
A Learning Game-Based Approach to Task-Dependent Edge Resource Allocation


Abstract
:1. Introduction
- We propose a two-stage resource allocation method in the context of dependent tasks.
- In the first stage, we model the problem of incentivizing users to request resources from edge servers as a multivariate Stackelberg game. We analyze the uniqueness of SE under the scenario of information sharing. Furthermore, we investigate the incentive problem in the absence of information sharing, and we transform it into a partially observable Markov decision process for multiple agents. To solve the SE in this situation, we design a learning-based game-theoretic reinforcement learning algorithm.
- In the second stage, to allocate resources effectively, we design a greedy-based deep reinforcement learning algorithm to minimize the task execution time.
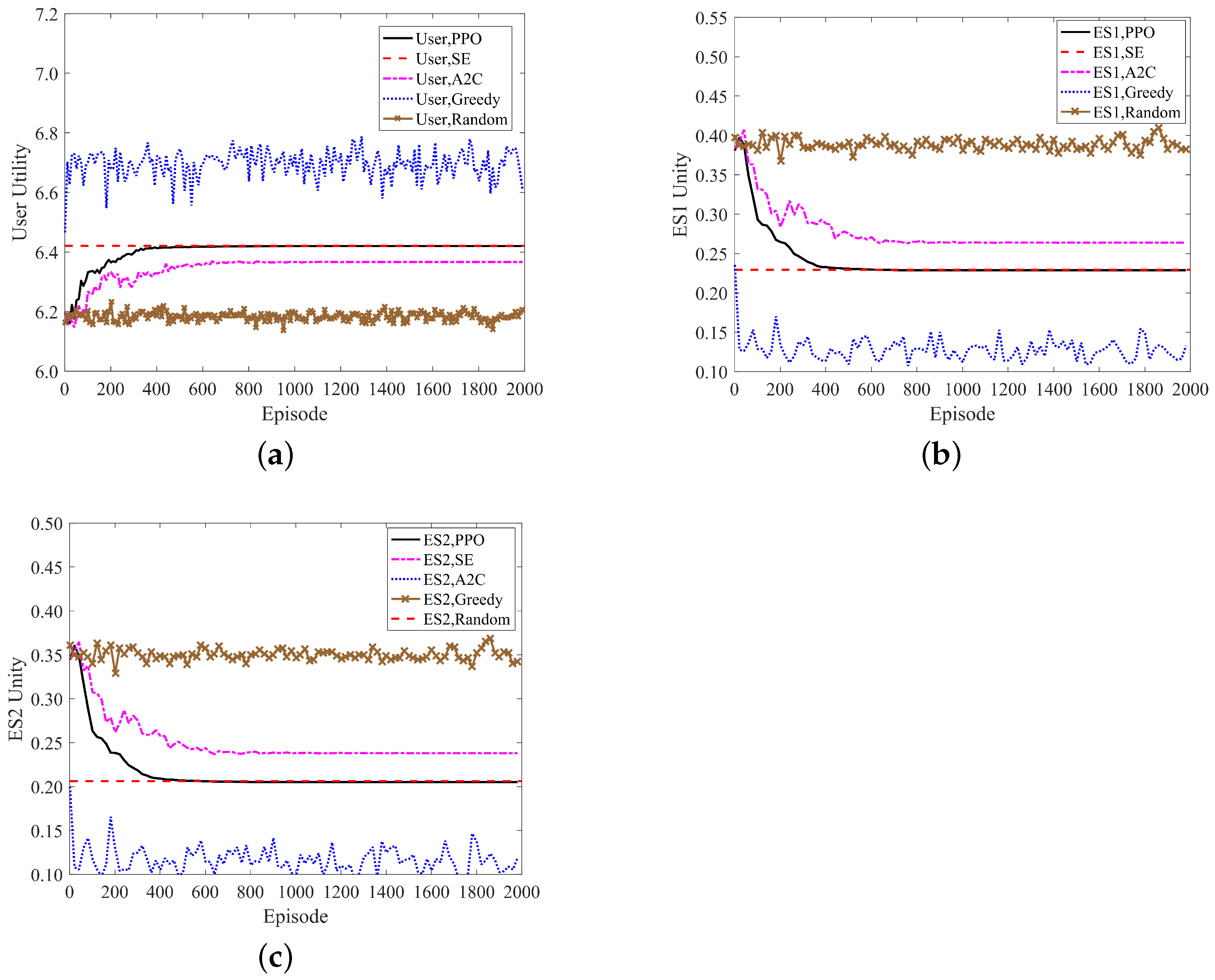
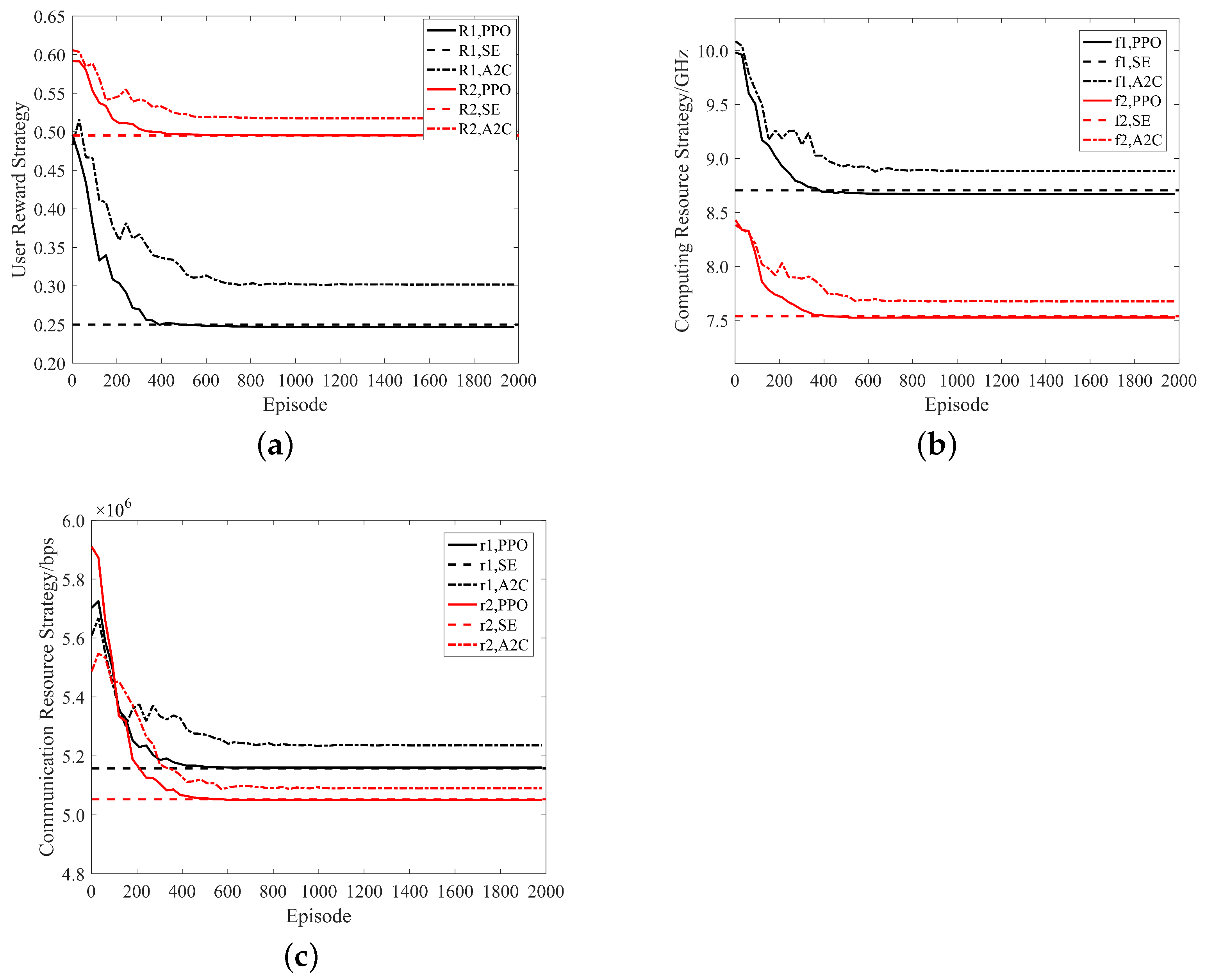
- Through experimental simulation, it is demonstrated that the reinforcement learning algorithm proposed in this paper, which is based on learning games, can achieve SE in scenarios without information disclosure, and that it outperforms the conventional A2C algorithm. The reinforcement learning algorithm, grounded in the principle of greediness, can significantly reduce the execution time of tasks.
2. Related Work and Preliminary Technology
2.1. Related Work
2.2. Preliminary Technology
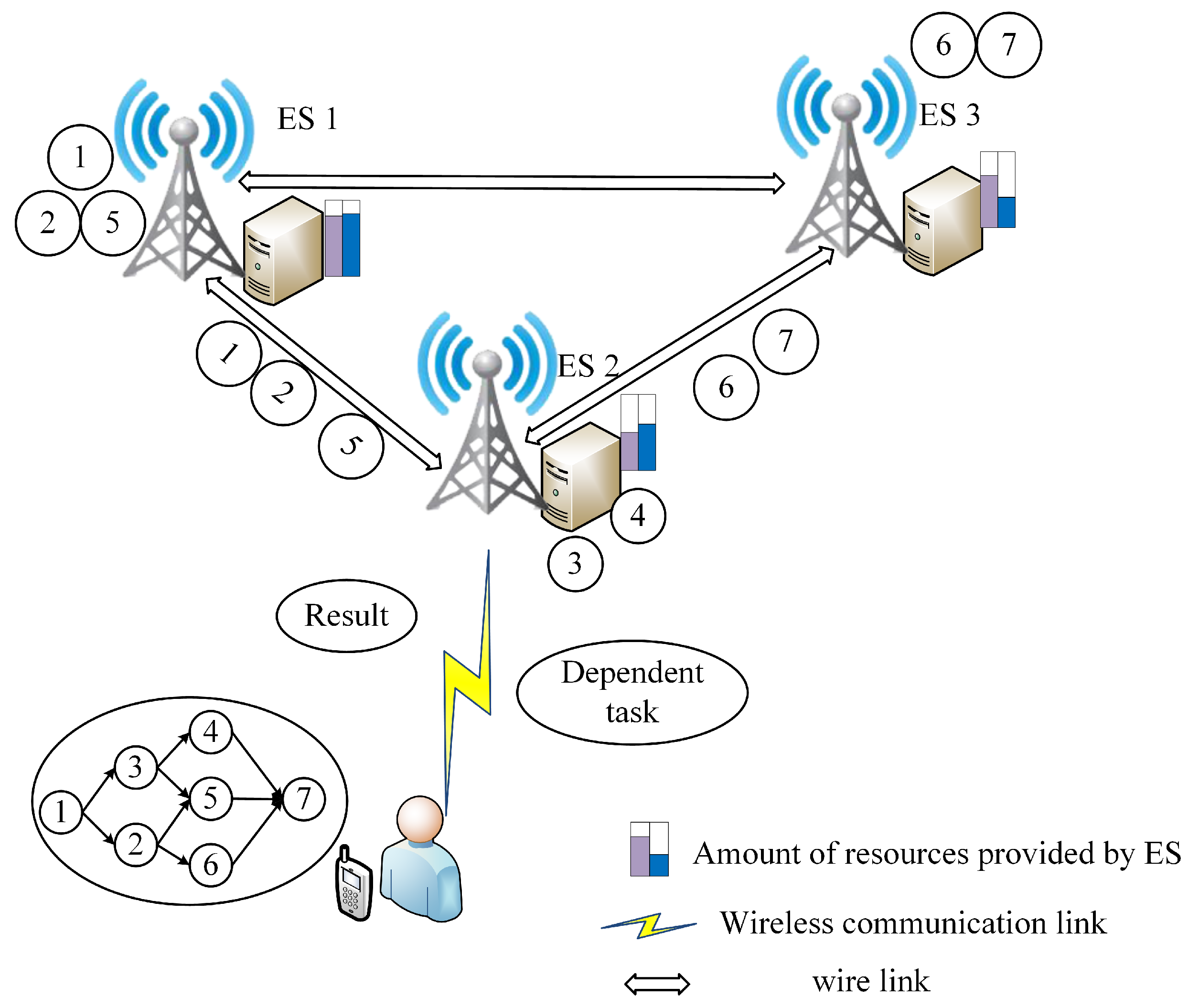
3. System Model
3.1. Local Computation
3.2. Edge Computation
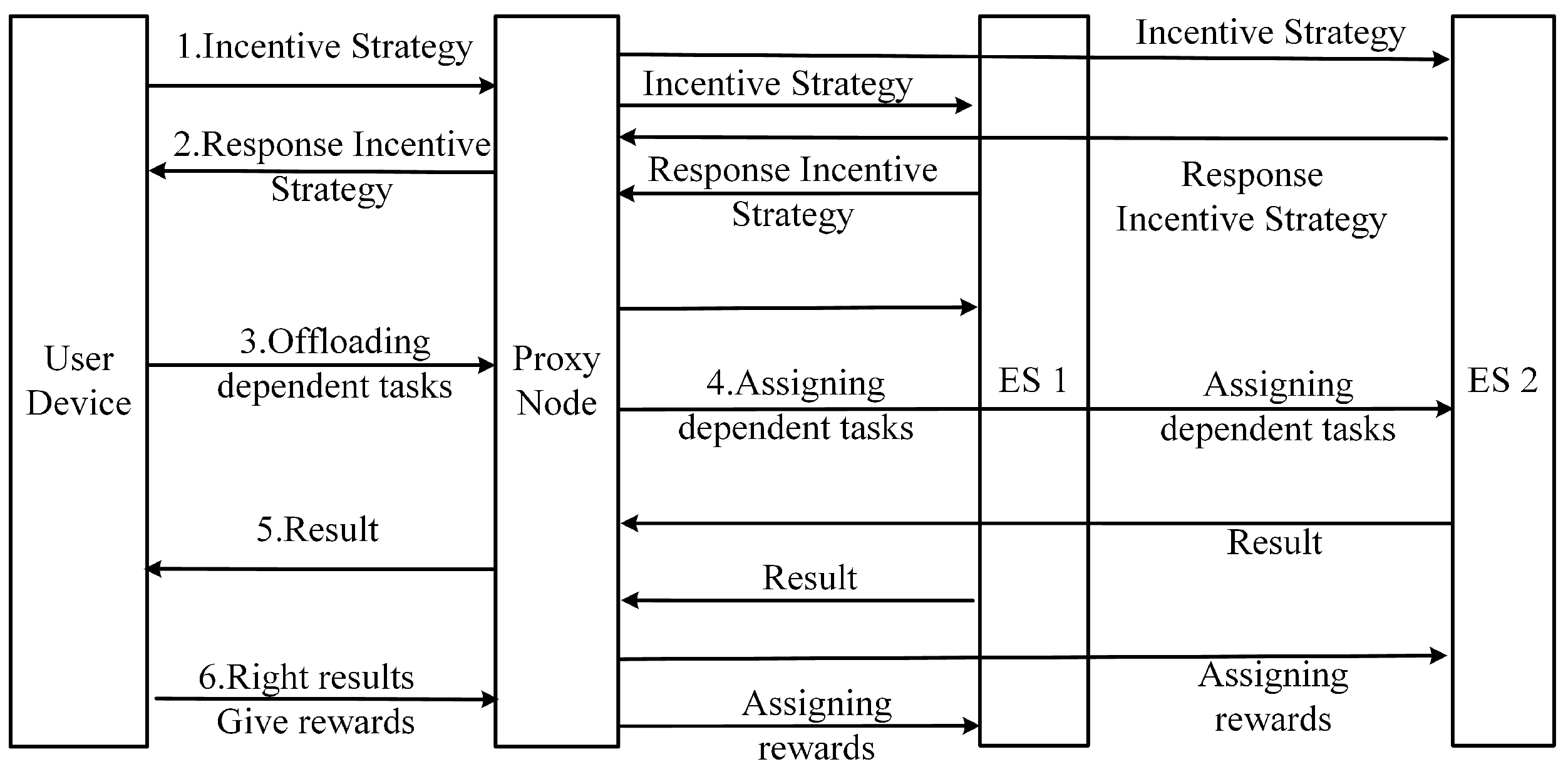
4. Incentives under Information Sharing Conditions
4.1. Participant Utility Functions
4.2. Problem Formulation
4.3. Stackelberg Equilibrium Analysis under Information Sharing Conditions
| Algorithm 1 Coordinate Alternation Method |
| Input: initialization |
| Output: optimal strategy |
| 1: while do |
| 2: while do |
| 3: for do |
| 4: calculation of the followers’ utility , by Equations (9) and (10) |
| 5: save the strategy that maximizes and as |
| 6: end for |
| 7: calculation of the leader’s utility U by Equation (12) |
| 8: save the strategy that maximizes U as |
| 9: end while |
| 10: end while |
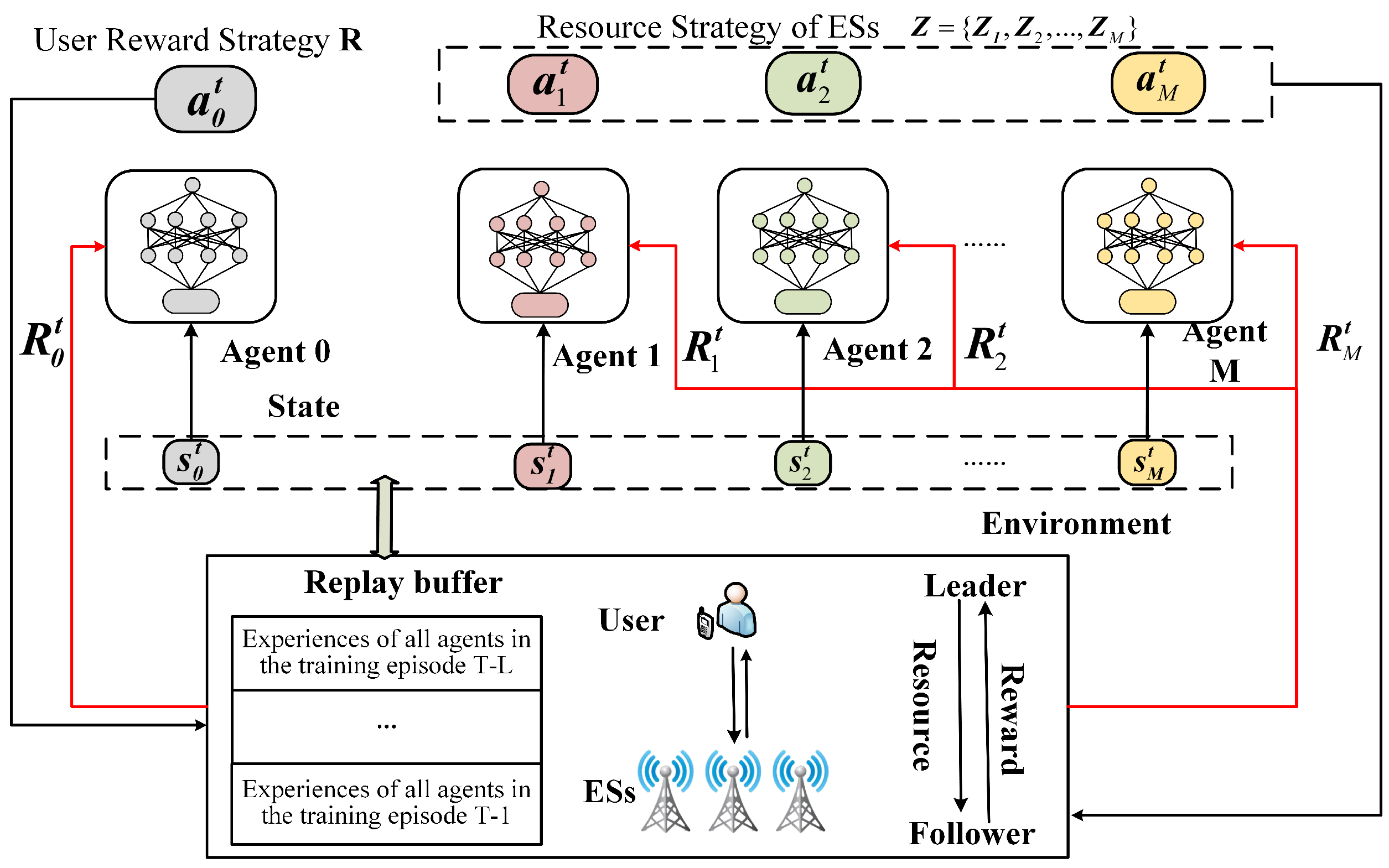
5. Study of the Incentives under Non-Information-Sharing Conditions
5.1. Overview
5.2. Design Details
5.3. Optimization of Learning Objectives and Strategies
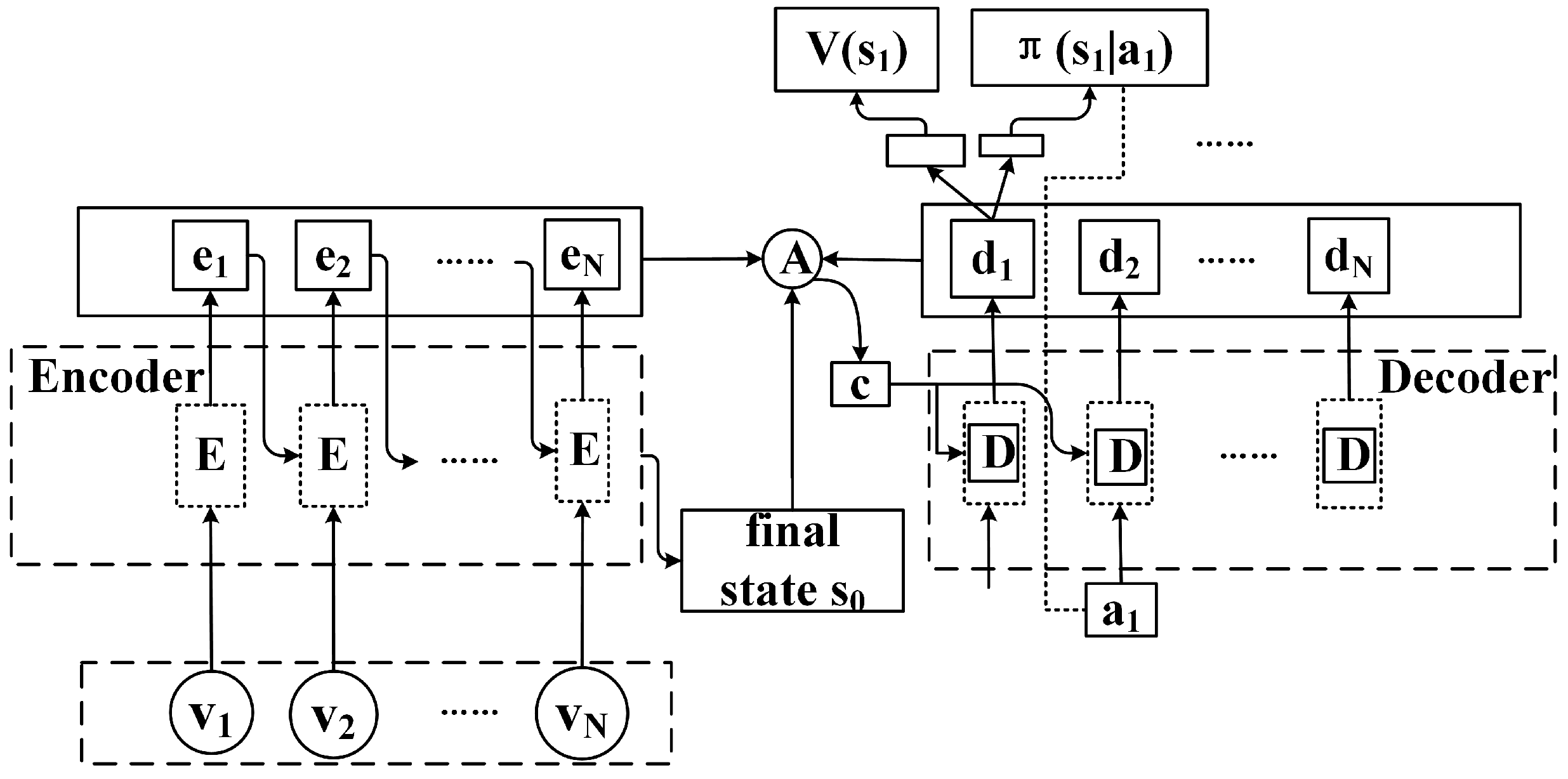
6. Task Allocation for DRL Based on Greedy Thinking
6.1. Overview
6.2. Design Details
6.3. Optimization of Learning Objectives and Strategies
7. Simulation Results
7.1. Performance Analysis of the Incentive Mechanism Algorithm Based on Learning Games
7.2. Analysis of the Effectiveness of the Greedy-Based DRL Algorithm
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lin, H.; Zeadally, S.; Chen, Z.; Labiod, H.; Wang, L. A survey on computation offloading modeling for edge computing. J. Netw. Comput. Appl. 2020, 169, 102781. [Google Scholar] [CrossRef]
- Islam, A.; Debnath, A.; Ghose, M.; Chakraborty, S. A survey on task offloading in multi-access edge computing. J. Syst. Archit. 2021, 118, 102225. [Google Scholar] [CrossRef]
- Patsias, V.; Amanatidis, P.; Karampatzakis, D.; Lagkas, T.; Michalakopoulou, K.; Nikitas, A. Task Allocation Methods and Optimization Techniques in Edge Computing: A Systematic Review of the Literature. Future Internet 2023, 15, 254. [Google Scholar] [CrossRef]
- Liu, B.; Xu, X.; Qi, L.; Ni, Q.; Dou, W. Task scheduling with precedence and placement constraints for resource utilization improvement in multi-user MEC environment. J. Syst. Archit. 2021, 114, 101970. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, J.; Zhou, Y.; Yang, L.; He, B.; Yang, Y. Dependent task offloading with energy-latency tradeoff in mobile edge computing. IET Commun. 2022, 16, 1993–2001. [Google Scholar] [CrossRef]
- An, X.; Fan, R.; Hu, H.; Zhang, N.; Atapattu, S.; Tsiftsis, T.A. Joint task offloading and resource allocation for IoT edge computing with sequential task dependency. IEEE Internet Things J. 2022, 9, 16546–16561. [Google Scholar] [CrossRef]
- Deng, X.; Li, J.; Liu, E.; Zhang, H. Task allocation algorithm and optimization model on edge collaboration. J. Syst. Archit. 2020, 110, 101778. [Google Scholar] [CrossRef]
- Ma, L.; Wang, X.; Wang, X.; Wang, L.; Shi, Y.; Huang, M. TCDA: Truthful combinatorial double auctions for mobile edge computing in industrial Internet of Things. IEEE Trans. Mob. Comput. 2021, 21, 4125–4138. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, B.; Li, C. Incentive Mechanisms for Mobile Edge Computing: Present and Future Directions. IEEE Netw. 2022, 36, 199–205. [Google Scholar] [CrossRef]
- Chen, J.; Yang, Y.; Wang, C.; Zhang, H.; Qiu, C.; Wang, X. Multitask offloading strategy optimization based on directed acyclic graphs for edge computing. IEEE Internet Things J. 2021, 9, 9367–9378. [Google Scholar] [CrossRef]
- Jia, R.; Zhao, K.; Wei, X.; Zhang, G.; Wang, Y.; Tu, G. Joint Trajectory Planning, Service Function Deploying, and DAG Task Scheduling in UAV-Empowered Edge Computing. Drones 2023, 7, 443. [Google Scholar] [CrossRef]
- Zhang, X.; Debroy, S. Resource Management in Mobile Edge Computing: A Comprehensive Survey. ACM Comput. Surv. 2023, 55, 1–37. [Google Scholar] [CrossRef]
- Mitsis, G.; Apostolopoulos, P.A.; Tsiropoulou, E.E.; Papavassiliou, S. Intelligent dynamic data offloading in a competitive mobile edge computing market. Future Internet 2019, 11, 118. [Google Scholar] [CrossRef]
- Zhang, K.; Yang, J.; Lin, Z. Computation Offloading and Resource Allocation Based on Game Theory in Symmetric MEC-Enabled Vehicular Networks. Symmetry 2023, 15, 1241. [Google Scholar] [CrossRef]
- Roostaei, R.; Dabiri, Z.; Movahedi, Z. A game-theoretic joint optimal pricing and resource allocation for mobile edge computing in NOMA-based 5G networks and beyond. Comput. Netw. 2021, 198, 108352. [Google Scholar] [CrossRef]
- Chen, Y.; Li, Z.; Yang, B.; Nai, K.; Li, K. A Stackelberg game approach to multiple resources allocation and pricing in mobile edge computing. Future Gener. Comput. Syst. 2020, 108, 273–287. [Google Scholar] [CrossRef]
- Kumar, S.; Gupta, R.; Lakshmanan, K.; Maurya, V. A game-theoretic approach for increasing resource utilization in edge computing enabled internet of things. IEEE Access 2022, 10, 57974–57989. [Google Scholar] [CrossRef]
- Zhang, H.; Yang, Y.; Shang, B.; Zhang, P. Joint resource allocation and multi-part collaborative task offloading in MEC systems. IEEE Trans. Veh. Technol. 2022, 71, 8877–8890. [Google Scholar] [CrossRef]
- Liang, J.; Li, K.; Liu, C.; Li, K. Joint offloading and scheduling decisions for DAG applications in mobile edge computing. Neurocomputing 2021, 424, 160–171. [Google Scholar] [CrossRef]
- Xiao, H.; Xu, C.; Ma, Y.; Yang, S.; Zhong, L.; Muntean, G.M. Edge intelligence: A computational task offloading scheme for dependent IoT application. IEEE Trans. Wirel. Commun. 2022, 21, 7222–7237. [Google Scholar] [CrossRef]
- Jiang, H.; Dai, X.; Xiao, Z.; Iyengar, A.K. Joint task offloading and resource allocation for energy-constrained mobile edge computing. IEEE Trans. Mob. Comput. 2022, 22, 4000–4015. [Google Scholar] [CrossRef]
- Chen, H.; Deng, S.; Zhu, H.; Zhao, H.; Jiang, R.; Dustdar, S.; Zomaya, A.Y. Mobility-aware offloading and resource allocation for distributed services collaboration. IEEE Trans. Parallel Distrib. Syst. 2022, 33, 2428–2443. [Google Scholar] [CrossRef]
- Chen, S.; Rui, L.; Gao, Z.; Li, W.; Qiu, X. Cache-Assisted Collaborative Task Offloading and Resource Allocation Strategy: A Metareinforcement Learning Approach. IEEE Internet Things J. 2022, 9, 19823–19842. [Google Scholar] [CrossRef]
- Avgeris, M.; Mechennef, M.; Leivadeas, A.; Lambadaris, I. A Two-Stage Cooperative Reinforcement Learning Scheme for Energy-Aware Computational Offloading. In Proceedings of the 2023 IEEE 24th International Conference on High Performance Switching and Routing (HPSR), Albuquerque, NM, USA, 5–7 June 2023; pp. 179–184. [Google Scholar]
- Chen, G.; Chen, Y.; Mai, Z.; Hao, C.; Yang, M.; Du, L. Incentive-Based Distributed Resource Allocation for Task Offloading and Collaborative Computing in MEC-Enabled Networks. IEEE Internet Things J. 2022, 10, 9077–9091. [Google Scholar] [CrossRef]
- Liu, Z.; Zhao, Y.; Song, J.; Qiu, C.; Chen, X.; Wang, X. Learn to coordinate for computation offloading and resource allocation in edge computing: A rational-based distributed approach. IEEE Trans. Netw. Sci. Eng. 2021, 9, 3136–3151. [Google Scholar] [CrossRef]
- Tao, M.; Ota, K.; Dong, M.; Yuan, H. Stackelberg game-based pricing and offloading in mobile edge computing. IEEE Wirel. Commun. Lett. 2021, 11, 883–887. [Google Scholar] [CrossRef]
- Seo, H.; Oh, H.; Choi, J.K.; Park, S. Differential Pricing-Based Task Offloading for Delay-Sensitive IoT Applications in Mobile Edge Computing System. IEEE Internet Things J. 2022, 9, 19116–19131. [Google Scholar] [CrossRef]
- Kang, H.; Li, M.; Fan, S.; Cai, W. Combinatorial Auction-enabled Dependency-Aware Offloading Strategy in Mobile Edge Computing. In Proceedings of the 2023 IEEE Wireless Communications and Networking Conference (WCNC), Scotland, UK, 26–29 March 2023; pp. 1–6. [Google Scholar]
- Bahreini, T.; Badri, H.; Grosu, D. Mechanisms for resource allocation and pricing in mobile edge computing systems. IEEE Trans. Parallel Distrib. Syst. 2021, 33, 667–682. [Google Scholar] [CrossRef]
- Liu, X.; Yu, J.; Feng, Z.; Gao, Y. Multi-agent reinforcement learning for resource allocation in IoT networks with edge computing. China Commun. 2020, 17, 220–236. [Google Scholar] [CrossRef]
- Li, S.; Hu, X.; Du, Y. Deep reinforcement learning and game theory for computation offloading in dynamic edge computing markets. IEEE Access 2021, 9, 121456–121466. [Google Scholar] [CrossRef]
- Song, F.; Xing, H.; Wang, X.; Luo, S.; Dai, P.; Li, K. Offloading dependent tasks in multi-access edge computing: A multi-objective reinforcement learning approach. Future Gener. Comput. Syst. 2022, 128, 333–348. [Google Scholar] [CrossRef]
- Huang, X.; Yu, R.; Pan, M.; Shu, L. Secure roadside unit hotspot against eavesdropping based traffic analysis in edge computing based internet of vehicles. IEEE Access 2018, 6, 62371–62383. [Google Scholar] [CrossRef]
- Zhou, H.; Wang, Z.; Cheng, N.; Zeng, D.; Fan, P. Stackelberg-Game-Based Computation Offloading Method in Cloud–Edge Computing Networks. IEEE Internet Things J. 2022, 9, 16510–16520. [Google Scholar] [CrossRef]
- Yang, D.; Xue, G.; Fang, X.; Tang, J. Incentive mechanisms for crowdsensing: Crowdsourcing with smartphones. IEEE/ACM Trans. Netw. 2015, 24, 1732–1744. [Google Scholar] [CrossRef]
- Huang, X.; Zhong, Y.; Wu, Y.; Li, P.; Yu, R. Privacy-preserving incentive mechanism for platoon assisted vehicular edge computing with deep reinforcement learning. China Commun. 2022, 19, 294–309. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Wang, J.; Hu, J.; Min, G.; Zhan, W.; Zomaya, A.Y.; Georgalas, N. Dependent task offloading for edge computing based on deep reinforcement learning. IEEE Trans. Comput. 2021, 71, 2449–2461. [Google Scholar] [CrossRef]
- Li, Z.; Cai, J.; He, S.; Zhao, H. Seq2seq dependency parsing. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 3203–3214. [Google Scholar]
- Chen, Y.; Zhang, S.; Xiao, M.; Qian, Z.; Wu, J.; Lu, S. Multi-user edge-assisted video analytics task offloading game based on deep reinforcement learning. In Proceedings of the 2020 IEEE 26th International Conference on Parallel and Distributed Systems (ICPADS), Hong Kong, China, 2–4 December 2020; pp. 266–273. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
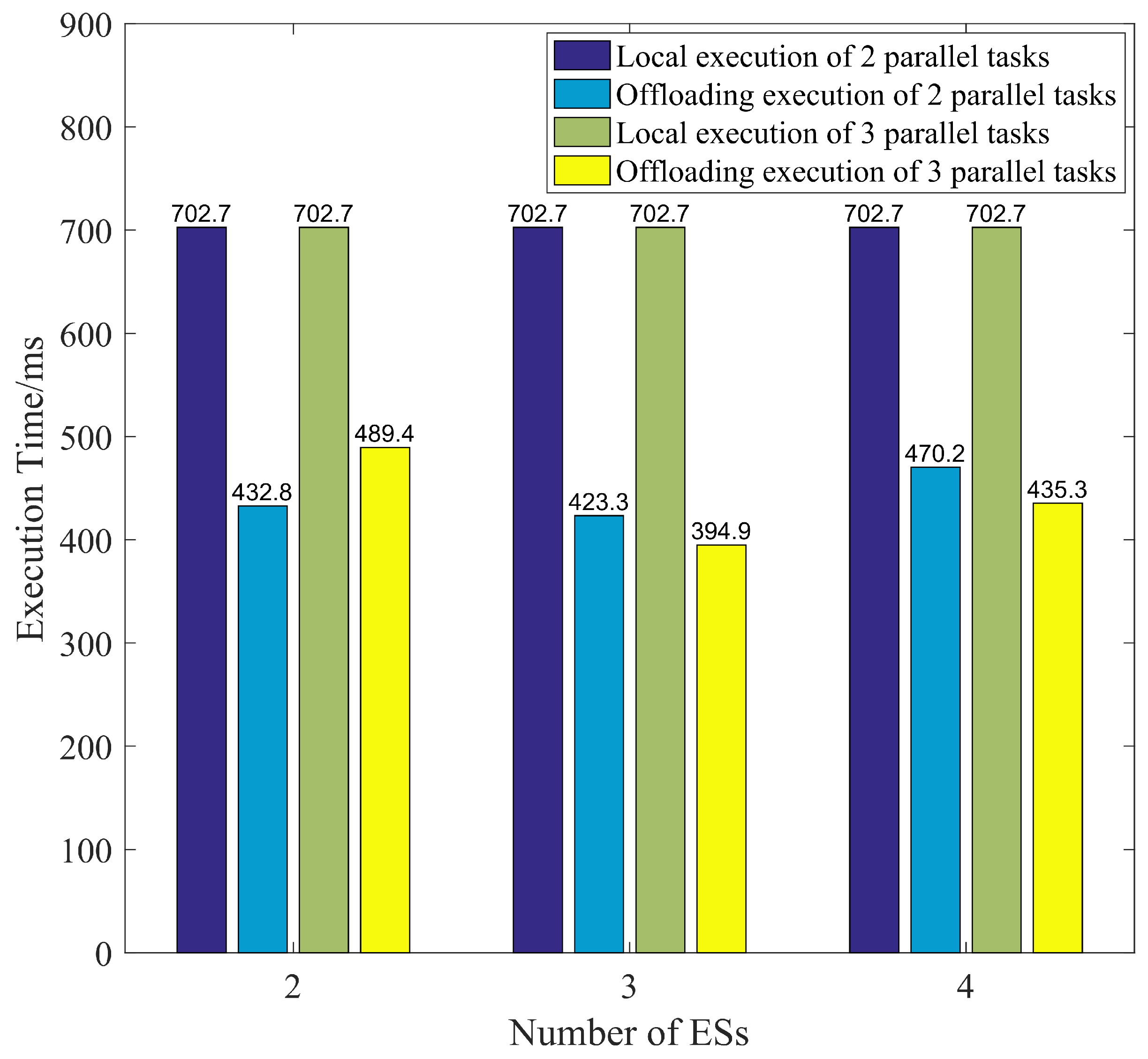{kind=link}
| Parameters | Value |
|---|---|
| User device computational power | 1 GHz |
| Effective switching capacitance | 10−27 |
| Transmit/receive task size | 5∼50 Kb |
| CPU cycles per bit of data processed | 500∼1500 cycles/bit |
| Unit cost of calculating energy consumption | 10−6∼10−5 |
| Incentive mechanism penalty factor | 20 |
| Task assignment penalty factor | 5 |
| Unit cost of communication rate | 10−4∼10−3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Ju, H.; Ren, Z. A Learning Game-Based Approach to Task-Dependent Edge Resource Allocation. Future Internet 2023, 15, 395. https://doi.org/10.3390/fi15120395
Li Z, Ju H, Ren Z. A Learning Game-Based Approach to Task-Dependent Edge Resource Allocation. Future Internet. 2023; 15(12):395. https://doi.org/10.3390/fi15120395
Chicago/Turabian StyleLi, Zuopeng, Hengshuai Ju, and Zepeng Ren. 2023. "A Learning Game-Based Approach to Task-Dependent Edge Resource Allocation" Future Internet 15, no. 12: 395. https://doi.org/10.3390/fi15120395