
A New Hybrid Model for Mapping Spatial Accessibility to Healthcare Services Using Machine Learning Methods

 , ,
, ,
Abstract
:1. Introduction
- What are the drawbacks of current spatial accessibility measures and methods?
- Are ML methods suitable for mapping spatial accessibility?
- How is the spatial accessibility to healthcare facilities and services in Isfahan from an ML perspective?
2. Literature Review and Background
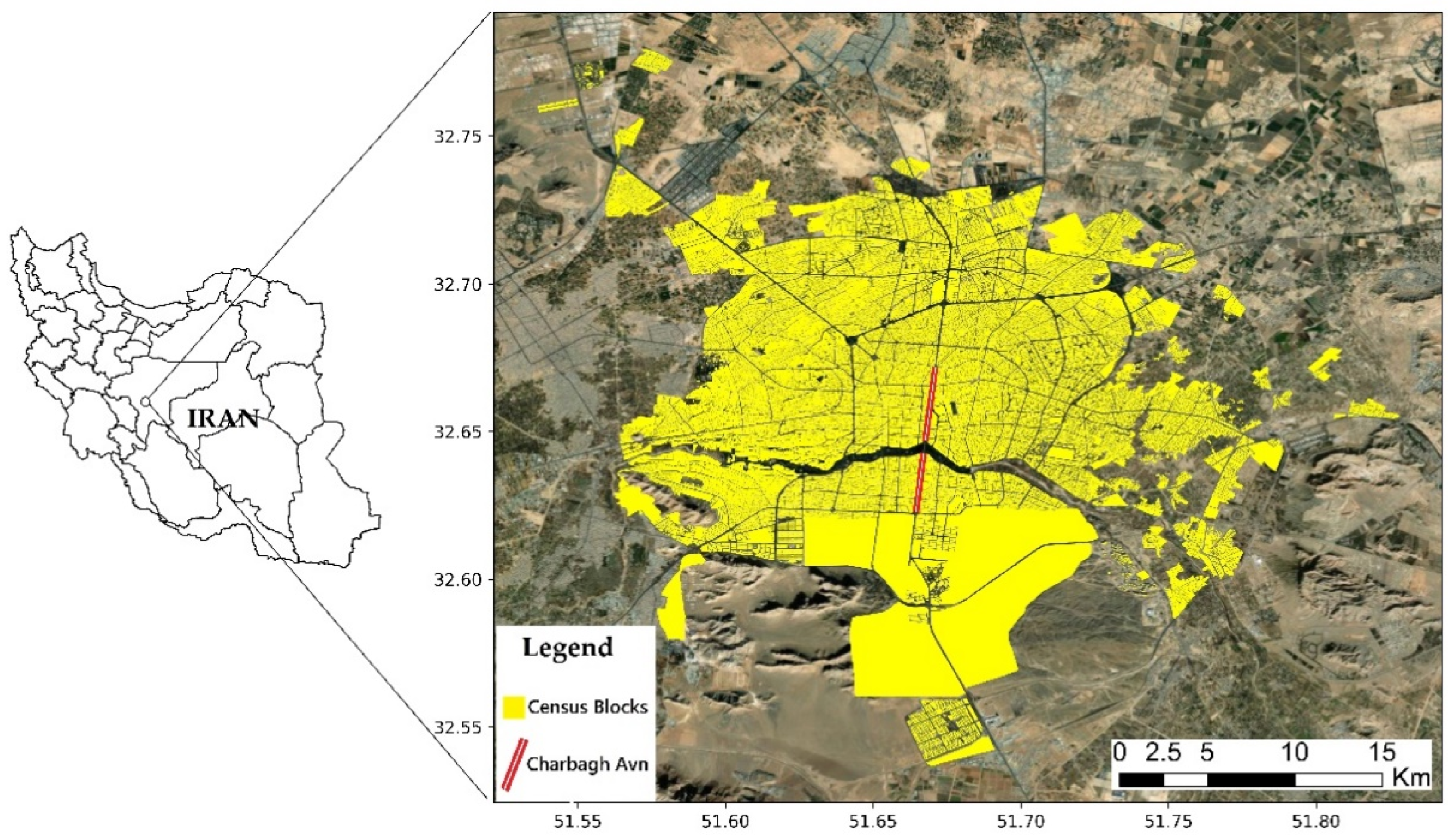
3. Case Study
4. Data and Methods
4.1. Data
4.2. Methodology
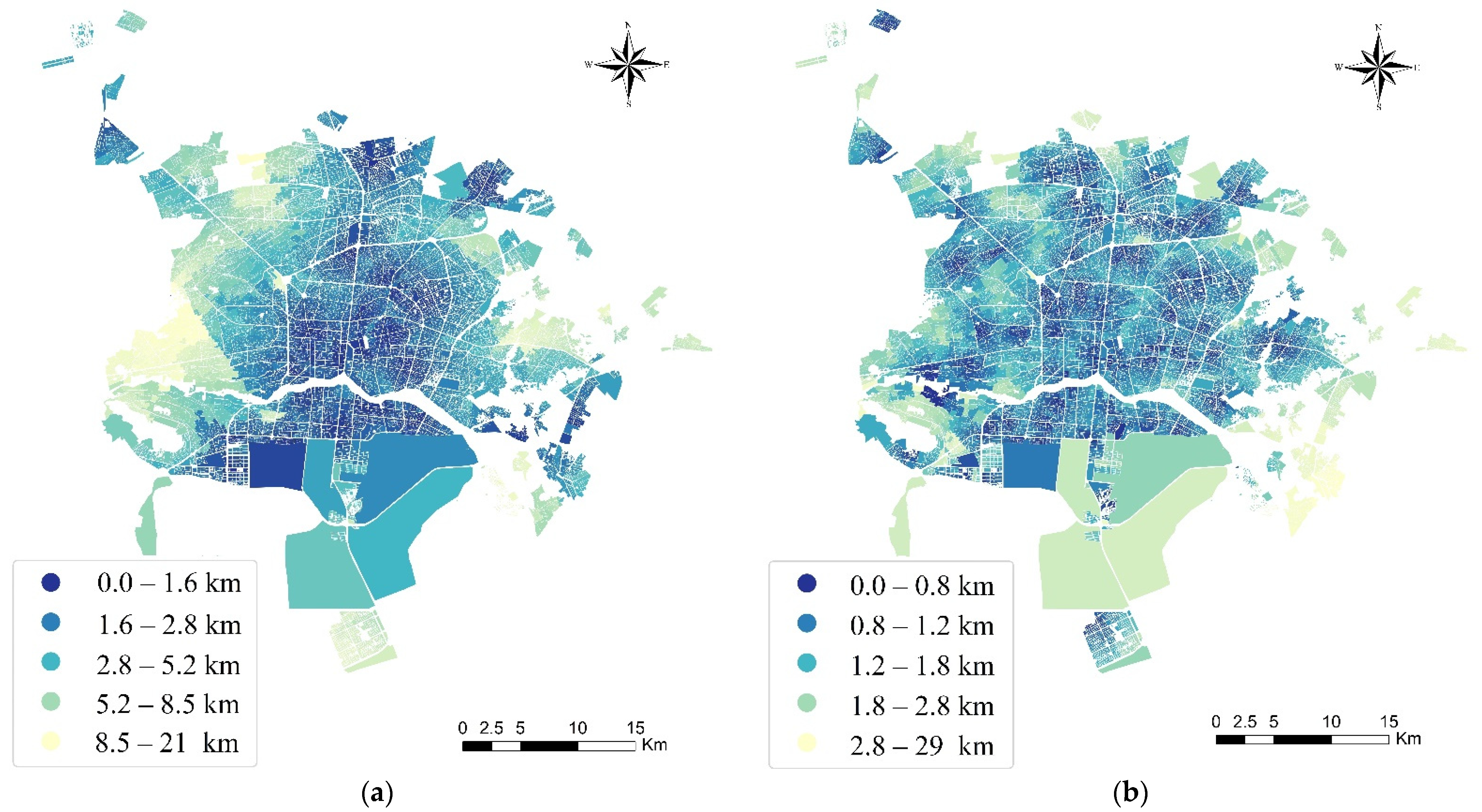
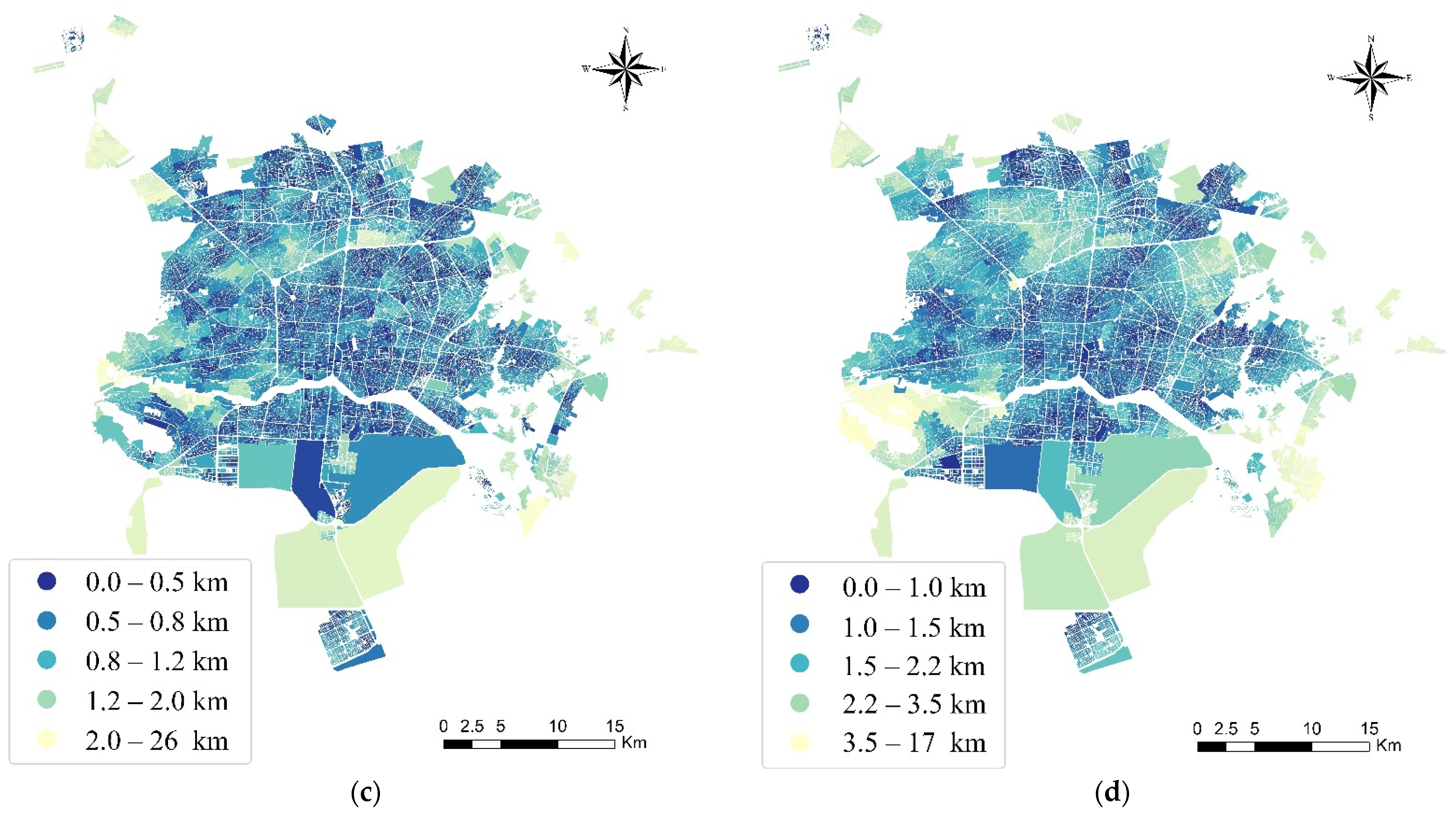
4.2.1. Distance Measurement
4.2.2. Weighting Variables
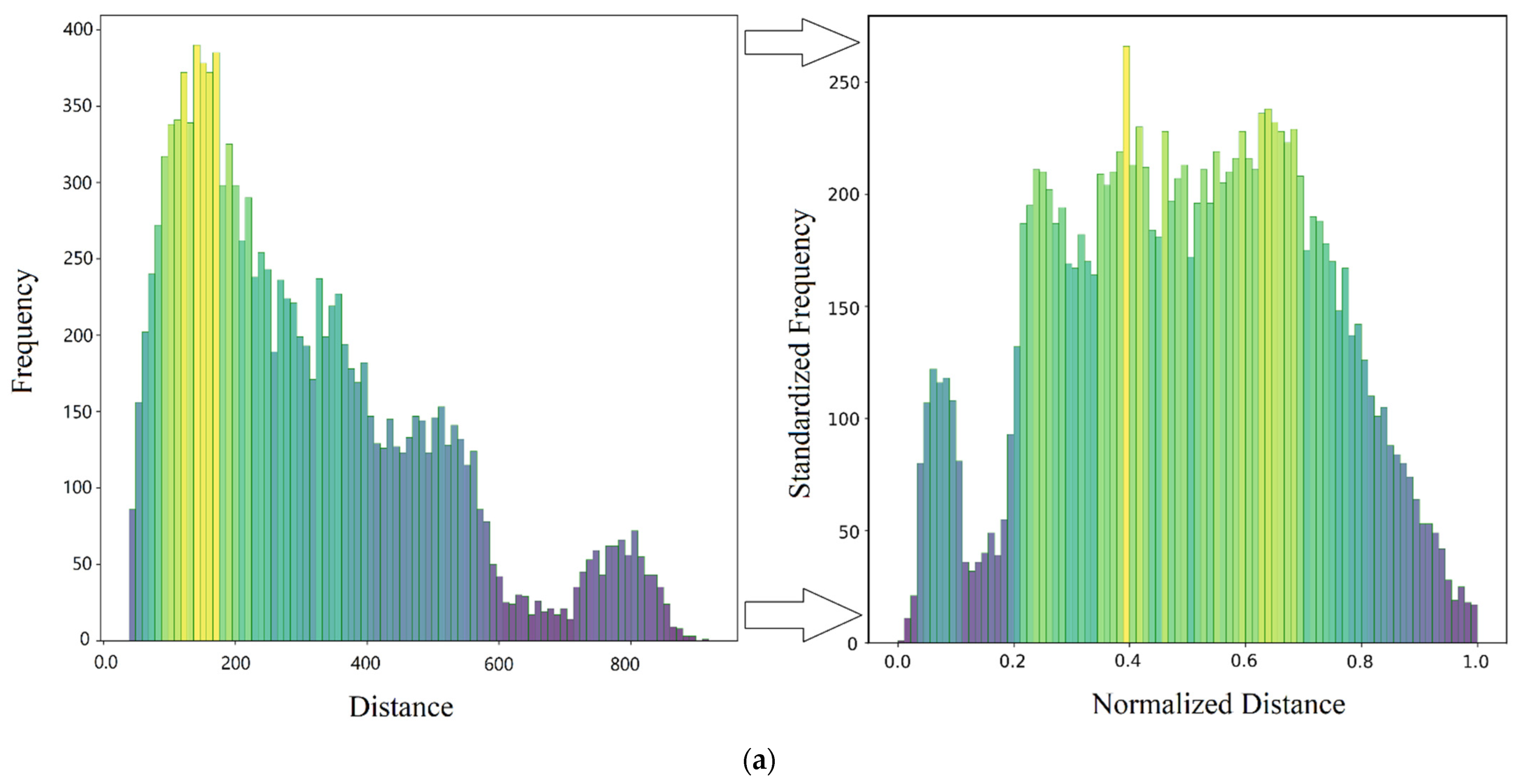
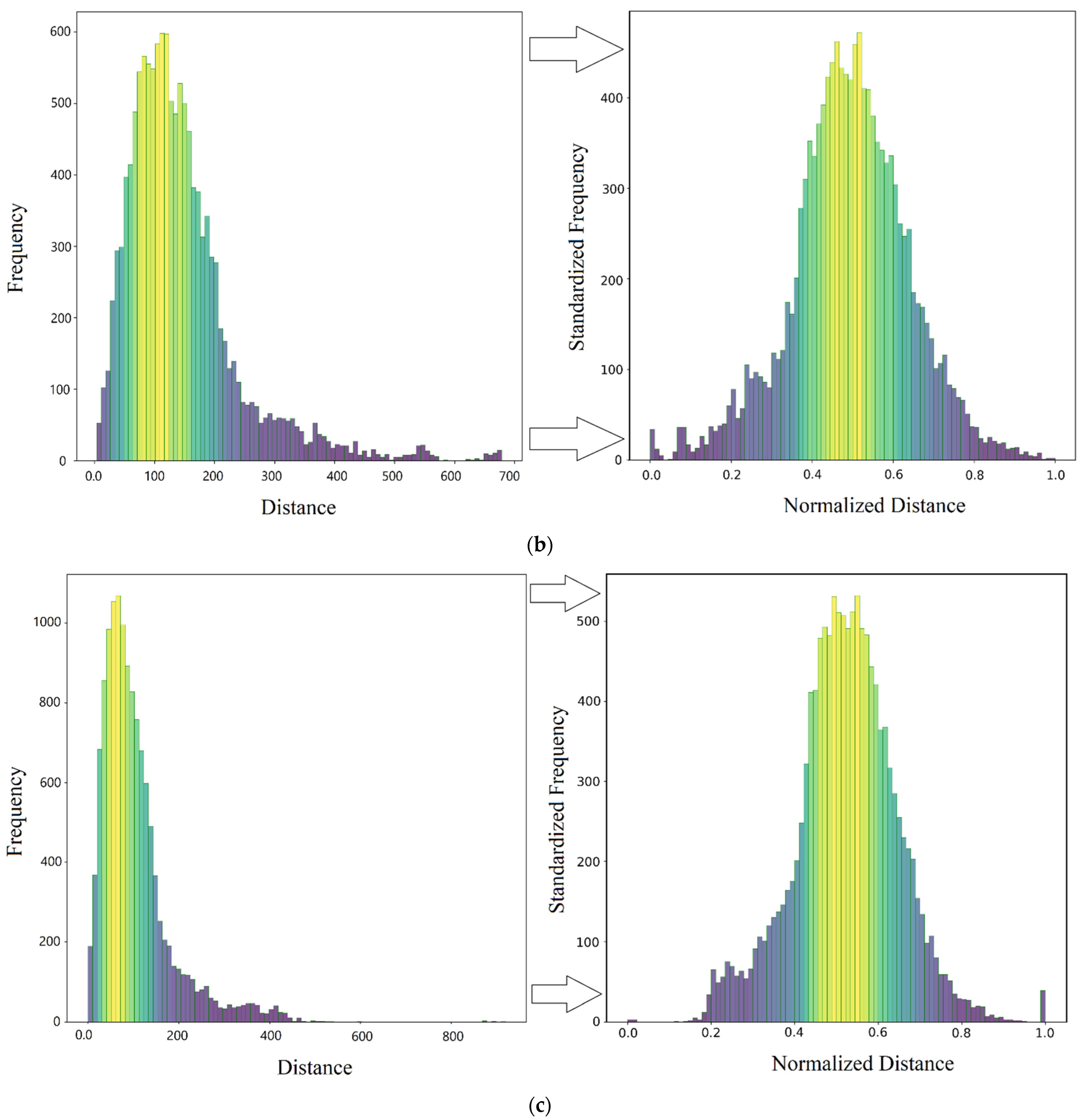
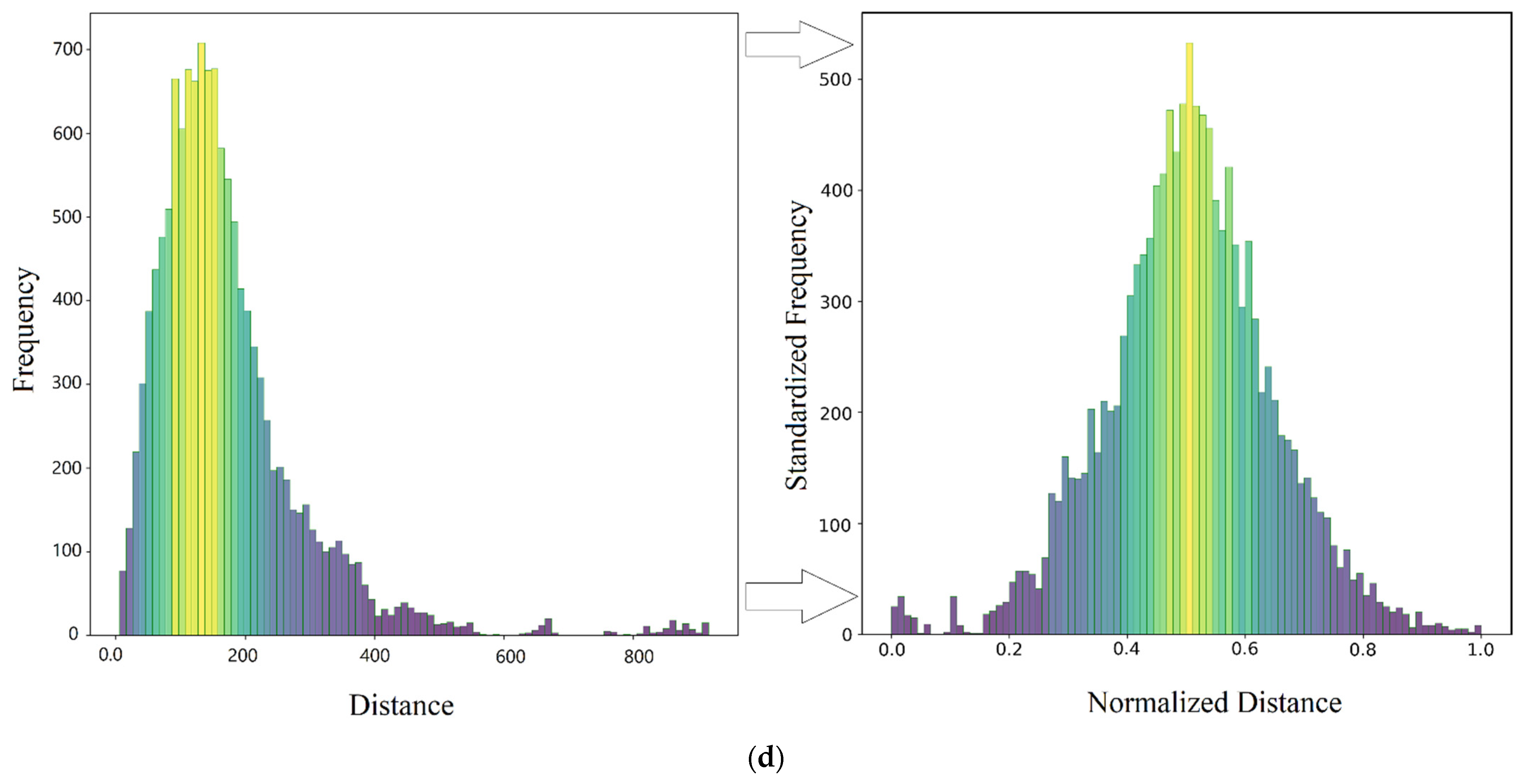
Normalization of Variables
Calculation of the Variable’s Entropy
Calculation of the Variable’s Entropy Weight
4.2.3. Standardization
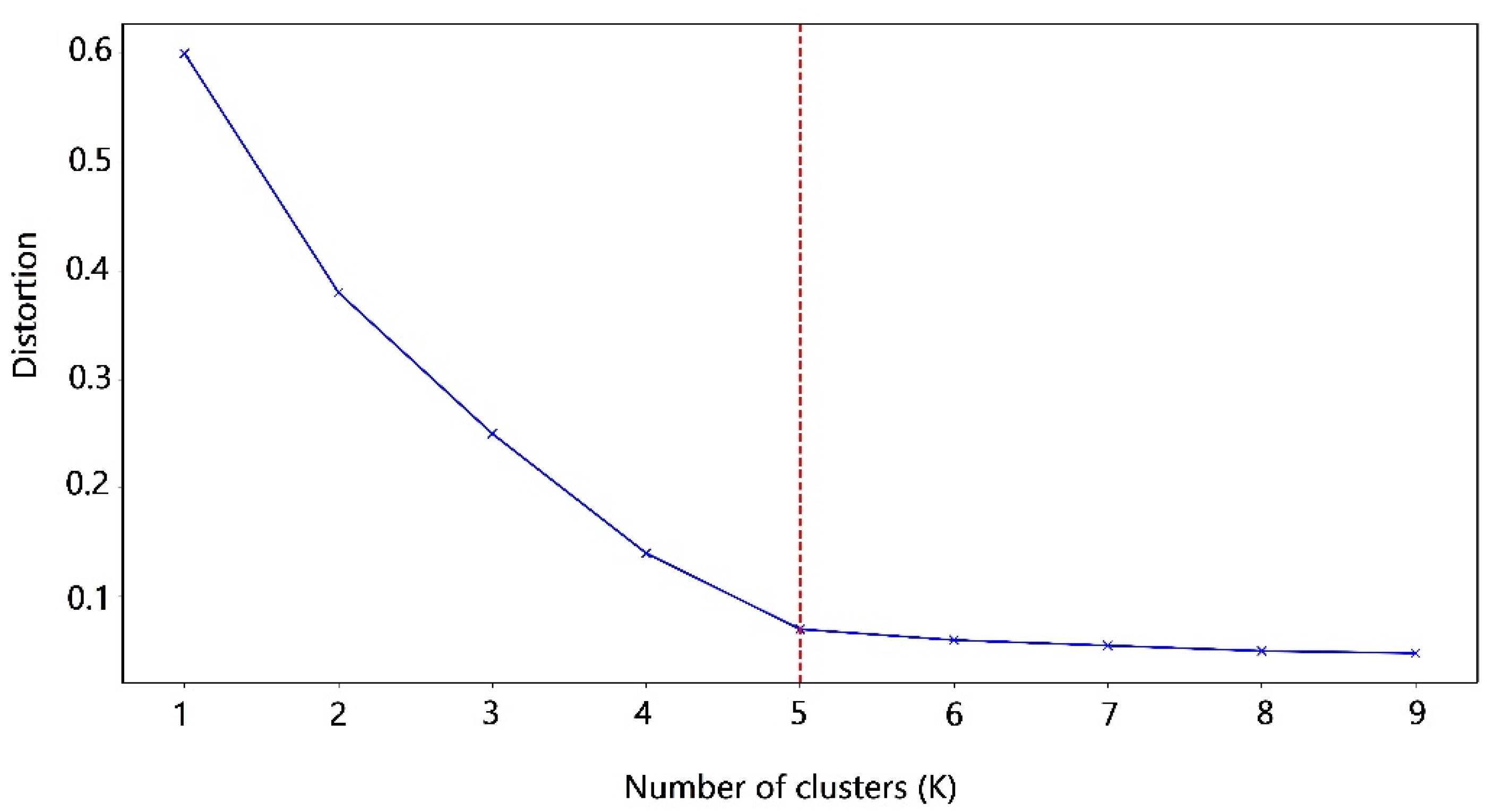
4.2.4. Choosing the Number of Clusters k
- Calculating distortion: It is calculated as the average of the squared distances from the cluster centers of the respective clusters to samples (census blocks’ centroid). Often, the Euclidean distance metric is used.
- Calculating inertia: It is the sum of squared distances of samples to their closest cluster center.
- Iterating steps 1 and 2 for values of k (1 to 9).
4.2.5. K-Means Clustering
- Selecting k random blocks from the data as centroids
- Assign all the blocks to the closest cluster centroid
- Computing the centroids of newly formed clusters
- Repeat steps 3 and 4
4.2.6. Agglomerative Clustering
4.2.7. Bisecting K-Means
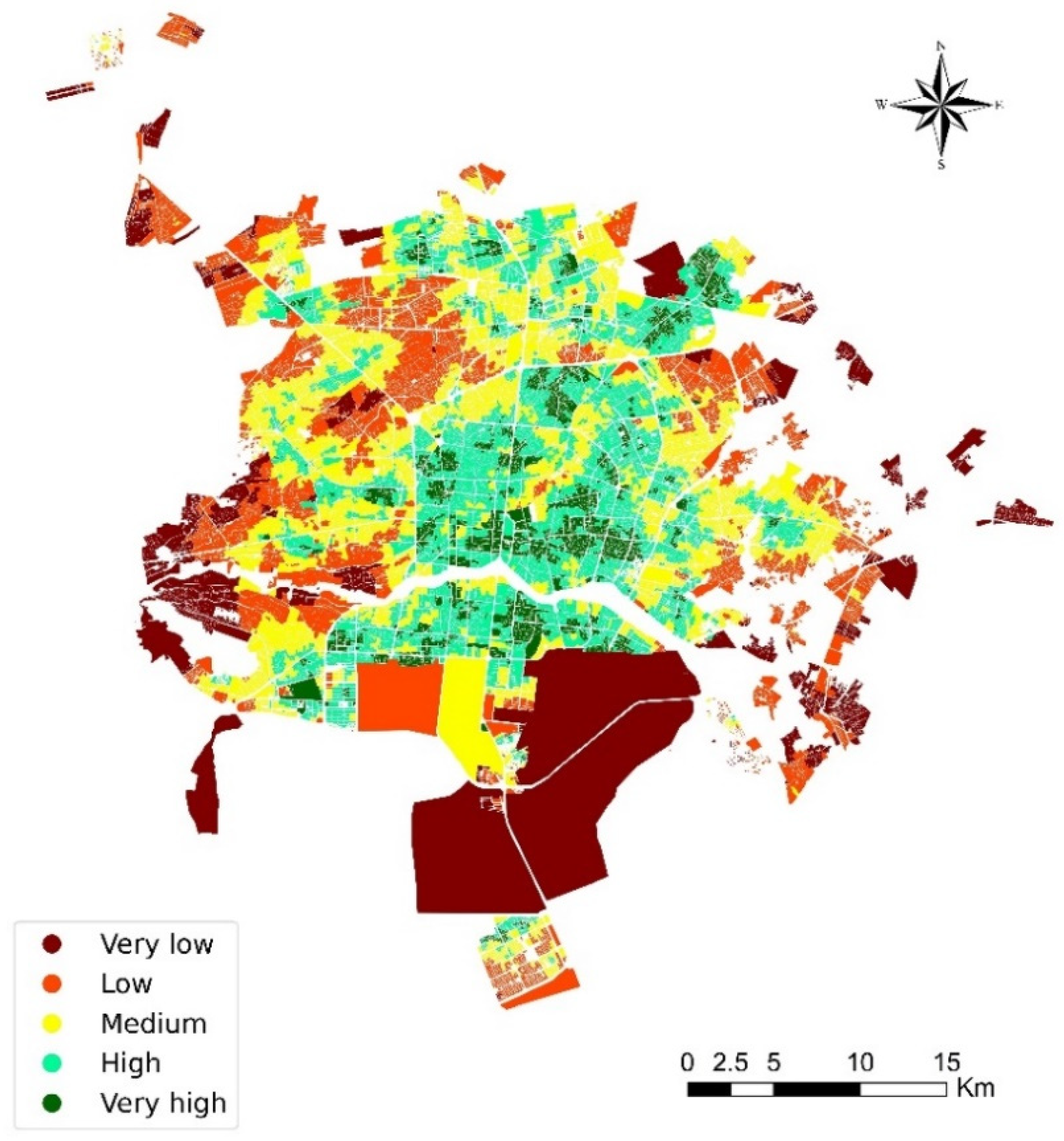
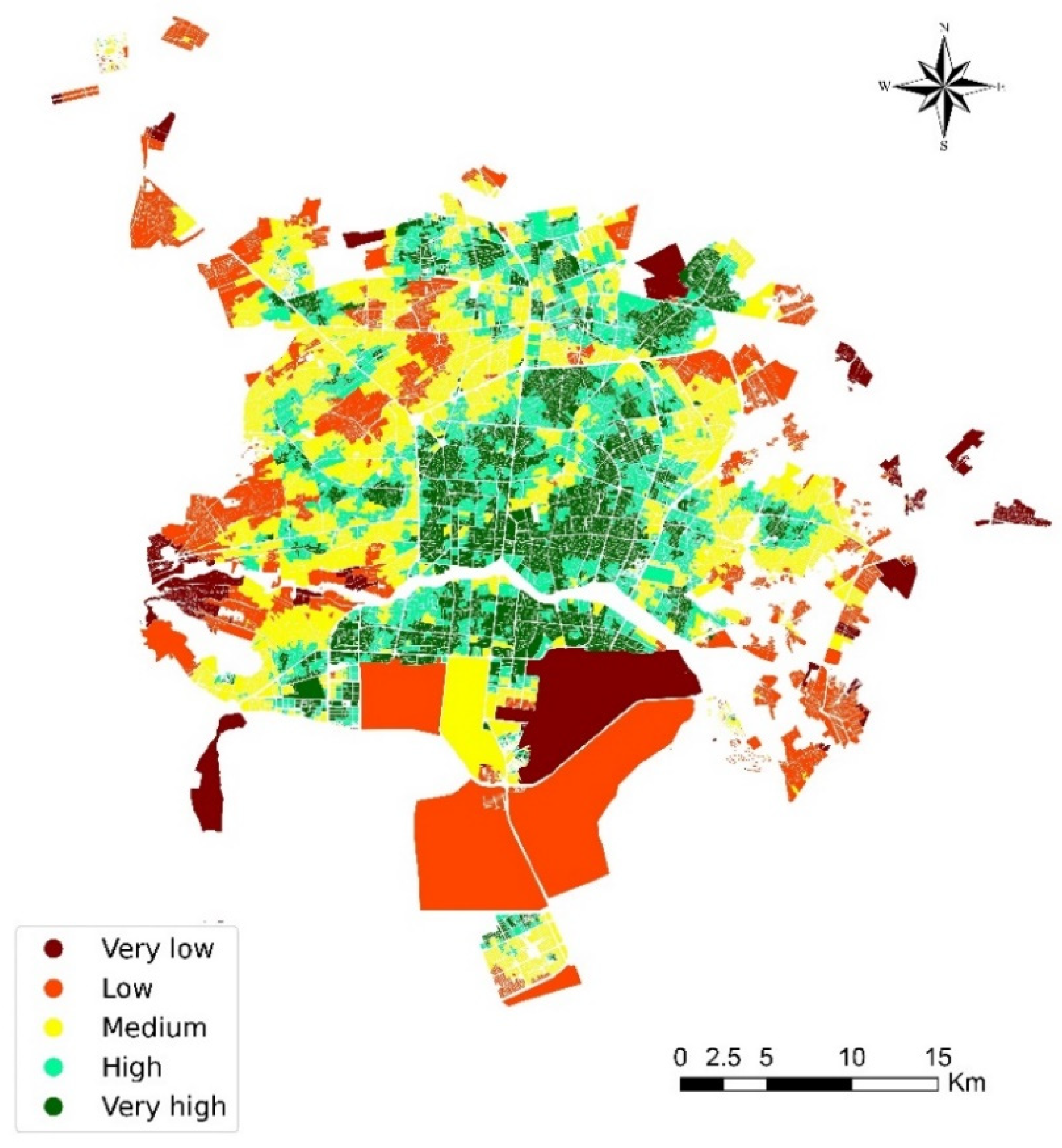
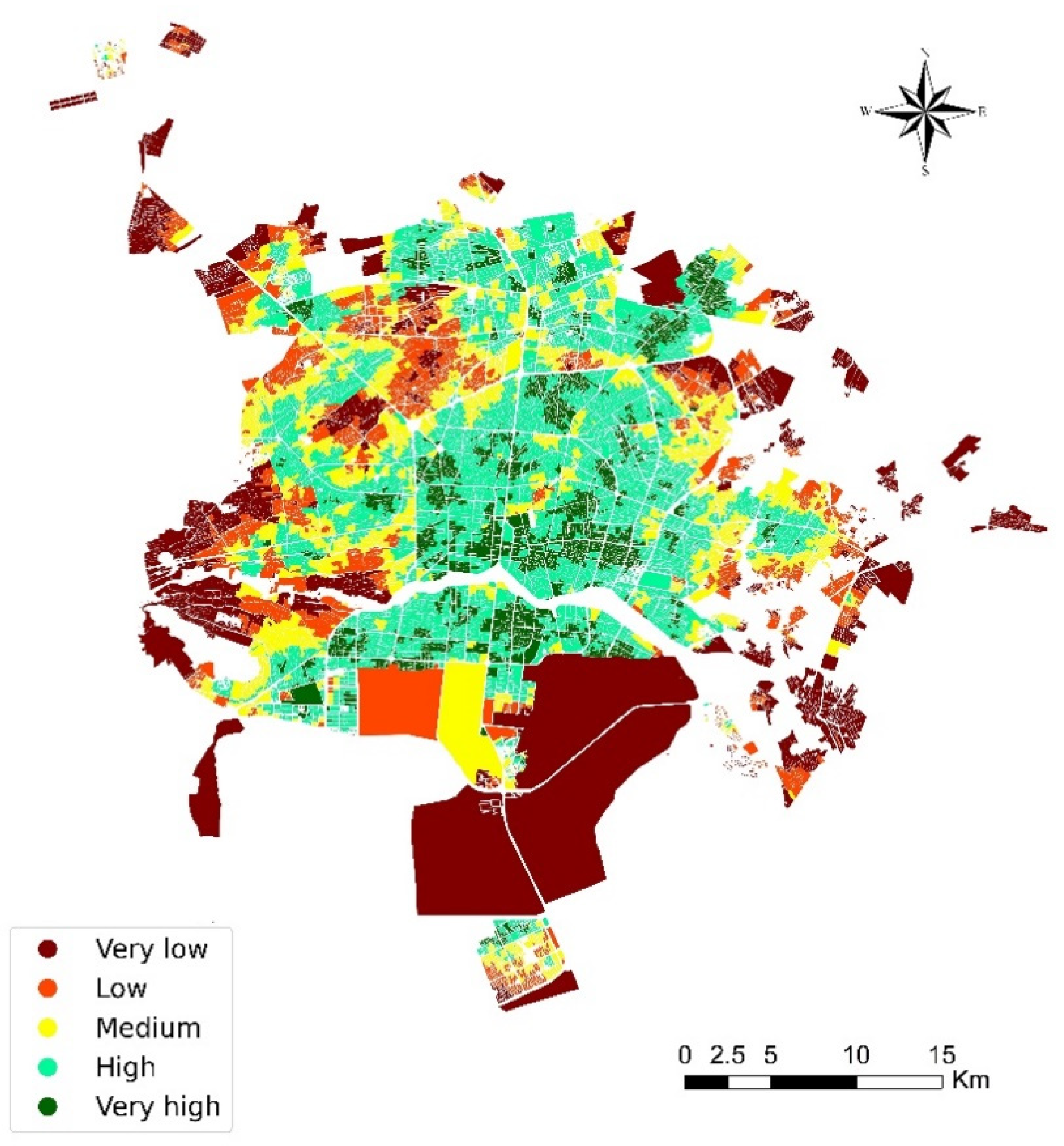
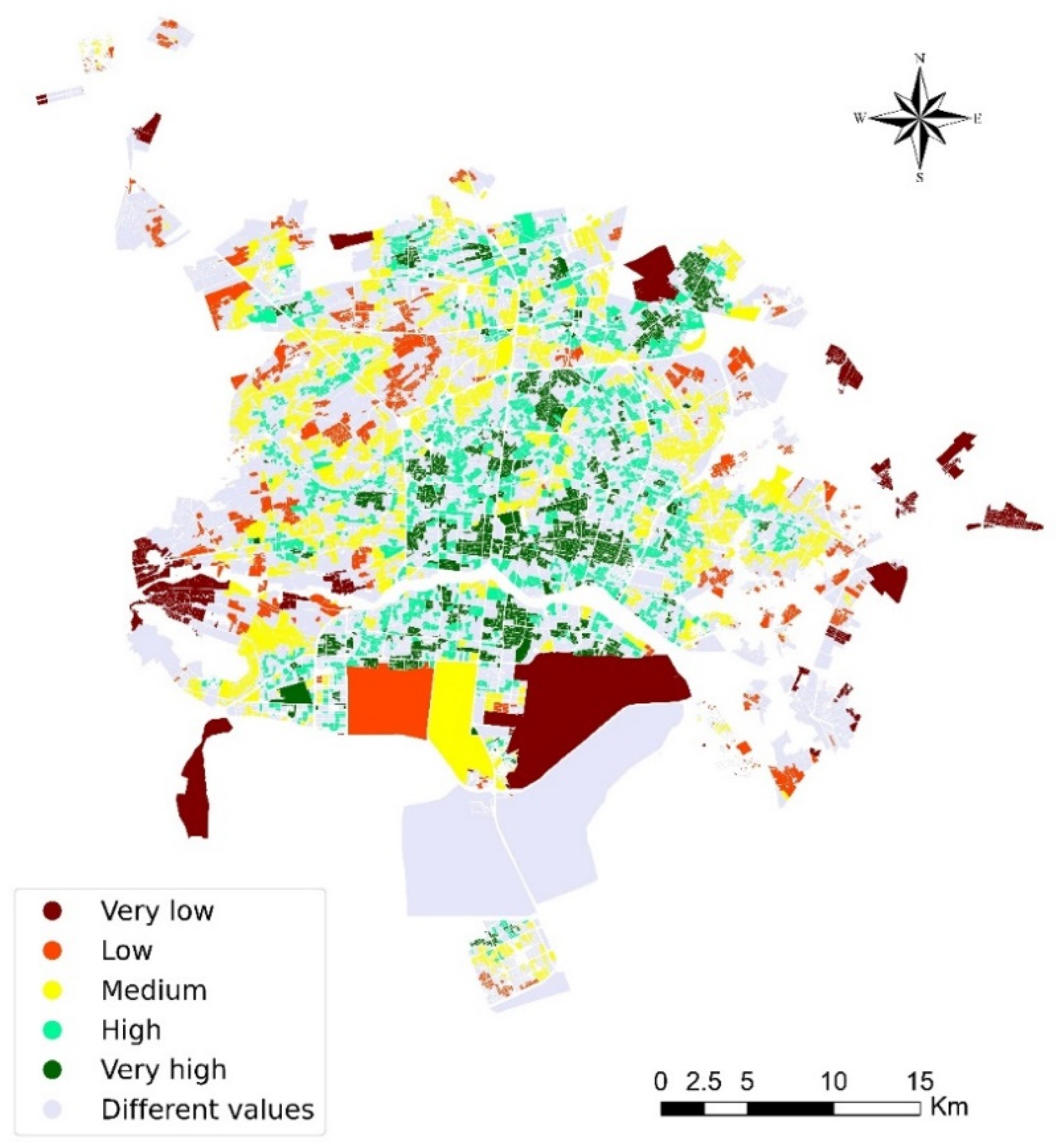
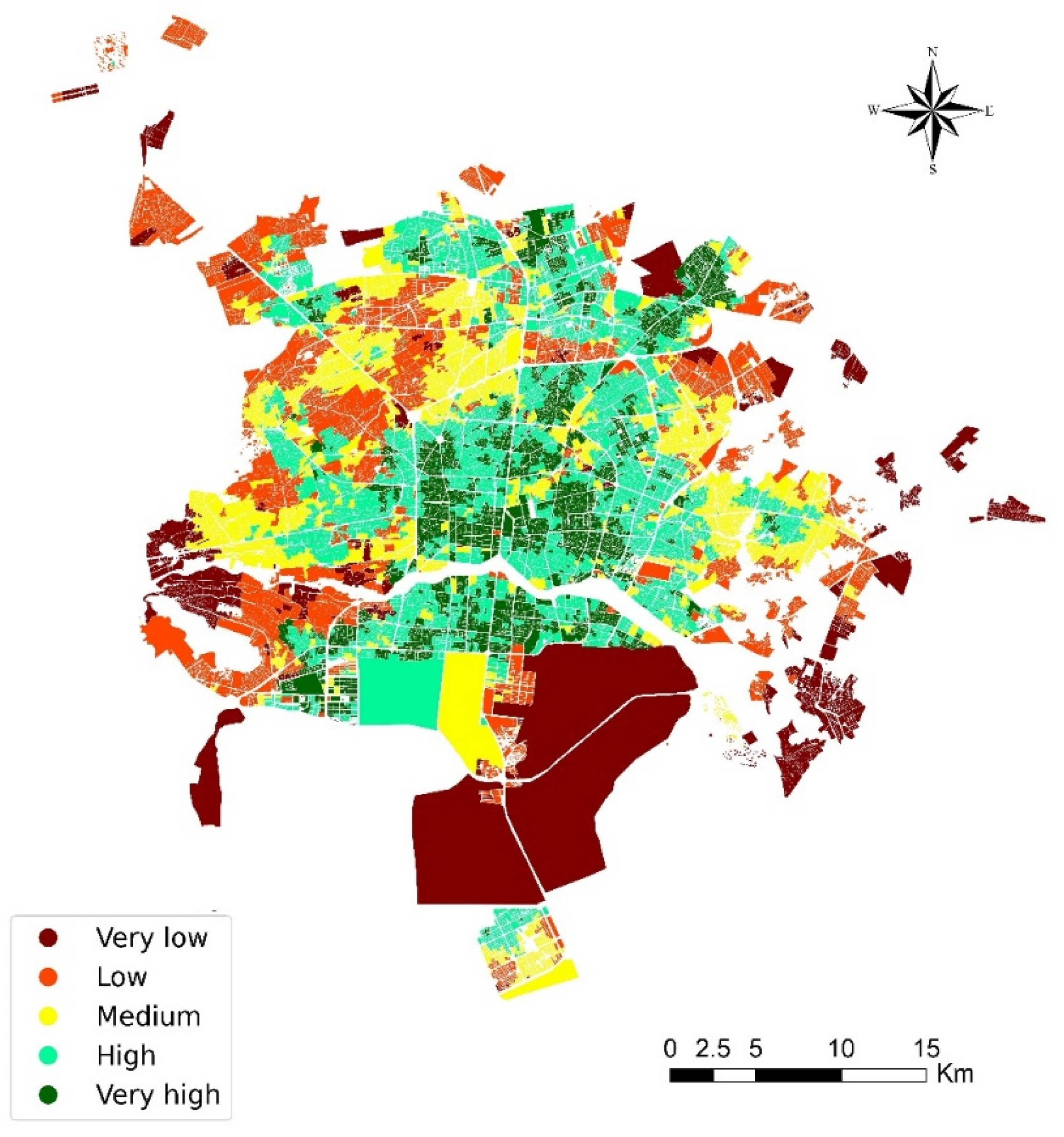
4.2.8. Spatial Accessibility Map
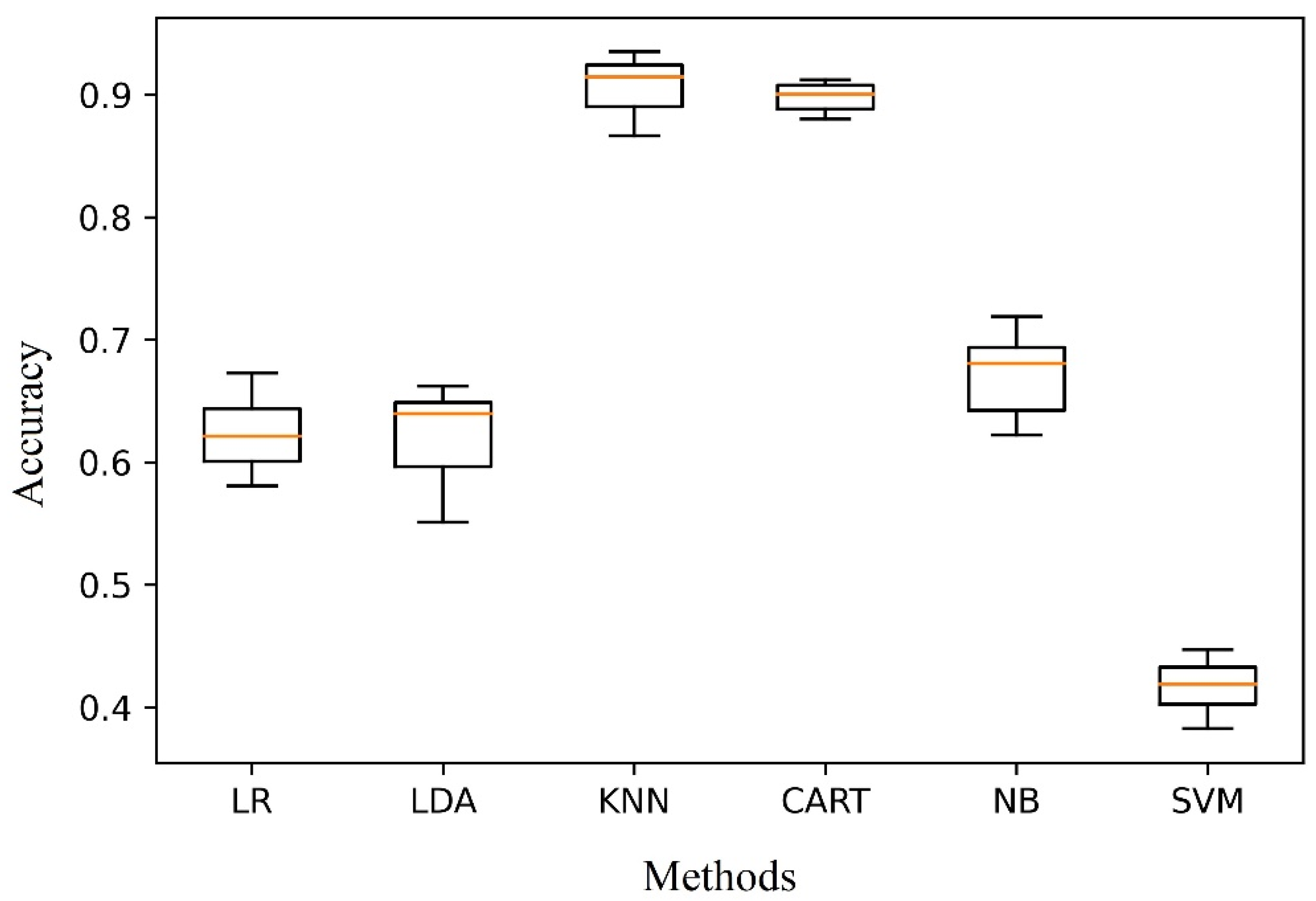
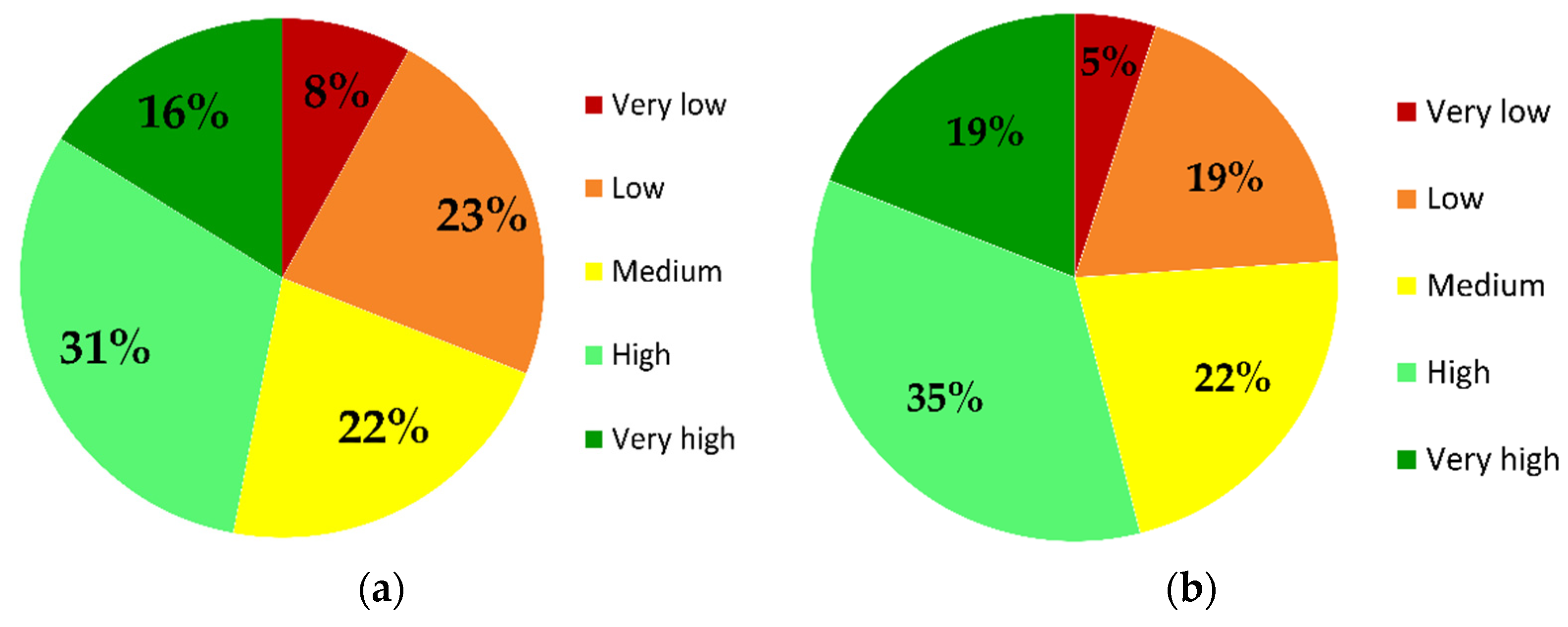
5. Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liburd, L.C.; Giles, W.; Jack, L., Jr. Health Equity: The Cornerstone of a Healthy Community. Natl. Civ. Rev. 2013, 102, 52–54. [Google Scholar] [CrossRef]
- Banks, J. Storytelling to Access Social Context and Advance Health Equity Research. Prev. Med. 2012, 55, 394–397. [Google Scholar] [PubMed]
- Johnson, J.D. Symbolic Innovations: Lessons from Health Services and Higher Education Organizations; Universal-Publishers: Irvine, CA, USA, 2017. [Google Scholar]
- Wakefield, M.; Williams, D.R.; Le Menestrel, S.; Flaubert, J.L. The Future of Nursing 2020–2030: Charting a Path to Achieve Health Equity; National Academy of Sciences: Washington, DC, USA, 2021. [Google Scholar]
- WHO. Quality and Accreditation in Health Care Services: A Global Review; WHO: Geneva, Switzerland, 2003.
- Rabiei-Dastjerdi, H.; Matthews, S.A. Who Gets What, Where, and How Much? Composite Index of Spatial Inequality for Small Areas in Tehran. Reg. Sci. Policy Pract. 2021, 13, 191–205. [Google Scholar] [CrossRef]
- Levesque, J.-F.; Harris, M.F.; Russell, G. Patient-Centred Access to Health Care: Conceptualising Access at the Interface of Health Systems and Populations. Int. J. Equity Health 2013, 12, 18. [Google Scholar] [CrossRef] [Green Version]
- Rabiei-Dastjerdi, H.; Matthews, S.A.; Ardalan, A. Measuring Spatial Accessibility to Urban Facilities and Services in Tehran. Spat. Demogr. 2018, 6, 17–34. [Google Scholar] [CrossRef]
- Rabiei-Dastjerdi, H.; McArdle, G.; Matthews, S.A.; Keenan, P. Gap analysis in decision support systems for real-estate in the era of the digital earth. Int. J. Digit. Earth. 2021, 14, 121–138. [Google Scholar] [CrossRef]
- Rabiei-Dastjerdi, H.; Matthews, S. Isfahan City Hospitals, Iran, in the Context of Urban Growth: New Developments and Future Challenges. Health Inf. Manag. 2018, 15, 1–2. [Google Scholar]
- Sharifzadegan, M.H.; Mamdohi, M.R. A P-Median-Model-Based Analysis of Spatial Inequality in Accessibility to Public Health Care Intended for Urban Health Development in Isfahan City. Soc. Welf. Q. 2010, 10, 265–285. [Google Scholar]
- Geurs, K.T.; De Montis, A.; Reggiani, A. Recent Advances and Applications in Accessibility Modelling. Comput. Environ. Urban Syst. 2015, 49, 82–85. [Google Scholar]
- Ricketts, T.C.; Goldsmith, L.J.; Holmes, G.M.; Randy, M.R.P.; Lee, R.; Taylor, D.H.; Ostermann, J. Designating Places and Populations as Medically Underserved: A Proposal for a New Approach. J. Health Care Poor Underserved 2007, 18, 567–589. [Google Scholar] [CrossRef]
- Drake, C.; Nagy, D.; Nguyen, T.; Kraemer, K.L.; Mair, C.; Wallace, D.; Donohue, J. A Comparison of Methods for Measuring Spatial Access to Health Care. Health Serv. Res. 2021, 56, 777–787. [Google Scholar] [CrossRef]
- Radke, J.; Mu, L. Spatial Decompositions, Modeling and Mapping Service Regions to Predict Access to Social Programs. Geogr. Inf. Sci. 2000, 6, 105–112. [Google Scholar]
- Fyer, G.E., Jr.; Drisko, J.; Krugman, R.D.; Vojir, C.P.; Prochazka, A.; Miyoshi, T.J.; Miller, M.E. Multi-Method Assessment of Access to Primary Medical Care in Rural Colorado. J. Rural. Health 1999, 15, 113–121. [Google Scholar] [CrossRef] [PubMed]
- McGrail, M.R. Spatial Accessibility of Primary Health Care Utilising the Two Step Floating Catchment Area Method: An Assessment of Recent Improvements. Int. J. Health Geogr. 2012, 11, 50. [Google Scholar]
- Dutt, A.K.; Dutta, H.M.; Jaiswal, J.; Monroe, C. Assessment of Service Adequacy of Primary Health Care Physicians in a Two County Region of Ohio, USA. GeoJournal 1986, 12, 443–455. [Google Scholar] [CrossRef]
- Luo, W.; Wang, F. Measures of Spatial Accessibility to Health Care in a GIS Environment: Synthesis and a Case Study in the Chicago Region. Environ. Plan. B Plan. Des. 2003, 30, 865–884. [Google Scholar] [CrossRef] [Green Version]
- Joseph, A.E.; Bantock, P.R. Measuring Potential Physical Accessibility to General Practitioners in Rural Areas: A Method and Case Study. Soc. Sci. Med. 1982, 16, 85–90. [Google Scholar] [CrossRef]
- Wang, F.; Luo, W. Assessing Spatial and Nonspatial Factors for Healthcare Access: Towards an Integrated Approach to Defining Health Professional Shortage Areas. Health Place 2005, 11, 131–146. [Google Scholar] [CrossRef]
- Luo, W.; Qi, Y. An Enhanced Two-Step Floating Catchment Area (E2SFCA) Method for Measuring Spatial Accessibility to Primary Care Physicians. Health Place 2009, 15, 1100–1107. [Google Scholar] [CrossRef]
- Pei, X.; Guo, P.; Chen, Q.; Li, J.; Liu, Z.; Sun, Y.; Zhang, X. An Improved Multi-Mode Two-Step Floating Catchment Area Method for Measuring Accessibility of Urban Park in Tianjin, China. Sustainability 2022, 14, 11592. [Google Scholar] [CrossRef]
- Delamater, P.L. Spatial Accessibility in Suboptimally Configured Health Care Systems: A Modified Two-Step Floating Catchment Area (M2SFCA) Metric. Health Place 2013, 24, 30–43. [Google Scholar] [CrossRef]
- Saxon, J.; Snow, D. A Rational Agent Model for the Spatial Accessibility of Primary Health Care. Ann. Am. Assoc. Geogr. 2020, 110, 205–222. [Google Scholar] [CrossRef]
- Chen, X.; Jia, P. A Comparative Analysis of Accessibility Measures by the Two-Step Floating Catchment Area (2SFCA) Method. Int. J. Geogr. Inf. Sci. 2019, 33, 1739–1758. [Google Scholar] [CrossRef]
- Luo, S.; Jiang, H.; Yi, D.; Liu, R.; Qin, J.; Liu, Y.; Zhang, J. PM2SFCA: Spatial Access to Urban Parks, Based on Park Perceptions and Multi-Travel Modes. A Case Study in Beijing. ISPRS Int. J. Geo-Inf. 2022, 11, 488. [Google Scholar] [CrossRef]
- Xing, L.; Liu, Y.; Wang, B.; Wang, Y.; Liu, H. An Environmental Justice Study on Spatial Access to Parks for Youth by Using an Improved 2SFCA Method in Wuhan, China. Cities 2020, 96, 102405. [Google Scholar] [CrossRef]
- Alahmari, N.; Alswedani, S.; Alzahrani, A.; Katib, I.; Albeshri, A.; Mehmood, R. Musawah: A Data-Driven AI Approach and Tool to Co-Create Healthcare Services with a Case Study on Cancer Disease in Saudi Arabia. Sustainability 2022, 14, 3313. [Google Scholar] [CrossRef]
- Rajamoorthy, R.; Arunachalam, G.; Kasinathan, P.; Devendiran, R.; Ahmadi, P.; Pandiyan, S.; Muthusamy, S.; Panchal, H.; Kazem, H.A.; Sharma, P. A Novel Intelligent Transport System Charging Scheduling for Electric Vehicles Using Grey Wolf Optimizer and Sail Fish Optimization Algorithms. Energy Sources Part A Recovery Util. Environ. Eff. 2022, 44, 3555–3575. [Google Scholar] [CrossRef]
- Bosnić, Z.; Kononenko, I. An Overview of Advances in Reliability Estimation of Individual Predictions in Machine Learning. Intell. Data Anal. 2009, 13, 385–401. [Google Scholar] [CrossRef] [Green Version]
- Sharma, P.; Sahoo, B.B.; Said, Z.; Hadiyanto, H.; Nguyen, X.P.; Nižetić, S.; Huang, Z.; Hoang, A.T.; Li, C. Application of Machine Learning and Box-Behnken Design in Optimizing Engine Characteristics Operated with a Dual-Fuel Mode of Algal Biodiesel and Waste-Derived Biogas. Int. J. Hydrogen Energy 2022. [Google Scholar] [CrossRef]
- Kang, M.; Jameson, N.J. Machine Learning: Fundamentals. Progn. Health Manag. Electron. Fundam. Mach. Learn. Internet Things 2018, 85–109. [Google Scholar] [CrossRef]
- Saravanan, R.; Sujatha, P. A State of Art Techniques on Machine Learning Algorithms: A Perspective of Supervised Learning Approaches in Data Classification. In Proceedings of the 2018 Second International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 14–15 June 2018; pp. 945–949. [Google Scholar]
- Celebi, M.E.; Aydin, K. Unsupervised Learning Algorithms; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- World Population Review Esfahan Population 2022 (Demographics, Maps, Graphs). Available online: https://worldpopulationreview.com/world-cities/esfahan-population (accessed on 17 September 2022).
- Statistical Center of Iran Statistical Center of Iran. Available online: https://irandataportal.syr.edu/census/census-2016 (accessed on 17 September 2022).
- Rabiei-Dastjerdi, H.; Matthews, S.A. The Potential Contributions of Geographic Information Science to the Study of Social Determinants of Health in Iran. J. Educ. Health Promot. 2018, 7, 17. [Google Scholar]
- Lange, T.; Law, M.H.C.; Jain, A.K.; Buhmann, J.M. Learning with Constrained and Unlabelled Data. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 731–738. [Google Scholar]
- Kirsten, M.; Wrobel, S. Relational Distance-Based Clustering. In Proceedings of the International Conference on Inductive Logic Programming, Madison, WI, USA, 22–24 July 1998; pp. 261–270. [Google Scholar]
- Murtagh, F.; Contreras, P. Algorithms for Hierarchical Clustering: An Overview. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2012, 2, 86–97. [Google Scholar]
- Ahmed, M.; Seraj, R.; Islam, S.M.S. The K-Means Algorithm: A Comprehensive Survey and Performance Evaluation. Electronics 2020, 9, 1295. [Google Scholar] [CrossRef]
- Likas, A.; Vlassis, N.; Verbeek, J.J. The Global K-Means Clustering Algorithm. Pattern Recognit. 2003, 36, 451–461. [Google Scholar] [CrossRef] [Green Version]
- Bouguettaya, A.; Yu, Q.; Liu, X.; Zhou, X.; Song, A. Efficient Agglomerative Hierarchical Clustering. Expert Syst. Appl. 2015, 42, 2785–2797. [Google Scholar] [CrossRef]
- Savaresi, S.M.; Boley, D.L. A Comparative Analysis on the Bisecting K-Means and the PDDP Clustering Algorithms. Intell. Data Anal. 2004, 8, 345–362. [Google Scholar] [CrossRef] [Green Version]
- Johnson, D.B. A Note on Dijkstra’s Shortest Path Algorithm. J. ACM 1973, 20, 385–388. [Google Scholar] [CrossRef]
- Hagberg, A.A.; Schult, D.A.; Swart, P.J. Exploring Network Structure, Dynamics, and Function Using NetworkX. In Proceedings of the 7th Python in Science Conference, Pasadena, CA, USA, 19–24 August 2008; pp. 11–15. [Google Scholar]
- Jing, L.; Ng, M.K.; Huang, J.Z. An Entropy Weighting K-Means Algorithm for Subspace Clustering of High-Dimensional Sparse Data. IEEE Trans. Knowl. Data Eng. 2007, 19, 1026–1041. [Google Scholar]
- Bromiley, P.A.; Thacker, N.A.; Bouhova-Thacker, E. Shannon Entropy, Renyi Entropy, and Information. Stat. Inf. Ser. 2004, 9, 10–42. [Google Scholar]
- Mohamad, I.B.; Usman, D. Standardization and Its Effects on K-Means Clustering Algorithm. Res. J. Appl. Sci. Eng. Technol. 2013, 6, 3299–3303. [Google Scholar] [CrossRef]
- Maes, C.; Redig, F.; Moffaert, A. Van On the Definition of Entropy Production, via Examples. J. Math. Phys. 2000, 41, 1528–1554. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.; Chen, X.-Y.; Zhang, H.; Xiong, L.-D.; Lei, H.; Deng, S.-H. Hyperparameter Optimization for Machine Learning Models Based on Bayesian Optimization. J. Electron. Sci. Technol. 2019, 17, 26–40. [Google Scholar]
- Yeo, I.; Johnson, R.A. A New Family of Power Transformations to Improve Normality or Symmetry. Biometrika 2000, 87, 954–959. [Google Scholar] [CrossRef]
- Beaulieu, N.C.; Hemachandra, K.T. Novel Simple Representations for Gaussian Class Multivariate Distributions with Generalized Correlation. IEEE Trans. Inf. Theory 2011, 57, 8072–8083. [Google Scholar]
- Rahmani, Y.; Alizadeh, M.M.; Schuh, H.; Wickert, J.; Tsai, L.-C. Probing Vertical Coupling Effects of Thunderstorms on Lower Ionosphere Using GNSS Data. Adv. Space Res. 2020, 66, 1967–1976. [Google Scholar] [CrossRef]
- Patil, C.; Baidari, I. Estimating the Optimal Number of Clusters k in a Dataset Using Data Depth. Data Sci. Eng. 2019, 4, 132–140. [Google Scholar]
- Bholowalia, P.; Kumar, A. EBK-Means: A Clustering Technique Based on Elbow Method and k-Means in WSN. Int. J. Comput. Appl. 2014, 105, 17–24. [Google Scholar]
- Teknomo, K. K-Means Clustering Tutorial. Medicine 2006, 100, 3. [Google Scholar]
- Müllner, D. Modern Hierarchical, Agglomerative Clustering Algorithms. arXiv 2011, arXiv:1109.2378. [Google Scholar]
- Steinbach, M.; Karypis, G.; Kumar, V. A Comparison of Document Clustering Techniques. 2000. Available online: https://conservancy.umn.edu/handle/11299/215421 (accessed on 17 September 2022).
- Ahsan, M.M.; Mahmud, M.A.P.; Saha, P.K.; Gupta, K.D.; Siddique, Z. Effect of Data Scaling Methods on Machine Learning Algorithms and Model Performance. Technologies 2021, 9, 52. [Google Scholar] [CrossRef]
- Alimohammadi, A.; Rabiei, H.R.; Firouzabadi, P.Z. A New Approach for Modeling Uncertainty in Remote Sensing Change Detection Process. In Proceedings of the 12th International Conference on Geoinformatics-Geospatial Information Research: Bridging the Pacific and Atlantic, Gävle, Sweden, 7–9 June 2004; pp. 7–9. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in {P}ython. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Hunter, J.D. Matplotlib: A 2D Graphics Environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Goldberger, J.; Hinton, G.E.; Roweis, S.; Salakhutdinov, R.R. Neighbourhood Components Analysis. In Proceedings of the Advances in Neural Information Processing Systems; Saul, L., Weiss, Y., Bottou, L., Eds.; MIT Press: Cambridge, MA, USA, 2004; Volume 17. [Google Scholar]
- Rabiei-Dastjerdi, H.; Amini, S.; McArdle, G.; Homayouni, S. City-Region or City? That Is the Question: Modelling Sprawl in Isfahan Using Geospatial Data and Technology. GeoJournal 2022, 1–21. [Google Scholar] [CrossRef]
- Zeaiean, P.; Rabiei, H.R.; Alimohamadi, A. Detection of Land Use/Cover Changes of Isfahan by Agricultural Lands Around Urban Area Using Remote Sensing and GIS Technologies. J. Spat. Plan. 2005, 9, 41–54. [Google Scholar]
- Kazazi, A.K.; Rabiei-Dastjerdi, H.; McArdle, G. Emerging Paradigm Shift in Urban Indicators: Integration of the Vertical Dimension. J. Environ. Manag. 2022, 316, 115234. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Entropy Weight |
|---|---|
| Distance to the nearest hospital | 0.174 |
| Distance to the nearest clinic | 0.266 |
| Distance to the nearest pharmacy | 0.310 |
| Distance to the nearest medical laboratory | 0.250 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khosravi Kazazi, A.; Amiri, F.; Rahmani, Y.; Samouei, R.; Rabiei-Dastjerdi, H. A New Hybrid Model for Mapping Spatial Accessibility to Healthcare Services Using Machine Learning Methods. Sustainability 2022, 14, 14106. https://doi.org/10.3390/su142114106
Khosravi Kazazi A, Amiri F, Rahmani Y, Samouei R, Rabiei-Dastjerdi H. A New Hybrid Model for Mapping Spatial Accessibility to Healthcare Services Using Machine Learning Methods. Sustainability. 2022; 14(21):14106. https://doi.org/10.3390/su142114106
Chicago/Turabian StyleKhosravi Kazazi, Ali, Fariba Amiri, Yaser Rahmani, Raheleh Samouei, and Hamidreza Rabiei-Dastjerdi. 2022. "A New Hybrid Model for Mapping Spatial Accessibility to Healthcare Services Using Machine Learning Methods" Sustainability 14, no. 21: 14106. https://doi.org/10.3390/su142114106