
Implementation and Evaluation of a Federated Learning Framework on Raspberry PI Platforms for IoT 6G Applications




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Technological Background
1.2. Contributions and Novelties
- Cooling Mechanism Impact (Section 4.1): We meticulously investigate the influence of cooling mechanisms on training accuracy, underscoring their practical significance in accelerating model convergence, especially in resource-constrained environments. This detailed analysis, expounded on in Section 4.1, elucidates the pivotal role of cooling mechanisms, providing valuable insights into optimizing FL performance.
- Heterogeneous Client Compensation (Section 4.2): Through a thorough exploration of asymmetric data distribution scenarios, both with and without random selection, we dissect the intricate dynamics of FL performance. Our study highlights the delicate balance necessary in distributing training data among diverse nodes, revealing the complexities of FL dynamics in real-world scenarios. These findings, presented in Section 4.2, offer critical insights into the challenges and solutions concerning data heterogeneity in FL setups.
- Overfitting Mitigation Strategies (Section 4.2): We tackle the challenge of overfitting in FL by implementing meticulous strategies. By integrating random selection techniques, we effectively mitigate overfitting risks, optimizing model generalization and ensuring the resilience of FL outcomes. This contribution, outlined in Section 4.2, underscores our commitment to enhancing the robustness of FL models.
- Scalability Analysis (Section 4.3): Our study provides a comprehensive exploration of FL scalability, assessing its performance with an increasing number of users. This analysis, detailed in Section 4.3, offers crucial insights into FL’s scalability potential, essential for its integration in large-scale, dynamic environments. It emphasizes the system’s adaptability to diverse user configurations, laying the foundation for FL’s applicability in real-world scenarios.
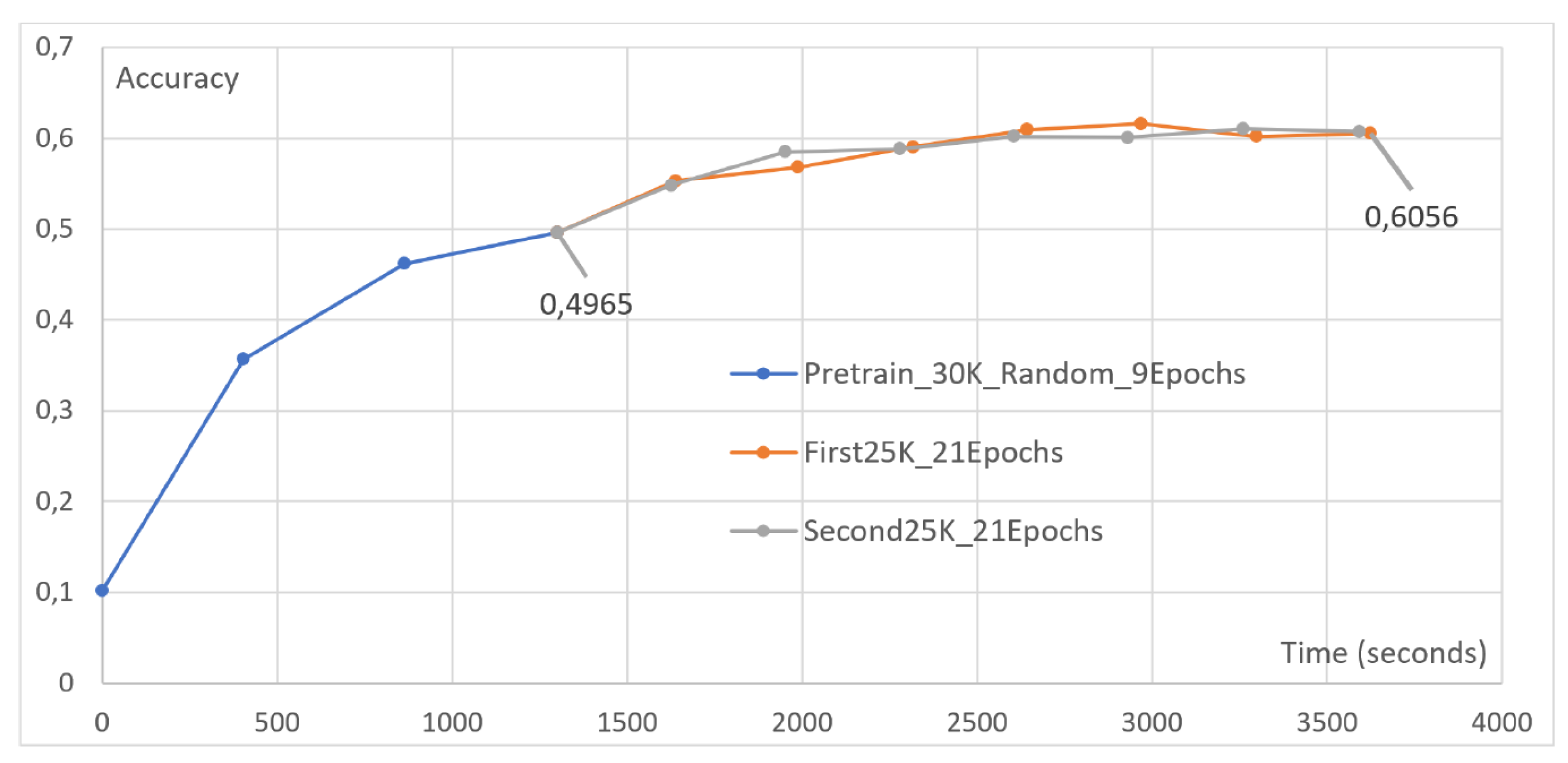
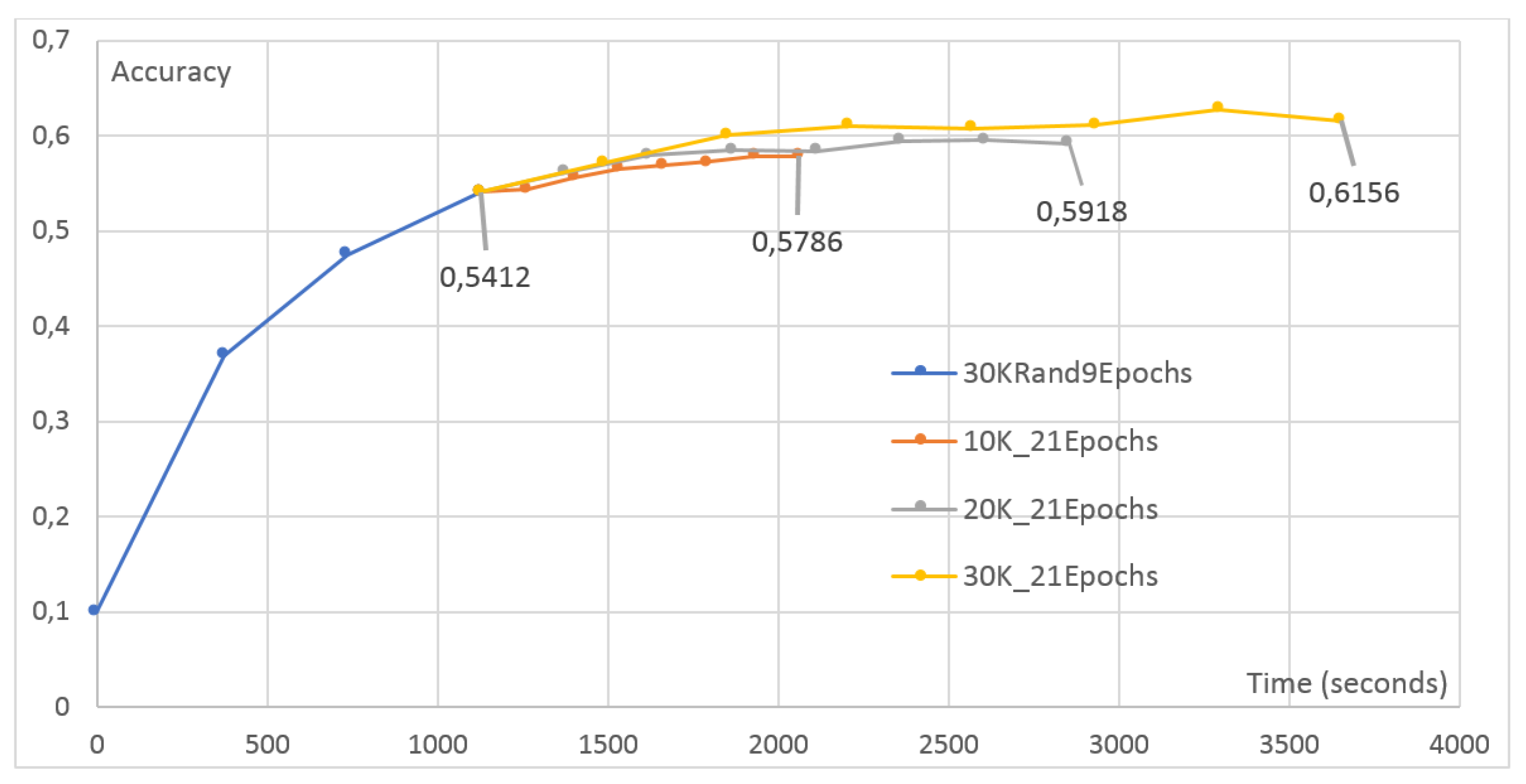
- Pretraining Effectiveness (Section 4.4): We delve into the effectiveness of pretraining techniques in enhancing accuracy rates. Pretraining emerges as a potent tool, significantly boosting the model’s performance and showcasing its potential in optimizing FL outcomes. This contribution, discussed in Section 4.4, highlights the practical implications of pretraining in FL applications, providing actionable insights for future implementations.
- Transfer Learning Impact (Section 4.5): In Section 4.5, we investigate the potential of Transfer Learning, evaluating its impact under diverse client configurations. Our results, underscore Transfer Learning’s capacity to enhance FL model performance, especially in the face of varied client scenarios. This analysis showcases Transfer Learning’s adaptability in real-world applications, emphasizing its role in improving FL outcomes across dynamic and heterogeneous environments.
1.3. Limitations
2. Distributed Machine Learning
- Selection of devices for learning
- Disparities in performance levels among the clients in use
- Management of heterogeneous training data
- Potential algorithms for local models’ aggregation
- Selection of a proper aggregation Strategy at the Parameter Server
- Resource allocation
- Synchronous FL: All devices participate in training the local models for a specific period, sending the parameters to the central server. In this case, the server receives the client models simultaneously and aggregates them with the certainty that it is using the contribution of all the devices. However, this approach poses some challenges, in the case of heterogeneous client nodes having different capabilities. In such cases, the less-performing clients are compelled to invest more resources to complete the training within the expected timeline. To match the latency performance of other, high-performing clients with more resources, devices can only use a subset of their data.
- Asynchronous FL: In this case, there are no time restrictions for local training operations, with each device training its model based on its own capabilities, after which it sends the parameters to the server that proceeds with aggregation. This approach is more appropriate even in the presence of unstable network connections, where a device without network access can continue to train its model until it reconnects. Such an asynchronous approach can potentially reduce the number of FL devices participating in the individual FL rounds. This also requires more complex server-side operations to manage the devices according to their needs.
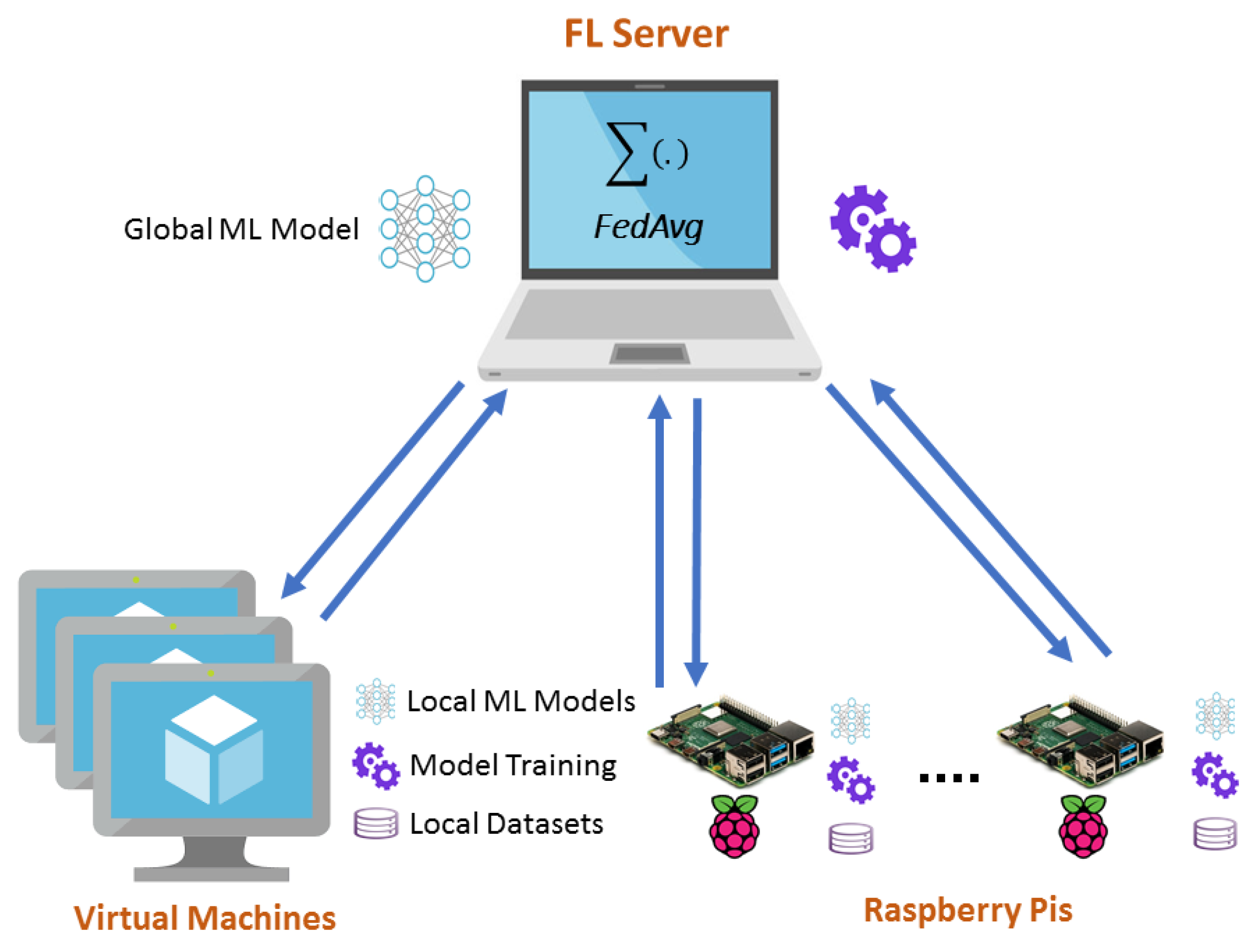
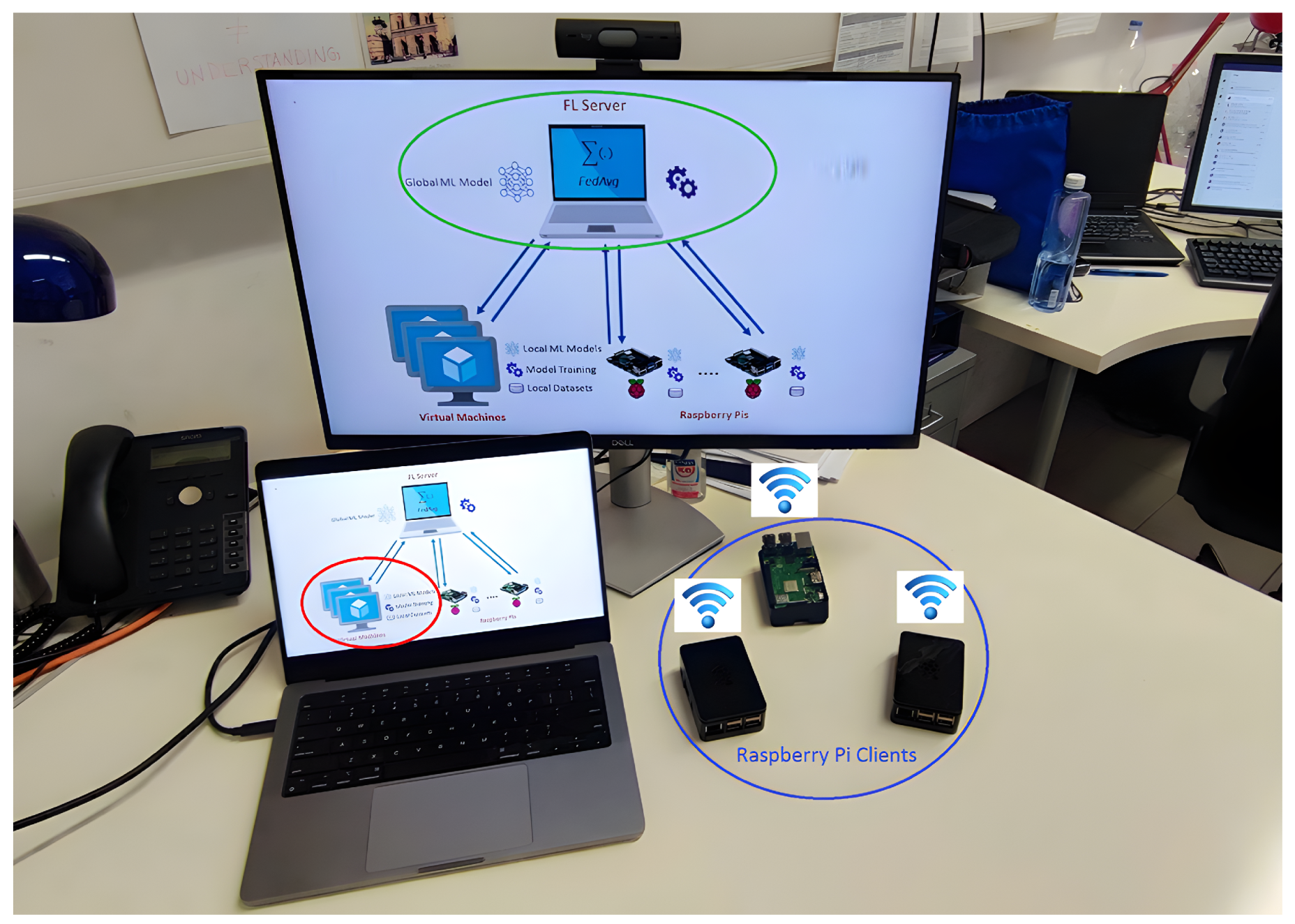
3. Implementation of the System
3.1. Server Configurations and Functionalities
| Algorithm 1: Federated Averaging (FedAvg) Algorithm |
 |
3.2. Client Configurations and Functionalities
4. Simulations and Performance Evaluations
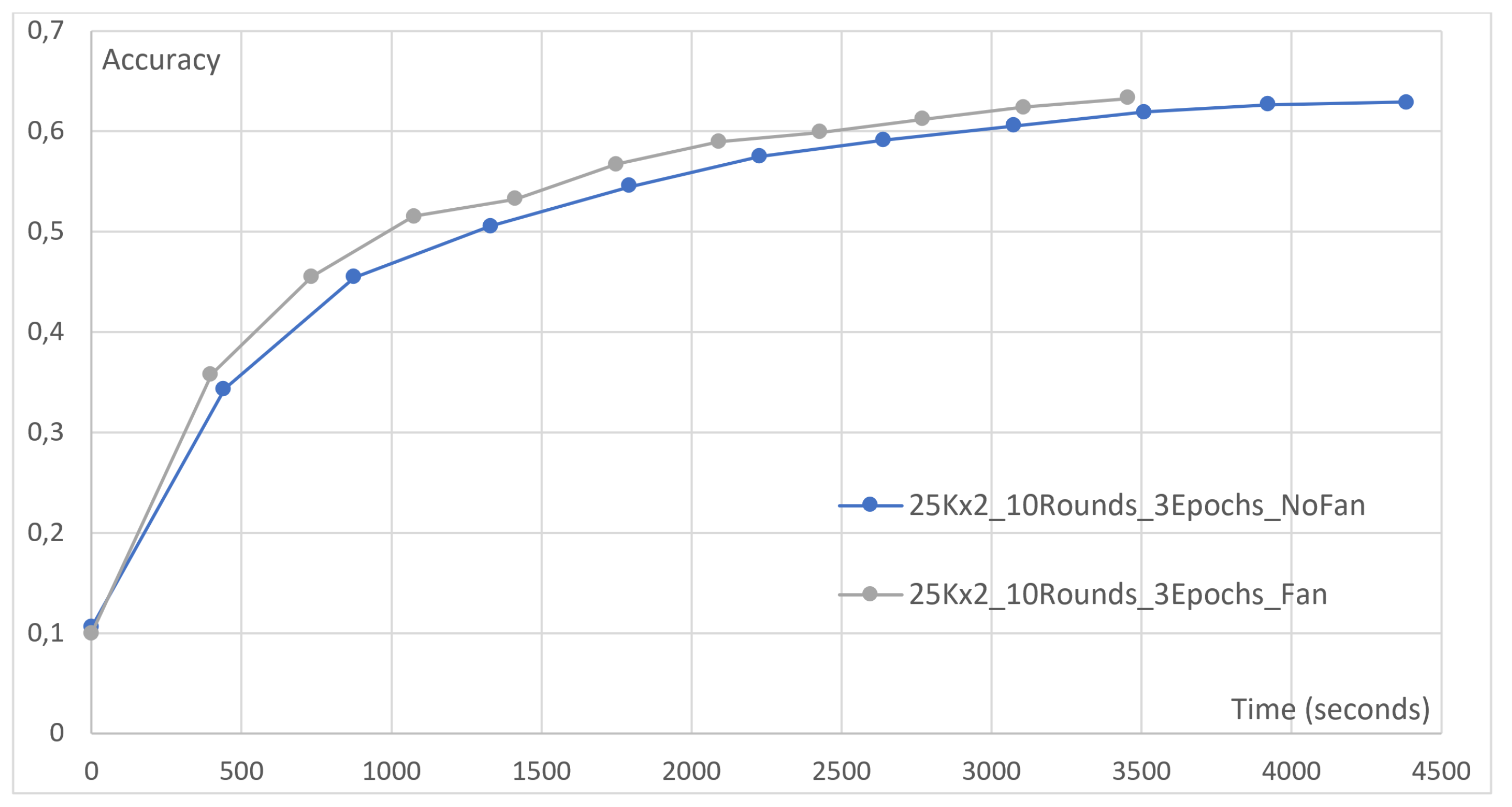
4.1. Effect of a Cooling Mechanism
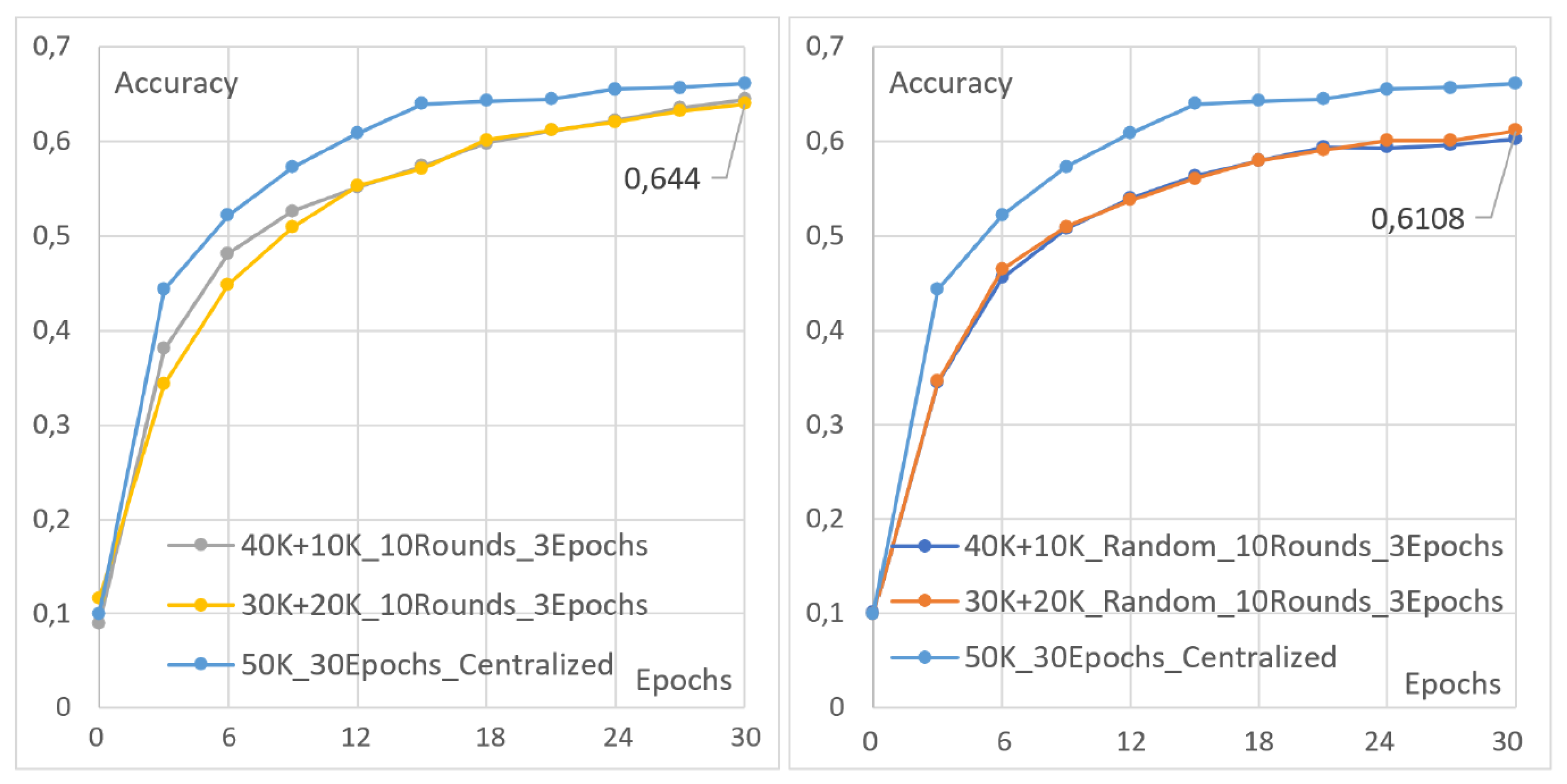
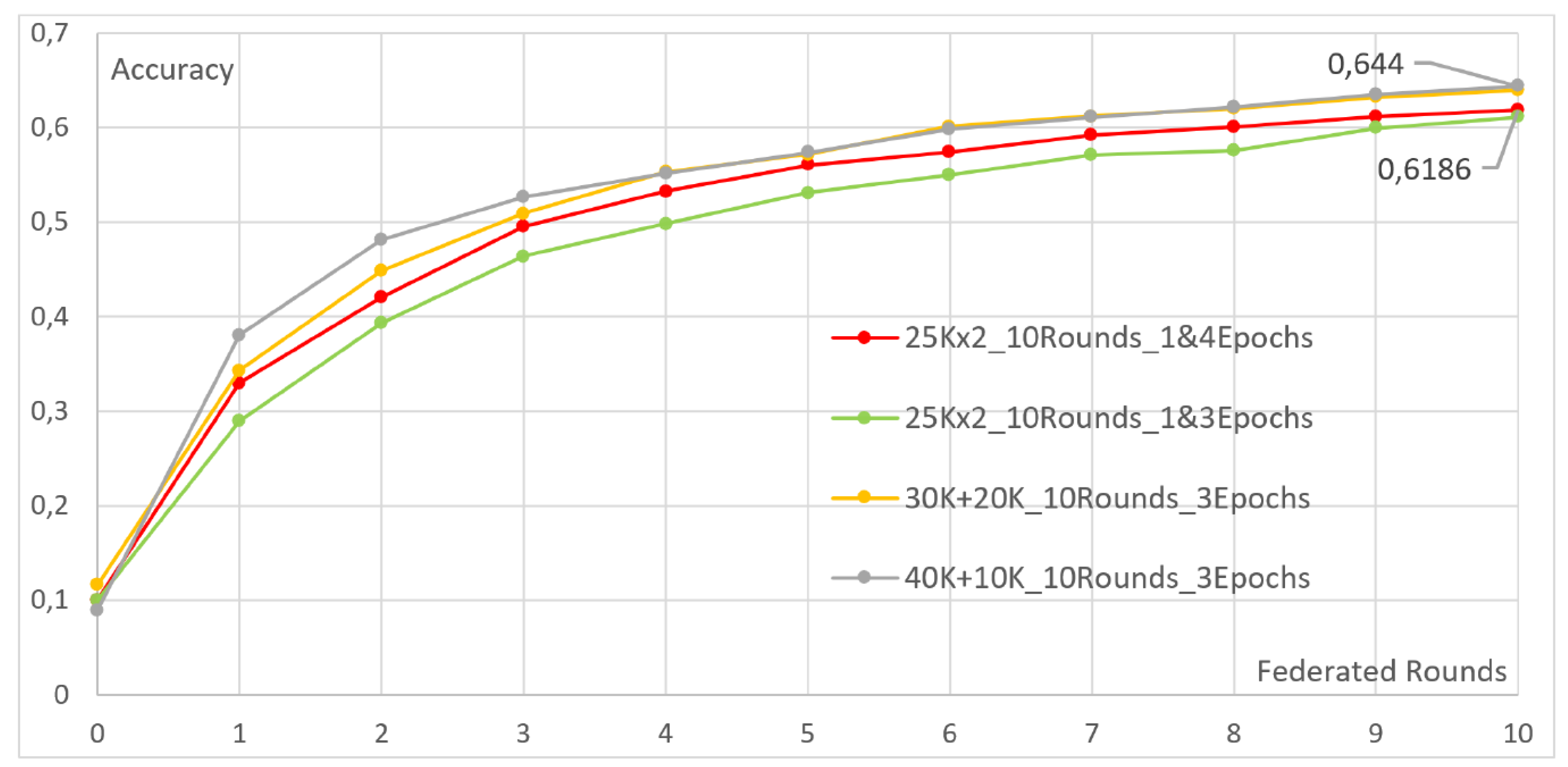
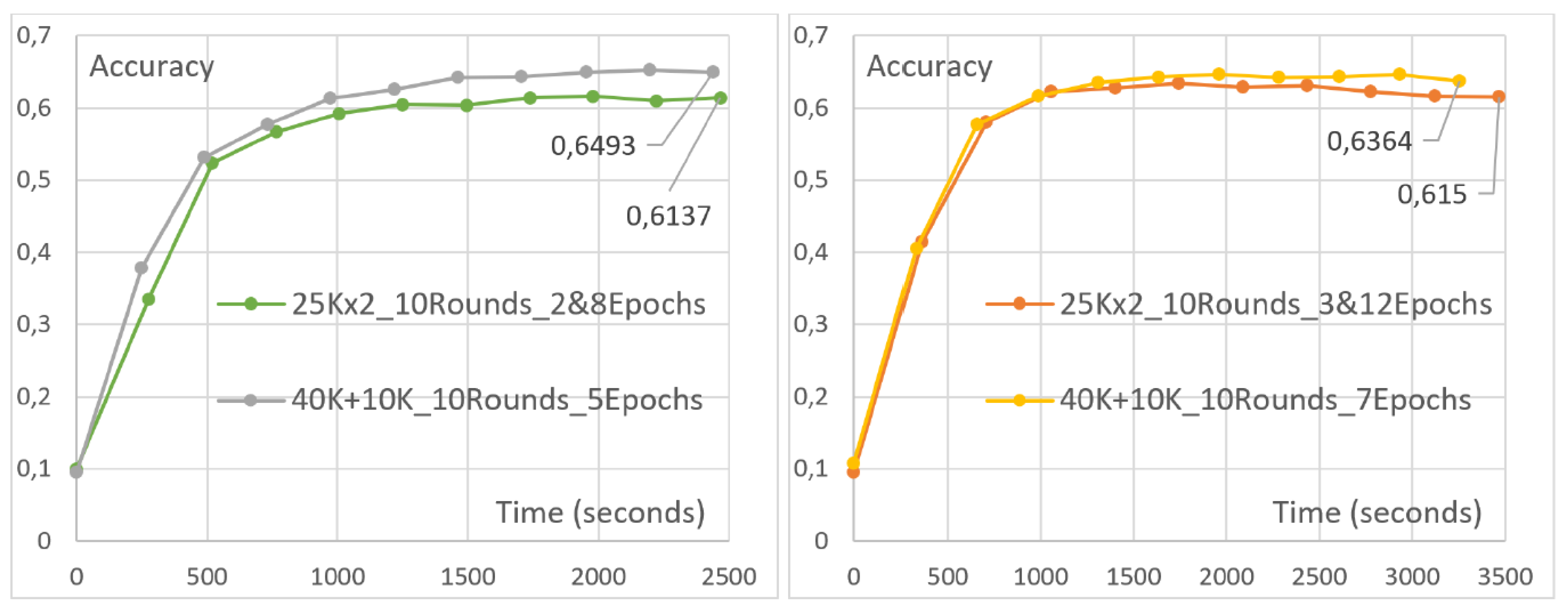
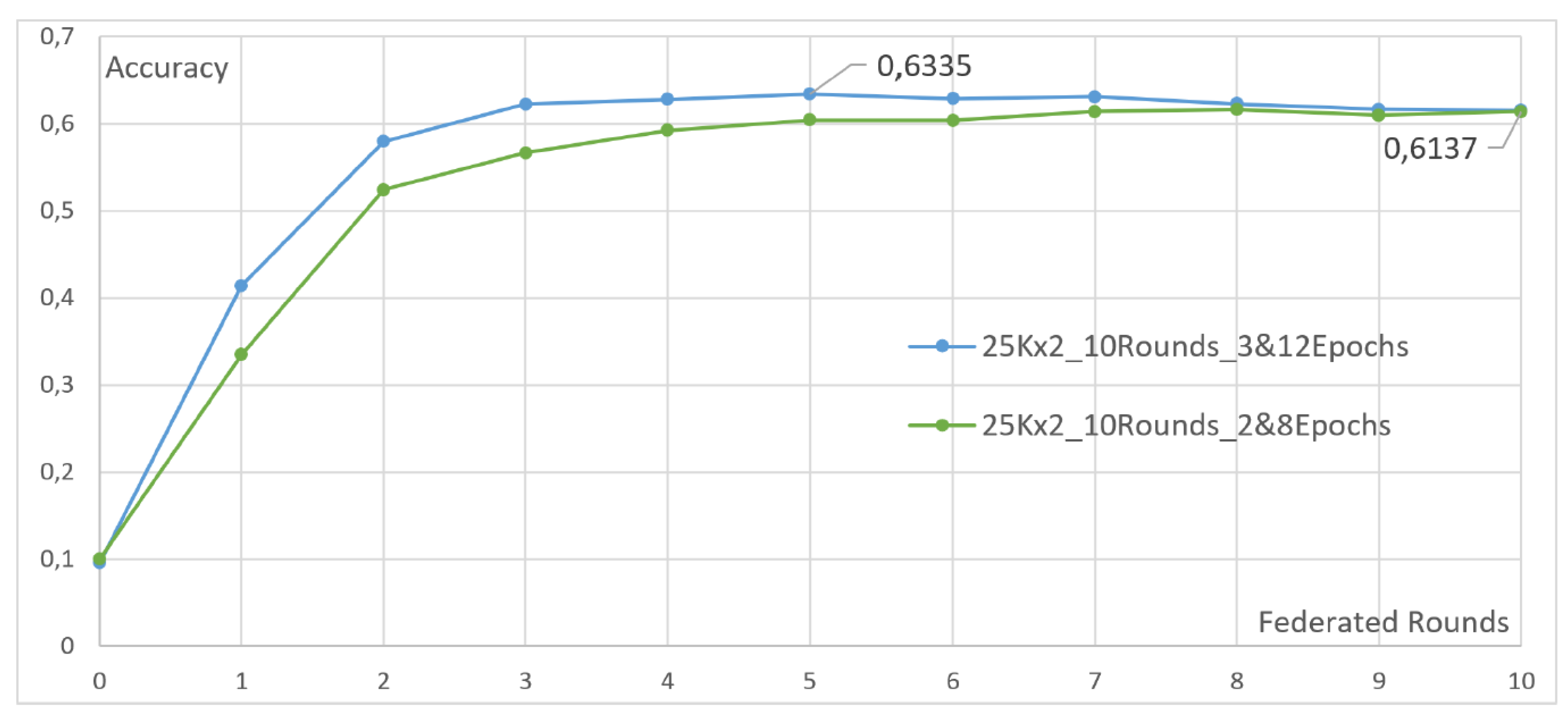
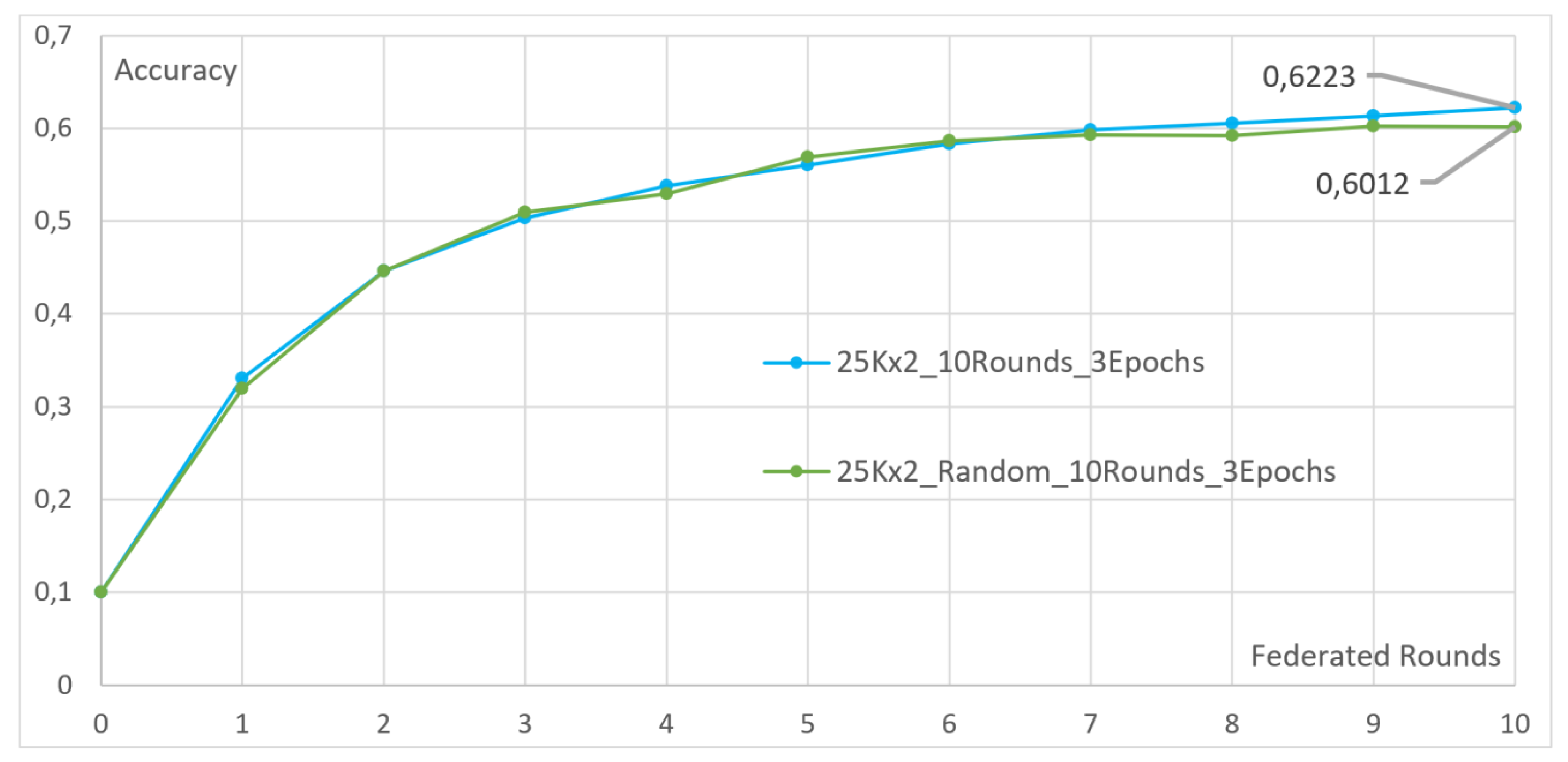
4.2. Heterogeneous Client Compensation
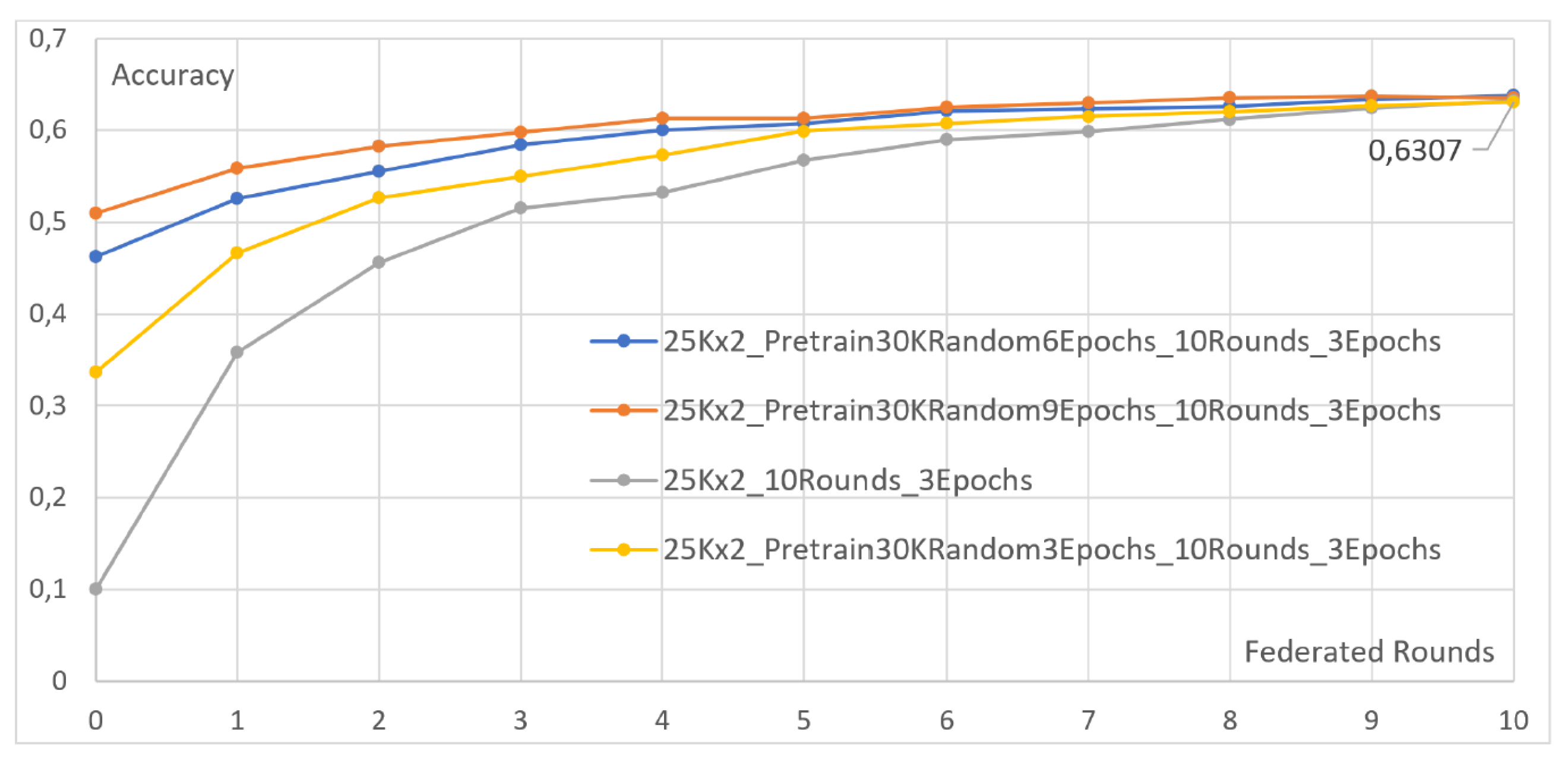
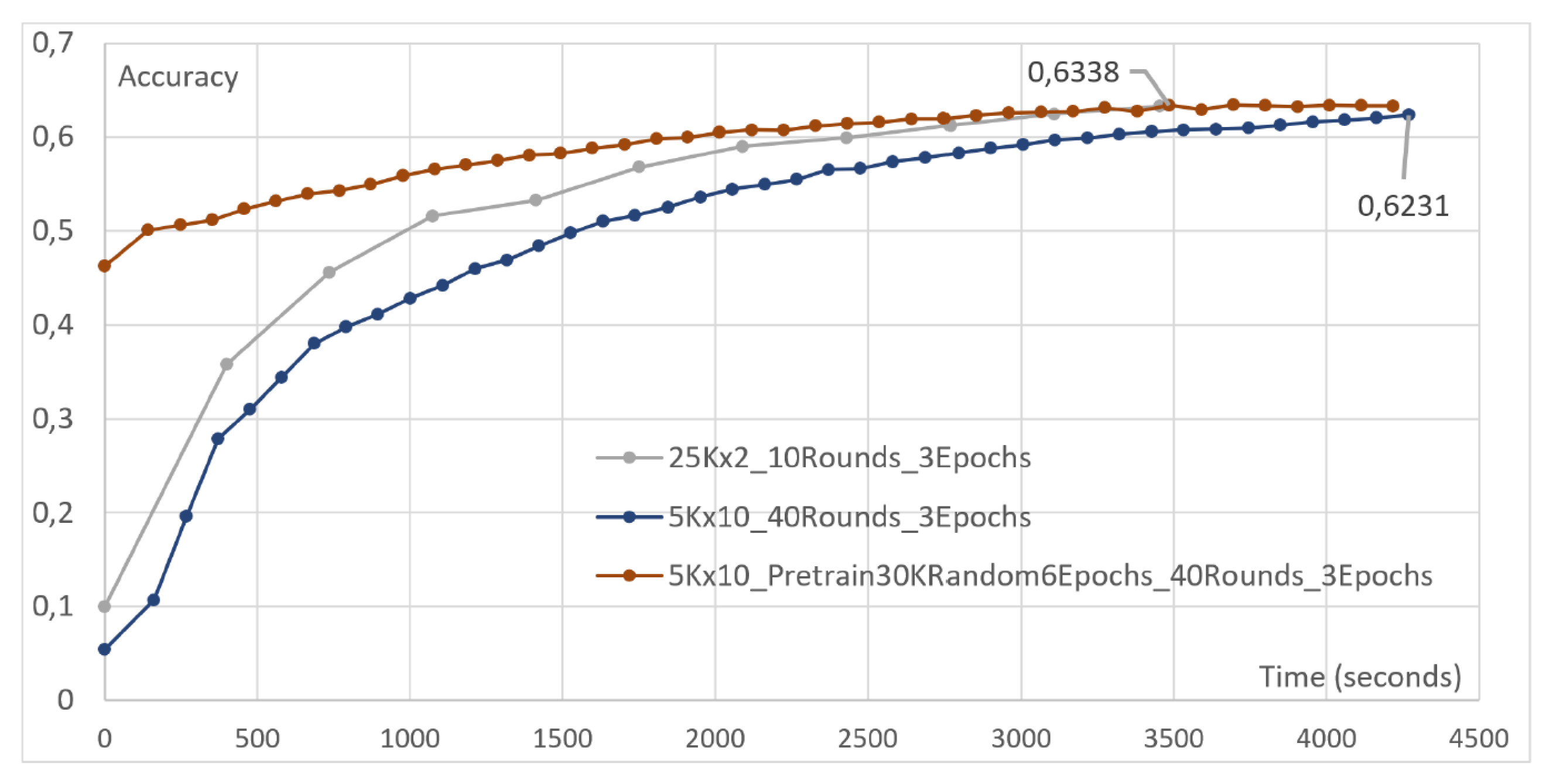
- Two clients, each with 25,000 images. The first client undergoes two local epochs, while the second undergoes eight.
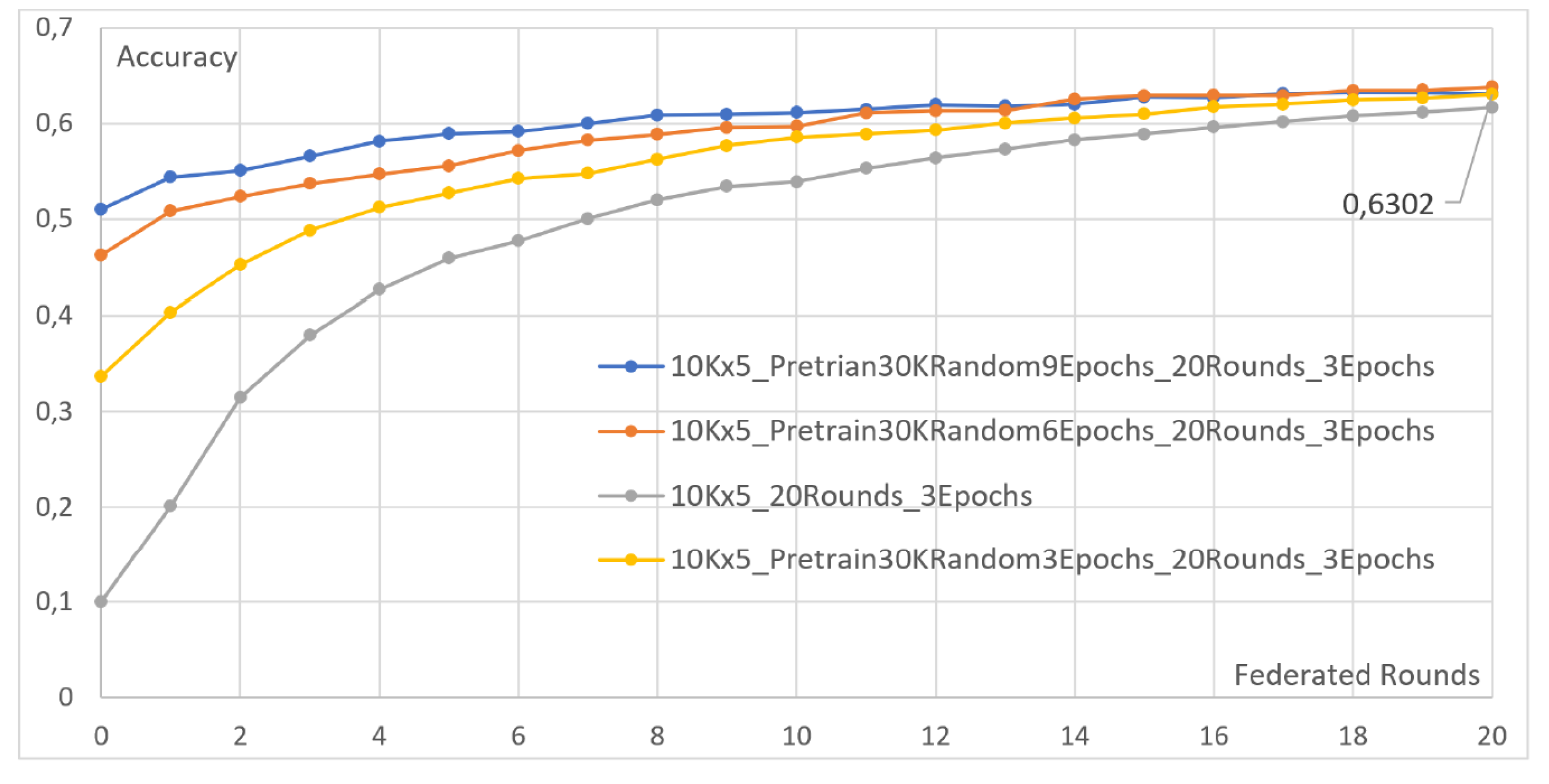
- Two clients, each with five local epochs. The first client is assigned 10,000 images, while the second is assigned 40,000.
- Two clients, each with 25,000 images. The first client undergoes three local epochs, while the second undergoes twelve.
- Two clients, each with seven local epochs. The first client is assigned 10,000 images, while the second is assigned 40,000.


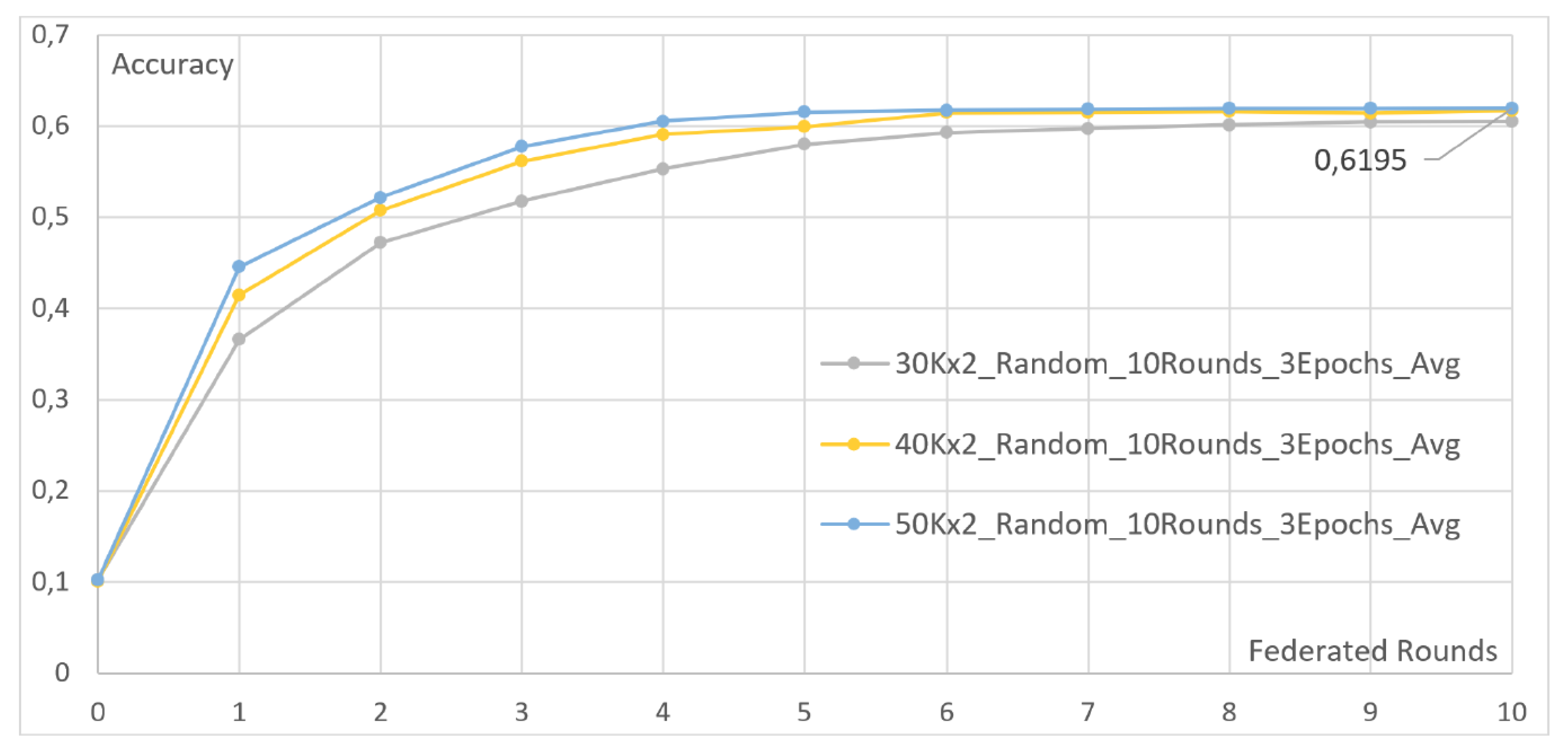
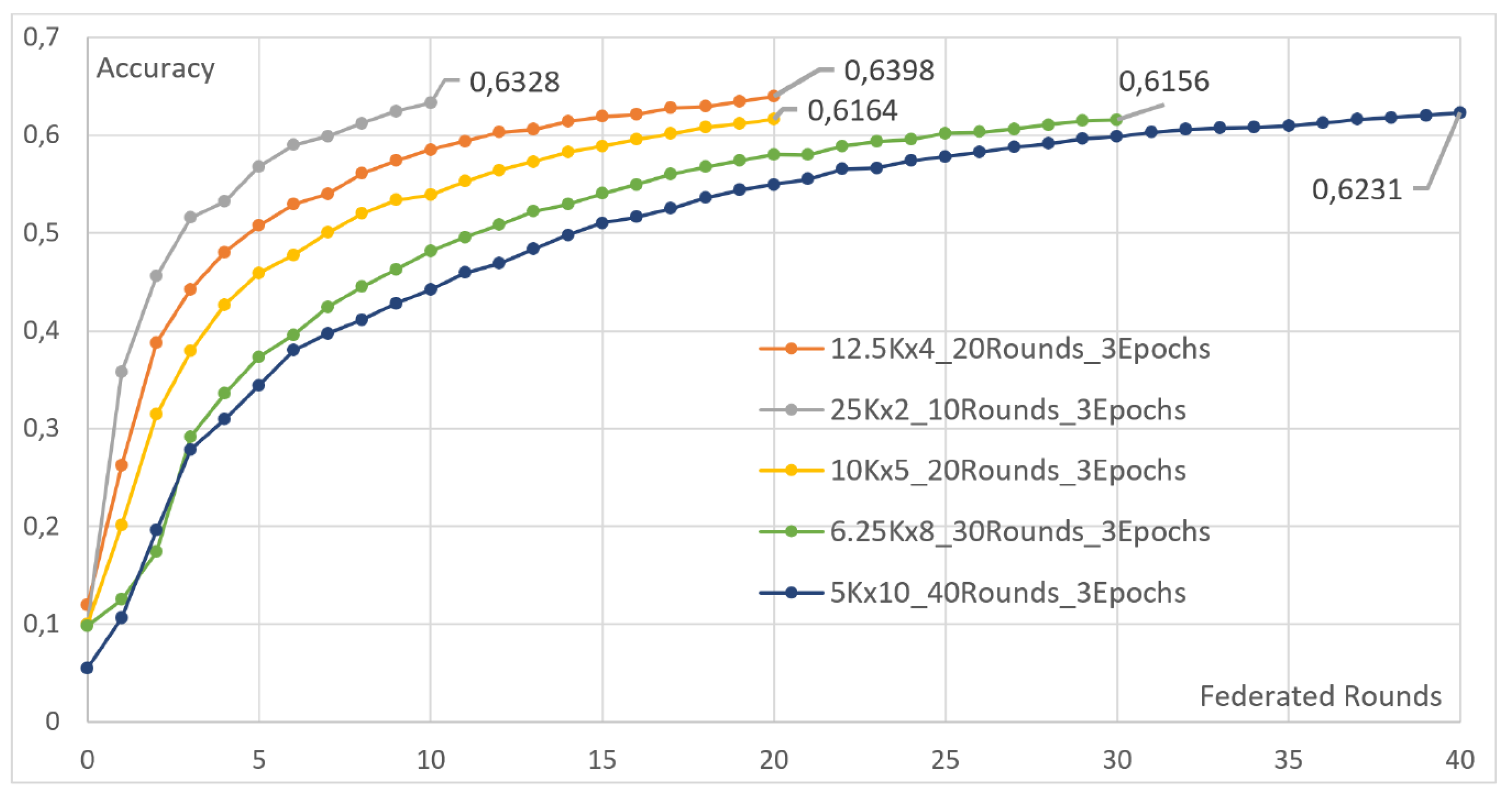
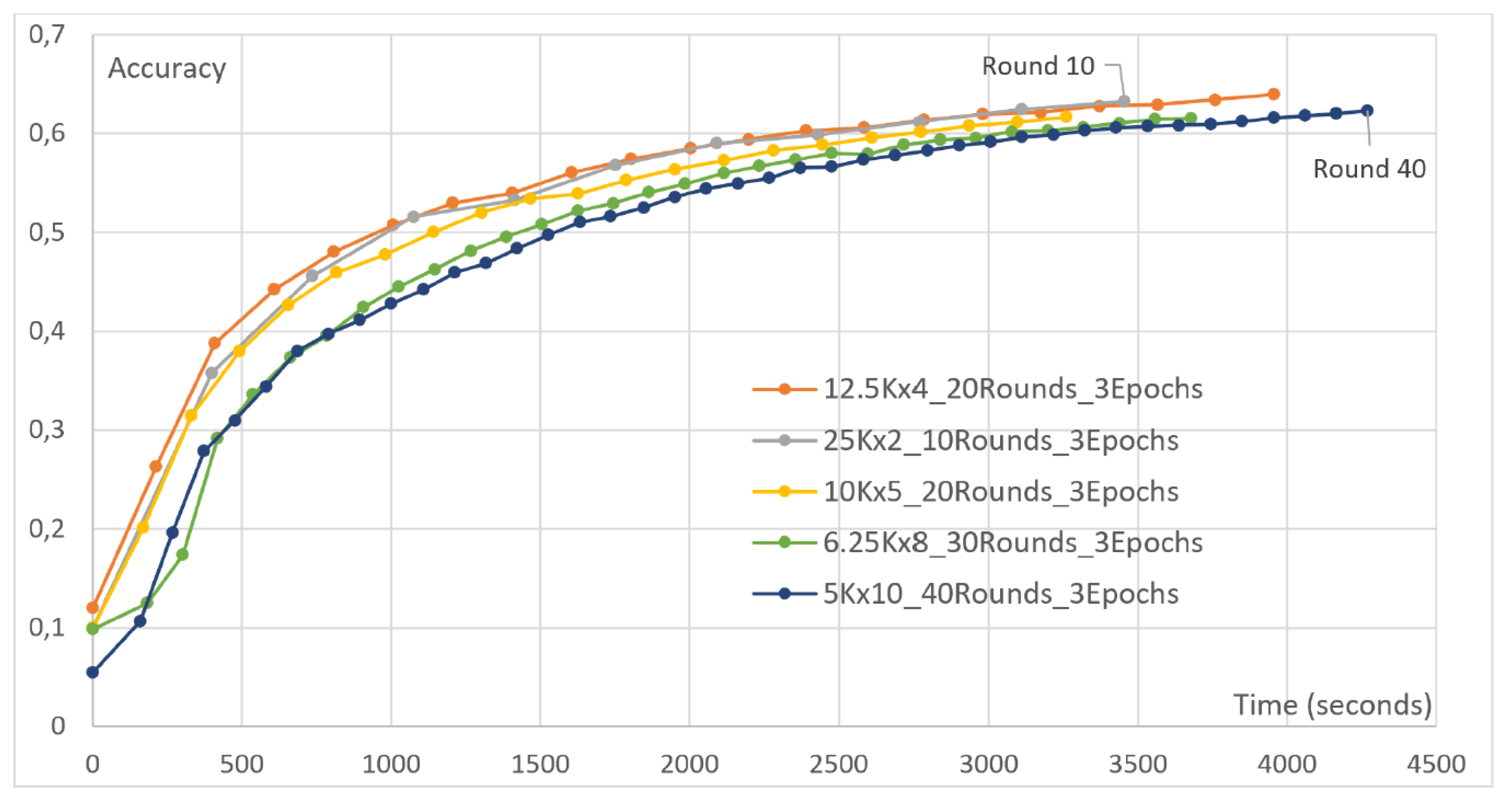
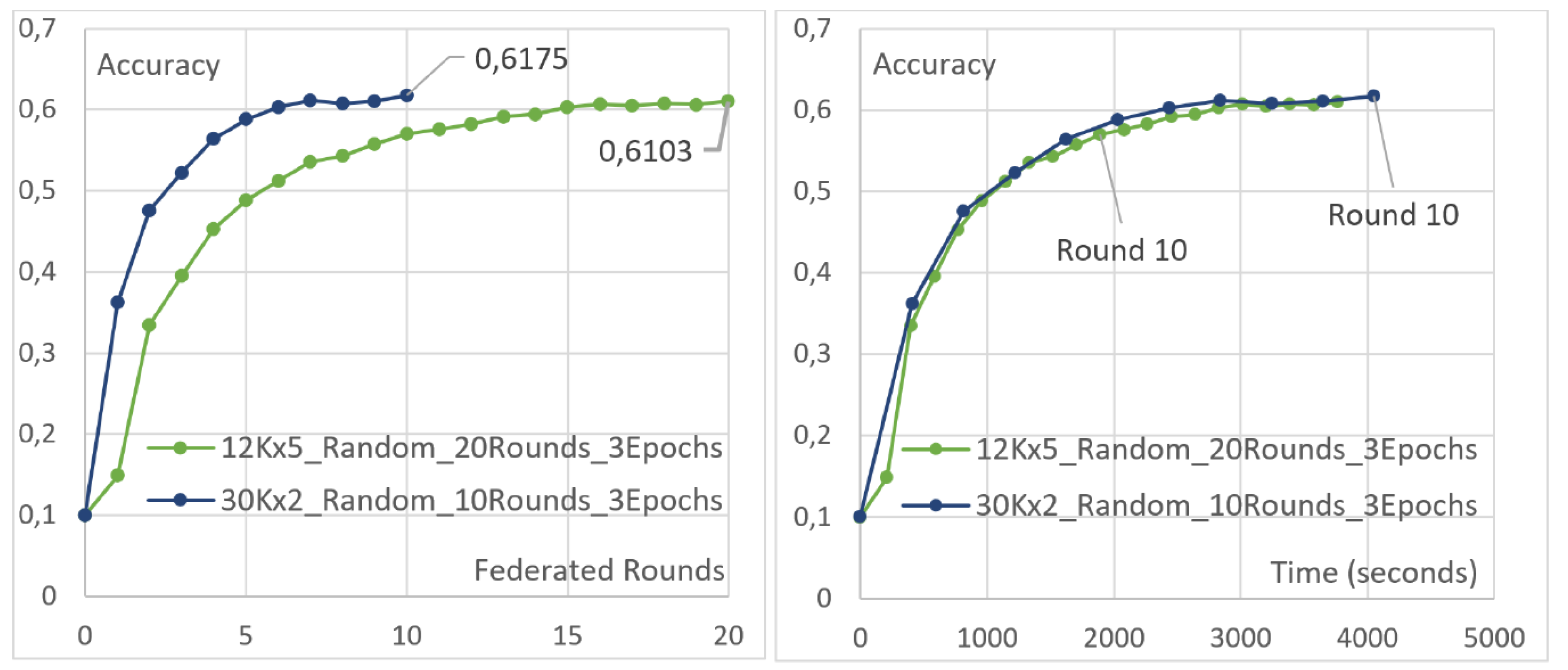
4.3. Increasing the Number of Clients
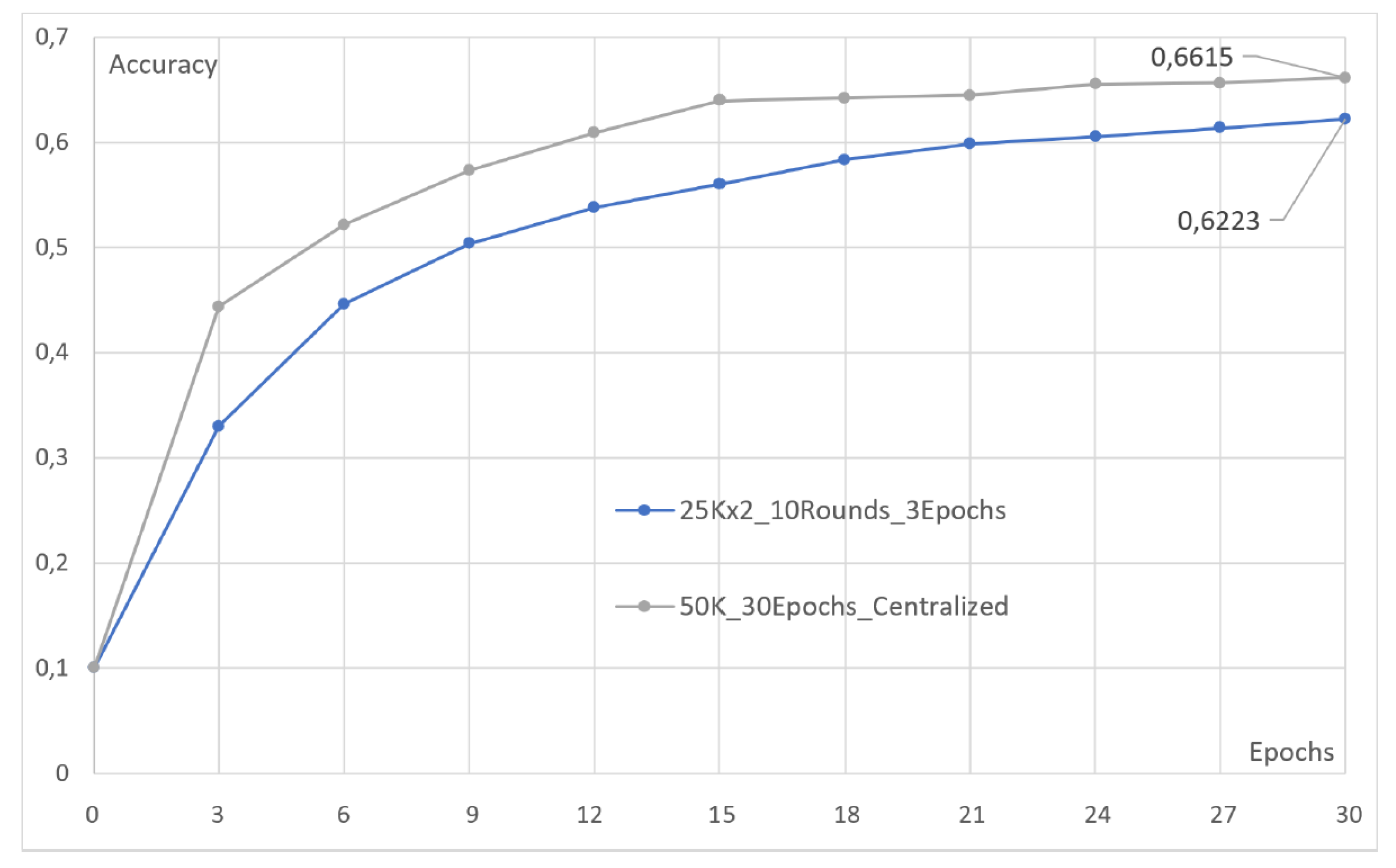
4.4. Effect of Pretraining
4.5. Transfer Learning
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Letaief, K.B.; Shi, Y.; Lu, J.; Lu, J. Edge Artificial Intelligence for 6G: Vision, Enabling Technologies, and Applications. IEEE J. Sel. Areas Commun. 2022, 40, 5–36. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Ding, M.; Pathirana, P.N.; Seneviratne, A.; Li, J.; Niyato, D.; Dobre, O.; Poor, H.V. 6G Internet of Things: A Comprehensive Survey. IEEE Internet Things J. 2022, 9, 359–383. [Google Scholar] [CrossRef]
- 6G Technology Overview, 2nd ed.; one6G White Paper; 2022; Available online: https://one6g.org/download/2699/ (accessed on 27 September 2023).
- Tang, F.; Mao, B.; Kawamoto, Y.; Kato, N. Survey on Machine Learning for Intelligent End-to-End Communication Toward 6G: From Network Access, Routing to Traffic Control and Streaming Adaption. IEEE Commun. Surv. Tutor. 2021, 23, 1578–1598. [Google Scholar] [CrossRef]
- Muscinelli, E.; Shinde, S.S.; Tarchi, D. Overview of Distributed Machine Learning Techniques for 6G Networks. Algorithms 2022, 15, 210. [Google Scholar] [CrossRef]
- Shinde, S.S.; Bozorgchenani, A.; Tarchi, D.; Ni, Q. On the Design of Federated Learning in Latency and Energy Constrained Computation Offloading Operations in Vehicular Edge Computing Systems. IEEE Trans. Veh. Technol. 2022, 71, 2041–2057. [Google Scholar] [CrossRef]
- Shinde, S.S.; Tarchi, D. Joint Air-Ground Distributed Federated Learning for Intelligent Transportation Systems. IEEE Trans. Intell. Transp. Syst. 2023, 24, 9996–10011. [Google Scholar] [CrossRef]
- Duan, Q.; Huang, J.; Hu, S.; Deng, R.; Lu, Z.; Yu, S. Combining Federated Learning and Edge Computing Toward Ubiquitous Intelligence in 6G Network: Challenges, Recent Advances, and Future Directions. IEEE Commun. Surv. Tutor. 2023; in press. [Google Scholar] [CrossRef]
- Morocho-Cayamcela, M.E.; Lee, H.; Lim, W. Machine Learning for 5G/B5G Mobile and Wireless Communications: Potential, Limitations, and Future Directions. IEEE Access 2019, 7, 137184–137206. [Google Scholar] [CrossRef]
- Praveen Kumar, D.; Amgoth, T.; Annavarapu, C.S.R. Machine learning algorithms for wireless sensor networks: A survey. Inf. Fusion 2019, 49, 1–25. [Google Scholar] [CrossRef]
- Fontanesi, G.; Ortíz, F.; Lagunas, E.; Baeza, V.M.; Vázquez, M.; Vásquez-Peralvo, J.; Minardi, M.; Vu, H.; Honnaiah, P.; Lacoste, C.; et al. Artificial Intelligence for Satellite Communication and Non-Terrestrial Networks: A Survey. arXiv 2023, arXiv:2304.13008. [Google Scholar]
- Lee, H.; Lee, S.H.; Quek, T.Q.S. Deep Learning for Distributed Optimization: Applications to Wireless Resource Management. IEEE J. Sel. Areas Commun. 2019, 37, 2251–2266. [Google Scholar] [CrossRef]
- Huang, J.; Wan, J.; Lv, B.; Ye, Q.; Chen, Y. Joint Computation Offloading and Resource Allocation for Edge-Cloud Collaboration in Internet of Vehicles via Deep Reinforcement Learning. IEEE Syst. J. 2023, 17, 2500–2511. [Google Scholar] [CrossRef]
- Song, H.; Liu, L.; Ashdown, J.; Yi, Y. A Deep Reinforcement Learning Framework for Spectrum Management in Dynamic Spectrum Access. IEEE Internet Things J. 2021, 8, 11208–11218. [Google Scholar] [CrossRef]
- Nayak, P.; Swetha, G.; Gupta, S.; Madhavi, K. Routing in wireless sensor networks using machine learning techniques: Challenges and opportunities. Measurement 2021, 178, 108974. [Google Scholar] [CrossRef]
- Yang, Z.; Chen, M.; Saad, W.; Hong, C.S.; Shikh-Bahaei, M. Energy Efficient Federated Learning Over Wireless Communication Networks. IEEE Trans. Wirel. Commun. 2021, 20, 1935–1949. [Google Scholar] [CrossRef]
- Jiang, J.C.; Kantarci, B.; Oktug, S.; Soyata, T. Federated Learning in Smart City Sensing: Challenges and Opportunities. Sensors 2020, 20, 6230. [Google Scholar] [CrossRef] [PubMed]
- Matthiesen, B.; Razmi, N.; Leyva-Mayorga, I.; Dekorsy, A.; Popovski, P. Federated Learning in Satellite Constellations. IEEE Netw. 2023; 1–16, in press. [Google Scholar] [CrossRef]
- Younus, M.U.; Khan, M.K.; Bhatti, A.R. Improving the Software-Defined Wireless Sensor Networks Routing Performance Using Reinforcement Learning. IEEE Internet Things J. 2022, 9, 3495–3508. [Google Scholar] [CrossRef]
- Dewangan, D.K.; Sahu, S.P. Deep Learning-Based Speed Bump Detection Model for Intelligent Vehicle System Using Raspberry Pi. IEEE Sens. J. 2021, 21, 3570–3578. [Google Scholar] [CrossRef]
- Cicceri, G.; Tricomi, G.; Benomar, Z.; Longo, F.; Puliafito, A.; Merlino, G. DILoCC: An approach for Distributed Incremental Learning across the Computing Continuum. In Proceedings of the 2021 IEEE International Conference on Smart Computing (SMARTCOMP), Irvine, CA, USA, 23–27 August 2021; pp. 113–120. [Google Scholar] [CrossRef]
- Mills, J.; Hu, J.; Min, G. Communication-Efficient Federated Learning for Wireless Edge Intelligence in IoT. IEEE Internet Things J. 2020, 7, 5986–5994. [Google Scholar] [CrossRef]
- Farkas, A.; Kertész, G.; Lovas, R. Parallel and Distributed Training of Deep Neural Networks: A brief overview. In Proceedings of the 2020 IEEE 24th International Conference on Intelligent Engineering Systems (INES), Reykjavík, Iceland, 8–10 July 2020; pp. 165–170. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated Learning: Challenges, Methods, and Future Directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Hong, C.S.; Khan, L.U.; Chen, M.; Chen, D.; Saad, W.; Han, Z. Federated Learning for Wireless Networks; Springer: Singapore, 2022. [Google Scholar]
- Zhang, Z.; Zhang, Y.; Guo, D.; Zhao, S.; Zhu, X. Communication-efficient federated continual learning for distributed learning system with Non-IID data. Sci. China Inf. Sci. 2023, 66, 122102. [Google Scholar] [CrossRef]


















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ridolfi, L.; Naseh, D.; Shinde, S.S.; Tarchi, D. Implementation and Evaluation of a Federated Learning Framework on Raspberry PI Platforms for IoT 6G Applications. Future Internet 2023, 15, 358. https://doi.org/10.3390/fi15110358
Ridolfi L, Naseh D, Shinde SS, Tarchi D. Implementation and Evaluation of a Federated Learning Framework on Raspberry PI Platforms for IoT 6G Applications. Future Internet. 2023; 15(11):358. https://doi.org/10.3390/fi15110358
Chicago/Turabian StyleRidolfi, Lorenzo, David Naseh, Swapnil Sadashiv Shinde, and Daniele Tarchi. 2023. "Implementation and Evaluation of a Federated Learning Framework on Raspberry PI Platforms for IoT 6G Applications" Future Internet 15, no. 11: 358. https://doi.org/10.3390/fi15110358