
Feasibility of Different Weather Data Sources Applied to Building Indoor Temperature Estimation Using LSTM Neural Networks

 , , and
, , and
Abstract
:1. Introduction
2. Materials and Methods
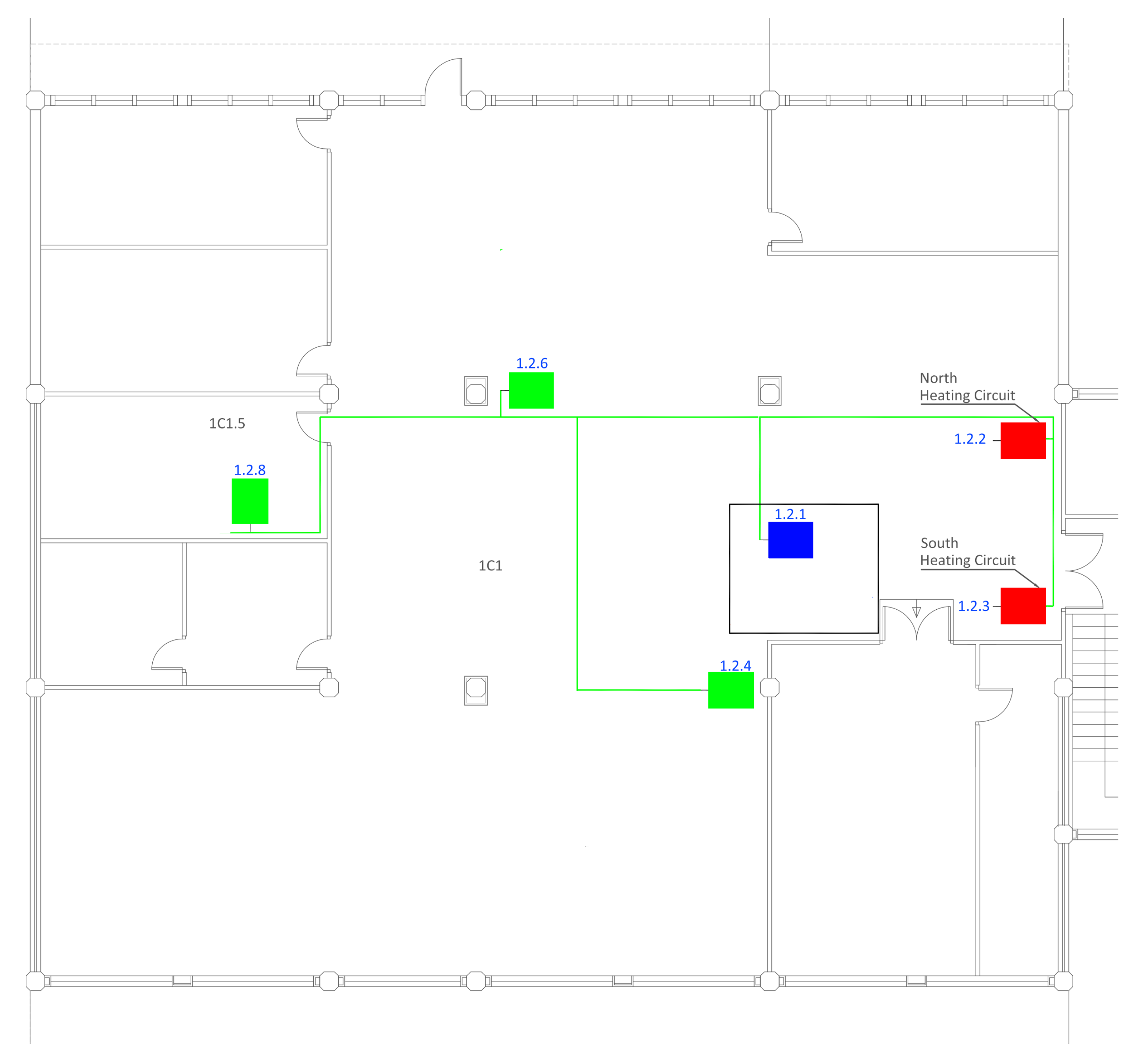
2.1. Building Data
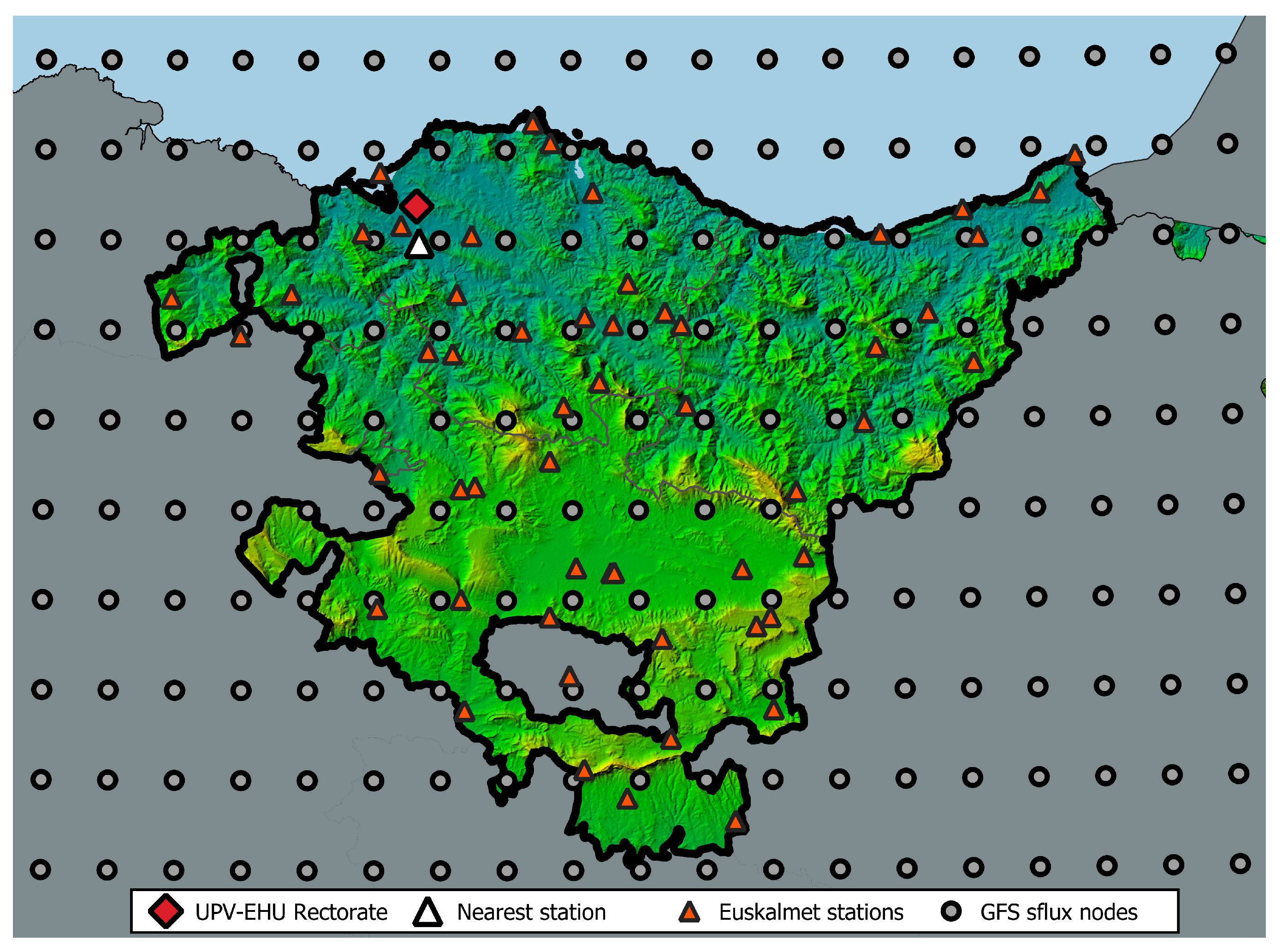
2.2. Meteorological Data
2.3. LSTM Neural Networks
2.4. Pre-Processing Data
2.5. Validation and Error Measurement
3. Results and Discussion
3.1. Meteo Data Analysis
3.2. Indoor Temperature Analysis
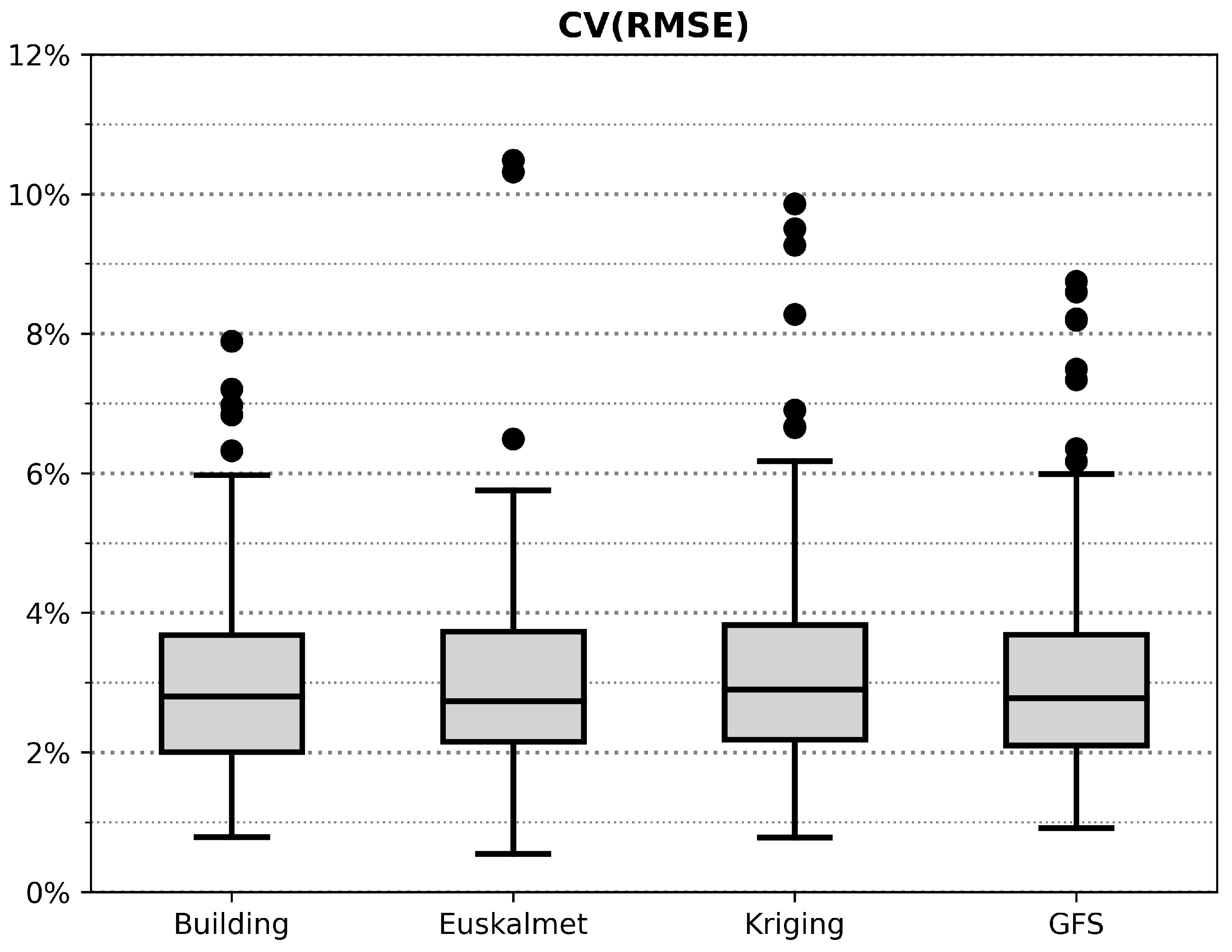
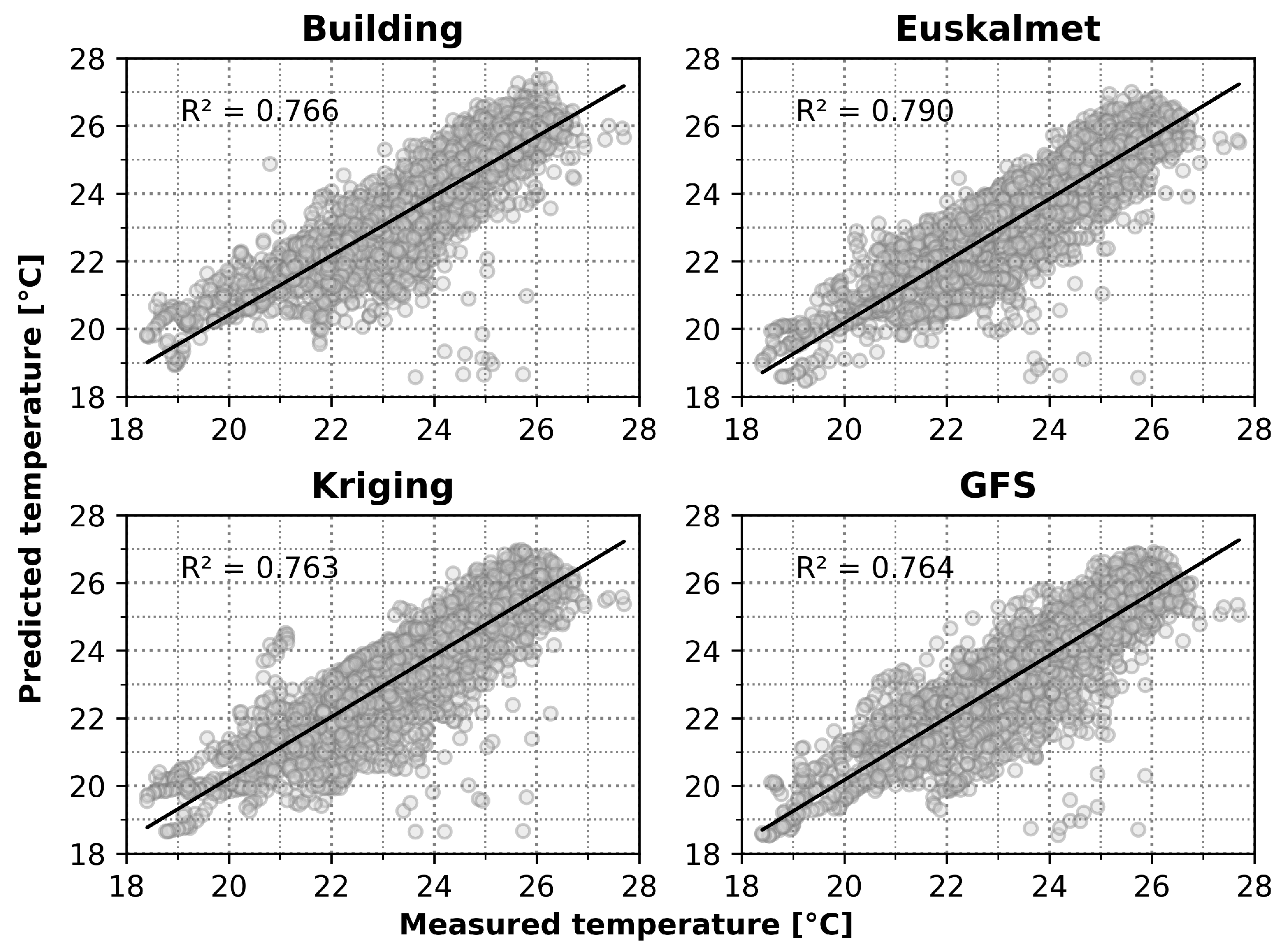
3.3. Error Measurement and Performance Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- United Nations, Department of Economic and Social Affairs. 2018 Revision of World Urbanization Prospects; United Nations, Department of Economic and Social Affairs: 2019. Available online: https://population.un.org/wup/Publications/Files/WUP2018-Report.pdf (accessed on 1 December 2021).
- European Commission, Department of Energy. Energy Efficiency in Buildings; European Commission, Department of Energy: 2020. Available online: https://ec.europa.eu/info/news/focus-energy-efficiency-buildings-2020-feb-17_en (accessed on 1 December 2021).
- U.S. Energy Information Administration. U.S. Energy Consumption by Source and Sector 2020; U.S. Energy Information Administration, 2020. Available online: https://www.eia.gov/energyexplained/us-energy-facts/ (accessed on 1 December 2021).
- International Energy Agency. Buildings Energy Efficiency 2020 Analysis; International Energy Agency: 2020. Available online: https://iea.blob.core.windows.net/assets/59268647-0b70-4e7b-9f78-269e5ee93f26/Energy_Efficiency_2020.pdf (accessed on 1 December 2021).
- Martínez-Mariño, S.; Eguía-Oller, P.; Granada-Álvarez, E.; Erkoreka-González, A. Simulation and validation of indoor temperatures and relative humidity in multi-zone buildings under occupancy conditions using multi-objective calibration. Build. Environ. 2021, 200, 107973. [Google Scholar] [CrossRef]
- Roberti, F.; Oberegger, U.; Gasparella, A. Calibrating historic building energy models to hourly indoor air and surface temperatures: Methodology and case study. Energy Build. 2015, 108, 236–243. [Google Scholar] [CrossRef] [Green Version]
- Bughio, M.; Khan, M.; Mahar, W.; Schuetze, T. Impact of passive energy efficiency measures on cooling energy demand in an architectural campus building in karachi, pakistan. Sustainability 2021, 13, 7251. [Google Scholar] [CrossRef]
- Martínez, S.; Eguía, P.; Granada, E.; Moazami, A.; Hamdy, M. A performance comparison of multi-objective optimization-based approaches for calibrating white-box building energy models. Energy Build. 2020, 216, 109942. [Google Scholar] [CrossRef]
- MacCarana, Y.; Panza, A.; Maroni, G.; Sarto, L.; Carta, M.; Reggiani, S. Comparison of model-based and data-driven approaches for modeling energy and comfort management systems, with a case study. In Proceedings of the 2019 IEEE International Conference on Environment and Electrical Engineering and 2019 IEEE Industrial and Commercial Power Systems Europe (EEEIC/I&CPS Europe), Genova, Italy, 11–14 June 2019. [Google Scholar] [CrossRef]
- Neto, A.; Fiorelli, F. Comparison between detailed model simulation and artificial neural network for forecasting building energy consumption. Energy Build. 2008, 40, 2169–2176. [Google Scholar] [CrossRef]
- Hung, N.; Babel, M.; Weesakul, S.; Tripathi, N. An artificial neural network model for rainfall forecasting in Bangkok, Thailand. Hydrol. Earth Syst. Sci. 2009, 13, 1413–1425. [Google Scholar] [CrossRef] [Green Version]
- Guresen, E.; Kayakutlu, G.; Daim, T. Using artificial neural network models in stock market index prediction. Expert Syst. Appl. 2011, 38, 10389–10397. [Google Scholar] [CrossRef]
- Martínez-Comesaña, M.; Ogando-Martínez, A.; Troncoso-Pastoriza, F.; López-Gómez, J.; Febrero-Garrido, L.; Granada-Álvarez, E. Use of optimised MLP neural networks for spatiotemporal estimation of indoor environmental conditions of existing buildings. Build. Environ. 2021, 205, 108243. [Google Scholar] [CrossRef]
- Kathirgamanathan, A.; De Rosa, M.; Mangina, E.; Finn, D. Data-driven predictive control for unlocking building energy flexibility: A review. Renew. Sustain. Energy Rev. 2021, 135, 110120. [Google Scholar] [CrossRef]
- Cordeiro-Costas, M.; Villanueva, D.; Eguía-Oller, P. Optimization of the electrical demand of an existing building with storage management through machine learning techniques. Appl. Sci. 2021, 11, 7991. [Google Scholar] [CrossRef]
- Attoue, N.; Shahrour, I.; Younes, R. Smart building: Use of the artificial neural network approach for indoor temperature forecasting. Energies 2018, 11, 395. [Google Scholar] [CrossRef] [Green Version]
- Xu, C.; Chen, H.; Wang, J.; Guo, Y.; Yuan, Y. Improving prediction performance for indoor temperature in public buildings based on a novel deep learning method. Build. Environ. 2019, 148, 128–135. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Elmaz, F.; Eyckerman, R.; Casteels, W.; Latré, S.; Hellinckx, P. CNN-LSTM architecture for predictive indoor temperature modeling. Build. Environ. 2021, 206, 108327. [Google Scholar] [CrossRef]
- Luo, X.; Oyedele, L. Forecasting building energy consumption: Adaptive long-short term memory neural networks driven by genetic algorithm. Adv. Eng. Inform. 2021, 50, 101357. [Google Scholar] [CrossRef]
- Imran; Ahmad, S.; Kim, D. Design and implementation of thermal comfort system based on tasks allocation mechanism in smart homes. Sustainability 2019, 11, 5849. [Google Scholar] [CrossRef] [Green Version]
- Hitimana, E.; Bajpai, G.; Musabe, R.; Sibomana, L.; Kayalvizhi, J. Implementation of iot framework with data analysis using deep learning methods for occupancy prediction in a building. Futur. Internet 2021, 13, 67. [Google Scholar] [CrossRef]
- Chan, A.; Chow, T.; Fong, S.; Lin, J. Generation of a typical meteorological year for Hong Kong. Energy Convers. Manag. 2006, 47, 87–96. [Google Scholar] [CrossRef]
- Suparta, W.; Rahman, R. Spatial interpolation of GPS PWV and meteorological variables over the west coast of Peninsular Malaysia during 2013 Klang Valley Flash Flood. Atmos. Res. 2016, 168, 205–219. [Google Scholar] [CrossRef]
- López Gómez, J.; Troncoso Pastoriza, F.; Fariña, E.; Eguía Oller, P.; Granada Álvarez, E. Use of a numerical weather prediction model as a meteorological source for the estimation of heating demand in building thermal simulations. Sustain. Cities Soc. 2020, 62, 102403. [Google Scholar] [CrossRef]
- Dalmau, R.; Pérez-Batlle, M.; Prats, X. Estimation and prediction of weather variables from surveillance data using spatio-temporal Kriging. In Proceedings of the 2017 IEEE/AIAA 36th Digital Avionics Systems Conference (DASC), St. Petersburg, FL, USA, 17–21 September 2017. [Google Scholar] [CrossRef] [Green Version]
- Kuo, P.F.; Huang, T.E.; Putra, I. Comparing kriging estimators using weather station data and local greenhouse sensors. Sensors 2021, 21, 1853. [Google Scholar] [CrossRef] [PubMed]
- National Oceanic and Atmospheric Administration. NOAA, NCEP Products Inventory. 2010. Available online: https://www.nco.ncep.noaa.gov/pmb/products/gfs/ (accessed on 1 December 2021).
- Krige, D. A statistical approach to some basic mine valuation problems on the Witwatersrand. J. Chem. Metall. Min. Soc. Afr. 1951, 52, 119–139. [Google Scholar]
- Matheron, G. Principles of geostatistics. Econ. Geol. 1963, 58, 1246–1266. [Google Scholar] [CrossRef]
- Pensado-Mariño, M.; Febrero-Garrido, L.; Pérez-Iribarren, E.; Oller, P.; Granada-álvarez, E. Estimation of heat loss coefficient and thermal demands of in-use building by capturing thermal inertia using lstm neural networks. Energies 2021, 14, 5188. [Google Scholar] [CrossRef]
- Sheela, K.; Deepa, S. Review on methods to fix number of hidden neurons in neural networks. Math. Probl. Eng. 2013, 2013, 425740. [Google Scholar] [CrossRef] [Green Version]
- Tej, M.; Holban, S. Determining Optimal Neural Network Architecture Using Regression Methods. In Proceedings of the 2018 International Conference on Development and Application Systems (DAS), Suceava, Romania, 24–26 May 2018; pp. 180–189. [Google Scholar] [CrossRef]
- Sheela, K.; Deepa, S. Selection of number of hidden neurons in neural networks in renewable energy systems. J. Sci. Ind. Res. 2014, 73, 686–688. [Google Scholar]
- Madhiarasan, M.; Deepa, S. A novel criterion to select hidden neuron numbers in improved back propagation networks for wind speed forecasting. Appl. Intell. 2016, 44, 878–893. [Google Scholar] [CrossRef]
- Bock, S.; Weis, M. A Proof of Local Convergence for the Adam Optimizer. In Proceedings of the 2019 International Joint Conference on Neural Networks, IJCNN 2019, Budapest, Hungary, 14–19 July 2019. [Google Scholar] [CrossRef]
- Eckle, K.; Schmidt-Hieber, J. A comparison of deep networks with ReLU activation function and linear spline-type methods. Neural Netw. 2019, 110, 232–242. [Google Scholar] [CrossRef]
- Li, M.; Zhang, T.; Chen, Y.; Smola, A.J. Efficient mini-batch training for stochastic optimization. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 661–670. [Google Scholar] [CrossRef]
- Bilbao, I.; Bilbao, J. Overfitting problem and the over-training in the era of data: Particularly for Artificial Neural Networks. In Proceedings of the 2017 Eighth International Conference on Intelligent Computing and Information Systems (ICICIS), Cairo, Egypt, 5–7 December 2017; pp. 173–177. [Google Scholar] [CrossRef]
- Gulli, A.; Pal, S. Deep Learning with Keras; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- ASHRAE. Guideline 14–2014—Measurement of Energy, Demand, and Water Savings; ASHRAE: Atlanta, GA, USA, 2014. [Google Scholar]
- Ruiz, G.; Bandera, C. Validation of calibrated energy models: Common errors. Energies 2017, 10, 1587. [Google Scholar] [CrossRef] [Green Version]
- Efficiency Valuation Organization. International Performance Measurement and Verification Protocol: Concepts and Options for Determining Energy and Water Savings; Efficiency Valuation Organization, 2012. Available online: https://www.nrel.gov/docs/fy02osti/31505.pdf (accessed on 1 December 2021).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Lower Limit | Upper Limit | Increase |
|---|---|---|---|
| LSTM-Hidden layers | 3-2 | 5-4 | 1-1 |
| Number of neurons | 50 | 200 | 50 |
| Number of epochs | 100 | 300 | 100 |
| Temperature | Relative Humidity | Irradiation | |
|---|---|---|---|
| Euskalmet | 0.17% | 0.59% | 0.67% |
| Kriging | 0.25% | 0.86% | 0.48% |
| GFS | 0.22% | 1.00% | 0.89% |
| January | February | March | April | May | Total | |
|---|---|---|---|---|---|---|
| Building | 3.14% | 2.87% | 3.12% | 3.30% | 2.76% | 3.04% |
| Euskalmet | 3.16% | 2.87% | 3.06% | 3.44% | 2.60% | 3.02% |
| Kriging | 3.32% | 2.71% | 3.74% | 3.42% | 2.74% | 3.19% |
| GFS | 2.80% | 2.59% | 3.50% | 3.98% | 2.76% | 3.13% |
| January | February | March | April | May | Total | |
|---|---|---|---|---|---|---|
| Building | −1.85% | −1.00% | −0.62% | 1.89% | 0.96% | −0.10% |
| Euskalmet | −0.50% | −0.51% | 0.34% | 2.03% | 0.74% | 0.45% |
| Kriging | −0.33% | 0.06% | −0.42% | 1.74% | 0.48% | 0.31% |
| GFS | −0.87% | −0.68% | −0.36% | 2.95% | 0.58% | 0.35% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pensado-Mariño, M.; Febrero-Garrido, L.; Eguía-Oller, P.; Granada-Álvarez, E. Feasibility of Different Weather Data Sources Applied to Building Indoor Temperature Estimation Using LSTM Neural Networks. Sustainability 2021, 13, 13735. https://doi.org/10.3390/su132413735
Pensado-Mariño M, Febrero-Garrido L, Eguía-Oller P, Granada-Álvarez E. Feasibility of Different Weather Data Sources Applied to Building Indoor Temperature Estimation Using LSTM Neural Networks. Sustainability. 2021; 13(24):13735. https://doi.org/10.3390/su132413735
Chicago/Turabian StylePensado-Mariño, Martín, Lara Febrero-Garrido, Pablo Eguía-Oller, and Enrique Granada-Álvarez. 2021. "Feasibility of Different Weather Data Sources Applied to Building Indoor Temperature Estimation Using LSTM Neural Networks" Sustainability 13, no. 24: 13735. https://doi.org/10.3390/su132413735