
Automatically Generating Scenarios from a Text Corpus: A Case Study on Electric Vehicles


Abstract
:1. Introduction
2. Background
2.1. Fuzzy Cognitive Maps
2.2. Natural Language Processing
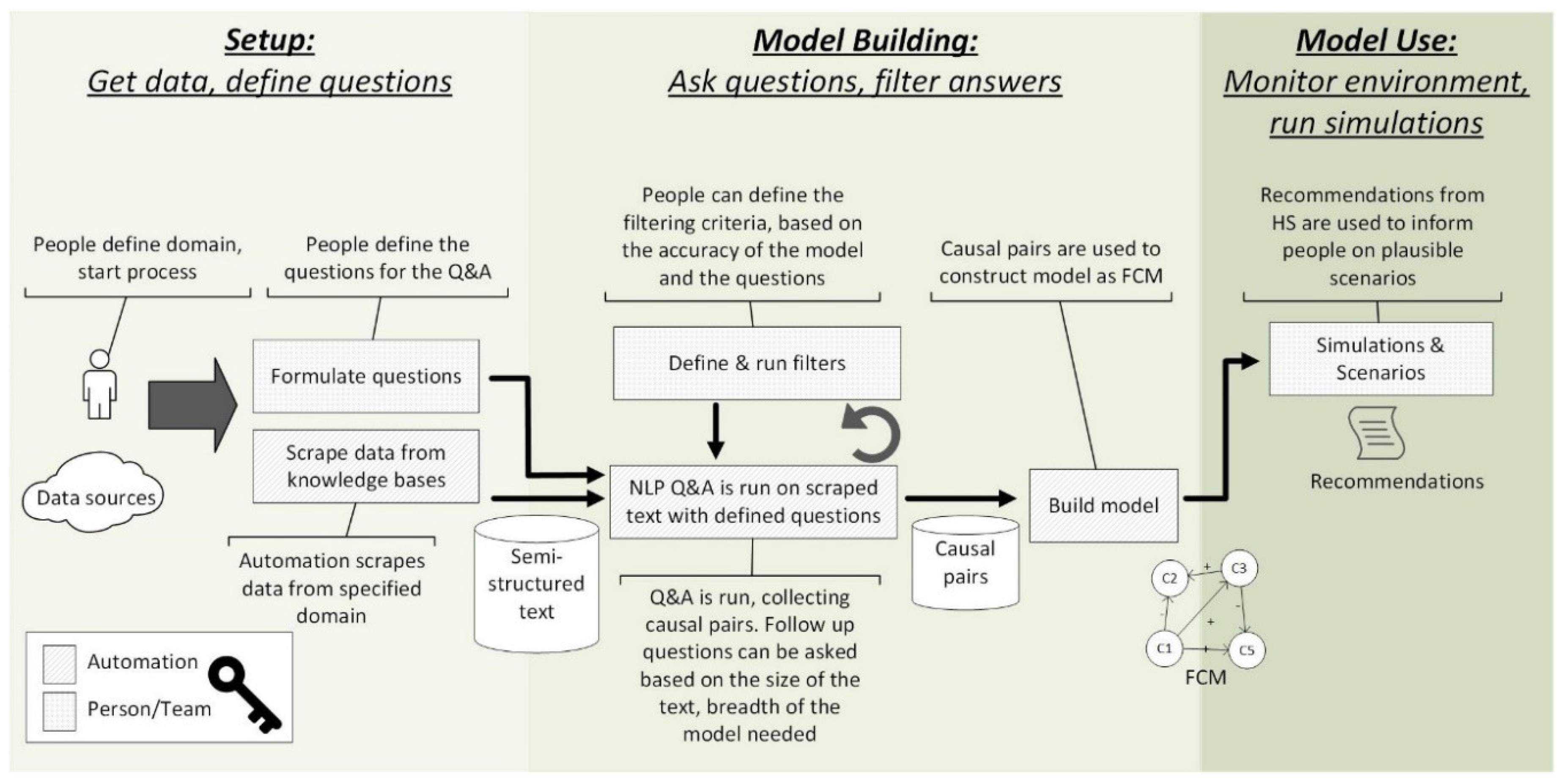
3. Design of the Proposed SAAM tool
Overview
4. Methods: Applying SAAM to Study Electric Vehicles
4.1. Overview
4.2. System Setup: Data Sources, Seed Questions, Parameters
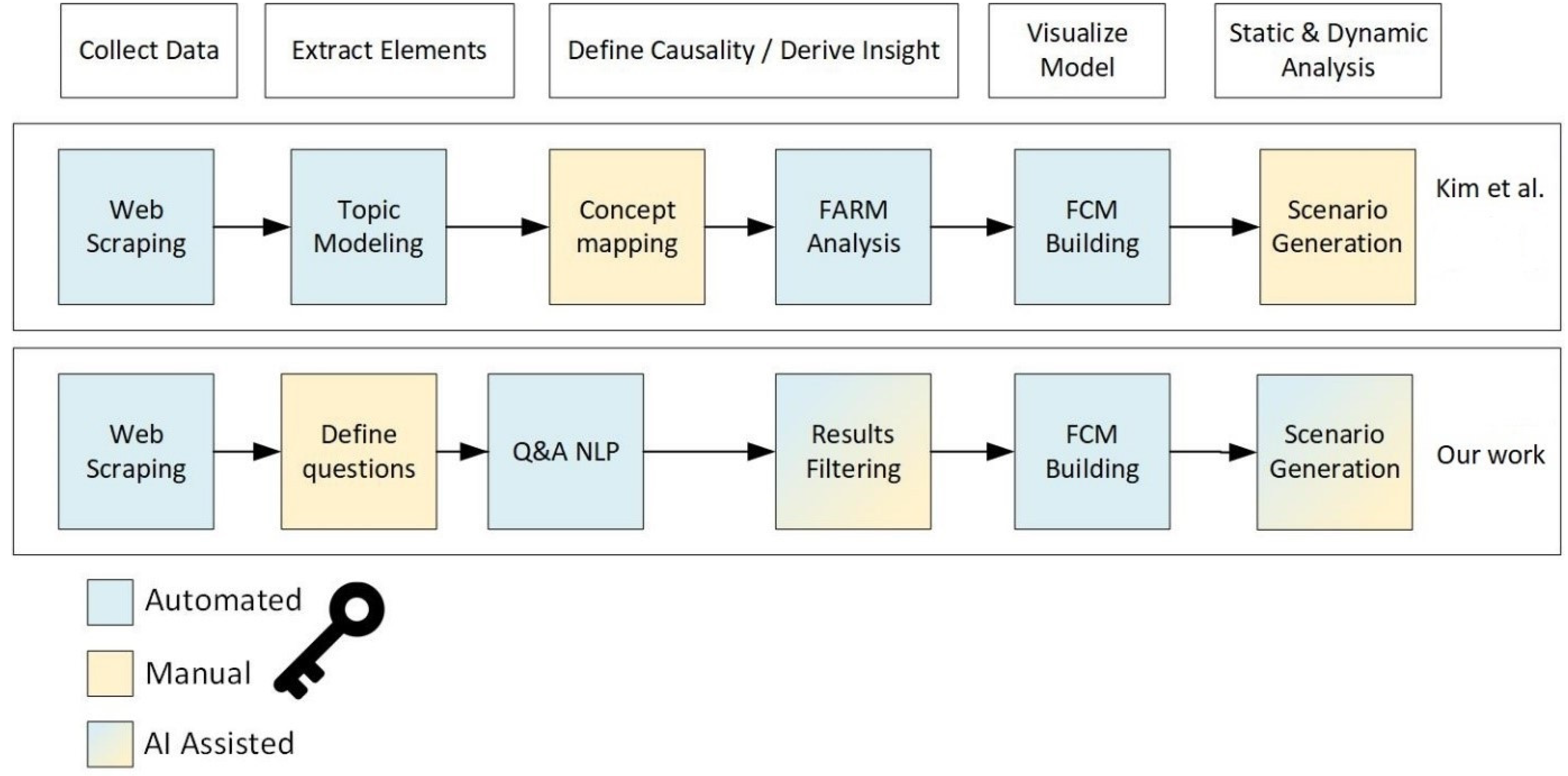
4.3. Comparison: Model Content and Simulated Scenarios
5. Results
5.1. Structural Comparison: Content of the Models
5.2. Scenario Comparisons
6. Discussion
6.1. Findings and Implications
6.2. Limitations and Opportunities for Future Studies
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories | Concepts | Bad Economy | Good Economy | Battery Fail | Deregulation |
|---|---|---|---|---|---|
| air pollution | greenhouse gas emissions | −0.952398323 | 0.952398323 | −0.957583063 | −0.959324401 |
| air pollution | no exhaust emissions | −0.952398323 | 0.952398323 | −0.957583063 | −0.959324401 |
| air pollution | the air | 0.957140415 | −0.957140415 | 0.937957076 | 0.957801403 |
| air pollution | your gas guzzler | −0.952398323 | 0.952398323 | −0.957583063 | −0.959324401 |
| alternative energy technology | clean renewable energy sources | 0.156727117 | −0.156727117 | 0 | 0.121182442 |
| alternative energy technology | polarisation systems | −0.952398323 | 0.952398323 | −0.957583063 | −0.959324401 |
| battery technology | batteries | −0.691699732 | 0.691699732 | −1 | −0.646327877 |
| battery technology | power and mileage limits | 0.156727117 | −0.156727117 | −1 | 0.121182442 |
| battery technology | recharge speed | 0.156727117 | −0.156727117 | −1 | 0.121182442 |
| other | thinking globally and acting locally | 0.156727117 | −0.156727117 | 0 | 0.121182442 |
| charging technology | a comprehensive charge station network | −0.952398323 | 0.952398323 | −0.957583063 | −0.959324401 |
| charging technology | generic super charging stations | −0.691699732 | 0.691699732 | 0 | −0.646327877 |
| costs reduction | evs cost | 0.957140415 | −0.957140415 | 0.961179751 | 0.957801403 |
| costs reduction | the falling price of batteries | 0.957500995 | −0.957500995 | −0.929606356 | 0.932011183 |
| economic activity | economic activity | −1 | 1 | −0.985312975 | 0.990740486 |
| economic revene | business development | −1 | 1 | −0.957583063 | −0.959324401 |
| economic revene | current unit sales | −1 | 1 | −0.957583063 | −0.959324401 |
| economic revene | wealth | −1 | 1 | 0 | 0.121182442 |
| energy effeciency | energy efficiency | −0.952398323 | 0.952398323 | −1 | −0.959324401 |
| energy pollution | energy pollution | 0.388947408 | −0.388947408 | 0.796604556 | −0.510951584 |
| government regulation | carbon pricing | 0.156727117 | −0.156727117 | 0 | 0.121182442 |
| government regulation | cities conservation | 0.873254834 | −0.873254834 | −0.774093871 | −1 |
| government regulation | governments | 0.156727117 | −0.156727117 | 0 | −1 |
| government regulation | incentives | −0.691699732 | 0.691699732 | 0 | −1 |
| government regulation | public investment | −0.902626096 | 0.902626096 | 0.686233755 | −1 |
| government regulation | regulation | −0.691699732 | 0.691699732 | 0 | −1 |
| industry-university collaboration | scholarships | −0.952398323 | 0.952398323 | −0.957583063 | −0.959324401 |
| job creation | employment | −1 | 1 | −0.90171281 | 0.940099166 |
| motor technology | electric motor | 0.972982612 | −0.972982612 | 0.999909188 | 0.976648732 |
| other | a completely carbon neutral transportation option | −0.952398323 | 0.952398323 | −0.957583063 | −0.959324401 |
| industry-university collaboration | aboriginal training | −0.952398323 | 0.952398323 | −0.957583063 | −0.959324401 |
| usability | artificial intelligence | 0.156727117 | −0.156727117 | 0 | 0.121182442 |
| other | biomimicry | 0.156727117 | −0.156727117 | 0 | 0.121182442 |
| other | confidence | −0.952398323 | 0.952398323 | −0.957583063 | −0.959324401 |
| other | durability | 0.156727117 | −0.156727117 | 0 | 0.121182442 |
| other | environmentally conscious citizens | 0.156727117 | −0.156727117 | 0 | 0.121182442 |
| usability | information technology | 0.156727117 | −0.156727117 | 0 | 0.121182442 |
| other | infrastructure | 0.96315824 | −0.96315824 | −0.774093871 | 0.995526376 |
| other | lack of hydrogen infrastructure | 0.924293982 | −0.924293982 | 0 | 0.915954432 |
| other | liability | 0.156727117 | −0.156727117 | 0 | 0.121182442 |
| other | oil and gas volatility | 0.156727117 | −0.156727117 | 0 | 0.121182442 |
| other | potential roadblocks | 0.957140415 | −0.957140415 | 0.937957076 | 0.957801403 |
| other | rare earth metals | 0.156727117 | −0.156727117 | 0 | 0.121182442 |
| other | remote communities | 0.156727117 | −0.156727117 | 0 | 0.121182442 |
| other | significant technology improvements | −0.957479374 | 0.957479374 | −0.060843278 | −0.957345752 |
| other | sustainability | 0.255551223 | −0.255551223 | 0.817909946 | 0.497931899 |
| other | the power and mileage limits | 0.924293982 | −0.924293982 | 0.961179751 | 0.915954432 |
| other | traffic congestion | 0.156727117 | −0.156727117 | 0 | 0.121182442 |
| other | transform mobility | −0.952398323 | 0.952398323 | −0.957583063 | −0.959324401 |
| public transportation | Self-driving vehicles | −0.74299687 | 0.74299687 | 0.542424672 | −0.816448312 |
| safety | economic and safety benefits | −1 | 1 | −0.957583063 | −0.959324401 |
| EV adoption | 0.901968281 | −0.901968281 | 0.798453798 | 0.889187005 |
References
- Firmansyah, H.S.; Supangkat, S.H.; Arman, A.A.; Giabbanelli, P.J. Identifying the components and interrelationships of smart cities in Indonesia: Supporting policymaking via fuzzy cognitive systems. IEEE Access 2019, 7, 46136–46151. [Google Scholar] [CrossRef]
- Bowman, G.; MacKay, R.B.; Masrani, S.; McKiernan, P. Storytelling and the scenario process: Understanding success and failure. Technol. Forecast. Soc. Chang. 2013, 80, 735–748. [Google Scholar] [CrossRef]
- Van Notten, P. Scenario Development: A Typology of Approaches. In Think Scenarios, Rethink Education; OECD: Paris, France, 2006. [Google Scholar]
- Derbyshire, J.; Giovannetti, E. Understanding the failure to understand New Product Development failures: Mitigating the uncertainty associated with innovating new products by combining scenario planning and forecasting. Technol. Forecast. Soc. Chang. 2017, 125, 334–344. [Google Scholar] [CrossRef]
- Collier, Z.A.; Hendrickson, D.; Polmateer, T.L.; Lambert, J.H. Scenario analysis and PERT/CPM applied to strategic investment at an automated container port. ASCE-ASME J. Risk Uncertain. Eng. Syst. Part A Civ. Eng. 2018, 4, 04018026. [Google Scholar] [CrossRef]
- Relich, M.; Bocewicz, G.; Rostek, K.; Banaszak, Z.A. A declarative approach to new product development project prototyping. IEEE Intell. Syst. 2020, 36, 88–95. [Google Scholar] [CrossRef]
- Açikgöz, A.; Latham, G.P.; Acikgoz, F. Mediation of scenario planning on the reflection-performance relationship in new product development teams. J. Bus. Ind. Mark. 2020, 36, 256–268. [Google Scholar] [CrossRef]
- Tiberius, V.; Siglow, C.; Sendra-García, J. Scenarios in business and management: The current stock and research opportunities. J. Bus. Res. 2020, 121, 235–242. [Google Scholar] [CrossRef]
- Lindgren, M.; Bandhold, H. (Eds.) Scenario Planning in Practice. In Scenario Planning: The Link between Future and Strategy; Palgrave Macmillan: London, UK, 2009; pp. 49–117. [Google Scholar]
- Spaniol, M.J.; Rowland, N.J. Defining scenario. Futures Foresight Sci. 2019, 1, e3. [Google Scholar] [CrossRef]
- Alcamo, J.; Henrichs, T. Chapter two towards guidelines for environmental scenario analysis. Dev. Integr. Environ. Assess. 2008, 2, 13–35. [Google Scholar] [CrossRef]
- Durance, P.; Godet, M. Scenario building: Uses and abuses. Technol. Forecast. Soc. Chang. 2010, 77, 1488–1492. [Google Scholar] [CrossRef] [Green Version]
- Godet, M.; Roubelat, F.; Editors, G. Scenario Planning: An Open Future. Technol. Forecast. Soc. Chang. 2000, 65, 1–123. [Google Scholar] [CrossRef]
- Van der Heijden, K. Scenarios: The Art of Strategic Conversation; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar]
- Bradfield, R.; Derbyshire, J.; Wright, G. The critical role of history in scenario thinking: Augmenting causal analysis within the intuitive logics scenario development methodology. Futures 2016, 77, 56–66. [Google Scholar] [CrossRef] [Green Version]
- Giabbanelli, P.J.; Galgoczy, M.C.; Nguyen, D.M.; Foy, R.; Rice, K.L.; Nataraj, N.; Brown, M.M.; Harper, C.R. Mapping the complexity of suicide by combining participatory modeling and network science. In Proceedings of the 2021 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Online, 8–11 November 2021; pp. 339–342. [Google Scholar]
- Hedelin, B.; Gray, S.; Woehlke, S.; BenDor, T.; Singer, A.; Jordan, R.; Zellner, M.; Giabbanelli, P.; Glynn, P.; Jenni, K.; et al. What’s left before participatory modeling can fully support real-world environmental planning processes: A case study review. Environ. Model. Softw. 2021, 143, 105073. [Google Scholar] [CrossRef]
- Keller, J.; Markmann, C.; von der Gracht, H.A. Foresight support systems to facilitate regional innovations: A conceptualization case for a German logistics cluster. Technol. Forecast. Soc. Chang. 2015, 97, 15–28. [Google Scholar] [CrossRef]
- Von der Gracht, H.A.; Bañuls, V.A.; Turoff, M.; Skulimowski, A.M.; Gordon, T.J. Foresight support systems: The future role of ICT for foresight. Technol. Forecast. Soc. Chang. 2015, 97, 1–6. [Google Scholar] [CrossRef]
- Kayser, V.; Blind, K. Extending the knowledge base of foresight: The contribution of text mining. Technol. Forecast. Soc. Chang. 2017, 116, 208–215. [Google Scholar] [CrossRef] [Green Version]
- Berg, S.; Wustmans, M.; Bröring, S. Identifying first signals of emerging dominance in a technological innovation system: A novel approach based on patents. Technol. Forecast. Soc. Chang. 2019, 146, 706–722. [Google Scholar] [CrossRef]
- Jeong, Y.; Park, I.; Yoon, B. Identifying emerging Research and Business Development (R&BD) areas based on topic modeling and visualization with intellectual property right data. Technol. Forecast. Soc. Chang. 2019, 146, 655–672. [Google Scholar] [CrossRef]
- Kose, T.; Sakata, I. Identifying technology convergence in the field of robotics research. Technol. Forecast. Soc. Chang. 2019, 146, 751–766. [Google Scholar] [CrossRef]
- Robinson, D.K.; Lagnau, A.; Boon, W.P. Innovation pathways in additive manufacturing: Methods for tracing emerging and branching paths from rapid prototyping to alternative applications. Technol. Forecast. Soc. Chang. 2019, 146, 733–750. [Google Scholar] [CrossRef] [Green Version]
- Ulman, M.; Šimek, P.; Masner, J.; Kogut, P.; Löytty, T.; Crehan, P.; Charvát, K.; Oliva, A.; Bergheim, S.R.; Kalaš, M.; et al. Towards Future Oriented Collaborative Policy Development for Rural Areas and People. AGRIS-Line Pap. Econ. Inform. 2020, 12, 111–124. [Google Scholar] [CrossRef] [Green Version]
- Son, C.; Kim, J.; Kim, Y. Developing scenario-based technology roadmap in the big data era: An utilisation of fuzzy cognitive map and text mining techniques. Technol. Anal. Strat. Manag. 2020, 32, 272–291. [Google Scholar] [CrossRef]
- Kayser, V.; Shala, E. Scenario development using web mining for outlining technology futures. Technol. Forecast. Soc. Chang. 2020, 156, 120086. [Google Scholar] [CrossRef]
- Gokhberg, L.; Kuzminov, I.; Khabirova, E.; Thurner, T. Advanced text-mining for trend analysis of Russia’s Extractive Industries. Futures 2020, 115, 102476. [Google Scholar] [CrossRef]
- Feblowitz, M.; Hassanzadeh, O.; Katz, M.; Sohrabi, S.; Srinivas, K.; Udrea, O. IBM Scenario Planning Advisor: A Neuro-Symbolic ERM Solution. Proc. AAAI Conf. Artif. Intell. 2021, 35, 16032–16034. Available online: https://ojs.aaai.org/index.php/AAAI/article/view/18003 (accessed on 6 February 2022).
- Davis, C.D.W. Scenario Acceleration through Automated Modelling (SAAM). Available online: https://github.com/cwhd/fuzzy-cognitive-horizon-scanning (accessed on 6 February 2022).
- Blumberg, G.; Broll, R.; Weber, C. The impact of electric vehicles on the future European electricity system—A scenario analysis. Energy Policy 2022, 161, 112751. [Google Scholar] [CrossRef]
- Kafaei, M.; Sedighizadeh, D.; Sedighizadeh, M.; Fini, A.S. An IGDT/Scenario based stochastic model for an energy hub considering hydrogen energy and electric vehicles: A case study of Qeshm Island, Iran. Int. J. Electr. Power Energy Syst. 2022, 135, 107477. [Google Scholar] [CrossRef]
- Yu, Z.; Lu, F.; Zou, Y.; Yang, X. Quantifying energy flexibility of commuter plug-in electric vehicles within a residence–office coupling virtual microgrid. Part II: Case study setup for scenario and sensitivity analysis. Energy Build. 2022, 254, 111552. [Google Scholar] [CrossRef]
- Singh, V.; Singh, V.; Vaibhav, S. A review and simple meta-analysis of factors influencing adoption of electric vehicles. Transp. Res. Part D Transp. Environ. 2020, 86, 102436. [Google Scholar] [CrossRef]
- Song, R.; Potoglou, D. Are Existing Battery Electric Vehicles Adoption Studies Able to Inform Policy? A Review for Policymakers. Sustainability 2020, 12, 6494. [Google Scholar] [CrossRef]
- Asif, U.; Schmidt, K. Fuel Cell Electric Vehicles (FCEV): Policy Advances to Enhance Commercial Success. Sustainability 2021, 13, 5149. [Google Scholar] [CrossRef]
- Capuder, T.; Sprčić, D.M.; Zoričić, D.; Pandžić, H. Review of challenges and assessment of electric vehicles integration policy goals: Integrated risk analysis approach. Int. J. Electr. Power Energy Syst. 2020, 119, 105894. [Google Scholar] [CrossRef]
- Whiston, M.M.; Azevedo, I.M.L.; Litster, S.; Samaras, C.; Whitefoot, K.S.; Whitacre, J.F. Expert elicitation on paths to advance fuel cell electric vehicles. Energy Policy 2022, 160, 112671. [Google Scholar] [CrossRef]
- Baumgarte, F.; Kaiser, M.; Keller, R. Policy support measures for widespread expansion of fast charging infrastructure for electric vehicles. Energy Policy 2021, 156, 112372. [Google Scholar] [CrossRef]
- Van Mierlo, J.; Berecibar, M.; El Baghdadi, M.; De Cauwer, C.; Messagie, M.; Coosemans, T.; Jacobs, V.A.; Hegazy, O. Beyond the State of the Art of Electric Vehicles: A Fact-Based Paper of the Current and Prospective Electric Vehicle Technologies. World Electr. Veh. J. 2021, 12, 20. [Google Scholar] [CrossRef]
- Bhatti, G.; Mohan, H.; Singh, R.R. Towards the future of smart electric vehicles: Digital twin technology. Renew. Sustain. Energy Rev. 2021, 141, 110801. [Google Scholar] [CrossRef]
- De Pinho, H. Generation of Systems Maps: Mapping Complex Systems and Population Health. In Systems Science and Population Health; Oxford University Press: Oxford, UK, 2017; pp. 61–67. [Google Scholar]
- Giabbanelli, P.J.; Rice, K.L.; Galgoczy, M.C.; Nataraj, N.; Brown, M.M.; Harper, C.R.; Nguyen, M.D.; Foy, R. Pathways to suicide or collections of vicious cycles? Understanding the complexity of suicide through causal mapping. Soc. Netw. Anal. Min. 2022, 12, 60. [Google Scholar] [CrossRef]
- McGlashan, J.; Johnstone, M.; Creighton, D.; De La Haye, K.; Allender, S. Quantifying a Systems Map: Network Analysis of a Childhood Obesity Causal Loop Diagram. PLoS ONE 2016, 11, e0165459. [Google Scholar] [CrossRef] [Green Version]
- Giabbanelli, P.J.; Tawfik, A.A.; Gupta, V.K. Learning Analytics to Support Teachers’ Assessment of Problem Solving: A Novel Application for Machine Learning and Graph Algorithms. In Utilizing Learning Analytics to Support Study Success; Springer: Cham, Switzerland, 2019; pp. 175–199. [Google Scholar] [CrossRef]
- Anjum, M.; Voinov, A.; Taghikhah, F.; Pileggi, S.F. Discussoo: Towards an intelligent tool for multi-scale participatory modeling. Environ. Model. Softw. 2021, 140, 105044. [Google Scholar] [CrossRef]
- Voinov, A.; Jenni, K.; Gray, S.; Kolagani, N.; Glynn, P.D.; Bommel, P.; Prell, C.; Zellner, M.; Paolisso, M.; Jordan, R.; et al. Tools and methods in participatory modeling: Selecting the right tool for the job. Environ. Model. Softw. 2018, 109, 232–255. [Google Scholar] [CrossRef] [Green Version]
- Lofgren, E. System Dynamics Models. In Systems Science and Population Health; Oxford University Press: Oxford, UK, 2017; pp. 77–86. [Google Scholar]
- Mkhitaryan, S.; Giabbanelli, P.J.; de Vries, N.K.; Crutzen, R. Dealing with complexity: How to use a hybrid approach to incorporate complexity in health behavior interventions. Intell. Med. 2020, 3, 100008. [Google Scholar] [CrossRef]
- Kininmonth, S.; Gray, S.; Kok, K. Expert modelling. In The Routledge Handbook of Research Methods for Social-Ecological Systems; Taylor & Francis: Oxfordshire, UK, 2021; p. 231. [Google Scholar]
- Amer, M.; Daim, T.U.; Jetter, A. Technology roadmap through fuzzy cognitive map-based scenarios: The case of wind energy sector of a developing country. Technol. Anal. Strat. Manag. 2016, 28, 131–155. [Google Scholar] [CrossRef]
- Zare, S.G.; Alipour, M.; Hafezi, M.; Stewart, R.A.; Rahman, A. Examining wind energy deployment pathways in complex macro-economic and political settings using a fuzzy cognitive map-based method. Energy 2022, 238, 121673. [Google Scholar] [CrossRef]
- Nasirzadeh, F.; Ghayoumian, M.; Khanzadi, M.; Cherati, M.R. Modelling the social dimension of sustainable development using fuzzy cognitive maps. Int. J. Constr. Manag. 2020, 20, 223–236. [Google Scholar] [CrossRef]
- Averbuch, B.; Thorsøe, M.H.; Kjeldsen, C. Using fuzzy cognitive mapping and social capital to explain differences in sustainability perceptions between farmers in the northeast US and Denmark. Agric. Hum. Values 2022, 39, 435–453. [Google Scholar] [CrossRef]
- Papageorgiou, K.; Singh, P.K.; Papageorgiou, E.; Chudasama, H.; Bochtis, D.; Stamoulis, G. Fuzzy Cognitive Map-Based Sustainable Socio-Economic Development Planning for Rural Communities. Sustainability 2019, 12, 305. [Google Scholar] [CrossRef] [Green Version]
- Aminpour, P.; Gray, S.A.; Beck, M.W.; Furman, K.L.; Tsakiri, I.; Gittman, R.K.; Grabowski, J.H.; Helgeson, J.; Josephs, L.; Ruth, M.; et al. Urbanized knowledge syndrome—erosion of diversity and systems thinking in urbanites’ mental models. npj Urban Sustain. 2022, 2, 11. [Google Scholar] [CrossRef]
- Morone, P.; Yilan, G.; Imbert, E. Using fuzzy cognitive maps to identify better policy strategies to valorize organic waste flows: An Italian case study. J. Clean. Prod. 2021, 319, 128722. [Google Scholar] [CrossRef]
- Mkhitaryan, S.; Giabbanelli, P.J. How modeling methods for fuzzy cognitive mapping can benefit from psychology research. In Proceedings of the 2021 Winter Simulation Conference (WSC), Phoenix, AZ, USA, 12–15 December 2021; pp. 1–2. [Google Scholar]
- Papageorgiou, E.I.; Salmeron, J.L. A Review of Fuzzy Cognitive Maps Research During the Last Decade. IEEE Trans. Fuzzy Syst. 2012, 21, 66–79. [Google Scholar] [CrossRef]
- Felix, G.; Nápoles, G.; Falcon, R.; Froelich, W.; Vanhoof, K.; Bello, R. A review on methods and software for fuzzy cognitive maps. Artif. Intell. Rev. 2019, 52, 1707–1737. [Google Scholar] [CrossRef]
- Kwon, H.; Park, Y. Proactive development of emerging technology in a socially responsible manner: Data-driven problem solving process using latent semantic analysis. J. Eng. Technol. Manag. 2018, 50, 45–60. [Google Scholar] [CrossRef]
- Sandhu, M.; Giabbanelli, P.J.; Mago, V.K. From Social Media to Expert Reports: The Impact of Source Selection on Automatically Validating Complex Conceptual Models of Obesity. In Society Computing and Social Media; Meiselwitz, G., Ed.; Springer: Cham, Switzerland, 2019; Volume 11578. [Google Scholar]
- Villalon, J.; Calvo, R.A. Concept maps as cognitive visualizations of writing assignments. J. Educ. Technol. Soc. 2011, 14, 16–27. Available online: https://www.jstor.org/stable/jeductechsoci.14.3.16?seq=1 (accessed on 6 February 2022).
- Hajek, P.; Prochazka, O.; Pachura, P. Fuzzy cognitive maps based on text analysis for supporting strategic planning. In Proceedings of the 2017 International Conference on Research and Innovation in Information Systems (ICRIIS), Langkawi, Malaysia, 16–17 July 2017; pp. 1–6. [Google Scholar]
- Pillutla, V.S.; Giabbanelli, P.J. Iterative generation of insight from text collections through mutually reinforcing visualizations and fuzzy cognitive maps. Appl. Soft Comput. 2019, 76, 459–472. [Google Scholar] [CrossRef]
- Lavin, E.A.; Giabbanelli, P.J.; Stefanik, A.T.; Gray, S.A.; Arlinghaus, R. Should we simulate mental models to assess whether they agree? In Proceedings of the Annual Simulation Symposium, San Diego, CA, USA, 15–18 April 2018; pp. 1–12. [Google Scholar]
- Kok, K. The potential of Fuzzy Cognitive Maps for semi-quantitative scenario development, with an example from Brazil. Glob. Environ. Chang. 2009, 19, 122–133. [Google Scholar] [CrossRef]
- Jetter, A.; Schweinfort, W. Building scenarios with Fuzzy Cognitive Maps: An exploratory study of solar energy. Futures 2011, 43, 52–66. [Google Scholar] [CrossRef]
- Van Vliet, M.; Kok, K.; Veldkamp, T. Linking stakeholders and modellers in scenario studies: The use of Fuzzy Cognitive Maps as a communication and learning tool. Futures 2010, 42, 1–14. [Google Scholar] [CrossRef]
- Jetter, A.J.; Kok, K. Fuzzy Cognitive Maps for futures studies—A methodological assessment of concepts and methods. Futures 2014, 61, 45–57. [Google Scholar] [CrossRef]
- Acheampong, F.A.; Nunoo-Mensah, H.; Chen, W. Transformer models for text-based emotion detection: A review of BERT-based approaches. Artif. Intell. Rev. 2021, 54, 5789–5829. [Google Scholar] [CrossRef]
- Dale, R. GPT-3: What’s it good for? Nat. Lang. Eng. 2021, 27, 113–118. [Google Scholar] [CrossRef]
- Galgoczy, M.C.; Phatak, A.; Vinson, D.; Mago, V.K.; Giabbanelli, P.J. (Re)shaping online narratives: When bots promote the message of President Trump during his first impeachment. PeerJ Comput. Sci. 2022, 8, e947. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Sabharwal, N.; Agrawal, A. BERT Model Applications: Question Answering System. In Hands-on Question Answering Systems with BERT; Apress: Berkeley, CA, USA, 2021. [Google Scholar]
- Hugging Face Project. Available online: https://huggingface.co/models (accessed on 6 February 2022).
- Sandhu, M.; Vinson, C.D.; Mago, V.K.; Giabbanelli, P.J. From associations to sarcasm: Mining the shift of opinions regarding the Supreme Court on twitter. Online Soc. Netw. Media 2019, 14, 100054. [Google Scholar] [CrossRef]
- Xin, D.; Ma, L.; Liu, J.; Macke, S.; Song, S.; Parameswaran, A. Accelerating human-in-the-loop machine learning: Challenges and opportunities. In Proceedings of the Second Workshop on Data Management for End-to-End Machine Learning, Houston, TX, USA, 15 June 2018; pp. 1–4. [Google Scholar]
- Wu, X.; Xiao, L.; Sun, Y.; Zhang, J.; Ma, T.; He, L. A survey of human-in-the-loop for machine learning. Future Gener. Comput. Syst. 2022, 135, 364–381. [Google Scholar] [CrossRef]
- Treasury, H.M. The Aqua Book: Guidance on Producing Quality Analysis for Government; H. M. Government: London, UK, 2015. [Google Scholar]
- Oliver, J.J.; Parrett, E. Managing future uncertainty: Reevaluating the role of scenario planning. Bus. Horiz. 2018, 61, 339–352. [Google Scholar] [CrossRef]
- Norouzi, N.; Fani, M.; Ziarani, Z.K. The fall of oil Age: A scenario planning approach over the last peak oil of human history by 2040. J. Pet. Sci. Eng. 2020, 188, 106827. [Google Scholar] [CrossRef]
- Reimer, N. SentenceTransformers. Available online: www.sbert.net (accessed on 6 February 2022).
- SeatGeek. Fuzzy String Matching in Python. Available online: https://github.com/seatgeek/thefuzz (accessed on 6 February 2022).
- Explosion. spaCy: Industrial-Strength Natural Language Processing. Available online: https://spacy.io/ (accessed on 6 February 2022).
- Universal Dependencies Contributors. Universal POS Tags. Available online: https://universaldependencies.org/u/pos/ (accessed on 6 February 2022).
- Kim, J.; Han, M.; Lee, Y.; Park, Y. Futuristic data-driven scenario building: Incorporating text mining and fuzzy association rule mining into fuzzy cognitive map. Expert Syst. Appl. 2016, 57, 311–323. [Google Scholar] [CrossRef]
- Siemens. Company, Innovation. Available online: https://new.siemens.com/global/en/company/innovation.html (accessed on 6 February 2022).
- MIT Technology Review. Available online: https://www.technologyreview.com/all-topics (accessed on 6 February 2022).
- Kurzweil. Tracking the Acceleration of Intelligence. Available online: http://www.kurzweilai.net (accessed on 6 February 2022).
- World Future Society. Available online: http://web.archive.org/web/*/http://www.wfs.org (accessed on 6 February 2022).
- FutureTimeLine. Available online: http://futuretimeline.net/index.htm (accessed on 6 February 2022).
- Turoń, K.; Kubik, A.; Chen, F. When, What and How to Teach about Electric Mobility? An Innovative Teaching Concept for All Stages of Education: Lessons from Poland. Energies 2021, 14, 6440. [Google Scholar] [CrossRef]
- Seljom, P.; Kvalbein, L.; Hellemo, L.; Kaut, M.; Ortiz, M.M. Stochastic modelling of variable renewables in long-term energy models: Dataset, scenario generation & quality of results. Energy 2021, 236, 121415. [Google Scholar] [CrossRef]
- Fiebrink, R.; Cook, P.R.; Trueman, D. Human model evaluation in interactive supervised learning. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Vancouver, BC, Canada; 2011; pp. 147–156. [Google Scholar]
- Robert, S.; Büttner, S.; Röcker, C.; Holzinger, A. Reasoning Under Uncertainty: Towards Collaborative Interactive Machine Learning. In Machine Learning for Health Informatics. Lecture Notes in Computer Science; Holzinger, A., Ed.; Springer: Cham, Switzerland, 2016; Volume 9605. [Google Scholar]
- Merritt, S.M. Affective Processes in Human—Automation Interactions. Hum. Factors J. Hum. Factors Ergon. Soc. 2011, 53, 356–370. [Google Scholar] [CrossRef]
- Czech, P. Autonomous vehicles: Basic issues. Sci. J. Silesian Univ. Technol. Ser. Transp. 2018, 100, 15–22. [Google Scholar] [CrossRef]
- Zhang, P.; Jetter, A. A framework for building integrative scenarios of autonomous vehicle technology application and impacts, using fuzzy cognitive maps (FCM). In Proceedings of the 2018 Portland International Conference on Management of Engineering and Technology (PICMET), Honolulu, HI, USA, 19–23 August 2018; pp. 1–14. [Google Scholar]
- Chapaloglou, S.; Varagnolo, D.; Marra, F.; Tedeschi, E. Data-informed scenario generation for statistically stable energy storage sizing in isolated power systems. J. Energy Storage 2022, 51, 104311. [Google Scholar] [CrossRef]
- Kamari, A.; Kirkegaard, P.H.; Schultz, C.P.L. PARADIS-A process integrating tool for rapid generation and evaluation of holistic renovation scenarios. J. Build. Eng. 2020, 34, 101944. [Google Scholar] [CrossRef]
- Maeda, E.E.; Haapasaari, P.; Helle, I.; Lehikoinen, A.; Voinov, A.; Kuikka, S. Black Boxes and the Role of Modeling in Environmental Policy Making. Front. Environ. Sci. 2021, 9, 63. [Google Scholar] [CrossRef]




| Answer | Confidence | Context |
|---|---|---|
| Fast fashion brands | 0.489 | on the other hand, fast fashion brands such as h & m, Zara, Topshop, have been blamed for creating poor labor welfare, severe environmental pollution as well as a massive amount of clothing disposal at the end of the product life cycle. |
| Global climate change | 0.00713 | introduction due to the aggravation of environmental pollution and global climate change, sustainable development has attracted more and more attention. |
| Overconsumption of energy | 0.00669 | by doing so, these companies alleviate conflicts of interest among participants and reduce pollution and overconsumption of energy. |
| Parameter/Input | Values | Purpose | Libraries Involved |
|---|---|---|---|
| Seed questions | String | The modeling team must define the problem of interest, which anchors the model. | N/A |
| Text collection | Resource set | Natural language processing is performed over a text corpus. It can be provided directly (e.g., as files or URLs) or retrieved from databases with search keywords. | Power Automate Desktop (to automate data collection) |
| Confidence threshold | [0, 1] | Filter results based on the confidence returned by the Q&A algorithm. The threshold range will vary based on the context; thus, the cut-off is up to the modeler. | Hugging Face Q&A |
| Semantic similarity threshold | [0, 100] (100 indicates perfect match) | Combine concepts that are semantically similar. This can use Levenshtein or cosine distance. A lower value will group many concepts, a higher value may create a model with different concepts but similar meanings. | fuzzywuzzy |
| POS Filtering | Array of POS tags (universal POS tags [86]) | Parts of speech may be returned as answers, but would not make intuitive sense as concepts. In addition, aggregate models often limited to only using nouns as concepts. | spaCy |
| Question | Subject | Weight | PESTEL Category |
|---|---|---|---|
| What technology is needed for electric vehicles? | EV adoption | 1 | Technology |
| Why use an electrified vehicle? | 1 | Open | |
| What are impediments? | −1 | ||
| What are political factors? | 1 | Political | |
| What are the benefits to the environment? | 1 | Environmental | |
| What hurts the environment? | Environment | −1 | |
| What are social benefits? | EV adoption | 1 | Social |
| What are social problems? | −1 | ||
| What social aspects affect electric vehicles? | 1 | ||
| What are the economic benefits? | Economy | 1 | Economic |
| What are economic problems? | −1 | ||
| What are economic drivers? | −1 | ||
| What are legal problems? | EV adoption | −1 | Legal |
| What are legal drivers? | 1 | ||
| What are legal benefits? | 1 |
| Category | SAAM Concepts | LSA Concepts |
|---|---|---|
| Air pollution | greenhouse gas emissions, no exhaust emissions, the air, your gas guzzler, energy pollution | Temperature, environment, pollution, atmosphere, carbon dioxide emission, greenhouse gas, CO2, eco |
| Alternative energy technology | clean renewable energy sources, polarization systems | Renewable energy, diesel, biofuel, biomass, geothermal, petroleum, gasoline, hybrid, photovoltaic, solar energy |
| Battery technology | batteries, power and mileage limits, recharge speed | Lithium battery, ion battery, acid battery, storage, battery life, lightweight, BMS, lithium ion battery |
| Charging technology | a comprehensive charge station network, generic supercharging stations | Wireless power, charger, recharge, power transmission, charger |
| Costs reduction | EVs cost, the falling price of batteries, incentives | Cost reduction, incentive, support, maintenance cost |
| Economic revenue | business development, current unit sales, wealth, economic activity | Economy, growth, sales, investment, revenue, GDP, trade, import, export |
| Energy efficiency | energy efficiency | Energy efficiency, energy consumption, efficiency improvement, energy density, mileage |
| Government regulation | carbon pricing, cities conservation, governments, incentives, public investment, regulation | Regulation, incentive, policy, government, limitation, standard, tax reduction, policy |
| Industry-university collaboration | scholarships, aboriginal training | Company, startup, university, laboratory, investment, partnership, entrepreneur, grid |
| Job creation | employment | Job, worker, manufacturing, services, employment |
| Motor technology | electric motor | Engine, inverter, magnet, DC, AC, torque, capacity, motor |
| Usability | information technology | Automation, sensor, network connection, software, comfort, assistant, internet |
| Public transportation | Self-driving vehicles | Transportation, electric bus, driver, passenger |
| Safety | economic and safety benefits, self-driving vehicles | Safety, driverless, collision, vibration, pressure, security, stability, obstacle warning, monitoring |
| Other | thinking globally and acting locally, a completely carbon neutral transportation option, biomimicry, confidence, durability, environmentally conscious citizens | |
| Application to tourism | Consumer, customer, tourism, growth, economy |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Davis, C.W.H.; Jetter, A.J.; Giabbanelli, P.J. Automatically Generating Scenarios from a Text Corpus: A Case Study on Electric Vehicles. Sustainability 2022, 14, 7938. https://doi.org/10.3390/su14137938
Davis CWH, Jetter AJ, Giabbanelli PJ. Automatically Generating Scenarios from a Text Corpus: A Case Study on Electric Vehicles. Sustainability. 2022; 14(13):7938. https://doi.org/10.3390/su14137938
Chicago/Turabian StyleDavis, Christopher W. H., Antonie J. Jetter, and Philippe J. Giabbanelli. 2022. "Automatically Generating Scenarios from a Text Corpus: A Case Study on Electric Vehicles" Sustainability 14, no. 13: 7938. https://doi.org/10.3390/su14137938