
Computer Architectures for Incremental Learning in Water Management



Abstract
:1. Introduction
2. Materials and Methods
2.1. Related Work
2.2. Typical Use Cases and Data Description
- Providing water security in agriculture (predicting water availability and demand, regulating irrigation schedules, setting sustainable limits on water allocation);
- Delivering water supply services (predicting supply and demand fluctuations, predicting availability of water resources, securing adequate water quantity and quality, semantic annotation of water demand, detecting anomalies throughout the water distribution network in households or district areas in terms of leakage, theft, etc.) Securing water in aquatic ecosystems (specifying environmental flow regimes to achieve sustainability, identifying water contamination, and regulating the quality);
- Reducing flood and drought risk (in-time storm water “hot spot” localization by operating early warning systems, constructing efficient flood control infrastructure, predicting drought events and taking the necessary preventive measures);
- Promoting integrated urban water management (IUWM) (suggesting possible locations of nature-based solution (NBS) interventions, designing land use change allocation, assessing groundwater levels for urban planning extension).
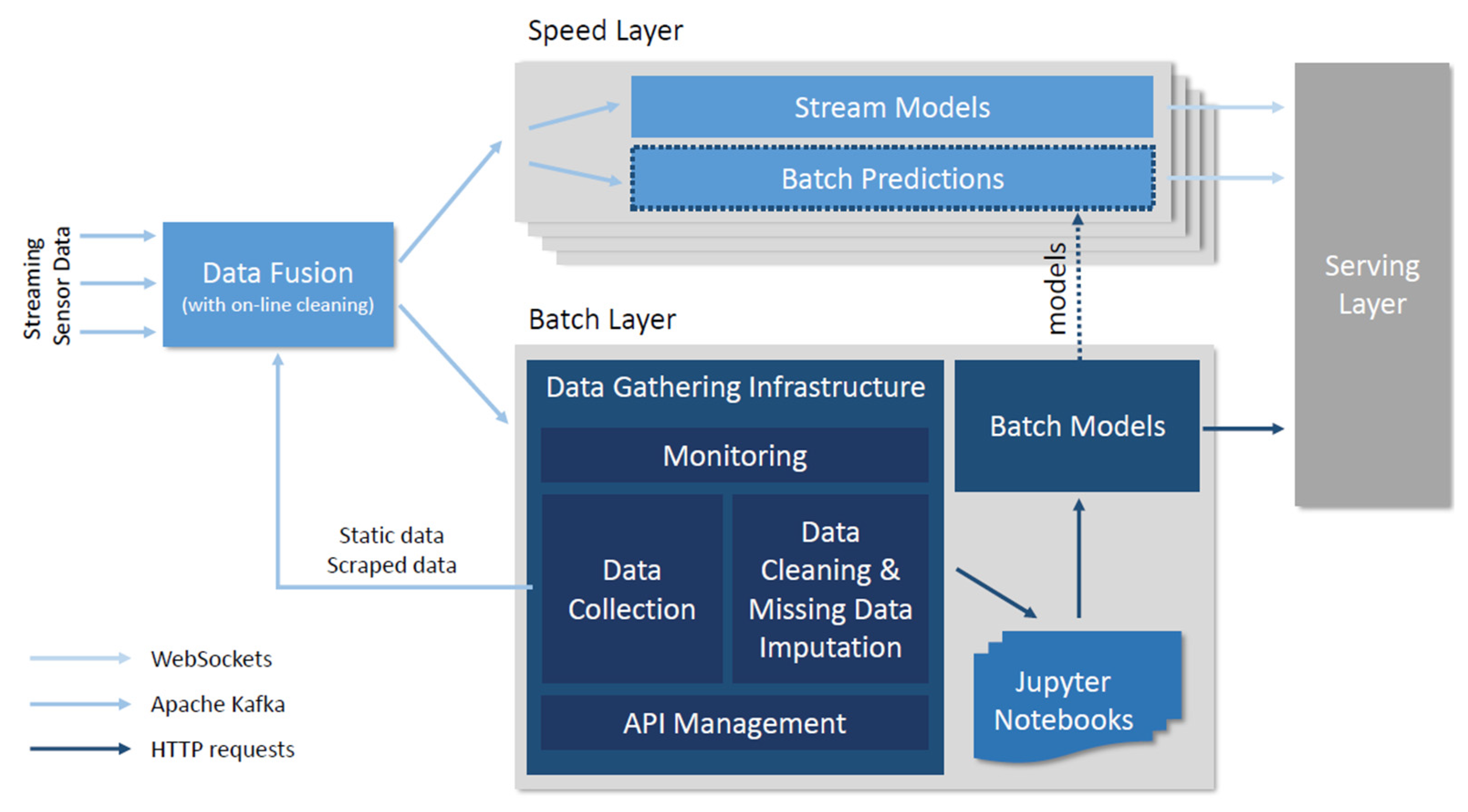
2.3. Architecture
2.4. Notes on the Implementation of Speed Layer
3. Results and Discussion
3.1. Data Gathering Infrastructure
3.2. Missing Data Imputation and Data Cleaning
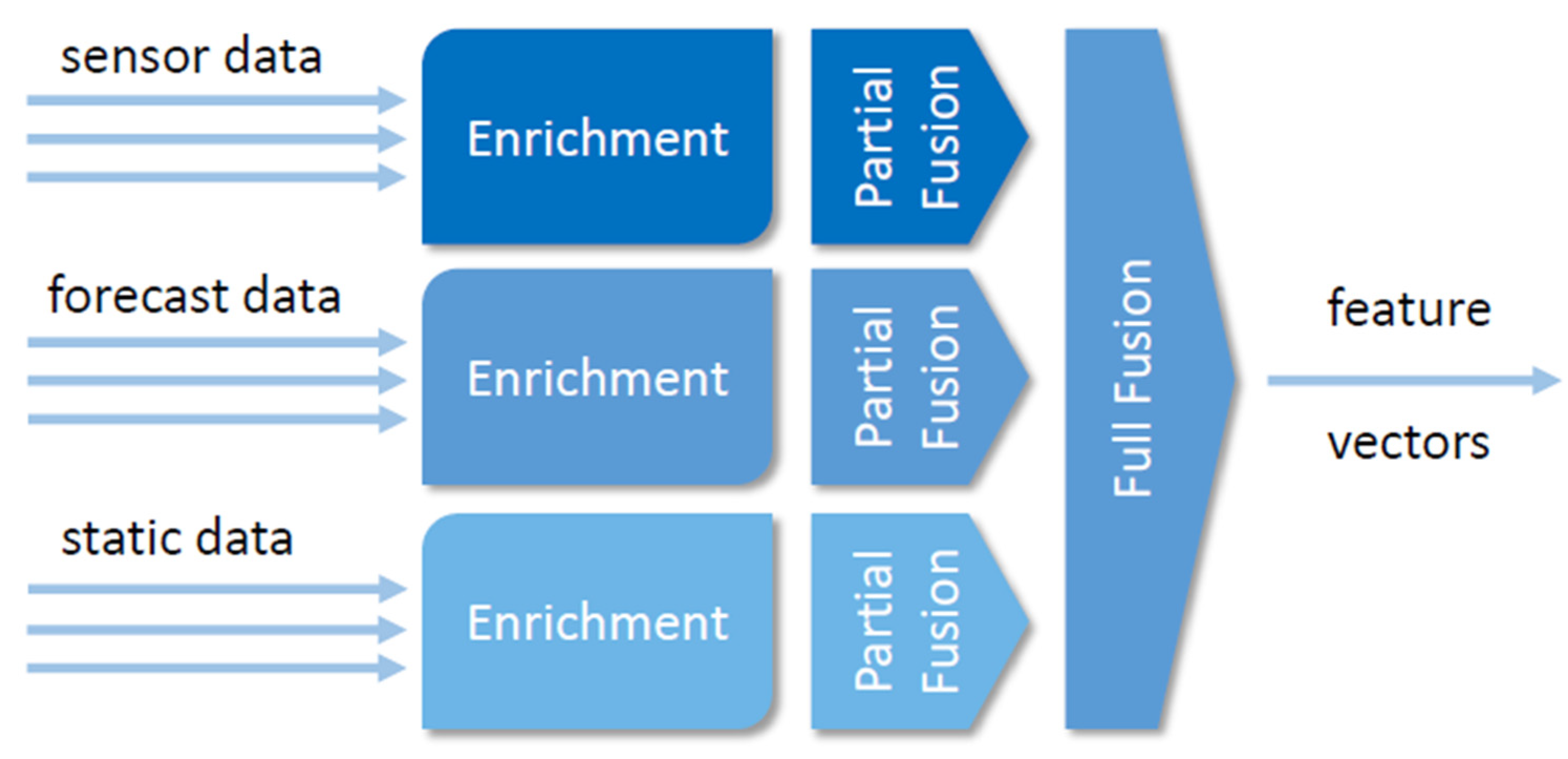
3.3. Real-Time Heterogenous Data Fusion
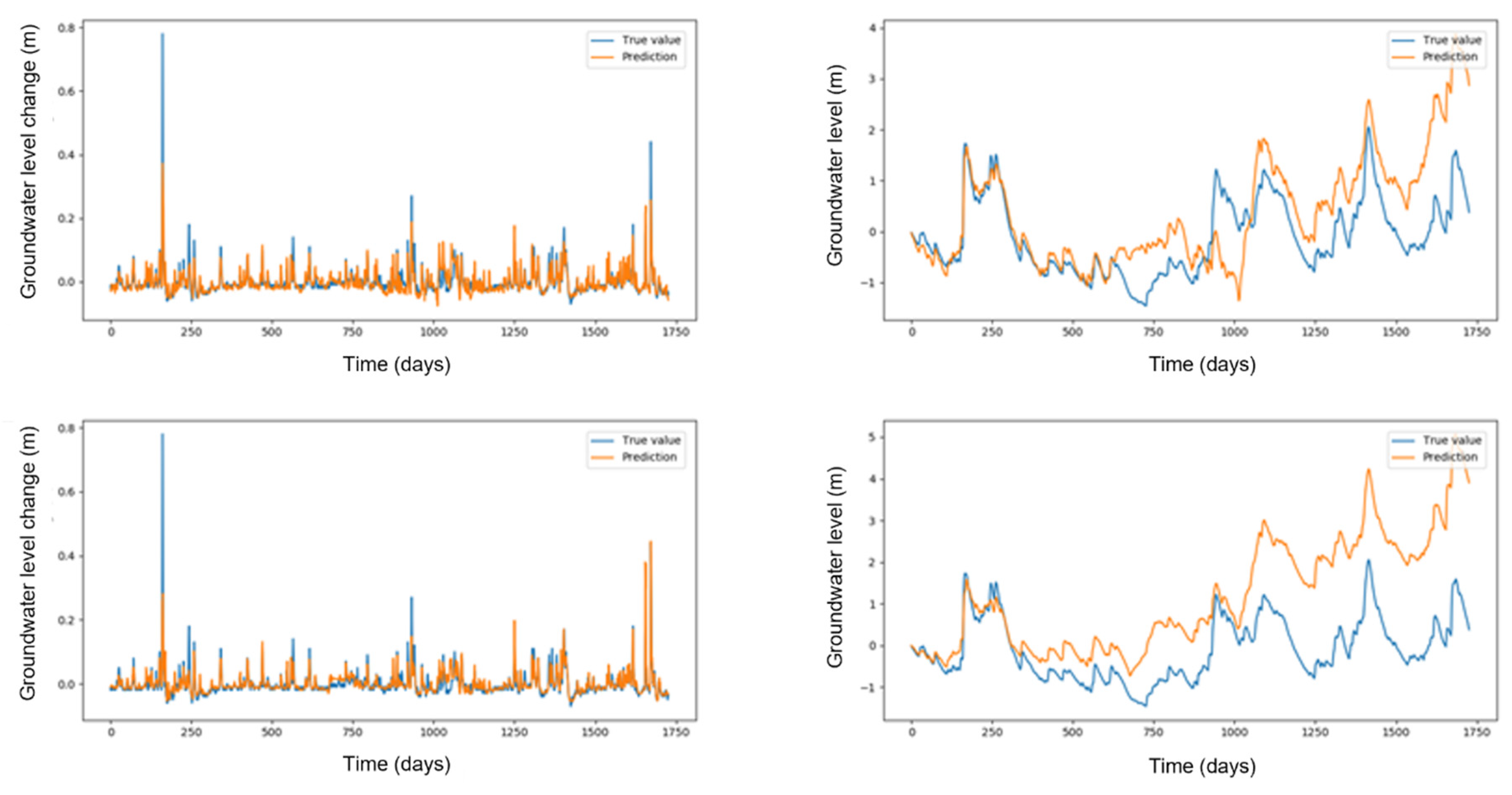
3.4. Data-Driven Modeling
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| API | Application Programming Interface |
| CRISP-DM | Cross–industry Standard Process for Data Mining |
| HTTP | Hyper–Text Transfer Protocol |
| ICT | Information and Communication Technology |
| IoT | Internet of Things |
| ISDI | IoT Streaming Data Integration |
| IUWM | Integrated Urban Water Management |
| MOA | Massive Online Analysis |
| SQL | Structured (English) Query Language |
| SWM | Smart Water Management |
| WMAP | Water Management Analytical Platform |
References
- Laspidou, C. ICT and stakeholder participation for improved urban water management in the cities of the future. Water Util. J. 2014, 8, 79–85. [Google Scholar]
- Cominola, A.; Giuliani, M.; Piga, D.; Castelletti, A.; Rizzoli, A. Benefits and challenges of using smart meters for advancing residential water demand modeling and management: A review. Environ. Model. Softw. 2015, 72, 198–214. [Google Scholar] [CrossRef] [Green Version]
- Ioannou, A.E.; Laspidou, C.S. The Water-Energy Nexus at City Level: The Case Study of Skiathos. Proceedings 2018, 2, 694. [Google Scholar] [CrossRef] [Green Version]
- Yang, L.; Yang, S.H.; Magiera, E.; Froelich, W.; Jach, T.; Laspidou, C. Domestic water consumption monitoring and behavior intervention by employing the internet of things technologies. Procedia Comput. Sci. 2017, 111, 367–375. [Google Scholar] [CrossRef]
- Rizou, S.; Kenda, K.; Kofinas, D.; Mellios, N.; Pergar, P.; Ritsos, P.D.; Vardakas, J.; Kalaboukas, K.; Laspidou, C.; Senožetnik, M.; et al. Water4Cities: An ICT Platform Enabling Holistic Surface Water and Groundwater Management for Sustainable Cities. Proceedings 2018, 2, 695. [Google Scholar] [CrossRef] [Green Version]
- Zaharia, M.; Xin, R.S.; Wendell, P.; Das, T.; Armbrust, M.; Dave, A.; Meng, X.; Rosen, J.; Venkataraman, S.; Franklin, M.J.; et al. Apache spark: A unified engine for big data processing. Commun. ACM 2016, 59, 56–65. [Google Scholar] [CrossRef]
- Marz, N.; Warren, J. Big Data: Principles and Best Practices of Scalable Realtime Data Systems, 1st ed.; Manning Publications Co.: Greenwich, CT, USA, 2015. [Google Scholar]
- Ta-Shma, P.; Akbar, A.; Gerson-Golan, G.; Hadash, G.; Carrez, F.; Moessner, K. An Ingestion and Analytics Architecture for IoT Applied to Smart City Use Cases. IEEE Internet Things J. 2018, 5, 765–774. [Google Scholar] [CrossRef] [Green Version]
- Aggarwal, C.C. Data Streams: Models and Algorithms (Advances in Database Systems); Springer: Secaucus, NJ, USA, 2006. [Google Scholar]
- Krempl, G.; Žliobaite, I.; Brzeziński, D.; Hüllermeier, E.; Last, M.; Lemaire, V.; Noack, T.; Shaker, A.; Sievi, S.; Spiliopoulou, M.; et al. Open challenges for data stream mining research. ACM SIGKDD Explor. Newsl. 2014, 16, 1–10. [Google Scholar] [CrossRef]
- Huang, G.B.; Chen, L.; Siew, C.K. Universal approximation using incremental constructive feedforward networks with random hidden nodes. IEEE Trans. Neural Netw. 2006, 17, 879–892. [Google Scholar] [CrossRef] [Green Version]
- Ikonomovska, E.; Gama, J.; Džeroski, S. Online tree-based ensembles and option trees for regression on evolving data streams. Neurocomputing 2015, 150, 458–470. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Yang, L.T.; Chen, Z.; Li, P. A survey on deep learning for big data. Inf. Fusion 2018, 42, 146–157. [Google Scholar] [CrossRef]
- Bifet, A.; Holmes, G.; Kirkby, R.; Pfahringer, B. MOA: Massive Online Analysis. J. Mach. Learn. Res. 2010, 11, 1601–1604. [Google Scholar]
- Montiel, J.; Read, J.; Bifet, A.; Abdessalem, T. Scikit-Multiflow: A Multi-output Streaming Framework. CoRR 2018, 19, 1–5. [Google Scholar]
- QMiner: Data Analytics Platform for Processing Streams of Structured and Unstructured Data. Available online: https://www.researchgate.net/publication/269100309_QMiner_Data_Analytics_Platform_for_Processing_Streams_of_Structured_and_Unstructured_Data (accessed on 1 January 2022).
- Kenda, K.; Kažič, B.; Novak, E.; Mladenić, D. Streaming Data Fusion for the Internet of Things. Sensors 2019, 19, 1955. [Google Scholar] [CrossRef] [Green Version]
- Tu, D.Q.; Kayes, A.; Rahayu, W.; Nguyen, K. ISDI: A New Window-Based Framework for Integrating IoT Streaming Data from Multiple Sources; Springer: Heidelberg, Germany, 2019; Volume 926, pp. 498–511. [Google Scholar]
- Manes, C.L.; Laspidou, C. Biosensors for Aquaculture and Food Safety. In Challenges and Innovations in Ocean In Situ Sensors: Measuring Inner Ocean Processes and Health in the Digital Age, 1st ed.; Delory, E., Pearlman, J., Eds.; Elsevier: Amsterdam, The Netherlands, 2018. [Google Scholar]
- Popović, T.; Latinović, N.; Pešić, A.; Zečević, Ž.; Krstajić, B.; Djukanović, S. Architecting an IoT-enabled platform for precision agriculture and ecological monitoring: A case study. Comput. Electron. Agric. 2017, 140, 255–265. [Google Scholar] [CrossRef]
- Kossieris, P.; Kozanis, S.; Hashmi, A.; Katsiri, E.; Vamvakeridou-Lyroudia, L.; Farmani, R.; Makropoulos, C.; Savic, D. A Web-based Platform for Water Efficient Households. Procedia Eng. 2014, 89, 1128–1135. [Google Scholar] [CrossRef] [Green Version]
- Catchment Hydrology Explorer for Water Stewards (CatchX Platform). Available online: https://ui.adsabs.harvard.edu/abs/2018EGUGA..20.9882A/abstract (accessed on 1 January 2022).
- Gaffoor, Z.; Pietersen, K.; Jovanovic, N.; Bagula, A.; Kanyerere, T. Big data analytics and its role to support groundwater management in the Southern African development community. Water 2020, 12, 2796. [Google Scholar] [CrossRef]
- Laspidou, C.; Kofinas, D.; Mellios, N.; Latinopoulos, D.; Papadimitriou, T. Investigation of factors affecting the trophic state of a shallow Mediterranean reconstructed lake. Ecol. Eng. 2017, 103, 154–163. [Google Scholar] [CrossRef]
- Mellios, N.; Moe, S.J.; Laspidou, C. Machine Learning Approaches for Predicting Health Risk of Cyanobacterial Blooms in Northern European Lakes. Water 2020, 12, 1191. [Google Scholar] [CrossRef] [Green Version]
- Kofinas, D.; Mellios, N.; Papageorgiou, E.; Laspidou, C. Urban water demand forecasting for the island of Skiathos. Procedia Eng. 2014, 89, 1023–1030. [Google Scholar] [CrossRef] [Green Version]
- Parkinson, J.N.; Tucci, C.; Goldenfum, J.A. (Eds.) Integrated Urban Water Management: Humid Tropics: UNESCO-IHP; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar]
- Oregi, X.; Roth, E.; Alsema, E.; van Ginkel, M.; Struik, D. Use of ICT tools for integration of energy in urban planning projects. Energy Procedia 2015, 83, 157–166. [Google Scholar] [CrossRef] [Green Version]
- Bricker, S.; Banks, V.; Galik, G.; Tapete, D.; Jones, R. Accounting for groundwater in future city visions. Land Use Policy 2017, 69, 618–630. [Google Scholar] [CrossRef]
- Senožetnik, M.; Herga, Z.; Šubic, T.; Bradeško, L.; Kenda, K.; Klemen, K.; Pergar, P.; Mladenić, D. IoT Middleware for Water Management. Proceedings 2018, 2, 696. [Google Scholar] [CrossRef] [Green Version]
- Pereira, D.A.; de Morais, W.O.; de Freitas, E.P. NoSQL real–time database performance comparison. Int. J. Parallel Emergent Distrib. Syst. 2018, 33, 144–156. [Google Scholar] [CrossRef]
- Shearer, C. The CRISP–DM model: The new blueprint for data mining. J. Data Warehous. 2000, 5, 13–22. [Google Scholar]
- Kenda, K.; Mladenić, D. Autonomous Sensor Data Cleaning in Stream Mining Setting. Bus. Syst. Res. J. 2018, 9, 69–79. [Google Scholar] [CrossRef] [Green Version]
- Kenda, K.; Koprivec, F.; Mladenić, D. Optimal Missing Value Estimation Algorithm for Groundwater Levels. Proceedings 2018, 2, 698. [Google Scholar] [CrossRef] [Green Version]
- Groundwater Levels for Slovenia–Data Set. Available online: https://researchgate.net/publication/336239471_Slovenia_-_groundwater_levels (accessed on 1 January 2022).
- Andjelov, M.; Frantar, P.; Mikulič, Z.; Pavlič, U.; Savić, V.; Souvent, P.; Uhan, J. Groundwater quantitative status assessment for River Basin Management Plan 2015-2021 in Slovenia. Geologija 2016, 59, 205–219. [Google Scholar] [CrossRef]
- Wu, X.; Zhu, X.; Wu, G.; Ding, W. Data mining with big data. IEEE Trans. Knowl. Data Eng. 2014, 26, 97–107. [Google Scholar]
- Kenda, K.; Ćerin, M.; Bogataj, M.; Senožetnik, M.; Klemen, K.; Pergar, P.; Laspidou, C.; Mladenić, D. Groundwater Modeling with Machine Learning Techniques: Ljubljana polje Aquifer. Proceedings 2018, 2, 697. [Google Scholar] [CrossRef] [Green Version]
- Koprivec, F.; Kenda, K.; Šircelj, B. FASTENER Feature Selection for Inference from Earth Observation Data. Entropy 2020, 22, 1198. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Typical Data Sources in the Water Domain | Indicative Subcategories |
|---|---|
| Surface and groundwater bodies data | groundwater level and pressure; permeability and storage capacity; river water level and discharge rates; flood inundation areas |
| Meteorological data | precipitation; temperature; evaporation; wind speed; radiation |
| Water repository data | accessible storage volume; water storage bathymetry and level; reservoir or tank water level; storage inflows, outflows and offtakes |
| Water exploitation data | volume of water taken from groundwater, rivers, lakes, and storage infrastructure; water pumping data |
| Water quality data | temperature; pH; oxygen; nutrients; chlorine concentration; electrical conductivity |
| Water pollutant data | heavy metals concentration; fertilizers; pesticides; bacteria; algae |
| Water distribution data | flow rate; pressure; energy consumption |
| Human-behavior data | water consumption; migration/tourism; public participation data |
| Spatial data | infrastructure; future and current land use; water bodies; static data based on previous measurements and process models; surface and topology; geological data; risk maps |
| Administrative data | water management area boundaries; water prices; water infrastructure inventories |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kenda, K.; Mellios, N.; Senožetnik, M.; Pergar, P. Computer Architectures for Incremental Learning in Water Management. Sustainability 2022, 14, 2886. https://doi.org/10.3390/su14052886
Kenda K, Mellios N, Senožetnik M, Pergar P. Computer Architectures for Incremental Learning in Water Management. Sustainability. 2022; 14(5):2886. https://doi.org/10.3390/su14052886
Chicago/Turabian StyleKenda, Klemen, Nikolaos Mellios, Matej Senožetnik, and Petra Pergar. 2022. "Computer Architectures for Incremental Learning in Water Management" Sustainability 14, no. 5: 2886. https://doi.org/10.3390/su14052886