
Investigation of Low-Frequency Data Significance in Electric Vehicle Drivetrain Durability Development
Abstract
:1. Introduction
2. Durability Theory and Statistical Assumption
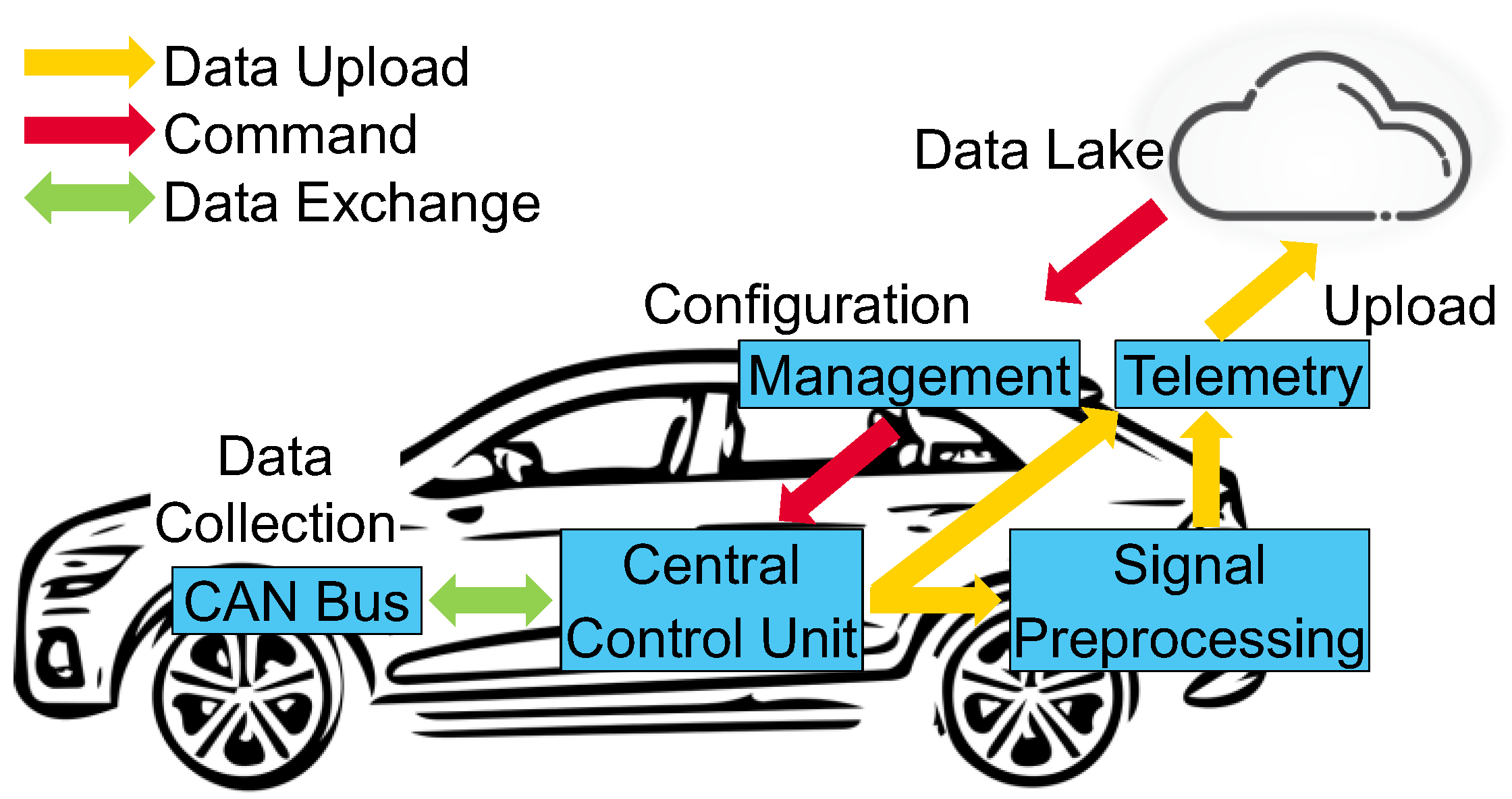
2.1. Drivetrain Durability Development
2.2. Statistical Assumption
3. Data Significance in a Durability Analysis
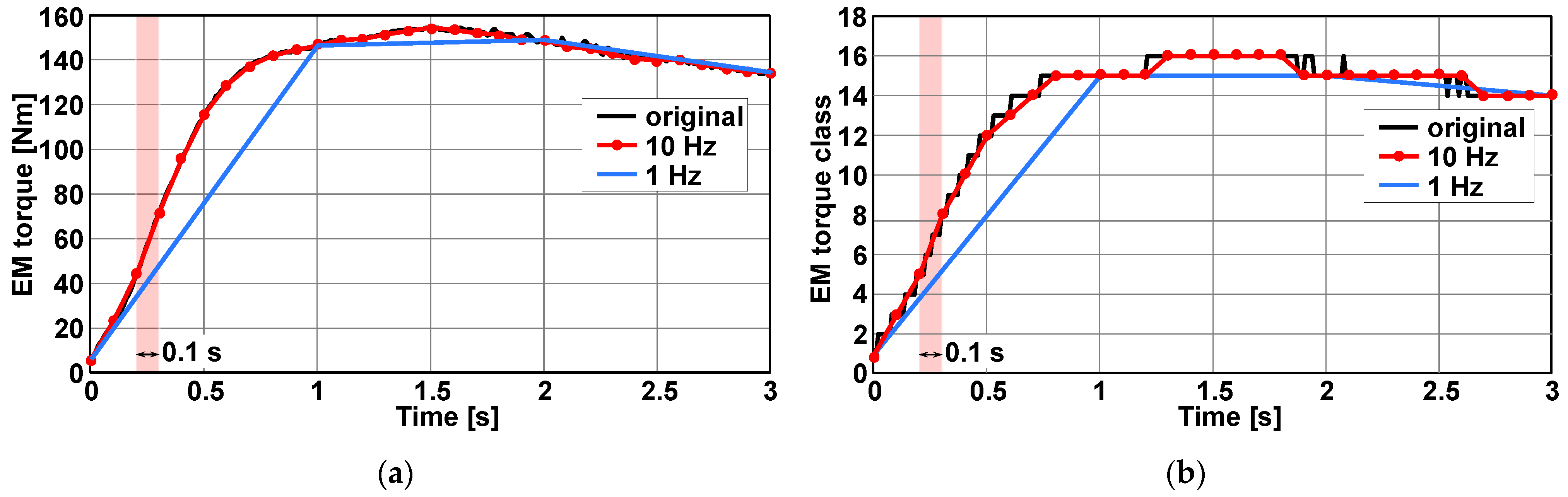
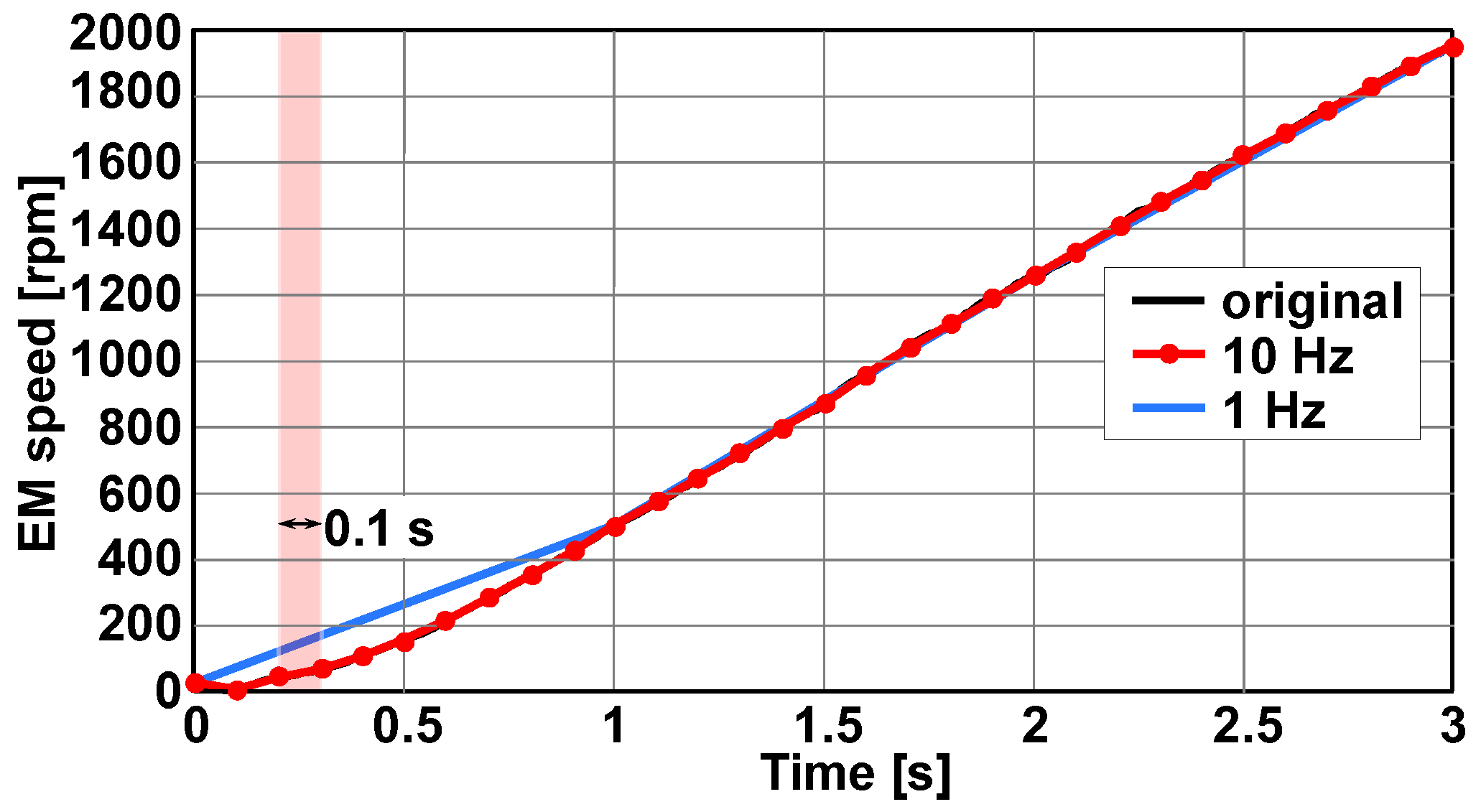
3.1. Signal and Classification Properties
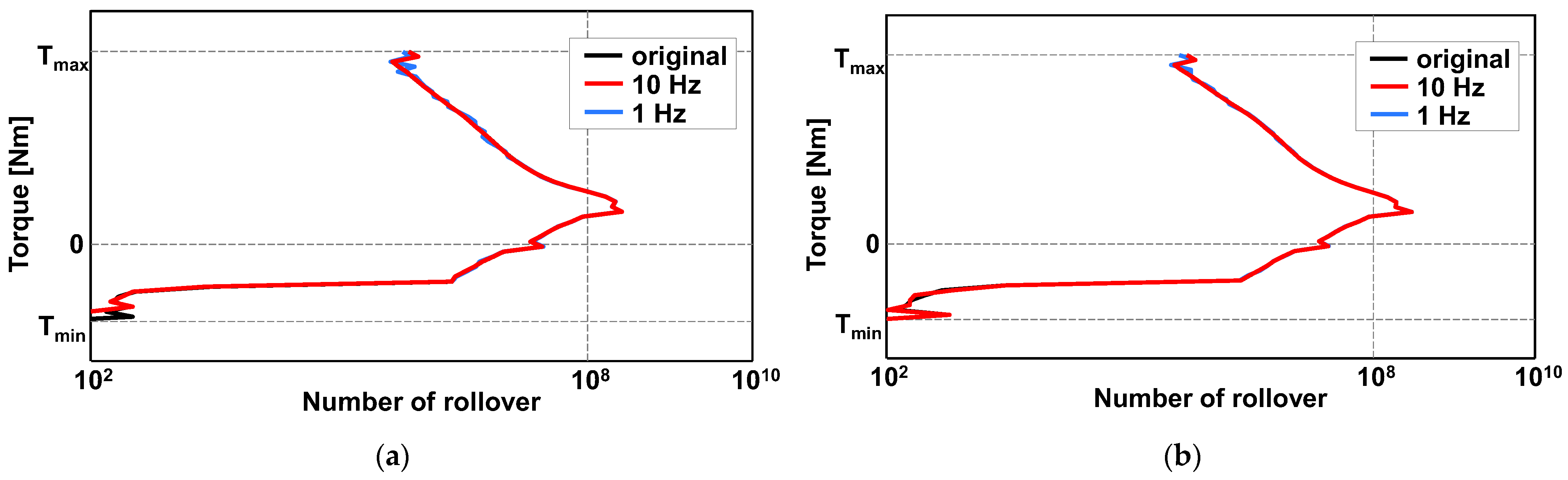
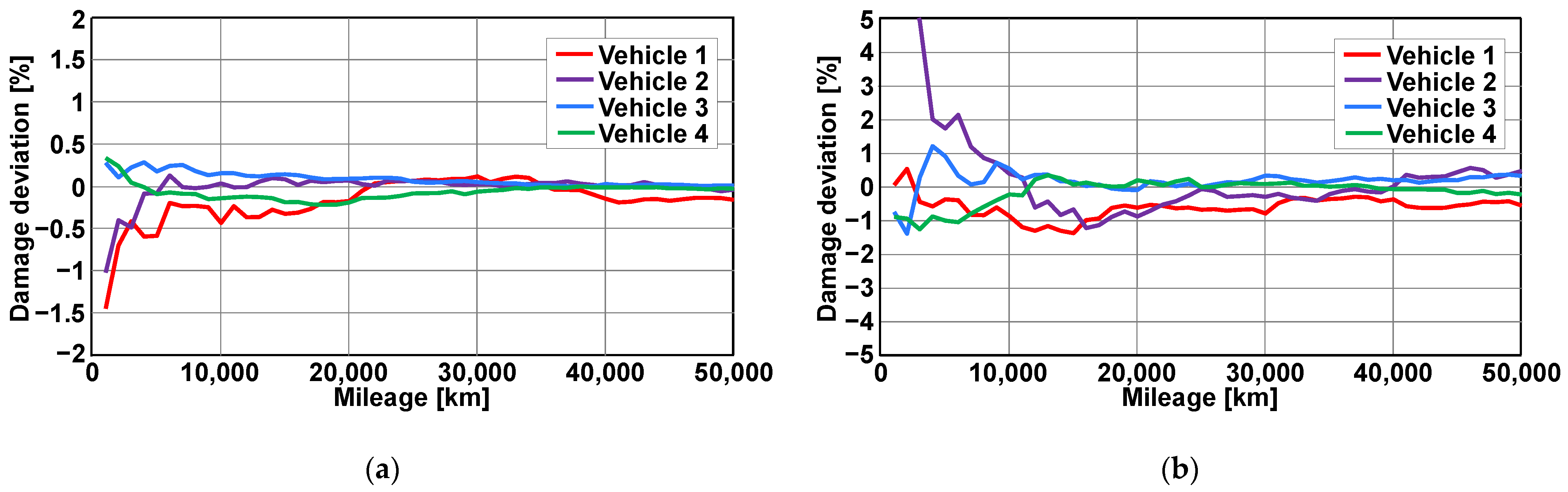
3.2. Significance of Low-Frequency Data for the Rollover Classification
3.3. Significance of Low-Frequency Data for the Time at Level Classification
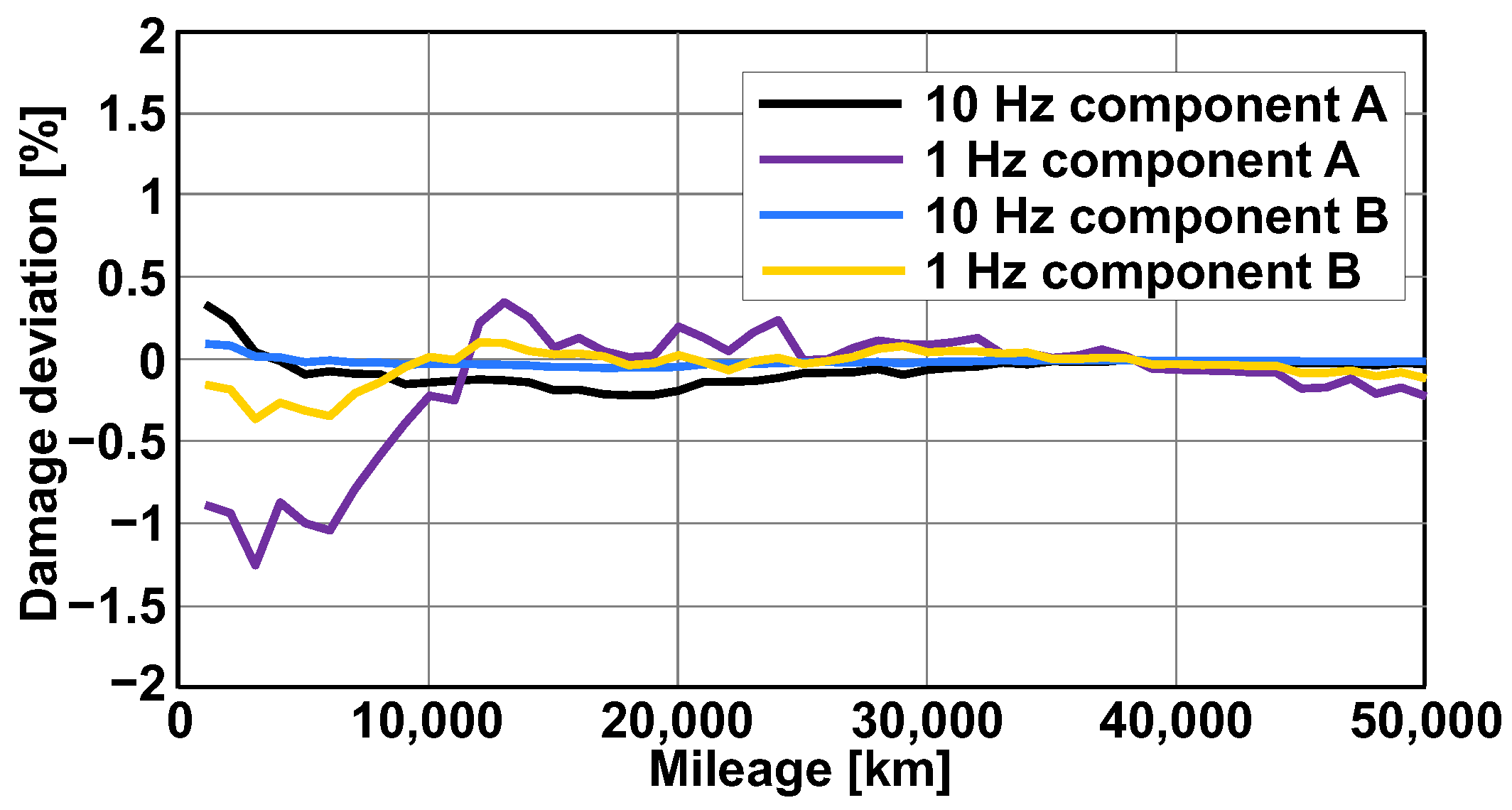
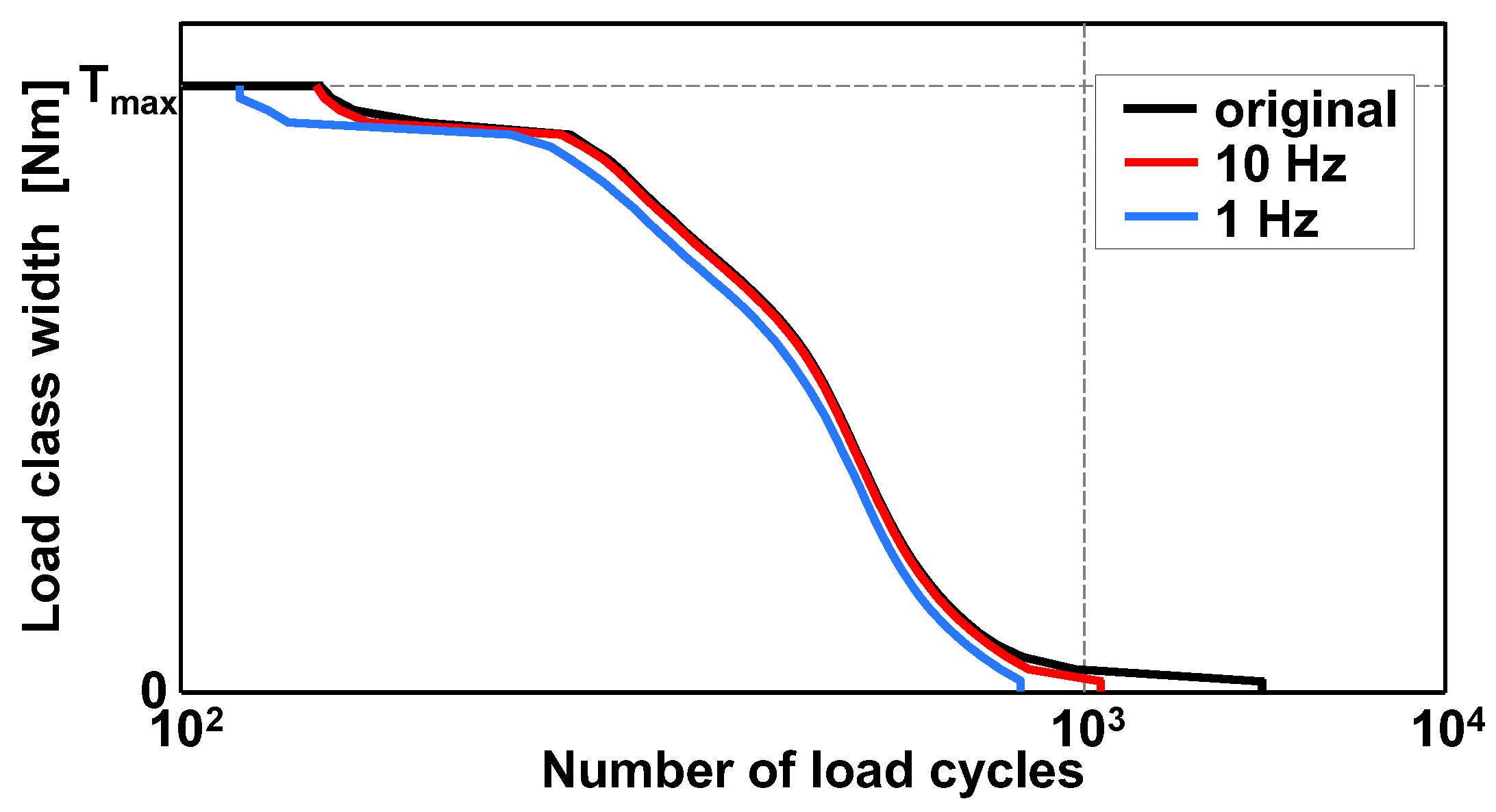
3.4. Significance of Low-Frequency Data for the Rainflow Classification
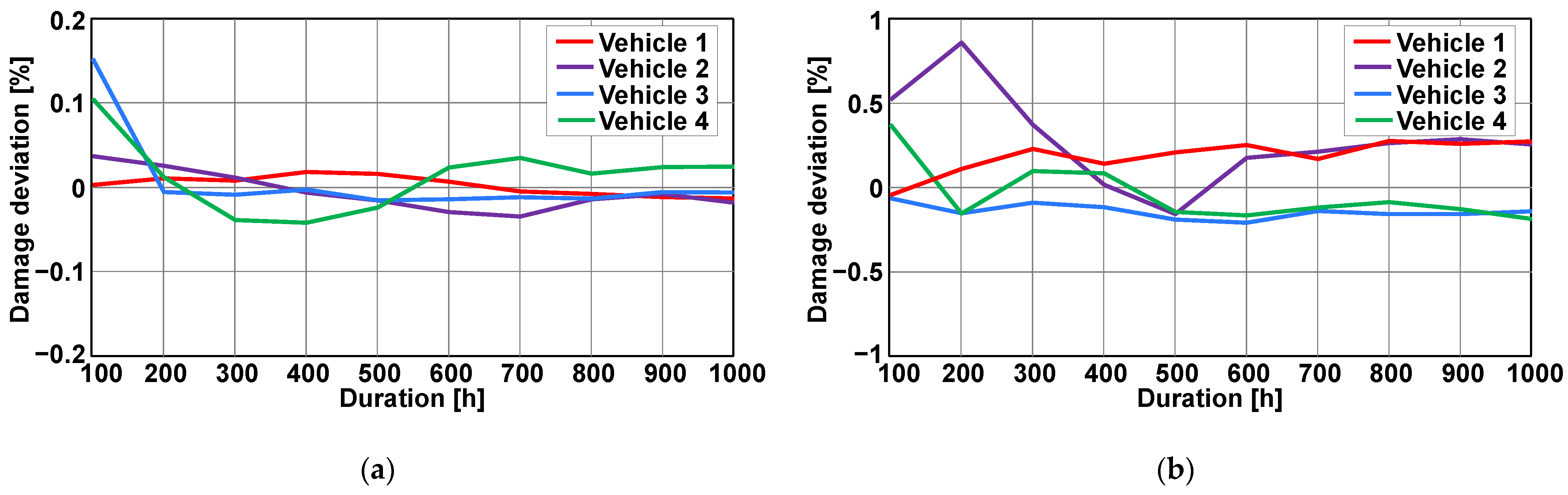
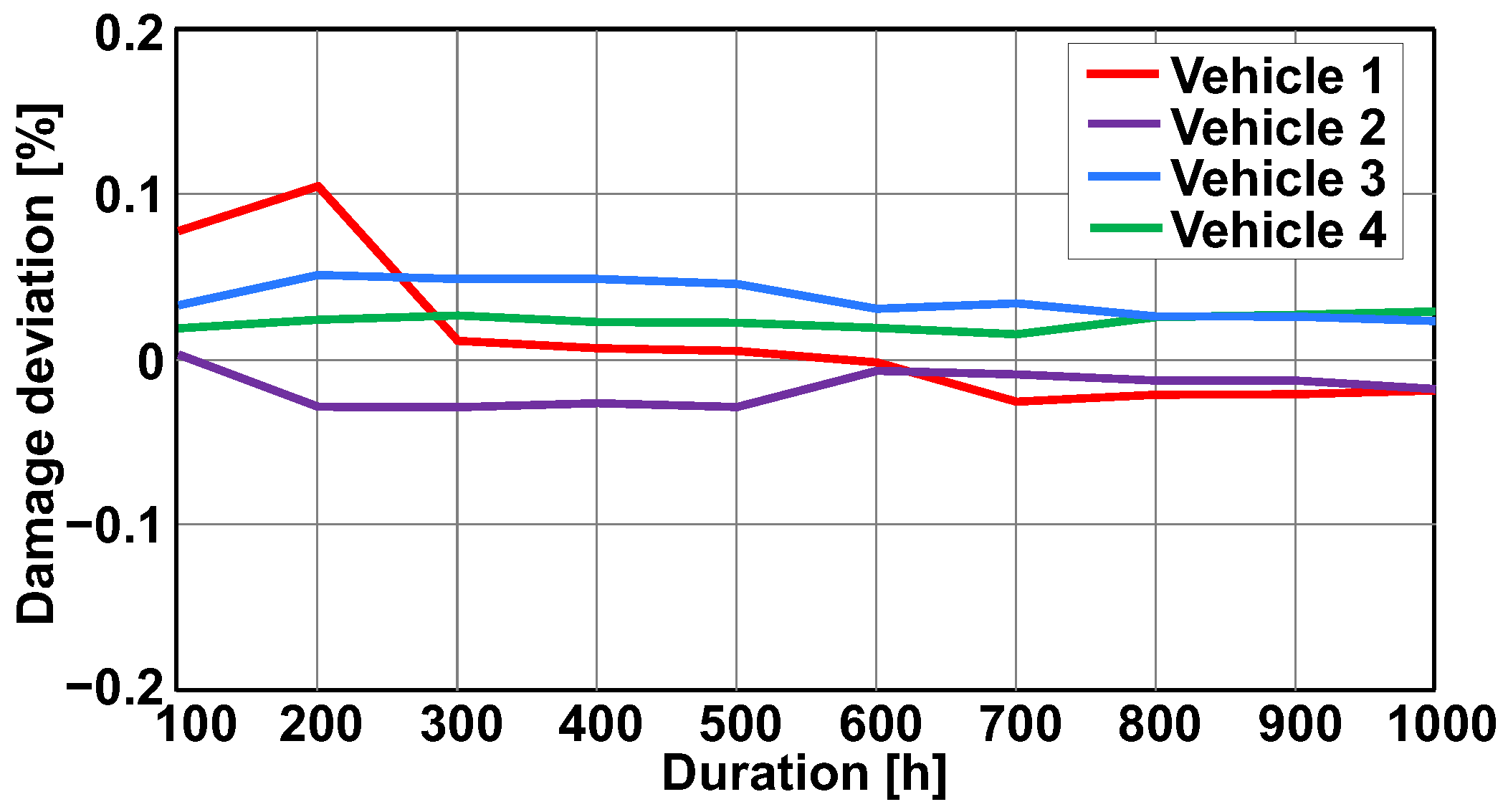
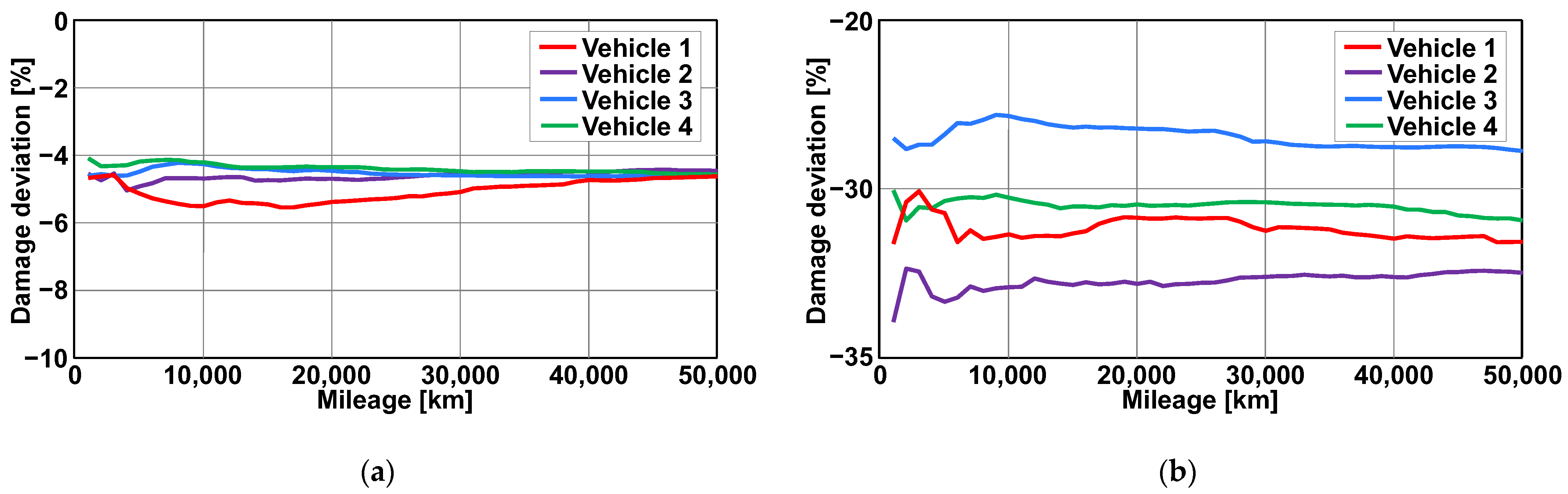
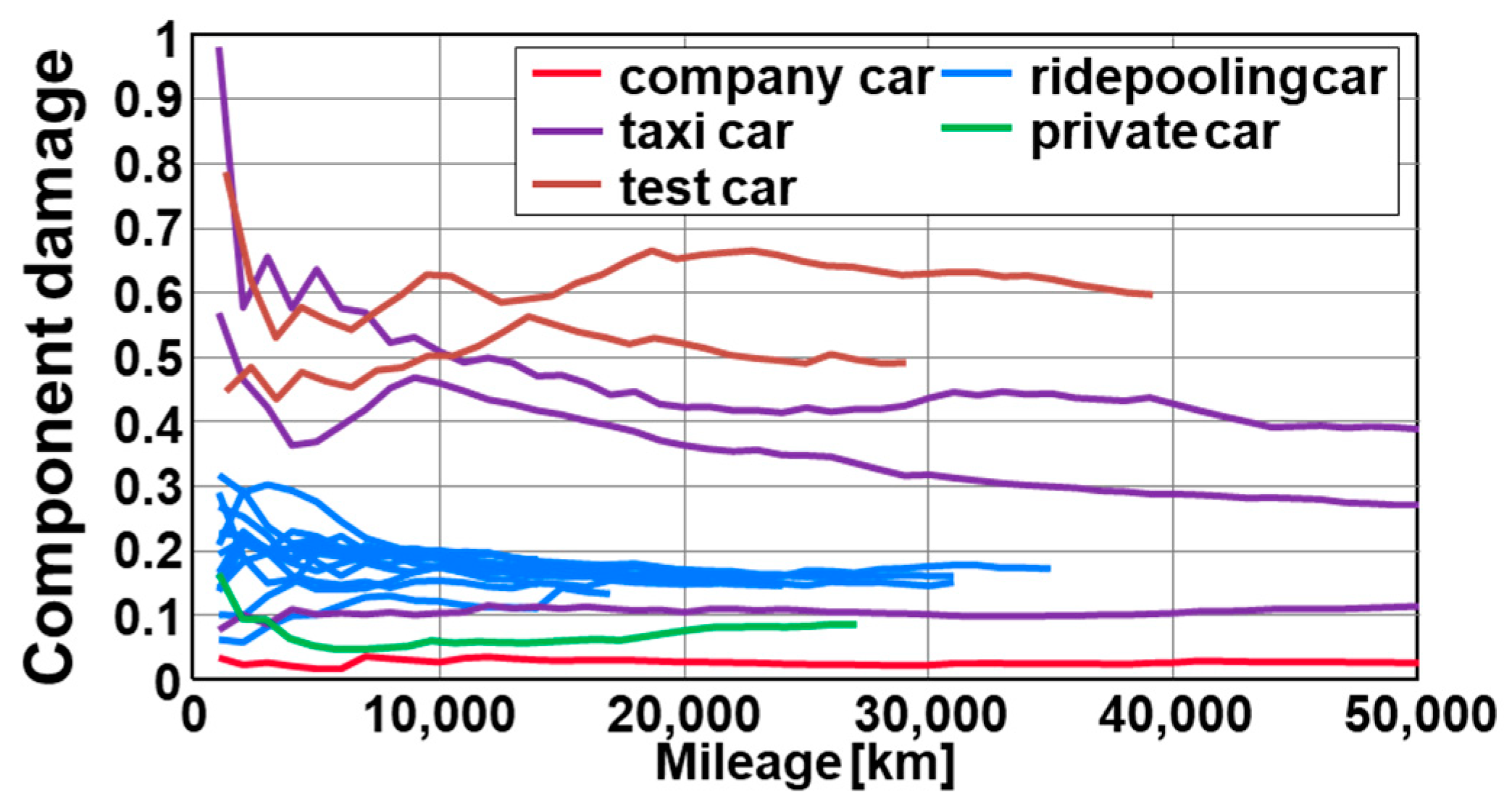
4. Statistical Stability of Data for Representative Damage
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sanguesa, J.A.; Torres-Sanz, V.; Garrido, P.; Martinez, F.J.; Marquez-Barja, J.M. A review on electric vehicles: Technologies and challenges. Smart Cities 2021, 4, 372–404. [Google Scholar] [CrossRef]
- Wahid, M.R.; Budiman, B.A.; Joelianto, E.; Aziz, M. A review on drive train technologies for passenger electric vehicles. Energies 2021, 14, 6742. [Google Scholar] [CrossRef]
- Shu, X.; Yang, W.; Guo, Y.; Wei, K.; Qin, B.; Zhu, G. A reliability study of electric vehicle battery from the perspective of power supply system. J. Power Sources 2020, 451, 227805. [Google Scholar] [CrossRef]
- Liu, Z.; Tan, C.; Leng, F. A reliability-based design concept for lithium-ion battery pack in electric vehicles. Reliab. Eng. Syst. Saf. 2015, 134, 169–177. [Google Scholar] [CrossRef]
- Shu, X.; Guo, Y.; Yang, W.; Wei, K.; Zhu, Y.; Zou, H. A detailed reliability study of the motor System in pure electric vans by the approach of fault tree analysis. IEEE Access 2019, 8, 5295–5307. [Google Scholar] [CrossRef]
- Tang, Q.; Shu, X.; Zhu, G.; Wang, J.; Yang, H. Reliability study of BEV powertrain system and its components—A case study. Processes 2021, 9, 762. [Google Scholar] [CrossRef]
- Tischmacher, H. Systematische Systemanalysen zur Elektrischen Belastung von Wältlagern bei Umrichtergespeisten Elektromotoren. Ph.D. Thesis, Universität Hannover, Hannover, Germany, 2017. [Google Scholar]
- Horst, M.; Schäfer, U.; Schmidt, R. Ermittlung von statistisch abgesicherten Kunden-Lastkollektiven für Personenkraftwagen. In DVM-Bericht Nr. 129; Fahrwerke und Betriebsfestigkeit: Osnabrück, Germany, 2002. [Google Scholar]
- Schimanski, S.; Barta, M.; Schröder, T.-F. Entwicklung eines autonomen Datenloggers zur Erfassung von Bewegungsdaten bei Elektro-Pkws für die Ableitung von nutzungszentrierten Dienstleistungsinnovationen. In Innovative Produkte und Dienstleistungen in der Mobilität; Springer Gabler: Wiesbaden, Germany, 2017. [Google Scholar]
- Wagner, M. Dataloggerbasierte Kundenkollektivermittlung für die Fahrzeugerprobung. Ph.D. Thesis, Technische Universität Braunschweig, Braunschweig, Germany, 2017. [Google Scholar]
- Pötter, K.; Till, R.; Horst, M. Kundenrelevante Betriebslasten—Neue Werkzeuge zur Ermittlung von Fahrzeuglasten im Kundenbetrieb. In DVM-Bericht Nr. 137; Auslegungs-und Absicherungskonzepte der Betriebsfestigkeit—Potenziale und Risiken: München, Germany, 2010. [Google Scholar]
- Grünitz, K.; Manz, H.; Meyer, S. Ermittlung der Betriebsbelastungen elektromechanischer Lenkgetriebe mittels belastungserfassender Software. In DVM-Bericht Nr. 134; Lastannahmen und Betriebsfestigkeit: Wolfsburg, Germany, 2007. [Google Scholar]
- Karspeck, T.; Klaiss, T.; Zellbeck, H. Reconstruction of Customer-Oriented Driving States by Efficient Data Storage on the Control Unit. In 9. Internationales Stuttgarter Symposium; Automobil-und Motorentechnik: Stuttgart, Germany, 2009. [Google Scholar]
- Grober, F.; Janssen, A.; Küçükay, F. Bedarfsgerechte Lastannahme für Fahrzeugbauteile auf Basis von Kunden-Felddaten. In DVM-Bericht Nr. 146; Lastannahmen und Anforderungsmanagement in der Betriebsfestigkeit—neue Trends: Wolfsburg, Germany, 2019. [Google Scholar]
- Grober, F. Optimierte Fahrzeugerprobung auf Basis von Kunden-Felddaten. Ph.D. Thesis, Technische Universität Braunschweig, Braunschweig, Germany, 2022. [Google Scholar]
- Ehrich, F. Big Data as Enabler for Customer-Oriented Automotive Development. Master’s Thesis, Technische Universität Wien, Vienna, Austria, 2018. [Google Scholar]
- Wöhler, A. Über Versuche zur Ermittlung der Festigkeit von Achsen. In Zeitschrift für Bauwesen; 1863; Volume 13, pp. 583–616. [Google Scholar]
- Haibach, E. Betriebsfestigkeit: Verfahren und Daten zur Bauteilberechnung; VDI Verlag: Düsseldorf, Germany, 1989. [Google Scholar]
- Miner, M.A.A. Cumulative damage in fatigue. Trans. J. Appl. Mech. 1945, 12, A159–A164. [Google Scholar] [CrossRef]
- Palmgren, A. Die Lebensdauer von Kugellagern. In VDI-Zeitschrift, Nr. 68; 1924. [Google Scholar]
- Hanisch, L.; Henke, M. Lifetime modelling of electrical machines using the methodology of design of experiments. Simul. Notes Eur. 2021, 31, 95–100. [Google Scholar] [CrossRef]
- Köhler, M.; Jenne, S.; Pötter, K.; Zenner, H. Load Assumption for Fatigue Design of Structures and Components; Springer-Verlag GmbH: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Matsuishi, M.; Endo, T. Fatigue of metals subjected to varying stress. Jap. Soc. Mech. Engin. Fukuoka/Jpn. 1968, 68, 37–40. [Google Scholar]
- Forschungsvereinigung Antriebstechnik, e.V. Zählverfahren zur Bildung von Kollektiven und Matrizen aus Zeitfunktionen; FVA-Richtlinie: Frankfurt, Germany, 2018. [Google Scholar]
- Wang, Y.; Han, X.; Xu, X.; Pan, Y.; Dai, F.; Zou, D.; Lu, L.; Ouyang, M. A comprehensive data-driven assessment scheme for power battery of large-scale electric vehicles in cloud platform. J. Energy Storage 2023, 64, 107210. [Google Scholar] [CrossRef]
- Song, L.; Zhang, K.; Liang, T.; Han, X.; Zhang, Y. Intelligent state of health estimation for lithium-ion battery pack based on big data analysis. J. Energy Storage 2020, 32, 101836. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, Z.; Liu, P.; Zhang, Z. Energy consumption analysis and prediction of electric vehicles based on real-world driving data. Appl. Energy 2020, 275, 115408. [Google Scholar] [CrossRef]
- Corti, A.; Manzoni, V.; Savaresi, S.M. Vehicle’s energy estimation using low frequency speed signal. In Proceedings of the 15th International IEEE Conference on Intelligent Transportation Systems, Anchorage, AK, USA, 16–19 September 2012; pp. 626–631. [Google Scholar]
- Shi, S.; Zhang, M.; Lin, N.; Yue, B. Low-cost reconstruction of typical driving cycles based on empirical information and low-frequency speed data. IEEE Trans. Veh. Technol. 2020, 69, 8221–8231. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, Z.; Liu, P.; Zhang, Z.; Li, X.; Qu, C. Driving cycles construction for electric vehicles considering road environment: A case study in Beijing. Appl. Energy 2019, 253, 113514. [Google Scholar] [CrossRef]
- Noering, F. Unsupervised Pattern Discovery in Automotive Time Series. Ph.D. Thesis, Technische Universität Braunschweig, Braunschweig, Germany, 2021. [Google Scholar]
- Heidenreich, N.; Opalinski, A.; Poll, G. Methode zur Analyse von Kundenkollektivmessungen mittels Einzelfahrtsegmentierung und Clusteralgorithmen. In Commercial Vehicle Technology 2020/2021; Springer Fachmedien Wiesbaden: Wiesbaden, Germany, 2021. [Google Scholar]
- Sree Dhevi, A.T. Imputing missing values using Inverse Distance Weighted Interpolation for time series data. In Proceedings of the 2014 Sixth International Conference on Advanced Computing (ICoAC), Chennai, India, 17–19 December 2014; pp. 255–259. [Google Scholar]
- Sidi, Y.; Harel, O. The treatment of incomplete data: Reporting, analysis, reproducibility, and replicability. Soc. Sci. Med. 2018, 209, 169–173. [Google Scholar] [CrossRef] [PubMed]
- Ma, Q.; Gu, Y.; Lee, W.-C.; Yu, G. Order-sensitive imputation for clustered missing values. IEEE Trans. Knowl. Data Eng. 2019, 31, 166–180. [Google Scholar] [CrossRef]
- Zhao, M.; Li, Y.; Chen, S.; Li, B. Missing value recovery for encoder signals using improved low-rank approximation. Mech. Syst. Signal Process. 2020, 139, 106595. [Google Scholar] [CrossRef]
- Lepot, M.; Aubin, J.-B.; Clemens, F.H.L.R. Interpolation in Time Series: An Introductive Overview of Existing Methods, Their Performance Criteria and Uncertainty Assessment. Water 2017, 9, 796. [Google Scholar] [CrossRef]
- Wegener, J.; van Putten, S.; Neubeck, J.; Wagner, A. Data Mining as an Enabler for Customer Data Driven Vehicle Development. In Proceedings of the Shanghai-Stuttgart-Symposium, Automotive and Powertrain Technology, Shanghai, China, 21–22 October 2021. [Google Scholar]
- Anagnostopoulos, G.; Stavropoulos, G.; Violos, J.; Leivadeas, A.; Varlamis, I. Enhancing Virtual Sensors to deal with Missing Values and Low Sampling Rates. In Proceedings of the 2023 11th IEEE International Conference on Mobile Cloud Computing, Services, and Engineering (MobileCloud), Athens, Greece, 17–20 July 2023; pp. 39–44. [Google Scholar]
- Porsche: Digitalisation of Vehicle Development. Available online: https://newsroom.porsche.com/en/2019/digital/porsche-digitalisation-vehicle-development-examples-16982.html (accessed on 21 January 2024).
- Mirfendreski, A. Powertrain Development with Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Property | Datalogger | Online Data Collection |
|---|---|---|
| Sample size | − | + |
| Data frequency | + | − |
| Online—Configurable | − | + |
| Online—Preprocessing | (−) | + |
| Effort | − | + |
| Classification | Signal | 10 Hz | 1 Hz |
|---|---|---|---|
| Rollover | EM Torque and Speed | 5000 km | 5000 km |
| Time at level | EM Power | 100 h | 100 h |
| Time at level | Pulse Inverter Temperature | - | 100 h |
| Rainflow | EM Torque | Not possible | Not possible |
| Rainflow | Pulse Inverter Temperature | - | Limited |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, M.; Noering, F.K.-D.; Öngün, Y.; Appelt, M.; Henze, R. Investigation of Low-Frequency Data Significance in Electric Vehicle Drivetrain Durability Development. World Electr. Veh. J. 2024, 15, 88. https://doi.org/10.3390/wevj15030088
Li M, Noering FK-D, Öngün Y, Appelt M, Henze R. Investigation of Low-Frequency Data Significance in Electric Vehicle Drivetrain Durability Development. World Electric Vehicle Journal. 2024; 15(3):88. https://doi.org/10.3390/wevj15030088
Chicago/Turabian StyleLi, Mingfei, Fabian Kai-Dietrich Noering, Yekta Öngün, Michael Appelt, and Roman Henze. 2024. "Investigation of Low-Frequency Data Significance in Electric Vehicle Drivetrain Durability Development" World Electric Vehicle Journal 15, no. 3: 88. https://doi.org/10.3390/wevj15030088