
Latent Autoregressive Student-t Prior Process Models to Assess Impact of Interventions in Time Series
Abstract
:1. Introduction
2. Background
3. Review of Gaussian Process Regression Models
3.1. GP and Sparse GP Regression
3.2. GP-NARX Models
3.3. GP-RLARX Models
4. Proposed Methods: Autoregressive TP Models
4.1. Review and Notation for Student-t Processes
4.2. TP-NARX Model
4.3. TP-RLARX Model
5. Application: IoT Temperature Time Series
5.1. Data Description
5.2. Results
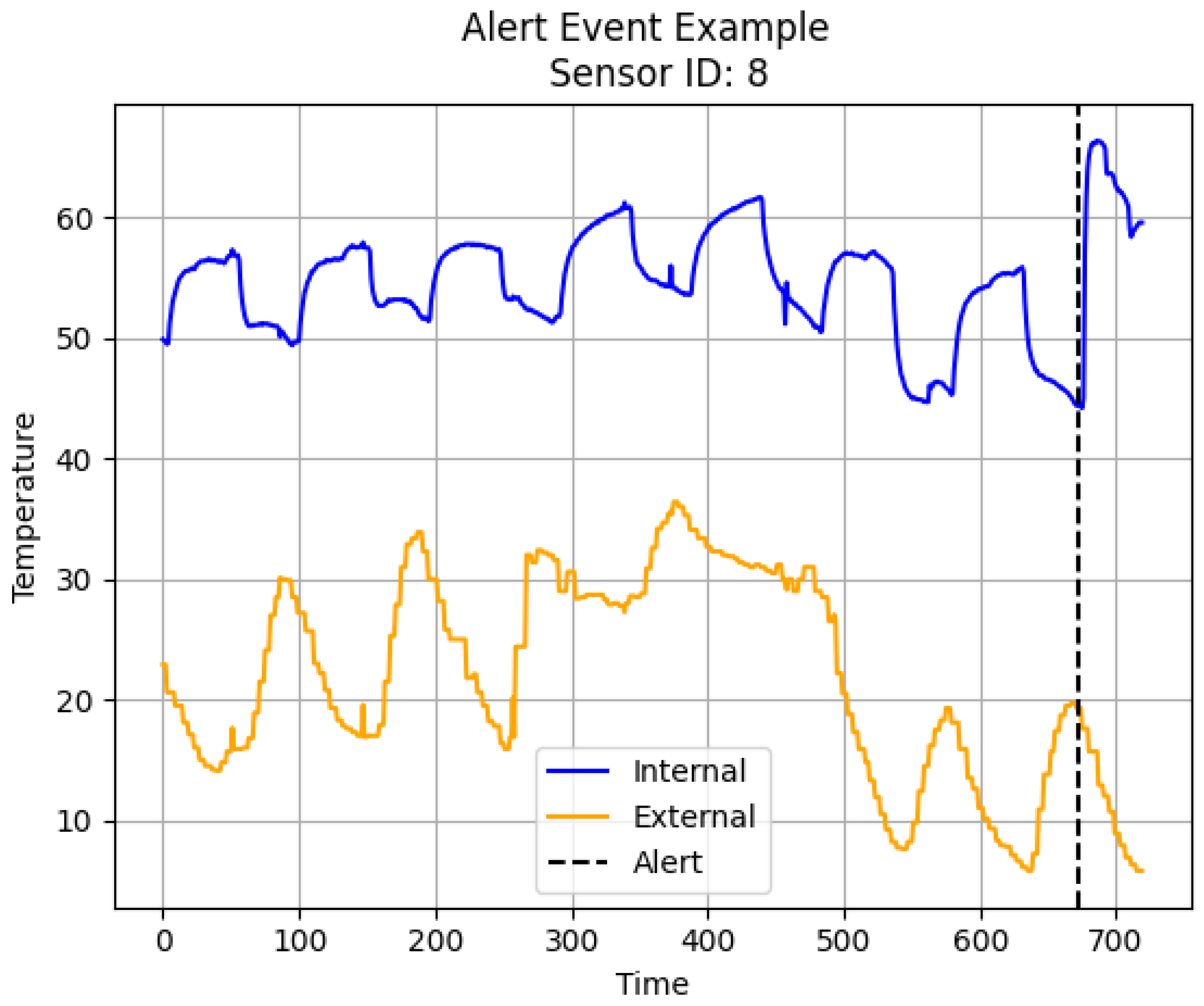
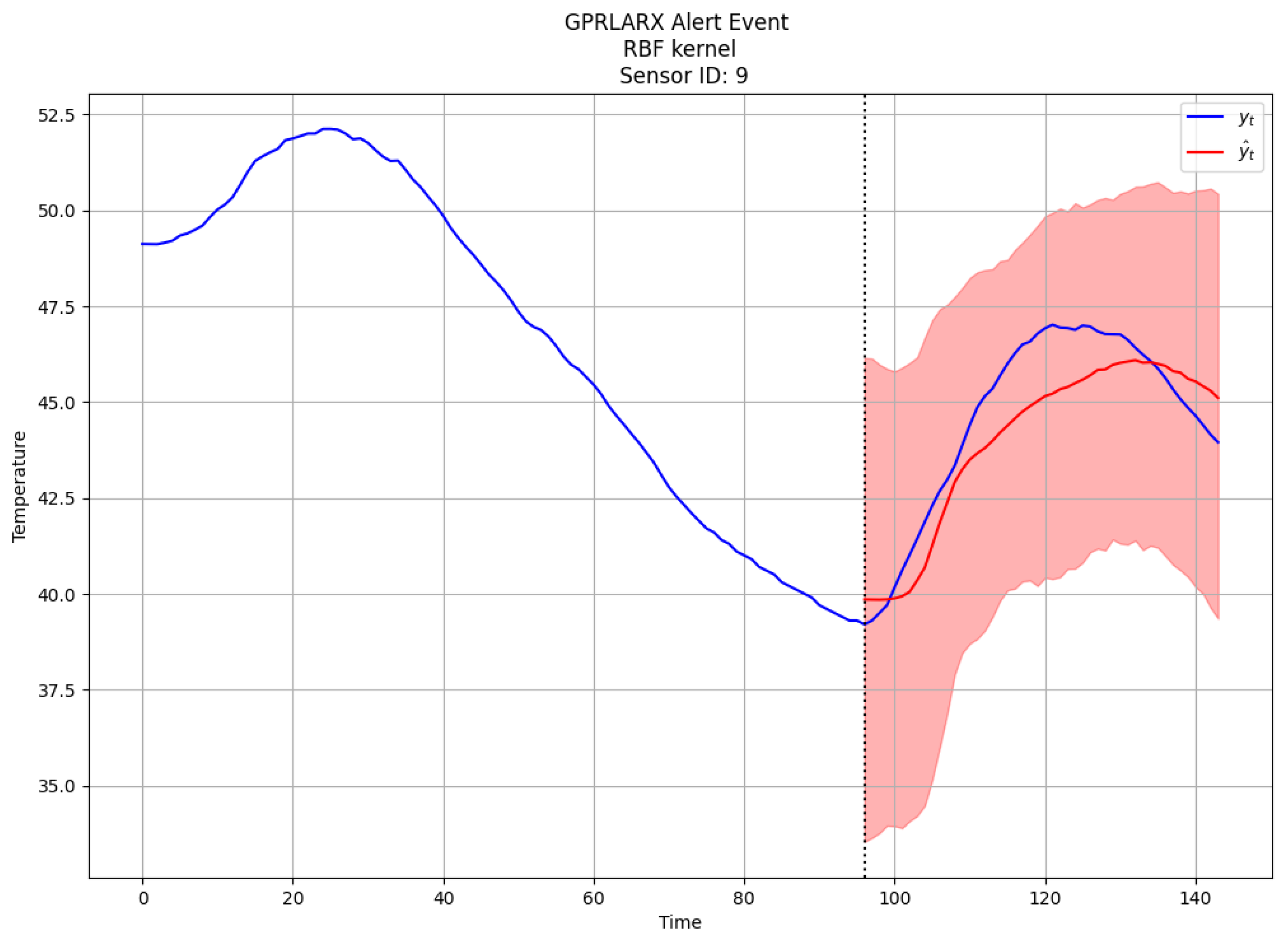
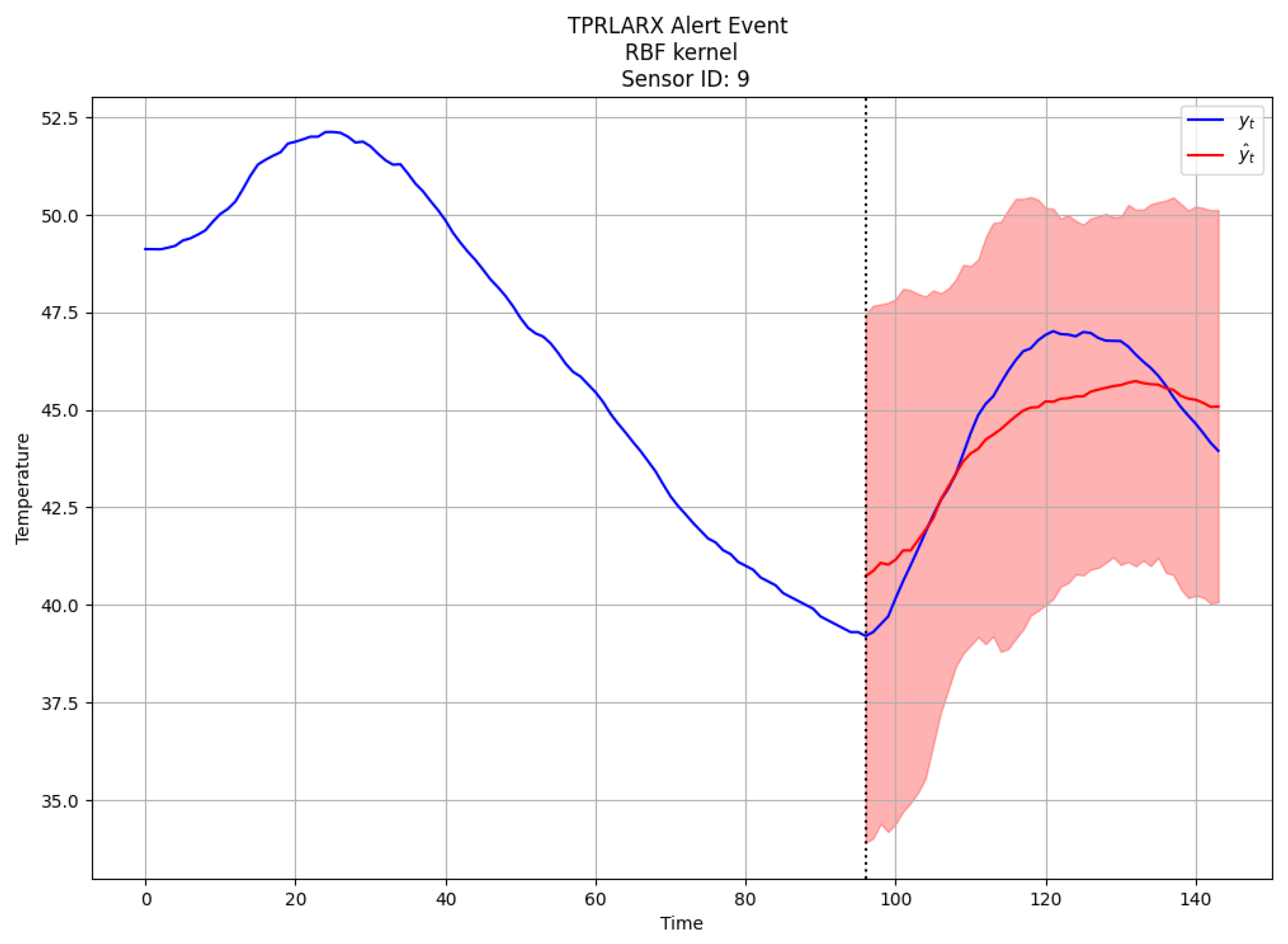
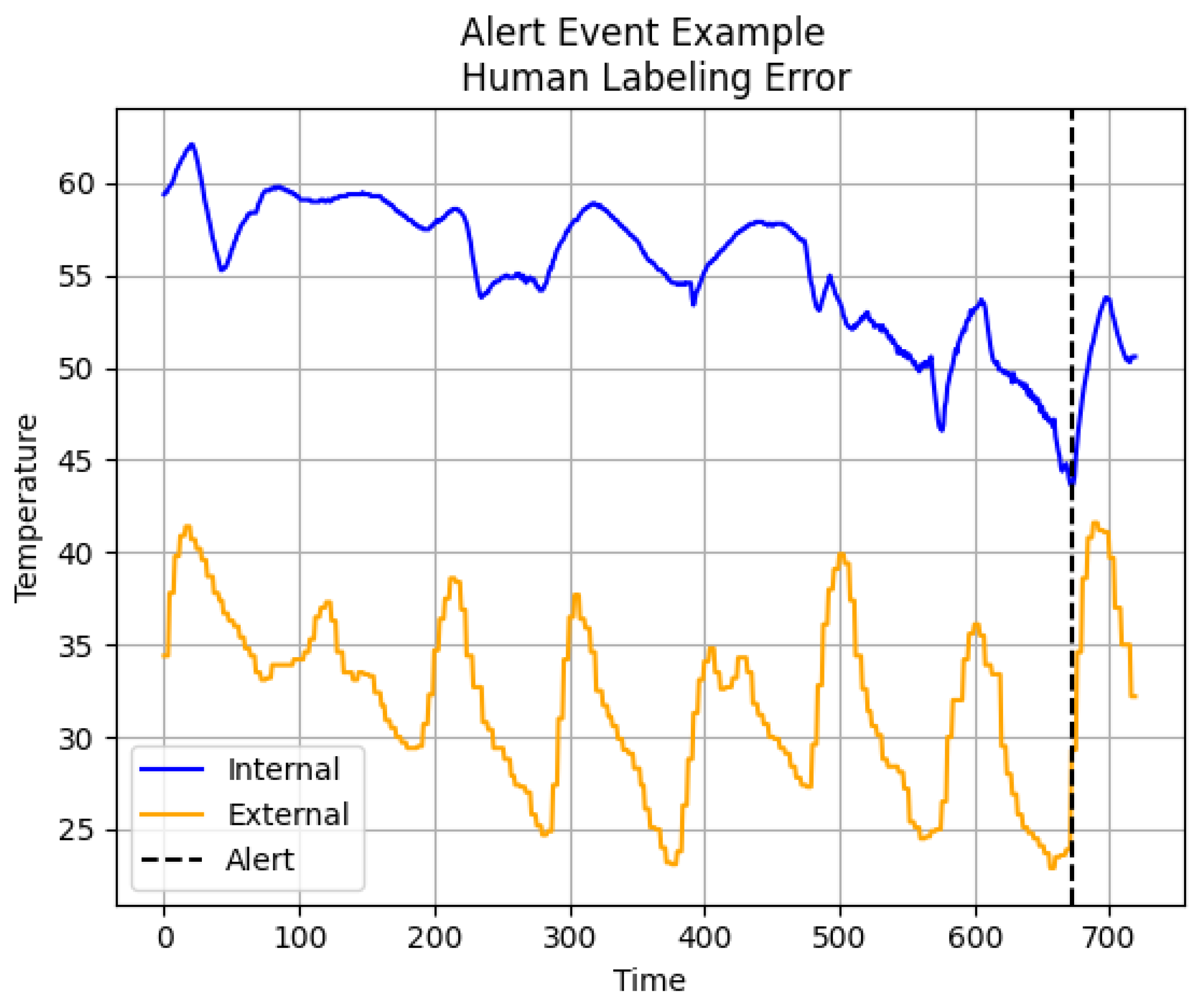
5.3. Intervention Impact Analysis and Interpretation
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Brockwell, P.J.; Davis, R.A. Introduction to Time Series and Forecasting; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Abraham, B. Intervention analysis and multiple time series. Biometrika 1980, 67, 73–78. [Google Scholar] [CrossRef]
- Shumway, R.H.; Stoffer, D.S.; Stoffer, D.S. Time Series Analysis and its Applications; Springer: Berlin/Heidelberg, Germany, 2000; Volume 3. [Google Scholar]
- Van den Brakel, J.; Roels, J. Intervention analysis with state-space models to estimate discontinuities due to a survey redesign. Ann. Appl. Stat. 2010, 4, 1105–1138. [Google Scholar] [CrossRef]
- Scott, S.L.; Varian, H.R. Predicting the present with Bayesian structural time series. Int. J. Math. Model. Numer. Optim. 2014, 5, 4–23. [Google Scholar] [CrossRef]
- Brodersen, K.H.; Gallusser, F.; Koehler, J.; Remy, N.; Scott, S.L. Inferring causal impact using Bayesian structural time-series models. Ann. Appl. Stat. 2015, 9, 247–274. [Google Scholar] [CrossRef]
- Schmitt, E.; Tull, C.; Atwater, P. Extending Bayesian structural time-series estimates of causal impact to many-household conservation initiatives. Ann. Appl. Stat. 2018, 12, 2517–2539. [Google Scholar] [CrossRef]
- Kurz, C.F.; Rehm, M.; Holle, R.; Teuner, C.; Laxy, M.; Schwarzkopf, L. The effect of bariatric surgery on health care costs: A synthetic control approach using Bayesian structural time series. Health Econ. 2019, 28, 1293–1307. [Google Scholar] [CrossRef]
- Ön, Z.B.; Greaves, A.; Akçer-Ön, S.; Özeren, M.S. A Bayesian test for the 4.2 ka BP abrupt climatic change event in southeast Europe and southwest Asia using structural time series analysis of paleoclimate data. Clim. Chang. 2021, 165, 1–19. [Google Scholar] [CrossRef]
- Toman, P.; Soliman, A.; Ravishanker, N.; Rajasekaran, S.; Lally, N.; D’Addeo, H. Understanding insured behavior through causal analysis of IoT streams. In Proceedings of the 2023 6th International Conference on Data Mining and Knowledge Discovery (DMKD 2023), Chongqing, China, 24–26 June 2023. [Google Scholar]
- Williams, C.K.; Rasmussen, C.E. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006; Volume 2. [Google Scholar]
- Mattos, C.L.C.; Damianou, A.; Barreto, G.A.; Lawrence, N.D. Latent autoregressive Gaussian processes models for robust system identification. IFAC-PapersOnLine 2016, 49, 1121–1126. [Google Scholar] [CrossRef]
- Shah, A.; Wilson, A.; Ghahramani, Z. Student-t processes as alternatives to Gaussian processes. In Proceedings of the Artificial Intelligence and Statistics, PMLR, Reykjavik, Iceland, 22–25 April 2014; pp. 877–885. [Google Scholar]
- Solin, A.; Särkkä, S. State space methods for efficient inference in Student-t process regression. In Proceedings of the Artificial Intelligence and Statistics, PMLR, San Diego, CA, USA, 9–12 May 2015; pp. 885–893. [Google Scholar]
- Meitz, M.; Preve, D.; Saikkonen, P. A mixture autoregressive model based on Student’st—Distribution. Commun.-Stat.-Theory Methods 2023, 52, 499–515. [Google Scholar] [CrossRef]
- Snelson, E.; Ghahramani, Z. Sparse Gaussian processes using pseudo-inputs. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 5–8 December 2005; Volume 18. [Google Scholar]
- Titsias, M. Variational learning of inducing variables in sparse Gaussian processes. In Proceedings of the Artificial Intelligence and Statistics, PMLR, Clearwater Beach, FL, USA, 16–18 April 2009; pp. 567–574. [Google Scholar]
- Hensman, J.; Fusi, N.; Lawrence, N.D. Gaussian processes for big data. arXiv 2013, arXiv:1309.6835. [Google Scholar]
- Hensman, J.; Matthews, A.; Ghahramani, Z. Scalable variational Gaussian process classification. In Proceedings of the Artificial Intelligence and Statistics, PMLR, San Diego, CA, USA, 9–12 May 2015; pp. 351–360. [Google Scholar]
- Blei, D.M.; Kucukelbir, A.; McAuliffe, J.D. Variational inference: A review for statisticians. J. Am. Stat. Assoc. 2017, 112, 859–877. [Google Scholar] [CrossRef]
- Girard, A.; Rasmussen, C.E.; Quinonero-Candela, J.; Murray-Smith, R.; Winther, O.; Larsen, J. Multiple-step ahead prediction for non linear dynamic systems–a Gaussian process treatment with propagation of the uncertainty. Adv. Neural Inf. Process. Syst. 2002, 15, 529–536. [Google Scholar]
- Girard, A. Approximate Methods for Propagation of Uncertainty with Gaussian Process Models; University of Glasgow (United Kingdom): Glasgow, UK, 2004. [Google Scholar]
- Groot, P.; Lucas, P.; Bosch, P. Multiple-step time series forecasting with sparse gaussian processes. In Proceedings of the 23rd Benelux Conference on Artificial Intelligence, Gent, Belgium, 3–4 November 2011. [Google Scholar]
- Gutjahr, T.; Ulmer, H.; Ament, C. Sparse Gaussian processes with uncertain inputs for multi-step ahead prediction. IFAC Proc. Vol. 2012, 45, 107–112. [Google Scholar] [CrossRef]
- Bijl, H.; Schön, T.B.; van Wingerden, J.W.; Verhaegen, M. System identification through online sparse Gaussian process regression with input noise. IFAC J. Syst. Control 2017, 2, 1–11. [Google Scholar] [CrossRef]
- Titsias, M.; Lawrence, N.D. Bayesian Gaussian process latent variable model. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; JMLR Workshop and Conference Proceedings. pp. 844–851. [Google Scholar]
- Xu, Z.; Kersting, K.; Von Ritter, L. Stochastic Online Anomaly Analysis for Streaming Time Series. In Proceedings of the IJCAI, Melbourne, Australia, 19–25 August 2017; pp. 3189–3195. [Google Scholar]
- Uchiyama, Y.; Nakagawa, K. TPLVM: Portfolio Construction by Student’st-Process Latent Variable Model. Mathematics 2020, 8, 449. [Google Scholar] [CrossRef]
- Peng, C.Y.; Cheng, Y.S. Student-t processes for degradation analysis. Technometrics 2020, 62, 223–235. [Google Scholar] [CrossRef]
- Lee, H.; Yun, E.; Yang, H.; Lee, J. Scale mixtures of neural network Gaussian processes. arXiv 2021, arXiv:2107.01408. [Google Scholar]
- Ranganath, R.; Gerrish, S.; Blei, D. Black box variational inference. In Proceedings of the Artificial Intelligence and Statistics, PMLR, Reykjavik, Iceland, 22–25 April 2014; pp. 814–822. [Google Scholar]
- Bingham, E.; Chen, J.P.; Jankowiak, M.; Obermeyer, F.; Pradhan, N.; Karaletsos, T.; Singh, R.; Szerlip, P.; Horsfall, P.; Goodman, N.D. Pyro: Deep Universal Probabilistic Programming. J. Mach. Learn. Res. 2018, 20, 973–978. [Google Scholar]
- Gneiting, T.; Raftery, A.E. Strictly proper scoring rules, prediction, and estimation. J. Am. Stat. Assoc. 2007, 102, 359–378. [Google Scholar] [CrossRef]
- Frigola, R.; Chen, Y.; Rasmussen, C.E. Variational Gaussian process state-space models. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Doerr, A.; Daniel, C.; Schiegg, M.; Duy, N.T.; Schaal, S.; Toussaint, M.; Sebastian, T. Probabilistic recurrent state-space models. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 1280–1289. [Google Scholar]
- Curi, S.; Melchior, S.; Berkenkamp, F.; Krause, A. Structured variational inference in partially observable unstable Gaussian process state space models. In Proceedings of the Learning for Dynamics and Control, PMLR, Berkeley, CA, USA, 11–12 June 2020; pp. 147–157. [Google Scholar]
- Krishnan, R.; Shalit, U.; Sontag, D. Structured inference networks for nonlinear state space models. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Characteristics | Pros | Cons |
|---|---|---|---|
| GP-NARX | 1. Target is a non-linear, autoregressive function of observed past values and exogenous predictors. 2. Trained via Type II MLE 3. Forecasts attained via simple Monte Carlo sampling | 1. Fast to train 2. Non-parametric GP prior 3. Predictive uncertainty | 1. Incapable of handling heavy-tailed noise outliers 2. Assumes a Gaussian likelihood |
| GP-RLARX | 1. Target variable is assumed to equal a latent state plus noise 2. Autoregressive behavior captured through latent state dynamics 3. Exogenous predictors can be placed at observed and latent level 4. Trained using variational Bayesian and sparse GP methods 5. Forecasts by sampling from approximate posterior | 1. Robust to heavy-tailed noise and outliers 2. Non-parametric sparse GP prior 3. Predictive uncertainty 4. Arbitrary likelihoods | 1. Slower to train than GP-NARX 2. Somewhat more challenging to train |
| Proposed Contributions | Summary | Findings |
|---|---|---|
| TP-NARX | Extends the GP-NARX model to the Student-t likelihood in order to accommodate heavy-tailed noise and outliers | 1. Gain robustness of a heavy-tailed likelihood without increasing computational speed relative to GP-NARX |
| TP-RLARX | Extends the GP-RLARX by substituting the latent GP prior with a Student-t process prior. Proposed method is now robust to heavy-tailed noise at the observational and latent levels. Derived the ELBO for this proposed model | 1. Gain robustness of a heavy-tailed latent state with minor increase to computational speed relative to GP-RLARX 2. TP-RLARX has performance at least as good as GP-RLARX on intervention analysis task. |
| Model | RMSE | sMAPE | CRPS | CPU Time |
|---|---|---|---|---|
| GP-NARX RBF | 13.456 | 0.046 | 10.705 | 33.69 |
| GP-NARX Matérn | 13.605 | 0.046 | 10.882 | 34.88 |
| GP-NARX Matérn | 13.669 | 0.047 | 10.875 | 34.63 |
| GP-NARX OU | 13.385 | 0.046 | 10.717 | 32.51 |
| GP-RLARX RBF | 15.748 | 0.051 | 12.253 | 741.50 |
| GP-RLARX Matérn | 15.610 | 0.051 | 12.429 | 889.78 |
| GP-RLARX Matérn | 15.453 | 0.051 | 12.309 | 954.87 |
| GP-RLARX OU | 14.831 | 0.049 | 11.798 | 907.22 |
| TP-NARX RBF | 13.110 | 0.044 | 10.340 | 31.95 |
| TP-NARX Matérn | 13.234 | 0.046 | 10.361 | 30.72 |
| TP-NARX Matérn | 13.073 | 0.046 | 10.361 | 31.27 |
| TP-NARX OU | 13.728 | 0.047 | 10.707 | 28.82 |
| TP-RLARX RBF | 13.666 | 0.046 | 10.886 | 967.20 |
| TP-RLARX Matérn | 13.149 | 0.046 | 10.481 | 1131.45 |
| TP-RLARX Matérn | 13.312 | 0.046 | 10.574 | 1129.89 |
| TP-RLARX OU | 13.003 | 0.045 | 10.394 | 1104.85 |
| (a) GP-NARX | (b) GP-RLARX | ||||
| Human Labels | Human Labels | ||||
| Predicted Labels | No Action | Action | Predicted Labels | No Action | Action |
| No Action | 33 | 7 | No Action | 38 | 10 |
| Action | 7 | 3 | Action | 2 | 0 |
| (c) TP-NARX | (d) TP-RLARX | ||||
| Human Labels | Human Labels | ||||
| Predicted Labels | No Action | Action | Predicted Labels | No Action | Action |
| No Action | 24 | 8 | No Action | 39 | 9 |
| Action | 16 | 2 | Action | 1 | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Toman, P.; Ravishanker, N.; Lally, N.; Rajasekaran, S. Latent Autoregressive Student-t Prior Process Models to Assess Impact of Interventions in Time Series. Future Internet 2024, 16, 8. https://doi.org/10.3390/fi16010008
Toman P, Ravishanker N, Lally N, Rajasekaran S. Latent Autoregressive Student-t Prior Process Models to Assess Impact of Interventions in Time Series. Future Internet. 2024; 16(1):8. https://doi.org/10.3390/fi16010008
Chicago/Turabian StyleToman, Patrick, Nalini Ravishanker, Nathan Lally, and Sanguthevar Rajasekaran. 2024. "Latent Autoregressive Student-t Prior Process Models to Assess Impact of Interventions in Time Series" Future Internet 16, no. 1: 8. https://doi.org/10.3390/fi16010008