Machine Learning for Conservation Planning in a Changing Climate

 ,
,  ,
, 
Abstract
:1. Introduction
1.1. Species Distribution Modeling
1.2. Study Objectives
Problem Statement
- How accurately can sage-grouse habitats be classified using each of the selected ML algorithms based on both continuous and categorical variables?
- How will sage-grouse habitats in Utah be impacted by the varying future emission scenarios that represent the state’s temperature-change trajectory most closely?
- Based on the prediction maps for future scenarios obtained from the models, how will the change in sage-grouse habitats affect current conservation areas?
2. Data and Materials
2.1. Study Area
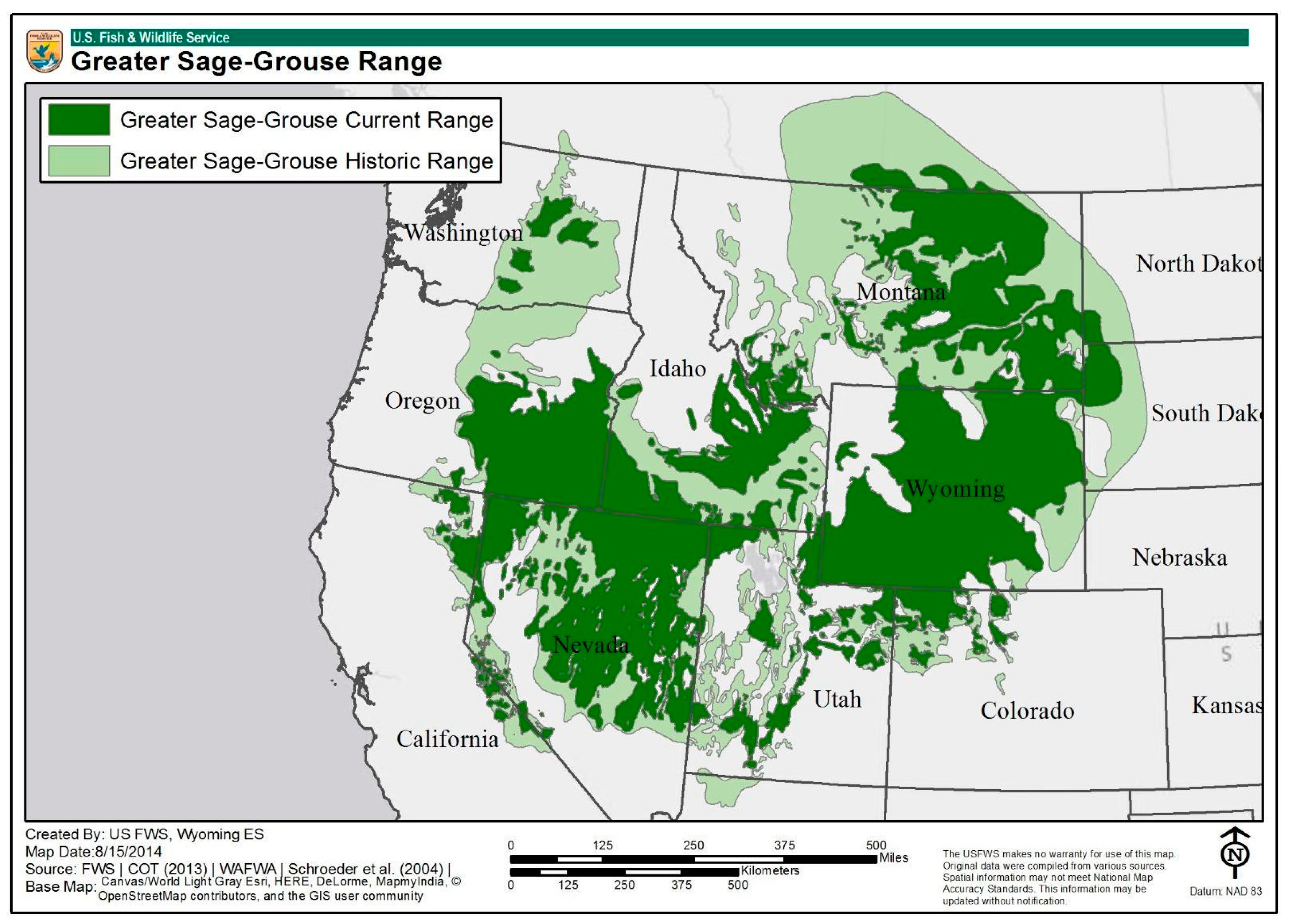
2.2. Species of Interest: Greater Sage-Grouse (Centrocercus urophasianus)
3. Data
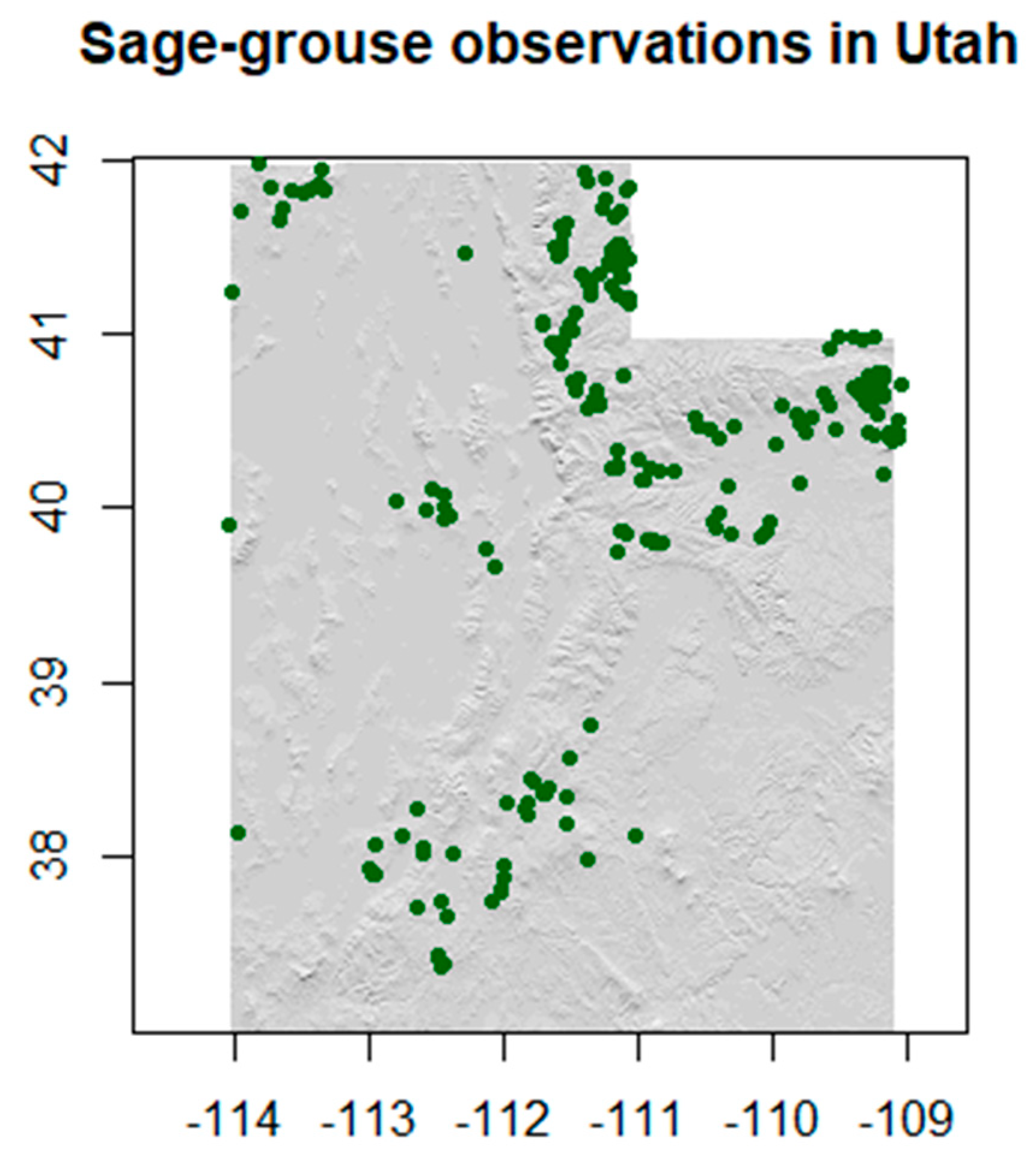
3.1. Wildlife Data
3.1.1. Data Processing
3.1.2. Creating Background/Pseudo-Absence Data
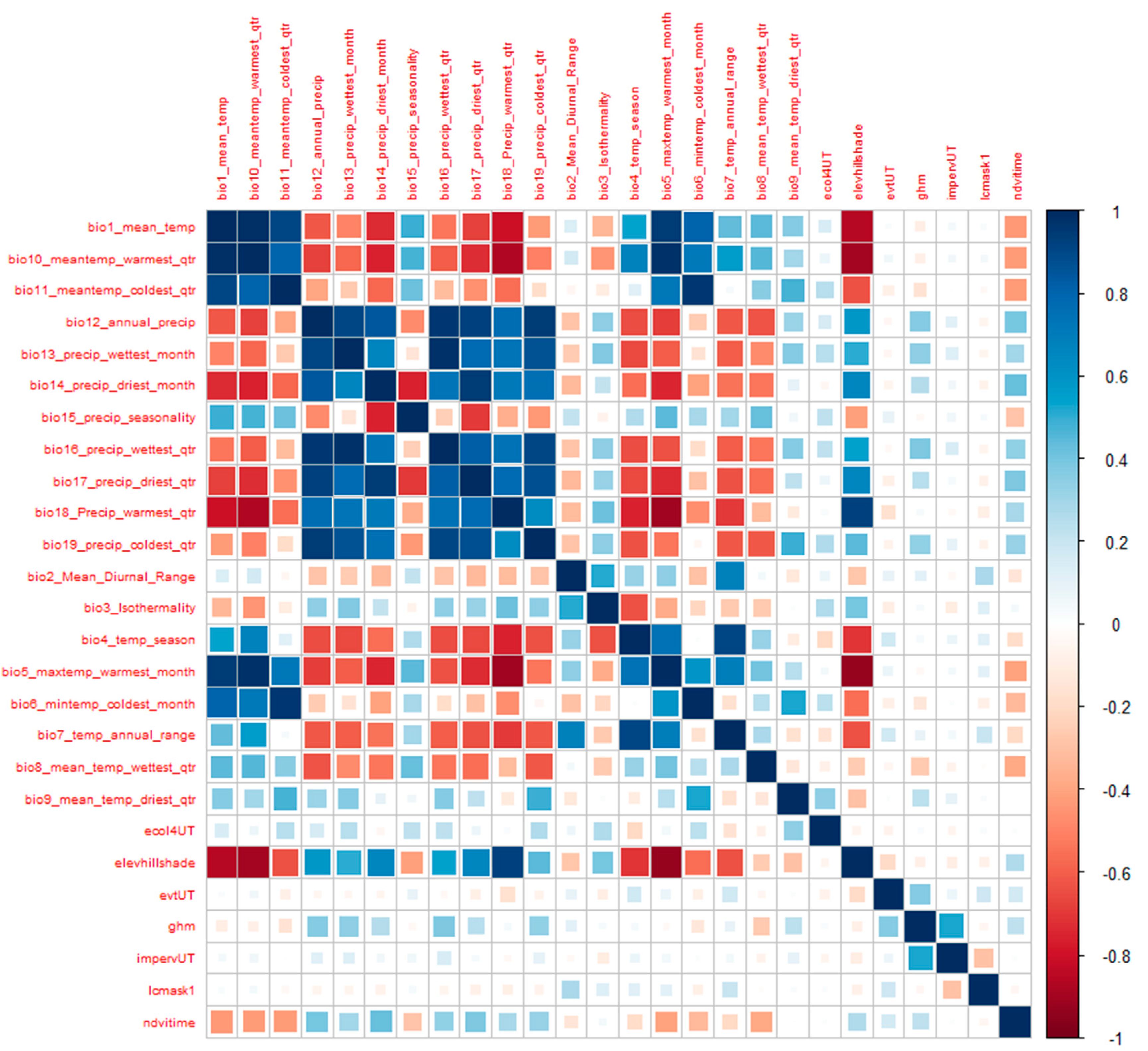
3.2. Environmental Data
Data Processing
3.3. Future Estimated Data
3.3.1. Climate Data Future Scenarios
3.3.2. Land Cover Future Scenarios
4. Methods
4.1. Machine Learning Algorithms
4.1.1. Random Forest
4.1.2. Support Vector Machine
4.1.3. Artificial Neural Network
4.1.4. MaxEnt
4.1.5. Model Tuning
4.1.6. Implementation
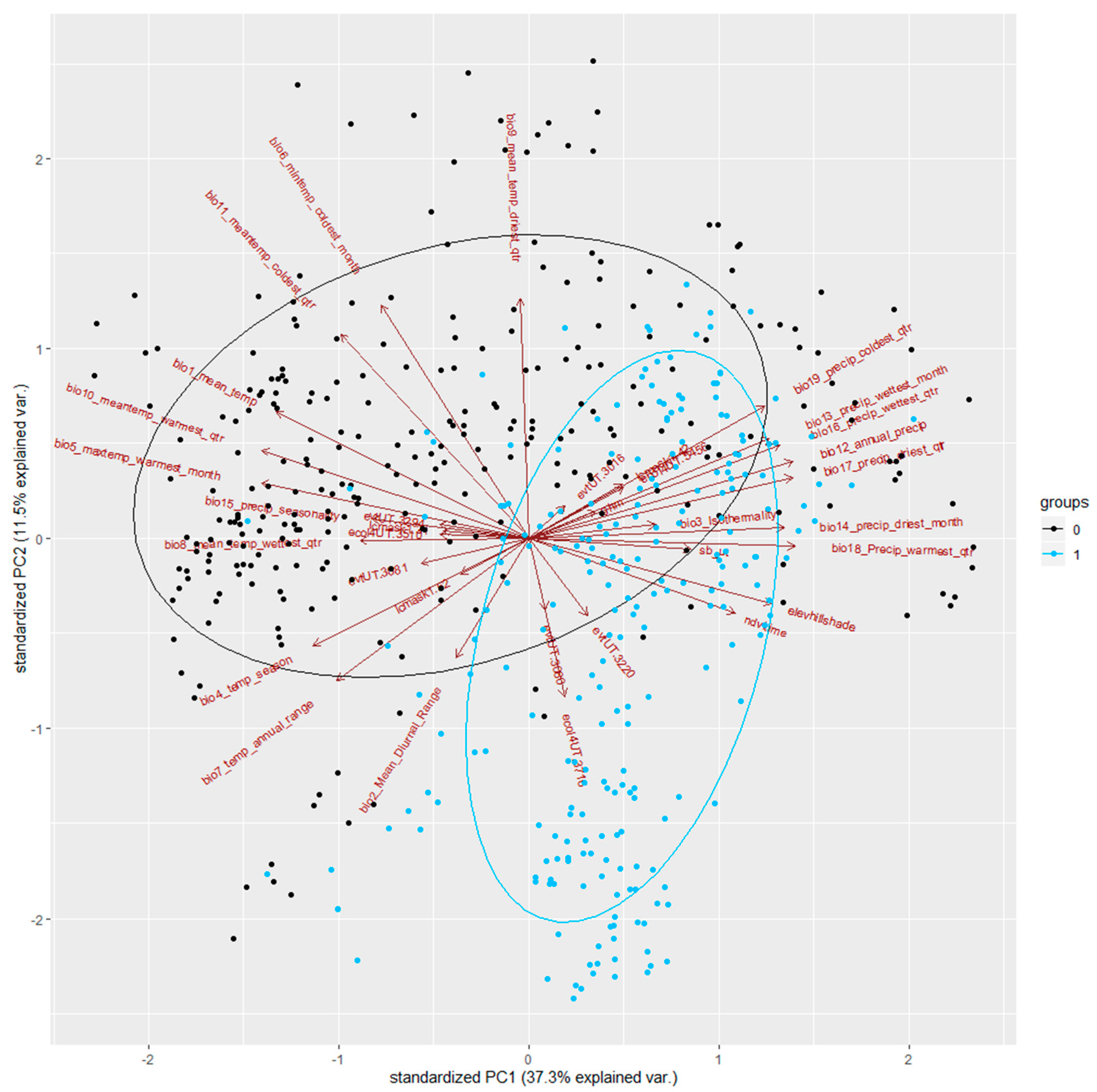
- (1).
- The X-axis represents PC1, the first component of the PCA, and the Y-axis represents the second component, PC2;
- (2).
- The points in blue are presence points, and those in black, absence points;
- (3).
- The ellipses represent the average distributions of the presence and absence points;
- (4).
- The arrows represent variables, and when two variables are pointing in the same direction or opposite directions, they are highly dependent (thus, independent when pointing in orthogonal directions);
- (5).
- The longer the arrow, the higher the importance of the variable for the overall environmental variation.
Setting up for RF, SVM and ANN Models
- trainControl: defines the type and number of resampling, as well as the search method. We used cross-validation with 10 folds, and with random search.
- metric: determines how the final model is defined, by selecting the tuning parameters with the highest value of the objective function. Amongst the functions available, we set it to “Accuracy”.
- tuneLength: sets the size of the default grid of the tuning parameters; set to 15 for all our models.
- preProcess: we selected to center and scale before resampling.
Future Predictions for Each Scenario
5. Results
5.1. Present
External Validation
5.2. Future
6. Discussion
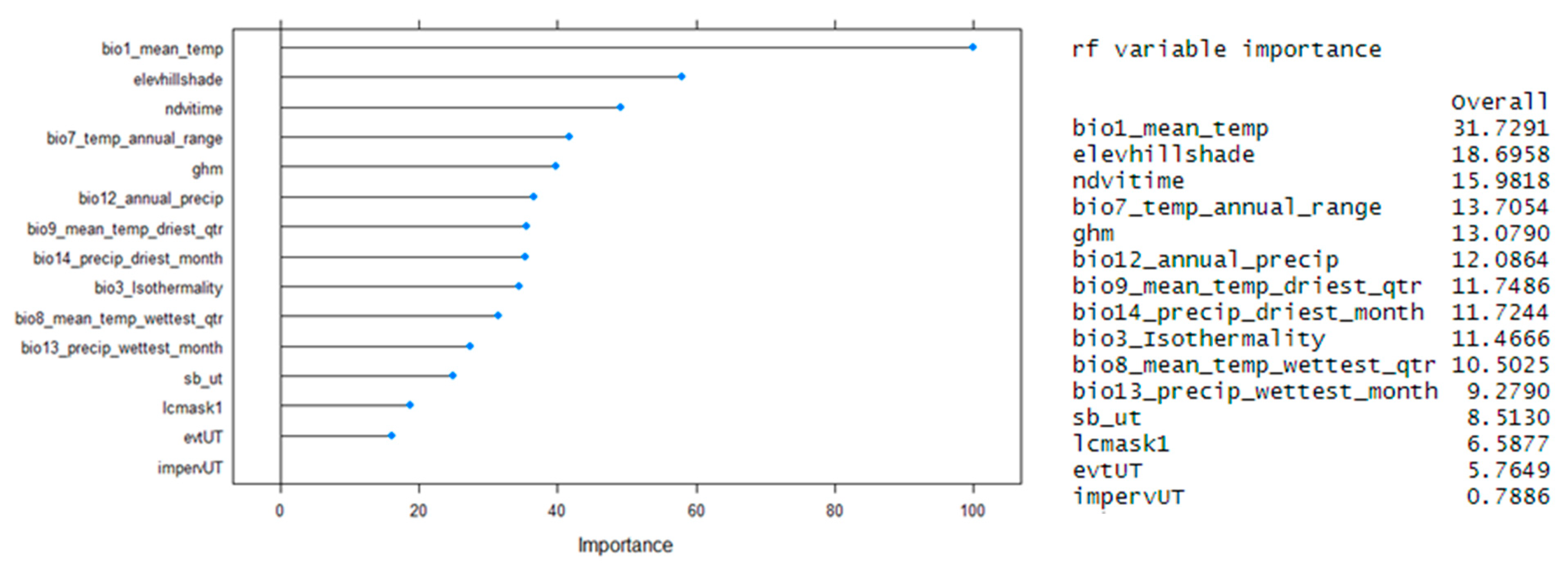
6.1. Current Situation and Overall Performance of the Models
6.1.1. How Accurately Can Sage-Grouse’s Habitats Be Classified Using Each of the Selected Machine Learning Algorithms Based on Both Continuous and Categorical Variables?
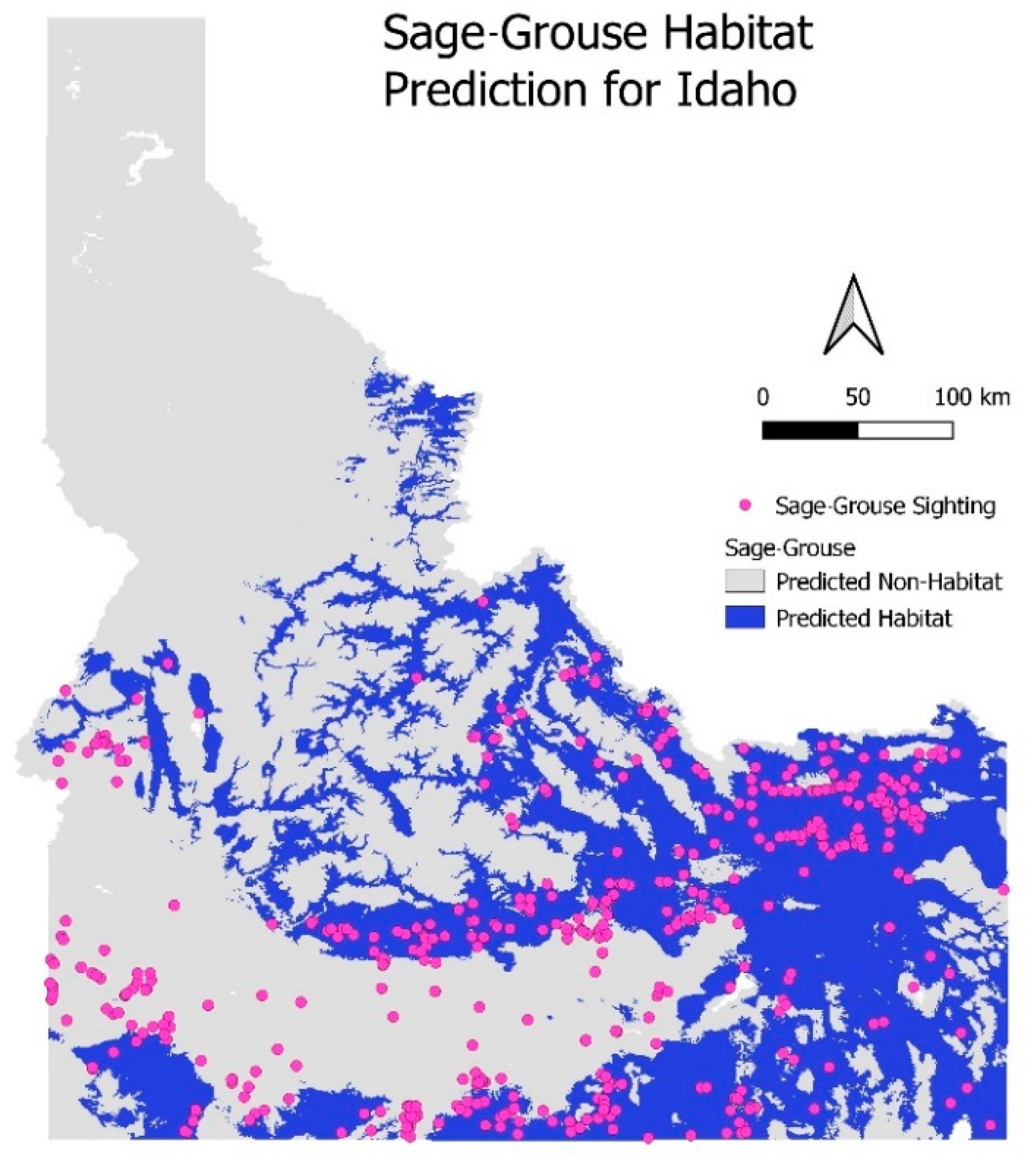
6.1.2. External Validation—Sage-Grouse Habitats in Idaho
6.2. Future Predictions: Implications and Limitations
6.2.1. How Will the Sage-Grouse Habitats in Utah Be Impacted by the Varying Future Emission Scenarios That Represent the State’s Temperature Change Trajectory Most Closely?
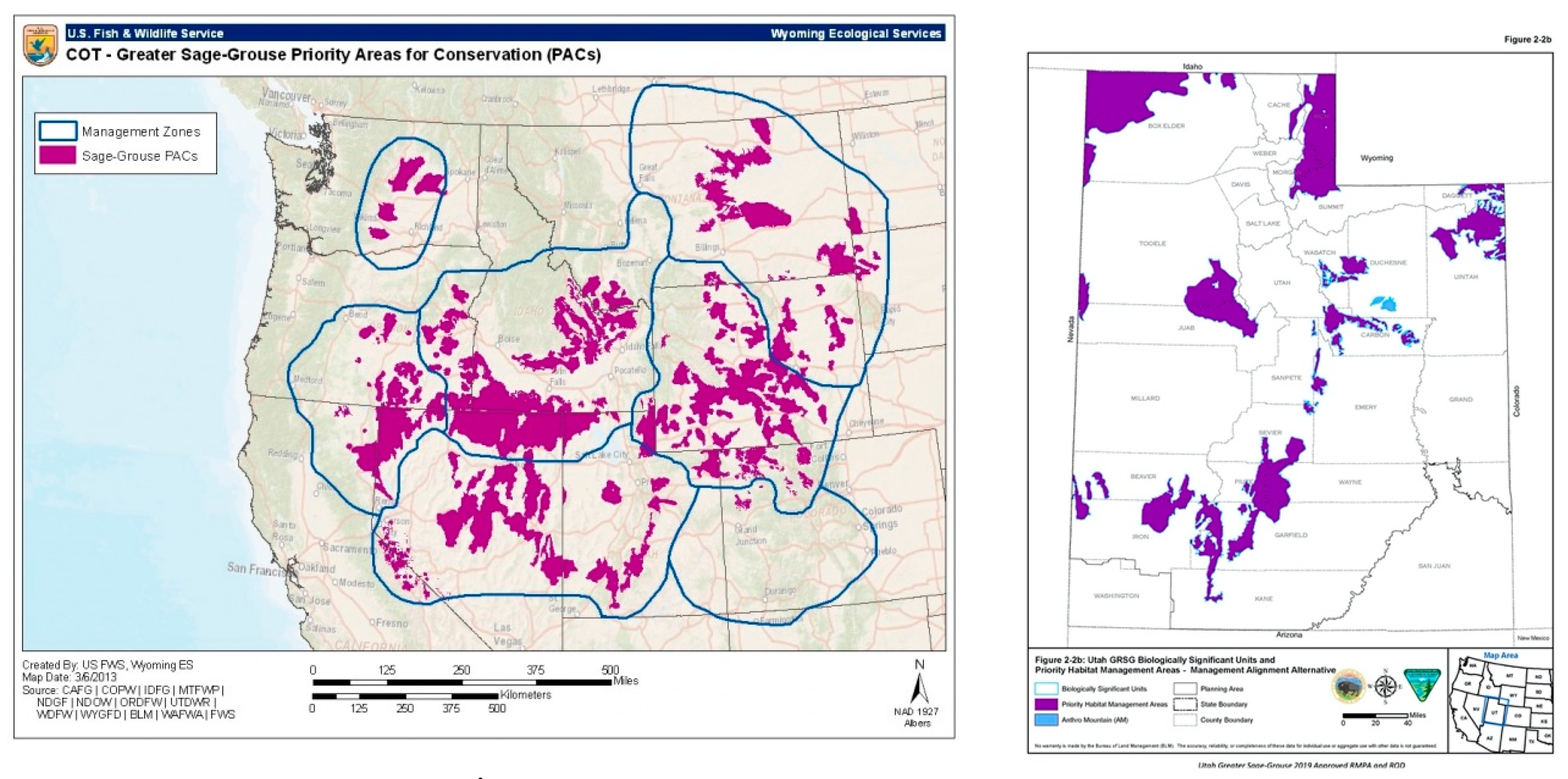
6.2.2. Based on the Prediction Maps for Future Scenarios Obtained from the Models, How Will the Change in Sage-Grouse Habitats Affect Current Conservation Areas?
How Do These Suggestions Follow the UN’s SDGs and the CBD Goals?
7. Limitations
8. Conclusions
9. Future Extension
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- European Commission. 4 August 2009. Available online: https://ec.europa.eu/environment/nature/info/pubs/docs/climate_change/en.pdf (accessed on 25 May 2020).
- Convention on Biological Diversity. “Introduction,” Convention on Biological Diversity. 2012. Available online: https://www.cbd.int/intro/ (accessed on 31 May 2020).
- United Nations. About the Sustainable Development Goals. 2020. Available online: https://www.un.org/sustainabledevelopment/sustainable-development-goals/ (accessed on 31 May 2020).
- Zhang, J.; Li, S. A Review of Machine Learning Based Species’ Distribution Modelling. In Proceedings of the 2017 International Conference on Industrial Informatics—Computing Technology, Intelligent Technology, Industrial Information Integration, Wuhan, China, 2–3 December 2017. [Google Scholar]
- Burnett, C. Modeling Habitat Use of a Fringe Greater SageGrouse Population at Multiple Spatial Scales. Utah State University. July 2013. Available online: https://extension.usu.edu/wildlife-interactions/ou-files/faqs/Modeling-Habitat-Use-of-a-Fringe-Greater-Sage-Grouse-Population.pdf (accessed on 23 May 2020).
- United States Environmental Protection Agency. What Climate Change Means for Utah. August 2016. Available online: https://19january2017snapshot.epa.gov/sites/production/files/2016-09/documents/climate-change-ut.pdf (accessed on 20 May 2020).
- Bureau of Land Management. State Threatened and Endangered Information. Bureau of Land Managment. 2019. Available online: https://www.blm.gov/programs/fish-and-wildlife/threatened-and-endangered/state-te-data/utah (accessed on 23 May 2020).
- Climate Central. Utah. 2020. Available online: https://statesatrisk.org/utah/all (accessed on 31 May 2020).
- Wilson, M.C.; Chen, X.Y.; Corlett, R.T.; Didham, R.K.; Ding, P.; Holt, R.D.; Holyoak, M.; Hu, G.; Hughes, A.C.; Jiang, L.; et al. Habitat fragmentation and biodiversity conservation: Key findings and future challenges. Lands. Ecol. 2016, 31, 219–227. [Google Scholar] [CrossRef] [Green Version]
- Crooks, K.R.; Burdett, C.L.; Theobald, D.M.; King, S.R.; di Marco, M.; Rondinini, C.; Boitani, L. Quantification of habitat fragmentation reveals extinction risk in terrestrial mammals. Proc. Natl. Acad. Sci. USA 2017, 114, 7635–7640. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huettmann, F. Machine Learning for ‘Strategic Conservation and Planning’: Patterns, Applications, Thoughts and Urgently Needed Global Progress for Sustainability. In Machine Learning for Ecology and Sustainable Natural Resource Management; Springer: Berlin, Germany, 2018. [Google Scholar]
- Game, E.T.; Lipsett-Moore, G.; Saxon, E.; Peterson, N.; Sheppard, S. Incorporating climate change adaptation into national conservation assessments. Glob. Chang. Biol. 2011, 17, 3150–3160. [Google Scholar] [CrossRef]
- Oliver, T.H.; Smithers, R.J.; Bailey, S.; Walkmsley, C.A.; Watts, K. A decision framework for considering climate change adaption in biodiversity conservation planning. J. Appl. Ecol. 2012, 49, 1247–1255. [Google Scholar] [CrossRef]
- Baltensperger, P.; Huettmann, F. Predictive spatial niche and biodiversity hotspot models for small mammal communities in Alaska: Applying machine-learning to conservation planning. Lands. Ecol. 2015, 30, 681–697. [Google Scholar] [CrossRef]
- Shaw, R. The 10 Best Machine Learning Algorithms for Data Science Beginners. Dataquest Labs, Inc. 2019. Available online: https://www.dataquest.io/blog/top-10-machine-learning-algorithms-for-beginners/ (accessed on 31 May 2020).
- Elith, J.; Leathwick, J.R. Species Distribution Models: Ecological Explanation and Prediction across Space and Time. Annu. Rev. Ecol. Evol. Syst. 2009, 40, 677–697. [Google Scholar] [CrossRef]
- Aguirre-Gutiérrez, J.; Raes, N. A Modeling Framework to Estimate and Project Species Distributions in Space and Time. Mt. Clim. Biodivers. 2018, 309–320. [Google Scholar]
- Sofaer, H.R.; Jarnevich, C.S.; Pearse, I.S.; Smyth, R.L.; Auer, S.; Cook, G.L.; Edwards, T.C., Jr.; Guala, G.F.; Howard, T.G.; Morisette, J.T.; et al. Development and Delivery of Species Distribution Models to Inform Decision-Making. BioScience 2019, 69, 544–557. [Google Scholar] [CrossRef]
- Netstate. Utah: The Geography of Utah. NSTATE, LLC. 25 February 2016. Available online: https://www.netstate.com/states/geography/ut_geography.htm (accessed on 26 May 2020).
- Utah Rivers Council. Climate Change. 2020. Available online: https://utahrivers.org/climate-change (accessed on 28 May 2020).
- NatureServe. Utah Conservation Summary. 2020. Available online: http://www.landscope.org/utah/overview/ (accessed on 29 May 2020).
- Park City Municipal. Community & Municipal Carbon Footprint. 2020. Available online: https://www.parkcity.org/departments/sustainability/community-municipal-carbon-footprint (accessed on 4 May 2020).
- USFWS. Greater Sage-grouse Conservation in Utah. U.S. Fish & Wildlife Service. 2020. Available online: https://www.fws.gov/greatersagegrouse/factsheets/UTGrSGFactSheet_FINAL.pdf (accessed on 15 May 2020).
- Opar, Tick Tock Goes the Sage-Grouse Conservation Clock; National Audobon Society: October 2015. Available online: https://www.audubon.org/magazine/september-october-2015/tick-tock-goes-sage-grouse (accessed on 16 May 2020).
- Connelly, J.W.; Knick, S.T.; Schroeder, M.A.; Stiver, S.J. Conservation Assessment of Greater Sage-Grouse and Sagebrush Habitats. DigitalCommons@USU; Western Association of Fish and Wildlife Agencies: Cheyenne, WY, USA, 2004. [Google Scholar]
- Stauffer, M.; Curtis, L.D. Governor: Utah Will Implement New Controversial Plan for Sage Grouse. KUTV. 15 January 2019. Available online: https://kutv.com/news/local/governor-utah-will-implement-new-plan-to-conserve-sage-grouse (accessed on 15 May 2020).
- Utah DNR. Greater Sage-Grouse. State of Utah. 1 May 2019. Available online: https://wildlife.utah.gov/greater-sage-grouse.html (accessed on 15 May 2020).
- Institute for Applied Ecology. Five Things You Didn’t Know About Sagebrush. 2020. Available online: https://appliedeco.org/five-things-you-didnt-know-about-sagebrush/ (accessed on 20 May 2020).
- Strategic Management Plan for Sage-grouse; Utah Division of Wildlife Resources: Salt Lake City, Utah, 2002.
- The National Wildlife Federation. Greater Sage-Grouse. The National Wildlife Federation. 2020. Available online: https://www.nwf.org/Educational-Resources/Wildlife-Guide/Birds/Greater-Sage-Grouse (accessed on 5 May 2020).
- Global Biodiversity Information Facility. 2020. Available online: https://www.gbif.org/ (accessed on 23 May 2020).
- Aarts, G.; Fieberg, J.; Matthiopoulos, J. Comparative interpretation of count, presence–absence and point methods for species distribution models. Methods Ecol. Evol. 2012, 3, 177–187. [Google Scholar] [CrossRef]
- Phillips, S.J.; Dudik, M.; Elith, J.; Graham, C.H.; Lehmann, A.; Leathwick, J.; Ferrier, S. Sample Selection Bias and Presence-Only Distribution Models: Implications for Background and Pseudo-Absence Data. Ecol. Appl. 2009, 19, 181–197. [Google Scholar]
- Senay, S.D.; Worner, S.P.; Ikeda, T. Novel Three-Step Pseudo-Absence Selection Technique for Improved Species Distribution Modelling. PLoS ONE 2013, 8, e71218. [Google Scholar]
- Dahlgren, D.K.; Messmer, T.; Crabb, B.A.; Larsen, R.T. Seasonal Movements of Greater Sage-grouse Populations in Utah: Implications for Species Conservation. Wildl. Soc. Bull. 2016, 40, 288–299. [Google Scholar] [CrossRef]
- Barbet-Massin, M.; Jiguet, F.; Albert, C.H.; Thuiller, W. Selecting pseudo-absences for species distribution models: How, where and how many? Methods Ecol. Evol. 2012, 3, 327–338. [Google Scholar]
- WorldClim. Downscaling Future and Past Climate Data from GCMs; WorldClim. 2020. Available online: https://worldclim.org/data/downscaling.html (accessed on 14 May 2020).
- Sohl, T.; Sayler, K.; Bouchard, M.; Reker, R.; Freisz, A.; Bennett, S.; Sleeter, B.; Sleeter, R.; Wilson, T.; Soulard, C.; et al. Conterminous United States Land Cover Projections—1992 to 2100, ScienceBase-Catalog. 2017. Available online: https://www.sciencebase.gov/catalog/item/5b96c2f9e4b0702d0e826f6d (accessed on 24 May 2020).
- Scikit-learn. Scikit-learn: Machine learning in Python. Scikit-learn. 2020. Available online: https://scikit-learn.org/stable/ (accessed on 25 August 2020).
- Gautier, L. rpy2 3.3.5. pypi.org. 2020. Available online: https://pypi.org/project/rpy2/ (accessed on 25 August 2020).
- Maxwell; Warner, T.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar]
- Zhou, V. Machine Learning for Beginners: An Introduction to Neural Networks. Towards Data Science. 2019. Available online: https://towardsdatascience.com/machine-learning-for-beginners-an-introductionto-neural-networks-d49f22d238f9 (accessed on 27 May 2020).
- Merow, C.; Smith, M.J.; Silander, J.A., Jr. A practical guide to MaxEnt for modeling species’ distribution: What it does, and why inputs and settings matter. Ecography 2013, 36, 1058–1069. [Google Scholar]
- Guillera-Arroita, G.; Lahoz-Monfort, J.J.; Elith, J. Maxent is not a presence–absence method: A comment on Thibaud et al. Methods Ecol. Evol. 2014, 5, 1192–1197. [Google Scholar]
- Wei, T.; Simko, V. Package ‘corrplot’. 17 October 2017. Available online: https://cran.r-project.org/web/packages/corrplot/corrplot.pdf (accessed on 31 May 2020).
- Bungaro, L. How to Evaluate your Machine Learning Model. Medium. 31 July 2018. Available online: https://medium.com/coinmonks/debugging-a-learning-algorithm-ef7c16936864 (accessed on 25 May 2020).
- Kuhn, M. Caret Package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar]
- Landis, J.R.; Koch, G.G. An Application of Hierarchical Kappa-type Statistics in the Assessment of Majority Agreement among Multiple Observers. Biometrics 1977, 33, 363–374. [Google Scholar] [CrossRef]
- Duan, R.-Y.; Kong, X.-Q.; Huang, M.-Y.; Fan, W.-Y.; Wang, Z.-G. The Predictive Performance and Stability of Six Species Distribution Models. PLoS ONE 2014, 9, e112764. [Google Scholar] [CrossRef] [Green Version]
- Elith, J.; Graham, C.H.; Anderson, R.P.; Dudı´k, M.; Ferrier, S.; Guisan, A.; Hijmans, R.J.; Huettmann, F.; Leathwick, J.R.; Lehmann, A.; et al. Novel methods improve prediction of species’ distributions from occurrence data. Ecography 2006, 29, 129–151. [Google Scholar] [CrossRef] [Green Version]
- Guisan, A.; Thuiller, W.; Zimmermann, N.E. Habitat Suitability and Distribution Models: With Application in R, Vols. Ecology, Biodiversity and Conservation; Cambridge University Press: Cambridge, UK, 2017. [Google Scholar]
- Rowland, M.M.; Vojta, C.D. A Technical Guide for Monitoring Wildlife Habitat; Forest Service: Washington, DC, USA, 2013. [Google Scholar]
- Shultz, L. Pocket Guide to Sagebrush. 2012. Available online: http://www.sagegrouseinitiative.com/wp-content/uploads/2013/07/SGI_Sagebrush_PocketGuide_Nov12.pdf (accessed on 20 May 2020).
- National Audubon Society. Greater Sage-Grouse. 2019. Available online: https://climate2014.audubon.org/birds/saggro/greater-sage-grouse (accessed on 21 May 2020).
- Connelly, J.W.; Rinkes, E.T.; Braun, C.E. Chapter Four Characteristics of Greater Sage-Grouse Habitats: A Landscape Species at Micro-And Macroscales. In Greater Sage-Grouse: Ecology and Conservation of a Landscape Species and Its Habitats; University of California Press: Berkeley, CA, USA, 2011. [Google Scholar]
- Knick, S.T.; Connelly, J.W. Greater Sage-Grouse: Ecology and Conservation of a Landscape Species and Its Habitats; University of California Press: Berkeley, CA, USA, 2011; p. 664. [Google Scholar]
- Laurance, W.F.; Nascimento, H.E.M.; Laurance, S.G.; Andrade, A.; Ewers, R.M.; Harms, K.E.; Luizão, R.C.C.; Ribeiro, J.E. Habitat Fragmentation, Variable Edge Effects, and the Landscape-Divergence Hypothesis. PLoS ONE 2007, 2, e1017. [Google Scholar] [CrossRef] [PubMed]
- Davis, D.M.; Reese, K.P.; Gardner, S.C.; Bird, K.L. Genetic structure of Greater Sage-Grouse (Centrocercus urophasianus) in a declining, peripheral population. Condor 2015, 117, 530–544. [Google Scholar]
- U.S. Fish and Wildlife Service. Greater Sage-grouse (Centrocercus urophasianus) Conservation Objectives: Final Report. February 2013. Available online: https://www.fws.gov/greatersagegrouse/documents/COT-Report-with-Dear-Interested-Reader-Letter.pdf (accessed on 31 May 2020).
- Vrijenhoek, R.C. Genetic Diversity and Fitness in Small Populations. In Conservation Genetics; Birkhäuser: Basel, Switzerland, 1994; pp. 37–53. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methodology | Use | Strengths | Weaknesses | Source |
|---|---|---|---|---|
| Use of Remote Sensing imagery to calculate vegetation extent, several environmental layers as background data and museum observations for species data. The MARXAN software was used for all planning strategies and run multiple times with target set data | Conservation strategy, implementation and assessment in response to biodiversity loss in Papua New Guinea | Addresses the static, unproductive approach to current conservation assessment efforts in this location, addresses impact of climate change on species relocation. Discovery that geophysical data should be used in conjunction with environmental layers for reliability of results | Theoretically based research, more concentrated on current conservation assessment procedures and limited in terms of tools used | [12] |
| Machine Learning algorithm Decision Trees is used to determine current and future species distribution | Creation of a decision framework enabling the identification and prioritization of current conservation-related action | Enables an adaptive strategy plan, inclusive of science, policy and practice. Can be used for local management for species at risk on a universal level. Combines both theoretical and practical knowledge of conservation, where restricted information can inhibit rational planning | Requires expert insight when determining answers for each of the three potential Decision Tree algorithm outputs regarding species adaptability; Adversely Sensitive, Climate Overlap, and New Climate Space | [13] |
| Use of both archived and openly accessible records for presence data of species, confirmed by ground truthing methods. Random Forest Machine Learning algorithm, in addition to TreeNet, Mars, CART and MaxEnt, in combination with top-performing predictor variables, assessed future conservation areas for investigated species | Establish present distribution and territory of small mammals at northern latitudes whilst considering forced relocation as a consequence of habitat alteration due to climate change | Concludes points for successful methodology and provides an initial framework for species mapping and monitoring that can be implemented on a broader spatial–temporal scale. Provides advanced material for Machine Learning algorithms used in species distribution modeling. Offers insight into understanding predictor variables and resolutions | [14] | |
| Machine Learning algorithm MaxEnt is used alongside Very High Frequency telemetry technology and predictor variables in locating undiscovered seasonal distributions of sage-grouse | Determine and model habitat preferences of periphery populations of sage-grouse | Considers both environmental and anthropogenic variables. All four final models produced demonstrated excellent predictability upon visual inspection. Contributes to the further understanding of Machine Learning algorithms, Species Distribution Models and individual characteristics of sage-grouse species | Certain areas highlighted by results indicated necessary further investigation in order to determine species distribution | [5] |
| Name | Sub-Category | Type | Resolution | Year | Source |
|---|---|---|---|---|---|
| Bioclimatic Variables | BIO1 Annual Mean Temperature | Continuous | 1 km | 1970–2000 | worldclim.org |
| * BIO2 Mean Diurnal Range (Mean of monthly (max temp-min temp)) | |||||
| BIO3 Isothermality (BIO2/BIO7) (x100) | |||||
| * BIO4 Temperature Seasonality (standard deviation x100) | |||||
| BIO5 Max Temperature of Warmest Month | |||||
| BIO6 Min Temperature of Coldest Month * | |||||
| BIO7 Temperature Annual Range (BIO5–BIO6) | |||||
| BIO8 Mean Temperature of Wettest Quarter | |||||
| BIO9 Mean Temperature of Driest Quarter | |||||
| * BIO10 Mean Temperature of Warmest Quarter | |||||
| * BIO11 Meant Temperature of Coldest Quarter | |||||
| BIO12 Annual Precipitation | |||||
| BIO13 Precipitation of Wettest Month | |||||
| BIO14 Precipitation of Driest Month | |||||
| BIO15 Precipitation Seasonality (Coefficient of Variation) | |||||
| * BIO16 Precipitation of Wettest Quarter | |||||
| * BIO17 Precipitation of Driest Quarter | |||||
| * BIO18 Precipitation of Warmest Quarter | |||||
| * BIO19 Precipitation of Coldest Quarter | |||||
| * Ecoregions | Level IV | Categorical | N/A (.shp) | 2012 | United States Environmental Protection Agency |
| Elevation | Auto-correlated DEM | Continuous | 2 m | 2018 | Utah AGRC |
| Global Human Modification (gHM) | Continuous | 1 km | 2016 | Conservation Science Partners, GEE | |
| Multi-Resolution Land Characteristics | CONUS Urban Imperviousness | Continuous | 30 m | 2016 | MRLC Consortium |
| CONUS Land Cover | Categorical | 2016 | |||
| CONUS Sagebrush Shrubland Fractional Component | Continuous | 2016 | |||
| Existing Vegetation (EVT) | Categorical | 30 m | 2014 | LANDFIRE | |
| Normalized Difference Vegetation Index (NDVI) | Time integrated | Contiguous | 1 km | 2013 | USGS Earth Explorer |
| Name | Sub-Category | Type | Resolution | Year | Source |
|---|---|---|---|---|---|
| Bioclimatic Variables | BIO1 Annual Mean Temperature | Continuous | 4.5 km | 2041–2060 | worldclim.org |
| BIO3 Isothermality (BIO2/BIO7) (x100) | |||||
| BIO7 Temperature Annual Range (BIO5–BIO6) | |||||
| BIO8 Mean Temperature of Wettest Quarter | |||||
| BIO9 Mean Temperature of Driest Quarter | |||||
| BIO12 Annual Precipitation | |||||
| BIO13 Precipitation of Wettest Month | |||||
| BIO14 Precipitation of Driest Month | |||||
| BIO15 Precipitation Seasonality (Coefficient of Variation) | |||||
| Elevation | Auto-correlated DEM | Continuous | 2 m | 2018 | Utah AGRC |
| Multi-Resolution Land Characteristics | CONUS Land Cover | Categorical | 250 m | 2100 | MRLC Consortium |
| Model | Hyperparameters |
|---|---|
| Support Vector Machines (RBF) | Sigma: determines the reach of a single training instance |
| Random forests | C (cost): controls training errors and margins |
| Artificial Neural Networks | Mtry: number of variables randomly sampled as candidates at each split |
| 0 | 1 | Omission Error | Commission Error | Producer Accuracy | User Accuracy | |||
|---|---|---|---|---|---|---|---|---|
| 0 | 79 | 7 | 86 | 0.177 | 0.0814 | 0.823 | 0.919 | SVM |
| 1 | 17 | 53 | 70 | 0.117 | 0.243 | 0.883 | 0.757 | |
| 96 | 60 | 156 | ||||||
| 0 | 82 | 8 | 90 | 0.146 | 0.089 | 0.854 | 0.911 | ANN |
| 1 | 14 | 52 | 66 | 0.133 | 0.212 | 0.867 | 0.788 | |
| 96 | 60 | 156 | ||||||
| 0 | 85 | 5 | 90 | 0.115 | 0.056 | 0.885 | 0.944 | RF |
| 1 | 11 | 55 | 66 | 0.083 | 0.167 | 0.917 | 0.833 | |
| 96 | 60 | 156 | ||||||
| 0 | 86 | 6 | 92 | 0.104 | 0.065 | 0.896 | 0.935 | MaxEnt |
| 1 | 10 | 54 | 64 | 0.1 | 0.156 | 0.9 | 0.844 | |
| 96 | 60 | 156 |
| Accuracy | Kappa | Sensitivity | Specificity | |
|---|---|---|---|---|
| SVM | 0.846 | 0.685 | 0.883 | 0.823 |
| RF | 0.897 | 0.787 | 0.917 | 0.885 |
| ANN | 0.859 | 0.708 | 0.867 | 0.854 |
| MaxEnt | 0.897 | 0.803 | 0.900 | 0.896 |
| Incorrectly Classified | Correctly Classified | Correct Classification Rate (%) | |
|---|---|---|---|
| RF | 154 | 292 | 65 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mosebo Fernandes, A.C.; Quintero Gonzalez, R.; Lenihan-Clarke, M.A.; Leslie Trotter, E.F.; Jokar Arsanjani, J. Machine Learning for Conservation Planning in a Changing Climate. Sustainability 2020, 12, 7657. https://doi.org/10.3390/su12187657
Mosebo Fernandes AC, Quintero Gonzalez R, Lenihan-Clarke MA, Leslie Trotter EF, Jokar Arsanjani J. Machine Learning for Conservation Planning in a Changing Climate. Sustainability. 2020; 12(18):7657. https://doi.org/10.3390/su12187657
Chicago/Turabian StyleMosebo Fernandes, Ana Cristina, Rebeca Quintero Gonzalez, Marie Ann Lenihan-Clarke, Ezra Francis Leslie Trotter, and Jamal Jokar Arsanjani. 2020. "Machine Learning for Conservation Planning in a Changing Climate" Sustainability 12, no. 18: 7657. https://doi.org/10.3390/su12187657