
A Review of Deep-Learning-Based Medical Image Segmentation Methods


Abstract
:1. Introduction
2. Medical Image Segmentation
2.1. Problem Definition
- Obtain medical imaging data set, generally including training set, validation set, and test set. When using machine learning for image processing, the data set is often divided into three parts. Among them, the training set is used to train the network model, the verification set is used to adjust the hyperparameters of the model, and the test set is used to verify the final effect of the model.
- Preprocess and expand the image, generally including standardization of input image, perform random rotation and random scaling on the input image to increase the size of the data set.
- Use appropriate medical image segmentation method to segment the medical image, and output the segmented images.
- Estimation performance evaluation. In order to verify the effectiveness of medical image segmentation, effective performance indicators need to be set to be verified. This is an integral part of the process.
2.2. Image Segmentation
3. Deep Learning
3.1. Overview of Deep Learning Network
3.2. Convolutional Neural Networks
3.2.1. 2D CNN
3.2.2. 3D CNN
3.2.3. Basic Deep Learning Architectures for Segmentation
3.3. Application of Deep Learning in Image Segmentation
4. Medical Image Segmentation Based on Deep Learning
4.1. Fully Convolutional Neural Networks
4.1.1. FCN
4.1.2. DeepLab v1
4.1.3. DeepLab v2
4.1.4. DeepLab v3 and DeepLab v3+
4.1.5. SegNet
4.1.6. Other FCN Structures
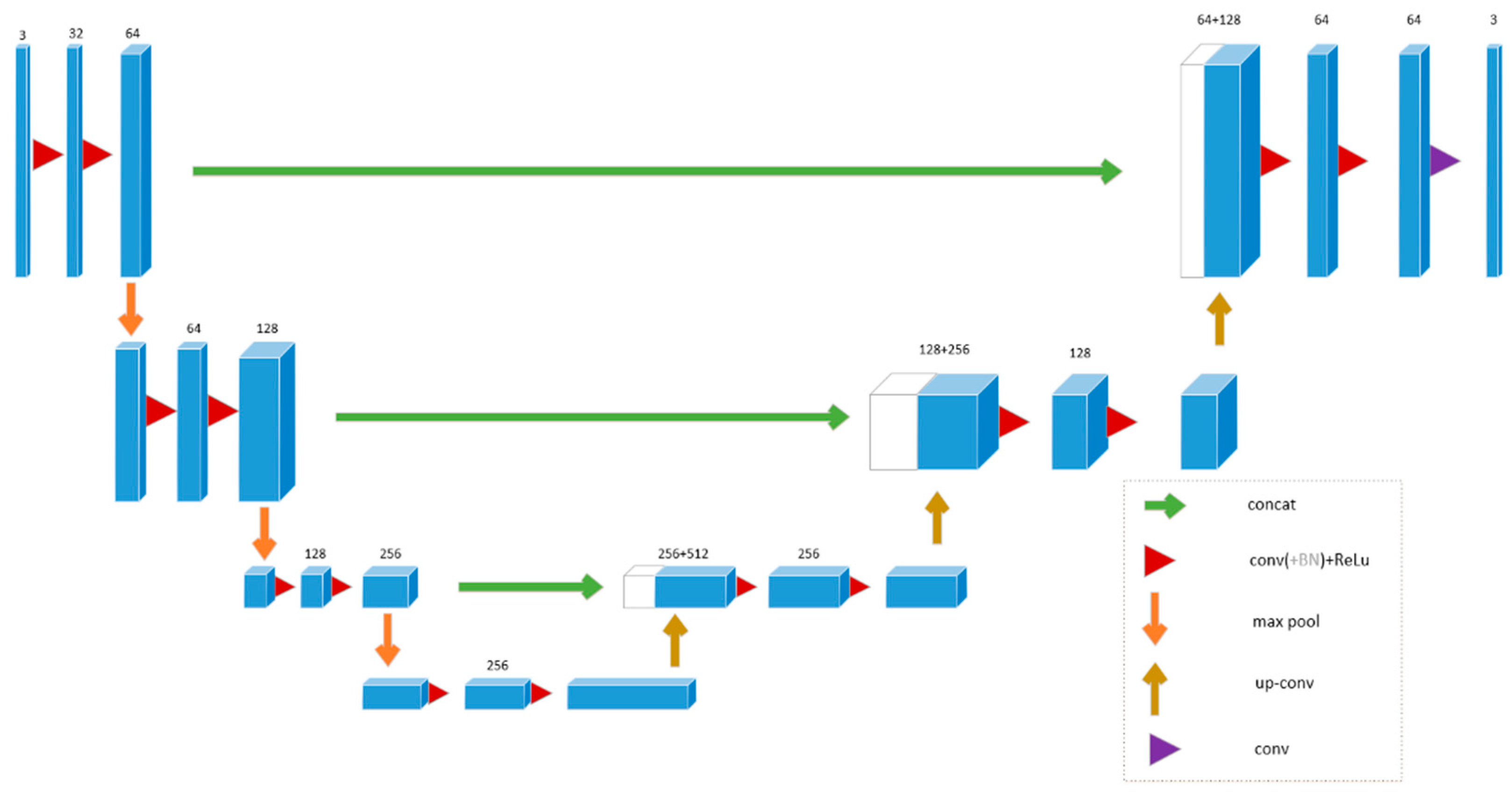
4.2. U-Net
4.2.1. 2D U-Net
4.2.2. 3D U-Net
4.2.3. V-Net
4.2.4. Other U-Net Structures
4.3. Generative Adversarial Network
4.3.1. First GAN for Segmentation
4.3.2. Segmentation Adversarial Network (SegAN)
4.3.3. Structure Correcting Adversarial Network (SCAN)
4.3.4. Projective Adversarial Network (PAN)
4.3.5. Distributed Asynchronized Discriminator GAN (AsynDGAN)
4.3.6. Other GAN Structures
5. The Segmentation Method for Various Human Organ Area
5.1. Brain
5.2. Eye
5.3. Chest
5.4. Abdomen
5.5. Cardiology
5.6. Other Organs and Lesion Segmentation
6. Segmentation Evaluation Metrics and Data Sets
6.1. Evaluation Metrics
6.2. Data Sets for Medical Image Segmentation
- Task01_BrainTumour: There are a total of 750, and the labels are divided into two categories: Glioma (necrotic/active tumor), edema. It is an MRI scan obtained in routine clinical practice.
- Task02_Heart: There are a total of 30, and the label is the left atrium. These data come from the Left Atrial Segmentation Challenge (LASC). Images were obtained on a 1.5T Achieva scanner with voxel resolution 1.25 × 1.25 × 2.7 mm3.
- Task03_Liver: There are 201 sheets in total, with labels divided into liver and tumors. The type of imaging is CT. The images were provided with an in-plane resolution of 0.5 to 1.0 mm, and slice thickness of 0.45 to 6.0 mm.
- Task04_Hippocampus: There are a total of 394, and the labels are hippocampus, head and body. The type of imaging is MRI. The data set consisted of MRI acquired in 90 healthy adults and 105 adults with a nonaffective psychotic disorder.
- Task05_Prostate: There are a total of 48, and the labels are: Prostate central gland, peripheral zone. The type of imaging is MRI. The prostate data set consisted of 48 multiparametric MRI studies provided by Radboud University (The Netherlands) reported in a previous segmentation study.
- Task06_Lung: There are a total of 96, and the label is lung tumor. The type of imaging is CT. The lung data set was comprised of patients with non-small-cell lung cancer from Stanford University. The tumor region was denoted by an expert thoracic radiologist on a representative CT cross section using OsiriX.
- Task07_Pancreas: There are a total of 420, with labels divided into pancreas and pancreatic mass (cyst or tumor). The type of imaging is CT. The pancreas data set consisted of patients whose pancreatic masses were removed.
- Task08_HepaticVessel: There are a total of 443, and the labels is liver vessels. The type of imaging is CT. This second liver data set consisted of patients with various primary and metastatic liver tumors.
- Task09_Spleen: There are a total of 61, and the label is the spleen. The type of imaging is CT. The spleen data set comprised of patients undergoing chemotherapy treatment for liver metastases at Memorial Sloan Kettering Cancer Center.
- Task10_Colon: There are a total of 190, and the label is colon cancer. The type of imaging is CT.
7. Conclusions and Future Directions
- Medical image segmentation is a cross-disciplinary field between these two disciplines span. Clinical medical pathology conditions are complex and diverse. However, artificial intelligence scientists do not understand clinical needs. Clinicians do not understand the specific technology of artificial intelligence. As a result, artificial intelligence cannot well meet the specific clinical needs. In order to promote the application of artificial intelligence in the medical field, extensive cooperation between clinicians and machine learning scientists should be strengthened. This cooperation will solve the problem that machine learning researchers cannot obtain medical data. It can also help machine learning researchers develop deep learning algorithms more in line with clinical needs and apply them to computer-aided diagnosis equipment, thereby improving diagnosis efficiency and accuracy.
- Medical images are different from natural images. There are differences between different medical images. This difference also affects the adaptability of the deep learning model during segmentation. The noise and artifacts of medical images are also a major problem in data preprocessing.
- Limitations of existing medical image data sets. The existing medical image data sets are small in scale. The training of deep learning algorithms requires a large amount of data set support, which leads to the problem of overfitting in the training process of deep learning models. One way to solve the insufficient amount of training data is data enhancement, such as geometric transformation, color space enhancement. GAN uses original data to synthesize new data. Another method is based on a meta-learning model to study medical image segmentation under small sample conditions.
- The deep learning model has its own flaws. It mainly focuses on three aspects: network structure design, 3D data segmentation model design and loss function design. The design of the network structure is worth exploring. The effect of modifying the network structure is significant and can be easily migrated to other tasks. 3D medical data can more accurately capture the geometric information of the target, which may be lost when the 3D data is sliced slice by slice. Therefore, a researchable direction is the design of 3D convolution models to process 3D medical image data. The design of loss function has always been a difficult point in deep learning research.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lateef, F.; Ruichek, Y. Survey on semantic segmentation using deep learning techniques. Neurocomputing 2019, 338, 321–348. [Google Scholar] [CrossRef]
- Shen, D.; Wu, G.; Suk, H.I. Deep learning in medical image analysis. Annu. Rev. Biomed. Eng. 2017, 19, 221–248. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, UK, 2016. [Google Scholar]
- Almeida, G.; Tavares, J.M.R.S. Deep learning in radiation oncology treatment planning for prostate cancer: A systematic review. J. Med. Syst. 2020, 44, 1–15. [Google Scholar] [CrossRef]
- Hesamian, M.H.; Jia, W.; He, X.; Kennedy, P. Deep learning techniques for medical image segmentation: Achievements and challenges. J. Digit. Imaging 2019, 32, 582–596. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Altaf, F.; Islam, S.M.S.; Akhtar, N.; Nanjua, N.K. Going deep in medical image analysis: Concepts, methods, challenges, and future directions. IEEE Access 2019, 7, 99540–99572. [Google Scholar] [CrossRef]
- Hu, P.; Cao, Y.; Wang, W.; Wei, B. Computer Assisted Three-Dimensional Reconstruction for Laparoscopic Resection in Adult Teratoma. J. Med. Imaging Health Inform. 2019, 9, 956–961. [Google Scholar] [CrossRef]
- Ess, A.; Müller, T.; Grabner, H.; Van Gool, L. Segmentation-Based Urban Traffic Scene Understanding. BMVC 2009, 1, 2. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–12 June 2012; pp. 3354–3361. [Google Scholar]
- Ma, Z.; Tavares, J.M.R.S.; Jorge, R.M.N. A review on the current segmentation algorithms for medical images. In Proceedings of the 1st International Conference on Imaging Theory and Applications, Lisbon, Portugal, 5–8 February 2009. [Google Scholar]
- Ferreira, A.; Gentil, F.; Tavares, J.M.R.S. Segmentation algorithms for ear image data towards biomechanical studies. Comput. Methods Biomech. Biomed. Eng. 2014, 17, 888–904. [Google Scholar] [CrossRef] [Green Version]
- Ma, Z.; Tavares, J.M.R.S.; Jorge, R.N.; Mascarenhas, T. A review of algorithms for medical image segmentation and their applications to the female pelvic cavity. Comput. Methods Biomech. Biomed. Eng. 2010, 13, 235–246. [Google Scholar] [CrossRef] [Green Version]
- Xu, A.; Wang, L.; Feng, S.; Qu, Y. Threshold-based level set method of image segmentation. In Proceedings of the Third International Conference on Intelligent Networks and Intelligent Systems, Shenyang, China, 1–3 November 2010; pp. 703–706. [Google Scholar]
- Cigla, C.; Alatan, A.A. Region-based image segmentation via graph cuts. In Proceedings of the 2008 15th IEEE International Conference on Image Processing, San Diego, CA, USA, 12–15 October 2008; pp. 2272–2275. [Google Scholar]
- Yu-Qian, Z.; Wei-Hua, G.; Zhen-Cheng, C.; Tang, J.-T.; Li, L.-Y. Medical images edge detection based on mathematical morphology. In Proceedings of the 2005 IEEE Engineering in Medicine and Biology 27th Annual Conference, Shanghai, China, 17–18 January 2006; pp. 6492–6495. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girschik, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015; pp. 1520–1528. [Google Scholar]
- Zhu, X.J. Semi-Supervised Learning Literature Survey; University of Winsconsin: Madison, WI, USA, 2005. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shshroudy, A.; Shuai, B.; Liu, I.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef] [Green Version]
- Hubel, D.H.; Wiesel, T.N. Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex. J. Physiol. 1962, 160, 106. [Google Scholar] [CrossRef] [PubMed]
- Fukushima, K.; Miyake, S. Neocognitron: A self-organizing neural network model for a mechanism of visual pattern recognition. In Competition and Cooperation in Neural Nets; Springer: Berlin, Germany, 1982; pp. 267–285. [Google Scholar]
- Lécun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 60, 1097–1105. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 16 June–1 July 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Qiu, Z.; Yao, T.; Mei, T. Learning spatio-temporal representation with pseudo-3d residual networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5533–5541. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Rundo, L.; Han, C.; Nagano, Y.; Zhang, J.; Hataya, R.; Militello, C.; Tangherloni, A.; Nobile, M.S.; Ferreti, C.; Besozzi, D.; et al. USE-Net, Incorporating Squeeze-and-Excitation blocks into U-Net for prostate zonal segmentation of multi-institutional MRI datasets. Neurocomputing 2019, 365, 31–43. [Google Scholar] [CrossRef] [Green Version]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 39, 91–99. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Krähenbühl, P.; Koltun, V. Efficient inference in fully connected crfs with gaussian edge potentials. Adv. Neural Inf. Process. Syst. 2011, 24, 109–117. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Zhou, X.; Takayama, R.; Wang, S.; Hara, T.; Fujita, H. Deep learning of the sectional appearances of 3D CT images for anatomical structure segmentation based on an FCN voting method. Med. Phys. 2017, 44, 5221–5233. [Google Scholar] [CrossRef] [PubMed]
- Christ, P.F.; Elshaer, M.E.A.; Ettlinger, F.; Tatavarty, S.; Bickel, M.; Bilic, P.; Rempfler, M.; Armbruster, M.; Hoffman, F.; D’Anastasi, M.; et al. Automatic liver and lesion segmentation in CT using cascaded fully convolutional neural networks and 3D conditional random fields. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Athens, Greece, 17–21 October 2016; pp. 415–423. [Google Scholar]
- Zhou, X.Y.; Shen, M.; Riga, C.; Yang, G.-Z.; Lee, S.-L. Focal fcn: Towards small object segmentation with limited training data. arXiv 2017, arXiv:1711.01506. [Google Scholar]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning dense volumetric segmentation from sparse annotation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Athens, Greece, 17–21 October 2016; pp. 424–432. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Xiao, X.; Lian, S.; Luo, Z.; Li, S. Weighted Res-UNet for high-quality retina vessel segmentation. In Proceedings of the 9th International Conference on Information Technology in Medicine and Education (ITME), Hangzhou, China, 19–21 October 2018; pp. 327–331. [Google Scholar]
- Li, X.; Chen, H.; Qi, X.; Dou, Q.; Fu, C.-W.; Heng, P.A. H-DenseUNet: Hybrid densely connected UNet for liver and tumor segmentation from CT volumes. IEEE Trans. Med. Imaging 2018, 37, 2663–2674. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ibtehaz, N.; Rahman, M.S. MultiResUNet: Rethinking the U-Net architecture for multimodal biomedical image segmentation. Neural Netw. 2020, 121, 74–87. [Google Scholar] [CrossRef] [PubMed]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; Mcdonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Wang, Z.; Zou, N.; Shen, D.; Ji, S. Non-Local U-Nets for Biomedical Image Segmentation. In Proceedings of the AAAI, New York, NY, USA, 7–12 February 2020; pp. 6315–6322. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Luc, P.; Couprie, C.; Chintala, S.; Verbeek, J. Semantic segmentation using adversarial networks. arXiv 2016, arXiv:1611.08408. [Google Scholar]
- Xue, Y.; Xu, T.; Zhang, H.; Long, L.R.; Huang, X. SegAN: Adversarial Network with Multi-scale L1 Loss for Medical Image Segmentation. Neuroinformatics 2018, 16, 383–392. [Google Scholar] [CrossRef] [Green Version]
- Dai, W.; Dong, N.; Wang, Z.; Liang, X.; Zhang, H.; Xing, E.P. Scan: Structure correcting adversarial network for organ segmentation in chest x-rays. In Mining Data for Financial Applications; Springer: Cham, Switzerland, 2018; pp. 263–273. [Google Scholar]
- Khosravan, N.; Mortazi, A.; Wallace, M.; Bagci, U. Pan: Projective adversarial network for medical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–18 October 2019; pp. 68–76. [Google Scholar]
- Chang, Q.; Qu, H.; Zhang, Y.; Sabuncu, M.; Chen, C.; Zhang, T.; Metaxas, D.N. Synthetic Learning: Learn from Distributed Asynchronized Discriminator GAN Without Sharing Medical Image Data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 13856–13866. [Google Scholar]
- Zhao, M.; Wang, L.; Chen, J.; Nie, D.; Cong, Y.; Ahmad, S.; Ho, A.; Yuan, P.; Fung, S.H.; Deng, H.H.; et al. Craniomaxillofacial bony structures segmentation from MRI with deep-supervision adversarial learning. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; pp. 720–727. [Google Scholar]
- Mondal, A.K.; Dolz, J.; Desrosiers, C. Few-shot 3d multi-modal medical image segmentation using generative adversarial learning. arXiv 2018, arXiv:1810.12241. [Google Scholar]
- Zhang, Y.; Yang, L.; Chen, J.; Fredericksen, M.; Hughes, D.P.; Chen, D.Z. Deep adversarial networks for biomedical image segmentation utilizing unannotated images. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Quebec City, QC, Canada, 10–14 September 2017; pp. 408–416. [Google Scholar]
- Yang, D.; Xu, D.; Zhou, S.K.; Georgescu, B.; Chen, M.; Grbic, S.; Metaxas, D.; Comaniciu, D. Automatic liver segmentation using an adversarial image-to-image network. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Quebec City, QC, Canada, 10–14 September 2017; pp. 507–515. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Bayramoglu, N.; Kaakinen, M.; Eklund, L.; Heikkila, J. Towards virtual h&e staining of hyperspectral lung histology images using conditional generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 64–71. [Google Scholar]
- Dar, S.U.H.; Yurt, M.; Karacan, L.; Erdem, A.; Erdem, E.; Çukur, T. Image synthesis in multi-contrast MRI with conditional generative adversarial networks. IEEE Trans. Med. Imaging 2019, 38, 2375–2388. [Google Scholar] [CrossRef] [Green Version]
- Wolterink, J.M.; Dinkla, A.M.; Savenije, M.H.F.; Seevinck, P.R.; van den Berg, C.A.; Išgum, I. Deep MR to CT synthesis using unpaired data. In Proceedings of the International Workshop on Simulation and Synthesis in Medical Imaging, Quebec City, QC, Canada, 10 September 2017; pp. 14–23. [Google Scholar]
- Tuan, T.A.; Pham, T.B.; Kim, J.Y.; Tavares, J.M.R. Alzheimer’s diagnosis using deep learning in segmenting and classifying 3D brain MR images. Int. J. Neurosci. 2020, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Myronenko, A. 3D MRI brain tumor segmentation using autoencoder regularization. In Proceedings of the International MICCAI Brainlesion Workshop, Shenzhen, China, 17 October 2018; pp. 311–320. [Google Scholar]
- Nie, D.; Wang, L.; Adeli, E.; Lao, C.; Lin, W.; Shen, D. 3-D fully convolutional networks for multimodal isointense infant brain image segmentation. IEEE Trans. Cybern. 2019, 49, 1123–1136. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Yi, L.; Chen, Q.; Meng, Z.; Dong, H.; He, Z. Edge-aware Fully Convolutional Network with CRF-RNN Layer for Hippocampus Segmentation. In Proceedings of the 2019 IEEE 8th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), Chongqing, China, 24–26 May 2019; pp. 803–806. [Google Scholar]
- Borne, L.; Rivière, D.; Mangin, J.F. Combining 3D U-Net and bottom-up geometric constraints for automatic cortical sulci recognition. In Proceedings of the International Conference on Medical Imaging with Deep Learning, London, UK, 8–10 July 2019. [Google Scholar]
- Casamitjana, A.; Catà, M.; Sánchez, I.; Combalia, M.; Vilaplana, V. Cascaded V-Net using ROI masks for brain tumor segmentation. In Proceedings of the International MICCAI Brainlesion Workshop, Quebec City, QC, Canada, 14 September 2017; pp. 381–391. [Google Scholar]
- Moeskops, P.; Veta, M.; Lafarge, M.W.; Eppenhof, K.A.J.; Pluim, J.P.W. Adversarial training and dilated convolutions for brain MRI segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2017; pp. 56–64. [Google Scholar]
- Rezaei, M.; Harmuth, K.; Gierke, W.; Kellermeier, T.; Fischer, M.; Yang, H.; Meinel, C. A conditional adversarial network for semantic segmentation of brain tumor. In Proceedings of the International MICCAI Brainlesion Workshop, Quebec City, QC, Canada, 14 September 2017; pp. 241–252. [Google Scholar]
- Giacomello, E.; LoIacono, D.; Mainardi, L. Brain MRI Tumor Segmentation with Adversarial Networks. arXiv 2019, arXiv:1910.02717. [Google Scholar]
- Leopold, H.A.; Orchard, J.; Zelek, J.S.; Lakshminarayanan, V. Pixelbnn: Augmenting the pixelcnn with batch normalization and the presentation of a fast architecture for retinal vessel segmentation. J. Imaging 2019, 5, 26. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Chung, A.C.S. Deep supervision with additional labels for retinal vessel segmentation task. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; pp. 83–91. [Google Scholar]
- Son, J.; Park, S.J.; Jung, K.H. Retinal vessel segmentation in fundoscopic images with generative adversarial networks. arXiv 2017, arXiv:1706.09318. [Google Scholar]
- Edupuganti, V.G.; Chawla, A.; Amit, K. Automatic optic disk and cup segmentation of fundus images using deep learning. In Proceedings of the 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 2227–2231. [Google Scholar]
- Shankaranarayana, S.M.; Ram, K.; Mitra, K.; Sivaprakasam, M. Joint optic disc and cup segmentation using fully convolutional and adversarial networks. In Fetal, Infant and Ophthalmic Medical Image Analysis; Springer: Cham, Switzerland, 2017; pp. 168–176. [Google Scholar]
- Bhandary, A.; Prabhu, G.A.; Rajinikanth, V.; Thanaraj, K.P.; Satapathy, S.C.; Robbins, D.E.; Shasky, C.; Zhang, Y.-D.; Tavares, J.M.R.; Raja, N.S.M. Deep-learning framework to detect lung abnormality—A study with chest X-Ray and lung CT scan images. Pattern Recognit. Lett. 2020, 129, 271–278. [Google Scholar] [CrossRef]
- Novikov, A.A.; Lenis, D.; Major, D.; Hladůvka, J.; Wimmer, M.; Bühler, K. Fully convolutional architectures for multiclass segmentation in chest radiographs. IEEE Trans. Med. Imaging 2018, 37, 1865–1876. [Google Scholar] [CrossRef] [Green Version]
- Anthimopoulos, M.M.; Christodoulidis, S.; Ebner, L.; Geiser, T.; Christe, A.; Mougiakakou, S. Semantic Segmentation of Pathological Lung Tissue with Dilated Fully Convolutional Networks. IEEE J. Biomed. Health Inform. 2019, 23, 714–722. [Google Scholar] [CrossRef] [Green Version]
- Jue, J.; Jason, H.; Neelam, T.; Andreas, R.; Sean, B.L.; Joseph, D.O.; Harini, V. Integrating cross-modality hallucinated MRI with CT to aid mediastinal lung tumor segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Shenzhen, China, 13–18 October 2019; pp. 221–229. [Google Scholar]
- Christ, P.F.; Ettlinger, F.; Grün, F.; Elshaera, M.E.A.; Lipkova, J.; Schlecht, S.; Ahmaddy, F.; Tatavarty, S.; Bickel, M.; Bilic, P.; et al. Automatic liver and tumor segmentation of CT and MRI volumes using cascaded fully convolutional neural networks. arXiv 2017, arXiv:1702.05970. [Google Scholar]
- Han, X. Automatic liver lesion segmentation using a deep convolutional neural network method. arXiv 2017, arXiv:1704.07239. [Google Scholar]
- Huo, Y.; Xu, Z.; Bao, S.; Bermudez, C.; Plassard, A.J.; Yao, Y.; Liu, J.; Assad, A.; Abramson, R.G.; Landman, B.A. Splenomegaly segmentation using global convolutional kernels and conditional generative adversarial networks. Med. Imaging 2018, 10574, 1057409. [Google Scholar]
- Tran, P.V. A fully convolutional neural network for cardiac segmentation in short-axis MRI. arXiv 2016, arXiv:1604.00494. [Google Scholar]
- Xu, Z.; Wu, Z.; Feng, J. CFUN: Combining faster R-CNN and U-net network for efficient whole heart segmentation. arXiv 2018, arXiv:1812.04914. [Google Scholar]
- Dong, S.; Luo, G.; Wang, K.; Cao, S.; Mercado, A.; Shmuilovich, O.; Zhang, H.; Li, S. VoxelAtlasGAN: 3D left ventricle segmentation on echocardiography with atlas guided generation and voxel-to-voxel discrimination. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; pp. 622–629. [Google Scholar]
- Zhang, J.; Du, J.; Liu, H.; Hou, X.; Zhao, Y.; Ding, M. LU-NET: An Improved U-Net for Ventricular Segmentation. IEEE Access 2019, 7, 92539–92546. [Google Scholar] [CrossRef]
- Ye, C.; Wang, W.; Zhang, S.; Wang, K. Multi-depth fusion network for whole-heart CT image segmentation. IEEE Access 2019, 7, 23421–23429. [Google Scholar] [CrossRef]
- Xia, Q.; Yao, Y.; Hu, Z.; Hao, A. Automatic 3D atrial segmentation from GE-MRIs using volumetric fully convolutional networks. In Proceedings of the International Workshop on Statistical Atlases and Computational Models of the Heart, Granada, Spain, 16 September 2018; pp. 211–220. [Google Scholar]
- Chen, C.; Qin, C.; Qiu, H.; Tarroni, G.; Duan, J.; Bai, W.; Rueckert, D. Deep Learning for Cardiac Image Segmentation: A Review. Front. Cardiovasc. Med. 2020, 7, 25. [Google Scholar] [CrossRef]
- Arshad, H.; Khan, M.A.; Sharif, M.I.; Yasmin, M.; Tavares, J.M.R.; Zhang, Y.D.; Satapathy, S.C. A multilevel paradigm for deep convolutional neural network features selection with an application to human gait recognition. Expert Syst. 2020, e12541. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, Y.; Yang, N.; Zheng, L.; Dey, N.; Ashour, A.S.; Rajinikanth, V.; Tavares, J.M.R.S.; Shi, F. Classification of mice hepatic granuloma microscopic images based on a deep convolutional neural network. Appl. Soft Comput. 2019, 74, 40–50. [Google Scholar] [CrossRef] [Green Version]
- Liu, F.; Zhou, Z.; Jang, H.; Samsonov, A.; Zhao, G.; Kijowski, R. Deep convolutional neural network and 3D deformable approach for tissue segmentation in musculoskeletal magnetic resonance imaging. Magn. Reson. Med. 2018, 79, 2379–2391. [Google Scholar] [CrossRef] [PubMed]
- Tran, T.; Kwon, O.H.; Kwon, K.R.; Lee, S.H.; Kang, K.W. Blood cell images segmentation using deep learning semantic segmentation. In Proceedings of the IEEE International Conference on Electronics and Communication Engineering, Essex, UK, 16–17 August 2018; pp. 13–16. [Google Scholar]
- Sekuboyina, A.; Rempfler, M.; Kukačka, J.; Tetteh, G.; Valentinitsch, A.; Kirschke, J.; Menze, B.H. Btrfly net: Vertebrae labelling with energy-based adversarial learning of local spine prior. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; pp. 649–657. [Google Scholar]
- Han, Z.; Wei, B.; Mercado, A.; Leung, S.; Li, S. Spine-GAN: Semantic segmentation of multiple spinal structures. Med. Image Anal. 2018, 50, 23–35. [Google Scholar] [CrossRef]
- Kohl, S.; Bonekamp, D.; Schlemmer, H.P.; Yaqubi, K.; Hohenfellner, M.; Hadaschik, B.; Radtke, J.P.; Maier-Hein, K. Adversarial networks for the detection of aggressive prostate cancer. arXiv 2017, arXiv:1702.08014. [Google Scholar]
- Taha, A.; Lo, P.; Li, J.; Zhao, T. Kid-net: Convolution networks for kidney vessels segmentation from ct-volumes. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; pp. 463–471. [Google Scholar]
- Izadi, S.; Mirikharaji, Z.; Kawahara, J.; Hamarneh, G. Generative adversarial networks to segment skin lesions. In Proceedings of the IEEE 15th International Symposium on Biomedical Imaging, Washington, DC, USA, 4–7 April 2018; pp. 881–884. [Google Scholar]
- Mirikharaji, Z.; Hamarneh, G. Star shape prior in fully convolutional networks for skin lesion segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; pp. 737–745. [Google Scholar]
- Wang, D.; Gu, C.; Wu, K.; Guan, X. Adversarial neural networks for basal membrane segmentation of microinvasive cervix carcinoma in histopathology images. In Proceedings of the 2017 International Conference on Machine Learning and Cybernetics, Ningbo, China, 9–12 July 2017. [Google Scholar]
- Simpson, A.L.; Antonelli, M.; Bakas, S.; Bilello, M.; Farahani, K.; Van Ginneken, B.; Kopp-Schneider, A.; Landman, B.A.; Litjens, G.; Menze, B.; et al. A large annotated medical image dataset for the development and evaluation of segmentation algorithms. arXiv 2019, arXiv:1902.09063. [Google Scholar]
- Van Ginneken, B.; Stegmann, M.B.; Loog, M. Segmentation of anatomical structures in chest radiographs using supervised methods: A comparative study on a public database. Med. Image Anal. 2006, 10, 19–40. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Menze, B.H.; Jakab, A.; Bauer, S.; Kalpathy-Cramer, J.; Farahani, K.; Kirby, J.; Burren, Y.; Porz, N.; Slotboom, J.; Wiest, R.; et al. The multimodal brain tumor image segmentation benchmark (BRATS). IEEE Trans. Med. Imaging 2014, 34, 1993–2024. [Google Scholar] [CrossRef]
- Heath, M.; Bowyer, K.; Kopans, D.; Kegelmeyer, P.; Moore, R.; Chang, K.; Munishkumaran, S. The digital database for screening mammography. In Proceedings of the 5th International Workshop on Digital Mammography, Toronto, ON, Canada, 11–14 June 2000; pp. 212–218. [Google Scholar]
- Bilic, P.; Christ, P.F.; Vorontsov, E.; Chlebus, G.; Chen, H.; Dou, Q.; Fu, C.-W.; Han, X.; Heng, P.-A.; Hesser, J.; et al. The liver tumor segmentation benchmark (lits). arXiv 2019, arXiv:1901.04056. [Google Scholar]
- Armato, S.G., III; McLennan, G.; Bidaut, L.; McNitt-Gray, M.F.; Meyer, C.R.; Reeves, A.P.; Zhao, B.; Aberle, D.A.; Henschke, C.I.; Hoffman, E.A.; et al. The lung image database consortium (LIDC) and image database resource initiative (IDRI): A completed reference database of lung nodules on CT scans. Med. Phys. 2011, 38, 915–931. [Google Scholar] [CrossRef] [PubMed]
- Marcus, D.S.; Fotenos, A.F.; Csernansky, J.G.; Morris, J.C.; Buckner, R.L. Open access series of imaging studies: Longitudinal MRI data in nondemented and demented older adults. J. Cogn. Neurosci. 2010, 22, 2677–2684. [Google Scholar] [CrossRef]
- Staal, J.; Abràmoff, M.D.; Niemeijer, M.; Viergever, M.A.; Van Ginneken, B. Ridge-based vessel segmentation in color images of the retina. IEEE Trans. Med. Imaging 2004, 23, 501–509. [Google Scholar] [CrossRef]
- Suckling, J.P. The mammographic image analysis society digital mammogram database. Digit. Mammo 1994, 17, 375–386. [Google Scholar]
- Fonseca, C.G.; Backhaus, M.; Bluemke, D.A.; Britten, R.D.; Chung, J.D.; Cowan, B.R.; Dinov, I.D.; Finn, J.P.; Hunter, P.J.; Kadish, A.H.; et al. The Cardiac Atlas Project—An imaging database for computational modeling and statistical atlases of the heart. Bioinformatics 2011, 27, 2288–2295. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Object | Modalities | Network Type | Data Set |
|---|---|---|---|---|
| Myronenko et al. [67] | Brain | MRI | FCN | BRATS2018 |
| Nie et al. [68] | Brain | MRI | 3D FCN | Infant brain images |
| Wang et al. [69] | Brain | MRI | FCN | ANDI data set and NITRC data set |
| Borne et al. [70] | Brain | MRI | 3D U-Net | 62 healthy brain images |
| Casamitjana et al. [71] | Brain | MRI | V-Net | BRATS2017 |
| Moeskops et al. [72] | Brain | MRI | GAN | MRBrainS13 |
| Rezaei et al. [73] | Brain | MRI | cGAN | BRATS 2017 |
| Giacomello et al. [74] | Brain | MRI | SegAN-CAT | BRATS2015, BRATS2019 |
| Reference | Object | Modalities | Network Type | Data Set |
|---|---|---|---|---|
| Leopold et al. [75] | Eye | Funduscopy | PixelBNN | DRIVE, STARE, CHASEDB1 |
| Zhang et al. [76] | Eye | Funduscopy | U-Net | DRIVE, STARE, CHASEDB1 |
| Jaemin et al. [77] | Eye | Funduscopy | GAN | DRIVE, STARE |
| Edupuganti et al. [78] | Eye | Funduscopy | FCN | Drishti-GS data set |
| Shankaranarayana et al. [79] | Eye | Funduscopy | FCN | RIM-ONE |
| Xiao et al. [46] | Eye | Funduscopy | Res-UNet | DRIVE |
| Reference | Object | Modalities | Network Type | Data Set |
|---|---|---|---|---|
| Dai et al. [54] | Chest | CXR | SCAN | JSRT, Montgomery |
| Novikov et al. [81] | Chest | CXR | U-Net | JSRT |
| Anthimopoulos et al. [82] | Chest | CT | FCN | A data set of 172 sparsely annotated CT scans |
| Jue et al. [83] | Chest | CT, MRI | U-Net, dense-FCN | TCIA, NSCLC |
| Reference | Object | Modalities | Network Type | Data Set |
|---|---|---|---|---|
| Christ et al. [84] | Liver | CT, MRI | FCN | 3DIRCADb and other |
| Han et al. [85] | Liver | CT | DCNN | LiTS |
| Oktay et al. [49] | Pancreas | CT | Attention U-Net | TCIA |
| Yang et al. [60] | Liver | CT | DI2IN-AN | 1000 CT volumes |
| Huo et al. [86] | Spleen | MRI | SSNet | 60 clinically acquired abdominal MRI scans |
| Reference | Object | Modalities | Network Type | Data Set |
|---|---|---|---|---|
| Tran et al. [87] | Left and right ventricles | MRI | FCN | SCD, LVSC, RVSC |
| Xu et al. [88] | The whole heart | CT | CFUN | MM-WHS2017 |
| Dong et al. [89] | Left ventricles | 3D echocardiography | VoxelAtlasGAN | 60 subjects on 3D echocardiography |
| Zhang et al. [90] | Cardiac | MRI | LU-Net | ACDC Stacom 2017 |
| Ye et al. [91] | The whole heart | CT | 3D U-Net | MICCAI 2017 whole-heart |
| Xia et al. [92] | Left atrium | MRI | 3D U-Net | LASC2018 |
| Reference | Object | Modalities | Network Type | Data Set |
|---|---|---|---|---|
| Liu et al. [96] | Musculoskeletal | MRI | SegNet | MICCAI Challenge data set |
| Tran et al. [97] | Cell | Microscopic | SegNet | ALL-IDB1 database |
| Sekuboyina et al. [98] | Spines | CT | Btrfly Net | 302 CT scans |
| Han et al. [99] | Spines | MRI | Spine-GAN | 253 multicenter clinical patients |
| Milletari et al. [45] | Prostate | MRI | V-Net | PROMISE2012 |
| Rundo et al. [30] | Prostate | MRI | USE-Net | three T2-weighted MRI data sets |
| kohl et al. [100] | Prostate | MRI | FCN | MRI images of 152 patients |
| Taha et al. [101] | Kidney | CT | Kid-Net | 236 subjects |
| Izadi et al. [102] | Skin | Dermoscopy | GAN | DermoFit |
| Mirikharaji et al. [103] | Skin | Dermoscopy | FCN | ISBI 2017 |
| Wang et al. [104] | Basal membrane | Histopathology | GAN | IPMCH |
| Data Set | Modalities | Objects | URL |
|---|---|---|---|
| MSD | MRI, CT | Various | http://medicaldecathlon.com/ |
| BRATS | MRI | Brain | https://www.med.upenn.edu/sbia/brats2018/data.html |
| DDSM | Mammography | Breast | http://www.eng.usf.edu/cvprg/Mammography/Database.html |
| ISLES | MRI | Brain | http://www.isles-challenge.org/ |
| LiTS | CT | Liver | https://competitions.codalab.org/competitions/17094 |
| PROMISE12 | MRI | Prostate | https://promise12.grand-challenge.org/ |
| LIDC-IDRI | CT | Lung | https://wiki.cancerimagingarchive.net/display/Public/LIDC-IDRI |
| OASIS | MRI, PET | Brain | https://www.oasis-brains.org/ |
| DRIVE | Funduscopy | Eye | https://drive.grand-challenge.org/ |
| STARE | Funduscopy | Eye | http://homes.esat.kuleuven.be/~mblaschk/projects/retina/ |
| CHASEDB1 | Funduscopy | Eye | https://blogs.kingston.ac.uk/retinal/chasedb1/ |
| MIAS | X-ray | Breast | https://www.repository.cam.ac.uk/handle/1810/250394?show=full |
| SCD | MRI | Cardiac | http://www.cardiacatlas.org/studies/ |
| SKI10 | MRI | Knee | http://www.ski10.org/ |
| HVSMR2018 | CMR | Heart | http://segchd.csail.mit.edu/ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Song, L.; Liu, S.; Zhang, Y. A Review of Deep-Learning-Based Medical Image Segmentation Methods. Sustainability 2021, 13, 1224. https://doi.org/10.3390/su13031224
Liu X, Song L, Liu S, Zhang Y. A Review of Deep-Learning-Based Medical Image Segmentation Methods. Sustainability. 2021; 13(3):1224. https://doi.org/10.3390/su13031224
Chicago/Turabian StyleLiu, Xiangbin, Liping Song, Shuai Liu, and Yudong Zhang. 2021. "A Review of Deep-Learning-Based Medical Image Segmentation Methods" Sustainability 13, no. 3: 1224. https://doi.org/10.3390/su13031224