People Analytics of Semantic Web Human Resource Résumés for Sustainable Talent Acquisition


Abstract
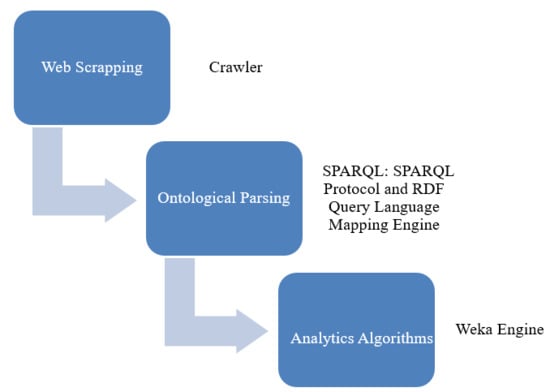
:
1. Introduction
2. Materials and Methods
2.1. Research Hypothesis
- (1)
- The web scraper component seeks résumé data across the Indeed résumé website [30]. It extracts data from résumés written in HTML and saves data in the comma-separated-value (CSV) format.
- (2)
- The mapping engine integrates data published using different vocabularies from the human resource ontology published by the Ontology Engineering Group. It transforms data from CSV to RDF by using terms defined as classes, sub-classes, and properties from other RDF files that represent ontologies.
- (3)
- The résumé RDF processor labels different features of the data mining classifier model. It uses SPARQL to query data from RDF and derives the features.
- (4)
- The classifier models use data and derive the prediction rules.
2.2. Data Acquisition
3. Results
4. Discussion
Author Contributions
Funding
Conflicts of Interest
References
- Carlson, K.D.; Kavanagh, M.J. HR metrics and workforce analytics. In Human Resource Information Systems: Basics Applications and Future Directions, 1st ed.; Kavanagh, M.J., Thite, M., Eds.; Sage Publishing: Thousand Oaks, CA, USA, 2012; pp. 150–174. [Google Scholar]
- Bányai, T.; Landschützer, C.; Bányai, Á. Markov-chain simulation-based analysis of human resource structure: How staff deployment and staffing affect sustainable human resource strategy. Sustainability 2018, 10, 3692. [Google Scholar] [CrossRef]
- Lunsford, D.L. An Output Model for Human Resource Development Analytics. Perform. Improv. Q. 2019, 32, 13–35. Available online: https://onlinelibrary.wiley.com/doi/abs/10.1002/piq.21284 (accessed on 15 June 2019). [CrossRef]
- Fotache, M. Data Processing Languages for Business Intelligence. SQL vs. R. Inform. Econ. 2016, 20, 48–61. Available online: http://revistaie.ase.ro/content/77/05%20-%20Fotache.pdf (accessed on 15 June 2019). [CrossRef]
- Păvăloaia, V.D.; Georgescu, M.R.; Popescul, D.; Radu, L.D. ESD for Public Administration: An Essential challenge for inventing the future of our society. Sustainability 2019, 11, 880. [Google Scholar] [CrossRef]
- Minastireanu, E.A.; Mesnita, G. Light GBM Machine Learning Algorithm to Online Click Fraud Detection. J. Inform. Assur. Cybersecur. 2019, 2019. Available online: https://ibimapublishing.com/articles/JIACS/2019/263928/ (accessed on 15 June 2019).
- King, K.G. Data Analytics in Human Resources: A Case Study and Critical Review. Hum. Resour. Dev. Revi. 2016, 15, 487–495. Available online: https://journals.sagepub.com/doi/abs/10.1177/1534484316675818 (accessed on 15 June 2019). [CrossRef]
- Fitz-Enz, J.; Mattox, J. Predictive Analytics for Human Resources; John Wiley: Hoboken, NJ, USA, 2014. [Google Scholar]
- Purohit, S.R. How LinkedIn Knows What Jobs You Are Interested In. UDACITY, 2014. Available online: https://blog.udacity.com/2014/05/how-linkedin-knows-what-jobs-you-are.html (accessed on 15 June 2019).
- Claus, L. HR disruption—Time Already to Reinvent Talent Management. BRQ Bus. Res. Q. 2019, in press, corrected proof. Available online: https://www.sciencedirect.com/science/article/pii/S2340943619302129 (accessed on 15 June 2019). [CrossRef]
- Srivastava, R.; Palshikar, G.K.; Pawar, S. Analytics for Improving talent acquisition processes. In Proceedings of the International Conference on Advanced Data Analysis, Business Analytics and Intelligence, Ahmedabad, India, 11–12 April 2015. ICADABAI 2015. [Google Scholar]
- Dutta, D.; Mishra, S.; Manimala, M.J. Talent Acquisition Group (TAG) atHCL Technologies: Improving the Quality of Hire Through Focused Metrics; Technical Report; IIMB-HBP: Bengaluru, India, 2015; Available online: http://research.iimb.ernet.in/handle/123456789/6698 (accessed on 15 June 2019).
- Faliagka, E.; Tsakalidis, A.; Tzimas, G. An Integrated e-Recruitment System for Automated Personality Mining and Applicant Ranking. Int. Res. 2012, 22, 551–568. Available online: https://www.emeraldinsight.com/doi/abs/10.1108/10662241211271545 (accessed on 15 June 2019). [CrossRef]
- Faliagka, E.; Ramantas, K.; Tsakalidis, A.; Tzimas, G. Application ofMachine Learning Algorithms to an online Recruitment System. In Proceedings of the ICIW 2012: The Seventh International Conference on Internet and Web Applications and Services, IARIA, Stuttgart, Germany, 27 May–1 June 2012; pp. 216–220. [Google Scholar]
- Palshikar, G.K.; Srivastava, R.; Pawar, S.; Hingmire, S.; Jain, A.; Chourasia, S.; Shah, M. Analytics-Led Talent Acquisition for Improving Efficiency and Effectiveness. In Advances in Analytics and Applications; Springer: Singapore, 2019; pp. 141–160. [Google Scholar]
- Mooney, R.J.; Bunescu, R. Mining Knowledge from Text Using Information Extraction. ACM SIGKDD Explor. Newsl. 2005, 7, 3–10. Available online: https://www.cs.utexas.edu/~ml/papers/text-kddexplore-05.pdf (accessed on 15 June 2019). [CrossRef]
- Téllez-Valero, A.; Montes-y-Gómez, M.; Villaseñor-Pineda, L.A. Machine learning approach to information extraction. In Computational Linguistics and Intelligent Text Processing. CICLing Lecture Notes in Computer Science; Gelbukh, A., Ed.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 539–547. Available online: https://link.springer.com/chapter/10.1007/978-3-540-30586-6_58 (accessed on 15 June 2019).
- Tomassetti, F.; Rizzo, G.; Vetro, A.; Ardito, L.; Torchiano, M.; Morisio, M. Linked data approach for selection process automation in systematic reviews. In Proceedings of the 15th Annual Conference on Evaluation & Assessment in Software Engineering, Durham, UK, 11–12 April 2011; Institution of Engineering and Technology (IET): Sunnyvale, CA, USA, 2011; pp. 31–50. [Google Scholar]
- Xu, Z.; Song, B.H. A machine learning application for human resource data mining problem. In Proceedings of the Advances in Knowledge Discovery and Data Mining, Singapore, 9–12 April 2006; Ng, W.K., Kitsuregawa, M., Li, J., Chang, K., Eds.; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2006; Volume 3918, pp. 847–856. [Google Scholar]
- Xie, F.; Tang, Q. Human resource development by fuzzy neural networks. In Proceedings of the 4th International Conference on Wireless Communications, Networking and Mobile Computing, Dalian, China, 12–14 October 2008; IEEE: Piscataway, NJ, USA, 2008; Volumes 1–31. [Google Scholar]
- Sivaram, N.; Ramar, K. Applicability of Clustering and Classification Algorithms for Recruitment Data Mining. Inte. J. Comput. Appl. 2010, 4, 23–28. Available online: https://pdfs.semanticscholar.org/22e3/1564b13413c537f246e7d59e9075df0db7f8.pdf (accessed on 15 June 2019). [CrossRef]
- Aldarra, S.; Muñoz, E. A Linked Data-Based Decision Tree Classifier to Review Movies. In Proceedings of the Know@LOD 2015, 4th Workshop on Knowledge Discovery and Data Mining Meets Linked Open Data co-located with 12th Extended Semantic Web Conference (ESWC 2015), Portoroz, Slovenia, 31 May 2015; Available online: http://ceur-ws.org/Vol-1365/paper10.pdf (accessed on 15 June 2019).
- Mehenni, T.; Moussaoui, A. Data Mining from Multiple Heterogeneous Relational Databases Using Decision Tree Classification. Pattern Recognit. Lett. 2012, 33, 1768–1775. Available online: https://dl.acm.org/citation.cfm?id=2343166 (accessed on 15 June 2019). [CrossRef]
- Sanchez-Marono, N.; Alonso-Betanzos, A.; Fontenla-Romero, O.; Polhill, J.G.; Craig, T. Empirically-Derived Behavioral Rules in Agent-Based Models Using Decision Trees Learned from Questionnaire Data. In Agent-Based Modeling of Sustainable Behaviors. Understanding Complex Systems; Alonso-Betanzos, A., Sánchez Maroño, N., Fontenla-Romero, O., Polhill, G.J., Craig, T., Bajo, J., Corchado, J.M., Eds.; Springer: Cham, Switzerland, 2017; pp. 53–76. [Google Scholar]
- Bizer, C.; Heese, R.; Mochol, M.; Oldakowski, R.; Tolksdorf, R.; Eckstein, R. The Impact of Semantic Web Technologies on Job Recruitment. In Proceedings of the 7 Internationale Tagung Wirtschaftsinformatik, Bamberg, Germany, 23–25 February 2005. [Google Scholar]
- Ristoski, P.; Petrovski, P.; Mika, P.; Paulheim, H. A Machine Learning Approach for Product Matching and Categorization. Semant. Web 2018, 1–22, Preprint. Available online: http://www.semantic-web-journal.net/system/files/swj1470.pdf (accessed on 15 June 2019).
- Ristoski, P.; Paulheim, H. Semantic Web in Data Mining and Knowledge Discovery: A Comprehensive Survey. Web Semant. Sci. Serv. Agents World Wide Web 2016, 36, 1–22. Available online: https://www.sciencedirect.com/science/article/pii/S1570826816000020 (accessed on 15 June 2019). [CrossRef]
- Min, H.; Emam, A. Developing the Profiles of Truck Drivers for Their Successful Recruitment and Retention: A Data Mining Approach. Int. J. Phys. Distrib. Logist. Manag. 2003, 33, 149–162. Available online: https://www.emeraldinsight.com/doi/abs/10.1108/09600030310469153 (accessed on 15 June 2019). [CrossRef]
- Gomez-Perez, A.; Fernández-López, M.; Corcho, O. Ontological Engineering: With Examples from the Areas of Knowledge Management, E-Commerce and the Semantic Web; Springer: Heidelberg, Germany, 2006. [Google Scholar]
- Simperl, E. A Case Study in Building Semantic eRecruitment Applications. In Semantic Web for Business: Cases and Applications; Garcia, R., Ed.; IGI Global: Hershey, PA, USA, 2008. [Google Scholar]
- Gregor, S.; Hevner, A.R. Positioning and Presenting Design Science Research for Maximum Impact. MIS Q. 2013, 37, 337–355. Available online: https://pdfs.semanticscholar.org/82a8/6371976aaf181a477745148eab07bb9ed143.pdf (accessed on 15 June 2019). [CrossRef]
- The Source Code. Available online: https://github.com/catalinstrimbei/rdf-mining-hr (accessed on 15 June 2019).
- Open Refine. Available online: http://openrefine.org/ (accessed on 15 June 2019).
- Ontology Engineering Group, Human Resource Ontology. Available online: http://mayor2.dia.fi.upm.es/oeg-upm/index.php/en/ontologies/99-hrmontology/ (accessed on 15 June 2019).
- Ericsson, K.A. The influence of experience and deliberate practice on the development of superior expert performance. In The Cambridge Handbook of Expertise and Expert Performance; Cambridge University Press: Cambridge, UK, 2006; Volume 38, pp. 685–705. [Google Scholar]
- Langer, J.; Feeney, M.K.; Lee, S.E. Employee Fit and Job Satisfaction in Bureaucratic and Entrepreneurial Work Environments. Rev. Public Pers. Adm. 2019, 39, 135–155. Available online: https://journals.sagepub.com/doi/abs/10.1177/0734371X17693056 (accessed on 15 June 2019). [CrossRef]
- Chambers, E.G.; Foulon, M.; Handfield-Jones, H.; Hankin, S.M.; Michaels, E.G. The War for Talent. McKinsey Q. 1998, 44–57. Available online: http://www.executivesondemand.net/managementsourcing/images/stories/artigos_pdf/gestao/The_war_for_talent.pdf (accessed on 15 June 2019).
- Bakotić, D. Relationship Between Job Satisfaction and Organisational Performance. Econ. Res. Ekon. Istraž. 2016, 29, 118–130. Available online: https://www.tandfonline.com/doi/full/10.1080/1331677X.2016.1163946 (accessed on 15 June 2019). [CrossRef]
- Mahmood Ali, M.; Qaseem, M.; Rajamani, L.; Govardhan, A. Extracting Useful Rules Through Improved Decision Tree Induction Using Information Entropy. Int. J. Inf. Sci. Tech. 2013, 3. Available online: https://arxiv.org/ftp/arxiv/papers/1302/1302.2436.pdf (accessed on 15 June 2019). [CrossRef]
- Melillo, P.; Orrico, A.; Chirico, F.; Pecchia, L.; Rossi, S.; Testa, F.; Simonelli, F. Identifying Fallers Among Ophthalmic Patients Using Classification Tree Methodology. PLoS ONE 2017. Available online: https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0174083 (accessed on 15 June 2019). [CrossRef]
- Davis, J.; Goadrich, M. The Relationship Between Precision-Recall and ROC Curves. In Proceedings of the 23 International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006. [Google Scholar]
- Kalampokis, E.; Zeginis, D.; Tarabanis, K. On Modeling Linked Open Statistical Data. J. Web Semant. 2019, 55, 56–68. Available online: https://www.sciencedirect.com/science/article/pii/S1570826818300544 (accessed on 15 June 2019). [CrossRef]
- Michel, F.; Zucker, C.F.; Corby, O.; Gandon, F. Enabling Automatic Discovery and Querying of Web APIs at Web Scale using Linked Data Standards. In Proceedings of the LDOW/LDDL Workshop of the 2019 World Wide Web Conference (WWW’19), San Francisco, CA, USA, 13–17 May 2019. [Google Scholar]
- Modi, K.J.; Garg, S.; Chaudhary, S. An Integrated Framework for RESTful Web Services Using Linked Open Data. Int. J. Grid High Perform. Comput. 2019, 11, 24–49. Available online: https://www.igi-global.com/article/an-integrated-framework-for-restful-web-services-using-linked-open-data/224029 (accessed on 15 June 2019). [CrossRef]
- Mochol, M.; Wache, H.; Nixon, L. Improving the Accuracy of Job Search with Semantic Techniques. In Proceedings of the 10th International Conference Business Information Systems, Poznan, Poland, 25–27 April 2007; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Kessler, R.; Torres-Moreno, J.; El-Beze, M. E-Gen: Automatic job offer processing system for human resources. In Proceedings of the Artificial Intelligence 6th Mexican International Conference on Advances in Artificial Intelligence (MICAI’07), Aguascalientes, Mexico, 4–10 November 2007; Rauch, J., Ras, Z., Berka, P., Elomas, T., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 985–995. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Ideas | Details |
|---|---|---|
| Total years of experience [35] | Extensive experience of activities in a domain is necessary to reach very high levels of performance. | “Expert performance is acquired gradually and the effective improvement of performance requires the opportunity to find suitable training tasks that the performer can master sequentially” |
| The years of experience at the current job position [36] | Values that are too big or too small are subject to further analysis | “Job satisfaction is positively correlated with mission valence, commitment, person–job fit, flexible work, pay, innovation, and a variety of other individual and organizational factors” |
| The average of the years of experience in every position held [37] | Variety in work experiences might influence forming high performers | “According to 50 senior executive search professionals the study surveyed, the average executive today will work in five companies; in another 10 years, it might be seven”. “Ineffective people often stay in position for years”. |
| The total number of positions held (Position_count) [38] | The total number of positions might influence forming high or low performers | “Job satisfaction more strongly determines organizational performance than organizational performance determines job satisfaction” |
| Features (Attributes) | Types/Values | SPARQL SELECT Clauses |
|---|---|---|
| Job_Seeker | String | |
| Education_Title (f1) | Master’s, Bachelor’s, Other | |
| Education_Title_Spec (f2) | Computer science, information technology, electronics, computer engineering, software engineering, computer applications, OTHER | Computer science, information technology, electronics, computer engineering, software engineering Master’s, Bachelor’s, Other, computer applications, OTHER |
| Java_Programming_Skills (f3) | True, False | Java, JEE, JSE, J2SE, J2EE |
| SQL_Programming_Skills (f4) | True, False | SQL, Oracle |
| NOSQL_Programming_Skills (f5) | True, False | NOSQL, Mongo DB |
| UML_Skills (f6) | True, False | UML |
| SOA_Developer_Skills (f7) | True, False | Web Service, SOA, REST, SOAP, JAX-RS, JAX-WS |
| Java_Web_Developer (f8) | True, False | Servlet, JSP, JSF, Struts |
| Web_Developer_Skills (f9) | True, False | HTML, Javascript, JQuery, Angular |
| DB_Developer_Skills (f10) | True, False | SQL, Oracle, MySQL, Postgres |
| Java_Persistence_Skills (f11) | True, False | JDBC, JPA, Java Persistence API, Hibernate |
| Years_Experience_last (f12) | Numeric | MAX(end_date)-MAX(begin_date) |
| Position_count (f13) | Numeric | COUNT(Position_held) |
| Years_experience_position (f14) | Numeric | AVERAGE(MAX(end_date)-MIN(begin_date), Position_count) |
| Position_held (f15) | JAVA developer, JEE developer, software engineer, other developer, other programmer, analyst, other engineer, other | JAVA developer, JEE developer, software engineer, other developer, other programmer, analyst, other engineer, other |
| Algorithm | Accuracy for the Dataset Containing Aggregated Features | ROC | PRC | Accuracy for the Dataset not Containing Aggregated Features | ROC | PRC |
|---|---|---|---|---|---|---|
| Classification via Regression | 0.94 | 0.836 | 0.950 | 0.86 | 0.667 | 0.888 |
| Support vector machine | 0.86 | 0.661 | 0.875 | 0.85 | 0.696 | 0.887 |
| k-NN | 0.95 | 0.936 | 0.983 | 0.87 | 0.907 | 0.979 |
| Naïve Bayes | 0.84 | 0.784 | 0.941 | 0.76 | 0.573 | 0.863 |
| Random forest | 0.98 | 0.998 | 1.000 | 0.87 | 0.904 | 0.979 |
| Decision tree | 0.80 | 0.822 | 0.953 | 0.82 | 0.474 | 0.818 |
| Precision | Recall | F-Measure | |
|---|---|---|---|
| Java developer | 0.858 | 0.919 | 0.888 |
| JEE developer | 0 | 0 | 00 |
| Software engineer | 0 | 0 | 0 |
| Other—Developer | 0 | 0 | 0 |
| Other—Programmer | 0 | 0 | 0 |
| Analyst | 0 | 0 | 0 |
| Other—Engineer | 0.857 | 1.0 | 0.923 |
| Other | 0 | 0 | 0 |
| a | b | c | d | e | f | g | h | Accuracy | |
|---|---|---|---|---|---|---|---|---|---|
| a = Java developer | 91 | 0 | 4 | 0 | 0 | 1 | 1 | 2 | 97/120 = 80.83 |
| b = JEE developer | 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| c = Software engineer | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| d = Other—Developer | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| e = Other—Programmer | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| f = Analyst | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | |
| g = Other—Engineer | 0 | 0 | 0 | 0 | 0 | 0 | 6 | 0 | |
| h = Other | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Precision | Recall | F-Measure | ROC | PRC | Class |
|---|---|---|---|---|---|
| Java_Programming_Skills (output) = (f1, f2, f4, f5, f6, f7, f8, f9, f10, f11, f12, f13, f14, f15) | |||||
| 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | True |
| 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | False |
| SQL_Programming_Skills (output) = (f1, f2, f3, f4, f6, f7, f8, f9, f10, f11, f12, f13, f14, f15) | |||||
| 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | True |
| 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | False |
| NOSQL_Programming_Skills (output) = (f1, f2, f3, f4, f6, f7, f8, f9, f10, f11, f12, f13, f14, f15) | |||||
| 0.806 | 0.543 | 0.649 | 0.804 | 0.747 | True |
| 0.764 | 0.919 | 0.834 | 0.804 | 0.845 | False |
| SOA_Developer_Skills (output) = (f1, f2, f3, f4, f5, f6, f8, f9, f10, f11, f12, f13, f14, f15) | |||||
| 0.962 | 1.0 | 0.981 | 0.932 | 0.976 | True |
| 1.0 | 0.789 | 0.882 | 0.932 | 0.872 | False |
| Java_Web_Developer_Skills (output) = (f1, f2, f3, f4, f5, f6, f7, f9, f10, f11, f12, f13, f14, f15) | |||||
| 0.980 | 0.960 | 0.970 | 0.954 | 0.948 | True |
| 0.810 | 0.895 | 0.850 | 0.954 | 0.803 | False |
| Web_Developer_Skills (output) = (f1, f2, f3, f4, f5, f6, f7, f8, f10, f11, f12, f13, f14, f15) | |||||
| 0.972 | 1.0 | 0.986 | 0.893 | 0.972 | True |
| 1.0 | 0.766 | 0.880 | 0.893 | 0.811 | False |
| DB_Developer_Skills (output) = (f1, f2, f3, f4, f5, f6, f7, f8, f9, f11, f12, f13, f14, f15) | |||||
| 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | True |
| 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | False |
| Java_Persistence_Skills (output) = (f1, f2, f3, f4, f5, f6, f7, f8, f9, f10, f12, f13, f14, f15) | |||||
| 0.863 | 0.932 | 0.896 | 0.793 | 0.883 | True |
| 0.760 | 0.594 | 0.667 | 0.793 | 0.670 | False |
| Important for Analytics | ||
|---|---|---|
| Contribution | Our Architecture | Others |
| Describing human resource data with RDF | Yes | Yes, but not for résumé data. There are many studies that describe data with RDF [42], propose tools to automatically describe data [43], or publish RDF data [44], but not résumé data. |
| Features derived with SPARQL by using aggregate functions | Yes In the case study, we defined the number of years spent in average at every position held, the number of positions held, and the number of years spent at the last position held. We found that they are important for Position_held and for predicting better some skills | Partial aggregate functions but to movie reviews [22]. |
| Features derived from Linked data mining | Yes In our case study, the Java web programming skills J48 classifier (Figure 9) identified that Java programming skills, Java persistence skills, and NOSQL programming skills are the features that split the data. The NOSQL programming skills J48 classifier (Figure 10) identified that Java persistence skills, UML skills, and Java web developer skills are features related to skills that split the data. | Partial [11] use of linear regression to predict human resource employability, but no classification machine learning algorithm to derive skills. In addition, they use linguistic analytics. We used the Semantic Web in order to offer a better representation. This representation is useful in future dataset querying so that when searching the dataset for people with certain skills, enhanced information be provided. Mochol et al. [45] use a dictionary of synonyms, but not the Semantic Web. Kessler et al. [46] classify the applicants with the support vector machine algorithm. We used decision tree algorithm to find the best predictors. To predict position held, we applied random forest, classification via regression, naive Bayes, k-NN, support vector machine and decision tree. |
| Features derived with SPARQL queries |
| JobSeeker has_average_work_experience xsd:integer |
| Features derived from other features (skills related to data from people résumé) |
| Java_Web_Developer_Skills is_related_to SOA_programming_skills |
| Attribute selection by using data mining |
| SOA_programming_skills isImportant in hiring Java developers |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Necula, S.-C.; Strîmbei, C. People Analytics of Semantic Web Human Resource Résumés for Sustainable Talent Acquisition. Sustainability 2019, 11, 3520. https://doi.org/10.3390/su11133520
Necula S-C, Strîmbei C. People Analytics of Semantic Web Human Resource Résumés for Sustainable Talent Acquisition. Sustainability. 2019; 11(13):3520. https://doi.org/10.3390/su11133520
Chicago/Turabian StyleNecula, Sabina-Cristiana, and Cătălin Strîmbei. 2019. "People Analytics of Semantic Web Human Resource Résumés for Sustainable Talent Acquisition" Sustainability 11, no. 13: 3520. https://doi.org/10.3390/su11133520