Construction Cost Estimation Using a Case-Based Reasoning Hybrid Genetic Algorithm Based on Local Search Method

 and
and
Abstract
:1. Introduction
2. Methods and Materials
2.1. Research Method
- (a)
- The implications are derived through the analysis of the preceding study.
- (b)
- The theoretical backgrounds and practical applications of case-based reasoning, genetic algorithms, and local search are studied considered for developing a hybrid genetic algorithm.
- (c)
- Correlative analysis with the data from three cases of apartment housing, military barracks, and office buildings are conducted, and then the corresponding correlation coefficient is calculated for each property.
- (d)
- A model for estimating case-based reasoning construction costs is developed using a hybrid genetic algorithm with local search application.
- (e)
- The validity of this study is verified by comparing the estimated accuracy of the hybrid GA–CBR model and the model with different weighting methods.
2.2. Literature Review
2.2.1. Case-Based Reasoning
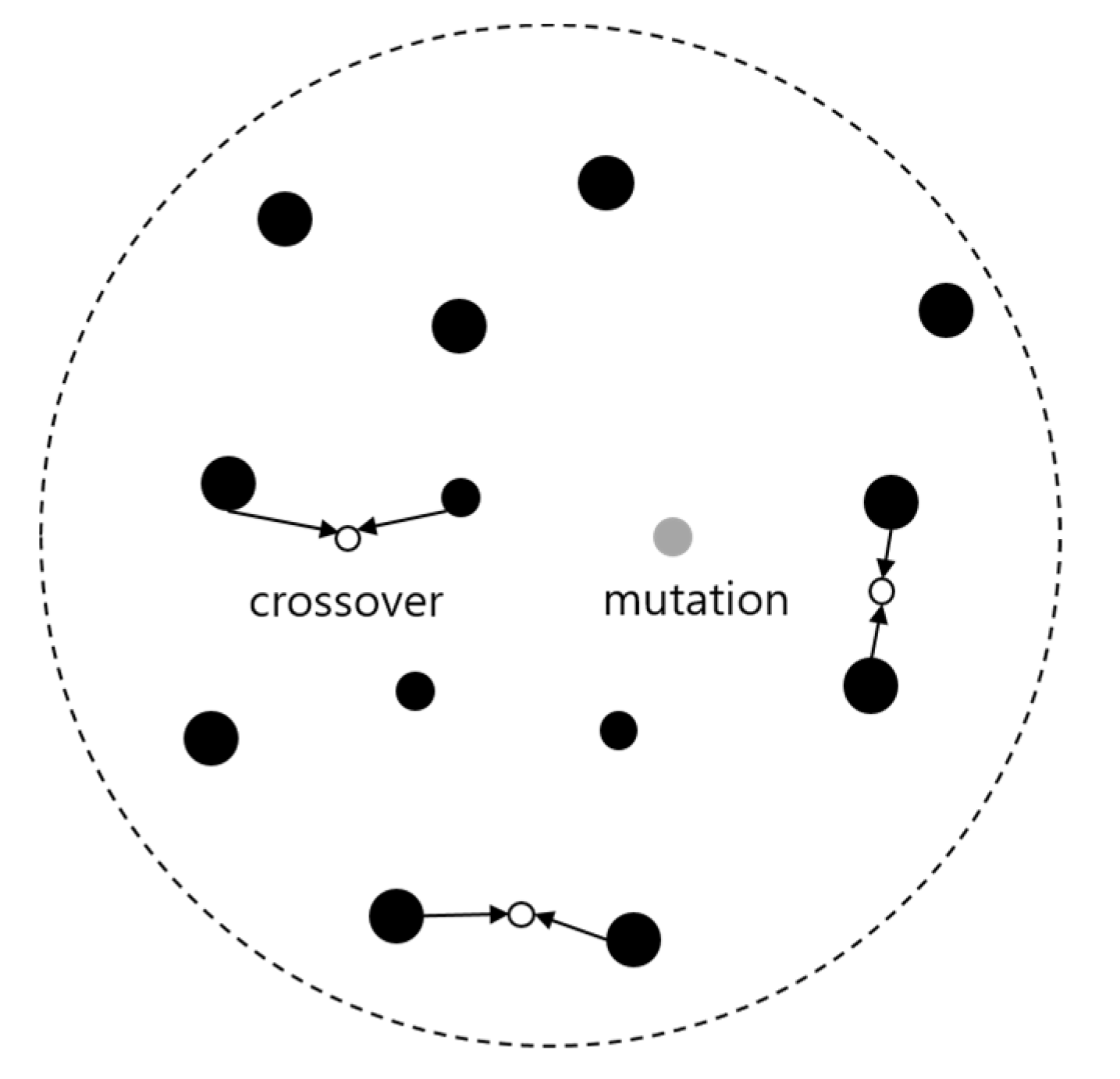
2.2.2. Genetic Algorithm (GA)
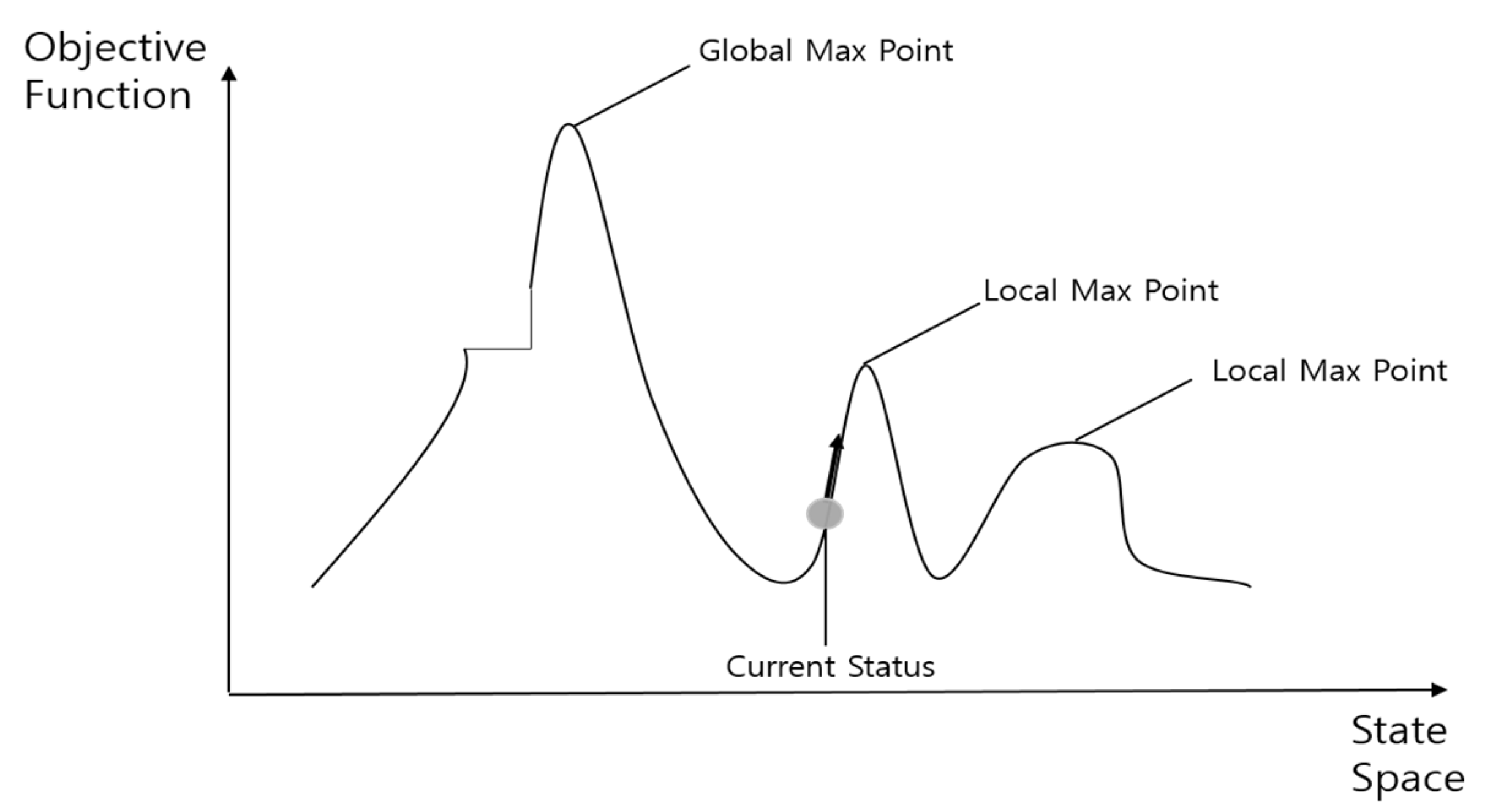
2.2.3. Local Search
3. Results
3.1. Determination of the Weight of Hybrid Genetic Algorithm by Local Search
- (a)
- For the initialization of populations by the existing genetic algorithm in any number, this research improved the method of population initialization by reflecting the correlation of each attribute in the existing population.
- (b)
- The next-generation evolution was carried out by reflecting the correlation coefficient calculated for each gene in the immediately preceding evolution of the generation within the genetic algorithm. Unlike conventional genetic algorithms, these two can reflect the properties of construction properties in the algorithm by applying correlation factors in calculating weights and expect a good performance by applying correlations of each attribute, rather than a random number.
3.1.1. Correlation Analysis
3.1.2. Public Apartments (Case 1)
3.1.3. Facilities (Barracks) (Case 2)
3.1.4. Office Buildings (Case 3)
3.1.5. Application of Local Search
3.2. Development of Cost Estimating Model
3.2.1. Weighted Value Calculation
3.2.2. Case Similarity
4. Discussion
4.1. Experimental Results
4.2. Model Verification
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Trost, S.M.; Oberlender, G.D. Predicting accuracy of early cost estimates using factor analysis and multivariate regression. J. Constr. Eng. Manag. 2003, 129, 198–204. [Google Scholar] [CrossRef]
- An, S.H.; Kang, K.I. A study on predicting construction cost of apartment housing using experts’ knowledge at the early stage of projects. J. Archit. Inst. Korea 2005, 21, 81–88. [Google Scholar]
- Kolodner, J. Case-Based Reasoning; Morgan Kaufmann: Middlesex County, MA, USA, 2014; ISBN 1483294498. [Google Scholar]
- Goh, Y.M.; Chua, D.K.H. Case-based reasoning for construction hazard identification: Case representation and retrieval. J. Constr. Eng. Manag. 2009, 135, 1181–1189. [Google Scholar] [CrossRef]
- Doğan, S.Z.; Arditi, D.; Günaydın, H.M. Determining attribute weights in a CBR model for early cost prediction of structural systems. J. Constr. Eng. Manag. 2006, 132, 1092–1098. [Google Scholar] [CrossRef] [Green Version]
- Park, M.-S.; Seong, K.-H.; Lee, H.-S.; Ji, S.-H.; Kim, S.-Y. Schematic cost estimation method using case-based reasoning: Focusing on determining attribute weight. Korean J. Constr. Eng. Manag. 2010, 11, 22–31. [Google Scholar] [CrossRef] [Green Version]
- Lee, H.-S.; Kim, E.; Kim, D. Pattern Recognition System Combining KNN rules and New Feature Weighting algorithm. J. Inst. Electron. Eng. Korea CI 2005, 42, 43–50. [Google Scholar]
- Hwang, J.-H.; Kim, S.-Y. Integer programming-based local search technique for linear constraint satisfaction optimization Problem. J. Korea Soc. Comput. Inf. 2010, 15, 47–55. [Google Scholar] [CrossRef]
- Hwang, J.-H. An Integration of Local Search and Constraint Programming for Solving Constraint Satisfaction Optimization Problems. J. Korea Soc. Comput. Inf. 2010, 15, 39–47. [Google Scholar] [CrossRef]
- Kang, M.-G.; Park, S.-W.; Im, S.-J.; Kim, H.-J. Parameter calibrations of a daily rainfall-runoff model using global optimization methods. J. Korea Water Resour. Assoc. 2002, 35, 541–552. [Google Scholar] [CrossRef] [Green Version]
- Burke, E.K.; Curtois, T.; Post, G.; Qu, R.; Veltman, B. A hybrid heuristic ordering and variable neighbourhood search for the nurse rostering problem. Eur. J. Oper. Res. 2008, 188, 330–341. [Google Scholar] [CrossRef] [Green Version]
- Qu, R.; He, F. A Hybrid Constraint Programming Approach for Nurse Rostering Problems. In Proceedings of the International Conference on Innovative Techniques and Applications of Artificial Intelligence; Springer: London, UK, 2008; pp. 211–224. [Google Scholar]
- Oh, I.-S.; Lee, J.-S.; Moon, B.-R. Hybrid genetic algorithms for feature selection. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 1424–1437. [Google Scholar] [PubMed] [Green Version]
- Aamodt, A.; Plaza, E. Case-based reasoning: Foundational issues, methodological variations, and system approaches. AI Commun. 1994, 7, 39–59. [Google Scholar] [CrossRef]
- Kim, B.; Hong, T. Revised case-based reasoning model development based on multiple regression analysis for railroad bridge construction. J. Constr. Eng. Manag. 2012, 138, 154–162. [Google Scholar] [CrossRef]
- Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Pearson Correlation Coefficient. In Noise Reduction in Speech Processing; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–4. [Google Scholar]
- Goldberg, D.E. Messy genetic algorithms: Motivation, analysis, and first results. Complex Syst. 1989, 3, 493–530. [Google Scholar]
- Lee, H.-S.; Kim, S.-Y.; Park, M.-S.; Ji, S.-H.; Seong, K.-H.; Pyeon, J.-H. A method of assigning weight values for qualitative attributes in CBR cost model. Korean J. Constr. Eng. Manag. 2011, 12, 53–61. [Google Scholar]
- Kim, G.H.; An, S.H.; Cho, H.K. Comparison of the Accuracy between Cost Prediction Models Based on Neural Network and Genetic Algorithm: Focused on Apartment Housing Project Cost. J. Archit. Inst. Korea 2006, 23, 111–118. [Google Scholar]
- De Backer, B.; Furnon, V.; Prosser, P.; Kilby, P.; Shaw, P. Local Search in Constraint Programming: Application to the Vehicle Routing Problem. In Proceedings of the Proc. CP-97 Workshop Indust. Constraint-Directed Scheduling; Schloss Hagenberg Austria: Hagenberg im Mühlkreis, Austria, 1997; pp. 1–15. [Google Scholar]
- Lau, T.L.; Tsang, E.P.K. Solving the Processor Configuration Problems with a Mutation-Based Genetic Algorithm. Int. J. Artif. Intell. Tools 1997, 6, 567–585. [Google Scholar] [CrossRef]
- Paredis, J. Genetic State-Space Search for Constrained Optimization Problems. In Proceedings of the IJCAI; Citeseer: Chambéry, France, 1993; pp. 967–973. [Google Scholar]
- Kim, H.-H.; Choi, J.-Y. An Efficient Search Algorithm for Flexible Manufacturing Systems (FMS) Scheduling Problem with Finite Capacity. IE Interfaces 2009, 22, 10–16. [Google Scholar]
- Zhou, H.; Deng, Z.; Xia, Y.; Fu, M. A new sampling method in particle filter based on Pearson correlation coefficient. Neurocomputing 2016, 216, 208–215. [Google Scholar] [CrossRef]
- Maaranen, H.; Miettinen, K.; Penttinen, A. On initial populations of a genetic algorithm for continuous optimization problems. J. Glob. Optim. 2007, 37, 405. [Google Scholar] [CrossRef]
- Ji, S.-H.; Park, M.-S.; Lee, H.-S.; Seong, K.-H.; Yoon, Y.-S. Method of Quantity Data Analysis for Building Construction Cost Estimation: Focusing on Finish Work of Public Apartment Project. Korean J. Constr. Eng. Manag. 2008, 9, 235–243. [Google Scholar]
- Christensen, P.; Dysert, L.R. Cost Estimate Classification System. In AACE International Recommended Practice 17R–97; AACE: Durham, NH, USA, 1997. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No | Attributes | Type | Correlation Coefficient |
|---|---|---|---|
| X1 | Number of households | Numeric | 0.8336 |
| X2 | Gross floor area | Numeric | 0.9701 |
| X3 | Number of unit floor households | Numeric | 0.6952 |
| X4 | Number of elevators | Numeric | 0.3865 |
| X5 | Number of floors | Numeric | 0.7290 |
| X6 | Number of pilots with household scale | Numeric | 0.4854 |
| X7 | Number of households of unit floor per elevator | Numeric | 0.4556 |
| X8 | Height between stories | Numeric | 0.5171 |
| X9 | Depth of pit | Numeric | 0.0166 |
| X10 | Roof type | Flat or inclined (1 or 0) | 0.4296 |
| X11 | Hallway type | Hall or corridor (1 or 0) | 0.4135 |
| X12 | Cost | Numeric | 1 |
| No | Attributes | Type | Correlation Coefficient |
|---|---|---|---|
| X1 | Number of capacity | Numeric | 0.8263 |
| X2 | Number of floors | Numeric | 0.6830 |
| X3 | Gross floor area | Numeric | 0.9814 |
| X4 | Building area | Numeric | 0.9306 |
| X5 | Room area | Numeric | 0.0295 |
| X6 | Office area | Numeric | 0.2108 |
| X7 | Basement floor status | Existence or Non(1 or 0) | 0.2936 |
| X8 | Pit status | Existence or Non(1 or 0) | 0.4160 |
| X9 | Cost | Numeric | 1 |
| No | Attributes | Type | Correlation Coefficient |
|---|---|---|---|
| X1 | Lot Area | Numeric | 0.1905 |
| X2 | Gross floor area | Numeric | 0.2512 |
| X3 | Building Coverage Ratio | Numeric | 0.0057 |
| X4 | Floor Area Ratio | Numeric | 0.0333 |
| X5 | Number of Underground Floor | Numeric | 0.2278 |
| X6 | Number of Ground Floor | Numeric | 0.2434 |
| X7 | Structure Type(RC) | Existence or Non(1 or 0) | 0.2717 |
| X8 | Structure Type(SRC) | Existence or Non(1 or 0) | 0.0965 |
| X9 | External Material | Metal or Stone(1 or 0) | 0.0518 |
| X10 | Cost | Numeric | 1 |
| Methodology | X1 | X2 | X3 | X4 | X5 | X6 | X7 | X8 | X9 | X10 | X11 | X12 | Error Rate (%) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Case1 (APT) | Hybrid GA–CBR | 0.1051 | 0.8741 | 0.0039 | 0.00032 | 0.0049 | 0.0006 | 0.0005 | 0.0008 | 2.571 × 10−8 | 0.0004 | 0.0004 | 0.0086 | 4.73 |
| Existing GA–CBR | 0.1254 | 0.1479 | 0.0412 | 0.01447 | 0.1420 | 0.0079 | 0.1417 | 0.1325 | 0.0077 | 0.0420 | 0.1335 | 0.0631 | 8.25 | |
| Uniform Weight | 0.0833 | 0.0833 | 0.0833 | 0.0833 | 0.0833 | 0.0833 | 0.0833 | 0.0833 | 0.0833 | 0.0833 | 0.0833 | 0.0833 | 11.18 | |
| Regression Analysis | 0.002 | 0.0005 | 0.0903 | 0.2543 | 0.0742 | 0.0240 | 0.080 | 0.0483 | 0.0237 | 0.0829 | 0.0971 | 0.2210 | 8.76 | |
| Case2 (Military) | Hybrid GA–CBR | 0.0024 | 0.0003 | 0.9245 | 0.0726 | 2.607 × 10−15 | 1.785 × 10−8 | 2.600 × 10−7 | 4.485 × 10−6 | 8.72 | ||||
| Existing GA–CBR | 0.1632 | 0.1540 | 0.1811 | 0.1931 | 0.0995 | 0.0712 | 0.0289 | 0.1091 | 14.87 | |||||
| Uniform Weight | 0.125 | 0.125 | 0.125 | 0.125 | 0.125 | 0.125 | 0.125 | 0.125 | 19.24 | |||||
| Regression Analysis | 0.0014 | 0.3112 | 0.0014 | 0.0015 | 0.216 | 0.1917 | 0.0721 | 0.204 | 9.03 | |||||
| Case3 (Office) | Hybrid GA–CBR | 0.0717 | 0.1146 | 2.865 × 10−6 | 0.0004 | 0.1116 | 0.2454 | 0.4309 | 0.0149 | 0.0004 | 7.67 | |||
| Existing GA–CBR | 0.0773 | 0.2155 | 0.0759 | 0.0732 | 0.2291 | 0.0739 | 0.1167 | 0.1379 | 0.0005377 | 8.00 | ||||
| Uniform Weight | 0.111 | 0.111 | 0.111 | 0.111 | 0.111 | 0.111 | 0.111 | 0.111 | 0.111 | 10.94 | ||||
| Regression Analysis | 2.99 × 10−6 | 5.42 × 10−6 | 8.53 × 10−5 | 0.0895 | 0.0254 | 0.3710 | 0.4305 | 0.0214 | 0.0618 | 8.82 |
| Hybrid GA–CBR | Existing GA–CBR | Uniform Weight | Regression Analysis | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Case | Actual Cost (Unit: USD) | Estimated Cost | Error (%) | Estimated Cost | Error (%) | Estimated Cost | Error (%) | Estimated Cost | Error (%) |
| A1 | 4,041,759 | 3,461,238 | 14.36 | 3,194,994 | 20.95 | 3,308,649 | 18.14 | 3,708,831 | 8.24 |
| A2 | 2,480,768 | 2,368,251 | 4.54 | 2,932,602 | 18.21 | 3,263,491 | 31.55 | 2,299,010 | 7.33 |
| A3 | 2,616,244 | 2,697,074 | 3.09 | 3,718,770 | 42.14 | 3,718,770 | 42.14 | 2,578,802 | 1.43 |
| A4 | 3,009,074 | 3,065,333 | 1.87 | 2,985,277 | 0.79 | 2,921,467 | 2.91 | 3,318,279 | 10.28 |
| ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ |
| A51 | 2,935,510 | 2,819,128 | 3.96 | 2,985,277 | 1.7 | 3,104,637 | 5.76 | 3,562,271 | 21.35 |
| A52 | 2,348,707 | 2,368,251 | 0.83 | 3,040,764 | 29.47 | 3,040,764 | 29.47 | 1,869,979 | 20.38 |
| Error mean | 4.73 | 8.25 | 11.18 | 8.76 | |||||
| M1 | 1,905,969 | 1,683,481 | 11.67 | 1,828,768 | 4.05 | 1,821,200 | 4.45 | 1,737,490 | 8.84 |
| M2 | 839,159 | 855,092 | 1.9 | 866,964 | 3.31 | 855,092 | 1.9 | 744,614 | 11.27 |
| M3 | 664,576 | 703,004 | 5.78 | 617,659 | 7.06 | 564,144 | 15.11 | 617,659 | 7.06 |
| M4 | 904,227 | 941,919 | 4.17 | 870,580 | 3.72 | 855,092 | 5.43 | 744,614 | 17.65 |
| ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ |
| M34 | 523,213 | 517,309 | 1.13 | 516,858 | 1.21 | 505,049 | 3.47 | 574,071 | 9.72 |
| M35 | 490,932 | 506,263 | 3.12 | 497,359 | 1.31 | 497,359 | 1.31 | 497,359 | 1.31 |
| Error mean | 8.72 | 14.87 | 19.24 | 9.03 | |||||
| O1 | 474,186 | 562,944 | 18.72 | 511,211 | 7.81 | 514,679 | 8.54 | 589,467 | 24.31 |
| O2 | 655,188 | 481,889 | 26.45 | 490,877 | 25.08 | 482,220 | 26.4 | 492,874 | 24.77 |
| O3 | 438,030 | 414,994 | 5.26 | 455,645 | 4.02 | 577,415 | 31.82 | 533,219 | 21.73 |
| ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ |
| O5 | 390,990 | 458,641 | 17.3 | 405,170 | 3.63 | 423,063 | 8.2 | 441,955 | 13.04 |
| O15 | 422,950 | 492,874 | 16.53 | 498,365 | 17.83 | 522,709 | 23.59 | 492,874 | 16.53 |
| O16 | 538,911 | 591,314 | 9.72 | 591,314 | 9.72 | 541,803 | 0.54 | 591,314 | 9.72 |
| Error mean | 7.67 | 8.00 | 10.94 | 8.82 | |||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jung, S.; Pyeon, J.-H.; Lee, H.-S.; Park, M.; Yoon, I.; Rho, J. Construction Cost Estimation Using a Case-Based Reasoning Hybrid Genetic Algorithm Based on Local Search Method. Sustainability 2020, 12, 7920. https://doi.org/10.3390/su12197920
Jung S, Pyeon J-H, Lee H-S, Park M, Yoon I, Rho J. Construction Cost Estimation Using a Case-Based Reasoning Hybrid Genetic Algorithm Based on Local Search Method. Sustainability. 2020; 12(19):7920. https://doi.org/10.3390/su12197920
Chicago/Turabian StyleJung, Sangsun, Jae-Ho Pyeon, Hyun-Soo Lee, Moonseo Park, Inseok Yoon, and Juhee Rho. 2020. "Construction Cost Estimation Using a Case-Based Reasoning Hybrid Genetic Algorithm Based on Local Search Method" Sustainability 12, no. 19: 7920. https://doi.org/10.3390/su12197920