



Product Evaluation Prediction Model Based on Multi-Level Deep Feature Fusion

Abstract
:1. Introduction
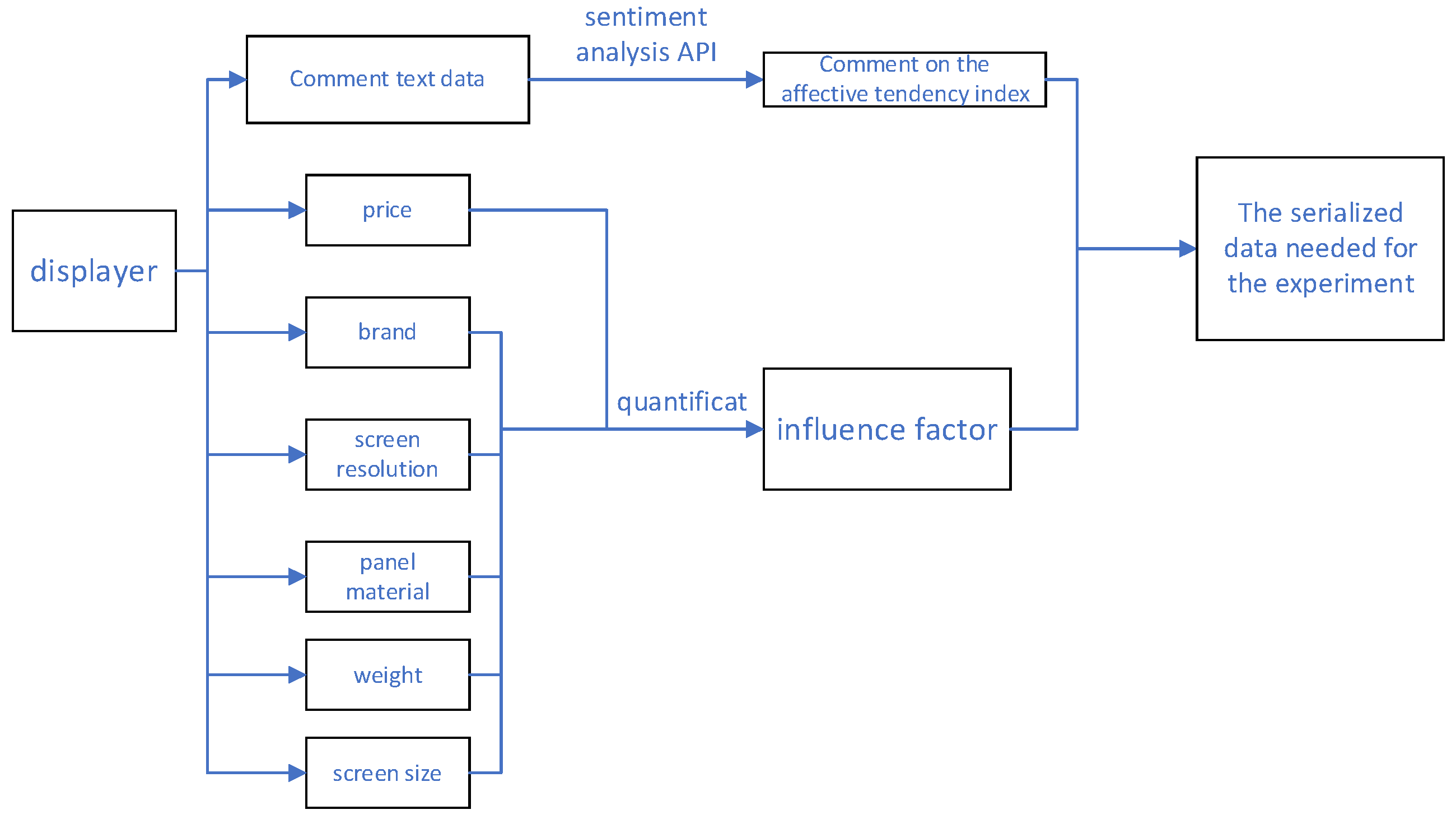
- The model uses the fine-grained emotional quantification of various evaluations of consumers’ online shopping products, and obtains the emotional value sequence data of the comprehensive customer experience.
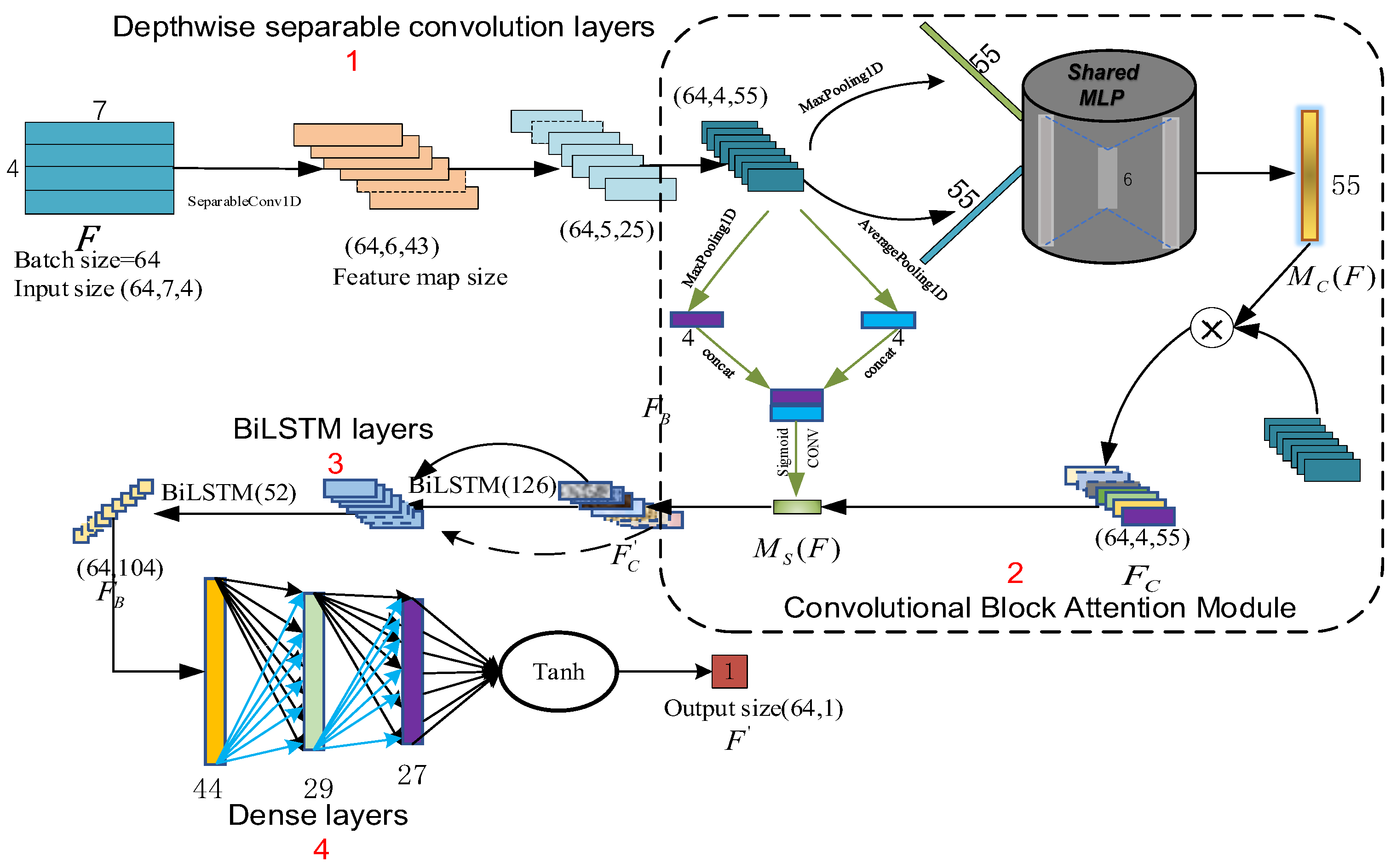
- DSCNN (Depthwise Separable Convolutions) to extract primary interconnected features from the data set affecting customer satisfaction, use CBAM (Convolutional Block Attention Module) to implement multi-dimensional separation feature attention strategy in channel and space dimensions, and analyze shallow feature channels and spatial dimensions through channel attention mechanism The importance of the multi-features is assigned different weights by different importances, which avoids the problem of poor prediction effect caused by the loss of important features during the training of the multi-hidden layer model.
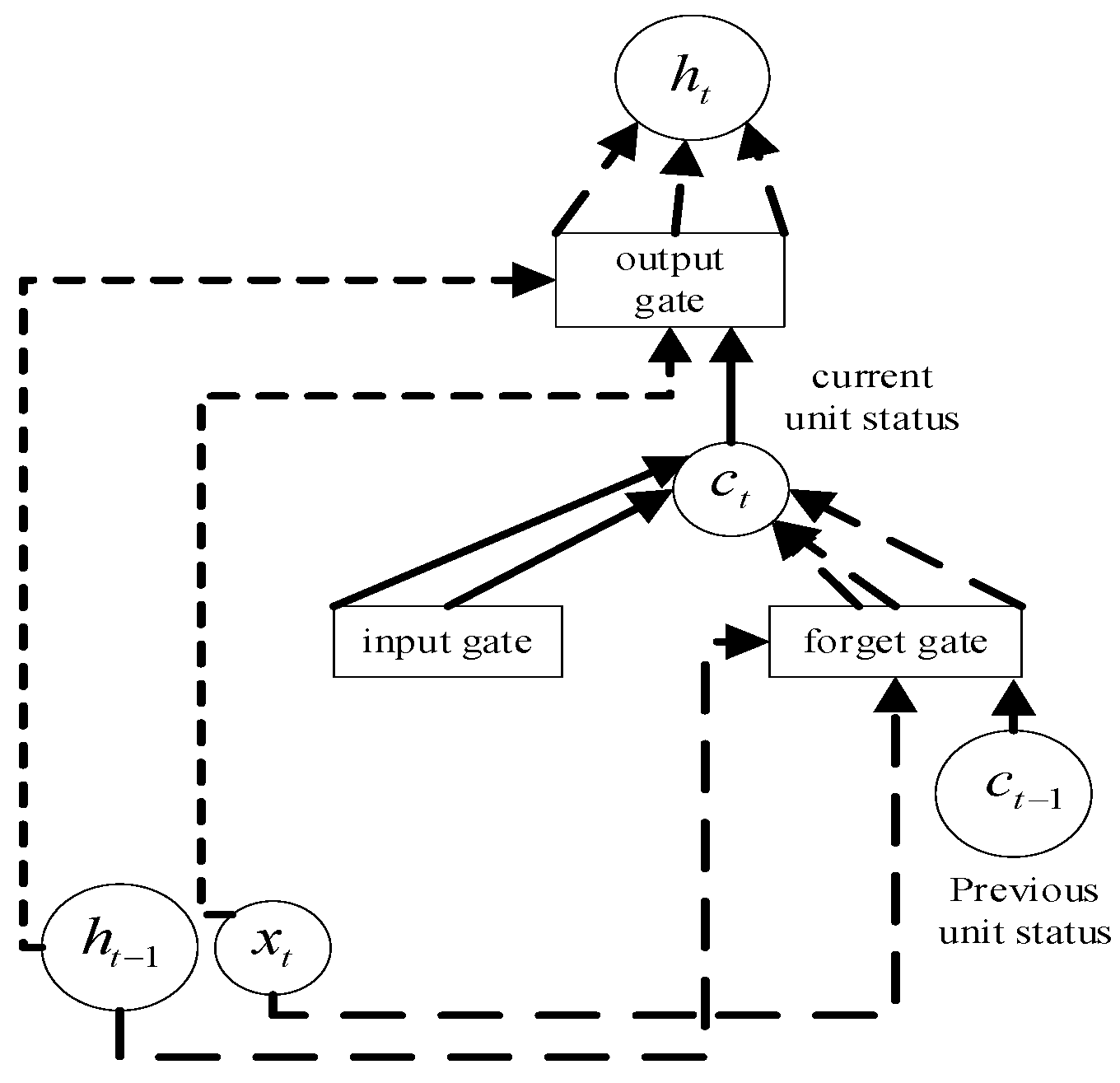
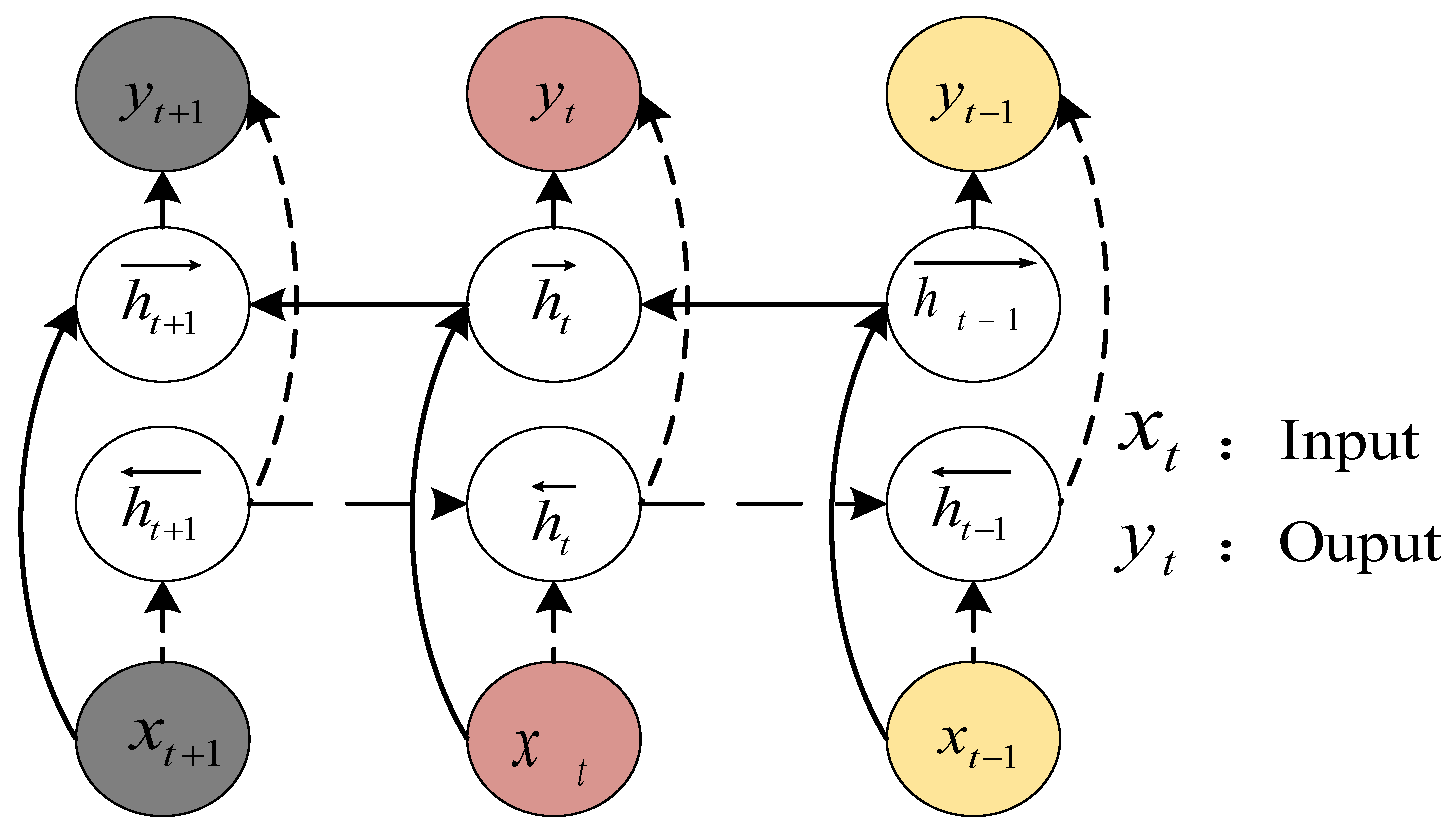
- Optimize BiLSTM (Bidirectional Long Short-Term Memory) learning performance by CBAM attention mechanism. BiLSTM is an improvement of RNN (Recurrent Neural Network) and LSTM (Long Short-Term Memory) [12,13,14]. In order to solve the problem of gradient disappearance and gradient explosion, it can process the combined features of the front and rear bidirectional sequences at the same time, thereby obtaining the feature map of the secondary deep analysis of the data.
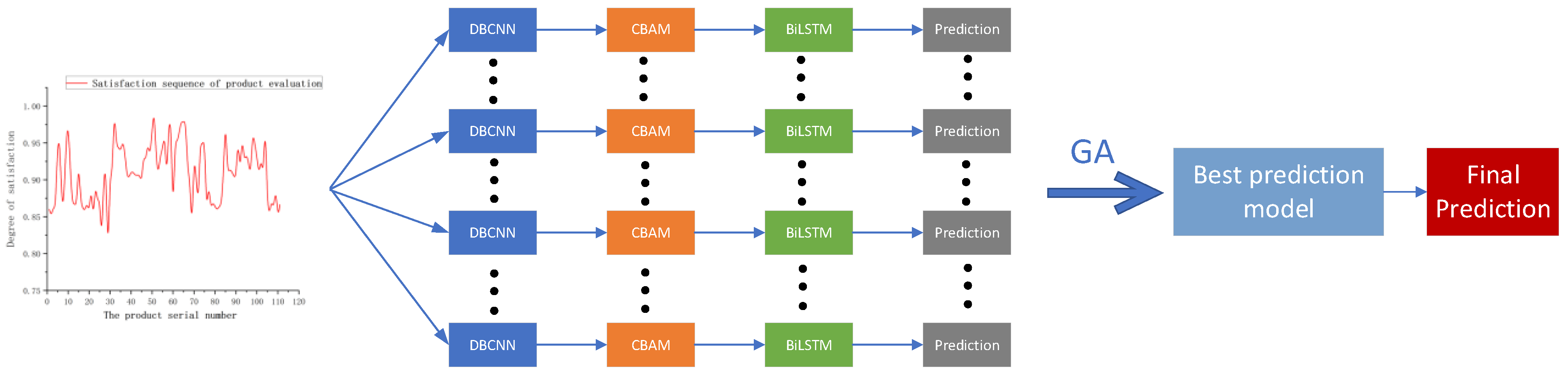
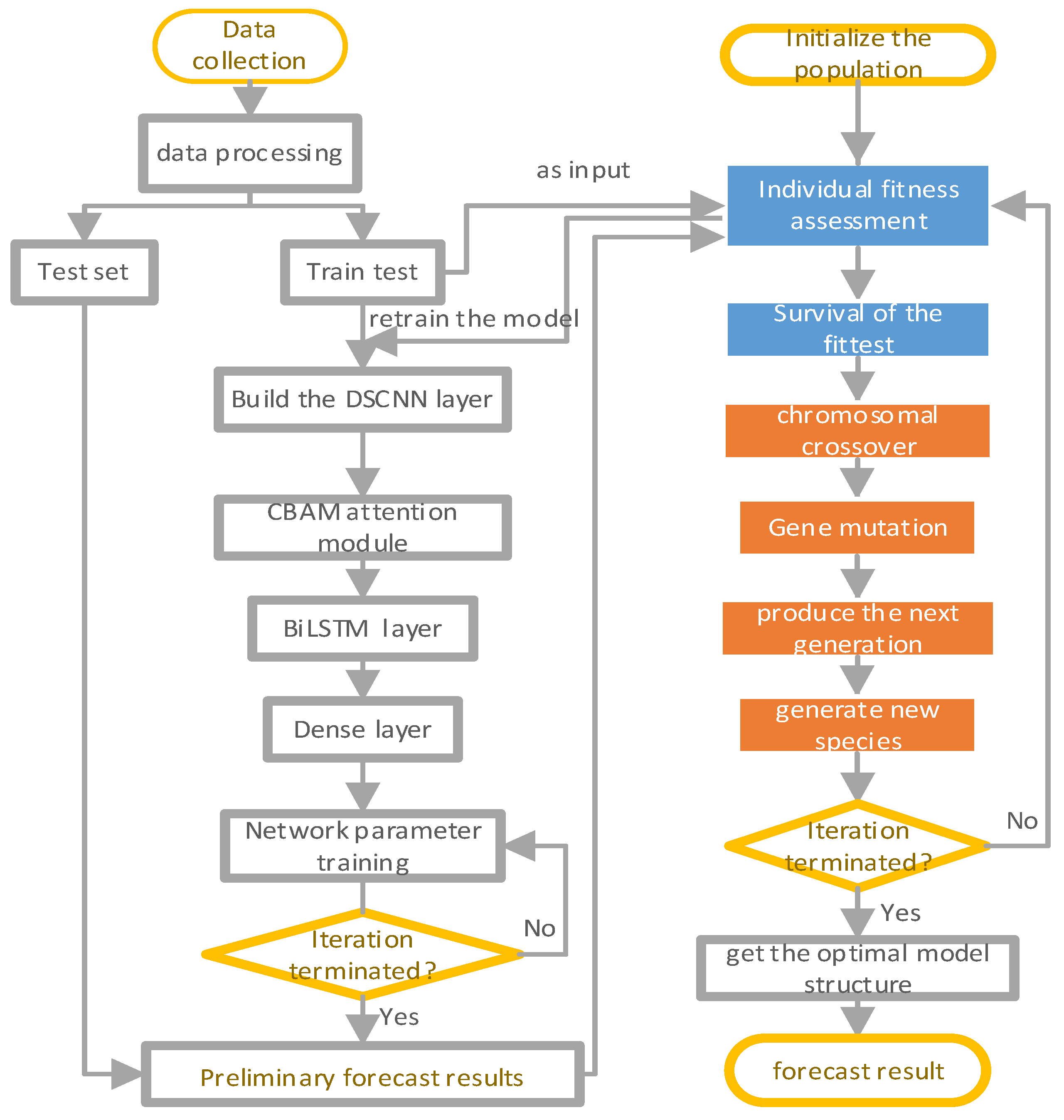
- Construct a multi-level deep feature fusion consisting of a channel-by-channel convolution layer, a point-by-point convolution layer, a maximum pooling layer, a weight distribution layer for channel and spatial dimension features, a bidirectional LSTM prediction layer, and a multi-layer Dense output layer. Product evaluation prediction model. The global optimization of the multi-layer model structure is carried out through the genetic algorithm, which highlights the learning advantages of each layer and eliminates the barriers of independent learning between each layer [15,16]. The ultimate goal is to improve the prediction accuracy of product evaluation satisfaction.
2. Using Genetic Algorithm to Optimize Spatiotemporal Correlation Forecast Model
2.1. Spatiotemporal Correlation Prediction Model
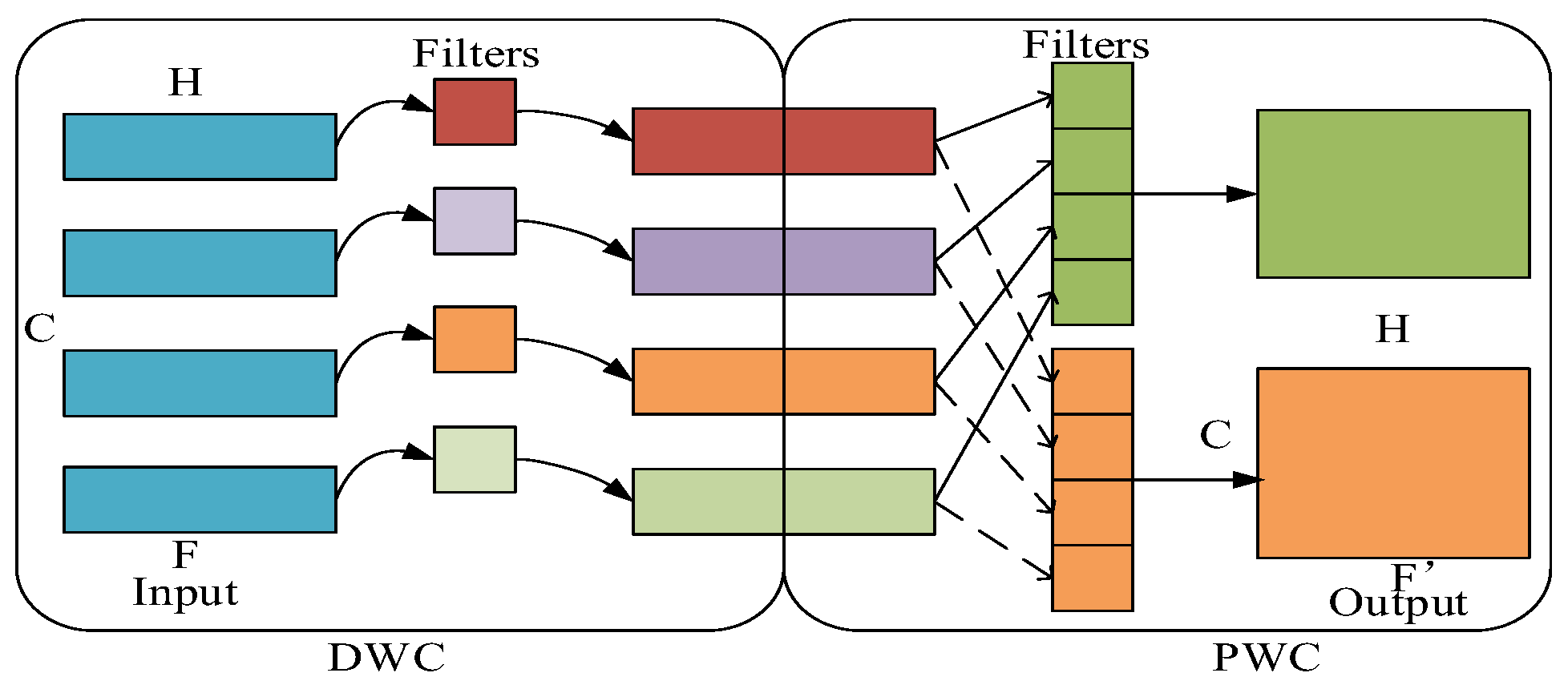
2.1.1. The First Feature Extraction Based on DSCNN
2.1.2. The Second Feature Extraction Based on BiLSTM
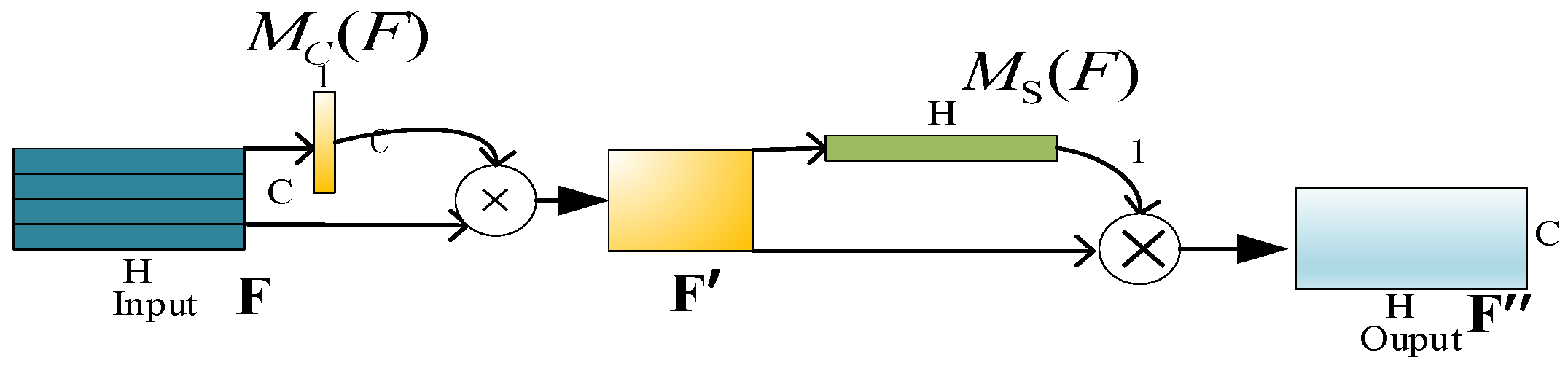
2.2. Multi-Channel and Multi-Location Attention Mechanism
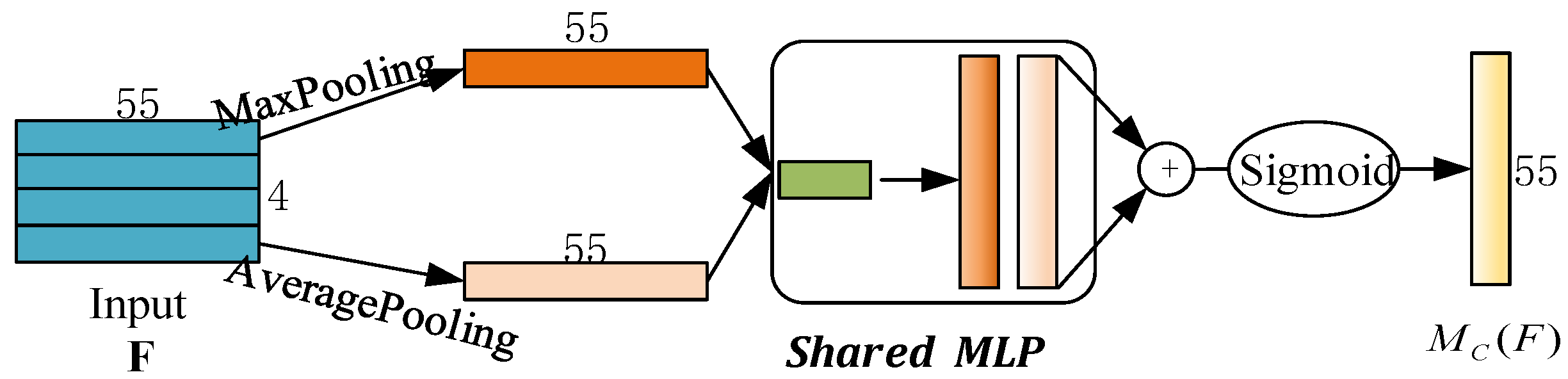
2.2.1. Attention Module of Channel Dimension
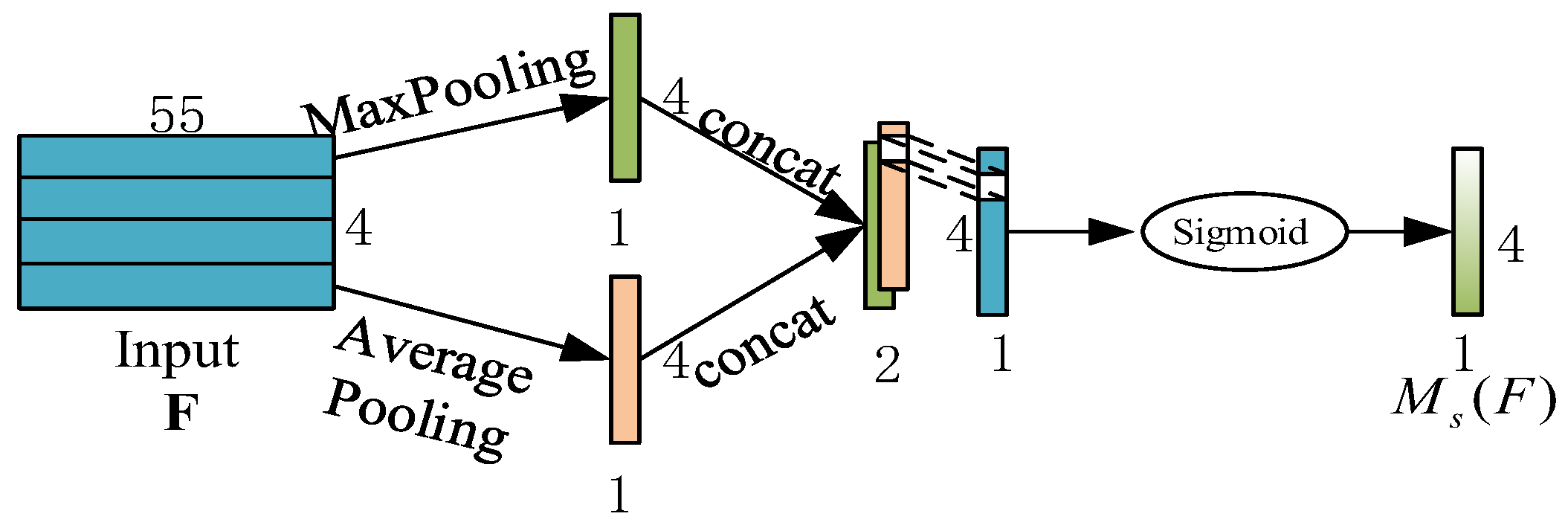
2.2.2. Attention Module in Spatial Dimension
3. Model Parameter Optimization Based on Genetic Algorithm
- First, determine the model structure that needs to be optimized, including the number of deep convolutional layers, the number of BiLSTM layers, the number of fully connected layers, and the number of neurons in each of the above layers.
- Secondly, set the parameters of the genetic algorithm (as shown in Table 1), where population represents the number of individuals in the population, is the probability of parental chromosome gene recombination, is the probability of gene mutation, and represents the evolutionary generation of the genetic algorithm.
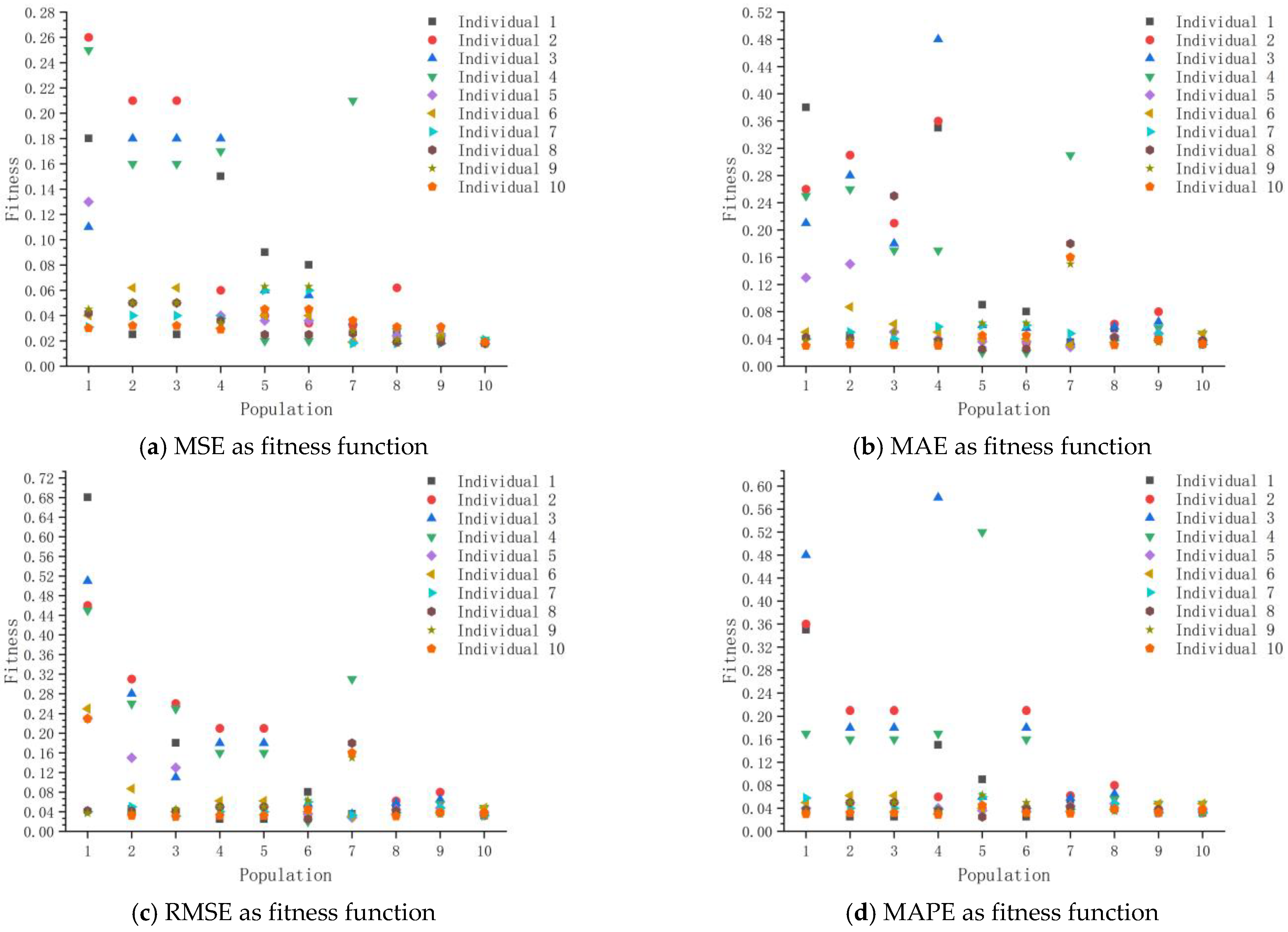
- The next step is to create the first population of the neural network, each of which is initialized with a random combination of descriptive attributes. In this paper, parameters to be optimized are put into the list and encoded with integers. There are 12 attributes to be optimized in the model, so the chromosomes of individuals in the population can be instantiated into a list containing 12 integers. When the above coding is completed, an individual genotype is formed, which is a possible value for the optimal solution of the model. The size of population in the genetic algorithm represents the number of individuals in the population. Random value is used to randomly assign value to each chromosome of all individuals. At this time, there are 10 types of individuals in the first-generation population, namely, there are 10 models with different structures, and each individual represents a possible optimal solution.
- After initialising the first generation population, the next step is to train the ten models using the dataset in this paper. The loss function during training is the mean square error (MSE) and the optimiser is Adam, with the goal of minimising the MSE. Other metrics used to evaluate the performance of the models were used to evaluate the performance of the models on the test set after training was completed, with one of the performance metrics used as a function of the fitness of the genetic algorithm to evaluate the merit of the models.
- When all individuals in the population are evaluated, the higher the fitness, the greater the probability of being selected for retention as a parent. The parent generation left from the previous generation is crossed by two chromosomes with probability, and gene mutation and generation of the next generation occur with probability, finally forming a new population. When twenty populations are generated, the iteration of genetic algorithm ends, and the individuals with the highest fitness are selected as the optimal model structure, so as to output the prediction results.
4. Experiment and Result Analysis
4.1. Experimental Data
4.2. Model Optimization Experiment
4.2.1. Model Performance Evaluation Indicators
4.2.2. Model Hyperparameter Tuning
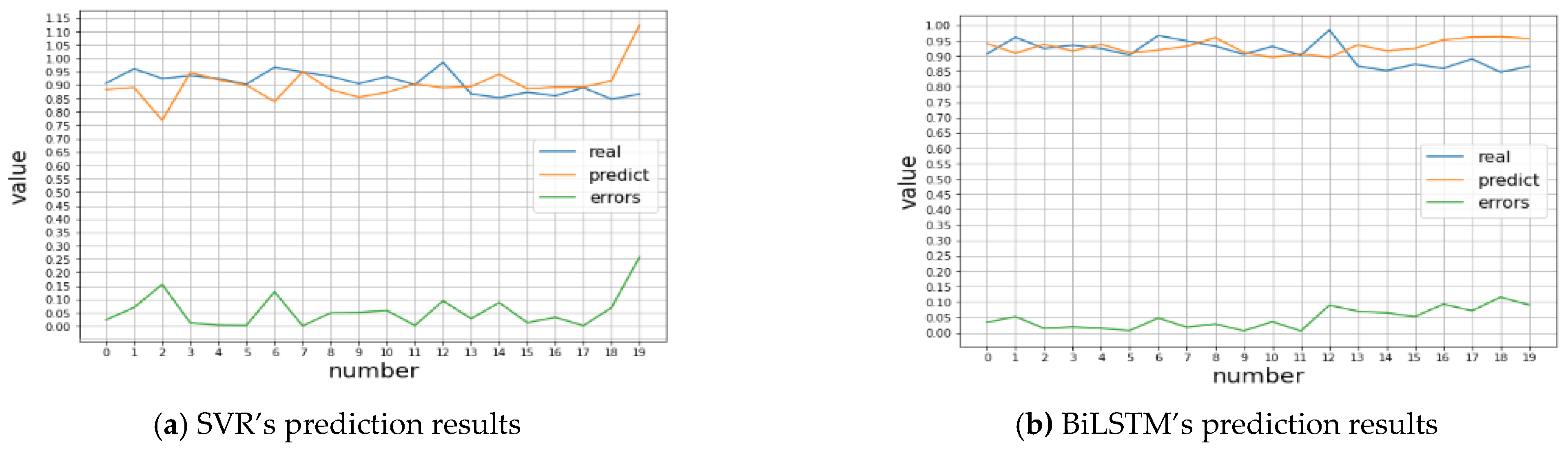
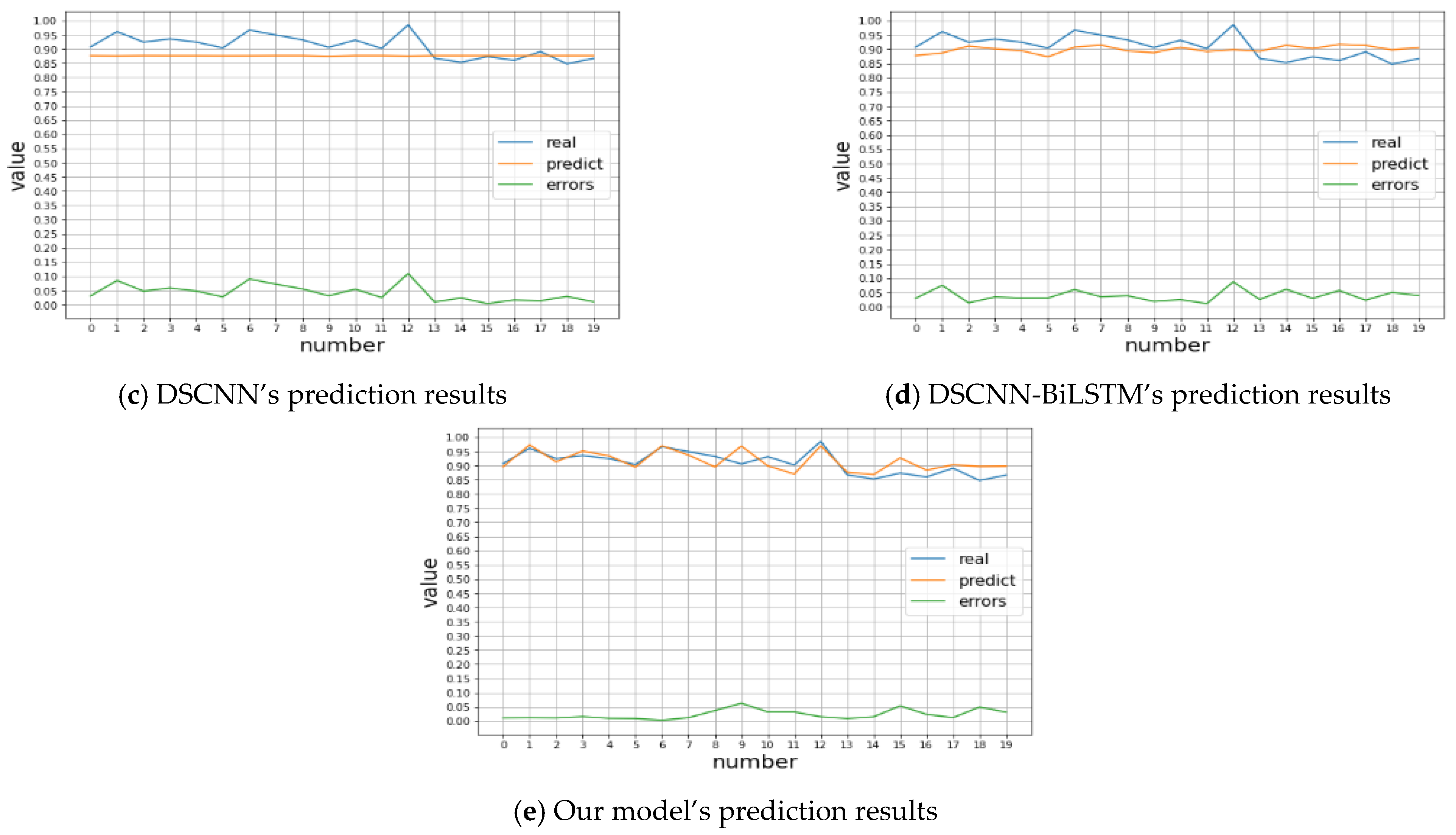
4.3. Comparative Experiment
4.4. Analysis of Results
5. Conclusions
- This paper raises a new DSCNN-BiLSTM prediction model which integrates attention mechanism with genetic algorithm optimization, and predicts customer satisfaction degree of a product from customer online comments, thus providing scientific decision-making for enterprise production design. Firstly, a shallow feature extraction model based on deep separable convolution is adopted to fully extract the associated features between product and evaluation satisfaction data from two dimensions, effectively solving the problem of insufficient feature extraction capability of classical convolution network. Secondly, the attention mechanism is embedded for secondary depth feature extraction, and the CBAM attention distribution feature weights are used to enhance the depth feature analysis capability of BiLSTM, which improves the self-learning capability of the algorithm and effectively solves the problem of important feature loss during long-term training. Finally, the number of layers and the number of neurons per layer of the depth-separable convolutional layers, BiLSTM layers and density layers are optimised using genetic algorithms, and the model parameters are retrained and optimised by calculating the fitness function values, so as to obtain the optimal network structure of the model. Compared with traditional machine learning algorithms such as SVR and DSCNN, BiLSTM has improved the performance of our model in predicting customer affective tendency index. The performance in MSE is especially surprising to us, which is as low as 0.001.
- Meanwhile, the deep learning network optimized by genetic algorithm has good self-adaptability, self-learning ability and generalization ability. The limitation of our model performance is that when predicting new data, the model parameters need to be adjusted by genetic algorithm, which can bring high prediction accuracy, but consumes a lot of time and computing resources.
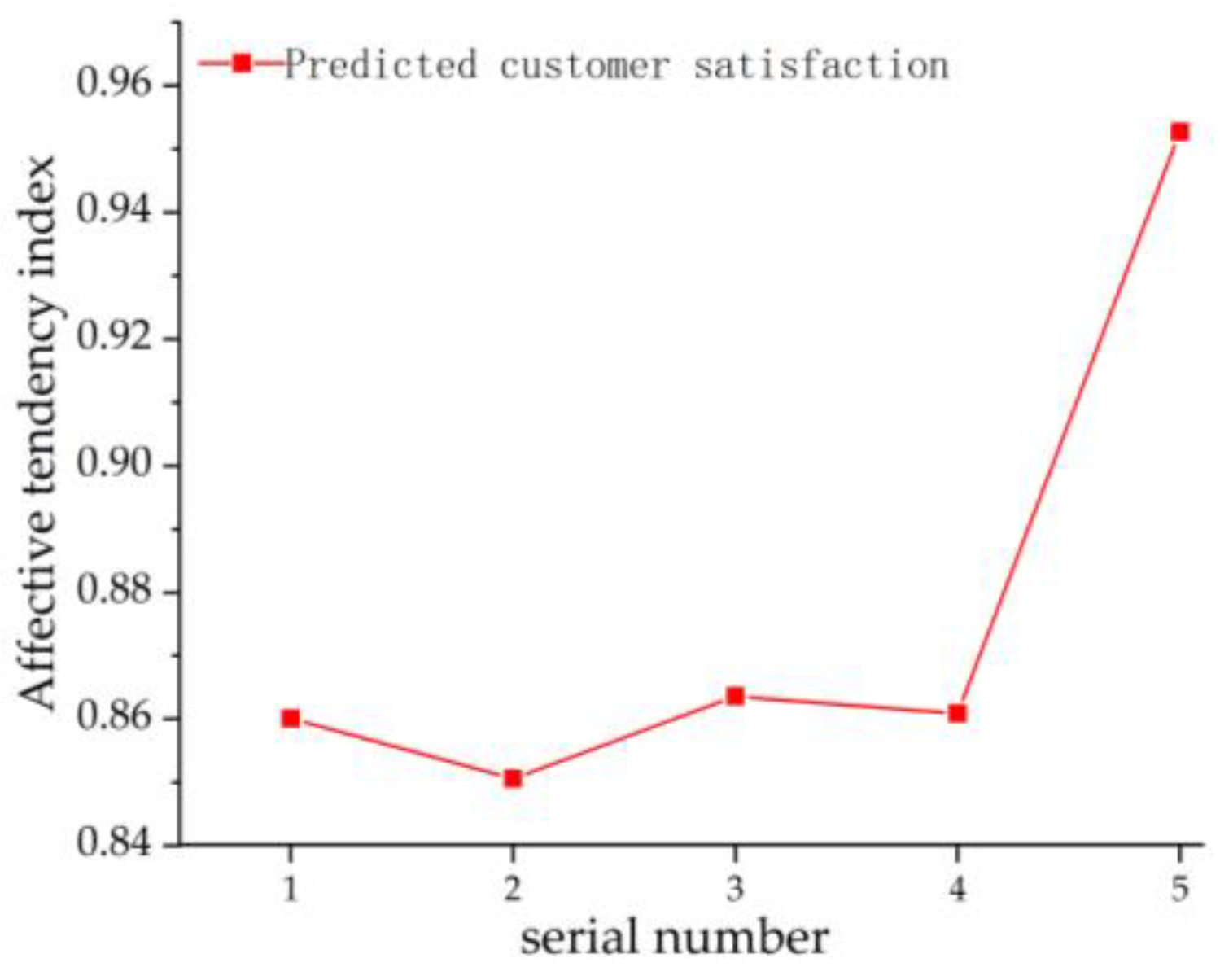
- This article takes screens as research object to analyze the fluctuation of customer satisfaction caused by the change of some important product attributes (such as price and resolution, etc.), which provides reference for enterprises in product development and design. In the future work, we plan to use the model in this paper to calculate the emotional value of texts, perform cluster analysis on online comments, and refine customers’ emotional tendency towards products from different perspectives, so as to replace the comprehensive evaluation of the emotional index in this paper. In addition, the optimization design of other adjustable parameters in the model is not limited to the structure of the model to further improve the performance of the model.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Abbreviation | Paraphrase |
| DSCNN | Depthwise Separable Convolutions |
| CBAM | Convolutional Block Attention Module |
| BiLSTM | Bidirectional Long Short-Term Memory |
| SVR | Support Vector Regression |
| QFD | Quality Function Deployment |
| HOQ | House of Quality |
| BP | Back Propagation |
| ss-rae | semi-supervised learning recursive autoencoder |
| NSGA-II | Non-inferior Sorting Genetic Algorithm II |
| SD | Semantic Differential |
| LSTM | Long Short-Term Memory |
| GA | Genetic Algorithm |
| CNN | Convolutional Neural Network |
| DWC | Depthwise Convolution |
| PWC | Pointwise Convolution |
| RNN | Recurrent Neural Network |
| CAM | Channel Attention Module |
| SAM | Spatial Attention Module |
| MLP | Multi-layer Perceptron |
| MSE | mean square error |
| MAE | mean absolute error |
| RMSE | root mean square error |
| MAPE | mean absolute percentage error |
| SMAPE | symmetric mean absolute percentage error |
References
- Pin, L.; Luo, Z.; Kunhao, T. Customer Satisfaction Degree Evaluation of Online Product Review. Acta Electron. Sin. 2014, 42, 740–746. [Google Scholar] [CrossRef]
- Li, Y.L.; Huang, M.; Chin, K.S.; Luo, X.G.; Han, Y. Integrating preference analysis and balanced scorecard to product planning house of quality. Comput. Ind. Eng. 2011, 60, 256–268. [Google Scholar] [CrossRef]
- Liu, B.; Chen, Y. Parametric evaluation method of product image based on review text. Packag. Eng. 2022, 1–11. Available online: http://kns.cnki.net/kcms/detail/50.1094.TB.20210719.1331.012.html (accessed on 7 January 2023).
- Huihua, C.; Faliang, H.; Chuandi, P. Mining User Satisfaction Based on Product Review Sentiment Analysis. J. Fujian Norm. Univ. (Nat. Sci. Ed.) 2017, 33, 14–21. [Google Scholar] [CrossRef]
- Weihua, L.; Yihan, N.; Zhibin, C.; Ruijun, L. User Review Data-Driven Product Optimization Design Method. J. Comput.-Aided Des. Comput. Graph. 2022, 34, 482–490. [Google Scholar] [CrossRef]
- Dou, R.; Li, W.; Nan, G.; Wang, X.; Zhou, Y. How can manufacturers make decisions on product appearance design? A research on optimal design based on customers’ emotional satisfaction. J. Manag. Sci. Eng. 2022, 6, 177–196. [Google Scholar] [CrossRef]
- Ma, Y.L.; Hu, Z.M. Online review of research in 2006–2011: Thematic analysis and trend forecast. Econ. Manag. Rev. 2012, 28, 69–75. [Google Scholar]
- Shang, Z.; Liu, H.; Zhu, S. The Method of Customer Online Reviews Based Product Design. Packag. Eng. 2021, 42, 10. [Google Scholar] [CrossRef]
- Lin, K.Y.; Chien, C.F.; Kerh, R. UNISON framework of data-driven innovation for extracting user experience of product design of wearable devices. Comput. Ind. Eng. 2016, 99, 487–502. [Google Scholar] [CrossRef]
- Ma, J.; Kim, H.M. Product family architecture design with predictive, data-driven product family design method. Res. Eng. Des. 2016, 27, 5–21. [Google Scholar] [CrossRef]
- Chan, K.Y.; Kwong, C.K.; Kremer, G.E. Predicting customer satisfaction based on online reviews and hybrid ensemble genetic programming algorithms. Eng. Appl. Artif. Intell. 2020, 95, 103902. [Google Scholar] [CrossRef]
- Agga, A.; Abbou, A.; Labbadi, M.; El Houm, Y. Short-term self consumption PV plant power production forecasts based on hybrid CNN-LSTM, ConvLSTM models. Renew. Energy 2021, 177, 101–112. [Google Scholar] [CrossRef]
- Zhang, J.; Peng, Y.; Ren, B.; Li, T. PM2.5 Concentration Prediction Based on CNN-BiLSTM and Attention Mechanism. Algorithms 2021, 14, 208. [Google Scholar] [CrossRef]
- Unlersen, M.F.; Balci, S.; Aslan, M.F.; Sabanci, K. The Speed Estimation via BiLSTM-Based Network of a BLDC Motor Drive for Fan Applications. Arab. J. Sci. Eng. 2021, 47, 2639–2648. [Google Scholar] [CrossRef]
- Stajkowski, S.; Kumar, D.; Samui, P.; Bonakdari, H.; Gharabaghi, B. Genetic-Algorithm-Optimized Sequential Model for Water Temperature Prediction. Sustainability 2020, 12, 5374. [Google Scholar] [CrossRef]
- Tsoumalis, G.I.; Bampos, Z.N.; Chatzis, G.V.; Biskas, P.N.; Keranidis, S.D. Minimization of natural gas consumption of domestic boilers with convolutional, long-short term memory neural networks and genetic algorithm. Appl. Energy 2021, 299, 117256. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar] [CrossRef] [Green Version]
- Haase, D.; Amthor, M. Rethinking lstms: How Intra-Kernel Correlations Lead to Improved MobileNets. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14600–14609. [Google Scholar] [CrossRef]
- Shan, L.; Liu, Y.; Tang, M.; Yang, M.; Bai, X. CNN-BiLSTM hybrid neural networks with attention mechanism for well log prediction. J. Pet. Sci. Eng. 2021, 205, 108838. [Google Scholar] [CrossRef]
- Zhao, X.; Bai, M.; Yang, X.; Liu, J.; Yu, D.; Chang, J. Short-term probabilistic predictions of wind multi-parameter based on one-dimensional convolutional neural network with attention mechanism and multivariate copula distribution estimation. Energy 2021, 234, 121306. [Google Scholar] [CrossRef]
- Cheng, Y.; Yao, L.; Zhang, G.; Tang, T.; Xiang, G.; Chen, H.; Feng, Y.; Cai, Z. Text Sentiment Orientation Analysis of Multi—Channels CNN and BiGRU Based on Attention Mechanism. J. Comput. Res. Dev. 2020, 57, 2583–2595. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional Block Attention Module; Springer: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Zhao, H.; Xue, L. Research on Stock Forecasting Based on LSTM-CNN-CBAM Model. Comput. Eng. Appl. 2021, 57, 203–207. [Google Scholar] [CrossRef]
- Du, X.; Gong, B.; Yu, P.; Shi, Y.; Kuzina, V.A.; Cheng, S. Research on CBAM-CNN based analog circuit fault diagnosis. Control Decis. 2021, 37, 2018–2609. [Google Scholar] [CrossRef]
- Lü, X.; Wu, Y.; Lian, J.; Zhang, Y.; Chen, C.; Wang, P.; Meng, L. Energy management of hybrid electric vehicles: A review of energy optimization of fuel cell hybrid power system based on genetic algorithm. Energy Convers. Manag. 2020, 205, 112474. [Google Scholar] [CrossRef]
- Garcia, A.M.; Sante, I.; Boullon, M.; Crecente, R. Calibration of an urban cellular automaton model by using statistical techniques and a genetic algorithm. application to a small urban settlement of nw spain. Int. J. Geogr. Inf. Sci. 2013, 27, 1593–1611. [Google Scholar] [CrossRef]
- Kantasa-Ard, A.; Nouiri, M.; Bekrar, A.; Ait el Cadi, A.; Sallez, Y. Machine learning for demand forecasting in the physical internet: Acase study of agricultural products in Thailand. Int. J. Prod. Res. 2021, 59, 7491–7515. [Google Scholar] [CrossRef]
- Nikbakht, S.; Anitescu, C.; Rabczuk, T. Optimizing the neural network hyperparameters utilizing genetic algorithm. J. Zhejiang Univ. -SCIENCE A 2021, 22, 407–426. [Google Scholar] [CrossRef]
- Kara, A. Multi-step influenza outbreak forecasting using deep lstm network and genetic algorithm. Expert Syst. Appl. 2021, 180, 115153. [Google Scholar] [CrossRef]
- Gao, J.; Tu, J.; Liu, K.; Li, Z. Decentralized control for the seismic response of high-rise building structures based on GA-LSTM. J. Vib. Shock. 2021, 40, 9. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| population | 10 |
| 0.5 | |
| 0.2 | |
| 20 |
| Comment | λ |
|---|---|
| The effect is super, the connection setting is convenient, go back and test the refresh rate and rgb color gamut. | 0.999909 |
| The power interface is easy to loosen, and the system response speed is slow. | 0.000644 |
| The screen is okay, and that’s it for the price. | 0.809492 |
| Fitness Function | MAE | MSE | RMSE | MAPE | SMAPE |
|---|---|---|---|---|---|
| MAE | 0.0322 | 0.0015 | 0.0389 | %3.5460 | %3.5496 |
| MSE | 0.0370 | 0.0018 | 0.0420 | %4.0497 | %4.0714 |
| RMSE | 0.0326 | 0.0015 | 0.0388 | %3.5929 | %3.5840 |
| MAPE | 0.0269 | 0.0010 | 0.0316 | %2.9543 | %2.9597 |
| Evaluation Indicators | |||||
|---|---|---|---|---|---|
| Predictive Model | MAE | MSE | RMSE | MAPE | SMAPE |
| SVR | 0.0571 | 0.0072 | 0.0850 | %6.3006 | %6.2532 |
| DSCNN | 0.0422 | 0.0026 | 0.0511 | %4.5046 | %4.6418 |
| BiLSTM | 0.0524 | 0.0041 | 0.0640 | %5.8822 | %5.6673 |
| DSCNN-BiLSTM | 0.0484 | 0.0035 | 0.0594 | %5.2893 | %5.3333 |
| Our model | 0.0269 | 0.0010 | 0.0316 | %2.9543 | %2.9597 |
| Serial Number | Brand | Price/Yuan | Resolution/px | Weight/kg | Screen Size/in | Panel Material | Customer Satisfaction |
|---|---|---|---|---|---|---|---|
| 1 | MI | 799 | 1920 × 1080 | 3.75 | 23.5 | IPS | 0.8601 |
| 2 | MI | 849 | 1920 × 1080 | 5.7 | 27 | IPS | 0.8506 |
| 3 | MI | 1299 | 2560 ×1440 | 5.7 | 27 | IPS | 0.8636 |
| 4 | MI | 749 | 1920 × 1080 | 5.3 | 23.5 | IPS | 0.8609 |
| 5 | MI | 1299 | 1920 × 1080 | 7.25 | 24.5 | IPS | 0.9527 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Q.; Li, H.; Zhang, Y.; Zheng, J. Product Evaluation Prediction Model Based on Multi-Level Deep Feature Fusion. Future Internet 2023, 15, 31. https://doi.org/10.3390/fi15010031
Zhou Q, Li H, Zhang Y, Zheng J. Product Evaluation Prediction Model Based on Multi-Level Deep Feature Fusion. Future Internet. 2023; 15(1):31. https://doi.org/10.3390/fi15010031
Chicago/Turabian StyleZhou, Qingyan, Hao Li, Youhua Zhang, and Junhong Zheng. 2023. "Product Evaluation Prediction Model Based on Multi-Level Deep Feature Fusion" Future Internet 15, no. 1: 31. https://doi.org/10.3390/fi15010031