Software-Defined Networking Using OpenFlow: Protocols, Applications and Architectural Design Choices

Abstract
:1. Introduction
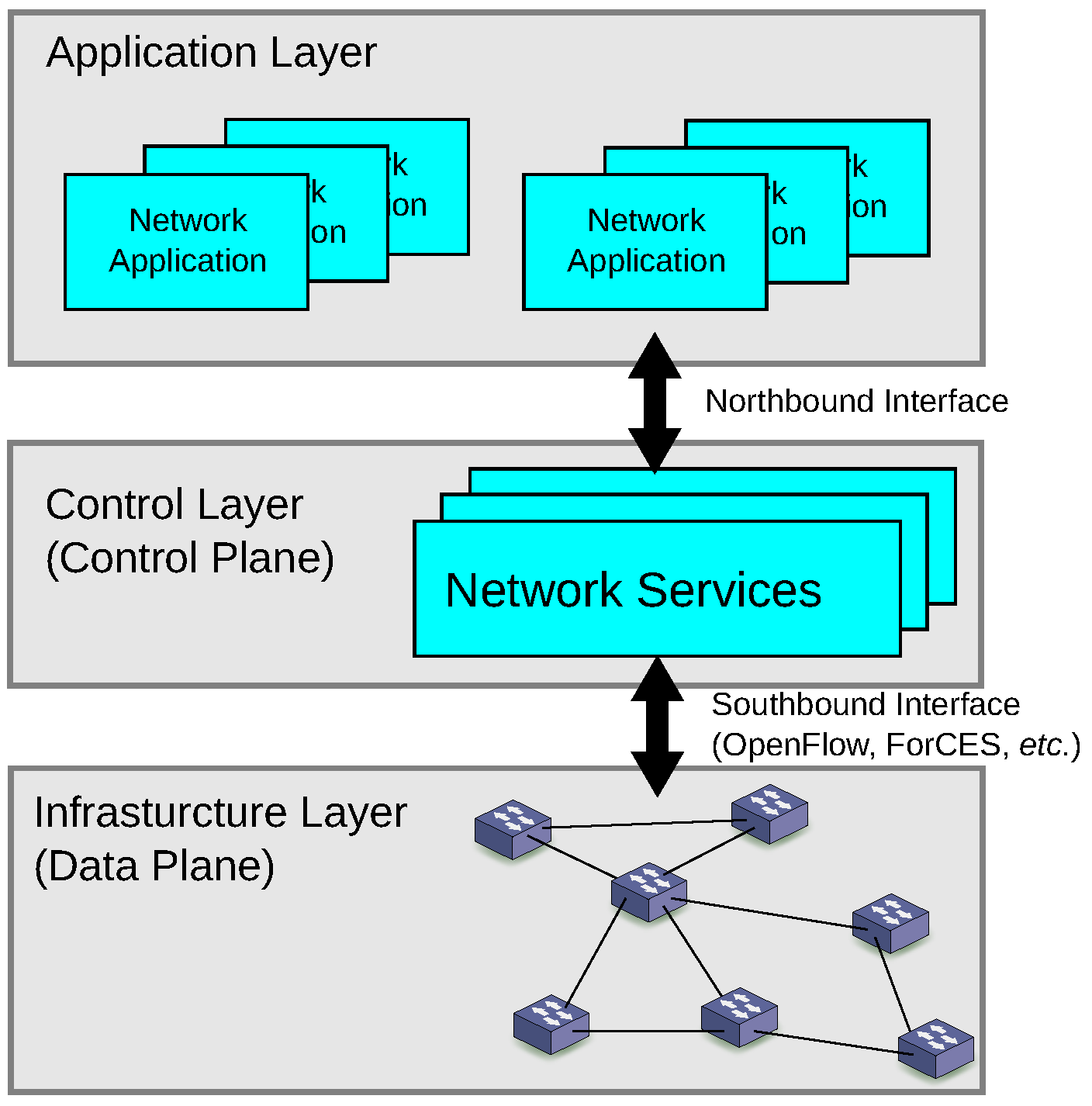
2. Software-Defined Networking
2.1. Definition

2.2. Protocol Options for the Southbound Interface
2.3. Northbound APIs for Network Applications
2.4. SDN, Active and Programmable Networks
3. The OpenFlow Protocol
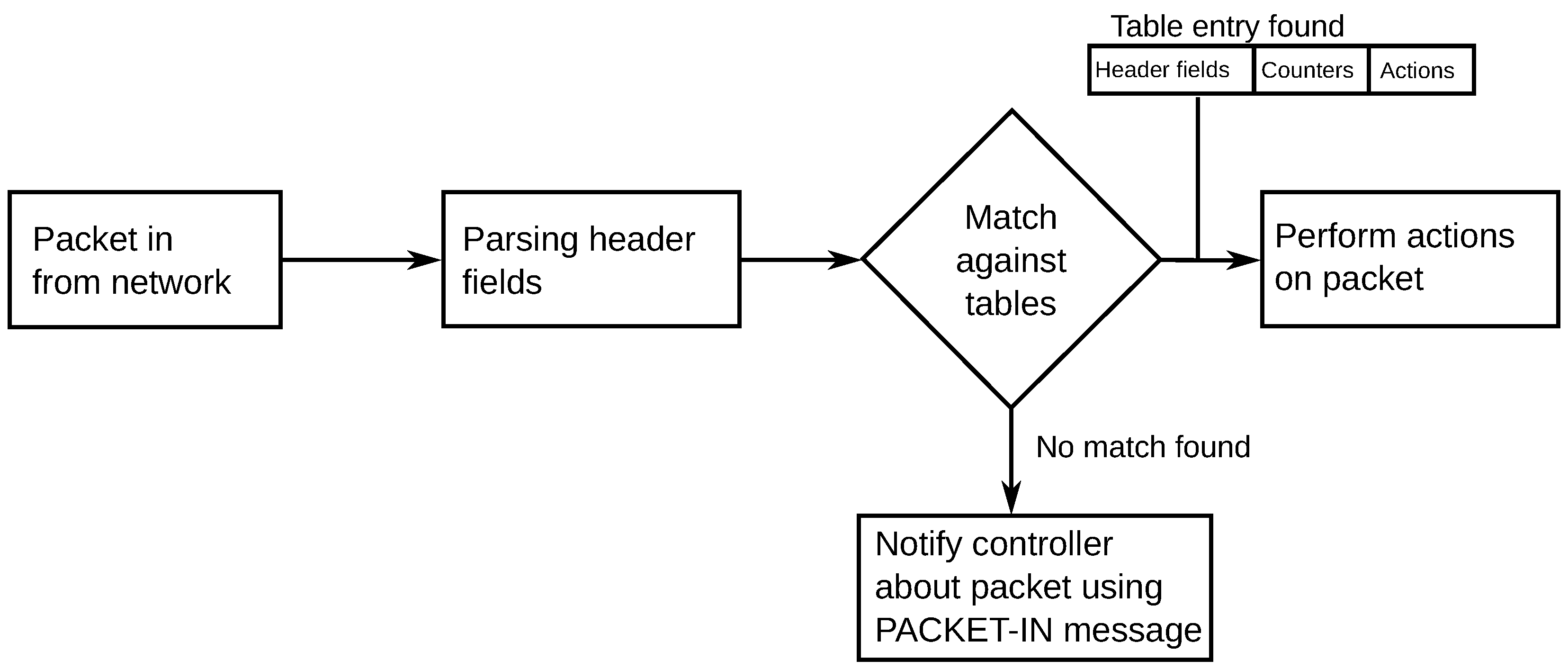
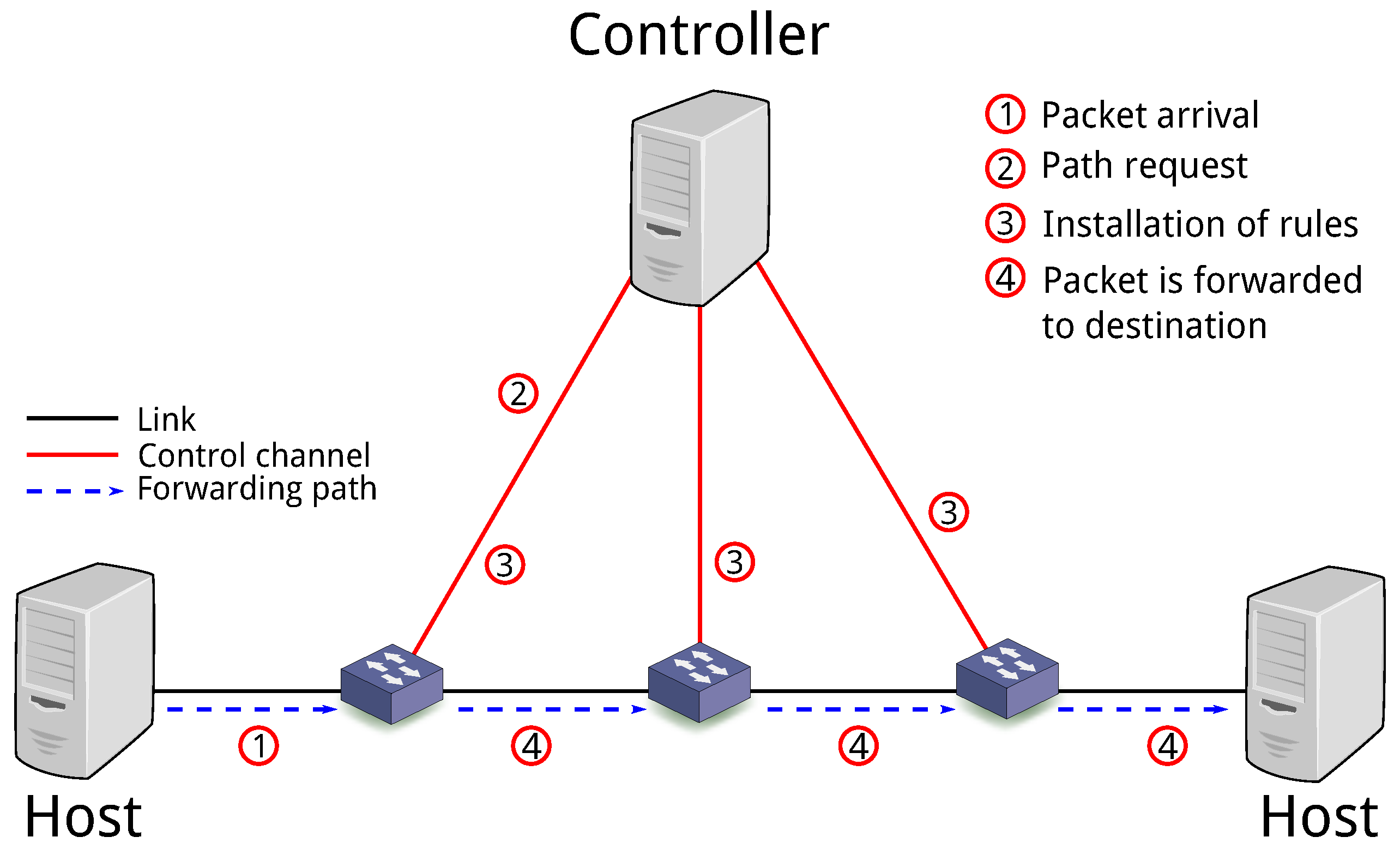
3.1. Overview


3.2. OpenFlow Specifications
3.2.1. OpenFlow 1.0
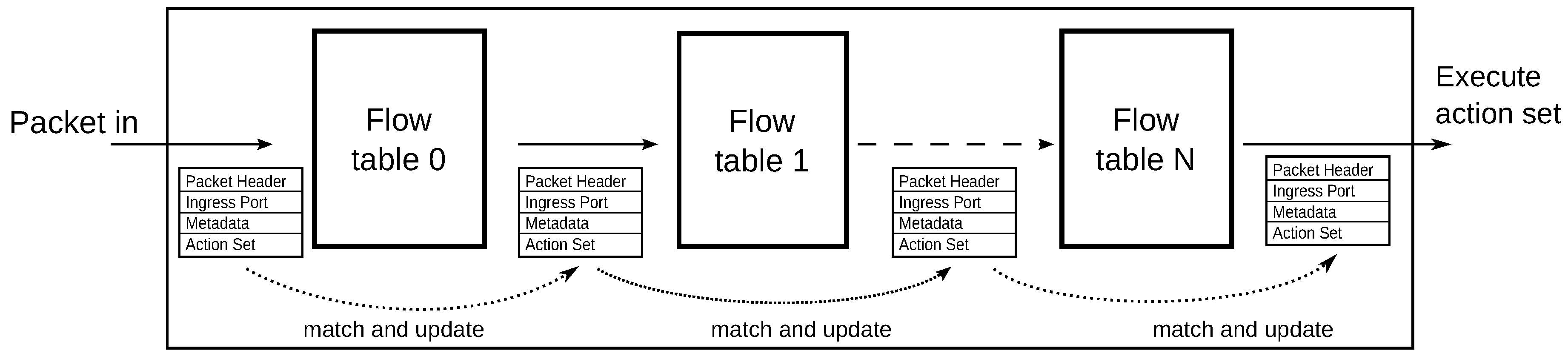
3.2.2. OpenFlow 1.1


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Instruction | Argument | Semantic |
|---|---|---|
| Apply-Actions | Action(s) | Applies actions immediately without adding them to the action set |
| Write-Actions | Action(s) | Merge the specified action(s) into the action set |
| Clear-Actions | - | Clear the action set |
| Write-Metadata | Metadata mask | Updates the metadata field |
| Goto-Table | Table ID | Perform matching on the next table |


3.2.3. OpenFlow 1.2
3.2.4. OpenFlow 1.3

3.2.5. OpenFlow 1.4
3.2.6. Summary of OpenFlow Specifications and Controllers
| OF 1.0 | OF 1.1 | OF 1.2 | OF 1.3 & OF 1.4 | |
|---|---|---|---|---|
| Ingress Port | X | X | X | X |
| Metadata | X | X | X | |
| Ethernet: src, dst, type | X | X | X | X |
| IPv4: src, dst, proto, ToS | X | X | X | X |
| TCP/UDP: src port, dst port | X | X | X | X |
| MPLS: label, traffic class | X | X | X | |
| OpenFlow Extensible Match (OXM) | X | X | ||
| IPv6: src, dst, flow label, ICMPv6 | X | X | ||
| IPv6 Extension Headers | X |
| OF 1.0 | OF 1.1 | OF 1.2 | OF 1.3 & OF 1.4 | |
|---|---|---|---|---|
| Per table statistics | X | X | X | X |
| Per flow statistics | X | X | X | X |
| Per port statistics | X | X | X | X |
| Per queue statistics | X | X | X | X |
| Group statistics | X | X | X | |
| Action bucket statistics | X | X | X | |
| Per-flow meter | X | |||
| Per-flow meter band | X |
| Name | Programming language | License | Comment |
|---|---|---|---|
| NOX[29] | C++ | GPL | Initially developed at Stanford University. NOX can be downloaded from [30]. |
| POX[30] | Python | Apache | Forked from the NOX controller. POX is written in Python and runs under various platforms. |
| Beacon [31] | Java | BSD | Initially developed at Stanford. |
| Floodlight [32] | Java | Apache | Forked from the Beacon controller and sponsored by Big Switch Networks. |
| Maestro [33] | Java | LGPL | Multi-threaded OpenFlow controller developed at Rice University. |
| NodeFLow [34] | JavaScript | MIT | JavaScript OpenFlow controller based on Node.JS. |
| Trema [35] | C and Ruby | GPL | Plugins can be written in C and in Ruby. Trema is developed by NEC. |
| OpenDaylight [36] | Java | EPL | OpenDaylight is hosted by the Linux Foundation, but has no restrictions on the operating system. |
3.2.7. OF-CONFIG
4. Innovation through SDN-Based Network Applications
4.1. SDN Network Management and Traffic Engineering
4.2. Load Balancing for Application Servers
4.3. Security and Network Access Control
4.4. Network Testing, Debugging and Verification
4.5. SDN Inter-Domain Routing
4.6. SDN-Based Network Virtualization
5. Design Choices for OpenFlow-Based SDN
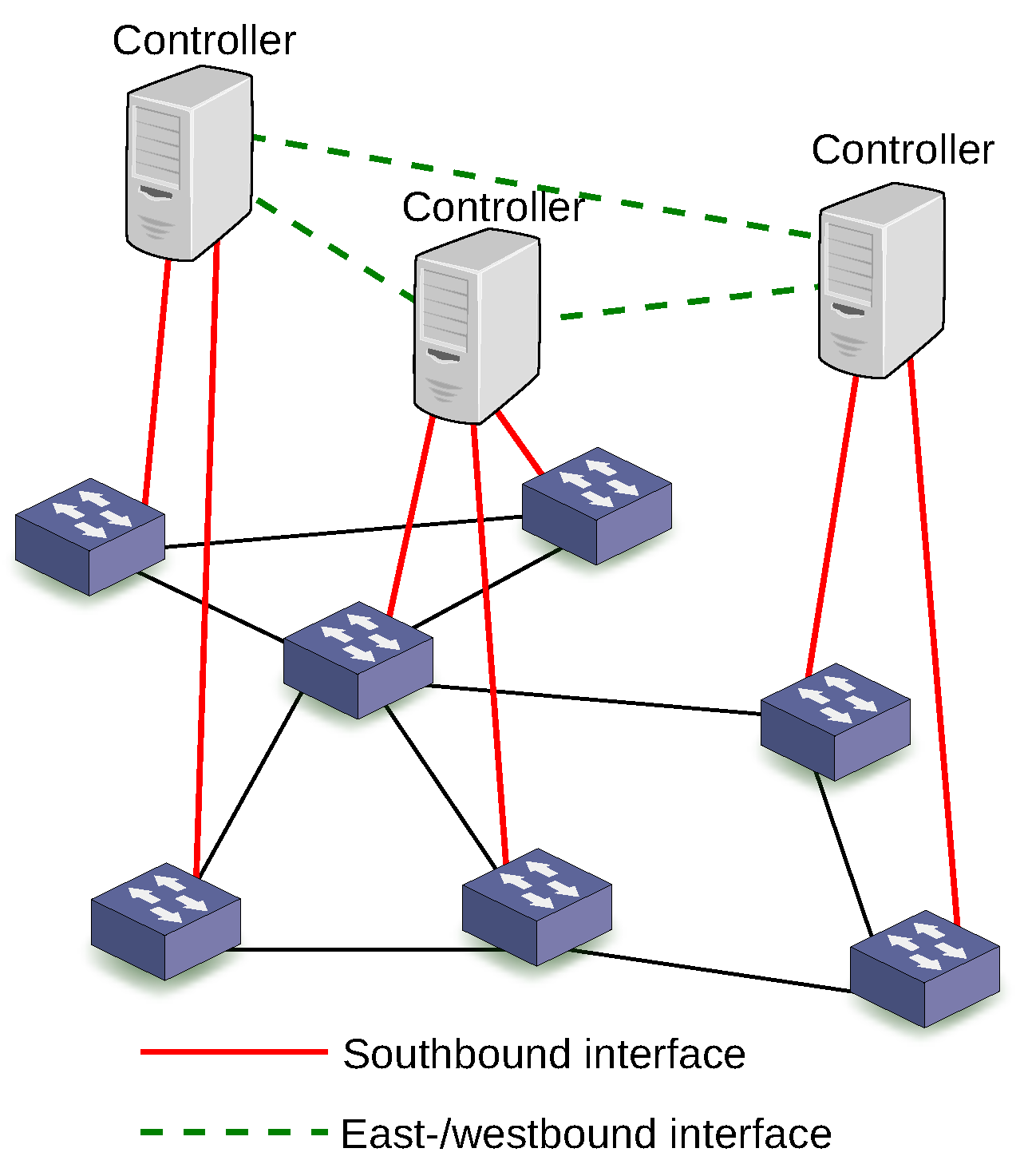
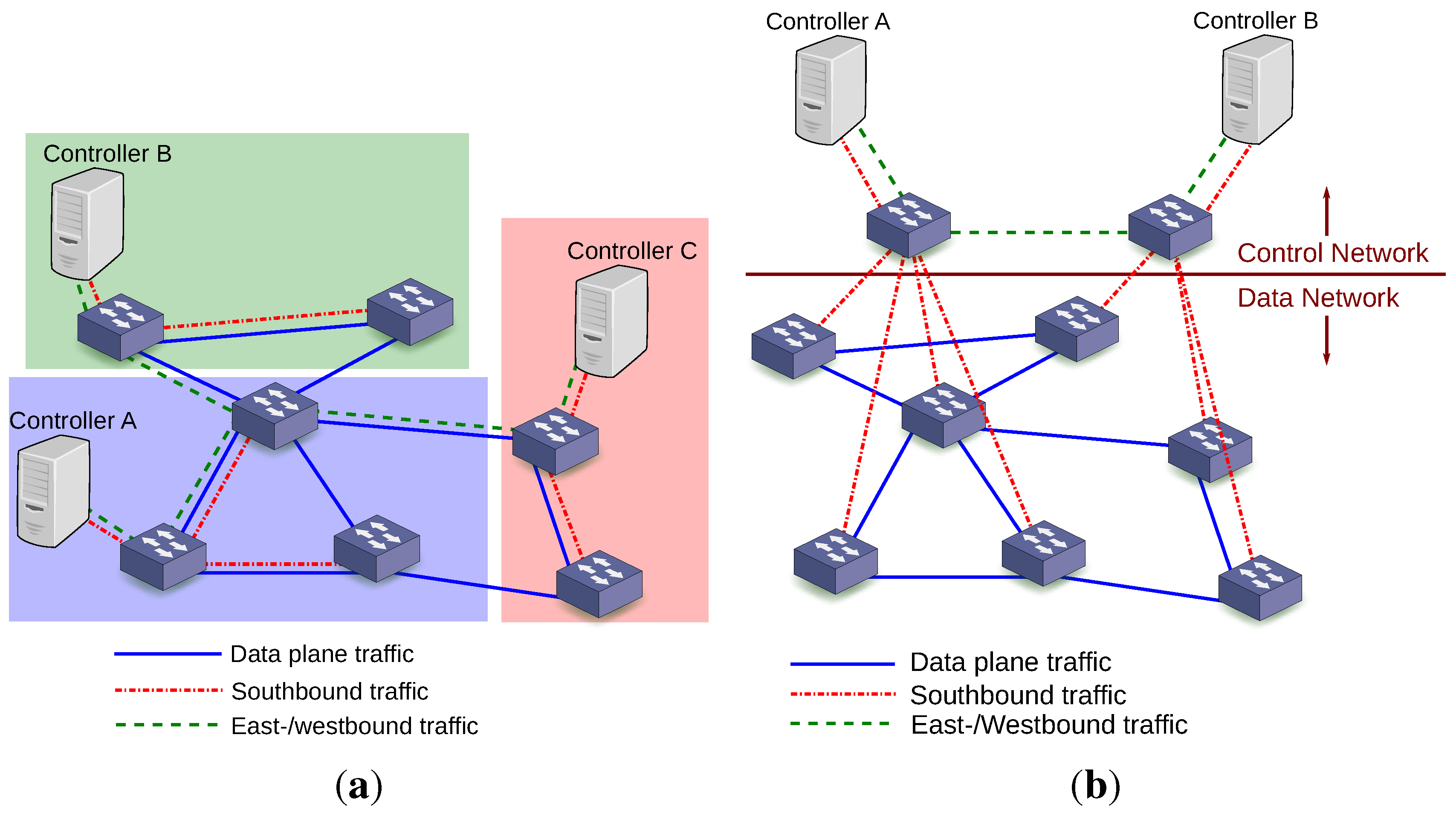
5.1. Control Plane: Physically vs. Logically Centralized

5.2. Control Plane: In-Band vs. Out-of-Band Signaling

5.3. Management of Flow Entries: Proactive vs. Reactive

5.4. Data Plane: Resilience
6. Performance of OpenFlow-Based SDNs
7. Discussion of OpenFlow-Based SDN
8. Conclusions
Acknowledgments
Conflicts of Interest
References
- Lara, A.; Kolasani, A.; Ramamurthy, B. Network Innovation Using OpenFlow: A Survey. IEEE Commun. Surv. Tutor. 2013, 16, 1–20. [Google Scholar] [CrossRef]
- Astuto, B.N.; Mendonça, M.; Nguyen, X.N.; Obraczka, K.; Turletti, T. A Survey of Software-Defined Networking: Past, Present, and Future of Programmable Networks. IEEE Commun. Surv. Tutor. 2014. [Google Scholar] [CrossRef]
- Jain, R.; Paul, S. Network Virtualization and Software Defined Networking for Cloud Computing: A Survey. IEEE Commun. Mag. 2013, 51, 24–31. [Google Scholar] [CrossRef]
- Open Networking Foundation. Available online: https://www.opennetworking.org/ (accessed on 22 July 2013).
- Doria, A.; Salim, J.H.; Haas, R.; Khosravi, H.; Wang, W.; Dong, L.; Gopal, R.; Halpern, J. Forwarding and Control Element Separation (ForCES) Protocol Specification. RFC 5810 (Proposed Standard). 2010. Available online: https://datatracker.ietf.org/doc/rfc5810/ (accessed on 22 July 2013).
- Yang, L.; Dantu, R.; Anderson, T.; Gopal, R. Forwarding and Control Element Separation (ForCES) Framework. RFC 3746 (Informational). 2004. Available online: https://datatracker.ietf.org/doc/rfc3746/ (accessed on 22 July 2013).
- Hares, S. Analysis of Comparisons between OpenFlow and ForCES. Internet Draft (Informational). 2012. Available online: https://datatracker.ietf.org/doc/draft-hares-forces-vs-openflow/ (accessed on 17 February 2014).
- Haleplidis, E.; Denazis, S.; Koufopavlou, O.; Halpern, J.; Salim, J.H. Software-Defined Networking: Experimenting with the Control to Forwarding Plane Interface. In Proceedings of the European Workshop on Software Defined Networks (EWSDN), Darmstadt, Germany, 25–26 October 2012; pp. 91–96.
- Lakshman, T.V.; Nandagopal, T.; Ramjee, R.; Sabnani, K.; Woo, T. The SoftRouter Architecture. In Proceedings of the ACM Workshop on Hot Topics in Networks (HotNets), San Diego, CA, USA, 15–16 November 2004.
- Zheng, H.; Zhang, X. Path Computation Element to Support Software-Defined Transport Networks Control. Internet Draft (Informational). 2014. Available online: https://datatracker.ietf.org/doc/draft-zheng-pce-for-sdn-transport/ (accessed on 2 March 2014).
- Rodriguez-Natal, A.; Barkai, S.; Ermagan, V.; Lewis, D.; Maino, F.; Farinacci, D. Software Defined Networking Extensions for the Locator/ID Separation Protocol. Internet Draft (Informational). 2014. Available online: http://wiki.tools.ietf.org/id/draft-rodrigueznatal-lisp-sdn-00.txt (accessed on 2 March 2014).
- Rexford, J.; Freedman, M.J.; Foster, N.; Harrison, R.; Monsanto, C.; Reitblatt, M.; Guha, A.; Katta, N.P.; Reich, J.; Schlesinger, C. Languages for Software-Defined Networks. IEEE Commun. Mag. 2013, 51, 128–134. [Google Scholar]
- Foster, N.; Harrison, R.; Freedman, M.J.; Monsanto, C.; Rexford, J.; Story, A.; Walker, D. Frenetic: A Network Programming Language. In Proceedings of the ACM SIGPLAN International Conference on Functional Programming, Tokyo, Japan, 19–21 September 2011.
- Monsanto, C.; Reich, J.; Foster, N.; Rexford, J.; Walker, D. Composing Software-Defined Networks. In Proceedings of the USENIX Syposium on Networked Systems Design & Implementation (NSDI), Lombard, IL, USA, 2–5 April 2013; pp. 1–14.
- Voellmy, A.; Kim, H.; Feamster, N. Procera: A Language for High-Level Reactive Network Control. In Proceedings of the ACM Workshop on Hot Topics in Software Defined Networks (HotSDN), Helsinki, Finland, 13–17 August 2012; pp. 43–48.
- Facca, F.M.; Salvadori, E.; Karl, H.; Lopez, D.R.; Gutierrez, P.A.A.; Kostic, D.; Riggio, R. NetIDE: First Steps towards an Integrated Development Environment for Portable Network Apps. In Proceedings of the European Workshop on Software Defined Networks (EWSDN), Berlin, Germany, 10–11 October 2013; pp. 105–110.
- Tennenhouse, D.L.; Wetherall, D.J. Towards an Active Network Architecture. ACM SIGCOMM Comput. Commun. Rev. 1996, 26, 5–18. [Google Scholar] [CrossRef]
- Campbell, A.T.; De Meer, H.G.; Kounavis, M.E.; Miki, K.; Vicente, J.B.; Villela, D. A Survey of Programmable Networks. ACM SIGCOMM Comput. Commun. Rev. 1999, 29, 7–23. [Google Scholar] [CrossRef]
- Feamster, N.; Rexford, J.; Zegura, E. The Road to SDN: An Intellectual History of Programmable Networks. ACM Queue 2013, 12, 20–40. [Google Scholar] [CrossRef]
- Chan, M.C.; Huard, J.F.; Lazar, A.A.; Lim, K.S. On Realizing a Broadband Kernel for Multimedia Networks. In Proceedings of the International COST 237 Workshop on Multimedia Telecommunications and Applications, Barcelona, Spain, 25–27 November 1996; pp. 56–74.
- McKeown, N.; Anderson, T.; Balakrishnan, H.; Parulkar, G.; Peterson, L.; Rexford, J.; Shenker, S.; Turner, J. OpenFlow: Enabling Innovation in Campus Networks. ACM SIGCOMM Comput. Commun. Rev. 2008, 38, 69–74. [Google Scholar] [CrossRef]
- OpenFlow Switch Consortium and Others. OpenFlow Switch Specification Version 1.0.0. 2009. Available online: https://www.opennetworking.org/images/stories/downloads/sdn-resources/onf-specifications/openflow/openflow-spec-v1.3.0.pdf (accessed on 25 November 2013).
- OpenFlow Switch Consortium and Others. OpenFlow Switch Specification Version 1.1.0. 2011. Available online: http://archive.openflow.org/documents/openflow-spec-v1.1.0.pdf (accessed on 25 November 2013).
- Pan, P.; Swallow, G.; Atlas, A. RFC4090: Fast Reroute Extensions to RSVP-TE for LSP Tunnels, 2005. Available online: https://datatracker.ietf.org/doc/rfc4090/ (accessed on 22 July 2013).
- Atlas, A.; Zinin, A. RFC5286: Basic Specification for IP Fast Reroute: Loop-Free Alternates, 2008. Available online: https://tools.ietf.org/html/rfc5286 (accessed on 22 July 2013).
- OpenFlow Switch Consortium and Others. OpenFlow Switch Specification Version 1.2.0. 2011. Available online: https://www.opennetworking.org/images/stories/downloads/sdn-resources/onf-specifications/openflow/openflow-spec-v1.2.pdf (accessed on 25 November 2013).
- OpenFlow Switch Consortium and Others. OpenFlow Switch Specification Version 1.3.0. 2012. Available online: https://www.opennetworking.org/images/stories/downloads/sdn-resources/onf-specifications/openflow/openflow-spec-v1.3.0.pdf (accessed on 25 November 2013).
- OpenFlow Switch Consortium and Others. OpenFlow Switch Specification Version 1.4.0. 2013. Available online: https://www.opennetworking.org/images/stories/downloads/sdn-resources/onf-specifications/openflow/openflow-spec-v1.4.0.pdf (accessed on 12 January 2014).
- Gude, N.; Koponen, T.; Pettit, J.; Pfaff, B.; Casado, M.; McKeown, N.; Shenker, S. NOX: Towards an Operating System for Networks. ACM SIGCOMM Comput. Commun. Rev. 2008, 38, 105–110. [Google Scholar] [CrossRef]
- NOXrepo.org. Available online: http://www.noxrepo.org (accessed on 16 November 2013).
- Erickson, D. The Beacon OpenFlow Controller. In Proceedings of the ACM Workshop on Hot Topics in Software Defined Networks (HotSDN), Hong Kong, China, 12–16 August 2013; pp. 13–18.
- Project Floodlight: Open Source Software for Building Software-Defined Networks. Available online: http://www.projectfloodlight.org/floodlight/ (accessed on 16 November 2013).
- Cai, Z.; Cox, A.L.; Eugene Ng, T.S. Maestro: Balancing Fairness, Latency and Throughput in the OpenFlow Control Plane; Technical Report; Rice University: Houston, TX, USA, 2011. [Google Scholar]
- NodeFLow OpenFlow Controller. Available online: https://github.com/gaberger/NodeFLow (accessed on 16 November 2013).
- Trema: Full-Stack OpenFlow Framework in Ruby and C. Available online: http://trema.github.io/trema/ (accessed on 16 November 2013).
- OpenDaylight. Available online: http://www.opendaylight.org/ (accessed on 22 February 2014).
- OpenFlow Switch Consortium and Others. Configuration and Management Protocol OF-CONFIG 1.0. 2011. Available online: https://www.opennetworking.org/images/stories/downloads/sdn-resources/onf-specifications/openflow-config/of-config1dot0-final.pdf (accessed on 25 November 2013).
- Jain, S.; Kumar, A.; Mandal, S.; Ong, J.; Poutievski, L.; Singh, A.; Venkata, S.; Wanderer, J.; Zhou, J.; Zhu, M.; et al. B4: Experience with a Globally-Deployed Software Defined WAN. In Proceedings of the ACM SIGCOMM Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication, Hong Kong, China, 13–17 August 2013; pp. 3–14.
- Kotani, D.; Suzuki, K.; Shimonishi, H. A Design and Implementation of OpenFlow Controller handling IP Multicast with Fast Tree Switching. In Proceedings of the IEEE/IPSJ International Symposium on Applications and the Internet (SAINT), Izmir, Turkey, 16–20 July 2012; pp. 60–67.
- Nakao, A. FLARE: Open Deeply Programmable Network Node Architecture. 2012. Available online: http://netseminar.stanford.edu/seminars/10_18_12.pdf (accessed on 24 January 2014).
- Reitblatt, M.; Foster, N.; Rexford, J.; Schlesinger, C.; Walker, D. Abstractions for Network Update. In Proceedings of the ACM SIGCOMM Conference on Applications, Technologies, Architectures, and Protocols for Computer Communication, Helsinki, Finland, 13–17 August 2012; pp. 323–334.
- Mattos, D.; Fernandes, N.; da Costa, V.; Cardoso, L.; Campista, M.; Costa, L.; Duarte, O. OMNI: OpenFlow MaNagement Infrastructure. In Proceedings of the International Conference on the Network of the Future (NOF), Paris, France, 28–30 November 2011; pp. 52–56.
- Wang, R.; Butnariu, D.; Rexford, J. OpenFlow-Based Server Load Balancing Gone Wild. In Proceedings of the USENIX Conference on Hot Topics in Management of Internet, Cloud, and Enterprise Networks and Services (Hot-ICE), Boston, MA, USA, 29 March 2011; pp. 12–12.
- Gember, A.; Prabhu, P.; Ghadiyali, Z.; Akella, A. Toward Software-Defined Middlebox Networking. In Proceedings of the ACM Workshop on Hot Topics in Networks (HotNets), Redmond, WA, USA, 29–30 October 2012; pp. 7–12.
- Initial Thoughts on Custom Network Processing via Waypoint Services. In Proceedings of the Workshop on Infrastrucures for Software/Hardware Co-Design (WISH), Chamonix, France, 2 April 2011; pp. 15–20.
- ETSI—Network Functions Industry Specification Group. Network Functions Virtualisation (NFV). 2013. Available online: http://portal.etsi.org/NFV/NFV_White_Paper2.pdf (accessed on 29 October 2013).
- Boucadair, M.; Jacquenet, C. Service Function Chaining: Framework & Architecture. Internet Draft (Intended Status: Standards Track). 2014. Available online: https://tools.ietf.org/search/draft-boucadair-sfc-framework-02 (accessed on 20 February 2014).
- John, W.; Pentikousis, K.; Agapiou, G.; Jacob, E.; Kind, M.; Manzalini, A.; Risso, F.; Staessens, D.; Steinert, R.; Meirosu, C. Research Directions in Network Service Chaining. In Proceedings of the IEEE Workshop on Software Defined Networks for Future Networks and Services (SDN4FNS), Trento, Italy, 11–13 November 2013; pp. 1–7.
- Nayak, A.; Reimers, A.; Feamster, N.; Clark, R. Resonance: Inference-based Dynamic Access Control for Enterprise Networks. In Proceedings of the Workshop on Research on Enterprise Networking (WREN), Barcelona, Spain, 21 August 2009; pp. 11–18.
- Khurshid, A.; Zhou, W.; Caesar, M.; Godfrey, P.B. VeriFlow: Verifying Network-Wide Invariants in Real Time. In Proceedings of the ACM Workshop on Hot Topics in Software Defined Networks (HotSDN), Helsinki, Finland, 13–17 August 2012; pp. 49–54.
- Yao, G.; Bi, J.; Xiao, P. Source Address Validation Solution with OpenFlow/NOX Architecture. In Proceedings of the IEEE International Conference on Network Protocols (ICNP), Vancouver, BC, Canada, 17–20 October 2011; pp. 7–12.
- Jafarian, J.H.; Al-Shaer, E.; Duan, Q. Openflow Random Host Mutation: Transparent Moving Target Defense Using Software Defined Networking. In Proceedings of the ACM Workshop on Hot Topics in Software Defined Networks (HotSDN), Helsinki, Finland, 13–17 August 2012; pp. 127–132.
- YuHunag, C.; MinChi, T.; YaoTing, C.; YuChieh, C.; YanRen, C. A Novel Design for Future On-Demand Service and Security. In Proceedings of the International Conference on Communication Technology (ICCT), Nanjing, China, 11–14 November 2010; pp. 385–388.
- Braga, R.; Mota, E.; Passito, A. Lightweight DDoS Flooding Attack Detection Using NOX/OpenFlow. In Proceedings of the IEEE Conference on Local Computer Networks (LCN), Denver, CO, USA, 11–14 October 2010; pp. 408–415.
- Porras, P.; Shin, S.; Yegneswaran, V.; Fong, M.; Tyson, M.; Gu, G. A Security Enforcement Kernel for OpenFlow Networks. In Proceedings of the ACM Workshop on Hot Topics in Software Defined Networks (HotSDN), Helsinki, Finland, 13–17 August 2012; pp. 121–126.
- Handigol, N.; Heller, B.; Jeyakumar, V.; Maziéres, D.; McKeown, N. Where is the Debugger for My Software-defined Network? In Proceedings of the ACM Workshop on Hot Topics in Software Defined Networks (HotSDN), Helsinki, Finland, 13–17 August 2012; pp. 55–60.
- Wundsam, A.; Levin, D.; Seetharaman, S.; Feldmann, A. OFRewind: Enabling Record and Replay Troubleshooting for Networks. In Proceedings of the USENIX Annual Technical Conference, Portland, OR, USA, 15–17 June 2011.
- Kuzniar, M.; Peresini, P.; Canini, M.; Venzano, D.; Kostic, D. A SOFT Way for Openflow Switch Interoperability Testing. In Proceedings of the ACM Conference on emerging Networking EXperiments and Technologies (CoNEXT), Nice, France, 10–13 December 2012; pp. 265–276.
- Canini, M.; Venzano, D.; Perešíni, P.; Kostić, D.; Rexford, J. A NICE Way to Test Openflow Applications. In Proceedings of the USENIX Syposium on Networked Systems Design & Implementation (NSDI), San Jose, CA, USA, 25–27 April 2012.
- Heller, B.; Scott, C.; McKeown, N.; Shenker, S.; Wundsam, A.; Zeng, H.; Whitlock, S.; Jeyakumar, V.; Handigol, N.; McCauley, J.; et al. Leveraging SDN Layering to Systematically Troubleshoot Networks. In Proceedings of the ACM Workshop on Hot Topics in Software Defined Networks (HotSDN), Hong Kong, China, 12–16 August 2013; pp. 37–42.
- Nascimento, M.R.; Rothenberg, C.E.; Salvador, M.R.; Magalhães, M.F. QuagFlow: Partnering Quagga with OpenFlow. ACM SIGCOMM Comput. Commun. Rev. 2010, 40, 441–442. [Google Scholar] [CrossRef]
- Nascimento, M.R.; Rothenberg, C.E.; Salvador, M.R.; Corrêa, C.N.A.; de Lucena, S.; Magalhães, M.F. Virtual Routers as a Service: The Routeflow Approach Leveraging Software-Defined Networks. In Proceedings of the International Conference on Future Internet Technologies (CFI), Seoul, Korea, 13–15 June 2011; pp. 34–37.
- Bennesby, R.; Fonseca, P.; Mota, E.; Passito, A. An Inter-AS Routing Component for Software-Defined Networks. In Proceedings of the IEEE/IFIP Network Operations and Management Symposium (NOMS), Maui, HI, USA, 16–20 April 2012; pp. 138–145.
- Caesar, M.; Caldwell, D.; Feamster, N.; Rexford, J.; Shaikh, A.; van der Merwe, J. Design and Implementation of a Routing Control Platform. In Proceedings of the USENIX Syposium on Networked Systems Design & Implementation (NSDI), Boston, MA, USA, 2–4 May 2005; pp. 15–28.
- Rothenberg, C.E.; Nascimento, M.R.; Salvador, M.R.; Corrêa, C.N.A.; de Lucena, S.C.; Raszuk, R. Revisiting Routing Control Platforms with the Eyes and Muscles of Software-Defined Networking. In Proceedings of the ACM Workshop on Hot Topics in Software Defined Networks (HotSDN), Helsinki, Finland, 13–17 August 2012; pp. 13–18.
- Sharafat, A.R.; Das, S.; Parulkar, G.; McKeown, N. MPLS-TE and MPLS VPNS with OpenFlow. ACM SIGCOMM Comput. Commun. Rev. 2011, 41, 452–453. [Google Scholar] [CrossRef]
- Azodolmolky, S.; Nejabati, R.; Escalona, E.; Jayakumar, R.; Efstathiou, N.; Simeonidou, D. Integrated OpenFlow-GMPLS Control Plane: An Overlay Model for Software Defined Packet Over Optical Networks. In Proceedings of the European Conference and Exposition on Optical Communications, Geneva, Switzerland, 18–22 September 2011.
- Gutz, S.; Story, A.; Schlesinger, C.; Foster, N. Splendid Isolation: A Slice Abstraction for Software-Defined Networks. In Proceedings of the ACM Workshop on Hot Topics in Software Defined Networks (HotSDN), Helsinki, Finland, 13–17 August 2012; pp. 79–84.
- Ferguson, A.D.; Guha, A.; Liang, C.; Fonseca, R.; Krishnamurthi, S. Hierarchical Policies for Software Defined Networks. In Proceedings of the ACM Workshop on Hot Topics in Software Defined Networks (HotSDN), Helsinki, Finland, 13–17 August 2012; pp. 37–42.
- Banikazemi, M.; Olshefski, D.; Shaikh, A.; Tracey, J.; Wang, G. Meridian: An SDN Platform for Cloud Network Services. IEEE Commun. Mag. 2013, 51, 120–127. [Google Scholar] [CrossRef]
- The OpenStack Foundatation. 2013. Available online: http://www.openstack.org/ (accessed on 22 July 2013).
- Heller, B.; Sherwood, R.; McKeown, N. The Controller Placement Problem. In Proceedings of the ACM Workshop on Hot Topics in Software Defined Networks (HotSDN), Helsinki, Finland, 13–17 August 2012; pp. 7–12.
- Hock, D.; Hartmann, M.; Gebert, S.; Jarschel, M.; Zinner, T.; Tran-Gia, P. Pareto-Optimal Resilient Controller Placement in SDN-based Core Networks. In Proceedings of the 25th International Teletraffic Congress (ITC), Shanghai, China, 10–12 September 2013; pp. 1–9.
- Tootoonchian, A.; Ganjali, Y. HyperFlow: A Distributed Control Plane for OpenFlow. In Proceedings of the USENIX Workshop on Research on Enterprise Networking (WREN), San Jose, CA, USA, 27 April 2010; p. 3.
- Yeganeh, S.H.; Ganjali, Y. Kandoo: A Framework for Efficient and Scalable Offloading of Control Applications. In Proceedings of the ACM Workshop on Hot Topics in Software Defined Networks (HotSDN), Helsinki, Finland, 13–17 August 2012; pp. 19–24.
- Levin, D.; Wundsam, A.; Heller, B.; Handigol, N.; Feldmann, A. Logically Centralized?: State Distribution Trade-offs in Software Defined Networks. In Proceedings of the ACM Workshop on Hot Topics in Software Defined Networks (HotSDN), Helsinki, Finland, 13–17 August 2012; pp. 1–6.
- Jarschel, M.; Oechsner, S.; Schlosser, D.; Pries, R.; Goll, S.; Tran-Gia, P. Modeling and Performance Evaluation of an OpenFlow Architecture. In Proceedings of the International Teletraffic Congress (ITC), San Francisco, CA, USA, 6–8 September 2011; pp. 1–7.
- Fernandez, M.P. Comparing OpenFlow Controller Paradigms Scalability: Reactive and Proactive. In Proceedings of the International Conference on Advanced Information Networking and Applications (AINA), Barcelona, Spain, 25–28 March 2013; pp. 1009–1016.
- CIDR REPORT. 2013. Available online: http://www.cidr-report.org/as2.0/ (accessed on 22 July 2013).
- Sarrar, N.; Uhlig, S.; Feldmann, A.; Sherwood, R.; Huang, X. Leveraging Zipf’s Law for Traffic Offloading. ACM SIGCOMM Comput. Commun. Rev. 2012, 42, 16–22. [Google Scholar] [CrossRef]
- Sarrar, N.; Feldmann, A.; Uhrig, S.; Sherwood, R.; Huang, X. Towards Hardware Accelerated Software Routers. In Proceedings of the ACM CoNEXT Student Workshop, Philadelphia, PA, USA, 3 December 2010; pp. 1–2.
- Soliman, M.; Nandy, B.; Lambadaris, I.; Ashwood-Smith, P. Source Routed Forwarding with Software Defined Control, Considerations and Implications. In Proceedings of the ACM CoNEXT Student Workshop, Nice, France, 10–13 December 2012; pp. 43–44.
- Ashwood-Smith, P.; Soliman, M.; Wan, T. SDN State Reduction. Internet Draft (Informational). 2013. Available online: https://tools.ietf.org/html/draft-ashwood-sdnrg-state-reduction-00 (accessed on 25 November 2013).
- Zhang, X.; Francis, P.; Wang, J.; Yoshida, K. Scaling IP Routing with the Core Router-Integrated Overlay. In Proceedings of the IEEE International Conference on Network Protocols (ICNP), Santa Barbara, CA, USA, 12–15 November 2006; pp. 147–156.
- Ballani, H.; Francis, P.; Cao, T.; Wang, J. ViAggre: Making Routers Last Longer! In Proceedings of the ACM Workshop on Hot Topics in Networks (HotNets), Calgary, AB, Canada, 6–7 October 2008; pp. 109–114.
- Francis, P.; Xu, X.; Ballani, H.; Jen, D.; Raszuk, R.; Zhang, L. FIB Suppression with Virtual Aggregation. IETF Internet Draft (Informational). 2012. Available online: http://wiki.tools.ietf.org/html/draft-ietf-grow-va-06 (accessed on 16 November 2013).
- Masuda, A.; Pelsser, C.; Shiomoto, K. SpliTable: Toward Routing Scalability through Distributed BGP Routing Tables. IEICE Trans. Commun. 2011, E94-B, 64–76. [Google Scholar] [CrossRef]
- Rètvàri, G.; Tapolcai, J.; Kõrösi, A.; Majdàn, A.; Heszberger, Z. Compressing IP Forwarding Tables: Towards Entropy Bounds and Beyond. In Proceedings of the ACM SIGCOMM Workshop on Hot Topics in Software Defined Networking (HotSDN), Hong Kong, China, 12–16 August 2013; pp. 111–122.
- Ford, A.; Raicu, C.; Handley, M.; Bonaventure, O. RFC6824: TCP Extensions for Multipath Operation with Multiple Addresses. IETF Internet Draft (Experimental). 2013. Available online: http://tools.ietf.org/html/rfc6824 (accessed on 22 February 2014).
- Sharma, S.; Staessens, D.; Colle, D.; Pickavet, M.; Demeester, P. OpenFlow: Meeting Carrier-Grade Recovery Requirements. Comput. Commun. 2013, 36, 656–665. [Google Scholar] [CrossRef]
- Kempf, J.; Bellagamba, E.; Kern, A.; Jocha, D.; Takàcs, A.; Sköldström, P. Scalable Fault Management for OpenFlow. In Proceedings of the IEEE International Conference on Communications (ICC), Ottawa, ON, Canada, 10–15 June 2012; pp. 6606–6610.
- Mogul, J.C.; Congdon, P. Hey, You Darned Counters!: Get off my ASIC! In Proceedings of the ACM Workshop on Hot Topics in Software Defined Networks (HotSDN), Helsinki, Finland, 13–17 August 2012; pp. 25–30.
- Narayanan, R.; Kotha, S.; Lin, G.; Khan, A.; Rizvi, S.; Javed, W.; Khan, H.; Khayam, S.A. Macroflows and Microflows: Enabling Rapid Network Innovation through a Split SDN Data Plane. In Proceedings of the European Workshop on Software Defined Networks (EWSDN), Darmstadt, Germany, 25–26 October 2012; pp. 79–84.
- Lu, G.; Miao, R.; Xiong, Y.; Guo, C. Using Cpu as a Traffic Co-Processing Unit in Commodity Switches. In Proceedings of the ACM Workshop on Hot Topics in Software Defined Networks (HotSDN), Helsinki, Finland, 13–17 August 2012; pp. 31–36.
- Chiba, Y.; Shinohara, Y.; Shimonishi, H. Source Flow: Handling Millions of Flows on Flow-Based Nodes. In Proceedings of the ACM SIGCOMM, New Delhi, India, 30 August–2 September 2010; pp. 465–466.
- Bianco, A.; Birke, R.; Giraudo, L.; Palacin, M. Openflow Switching: Data Plane Performance. In Proceedings of the IEEE International Conference on Communications (ICC), Cape Town, South Africa, 23–27 May 2010; pp. 1–5.
- Draves, R.; King, C.; Srinivasan, V.; Zill, B. Constructing Optimal IP Routing Tables. In Proceedings of the IEEE Infocom, New York, NY, USA, 21–25 March 1999; pp. 88–97.
- Liu, A.X.; Meiners, C.R.; Torng, E. TCAM Razor: A Systematic Approach Towards Minimizing Packet Classifiers in TCAMs. IEEE/ACM Trans. Netw. 2010, 18, 490–500. [Google Scholar] [CrossRef]
- Meiners, C.R.; Liu, A.X.; Torng, E. Bit Weaving: A Non-Prefix Approach to Compressing Packet Classifiers in TCAMs. IEEE/ACM Trans. Netw. 2012, 20, 488–500. [Google Scholar] [CrossRef]
- McGeer, R.; Yalagandula, P. Minimizing Rulesets for TCAM Implementation. In Proceedings of the IEEE Infocom, Rio de Janeiro, Brazil, 19–25 April 2009; pp. 1314–1322.
- Yu, M.; Rexford, J.; Freedman, M.J.; Wang, J. Scalable Flow-Based Networking with DIFANE. ACM SIGCOMM Comput. Commun. Rev. 2010, 40, 351–362. [Google Scholar] [CrossRef]
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Braun, W.; Menth, M. Software-Defined Networking Using OpenFlow: Protocols, Applications and Architectural Design Choices. Future Internet 2014, 6, 302-336. https://doi.org/10.3390/fi6020302
Braun W, Menth M. Software-Defined Networking Using OpenFlow: Protocols, Applications and Architectural Design Choices. Future Internet. 2014; 6(2):302-336. https://doi.org/10.3390/fi6020302
Chicago/Turabian StyleBraun, Wolfgang, and Michael Menth. 2014. "Software-Defined Networking Using OpenFlow: Protocols, Applications and Architectural Design Choices" Future Internet 6, no. 2: 302-336. https://doi.org/10.3390/fi6020302