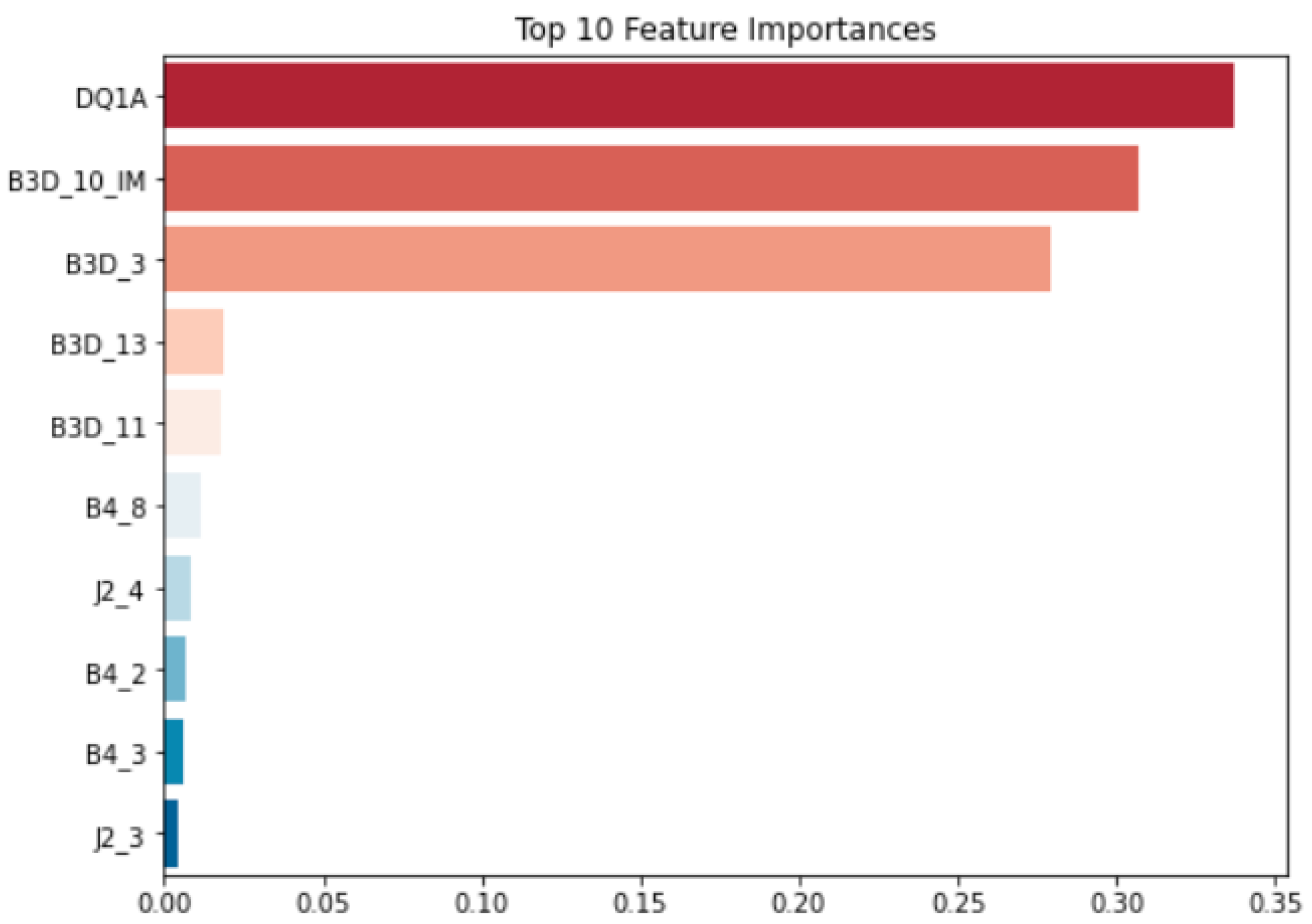
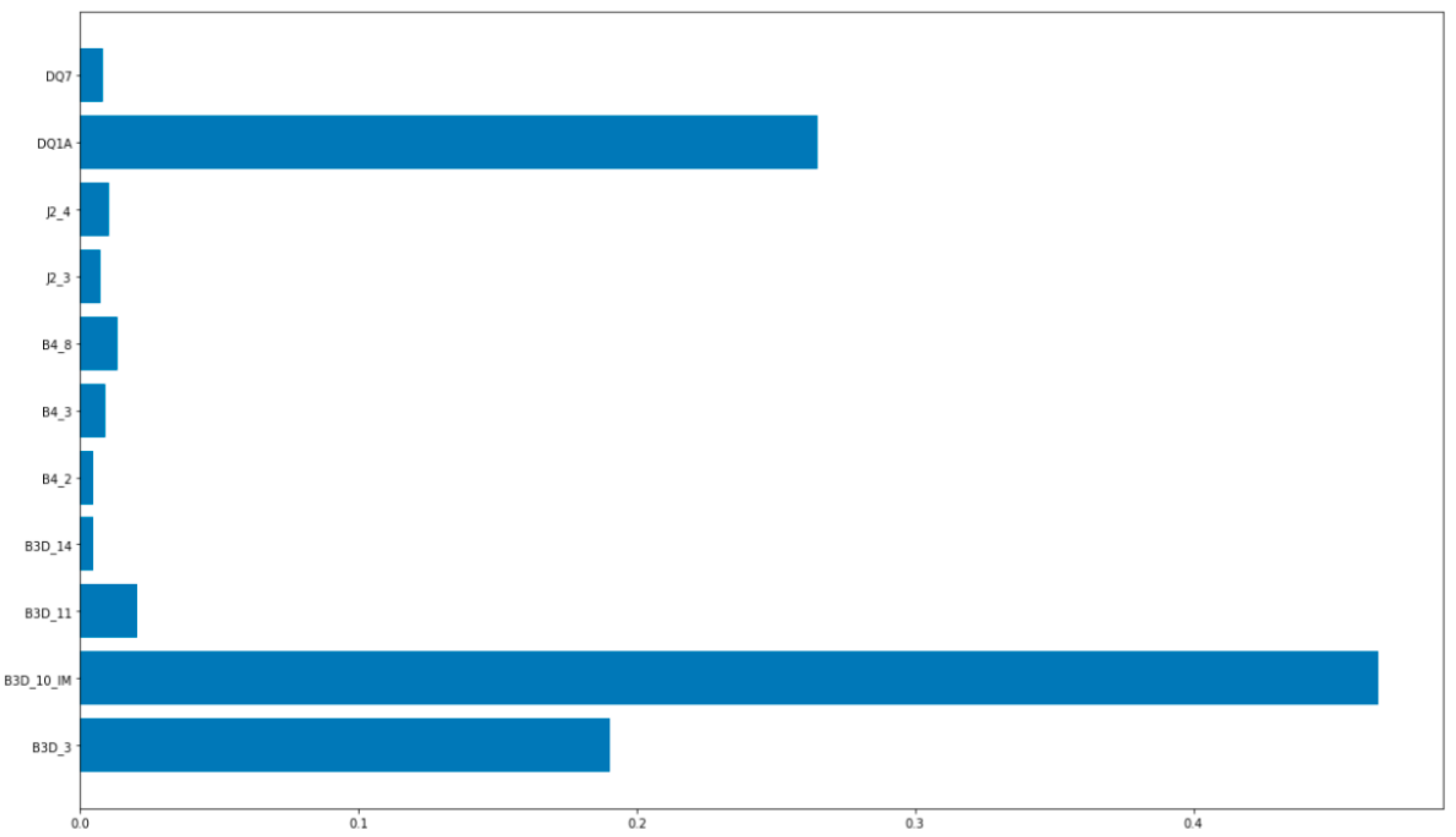
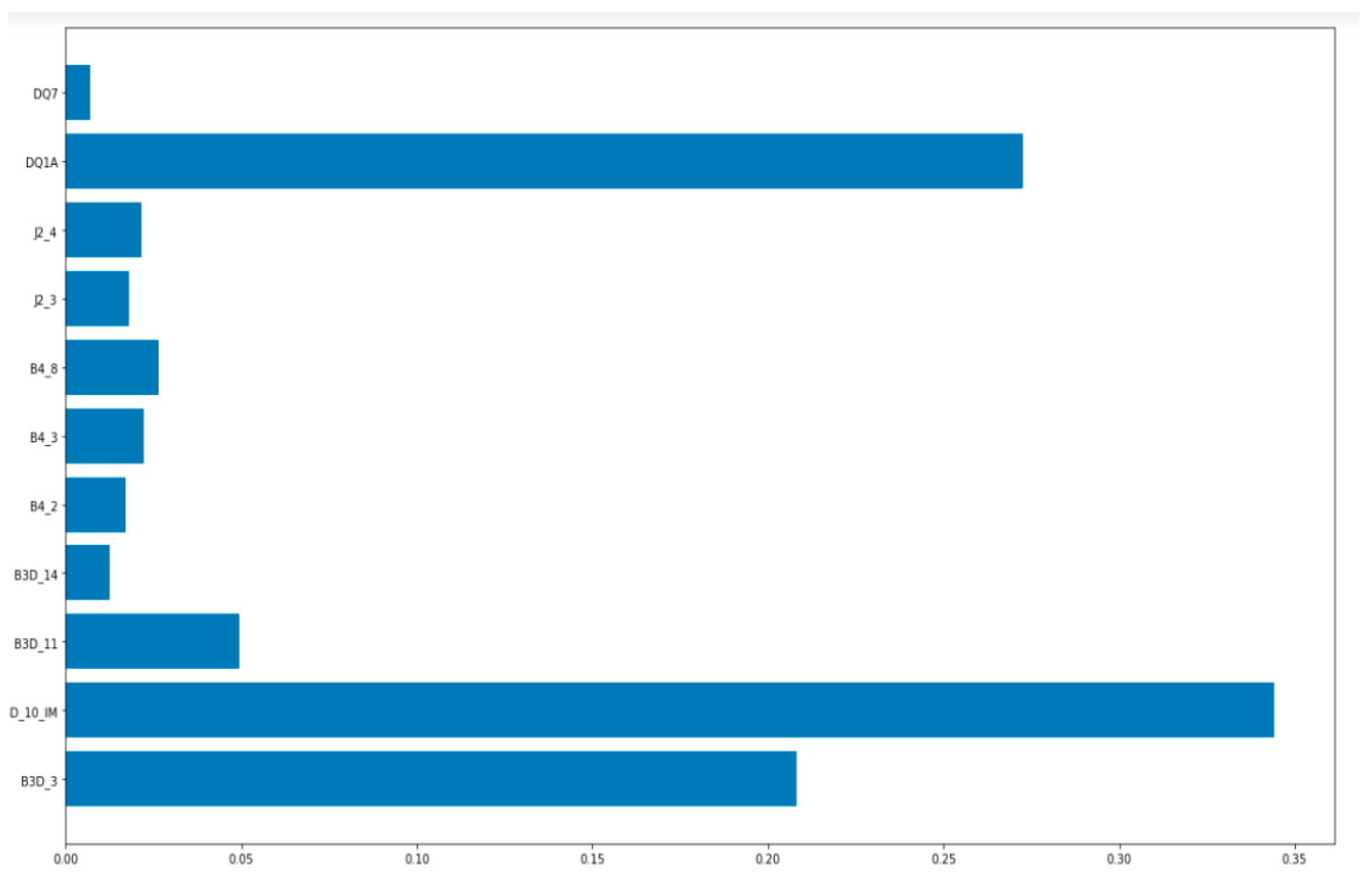
3.1. Gradient Boost Machine (GBM)
3.2. Grid Search
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Boeren, E.; Nicaise, I.; Baert, H. Theoretical models of participation in adult education: The need for an integrated model. Int. J. Lifelong Educ. 2010, 29, 45–61. [Google Scholar] [CrossRef] [Green Version]
- Boeren, E. Understanding adult lifelong learning participation as a layered problem. Stud. Contin. Educ. 2017, 39, 161–175. [Google Scholar] [CrossRef] [Green Version]
- Knipprath, H.; De Rick, K. How social and human capital predict participation in lifelong learning: A longitudinal data analysis. Adult Educ. Q. 2015, 65, 50–66. [Google Scholar] [CrossRef]
- Kyndt, E.; Govaerts, N.; Dochy, F.; Baert, H. The learning intention of low-qualified employees: A key for participation in lifelong learning and continuous training. Vocat. Learn. 2011, 4, 211–229. [Google Scholar] [CrossRef]
- Lee, J.; Lee, E.; Park, M. Exploring the Recognition of Education and Skills Mismatch as Determinants of Lifelong Learning Participation for Workers. Lifelong Learn. Soc. 2016, 12, 29–57. [Google Scholar] [CrossRef]
- Lee, Y.; Sun, J.; Lee, M. Development of Deep Learning Based Deterioration Prediction Model for the Maintenance Planning of Highway Pavement. Korea J. Constr. Eng. Manag. 2019, 20, 34–43. [Google Scholar]
- Ajzen, I.; Fishbein, M. Understanding Attitudes and Predicting Social Behavior; Prentice-Hall: Englewood Cliffs, NJ, USA, 1980. [Google Scholar]
- Maurer, T.J.; Weiss, E.M.; Barbeite, F.G. A model of involvement in work-related learning and development activity: The effects of individual, situational, motivational, and age variables. J. Appl. Psychol. 2003, 88, 707–724. [Google Scholar] [CrossRef] [PubMed]
- Rainbird, H. Skilling the unskilled: Access to work-based learning and the lifelong learning agenda. J. Educ. Work. 2000, 13, 183–197. [Google Scholar] [CrossRef]
- Baert, H.; De Rick, K.; Van Valckenborgh, K. Towards the conceptualisation of learning climate. In Adult Education: New Routes New Landscapes; Vieira de Castro, R., Sancho, A.V., Guimaraes, V., Eds.; University de Minho: Braga, Portugal, 2006; pp. 87–111. [Google Scholar]
- Baert, H. The game of training needs and training necessity within lifelong learning. In Adult Educational Theory in Transformation; Katus, J., Kessels, W.M., Schedler, P.E., Eds.; Boom: Meppel, The Netherlands, 1998; pp. 107–118. [Google Scholar]
- Ajzen, I.; Fishbein, M. A Bayesian analysis of attribution processes. Psychol. Bull. 1975, 82, 261–277. [Google Scholar] [CrossRef]
- Confessore, G.J.; Park, E. Factor validation of the learner autonomy profile, version 3.0 and extraction of the short form. Int. J. Self-Dir. Learn. 2004, 1, 39–58. [Google Scholar]
- Silva, T.; Cahalan, M.; Lacireno-Paquet, N. Adult Education Participation Decisions and Barriers: Review of Conceptual Frameworks and Empirical Studies; Working Paper Series; National Center for Education Statistics: Washington, DC, USA, 1998. [Google Scholar]
- Longworth, N.; Davies, W.K. Lifelong Learning: New Visions, New Implications, New Roles–for Industry, Government, Education and the Community for the 21st Century; Kogan Page: London, UK, 1996. [Google Scholar]
- Cross, K.P. Adults as Learners. Increasing Participation and Facilitating Learning; Jossey-Bass: San Francisco, CA, USA, 1981. [Google Scholar]
- Darkenwald, G.G.; Merriam, S.B. Adult Education: Foundations of Practice; Harper and Row: New York, NY, USA, 1982. [Google Scholar]
- OECD. Beyond Rhetoric: Adult Learning Policies and Practices; OECD: Paris, France, 2003. [Google Scholar]
- Ministry of Education; KEDI. 2013 Lifelong Learning Status of Korean Adults; KEDI Research Report SM2013-09; KEDI: Jincheon, Korea, 2013. [Google Scholar]
- Darkenwald, G.G. Retaining Adult Students; Information Series No. 225; ERIC: Columbus, OH, USA, 1981. [Google Scholar]
- Ivy, J. A new higher education marketing mix: The 7ps for marketing. Int. J. Educ. Manag. 2008, 22, 288–299. [Google Scholar] [CrossRef]
- Parasuraman, A.; Zeithaml, V.A.; Malhotra, A. Service quality delivery through web sites: A critical review of extant knowledge. J. Acad. Mark. Sci. 2002, 30, 362–375. [Google Scholar]
- Emmalou Van Tilburg, N. Why adults participate? J. Ext. 1992, 30, 12–13. [Google Scholar]
- Thongmak, M. Inquiring into lifelong learning intention: Comparisons of gender, employment status, and media exposure. Int. J. Lifelong Educ. 2021, 40, 72–90. [Google Scholar] [CrossRef]
- Bronfenbrenner, U. The Ecology of Human Development; Harvard University Press: Cambridge, MA, USA, 1979; p. 7. [Google Scholar]
- Bronfenbrenner, U. Ecology of the family as a context for human development: Research perspectives. Dev. Psychol. 1986, 22, 723–742. [Google Scholar] [CrossRef]
- Bronfenbrenner, U. Developmental ecology throrgh space and time: A future perspective. In Examining Lives in Context: Perspectives on the Ecology of Human Development; Moen, P., Elder, G.H., Luscher, K., Eds.; American Psychological Association: Washington, DC, USA, 1995; pp. 619–647. [Google Scholar]
- Park, T.; Kim, C. Predicting the variables that determine university (re-) entrance as a career development using support vector machines with recursive feature elimination: The case of South Korea. Sustainability 2020, 12, 7365. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Chen, J.; Li, S.; Liang, C.; Xu, Q.; Li, Y.; Qin, H.; Fuhrmann, J.J. Response of microbial community structure and function to short-term biochar amendment in an intensively managed bamboo (Phyllostachys praecox) plantation soil: Effect of particle size and addition rate. Sci. Total Environ. 2017, 574, 24–33. [Google Scholar] [CrossRef] [PubMed]
- Lee, Y.; Sun, J. Predicting Highway Concrete Pavement Damage using XGBoost. Korean J. Constr. Eng. Manag. 2020, 21, 46–55. [Google Scholar]
- Jain, A. Complete Machine Learning Guide to Parameter Tuning in Gradient Boosting (GBM) in Python. Anal. Vidhya. 2016. Available online: https://www.analyticsvidhya.com/blog/2016/02/complete-guide-parameter-tuning-gradient-boosting-gbm-python/ (accessed on 22 November 2021).
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Yağcı, M. Educational data mining: Prediction of students’ academic performance using machine learning algorithms. Smart Learn. Environ. 2022, 9, 11. [Google Scholar] [CrossRef]
- De Meester, K.; Scheeren, J.; Van Damme, D. Analyse van de barrières voor deelname aan permanente vorming. In Bevordering van Deelname en Deelnamekansen Inzake Arbeidsmarktgerichte Permanente Vorming; Baert, H., Douterlunge, M., Van Damme, D., Kusters, W., Van Wiele, I., Baert, T., Wouters, M., De Meester, K., Scheeren, J., Eds.; Leuven/Gent: Leuven, Belgium, 2001; pp. 156–210. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level | Factors |
|---|---|
| Micro-level | Characteristics of the Learner (Individual Characteristics)
|
| Meso-level | Characteristics of the Institutional Programs and Learning Activities |
| Macro-level | Characteristics of the Social Context and its Actors |
| Micro-Level | B3D_10_IM | Self-Pay Learning Expenses—Vocational Competency Improvement Education (1) (after non-response substitution) | Learning expenses spent in the past year $__________________ |
| DQ1A | Highest level of education completed—school level (including non-response) | ① Uneducated, ② Elementary school, ③ Middle school, ④ High school, ⑤ University (2 or 3-year university), ⑥ University (4-year university), ⑦ Graduate school (Master), ⑧ Graduate school (Ph.D.) | |
| DQ7 | Main source of income | ① Earned by me, ② Interest and rental income, ③ Allowance money from family, relatives, and children, ④ Pension, ⑤ Subsidy, ⑥ Others | |
| Meso-Level | B3D_3 | Program Type—Vocational Competency Improvement Education (1) | ① Lectures taught by instructors at a certain place, ② On-the-job training programs, ③ Remote/Cyber courses, ④ Professional seminars and workshops, ⑤ Study clubs, ⑥ Other lectures and private tutoring |
| B3D_14 | Program Satisfaction—Vocational Competency Improvement Education (1) | ① Very dissatisfied, ② Dissatisfied, ③ Normal, ④ Satisfied, ⑤ Very satisfied | |
| B4_2 | Increasing psychological satisfaction and happiness | ① Not helpful at all, ② Not very helpful, ③ Medium, ④ Slightly helpful, ⑤ Very helpful, ⑥ Not applicable | |
| B4_3 | Self-development, such as cultivating culture and acquiring knowledge | ① Not helpful at all, ② Not very helpful, ③ Medium, ④ Slightly helpful, ⑤ Very helpful, ⑥ Not applicable | |
| Macro-Level | B3D_11 | Whether external support for learning expenses is provided—Vocational Competency Improvement Education (1) | ① Yes, ② No |
| B4_8 | Social Participation (Volunteer Service and Community/Social Activities) | ① Not helpful at all, ② Not very helpful, ③ Medium, ④ Slightly helpful, ⑤ Very helpful, ⑥ Not applicable | |
| J2_3 | Degree of improvement in quality of life by participation in lifelong learning—Satisfaction with social participation | ① Not helpful at all, ② Not very helpful, ③ Medium, ④ Slightly helpful, ⑤ Very helpful, | |
| J2_4 | Degree of improvement in quality of life by participation in lifelong learning—Economic stability | ① Not helpful at all, ② Not very helpful, ③ Medium, ④ Slightly helpful, ⑤ Very helpful, |
| DQ9 | Employment type | ① Wage worker, ② Non-wage worker |
| Train_Score | Test_Score | |
|---|---|---|
| Gradient Boosting | 0.8598726114649682 | 0.847949080622348 |
| Grid Search | 0.8646496815286624 | 0.848656294200848 |
| Gradient Boosting | Grid Search | |
|---|---|---|
| Overall accuracy | 0.84795 | 0.84866 |
| Sensitivity | 0.95414 | 0.95054 |
| Precision | 0.86612 | 0.86924 |
| Specificity | 0.45695364 | 0.47350993 |
| f1_score | 0.90800 | 0.90808 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, C.; Park, T. Predicting Determinants of Lifelong Learning Intention Using Gradient Boosting Machine (GBM) with Grid Search. Sustainability 2022, 14, 5256. https://doi.org/10.3390/su14095256
Kim C, Park T. Predicting Determinants of Lifelong Learning Intention Using Gradient Boosting Machine (GBM) with Grid Search. Sustainability. 2022; 14(9):5256. https://doi.org/10.3390/su14095256
Chicago/Turabian StyleKim, Chayoung, and Taejung Park. 2022. "Predicting Determinants of Lifelong Learning Intention Using Gradient Boosting Machine (GBM) with Grid Search" Sustainability 14, no. 9: 5256. https://doi.org/10.3390/su14095256