

A Hybrid Model for China’s Soybean Spot Price Prediction by Integrating CEEMDAN with Fuzzy Entropy Clustering and CNN-GRU-Attention
Abstract
:1. Introduction
2. Methodology
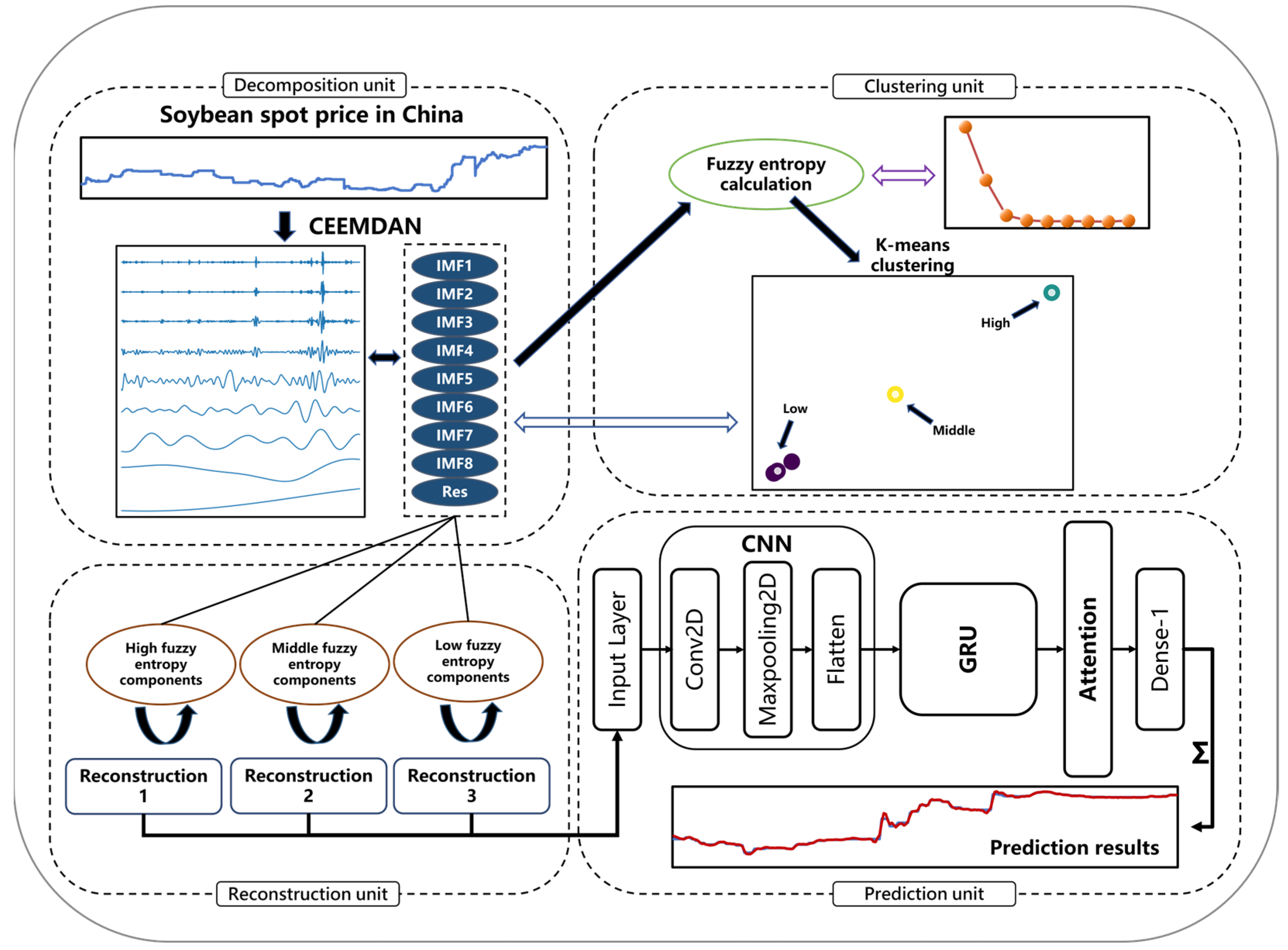
2.1. Overall Framework of the Mixed-Method Model
- (1)
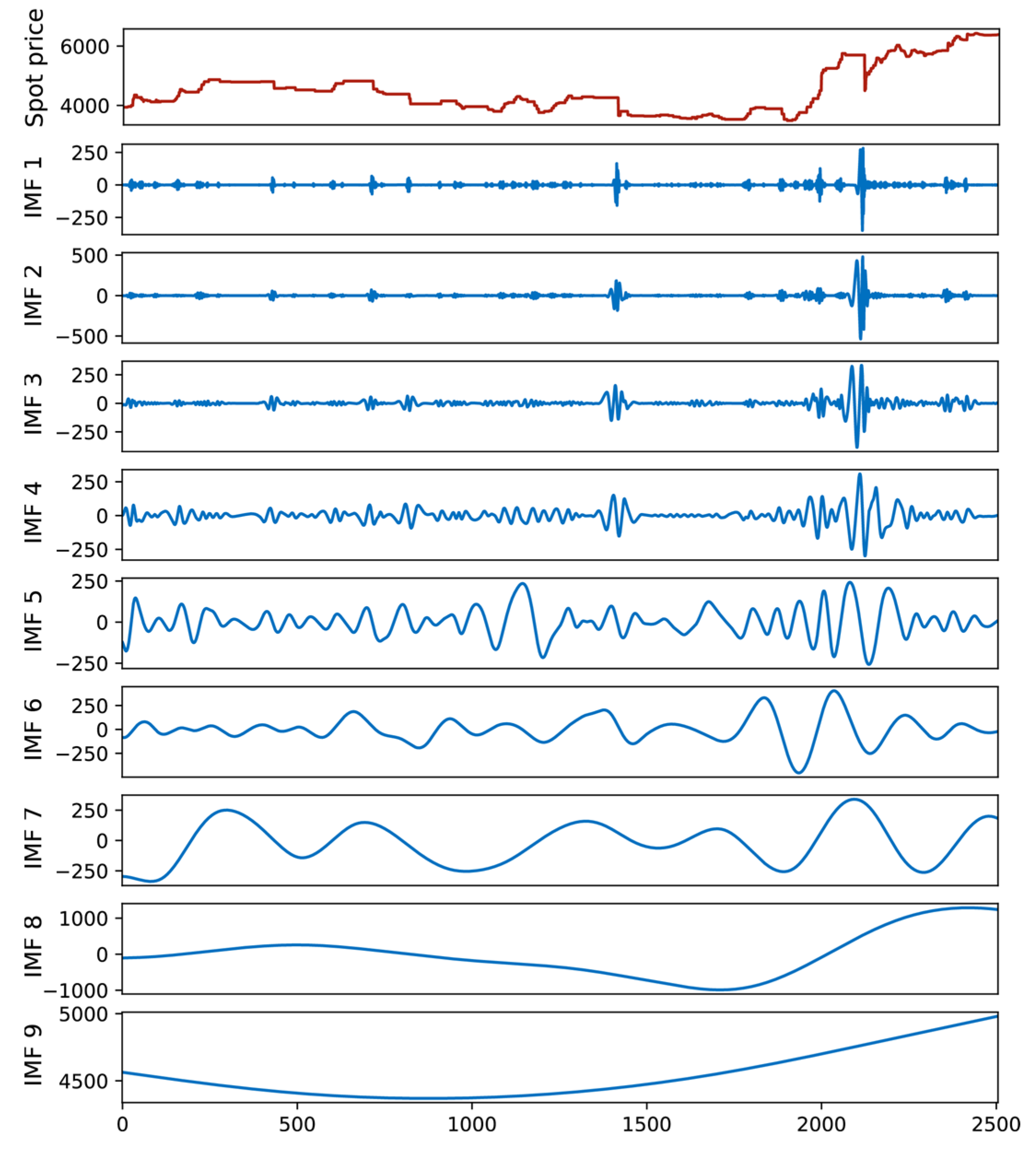
- Soybean prices are decomposed by CEEMDAN into IMFs and Residual, which are then sorted from high to low frequencies;
- (2)
- K-means clustering is repeated for the decomposed components after the fuzzy entropy magnitude is calculated. An approximate component reconstruction is then performed;
- (3)
- Three types of reconstructed components are predicted by the CNN-GRU-Attention model, and then the outcomes are linearly integrated to get the final results.
2.2. CEEMDAN
2.3. Fuzzy Entropy and K-Means Clustering
2.3.1. Fuzzy Entropy
2.3.2. K-Means Clustering
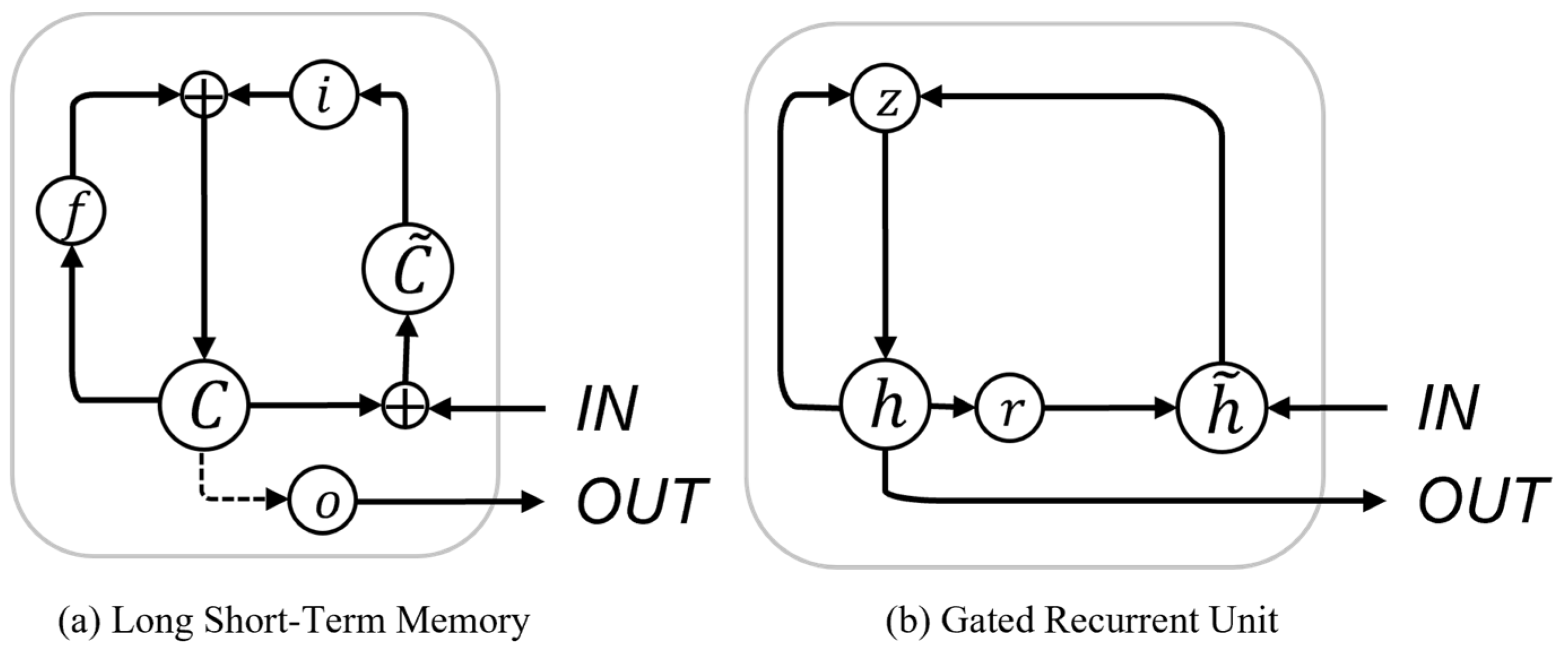
2.4. Description of CNN-GRU-Attention
2.4.1. CNN
2.4.2. GRU
2.4.3. Attention Mechanism
3. Analysis of Experiments
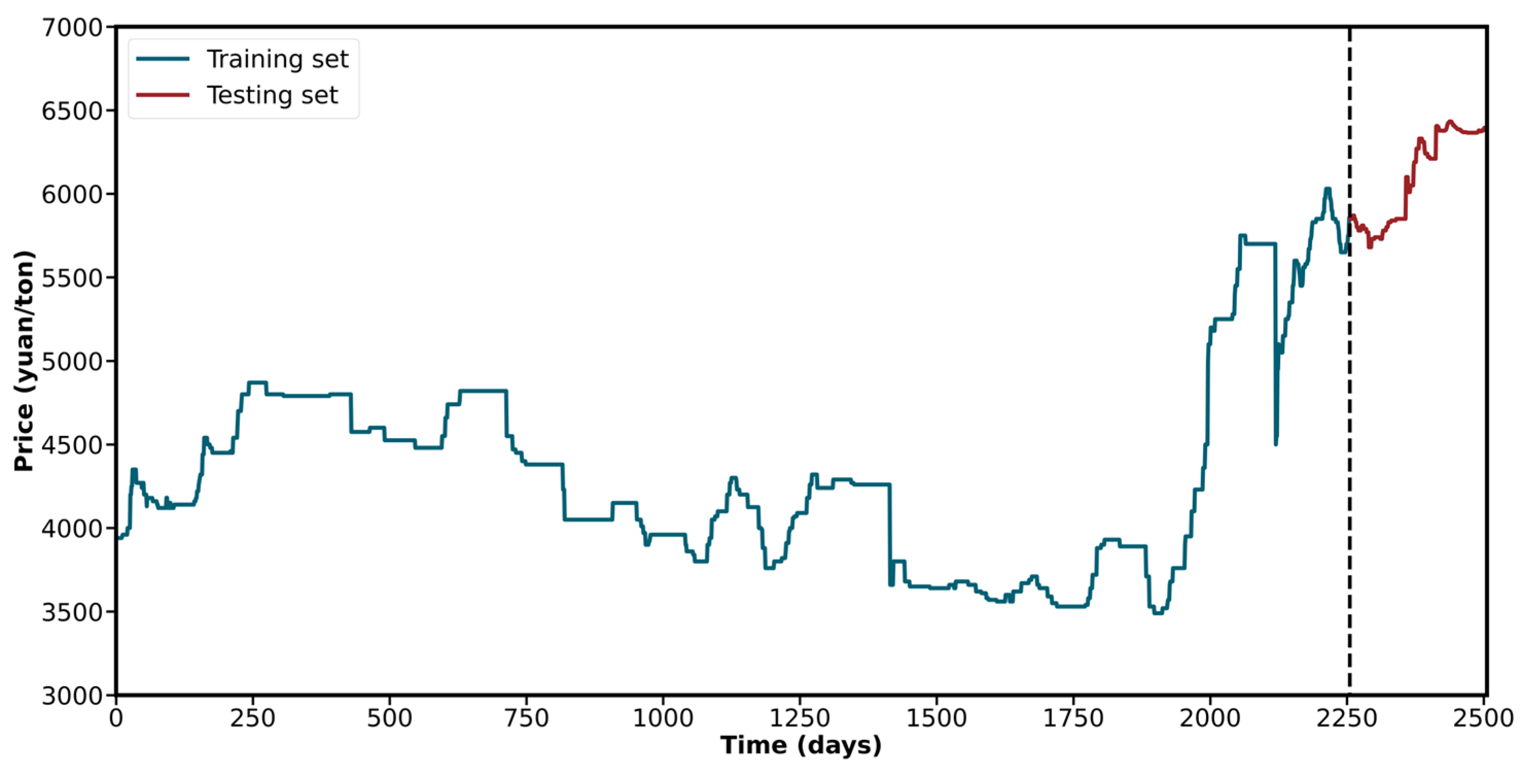
3.1. Data Sources and Standard Measurement
3.2. CEEMDAN Processing
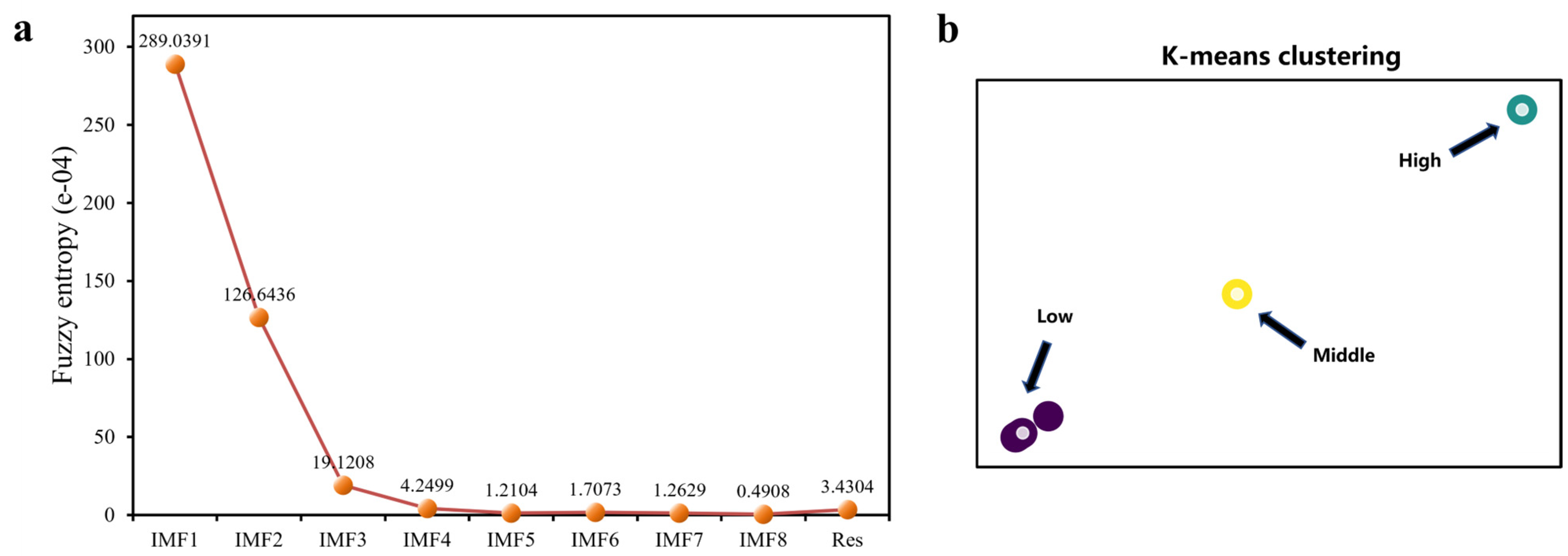
3.3. Fuzzy Entropy-Based Components Clustering
3.4. Model Instructions and Parameter Setting
3.5. Prediction Results
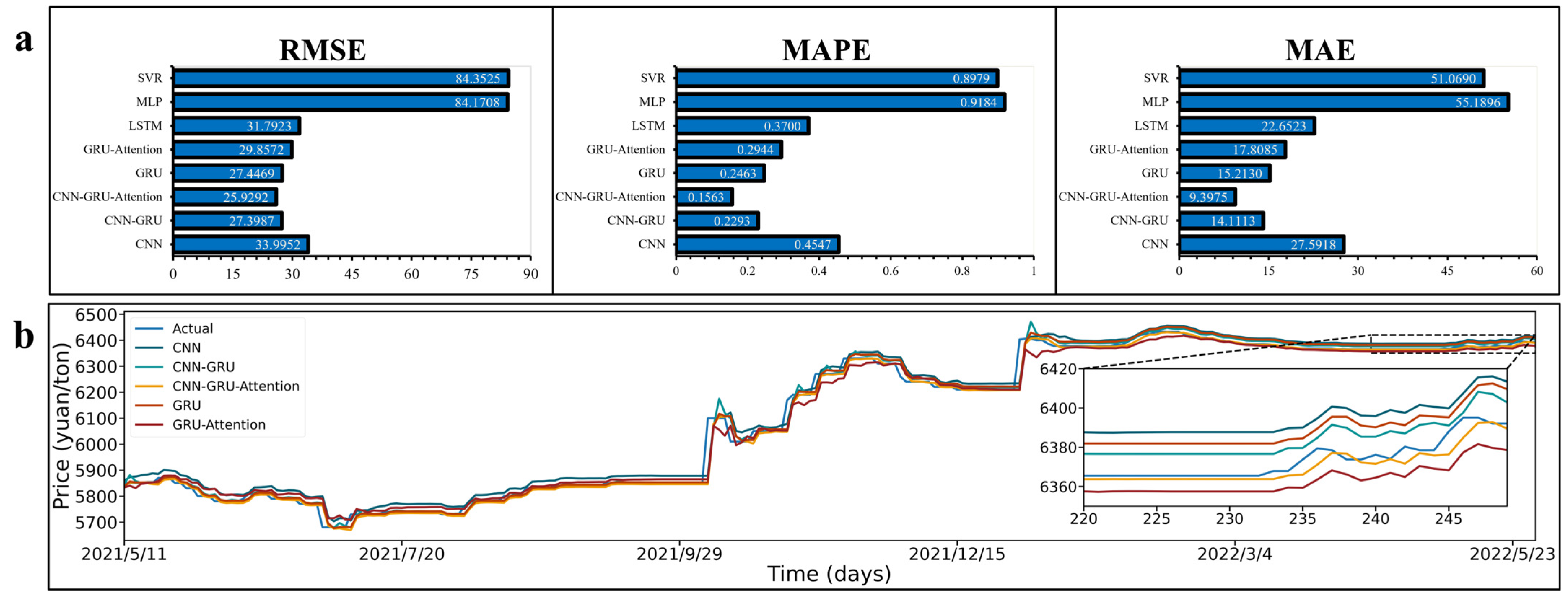
3.5.1. Comparison of the Prediction Part
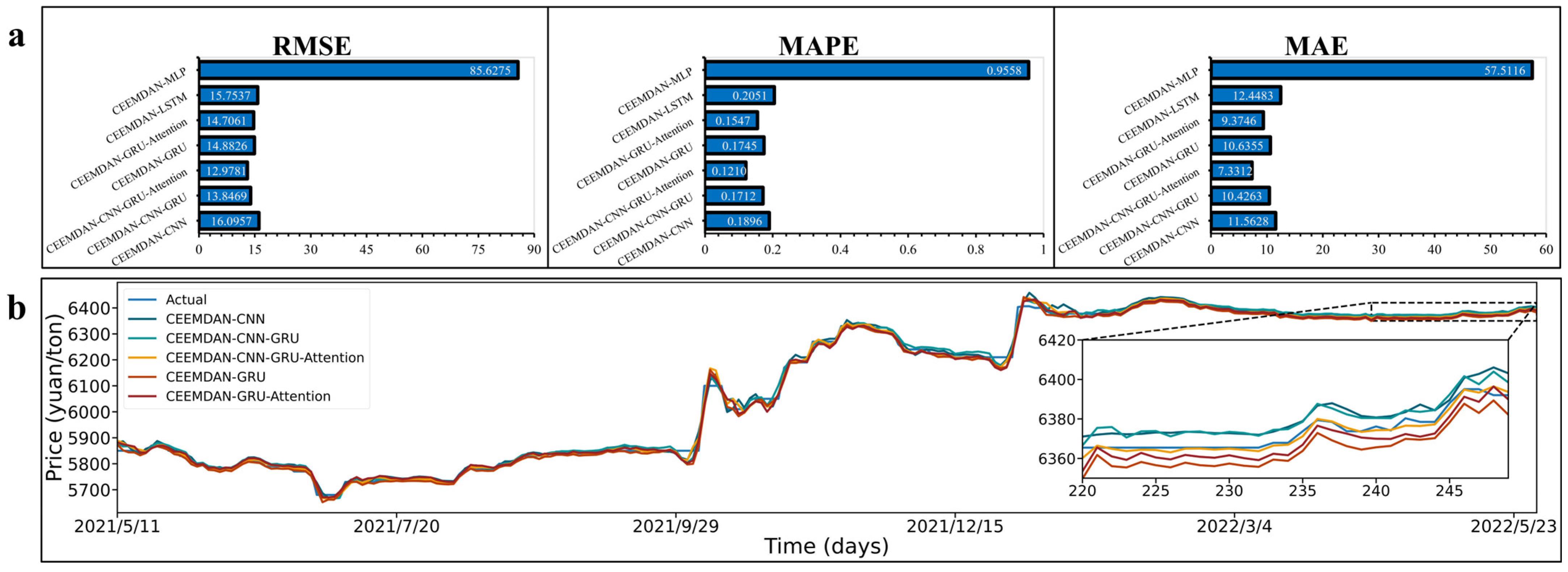
3.5.2. Comparison of the Hybrid Models
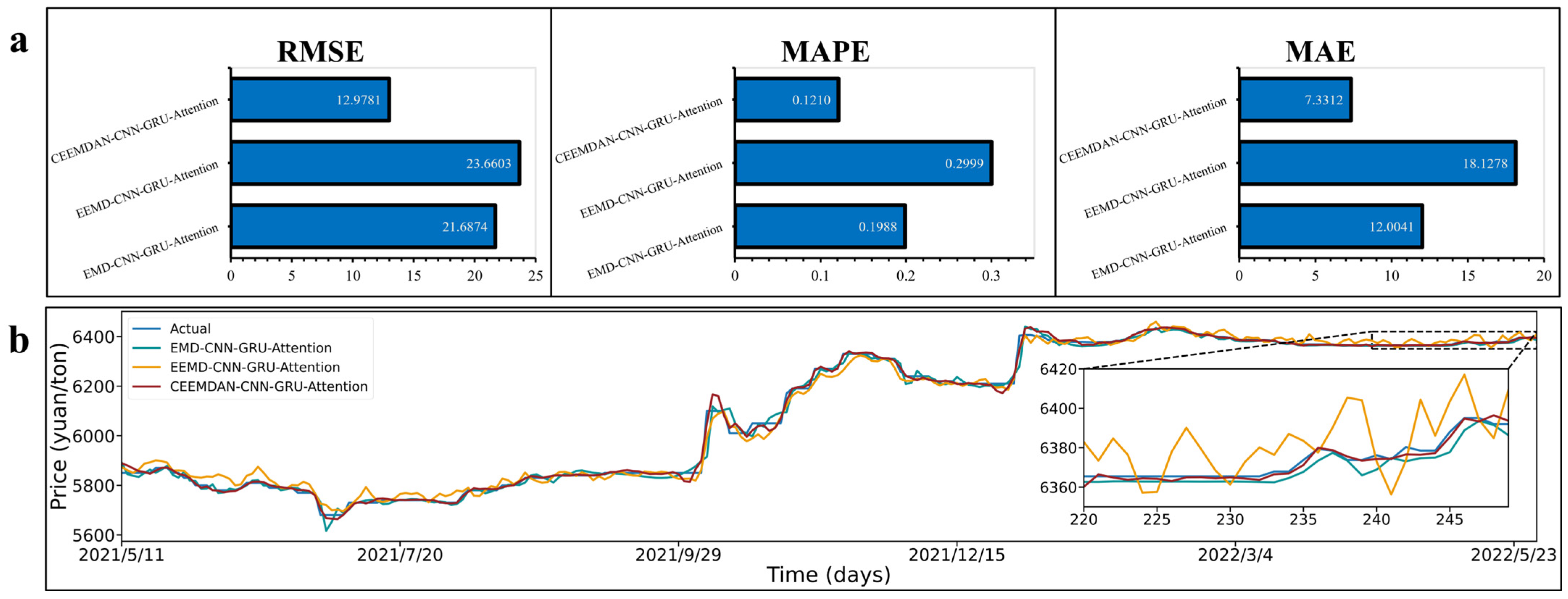
3.5.3. Comparison of Various Decomposition Methods
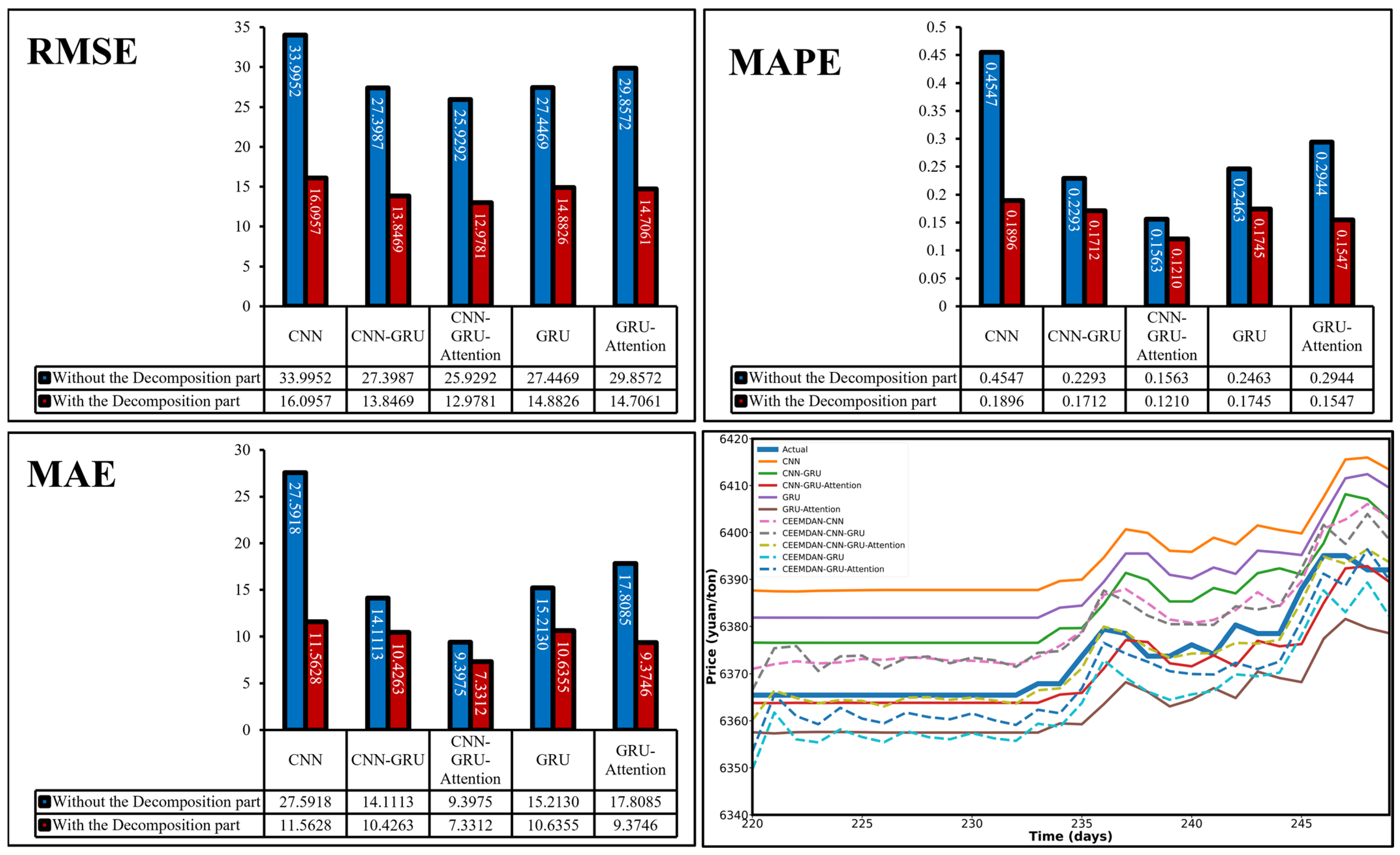
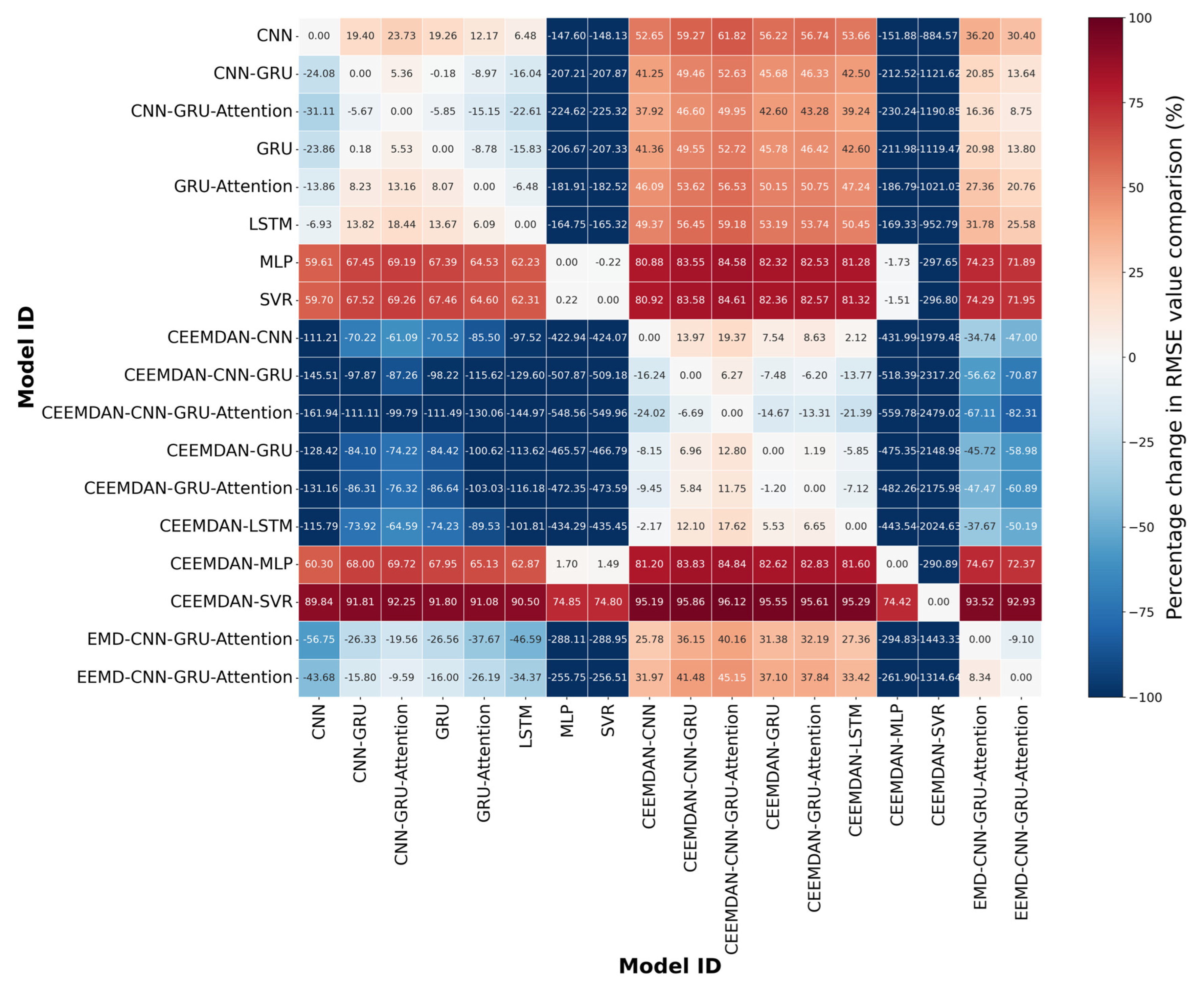
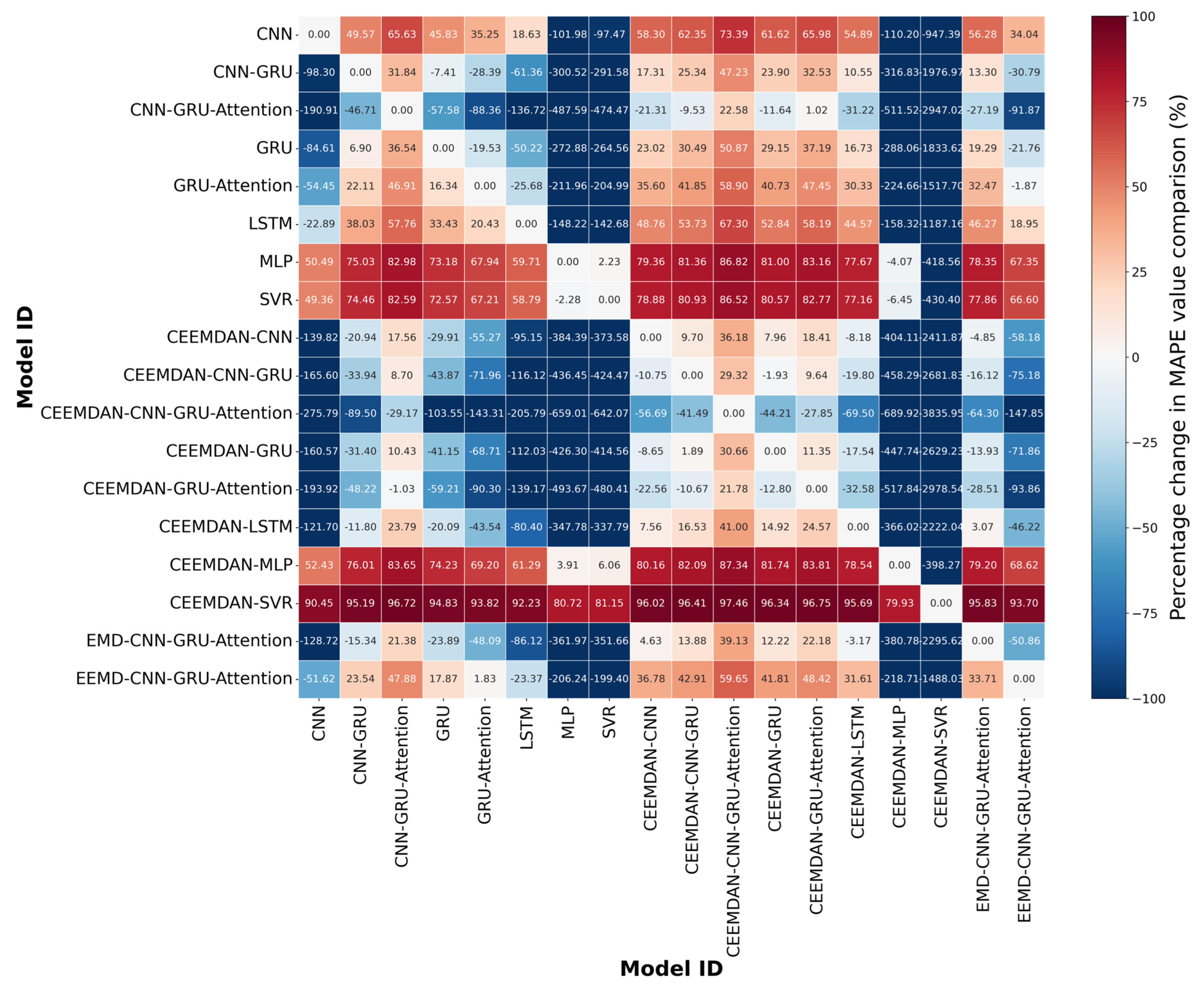
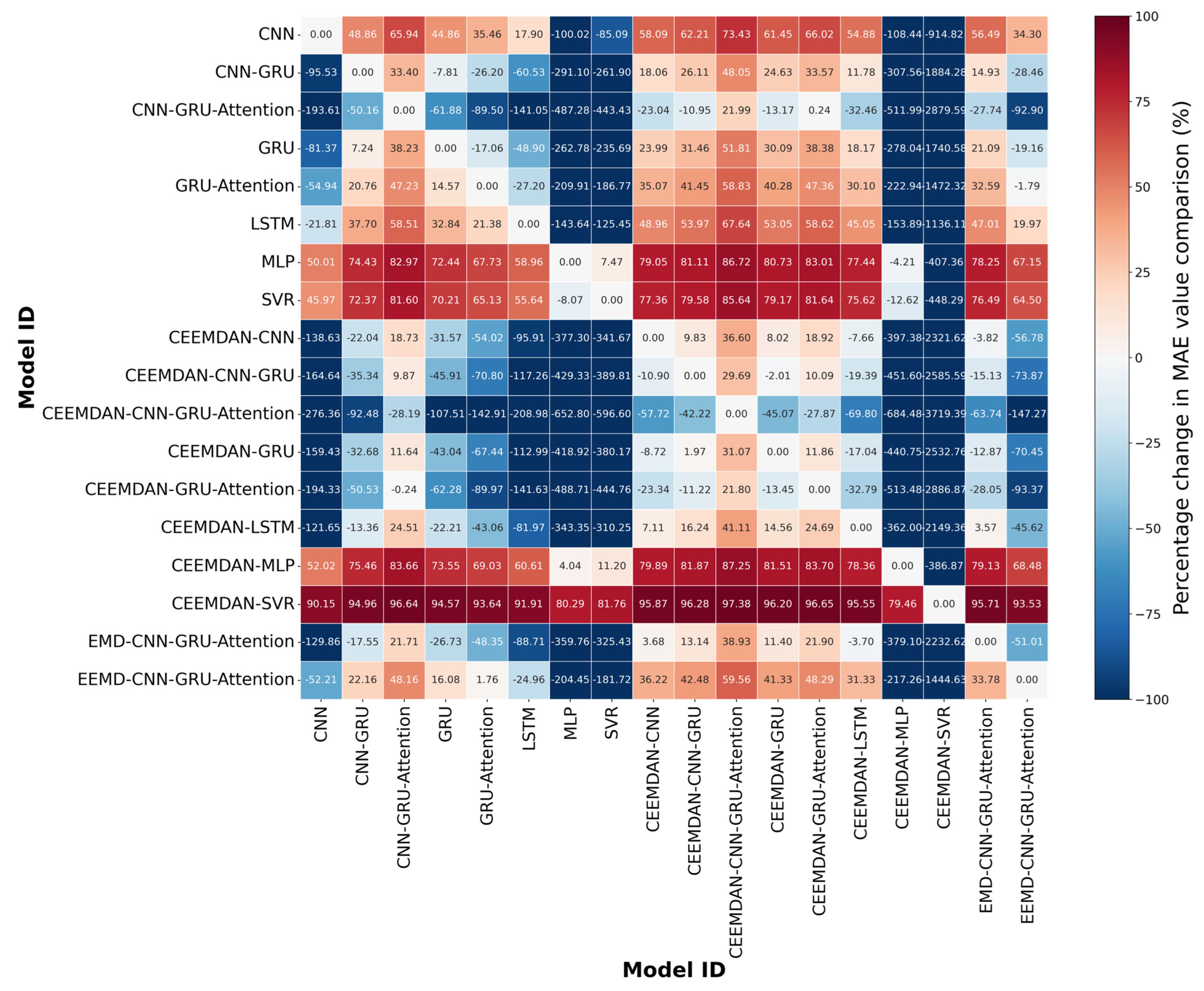
3.5.4. The Comparison of All Model Components
4. Conclusions and Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| ARIMA | Autoregressive integrated moving average |
| CEEMDAN | Complete ensemble empirical mode decomposition with adaptive noise |
| CNN | Convolutional neural network |
| EEMD | Ensemble empirical mode decomposition |
| EMD | Empirical mode decomposition |
| GARCH | Autoregressive conditional heteroskedasticity |
| GRU | Gated recurrent unit |
| IMF | Intrinsic mode function |
| LSTM | Long short-term memory |
| MAE | Mean absolute error |
| MAPE | Mean absolute percentage error |
| MLP | Multilayer perceptron |
| RMSE | Root mean square error |
| RNN | Recurrent neural network |
| SVM | Support vector machine |
| SVR | Support vector regression |
| VAR | Vector autoregression |
| VMD | Variational mode decomposition |
References
- Yao, H.; Zuo, X.; Zuo, D.; Lin, H.; Huang, X.; Zang, C. Study on soybean potential productivity and food security in China under the influence of COVID-19 outbreak. Geogr. Sustain. 2020, 1, 163–171. [Google Scholar] [CrossRef]
- Mallory, M.L. Impact of COVID-19 on medium-term export prospects for soybeans, corn, beef, pork, and poultry. Appl. Econ. Perspect. Policy 2021, 43, 292–303. [Google Scholar] [CrossRef] [PubMed]
- Yu, X.; Liu, C.; Wang, H.; Feil, J.-H. The impact of COVID-19 on food prices in China: Evidence of four major food products from Beijing, Shandong and Hubei Provinces. China Agric. Econ. Rev. 2020, 12, 445–458. [Google Scholar] [CrossRef]
- Kumar, A.; Pinto, P.; Hawaldar, I.T.; Spulbar, C.M.; Birau, F.R. Crude oil futures to manage the price risk of natural rubber: Empirical evidence from India. Agric. Econ. 2021, 67, 423–434. [Google Scholar] [CrossRef]
- Panagiotou, D.; Tseriki, A. Directional predictability between trading volume and price returns in the agricultural futures markets: Risk implications for traders. J. Risk Financ. 2022, 23, 264–288. [Google Scholar] [CrossRef]
- Salisu, A.A.; Vo, X.V.; Lawal, A. Hedging oil price risk with gold during COVID-19 pandemic. Resour. Policy 2020, 70, 101897. [Google Scholar] [CrossRef]
- Goodwin, B.K.; Schnepf, R.; Dohlman, E. Modelling soybean prices in a changing policy environment. Appl. Econ. 2005, 37, 253–263. [Google Scholar] [CrossRef]
- Xu, X.; Zhang, Y. Commodity price forecasting via neural networks for coffee, corn, cotton, oats, soybeans, soybean oil, sugar, and wheat. Intell. Syst. Account. Financ. Manag. 2022, 29, 169–181. [Google Scholar] [CrossRef]
- Darroch, M.A.; Akridge, J.T.; Boehlje, M.D. Capturing value in the supply chain: The case of high oleic acid soybeans. Int. Food Agribus. Manag. Rev. 2002, 5, 87–103. [Google Scholar] [CrossRef]
- Jia, F.; Peng, S.; Green, J.; Koh, L.; Chen, X. Soybean supply chain management and sustainability: A systematic literature review. J. Clean. Prod. 2020, 255, 120254. [Google Scholar] [CrossRef]
- Richter, M.C.; Sørensen, C. Stochastic volatility and seasonality in commodity futures and options: The case of soybeans. SSRN 2002, 45, 301994. [Google Scholar] [CrossRef] [Green Version]
- Ahumada, H.; Cornejo, M. Forecasting food prices: The case of corn, soybeans and wheat. Int. J. Forecast. 2016, 32, 838–848. [Google Scholar] [CrossRef]
- Wu, L.; Liu, S.; Yang, Y. Grey double exponential smoothing model and its application on pig price forecasting in China. Appl. Soft Comput. 2016, 39, 117–123. [Google Scholar] [CrossRef] [Green Version]
- Yu, Z.; Qin, L.; Chen, Y.; Parmar, M. Stock price forecasting based on LLE-BP neural network model. Phys. A Stat. Mech. Appl. 2020, 553, 124197. [Google Scholar] [CrossRef]
- Wu, Y.-X.; Wu, Q.-B.; Zhu, J.-Q. Improved EEMD-based crude oil price forecasting using LSTM networks. Phys. A Stat. Mech. Appl. 2019, 516, 114–124. [Google Scholar] [CrossRef]
- Yu, L.; Zhao, Y.; Tang, L. A compressed sensing based AI learning paradigm for crude oil price forecasting. Energy Econ. 2014, 46, 236–245. [Google Scholar] [CrossRef]
- Kuo, P.-H.; Huang, C.-J. An electricity price forecasting model by hybrid structured deep neural networks. Sustainability 2018, 10, 1280. [Google Scholar] [CrossRef] [Green Version]
- Nogay, H.S.; Akinci, T.C.; Yilmaz, M. Detection of invisible cracks in ceramic materials using by pre-trained deep convolutional neural network. Neural Comput. Appl. 2021, 34, 1423–1432. [Google Scholar] [CrossRef]
- Subramaniam, S.; Raju, N.; Ganesan, A.; Rajavel, N.; Chenniappan, M.; Prakash, C.; Pramanik, A.; Basak, A.K.; Dixit, S. Artificial Intelligence Technologies for Forecasting Air Pollution and Human Health: A Narrative Review. Sustainability 2022, 14, 9951. [Google Scholar] [CrossRef]
- Yu, L.; Dai, W.; Tang, L. A novel decomposition ensemble model with extended extreme learning machine for crude oil price forecasting. Eng. Appl. Artif. Intell. 2016, 47, 110–121. [Google Scholar] [CrossRef]
- Zhou, S.; Zhou, L.; Mao, M.; Tai, H.-M.; Wan, Y. An optimized heterogeneous structure LSTM network for electricity price forecasting. IEEE Access 2019, 7, 108161–108173. [Google Scholar] [CrossRef]
- He, Z.; Guo, Q.; Wang, Z.; Li, X. Prediction of monthly PM2. 5 concentration in Liaocheng in China employing artificial neural network. Atmosphere 2022, 13, 1221. [Google Scholar] [CrossRef]
- O’Leary, C.; Lynch, C.; Bain, R.; Smith, G.; Grimes, D. A Comparison of Deep Learning vs. Traditional Machine Learning for Electricity Price Forecasting. In Proceedings of the 2021 4th International Conference on Information and Computer Technologies (ICICT), Kahului, HI, USA, 11–14 March 2021; pp. 6–12. [Google Scholar] [CrossRef]
- Ahmed, A.M.; Deo, R.C.; Raj, N.; Ghahramani, A.; Feng, Q.; Yin, Z.; Yang, L. Deep learning forecasts of soil moisture: Convolutional neural network and gated recurrent unit models coupled with satellite-derived MODIS, observations and synoptic-scale climate index data. Remote Sens. 2021, 13, 554. [Google Scholar] [CrossRef]
- Chen, S.; Dong, S.; Cao, Z.; Guo, J. A compound approach for monthly runoff forecasting based on multiscale analysis and deep network with sequential structure. Water 2020, 12, 2274. [Google Scholar] [CrossRef]
- Wang, L.; Feng, J.; Sui, X.; Chu, X.; Mu, W. Agricultural product price forecasting methods: Research advances and trend. Br. Food J. 2020, 122, 2121–2138. [Google Scholar] [CrossRef]
- Jammazi, R.; Aloui, C. Crude oil price forecasting: Experimental evidence from wavelet decomposition and neural network modeling. Energy Econ. 2012, 34, 828–841. [Google Scholar] [CrossRef]
- Yang, W.; Wang, J.; Niu, T.; Du, P. A hybrid forecasting system based on a dual decomposition strategy and multi-objective optimization for electricity price forecasting. Appl. Energy 2019, 235, 1205–1225. [Google Scholar] [CrossRef]
- Li, H.; Jin, F.; Sun, S.; Li, Y. A new secondary decomposition ensemble learning approach for carbon price forecasting. Knowl. Based Syst. 2021, 214, 106686. [Google Scholar] [CrossRef]
- Yilmaz, M. Wavelet Based and Statistical EEG Analysis in Patients with Schizophrenia. Trait. Signal 2021, 35, 1477–1483. [Google Scholar] [CrossRef]
- Wang, D.; Luo, H.; Grunder, O.; Lin, Y.; Guo, H. Multi-step ahead electricity price forecasting using a hybrid model based on two-layer decomposition technique and BP neural network optimized by firefly algorithm. Appl. Energy 2017, 190, 390–407. [Google Scholar] [CrossRef]
- Tang, L.; Wu, Y.; Yu, L. A non-iterative decomposition-ensemble learning paradigm using RVFL network for crude oil price forecasting. Appl. Soft Comput. 2018, 70, 1097–1108. [Google Scholar] [CrossRef]
- Nogay, H.S.; Akinci, T.C.; Yilmaz, M. Comparative Experimental Investigation and Application of Five Classic Pre-Trained Deep Convolutional Neural Networks via Transfer Learning for Diagnosis of Breast Cancer. Adv. Sci. Technol. Res. J. 2021, 15, 1–8. [Google Scholar] [CrossRef]
- Nikou, M.; Mansourfar, G.; Bagherzadeh, J. Stock price prediction using DEEP learning algorithm and its comparison with machine learning algorithms. Intell. Syst. Account. Financ. Manag. 2019, 26, 164–174. [Google Scholar] [CrossRef]
- Selvin, S.; Vinayakumar, R.; Gopalakrishnan, E.; Menon, V.K.; Soman, K. Stock Price Prediction Using LSTM, RNN and CNN-Sliding Window Model. In Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Karnataka, India, 13–16 September 2017; pp. 1643–1647. [Google Scholar] [CrossRef]
- Ji, S.; Kim, J.; Im, H. A comparative study of bitcoin price prediction using deep learning. Mathematics 2019, 7, 898. [Google Scholar] [CrossRef] [Green Version]
- Niu, H.; Xu, K. A hybrid model combining variational mode decomposition and an attention-GRU network for stock price index forecasting. Math. Biosci. Eng. 2020, 17, 7151–7166. [Google Scholar] [CrossRef]
- Fang, Y.; Guan, B.; Wu, S.; Heravi, S. Optimal forecast combination based on ensemble empirical mode decomposition for agricultural commodity futures prices. J. Forecast. 2020, 39, 877–886. [Google Scholar] [CrossRef]
- Wang, B.; Liu, P.; Chao, Z.; Junmei, W.; Chen, W.; Cao, N.; O’Hare, G.M.; Wen, F. Research on Hybrid Model of Garlic Short-term Price Forecasting based on Big Data. Comput. Mater. Contin. 2018, 57, 283–296. [Google Scholar] [CrossRef]
- Cao, J.; Li, Z.; Li, J. Financial time series forecasting model based on CEEMDAN and LSTM. Phys. A Stat. Mech. Its Appl. 2018, 519, 127–139. [Google Scholar] [CrossRef]
- Chen, Y.; Dong, Z.; Wang, Y.; Su, J.; Han, Z.; Zhou, D.; Zhang, K.; Zhao, Y.; Bao, Y. Short-term wind speed predicting framework based on EEMD-GA-LSTM method under large scaled wind history. Energy Convers. Manag. 2021, 227, 113559. [Google Scholar] [CrossRef]
- Xie, Q.; Liu, R.; Li, J.; Wang, X. Multi-scale analysis of influencing factors for soybean futures price risk: Adaptive Fourier decomposition mathematical model applied for the case of China. Int. J. Wavelets Multiresolution Inf. Process. 2021, 19, 2150017. [Google Scholar] [CrossRef]
- Wang, D.; Yue, C.; Wei, S.; Lv, J. Performance analysis of four decomposition-ensemble models for one-day-ahead agricultural commodity futures price forecasting. Algorithms 2017, 10, 108. [Google Scholar] [CrossRef]
- Liu, H.; Shen, L. Forecasting carbon price using empirical wavelet transform and gated recurrent unit neural network. Carbon Manag. 2020, 11, 25–37. [Google Scholar] [CrossRef]
- Gao, X.; Li, X.; Zhao, B.; Ji, W.; Jing, X.; He, Y. Short-term electricity load forecasting model based on EMD-GRU with feature selection. Energies 2019, 12, 1140. [Google Scholar] [CrossRef] [Green Version]
- Liu, M.-D.; Ding, L.; Bai, Y.-L. Application of hybrid model based on empirical mode decomposition, novel recurrent neural networks and the ARIMA to wind speed prediction. Energy Convers. Manag. 2021, 233, 113917. [Google Scholar] [CrossRef]
- Jin, X.-B.; Yang, N.-X.; Wang, X.-Y.; Bai, Y.-T.; Su, T.-L.; Kong, J.-L. Deep hybrid model based on EMD with classification by frequency characteristics for long-term air quality prediction. Mathematics 2020, 8, 214. [Google Scholar] [CrossRef] [Green Version]
- Torres, M.E.; Colominas, M.A.; Schlotthauer, G.; Flandrin, P. A Complete Ensemble Empirical Mode Decomposition with Adaptive Noise. In Proceedings of the 2011 IEEE international Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 4144–4147. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.-C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. Lond. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, N.E. Ensemble empirical mode decomposition: A noise-assisted data analysis method. Adv. Adapt. Data Anal. 2009, 1, 1–41. [Google Scholar] [CrossRef]
- Chen, W.; Wang, Z.; Xie, H.; Yu, W. Characterization of Surface EMG Signal Based on Fuzzy Entropy. IEEE Trans. Neural Syst. Rehabilitation Eng. 2007, 15, 266–272. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A K-Means Clustering Algorithm. J. R. Stat. Soc. Ser. Appl. Stat. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar] [CrossRef]
- Ribeiro, M.H.D.M.; dos Santos Coelho, L. Ensemble approach based on bagging, boosting and stacking for short-term prediction in agribusiness time series. Appl. Soft Comput. 2020, 86, 105837. [Google Scholar] [CrossRef]
- Makala, D.; Li, Z. Prediction of Gold Price with ARIMA and SVM. J. Phys. Conf. Ser. 2021, 1767, 012022. [Google Scholar] [CrossRef]
- Do, Q.H.; Yen, T.T.H. Predicting primary commodity prices in the international market: An application of group method of data handling neural network. J. Manag. Inf. Decis. Sci. 2019, 22, 471–482. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object | Count | Mean | Min | Max | Standard Deviation |
|---|---|---|---|---|---|
| Soybean | 2505 | 4499.3869 | 3490.0000 | 6433.5400 | 779.6956 |
| Training set | 2255 | 4321.7175 | 3490.0000 | 6030.0000 | 592.3186 |
| Testing set | 250 | 6101.9643 | 5680.0000 | 6433.5400 | 270.3752 |
| IMF1 | IMF2 | IMF3 | IMF4 | IMF5 | IMF6 | IMF7 | IMF8 | Res |
|---|---|---|---|---|---|---|---|---|
| H1 | M1 | L1 | L2 | L3 | L4 | L5 | L6 | L7 |
| Model | Model Instruction | Abbreviation |
|---|---|---|
| Model 1 | Convolutional Neural Network | CNN |
| Model 2 | Combined model of Convolutional Neural Network and Gated Recurrent Unit | CNN-GRU |
| Model 3 | Combined model of Convolutional Neural Network and Gated Recurrent Unit with Attention mechanism | CNN-GRU-Attention |
| Model 4 | Gated Recurrent Unit | GRU |
| Model 5 | Gated Recurrent Unit with Attention mechanism | GRU-Attention |
| Model 6 | Long Short-term Memory network | LSTM |
| Model 7 | Multilayer Perceptron model | MLP |
| Model 8 | Support Vector Regression model | SVR |
| Model 9 | A hybrid model by integrating CEEMDAN with fuzzy entropy clustering and CNN | CEEMDAN-CNN |
| Model 10 | A hybrid model by integrating CEEMDAN with fuzzy entropy clustering and CNN-GRU | CEEMDAN-CNN-GRU |
| Model 11 (Proposed model) | A hybrid model by integrating CEEMDAN with fuzzy entropy clustering and CNN-GRU with Attention mechanism | CEEMDAN-CNN-GRU-Attention |
| Model 12 | A hybrid model by integrating CEEMDAN with fuzzy entropy clustering and GRU | CEEMDAN-GRU |
| Model 13 | A hybrid model by integrating CEEMDAN with fuzzy entropy clustering and GRU with Attention mechanism | CEEMDAN-GRU-Attention |
| Model 14 | A hybrid model by integrating CEEMDAN with fuzzy entropy clustering and LSTM | CEEMDAN-LSTM |
| Model 15 | A hybrid model by integrating CEEMDAN with fuzzy entropy clustering and MLP | CEEMDAN-MLP |
| Model 16 | A hybrid model by integrating CEEMDAN with fuzzy entropy clustering and SVR | CEEMDAN-SVR |
| Model 17 | A hybrid model by integrating EMD with fuzzy entropy clustering and CNN-GRU with Attention mechanism | EMD-CNN-GRU-Attention |
| Model 18 | A hybrid model by integrating EEMD with fuzzy entropy clustering and CNN-GRU with Attention mechanism | EEMD-CNN-GRU-Attention |
| Models | Parameters | Values |
|---|---|---|
| CNN | Filters | 64 |
| Kernel size | 2 | |
| Activation | Relu | |
| Pooling size | 2 | |
| Flatten | - | |
| Epochs | 500 | |
| Batch size | 64 | |
| GRU | Neurons | 128 |
| Activation | tanh | |
| Epochs | 500 | |
| Batch size | 64 | |
| Attention | Weights compute | Softmax |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, D.; Tang, Z.; Cai, Y. A Hybrid Model for China’s Soybean Spot Price Prediction by Integrating CEEMDAN with Fuzzy Entropy Clustering and CNN-GRU-Attention. Sustainability 2022, 14, 15522. https://doi.org/10.3390/su142315522
Liu D, Tang Z, Cai Y. A Hybrid Model for China’s Soybean Spot Price Prediction by Integrating CEEMDAN with Fuzzy Entropy Clustering and CNN-GRU-Attention. Sustainability. 2022; 14(23):15522. https://doi.org/10.3390/su142315522
Chicago/Turabian StyleLiu, Dinggao, Zhenpeng Tang, and Yi Cai. 2022. "A Hybrid Model for China’s Soybean Spot Price Prediction by Integrating CEEMDAN with Fuzzy Entropy Clustering and CNN-GRU-Attention" Sustainability 14, no. 23: 15522. https://doi.org/10.3390/su142315522