
Polarity and Subjectivity Detection with Multitask Learning and BERT Embedding



Abstract
:1. Introduction
2. Related Work
- It helps in achieving generalization for multiple tasks;
- Each task improves its performance in association with the other participating tasks;
- Offers reduced complexity because a single system can handle multiple problems or tasks simultaneously.
- Implicit data augmentation: Learning only one task carries the risk of overfitting that task while learning jointly enables the model to obtain a better representation by averaging noise patterns. MTL effectively increases the sample size we are using to train our model by sharing the learnt features.
- Attention focusing: If the data are insufficient and high-dimensional, it can be challenging for a model to distinguish between relevant and irrelevant features.
- Eavesdropping: We can allow the model to eavesdrop through MTL; i.e., tasks challenging to learn for one model are learnt by the other model.
- Representation bias: MTL biases the model to prefer representations that other tasks also prefer, which helps the model to generalize new tasks in the future.
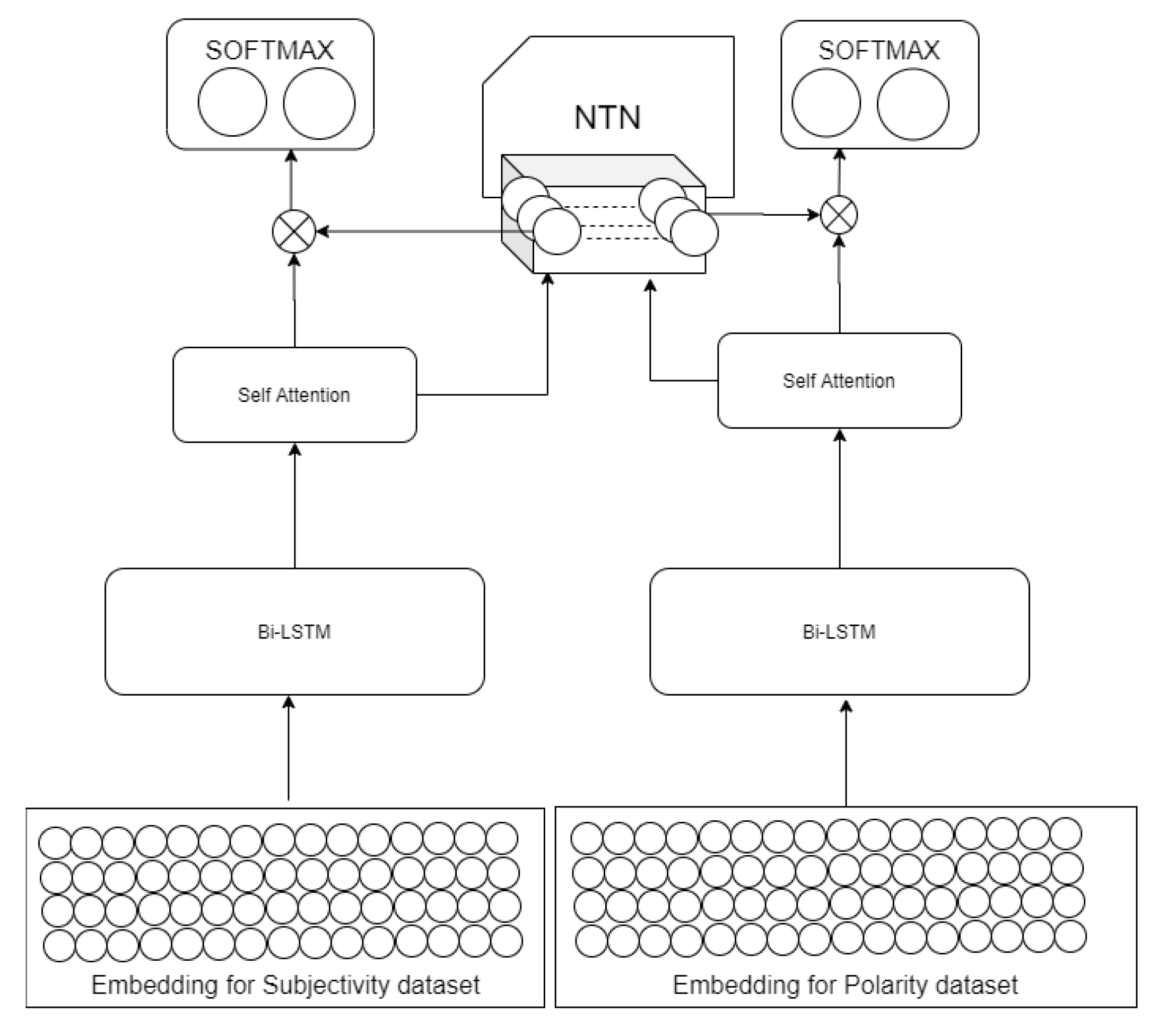
3. Proposed Multitask Learning (MTL) Based Framework
| Algorithm 1: Multitask BERT based Sentiment and Subjectivity |
| Result: Class |
| 1. = BERT(S) |
| 2. = BILSTM() |
| 3. = TDFC() |
| 4. = Drop() |
| 5. = Attention() |
| 6. = FC() |
| 7. = Drop() |
| 8. = Flatten() |
| 9. = FC() |
| 10. N = NTN([]) |
| 11. = |
| 12. = FC() |
| Result: BERT Embedding |
| initialization |
| 1. Token = BERTTokenizer(S) |
| 2. id = Map(Token, ID) |
| 3. S-new = Pad(S, maxlen) |
| 4. embedding = transformer(S-new) |
3.1. Embedding
BERT Embedding
3.2. Bidirectional LSTM Layer
3.3. Self Attention Network
3.4. Neural Tensor Network (NTN)
3.5. Classification
3.5.1. Sentiment Classification
3.5.2. Subjectivity Classification
4. Experiments
4.1. Dataset
- POL: The dataset contains 5331 positive and 5331 negative processed sentences. We selected 5000 sentences from each class randomly, i.e., 5000 positive and 5000 negative sentences.
- SUBJ: The dataset contains 5000 subjectively and 5000 objectively processed sentences.
4.2. Baselines and Model Variants
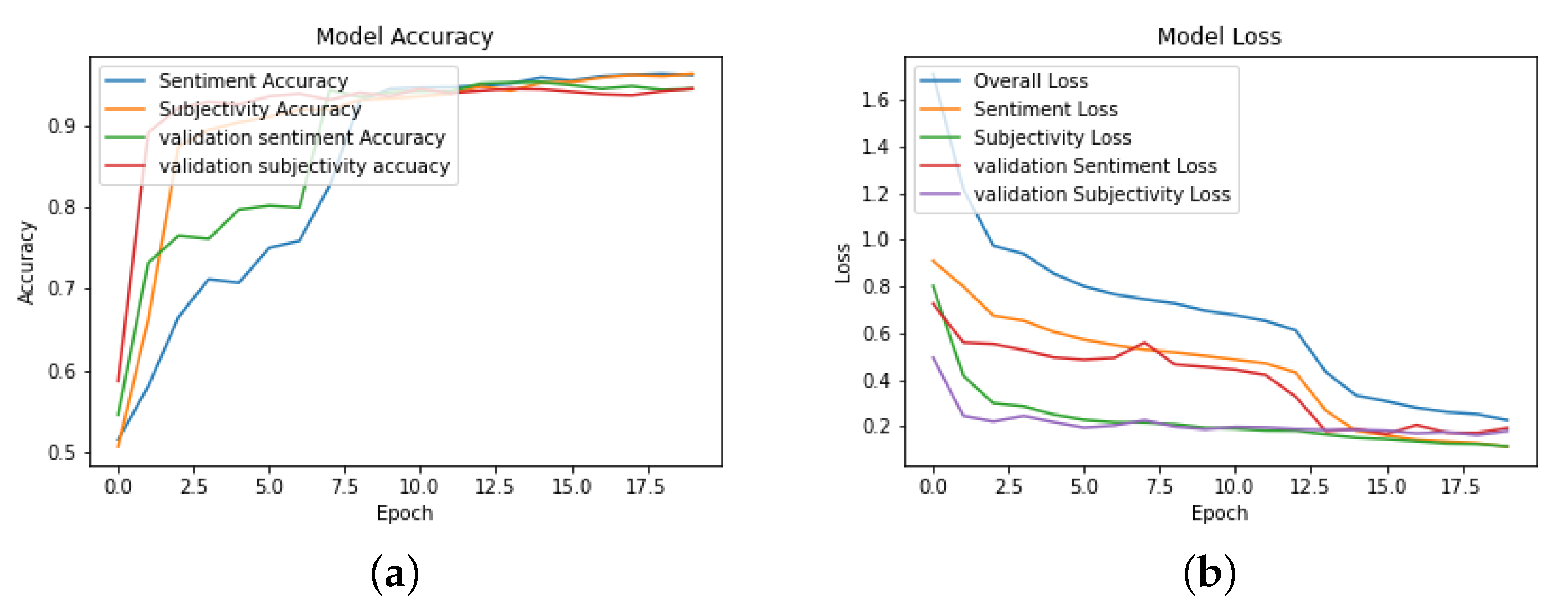
4.3. Hyperparameters and Training
- Trainable parameters for the MTL model: 14,942,052.
- Trainable parameters for the individual models: 1,923,746.
4.4. Results and Discussions
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pang, B.; Lee, L. Seeing Stars: Exploiting Class Relationships For Sentiment Categorization With Respect To Rating Scales. arXiv 2005, arXiv:cs/0506075. [Google Scholar]
- Satapathy, R.; Cambria, E.; Nanetti, A.; Hussain, A. A review of shorthand systems: From brachygraphy to microtext and beyond. Cogn. Comput. 2020, 12, 778–792. [Google Scholar] [CrossRef]
- Caruana, R. Multitask learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs Up? Sentiment Classification Using Machine Learning Techniques. arXiv 2002, arXiv:cs/0205070. [Google Scholar]
- Pang, B.; Lee, L. A Sentimental Education: Sentiment Analysis Using Subjectivity. arXiv 2004, arXiv:cs/0409058. [Google Scholar]
- Balikas, G.; Moura, S.; Amini, M.R. Multitask learning for fine-grained twitter sentiment analysis. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Shinjuku, Tokyo, Japan, 7–11 August 2017; pp. 1005–1008. [Google Scholar]
- Majumder, N.; Poria, S.; Peng, H.; Chhaya, N.; Cambria, E.; Gelbukh, A. Sentiment and sarcasm classification with multitask learning. IEEE Intell. Syst. 2019, 34, 38–43. [Google Scholar] [CrossRef] [Green Version]
- Liu, P.; Qiu, X.; Huang, X.J. Adversarial Multi-task Learning for Text Classification. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BA, Canada, 30 July–4 August 2017; pp. 1–10. [Google Scholar]
- Kochkina, E.; Liakata, M.; Zubiaga, A. All-in-one: Multi-task Learning for Rumour Verification. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 3402–3413. [Google Scholar]
- Mishra, A.; Tamilselvam, S.; Dasgupta, R.; Nagar, S.; Dey, K. Cognition-Cognizant Sentiment Analysis With Multitask Subjectivity Summarization Based on Annotators’ Gaze Behavior. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 5884–5891. [Google Scholar]
- Chaturvedi, I.; Ragusa, E.; Gastaldo, P.; Zunino, R.; Cambria, E. Bayesian network based extreme learning machine for subjectivity detection. J. Frankl. Inst. 2018, 355, 1780–1797. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Rashkin, H.; Smith, E.M.; Li, M.; Boureau, Y.L. Towards Empathetic Open-domain Conversation Models: A New Benchmark and Dataset. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5370–5381. [Google Scholar]
- Alonso, H.M.; Plank, B. When is multitask learning effective? Semantic sequence prediction under varying data conditions. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, Valencia, Spain, 3 April 2017; pp. 44–53. [Google Scholar]
- Stein, C. Inadmissibility of the Usual Estimator for the Mean of a Multivariate Normal Distribution. In Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics, Berkeley, CA, USA, 1 January 1956; pp. 197–206. [Google Scholar]
- Obozinski, G.; Taskar, B.; Jordan, M.I. Joint covariate selection and joint subspace selection for multiple classification problems. Stat. Comput. 2010, 20, 234–252. [Google Scholar] [CrossRef] [Green Version]
- Collobert, R.; Weston, J. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th international conference on Machine learning, Helsinki, Finland, 5–9 July 2008; pp. 160–167. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Liu, X.; Gao, J.; He, X.; Deng, L.; Duh, K.; Wang, Y.Y. Representation Learning Using Multi-Task Deep Neural Networks for Semantic Classification and Information Retrieval. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, CO, USA, 4 June 2015; pp. 912–921. [Google Scholar]
- Bansal, T.; Belanger, D.; McCallum, A. Ask the gru: Multi-task learning for deep text recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 107–114. [Google Scholar]
- Yim, J.; Jung, H.; Yoo, B.; Choi, C.; Park, D.; Kim, J. Rotating your face using multi-task deep neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 676–684. [Google Scholar]
- Torralba, A.; Murphy, K.P.; Freeman, W.T. Sharing visual features for multiclass and multiview object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 854–869. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Misra, I.; Shrivastava, A.; Gupta, A.; Hebert, M. Cross-stitch networks for multi-task learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NA, USA, 27–30 June 2016; pp. 3994–4003. [Google Scholar]
- Wiebe, J.; Bruce, R.; O’Hara, T.P. Development and use of a gold-standard data set for subjectivity classifications. In Proceedings of the 37th annual meeting of the Association for Computational Linguistics, College Park, MD, USA, 20–26 June 1999; pp. 246–253. [Google Scholar]
- Crawshaw, M. Multi-task learning with deep neural networks: A survey. arXiv 2020, arXiv:2009.09796. [Google Scholar]
- Socher, R.; Chen, D.; Manning, C.D.; Ng, A. Reasoning with neural tensor networks for knowledge base completion. Adv. Neural Inf. Process. Syst. 2013, 26, 926–934. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. HuggingFace’s Transformers: State-of-the-art Natural Language Processing. arXiv 2019, arXiv:1910.03771. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 5998–6008. [Google Scholar] [CrossRef]
- Cambria, E.; Li, Y.; Xing, F.; Poria, S.; Kwok, K. SenticNet 6: Ensemble Application of Symbolic and Subsymbolic AI for Sentiment Analysis. In Proceedings of the CIKM, Virtual Event, Ireland, 19–23 October 2020; pp. 105–114. [Google Scholar]
- Zhao, H.; Lu, Z.; Poupart, P. Self-adaptive hierarchical sentence model. In Proceedings of the 24th International Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 4069–4076. [Google Scholar]
- Amplayo, R.K.; Lee, K.; Yeo, J.; Hwang, S.W. Translations as additional contexts for sentence classification. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 3955–3961. [Google Scholar]
- Liu, P.; Qiu, X.; Huang, X. Recurrent neural network for text classification with multi-task learning. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 2873–2879. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015; pp. 2873–2879. [Google Scholar]



{kind=link}
{kind=link}
| Dataset | Train | Dev | Test | Max Length | Avg. Length | Vocabulary |
|---|---|---|---|---|---|---|
| POL | 7.2K | 800 | 2K | 40 | 15 | 16.5k |
| SUBJ | 7.2K | 800 | 2K | 85 | 17 | 18.5k |
| Framework | Subjective | Polarity | |
|---|---|---|---|
| Baselines | SenticNet 6 [30] | - | 92.8% |
| Subjectivity detector [6] | 92% | - | |
| AdaSent [31] | 95.5% | 83.1% | |
| CNN+MCFA [32] | 95.2% | 83.2% | |
| Multitask uniform layer [33] | 93.4% | 87.1% | |
| Multitask shared-layer [33] | 94.1% | 87.9% | |
| 92.3% | 92.1% | ||
| BERT Embedding | - | 77.5% | |
| 93.5% | - | ||
| 95.1% | 94.6% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Satapathy, R.; Pardeshi, S.R.; Cambria, E. Polarity and Subjectivity Detection with Multitask Learning and BERT Embedding. Future Internet 2022, 14, 191. https://doi.org/10.3390/fi14070191
Satapathy R, Pardeshi SR, Cambria E. Polarity and Subjectivity Detection with Multitask Learning and BERT Embedding. Future Internet. 2022; 14(7):191. https://doi.org/10.3390/fi14070191
Chicago/Turabian StyleSatapathy, Ranjan, Shweta Rajesh Pardeshi, and Erik Cambria. 2022. "Polarity and Subjectivity Detection with Multitask Learning and BERT Embedding" Future Internet 14, no. 7: 191. https://doi.org/10.3390/fi14070191