
Medical Internet-of-Things Based Breast Cancer Diagnosis Using Hyperparameter-Optimized Neural Networks

 , , and
, , and
Abstract
:1. Introduction
- A novel framework for the optimization of hyperparameters of the convolutional neural network (CNN) and artificial neural network (ANN) models for achieving optimal classification results.
- An experimental comparison of SVM and MLP classifiers that have been trained and evaluated utilizing particle swarm optimization (PSO) for feature selection.
- The suggested approach can be easily integrated into the medical IoT-based healthcare system and used to effectively diagnose breast cancer.
2. Related Works
3. Materials and Methods
3.1. Dataset
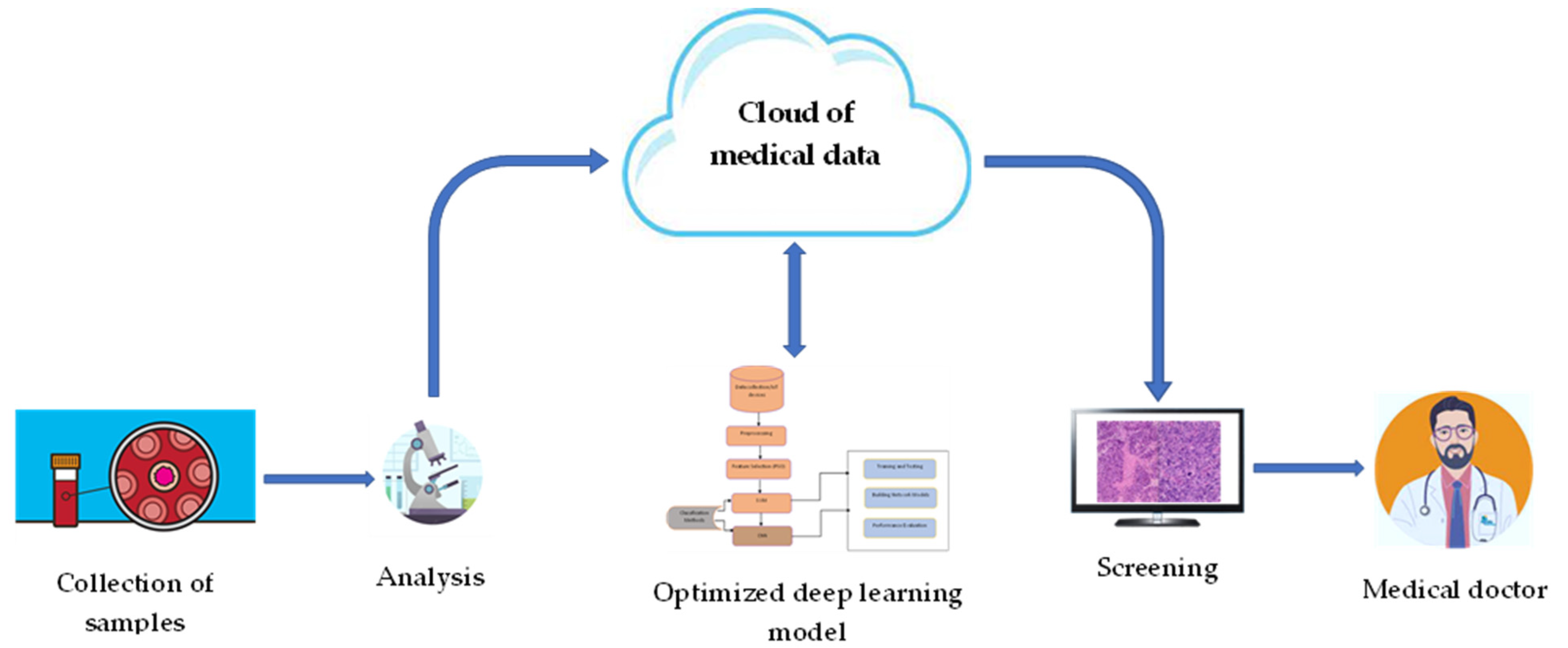
3.2. Overall IoMT-Based Framework
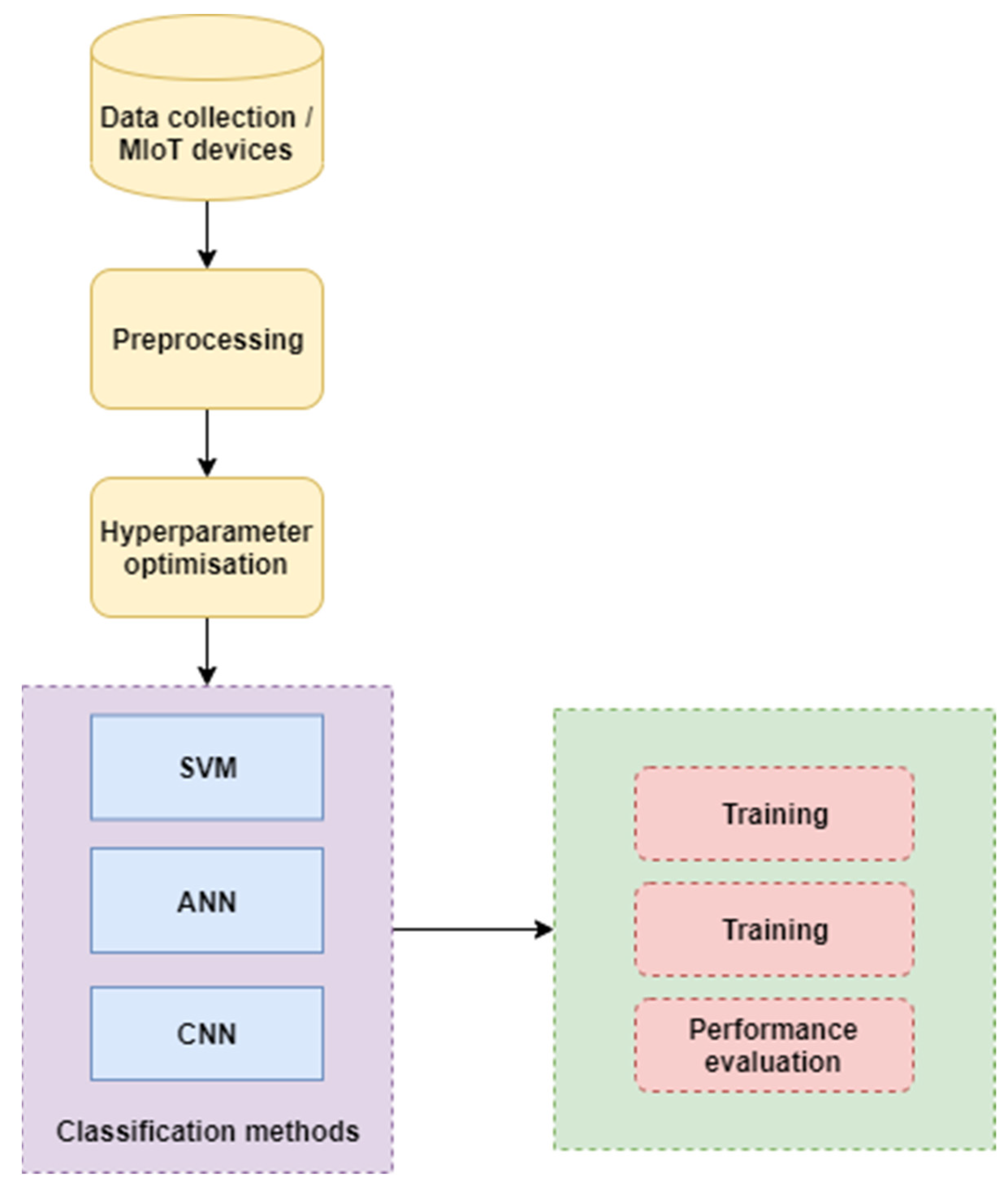
3.3. Proposed Methodology
3.4. Data Preprocessing
3.5. Artificial Neural Networks (ANNs)
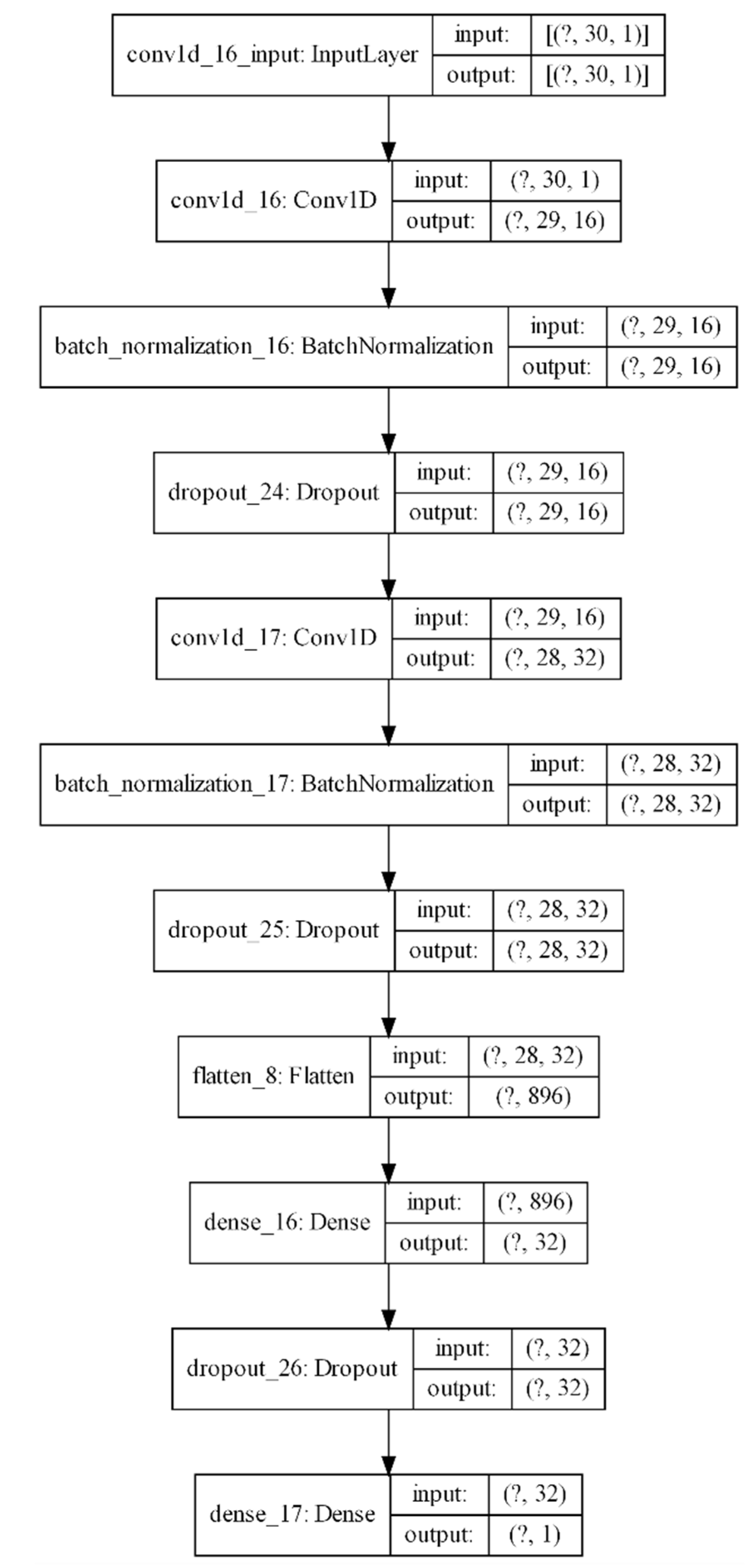
3.6. Convolutional Neural Networks (CNNs)
3.7. Hyperparameter Optimization
- The manual search determines the hyperparameter value based on the researcher’s intuition or expertise and can be employed when the researcher has a strong grasp of neural network topology and learning data. However, the criteria for setting hyperparameters are vague and necessitating several experimentations.
- Grid-based search (GS) identifies the hyperparameter with the highest performance by calculating many values for each hyperparameter and combining them. GS is straightforward, easy to use, and requires minimal prior knowledge. With GS, all potential hyperparameter value combinations are explored to identify the ideal values based on the upper and lower limits of each hyperparameter and a predefined step size, which creates the hyperparameter value space. Because GS runs all potential combinations, it is considered comprehensive. The combination of required runs increases exponentially as the number increases, which is a weakness of GS. As a result, GS takes a long time and has a significant computational cost. Another disadvantage of utilizing GS is that, owing to the nature of some ML algorithms, such as ANN and CNN, rerunning algorithms with the same settings will get differing prediction results and thus different performance.
3.8. Baseline Machine Learning Classifiers for Comparison
3.9. Performance Evaluation Metric
- Classification Accuracy: demonstrates the performance of the classification system.
- Recall: The ratio of accurately predicted positive observations to all observed positive observations in the actual class.
- Specificity shows that a prediction is negative and the individual is healthy.
- F1-Score: This is the harmonic mean of precision and recall.
- Precision refers to the accuracy with which the model makes a correct diagnosis.
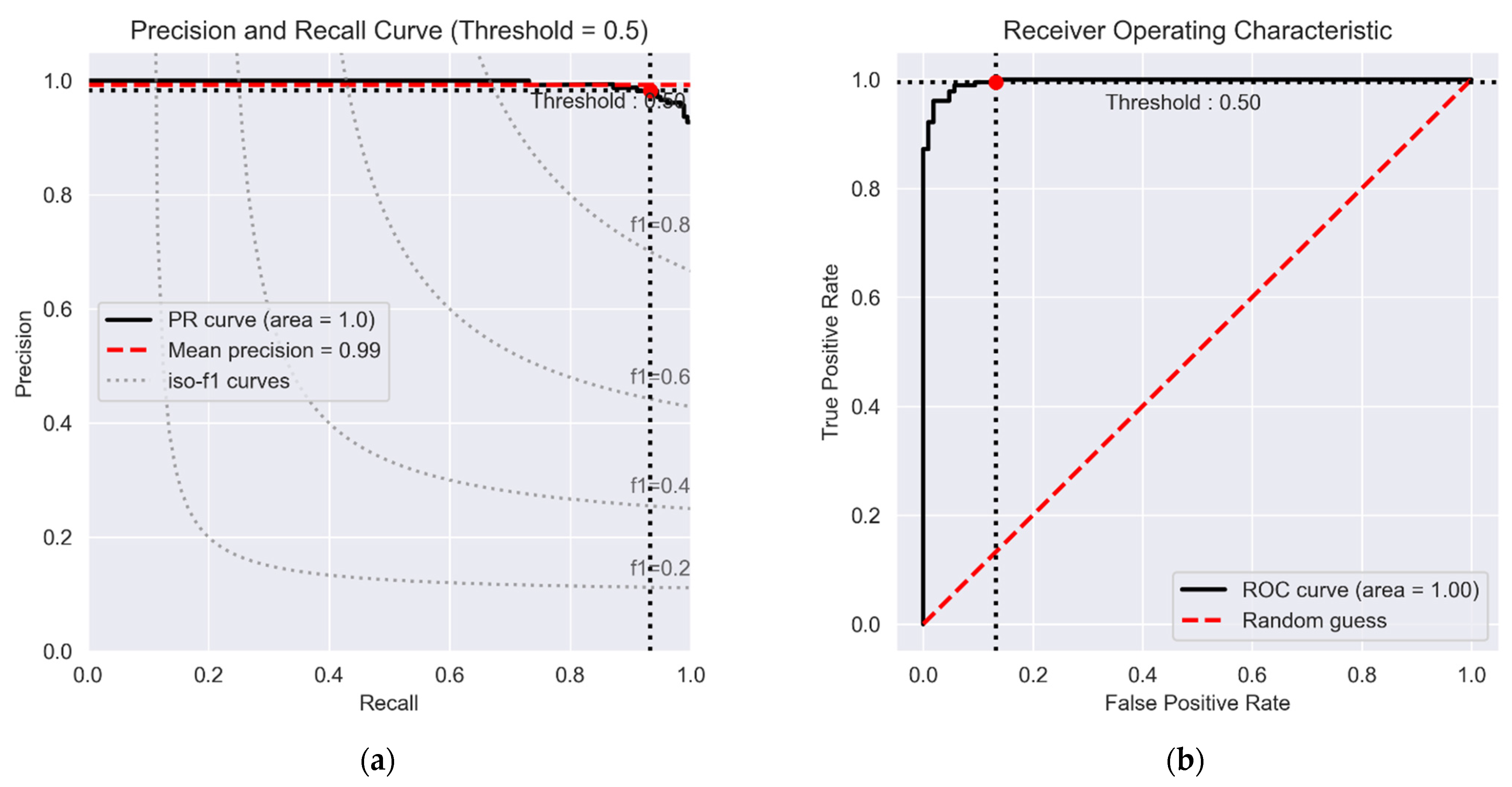
- Receiver Operator Characteristics (ROC) is a curve that draws the TPs against the FPs at various threshold values for evaluation of binary classification results.
- The precision-recall (PR) curve is used to assess binary classification algorithms’ performance. PR curves, like ROC curves, provide a graphical depiction of a classifier’s performance by calculating and plotting precision against recall for a single classifier over a range of thresholds rather than a single number.
4. Experimental Results and Analysis
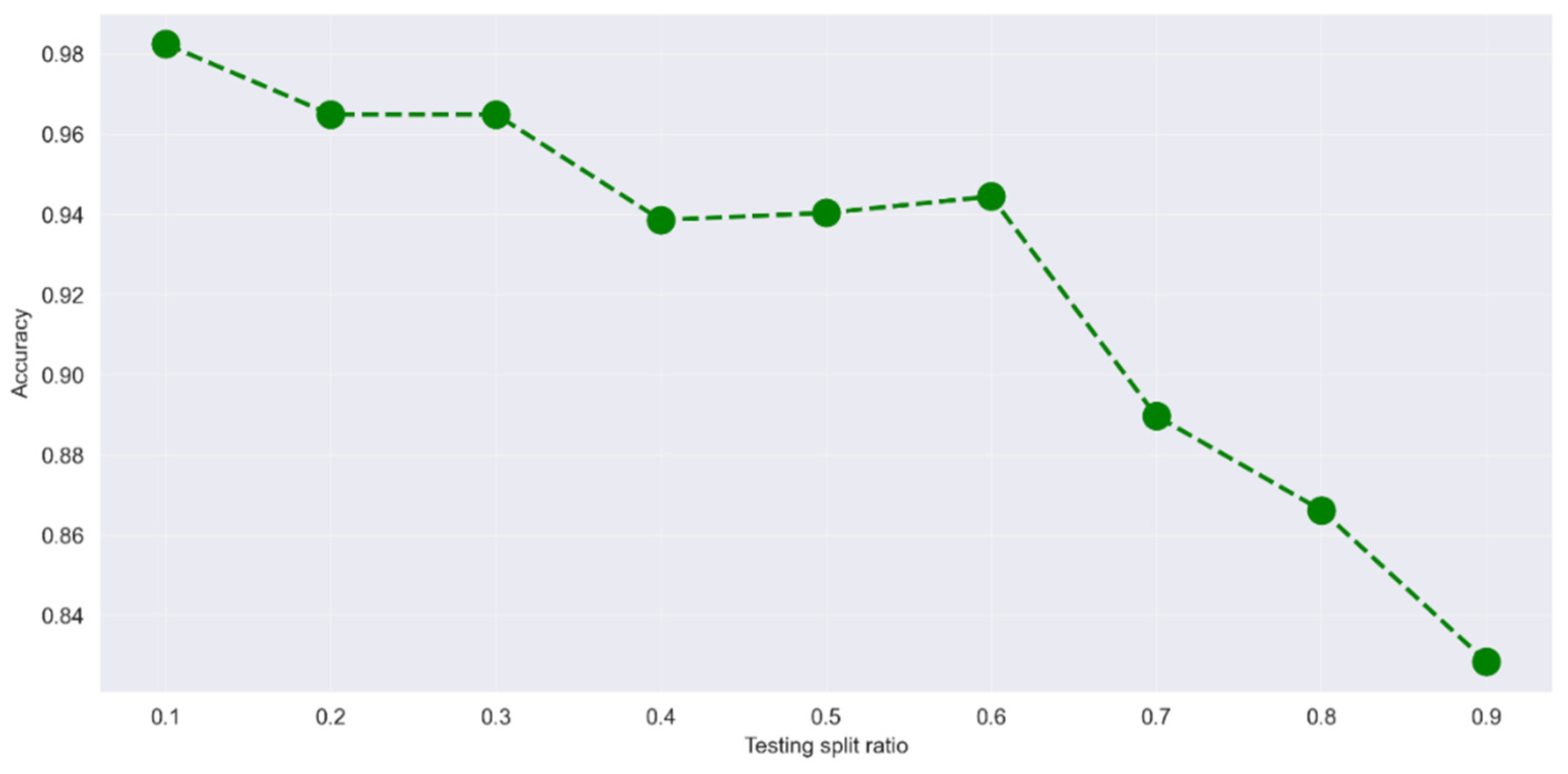
4.1. Dataset and Experimental Settings
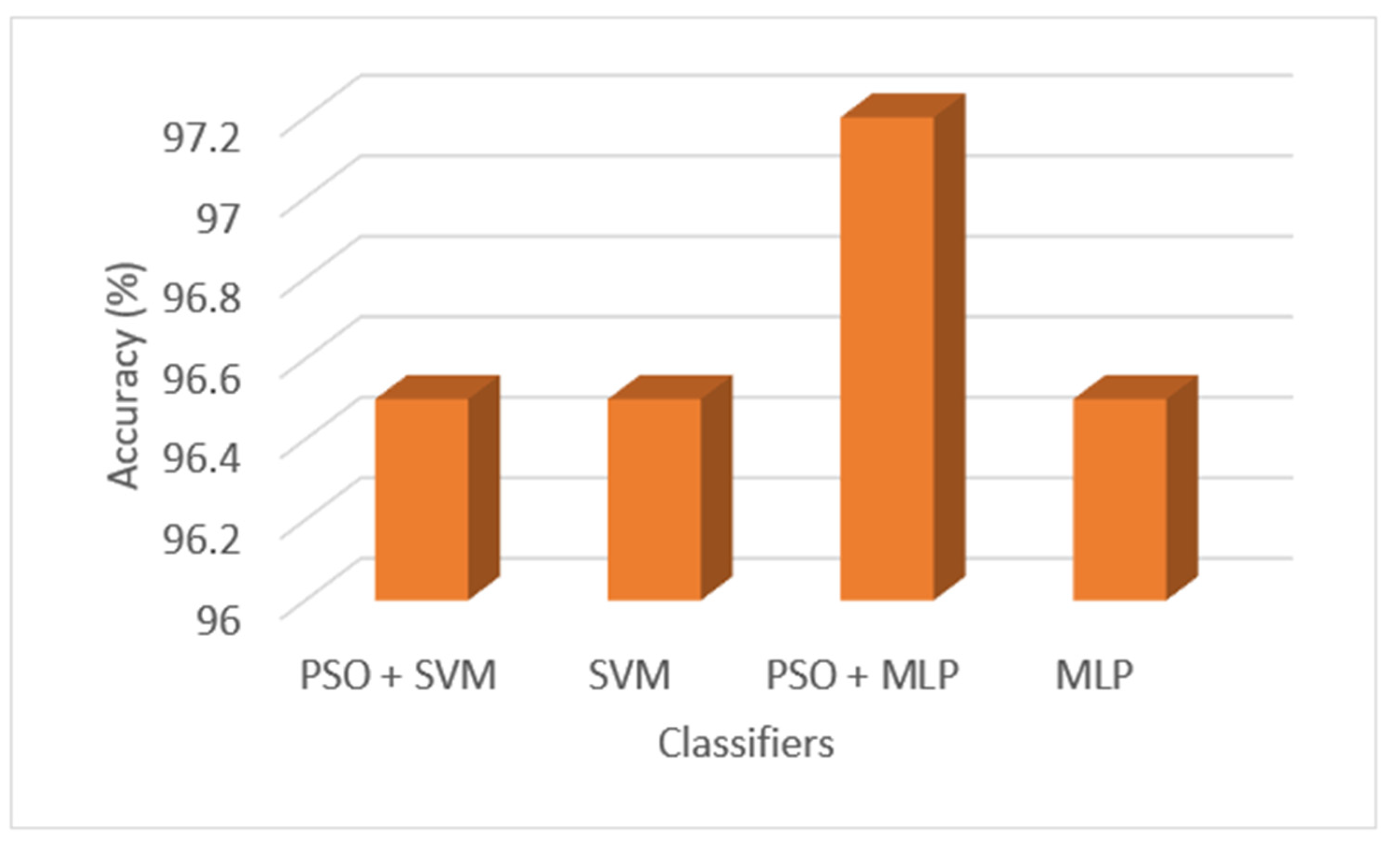
4.2. Analysis of the Baseline Classifier Results
4.3. Optimization of Hyperparameters of the CNN and ANN Models
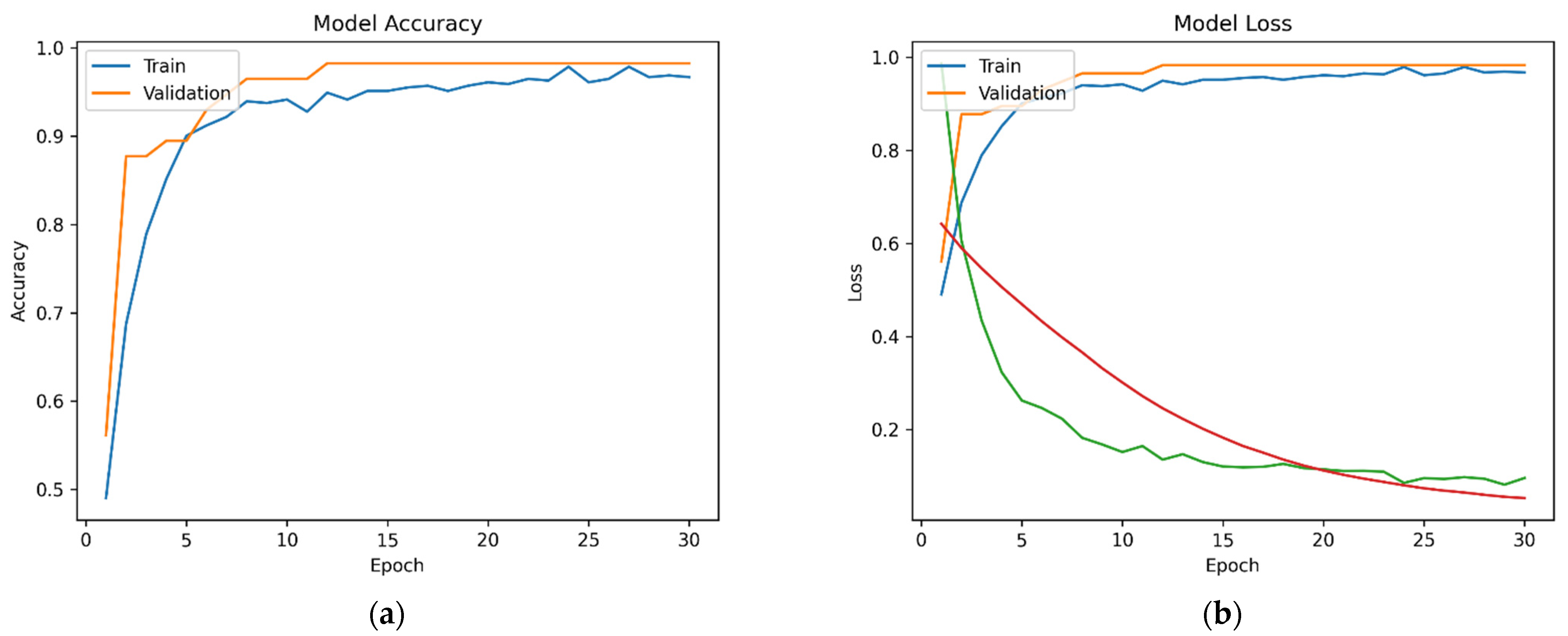
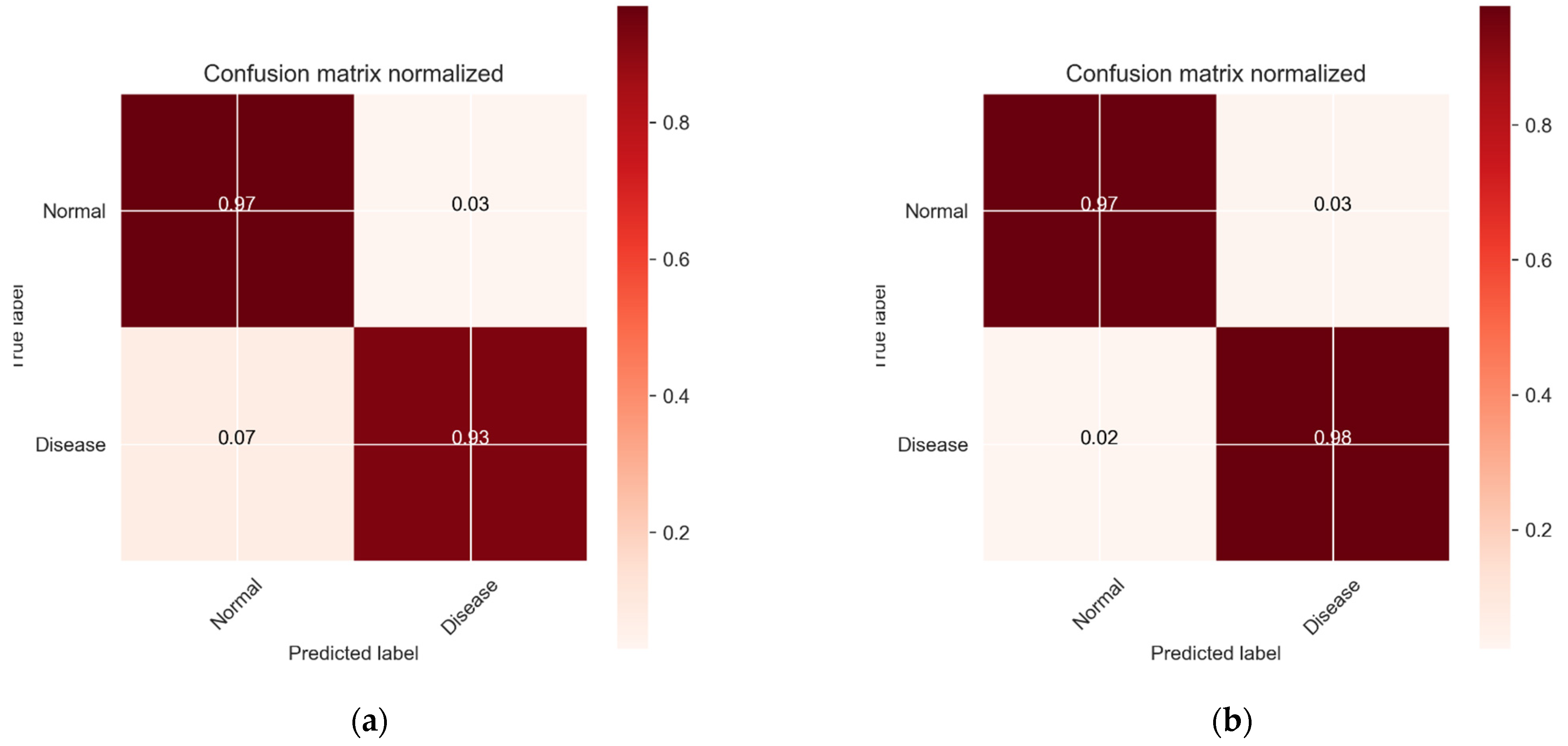
4.4. Results of Top-Performing CNN Model
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BC | Breast Cancer |
| ML | Machine Learning |
| DL | Deep learning |
| GS | Grid based search |
| DOE | Designs of Experiment |
| PSO | Particle Swarm Optimization |
| IoT | Internet of Things |
| AI | Artificial Intelligence |
| ANN | Artificial Neural Network |
| CNN | Convolutional neural network |
| SVM | Support Vector Machine |
| MLP | Multilayer perceptron |
| WDBC | Wisconsin Diagnostic Breast Cancer |
| IoMT | Internet of Medical Things |
| NB | Naïve Bayes |
| DT | Decision Tree |
| RF | Random Forest |
| kNN | K-Nearest Neighbor |
| LDA | Linear Discriminant Analysis |
| LR | Logistic Regression |
| RFSS | Representative Feature Subset Selection |
References
- Anand, P.; Kunnumakara, A.B.; Sundaram, C.; Harikumar, K.B.; Tharakan, S.T.; Lai, O.S.; Sung, B.; Aggarwal, B.B. Cancer is a Preventable Disease that Requires Major Lifestyle Changes. Pharm. Res. 2008, 25, 2097–2116. [Google Scholar] [CrossRef] [PubMed]
- Wild, C.P.; Stewart, B.W.; Wild, C. World Cancer Report 2014; World Health Organization: Geneva, Switzerland, 2014. [Google Scholar]
- Siegel, R.; Ma, J.; Zou, Z.; Jemal, A. Cancer statistics, 2014. CA Cancer J. Clin. 2014, 64, 9–29. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- De Martel, C.; Ferlay, J.; Franceschi, S.; Vignat, J.; Bray, F.; Forman, D.; Plummer, M. Global burden of cancers at-tributable to infections in 2008: A review and synthetic analysis. Lancet Oncol. 2012, 13, 607–615. [Google Scholar] [CrossRef]
- Kim, W.; Kim, K.S.; Lee, J.E.; Noh, D.Y.; Kim, S.W.; Jung, Y.S.; Park, M.Y.; Park, R.W. Development of novel breast cancer re-currence prediction model using support vector machine. J. Breast Cancer 2012, 15, 230–238. [Google Scholar] [CrossRef] [Green Version]
- Ahmad, L.G.; Eshlaghy, A.T.; Poorebrahimi, A.; Ebrahimi, M.; Razavi, A.R. Using three machine learning techniques for predicting breast cancer recurrence. J. Health Med. Inf. 2013, 4, 3. [Google Scholar]
- Kashyap, D.; Kaur, H. Cell-free miRNAs as non-invasive biomarkers in breast cancer: Significance in early diagnosis and metastasis prediction. Life Sci. 2020, 246, 117417. [Google Scholar] [CrossRef]
- Kadry, S.; Damasevicius, R.; Taniar, D.; Rajinikanth, V.; Lawal, I.A. Extraction of tumour in breast MRI using joint thresholding and segmentation—A study. In Proceedings of the 2021 IEEE 7th International Conference on Bio Signals, Images and Instrumentation, Chennai, India, 25–27 March 2021. ICBSII 2021. [Google Scholar] [CrossRef]
- Rajinikanth, V.; Kadry, S.; Taniar, D.; Damasevicius, R.; Rauf, H.T. Breast-cancer detection using thermal images with marine-predators-algorithm selected features. In Proceedings of the 2021 IEEE 7th International Conference on Bio Signals, Images and Instrumentation, Chennai, India, 25–27 March 2021. ICBSII 2021. [Google Scholar] [CrossRef]
- Maqsood, S.; Damaševičius, R.; Maskeliūnas, R. TTCNN: A Breast Cancer Detection and Classification towards Computer-Aided Diagnosis Using Digital Mammography in Early Stages. Appl. Sci. 2022, 12, 3273. [Google Scholar] [CrossRef]
- Azeez, N.A.; Towolawi, T.; Van der Vyver, C.; Misra, S.; Adewumi, A.; Damaševičius, R.; Ahuja, R. A fuzzy expert system for diagnosing and analyzing human diseases. In Advances in Intelligent Systems and Computing; Springer Nature: Berlin, Switzerland, 2019; pp. 474–484. [Google Scholar] [CrossRef]
- Lauraitis, A.; Maskeliūnas, R.; Damaševičius, R. ANN and Fuzzy Logic Based Model to Evaluate Huntington Disease Symptoms. J. Health Eng. 2018, 2018, 4581272. [Google Scholar] [CrossRef] [Green Version]
- Barracliffe, L.; Arandjelovic, O.; Humphris, G. A pilot study of breast cancer patients: Can machine learning predict healthcare professionals’ responses to patient emotions. In Proceedings of the International Conference on Bioinformatics and Computational Biology, Honolulu, HI, USA, 20–22 March 2017; pp. 20–22. [Google Scholar]
- Hassan, M.A.; Malik, A.S.; Fofi, D.; Karasfi, B.; Meriaudeau, F. Towards health monitoring using remote heart rate measurement using digital camera: A feasibility study. Measurement 2020, 149, 106804. [Google Scholar] [CrossRef]
- Al-Turjman, F.; Alturjman, S. Context-sensitive access in the industrial internet of things (IIoT) healthcare applications. IEEE Trans. Ind. Inform. 2018, 14, 2736–2744. [Google Scholar] [CrossRef]
- Dourado, C.M.J.M.; Da Silva, S.P.P.; Da Nobrega, R.V.M.; Filho, P.P.R.; Muhammad, K.; De Albuquerque, V.H.C. An Open IoHT-Based Deep Learning Framework for Online Medical Image Recognition. IEEE J. Sel. Areas Commun. 2020, 39, 541–548. [Google Scholar] [CrossRef]
- Parah, S.A.; Kaw, J.A.; Bellavista, P.; Loan, N.A.; Bhat, G.M.; Muhammad, K.; de Albuquerque, V.H.C. Efficient Security and Authentication for Edge-Based Internet of Medical Things. IEEE Internet Things J. 2020, 8, 15652–15662. [Google Scholar] [CrossRef]
- Dimitrov, D.V. Medical internet of things and big data in healthcare. Healthc. Inform. Res. 2016, 22, 156–163. [Google Scholar] [CrossRef] [PubMed]
- Deebak, B.D.; Al-Turjman, F.; Aloqaily, M.; Alfandi, O. An authentic-based privacy preservation protocol for smart e-healthcare systems in IoT. IEEE Access 2019, 7, 135632–135649. [Google Scholar] [CrossRef]
- Al-Turjman, F.; Zahmatkesh, H.; Mostarda, L. Quantifying uncertainty on the internet of medical things and big-data services using intelligence and deep learning. IEEE Access 2019, 7, 115749–115759. [Google Scholar] [CrossRef]
- Huang, C.; Zhang, G.; Chen, S.; Albuquerque, V. Healthcare Industry 4.0: A Novel Intelligent Multi-sampling Tensor Network for Detection and Classification of Oral Cancer. IEEE Trans. Ind. Inform. 2022, 1. [Google Scholar] [CrossRef]
- Alzubi, J.A.; Manikandan, R.; Alzubi, O.; Qiqieh, I.; Rahim, R.; Gupta, D.; Khanna, A. Hashed Needham Schroeder industrial IoT-based cost-optimized deep secured data transmission in the cloud. Measurement 2019, 150, 107077. [Google Scholar] [CrossRef]
- Sharma, A.; Kulshrestha, S.; Daniel, S. Machine learning approaches for breast cancer diagnosis and prognosis. In 2017 International Conference on Soft Computing and Its Engineering Applications (icSoftComp); IEEE: Piscataway, NI, USA, 2017; pp. 1–5. [Google Scholar]
- Chougrad, H.; Zouaki, H.; Alheyane, O. Deep convolutional neural networks for breast cancer screening. Comput. Methods Programs Biomed. 2018, 157, 19–30. [Google Scholar] [CrossRef]
- Zebari, D.A.; Ibrahim, D.A.; Zeebaree, D.Q.; Haron, H.; Salih, M.S.; Damaševičius, R.; Mohammed, M.A. Systematic review of computing approaches for breast cancer detection based computer aided diagnosis using mammo-gram images. Appl. Artif. Intell. 2021, 35, 2157–2203. [Google Scholar] [CrossRef]
- Amrane, M.; Oukid, S.; Gagaoua, I.; Ensari, T. Breast cancer classification using machine learning. In 2018 Electric Electronics, Computer Science, Biomedical Engineerings Meeting (EBBT); IEEE: Piscataway, NI, USA, 2018; pp. 1–4. [Google Scholar]
- Dasgupta, S.; Rajapakshe, K.; Zhu, B.; Nikolai, B.; Yi, P.; Putluri, N.; Choi, J.M.; Jung, S.Y.; Coarfa, C.; Westbrook, T.F.; et al. Metabolic enzyme PFKFB4 activates transcriptional coactivator SRC-3 to drive breast cancer. Nature 2018, 556, 249–254. [Google Scholar] [CrossRef]
- Gupta, A.; Kaushik, B.N. Feature selection from a biological database for breast cancer prediction and detection using a machine learning classifier. J. Artif. Intell. 2018, 57, 23–33. [Google Scholar] [CrossRef]
- Yue, W.; Wang, Z.; Chen, H.; Payne, A.; Liu, X. Machine learning with applications in breast cancer diagnosis and prognosis. Designs 2018, 2, 13. [Google Scholar] [CrossRef] [Green Version]
- Omondiagbe, D.A.; Veeramani, S.; Sidhu, A.S. Machine learning classification techniques for breast cancer diagnosis. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2019; Volume 495, p. 012033. [Google Scholar]
- Li, Y.; Chen, Z. Performance evaluation of machine learning methods for breast cancer prediction. Appl Comput. Math 2018, 7, 212–216. [Google Scholar] [CrossRef]
- Hajiabadi, H.; Babaiyan, V.; Zabihzadeh, D.; Hajiabadi, M. Combination of loss functions for robust breast cancer prediction. Comput. Electr. Eng. 2020, 84, 106624. [Google Scholar] [CrossRef]
- Shravya, C.; Pravalika, K.; Subhani, S. Prediction of breast cancer using supervised machine learning techniques. Int. J. Innov. Technol. Explor. Eng. 2019, 8, 1106–1110. [Google Scholar]
- Chaurasia, V.; Pal, S.; Tiwari, B. Prediction of benign and malignant breast cancer using data mining techniques. J. Algorithms Comput. Technol. 2018, 12, 119–126. [Google Scholar] [CrossRef] [Green Version]
- Aavula, R.; Bhramaramba, R. XBPF: An extensible breast cancer prognosis framework for predicting susceptibility, recurrence, and survivability. Int. J. Eng. Adv. Technol 2019, 8, 2249–8958. [Google Scholar]
- Nandagopal, V.; Geeitha, S.; Kumar, K.V.; Anbarasi, J. Feasible analysis of gene expression–a computational-based classification for breast cancer. Measurement 2019, 140, 120–125. [Google Scholar] [CrossRef]
- Abdar, M.; Zomorodi-Moghadam, M.; Zhou, X.; Gururajan, R.; Tao, X.; Barua, P.D.; Gururajan, R. A new nested ensemble technique for automated diagnosis of breast cancer. Pattern Recognit. Lett. 2020, 132, 123–131. [Google Scholar] [CrossRef]
- Wang, L. Microwave Sensors for Breast Cancer Detection. Sensors 2018, 18, 655. [Google Scholar] [CrossRef] [Green Version]
- Mansour, R.F. A Robust Deep Neural Network Based Breast Cancer Detection and Classification. Int. J. Comput. Intell. Appl. 2020, 19, 2050007. [Google Scholar] [CrossRef]
- Ragab, M.; Albukhari, A.; Alyami, J.; Mansour, R.F. Ensemble Deep-Learning-Enabled Clinical Decision Support System for Breast Cancer Diagnosis and Classification on Ultrasound Images. Biology 2022, 11, 439. [Google Scholar] [CrossRef] [PubMed]
- Lee, K.Y.; Park, J.B. Application of particle swarm optimization to economic dispatch problem: Advantages and dis-advantages. In 2006 IEEE PES Power Systems Conference and Exposition; IEEE: Piscataway, NI, USA, 2006; pp. 188–192. [Google Scholar]
- Abu Khurma, R.; Aljarah, I.; Sharieh, A.; Elaziz, M.A.; Damaševičius, R.; Krilavičius, T. A review of the modification strategies of the nature inspired algorithms for feature selection problem. Mathematics 2022, 10, 464. [Google Scholar] [CrossRef]
- Cooney, C.; Korik, A.; Folli, R.; Coyle, D. Evaluation of hyperparameter optimization in machine and deep learning methods for decoding imagined speech eeg. Sensors 2020, 20, 4629. [Google Scholar] [CrossRef]
- Mostafa, S.S.; Mendonca, F.; Ravelo-Garcia, A.G.; Juliá-Serdá, G.G.; Morgado-Dias, F. Multi-objective hyperparameter optimization of convolutional neural network for obstructive sleep apnea detection. IEEE Access 2020, 8, 129586–129599. [Google Scholar] [CrossRef]
- Raji, I.D.; Bello-Salau, H.; Umoh, I.J.; Onumanyi, A.J.; Adegboye, M.A.; Salawudeen, A.T. Simple deterministic selection-based genetic algorithm for hyperparameter tuning of machine learning models. Appl. Sci. 2022, 12, 1186. [Google Scholar] [CrossRef]
- Yang, L.; Shami, A. On hyperparameter optimization of machine learning algorithms: Theory and practice. Neurocomputing 2020, 415, 295–316. [Google Scholar] [CrossRef]
- George, G.; Raj, V.C. Review on feature selection techniques and the impact of SVM for cancer classification using gene expression profile. arXiv 2011, arXiv:1109.1062. [Google Scholar]
- Maskeliunas, R.; Lauraitis, A.; Damasevicius, R.; Misra, S. Multi-class model MOV-OVR for automatic evaluation of tremor disorders in Huntington’s disease. In Communications in Computer and Information Science; Springer International Publishing: New York, NY, USA, 2021; pp. 3–14. [Google Scholar] [CrossRef]
- Akay, M.F. Support vector machines combined with feature selection for breast cancer diagnosis. Expert Syst. Appl. 2009, 36, 3240–3247. [Google Scholar] [CrossRef]
- Kourou, K.; Exarchos, T.P.; Exarchos, K.P.; Karamouzis, M.V.; Fotiadis, D.I. Machine learning applications in cancer prognosis and prediction. Comput. Struct. Biotechnol. J. 2015, 13, 8–17. [Google Scholar] [CrossRef] [Green Version]
- Memon, M.H.; Li, J.P.; Haq, A.U.; Zhou, W. Breast cancer detection in the IoT health environment using modified recursive feature selection. Wirel. Commun. Mob. Comput. 2019, 2019, 5176705. [Google Scholar] [CrossRef] [Green Version]
- Lattanzi, E.; Donati, M.; Freschi, V. Exploring Artificial Neural Networks Efficiency in Tiny Wearable Devices for Human Activity Recognition. Sensors 2022, 22, 2637. [Google Scholar] [CrossRef] [PubMed]
- Pontes, F.J.; Amorim, G.F.; Balestrassi, P.P.; Paiva, A.P.; Ferreira, J.R. Design of experiments and focused grid search for neural network parameter optimization. Neurocomputing 2016, 186, 22–34. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Ogundokun, R.O.; Awotunde, J.B.; Sadiku, P.; Adeniyi, E.A.; Abiodun, M.; Dauda, O.I. An enhanced intrusion detec-tion system using particle swarm optimization feature extraction technique. Procedia Comput. Sci. 2021, 193, 504–512. [Google Scholar] [CrossRef]
- Ogundokun, R.O.; Misra, S.; Bajeh, A.O.; Okoro, U.O.; Ahuja, R. An Integrated IDS Using ICA-Based Feature Selection and SVM Classification Method. In Illumination of Artificial Intel-Ligence in Cybersecurity and Forensics; Springer: Cham, Switzerland, 2022; pp. 255–271. [Google Scholar]
- Alade, O.M.; Sowunmi, O.Y.; Misra, S.; Maskeliūnas, R.; Damaševičius, R. A neural network based expert system for the diagnosis of diabetes mellitus. In Advances in Intelligent Systems and Computing; Springer: Berlin, Switzerland, 2018; pp. 14–22. [Google Scholar]
- Damasevicius, R. Optimization of SVM parameters for recognition of regulatory DNA sequences. Top 2010, 18, 339–353. [Google Scholar] [CrossRef]
- Zhang, M.; Jing, W.; Lin, J.; Fang, N.; Wei, W.; Woźniak, M.; Damaševičius, R. NAS-HRIS: Automatic design and architecture search of neural network for semantic segmentation in remote sensing images. Sensors 2020, 20, 5292. [Google Scholar] [CrossRef]
- Omoregbe, N.A.I.; Ndaman, I.O.; Misra, S.; Abayomi-Alli, O.O.; Damaševičius, R. Text messaging-based medical diagnosis using natural language processing and fuzzy logic. J. Health Eng. 2020, 2020, 8839524. [Google Scholar] [CrossRef]
- Vanagas, G.; Engelbrecht, R.; Damaševičius, R.; Suomi, R.; Solanas, A. EHealth solutions for the integrated healthcare. J. Health Eng. 2018, 2018, 3846892. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Methods (Models) | Dataset | Accuracy |
|---|---|---|---|
| Chougrad et al. [24] | VGG16, ResNet50, Inception v3 | MIAS | 98.23% |
| Amrane et al. [26] | Naive Bayes (NB), k-nearest neighbor (KNN) | Wisconsin Breast Cancer (WBC) | 97.5% |
| Hajiabadi et al. [32] | Artificial Neural Network (ANN) | WBC | 97% |
| Shravya et al. [33] | Support Vector Machine (SVM) | WBC | 92.78% |
| Chaurasia et al. [34] | NB | WBC | 97.36% |
| Aavula and Bhramaramba [35] | SVM with representative feature subset selection | SEER | 98.90% |
| Abdar et al. [37] | Nested ensemble classifiers with BayesNet and Naïve Bayes | WBC | 98.07% |
| Mansour [39] | AlexNet | BreakHis | 96.70% |
| Ragab et al. [40] | Ensemble of deep learning models (SqueezeNet, VGG-16, VGG-19) with Cat Swarm Optimization and Multilayer Perceptron | Breast Ultrasound Dataset | 97.09% |
| Hyperparameter | Description | Range |
|---|---|---|
| Activation Function | Neuron’s activation function | ReLU, SeLU, Sigmoid |
| Batch Size | Group size of training data divisions | 8, 16, 32 |
| Epoch | Number of learning iterations | 20, 50, 100 |
| Kernel Count | Kernel count of convolutional layer | 8, 16, 32 |
| Kernel Size | Kernel size of convolutional layer | 1, 2, 3 |
| Layer Depth | Number of layers constituting entire network | 1, 2, 3 |
| Learning Rate | Weight change updated during learning | 0.01, 0.001, 0.0001 |
| Loss Function | Function to calculate error | Binary crossentropy, L2 loss |
| Neuron Count | Neuron count in the final fully-connected layer | 8, 16, 32 |
| Stride | Number of moving pixels of kernel during convolution | 1, 2, 3 |
| Hyperparameter | Description | Range |
|---|---|---|
| Number of hidden layers | Number of inner layers between the input and output layers | 1, 2, 3 |
| No. of hidden nodes | No. of neurons in the hidden layer | 1–10 |
| No. of training cycles | Number of the training iterations | 10–1000 |
| Learning rate | Change in weight updated during learning | 0.0001–0.1 |
| Learning algorithm | The optimization algorithm that performs the learning process in a neural network | SDG, Adam, RMDprop |
| Activation functions | Neuron’s activation function | Tangent, Linear |
| Learning rate decay | The rate function of the decay of the learning rate during learning iterations | Exponential, linear |
| Error function: | The function which is minimized during training of the neural network | Log loss, mean square error |
| Epoch limit | Maximum number of learning iterations | 20, 50, 100 |
| Mini batch size | Group size submitted to model during training | 10, 20, 30 |
| Patience | A delay to the trigger in terms of the number of epochs on which we would like to see no improvement. | 2, 5, 10 |
| Measures | SVM (%) | MLP (%) |
|---|---|---|
| Recall | 97.0 | 97.8 |
| Specificity | 95.7 | 96.3 |
| F1-score | 97.0 | 97.6 |
| Precision | 97.0 | 97.8 |
| Accuracy | 96.5 | 97.2 |
| Measures | SVM (%) | MLP (%) |
|---|---|---|
| Recall | 97.0 | 97.0 |
| Specificity | 95.7 | 95.7 |
| F1-score | 97.0 | 97.0 |
| Precision | 97.0 | 97.0 |
| Accuracy | 96.5 | 96.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ogundokun, R.O.; Misra, S.; Douglas, M.; Damaševičius, R.; Maskeliūnas, R. Medical Internet-of-Things Based Breast Cancer Diagnosis Using Hyperparameter-Optimized Neural Networks. Future Internet 2022, 14, 153. https://doi.org/10.3390/fi14050153
Ogundokun RO, Misra S, Douglas M, Damaševičius R, Maskeliūnas R. Medical Internet-of-Things Based Breast Cancer Diagnosis Using Hyperparameter-Optimized Neural Networks. Future Internet. 2022; 14(5):153. https://doi.org/10.3390/fi14050153
Chicago/Turabian StyleOgundokun, Roseline Oluwaseun, Sanjay Misra, Mychal Douglas, Robertas Damaševičius, and Rytis Maskeliūnas. 2022. "Medical Internet-of-Things Based Breast Cancer Diagnosis Using Hyperparameter-Optimized Neural Networks" Future Internet 14, no. 5: 153. https://doi.org/10.3390/fi14050153