
Federated Adversarial Training Strategies for Achieving Privacy and Security in Sustainable Smart City Applications



Abstract
:1. Introduction
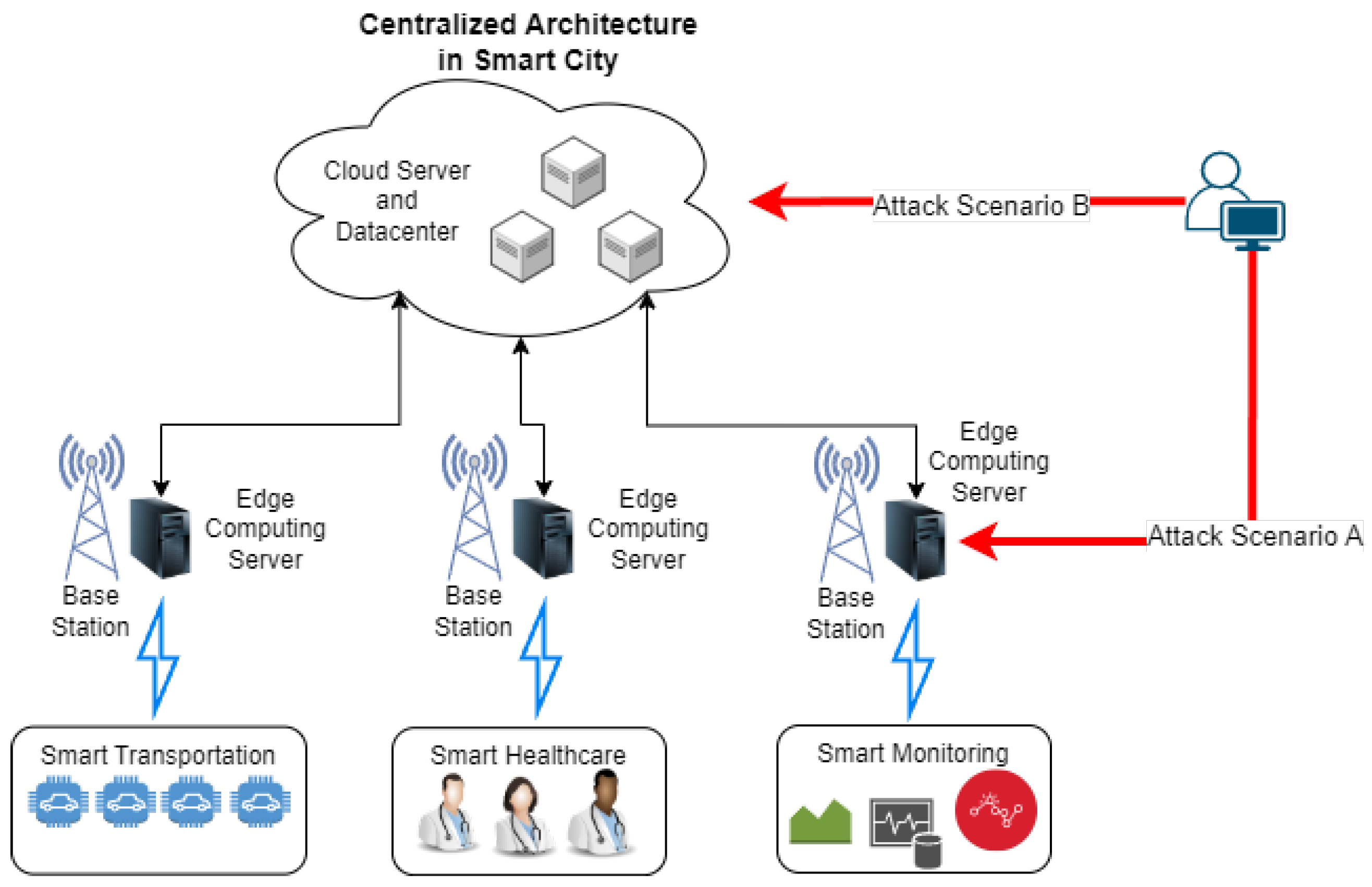
- Scenario A: An adversary attempts to compromise an FC. FCs can be a wide variety of devices, including personal computers, IoT devices, smartphones, and minicomputers (e.g., Raspberry Pi (Raspberry Pi, Wales, UK) and NVIDIA Jetson Nano (NVIDIA, China)). If the attack is successful, only the affected client’s data will be compromised; the data of other clients will remain unaffected [13,14]. This is a significant advantage over cloud-based architectures, which are vulnerable to large-scale data breaches.
- Scenario B: An adversary attempts to gain unauthorized access to the federated server (FS). However, since FL data are primarily stored on FCs, a successful attack on the FS would not expose any FL data. Therefore, FL can significantly enhance the security and privacy of conventional IoT systems. By adopting FL, organizations can improve data protection and reduce the risk of data intrusions similar to the one that occurred at Orvibo [7].
- We conducted a thorough examination of a wide range of adversarial attack scenarios targeting federated learning.
- Our findings have been experimentally validated, leading to the presentation of an adversarial learning strategy aimed at enhancing the overall robustness of the global model.
- We have successfully demonstrated the practicality of implementing our technique in situations with limited data capacity on the client side. It is important to note that prior research has recognized the challenges related to integrating adversarial training in a federated context, primarily due to the data-intensive nature of this training process.
- Our study provides valuable insights that can serve as a foundation for the development of additional defense scenarios and countermeasures against adversarial attacks, ultimately contributing to the reinforcement of security measures for sustainable smart city applications.
2. Related Work
3. Materials and Methods
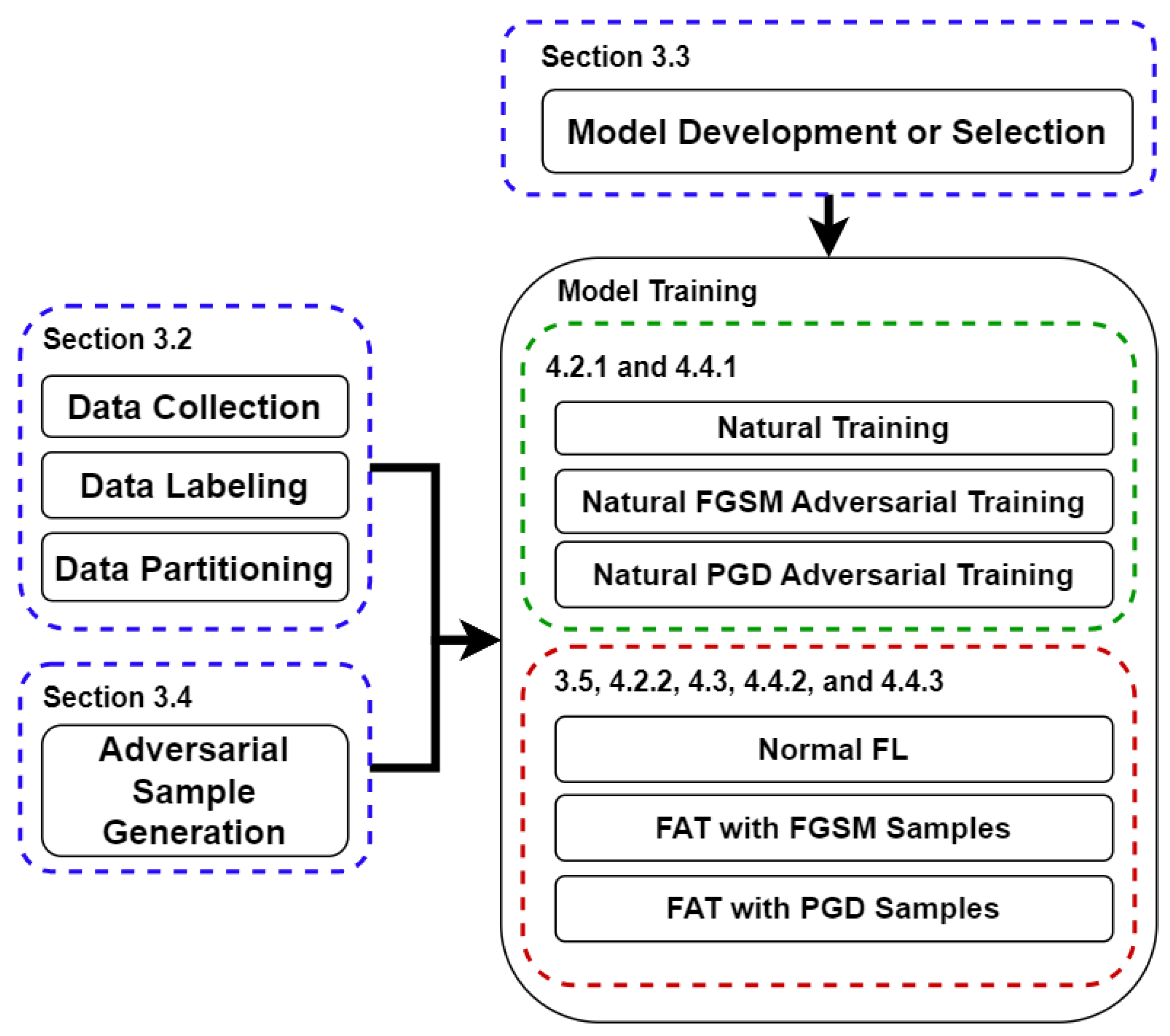
3.1. Overall Research Workflow
- Data Collection:
- The dataset utilized in this study was accessible for download from our Kaggle repository [49]. Alternatively, researchers had the flexibility to use their own dataset tailored to specific applications, as the proposed method was application-agnostic.
- A comprehensive explanation of the dataset processing was available in Section 3.2. The set of images utilized in this research is illustrated in Figure 4.
- Data Labeling:
- Immediate labeling of the dataset occurred right after capturing the images or videos to ensure accuracy.
- Given that the dataset’s primary purpose was air quality measurement, label values were extracted from official website data, providing air quality parameters at the time of data capture.
- For alternative datasets, meticulous attention to correct labeling was imperative.
- Data Partitioning:
- Recognizing that federated client computational power is typically less powerful than that of the central server, handling only a limited amount of data is feasible.
- To showcase the proposed method, the dataset was partitioned into smaller subsets, each containing 1224 images. These subsets were then distributed across all clients and servers for experimentation.
- If federated clients lacked GPU support, it was advisable to reduce the number of subsets to prevent extended processing times, ensuring a more efficient execution of the entire process.
- Model Development or Selection:
- Researchers could choose any model, whether self-developed or established (e.g., MobileNet, ResNet, VGG16), as long as it met their study’s objectives and enhanced the global model’s robustness.
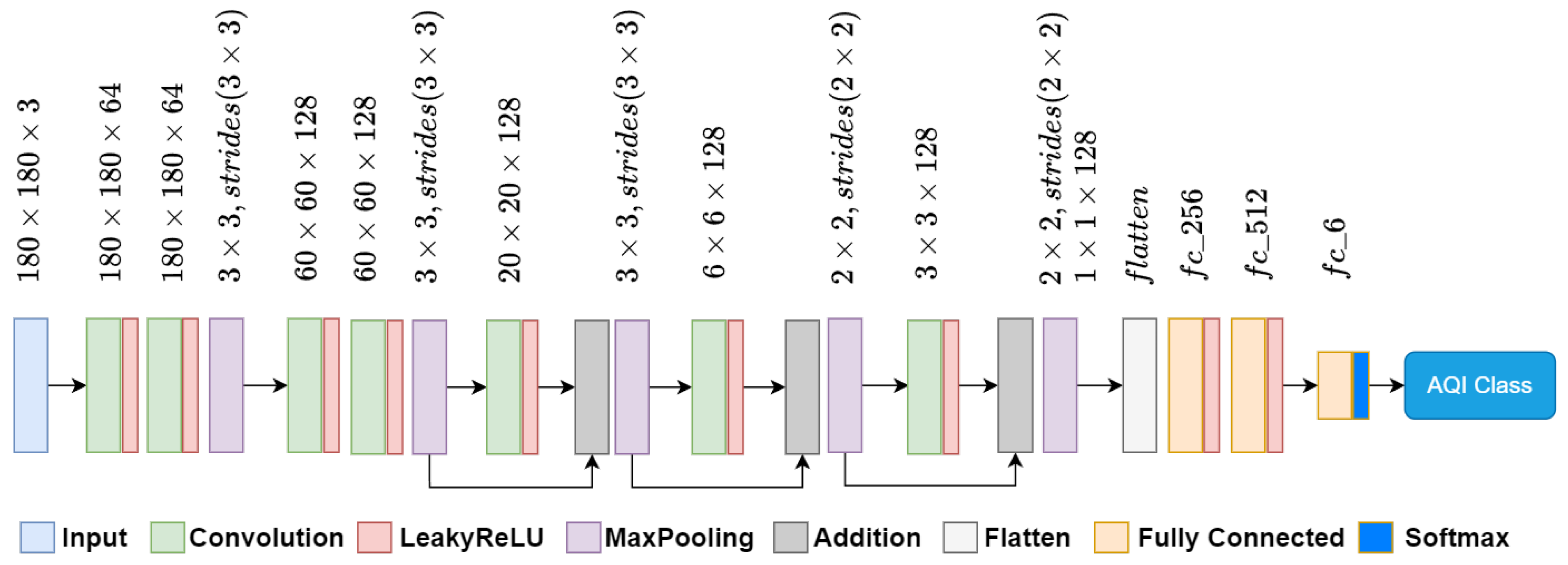
- The detailed architecture of our chosen model is provided in Section 3.3.
- Adversarial Sample Generation:
- For adversarial training to be conducted, adversarial samples were required.
- In order to generate adversarial samples, the original dataset was utilized. A variety of attack techniques were capable of producing adversarial samples.
- In this research, we specifically employed the FGSM and PGD methods, each meticulously explained in Section 3.4.
- The data label for the adversarial samples was the same as the original dataset used.
- It was recommended to perform adversarial sample generation after data partitioning for ease of data verification, considering the time-intensive nature of the process.
- Natural Training:
- Natural (conventional) model training was performed using a dataset comprising normal data devoid of adversarial samples.
- The objective was to obtain key metrics, particularly model accuracy, serving as a baseline for comparison with subsequent experimental results.
- Further details on this training step were elaborated in Section 4.2.1, with hyperparameters specified in Table 1.
- Natural FGSM Adversarial Training:
- This phase mirrored natural training, with the distinction that the dataset incorporated both normal and FGSM adversarial samples. The dataset composition was detailed in Section 4.4.1.
- Natural PGD Adversarial Training:
- Similar to natural training, this step involved utilizing a dataset comprising normal data alongside PGD adversarial samples (see Section 4.4.1 for dataset details).
- Normal FL:
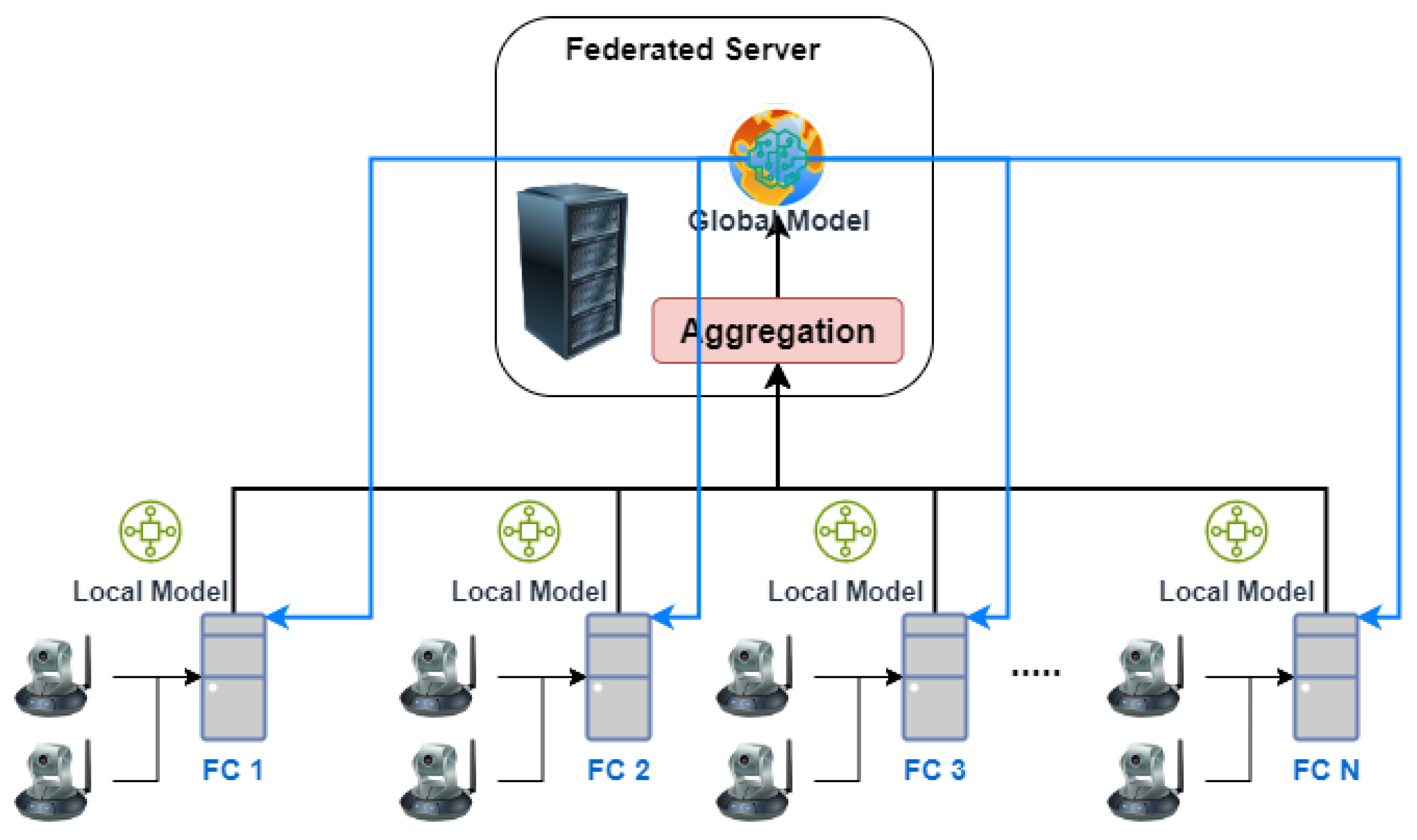
- This step employed one federated server and four federated clients (with the option to add more based on available resources in replication) and focused on observing global model performance under non-attack conditions.
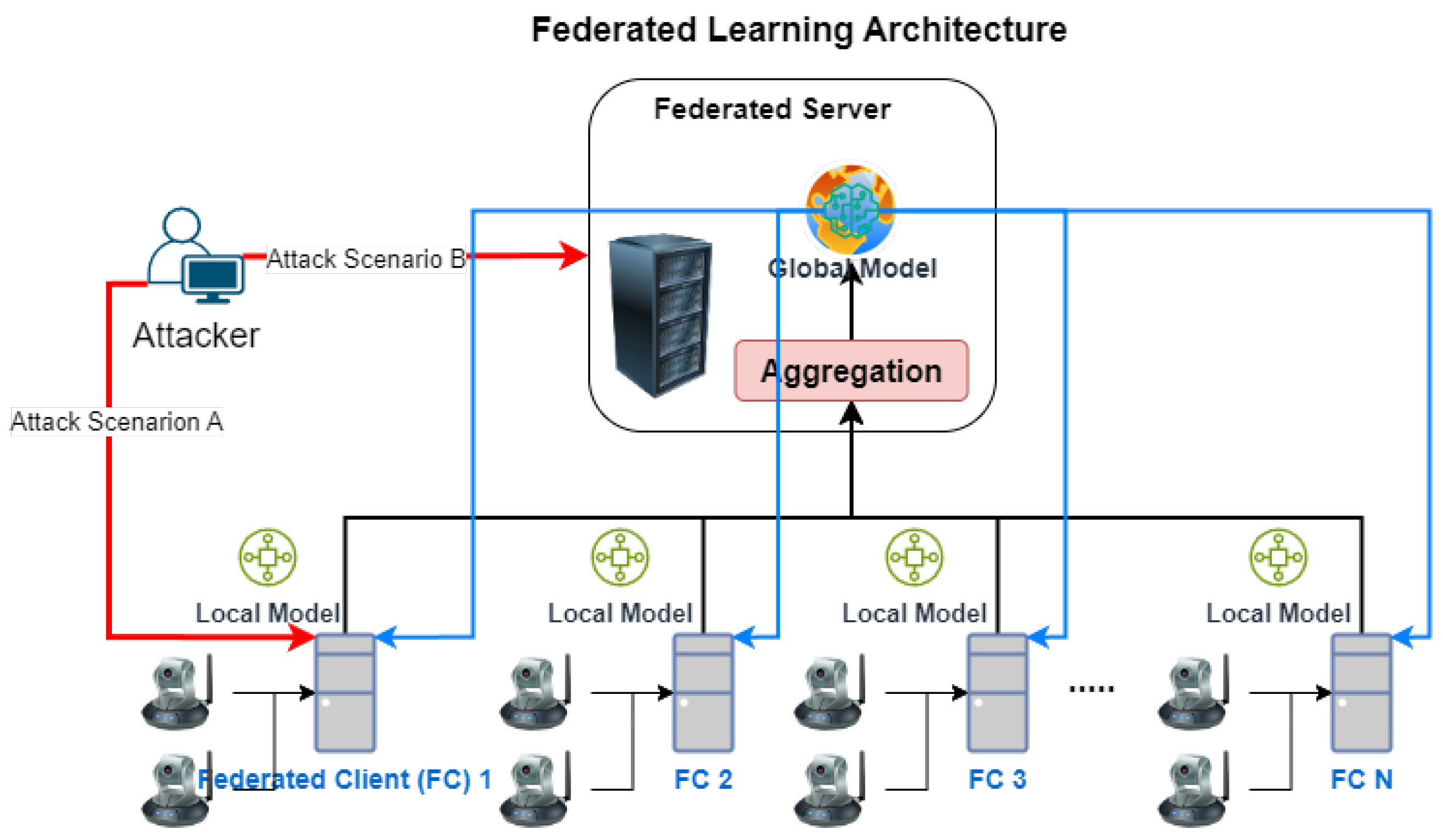
- The primary objective was to examine the process under ideal circumstances, establishing a baseline for global model accuracy. The FL architecture is depicted in Figure 6, and a comprehensive explanation of FL is provided in Section 3.5. FedAvg (Algorithm 1) served as the aggregation method, and the FL hyperparameters are detailed in Table 2 (refer to Section 4.2.2).
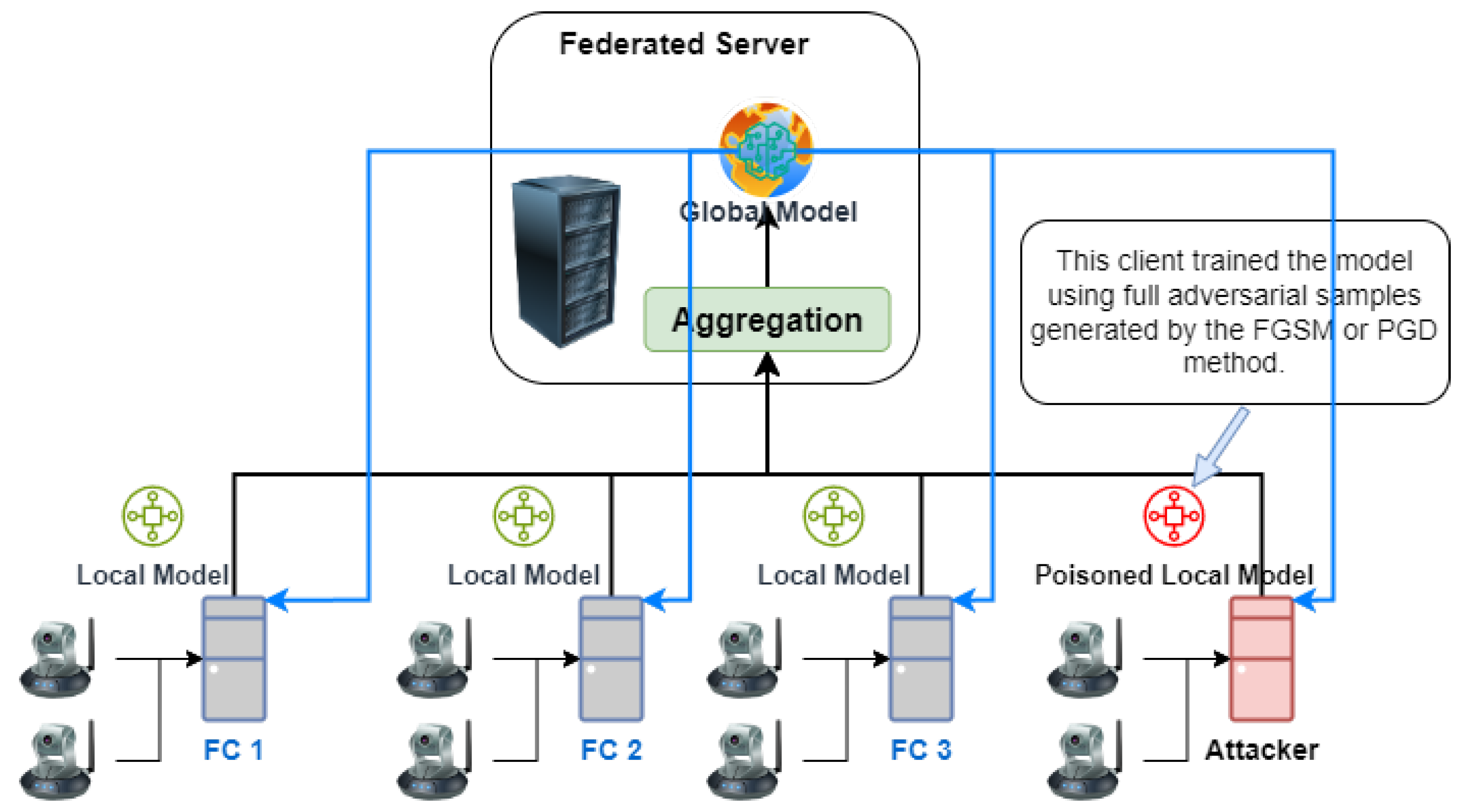
- FAT with FGSM Samples:
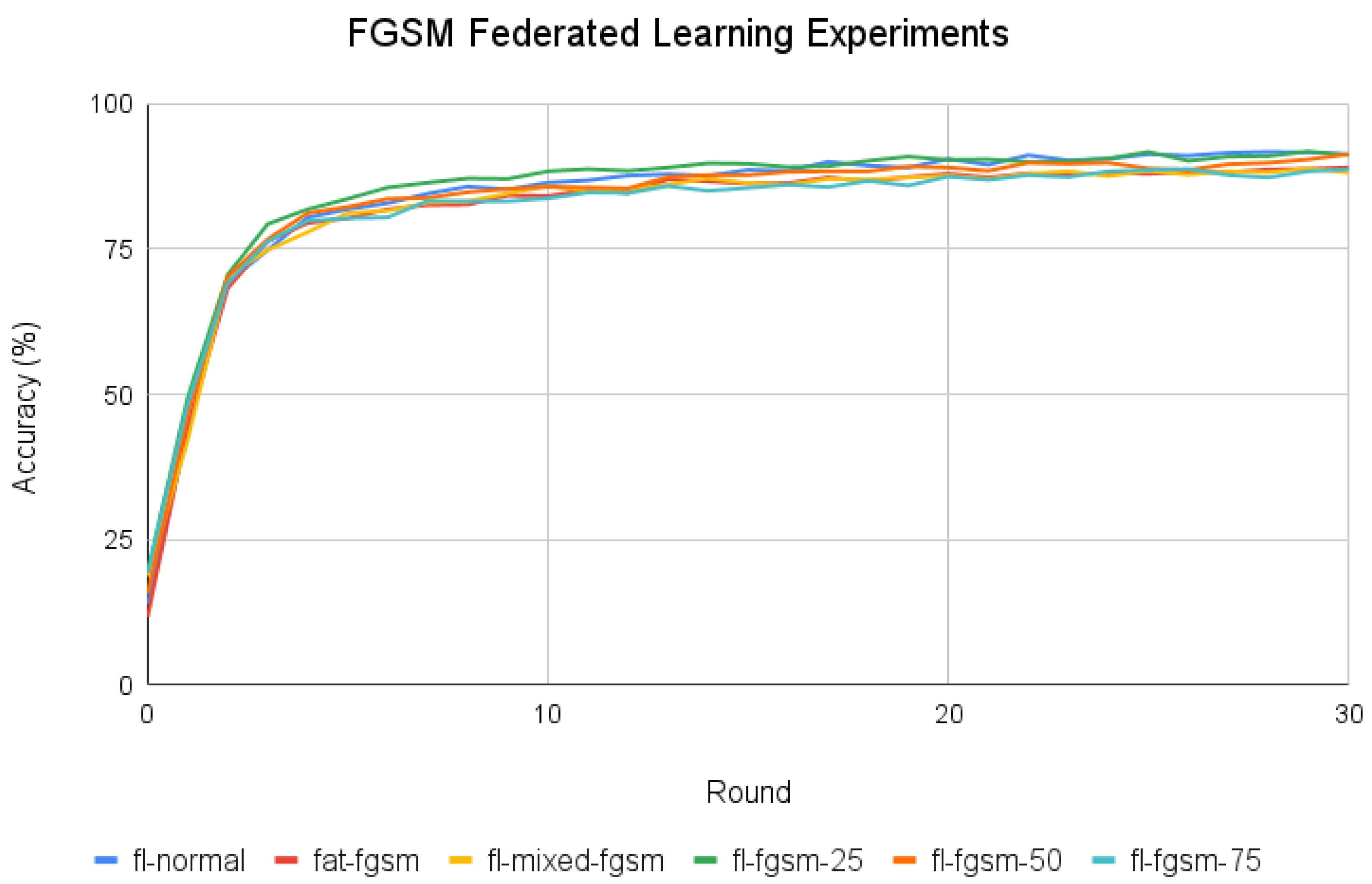
- This step encompassed various experimental scenarios, exploring distinct client settings, dataset distributions, and the number of attacks. Scenario names included fl-fgsm-25, fl-fgsm-50, fl-fgsm-75, fl-mixed-fgsm, and fat-fgsm (refer to Table 3 for clarity).
- FGSM adversarial samples were employed as a dataset for conducting attacks. The attacking process is illustrated in Figure 7 (Section 4.3). A comprehensive presentation of results and discussions for this step is available in Section 4.4.2.
- FAT with PGD Samples:
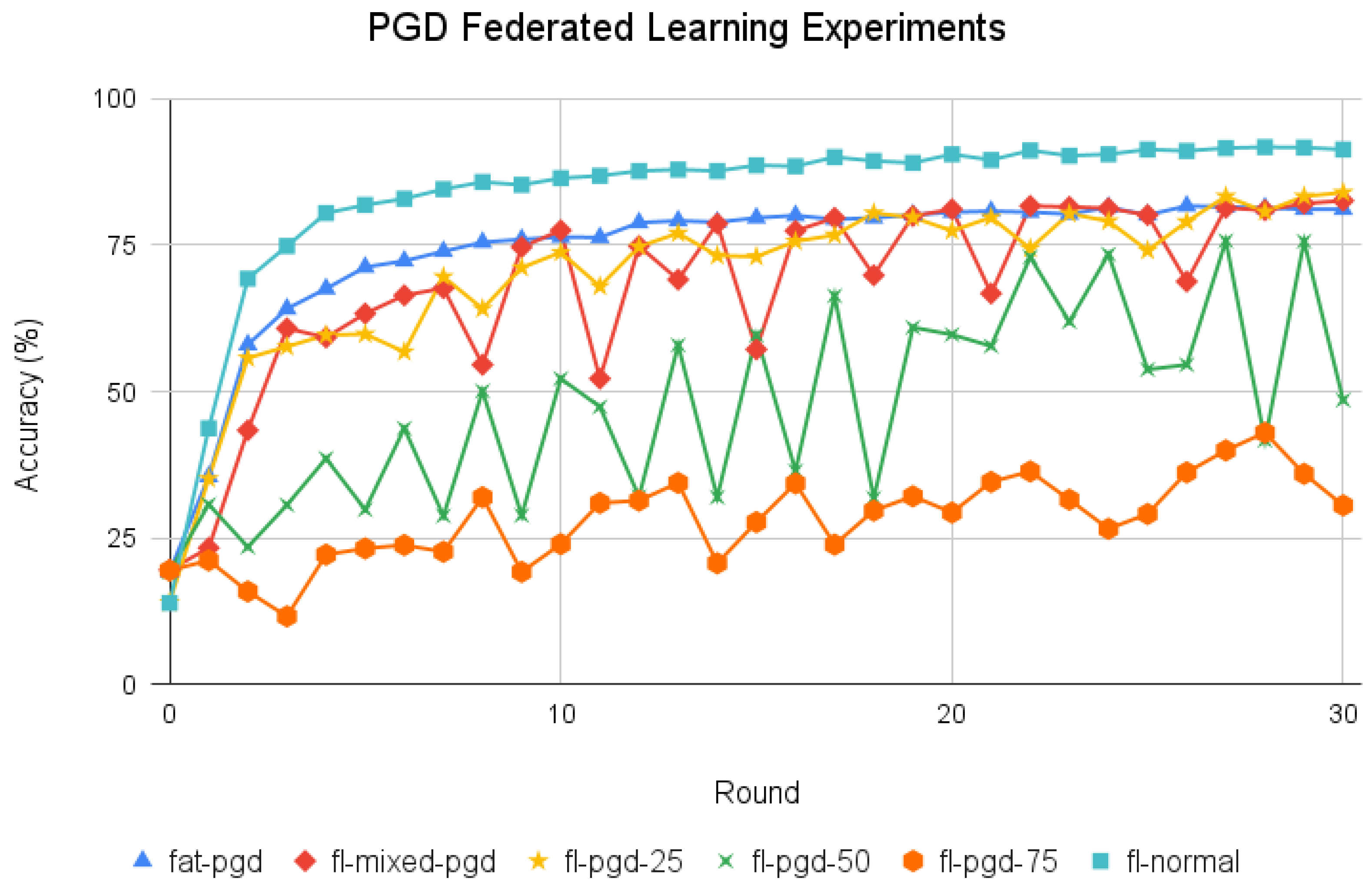
- Similar to the previous step, this step utilized PGD adversarial samples for attack scenarios. The scenario names encompassed fl-pgd-25, fl-pgd-50, fl-pgd-75, fl-mixed-pgd, and fat-pgd (refer to Table 3 for clarity).
- The comprehensive results and discussions pertaining to this step are provided in Section 4.4.3.
3.2. Dataset
3.3. Model
3.4. Adversarial Attacks
3.5. Federated Learning
- The server distributed the global model or global weight to each client (blue line);
- The client utilized its own data to locally retrain the global model;
- Each client transmitted its trained local model to the server (black line);
- The server aggregated all the models into a new global model;
- The server updated each client’s model with a new global model or weight (blue line) and repeated steps 1 through 5.
| Algorithm 1 Federated Learning (FedAvg) [62] |
Input:
Server executes:
ClientUpdate(): // Run on client k
|
4. Experiment Results and Discussion
4.1. Experimental Environment
4.2. Experimental Parameters
4.2.1. Natural Model Training Parameters
4.2.2. Normal FL and FAT Parameters
4.3. Attacks in FL and FAT Strategies for Defense
4.4. Performance Evaluation and Discussion
4.4.1. Natural Model Training and Natural Model Adversarial Training Results
4.4.2. FAT with FGSM Samples Results
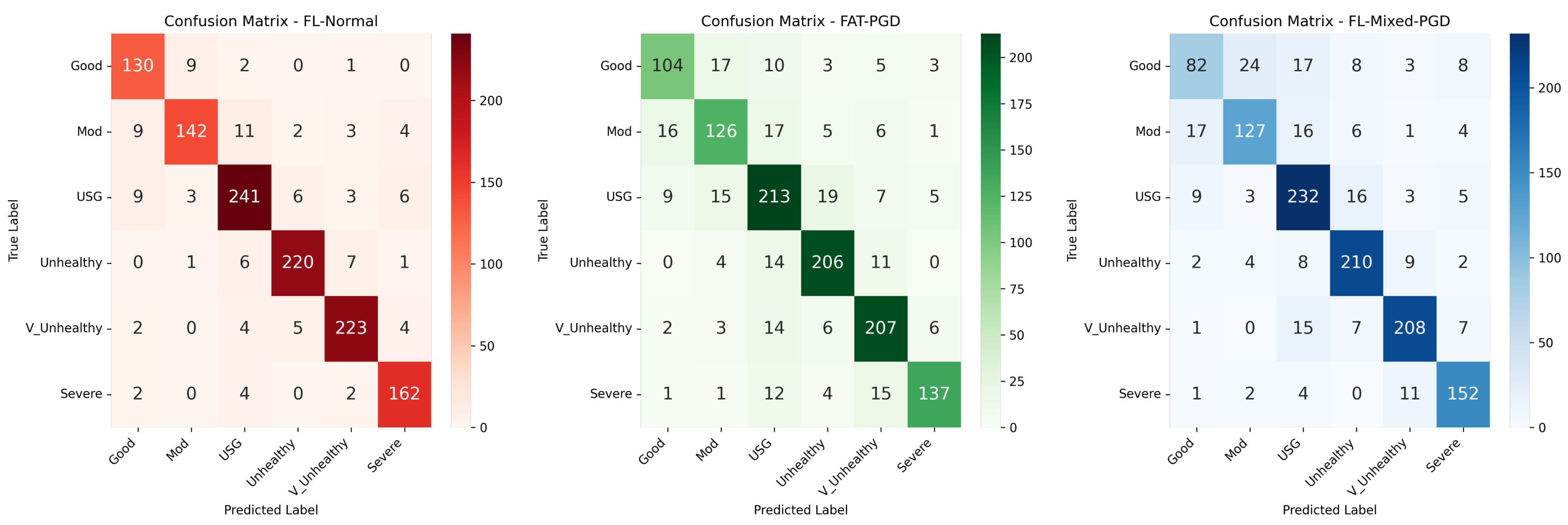
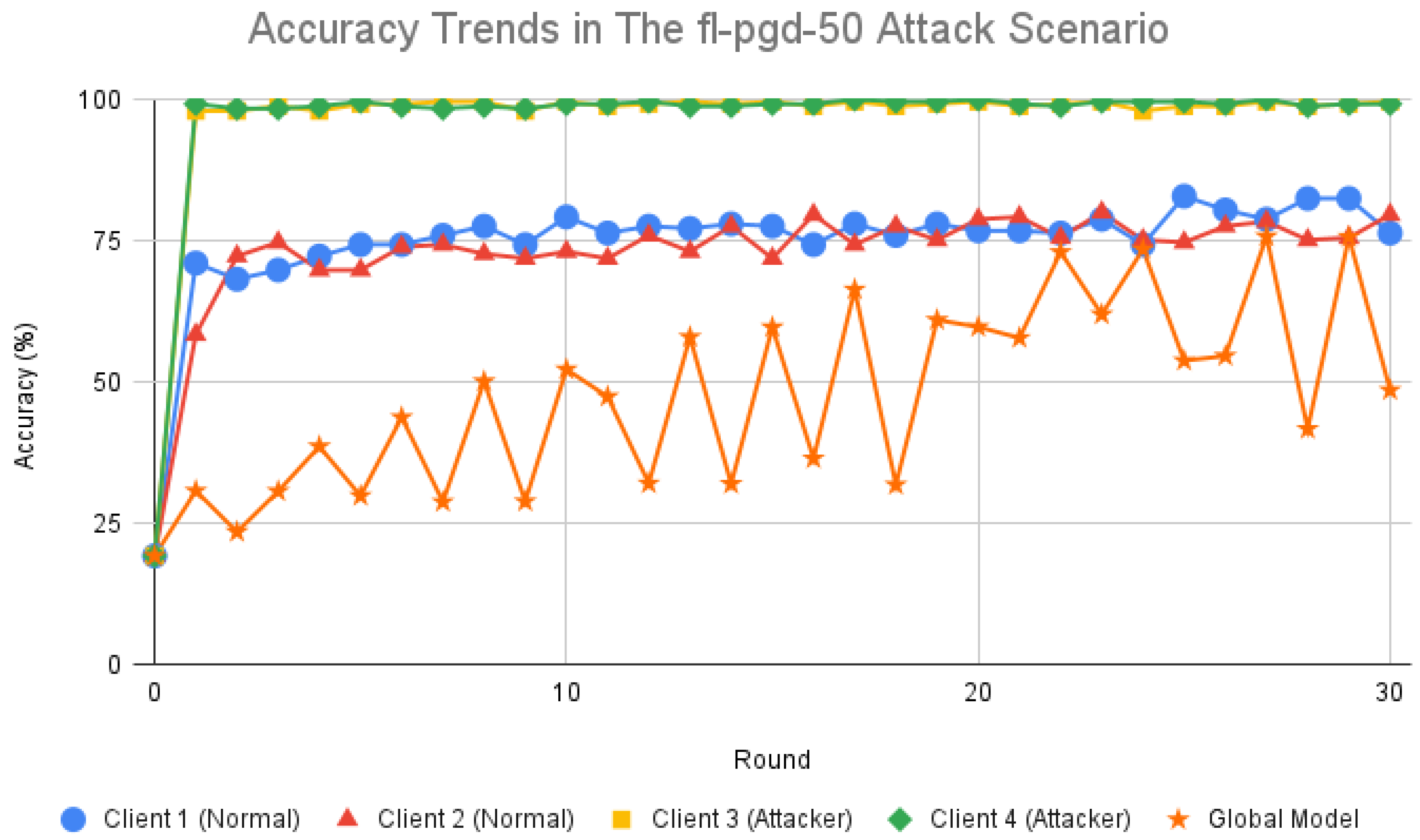
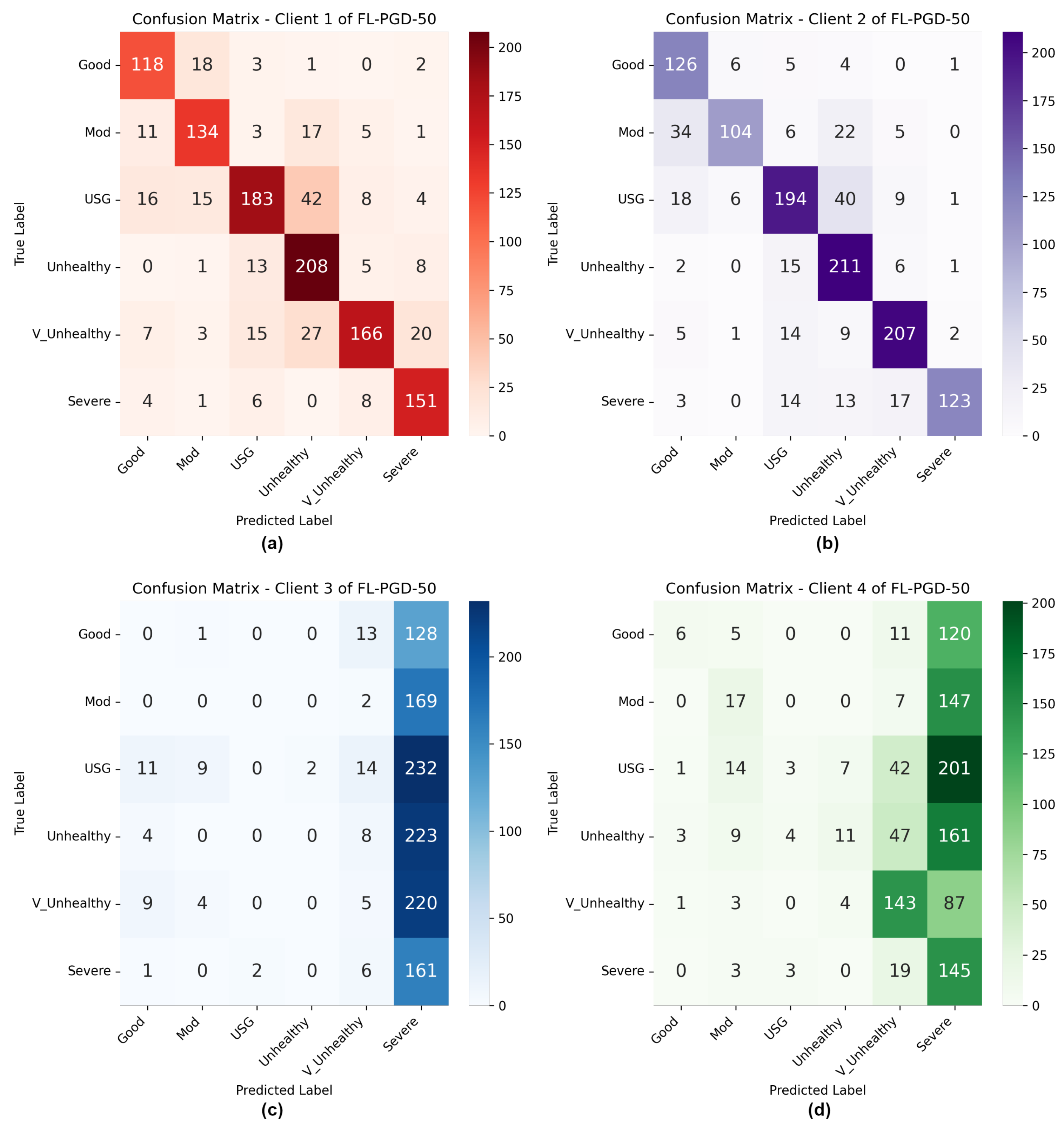
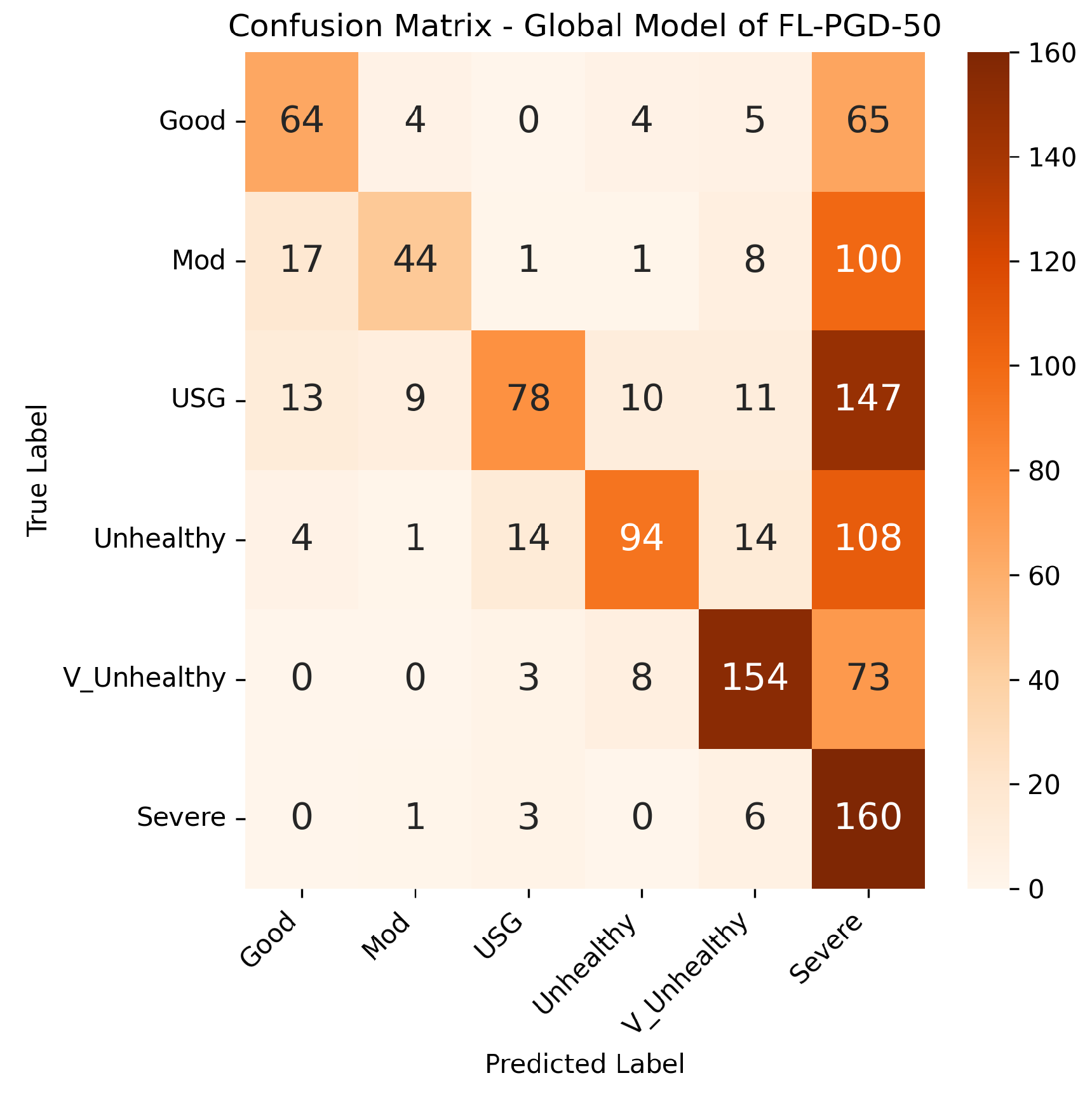
4.4.3. FAT with PGD Samples Results
4.4.4. Defense Mechanism Suggestions for Future Works
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cheng, L.; Liu, F.; Yao, D.D. Enterprise data breach: Causes, challenges, prevention, and future directions. WIREs Data Min. Knowl. Discov. 2017, 7, e1211. [Google Scholar] [CrossRef]
- Neto, N.N.; Madnick, S.; Paula, A.M.G.D.; Borges, N.M. Developing a Global Data Breach Database and the Challenges Encountered. J. Data Inf. Qual. 2021, 13, 1–33. [Google Scholar] [CrossRef]
- Neto, N.N.; Madnick, S.; Paula, A.M.G.D.; Borges, N.M. Cyber Security Data Breaches. 2020. Available online: https://databreachdb.com/ (accessed on 1 October 2023).
- Cadwalladr, C.; Graham-Harrison, E. Revealed: 50 million Facebook profiles harvested for Cambridge Analytica in major data breach. Guardian 2018, 17, 22. [Google Scholar]
- Wang, P.; Johnson, C. Cybersecurity incident handling: A case study of the Equifax data breach. Issues Inf. Syst. 2018, 19, 150–159. [Google Scholar]
- Zou, Y.; Mhaidli, A.H.; McCall, A.; Schaub, F. “I’ve Got Nothing to Lose”: Consumers’ Risk Perceptions and Protective Actions after the Equifax Data Breach. In Proceedings of the Fourteenth Symposium on Usable Privacy and Security (SOUPS 2018), Baltimore, MD, USA, 12–14 August 2018; pp. 197–216. [Google Scholar]
- Leong, Y.Y.; Chen, Y.C. Cyber risk cost and management in IoT devices-linked health insurance. Geneva Pap. Risk Insur. Issues Pract. 2020, 45, 737–759. [Google Scholar] [CrossRef]
- Nair, A.K.; Raj, E.D.; Sahoo, J. A robust analysis of adversarial attacks on federated learning environments. Comput. Stand. Interfaces 2023, 86, 103723. [Google Scholar] [CrossRef]
- Zhu, L.; Liu, Z.; Han, S. Deep Leakage from Gradients. arXiv 2019, arXiv:1906.08935. [Google Scholar]
- Lim, J.Q.; Chan, C.S. From Gradient Leakage To Adversarial Attacks In Federated Learning. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 3602–3606. [Google Scholar] [CrossRef]
- Zhao, B.; Mopuri, K.R.; Bilen, H. iDLG: Improved Deep Leakage from Gradients. arXiv 2020, arXiv:2001.02610. [Google Scholar]
- Geiping, J.; Bauermeister, H.; Dröge, H.; Moeller, M. Inverting gradients-How easy is it to break privacy in federated learning? In Proceedings of the 34th International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 6–12 December 2020; pp. 16937–16947. [Google Scholar]
- Shen, S.; Zhu, T.; Wu, D.; Wang, W.; Zhou, W. From distributed machine learning to federated learning: In the view of data privacy and security. Concurr. Comput. Pract. Exp. 2022, 34, e6002. [Google Scholar] [CrossRef]
- Hsiung, P.A.; Utomo, S.; A, J.; Rouniyar, A.; Hsu, H.C.; Jiang, G.H.; Chang, C.H.; Tang, K.C. Trustworthy AI and Federated Learning for Sustainable Smart Cities. 2023. Available online: https://smartcities.ieee.org/newsletter/january-2023/trustworthy-ai-and-federated-learning-for-sustainable-smart-cities (accessed on 29 September 2023).
- Vu Khanh, Q.; Nguyen, V.H.; Minh, Q.N.; Dang Van, A.; Le Anh, N.; Chehri, A. An efficient edge computing management mechanism for sustainable smart cities. Sustain. Comput. Inform. Syst. 2023, 38, 100867. [Google Scholar] [CrossRef]
- Debauche, O.; Mahmoudi, S.; Guttadauria, A. A New Edge Computing Architecture for IoT and Multimedia Data Management. Information 2022, 13, 89. [Google Scholar] [CrossRef]
- Badidi, E.; Mahrez, Z.; Sabir, E. Fog Computing for Smart Cities’ Big Data Management and Analytics: A Review. Future Internet 2020, 12, 190. [Google Scholar] [CrossRef]
- Sittón-Candanedo, I.; Alonso, R.S.; García, O.; Muñoz, L.; Rodríguez-González, S. Edge Computing, IoT and Social Computing in Smart Energy Scenarios. Sensors 2019, 19, 3353. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D.G.; Ni, C.H.; Zhang, J.; Zhang, T.; Yang, P.; Wang, J.X.; Yan, H.R. A Novel Edge Computing Architecture Based on Adaptive Stratified Sampling. Comput. Commun. 2022, 183, 121–135. [Google Scholar] [CrossRef]
- Lv, Z.; Chen, D.; Lou, R.; Wang, Q. Intelligent edge computing based on machine learning for smart city. Future Gener. Comput. Syst. 2021, 115, 90–99. [Google Scholar] [CrossRef]
- Li, H.; Ota, K.; Dong, M. Learning IoT in Edge: Deep Learning for the Internet of Things with Edge Computing. IEEE Netw. 2018, 32, 96–101. [Google Scholar] [CrossRef]
- Barba-Guaman, L.; Eugenio Naranjo, J.; Ortiz, A. Deep Learning Framework for Vehicle and Pedestrian Detection in Rural Roads on an Embedded GPU. Electronics 2020, 9, 589. [Google Scholar] [CrossRef]
- Rajagopal, A.; Bouganis, C.S. perf4sight: A toolflow to model CNN training performance on Edge GPUs. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 963–971. [Google Scholar] [CrossRef]
- Mathur, A.; Beutel, D.J.; de Gusmão, P.P.B.; Fernandez-Marques, J.; Topal, T.; Qiu, X.; Parcollet, T.; Gao, Y.; Lane, N.D. On-device Federated Learning with Flower. arXiv 2021, arXiv:2104.03042. [Google Scholar]
- Ahmed, K.M.; Imteaj, A.; Amini, M.H. Federated Deep Learning for Heterogeneous Edge Computing. In Proceedings of the 2021 20th IEEE International Conference on Machine Learning and Applications (ICMLA), Pasadena, CA, USA, 13–15 December 2021; pp. 1146–1152. [Google Scholar] [CrossRef]
- Truong, H.T.; Ta, B.P.; Le, Q.A.; Nguyen, D.M.; Le, C.T.; Nguyen, H.X.; Do, H.T.; Nguyen, H.T.; Tran, K.P. Light-weight federated learning-based anomaly detection for time-series data in industrial control systems. Comput. Ind. 2022, 140, 103692. [Google Scholar] [CrossRef]
- Yamany, W.; Moustafa, N.; Turnbull, B. OQFL: An Optimized Quantum-Based Federated Learning Framework for Defending Against Adversarial Attacks in Intelligent Transportation Systems. IEEE Trans. Intell. Transp. Syst. 2023, 24, 893–903. [Google Scholar] [CrossRef]
- Qayyum, A.; Janjua, M.U.; Qadir, J. Making federated learning robust to adversarial attacks by learning data and model association. Comput. Secur. 2022, 121, 102827. [Google Scholar] [CrossRef]
- Hu, F.; Zhou, W.; Liao, K.; Li, H.; Tong, D. Toward Federated Learning Models Resistant to Adversarial Attacks. IEEE Internet Things J. 2023, 10, 16917–16930. [Google Scholar] [CrossRef]
- Hong, J.; Wang, H.; Wang, Z.; Zhou, J. Federated Robustness Propagation: Sharing Robustness in Heterogeneous Federated Learning. arXiv 2022, arXiv:2106.10196. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.; Yao, J.; Liu, T.; Yao, Q.; Xu, J.; Han, B. Combating Exacerbated Heterogeneity for Robust Models in Federated Learning. arXiv 2023, arXiv:2303.00250. [Google Scholar]
- Chen, Z.; Tian, P.; Liao, W.; Yu, W. Zero Knowledge Clustering Based Adversarial Mitigation in Heterogeneous Federated Learning. IEEE Trans. Netw. Sci. Eng. 2021, 8, 1070–1083. [Google Scholar] [CrossRef]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and Open Problems in Federated Learning. arXiv 2021, arXiv:1912.04977. [Google Scholar]
- Shah, D.; Dube, P.; Chakraborty, S.; Verma, A. Adversarial training in communication constrained federated learning. arXiv 2021, arXiv:2103.01319. [Google Scholar]
- Jere, M.S.; Farnan, T.; Koushanfar, F. A Taxonomy of Attacks on Federated Learning. IEEE Secur. Priv. 2021, 19, 20–28. [Google Scholar] [CrossRef]
- Zizzo, G.; Rawat, A.; Sinn, M.; Buesser, B. FAT: Federated Adversarial Training. arXiv 2020, arXiv:2012.01791. [Google Scholar]
- Singh, S.K.; Azzaoui, A.E.; Kim, T.W.; Pan, Y.; Park, J.H. DeepBlockScheme: A Deep Learning-Based Blockchain Driven Scheme for Secure Smart City. Hum. Centric Comput. Inf. Sci. 2021, 11, 1–12. [Google Scholar] [CrossRef]
- Kumar, P.; Kumar, R.; Srivastava, G.; Gupta, G.P.; Tripathi, R.; Gadekallu, T.R.; Xiong, N.N. PPSF: A Privacy-Preserving and Secure Framework Using Blockchain-Based Machine-Learning for IoT-Driven Smart Cities. IEEE Trans. Netw. Sci. Eng. 2021, 8, 2326–2341. [Google Scholar] [CrossRef]
- Singh, S.K.; Jeong, Y.S.; Park, J.H. A deep learning-based IoT-oriented infrastructure for secure smart City. Sustain. Cities Soc. 2020, 60, 102252. [Google Scholar] [CrossRef]
- Utomo, S.; John, A.; Rouniyar, A.; Hsu, H.C.; Hsiung, P.A. Federated Trustworthy AI Architecture for Smart Cities. In Proceedings of the 2022 IEEE International Smart Cities Conference (ISC2), Paphos, Cyprus, 26–29 September 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Floridi, L. Establishing the rules for building trustworthy AI. Nat. Mach. Intell. 2019, 1, 261–262. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Ding, M.; Pathirana, P.N.; Seneviratne, A.; Li, J.; Vincent Poor, H. Federated Learning for Internet of Things: A Comprehensive Survey. IEEE Commun. Surv. Tutorials 2021, 23, 1622–1658. [Google Scholar] [CrossRef]
- Singh, S.; Rathore, S.; Alfarraj, O.; Tolba, A.; Yoon, B. A framework for privacy-preservation of IoT healthcare data using Federated Learning and blockchain technology. Future Gener. Comput. Syst. 2022, 129, 380–388. [Google Scholar] [CrossRef]
- Bao, Z.; Lin, Y.; Zhang, S.; Li, Z.; Mao, S. Threat of Adversarial Attacks on DL-Based IoT Device Identification. IEEE Internet Things J. 2022, 9, 9012–9024. [Google Scholar] [CrossRef]
- Ibitoye, O.; Shafiq, O.; Matrawy, A. Analyzing Adversarial Attacks against Deep Learning for Intrusion Detection in IoT Networks. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Big Island, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Luo, Z.; Zhao, S.; Lu, Z.; Sagduyu, Y.E.; Xu, J. Adversarial machine learning based partial-model attack in IoT. In Proceedings of the 2nd ACM Workshop on Wireless Security and Machine Learning, New York, NY, USA, 13 July 2020; pp. 13–18. [Google Scholar] [CrossRef]
- Anthi, E.; Williams, L.; Javed, A.; Burnap, P. Hardening machine learning denial of service (DoS) defences against adversarial attacks in IoT smart home networks. Comput. Secur. 2021, 108, 102352. [Google Scholar] [CrossRef]
- Zhao, Y.; Chen, J.; Zhang, J.; Wu, D.; Blumenstein, M.; Yu, S. Detecting and mitigating poisoning attacks in federated learning using generative adversarial networks. Concurr. Comput. Pract. Exp. 2022, 34, e5906. [Google Scholar] [CrossRef]
- Rouniyar, A.; Utomo, S.; A, J.; Hsiung, P.A. Air Pollution Image Dataset from India and Nepal. 2023. Available online: https://www.kaggle.com/datasets/adarshrouniyar/air-pollution-image-dataset-from-india-and-nepal (accessed on 27 June 2023).
- Utomo, S.; Rouniyar, A.; Jiang, G.H.; Chang, C.H.; Tang, K.C.; Hsu, H.C.; Hsiung, P.A. Eff-AQI: An Efficient CNN-Based Model for Air Pollution Estimation: A Study Case in India. In Proceedings of the 2023 ACM Conference on Information Technology for Social Good, Lisbon, Portugal, 6–8 September 2023; GoodIT ’23. pp. 165–172. [Google Scholar] [CrossRef]
- National Air Quality Index. Available online: https://app.cpcbccr.com/AQI_India/ (accessed on 27 June 2023).
- Hourly Weather in Biratnagar, Nepal. Available online: https://www.tomorrow.io/weather/NP/4/Biratnagar/079711/hourly/ (accessed on 27 June 2023).
- Zhang, K.; Chen, Z.; Xiang, Y. Vision-Based Particulate Matter Estimation. In Deep Learning Applications: In Computer Vision, Signals and Networks; World Scientific: Singapore, 2023; pp. 3–17. [Google Scholar] [CrossRef]
- Utomo, S.; John, A.; Pratap, A.; Jiang, Z.S.; Karthikeyan, P.; Hsiung, P.A. AIX Implementation in Image-Based PM2. 5 Estimation: Toward an AI Model for Better Understanding. In Proceedings of the 2023 15th International Conference on Knowledge and Smart Technology (KST), Phuket, Thailand, 21–24 February 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, Y.; Yue, S. Air quality classification and measurement based on double output vision transformer. IEEE Internet Things J. 2022, 9, 20975–20984. [Google Scholar] [CrossRef]
- Zhang, Q.; Fu, F.; Tian, R. A deep learning and image-based model for air quality estimation. Sci. Total Environ. 2020, 724, 138178. [Google Scholar] [CrossRef]
- Zhang, J.; Li, B.; Chen, C.; Lyu, L.; Wu, S.; Ding, S.; Wu, C. Delving into the Adversarial Robustness of Federated Learning. arXiv 2023, arXiv:2302.09479. [Google Scholar] [CrossRef]
- Li, X.; Song, Z.; Yang, J. Federated Adversarial Learning: A Framework with Convergence Analysis. Proc. Mach. Learn. Res. 2022, 202, 19932–19959. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. arXiv 2019, arXiv:1706.06083. [Google Scholar]
- Zhao, W.; Alwidian, S.; Mahmoud, Q.H. Adversarial Training Methods for Deep Learning: A Systematic Review. Algorithms 2022, 15, 283. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the Machine Learning Research (PMLR), Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Beutel, D.J.; Topal, T.; Mathur, A.; Qiu, X.; Fernandez-Marques, J.; Gao, Y.; Sani, L.; Kwing, H.L.; Parcollet, T.; Gusmão, P.P.D.; et al. Flower: A Friendly Federated Learning Research Framework. arXiv 2020, arXiv:2007.14390. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Value |
|---|---|
| Batch Size | 32 |
| Maximum Epochs | 100 |
| Early Stopping Patience | 7 |
| Early Stopping Monitor | Validation Loss |
| Model Checkpoint Monitor | Validation Loss |
| Model Checkpoint Trigger | Minimum |
| Save Best Weight Only | True |
| Loss Function | Categorical Crossentropy |
| Optimizer | ADAM |
| Learning Rate | 0.0001 () |
| Hyperparameter | Value |
|---|---|
| Communication Round | 30 |
| Aggregation | FedAvg |
| Client’s Local Epoch | 35 if server round < 6 else 15 |
| Client’s Batch Size | 16 |
| Client’s Early Stopping Patience | 7 |
| Client’s Early Stopping Monitor | Validation Loss |
| Client’s Model Checkpoint Monitor | Validation Loss |
| Client’s Model Checkpoint Trigger | Minimum |
| Client’s Save Best Weight Only | True |
| Client’s Loss Function | Categorical Crossentropy |
| Client’s Optimizer | ADAM |
| Client’s Learning Rate | 0.0001 () |
| Number of Clients | 4 |
| Client Selection | All |
| Scenario Name | Datase Used in Clients | Purpose of Experiments |
|---|---|---|
| fl-normal | All clients used a normal dataset | To obtain baseline accuracy |
| fl-fgsm-25 | 1 client used full FGSM adversarial samples dataset; 3 clients used a normal dataset | To observe the attack’s effect on the global model |
| fl-fgsm-50 | 2 clients used full FGSM adversarial samples dataset; 2 clients used a normal dataset | To observe the attack’s effect on the global model |
| fl-fgsm-75 | 3 clients used full FGSM adversarial samples dataset; 1 client used a normal dataset | To observe the attack’s effect on the global model |
| fl-mixed-fgsm | 1 client used full FGSM adversarial samples dataset; 1 client used a normal dataset; 2 clients used mixed 50% normal dataset and 50% FGSM adversarial samples dataset | To observe the attack’s effect on the global model as well as the feasibility of this scenario for defense mechanisms |
| fat-fgsm | All clients used mixed 50% normal dataset and 50% FGSM adversarial samples dataset | Defense mechanisms to train a robust global model |
| fl-pgd-25 | 1 client used full PGD adversarial samples dataset; 3 clients used a normal dataset | To observe the attack’s effect on the global model |
| fl-pgd-50 | 2 clients used full PGD adversarial samples dataset; 2 clients used a normal dataset | To observe the attack’s effect on the global model |
| fl-pgd-75 | 3 clients used full PGD adversarial samples dataset; 1 client used a normal dataset | To observe the attack’s effect on the global model |
| fl-mixed-pgd | 1 client used full PGD adversarial samples dataset; 1 client used a normal dataset; 2 clients used mixed 50% normal dataset and 50% PGD adversarial samples dataset | To observe the attack’s effect on the global model as well as the feasibility of this scenario for defense mechanisms |
| fat-pgd | All clients used mixed 50% normal dataset and 50% PGD adversarial samples dataset | Defense mechanisms to train a robust global model |
| Methods | Test Result | Test Result in Unseen Data |
|---|---|---|
| Normal data | 91.92% | 90.36% |
| Mixed normal data and FGSM samples | 91.65% | 91.01% |
| Mixed normal data and PGD samples | 94.28% | 92.16% |
| Scenario Name | Accuracy (%) |
|---|---|
| fl-normal | 91.34 |
| fat-fgsm | 89.05 |
| fl-mixed-fgsm | 88.15 |
| fl-fgsm-25 | 91.18 |
| fl-fgsm-50 | 91.34 |
| fl-fgsm-75 | 88.73 |
| Scenario Name | Accuracy (%) |
|---|---|
| fl-normal | 91.34 |
| fat-pgd | 81.13 |
| fl-mixed-pgd | 82.60 |
| fl-pgd-25 | 83.99 |
| fl-pgd-50 | 48.53 |
| fl-pgd-75 | 30.56 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Utomo, S.; Rouniyar, A.; Hsu, H.-C.; Hsiung, P.-A. Federated Adversarial Training Strategies for Achieving Privacy and Security in Sustainable Smart City Applications. Future Internet 2023, 15, 371. https://doi.org/10.3390/fi15110371
Utomo S, Rouniyar A, Hsu H-C, Hsiung P-A. Federated Adversarial Training Strategies for Achieving Privacy and Security in Sustainable Smart City Applications. Future Internet. 2023; 15(11):371. https://doi.org/10.3390/fi15110371
Chicago/Turabian StyleUtomo, Sapdo, Adarsh Rouniyar, Hsiu-Chun Hsu, and Pao-Ann Hsiung. 2023. "Federated Adversarial Training Strategies for Achieving Privacy and Security in Sustainable Smart City Applications" Future Internet 15, no. 11: 371. https://doi.org/10.3390/fi15110371