
Remaining Useful Life Prediction of Wind Turbine Gearbox Bearings with Limited Samples Based on Prior Knowledge and PI-LSTM
Abstract
:1. Introduction
2. Literature Review
2.1. RUL Prediction of WT Components Using DNNs
2.2. Few-Shot Learning
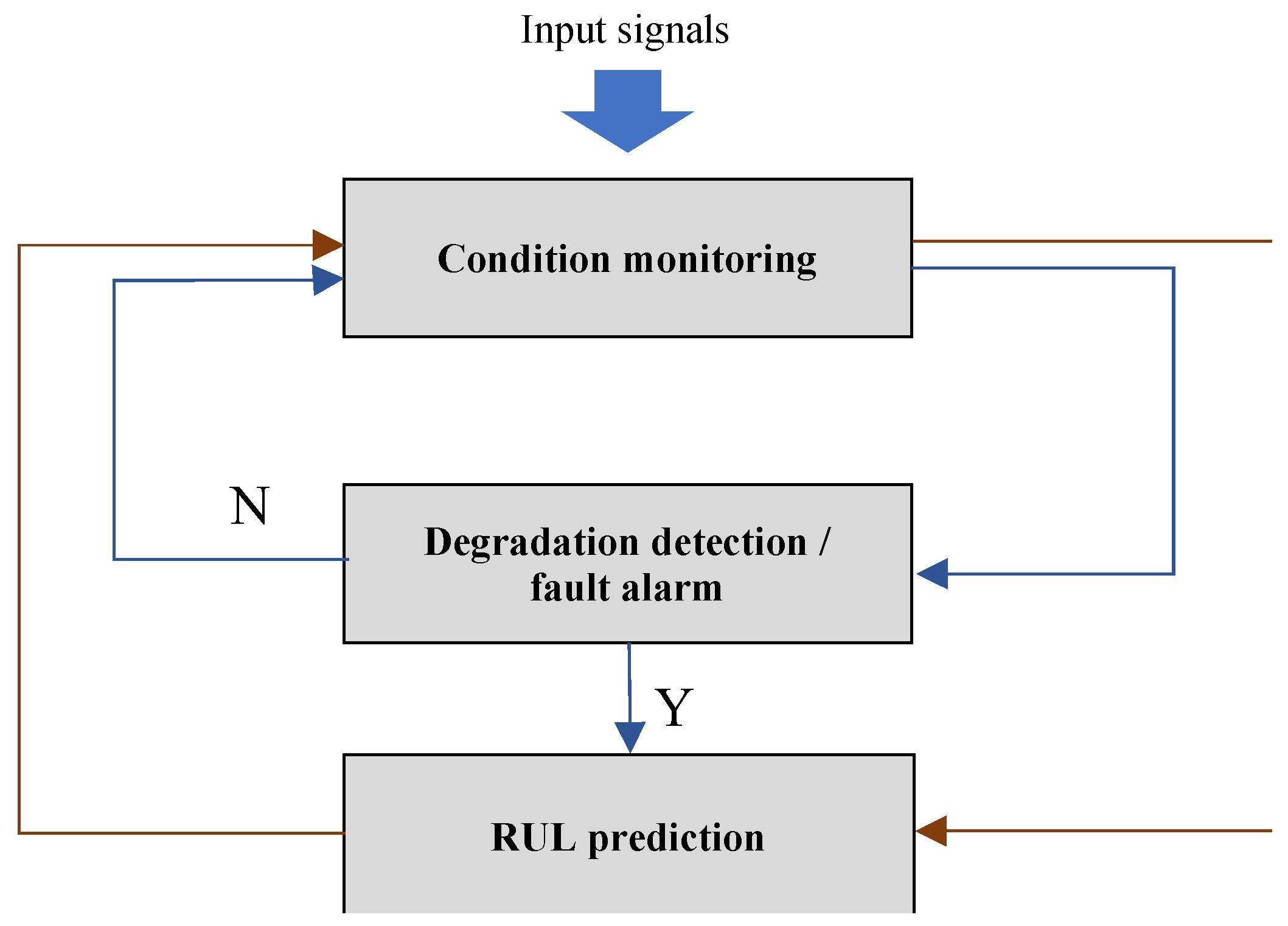
3. Problem Definition
4. The Proposed Method
4.1. Wiener Degradation Model Construction and Training
4.1.1. The Construction of the Wiener Model
4.1.2. The Offline Training of the Constructed Wiener Model
4.2. Wiener Degradation Model Construction and Training
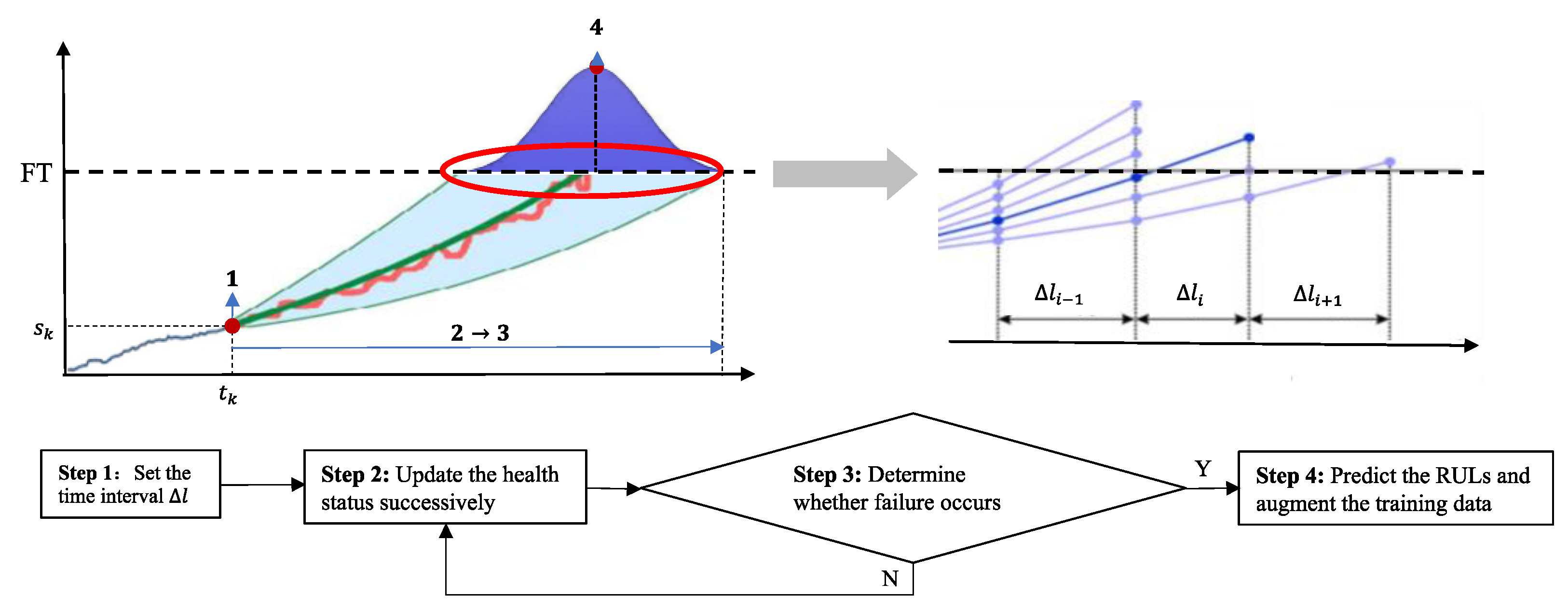
- Set the time interval of the health status transition . Normally, if high-frequent signals are collected, the time interval can be set to a multiple of the data acquisition interval of sensors. Otherwise, can be equivalent to the data acquisition interval. In addition, a total of particles are generated, representing virtual WT gearbox bearings, where is the initial health status of the nth bearing.
- Update the health status successively based on the transition function derived by Equation (3):where is the health status of the nth particle after the ith transition interval, ; .
- In the ith transition interval , determine whether each particle fails according to the relationship between the health status and the FT . If the particles have not failed, repeat step 2 until the health statuses of all particles reach or exceed ; then, go to step 4.
4.3. PI-LSTM Construction and Training
4.3.1. The Construction of PI-LSTM
4.3.2. The Offline Training of the Constructed PI-LSTM
4.4. PI-LSTM Fine-Tuning
4.5. RUL Prediction of WT Gearbox Bearings
5. Case Study
5.1. Data Collection
5.2. Experimental Details
5.2.1. Parameter Selection
5.2.2. Hyper-Parameter Setting
5.2.3. Other Details
5.3. Results and Discussion
5.3.1. Metrics for RUL Prediction
5.3.2. Method Verification
- Each part of the proposed method has a good effect.
- 2.
- The introduced prior knowledge shows a promising effect.
- 3.
- The deviations contained in the prior knowledge are reduced through fine-tuning.
5.3.3. Method Comparison
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yucesan, Y.A.; Dourado, A.; Viana, F. A survey of modeling for prognosis and health management of industrial equipment. Adv. Eng. Inform. 2021, 50, 101404. [Google Scholar] [CrossRef]
- Rezamand, M.; Kordestani, M.; Carriveau, R.; Ting, S.K.; Saif, M. Critical wind turbine components prognostics: A comprehensive review. IEEE Trans. Instrum. Meas. 2020, 69, 9306–9328. [Google Scholar] [CrossRef]
- Breteler, D.; Kaidis, C.; Tinga, T.; Loendersloot, R. Physics based methodology for wind turbine failure detection, diagnostics & prognostics. In Proceedings of the European Wind Energy Association Annual Conference and Exhibition, Paris, France, 17–20 November 2015; pp. 1–9. [Google Scholar]
- Li, Y.; Kurfess, T.; Liang, S.Y. Stochastic prognostics for rolling element bearings. Mech. Syst. Signal Process. 2000, 14, 747–762. [Google Scholar] [CrossRef]
- Oppenheimer, C.H.; Loparo, K.A. Physically based diagnosis and prognosis of cracked rotor shafts. In Proceedings of the SPIE-The International Society for Optical Engineering, Orlando, FL, USA, 16 July 2002; Volume 4733, pp. 122–132. [Google Scholar]
- Marble, S.; Morton, B.P. Predicting the remaining life of propulsion system bearings. In Proceedings of the IEEE Aerospace Conference, Big Sky, MT, USA, 4–11 March 2006. [Google Scholar]
- Qiu, J.; Seth, B.B.; Liang, S.Y.; Zhang, C. Damage mechanics approach for bearing lifetime prognostics. Mech. Syst. Signal Process. 2002, 16, 817–829. [Google Scholar] [CrossRef]
- Liao, G.B.; Yin, H.P.; Chen, M.; Lin, Z. Remaining useful life prediction for multi-phase deteriorating process based on Wiener process. Reliab. Eng. Syst. Safe. 2021, 207, 107361. [Google Scholar] [CrossRef]
- Zhang, Z.X.; Si, X.S.; Hu, C.H.; Lei, Y.G. Degradation data analysis and remaining useful life estimation: A review on Wiener-process-based methods. Eur. J. Oper. Res. 2018, 271, 775–796. [Google Scholar] [CrossRef]
- Zhang, C.; Kong, F.T. Application of gamma process and maintenance cost for fatigue damage of wind turbine blade. Energy Procedia 2019, 158, 3729–3734. [Google Scholar] [CrossRef]
- Wang, J.J.; Liang, Y.Y.; Zheng, Y.H.; Gao, R.X.; Zhang, F.L. An integrated fault diagnosis and prognosis approach for predictive maintenance of wind turbine bearing with limited samples. Renew. Energy 2020, 145, 642–650. [Google Scholar] [CrossRef]
- Merainani, B.; Laddada, S.; Bechhoefer, E.; Mohamed, A.A.C.; Benazzouza, D. An integrated methodology for estimating the remaining useful life of high-speed wind turbine shaft bearings with limited samples. Renew. Energy 2021, 182, 1141–1151. [Google Scholar] [CrossRef]
- Jiang, J.R.; Lee, J.E.; Zeng, Y.M. Time series multiple channel convolutional neural network with attention-based long short-term memory for predicting bearing remaining useful life. Sensors 2020, 20, 166. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.Y.; Liu, H.; Jia, W.J.; Zhang, D.H.; Tan, J.R. A multi-head neural network with unsymmetrical constraints for remaining useful life prediction. Adv. Eng. Inform. 2021, 50, 101396. [Google Scholar] [CrossRef]
- Cheng, Y.W.; Hu, K.; Wu, J.; Zhu, H.P.; Shao, X.Y. A convolutional neural network based degradation indicator construction and health prognosis using bidirectional long short-term memory network for rolling bearings. Adv. Eng. Inform. 2021, 48, 101247. [Google Scholar] [CrossRef]
- Desai, A.; Guo, Y.; Sheng, S.; Phillips, C.; Williams, L. Prognosis of wind turbine gearbox bearing failures using SCADA and modeled data. In Proceedings of the Annual Conference of the Prognostics and Health Management Society, online, 9–13 November 2020. [Google Scholar]
- Teng, W.; Zhang, X.L.; Liu, Y.B.; Kusiak, A.; Ma, Z.Y. Prognosis of the remaining useful life of bearings in a wind turbine gearbox. Energies 2016, 10, 32. [Google Scholar] [CrossRef]
- Elasha, F.; Shanbr, S.; Li, X.C.; David, M. Prognosis of a wind turbine gearbox bearing using supervised machine learning. Sensors 2019, 19, 3092. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Z.B.; Wu, J.Y.; Wong, D.; Sun, C.; Yan, R.Q. Probabilistic remaining useful life prediction based on deep convolutional neural network. In Proceedings of the 9th International Conference on Through-life Engineering Services, Cranfield, Bedfordshire, UK, 3–4 November 2020. [Google Scholar]
- Jia, X.J.; Han, Y.; Li, Y.J.; Sang, Y.C.; Zhang, G.L. Condition monitoring and performance forecasting of wind turbines based on denoising autoencoder and novel convolutional neural networks. Energy Rep. 2021, 7, 6354–6365. [Google Scholar]
- Pan, Y.B.; Hong, R.J.; Chen, J.; Wu, W.W. A hybrid DBN-SOM-PF-based prognostic approach of remaining useful life for wind turbine gearbox. Renew. Energy 2020, 152, 138–154. [Google Scholar] [CrossRef]
- Guo, L.; Li, N.P.; Jia, F.; Lei, Y.G.; Lin, J. A recurrent neural network based health indicator for remaining useful life prediction of bearings. Neurocomputing 2017, 240, 98–109. [Google Scholar] [CrossRef]
- Wang, S.S.; Chen, J.; Wang, H.; Zhang, D.Z. Degradation evaluation of slewing bearing using HMM and improved GRU. Measurement 2019, 146, 385–395. [Google Scholar] [CrossRef]
- Zhu, L.P.; Zhang, X.R. Time series data-driven online prognosis of wind turbine faults in presence of SCADA data loss. IEEE Trans. Sustain. Energy 2020, 12, 1289–1300. [Google Scholar] [CrossRef]
- Sayah, M.; Guebli, D.; Noureddine, Z.; Masry, Z.A. Deep LSTM enhancement for RUL prediction using Gaussian mixture models. Automat. Control Comput. Sci. 2021, 55, 15–25. [Google Scholar] [CrossRef]
- Wang, Y.Q.; Yao, Q.M.; Kwok, J.T.; Ni, L.M. Generalizing from a few examples: A survey on few-shot learning. ACM Comput. Surv. 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Li, F.F.; Fergus, R.; Perona, P. One-shot learning of object categories. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 594–611. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; Wierstra, D. Matching networks for one shot learning. In Proceedings of the 30th Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 3637–3645. [Google Scholar]
- Yu, M.; Guo, X.X.; Yi, J.F.; Chang, S.Y.; Potdar, S.; Cheng, Y.; Tesauro, G.; Wang, H.Y.; Zhou, B. Diverse few-shot text classification with multiple metrics. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018. [Google Scholar]
- Vartak, M.; Thiagarajan, A.; Miranda, C.; Bratman, J.; Larochelle, H. A meta-learning perspective on cold-start recommendations for items. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Los Angeles, CA, USA, 4–9 December 2017; pp. 6907–6917. [Google Scholar]
- Chen, W.B.; Chen, W.Z.; Liu, H.X.; Wang, Y.Q.; Bi, C.L.; Gu, Y. A RUL prediction method of small sample equipment based on DCNN-BiLSTM and domain adaptation. Mathematics 2022, 10, 1022. [Google Scholar] [CrossRef]
- Zhang, B.; Zhang, S.H.; Li, W.H. Bearing performance degradation assessment using long short-term memory recurrent network. Comput. Ind. 2019, 106, 14–29. [Google Scholar] [CrossRef]
- Kong, Z.M.; Cui, Y.; Xia, Z.; Lv, H. Convolution and long short-term memory hybrid deep neural networks for remaining useful life prognostics. Appl. Sci. 2019, 9, 4156. [Google Scholar] [CrossRef]
- Gao, Z.W.; Liu, X.X. An overview on fault diagnosis, prognosis and resilient control for wind turbine systems. Processes 2021, 9, 300. [Google Scholar] [CrossRef]
- Kramti, S.E.; Saidi, L.; Ali, J.B.; Sayadi, M. Particle filter based approach for wind turbine high-speed shaft bearing health prognosis. In Proceedings of the 2019 IEEE International Conference on Signal, Control and Communication, Hammamet, Tunisia, 16–18 December 2019. [Google Scholar]
- Teng, W.; Han, C.; Hu, Y.K.; Cheng, X.; Song, L.; Liu, Y.B. A robust model-based approach for bearing remaining useful life prognosis in wind turbines. IEEE Access 2020, 8, 47133–47143. [Google Scholar] [CrossRef]
- Noman, K.; He, Q.; Peng, Z.K.; Wang, D. Dynamic degradation quantification of wind turbine high speed shaft bearing based on oscillation based sparsity indices. J. Phys. Conf. Ser. 2021, 1880, 012013. [Google Scholar] [CrossRef]
- Hu, Y.G.; Li, H.; Shi, P.P.; Chai, Z.S.; Wang, K.; Xie, X.J.; Chen, Z. A prediction method for the real-time remaining useful life of wind turbine bearings based on the Wiener process. Renew. Energy 2018, 127, 452–460. [Google Scholar] [CrossRef]
- Mu, S.; Su, Y.L.; Jing, K.; Li, C. Remaining life prediction of wind turbine bearing based on Wiener process. Mater. Sci. Eng. 2020, 788, 012089. [Google Scholar]
- Li, N.P.; Lei, Y.G.; Guo, L.; Yan, T.; Lin, J. Remaining useful life prediction based on a general expression of stochastic process models. IEEE Trans. Ind. Electron. 2017, 64, 5709–5718. [Google Scholar] [CrossRef]
- Chen, L.T.; Xu, G.H.; Zhang, S.C.; Yan, W.Q.; Wu, Q.Q. Health indicator construction of machinery based on end-to-end trainable convolution recurrent neural networks. J. Manuf. Syst. 2020, 54, 1–11. [Google Scholar] [CrossRef]
- Lee, S.; Park, W.; Jung, S. Fault detection of aircraft system with random forest algorithm and similarity measure. Sci. World J. 2014, 6, 727359. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Melis, G.; Kočiský, T.; Blunsom, P. Mogrifier LSTM. In Proceedings of the International Conference on Learning Representations, online, 26–30 April 2020. [Google Scholar]
- Xiao, X.C.; Liu, J.X.; Liu, D.S.; Tang, Y.F.; Zhang, F. Condition monitoring of wind turbine main bearing based on multivariate time series forecasting. Energies 2022, 15, 1951. [Google Scholar] [CrossRef]
- Golovin, D.; Solnik, B.; Moitra, S.; Kochanski, G.; Karro, J.; Sculley, D. Google vizier: A service for black-box optimization. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1487–1495. [Google Scholar]
- Chen, Z.; Wu, M.; Zhao, R.; Guretno, F.; Li, X. Machine remaining useful life prediction via an attention based deep learning approach. IEEE Trans. Ind. Electron. 2020, 68, 2521–2531. [Google Scholar] [CrossRef]
- Rathore, M.S.; Harsha, S.P. Prognostics analysis of rolling bearing based on Bi-directional LSTM and attention mechanism. J. Fail. Anal. Prev. 2022, 22, 704–723. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Technical Parameter | Value |
|---|---|
| Rated power | 2000 kW |
| Cut-in wind speed | 5 m/s |
| Rated wind speed | 13 m/s |
| Cut-out wind speed | 24 m/s |
| Rotor diameter | 90 m |
| Rotor-swept area | 6476 m2 |
| Number of blades | 3 |
| Maximum rotor speed | 14.9 rpm |
| Tip speed | 70 m/s |
| Maximum generator speed | 2014 rpm |
| Generator voltage | 700 V |
| Grid frequency | 52 Hz |
| Hub height | 76 m |
| No. | Layer | [Kernel Size, Channel], Stride | Output Size |
|---|---|---|---|
| 0 | Input | / | |
| 1 | Conv_1 | ||
| 2 | Residual_block_1 | ||
| 3 | Residual_block_2 | ||
| 4 | Residual_block_3 | ||
| 5 | Residual_block_4 | ||
| 6 | LSTM | / | |
| 7 | Fully connected | / | 1 |
| Model | Hyper-Parameters | Value |
|---|---|---|
| Wiener degradation model | The highest power of polynomial fitting of | 4 |
| PI-LSTM | Learning rate | 0.005 |
| Decay rate of learning rate | 0.98 | |
| Number of hidden layers | 3 | |
| Dropout rate (the first type) | 0.2 | |
| Dropout rate (the second type) | 0.2 | |
| Dropout rate (the third type) | 0.45 | |
| The highest power of polynomial fitting on the top | 3 |
| Method Condition | S-Score | RMSE |
|---|---|---|
| 1. PI-LSTM only | 2.53 | 1.46 |
| 2. LSTM fine-tuning | 2.88 | 1.83 |
| 3. Bi-LSTM fine-tuning | 2.63 | 1.70 |
| 4. Bi-LSTM(A) fine-tuning | 2.37 | 1.52 |
| 5. PI-LSTM | 1.69 | 0.88 |
| 6. PI-LSTM frozen fine-tuning | 1.43 | 0.61 |
| 7. PI-LSTM fine-tuning (the proposed method) | 1.28 | 0.44 |
| Method Condition | S-Score | RMSE |
|---|---|---|
| MGRU | 3.23 | 1.72 |
| MHNN | 1.84 | 1.16 |
| The multi-phase Wiener process model | 2.06 | 1.27 |
| The proposed method | 1.28 | 0.44 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Gao, P.; Chu, X. Remaining Useful Life Prediction of Wind Turbine Gearbox Bearings with Limited Samples Based on Prior Knowledge and PI-LSTM. Sustainability 2022, 14, 12094. https://doi.org/10.3390/su141912094
Wang Z, Gao P, Chu X. Remaining Useful Life Prediction of Wind Turbine Gearbox Bearings with Limited Samples Based on Prior Knowledge and PI-LSTM. Sustainability. 2022; 14(19):12094. https://doi.org/10.3390/su141912094
Chicago/Turabian StyleWang, Zheng, Peng Gao, and Xuening Chu. 2022. "Remaining Useful Life Prediction of Wind Turbine Gearbox Bearings with Limited Samples Based on Prior Knowledge and PI-LSTM" Sustainability 14, no. 19: 12094. https://doi.org/10.3390/su141912094