

Teacher-Assistant Knowledge Distillation Based Indoor Positioning System

Abstract
:1. Introduction
- Two CNN-based IPS with different complexities are generated to prove that the model’s complexity will affect the performance of the positioning system. Then, knowledge distillation is performed so that the simple model can mimic the performance of the larger model.
- Two CNN-based algorithms are developed as the teacher assistant model. Then, we proposed a TAKD framework to distill knowledge from the pre-trained teacher model to the teacher assistant model and lastly, to the student model. Ultimately, we investigate the benefit of employing the proposed technique by comparing the performance of IPSs that utilize the TAKD framework, the baseline KD framework and the performance of CNN-based IPS.
2. Related Works
3. Existing Methods
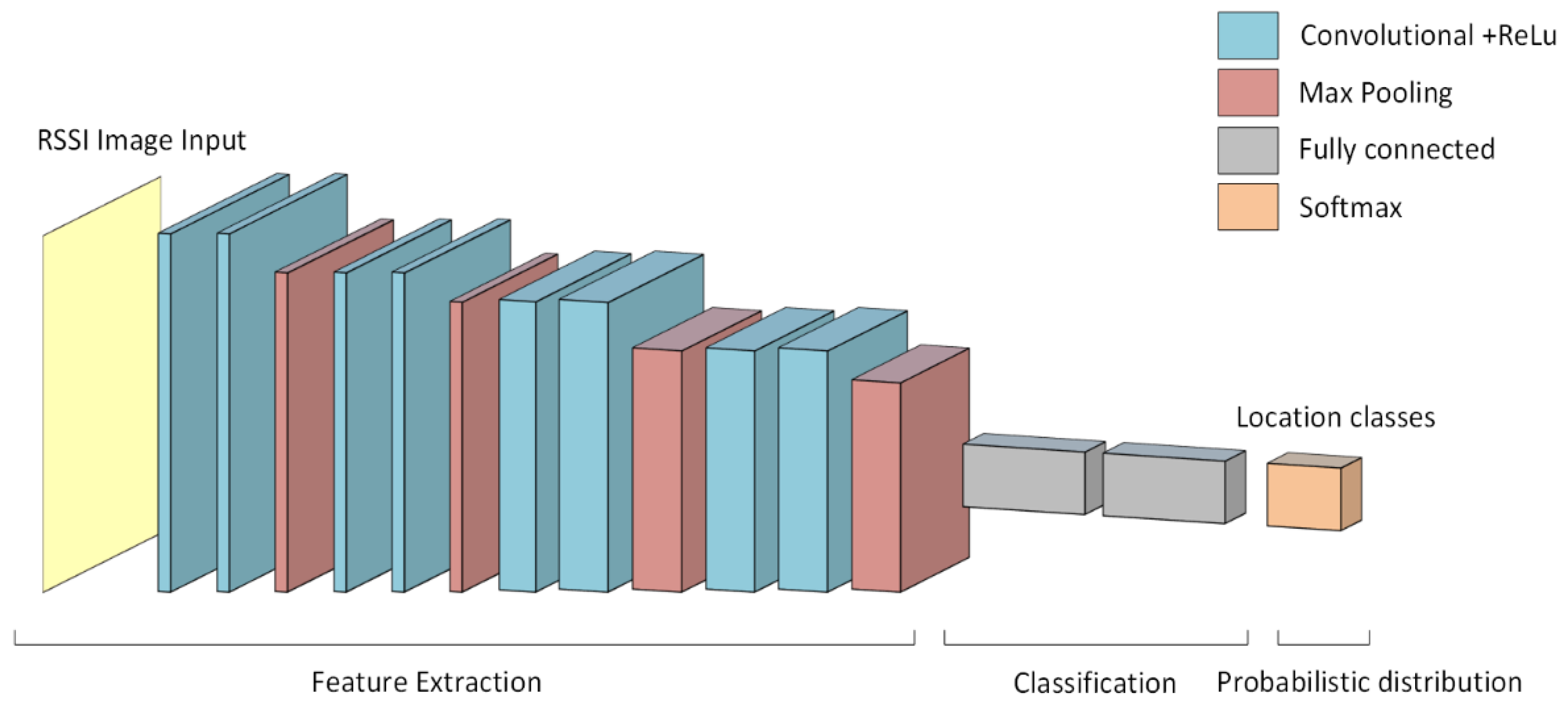
3.1. CNN-Based IPS
3.2. Knowledge Distillation CNN-IPS (KD-CNN-IPS)
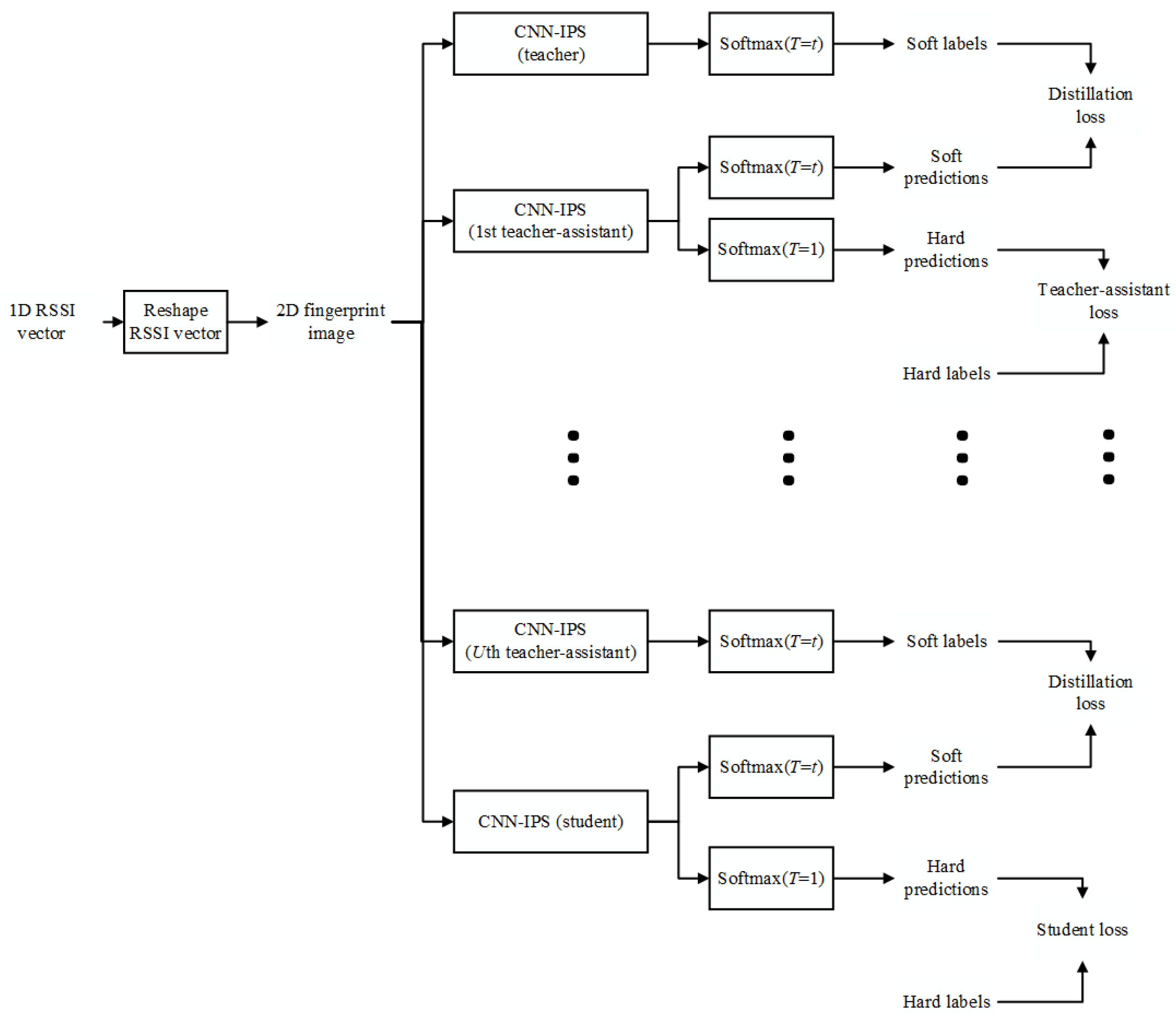
4. Teacher-Assistant Knowledge Distillation Based Indoor Positioning System
| Algorithm 1: Teacher-assistant knowledge distillation | |||||
| Input: : The RSS value of the nth sample from the kth AP N: Total number of samples K: Total number of APs | |||||
| Output: Location class | |||||
| 1 | : | if where c2 is an integer then | |||
| 2 | : | is padded with 0. | |||
| 3 | : | end if | |||
| 4 | : | is transformed into . | |||
| 5 | : | for do | |||
| Train the teacher model | |||||
| 6 | : | Employ as the input of the teacher model. | |||
| 7 | : | Apply (3) to calculate the soft labels for the teacher network. | |||
| Train the teacher-assistant model | |||||
| 8 | : | for do | |||
| 9 | : | Employ as the input of the teacher-assistant model. | |||
| 10 | : | Apply (1) to generate the uth teacher assistant’s hard predictions. | |||
| 11 | : | Apply (3) to generate the uth teacher assistant’s soft prediction . | |||
| 12 | : | Execute (2) to calculate teacher-assistant cross-entropy loss. | |||
| 13 | : | if u = 1 then | |||
| 14 | : | Execute (5) to calculate distillation loss. | |||
| 15 | : | Apply loss function from (7) to train the teacher-assistant model. | |||
| 16 | : | if u > 1 then | |||
| 17 | : | Execute (5) to calculate distillation loss. | |||
| 18 | : | Apply loss function from (8) to train the teacher-assistant model. | |||
| 19 | : | end if | |||
| end for | |||||
| Train the student model | |||||
| 20 | : | Apply as the input of the student model. | |||
| 21 | : | Apply (1) to generate student’s hard predictions. | |||
| 22 | : | Apply (3) to generate student’s soft prediction . | |||
| 23 | : | Execute (2) to calculate student cross-entropy loss. | |||
| 24 | : | Execute (5) to calculate distillation loss. | |||
| 25 | : | Apply loss function from (9) to train the student model. | |||
| 26 | : | end | |||
5. Results and Analysis
5.1. Simulation Setting
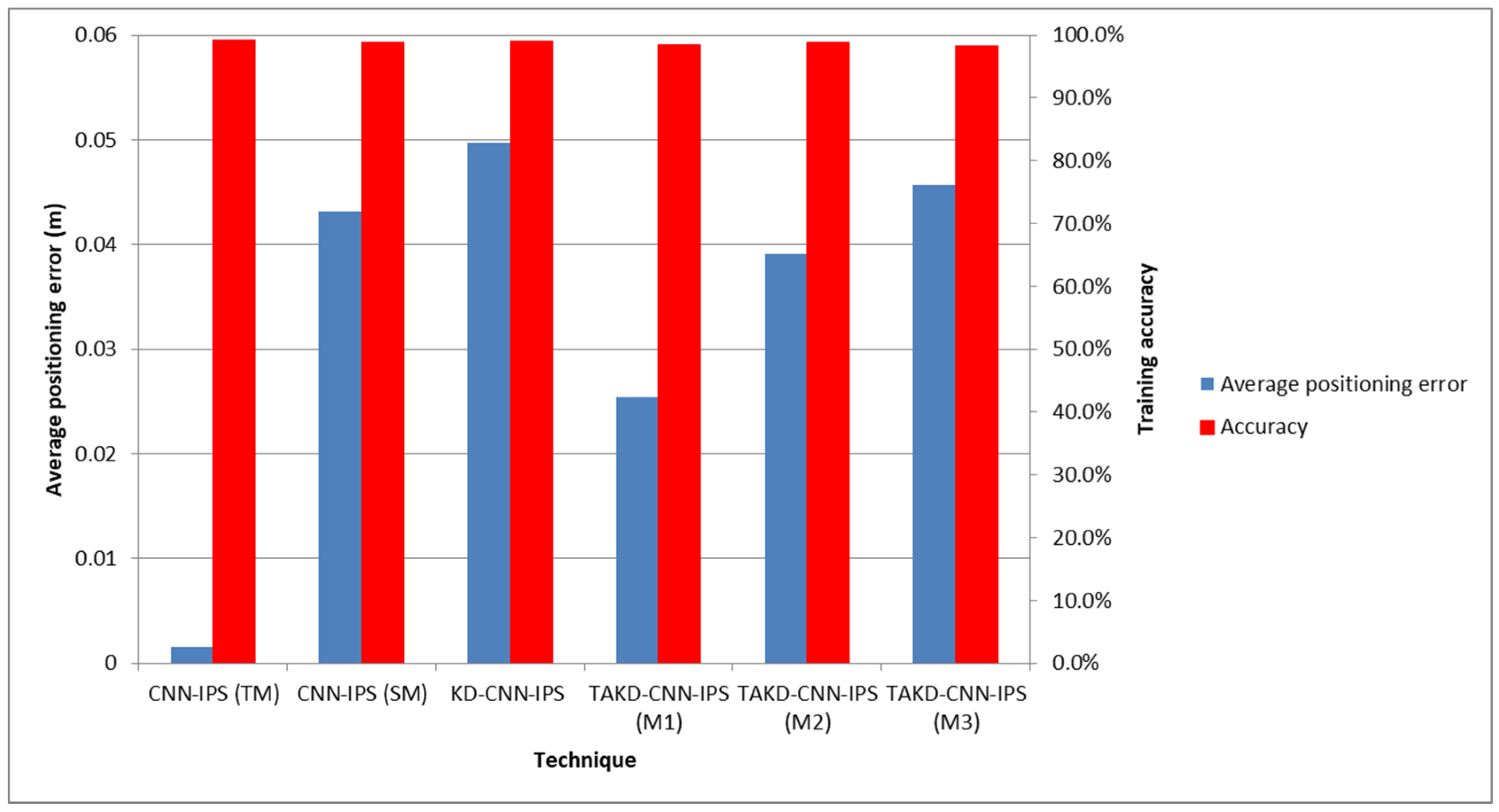
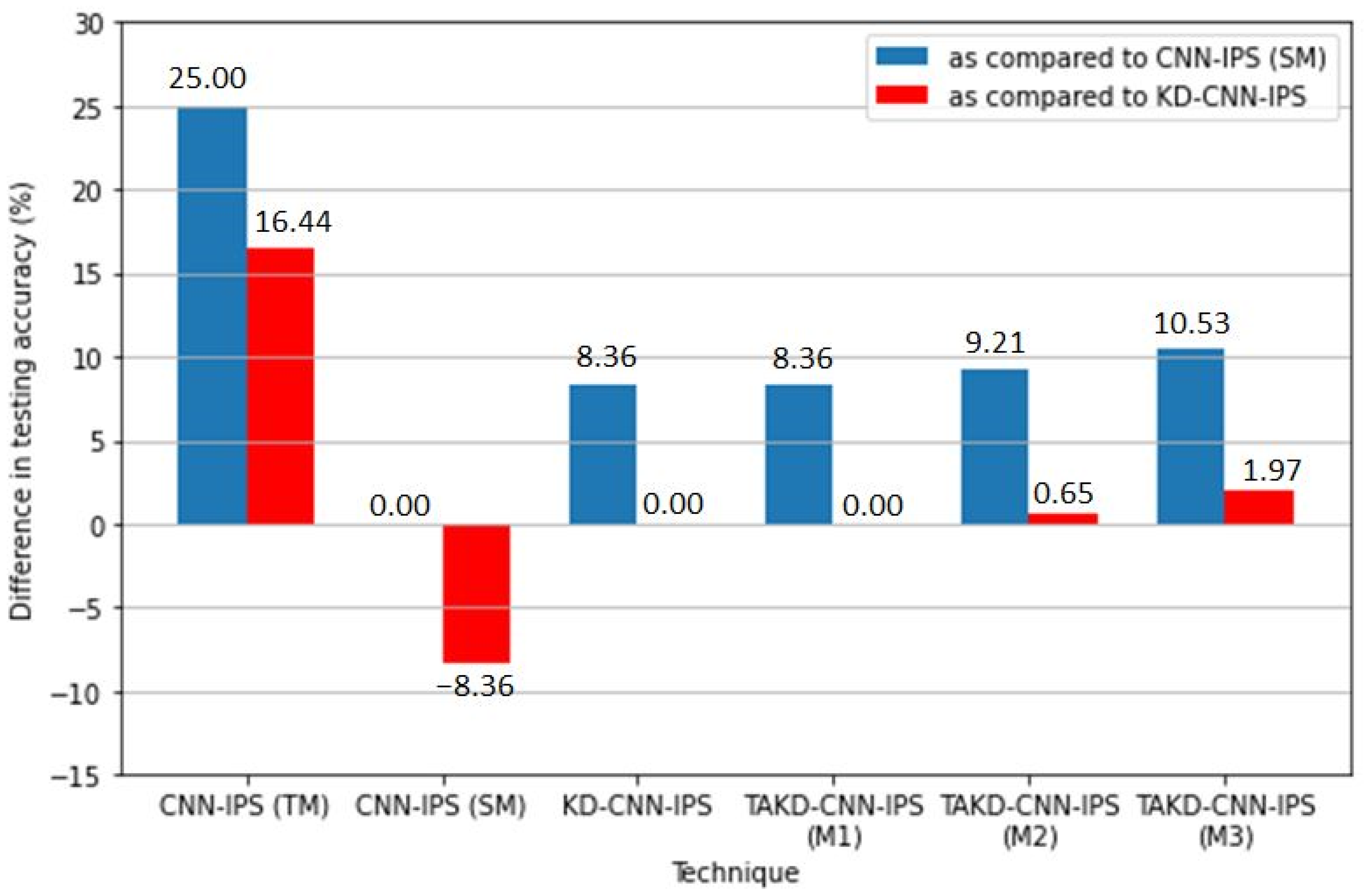
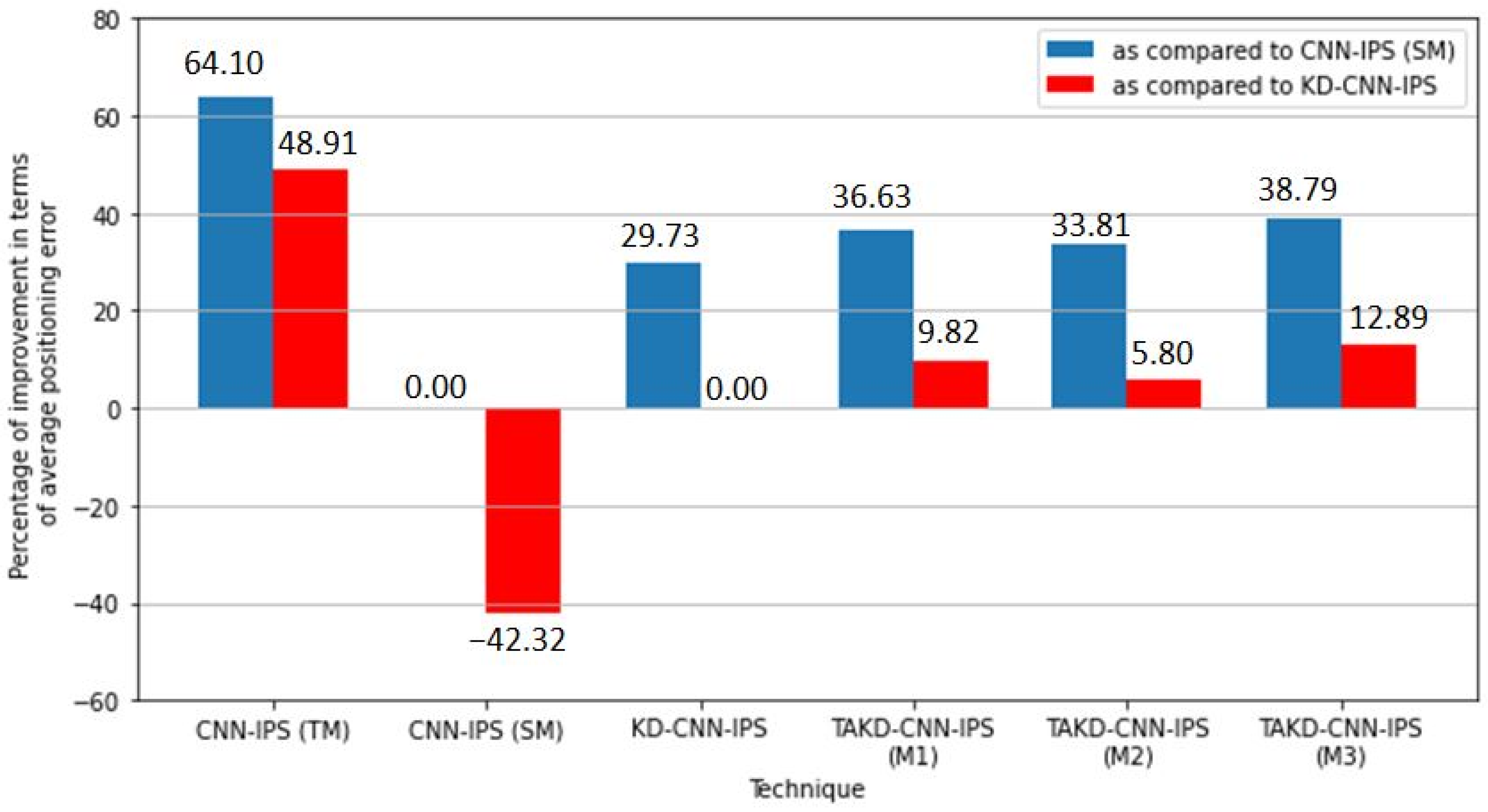
5.2. Results and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gupta, R.; Rao, U.P. An Exploration to Location Based Service and Its Privacy Preserving Techniques: A Survey. Wirel. Pers. Commun. 2017, 96, 1973–2007. [Google Scholar] [CrossRef]
- Statista. Number of Location-Based Service Users in the United States from 2013 to 2018 (in Millions). 2015. Available online: http://www.statista.com/statistics/436071/location-based-service-users-usa/ (accessed on 30 May 2022).
- Mahida, P.; Shahrestani, S.; Cheung, H. Deep Learning-Based Positioning of Visually Impaired People in Indoor Environments. Sensors 2020, 20, 6238. [Google Scholar] [CrossRef] [PubMed]
- Hung, C.-H.; Fanjiang, Y.-Y.; Lee, Y.-S.; Wu, Y.-C. Design and Implementation of an Indoor Warning System with Physiological Signal Monitoring for People Isolated at Home. Sensors 2022, 22, 590. [Google Scholar] [CrossRef] [PubMed]
- Indoor Positioning and Navigation Market—Forecast (2020–2025). Available online: https://www.researchandmarkets.com/reports/4531980/indoor-positioning-and-navigation-market#:~:text=The%20global%20Indoor%20Positioning%20and,at%20a%20CAGR%20of%2027.9%25 (accessed on 30 May 2022).
- Mainetti, L.; Patrono, L.; Sergi, I. A Survey on Indoor Positioning Systems. In Proceedings of the 22nd International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Split, Croatia, 17–19 September 2014. [Google Scholar]
- Obeidat, H.; Shuaieb, W.; Obeidat, O.; Abd-Alhameed, R. A Review of Indoor Localization Techniques and Wireless Technologies. Wirel. Pers. Commun. 2021, 119, 289–327. [Google Scholar] [CrossRef]
- Gentile, C.; Alsindi, N.; Raulefs, R.; Teolis, C. Geolocation Techniques: Principles and Applications; Springer: New York, NY, USA, 2013. [Google Scholar]
- Liu, Y.; Yang, Z.; Wang, X.; Jian, L. Location, Localization, and Localizability. J. Comput. Sci. Technol. 2010, 25, 274–297. [Google Scholar] [CrossRef] [Green Version]
- Yu, X.-M.; Wang, H.; Wu, J. A method of fingerprint indoor localization based on received signal strength difference using compressive sensing. EURASIP J. Wirel. Commun. Netw. 2020, 2020, 72. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.; Qu, W.; Qiu, T.; Zhao, L.; Atiquzzaman, M.; Wu, D.O. Indoor Intelligent Fingerprint-Based Localization: Principes, Approaches and Challenges. IEEE Commun. Surv. Tutor. 2020, 22, 2634–2657. [Google Scholar] [CrossRef]
- Basiri, A.; Lohan, E.S.; Moore, T.; Winstanley, A.; Peltola, P.; Hill, C.; Amirian, P.; e Silva, P.F. Indoor location based services challenges, requirements and usability of current solutions. Comput. Sci. Rev. 2017, 24, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Al-Ayyoub, M.; Nuseir, A.; Alsmearat, K.; Jararweh, Y.; Gupta, B. Deep learning for Arabic NLP: A survey. J. Comput. Sci. 2018, 26, 522–531. [Google Scholar] [CrossRef]
- Nagajyothi, D.; Siddaiah, P. Speech Recognition Using Convolutional Neural Networks. Int. J. Eng. Technol. 2018, 7, 133–137. [Google Scholar] [CrossRef]
- Jiao, L.; Zhao, J. A Survey on the New Generation of Deep Learning in Image Processing. IEEE Access 2019, 7, 172231–172263. [Google Scholar] [CrossRef]
- Jang, J.-W.; Hong, S.-H. Indoor Localization with Wi-Fi Fingerprinting Using Convolutional Neural Network. In Proceedings of the 2018 Tenth International Conference on Ubiquitous and Future Networks (ICUFN), Prague, Czech Republic, 3–6 July 2018. [Google Scholar]
- Mirzadeh, S.I.; Farajtabar, M.; Li, A.; Levine, N.; Matsukawa, A.; Ghasemzadeh, H. Improved Knowledge Distillation via Teacher Assistant. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Bahl, P.; Padmanabhan, V.N. RADAR: An In-Building RF-Based user Location and Tracking System. In Proceedings of the Conference on Computer Communications. nineteenth Annual Joint Conference of the IEEE Computer and Communications Societies, Tel Aviv, Israel, 20–26 March 2000. [Google Scholar]
- Torres-Sospedra, J.; Montoliu, R.; Martinez-Uso, A.; Avariento, J.P.; Arnau, T.J.; Benedito-Bordonau, M.; Huerta, J. UJIIndoorLoc: A New Multi-Building and Multi-Floor Database for WLAN Fingerprint-Based Indoor Localization Problems. In Proceedings of the 2014 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Busan, Korea, 27–30 October 2014. [Google Scholar]
- Torres-Sospedra, J.; Montoliu, R.; Trilles, S.; Belmonte, O.; Huerta, J. Comprehensive analysis of distance and similarity measures for Wi-Fi fingerprinting indoor positioning system. Expert Syst. Appl. 2015, 42, 9263–9278. [Google Scholar] [CrossRef]
- Yim, J. Introducing a decision tree-based indoor positioning technique. Expert Syst. Appl. 2008, 34, 1296–1302. [Google Scholar] [CrossRef]
- Calderoni, L.; Ferrara, M.; Franco, A.; Maio, D. Indoor localization in a hospital environment using Random Forest classifiers. Expert Syst. Appl. 2015, 42, 125–134. [Google Scholar] [CrossRef]
- Wang, P.; Fan, E.; Wang, P. Comparative analysis of image classification algorithms based on traditional machine learning and deep learning. Pattern Recognit. Lett. 2020, 141, 61–67. [Google Scholar] [CrossRef]
- Zhang, W.; Liu, K.; Zhang, W.; Zhang, Y.; Gu, J. Deep Neural Networks for wireless localization in indoor and outdoor environments. Neurocomputing 2016, 194, 279–287. [Google Scholar] [CrossRef]
- Nowicki, M.; Wietrzykowski, J. Low-Effort Place Recognition with WiFi Fingerprints Using Deep Learning. In Automation 2017; Szewczyk, R., Zieliński, C., Kaliczyńska, M., Eds.; Springer: Cham, Switzerland, 2017; Volume 550, pp. 575–584. [Google Scholar]
- Kim, K.S.; Lee, S.; Huang, K. A scalable deep neural network architecture for multi-building and multi-floor indoor localization based on Wi-Fi fingerprinting. Big Data Anal. 2018, 3, 4. [Google Scholar] [CrossRef] [Green Version]
- Mitall, A.; Tiku, S.; Pascricha, S. Adapting Convolutional Neural Networks for Indoor Localization with Smart Mobile Devices. In Proceedings of the 2018 on Great Lakes Symposium on VSLI, Chicago, IL, USA, 23–25 May 2018. [Google Scholar]
- Song, X.; Fan, X.; He, X.; Xiang, C.; Ye, Q.; Huang, X.; Fang, G.; Chen, L.L.; Qin, J.; Wang, Z. CNNLoc: Deep-Learning Based Indoor Localization with Wi-Fi Fingerprinting. In Proceedings of the 2019 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation, Liecester, UK, 19–23 August 2019. [Google Scholar]
- Mazlan, A.B.; Ng, Y.H.; Tan, C.K. A Fast Indoor Positioning Using a Knowledge-Distilled Convolutional Neural Network (KD-CNN). IEEE Access 2022, 10, 65326–65338. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. In Proceedings of the NIPS Deep Learning and Representation Learning Workshop, Montréal, QC, Canada, 12 December 2014. [Google Scholar]
- Alkhulaifi, A.; Alsahli, F.; Ahmad, I. Knowledge distillation in deep learning and its application. PeerJ Comput. Sci. 2021, 7, 474. [Google Scholar] [CrossRef] [PubMed]
- Montoliu, R.; Sansano, E.; Torres-Sospedra, J.; Belmonte, O. IndoorLoc platform: A Public Repository for Comparing and Evaluating Indoor Positioning Systems. In Proceedings of the 2017 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Sapporo, Japan, 18–21 September 2017. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Work | Methods | Motive | Input Variable (s) | Output | Findings | Limitation |
|---|---|---|---|---|---|---|
| [18] | kNN algorithm, with a Euclidean distance similarity metric | Build a RF based locating and tracking system | WiFi RSS | Estimated position | The first WiFi fingerprinting system RADAR. Median localization error of 2.94 m. | Poor positioning performance in complex indoor environment due to its inability to fully learn reliable feature from training data. |
| [19] | 1-NN algorithm, with a Euclidean distance similarity metric | Create database for multi-floor and multi-building localization comparison | 520 WiFi RSS | Estimated floor, estimated building and estimated position (x, y) | The positioning system achieves a mean error of 7.9 m and a success rate of 89.92%. | Poor positioning performance |
| [21] | Decision tree | Build an efficient positioning technique using fingerprint method | WiFi RSS | Estimated position | Achieved a higher computational efficiency than 1-NN | Poor positioning performance |
| [24] | DNN pretrained by SDA + HMM | Build an indoor/outdoor wireless positioning | 163 WiFi RSS | Estimated grid | RMSE of 0.39 m for indoor environment. | High computational complexity |
| [25] | DNN(SAE) | Build a multi-building and multi-floor classification | 520 WiFi RSS | Estimated building and floor | Classification accuracy of 92% | The approach only consider building and floor estimation, therefore it does not estimate any specific coordinate. |
| [26] | DNN(SAE+ feed-forward multi-label classifier) | Build a scalable deep learning architecture for multi-building and multi-floor | 520 WiFi RSS | Estimated floor, estimated building and estimated position (x, y) | Positioning error of 9.29 m and the building and floor success rate is 99.82% and 91.27% respectively. | High computational complexity |
| [27] | CNN | Extract images out of fingerprint to train CNN | WiFi RSS | Fine-grain location | Lowest mean error compared to DNN, SVR and KNN Average localization error of less than 2 m. | High computational complexity |
| [28] | 1D-CNN +SAE | Build a deep-learning model for multi-building and multi-floor indoor localization | 520 WiFi RSS | Estimated floor, estimated building and estimated position (x, y) | Achieved highest floor success rate compared to other technique Success rate of building and floor localization is 100% and 95% respectively. Positioning errors of 7.6 m | High computational complexity |
| [29] | KD-CNN | Improve the performance of a simple CNN-IPS model | 14 BLE RSS | Location class (x, y, z) | The KD-CNN-IPS achieve better accuracy and average error than CNN-IPS. Positioning error as low as 1.5 m is achieved. | Poor positioning performance when the complexity gap between the teacher and student models is large. |
| CNN Model | Settings |
|---|---|
| Size 8 | No of convolutional layers: 8 Filter size: 2 × 2 No of filters: 32, 32, 32, 32, 128, 128, 128, 128 Activation function after convolutional layers: ReLU No of max pooling layers: 4 Kernel size: 2 × 2 Strides: 1 × 1 Fully connected layers: 10368 nodes Hidden layer: 110 nodes Output: 110 nodes |
| Size 6 | No of convolutional layers: 6 Filter size: 2 × 2 No of filters: 32, 32, 32, 32, 32, 32 Activation function after convolutional layers: ReLU No of max pooling layers: 3 Kernel size: 2 × 2 Strides: 1 × 1 Fully connected layers: 3200 nodes Hidden layer: 110 nodes Output: 110 nodes |
| Size 4 | No of convolutional layers: 4 Filter size: 2 × 2 No of filters: 32, 32, 32, 32 Activation function after convolutional layers: ReLU No of max pooling layers: 2 Kernel size: 2 × 2 Strides: 1 × 1 Fully connected layers: 3872 nodes Hidden layer: 110 nodes Output: 110 nodes |
| Size 1 | No of convolutional layers: 1 Filter size: 3 × 3 No of filters: 16 Activation function after convolutional layers: ReLU No of max pooling layers: 1 Kernel size: 2 × 2 Strides: 2 × 2 Fully connected layers: 576 nodes Output: 110 nodes |
| Technique | Model Training Paths | Hyperparameters Setting | |
|---|---|---|---|
| Overall Path | Individual Path | ||
| CNN-IPS (TM) | Size 8 | Size 8 | Epochs: 426 |
| CNN-IPS (SM) | Size 1 | Size 1 | Epochs: 100 |
| KD-CNN-IPS | Size 8 -> Size 1 | Size 8 | Epochs: 426 |
| Size 8 -> Size 1 | Epochs: 100 T: 2 𝛼: 0.1 | ||
| TAKD-CNN-IPS (M1) | Size 8 -> Size 4 -> Size 1 | Size 8 | Epochs: 426 |
| Size 8 -> Size 4 | Epochs: 100 T: 2 𝛼: 0.1 | ||
| Size 4 -> Size 1 | Epochs: 100 T: 2 𝛼: 0.1 | ||
| TAKD-CNN-IPS (M2) | Size 8 -> Size 6 -> Size 1 | Size 8 | Epochs: 426 |
| Size 8 -> Size 6 | Epochs: 100 T: 2 𝛼: 0.1 | ||
| Size 6 -> Size 1 | Epochs: 100 T: 2 𝛼: 0.1 | ||
| TAKD-CNN-IPS (M3) | Size 8 -> Size 6 -> Size 4 -> Size 1 | Size 8 | Epochs: 426 |
| Size 8 -> Size 6 | Epochs: 100 T: 2 𝛼: 0.5 | ||
| Size 6 -> Size 4 | Epochs: 100 T: 2 𝛼: 0.3 | ||
| Size 4 -> Size 1 | Epochs: 100 T: 2 𝛼: 0.1 | ||
| Phase | Classification Performance | CNN-IPS (TM) | CNN-IPS (SM) |
|---|---|---|---|
| Training | Accuracy | 0.9912 | 0.9875 |
| Loss | 0.0341 | 0.0819 | |
| Testing | Accuracy | 0.7368 | 0.4868 |
| Loss | 3.2395 | 4.5638 | |
| Average positioning error (m) | 0.8003 | 2.2291 | |
| Min positioning error (m) | 0 | 0 | |
| Max positioning error (m) | 10.6820 | 15.1630 | |
| 25th percentile (m) | 0 | 0 | |
| 50th percentile (m) | 0 | 0.9900 | |
| 75th percentile (m) | 1.0100 | 3.0804 | |
| 95th percentile (m) | 3.9280 | 8.3371 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mazlan, A.B.; Ng, Y.H.; Tan, C.K. Teacher-Assistant Knowledge Distillation Based Indoor Positioning System. Sustainability 2022, 14, 14652. https://doi.org/10.3390/su142114652
Mazlan AB, Ng YH, Tan CK. Teacher-Assistant Knowledge Distillation Based Indoor Positioning System. Sustainability. 2022; 14(21):14652. https://doi.org/10.3390/su142114652
Chicago/Turabian StyleMazlan, Aqilah Binti, Yin Hoe Ng, and Chee Keong Tan. 2022. "Teacher-Assistant Knowledge Distillation Based Indoor Positioning System" Sustainability 14, no. 21: 14652. https://doi.org/10.3390/su142114652