
Predicting Student Outcomes in Online Courses Using Machine Learning Techniques: A Review



Abstract
:1. Introduction
1.1. Previous Reviews of Student Outcome Prediction
1.2. Method
- What is the process followed by researchers for learner outcome prediction?
- What are the predictive variables used to predict learner outcome?
- What are the learner outcomes used in the literature?
- What are the online learning platforms used in the literature?
- What are the machine learning methodologies used in the literature?
- What are the challenges and limitations, and future directions of this field?
1.3. Study Selection
1.4. Student Outcomes Prediction Model Process
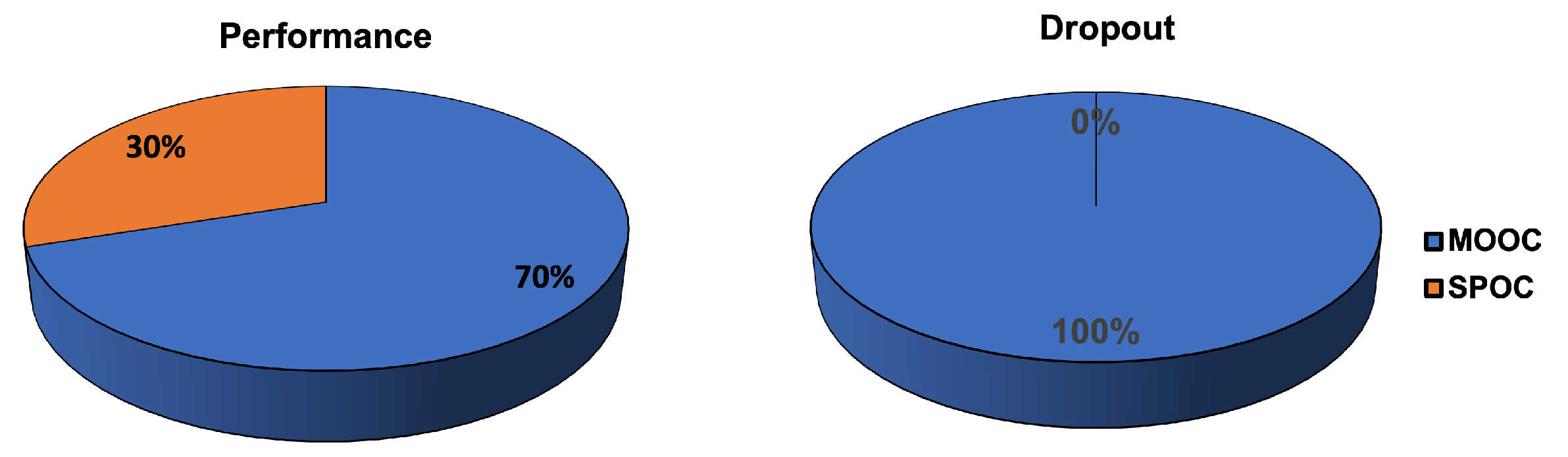
2. Online Learning Environment
3. Courses
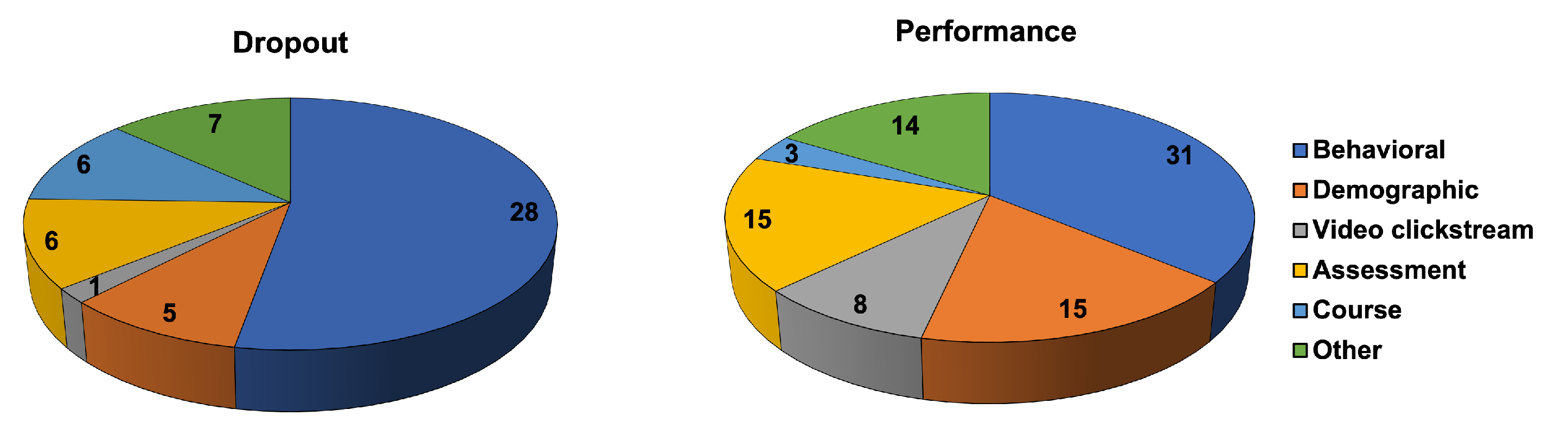
4. Predictive Variables
5. Features Engineering
6. Feature Selection
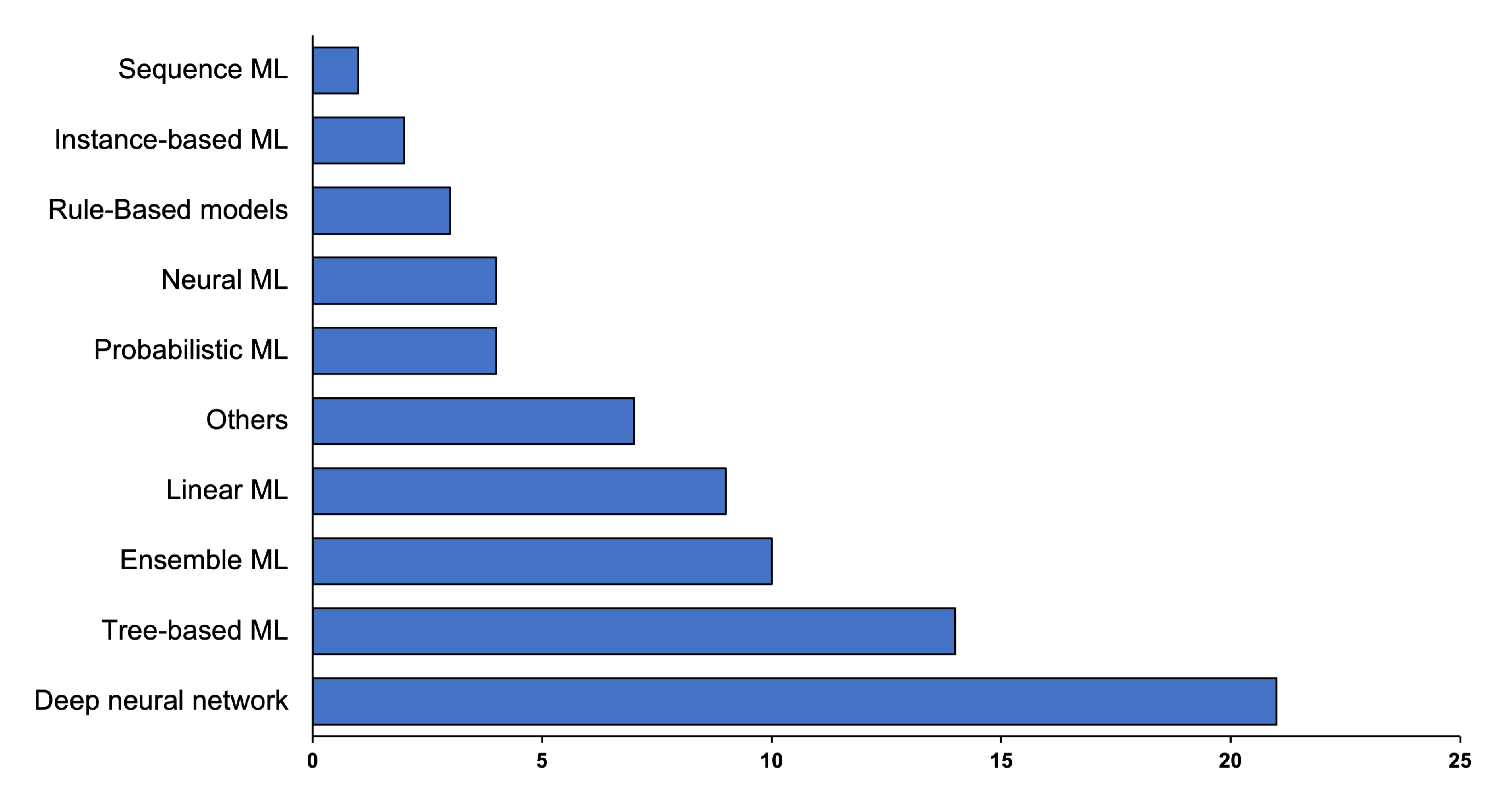
7. Models
8. Evaluation Metrics
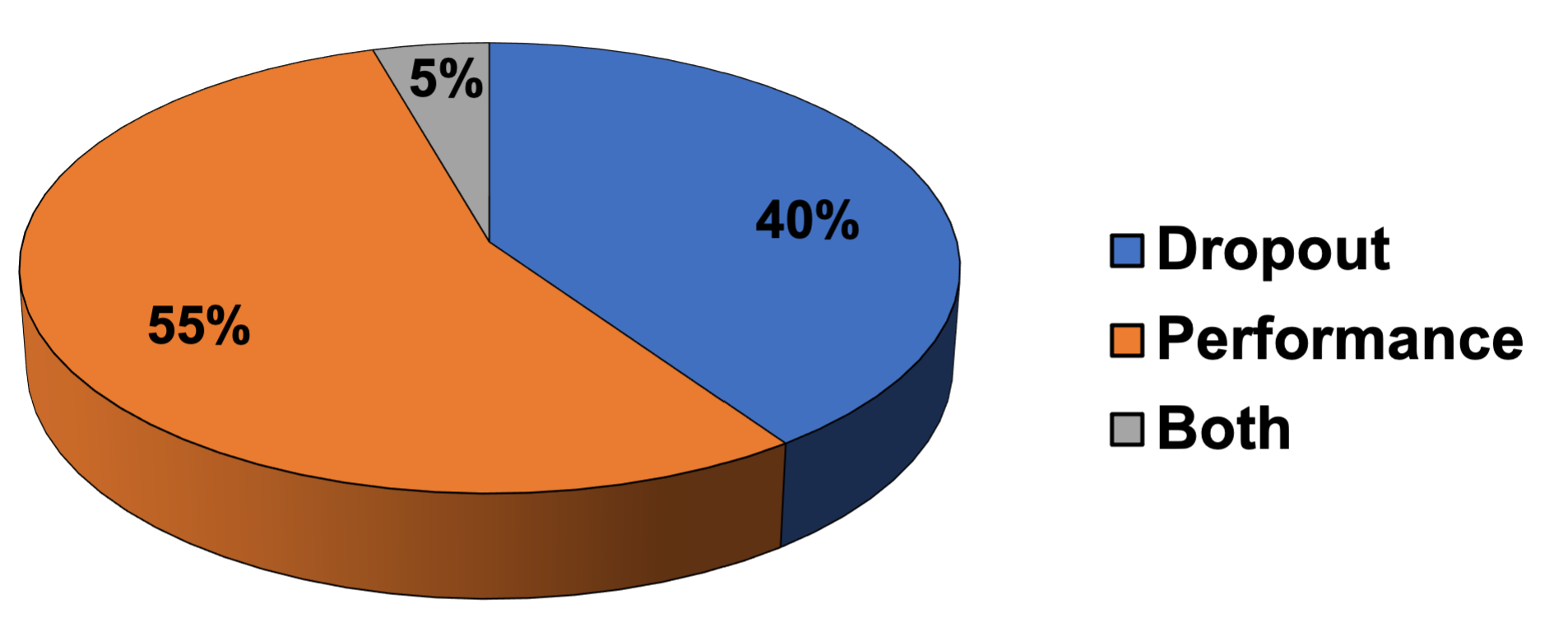
9. Student Outcomes
9.1. Predicting Students Performance
9.1.1. Certificate Acquisition Prediction
9.1.2. Grade Prediction
9.1.3. Students-at-Risk Prediction
9.2. Student Dropout and Retention Prediction
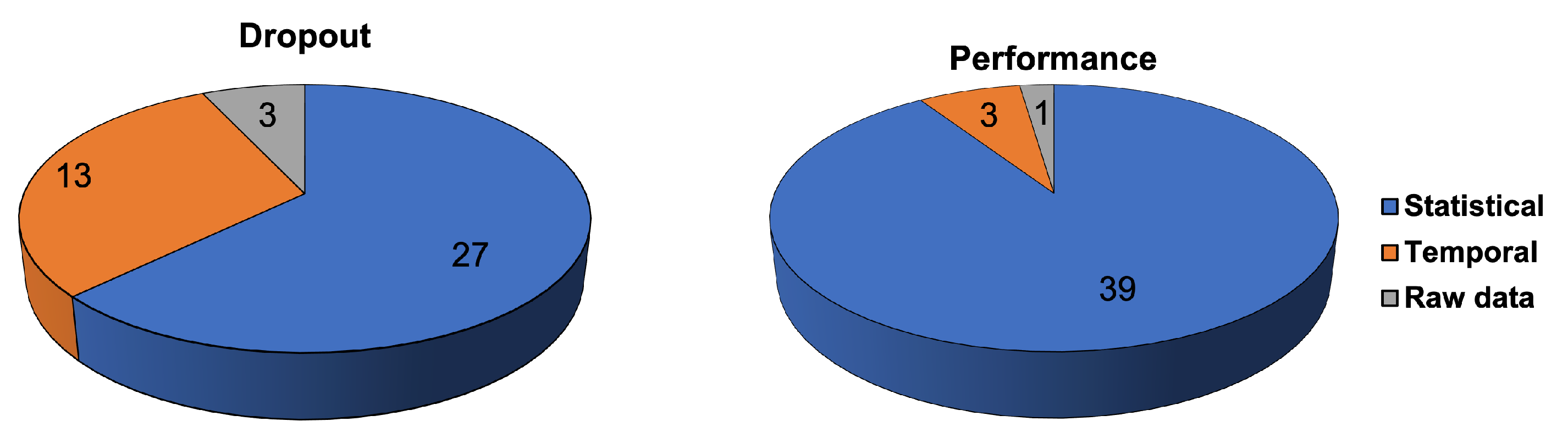
9.2.1. Statistical Features
9.2.2. Temporal Features

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Type | Platform Dataset | Sample/ Course | Features | FE | Model | Class | Output | Accuracy | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| B | D | V | A | C | O | S | T | R | ||||||||
| [73] | MOOC | KDDcup | 96,529/39 | √ | √ | √ | c-RF | Binary | Dropout | 0.93 | ||||||
| [71] | MOOC | KDDcup | 200,000/39 | √ | √ | √ | √ | Stacked ensemble | Binary | Dropout | 0.91 | |||||
| CNN + RNN | Binary | Dropout | 0.92 | |||||||||||||
| [76] | MOOC | Canvas | 3617/1 | √ | √ | √ | √ | √ | DL | Binary | Dropout | w7:0.97 | ||||
| [83] | MOOC | KDDcup | 120,542/39 | √ | √ | √ | RFE + LR | Binary | Dropout | 0.87 | ||||||
| [88] | MOOC | LMS | -/6 | √ | √ | √ | RNN-LSTM | Binary | Dropout | 0.90 | ||||||
| [89] | MOOC | KDDcup | 79,186/39 | √ | √ | √ | CNN + LSTM + SVM | Binary | Dropout | F1 = 0.95 | ||||||
| [84] | MOOC | KDDcup | 112,448/39 | √ | √ | √ | √ | √ | GB | Binary | Dropout | AUC = 0.89 | ||||
| [15] | MOOC | OULAD | 32,594/22 | √ | √ | √ | √ | GBM | Binary | Dropout | AUC = 0.91 | |||||
| [26] | MOOC | HMedx | 641,138/- | √ | √ | DNN | Binary | Dropout | 0.99 | |||||||
| [85] | MOOC | OULAD | 32,593/22 | √ | √ | √ | √ | ANN | Binary | Dropout | AUC = 0.93 | |||||
| [72] | MOOC | - | 10,554/- | √ | √ | √ | √ | √ | LLM | Binary | Dropout | F1 = 0.84 | ||||
| [92] | MOOC | KDDcup | 79,186/39 | √ | √ | √ | FWTS-CNN | Binary | Dropout | 0.87 | ||||||
| [77] | MOOC | KDDcup | 112,448/39 | √ | √ | Gaussian NB | Binary | Dropout | F1 = 0.85 | |||||||
| [96] | MOOC | KDDcup | 120542/39 | √ | √ | √ | √ | CNN + SE + GRU | Binary | Dropout | 0.95 | |||||
| [69] | MOOC | Moodle | 46,895/8 | √ | √ | ANN | Binary | Dropout | 0.89 | |||||||
| [23] | MOOC | KDDcup | 120,542/39 | √ | √ | √ | RVFLNN | Binary | Dropout | 0.93 | ||||||
| [86] | MOOC | KDDcup | 53,596/6 | √ | √ | SVM | Binary | Dropout | F1 = 0.90 | |||||||
| [24] | MOOC | KDDcup | 120,542/39 | √ | √ | √ | MMSE | Binary | Dropout | 0.88 | ||||||
| [90] | MOOC | KDDcup | 120,542/39 | √ | √ | √ | CNN | Binary | Dropout | 0.88 | ||||||
| [95] | MOOC | KDDcup | 12,004/1 | √ | √ | √ | Attention + CRF | Binary | Dropout | 0.84 | ||||||
| [74] | MOOC | Moodle | 700/1 | √ | √ | √ | √ | LightGBM | Binary | Dropout | 0.96 | |||||
| [75] | MOOC | Future Learn | 251,662/7 | √ | √ | √ | RF, Adaboost | Binary | Dropout | 0.95 | ||||||
10. Summary, Challenges and Limitations
- –
- There is no consensus among researchers on the definition of dropout, success, and other related terminologies. For example, some researchers considered a student to be a dropout if they fail to complete a specific percentage of the assessments (e.g., ) [70], or if they were not active for several consecutive days [73]. Others considered dropout to be the inability to pass a course, and some did not provide any precise definition. The inconsistency in defining dropout and other related terminologies could be a concern to researchers, since it influences how dropout is assessed, addressed, and investigated [97].
- –
- Most proposed approaches use MOOC datasets in which students are self-motivated and are not required or obligated to participate in the courses. Thus, there is an enormous disparity between learners who are registered for curiosity, who, for example, view some videos and do not complete the required assignments, and those who are registered to finish the course, which may make identifying dropouts or failure relatively easy tasks. Exploring other types of online environments, such as SPOCs, might introduce more challenges, as learners may attempt to finish the course but fail or withdraw due to their lack of knowledge or other reasons.
- –
- Most studies also proposed systems that predict student outcomes when students approach the end of the course. Only a small number of studies considered early predictions of user outcomes, while many studies did not report the duration of data collection. This made it difficult to compare the different proposed methods, as the duration of the extracted features varied significantly. In addition, some studies used a subset of publicly available datasets, making it difficult to compare different methods on benchmark datasets.
- –
- Most studies employed feature-engineering techniques to calculate students’ statistical features as a whole. These features were often chosen arbitrarily or using statistical techniques such as correlation analysis. Some recent studies looked into methods that automatically extract temporal features from raw data by mapping raw features into numerical representations, such as one-hot encoding, and then using deep-learning methods, in particular, convolution functions, to extract features. Despite the usefulness of these techniques, the generated representations are often very sparse and less useful for comparing user behavior.
- –
- Several limitations have been addressed by researchers in this field. One of these limitations is the problem of multi-valued instances, in which some instances containing the same patterns have different outcomes [98]. In addition, the dropout-prediction task is well known to be imbalanced because the proportion of the positive class is much larger than that of the negative class. Several studies also use methods to handle the problem of class imbalance by either oversampling of the minority class [34,87] or under-sampling of the majority class [66].
- –
- One of the observed challenges is the quality of the training samples in which a large number of attributes are clickstream data which might be less representative when learners do not interact or engage in learning activities. This practice is common among students who register in MOOCs for curiosity [86].
- –
- Learning analytic systems are based on large volumes of real-time data collected over a protracted period. Analyzing, combining, and linking multiple forms of learners’ data to forecast their outcomes or any part of the learning process has raised many ethical challenges that cannot be properly measured using traditional ethical procedures [99]. The risks of de-anonymizing learners’ identities [100] and decontextualizing data [101] are some of the potential risks of this practice.
11. Conclusions and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Arce, M.E.; Crespo, B.; Míguez-Álvarez, C. Higher Education Drop-out in Spain–Particular Case of Universities in Galicia. Int. Educ. Stud. 2015, 8, 247–264. [Google Scholar] [CrossRef] [Green Version]
- Xavier, M.; Meneses, J. Dropout in Online Higher Education: A Scoping Review from 2014 to 2018; ELearn Center, Universitat Oberta de Catalunya: Barcelona, Spain, 2020. [Google Scholar]
- Baker, R.S.; Inventado, P.S. Educational Data Mining and Learning Analytics. In Learning Analytics: From Research to Practice; Larusson, J.A., White, B., Eds.; Springer: New York, NY, USA, 2014; pp. 61–75. [Google Scholar] [CrossRef] [Green Version]
- Moreno-Marcos, P.M.; Alario-Hoyos, C.; MuÃśoz-Merino, P.J.; Kloos, C.D. Prediction in MOOCs: A Review and Future Research Directions. IEEE Trans. Learn. Technol. 2019, 12, 384–401. [Google Scholar] [CrossRef]
- Ranjeeth, S.; Latchoumi, T.; Paul, P.V. A survey on predictive models of learning analytics. Procedia Comput. Sci. 2020, 167, 37–46. [Google Scholar] [CrossRef]
- Hamim, T.; Benabbou, F.; Sael, N. Survey of Machine Learning Techniques for Student Profile Modelling. Int. J. Emerg. Technol. Learn. 2021, 16, 136–151. [Google Scholar] [CrossRef]
- Prenkaj, B.; Velardi, P.; Stilo, G.; Distante, D.; Faralli, S. A survey of machine learning approaches for student dropout prediction in online courses. ACM Comput. Surv. (CSUR) 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Gardner, J.; Brooks, C. Student success prediction in MOOCs. User Model. User-Adapt. Interact. 2018, 28, 127–203. [Google Scholar] [CrossRef] [Green Version]
- Katarya, R.; Gaba, J.; Garg, A.; Verma, V. A review on machine learning based student’s academic performance prediction systems. In Proceedings of the 2021 International Conference on Artificial Intelligence and Smart Systems (ICAIS), Coimbatore, India, 25–27 March 2021; pp. 254–259. [Google Scholar] [CrossRef]
- Filius, R.M.; Uijl, S.G. Teaching Methodologies for Scalable Online Education. In Handbook for Online Learning Contexts: Digital, Mobile and Open; Springer: Berlin/Heidelberg, Germany, 2021; pp. 55–65. [Google Scholar]
- Amrieh, E.A.; Hamtini, T.M.; Aljarah, I. Mining Educational Data to Predict Student’s academic Performance using Ensemble Methods. Int. J. Database Theory Appl. 2016, 9, 119–136. [Google Scholar] [CrossRef]
- Rahman, M.H.; Islam, M.R. Predict Student’s Academic Performance and Evaluate the Impact of Different Attributes on the Performance Using Data Mining Techniques. In Proceedings of the 2017 2nd International Conference on Electrical Electronic Engineering (ICEEE), Rajshahi, Bangladesh, 27–29 December 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Kuzilek, J.; Hlosta, M.; Zdrahal, Z. Open university learning analytics dataset. Sci. Data 2017, 4, 170171. [Google Scholar] [CrossRef] [Green Version]
- Adnan, M.; Habib, A.; Ashraf, J.; Mussadiq, S.; Raza, A.A.; Abid, M.; Bashir, M.; Khan, S.U. Predicting at-Risk Students at Different Percentages of Course Length for Early Intervention Using Machine Learning Models. IEEE Access 2021, 9, 7519–7539. [Google Scholar] [CrossRef]
- Jha, N.; Ghergulescu, I.; Moldovan, A. OULAD MOOC Dropout and Result Prediction using Ensemble, Deep Learning and Regression Techniques. In Proceedings of the 11th International Conference on Computer Supported Education, Heraklion, Greece, 2–4 May 2019; SciTePress: SetÞbal, Portugal, 2019; Volume 2, pp. 154–164. [Google Scholar] [CrossRef]
- Song, X.; Li, J.; Sun, S.; Yin, H.; Dawson, P.; Doss, R.R.M. SEPN: A Sequential Engagement Based Academic Performance Prediction Model. IEEE Intell. Syst. 2021, 36, 46–53. [Google Scholar] [CrossRef]
- Hussain, M.; Zhu, W.; Zhang, W.; Abidi, R. Student Engagement Predictions in an e-Learning System and Their Impact on Student Course Assessment Scores. Comput. Intell. Neurosci. 2018, 2018, 6347186. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stanford, U. Center for Advanced Research through Online Learning (CAROL). Available online: https://carol.stanford.edu (accessed on 24 August 2021).
- Mubarak, A.A.; Cao, H.; Hezam, I.M. Deep analytic model for student dropout prediction in massive open online courses. Comput. Electr. Eng. 2021, 93, 107271. [Google Scholar] [CrossRef]
- Mourdi, Y.; Sadgal, M.; El Kabtane, H.; Berrada Fathi, W. A machine learning-based methodology to predict learners’ dropout, success or failure in MOOCs. Int. J. Web Inf. Syst. 2019, 15, 489–509. [Google Scholar] [CrossRef]
- Mourdi, Y.; Sadgal, M.; Berrada Fathi, W.; El Kabtane, H. A Machine Learning Based Approach to Enhance Mooc Users’ Classification. Turk. Online J. Distance Educ. 2020, 21, 47–68. [Google Scholar] [CrossRef]
- KDD. KDD Cup 2015. Available online: https://kdd.org/kdd-cup (accessed on 24 August 2021).
- Lai, S.; Zhao, Y.; Yang, Y. Broad Learning System for Predicting Student Dropout in Massive Open Online Courses. In Proceedings of the 2020 8th International Conference on Information and Education Technology, Okayama, Japan, 28–30 March 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 12–17. [Google Scholar] [CrossRef]
- Zhou, Y.; Xu, Z. Multi-Model Stacking Ensemble Learning for Dropout Prediction in MOOCs. J. Phys. Conf. Ser. 2020, 1607, 012004. [Google Scholar] [CrossRef]
- Ho, A.D.; Reich, J.; Nesterko, S.; Seaton, D.T.; Mullaney, T.; Waldo, J.; Chuang, I. HarvardX and MITx: The first year of Open Online Courses; HarvardX and MITx Working Paper No. 1; Harvard University: Cambridge, MA, USA, 2014. [Google Scholar]
- Imran, A.; Dalipi, F.; Kastrati, Z. Predicting Student Dropout in a MOOC: An Evaluation of a Deep Neural Network Model. In Proceedings of the 2019 5th International Conference on Computing and Artificial Intelligence, Bali, Indonesia, 19–22 April 2019; pp. 190–195. [Google Scholar] [CrossRef]
- Al-Shabandar, R.; Hussain, A.; Laws, A.; Keight, R.; Lunn, J.; Radi, N. Machine learning approaches to predict learning outcomes in Massive open online courses. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 713–720. [Google Scholar] [CrossRef]
- Liu, K.F.-R.; Chen, J.-S. Prediction and assessment of student learning outcomes in calculus a decision support of integrating data mining and Bayesian belief networks. In Proceedings of the 2011 3rd International Conference on Computer Research and Development, Shanghai, China, 11–13 March 2011; Volume 1, pp. 299–303. [Google Scholar] [CrossRef]
- Wu, W.H.; Jim Wu, Y.C.; Chen, C.Y.; Kao, H.Y.; Lin, C.H.; Huang, S.H. Review of Trends from Mobile Learning Studies: A Meta-Analysis. Comput. Educ. 2012, 59, 817–827. [Google Scholar] [CrossRef]
- Chen, W.; Brinton, C.G.; Cao, D.; Mason-Singh, A.; Lu, C.; Chiang, M. Early Detection Prediction of Learning Outcomes in Online Short-Courses via Learning Behaviors. IEEE Trans. Learn. Technol. 2019, 12, 44–58. [Google Scholar] [CrossRef]
- Korosi, G.; Esztelecki, P.; Farkas, R.; TÃşth, K. Clickstream-Based outcome prediction in short video MOOCs. In Proceedings of the 2018 International Conference on Computer, Information and Telecommunication Systems (CITS), Colmar, France, 11–13 July 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Pereira, F.D.; Oliveira, E.; Cristea, A.; Fernandes, D.; Silva, L.; Aguiar, G.; Alamri, A.; Alshehri, M. Early Dropout Prediction for Programming Courses Supported by Online Judges. In Artificial Intelligence in Education; Isotani, S., Millán, E., Ogan, A., Hastings, P., McLaren, B., Luckin, R., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 67–72. [Google Scholar]
- Huang, A.Y.; Lu, O.H.; Huang, J.C.; Yin, C.J.; Yang, S.J. Predicting students’ academic performance by using educational big data and learning analytics: Evaluation of classification methods and learning logs. Interact. Learn. Environ. 2020, 28, 206–230. [Google Scholar] [CrossRef]
- Gregori, E.B.; Zhang, J.; Galván-Fernández, C.; de Asís Fernández-Navarro, F. Learner support in MOOCs: Identifying variables linked to completion. Comput. Educ. 2018, 122, 153–168. [Google Scholar] [CrossRef]
- Liu, D.; Zhang, Y.; Zhang, J.; Li, Q.; Zhang, C.; Yin, Y. Multiple Features Fusion Attention Mechanism Enhanced Deep Knowledge Tracing for Student Performance Prediction. IEEE Access 2020, 8, 194894–194903. [Google Scholar] [CrossRef]
- Faraggi, D.; Reiser, B. Estimation of the area under the ROC curve. Stat. Med. 2002, 21, 3093–3106. [Google Scholar] [CrossRef] [PubMed]
- Hutter, F.; Kotthoff, L.; Vanschoren, J. Automated Machine Learning: Methods, Systems, Challenges; Springer Nature: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Bravo-Agapito, J.; Romero, S.J.; Pamplona, S. Early prediction of undergraduate Student’s academic performance in completely online learning: A five-year study. Comput. Hum. Behav. 2021, 115, 106595. [Google Scholar] [CrossRef]
- Villagra-Arnedo, C.J.; Gallego-Duran, F.J.; Compan, P.; Llorens Largo, F.; Molina-Carmona, R. Predicting academic performance from Behavioural and learning data. Int. J. Des. Nat. Ecodynamics 2016, 11, 239–249. [Google Scholar] [CrossRef] [Green Version]
- Kondo, N.; Okubo, M.; Hatanaka, T. Early Detection of At-Risk Students Using Machine Learning Based on LMS Log Data. In Proceedings of the 2017 6th IIAI International Congress on Advanced Applied Informatics (IIAI-AAI), Shizuoka, Japan, 9–13 July 2017; pp. 198–201. [Google Scholar] [CrossRef]
- Ruipérez-Valiente, J.A.; Cobos, R.; Muñoz-Merino, P.J.; Andujar, Á.; Delgado Kloos, C. Early prediction and variable importance of certificate accomplishment in a MOOC. In European Conference on Massive Open Online Courses; Springer: Berlin/Heidelberg, Germany, 2017; pp. 263–272. [Google Scholar]
- Liang, K.; Zhang, Y.; He, Y.; Zhou, Y.; Tan, W.; Li, X. Online Behavior Analysis-Based Student Profile for Intelligent E-Learning. J. Electr. Comput. Eng. 2017, 2017, 9720396. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Wu, J.; Gao, X.; Feng, K. An early warning model of student achievement based on decision trees algorithm. In Proceedings of the 2017 IEEE 6th International Conference on Teaching, Assessment, and Learning for Engineering (TALE), Hong Kong, China, 21–14 December 2017; pp. 222–517. [Google Scholar] [CrossRef]
- Yang, T.Y.; Brinton, C.G.; Joe-Wong, C.; Chiang, M. Behavior-Based Grade Prediction for MOOCs Via Time Series Neural Networks. IEEE J. Sel. Top. Signal Process. 2017, 11, 716–728. [Google Scholar] [CrossRef]
- Cobos, R.; Olmos, L. A Learning Analytics Tool for Predictive Modeling of Dropout and Certificate Acquisition on MOOCs for Professional Learning. In Proceedings of the 2018 IEEE International Conference on Industrial Engineering and Engineering Management (IEEM), Bangkok, Thailand, 16–19 December 2018; pp. 1533–1537. [Google Scholar] [CrossRef]
- Chiu, Y.C.; Hsu, H.J.; Wu, J.; Yang, D.L. Predicting student performance in MOOCs using learning activity data. J. Inf. Sci. Eng. 2018, 34, 1223–1235. [Google Scholar] [CrossRef]
- Cano, A.; Leonard, J.D. Interpretable Multiview Early Warning System Adapted to Underrepresented Student Populations. IEEE Trans. Learn. Technol. 2019, 12, 198–211. [Google Scholar] [CrossRef]
- Xiao, B.; Liang, M.; Ma, J. The Application of CART Algorithm in Analyzing Relationship of MOOC Learning Behavior and Grades. In Proceedings of the 2018 International Conference on Sensor Networks and Signal Processing (SNSP), Xi’an, China, 28–31 October 2018; pp. 250–254. [Google Scholar] [CrossRef]
- Hussain, M.; Hussain, S.; Zhang, W.; Zhu, W.; Theodorou, P.; Abidi, S.M.R. Mining Moodle Data to Detect the Inactive and Low-Performance Students during the Moodle Course. In Proceedings of the 2nd International Conference on Big Data Research, Hangzhou, China, 18–20 May 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 133–140. [Google Scholar] [CrossRef]
- Yu, C. SPOC-MFLP: A multi-feature learning prediction model for SPOC students using machine learning. J. Appl. Sci. Eng. 2018, 21, 279–290. [Google Scholar] [CrossRef]
- Al-Shabandar, R.; Hussain, A.J.; Liatsis, P.; Keight, R. Detecting At-Risk Students With Early Interventions Using Machine Learning Techniques. IEEE Access 2019, 7, 149464–149478. [Google Scholar] [CrossRef]
- Qu, S.; Li, K.; Wu, B.; Zhang, S.; Wang, Y. Predicting Student Achievement Based on Temporal Learning Behavior in MOOCs. Appl. Sci. 2019, 9, 5539. [Google Scholar] [CrossRef] [Green Version]
- Kostopoulos, G.; Kotsiantis, S.; Fazakis, N.; Koutsonikos, G.; Pierrakeas, C. A semi-supervised regression algorithm for grade prediction of students in distance learning courses. Int. J. Artif. Intell. Tools 2019, 28, 1940001. [Google Scholar] [CrossRef]
- Wan, H.; Liu, K.; Yu, Q.; Gao, X. Pedagogical Intervention Practices: Improving Learning Engagement Based on Early Prediction. IEEE Trans. Learn. Technol. 2019, 12, 278–289. [Google Scholar] [CrossRef]
- Sun, D.; Mao, Y.; Du, J.; Xu, P.; Zheng, Q.; Sun, H. Deep Learning for Dropout Prediction in MOOCs. In Proceedings of the 2019 Eighth International Conference on Educational Innovation through Technology (EITT), Biloxi, MS, USA, 27–31 October 2019; pp. 87–90. [Google Scholar] [CrossRef]
- Chunzi, S.; Xuanren, W.; Ling, L. The Application of Big Data Analytics in Online Foreign Language Learning among College Students: Empirical Research on Monitoring the Learning Outcomes and Predicting Final Grades. In Proceedings of the 2020 2nd International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI), Taiyuan, China, 23–25 October 2020; pp. 266–269. [Google Scholar] [CrossRef]
- Kőrösi, G.; Farkas, R. MOOC Performance Prediction by Deep Learning from Raw Clickstream Data. In International Conference on Advances in Computing and Data Sciences; Springer: Berlin/Heidelberg, Germany, 2020; pp. 474–485. [Google Scholar] [CrossRef]
- Karlos, S.; Kostopoulos, G.; Kotsiantis, S. Predicting and Interpreting Students’ Grades in Distance Higher Education through a Semi-Regression Method. Appl. Sci. 2020, 10, 8413. [Google Scholar] [CrossRef]
- Xiao, F.; Li, Q.; Huang, H.; Sun, L.; Xu, X. MOLEAS: A Multi-stage Online Learning Effectiveness Assessment Scheme in MOOC. In Proceedings of the 2020 IEEE International Conference on Teaching, Assessment, and Learning for Engineering (TALE), Takamatsu, Japan, 8–11 December 2020; pp. 31–38. [Google Scholar] [CrossRef]
- Lemay, D.; Doleck, T. Grade prediction of weekly assignments in MOOCS: Mining video-viewing behavior. Educ. Inf. Technol. 2020, 25, 1333–1342. [Google Scholar] [CrossRef]
- KokoÃğ, M.; AkÃğapÄśnar, G.; Hasnine, M. Unfolding Students’ Online Assignment Submission Behavioral Patterns using Temporal Learning Analytics. Educ. Technol. Soc. 2021, 24, 223–235. [Google Scholar]
- El Aouifi, H.; El Hajji, M.; Es-saady, Y.; Hassan, D. Predicting learner’s performance through video sequences viewing behavior analysis using educational data-mining. Educ. Inf. Technol. 2021, 26, 5799–5814. [Google Scholar] [CrossRef]
- Chi, D.; Huang, Y. Research on Application of Online Teaching Performance Prediction Based on Data Mining Algorithm. In Proceedings of the 2021 IEEE International Conference on Consumer Electronics and Computer Engineering (ICCECE), Guangzhou, China, 15–17 January 2021; pp. 394–397. [Google Scholar] [CrossRef]
- Singh, A.; Sachan, A. Student Clickstreams Activity Based Performance of Online Course. In International Conference on Artificial Intelligence and Sustainable Computing; Springer: Berlin/Heidelberg, Germany, 2021; pp. 242–253. [Google Scholar] [CrossRef]
- Lee, C.A.; Tzeng, J.W.; Huang, N.F.; Su, Y.S. Prediction of Student Performance in Massive Open Online Courses Using Deep Learning System Based on Learning Behaviors. Educ. Technol. Soc. 2021, 24, 130–146. [Google Scholar]
- HarvardX. HarvardX Person-Course Academic Year 2013 De-Identified Dataset, Version 3.0; Harvard University: Cambridge, MA, USA, 2014. [Google Scholar] [CrossRef]
- Hühn, J.; Hüllermeier, E. FURIA: An algorithm for unordered fuzzy rule induction. Data Min. Knowl. Discov. 2009, 19, 293–319. [Google Scholar] [CrossRef] [Green Version]
- Mubarak, A.A.; Cao, H.; Ahmed, S.A. Predictive learning analytics using deep learning model in MOOCs’ courses videos. Educ. Inf. Technol. 2021, 26, 371–392. [Google Scholar]
- MonllaÃş OlivÃľ, D.; Huynh, D.; Reynolds, M.; Dougiamas, M.; Wiese, D. A supervised learning framework: Using assessment to identify students at risk of dropping out of a MOOC. J. Comput. High. Educ. 2020, 32. [Google Scholar] [CrossRef]
- Burgos, C.; Campanario, M.L.; de la Peña, D.; Lara, J.A.; Lizcano, D.; Martínez, M.A. Data mining for modeling students’ performance: A tutoring action plan to prevent academic dropout. Comput. Electr. Eng. 2018, 66, 541–556. [Google Scholar] [CrossRef]
- Laveti, R.N.; Kuppili, S.; Ch, J.; Pal, S.N.; Babu, N.S.C. Implementation of learning analytics framework for MOOCs using state-of-the-art in-memory computing. In Proceedings of the 2017 5th National Conference on E-Learning E-Learning Technologies (ELELTECH), Hyderabad, India, 3–4 August 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Coussement, K.; Phan, M.; De Caigny, A.; Benoit, D.F.; Raes, A. Predicting student dropout in subscription-based online learning environments: The beneficial impact of the logit leaf model. Decis. Support Syst. 2020, 135, 113325. [Google Scholar] [CrossRef]
- Hong, B.; Wei, Z.; Yang, Y. Discovering learning behavior patterns to predict dropout in MOOC. In Proceedings of the 2017 12th International Conference on Computer Science and Education (ICCSE), Houston, TX, USA, 22–25 August 2017; pp. 700–704. [Google Scholar] [CrossRef]
- Panagiotakopoulos, T.; Kotsiantis, S.; Kostopoulos, G.; Iatrellis, O.; Kameas, A. Early Dropout Prediction in MOOCs through Supervised Learning and Hyperparameter Optimization. Electronics 2021, 10, 1701. [Google Scholar] [CrossRef]
- Alamri, A.; Sun, Z.; Cristea, A.I.; Steward, C.; Pereira, F.D. MOOC next week dropout prediction: Weekly assessing time and learning patterns. In International Conference on Intelligent Tutoring Systems; Springer: Berlin/Heidelberg, Germany, 2021; pp. 119–130. [Google Scholar]
- Xing, W.; Du, D. Dropout Prediction in MOOCs: Using Deep Learning for Personalized Intervention. J. Educ. Comput. Res. 2018, 57, 547–570. [Google Scholar] [CrossRef]
- Liu, K.; Tatinati, S.; Khong, A.W.H. A Weighted Feature Extraction Technique Based on Temporal Accumulation of Learner Behavior Features for Early Prediction of Dropouts. In Proceedings of the 2020 IEEE International Conference on Teaching, Assessment, and Learning for Engineering (TALE), Takamatsu, Japan, 8–11 December 2020; pp. 295–302. [Google Scholar] [CrossRef]
- Xing, W.; Chen, X.; Stein, J.; Marcinkowski, M. Temporal predication of dropouts in MOOCs: Reaching the low hanging fruit through stacking generalization. Comput. Hum. Behav. 2016, 58, 119–129. [Google Scholar] [CrossRef]
- Taylor, C.; Veeramachaneni, K.; O’Reilly, U.M. Likely to stop? predicting stopout in massive open online courses. arXiv 2014, arXiv:1408.3382. [Google Scholar]
- Kloft, M.; Stiehler, F.; Zheng, Z.; Pinkwart, N. Predicting MOOC dropout over weeks using machine learning methods. In Proceedings of the EMNLP 2014 Workshop on Analysis of Large Scale Social Interaction in MOOCs, Doha, Qatar, 25 October 2014; Humboldt University of Berlin: Berlin, Germany, 2014; pp. 60–65. [Google Scholar]
- Halawa, S.; Greene, D.; Mitchell, J. Dropout prediction in MOOCs using learner activity features. Proc. Second. Eur. Mooc Stakehold. Summit 2014, 37, 58–65. [Google Scholar]
- Whitehill, J.; Williams, J.; Lopez, G.; Coleman, C.; Reich, J. Beyond prediction: First steps toward automatic intervention in MOOC student stopout; Available at SSRN 2611750; Elsevier: Amsterdam, The Netherlands, 2015. [Google Scholar]
- Qiu, L.; Liu, Y.; Liu, Y. An Integrated Framework With Feature Selection for Dropout Prediction in Massive Open Online Courses. IEEE Access 2018, 6, 71474–71484. [Google Scholar] [CrossRef]
- Ardchir, S.; Ouassit, Y.; Ounacer, S.; Jihal, H.; EL Goumari, M.Y.; Azouazi, M. Improving Prediction of MOOCs Student Dropout Using a Feature Engineering Approach. In International Conference on Advanced Intelligent Systems for Sustainable Development; Springer: Berlin/Heidelberg, Germany, 2019; pp. 146–156. [Google Scholar]
- Nazif, A.M.; Sedky, A.A.H.; Badawy, O.M. MOOC’s Student Results Classification by Comparing PNN and other Classifiers with Features Selection. In Proceedings of the 2020 21st International Arab Conference on Information Technology (ACIT), Giza, Egypt, 28–30 November 2020; pp. 1–9. [Google Scholar]
- Jin, C. Dropout prediction model in MOOC based on clickstream data and student sample weight. Soft Comput. 2021, 25, 8971–8988. [Google Scholar] [CrossRef]
- Mulyani, E.; Hidayah, I.; Fauziati, S. Dropout Prediction Optimization through SMOTE and Ensemble Learning. In Proceedings of the 2019 International Seminar on Research of Information Technology and Intelligent Systems (ISRITI), Yogyakarta, Indonesia, 5–6 December 2019; pp. 516–521. [Google Scholar] [CrossRef]
- Xiong, F.; Zou, K.; Liu, Z.; Wang, H. Predicting Learning Status in MOOCs Using LSTM. In Proceedings of the ACM Turing Celebration Conference—China; Association for Computing Machinery: New York, NY, USA, 2019; pp. 1–5. [Google Scholar] [CrossRef] [Green Version]
- Wu, N.; Zhang, L.; Gao, Y.; Zhang, M.; Sun, X.; Feng, J. CLMS-Net: Dropout Prediction in MOOCs with Deep Learning. In Proceedings of the ACM Turing Celebration Conference—China; Association for Computing Machinery: New York, NY, USA, 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Wen, Y.; Tian, Y.; Wen, B.; Zhou, Q.; Cai, G.; Liu, S. Consideration of the local correlation of learning behaviors to predict dropouts from MOOCs. Tsinghua Sci. Technol. 2020, 25, 336–347. [Google Scholar] [CrossRef]
- Qiu, L.; Liu, Y.; Hu, Q.; Liu, Y. Student dropout prediction in massive open online courses by convolutional neural networks. Soft Comput. A Fusion Found. Methodol. Appl. 2019, 23, 10287. [Google Scholar] [CrossRef]
- Zheng, Y.; Gao, Z.; Wang, Y.; Fu, Q. MOOC Dropout Prediction Using FWTS-CNN Model Based on Fused Feature Weighting and Time Series. IEEE Access 2020, 8, 225324–225335. [Google Scholar] [CrossRef]
- Wang, W.; Yu, H.; Miao, C. Deep Model for Dropout Prediction in MOOCs. In Proceedings of the 2nd International Conference on Crowd Science and Engineering, Beijing, China, 6–9 July 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 26–32. [Google Scholar] [CrossRef]
- Fu, Q.; Gao, Z.; Zhou, J.; Zheng, Y. CLSA: A novel deep learning model for MOOC dropout prediction. Comput. Electr. Eng. 2021, 94, 107315. [Google Scholar] [CrossRef]
- Yin, S.; Lei, L.; Wang, H.; Chen, W. Power of Attention in MOOC Dropout Prediction. IEEE Access 2020, 8, 202993–203002. [Google Scholar] [CrossRef]
- Zhang, Y.; Chang, L.; Liu, T. MOOCs Dropout Prediction Based on Hybrid Deep Neural Network. In Proceedings of the 2020 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery (CyberC), Chongqing, China, 29–30 October 2020; pp. 197–203. [Google Scholar] [CrossRef]
- Ashby, A. Monitoring student retention in the Open University: Definition, measurement, interpretation and action. Open Learn. Open Distance-Learn. 2004, 19, 65–77. [Google Scholar] [CrossRef]
- Ng, K.H.R.; Tatinati, S.; Khong, A.W.H. Grade Prediction From Multi-Valued Click-Stream Traces via Bayesian-Regularized Deep Neural Networks. IEEE Trans. Signal Process. 2021, 69, 1477–1491. [Google Scholar] [CrossRef]
- Hakimi, L.; Eynon, R.; Murphy, V.A. The Ethics of Using Digital Trace Data in Education: A Thematic Review of the Research Landscape. Rev. Educ. Res. 2021, 91, 671–717. [Google Scholar] [CrossRef]
- Oboler, A.; Welsh, K.; Cruz, L. The danger of big data: Social media as computational social science. First Monday 2012, 17, 3993. [Google Scholar]
- Eynon, R.; Fry, J.; Schroeder, R. The ethics of online research. SAGE Handb. Online Res. Methods 2017, 2, 19–37. [Google Scholar]








| Concept | Search Query |
|---|---|
| Learner Performance | (“Grade” OR “Performance” “Success” OR “Failure” OR “Certificate” OR “At-risk”) |
| Learner Dropout | (“Dropout” OR “Retention” OR “Completion” OR “Attrition” OR “Withdrawal”) |
| Online Learning | (“Online learning” OR “MOOC” OR “Online course” OR “Online Education”) |
| Machine Learning | (“Classification” OR “Prediction” OR “Machine Learning” OR " Predictive model” OR “Deep learning”) |
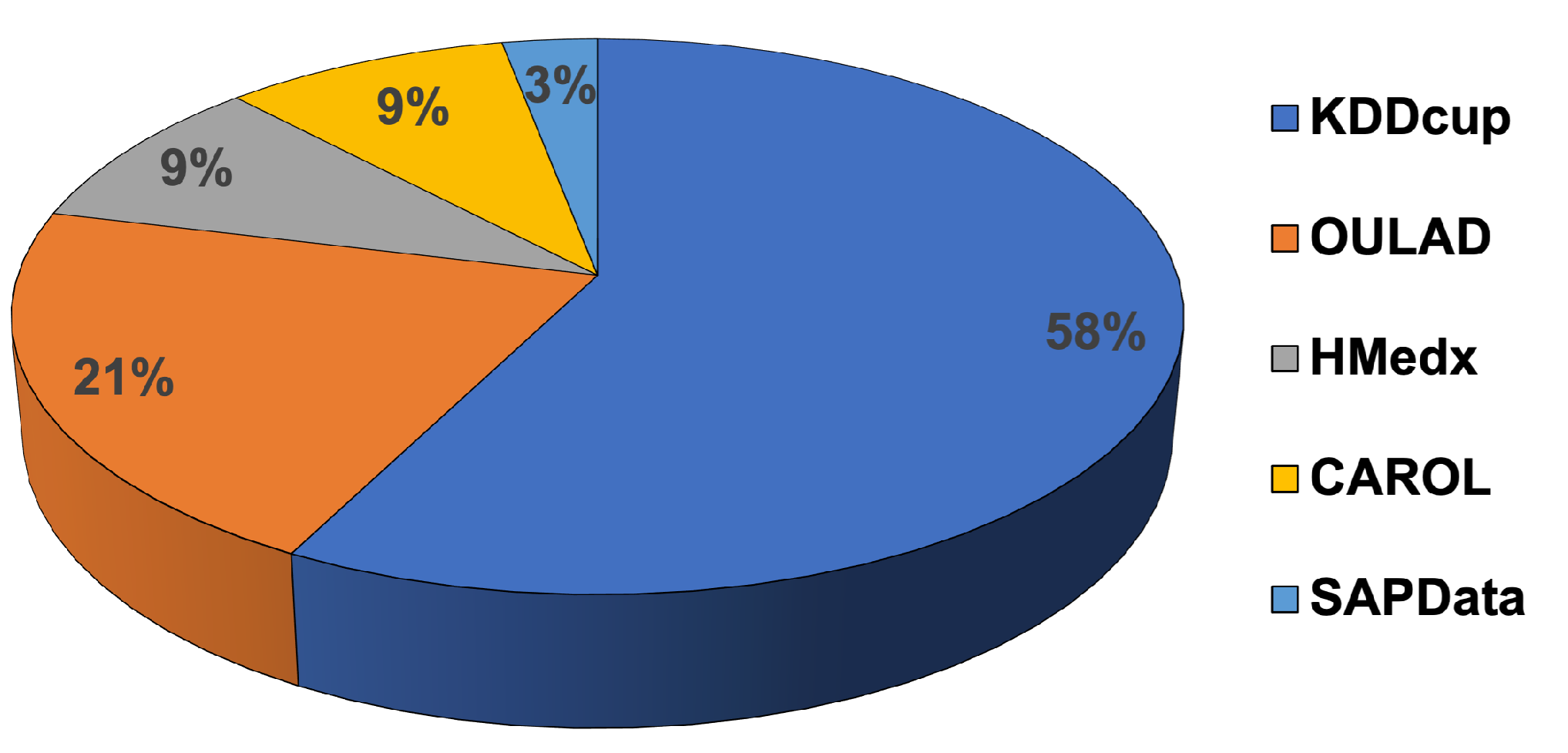
| Ref. | Dataset | Platform | Courses | Records | Features | Outcomes |
|---|---|---|---|---|---|---|
| [11] | SAPData | Kalboard 360 | 12 | 480 | Demographic, Academic Background, Interaction | Performance |
| [13] | OULAD | OU VLE | 22 | 32,593 | Demographic, Registration, Assessment, Interaction | Performance |
| [18] | CAROL | OpenEdX | 5 | 78,623 | Interaction, Assessment | Dropout, performance |
| [22] | KDDcup | XuetangX | 39 | 120,542 | Enrollment, Course, Interaction | Dropout |
| [25] | HMedx | edX | 17 | 597,692 | Academic Background, Video Interaction, Assessment | Dropout, performance |
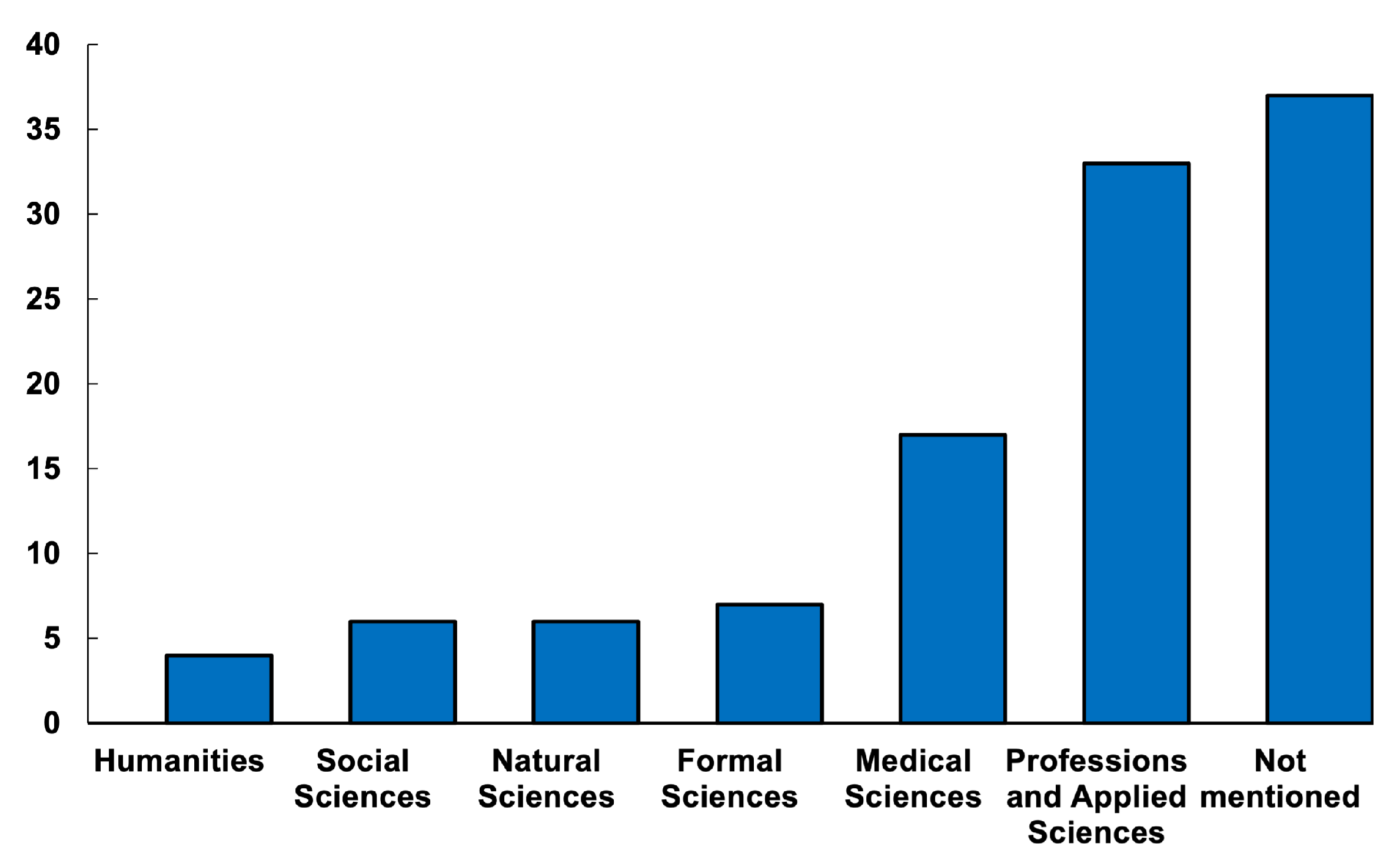
| Subject Category | Example Subject | No. of Studies |
|---|---|---|
| Humanities | Online foreign language teaching, understanding language | 6 |
| Social sciences | General sociology, Social science | 7 |
| Natural sciences | Analytical chemistry laboratory, Physics III | 6 |
| Formal sciences | Assembly Language, C programming, Calculus I | 33 |
| Medical sciences | First aid general knowledge, Public health research | 4 |
| Professions and applied sciences | Circuits and Electronics | 17 |
| Not mentioned | - | 37 |
| Category | Features |
|---|---|
| Demographic features | Date of birth, birthplace, age, gender, parent responsible for student, nationality, mother tongue |
| Academic background | Studying semester, GPA, grade level, section, education |
| Enrollment data | Information about student’s enrollment on a course |
| Course data | No. of enrolled students, drop rate, course modules |
| Attendance data | Student absent from class |
| Learning interaction (log data) | Activity, visit resources, downloaded resources, play resources, access a piece of content, class participation, logins, starting a lesson, page navigation, page closes |
| Multimedia/video interactive data | Pause, replay, stop, open, close |
| Practice data | Questions answered, tests, tries, assessment scores |
| Participation data | Discussions on forums, polls, messages posted, messages read |
| Model Category | Models |
|---|---|
| Probabilistic model | Naive Bayes, Bayes network, Bayesian generalized linear (BGL), Bayesian belief networks, |
| Linear models | Logistic regression (LR), support vector machine (SVM), linear discriminant analysis (LDA), generalized linear model (GLM), lasso linear regression (LLG), boosted logistic regression |
| Ensemble methods | Bagging, boosting, stacking, AdaBoost, gradient boosting (GB), eXtreme gradient boosting (xgbLinear), stochastic gradient boosting (SGB) |
| Tree-based models | Decision tree (DT), random forest (RF), Bayesian additive regression trees (BART) |
| Rule-Based models | Rule-based classifier(JRip), fuzzy set rules |
| Instance-based learning | k-nearest neighbors (kNN) |
| Neural network | Multilayer perceptron(MLP) or artificial neural network (ANN) |
| Sequence ML models | Conditional random fields (CRF) |
| Deep neural network | Recurrent neural network (RNN), gated recurrent unit (GRU), long short-term memory (LSTM), convolutional neural network (CNN), squeeze-and-excitation networks (SE-net) |
| Others | Search algorithms (Kstar), optimization algorithm (pigeon-inspired optimization (PIO)), matrix completion, unsupervised learning model (self organized map (SOM)) |
| Prediction Task | Metric | Formula |
|---|---|---|
| Classification | Precision (P) | |
| Recall (R) | ||
| Accuracy | ||
| F-score | ||
| Regression | MSE | |
| RMSE | ||
| MAE | ||
| Ref. | Type | Platform Dataset | Sample/ Course | Features | FE | Model | Class | Output | Accuracy | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| B | D | V | A | C | O | S | T | R | ||||||||
| [39] | SPOC | 336/1 | √ | √ | SVM | Multi | Grade | 0.95 | ||||||||
| [12] | MOOC | SAPData | 500/12 | √ | √ | √ | √ | MLP | Multi | Grade | 0.84 | |||||
| [40] | SPOC | 202/- | √ | √ | √ | LR | Binary | At risk | F1 = 0.66 | |||||||
| [41] | MOOC | edX | 3530/1 | √ | √ | RF | Binary | Certificate | w5:0.95 | |||||||
| [27] | MOOC | HMedx | 597,692/15 | √ | √ | √ | RF | Binary | Certificate | 0.99 | ||||||
| [42] | MOOC | 9990/1 | √ | √ | √ | LSVM | Binary | Certificate | w7:0.99 | |||||||
| [43] | SPOC | Moodle | -/1 | √ | √ | DT | Binary | Grade | w7:F1 = 0.85 | |||||||
| [44] | MOOC | Coursera | -/2 | √ | √ | √ | RNN | Reg. | Grade | RMSE = 0.058 | ||||||
| [45] | MOOC | edX | 18,927/15 | √ | √ | √ | √ | BGL | Binary | Certificate | w3:AUC = 0.90 | |||||
| [31] | MOOC | 603/1 | √ | √ | √ | √ | RF+ Bagging | Binary | Certificate | 0.79 | ||||||
| [46] | MOOC | edX | 5537/9 | √ | √ | LR | Binary | Pass/fail | w5:0.94 | |||||||
| [47] | SPOC | Blackboard | -/- | √ | √ | √ | √ | GP | Binary | At risk | 0.89 | |||||
| [48] | MOOC | 300/1 | √ | √ | √ | CART | Multi | Grade | 0.90 | |||||||
| [20] | MOOC | CAROL | 3585/1 | √ | √ | √ | √ | DL | Multi | Pass/fail | w8:0.98 | |||||
| [49] | SPOC | Moodle | 6119/1 | √ ** | √ * | √ | FURIA | Multi | Grade | 0.76 *, 0.99 ** | ||||||
| [50] | SPOC | Fanya | 5542/1 | √ | √ | √ | √ | √ | LR * DNN ** | Reg. * Multi ** | Grade | MSE = 20 * 0.88 ** | ||||
| [34] | MOOC | UCATx, coursera | 24,789/5 | √ | √ | √ | SMOTE SSELM | Binary | Complete | 0.97 | ||||||
| [51] | MOOC | HMedx OULAD | 8000/6 | √ | √ | √ | GBM | Binary | At risk | 0.95 | ||||||
| [30] | SPOC | -/3 | √ | √ | √ | √ | RF | Binary | Pass/fail | w1:AUC = 0.85 | ||||||
| [52] | MOOC | 1528/1 | √ | √ | √ | LSTM + DSP | Binary | Pass/fail | 0.91 | |||||||
| [15] | MOOC | OULAD | 22,437/22 | √ | √ | √ | √ | GBM | Binary | Pass/fail | AUC = 0.93 | |||||
| [53] | MOOC | HPU LMS | 1073/1 | √ | √ | √ | √ | SSL Regression | Reg. | Grade | MAE = 1.146 | |||||
| [54] | SPOC | edX | 124/1 | √ | √ | √ | √ | TrAdaboost | Binary | At risk | AUC = 0.70 | |||||
| [55] | MOOC | XuetangX | 12,847/1 | √ | √ | GRU-RNN | Reg. | Complete | = 0.84 | |||||||
| [26] | MOOC | HMedx | 641,138/- | √ | √ | DNN | Binary | Certificate | 0.89 | |||||||
| [56] | SPOC | 122/1 | √ | √ | √ | Regression analysis | Reg. | Grade | 0.85 | |||||||
| [57] | MOOC | Lagunita | 130,000/1 | √ | √ | √ | RNN ** RNN * | Multi ** Reg. * | Grade | w5:0.55 ** RMSE = 8.65 * | ||||||
| [58] | MOOC | HPU LMS | 1073/1 | √ | √ | √ | √ | √ | Multiview SSL Regression | Reg. | Grade | MAE = 1.07 | ||||
| [59] | MOOC | 1075/2 | √ | √ | √ | SVT | Reg. | Grade | RMSE = 0.30 | |||||||
| [60] | MOOC | edX | 6241/2 | √ | √ | JRIP | Binary | Grade | 0.70 | |||||||
| [33] | MOOC | edX | -/3 | √ | √ | √ | RF | Binary | Grade | 0.79 | ||||||
| [21] | MOOC | CAROL | 49,551/4 | √ | √ | √ | √ | Ensemble | Multi | Pass/fail | w7:0.93 | |||||
| [61] | SPOC | Moodle | 69/1 | √ | √ | ARM | Binary | Grade | ||||||||
| [14] | MOOC | OULAD | 32,593/7 | √ | √ | √ | √ | √ | RF *, GB ** | Binary * Multi ** | At risk, Grade | 0.91 * 0.73 ** | ||||
| [62] | MOOC | Moodle | 66/1 | √ | √ | KNN | Binary | At risk | 0.65 | |||||||
| [63] | SPOC | 104/ 1 | √ | √ | √ | √ | NB | Multi | Grade | 0.86 | ||||||
| [16] | MOOC | OULAD | 32,593/- | √ | √ | √ | √ | CNN + LSTM | Multi | Grade | 0.61 | |||||
| [64] | SPOC | Moodle | 150/1 | √ | √ | √ | √ | KNN | Multi | Grade | 0.87 | |||||
| [38] | MOOC | Moodle | 802/4 | √ | √ | √ | LR | Reg. | Grade | RMSEA = 0.13 | ||||||
| [65] | MOOC | 2556/2 | √ | √ | √ | √ | DNN | Reg. | Grade | w5:MAE = 6.8 | ||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alhothali, A.; Albsisi, M.; Assalahi, H.; Aldosemani, T. Predicting Student Outcomes in Online Courses Using Machine Learning Techniques: A Review. Sustainability 2022, 14, 6199. https://doi.org/10.3390/su14106199
Alhothali A, Albsisi M, Assalahi H, Aldosemani T. Predicting Student Outcomes in Online Courses Using Machine Learning Techniques: A Review. Sustainability. 2022; 14(10):6199. https://doi.org/10.3390/su14106199
Chicago/Turabian StyleAlhothali, Areej, Maram Albsisi, Hussein Assalahi, and Tahani Aldosemani. 2022. "Predicting Student Outcomes in Online Courses Using Machine Learning Techniques: A Review" Sustainability 14, no. 10: 6199. https://doi.org/10.3390/su14106199