
Research on the Construction of a Knowledge Graph and Knowledge Reasoning Model in the Field of Urban Traffic


Abstract
:1. Introduction
1.1. Background
1.2. Related Works
2. Framework and Data
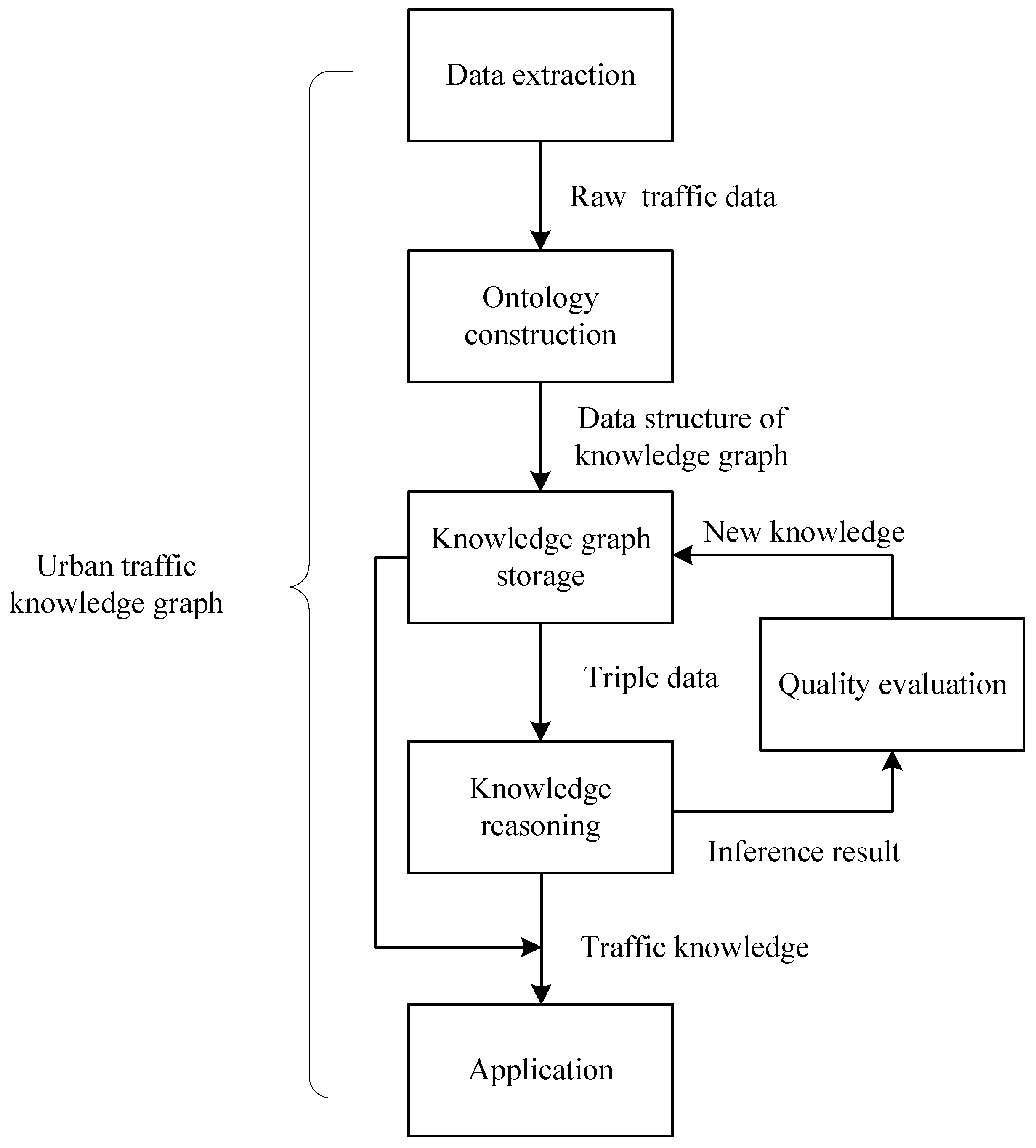
2.1. Overall Framework
2.2. Data Collection and Preprocessing
- (1)
- Metro static basic data
- (2)
- Metro AFC swipe data
- (3)
- Urban road network data
- (4)
- Points of interest data
- (5)
- Traffic situation data on urban roads
3. Methods
3.1. Ontology Construction of Urban Traffic
- (1)
- Define the class and its hierarchical structure
- (2)
- Define the attributes of the class
- (3)
- Define the relationship between classes
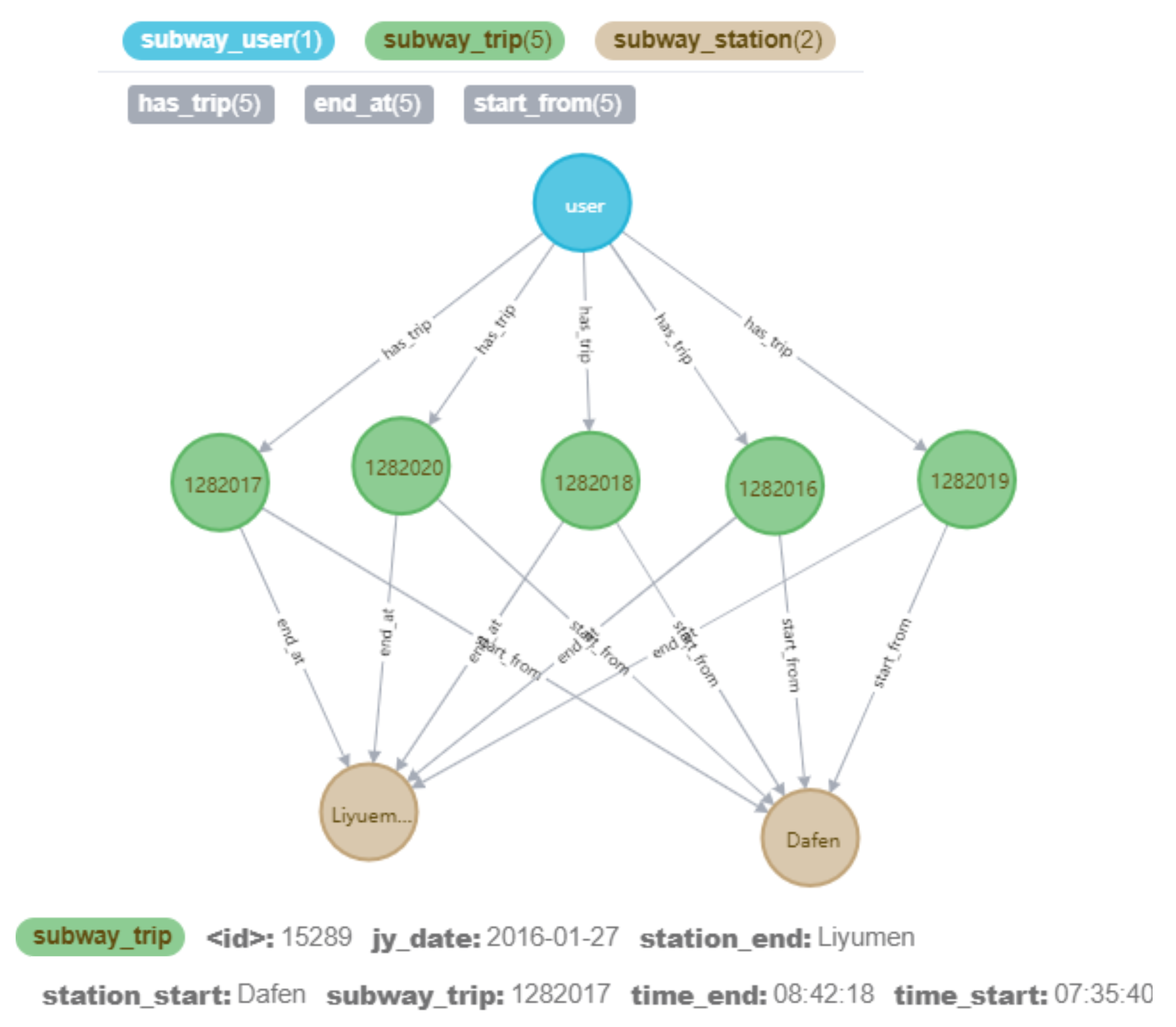
3.2. Storage of an Urban Traffic Knowledge Graph
- (1)
- The public traffic knowledge graph
- (2)
- The urban road traffic knowledge graph
3.3. Knowledge Reasoning Model Based on Representation Learning
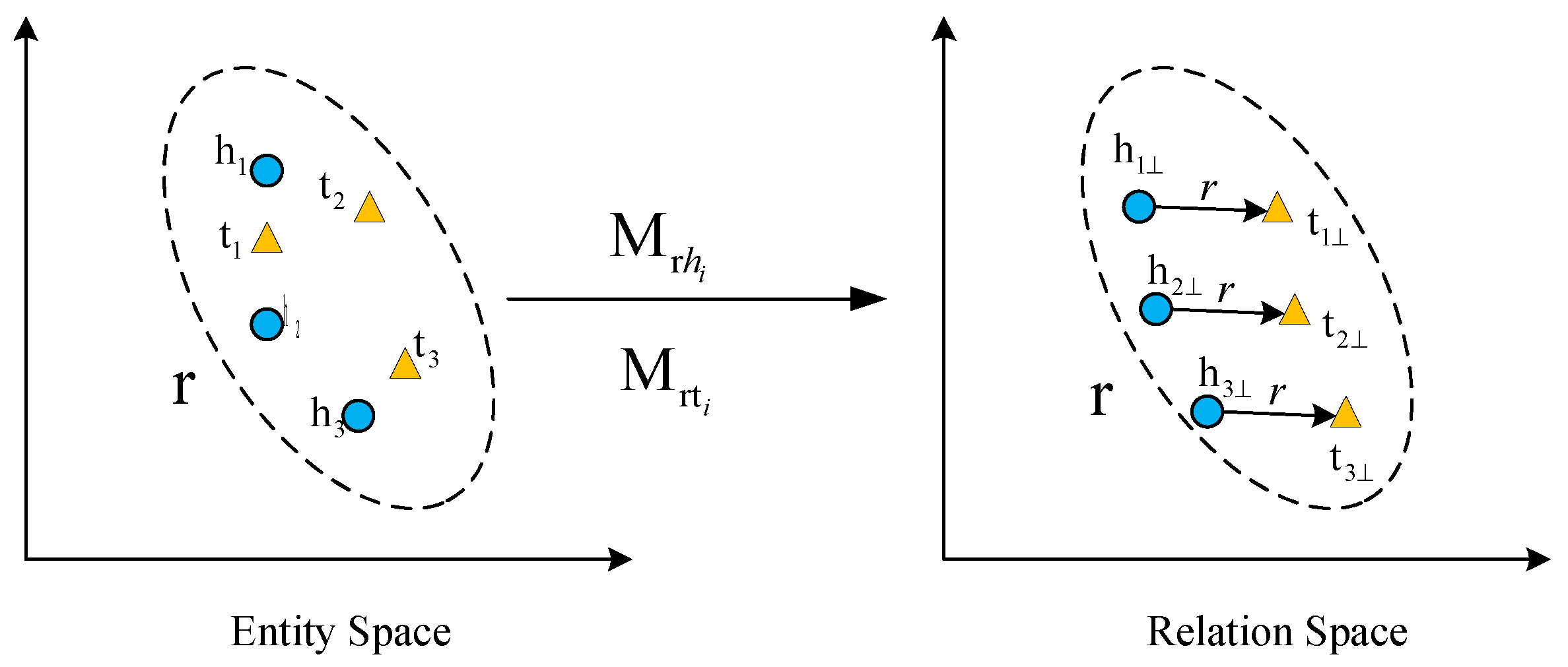
3.3.1. Model Definition
3.3.2. Construction Method of Negative Sample
- The average number of tail entities associated with each head entity is recorded as ;
- the average number of head entities associated with each tail entity is recorded as .
- The ordered index of all entities within the domain constraint of the relationship type ;
- The ordered index of all entities within the range constraint of the relationship type .
3.3.3. Model Training Process
| Algorithm 1. Reasoning algorithm training process based on representation learning. |
Input: Training sample set S, total number of samples N, entity set E, relationship set R, learning rate , embedding dimension k, boundary , The maximum number of iterations M, the number of small batch samples Output: Vector representation of entities and relationships 1: /* initialize */ 2: for each do 3: 4:
end for 5: for each do 6: 7:
end for 8:
whiledo 9: while do 10: 11: 12: for each do 13: 14: 15: end for 16: Update embedding w.r.t 17: 18: 19: end while 20: 21: 22:
end while |
3.3.4. Experiment and Results Analysis
3.4. Knowledge Discovery Based on the Knowledge Graph
- (1)
- Relationship path discovery
- (2)
- Similar travelers found
- (3)
- Shortest path query
4. Conclusions
- (1)
- The urban traffic knowledge graph constructed in this paper aims to discover potential relationship between different traffic entities, such as discovering traffic entities related to road congestion. Compared to the congestion detection of other knowledge graphs, it can more effectively assist managers in formulating strategies to alleviate road congestion.
- (2)
- The problem that the conclusions of traditional transportation research cannot be widely promoted can be solved by the knowledge graph. The knowledge contained in the knowledge graph is universal; a set of traffic knowledge systems that can be shared and reused was formed in our paper. Moreover, with the accumulation of relevant data, the new knowledge obtained through reasoning can optimize and enrich the original knowledge graph.
- (3)
- Based on the constructed urban traffic knowledge graph, it is possible to realize traffic knowledge discovery and intelligent question answering of urban traffic services, such as similar traveler discovery and the shortest path query.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Qi, B. Research on Urban Traffic Governance and Optimizing Strategy Based on Big Data. In Proceedings of the 2020 IEEE International Conference on Power, Intelligent Computing and Systems (ICPICS), Shenyang, China, 28–30 July 2020; pp. 188–192. [Google Scholar] [CrossRef]
- Zheng, Z.; Liu, Y.; Zhang, Y.; Wen, C. TCMKG: A Deep Learning Based Traditional Chinese Medicine Knowledge Graph Platform. In Proceedings of the 2020 IEEE International Conference on Knowledge Graph (ICKG), Nanjing, China, 9–11 August 2020; pp. 560–564. [Google Scholar] [CrossRef]
- Singhal, A. Introducing the Knowledge Graph Things, Not Strings. Available online: https://www.blog.google/products/search/introducing-knowledge-graph-things-not/ (accessed on 5 January 2021).
- Suchanek, F.M.; Kasneci, G.; Weikum, G. YAGO: A Core of Semantic Knowledge Unifying WordNet and Wikipedia. In Proceedings of the International Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 697–706. [Google Scholar] [CrossRef] [Green Version]
- Bollacker, K.D.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the Sigmod Conference, Vancouver, BC, Canada, 10–12 June 2008; pp. 1247–1250. [Google Scholar] [CrossRef]
- Lehmann, J. DBpedia: A large-scale, multilingual knowledge base extracted from wikipedia. Semant. Web 2021, 7, 154–165. [Google Scholar] [CrossRef] [Green Version]
- Niu, X.; Sun, X.; Wang, H.; Rong, S.; Qi, G.; Yu, Y. Zhishi.me—Weaving Chinese Linking Open Data. In Proceedings of the Semantic Web, ISWC 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 205–220. [Google Scholar] [CrossRef] [Green Version]
- Xu, B.; Xu, Y.; Liang, J.; Xie, C.; Liang, B.; Cui, W.; Xiao, Y. CN-DBpedia: A Never-Ending Chinese Knowledge Extraction System; Springer: Cham, Switzerland, 2017; pp. 428–438. [Google Scholar] [CrossRef]
- Gong, F.; Wang, M.; Wang, H.; Wang, S.; Liu, M. SMR: Medical Knowledge Graph Embedding for Safe Medicine Recommendation. Big Data Res. 2021, 23. [Google Scholar] [CrossRef]
- KGBC: Knowledge Graph of Breast Cancer. Available online: http://wasp.cs.vu.nl/BreastCancerKG/ (accessed on 18 January 2021).
- Zhang, Q.; Wen, Y.; Zhou, C.; Long, H.; Dong, H.; Zhang, F.; Xiao, C. Construction of Knowledge Graphs for Maritime Dangerous Goods. Sustainability 2019, 11, 2849. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Jiang, R.; He, Z.; Chen, X.; Zhou, X.S. Trajectory Data-Based Traffic Flow Studies: A Revisit. Transp. Res. Part C Emerg. Technol. 2020, 114, 225–240. [Google Scholar] [CrossRef]
- Ma, D.; Song, X.B.; Li, P. Daily Traffic Flow Forecasting Through a Contextual Convolutional Recurrent Neural Network Modeling Inter-and Intra-Day Traffic Patterns. IEEE Trans. Intell. Transp. Syst. 2020, 1–10. [Google Scholar] [CrossRef]
- Mohammed, O.; Kianfar, J. A Machine Learning Approach to Short-Term Traffic Flow Prediction: A Case Study of Interstate 64 in Missouri. In Proceedings of the 2018 IEEE International Smart Cities Conference (ISC2), Kansas City, MI, USA, 16–19 September 2018. [Google Scholar]
- Shen, L.; Liu, R.; Yao, Z.; Wu, W.; Yang, H. Development of Dynamic Platoon Dispersion Models for Predictive Traffic Signal Control. IEEE Trans. Intell. Transp. Syst. 2019, 20, 431–440. [Google Scholar] [CrossRef]
- Xiao, J.; Song, X.B.; Ma, X.; Jin, S. A Back-Pressure-Based Model With Fixed Phase Sequences for Traffic Signal Optimization Under Oversaturated Networks. IEEE Trans. Intell. Transp. Syst. 2020, 1–12. [Google Scholar] [CrossRef]
- Zhang, N.; Chen, H.; Chen, X.; Chen, J. Semantic Framework of Internet of Things for Smart Cities: Case Studies. Sensors 2016, 16, 1501. [Google Scholar] [CrossRef] [PubMed]
- Zhang, N.; Deng, S.; Chen, H.; Chen, X.; Chen, J.; Li, X.; Zhang, Y. Structured Knowledge Base as Prior Knowledge to Improve Urban Data Analysis. ISPRS Int. J. Geo-Inf. 2018, 7, 264. [Google Scholar] [CrossRef] [Green Version]
- Muppalla, R.; Lalithsena, S.; Banerjee, T.; Sheth, A. A Knowledge Graph Framework for Detecting Traffic Events Using Stationary Cameras. Ind. Knowl. Graphs 2017, 2017, 431–436. [Google Scholar] [CrossRef]
- Zhou, G.; Chen, F. Urban Congestion Areas Prediction By Combining Knowledge Graph And Deep Spatio-Temporal Convolutional Neural Network. In Proceedings of the 2019 4th International Conference on Electromechanical Control Technology and Transportation (ICECTT), Guilin, China, 26–28 April 2019; pp. 105–108. [Google Scholar] [CrossRef]
- Kusmawan, P.; Hong, B.; Jeon, S.; Lee, J.; Kwon, J. Computing Traffic Congestion Degree Using SNS-based Graph Structure. In Proceedings of the 2014 IEEE/ACS 11th International Conference on Computer Systems and Applications (AICCSA), Doha, Qatar, 10–13 November 2014; pp. 397–404. [Google Scholar] [CrossRef]
- Lu, S.Y.; Hsu, K.; Kuo, L. A Semantic Service Match Approach Based on WordNet and SWRL Rules. In Proceedings of the 2013 IEEE 10th International Conference on e-Business Engineering, Coventry, UK, 11–13 September 2013; pp. 419–422. [Google Scholar] [CrossRef]
- Lehmann, J. DL-Learner: Learning Concepts in Description Logics. J. Mach. Learn. Res. 2009, 10, 2639–2642. [Google Scholar] [CrossRef]
- Gangemi, A.; Nuzzolese, A.; Presutti, V.; Draicchio, F.; Musetti, A.; Ciancarini, P. Automatic Typing of DBpedia Entities; Springer: Berlin/Heidelberg, Germany, 2012; pp. 65–81. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Sun, M.; Lin, Y.; Xie, R. Knowledge Representation Learning: A Review. Comput. Res. Dev. 2016, 53, 247–261. [Google Scholar] [CrossRef]
- Bordes, A.; Weston, J.; Collobert, R.; Bengio, Y. Learning Structured Embeddings of Knowledge Bases. In Proceedings of the Aaai Conference on Artificial Intelligence, San Francisco, CA, USA, 7–11 August 2011; Volume 1, pp. 301–306. [Google Scholar]
- Socher, R.; Chen, D.; Manning, C.; Ng, A. Reasoning with neural tensor networks for knowledge base completion. Lake Tahoe 2013, 2013, 926–934. [Google Scholar]
- Nickel, M.; Tresp, V.; Kriegel, H.P. A Three-Way Model for Collective Learning on Multi-Relational Data. In Proceedings of the 28th International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011; pp. 809–816. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. In Proceedings of the Workshop at ICLR, Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating Embeddings for Modeling Multi-relational Data. In Proceedings of the Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 2787–2795. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge Graph Embedding by Translating on Hyperplanes. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Quebec City, QC, Canada, 27–31 July 2014; pp. 1112–1119. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning entity and relation embeddings for knowledge graph completion. In Proceedings of the AAAI, Austin, TX, USA, 25–30 January 2015; pp. 2181–2187. [Google Scholar]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge Graph Embedding via Dynamic Mapping Matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics, Beijing, China, 26–31 July 2015; pp. 687–696. [Google Scholar]
- AMapl. AutoNavi Web Service API. Available online: https://developer.amap.com/api/webservice/summary/ (accessed on 1 May 2020).
- Hu, L.W.; Yang, J.Q.; He, Y.R.; Meng, L.; Luo, Z.W.; Hu, C.Y. Urban Traffic Congestion Radiation Model and Damage Caused to Service Capacity of Road Network. China J. Highw. Transp. 2019, 32, 149–158. [Google Scholar]
- Peng, S.; Chen, S.; Xu, Q.; Niu, J. Spatial characteristics of land use based on POI and urban rail transit passenger flow. Acta Geogr. Sin. 2021, 76, 459–470. [Google Scholar]
- JIA, M.; ZHANG, Y.; PAN, T.; WU, W.; SU, F. Ontology Modeling of Marine Environmental Disaster Chain for Internet Information Extraction: A Case Study on Typhoon Disaster. J. Geo-Inf. Sci. 2020, 22, 2289–2303. [Google Scholar]
- Noy, N.; Mcguinness, D. Ontology Development 101: A Guide to Creating Your First Ontology; Stanford University: Stanford, CA, USA, 2001. [Google Scholar]
- Stanford Universityl. Protégé 5 Documentation. Available online: https://protege.stanford.edu/support.php#documentationSupport (accessed on 3 December 2020).
- Jouili, S.; Vansteenberghe, V. An Empirical Comparison of Graph Databases. In Proceedings of the 2013 International Conference on Social Computing, Washington, DC, USA, 8–14 September 2013; pp. 708–715. [Google Scholar] [CrossRef]
- Krompass, D.; Baier, S.; Tresp, V. Type-Constrained Representation Learning in Knowledge Graphs. In Proceedings of the 14th International Semantic Web Conference (ISWC), Bethlehem, PA, USA, 11–15 October 2015. [Google Scholar] [CrossRef] [Green Version]
- Han, X.; Cao, S.; Lv, X.; Lin, Y.; Liu, Z.; Sun, M.; Li, J. OpenKE: An Open Toolkit for Knowledge Embedding. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Brussels, Belgium, 31 October–4 November 2018; pp. 139–144. [Google Scholar] [CrossRef] [Green Version]
- Neo4j Graph Algorithms. Available online: https://neo4j.com/docs/graph-algorithms/current/labs-algorithms/jaccard/ (accessed on 4 January 2021).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Serial Number | Field Name | Data Types | Description |
|---|---|---|---|
| 1 | LINE_NAME | BIGINT | Metro line name |
| 2 | LINE_ID | BIGINT | Line number |
| 3 | STATION_NAME | VARCHAR | Metro station name |
| 4 | STATION_INDEX | INT | Station serial number |
| 5 | STATION_ID | BIGINT | Station number |
| 6 | STATION_POSITION | VARCHAR | Coordinates |
| 7 | CROSS_LINE | VARCHAR | Line through this station |
| Serial Number | Field Name | Data Types | Description |
|---|---|---|---|
| 1 | CARD_ID | FLOAT | IC card unique code |
| 2 | COST_TYPE | INT | Transaction type |
| 3 | COST_TIME | TIMESTAMP | Transaction time |
| 4 | LINE_NAME | VARCHAR | Line name |
| 5 | STATION_NAME | VARCHAR | Station name |
| 6 | VEHICLE_NUM | VARCHAR | License plate number |
| Serial Number | Field Name | Data Types | Description |
|---|---|---|---|
| 1 | NODE_ID | NUMERIC | Node unique ID |
| 2 | OSM_HIGHWAY | VARCHAR | Node type |
| 3 | Control_TYPE | INT | Traffic control type |
| 4 | POSITION | VARCHAR | Coordinate |
| Serial Number | Field Name | Data Types | Description |
|---|---|---|---|
| 1 | ROAD_NAME | VARCHAR | Road name |
| 2 | LINK_ID | NUMERIC | Link ID |
| 3 | FROM_NODE_ID | NUMERIC | Start node ID |
| 4 | TO_NODE_ID | NUMERIC | End node ID |
| 5 | LENGTH | DOUBLE | Length, unit: meters |
| 6 | GEOMETRY | GEOMETRY | Location,WKT |
| Serial Number | Field Name | Data Types | Description |
|---|---|---|---|
| 1 | POI_ID | VARCHAR | POI ID |
| 2 | POI_NAME | VARCHAR | POI name |
| 3 | TYPE_CODE | NUMERIC | Type code |
| 4 | ADDRESS | VARCHAR | Address |
| 5 | POI_LOCATION | VARCHAR | Coordinates |
| Serial Number | Field Name | Data Types | Description |
|---|---|---|---|
| 1 | ROAD_NAME | VARCHAR | Road name |
| 2 | STATUS | INT | Road situation |
| 3 | DIRECTION | VARCHAR | Section direction |
| 4 | ANGLE | INT | Vehicle driving angle |
| 5 | SPEED | INT | Average speed of road |
| 6 | ROAD_POLYGON | VARCHAR | Location, WKT |
| 7 | DATE_TIME | TIMESTAMP | Record time |
| Classes | Attributes |
|---|---|
| Public transit | Line name, starting station, terminal station, and first and last vehicle time |
| Transport junction | Station name, coordinate, and line ID of the station |
| Urban road | Road name, road class, road location, driving direction, and road length |
| Traffic participants | Unique ID of person |
| Traffic situation | Road name, average speed, recording date, and recording time |
| Points of interest | ID, name, category, address, and coordinates |
| Type | Name | Attributes |
|---|---|---|
| Entity | Passenger in metro | ID of the person’s IC card |
| Itinerary | Departure time and station and arrival time and station | |
| Metro line | Line name, direction, start/terminal station and time, and line ID | |
| Metro station | Station name, Line id, and coordinates | |
| Relationship | Passenger-have-Itinerary | Sequence number |
| Itinerary-start/end-Station | Departure time/end time | |
| Station-belong-Line | Sequence number of the station in the line | |
| Station-near_by-Station | Line ID and drive direction |
| Type | Name | Attributes |
|---|---|---|
| Entity | Intersection | Intersection number, control type, and coordinates |
| Road Section | Section number, section length, road name, and section location | |
| Road | Road number, road name, road grade, and driving direction | |
| Points of Interest | POI ID, POI name, address, and coordinates | |
| Date | Date number and date name | |
| Time | Time code, time name, and before/after school type | |
| Traffic situation | Traffic situation number and speed value | |
| Relationship | Intersection-link-Section | Link_form/to_node (type) and road name |
| Section-belong-Road | Section_belong_street(type) and road name | |
| POI-located-Road | POI name and road name | |
| Road-date_attribute-Date | Road_date(type) | |
| Date-time_attribute-Time | Date_time(type) | |
| Time-attribute-Situation | Time_speed(type), date, time, and direction |
| Entities | Relationships | Training Set | Test Set | Validation Set |
|---|---|---|---|---|
| 597,216 | 4 | 1,269,031 | 149,299 | 74,647 |
| Model | Learning Rate | Dimension | Margin | Batch_SIZE | Iterations |
|---|---|---|---|---|---|
| TransE | 0.01 | 100 | 1 | 128 | 500 |
| TransH | 0.01 | 100 | 0.25 | 256 | 500 |
| TransD | 1 | 50 | 1 | 256 | 500 |
| Model | Head Entity Prediction | Tail Entity Prediction | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MRR | MR | hits@10 | hits@3 | hits@1 | MRR | MR | hits@10 | hits@3 | hits@1 | |
| TransE | 0.16 | 136703 | 30.2% | 20.3% | 10.0% | 0.09 | 34 | 24.2% | 7.2% | 2.1% |
| TransH | 0.32 | 93292 | 50.0% | 32.5% | 27.5% | 0.19 | 42 | 35.0% | 22.5% | 10.0% |
| TransD | 0.35 | 78162 | 50.0% | 35.0% | 30.0% | 0.23 | 33 | 37.5% | 27.5% | 17.5% |
| Input (Head and Relationship) | Predicted Tails |
|---|---|
| Before_7:15, time_speed | Before_7:15, Beijing no. 3 middle school, 45, 40, 30 |
| After_7:15, time_speed | 35, 30, 7:15, 40, 45 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, J.; Qiu, Q.; Guo, W.; Li, T. Research on the Construction of a Knowledge Graph and Knowledge Reasoning Model in the Field of Urban Traffic. Sustainability 2021, 13, 3191. https://doi.org/10.3390/su13063191
Tan J, Qiu Q, Guo W, Li T. Research on the Construction of a Knowledge Graph and Knowledge Reasoning Model in the Field of Urban Traffic. Sustainability. 2021; 13(6):3191. https://doi.org/10.3390/su13063191
Chicago/Turabian StyleTan, Jiyuan, Qianqian Qiu, Weiwei Guo, and Tingshuai Li. 2021. "Research on the Construction of a Knowledge Graph and Knowledge Reasoning Model in the Field of Urban Traffic" Sustainability 13, no. 6: 3191. https://doi.org/10.3390/su13063191