
A Deep Learning-Based Model for Date Fruit Classification





Abstract
:1. Introduction
- A detailed review has been conducted to investigate the most promising work in the machine learning/deep learning domain for date fruit classification.
- A new dataset containing eight different types of date fruit has been created.
- A new optimized model based on advanced deep learning techniques has been proposed for the classification of date fruit. Furthermore, different preprocessing techniques have been employed to avoid the chance of overfitting.
- An optimization technique has been implemented to monitor any positive change in terms of accuracy in the model, based on a backup of the optimal model taken at the end of each iteration to affirm the proposed model’s accuracy with the minimum validation loss.
2. Related Work
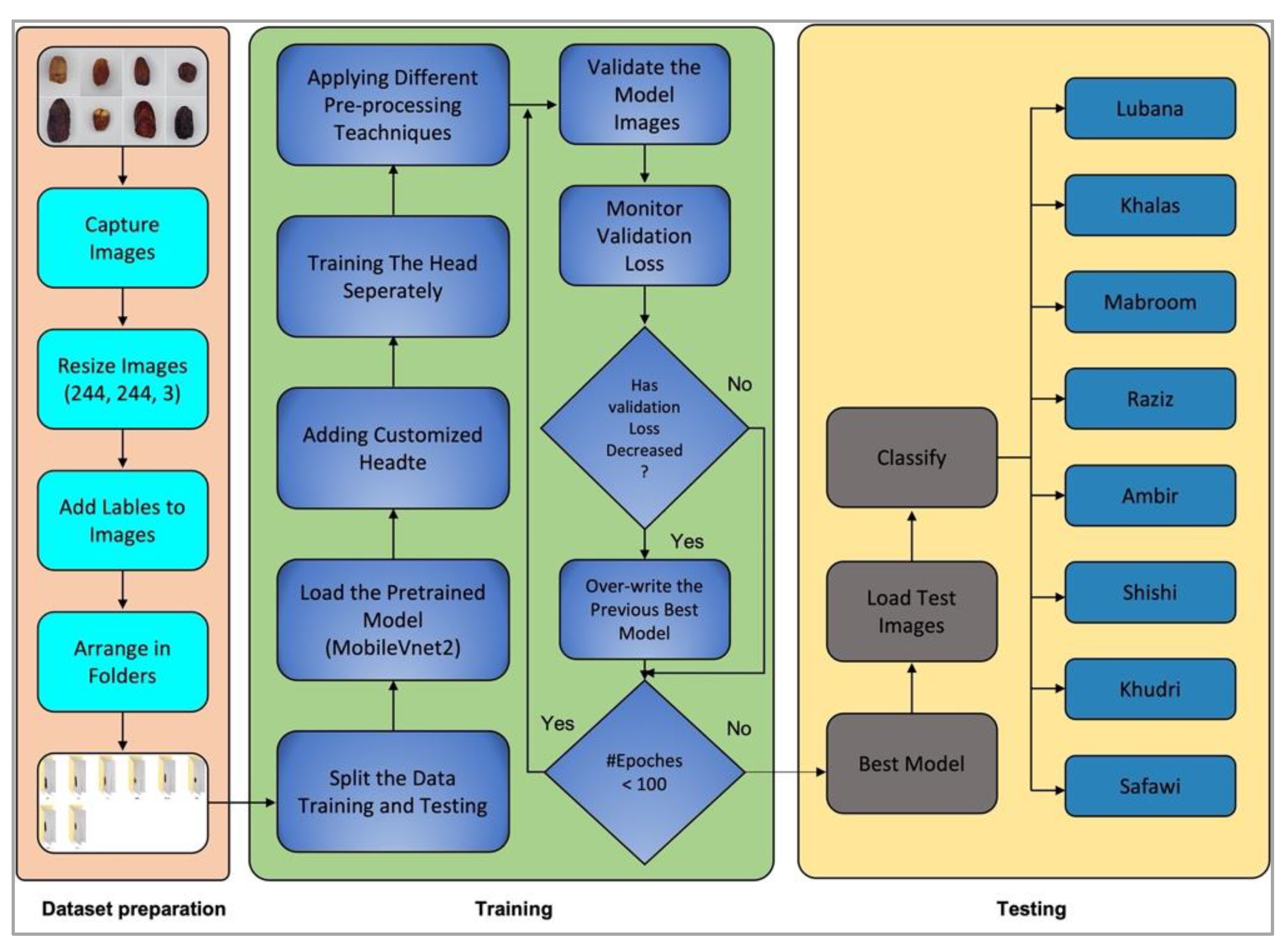
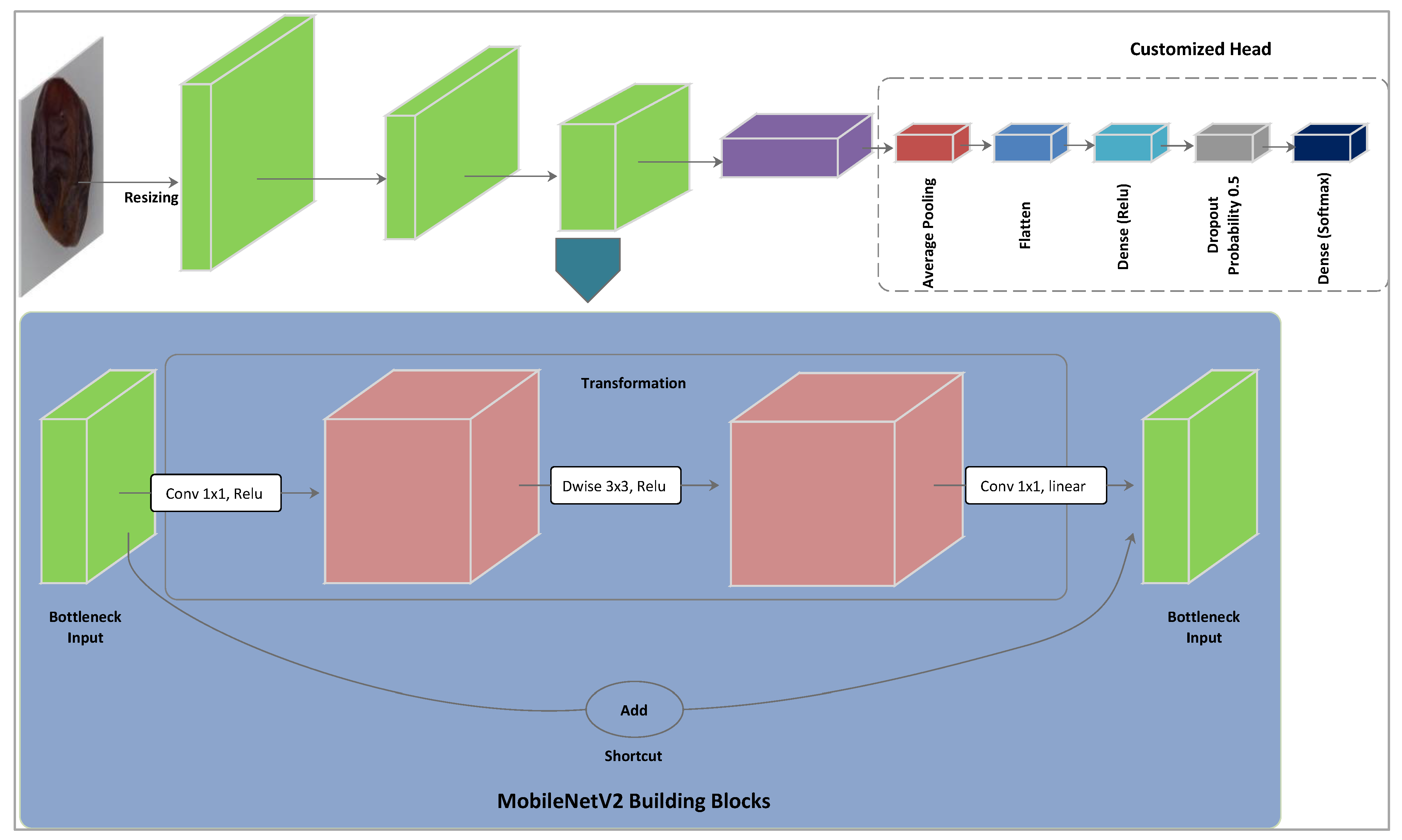
3. Proposed Model
3.1. Dataset Preparation
3.2. Training
- Data Augmentation: In data augmentation, different types of images are artificially created in various processing manners or by combining multiple processing methods, such as random rotations, shifts, shears, and flips. So, the MobileNetV2 architecture was modified by adding five different layers as mentioned earlier, and by incorporating many preprocessing techniques. To generate augmented images, this research work used an inbuilt function in Keras’ Library [34]. For each image, 10 different images were created randomly by incorporating different methods such as zooming the image by 20%, rotating by 30%, width shifting by 10%, and adjusting height by 10%.
- Adaptive Learning Rate: Learning rate schedules seek to adjust the learning rate during the training process by reducing the learning rate according to the pre-defined schedule. Common learning rate schedules include time-based decay, step decay, and exponential decay. For this work, the initial learning rate was set to INIT_LR = 0.0001 and then the decay of the form decay = INIT_LT/EPOCHS was used.
- Model Checkpointing: This is the technique where checkpoints are set to save the weights of the models whenever there is a positive change in the classification accuracy on the validation dataset. It is used to control and monitor ML models during training at some frequency (for example, at the end of each epoch/batch). It allows us to specify a quantity to monitor, such as loss or accuracy on training or a validation dataset, and thereafter it can save model weights or an entire model whenever the monitored quantity is optimum when compared to the last epoch/batch. In this research work, a model checkpoint of the form checkpoint = Model Checkpoint (fname, monitor = “val_loss”, mode = “min”, save_best_only = True, verbose = 1) was used. This callback monitored the validation loss of the model and would overwrite the trained model only when there was a decrease in the loss as compared to the previous best model.
- Dropout: This technique is used to avoid the overfitting of a model. In this technique, neurons are randomly selected and ignored/dropped out during training. This indicates that the contribution of these neurons is temporally ignored to the activation of downstream neurons and any weight changes are not implemented on any neuron on the backward pass.
3.3. Testing
4. Experimental Setup
4.1. Model Selection
4.2. Training and Testing Data
4.3. Performance Measures
- True Positive: If, for instance, a presented image is of a Lubana date fruit, and the model classifies it as a Lubana date fruit image.
- True Negative: If, for instance, a presented image is not of Lubana date fruit, and the model does not classify it as a date fruit image.
- False Positive: If, for instance, a presented image is not of Lubana date fruit; however, the model incorrectly classifies it as the Lubana date fruit image.
- False Negative: If, for instance, a presented image is of Lubana date fruit; however, the model incorrectly classifies it as something else.
- Accuracy: The proportion of the total number of correct predictions, which is a sum of total correct positive and total correct negative instances over the total number of instances.
- Precision: A ratio of correct positive prediction over the total number of positively predicted instances and is computed as true positive over the sum of true positive and false positive.
- Recall: A ratio of correct positive prediction over the total number of actual positive classes was computed as true positive over the sum of the true positive and false negative.
- Macro Average: The function to compute F-1 for each label and returns the average without considering the proportion for each label in the dataset.
- Weighted Average: The function to compute F-1 for each label and returns the average considering the proportion for each label in the dataset.
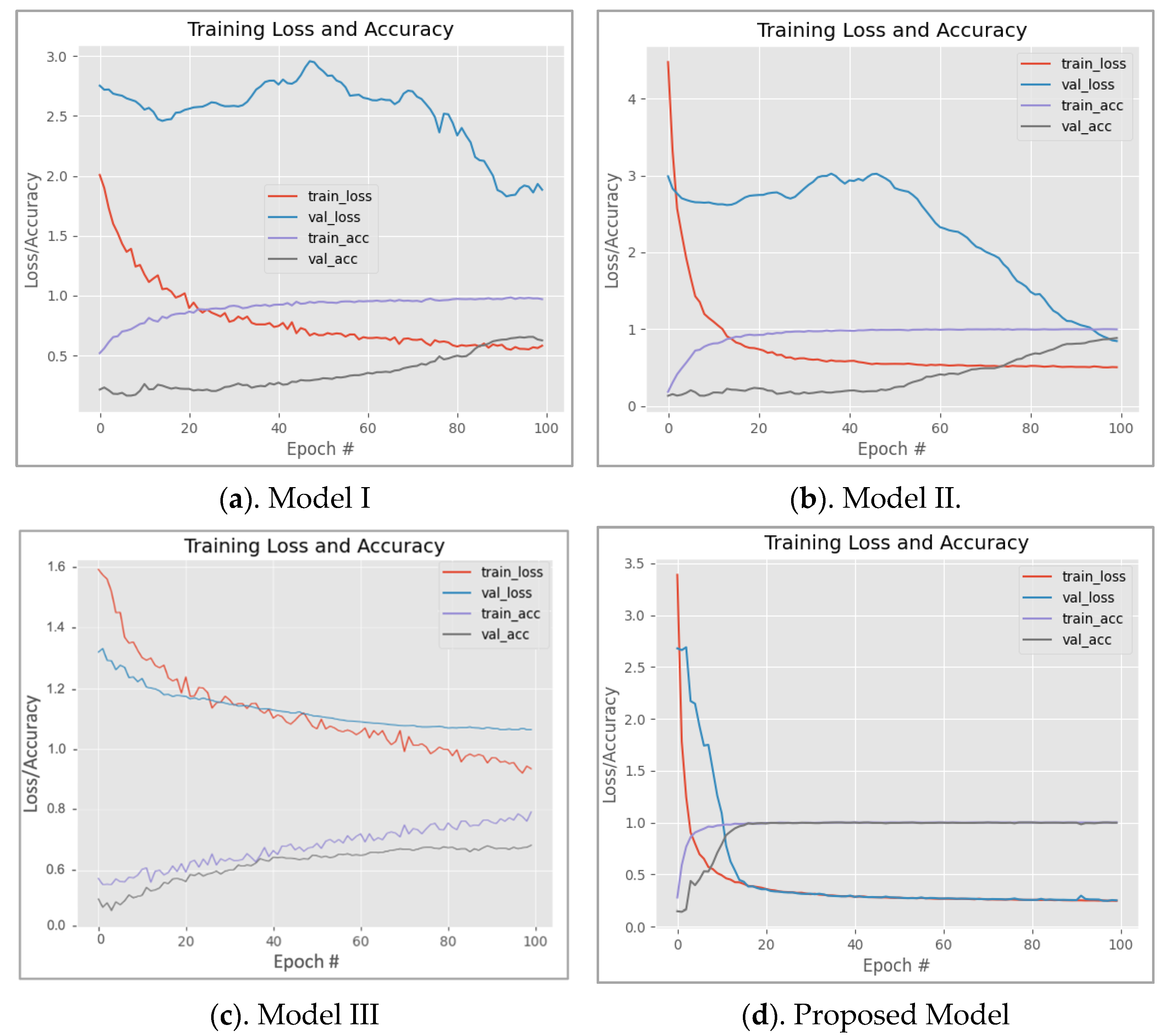
5. Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Timmer, C. Agriculture and economic development revisited. Agric. Syst. 1992, 40, 21–58. [Google Scholar] [CrossRef]
- King, A. Technology: The Future of Agriculture. Nature 2017, 544, S21–S23. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, X.; Shu, L.; Chen, J.; Ferrag, M.A.; Wu, J.; Nurellari, E.; Huang, K. A Survey on Smart Agriculture: Development Modes, Technologies, and Security and Privacy Challenges. IEEE/CAA J. Autom. Sin. 2020, 8, 273–302. [Google Scholar] [CrossRef]
- Escamilla-García, A.; Soto-Zarazúa, G.M.; Toledano-Ayala, M.; Rivas-Araiza, E.; Gastélum-Barrios, A. Applications of Artificial Neural Networks in Greenhouse Technology and Overview for Smart Agriculture Development. Appl. Sci. 2020, 10, 3835. [Google Scholar] [CrossRef]
- Liu, W.; Shao, X.-F.; Wu, C.-H.; Qiao, P. A systematic literature review on applications of information and communication technologies and blockchain technologies for precision agriculture development. J. Clean. Prod. 2021, 298, 126763. [Google Scholar] [CrossRef]
- Ali, Q.; Ahmar, S.; Sohail, M.A.; Kamran, M.; Ali, M.; Saleem, M.H.; Rizwan, M.; Ahmed, A.M.; Mora-Poblete, F.; Júnior, A.T.D.A.; et al. Research advances and applications of biosensing technology for the diagnosis of pathogens in sustainable agriculture. Environ. Sci. Pollut. Res. 2021, 28, 9002–9019. [Google Scholar] [CrossRef]
- Chen, X.; Zhou, G.; Chen, A.; Pu, L.; Chen, W. The fruit classification algorithm based on the multi-optimization convolutional neural network. Multimed. Tools Appl. 2021, 80, 11313–11330. [Google Scholar] [CrossRef]
- Hossain, M.S.; Al-Hammadi, M.H.; Muhammad, G. Automatic Fruit Classification Using Deep Learning for Industrial Applications. IEEE Trans. Ind. Informatics 2018, 15, 1027–1034. [Google Scholar] [CrossRef]
- Alresheedi, K.M.; Aladhadh, S.; Khan, R.U.; Qamar, A.M. Dates Fruit Recognition: From Classical Fusion to Deep Learning. Comput. Syst. Sci. Eng. 2022, 40, 151–166. [Google Scholar] [CrossRef]
- Faisal, M.; Albogamy, F.; Elgibreen, H.; Algabri, M.; Alqershi, F.A. Deep Learning and Computer Vision for Estimating Date Fruits Type, Maturity Level, and Weight. IEEE Access 2020, 8, 206770–206782. [Google Scholar] [CrossRef]
- Available online: Https://Www.Mewa.Gov.Sa/En/MediaCenter/News/Pages/News201220.Aspx (accessed on 21 April 2022).
- Meshram, V.; Patil, K.; Meshram, V.; Hanchate, D.; Ramkteke, S. Machine learning in agriculture domain: A state-of-art survey. Artif. Intell. Life Sci. 2021, 1, 100010. [Google Scholar] [CrossRef]
- O’Mahony, N.; Campbell, S.; Carvalho, A.; Harapanahalli, S.; Hernandez, G.V.; Krpalkova, L.; Riordan, D.; Walsh, J. Deep Learning vs. Traditional Computer Vision. In Proceedings of the Science and Information Conference; Springer: Berlin/Heidelberg, Germany, 2019; pp. 128–144. [Google Scholar]
- Behera, S.K.; Rath, A.K.; Mahapatra, A.; Sethy, P.K. Identification, classification & grading of fruits using machine learning & computer intelligence: A review. J. Ambient Intell. Humaniz. Comput. 2020, 1–11. [Google Scholar] [CrossRef]
- Bhargava, A.; Bansal, A. Fruits and vegetables quality evaluation using computer vision: A review. J. King Saud Univ.-Comput. Inf. Sci. 2021, 33, 243–257. [Google Scholar] [CrossRef]
- Sarvamangala, D.R.; Kulkarni, R.V. Convolutional neural networks in medical image understanding: A survey. Evol. Intell. 2021, 15, 1–22. [Google Scholar] [CrossRef] [PubMed]
- Zheng, M.; Xu, J.; Shen, Y.; Tian, C.; Li, J.; Fei, L.; Zong, M.; Liu, X. Attention-based CNNs for Image Classification: A Survey. J. Phys. Conf. Ser. 2022, 2171, 012068. [Google Scholar] [CrossRef]
- Altaheri, H.; Alsulaiman, M.; Muhammad, G. Date Fruit Classification for Robotic Harvesting in a Natural Environment Using Deep Learning. IEEE Access 2019, 7, 117115–117133. [Google Scholar] [CrossRef]
- Nasiri, A.; Taheri-Garavand, A.; Zhang, Y.-D. Image-based deep learning automated sorting of date fruit. Postharvest Biol. Technol. 2019, 153, 133–141. [Google Scholar] [CrossRef]
- Magsi, A.; Mahar, J.A.; Danwar, S.H. Date Fruit Recognition using Feature Extraction Techniques and Deep Convolutional Neural Network. Indian J. Sci. Technol. 2019, 12, 1–12. [Google Scholar] [CrossRef]
- Pérez-Pérez, B.; Vázquez, J.G.; Salomón-Torres, R. Evaluation of Convolutional Neural Networks’ Hyperparameters with Transfer Learning to Determine Sorting of Ripe Medjool Dates. Agriculture 2021, 11, 115. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–28 June 2018; pp. 4510–4520. [Google Scholar]
- Hamid, Y.; Wani, S.; Soomro, A.B.; Alwan, A.A.; Gulzar, Y. Smart Seed Classification System Based on MobileNetV2 Architecture. In Proceedings of the 2022 2nd International Conference on Computing and Information Technology (ICCIT), Tabuk, Saudi Arabia, 25–27 January 2022; pp. 217–222. [Google Scholar]
- Gulzar, Y.; Hamid, Y.; Soomro, A.B.; Alwan, A.A.; Journaux, L. A Convolution Neural Network-Based Seed Classification System. Symmetry 2020, 12, 2018. [Google Scholar] [CrossRef]
- Naik, S.; Patel, B. Machine Vision based Fruit Classification and Grading—A Review. Int. J. Comput. Appl. 2017, 170, 22–34. [Google Scholar] [CrossRef]
- Sharmila, A.; Dhivya Priya, E.L.; Gokul Anand, K.R.; Sujin, J.S.; Soundarya, B.; Krishnaraj, R. Fruit Recognition Approach by Incorporating MultilayerConvolution Neural Network. In Proceedings of the 2022 4th International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 20–22 January 2022; pp. 1042–1046. [Google Scholar]
- Gill, H.S.; Khehra, B.S. An integrated approach using CNN-RNN-LSTM for classification of fruit images. Mater. Today Proc. 2021, 51, 591–595. [Google Scholar] [CrossRef]
- Shoshan, T.; Bechar, A.; Cohen, Y.; Sadowsky, A.; Berman, S. Segmentation and motion parameter estimation for robotic Medjoul-date thinning. Precis. Agric. 2021, 23, 514–537. [Google Scholar] [CrossRef]
- Altaheri, H.; Alsulaiman, M.; Muhammad, G.; Amin, S.U.; Bencherif, M.; Mekhtiche, M. Date fruit dataset for intelligent harvesting. Data Brief 2019, 26, 104514. [Google Scholar] [CrossRef] [PubMed]
- Haidar, A.; Dong, H.; Mavridis, N. Image-Based Date Fruit Classification. In Proceedings of the 2012 IV International Congress on Ultra Modern Telecommunications and Control Systems, St. Petersburg, Russia, 3–5 October 2012; pp. 357–363. [Google Scholar]
- Alavi, N. Quality determination of Mozafati dates using Mamdani fuzzy inference system. J. Saudi Soc. Agric. Sci. 2012, 12, 137–142. [Google Scholar] [CrossRef] [Green Version]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A Survey on Deep Transfer Learning. In Proceedings of the International Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2018; pp. 270–279. [Google Scholar]
- Arnold, T.B. kerasR: R Interface to the Keras Deep Learning Library. J. Open Source Softw. 2017, 2, 296. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. NIPS 2012, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556v6. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S. No | Date Fruit | No. of Images |
|---|---|---|
| 1 | Lubana | 204 |
| 2 | Khalas | 205 |
| 3 | Mabroom | 206 |
| 4 | Raziz | 203 |
| 5 | Ambir | 240 |
| 6 | Shishi | 215 |
| 7 | Khudri | 224 |
| 8 | Safawi | 220 |
| Models | Precision | Recall | F1-Score |
|---|---|---|---|
| AlexNet | 0.55 | 0.62 | 0.58 |
| VGG16 | 0.62 | 0.67 | 0.64 |
| InceptionV3 | 0.59 | 0.51 | 0.54 |
| ResNet | 0.63 | 0.66 | 0.64 |
| MobileNetV2 | 0.64 | 0.67 | 0.64 |
| Date Fruits | Precision | Recall | F1-Score | Support |
|---|---|---|---|---|
| Lubana | 1 | 1 | 1 | 51 |
| Khalas | 1 | 1 | 1 | 52 |
| Mabroom | 1 | 0.98 | 0.99 | 52 |
| Raziz | 1 | 1 | 1 | 51 |
| Ambir | 0.99 | 0.97 | 0.98 | 60 |
| Shishi | 1 | 0.97 | 0.98 | 54 |
| Khudri | 0.97 | 1 | 0.99 | 56 |
| Safawi | 0.97 | 1 | 0.98 | 55 |
| Accuracy | - | - | 0.99 | 431 |
| Macro Avg | 0.99 | 0.99 | 0.99 | 431 |
| Weighted Avg | 0.99 | 0.99 | 0.99 | 431 |
| Models | Precision | Recall | F1-Score |
|---|---|---|---|
| AlexNet | 0.70 | 0.85 | 0.77 |
| VGG16 | 0.87 | 0.81 | 0.84 |
| InceptionV3 | 0.75 | 0.97 | 0.77 |
| ResNet | 0.85 | 0.82 | 0.83 |
| Proposed Model | 0.99 | 0.99 | 0.99 |
| Paper | Dataset | Date Types | Method/Model | Classification Type | Precision (%) | Recall (%) | Accuracy (%) |
|---|---|---|---|---|---|---|---|
| [18] | Self-collected | 5 | VGG-16 | Identification and others | - | - | 99.01 |
| [19] | Self-collected | 4 | VGG-16 | Healthy vs. defective | 96.63 | 97.33 | 96.98 |
| [9] | Self-collected | 9 | ALEXNET | Identification | - | - | 94.2 |
| [20] | Self-collected | 3 | DNN | Identification | - | - | 97.2 |
| [10] | [18] | 5 | ResNet | Identification and others | 99.64 | 99.08 | 99.05 |
| [21] | Self-collected | 1 | VGG-19 | Sorting | - | - | 99.32 |
| Proposed Model | Self-collected | 8 | MobileNetV2 | Identification | 99.0 | 99.0 | 99.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Albarrak, K.; Gulzar, Y.; Hamid, Y.; Mehmood, A.; Soomro, A.B. A Deep Learning-Based Model for Date Fruit Classification. Sustainability 2022, 14, 6339. https://doi.org/10.3390/su14106339
Albarrak K, Gulzar Y, Hamid Y, Mehmood A, Soomro AB. A Deep Learning-Based Model for Date Fruit Classification. Sustainability. 2022; 14(10):6339. https://doi.org/10.3390/su14106339
Chicago/Turabian StyleAlbarrak, Khalied, Yonis Gulzar, Yasir Hamid, Abid Mehmood, and Arjumand Bano Soomro. 2022. "A Deep Learning-Based Model for Date Fruit Classification" Sustainability 14, no. 10: 6339. https://doi.org/10.3390/su14106339