1. Introduction
The study and understanding of space–time distribution and changes in seawater temperature is an important aspect of oceanography, and it is of great significance to marine fisheries, aquaculture, and marine operations [
1,
2]. Sea surface temperature (SST) is a key parameter for measuring ocean thermal energy, and it also has a significant impact on regional climate change. For example, the seasonal prediction of high temperature anomalies in the eastern United States was improved by studying the evolution mode of SST anomalies; seasonal surface temperature anomalies in Europe were improved by studying SST anomalies in northern European waters; and the El Niño-Southern oscillation (ENSO) over the equatorial eastern Pacific can be effectively predicted by studying the variation law of SST [
3,
4,
5,
6]. Therefore, the accurate forecasting of SST is the basis for our understanding of local and global climate characteristics. However, the ocean not only has independent tidal and ocean current systems, but also multi-dimensional information, complex spatio-temporal correlations, a large area, a multi-model, remote correlation, and other problems, which cause great difficulties for the prediction and mechanisms of discovery of SST.
At present, the prediction methods of SST time series data can be divided into three categories. The first is a numerically-based approach, which predicts ocean elements according to a set of predefined rules such as those of coupled ocean-atmosphere models (GCMS) [
7,
8,
9]. However, these methods not only require extremely high computational resources and a professional knowledge of thermodynamics [
10], but also involve complex external data, which requires a large amount of model start-up time and set of integral assumptions. In addition, because these methods need to predict many parameters at the same time, it is a difficult task to accurately predict a single parameter for this method [
11]. Secondly, some methods of machine learning technology show a great performance in the prediction of complex time series, for example, KNN [
12] for ocean current prediction and SVR [
13] for wind field prediction. However, in the process of prediction, these methods only consider the temporal correlation of the data and ignore the spatial information, which leads to the failure of the model to effectively capture the spatio-temporal-dependent information of nonlinear correlation. Thirdly, with the development of deep learning, more and more researchers have begun to use neural networks to predict ocean elements. A lot of methods based on neural networks are widely applied in predicting sea surface temperature [
14]. Zhang Q et al. [
5] proposed a fully connected network model (FC_LSTM) based on LSTM for sea surface temperature prediction. Xie J et al. [
15] built a GED model, composed of GRU and an attention mechanism, which can be used to predict multi-scale SST. However, the above methods regard SST prediction as a single-source time-series prediction problem and do not make full use of the hidden relationship between time and space. This will not only lead to a failure to learn the fusion mode of multi-elements in the actual complex marine environment, but also cause the loss of fusion information and a decline in prediction accuracy.
At the same time, the graph neural networks (GNNs) have made great progress in dealing with relation dependence. GNNs can make full use of the relationship between variables, especially in the spatio-temporal correlation, due to the characteristics of graph neural networks of replacement invariance, local connectivity, and composition. Existing graph neural network methods usually use GCN-based methods to model unstructured sequences and the inter-dependencies of different variables such as ASTGCN [
16], STSGCN [
17], and GMAN [
18]. These methods take multivariate time series and externally predefined graph structures as inputs to predict future values or labels of multivariate time series. Compared with the previous methods, these methods have made significant improvements. However, these methods still cannot be used for SST time series because of the following difficulties:
Graph structure learning method: At present, most GNNs implement spatio-temporal series prediction based on predefined graph structure, but there is no graph structure displayed in SST time series data. The relationship between spatial points in the SST data set is hidden in the data, which needs to be mined instead of existing as prior knowledge. Therefore, how to mine the relationship between variables from the SST data and learn graph structure by deep learning remains a big challenge at present.
End-to-end framework: At present, most GNNs only update the hidden state of input sequence data in the learning process, neglecting to update the graph structure in time. Therefore, how to learn the graph structure and time series data simultaneously in a unified end-to-end framework is also a challenge.
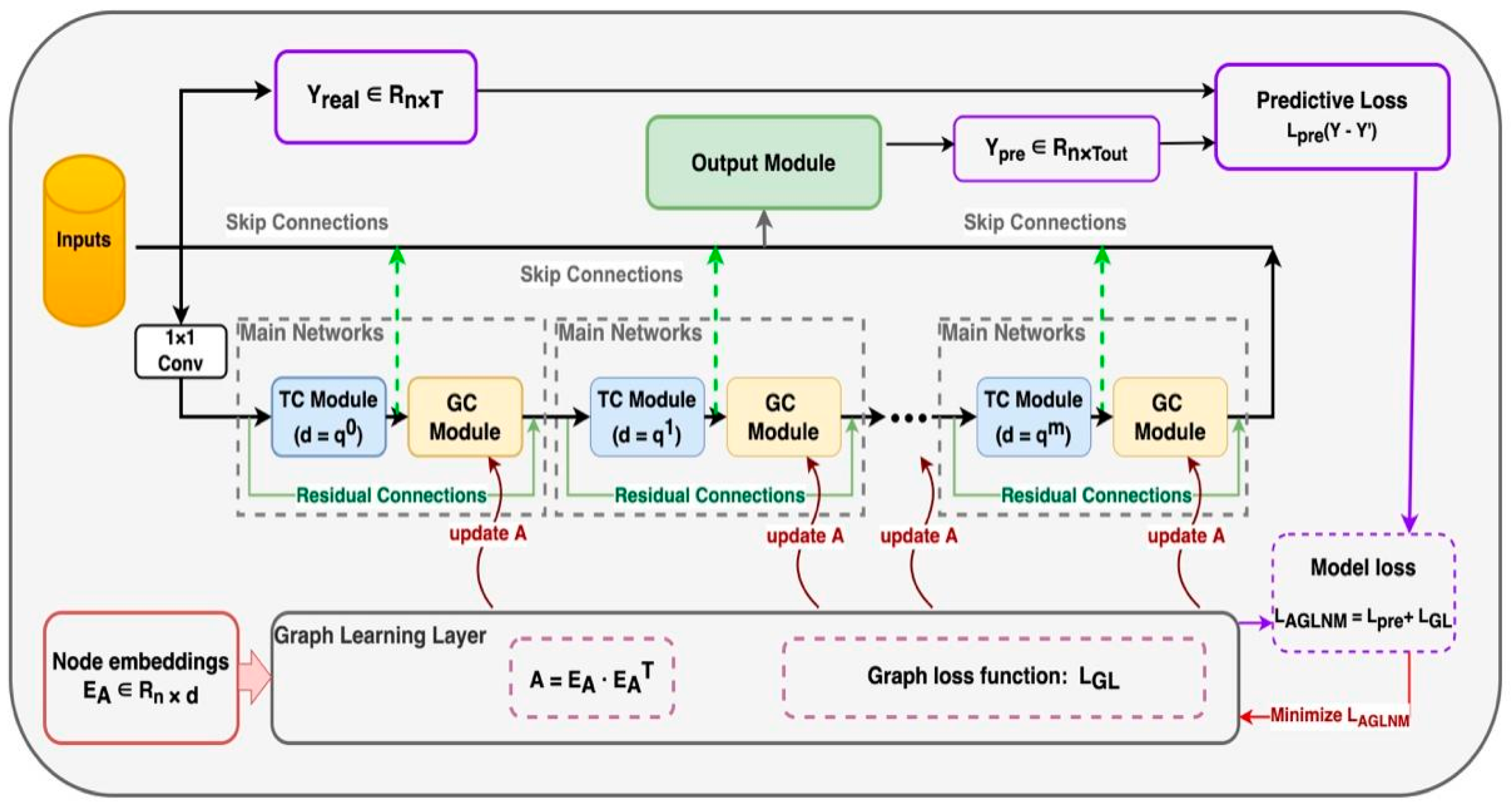
To solve the above problems, this paper proposes a graph neural network model (AGLNM) specially designed for spatio-temporal series prediction, which can automatically learn and model the relationship between variables. The AGLNM mainly consists of a graph learning module, graph convolution module, and time convolution module.
The contribution points of this paper are as follows:
The graph learning module designed by this paper breaks the current limitation of GNN application in SST data sets without an explicit graph structure; the module can not only mine the hidden spatial-temporal dependencies in SST sequential data, but also process SST data without a predefined graph structure by automatically learning the graph structure.
This paper proposes an end-to-end framework which includes a graph learning module, graph convolution module, and time convolution module. In this framework, a graph loss mechanism is added to guide the graph structure to update to the optimal direction according to downstream tasks, which makes the final graph structure effectively aid in SST prediction. Compared with other models, the mean absolute error of this model is reduced by more than 13%, and it can be transplanted to data sets without graph structure.
In this paper, AGLNM is evaluated for the first time on two remote-sensing SEA surface temperature data sets, and compared with several representative time series prediction models. The experimental results show that the performance of AGLMN is better than other advanced models.
The rest of this article is organized as follows. In
Section 2, we formulate the question and presents the details of the proposed AGLNM. In
Section 3, we evaluate the performance of the AGLNM and analyze the experimental results. Finally,
Section 4 gives our conclusions.
2. Materials and Methods
2.1. Problem Description
This paper mainly studies the prediction of sea surface temperature time series data. Since the SST data itself has spatial information, we can divide the SST data set into grid data according to latitude and longitude. Then, we regard the SST data set as a grid data set S composed of multi-variable time series X, where X represents the time series data set under different latitude and longitude, and N represents the number of grids after latitude and longitude division of the data set. For each time series data X, a training window with time step P and a prediction window with time step Q are given. Our purpose is to find a mapping function which could predict the SST sequence Y at the future time according to the SST sequence X at the past time. The X, Y, and the mapping function F are defined as follows:
where
represents the temperature value of the time series data at
ti moment, and P and Q represent the length of the historical series and the predicted series, respectively.
In this paper, is used to represent the graph formed on sea surface temperature data, where V is the set of spatial nodes of SST information, E is the set of associated relations between spatial nodes, and N is used to represent the number of spatial nodes in the graph. In addition, A represents the collar matrix of the relation between the spatial nodes V in the graph, specifically expressed as with if and elsewise.
2.2. Method Overview
Figure 1 briefly describes the end-to-end framework structure of the proposed approach, which is called the adaptive graph learning network model (AGLNM). The model framework mainly includes a graph learning module, a graph loss mechanism, graph convolution modules, and time convolution modules. The graph learning module can mine the adaptive adjacency matrix from the data, discover the hidden association between nodes, and then serve as the input for the graph convolution module. The graph loss mechanism can continuously update and optimize the adaptive adjacency matrix to the real dependence between the spatial points hidden in the SST data. The graph convolution module can be used to capture the dependencies between SST spatial points. The time convolution module is used to mine the time series pattern corresponding to each space point. In addition, residual links are added before and after each pair of spatio-temporal convolution modules to avoid the problem of gradient disappearance. The output of the final model will project the hidden correlation features of the SST time series into the output dimensions of the desired prediction series. Each module of the model is explained in detail in the following sections.
2.3. Adaptive Graph Learning Network (AGLN)
The graph learning module is designed to mine adaptive adjacency matrices driven by the data. However, in terms of time series prediction, most of the existing graph neural network methods based on mining adjacency matrices rely heavily on predetermined graph structure and cannot update graph structure over time during training, that is, adjacency matrix A needs to be calculated according to a distance function or similarity function before input to the model. Firstly, this method of calculating violence requires a great deal of domain knowledge. Secondly, predefined graph structures containing only explicit spatial information cannot mine hidden spatial dependencies for this prediction task, which may lead to considerable bias in the final prediction. Finally, predefined graph structures are not portable or compatible with other prediction tasks. To solve the above problems, the graph learning module proposed herein is an adaptive graph learning network (AGLN) driven by raw data, which is specifically used to automatically mine the hidden interdependence in real data. The adjacency matrix A containing the graph structure information is calculated by Formula (4). Specific instructions are as follows:
where
A is the adjacency matrix,
D is the degree matrix,
represents the node embedding matrix randomly initialized by AGLN for all nodes which can be learned and updated through the training process,
N represents the number of nodes or spatial points, and
d represents the dimension of node embedding. The transition matrix
is the adaptive matrix obtained after the normalization of adjacency matrix
A by the softmax function. It is worth noting that we directly update and calculate the dot product
of adjacency matrix
A and Laplace matrix
L, instead of generating adjacency matrix
A and Laplace matrix
L separately, which can reduce the computational overhead in the iterative training process.
In addition, the AGLN adds the following graph loss mechanism to continuously update and optimize the adjacency matrix
A toward the real spatial dependence of the SST data.
where
represents the spatial dependence relation between node
i and node
j,
is the calculation formula for the dependence relation between space point
i and
j. The smaller the value is, the larger the value of transition matrix
will be. Due to the simple property of transition matrix
, the second term in the formula can control the sparsity of the learned adjacency matrix
A.
It can be seen from Formula (5) that LGL is a graph loss function driven by the spatial node data. Therefore, minimizing LGL enables the AGLNM to adaptively mine the real spatial correlation hidden in SST data. However, minimizing the value of the graph loss function LGL alone may only provide a general solution. Therefore, we used LGL as the regularization term in the final loss function of this paper to participate in the training. The node-embedding matrix EA captures the hidden spatial dependencies between different nodes through automatic updating in training, and finally generates the adaptive adjacency matrix, which is then used as the input of the next graph convolution network.
2.4. Time Convolution Module
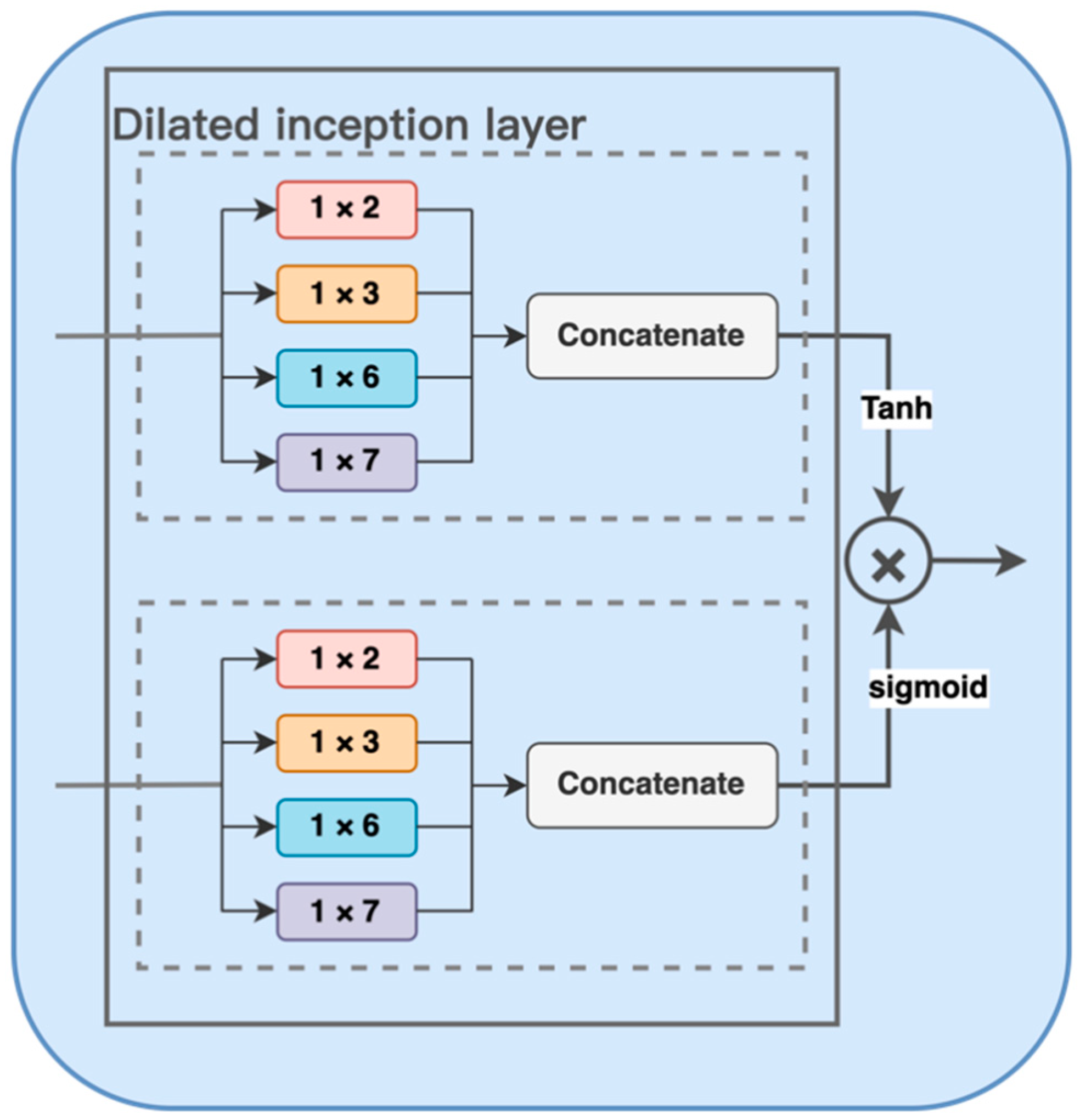
The time convolution module contained in the AGLN model proposed in this paper mainly adopts a gated structure and dilated convolution. The gated structure extracts multiple time patterns from the data by adopting multiple convolution modes in each convolution layer so as to effectively control the information flow. By controlling the expansion coefficient, dilatation convolution can enable the model to process longer time series in SST prediction tasks so as to better mine the hidden time correlation of SST data.
Figure 2 is the structural schematic diagram of the time convolution module. We design four one-dimensional convolution filters of different sizes as the initial layer of the time convolution module, which can extract the sequence patterns contained in the SST time series data. Then, the tangent hyperbolic activation function, sigmoid activation function, and a gating device are used to control the amount of information transmitted to the downstream task.
First of all, in order to simultaneously capture the long and short term signal patterns in SST data, we consider using multiple filters of different sizes to form an initial dilated convolution layer. It is worth noting that we need to choose the appropriate filter size to cover several inherent periods of the time series, such as 3, 7, 9, and 30. According to the periodicity of SST data changes, four filters with sizes of 1 × 2, 1 × 3, 1 × 6 and 1 × 7 are selected as a set of standard extended one-dimensional expansion convolution layers.
Secondly, in order to enable the model to better deal with long time series data in SST prediction tasks, we need to select an appropriate expansion coefficient. In standard convolutional networks, the field of view increases with the network depth and the number of convolutional kernels. However, SST time series prediction needs to deal with a large field of vision. If we use standard convolution, we have to design a very deep network or a very large filter, which leads to an explosion in model complexity and computation cost. Therefore, in order to avoid such a situation, we use the expansion coefficient
dn to increase the field of view and reduce the computational complexity of the model by changing the input down-sampling frequency. For example, when the expansion coefficient
dn is one, the field size
V of the dilated convolutional network can be calculated by Formula (6).
where
V is the size of the field of vision of the convolutional network,
d is the depth of the convolutional network,
k is the size of the convolution kernel or the size of the filter, and
q is the growth rate of the expansion coefficient,
q > 1.
As can be seen from Formula (6), in the case of the same number of deep convolution kernels in the network, compared with the standard convolution field with linear growth, the field of field of empty convolution can grow exponentially with the depth of the network. In this way, a longer time series pattern can be captured by processing a larger field. According to the above principle, the initial output of the expansion convolution layer can be calculated by Formula (8).
where
is the one-dimensional sequence input,
s is the step size,
t is the time,
dn is the expansion coefficient, and
,
,
, and
are four filters of different sizes. The module truncates the output of the four filters to the same length as the largest filter and then connects a set of filters across the channel dimension to output
Z.
2.5. Graph Convolution Module
As described in
Section 2.1 regarding the principle of adaptive graph generation, the function of the graph convolution module is to capture the spatial features of nodes with known node structure information. Kipf et al. proposed a first-order approximation algorithm that smoothens node spatial information by aggregation and transformation of adjacent information of nodes and the algorithm-defined graph convolution layer as in Formula (9) [
19,
20].
where
represents the adaptive adjacency matrix or transition matrix,
represents the input time series,
represents the output prediction time series,
represents the model parameter matrix,
D represents the data input dimension, and
M represents the number of layers of the graph convolution module.
The graph convolution layer can also extract node space features based on the local structure information of the graph. Li et al. proposed a spatio-temporal model containing a diffusion convolution layer by modeling the diffusion process of graph signals and proved the effectiveness of a diffusion convolution layer in predicting road traffic flow sequences [
21]. According to the form of Formula (9), the diffusion convolution layer is defined as in Formula (10) [
21].
where
represents a finite step, and
represents the power series of the transition matrix
. Because SST time series data belong to undirected graphs, we propose the graph convolution layer formula as shown in Formula (11) by combining the time dependence and hidden dependence of adaptive graph learning layer in this paper.
where
is the adaptive adjacency matrix,
represents the input history time series,
represents the output prediction time series, and
represents the model parameter matrix. In this paper, graph convolution belongs to a space-based method. Although the graph signal and node feature matrix are used interchangeably in this paper for consistency, the graph convolution represented by the above formula is still interpretable and can aggregate transform feature information from different neighborhoods.
5. Conclusions
Most of the existing SST prediction methods fail to fully mine and utilize the spatial correlation of SST, and most of the graph neural networks which model the variable relationship rely heavily on the predefined graph structure (i.e., use prior knowledge to construct the spatial point dependence). To solve the above problems, this paper specially designed an end-to-end model AGLNM for SST prediction without explicit graph structure, which can automatically learn the relationship between variables and accurately capture the fine-grained spatial correlations hidden in sequence data.
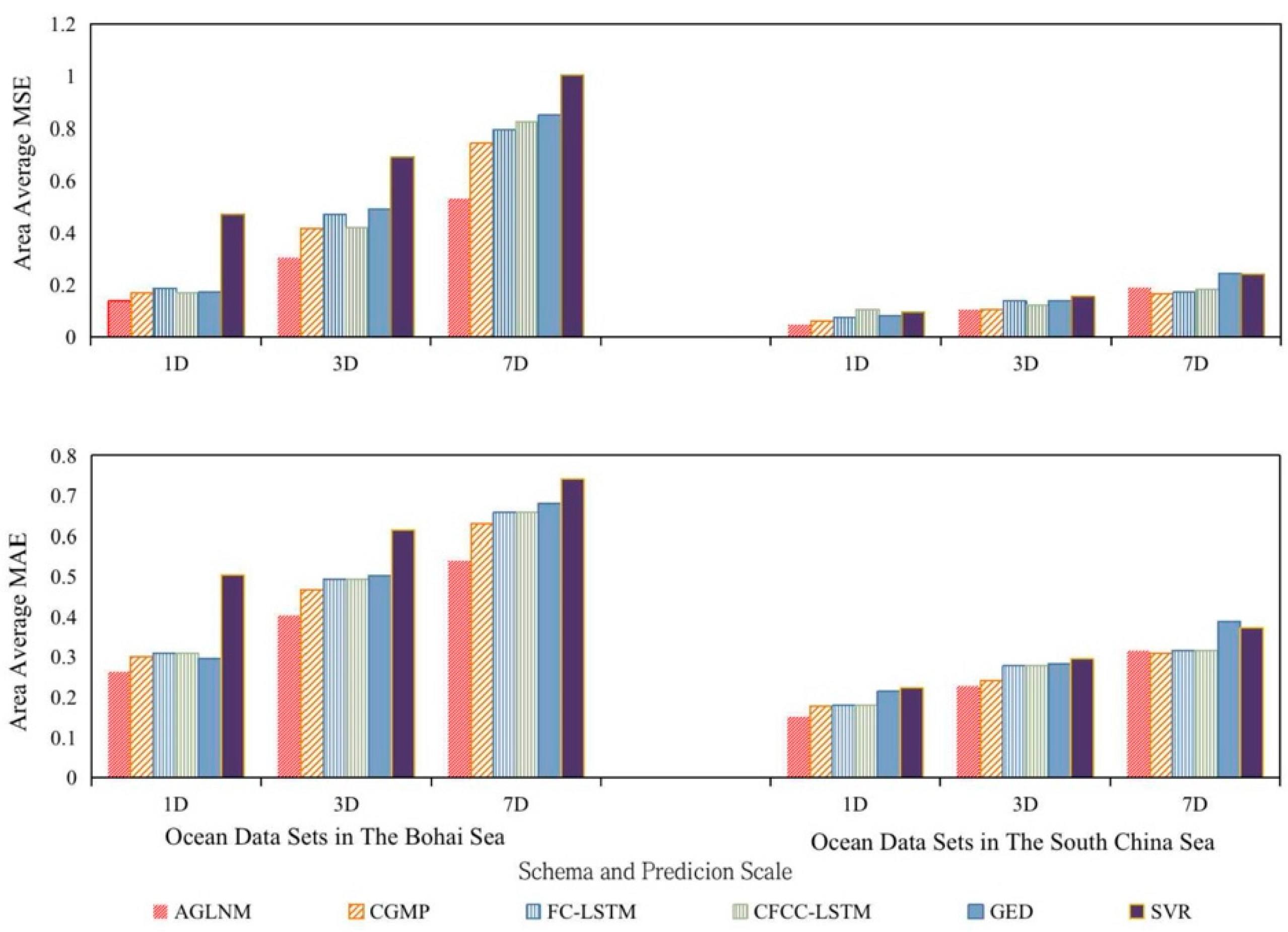
The experimental results of the performance test on the Bohai sea and South China Sea SST data sets show that: Firstly, AGLNM can effectively capture the dependence relationship between ocean spatial points. Secondly, the overall performance of the AGLNM is significantly better than that of the CGMP, FC-LSTM, CFCC-LSTM, GED, and SVR models in different sea areas and at different prediction scales. Finally, under the same prediction scale, the SST of the South China Sea is easier to predict than that of the Bohai Sea.
The AGLNM proposed in this paper has a better portability and can self-mine the hidden spatial association relationship contained in the data set that is the most consistent with the characteristics of the real data and can be better applied to large and complex data sets in the future. Based on the advantages and disadvantages of the AGLNM, the model can be better applied to data sets with more complex environments, large feature fluctuations, and stronger time-space correlations, such as the data set of the first island chain affected by monsoons, ocean currents, and man-made operations simultaneously, which can make full use to the advantages of the model and have stronger military significance.






{kind=link}
{kind=link}
{kind=link}