
Cloud-Based Collaborative Road-Damage Monitoring with Deep Learning and Smartphones

 , , ,
, , ,
Abstract
:1. Introduction
2. Literature Review
2.1. Related Work
2.2. Challenges and Gaps
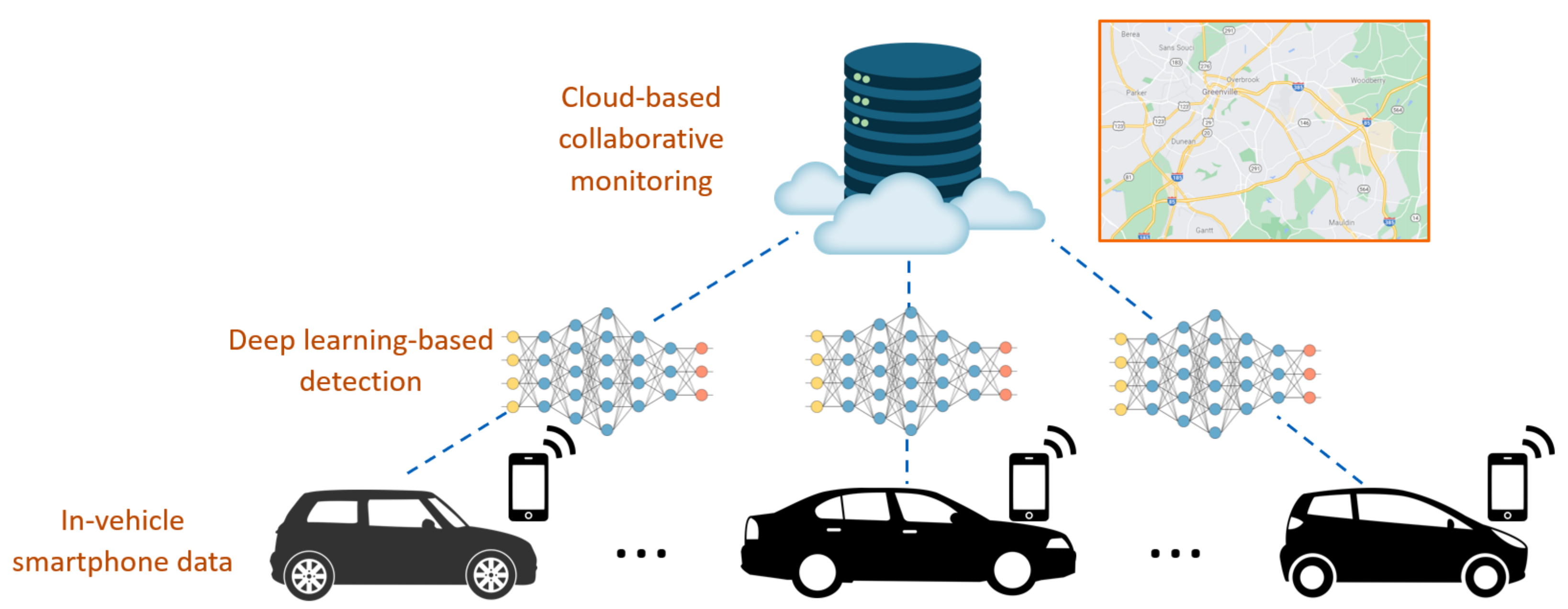
3. Cloud-Based Collaborative Road-Surface Monitoring
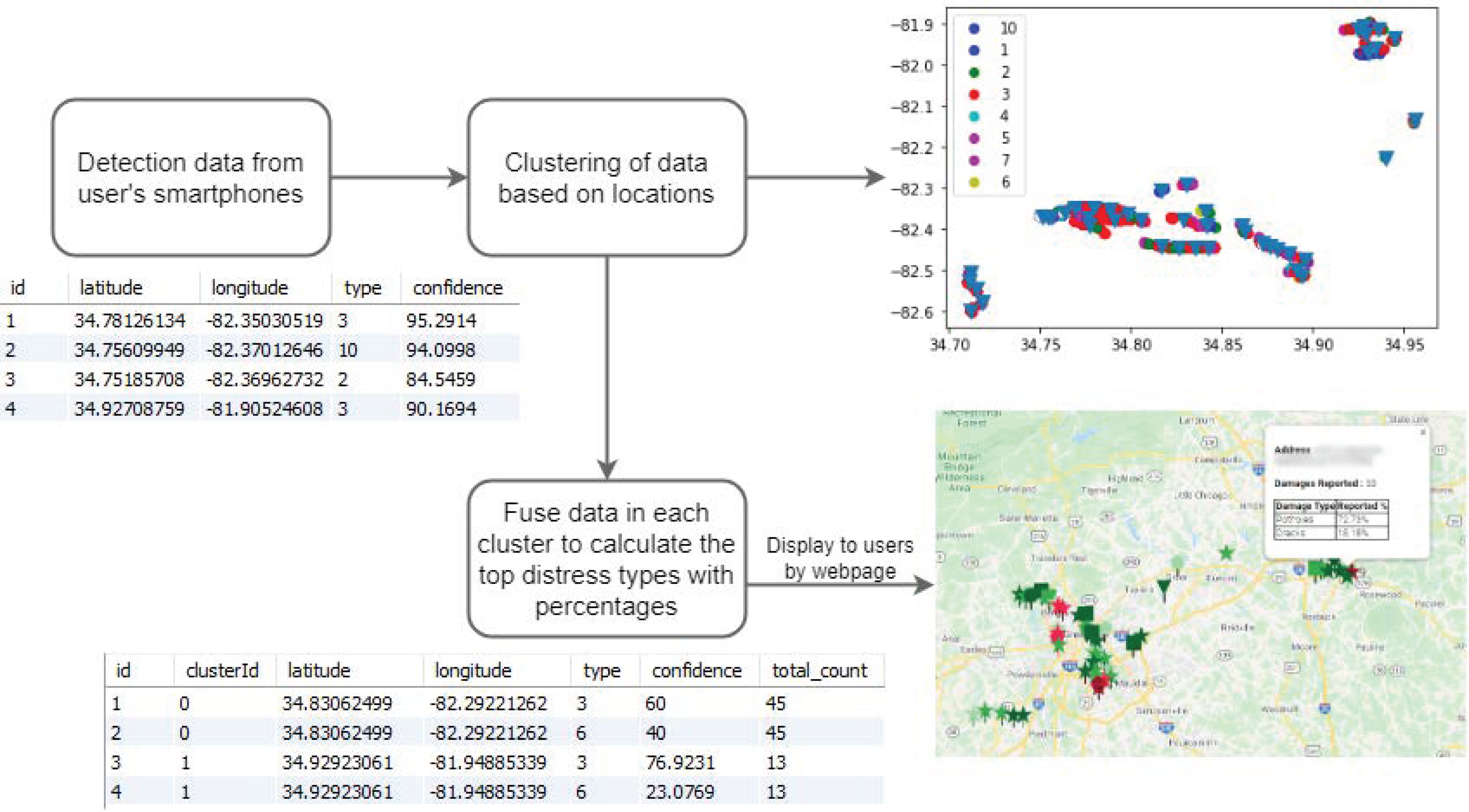
3.1. Framework of Cloud-Based Collaborative Road-Damage Monitoring Method
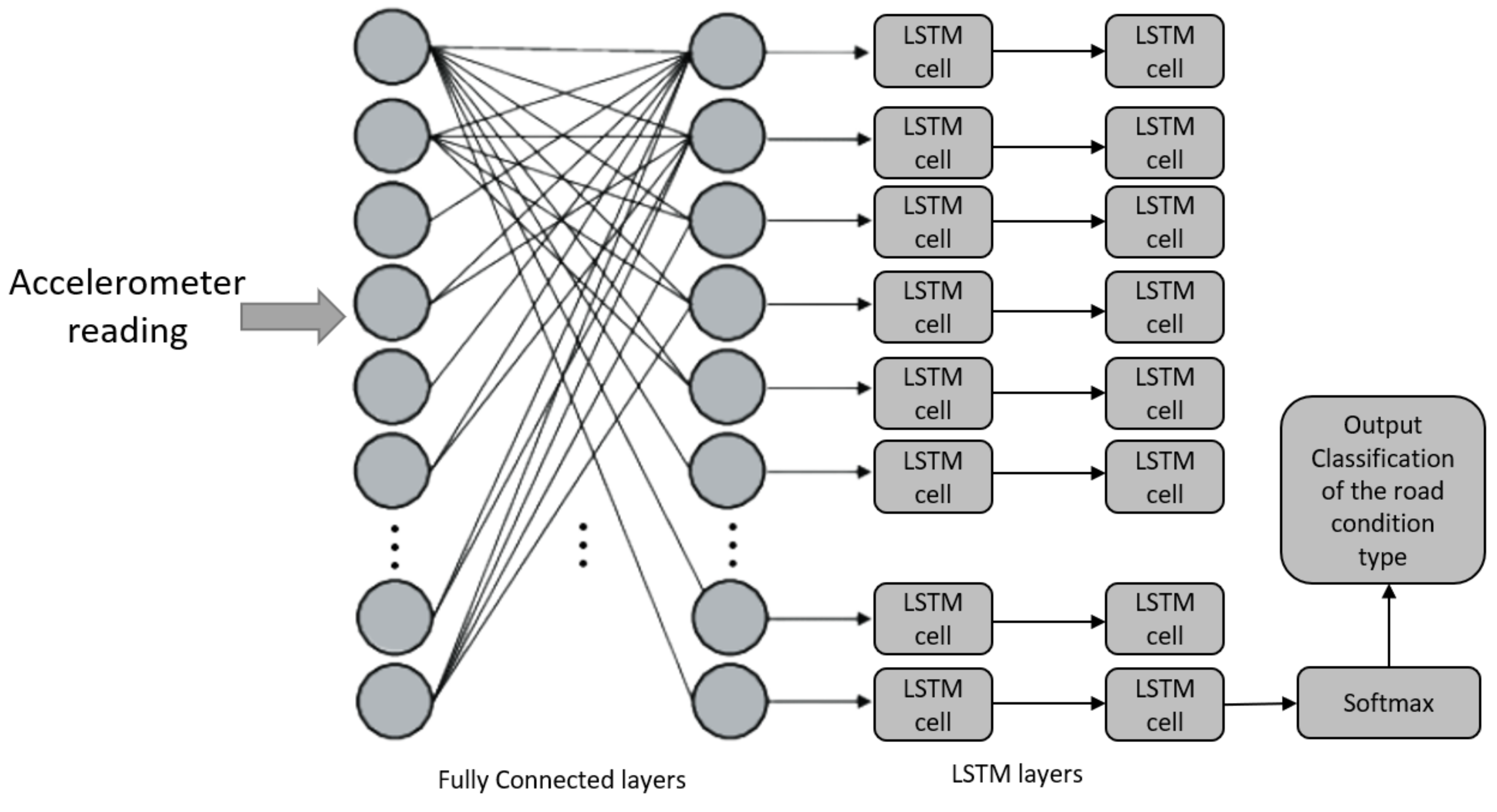
3.2. Motion-Based Road-Damage Detection
3.3. Vision-Based Road-Damage Detection
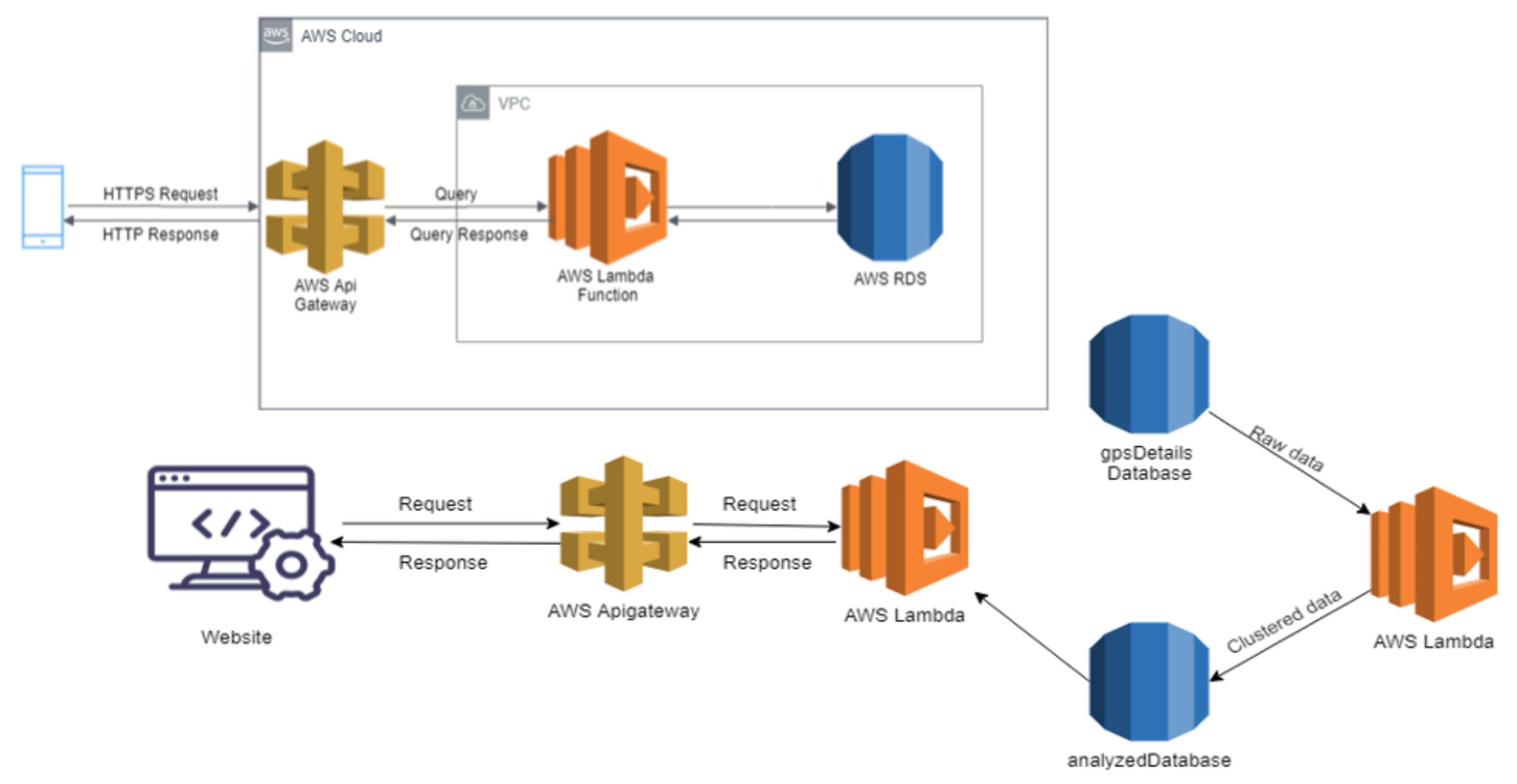
3.4. Cloud-Based Collaborative Fusion
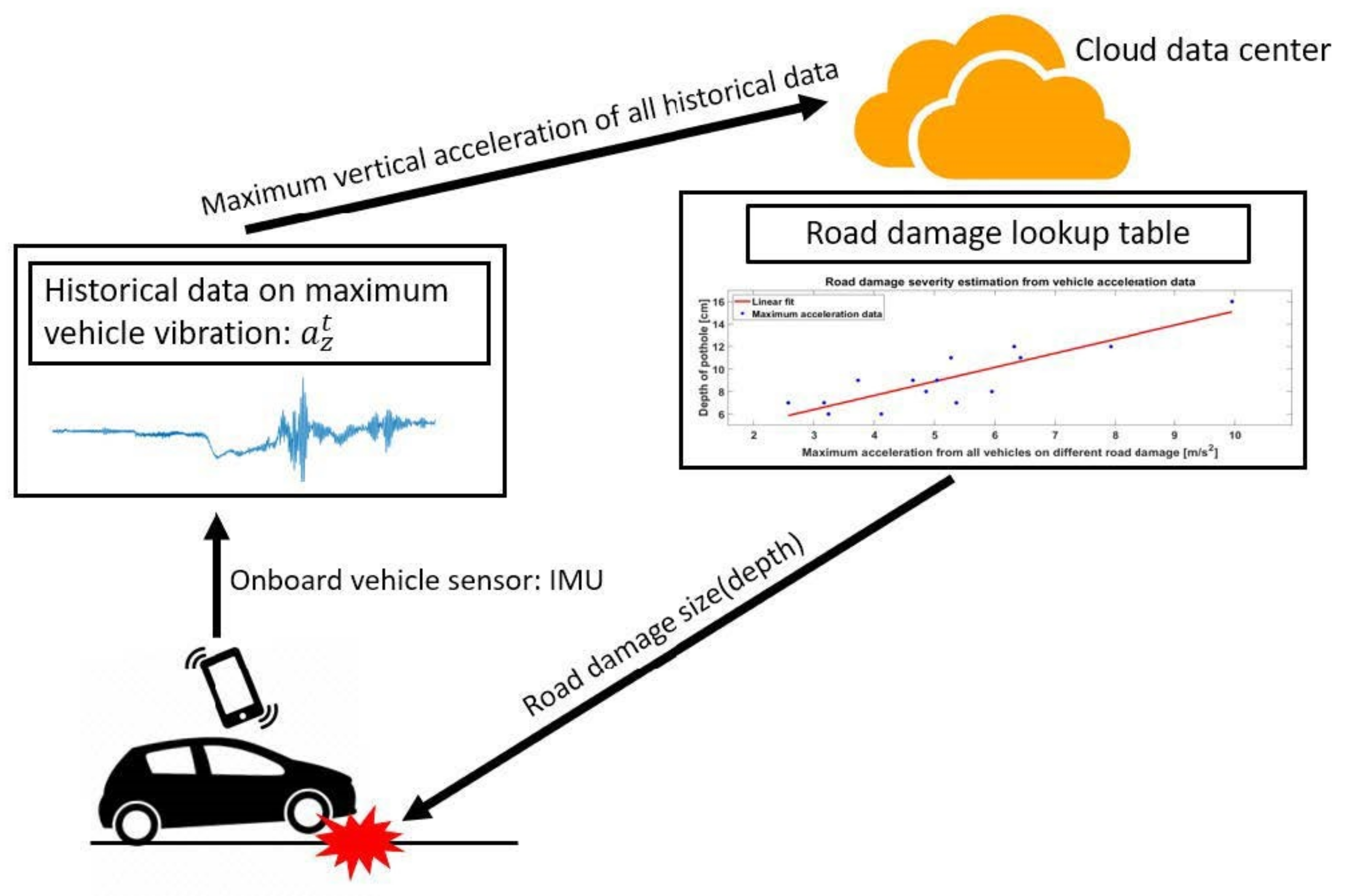
3.5. Road-Damage Severity Estimation
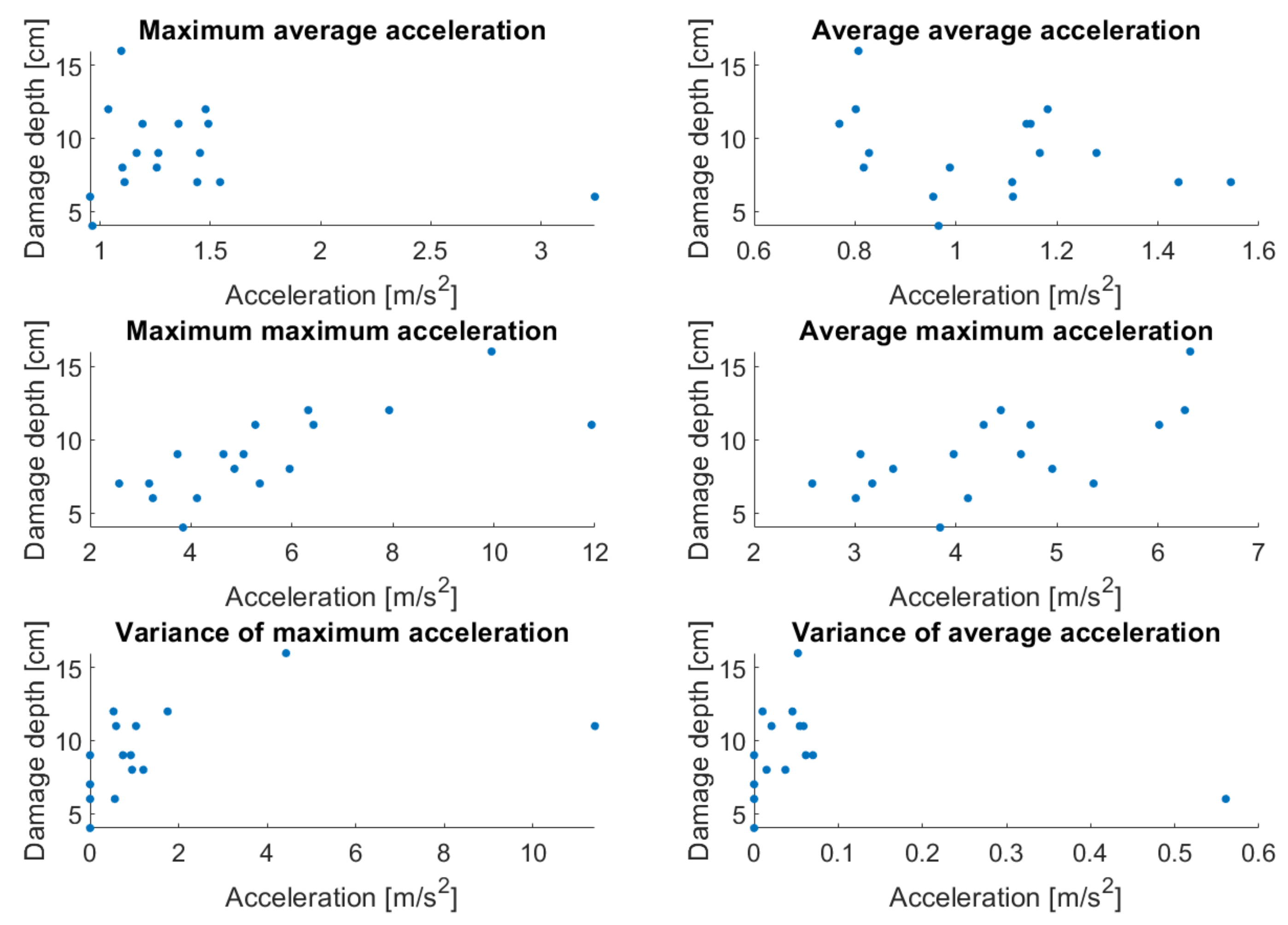
3.5.1. Method Design and Data Acquisition
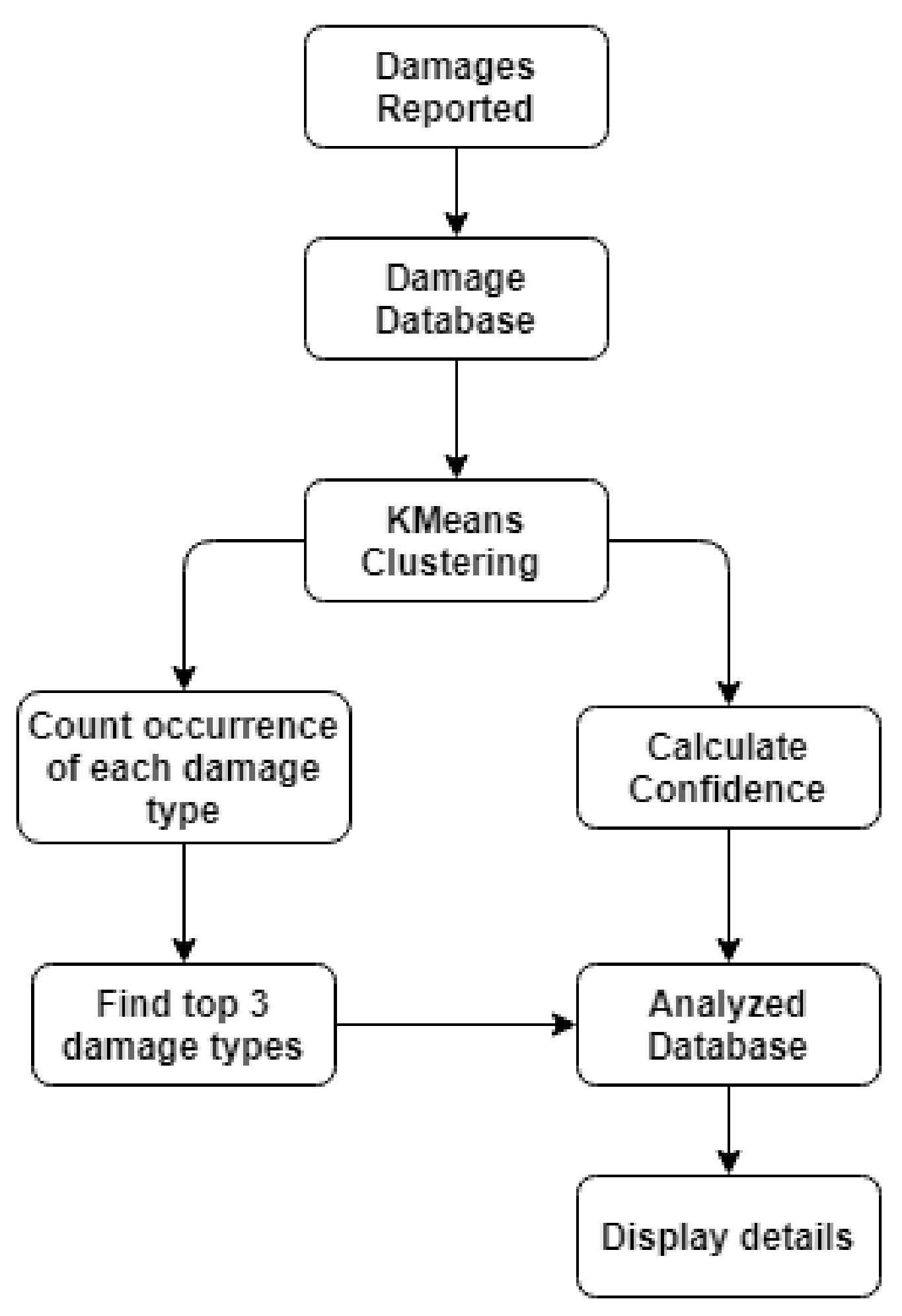
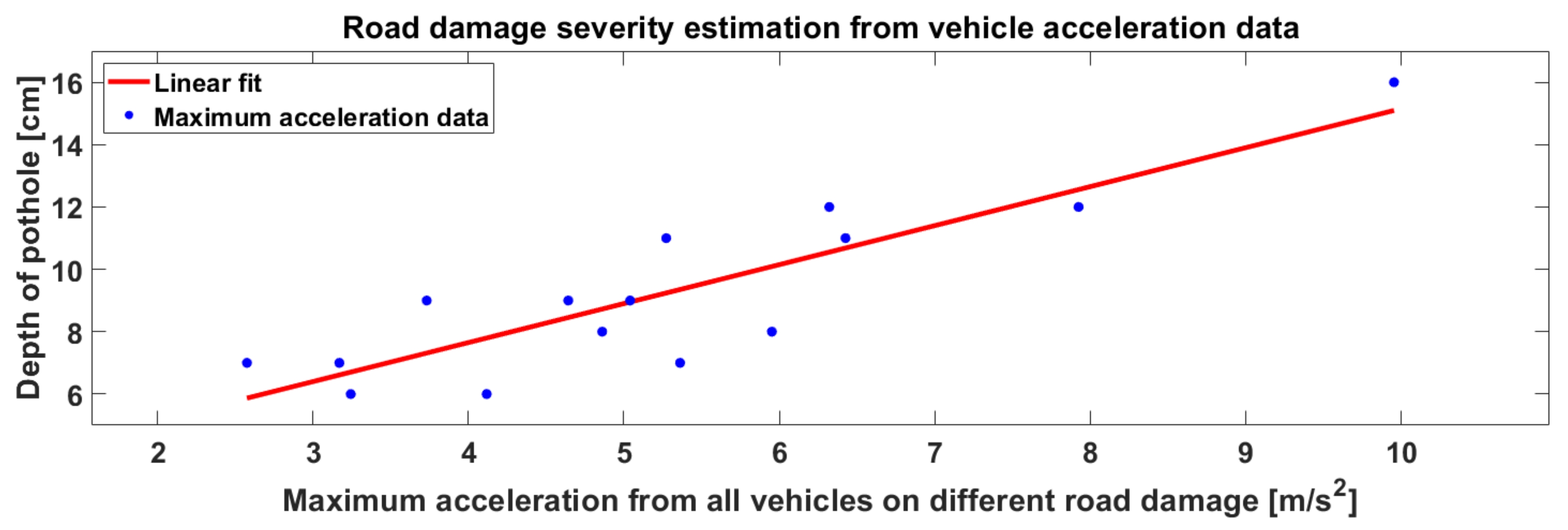
3.5.2. Cloud-Based Road-Damage Severity Estimation
4. Experiment Results
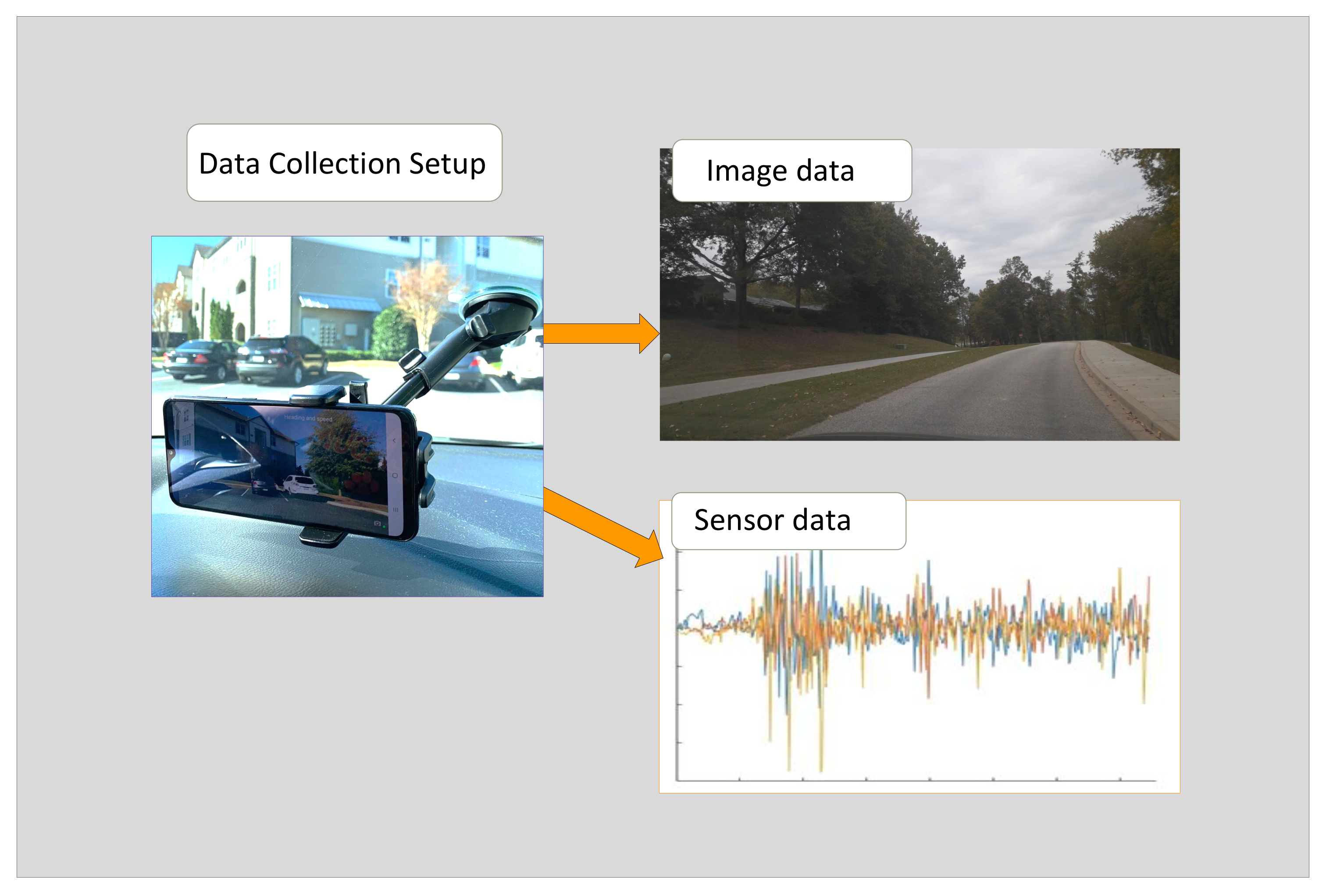
4.1. Experimental Setup and Data Collection
4.1.1. Setup and Application Development
4.1.2. Data Collection
4.2. Experimental Result and Analysis
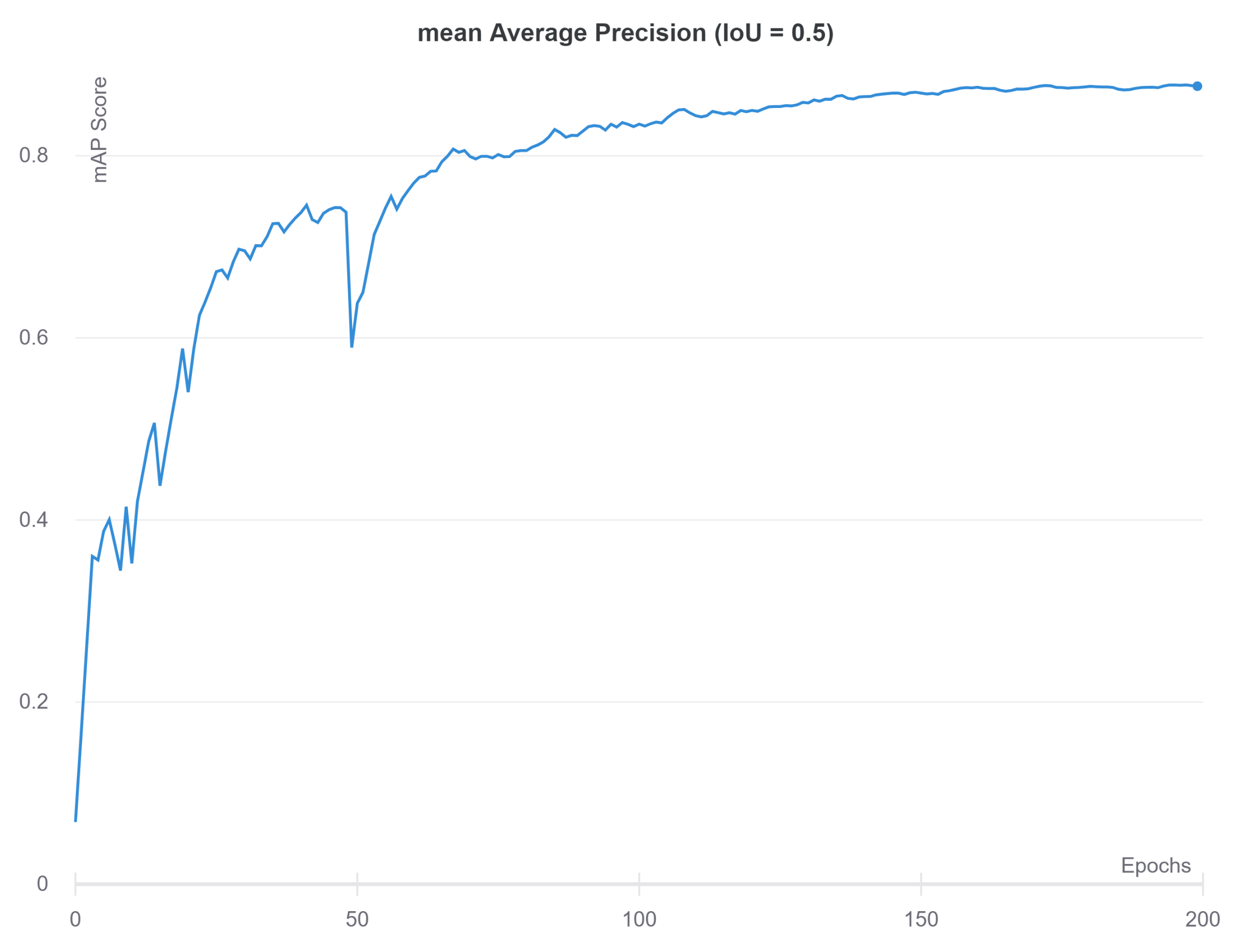
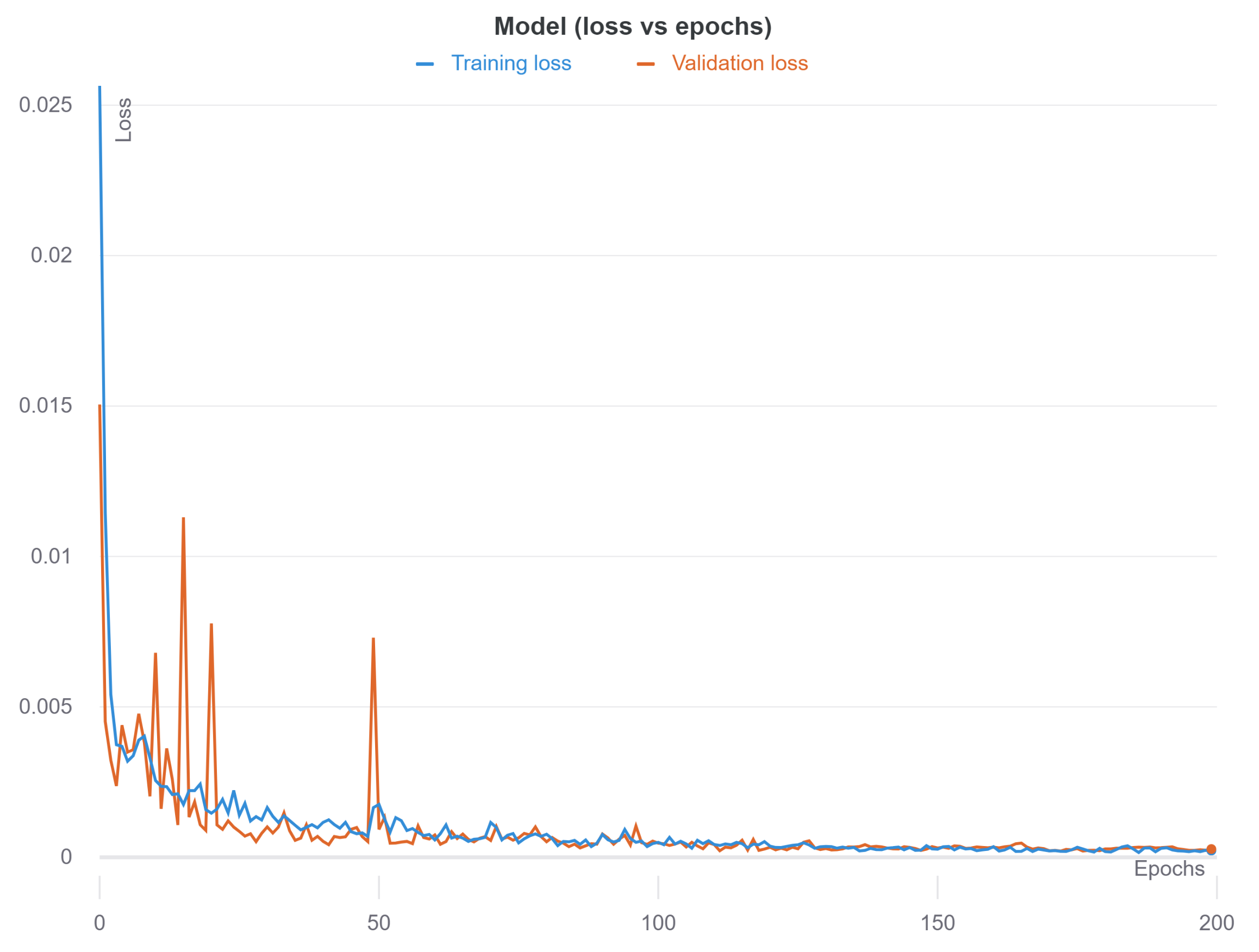
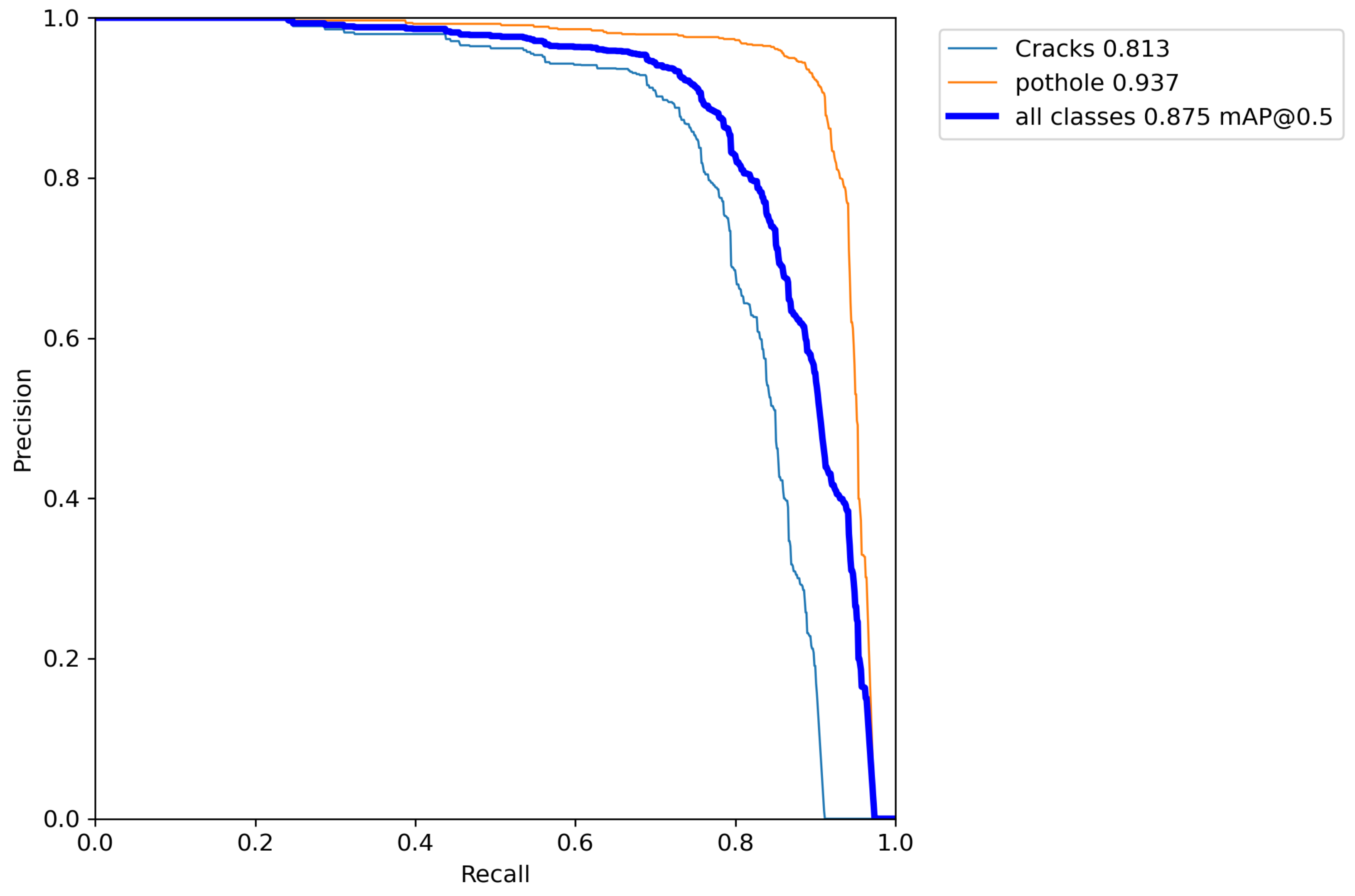
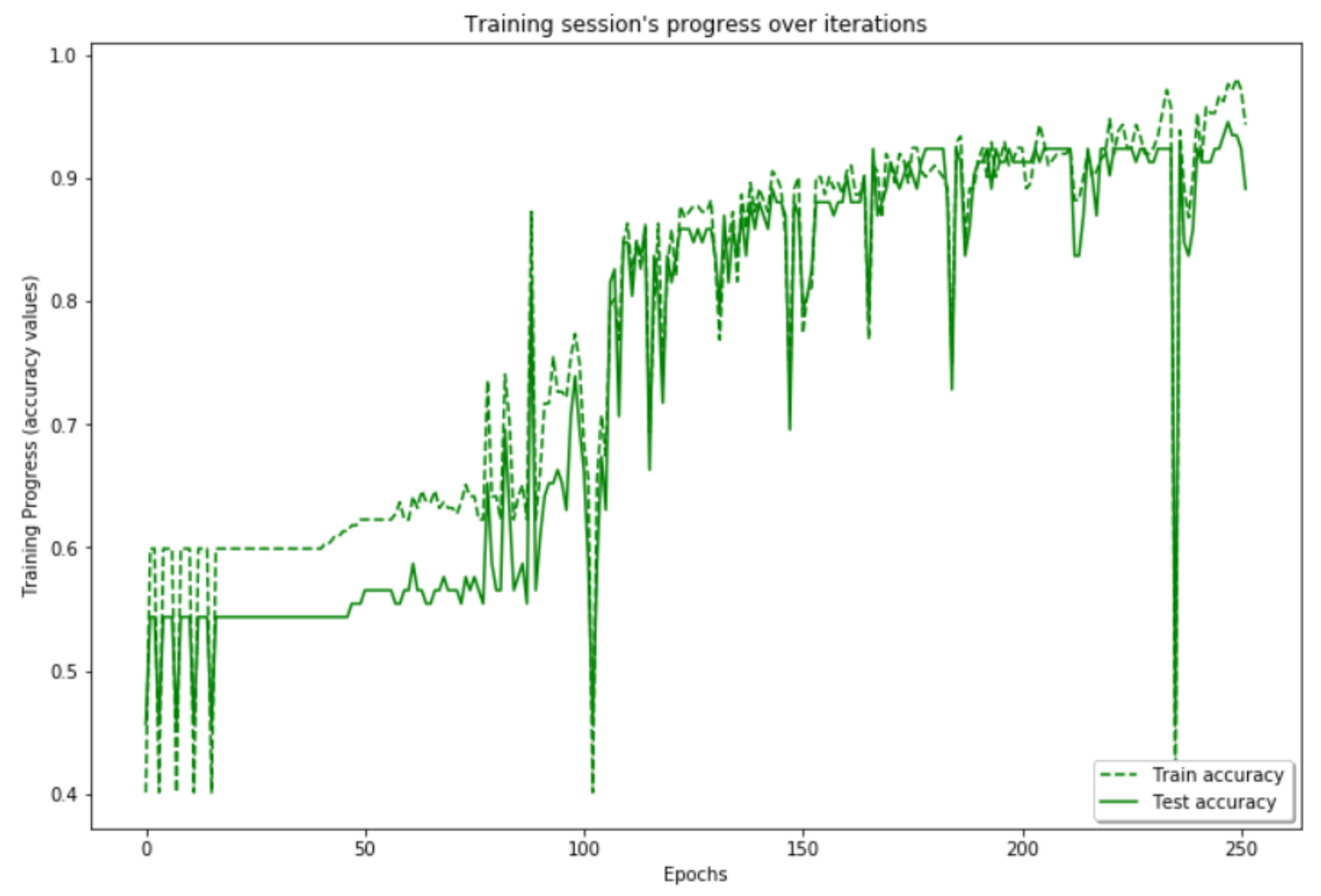
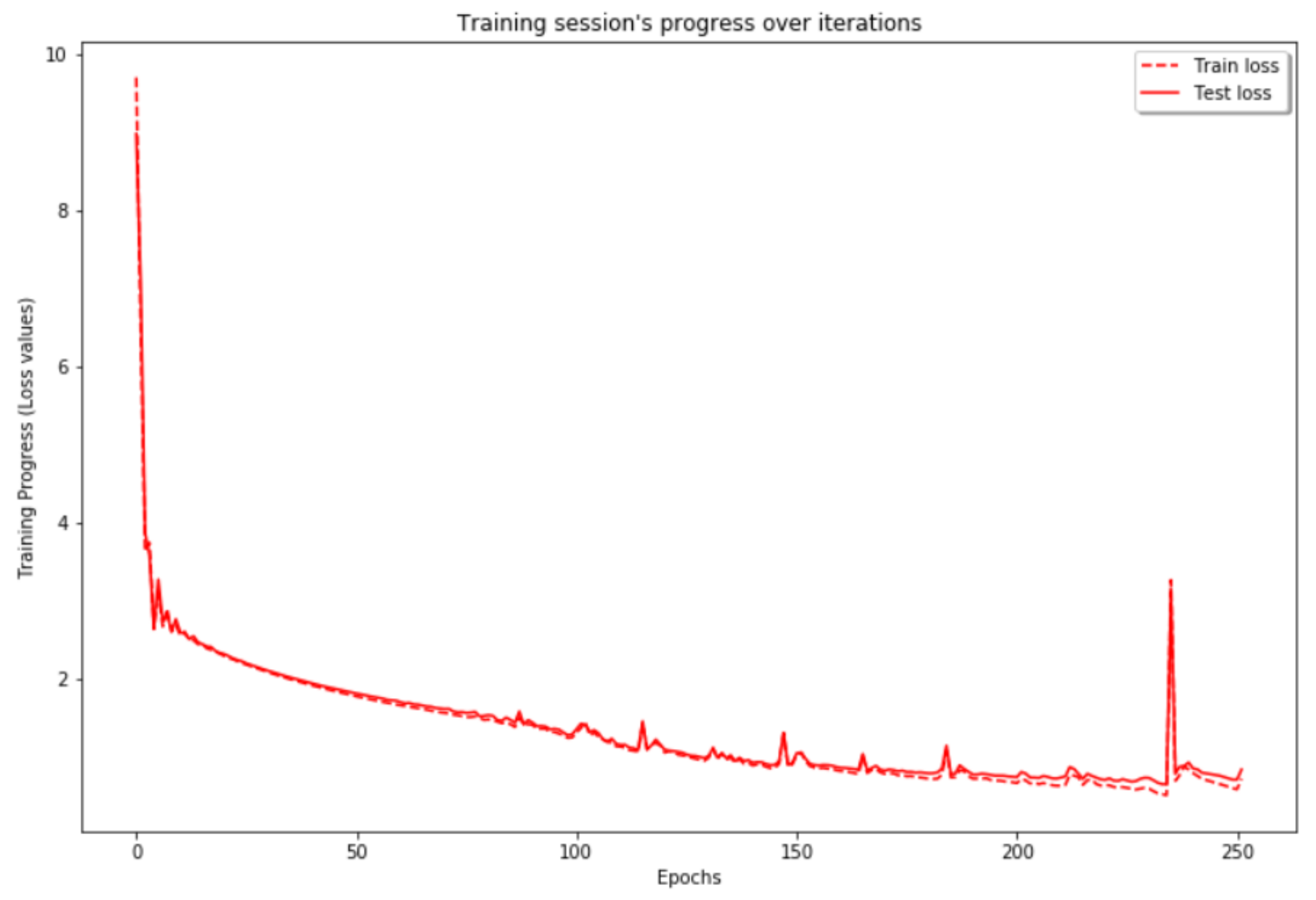
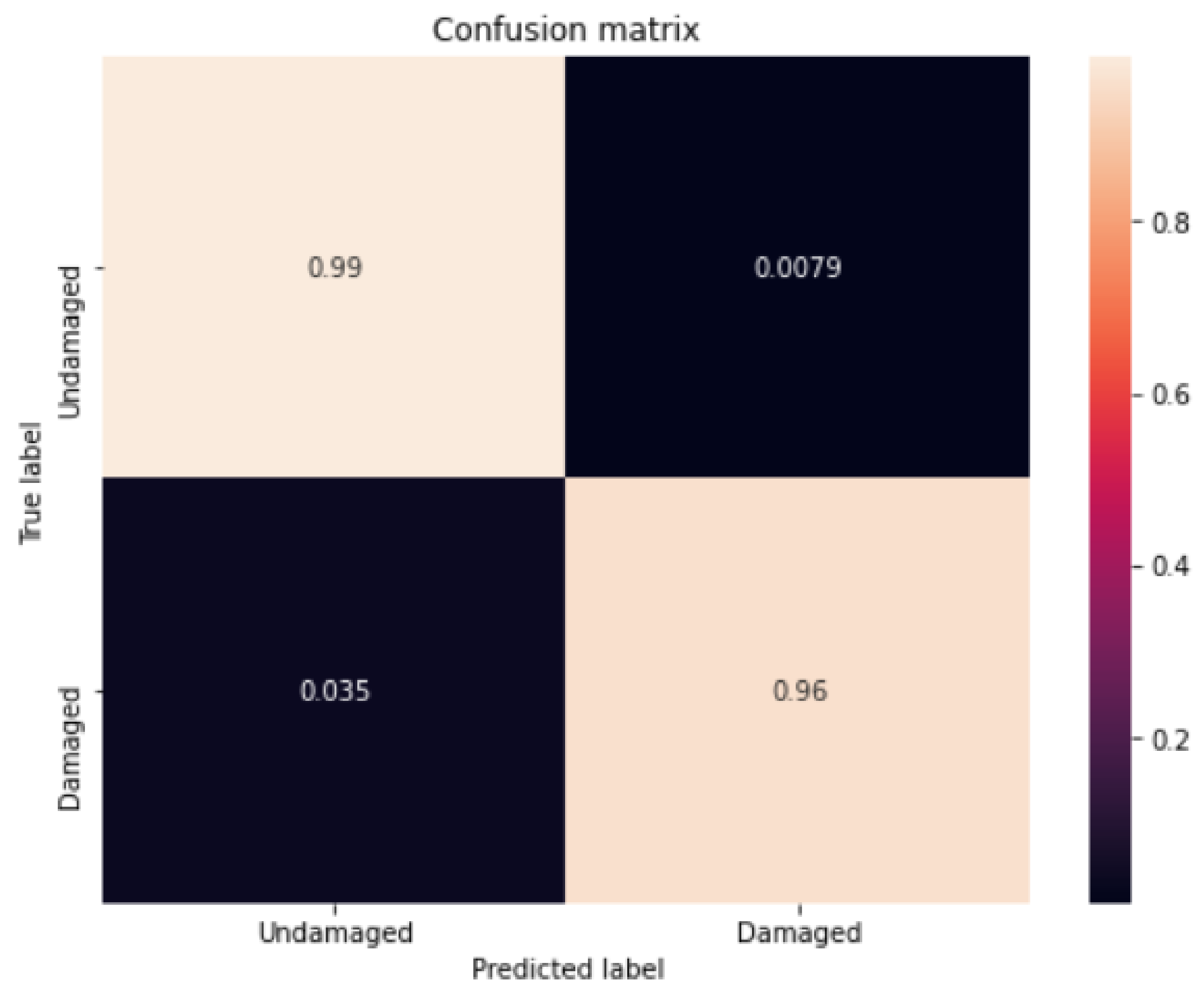
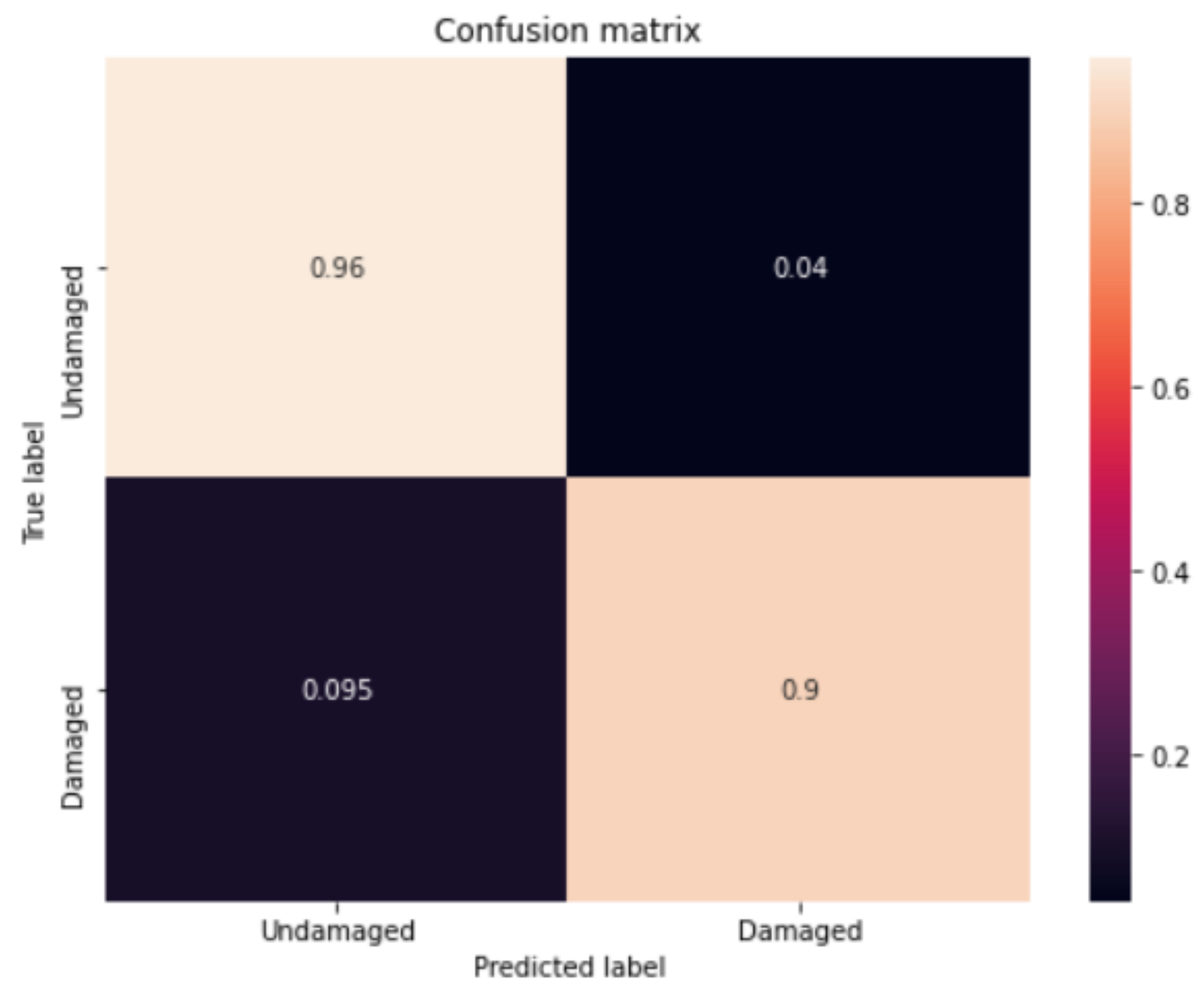
4.2.1. Results of Vision-Based Road-Surface Detection
4.2.2. Results of Motion-Based Road-Damage Detection
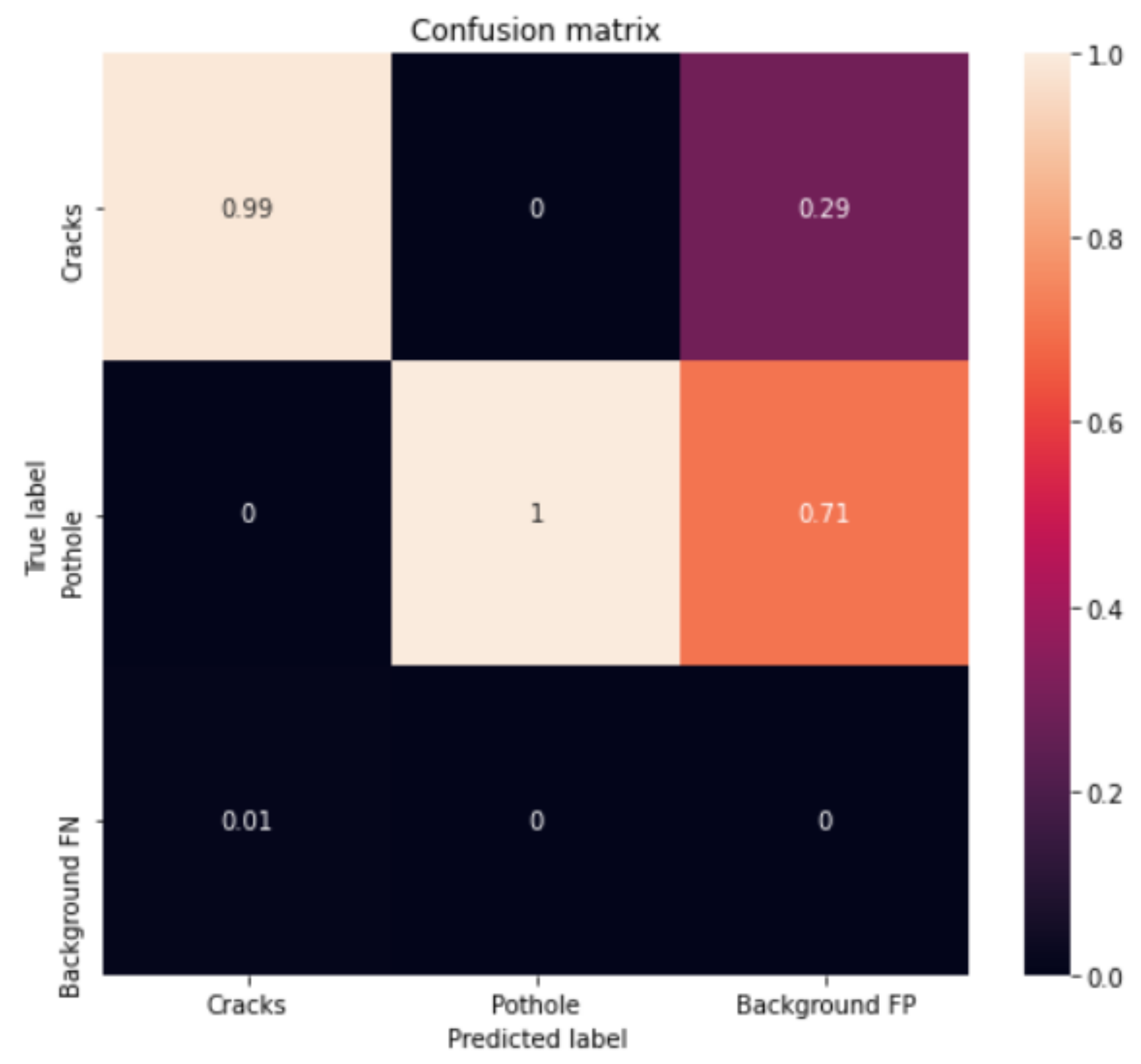
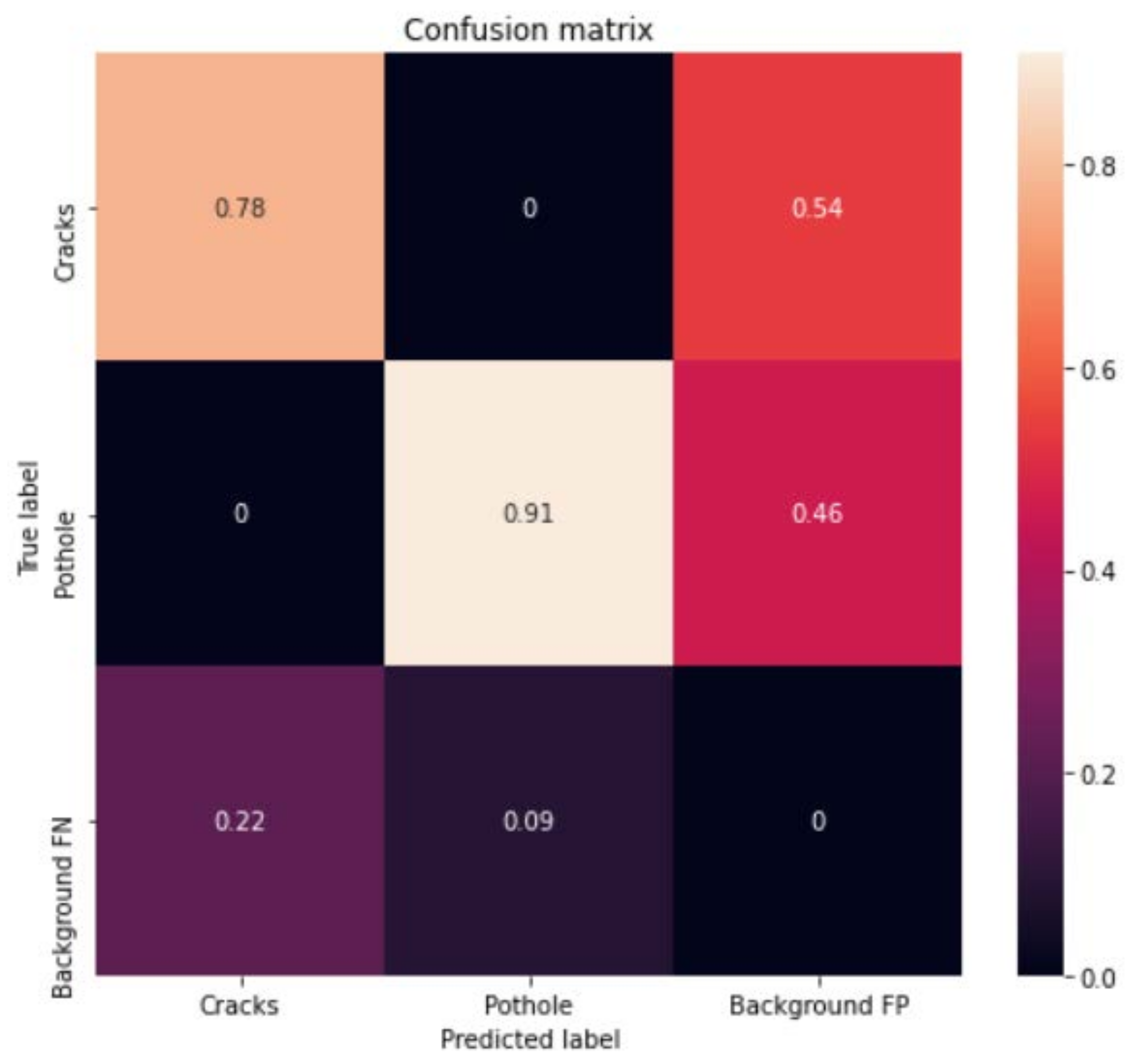
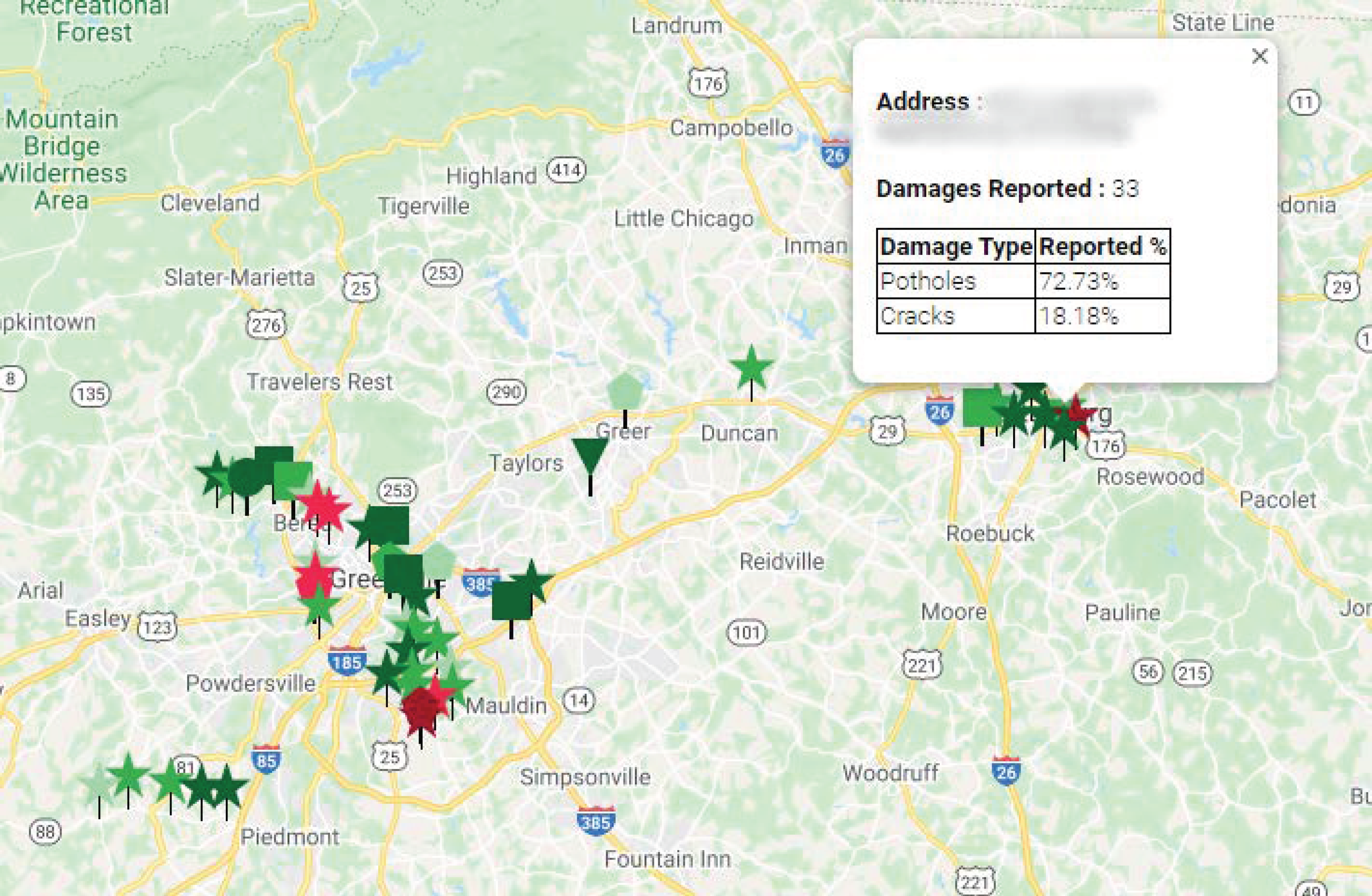
4.2.3. Results of Cloud-Based Collaborative Fusion
- Star: pothole;
- Square: cracks;
- Others: reserved;

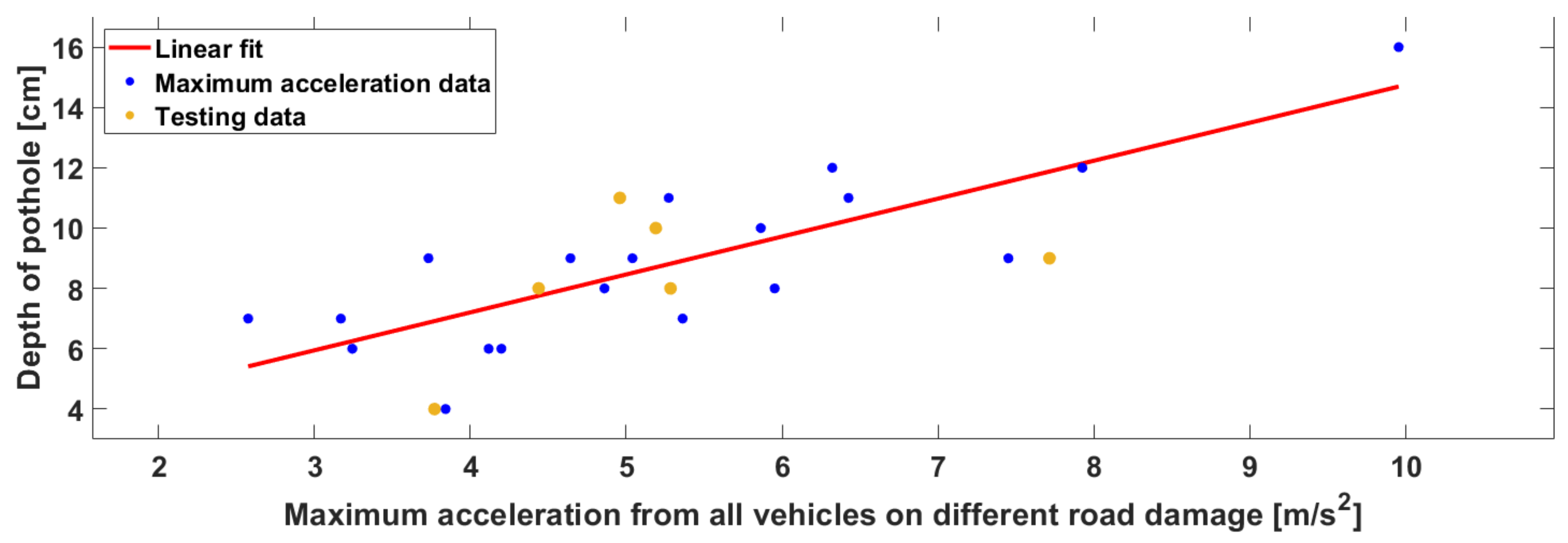
4.2.4. Results of Cloud-Based Road-Damage Severity Estimation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Singh, S. Critical Reasons for Crashes Investigated in the National Motor Vehicle Crash Causation Survey. Technical Report; 2015. Available online: http://www-nrd.nhtsa.dot.gov/Pubs/812115.pdf (accessed on 19 May 2022).
- Abulizi, N.; Kawamura, A.; Tomiyama, K.; Fujita, S. Measuring and evaluating of road roughness conditions with a compact road profiler and ArcGIS. J. Traffic Transp. Eng. 2016, 3, 398–411. [Google Scholar] [CrossRef] [Green Version]
- González, A.; O’brien, E.J.; Li, Y.Y.; Cashell, K. The use of vehicle acceleration measurements to estimate road roughness. Veh. Syst. Dyn. 2008, 46, 483–499. [Google Scholar] [CrossRef]
- Mednis, A.; Elsts, A.; Selavo, L. Embedded solution for road condition monitoring using vehicular sensor networks. In Proceedings of the 2012 6th International Conference on Application of Information and Communication Technologies (AICT), Tbilisi, Georgia, 17–19 October 2012; pp. 1–5. [Google Scholar]
- De Zoysa, K.; Keppitiyagama, C.; Seneviratne, G.P.; Shihan, W. A public transport system based sensor network for road surface condition monitoring. In Proceedings of the 2007 Workshop on Networked Systems for Developing Regions, Kyoto, Japan, 27 August 2007; pp. 1–6. [Google Scholar]
- Gunawan, F.E.; Soewito, B. A vibratory-based method for road damage classification. In Proceedings of the 2015 International Seminar on Intelligent Technology and Its Applications (ISITIA), Surabaya, Indonesia, 20–21 May 2015; pp. 1–4. [Google Scholar]
- Mednis, A.; Strazdins, G.; Zviedris, R.; Kanonirs, G.; Selavo, L. Real time pothole detection using android smartphones with accelerometers. In Proceedings of the 2011 International Conference on Distributed Computing in Sensor Systems and Workshops (DCOSS), Barcelona, Spain, 27–29 June 2011; pp. 1–6. [Google Scholar]
- Sebestyen, G.; Muresan, D.; Hangan, A. Road quality evaluation with mobile devices. In Proceedings of the 2015 16th International Carpathian Control Conference (ICCC), Szilvasvarad, Hungary, 27–30 May 2015; pp. 458–464. [Google Scholar]
- Bhoraskar, R.; Vankadhara, N.; Raman, B.; Kulkarni, P. Wolverine: Traffic and road condition estimation using smartphone sensors. In Proceedings of the 2012 Fourth International Conference on Communication Systems And Networks (COMSNETS 2012), Bangalore, India, 3–7 January 2012; pp. 1–6. [Google Scholar]
- Perttunen, M.; Mazhelis, O.; Cong, F.; Kauppila, M.; Leppänen, T.; Kantola, J.; Collin, J.; Pirttikangas, S.; Haverinen, J.; Ristaniemi, T.; et al. Distributed road surface condition monitoring using mobile phones. In Proceedings of the International Conference on Ubiquitous Intelligence and Computing, Banff, AB, Canada, 2–4 September 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 64–78. [Google Scholar]
- Varona, B.; Monteserin, A.; Teyseyre, A. A deep learning approach to automatic road surface monitoring and pothole detection. Pers. Ubiquitous Comput. 2020, 24, 519–534. [Google Scholar] [CrossRef]
- Menegazzo, J.; von Wangenheim, A. Multi-Contextual and Multi-Aspect Analysis for Road Surface Type Classification Through Inertial Sensors and Deep Learning. In Proceedings of the 2020 X Brazilian Symposium on Computing Systems Engineering (SBESC), Florianopolis, Brazil, 24–27 November 2020; pp. 1–8. [Google Scholar]
- Chatterjee, A.; Tsai, Y.C. Training and testing of smartphone-based pavement condition estimation models using 3d pavement data. J. Comput. Civ. Eng. 2020, 34, 04020043. [Google Scholar] [CrossRef]
- Li, Y.; Liu, C.; Shen, Y.; Cao, J.; Yu, S.; Du, Y. RoadID: A Dedicated Deep Convolutional Neural Network for Multipavement Distress Detection. J. Transp. Eng. Part B Pavements 2021, 147, 04021057. [Google Scholar] [CrossRef]
- Tsai, Y.C.; Kaul, V.; Mersereau, R.M. Critical assessment of pavement distress segmentation methods. J. Transp. Eng. 2010, 136, 11–19. [Google Scholar] [CrossRef]
- Llopis-Castelló, D.; Paredes, R.; Parreño-Lara, M.; García-Segura, T.; Pellicer, E. Automatic classification and quantification of basic distresses on urban flexible pavement through convolutional neural networks. J. Transp. Eng. Part B Pavements 2021, 147, 04021063. [Google Scholar] [CrossRef]
- Alipour, M.; Harris, D.K.; Miller, G.R. Robust pixel-level crack detection using deep fully convolutional neural networks. J. Comput. Civ. Eng. 2019, 33, 04019040. [Google Scholar] [CrossRef]
- Wang, W.; Wu, B.; Yang, S.; Wang, Z. Road damage detection and classification with faster R-CNN. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 5220–5223. [Google Scholar]
- Doshi, K.; Yilmaz, Y. Road damage detection using deep ensemble learning. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 5540–5544. [Google Scholar]
- Naddaf-Sh, S.; Naddaf-Sh, M.M.; Kashani, A.R.; Zargarzadeh, H. An efficient and scalable deep learning approach for road damage detection. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 5602–5608. [Google Scholar]
- Hegde, V.; Trivedi, D.; Alfarrarjeh, A.; Deepak, A.; Kim, S.H.; Shahabi, C. Yet another deep learning approach for road damage detection using ensemble learning. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 5553–5558. [Google Scholar]
- Mandal, V.; Mussah, A.R.; Adu-Gyamfi, Y. Deep learning frameworks for pavement distress classification: A comparative analysis. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 5577–5583. [Google Scholar]
- Hascoet, T.; Zhang, Y.; Persch, A.; Takashima, R.; Takiguchi, T.; Ariki, Y. Fasterrcnn monitoring of road damages: Competition and deployment. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 5545–5552. [Google Scholar]
- Pham, V.; Pham, C.; Dang, T. Road damage detection and classification with detectron2 and faster r-cnn. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 5592–5601. [Google Scholar]
- Ameddah, M.A.; Das, B.; Almhana, J. Cloud-assisted real-time road condition monitoring system for vehicles. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–6. [Google Scholar]
- Ghose, A.; Biswas, P.; Bhaumik, C.; Sharma, M.; Pal, A.; Jha, A. Road condition monitoring and alert application: Using in-vehicle smartphone as internet-connected sensor. In Proceedings of the 2012 IEEE international conference on pervasive computing and communications workshops, Lugano, Switzerland, 19–23 March 2012; pp. 489–491. [Google Scholar]
- Yuan, Y.; Islam, M.S.; Yuan, Y.; Wang, S.; Baker, T.; Kolbe, L.M. EcRD: Edge-cloud computing framework for smart road damage detection and warning. IEEE Internet Things J. 2020, 8, 12734–12747. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Na, S.; Xumin, L.; Yong, G. Research on k-means clustering algorithm: An improved k-means clustering algorithm. In Proceedings of the 2010 Third International Symposium on Intelligent Information Technology and Security Informatics, Ji’an, China, 2–4 April 2010; pp. 63–67. [Google Scholar]
- Jain, A.K.; Murty, M.N.; Flynn, P.J. Data clustering: A review. ACM Comput. Surv. 1999, 31, 264–323. [Google Scholar] [CrossRef]
- Nazeer, K.A.; Sebastian, M. Improving the Accuracy and Efficiency of the k-means Clustering Algorithm. In The World Congress on Engineering; Association of Engineers London: London, UK, 2009; Volume 1, pp. 1–3. [Google Scholar]
- Karthik, R.; Cuclurciello, E.; Dujianyi; Rosson, D. e-lab Video Sensor App for Data Recording. 2017. Available online: https://github.com/e-lab/VideoSensors (accessed on 19 May 2022).
- Maeda, H.; Kashiyama, T.; Sekimoto, Y.; Seto, T.; Omata, H. Generative adversarial network for road damage detection. Comput.-Aided Civ. Infrastruct. Eng. 2021, 36, 47–60. [Google Scholar] [CrossRef]
- Patel, S. Pothole Dataset. 2019. Available online: https://www.kaggle.com/datasets/sachinpatel21/pothole-image-dataset (accessed on 19 May 2022).






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Count | Class | Count |
|---|---|---|---|
| Bump | 39 | Construction Joint | 156 |
| Crack | 721 | Undamaged | 310 |
| Spall | 152 |
| Class | Count |
|---|---|
| Damaged | 378 |
| Undamaged | 310 |
| Class | Count |
|---|---|
| Potholes | 893 |
| Cracks | 767 |
| Total Annotations | 1660 |
| Total Images after Augmentation | 3000 |
| Class | Annotations | Precision | Recall | mAP@0.5 IOU |
|---|---|---|---|---|
| Potholes | 1826 | 0.898 | 0.999 | 0.997 |
| Cracks | 1621 | 0.999 | 0.984 | 0.996 |
| Total | 3447 | 0.994 | 0.991 | 0.997 |
| Class | Annotations | Precision | Recall | mAP@0.5 IOU |
|---|---|---|---|---|
| Potholes | 779 | 0.932 | 0.893 | 0.937 |
| Cracks | 660 | 0.888 | 0.730 | 0.813 |
| Total | 1439 | 0.910 | 0.812 | 0.875 |
| Parameter Name | Parameter Used |
|---|---|
| Optimizer | Adam |
| Loss regularization | L2 (L2 loss used is 0.015) |
| Learning rate | 0.005 |
| Batch size | 64 |
| Estimated data [cm] | 8.82 | 11.88 | 8.7 | 8.41 | 7.76 | 6.92 |
| Measured data [cm] | 8 | 9 | 10 | 11 | 8 | 4 |
| Error [cm] | 0.82 | 2.88 | 1.3 | 2.59 | 0.24 | 2.92 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ramesh, A.; Nikam, D.; Balachandran, V.N.; Guo, L.; Wang, R.; Hu, L.; Comert, G.; Jia, Y. Cloud-Based Collaborative Road-Damage Monitoring with Deep Learning and Smartphones. Sustainability 2022, 14, 8682. https://doi.org/10.3390/su14148682
Ramesh A, Nikam D, Balachandran VN, Guo L, Wang R, Hu L, Comert G, Jia Y. Cloud-Based Collaborative Road-Damage Monitoring with Deep Learning and Smartphones. Sustainability. 2022; 14(14):8682. https://doi.org/10.3390/su14148682
Chicago/Turabian StyleRamesh, Akshatha, Dhananjay Nikam, Venkat Narayanan Balachandran, Longxiang Guo, Rongyao Wang, Leo Hu, Gurcan Comert, and Yunyi Jia. 2022. "Cloud-Based Collaborative Road-Damage Monitoring with Deep Learning and Smartphones" Sustainability 14, no. 14: 8682. https://doi.org/10.3390/su14148682