1. Introduction
Noisy environments undoubtedly lead to a degradation in the intelligibility of speech, and hence make it more difficult to understand the spoken message, especially for older individuals or those with hearing loss. This is so because noise masks part of the speech signal, leading to a loss of acoustic information and thus to an increase in recognition errors [
1]. The noises that generate the greatest changes in speech production are those that share spectral components with vocalization, as well as those of greatest intensity, which thus involve a decrease in the signal-to-noise ratio (SNR) [
2,
3,
4,
5].
SNR loss is not reflected, nor can be predicted, by means of tonal audiometry [
6,
7,
8]. However, there does appear to be a relationship between the degree of hearing loss and the SNR loss. That is, the greater the degree of hearing loss, the greater the SNR loss [
9,
10,
11], especially if this loss affects high-frequency acoustic signals to a greater extent than other frequencies [
12]. Because of the difficulties in comprehension by the listener involved in a speech-in-noise situation, especially in older people and/or those with hearing loss, incorporating speech-in-noise tests into hearing tests has been highly recommended [
13].
However, the oral communication system has mechanisms to cope with the effects of noise on speech. The most studied of these has been the so-called “Lombard effect”.
1.1. The Lombard Effect
The Lombard effect, first described in 1911 by Etienne Lombard [
14], is an unconscious adaptation by the speaker to the noise through a series of changes in speech to improve the intelligibility of the message. Over the last hundred years, the Lombard effect has been studied in countless research studies. In summary, we can say that, even when taking into account differences due to the nature of the speaker, the context, and the environment, most studies agree in pointing out some consequences of the Lombard effect on the signal in interactive situations [
2,
15,
16,
17,
18,
19,
20,
21].
Table 1 sets out these characteristics.
All these aspects of the Lombard effect typically affect words with greater semantic load the most, with functional words, which tend to have a lower information load, being less affected [
5,
17].
The Lombard effect has been assessed in Spanish, with results similar to those found in other studies of other languages, although in comparison with American English and French there is a tendency in Spanish towards a greater variation of the second formant and of speech intensity [
22]. In Junqua [
16], significant differences were also found between male and female speakers, with Lombard speech by females being more intelligible. This set of features makes speech produced under the Lombard effect more intelligible than speech produced in silence when presented under equal SNR conditions [
3,
5,
23].
As can be deduced from the above information, the Lombard effect goes far beyond a simple increase in signal intensity and it does not only affect the signal-to-noise ratio, but also involves frequency and temporal changes aimed at improving signal perceptibility. A hearing evaluation that aims to reproduce as closely as possible the natural conditions of verbal communication should consider this effect, which occurs naturally and continuously in verbal interactions.
1.2. Assessment of Signal-to-Noise Loss Using Speech-in-Noise Tests
Over recent years, tests to assess speech-in-noise and quantify the SNR loss quickly and reliably have gained prominence. Its use has demonstrated many benefits. On the one hand, these tests favour the selection and fitting of hearing aids, providing realistic expectations in terms of their use [
6]. On the other hand, they allow for an assessment of the need to add aural rehabilitation to the fitting of hearing aids [
24,
25,
26,
27,
28]. These tests are also helpful in the post-fitting phases when the effectiveness of hearing aids is assessed and validated [
29], as well as in assessing the usefulness of hearing assistive technology such as remote microphones [
30,
31]. Since then, various speech-in-noise tests have been developed. These tests are differentiated according to the verbal stimulus presented, the SNR used, and approximate application time.
Table 2 sets out the main speech-in-noise tests and summarises their primary characteristics.
Research has made it possible to compare the effectiveness of some of the most frequently used tests in the evaluation of signal-to-noise loss. In particular, Duncan and Aarts [
39] compared the HINT and QuickSIN tests, noting the advantages of the latter in terms of both usability and sensitivity for subjects with hearing loss. The results of Wilson, McArdle, and Smith [
12] indicated that the QuickSIN and WIN tests are more sensitive measures of recognition in background noise than the BKB-SIN and HINT tests. More recently, Sultan et al. [
40] reported a higher correlation of the QuickSIN test with the background noise (BN) subscale of the Abbreviated Profile of Hearing Aid Benefit (APHAB) questionnaire [
41] as compared to the HINT test, both in normal hearing subjects and in subjects with hearing loss. In a systematic review of 21 studies on the relationship between auditory behavioural measures and hearing aid satisfaction, Davidson et al. [
42] conclude that speech-in-noise tests had the highest associations with hearing aid satisfaction, and specifically the QuickSIN was found to be a significant predictor of hearing aid satisfaction.
Although the tests listed are the most frequently used, both in their original English version and in adaptations to other languages, additional tests of this type are still being developed. In some cases, additional tests are developed for use in specific populations, as in the case of AzBio [
43], which is used with people with cochlear implants. Other tests have emerged as a consequence of technological advances, greater accessibility by individuals, or lower cost, such as those that allow the initial screening of hearing using mobile phones [
44,
45,
46,
47].
At present, in Spain, the most frequently used verbal test in audiological assessments is verbal audiometry with lists of words with two syllables [
48]. Although this test is very useful for traditional speech audiometry, its effectiveness is reduced when including background noise; in addition, it relies only on single words, not sentences. Isolated monosyllabic or bisyllabic words, recorded and reproduced at uniform intensity levels, are not representative of real-world speech. Sentences are a closer and more realistic representation of everyday speech [
35,
49,
50]. With regards to speech-in-noise tests for the adult population, we have some adapted to Spanish: the Digit Triplet Identification Test [
51], the Sentence Matrix Test for Spanish speakers [
52], the Spanish adaptation of HINT [
53], SPIN adapted for Spanish as Spanish Sentence Lists (LFE in Spanish) [
54], and its shortened version [
55]. However, these tests have not had a great impact at the clinical level, either because they take a long time to administer, they require the prior training of the patient, or simply because they are not easily accessible by the clinicians. A set of 700 phonetically balanced Spanish sentences is also available called the Sharvard Corpus [
56], but verbal material for audiometry in noise requires an added control of variables, as will be discussed below, which prevents the use of these sentences and demands the construction of an ad hoc corpus.
Finally, it is surprising that despite the fact that speakers produce Lombard speech when in background noise to improve both SNR and speech discrimination, few tests take this effect into account when assessing speech intelligibility in noise. Incorporating Lombard speech into a speech-in-noise test would allow for more realistic speech-in-noise discrimination data. In Spanish, the Verbal Noise Hearing Test (Prueba de Audiometría Verbal en Ruido (PAVER) in Spanish) developed by Marrero-Aguiar
57 is itself based on the QuickSIN test. It is the only such test that takes this effect into consideration in the paediatric population. It contains three blocks of sentences, one of which includes the Lombard effect.
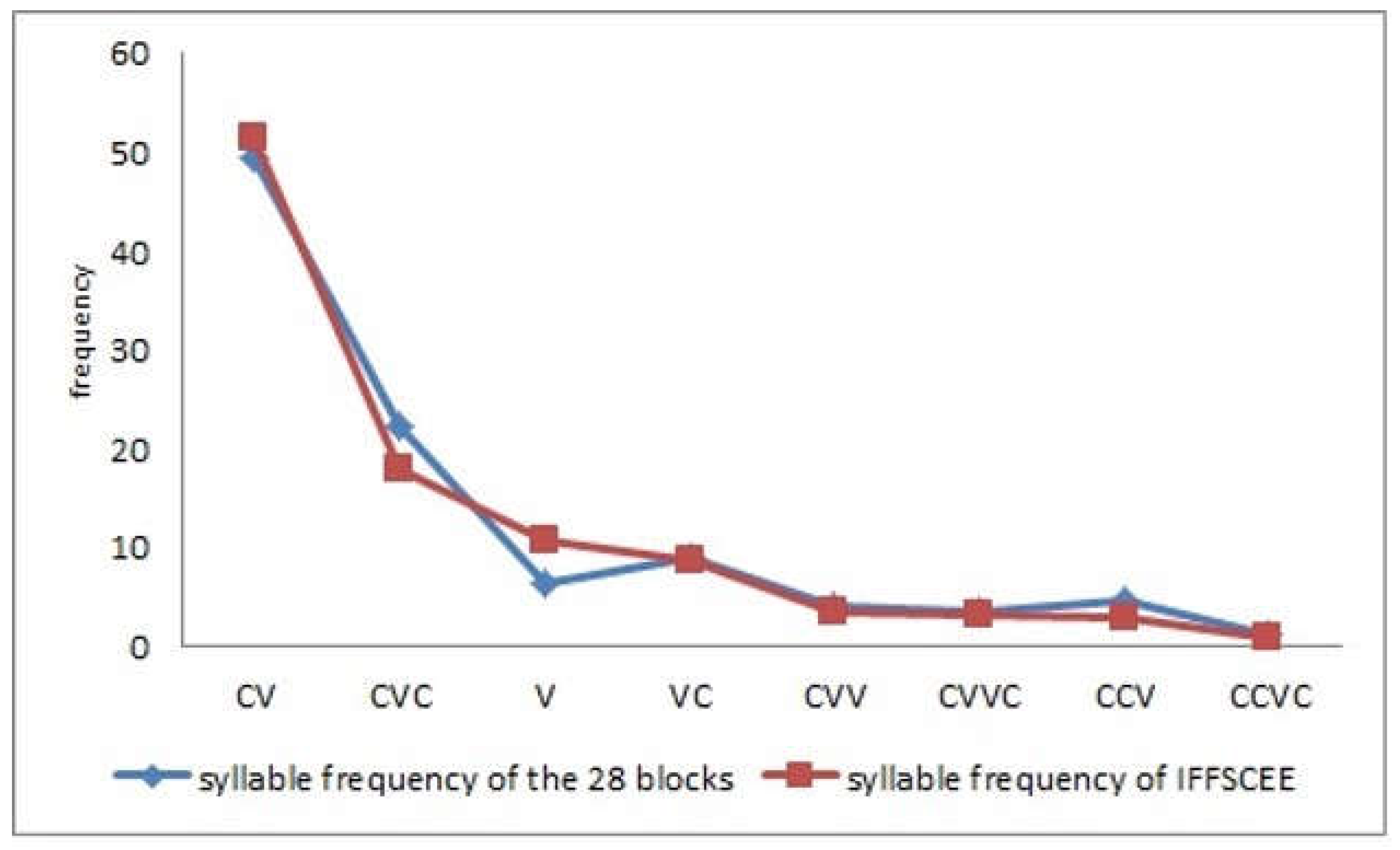
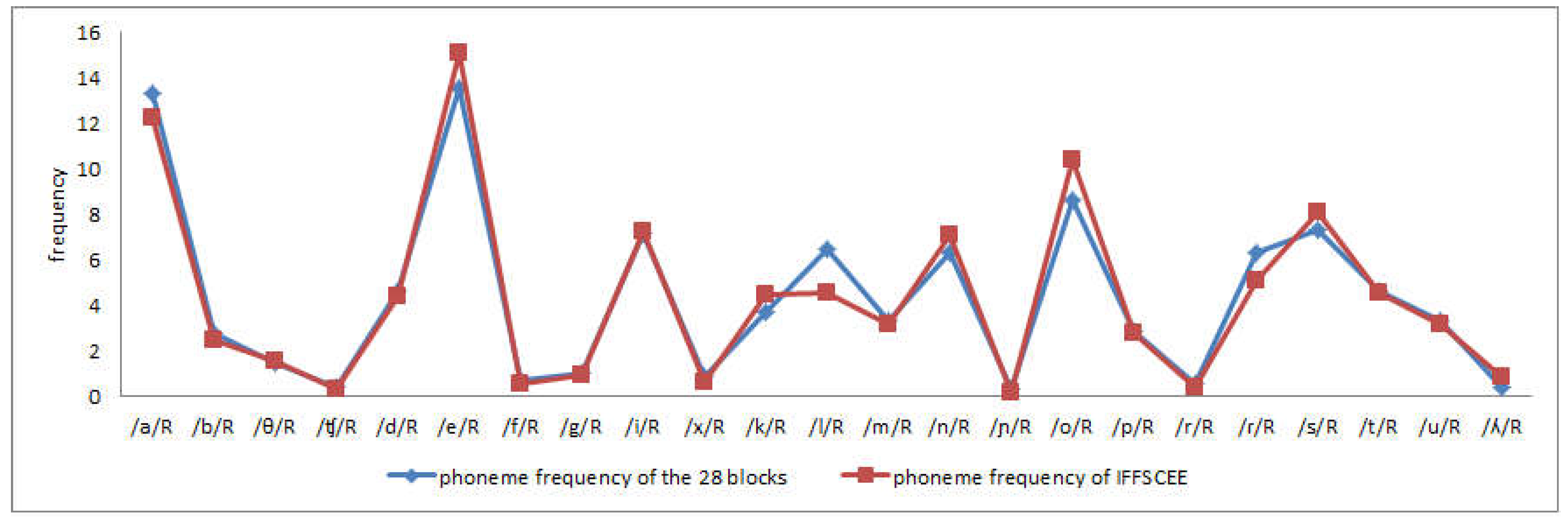
Based on all the above, the development of a speech-in-noise test for the adult population in Spanish seems to be useful and indeed necessary. To this end, the QuickSIN test was taken as a model, due to its speed, simplicity of administration, and because of the amount of information it yields. The QuickSIN pattern was maintained in terms of the number of keywords per sentence (five) and the number of sentences in each list (six), but adaptations from English to Spanish involved taking into account the differences between the two languages in terms of lexical quantity and distribution, sentence length, word length, vowel and consonant use, weight of functional and lexical words, sounds, symmetry in orthographic, morphological and syntactic parameters, and similarities in terms of the conceptual organisation underlying the words themselves [
58]. The choice of speech materials and background noise will, as Villchur [
50] points out, be a compromise between realism and reproducibility. In other words, the aim is to reproduce an everyday speech situation with noise.
Another contribution of this test has been the incorporation of the Lombard effect to compare the results obtained when the speech is presented without this effect (as in the rest of the SIN tests) and when it is a Lombard speech. We assume that the Lombard lists will present a higher score and that it will be maintained with lower SNR values. The results will make it possible to establish the need to incorporate this effect in the SIN tests or to maintain only the recording of the verbal material under the same conditions as has been done so far in the existing speech-in-noise tests.
3. Discussion
As already indicated, there are currently very few Spanish-adapted tests of speech-in-noise for the adult population (Digit Triplet Identification, Sentence Matrix Test for Spanish speakers, HINT adapted to Spanish, SPIN adapted to Spanish as Spanish Sentence Lists (LFE), and its reduced version), and they offer little scope in terms of having an impact at the clinical level, sometimes because they involve long application times. The Spanish hearing test for speech-in-noise (PAHRE) aims to overcome some of these previous drawbacks. It is short, since its application in binaural conditions does not exceed three minutes, easy to administer through any clinical audiometer without the need for prior preparation or complex explanations for the patient, but with high reliability when assessing speech-in-noise.
The results obtained from the analysis of the material described here have allow us to confirm that this material is indeed representative of spoken Spanish both at a semantic, syllabic, and phonetic level. Therefore, it can be included as a speech-in noise test to complete the hearing tests that are carried out in the clinic in Spain. We found that both the length of the sentences and their syntactic complexity are such that their exact and immediate reproduction is possible following their presentation in auditory mode, regardless of the age of subjects. These findings reflect the criteria set out in Véliz et al. [
61], which were taken into account when designing the hearing test.
Although the QuickSIN speech-in-noise test [
37] has been taken as a reference for the development of our Spanish auditory test, a series of new aspects have been introduced with respect to the original test. First, the Lombard effect was incorporated, given that it is characteristic of vocal production in situations with background noise. It was considered essential to incorporate this effect into a speech-in-noise test as it more realistically reflects vocal production and, thus, characteristic speech discrimination in a noisy environment. However, we wanted to also include spoken speech in silence to make the test equal to the rest of the speech-in-noise tests. Thus, in PAHRE, two blocks of Spanish keyword sentences were used, one without the Lombard effect and the other with the Lombard effect. This test complements the one developed in Spanish by Marrero-Aguiar [
57] for the paediatric population, given the scarcity of hearing tests for the adult population that incorporate the Lombard effect.
The spoken-in-silence block (without the Lombard effect) provide similar results to those obtained with most of the speech-in-noise tests, which allows them to be compared when presented in the same conditions. On the other hand, the block with the Lombard effect allows to evaluate speech discrimination in conditions more representative of a noisy environment by incorporating the vocal characteristics that are generated in a speaker in these conditions. The results obtained in both blocks allow comparisons to be made regarding speech discrimination with the same SNR values.
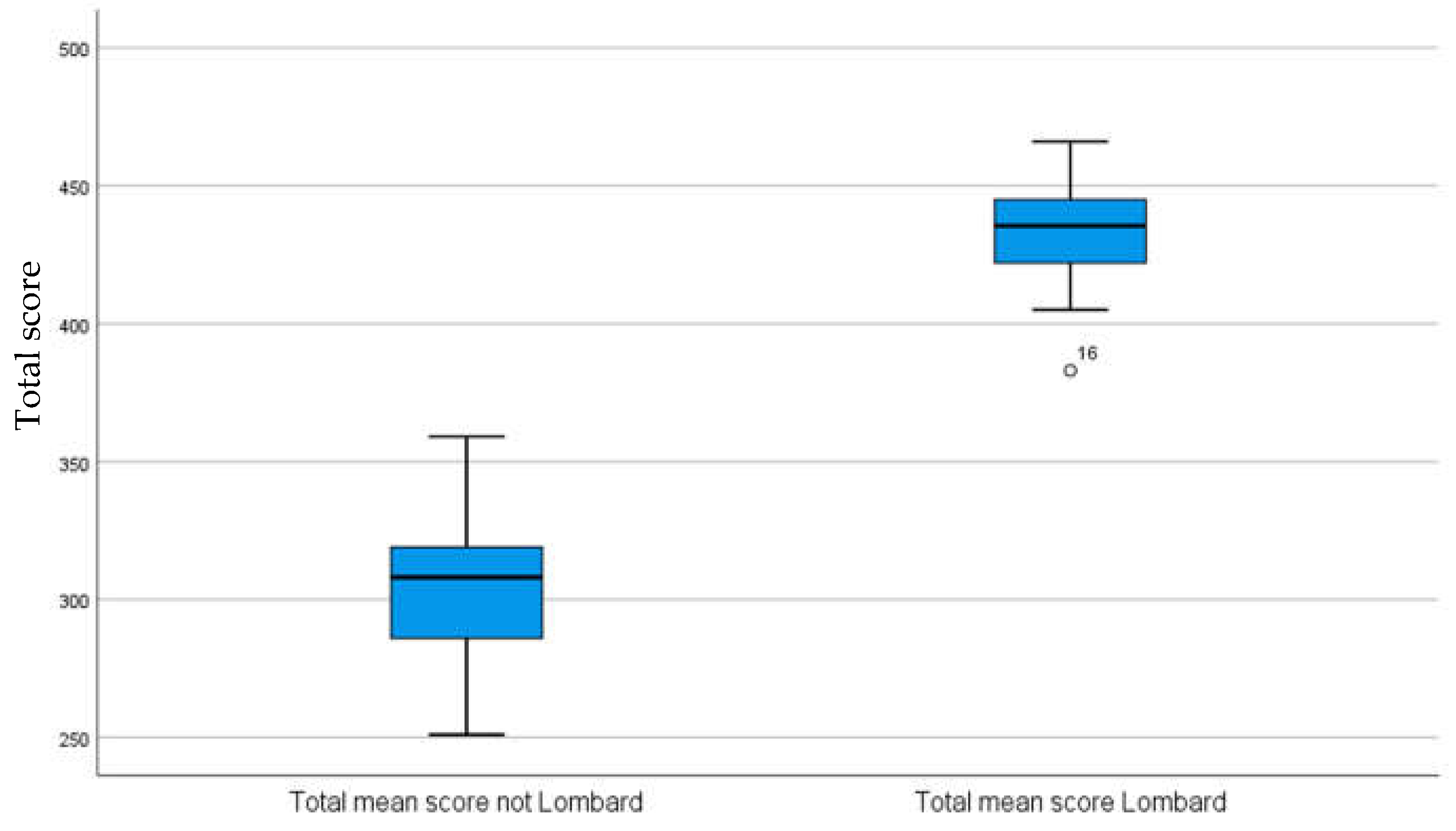
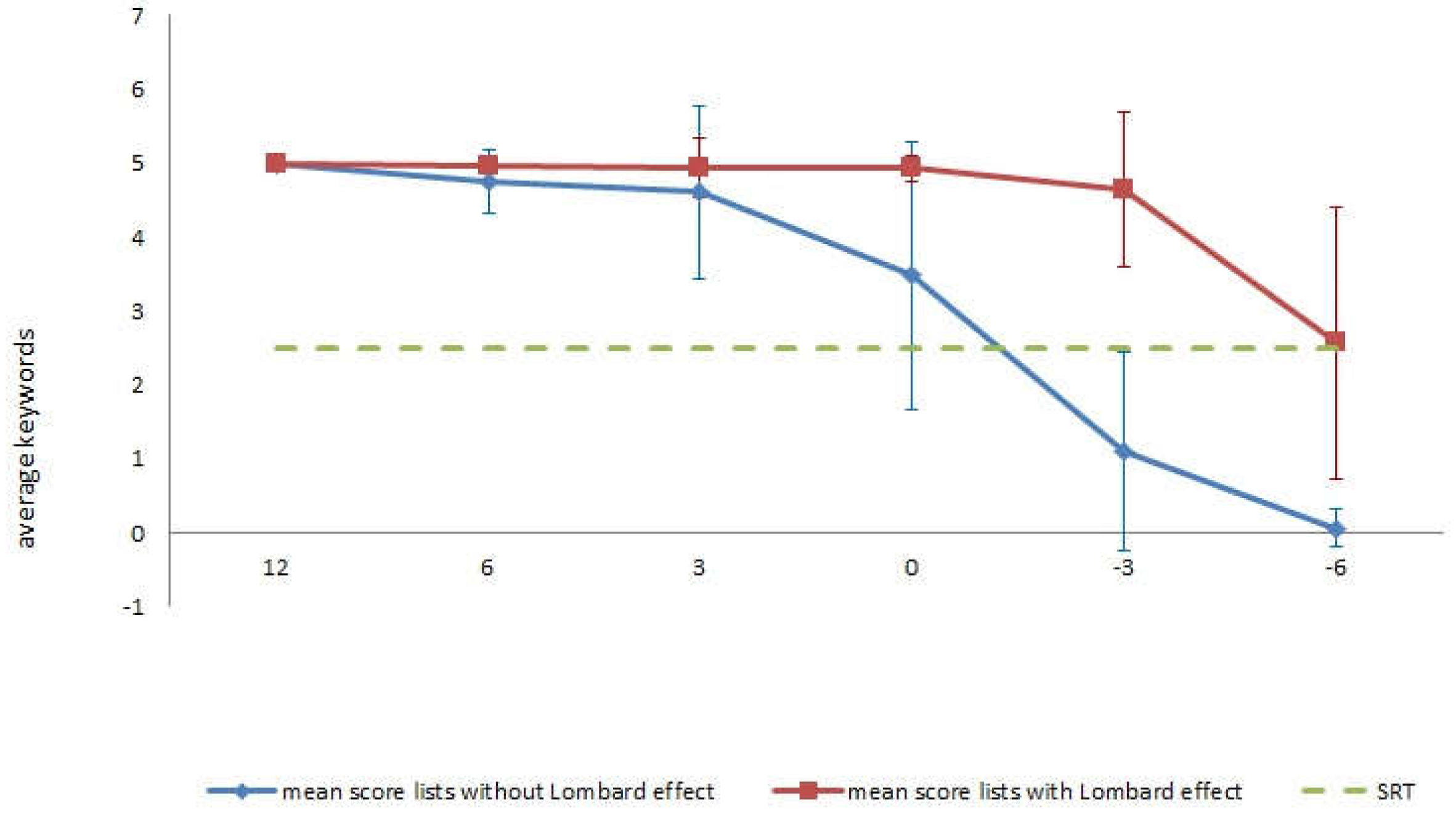
As expected, and in line with previous studies [
3,
5,
23,
57], it was confirmed that the lists recorded under the Lombard effect are more intelligible than the lists recorded in silence, maintaining greater discrimination as SNR decreases and greater intelligibility when presented in the same SNR conditions.
Incorporating the list of sentences with the Lombard effect slightly increased the time of the application of the test with respect to the QuickSIN, yet it still does not exceed two minutes in the binaural condition, and in this sense, we consider that the cost-benefit ratio is positive, given the extra information that it provides.
Another difference of PAHRE with respect to QuickSIN was not incorporating band-pass filtered lists in any frequency range as the purpose of the test is to administer the test to people with different degrees of hearing loss.
Finally, in contrast to QuickSIN, in PAHRE variations have been made in the SNR, starting from a positive value of less than +25 dB, in addition to decreasing the SNR until reaching negative values in SNR steps of less than 5 dB (except between the first and second sentence). The different SNR values had to allow total discrimination in the first sentence and null discrimination in the last sentence, obtaining progressively lower results as the SNR decreased. It was decided to start the test with SNR +12 dB as it was verified that the participants could repeat all the words with this SNR both in the Lombard and non-Lombard conditions. Therefore, it was unnecessary to include higher SNR values as they did not provide information of interest. The decision regarding the descent of the steps was based on the results obtained. Although with the SNR +15, +9, +6, +3, 0, and −3 dB, the purpose established in the non-Lombard block was achieved, and in the case of the Lombard block null discrimination was not achieved with SNR −3 dB. Since one of the points of interest in the elaboration of this test was the incorporation of the Lombard effect, it was decided to use the SNR +12, +6, +3, 0, −3, and −6 dB to achieve the marked purpose as well in the Lombard block although this decision implied zero discrimination in the last two consecutive steps of the non-Lombard lists. This difference with respect to discrimination based on SNR between the two lists is due to the characteristics of Lombard speech (increased intensity, greater emphasis on high frequencies, reduced speech speed, and more pronounced articulation) that imply large benefits for speech discrimination in noise.
The aim here was to ensure that the person being tested starts the test successfully, and also to obtain more precise information by using 3 dB steps (smaller steps were discarded because of their impact on the time taken to carry out the test, with consequently greater effort and fatigue by the person being tested). These aspects are considered essential because they allow the improvement of the selection and fitting of the hearing aids based on its advanced features to improve SNR, such as directionality and digital noise reduction [
25,
27,
28,
71]. Prospective studies of this test will be necessary to assess the speech discrimination loss as the SNR decreases for different age groups in the normal hearing people. Similarly, it will also be necessary to obtain data on the speech reception threshold (SRT) in noise for these same age groups. In this way, this information will allow assessment of the SNR loss in the people with hearing loss and, therefore, the degrees of speaking in noise difficulty as established by the QuickSIN test (mild, moderate, or severe). Based on these results, patient-centred clinical decisions can be made regarding the advanced features of the hearing aid, the use of hearing assistive technology taking as an example the recent study by Davidson et al. [
71], or even the need for auditory training.
The results obtained from future studies will present information for both conditions (no Lombard and Lombard). We assume that both the speech discrimination curves as a function of SNR as well as SRT will be better in the Lombard lists for any age group. These future studies will establish the need to maintain both lists in the test due to the information obtained with them and the usefulness of this information for auditory rehabilitation or, on the contrary, to limit the test to one of these two lists.
Limitations of the current study include the decision not to take into account influential variables in the loss of signal-to-noise ratio such as age, speech intelligibility index, and cognitive processing (cf. Humes [
72]). Such variables might indeed explain differences in the results obtained when comparing the data on both lists. In the future, and with a larger sample of people of different ages and hearing conditions, these variables will be considered, so that reference curves can be obtained for clinical use.
Although the duration of this test is short and the level of demand required by the patient is limited, we cannot guarantee that it will not cause fatigue since no type of measure has been used to assess it.
Finally, although this data has not been studied or analysed, we believe that this test could be used by non-Spanish-speaking clinicians who work with Spanish-speaking patients with the help of an interpreter. The simplicity of the test and the added help of the response format in which the key words to be repeated by the patient are highlighted, facilitate the administration and evaluation of the test by the interpreter. For this reason, we consider that prior informative training for the interpreter would be sufficient without the need for detailed training. The results for each SNR as well as the SNR loss could be obtained directly and communicated to the patient.







{kind=link}
{kind=link}
{kind=link}
{kind=link}