1. Introduction
People who listen well create many benefits for their conversation partners (the speakers) and themselves. For example, good listeners reduce the speaker’s depression [
1], the extremism of their attitudes [
2], and facilitate attitudinal clarity [
3]. In addition, good listeners benefit themselves by gaining new knowledge, performing better on the job [
4,
5], being liked by their conversation partners [
6], and becoming more humble [
7].
Furthermore, listening appears to contribute to the quality of romantic relationships. When people perceive that their romantic partner listens well to them, they are more satisfied with their relationships [
8], less likely to report violence in the relationships [
9,
10,
11] and relationship dissolution [
12], and more likely to report self-disclosure [
9] and fulfillment of the psychological needs of community and agency [
13]. In short, listening appears to be a potent driver of sustainable social relationships.
Given the listening benefits, a question arises about what brings people to listen well (or poorly). According to Carl Rogers, people listen well in therapy [
14] and in any relationship [
15] when they hold a listening “attitude.” The listening attitude is people’s cognitive schemas and beliefs about listening. Beliefs about behaviors, such as belief in listening effectiveness, contribute to forming an attitude, which, in turn, influences the intention to behave accordingly [
16]. Specifically, according to the theory of planned behavior [
16], beliefs about behaviors link behaviors to outcomes. The more a person associates desirable outcomes with a specific behavior, the stronger the attitude towards that behavior. People with a strong attitude towards a given behavior will likely intend to emit such behaviors and eventually behave accordingly.
Carl Rogers claimed that cultivating a listening attitude is more important for successful communication than learning techniques (e.g., “active listening”). Indeed, some applications of “active listening” techniques became far removed from Rogers’ philosophy. Rogers emphasized the listeners’ attitudes and beliefs over the instrumental effects of a listening technique. As stated in one study: “professional training… fosters instrumentalized listening that… crushes the spirit of individuals” [
17]. Thus, it seems there is a need to capture the listening attitude, defined as people’s schema about what constitutes good listening and its consequences. A measure of a listening schema could address multiple issues in the field of listening that cannot be addressed with existing measures of self-reported listening: (a) the listener’s self-reported listening quality may not be a good predictor of the speakers’, or observers’, perception of listening quality [
18]; yet self-reported listening schema may be able to predict others’ perceptions of listening quality, (b) some people trained in listening may report that they are poorer listeners than untrained people because some untrained people are ignorant of their lack of skill [
19]; yet, it is possible that training increases the endorsement of the listening schema, and (c) people whose job is to listen to traumatic stories are known to suffer from second-hand trauma [
20]; yet, it is possible that self-reported listening in these occupations predicts second-hand trauma, whereas a listening schema may serve as a buffer against it.
Thus, having a measure to assess the listening schema could serve as a foundation for several lines of research that can advance the field of listening. The project described below takes the first step by developing a scale that assesses people’s listening beliefs and schemas and tests its validity in a romantic context. We first established that the listener’s listening schema predicts the speaker’s experience and then tested whether it can predict variance that cannot be predicted by self-reported listening. If successful, the new measure could be used in future research to assess the effectiveness of listening training, test as a buffer against second-hand trauma, and elucidate the cognitive antecedents of desirable listening behaviors contributing to sustainable relationships.
1.1. Rogers’s Concept of Effective Listening
As part of his client-centered therapy approach, Rogers [
21] proposed fundamental principles for effective listening: (1) the clients are responsible for themselves, and the counselor is willing for the clients to retain this responsibility; (2) the counselor has confidence in the internal capacities of the clients and in their motivation to grow in a positive direction; (3) the counselor should create a warm and permissive atmosphere, in which the client feels free to raise any emotion or thought; (4) the limits that the counselor sets will be minimal and straightforward, and will only apply to behavior and not to feelings or desires; (5) the counselor must demonstrate a deep understanding and acceptance towards the feelings and content coming from the client; (6) the counselor should avoid, as much as possible, any action or expression which contradicts these principles, for example: questioning, probing, blaming, interpreting, giving advice, persuading, or offering reassurance. These principles can be applied to everyday, interpersonal, and non-therapeutic situations [
2,
22]. The principles referring to a counselor listening to a client can be applied to any listener listening to any speaker in every domain.
Although Rogers described the type of attitudes or beliefs about listening that would produce desirable listening, his writing about the topic (both in the 1949 paper and his classical 1951 book) is vague and contains hundreds of statements. Therefore, in the present project, we collected statements from his 1949 article, analyzed their content, built questionnaire items, and tested their structure, reliability, and validity in six studies. Based on this work, we offer a tool to measure listening schema.
1.2. Overview
In Study One, we reviewed Rogers’s text [
21] and generated items for a survey measuring belief in listening. In Study Two, we administered these items to an international pool of participants and uncovered their dimensionality with exploratory factor analysis (EFA). In Study Three, we translated the survey to Hebrew and used cognitive interviews to uncover ambiguities in the items. Building on Study Two and Study Three, in Study Four, we pruned the survey and tested its validity in predicting romantic partners’ perception of listening in Hebrew. In Study Five, we replicated Study Four on a larger sample in English, tested the scale’s test–retest reliability, and subjected it to incremental validity tests. Finally, in Study Six, we contacted the participants of Study Five eight months later, measured their relationship sustainability with various measures, and demonstrated the incremental validity of our scale in predicting it.
2. Study One: Materials and Methods
Our goal in Study One was to extract themes and write items capturing the theoretical stance of Rogers regarding the belief in listening that is a pre-requisite to a good listening experience. Rogers wrote extensively about this topic, especially in his best-known book on client-centered therapy [
14]. However, we focused on his 1949 paper because it was dedicated to the belief in listening [
21].
To extract themes and items from Rogers’s 1949 paper, 11 subject-matter experts (SMEs), including some of the authors, read it. The SMEs were either seasoned researchers or advanced undergraduate students attending a year-long seminar on listening. While reading the paper, the SMEs extracted 170 statements describing effective listeners. These statements were divided randomly into two equal parts. The statements in each part were categorized independently into themes by two co-author SMEs, where each worked on one part only. These two SMEs then compared the themes, merged and pruned them, and then pruned the items needed to represent the themes. Next, all SMEs reviewed the themes and items for clarity, meaning, and phrasing.
3. Study One: Results and Discussion
The discussion of all SMEs culminated with six themes and 46 non-redundant items. The themes were general (G), listening behavior (B), listening attitude (A), speaker capacity (S), listener capacity (L), and listener character (C). The themes and the items are presented in
Table 1, along with the results of Study Two. Based on Study One, we ran two studies in parallel. In Study Two, we considered the themes found in Study One as a loose hypothesis about the likely factorial structure of data we collected in Study Two. In Study Three, we translated the items into Hebrew. Once the results of Study Two were available, we improved the items in Hebrew with cognitive interviews and back-translated the final version into English.
4. Study Two: Materials and Methods
In 2020, we recruited participants to answer a Qualtrics survey from Prolific services and volunteers. The data indicated 589 openings of the Qualtrics link, of which 467 were from a link sent to Prolific workers and 122 to volunteers. Some records had all the data missing, and some had excessive missing data. Therefore, we dropped all records with ten or more missing items, yielding 552 records. We embedded an attention check question towards the end of the questionnaire, asking participants to respond with four on a 0 to 10 scale. This attention check was passed by 478. In addition, two respondents did not complete the last screen of listening belief items, and they were also dropped.
We inspected all study variables numerically and graphically with an exploratory data analysis function,
basic_eda, in R (
https://blog.datascienceheroes.com/exploratory-data-analysis-in-r-intro/ accessed on 5 October 2022). There were no severe outliers, and thus we retained all the remaining respondents. We also calculated the variance in their responses to all the Likert-type items for each respondent. Low variance suggested that the respondent used the same or similar responses to all items; high variance suggested mainly using extreme response options (0 or 10). We inspected the respondents with the lowest and the highest variances. None had uniform responses. Among respondents with low variance, some used only the 4, 5, or 6 response option, while among respondents with high variance, some used 0, 5, and 10 frequently. These appear to be legitimate individual differences in response style, so we retained them all. Thus, we obtained a final sample of
N = 476,
Mage = 22.6,
SD = 10.9, 38% females, and 84.7% were Prolific workers.
We offered Prolific workers a small monetary inducement to participate in the survey and asked the remainder to participate voluntarily. We presented the items generated in Study One (
Table 1) in a random order, followed by the demographic questions. For all analyses, we used
R [version 4.0.4], [
23].
To determine the number of factors, we used the
n_factor function of the
parameters package in R [
24]. This function uses 23 different methods to estimate the number of factors underlying the correlation matrix and indicates the likely number of factors based on consensus among methods. Based on the most likely number of factors, we subjected the data to an EFA with
oblimin rotation (the default), using the
fa function of the
psych package [
25]. Finally, we selected the items with EFA loadings > 0.40 and subjected them to confirmatory factor analysis (CFA) to construct meaningful scales. Following the initial CFA results, we searched for items with multiple residual covariances. Residual covariances could result from similar wording effects, and we considered discarding these items. Specifically, we planned to consider removing items with multiple residual correlations exceeding 0.10 [
26].
5. Study Two: Results and Discussion
The search for the number of factors underlying the responses to the listening belief items (using the
n_factor function) suggested that either a one-factor or three-factor solution was most viable (
Table S1 on the OSF site; see
Supplementary Materials). The three-factor solution included Velicer’s MAP criterion—the most accurate method overall in simulations [
27]. We also inspected other solutions. For example, we inspected a ten-factor solution indicated by parallel analysis and the Kaiser criterion. However, these solutions were not interpretable. Inspecting the results of EFA with three factors (
Table 1) indicated that two of the themes proposed by the SMEs emerged as factors: a belief that the listener affects the well-being of the speaker (L) and the belief that the speaker (S) benefits and thrives thanks to listening. The third factor was composed of items from the various themes, and its loadings were lower than for items of the first two factors. This factor appears to reflect behaviors respondents believe to be part of good listening. Several items appear useless as their loadings were below 0.40 on all factors. Their uniqueness was very high (they are not correlated highly with the other items), and their complexity was much higher than one, reflecting deviation from the ideal of a simple structure (
Table 1).
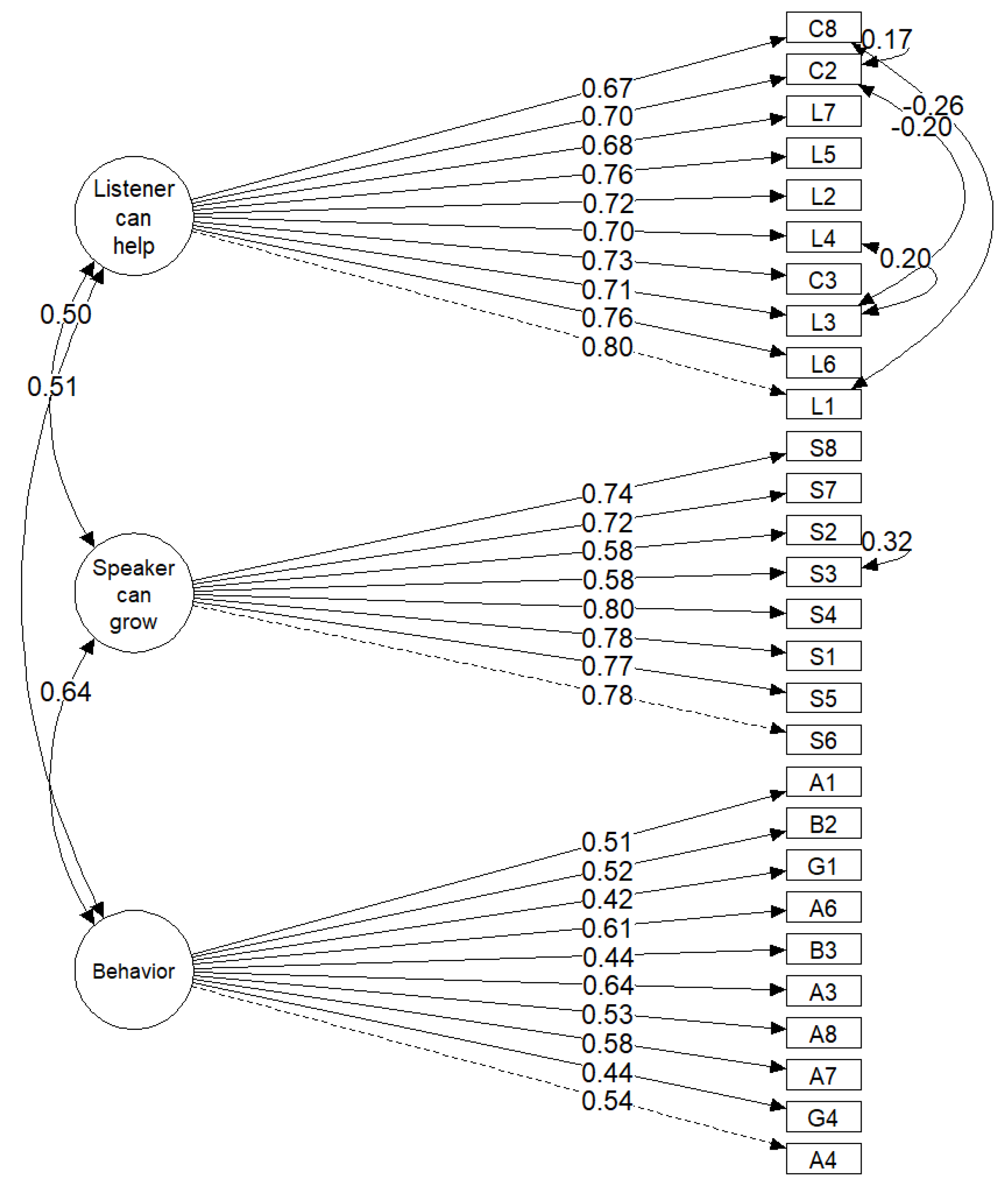
Next, we subjected the items with loadings > 0.40 to CFA. Some of the CFA fit measures were unacceptable, χ
2492 = 1171.4,
p < 0.01, CFI = 0.90, and some were reasonable, RMSEA = 0.054 [0.05, 0.058], SRMR = 0.053. Therefore, we discarded items with three or more residual correlations exceeding 0.10. Next, we allowed five covariances with the highest residual correlations (
Figure 1). Although this model still deviated from the data significantly, χ
2342 = 586.0,
p < 0.01, the other fit indices were excellent, CFI = 0.96, RMSEA = 0.039 [0.033, 0.044], SRMR = 0.045. This model shows no covariances between items loaded on different latent variables, suggesting that the latent variables have a relatively simple structure. It also shows that the inter-factor correlations are much lower than one. The loadings of the behavior-latent variable were systematically lower than for the first two factors (not surprisingly, given that this factor emerged last in the EFA).
Last, we tested whether gender and age were associated with the response to our survey. Females scored higher than males on the listening schema scale, r = 0.12 [0.03, 0.21].
Table S2 reports the means and standard deviations for females and males. Age was not correlated with the listening schema scale, r = 0.03 [−0.06, 0.12].
In summary, in Study Two, we subjected 46 items written to measure the belief in listening to EFA and CFA. EFA suggested that the belief in listening has three components: belief in the effectiveness of the listener in benefiting the speaker, belief in the speaker’s abilities to benefit from being listened to, and a schema of the behaviors constituting good listening. CFA suggested that 28 items could reliably capture these three dimensions, even among non-English speakers (
Table 2).
6. Study Three: Materials and Methods
In Study Three, we created Hebrew versions of the items created in Study One. We chose Hebrew because it is the authors’ mother tongue, and we had access to Hebrew-speaking participants (Study Four). Because Study Two indicated that the behavior factor has relatively low loadings and reliability, we also conducted cognitive interviews [
28] regarding these items.
6.1. Translation
A good translation retains each item’s semantic content, structure, and measurement properties (Harkness et al., 2010). To achieve this ideal, we followed the best-practice guidelines of the Cross-Cultural Survey Guidelines (
https://ccsg.isr.umich.edu/ accessed on 5 October 2022) in their chapter on translation guidelines (
https://ccsg.isr.umich.edu/chapters/translation/ accessed on 5 October 2022). Therefore, we created two parallel translations. Next, our SMEs reviewed and refined the initial drafts of the translations. Then, one listening SME served as an experienced adjudicator who approved the final translation version before the pre-test. This translation process and the various questionnaire versions were fully documented and available on the OSF site.
6.2. Cognitive Interview
It is recommended to use cognitive interviews to evaluate questionnaire items’ quality, such as those developed in the present research [
28]. Cognitive interviewing is defined as “the administration of draft survey questions while collecting additional verbal information about the survey responses, which is used to evaluate the quality of the response or to help determine whether the question is generating the information that its author intends” [
28]. Cognitive interviews are performed with two primary paradigms: think-aloud or probe. In the think-aloud procedure, the cognitive interviewer facilitates participants’ verbalization of their thought processes with minimal intervention. In probing, the interviewer guides the interaction proactively and asks additional direct questions about the basis for responses and follow-up questions. We used the think-aloud general procedure to test the quality of the items, alongside specific probes, when necessary.
One of the authors interviewed three women and three men in the age range of 23–57. The author gave a serial number for each interview and kept it separate from their names to maintain their privacy. This author asked the respondents to answer a set of questions regarding each item from the behavioral factor found in Study Two (G1, G2, B3, A1, A3, A4, A6, A7, and A8). Specifically, the author asked the interviewees to answer the following questions:
Try to think aloud: What comes to mind when you read this question?
Elaborative probe: Tell me more about that.
Comprehension probe: What does the term ___ mean to you?
Paraphrase: Can you repeat that question in your own words?
Process probe: How did you arrive at this answer?
This author wrote down their answers and tabulated them after the interviews.
7. Study Three: Results and Discussion
The two translators arrived at similar, but not identical, Hebrew versions of the 46 items written in Study One (see Section A in the Hebrew Translation document for Study Three in the
Supplemental Materials at the OSF site). Two authors chose the more appropriate translation. Next, we constructed a male and a female survey version (Section B in the Hebrew Translation document for Study Three in the
Supplemental Materials at the OSF site). Hebrew is a gendered language (it has grammatical gender). Often, the male version is presented to both genders, requesting females to assume the male version pertains to themselves. Here, the availability of a female version may help females provide answers closer to their self-perception than to their expected gender role.
Using the Hebrew version, we ran cognitive interviews on the behavior factor. The summary, in Hebrew, of the interviewees’ responses is available in Section C for Study Three in the
Supplemental Materials at the OSF site. The interviews revealed problematic items, including items that provoked intense resistance, interpreted in multiple ways, and one poorly understood item. For example, item A3 (“A good listener conveys a complete acceptance of the speaker’s attitudes and feelings.”), provoked intense disagreement because the word
acceptance in this item was construed as agreeing with the speaker and legitimizing whatever the speaker said.
Similarly, respondents wondered if the word respect in G4 (“Good listening occurs when the listener respects the speaker”) indicated agreement with the speaker. This pattern may suggest that Rogers’s view of effective listening is rare. On the one hand, an item with a rare endorsement rate may create an efficient item, hence, discriminating between people who endorse Rogers’s views and those who do not. On the other hand, it may antagonize respondents who may see these items suggesting that listening entails respecting and accepting the speaker at all costs, which some respondents described as lacking genuineness.
Other items were unclear and produced disagreement about the meaning. For example, the term uninterrupted in G1 (“Successful listening is uninterrupted”) was unclear. Is the listener not interrupting, or is the environment free from noise and distractions? In addition, the article “the” in A1 (“A good listener gives the speaker the feeling that he/she are the ones that matter in the interaction.”) suggested a lack of reciprocity, hinting that the listener is unimportant. Last, five interviewees did not understand item A6 (“A good listener aspires to be in complete cooperation with the speaker”).
Based on insights from the interviews, we dropped item A6 and rewrote the other items in Hebrew (Section D for Study Three in the
Supplemental Materials at the OSF site). Next, we translated these items back into English. We back-translated these items into Hebrew to guarantee the translation fidelity (Section E for Study Three in the
Supplemental Materials at the OSF site). The final translation of the relevant items is shown in
Table 3, and for the complete scale in Section F for Study Three in the
Supplemental Materials at the OSF site.
Study Two suggested three dimensions of the listening schema, where one had relatively low reliability. Study Three offered a Hebrew translation and better items to assess the dimension with low reliability in Study Two. Equipped with the results, we sought to test the predictive validity of the new scale in Study Four and Study Five. In Study Four, we asked romantic couples to take a short version of the survey in Hebrew and rate the quality of listening they received from their partner. If our measure reflects their listening schema, which supposedly affects their listening behavior, their partner should be able to perceive it.
Hypothesis 1 (H1): The more a person endorses the Rogerian listening schema, the better their romantic partner perceives the listening quality they receive from that person.
8. Study Four: Materials and Methods
8.1. Participants
In 2021, we approached both heterosexual and gay Israeli couples via WhatsApp and Facebook to volunteer to take a short Qualtrics survey on listening. Of the 198 clicks on the link we provided the volunteers, 80 were false starts with no responses. Three respondents had extensive missing data (12 or more missing items out of 34), and 12 responses were entered only by one person from the couple. We dropped their responses, leaving 100 responses from 50 couples. Of these couples, two had the same gender, 50% were females, the average age was 34.2, SD = 13.6, and they were on average 10.4 years in a relationship, SD = 13.2.
8.2. Measures
Listening belief. We used 23 listening belief items identified in Study Two. These items were taken from the Hebrew translation reported in Study Three. Yet, the cognitive interviews of Study Three and Study Four were carried out simultaneously. Thus, the items amended in Study Three were not available in Study Four. Hence, we used Study Three′s item translation without its suggested item amendments. (The amended items were used in Study Five.) We subjected the items to CFA, testing a three-factor model and obtained a reasonable fit, χ
2227 = 303.5,
p < 0.01, CFI = 0.92, RMSEA = 0.058 [0.039, 0.074], SRMR = 0.069. While this fit could be improved by allowing some covariances, we thought it would just overfit a model with this small sample [
23]. Next, we constructed three scales that yielded acceptable reliabilities: belief in the listener effect on the speaker had six items (L1, L 6, L 3, C 3, L 4, and L 7 in
Table 1), α = 0.82; belief in the speaker’s benefits from being listened to had eight items (S1 through S8 in
Table 1), α = 0.93; good listening behaviors schema had nine items (A4, G4, A7, A8, A3, B3, G1, A6, and A1 in
Table 1), α = 0.67. Note that the last reliability is lower than the one observed in Study Two, α = 0.79. To check whether this was a function of dropping item B2 in this version, we removed it from Study Two and found α = 0.77; the loss of an item does not explain this lower reliability. Still, the different samples and languages could have caused this difference.
Table 4 shows the means, standard deviations, correlations, and reliabilities for the total Rogerian listening schema scale, its three subscales, and the dependent variables (constructive and destructive listening).
Perceived Listening. Comprehensive psychometric studies of listening items suggested that two factors repeatedly underlie listening questionnaire items: constructive and destructive listening [
26,
27,
28]. Items tapping listening desired by speakers (e.g., “X understands me”) form a different factor than items tapping listening undesired by speakers (e.g., “X does not pay attention to what I say”). These factors are, as could be expected, strongly and negatively correlated. Still, their correlation is not high enough to suggest one bi-polar construct, but rather two uni-polar constructs [
26]. Although most past listening research ignored the possible role of destructive listening, we included it in our investigation to explore the different potential effects of these scales.
We sought to measure these two constructs with a few items to reduce participants’ fatigue. Based on the conclusion of Lipetz, Kluger, and Bodie [
28] that even a single item such as “X listens to me” could reliably measure (constructive) listening, we adapted seven items from Kluger and Bouskila-Yam [
27] and Lipetz, Kluger, and Bodie [
28]. Four items reflect constructive listening, and three reflect destructive listening. The items were “Creates a positive atmosphere for me to talk”; “Criticizes my feelings”; “Asks continuing questions like ‘could you tell me more?’”; “Begins to talk before I finish talking”; “Changes the subject too frequently”; “Listens to me well”; “Understands me.” Participants were asked to indicate how each item captures how they experienced their partner’s listening from 0 = strongly disagree to 10 = strongly agree. A CFA supported the two-factor structure, χ
213 = 17.4,
p = 0.18, CFI = 0.98, RMSEA = 0.058 [0.000, 0.122], SRMR = 0.058 [sic.]. The item with the highest loading on the constructive listening scale was “Listens to me well,” 0.87. This figure is consistent with Lipetz et al.’s (2020) observation that people perceive listening holistically. The item with the highest loading on the destructive listening scale was “Changes the subject too frequently,” 0.82. The constructive and destructive scales were reliable, α’s = 0.81 and 0.73, respectively. We did not have an a priori prediction of whether H1 will be equally supported with both the constructive and the destructive listening scales. Thus, we tested both.
8.3. Analysis
Our hypothesis is dyadic; it states that, in romantic couples, when a person endorses a Rogerian listening schema, their partner will report that they listen well. To test this hypothesis, we structured the data pairwise, where each record contains data provided by the respondent (the actor) and their romantic partner [
29]. Given that the data are dyadic, the responses of each couple to the dependent variable (perceived listening) may be interdependent. Interdependence may need to be modeled (e.g., with multilevel modeling). Else, the standard errors may be too large, creating a bias in the statistical conclusions. The interdependence is assessed with the intra-class correlation (
ICC). Yet, only when
ICC is higher than 0.45, does ignoring the data’s interdependency become consequential in dyadic analyses [
29]. Hence, we first tested the
ICCs and found that we could proceed with the ordinary least squares approach without losing accuracy. Moreover, because most of our sample was heterosexual couples, we tested whether the results could be distinguishable by gender [
29].
9. Study Four: Results and Discussion
Table 4 shows at the top (bottom) panel the results for the actor (partner). The bottom panel does not show the descriptive statistics because they are identical to the top panel (every partner is also an actor). As shown in
Table 4, the correlations between the actor and partner scores (i.e., the
ICCs) for the constructive,
r = 0.15, and destructive listening scales,
r = 0.18, were relatively low and insignificant. Because both were below the threshold of 0.45, modeling interdependence is unnecessary [
29]. Given the low
ICCs, the significance test of the zero-order correlations in
Table 5 could be trusted to have an inconsequential effect on statistical conclusion validity [
29]. Finally, the correlations on the top panel are
intrapersonal; the correlations with the partner-reported listening are
interpersonal, testing H1.
The box in
Table 4 highlights the test of H1. The more the actor endorses the Rogerian listening schema, the more their partner reports that they listen
constructively,
r = 0.23. [As expected, the test of this hypothesis with multilevel modeling where the data are nested within couples suggests the same conclusions: a standardized effect of 0.23 and
p = 0.022.] This effect is even more substantial for the benefit-for-speaker subscale,
r = 0.32, but not for the other two subscales. These results suggest that the support of H1 found with the total score stems from the belief that listening can benefit the speaker. Some surprising results are indicated by the destructive listening measure, which shows an insignificant positive correlation with the Rogerian listening schema (as seen in row 12 of
Table 4), which we expected to be negative. It is hard to interpret these results because of their insignificance. However, H1 was supported by the constructive listening measure.
We tested whether the above results were moderated by any demographic variables in auxiliary analyses. There was no evidence that gender moderates the effect of the benefit-for-speaker subscale on the partner’s report of either
destructive or
constructive listening; the estimate of the standardized interaction was β = −0.02/−0.02, 95%
CI [−0.21–0.18]/ [−0.12–0.08],
p = 0.88/0.64. These results show that the dyadic data are indistinguishable by gender. Both age and years together moderated this relationship on constructive listening, suggesting that the belief predicts actual constructive listening more among older couples and couples in longer relationships. However, diagnostics of these regressions indicated that this could result from multivariate outliers. Therefore, we did not interpret this finding further, which was not replicated with a larger sample in Study Five. We also tested whether any of the subscales were superior predictors of listening. Whereas the results in
Table 4 clearly show validity differences (inside the box), these differences did not replicate in Study Five, and thus we do not report them.
Last, unlike Study Two, gender was not correlated with the listening schema, r = 0.03 [−0.17, 0.23], and like Study Two, age was not correlated with the listening schema, r = 0.11 [−0.03, 0.31].
In summary, Study Four provided some support for the validity of the new scale, showing that a listening schema that one person has predicts the perception of constructive listening reported by their romantic partner. Nevertheless, Study Four was based on a relatively small sample and did not test the construct validity of the new measure by correlating it with measures of similar constructs and testing its divergent and incremental validity.
10. Study Five: Introduction
In Study Five, we sought to (a) replicate the predictive validity of the new scale observed in Study Four, (b) use Study Three’s results to improve the reliability of its third factor, (c) show evidence for its test–retest stability, (d) create a version of listening schema measure tailored to one’s romantic partner, and (e) subject the latter to multiple tests of divergent validity. For establishing divergent validity, we measured three constructs that might overlap with our new measure: (a) self-reported listening, (b) the light triad, and (c) growth mindset of personality.
First, although the results of Study Four provide initial evidence for the validity of the new scale, the sample of Study Four was relatively small, so a replication with a larger sample is needed. Specifically, in Study Four, we found that the actor’s listening schema, and the benefit-for-speaker subscale predict constructive listening as perceived by the partner. If this effect is robust, it should be replicated in Study Five.
Second, in Study Four, we did not use the insight from Study Three to improve the measurement of the third factor of the listening behaviors subscale. Therefore, in Study Five, we updated the items of this subscale based on the cognitive interviews of Study Three (see bracketed text in
Table 2 representing the items in Study Two and Study Four and replaced them with text for Study Five). We anticipate that this would improve the reliability of this subscale.
Third, given that the listening schema is construed as a relatively stable set of cognitions and beliefs, our new scale should be relatively stable and thus anticipated that we would find acceptable test–retest correlations. Test–retest reliability will expand the reliability portfolio of the new measure.
Fourth, one methodological concern about Study Four is measuring a general listening schema to predict listening experienced by a single (romantic) partner. Based on the theory of planned behavior [
14], validity is likely to be higher when there is a match between the breadth of predictor and criterion. The listening schema used in Study Four might predict the average perceived listening reported by multiple informants (e.g., a romantic partner, friends, family members, and colleagues). It may also have higher validity when the listening schema scale is tailored to the target. This match could be achieved, for example, by changing the item “A good listener trusts the speaker’s ability to reach a constructive self-direction” to “When I listen well to my partner, I trust my partner’s ability to reach a constructive self-direction.” Therefore:
Hypothesis 2 (H2): The partner-specific listening schema predicts the partner’s listening experience better than the general listening schema.
Fifth, we sought to test the divergent and predictive validity of the new measure against three measures of similar but conceptually distinct constructs. Our tests included (a) the disattenuated correlations between the new scale and three measures and (b) the incremental predictive validity of our measure in explaining the partner’s listening experience. A weak test of divergent validity suggests that the correlation between the listening schema and the competing measure is significantly lower than one (corrected for disattenutation). A strong form of it would be that the upper limit of the confidence interval for the covariance between the two latent variables based on these measures would be below 0.80 [
30]. We tested both forms of divergent validity. Once divergent validity is demonstrated, it is desirable to show that the new measure can predict variance that existing measures cannot explain. Thus, we tested whether the listening schema predicts unique variance that cannot be accounted for by any of the three competing measures.
The first theoretical-candidate construct for demonstrating divergent validity for the listening schema scale is self-reported listening. Both the listening schema and self-reported listening pertain to the same domain. However, some evidences show that self-reported listening does not predict the perceived listening reported by either the speaker or an observer [
31]. In contrast, our new scale predicted the speaker’s experience (Study Four). Therefore, we predicted that the listening schema scale would diverge from the self-reported listening scale.
Hypothesis 3 (H3): The listening schema is divergent from self-reported listening. Their disattenuated correlation is significantly lower than one (weak form), and the upper limit of their disattenuated correlation is lower than 0.80 (strong form).
Furthermore, we sought to combine H2 and H3 by subjecting the measure of partner-specific listening schema to a stringent predictive validity test. The partner-specific listening schema is likely to correlate with the general listening schema and the self-reported listening. Nevertheless, for the partner-specific listening schema to pass a stringent validity test, it should predict the partner’s listening report, even when controlling for the general listening schema and the self-reported listening. Specifically:
Hypothesis 4 (H4): The actor’s listening schema regarding their romantic partner is the best predictor of their romantic partner’s listening rating, controlling for (a) the actor’s general listening schema and (b) the actor’s self-reported listening to their partner.
A second variable that may correlate highly with the listening schema is the light triad of personality [
32,
33]. The light triad of personality is “composed of Faith in Humanity, Humanism, and Kantianism, which describes loving and beneficent orientation towards others has been recently proposed as an antithesis to the dark triad concept of malevolent personality” [
32]. The light triad is likely to correlate with the listening schema because the latter includes the belief that others do well for themselves positively. However, whereas the light triad is about “loving and beneficent orientation toward others” [
33], the listening schema is specific to listening. Therefore:
Hypothesis 5 (H5): The listening schema positively correlates with the light triad but diverges from it and explains unique variance in the partner’s listening experience.
The third construct that may correlate highly with the listening schema is an implicit theory of personality malleability [
34,
35]. Implicit theories of personality, or mindsets, range from malleable to fixed views. Those holding a malleable or growth mindset are less likely to seek revenge following social conflict [
35], more likely to show humility [
36], less likely to experience distress, and more likely to value psychological therapy and use active coping or reframing problems to reduce their negative impact [
37]. Moreover, in a scenario study [
38], a growth mindset was correlated 0.21 with self-reported imagined listening (a variable named there as “opening behavior”). The latter finding suggests that a growth mindset is part of the network of variables predicting listening. Yet, a malleable theory of personality is general. The listening schema is specific to the context of listening. Therefore:
Hypothesis 6 (H6): The listening schema positively correlates with a growth mindset of personality but diverges from it and explains unique variance in the partner’s listening experience.
We pre-registered our hypotheses and research plan at
https://aspredicted.org/pw7tr.pdf (created on 21 December 2021). However, all the above hypotheses are slightly different from the pre-registered hypotheses. Specifically, wherever we state above “listening schema,” we pre-registered “the benefit-for-speaker subscale” because it was the best predictor in Study Four. As a preview, in Study Five, the total listening schema score was the best predictor. Therefore, we presented the hypotheses about the listening schema (total score) for simplicity.
11. Study Five: Materials and Methods
11.1. Participants
To calculate the desired statistical power for Study Five, we consulted Study Four. The validity of the full scale as a predictor of constructive listening was 0.23. To be conservative, we calculated the sample size needed to detect a correlation of 0.20 with 90% power, using α = 0.05, and obtained N = 208. Therefore, we planned to collect data from 208 couples.
We anticipated some data loss in the retest phase. We also embedded attention-checking questions in the survey and planned to discard any pair for which at least one of the partners failed two attention checks. In addition, we planned to discard data of any couple for which at least one of the partners had either a perceived listening score or a belief score more extreme than 3 SD from the mean. Finally, we restricted the Prolific samples to heterosexual couples in a relationship for at least one year and native English speakers. These restrictions simplify data analyses at the cost of limiting generalizability, for example, to heterosexual couples.
In December 2021, we approached 496 Prolific workers interested in our study. We asked them if they could join with a partner with whom they had had a romantic relationship for over one year and be willing to participate twice with a two-week gap between the first and second administration. Of these, 414 appeared eligible, but we could approach only 244 partners, of whom 239 were eligible. We succeeded in matching 222 couples and invited them to participate in Time 1 survey. Of these, 217 actors but only 205 of their partners answered Time 1 survey. Of these, we had only 190 couples (380 individuals) with complete data for whom none of them failed more than one attention check. We invited them to take part in Time 2 survey. Of these, 188 actors but only 181 of their partners answered Time 2 survey. After removing participants who failed more than one attention check, we had 351 valid individual responses for calculating test–retest reliability.
After all data analyses were completed, we discovered that 18 couples took the survey twice in Time 1, and 12 took the survey twice in Time 2. We were concerned that their answers might not be reliable and thus constructed a dummy code representing the participants who took the survey twice. This dummy code was not related significantly to any of our dependent variables. Therefore, we removed the second answer of those participants, yielding a final valid sample of 191 actors with 181 of their partners answering the Time 1 survey, 165 actors and 168 of their partners answering Time 2, and 333 valid responses to calculate the test–retest reliability.
We paid each participant GBD 1.25 for each time they completed a survey. The average reported age was 39.2, SD = 10.4, 13.7 years in relationships, SD = 9.2, and 96% checked that they were native English speakers. We retained participants’ responses with inconsistent demographic data (e.g., reported a different length of the relationship than their partner did) and tested that dropping them had negligible effects on the estimates of interest.
11.2. Measures
General listening schema. We used the 27 items identified in Study Two and modified in Study Three (
Appendix A). Based on Study Three, several items in the behavior subscale were modified. In addition, a few items were rewritten to improve grammar, readability, and ease of reading by starting every item with “A good listener.” We subjected the items to CFA, testing a three-factor model and obtained questionable fit indices (column 1 in
Table 5). Therefore, we searched for covariances needed to improve the fit measures under the constraint that covariances will be allowed only between items that belong to the same factor. Adding 11 covariances (3% of all possible 351 covariances) produced a good fit (column 2 in
Table 5). We repeated these analyses (with the same covariances) and replicated the results on data from Time 2 (columns 5 and 7 in
Table 5).
Partner listening belief. The general listening belief scale was rewritten to refer to the respondent’s partner. Thus, instead of starting the questions with “A good listener…,” we wrote, “When I listen to my partner, I …” We subjected the items to CFA, testing a three-factor model and obtained a good fit both in Time 1 and Time 2 (columns 3 and 7 in
Table 5). Adding four covariances between items belonging to the same factor slightly improved the fit (columns 4 and 8 in
Table 5).
Perceived Listening. The same items used in Study Four were used here.
Self-reported listening. We adapted the listening items used in Study Four to self-report. For example, the item “My partner creates a positive atmosphere for me to talk” was rewritten as “I create a positive atmosphere for my partner to talk”.
The light triad. We employed the 12-item light triad scale developed by Kaufman et al. (2019). Example items are “I tend to see the best in people”, “I tend to admire others”, and “I prefer honesty over charm”.
Mindset. We employed a 5-item measure reported by Chiu et al. [
31] that has three items measuring fixed mindset (e.g., “The kind of person someone is is something very basic about them and it can’t be changed very much”), and two items measuring growth mindset (e.g., “Everyone, no matter who they are, can significantly change their basic characteristics”).
Demographics. We measured gender, age, number of years the couple was together, and whether the respondent was a native-English speaker.
11.3. Procedure
Couples responded to our questionnaires twice, two weeks apart. The questionnaires were identical. We presented the questionnaires in the following order: the general listening schema, the personality measures (the light triad and mindset, in random order), the partner-specific listening schema, self-reported listening to the partner, and a rating of the partner’s listening. We chose this order to have the general scales first and those about the partner later (with the personality measures in between) to prevent respondents from generalizing their responses from their responses about their partner when they answered the general questions. Nevertheless, we randomized the item order within each measure. We sent an invitation to take the second survey through a service of Prolific at least 14 days after both members completed the survey for the first time.
12. Study Five: Results and Discussion
Before testing our hypotheses, we inspected the listening schema scale’s internal consistency and test–retest reliabilities. As shown in
Table 6, the internal consistency estimates were very good for the total score and the subscales, both when measured concerning a general schema and the partner. Notably, the schema subscale of behavior had α = 0.67 in Study Four. After modifying some of its items, in Study Five, we found α = 0.87 and 0.89 in Time 1 and Time 2, respectively. Seven out of eight test–retest reliability estimates for the general and partner listening schema and their subscales were between 0.60 and 0.70, and one was 0.52 (the diagonal in bold on the lower part of
Table 6). Whereas these estimates indicate borderline test–retest reliability, they are on par with test–retest reliabilities of established measures (e.g., mindset).
Next, we tested whether data are distinguishable by gender. Following Figure 6.4 in Kenny, Kashy, and Cook [
29], we ran an omnibus test where we modeled the covariances among the latent variables of partner-specific listening schema scale, self-reported listening, and partner-reported listening. Next, we created separate models for males and females and constrained all its parameters (covariances, variances, and intercepts). The constrained model was not worse than the unconstrained model, χ
212 = 15.8,
p = 0.20, suggesting that overall, the data are indistinguishable by gender.
In Study Five, we repeated the test of H1 that the actor’s listening schema predicts the partner’s report of their listening. As seen in the first four columns of the box in
Table 7, the actor’s schema and its subscales were positively (negatively) and significantly associated with the partner’s constructive (destructive) listening report, supporting H1.
H2 suggested that the partner-specific listening schema predicts the partner’s listening report better than the general listening schema. H2 is consistently supported, as all eight correlations of the partner-specific schema are larger than those of the general schema with the partner’s listening report (all inside the box in
Table 7). H2 is also supported with a formal test (column H3 in
Table 8). We tested the partner-specific listening schema’s incremental validity both with concurrent validity (Time 1) and predictive validity (Time 2). When regressing partner’s constructive listening in Time 1, for example, on both the general and partner-specific listening schema, the β for the partner-specific listening schema is 0.38,
p <.001, but it is reduced for the general listening schema to 0.02,
p = 0.75. Similar results were observed for the partner’s report of destructive listening; β = −0.37,
p <.001, and β = 0.07,
p = 0.30. The results are similar when regressing the partner’s constructive listening in Time 2 (see Panel b).
H3 suggested that the listening schema diverges from self-reported listening. As shown in column 11 and row four of
Table 7, the disattenuated correlations for the general schema of listening diverge from self-reported listening, as all the disattenuated correlations are below 0.50, supporting H3. However, the disattenuated correlations for the total scale of the schema of listening to the partner show a 0.79 disattenuated correlations with self-reported listening, with an upper confidence interval (not shown) exceeding 0.80, but lower than 0.90, suggesting only a marginal problem with divergent validity [
30]. That is, the divergent validity predicted in H3 is supported only in its weak form (the disattenuated correlation is significantly lower than one), but not in its strong form (the upper limit of the disattenuated correlations is lower than 0.80). H4 suggested that the actor’s partner-specific listening schema is the best predictor of the romantic partner’s listening rating, controlling for (a) the actor’s general listening schema and (b) the actor’s self-reported listening to their partner.
Table 7 shows that contrary to H4, the actor’s self-reported constructive (destructive) listening was the best predictor of the partner’s constructive (destructive) listening report,
r = 0.53 (0.42). To test whether the listening schema has incremental predictive validity, we regressed the partner’s listening report on the actor’s self-reported listening and the listening schema. As shown in column H4 in
Table 8, the partner-specific listening schema did not have incremental validity both in Time 1 and in Time 2 for constructive partner-reported listening. It only did have incremental validity in Time 1, predicting the destructive partner-reported listening, β = −0.17,
p < 0.02. Thus, H4 is mostly unsupported. The actors’ partner-specific listening schema does not predict the partner’s listening report better than the actor’s self-reported listening. Instead, the actor’s self-reported listening best predicts the partner’s listening experience.
H5 suggested that the actor’s listening schema positively correlates with their light triad, but is below 0.80. As shown in row one in
Table 7, all scales and subscales of the listening schema were correlated with the light triad. Still, the highest disattenuated correlation was 0.61, and its upper confidence interval did not exceed 0.80, suggesting that the light triad measure diverges from all listening schema measures. However, the actor’s light triad also predicted the partner’s reported listening as efficiently as the actor’s general listening schema. Therefore, we tested whether the actor’s specific listening schema predicts the partner’s reported listening after controlling for the actor’s light triad and self-reported listening. As shown in column H5 in
Table 8, the partner-specific listening schema had incremental validity only in Time 1 and only for the destructive partner-reported listening. Thus, H5 is partially supported. The listening schema measure appears to measure a different construct than the light triad. Still, it does not predict the partner’s listening report once controlling for the self-reported listening and the light triad.
H6 is similar to H5; only it pertains to the growth mindset measure. As shown in row three and column two in
Table 7, mindset correlates positively with the listening schema. Still, the correlations are low, and some are insignificant, suggesting that the listening schema diverges from the growth mindset measure.
Finally, females reported marginally higher listening schema than males, r = 0.08 [−0.02, 0.18], and, as in Study Two and Study Four, age was not correlated with the listening schema, r = −0.08 [−0.18, 0.02].
To complete the validity portfolio of our new measure, we sought to demonstrate that it can predict not only the partner’s listening perception but also the sustainability and the quality of the romantic relationship. Therefore, in Study Six, we re-contacted Study Five’s participants eight months after they completed the Time 2 survey. We hypothesized that the new measure will predict their relationship quality and that the quality will be manifested in commitment to one’s partner [
32], trusting one’s partner [
33], and relationship resilience [
34]. Specifically:
Hypothesis 7 (H7): The partner-specific listening schema of one person in a romantic couple predicts (a) commitment to their partner, (b) trust in their partner, and (c) the resilience of the relationship, both as reported by that person and their partner.
Because we found in Study Five that self-reported listening was also a good predictor of the partner’s experience, we also hypothesized that:
Hypothesis 8 (H8): Self-reported listening of one person in a romantic couple predicts (a) commitment to the partner, (b) trust in the partner, and (c) the resilience of the relationship, both as reported by that person and the partner.
Last, we sought to expand the test of H4 and determine whether the new measure predicts romantic outcomes better than self-reported listening:
Hypothesis 9 (H9): The partner-specific listening schema of one person in a romantic couple predicts (a) commitment to the partner, (b) trust in the partner, and (c) the resilience of the relationship, both as reported by that person and the partner,after controlling for self-reported listening.
13. Study Six: Materials and Methods
13.1. Participants
We contacted all 183 couples who fully completed our surveys in T1 and T2.
13.2. Measures
Commitment. A 7-item measure of commitment to one’s partner [
32]. An example item is “I am committed to maintaining my relationship with my partner”.
Trust. A 5-item measure of trust in one’s partner [
33]. An example item is “I feel that I can trust my partner completely”.
Resilience. A 6-item measure of relationship resilience [
34]. An example item is “My partner and I… help each other by remaining strong in the face of a difficult situation”.
14. Study Six: Results and Discussion
Table 9 presents the basic information about the three measures of the sustainability of the romantic relationship. As can be expected, the three variables are positively and strongly correlated. Yet, their disattenuated correlations suggest that they are sufficiently divergent.
Table S3 presents the correlations of these variables with all variables reported in Study Five for Time 1 and Time 2.
Table S4 presents the correlations of these variables with all variables reported in Study Five for the actor and the partner. The
ICCs of these variables are 0.47, 0.52, and 0.55 for commitment, trust, and resilience, respectively (see
Table S4). These high
ICCs indicate that our hypotheses needed to be tested with multilevel modeling, or else the standard errors of the regressions would be smaller than warranted, producing too liberal significance tests [
29].
We tested H7, H8, and H9 twice. We tested them on the self-reported sustainability measures (
Table 10) and partner-reported sustainability measures (
Table 11). H7 was fully supported. The partner-specific listening schema of one person in a romantic couple predicted (a) commitment to the partner, (b) trust in the partner, and (c) the resilience of the relationship, as reported eight months later both by that person (
Table 10) and their partner (
Table 11). The standardized coefficients ranged from 0.17 (predicting partner-reported trust) to 0.37 (predicting self-reported trust).
H8 was largely supported. For five out of six models, at least one of the measures of listening (constructive and destructive) predicted the sustainability measures. Only the commitment reported by one’s partner was not predicted by any listening measures. Finally, H9 was supported in four out of the six models. After controlling for self-reported listening (H8 in
Table 10), the listening schema still predicted self-reported (a) commitment to the partner, (b) trust in the partner, and (c) resilience of the relationship. Moreover, after controlling for self-reported listening (H8 in
Table 11), the listening schema still predicted partner-reported commitment marginally (panel a) and resilience significantly (panel c). Thus, H9 is fully supported by self-reported relationship sustainability and partly supported by partner reports.
Study Six demonstrates the utility of our new measure of listening schema. This measure consistently predicts three relationship sustainability measures collected eight months after measuring the listening schema. It did so even when the schema measure was reported by one partner and the sustainability by the other, ruling out mono-source bias in interpreting these results. These findings establish the validity of the new measure. Moreover, the listening schema consistently demonstrated incremental validity over self-reported listening in predicting self-reported relationship sustainability. It also partially demonstrated incremental validity over self-reported listening in predicting trust and resilience. These findings establish the incremental validity of the new measure: it has the potential to explain relationship sustainability variance that similar measures cannot.
Our results preclude a causal explanation because they were established with observational data. Yet, people who endorse the listening schema may believe that their mere listening would help their partner. Consequently, they are likely to listen constructively and avoid destructive listening. Listening likely creates psychological safety for the partner, facilitating self-exploration and growth. The opportunity for self-exploration is likely to be a reward for the partner. Experiencing this reward would contribute to the attachment to the listening partner, reducing conflicts and increasing the sustainability of the relationships [
5]. Yet, this causal chain would benefit from experimental work testing each component.
15. General Discussion
We developed a new scale to tap the schema of a good listener, a set of beliefs about what constitutes high-quality listening, based on the writings of Carl Rogers [
21]. These beliefs influence the intention to listen accordingly and to maintain high-quality listening. In Study One, we constructed 46 items. In Study Two, we administered these items to an internationally diverse sample in English and discovered three factors: the listener’s belief in being able to help the speaker; the listener’s belief in the ability of the speaker to benefit from listening; a schema of the behaviors constituting good listening. We offered a reduced 28-item scale. In Study Three, we translated the scale to Hebrew, probed some difficulties found in the last factor, and proposed a final 27-item scale. In Study Four, we replicated the factorial structure in Hebrew and obtained partial evidence of the scale validity. Then, in Study Five, we replicated the factorial structure, adapted the scale to measure a partner-specific listening schema, and showed that the latter is a good predictor of a partner’s reported listening, showing divergent validity but not incremental validity from competing constructs. Finally, in Study Six, we used the partner-specific listening schema to predict the relationship sustainability eight months later. The results showed that the new measures consistently predict commitment, trust, and resiliency reported by the focal person and their partner. This prediction was held even when measures of perceived listening were controlled in four out of six tests.
To our surprise, Study Five showed that self-reported listening was both highly correlated with our new measure of listening schema and an excellent predictor of perceived listening reported by their partner. Yet, in Study Six, the most consistent predictor of relationship sustainability was the listening schema. That is, in Study Five, self-reported listening was sufficient to predict the criteria, but in Study Six, it was not. This pattern has implications for our new measure’s construct validity and the potential validity of self-reported listening.
Below, we offer three conceptual reasons to consider self-reported listening and the listening schema as sibling constructs [
35], not twins. In some contexts, they may appear too similar to have incremental validity; in others, they may be separable.
First, self-reported listening may change differently than the listening schema following training in listening. Before training, people may think they are better listeners than others due to a simple egocentric bias. Note, for example, in
Table 6 and
Table 7, that the mean of self-reported constructive (destructive) listening is higher (lower) than the mean of partner-reported constructive (destructive) listening. Yet, after training, as we observe in the reflections of participants in our training workshops, many trainees realize how hard it is to listen and report that they are poorer listeners than they previously thought. In contrast, before training, people may not endorse the Rogerian listening schema. Yet, training is likely to elevate their Rogerian listening schema because they experienced how valuable listening was for them and their partners. Therefore, the context of training in listening may be one in which the construct of listening schema is differentiated from self-reported listening. If supported empirically, it would suggest that our new measure of listening schema is the ideal measure to assess the effectiveness of listening training.
Second, the listening schema may attenuate the effect of self-reported listening to trauma victims. People who listen to traumatic stories (e.g., social workers listening to rape victims) are at risk of suffering second-hand trauma [
20]—stress experienced following listening to stories of trauma [
36]. Yet, it could be that some listeners are less prone to second-hand trauma because they believe that their mere listening helped the person who shared the trauma. In contrast, those who do not endorse the Rogerian listening schema may feel helpless and develop a negative view of humanity. For example, spouses of war veterans may not listen to their partner because of an unconscious fear of being exposed to horrors and feeling helpless. They may fear helplessness because they are unaware that listening can contribute to their partner’s well-being. Therefore, the listening schema may be a moderator, explaining why some people are less prone to second-hand trauma. Thus, the context of listening to trauma may be another one in which the construct of listening schema is differentiated from self-reported listening, by having one moderate the other. If supported empirically, it may have practical implications: strengthening the listening schema can help protect therapists, spouses, and people in general from second-hand trauma.
Next, we turn to the potential validity of self-reported listening. Our results differ from past findings that self-reported listening correlates neither with speaker-reported listening perceptions nor observer evaluation [
18]. The difference in these results can be explained by the measures of self-reported listening. Whereas Bodie, Jones, Vickery, Hatcher, and Cannava [
18] collected self-reported listening on a general measure, we used a measure of self-reported listening tailored to one’s specific partner. This explanation is consistent with findings that perceived listening varies from partner to partner [
37]. Another difference between these studies is that Bodie, Jones, Vickery, Hatcher, and Cannava [
18] sampled unacquainted undergraduate students while ours were highly acquainted romantic partners. Indeed, one small-sample study,
N = 18, reported a 0.93 correlation between supervisors’ self-rated listening and their 43 subordinates’ average listening rating [
38].
In addition, Lehmann, Kluger, and Van Tongeren [
7] asked participants in two experiments manipulating listening to self-report their listening and rate the listening of their partner. They found correlations of 0.81 and 0.85. Thus, when self-reported listening refers to self-perception of listening as a trait, it does not seem to predict a specific partner’s reported listening. When self-reported listening refers to the self-perception of listening to a specific person, it does predict the specific partner’s reported listening. Still, the effect size ranged from about 0.50, found here, to about 0.90 [
38]. The difference between these studies calls for future scrutiny of self-reported listening as a predictor of perceived listening reported by others. If self-reported listening is a valid predictor of the partner’s experience, it will have far-reaching implications for the listening field. Self-reported listening could be used as a proxy for other reported listening when the self-report is tailored to a particular partner. The lesson we draw from this finding is the dire need for replication. Before the field of listening can rely on self-reported listening as a valid predictor of perceived listening reported by others, our explanation should be rigorously tested.
Four limitations of our work should be considered in future investigations of the Rogerian listening schema. First, causality cannot be inferred from any of our studies. Therefore, future studies could, for example, randomly assign some people to be trained in listening and test whether it increases the endorsement of a Rogerian listening schema while not necessarily self-reported listening. Second, the relative predicting power of the subscales in Study Four was different than in Study Five, and the intercorrelations among the subscales were high. It is not clear whether these subscales have a unique predictive power. Additional empirical work would be needed to determine whether only the total score of the 27-item measure should be used. Perhaps, experimental work might discover different effects on the various subscales. Finally, the strong correlation between the listening schema and self-reported listening was not expected, and future research should attempt to define their theoretical and empirical divergence.
In conclusion, we translated Rogers’s (1949) view of good listening into a measure of the Rogerian listening schema. We found that three latent factors underlie this scale: belief that listening can help a speaker, trust in the speaker’s ability to benefit from listening, and schema of a particular set of behaviors that constitute good listening. We demonstrated evidence for the validity of the new scale and showed that it predicts the romantic partner’s report of perceived listening and relationship sustainability. This scale could be used to probe deep-seated obstacles to creating good communication among romantic partners and assessing the effects of listening training. All of these are waiting for further research.


 ,
, 

{kind=link}