

Proximal Policy Optimization Based Intelligent Energy Management for Plug-In Hybrid Electric Bus Considering Battery Thermal Characteristic

Abstract
:1. Introduction
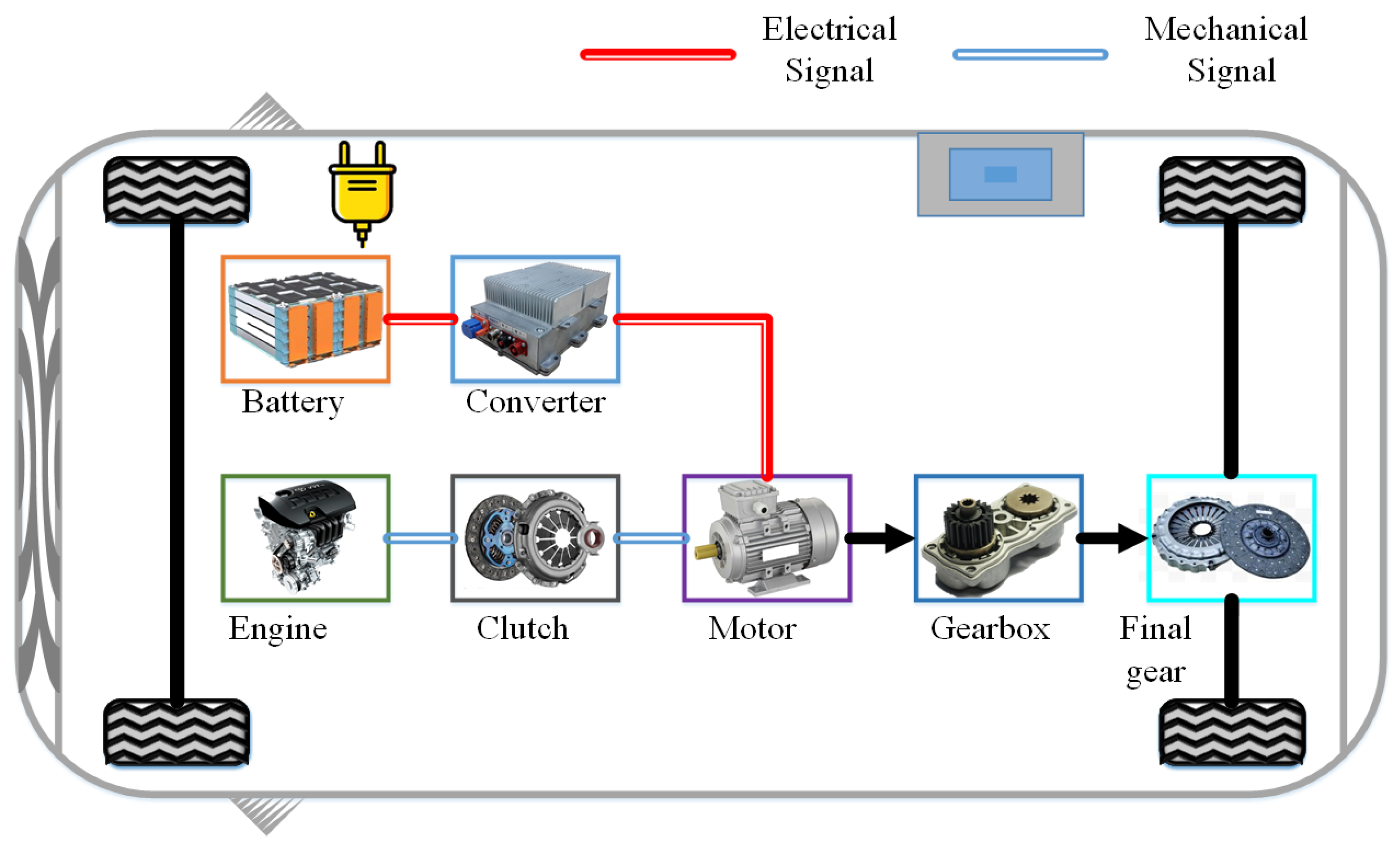
2. System Modeling of PHEB
2.1. Engine Model
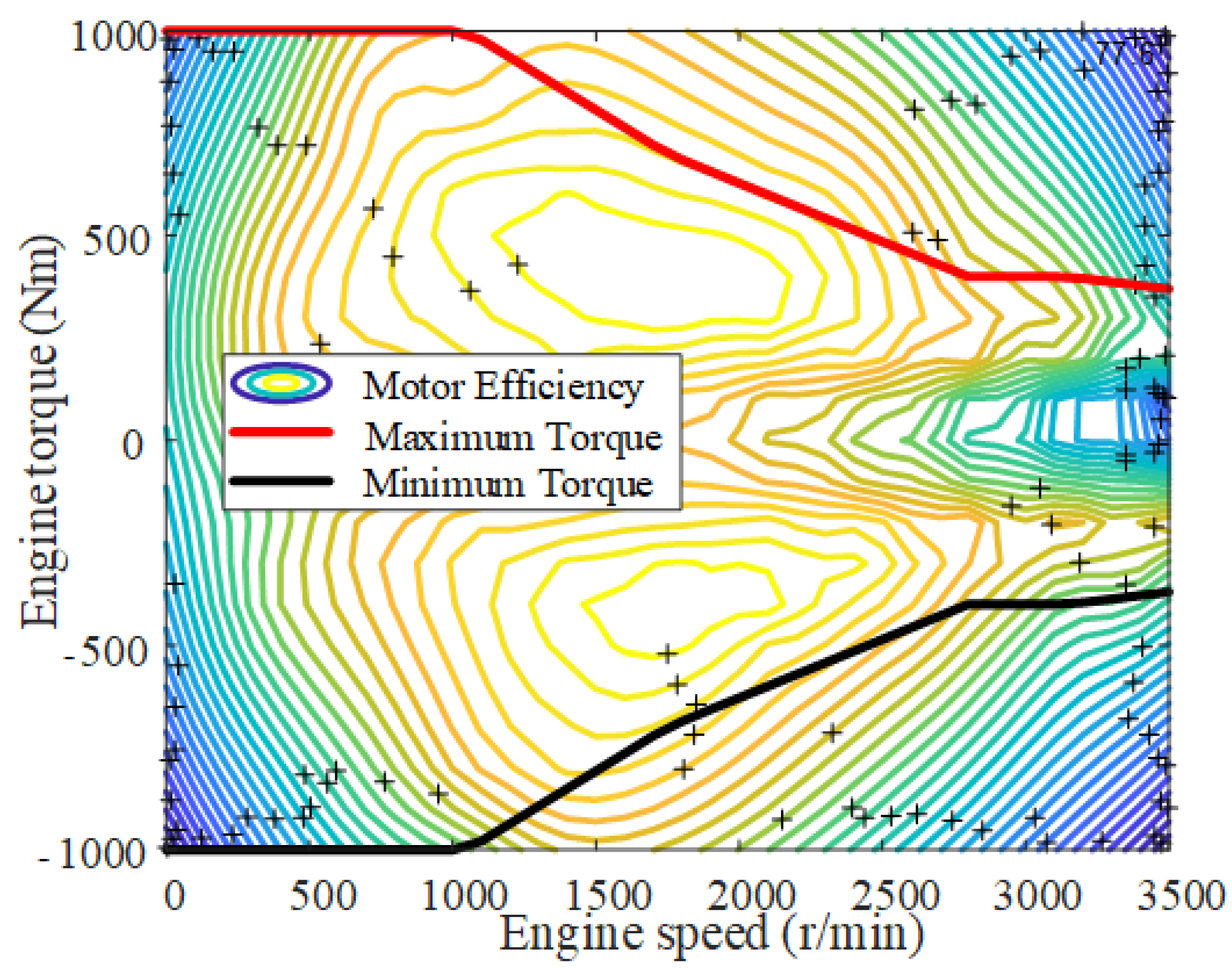
2.2. Motor Model
2.3. Battery Electrical Model
2.4. Battery Thermal Model
3. EMSs Based on PPO-Clip and PPO-Penalty
3.1. RL Algorithm
3.2. PPO-Clip and PPO-Penalty Algorithms
3.3. Design of Network and Algorithm
| Algorithm 1 PPO-Clip and PPO-Penalty algorithms. |
|
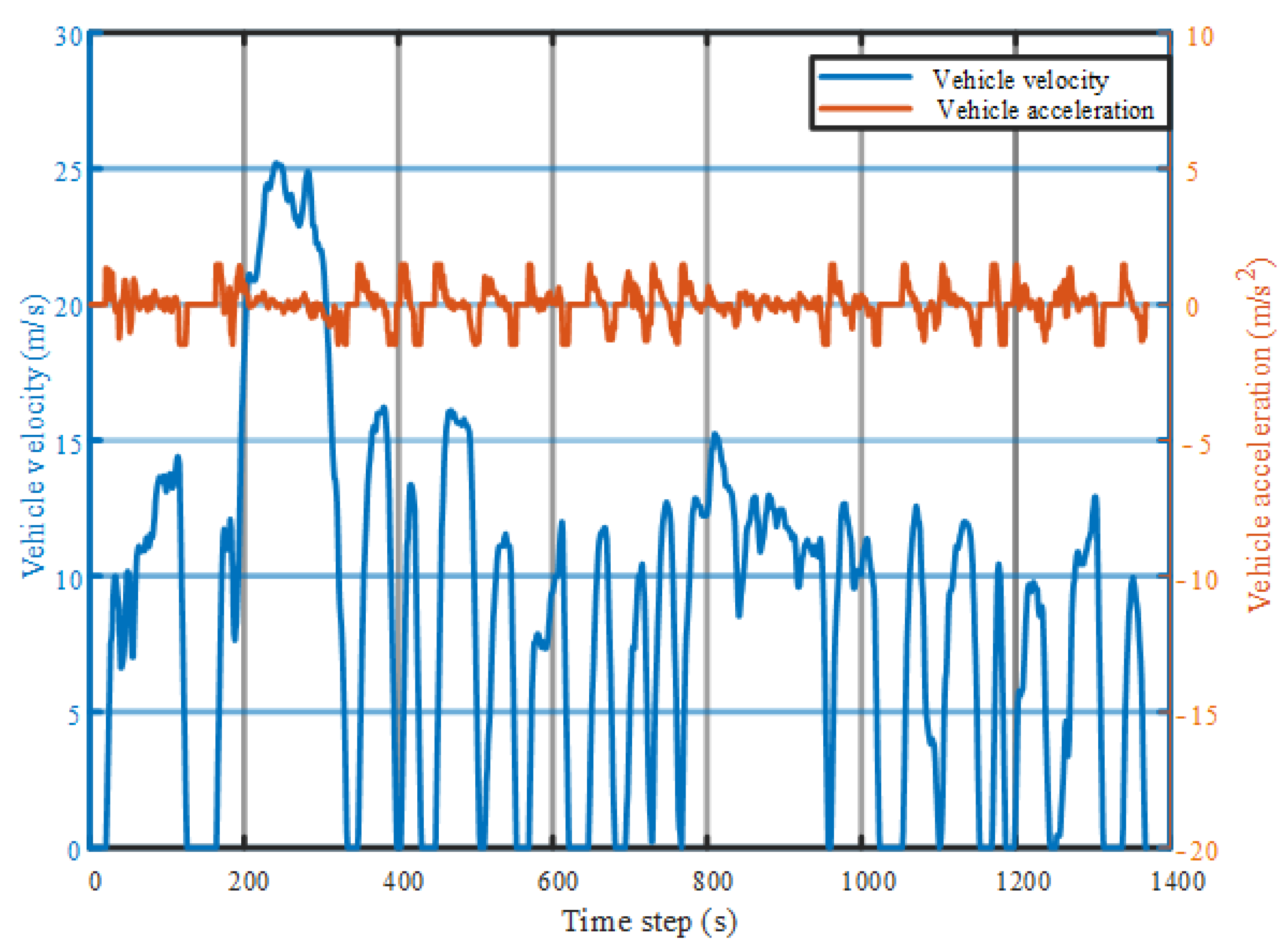
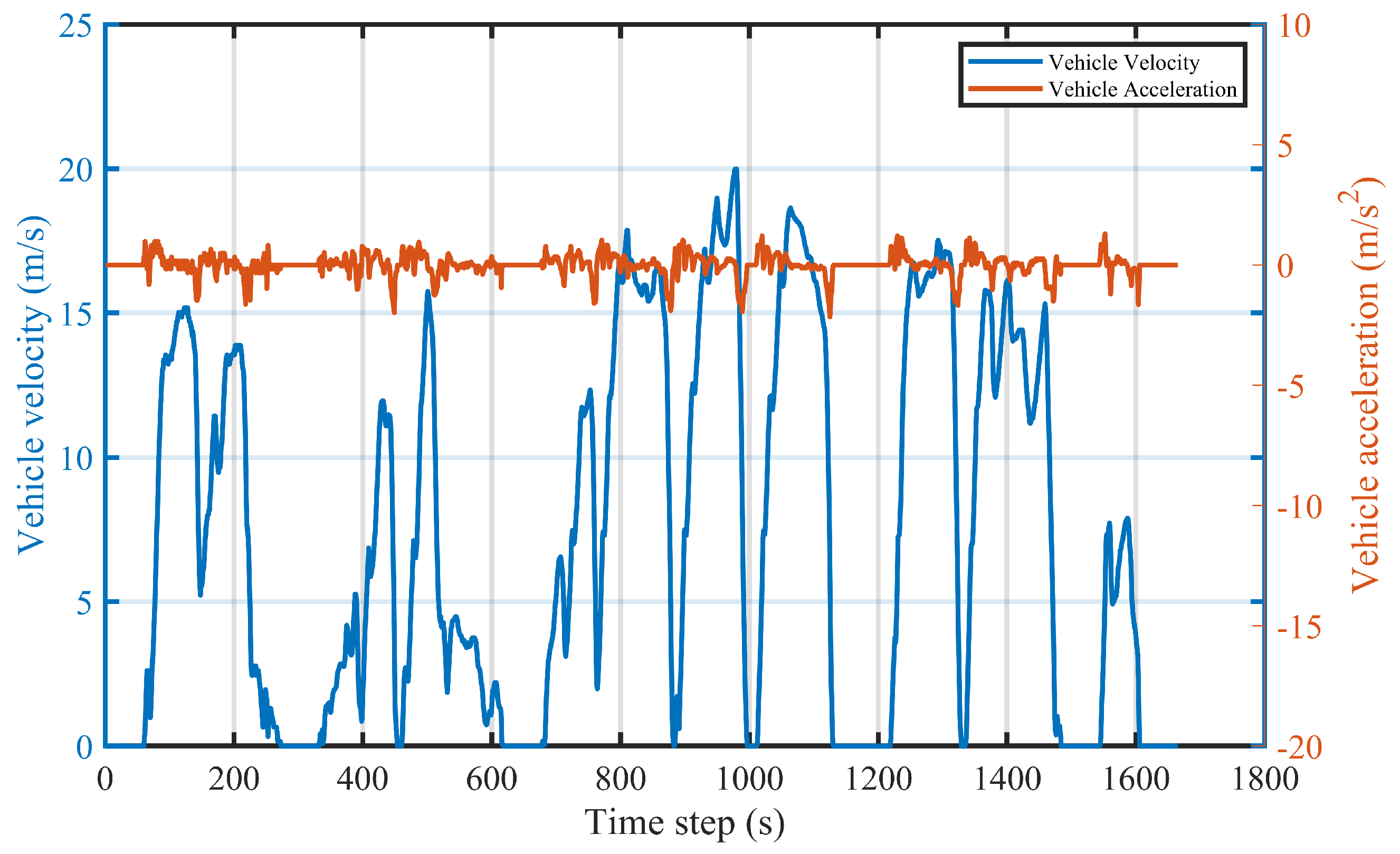
4. Simulation Results and Analysis
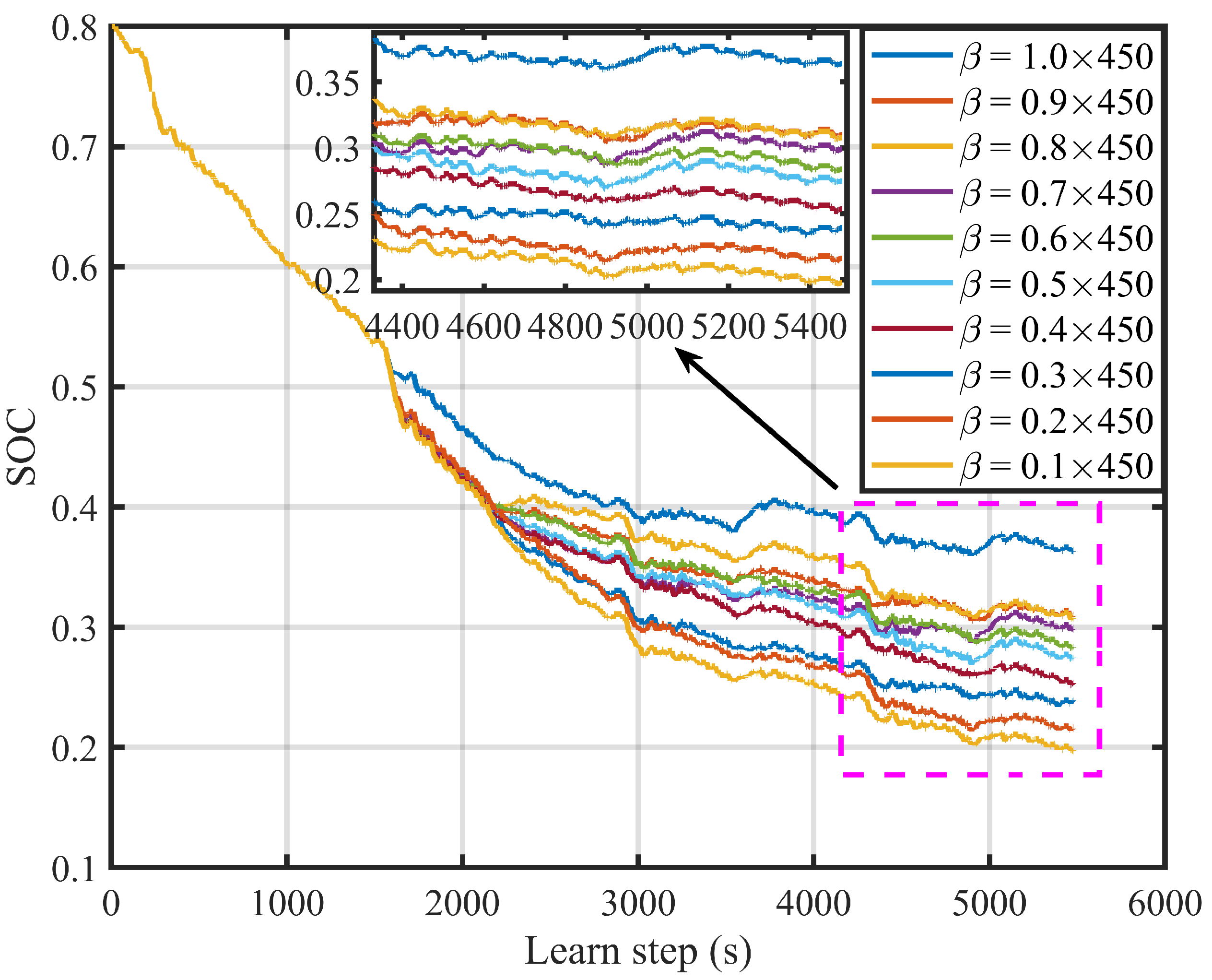
4.1. Tradeoff between Multiple Objectives
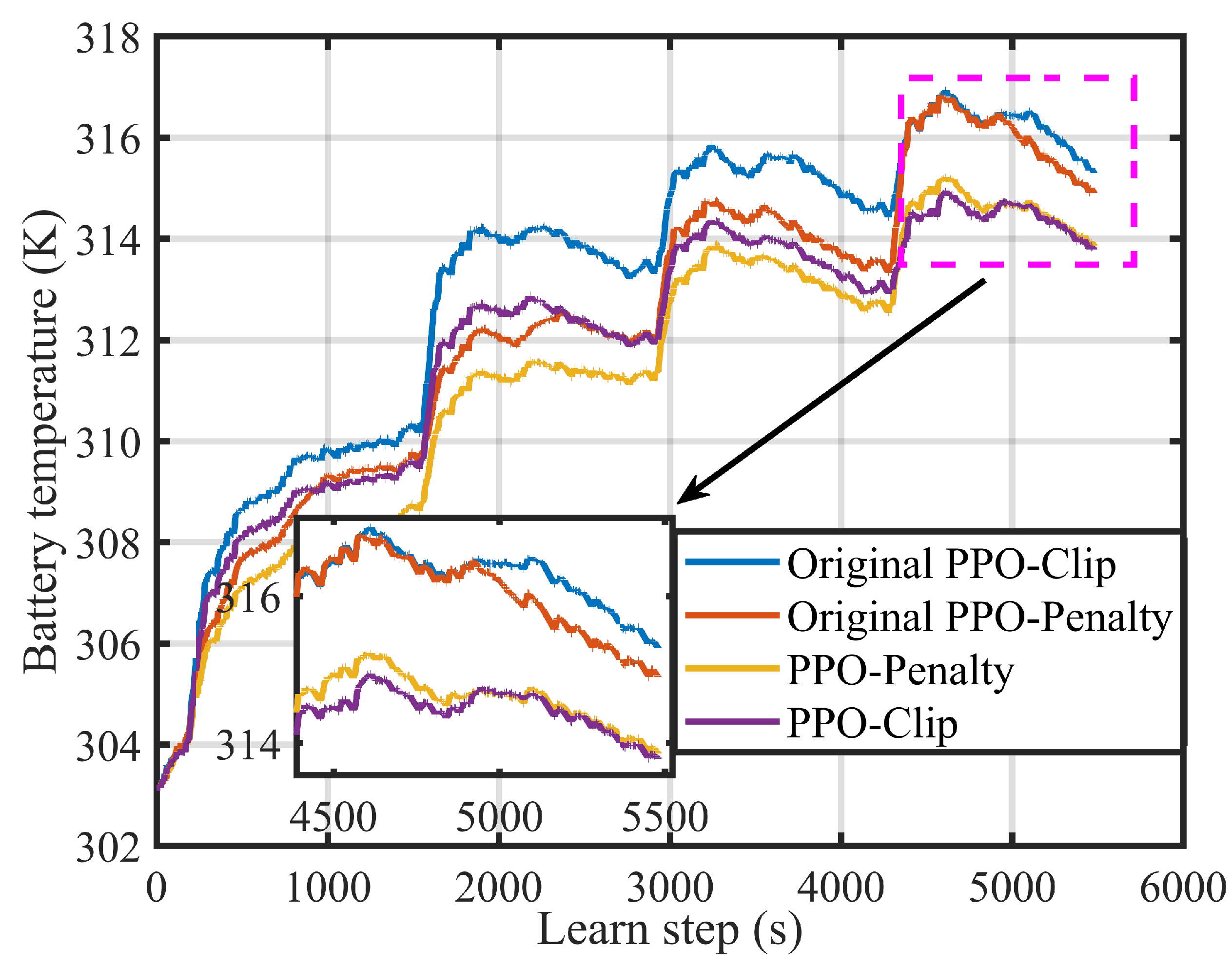
4.2. Effectiveness of EMSs Based on PPO-Clip and PPO-Penalty
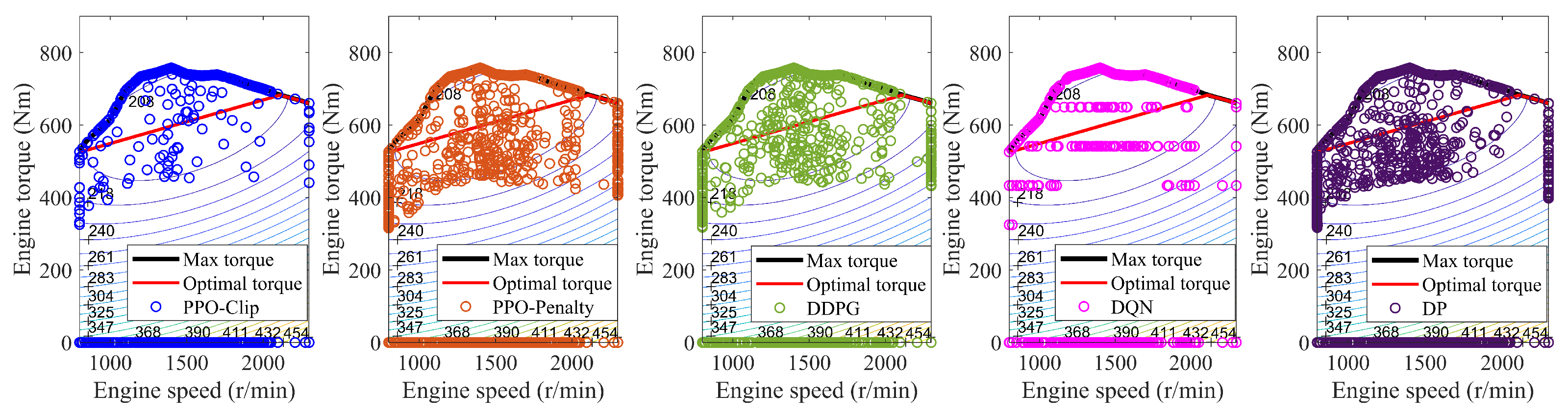
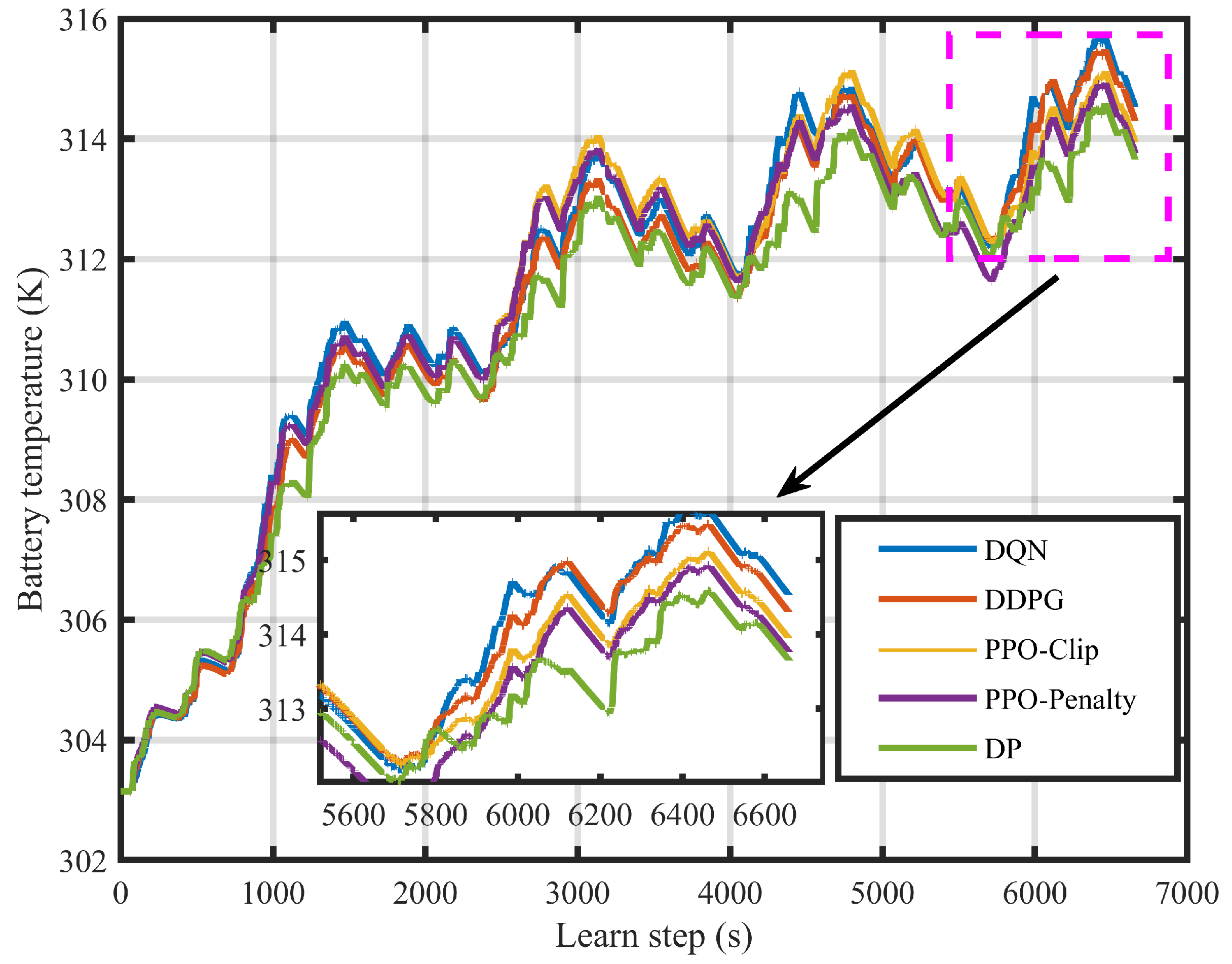
4.3. Superiority of EMSs Based on PPO-Clip and PPO-Penalty
4.4. Adaptability of EMSs Based on PPO-Clip and PPO-Penalty Algorithms
4.5. Robustness of EMSs Based on PPO-Clip and PPO-Penalty
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| vehicle driving force | total battery power consumption | ||
| M | vehicle mass | power flowing into or out of the battery | |
| g | gravitational acceleration | battery power loss | |
| f | rolling resistance coefficient | internal resistance | |
| road slope | charge and discharge current | ||
| air resistance coefficient | terminal voltage | ||
| air density | battery temperature | ||
| A | vehicle frontal area | battery mass | |
| v | vehicle velocity | average specific heat capacity | |
| correction factor | h | heat exchange coefficient | |
| fuel consumption rate | heat exchange area | ||
| engine torque | environment temperature | ||
| engine speed | battery heating rate | ||
| motor operating efficiency | initial battery temperature | ||
| motor torque | battery temperature at the previous moment | ||
| motor speed | diesel density | ||
| reward function in times of k | electric consumption | ||
| the action-value function | engine operating efficiency | ||
| heating value | discount factor |
References
- Ahmad, A.; Alam, M.S.; Chabaan, R. A Comprehensive Review of Wireless Charging Technologies for Electric Vehicles. IEEE Trans. Transp. Electrif. 2017, 4, 38–63. [Google Scholar] [CrossRef]
- Zhou, Y.; Ravey, A.; Péra, M.C. A survey on driving prediction techniques for predictive energy management of plug-in hybrid electric vehicles. J. Power Sources 2019, 412, 480–495. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, C.; Huang, Z.; Xu, L.; Liu, Z.; Liu, M. Real-time energy management strategy for fuel cell range extender vehicles based on nonlinear control. IEEE Trans. Transp. Electrif. 2019, 5, 1294–1305. [Google Scholar] [CrossRef]
- Flah, A.; Chokri, M. A Novel Energy Optimization Approach for Electrical Vehicles in a Smart City. Energies 2019, 12, 929. [Google Scholar]
- Xie, S.; Qi, S.; Lang, K. A data-driven power management strategy for plug-in hybrid electric vehicles including optimal battery depth of discharging. IEEE Trans. Ind. Inform. 2019, 16, 3387–3396. [Google Scholar] [CrossRef]
- Mohamed, N.; Aymen, F.; Ali, Z.M.; Zobaa, A.F.; Aleem, S.H.E.A. Efficient Power Management Strategy of Electric Vehicles Based Hybrid Renewable Energy. Sustainability 2021, 13, 7351. [Google Scholar] [CrossRef]
- Sabri, M.F.M.; Danapalasingam, K.A.; Rahmat, M.F. A review on hybrid electric vehicles architecture and energy management strategies. Renewable and Sustainable Energy Reviews. Renew. Sustain. Energy Rev. 2016, 53, 1433–1442. [Google Scholar] [CrossRef]
- Tran, D.D.; Vafaeipour, M.; El Baghdadi, M.; Barrero, R.; Van Mierlo, J.; Hegazy, O. Thorough state-of-the-art analysis of electric and hybrid vehicle powertrains: Topologies and integrated energy management strategies. Renew. Sustain. Energy Rev. 2020, 119, 109596. [Google Scholar] [CrossRef]
- Taherzadeh, E.; Dabbaghjamanesh, M.; Gitizadeh, M.; Rahideh, A. A new efficient fuel optimization in blended charge depletion/charge sustenance control strategy for plug-in hybrid electric vehicles. IEEE Trans. Intell. Veh. 2018, 3, 374–383. [Google Scholar] [CrossRef]
- Yin, H.; Zhou, W.; Li, M.; Ma, C.; Zhao, C. An adaptive fuzzy logic-based energy management strategy on battery/ultracapacitor hybrid electric vehicles. IEEE Trans. Transp. Electrif. 2016, 2, 300–311. [Google Scholar] [CrossRef]
- Liu, J.; Chen, Y.; Li, W.; Shang, F.; Zhan, J. Hybrid-trip-model-based energy management of a PHEV with computation-optimized dynamic programming. IEEE Transactions on Vehicular Technology. IEEE Trans. Veh. Technol. 2017, 67, 338–353. [Google Scholar] [CrossRef]
- Peng, J.; He, H.; Xiong, R. Rule based energy management strategy for a series–parallel plug-in hybrid electric bus optimized by dynamic programming. Appl. Energy 2008, 185, 1633–1643. [Google Scholar] [CrossRef]
- Schmid, R.; Buerger, J.; Bajcinca, N. Energy management strategy for plug-in-hybrid electric vehicles based on predictive PMP. IEEE Trans. Control Syst. Technol. 2021, 29, 2548–2560. [Google Scholar] [CrossRef]
- Xie, S.; Hu, X.; Xin, Z.; Brighton, J. Pontryagin’s minimum principle based model predictive control of energy management for a plug-in hybrid electric bus. Appl. Energy 2019, 236, 893–905. [Google Scholar] [CrossRef]
- Hu, X.; Murgovski, N.; Johannesson, L.M.; Egardt, B. Comparison of three electrochemical energy buffers applied to a hybrid bus powertrain with simultaneous optimal sizing and energy management. IEEE Trans. Intell. Trans. Syst. 2014, 15, 1193–1205. [Google Scholar] [CrossRef]
- Hadj-Said, S.; Colin, G.; Ketfi-Cherif, A.; Chamaillard, Y. Convex optimization for energy management of parallel hybrid electric vehicles. IFAC-PapersOnLine. IFAC-PapersOnLine 2016, 49, 271–276. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, X.; Sun, Y.; You, S. Model predictive control strategy for energy optimization of series-parallel hybrid electric vehicle. J. Clean. Prod. 2018, 199, 348–358. [Google Scholar] [CrossRef]
- Xie, S.; Hu, X.; Qi, S.; Tang, X.; Lang, K.; Xin, Z.; Brighton, J. Model predictive energy management for plug-in hybrid electric vehicles considering optimal battery depth of discharge. Energy 2019, 173, 667–678. [Google Scholar] [CrossRef]
- Zhu, L.; Tao, F.; Fu, Z.; Wang, N.; Ji, B.; Dong, Y. Optimization Based Adaptive Cruise Control and Energy Management Strategy for Connected and Automated FCHEV. IEEE Trans. Intell. Transp. Syst. 2022, 23, 21620–21629. [Google Scholar] [CrossRef]
- Han, J.; Kum, D.; Park, Y. Synthesis of predictive equivalent consumption minimization strategy for hybrid electric vehicles based on closed-form solution of optimal equivalence factor. IEEE Trans. Veh. Technol. 2017, 66, 5604–5616. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Hassabis, D. Mastering the game of Go with deep neural networks and tree search. J. Abbr. 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Vázquez-Canteli, J.R.; Nagy, Z. Reinforcement learning for demand response: A review of algorithms and modeling techniques. Appl. Energy 2019, 235, 1072–1089. [Google Scholar] [CrossRef]
- Zhou, Q.; Li, J.; Shuai, B.; Williams, H.; He, Y.; Li, Z.; Yan, F. Multi-step reinforcement learning for model-free predictive energy management of an electrified off-highway vehicle. Appl. Energy 2019, 255, 113755. [Google Scholar] [CrossRef]
- Wu, J.; He, H.; Peng, J.; Li, Y.; Li, Z. Continuous reinforcement learning of energy management with deep Q network for a power split hybrid electric bus. Appl. Energy 2018, 222, 799–811. [Google Scholar] [CrossRef]
- Hu, Y.; Li, W.; Xu, K.; Zahid, T.; Qin, F.; Li, C. Energy management strategy for a hybrid electric vehicle based on deep reinforcement learning. Appl. Ences 2018, 8, 187. [Google Scholar] [CrossRef]
- Li, Y.; He, H.; Khajepour, A.; Wang, H.; Peng, J. Energy management for a power-split hybrid electric bus via deep reinforcement learning with terrain information. Appl. Energy 2019, 255, 113762. [Google Scholar] [CrossRef]
- Wu, Y.; Tan, H.; Peng, J.; Zhang, H.; He, H. Deep reinforcement learning of energy management with continuous control strategy and traffic information for a series-parallel plug-in hybrid electric bus. Appl. Energy 2019, 247, 454–466. [Google Scholar] [CrossRef]
- Lian, R.; Peng, J.; Wu, Y.; Tan, H.; Zhang, H. Rule-interposing deep reinforcement learning based energy management strategy for power-split hybrid electric vehicle. Energy 2020, 197, 117297. [Google Scholar] [CrossRef]
- Xu, D.; Cui, Y.; Ye, J.; Cha, S.W.; Li, A.; Zheng, C. A soft actor-critic-based energy management strategy for electric vehicles with hybrid energy storage systems. J. Power Sources 2022, 524, 231099. [Google Scholar] [CrossRef]
- Zhou, J.; Xue, S.; Xue, Y.; Liao, Y.; Liu, J.; Zhao, W. A novel energy management strategy of hybrid electric vehicle via an improved TD3 deep reinforcement learning. Energy 2021, 224, 120118. [Google Scholar] [CrossRef]
- Tang, X.; Chen, J.; Liu, T.; Qin, Y.; Cao, D. Distributed deep reinforcement learning-based energy and emission management strategy for hybrid electric vehicles. IEEE Trans. Veh. Technol. 2021, 70, 9922–9934. [Google Scholar] [CrossRef]
- Liu, T.; Wang, B.; Tan, W.; Lu, S.; Yang, Y. Data-driven transferred energy management strategy for hybrid electric vehicles via deep reinforcement learning. arXiv 2020, arXiv:2009.03289. [Google Scholar]
- Zhou, Q.; Du, C. A two-term energy management strategy of hybrid electric vehicles for power distribution and gear selection with intelligent state-of-charge reference. J. Energy Storage 2021, 42, 103054. [Google Scholar] [CrossRef]
- Tang, X.; Jia, T.; Hu, X.; Huang, Y.; Deng, Z.; Pu, H. Naturalistic data-driven predictive energy management for plug-in hybrid electric vehicles. IEEE Trans. Transp. Electrif. 2020, 7, 497–508. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Heess, N.; TB, D.; Sriram, S.; Lemmon, J.; Merel, J.; Wayne, G.; Silver, D. Emergence of locomotion behaviours in rich environments. arXiv 2017, arXiv:1707.02286. [Google Scholar]
- Du, G.; Zou, Y.; Zhang, X.; Liu, T.; Wu, J.; He, D. Deep reinforcement learning based energy management for a hybrid electric vehicle. Energy 2020, 201, 117591. [Google Scholar] [CrossRef]
- Zhang, B.; Hu, W.; Cao, D.; Huang, Q.; Chen, Z.; Blaabjerg, F. Deep reinforcement learning–based approach for optimizing energy conversion in integrated electrical and heating system with renewable energy. Energy Convers. Manag. 2019, 202, 112199. [Google Scholar] [CrossRef]
- Wang, Y.; Tan, H.; Wu, Y.; Peng, J. Hybrid electric vehicle energy management with computer vision and deep reinforcement learning. IEEE Trans. Ind. Inform. 2020, 17, 3857–3868. [Google Scholar] [CrossRef]
- Wang, W.; Guo, X.; Yang, C.; Zhang, Y.; Zhao, Y.; Huang, D.; Xiang, C. A multi-objective optimization energy management strategy for power split HEV based on velocity prediction. Energy 2022, 238, 121714. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Component | Parameters | Value |
|---|---|---|
| Curb mass | 10,500 kg | |
| Vehicle | Drag coefficient | 0.65 |
| Frontal area | 6.75 m | |
| Battery | Capacity | 90 Ah |
| Voltage | 560 V | |
| Motor | Peak power | 135 kW |
| Peak torque | 1000 Nm | |
| Engine | Peak power | 155 kW |
| Peak torque | 760 Nm |
| Parameters | Value |
|---|---|
| Hidden layer | 1 |
| Number of neurons | 100 |
| Learning rate | 0.001 (AN) |
| 0.002 (CN) | |
| Discount factor | 0.99 |
| Minibatch size | 64 |
| The Weight Coefficient () | Equivalent Fuel Consumption (L/100 km) | Terminal SOC |
|---|---|---|
| = 1.00 × 450 | 19.706 | 0.364 |
| = 0.90 × 450 | 19.319 | 0.309 |
| = 0.80 × 450 | 18.993 | 0.308 |
| = 0.70 × 450 | 18.572 | 0.299 |
| = 0.60 × 450 | 18.544 | 0.284 |
| = 0.50 × 450 | 18.173 | 0.275 |
| = 0.40 × 450 | 18.005 | 0.254 |
| = 0.30 × 450 | 17.639 | 0.239 |
| = 0.20 × 450 | 17.248 | 0.216 |
| = 0.10 × 450 | 16.899 | 0.198 |
| The Weight of Battery Temperature | Equivalent Fuel Consumption | Terminal SOC | Terminal Battery Temperature |
|---|---|---|---|
| = 1.00 | 20.555 | 0.375 | 313.066 |
| = 0.90 | 19.651 | 0.320 | 313.341 |
| = 0.75 | 19.057 | 0.309 | 313.383 |
| = 0.60 | 18.655 | 0.298 | 313.553 |
| = 0.50 | 17.899 | 0.276 | 313.836 |
| = 0.40 | 17.714 | 0.254 | 313.861 |
| = 0.25 | 17.553 | 0.228 | 314.195 |
| = 0.10 | 16.083 | 0.161 | 314.442 |
| Algorithm | Equivalent Fuel Consumption (L/100 km) | Terminal SOC | Battery Temperature (K) |
|---|---|---|---|
| Original PPO-Clip | 17.873 | 0.277 | 315.287 |
| PPO-Clip | 17.779 | 0.280 | 313.778 |
| Original PPO-Penalty | 18.255 | 0.291 | 314.892 |
| PPO-Penalty | 18.205 | 0.287 | 313.854 |
| Algorithm | Terminal SOC | Battery Temperature (K) | Computing Time (s) | Equivalent Fuel Consumption (L/100 km) | Saving Rate (%) |
|---|---|---|---|---|---|
| DP | 0.293 | 313.369 | 9504 | 17.481 | - |
| DQN | 0.310 | 314.495 | 1657 | 19.231 | −10.01 |
| DDPG | 0.304 | 313.921 | 2296 | 18.917 | −8.21 |
| PPO-Clip | 0.280 | 313.778 | 1449 | 17.779 | −1.70 |
| PPO-Penalty | 0.287 | 313.854 | 1435 | 18.205 | −4.14 |
| Algorithm | Terminal SOC | Battery Temperature (K) | Equivalent Fuel Consumption (L/100 km) |
|---|---|---|---|
| DP | 0.296 | 313.649 | 18.679 |
| DQN | 0.287 | 314.519 | 20.418 |
| DDPG | 0.286 | 314.296 | 20.093 |
| PPO-Clip | 0.288 | 313.938 | 18.960 |
| PPO-Penalty | 0.293 | 313.759 | 19.138 |
| Algorithm | Terminal SOC | Battery Temperature (K) | Computing Time (s) | Equivalent Fuel Consumption (L/100 km) | Saving Rate (%) |
|---|---|---|---|---|---|
| DP | 0.296 | 313.649 | 11,232 | 18.679 | - |
| DQN | 0.287 | 314.519 | 2338 | 20.418 | −9.31 |
| DDPG | 0.286 | 314.296 | 3556 | 20.093 | −7.59 |
| PPO-Clip | 0.288 | 313.938 | 1858 | 18.960 | −1.50 |
| PPO-Penalty | 0.293 | 313.759 | 1855 | 19.138 | −2.45 |
| Algorithm | Terminal SOC | Battery Temperature (K) | Equivalent Fuel Consumption (L/100 km) |
|---|---|---|---|
| DP | 0.303 | 313.124 | 17.972 |
| ECMS | 0.308 | 314.114 | 20.122 |
| DQN | 0.300 | 313.552 | 19.571 |
| DDPG | 0.299 | 313.466 | 19.228 |
| PPO-Clip | 0.292 | 313.232 | 18.026 |
| PPO-Penalty | 0.302 | 313.326 | 18.186 |
| PPO-Clip | |||
| (with sensor noise) | 0.306 | 313.394 | 18.443 |
| PPO-Penalty | |||
| (with sensor noise) | 0.299 | 313.437 | 18.391 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Li, T.; Cui, W.; Cui, N. Proximal Policy Optimization Based Intelligent Energy Management for Plug-In Hybrid Electric Bus Considering Battery Thermal Characteristic. World Electr. Veh. J. 2023, 14, 47. https://doi.org/10.3390/wevj14020047
Zhang C, Li T, Cui W, Cui N. Proximal Policy Optimization Based Intelligent Energy Management for Plug-In Hybrid Electric Bus Considering Battery Thermal Characteristic. World Electric Vehicle Journal. 2023; 14(2):47. https://doi.org/10.3390/wevj14020047
Chicago/Turabian StyleZhang, Chunmei, Tao Li, Wei Cui, and Naxin Cui. 2023. "Proximal Policy Optimization Based Intelligent Energy Management for Plug-In Hybrid Electric Bus Considering Battery Thermal Characteristic" World Electric Vehicle Journal 14, no. 2: 47. https://doi.org/10.3390/wevj14020047