
Neural Network-Based Price Tag Data Analysis

 , ,
, ,  , , and
, , and
Abstract
:1. Introduction
2. Related Works
- Price tag scanning, OCR and data capturing by Klippa [15], a software that allows users to extract information from price tag images, which is targeted at the retail store customers. Its advantages are high recognition accuracy and the ability to use different output formats (JSON, CSV, XLSX, XML). The disadvantage is that it has a small number of supported languages.
- Price tag recognition: a smartphone instead of a PDT by Neti [16] is a software designed to automatically compare prices with the price database. It targets store owners and employees. The advantages are user friendliness and high recognition accuracy. The disadvantage is the lack of product description recognition capability.
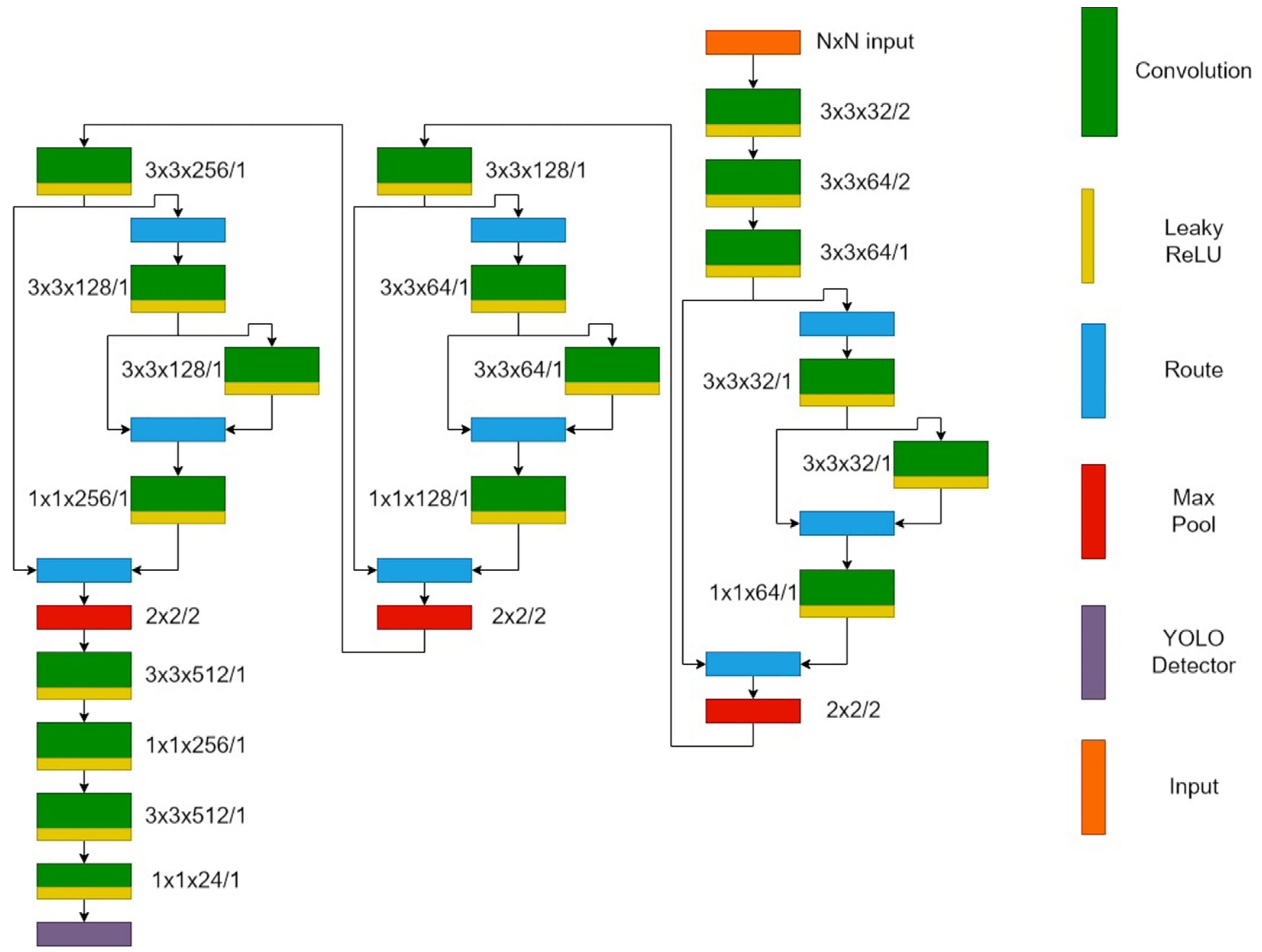
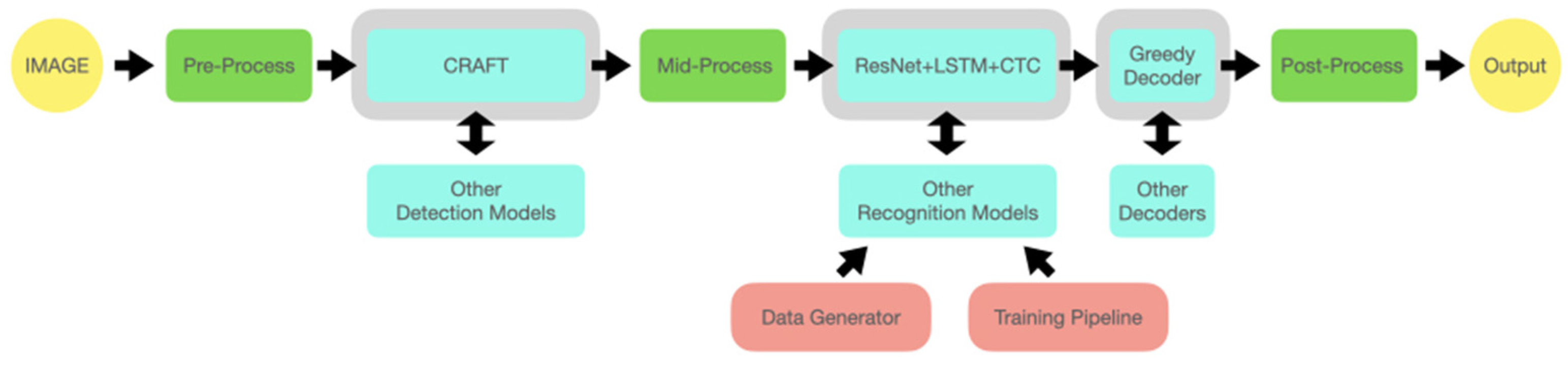
3. Materials and Methods
- Segmenting images to highlight areas containing data of interest;
- Selecting segment coordinates;
- Cutting the segments out in accordance with the obtained coordinates;
- Applying Optical Character Recognition (OCR) to the selected areas;
- Searching for necessary information (quantity of products) within the product description.
- LabelImg graphical image annotation tool;
- Server CPU: Intel® Xeon® E7-4809 v4;
- Server OS: Ubuntu Server.
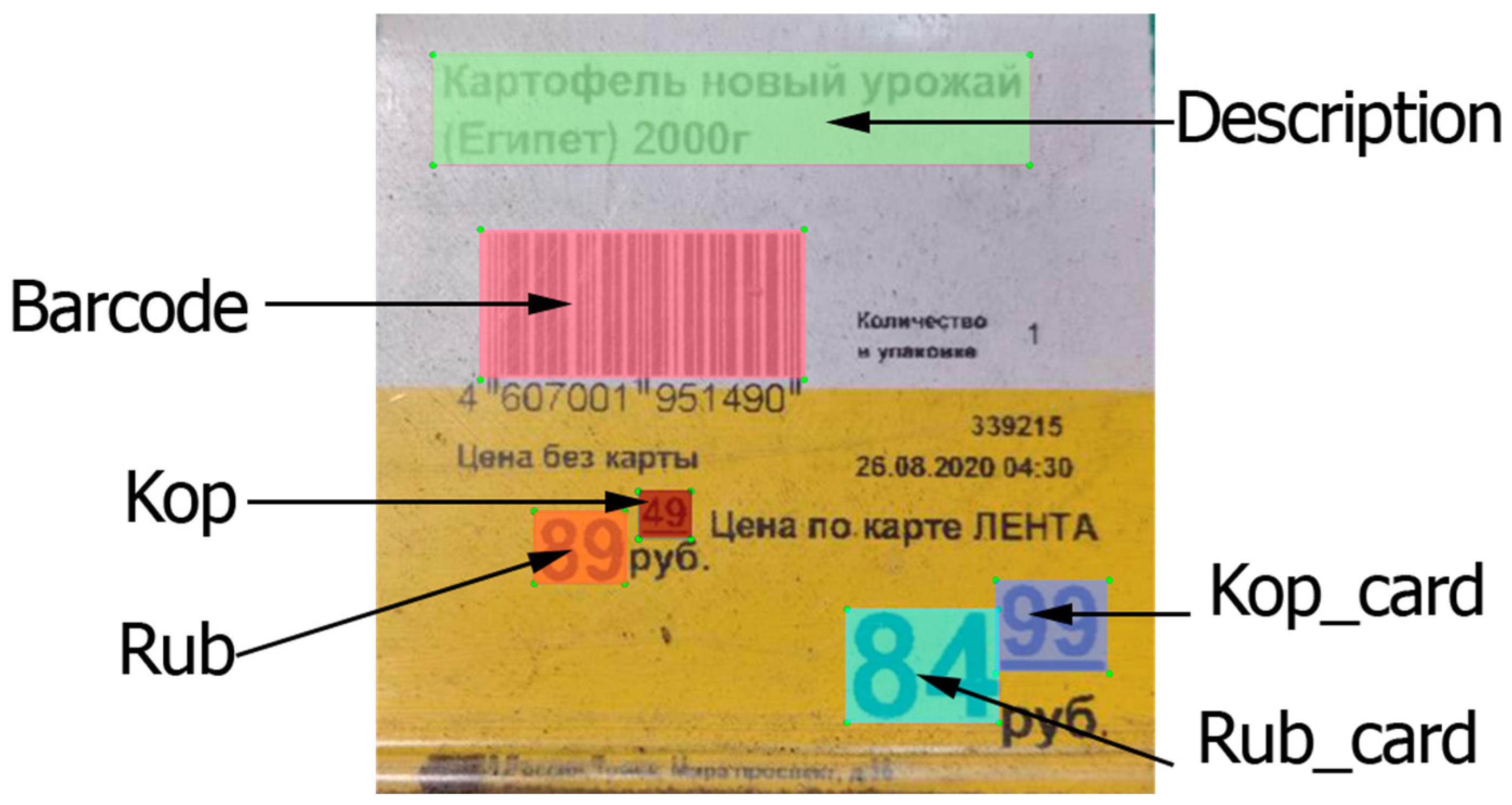
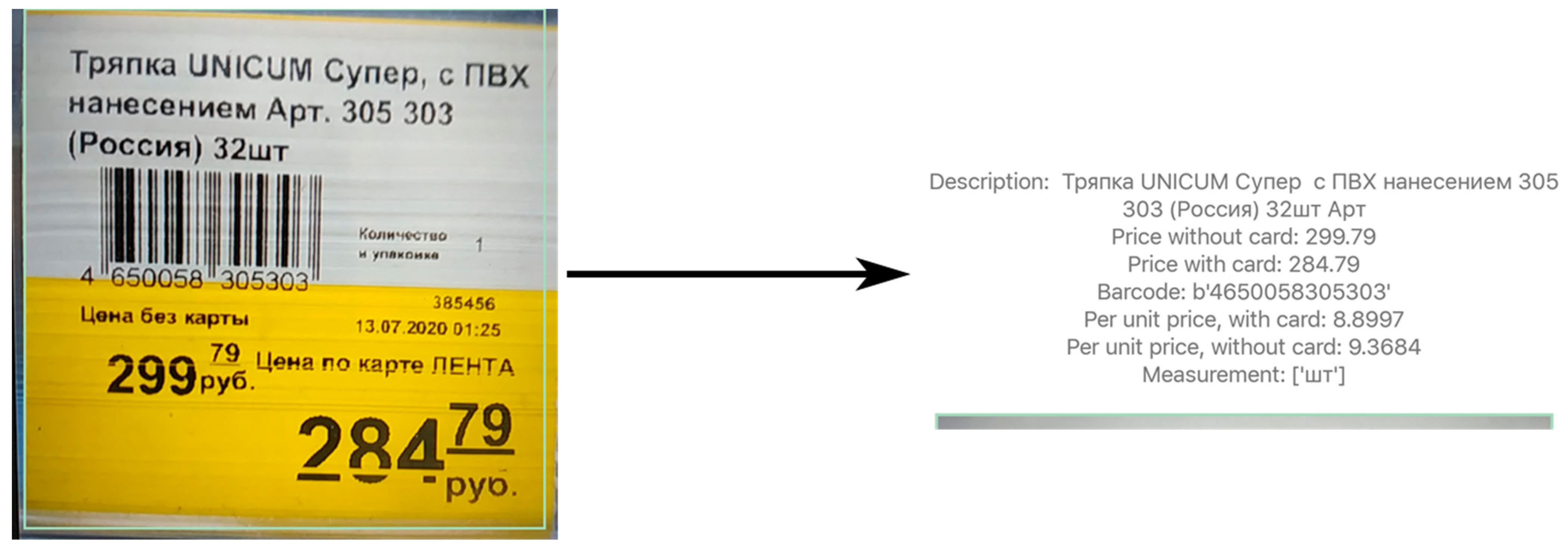
- Description, which is a product name and description;
- Barcode, which is an EAN-13 product barcode;
- Rub, which is a product price in rubles;
- Kop, which is a product price in kopecks;
- Rub_card, which is a product price in rubles, including a discount for “Lenta” card holders;
- Kop_card, which is a product price in kopecks, including a discount for “Lenta” card holders.
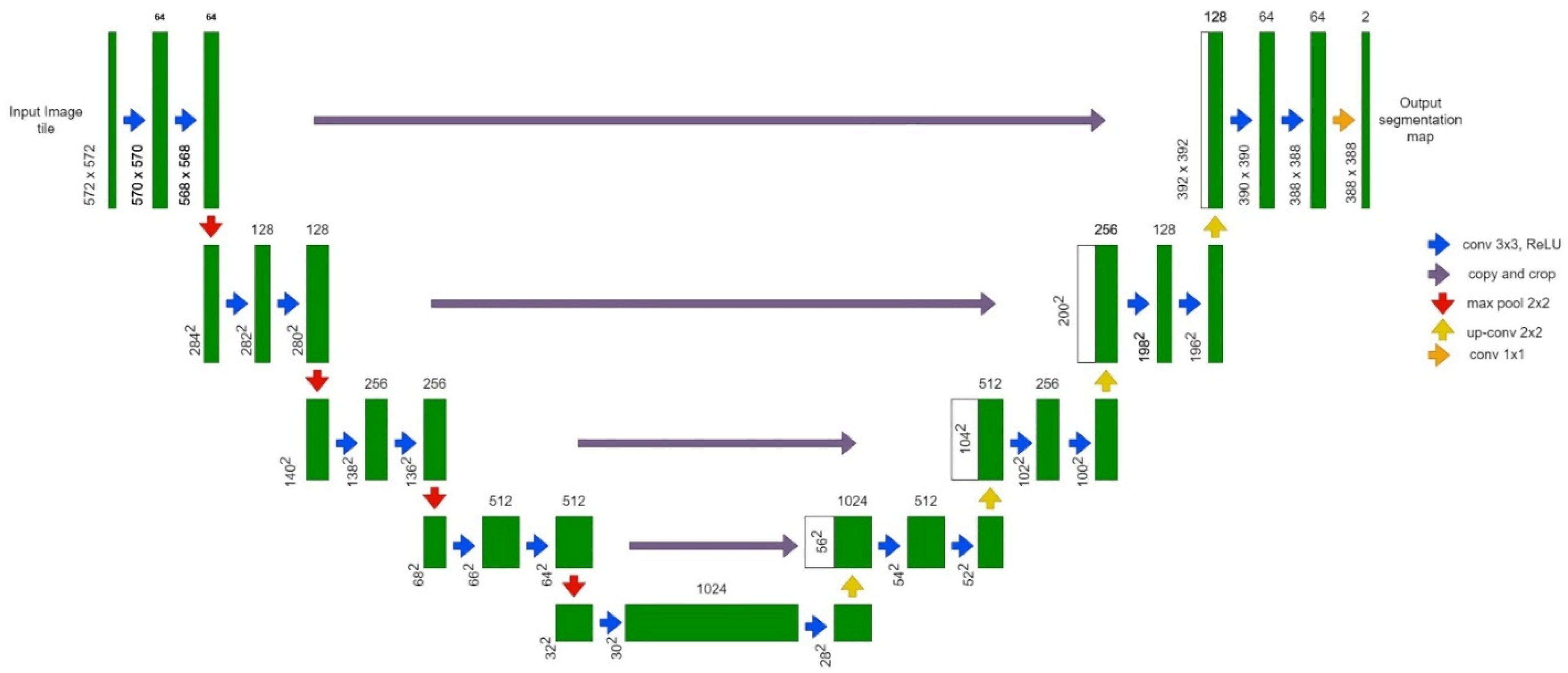
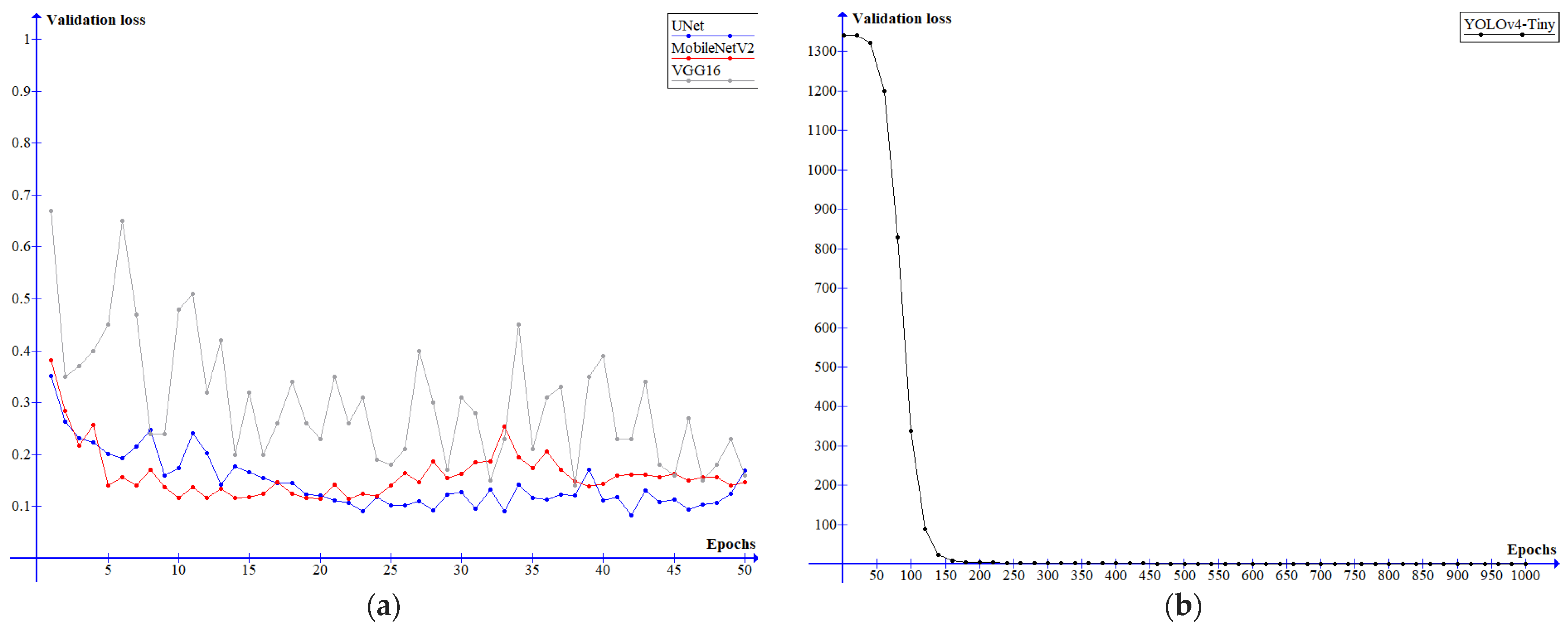
- UNet: loss function—cross entropy; optimizer—Adam algorithm with learning rate lr = 0.0001; batch size—5; number of iterations per epoch—12.
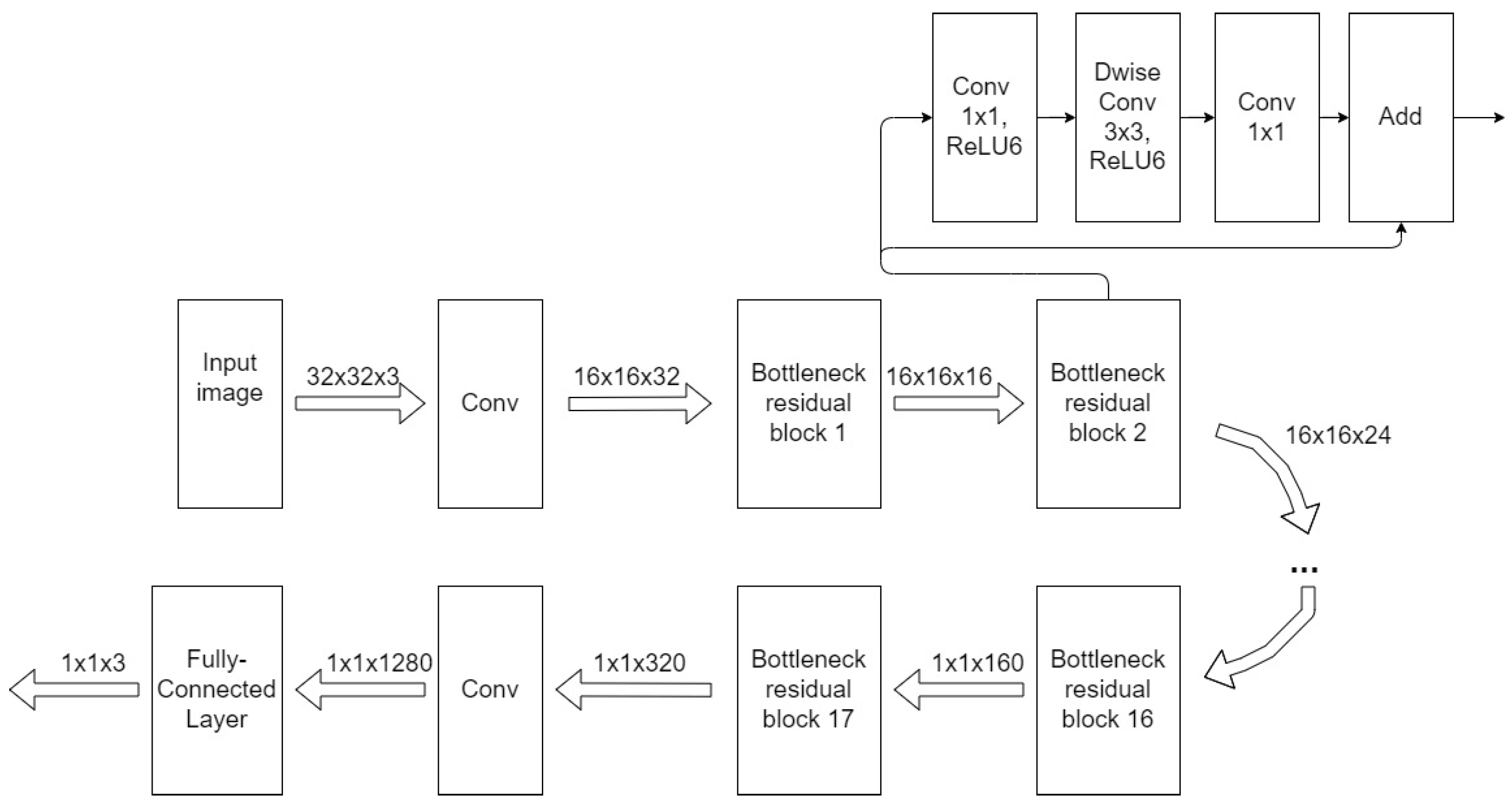
- MobileNetV2: loss function—cross entropy; optimizer—Adam algorithm with learning rate lr = 0.0001; batch size—5; number of iterations per epoch—12.
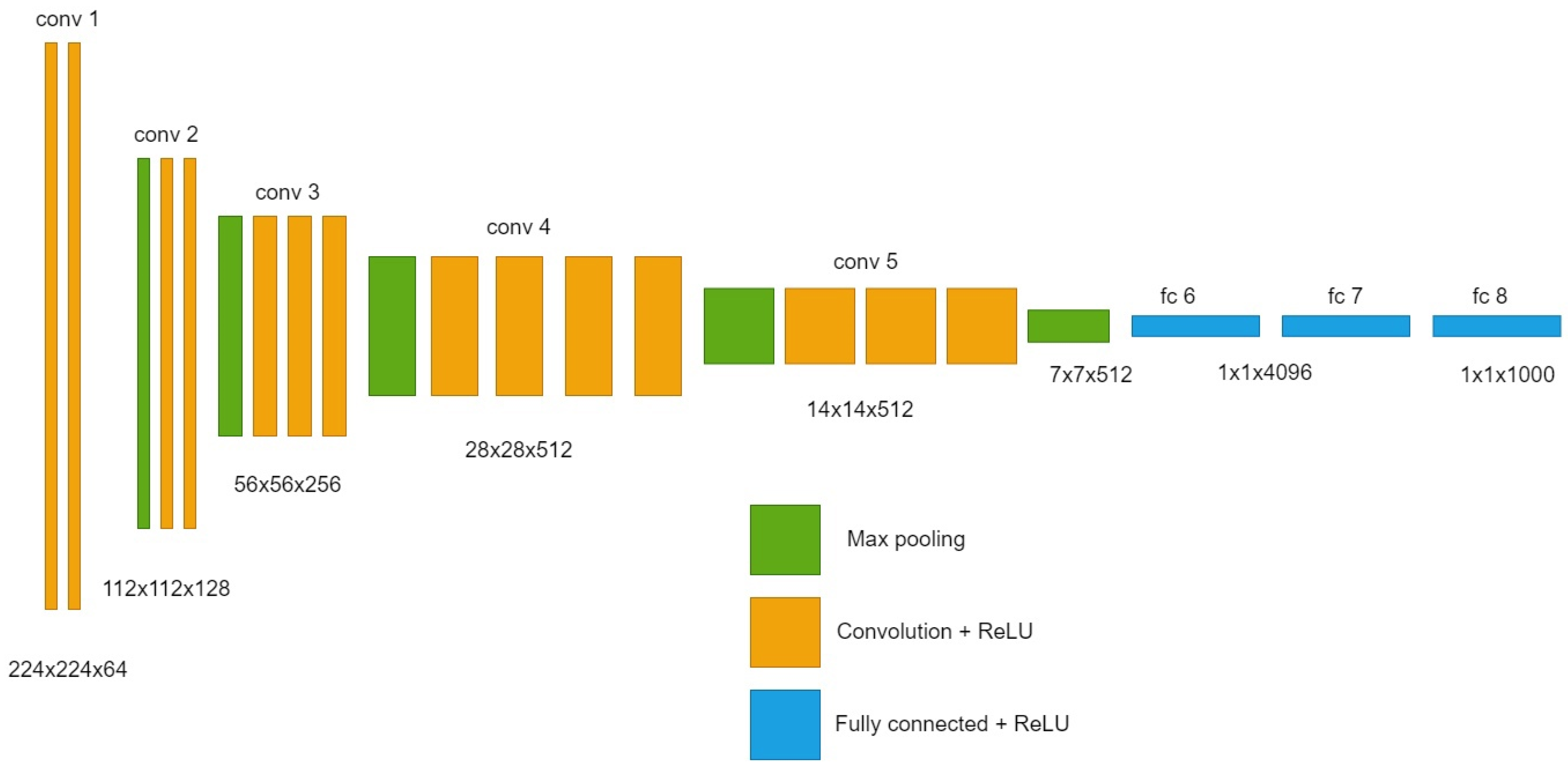
- VGG16: loss function—mean squared error (MSE); Optimizer—Adagrad; batch size—5; number of iterations per epoch—12.
- YOLOv4-tiny: loss function—complete intersection over Union (CIoU); optimizer—stochastic gradient descent (SGD); batch size—64; number of iterations per epoch—24.
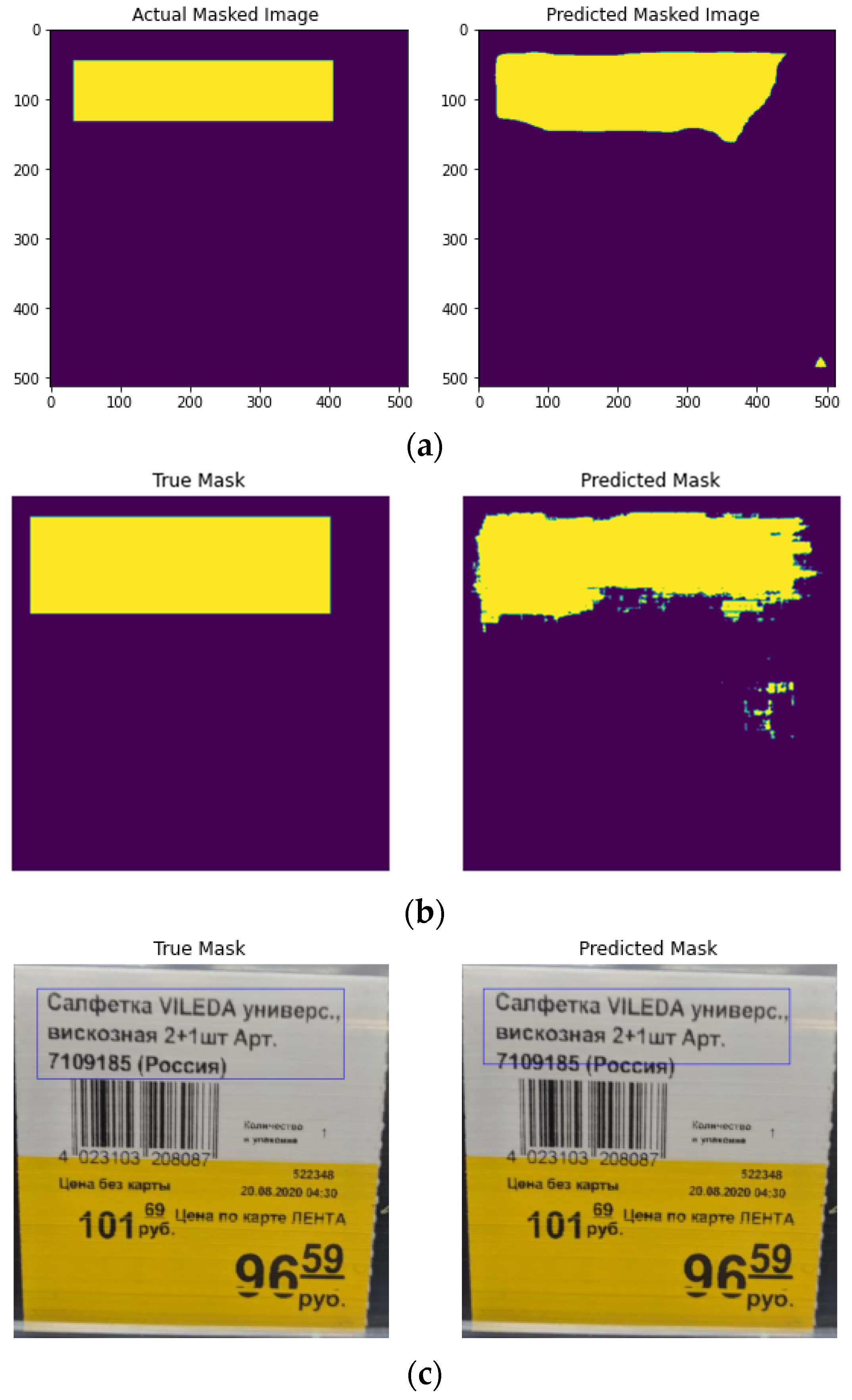
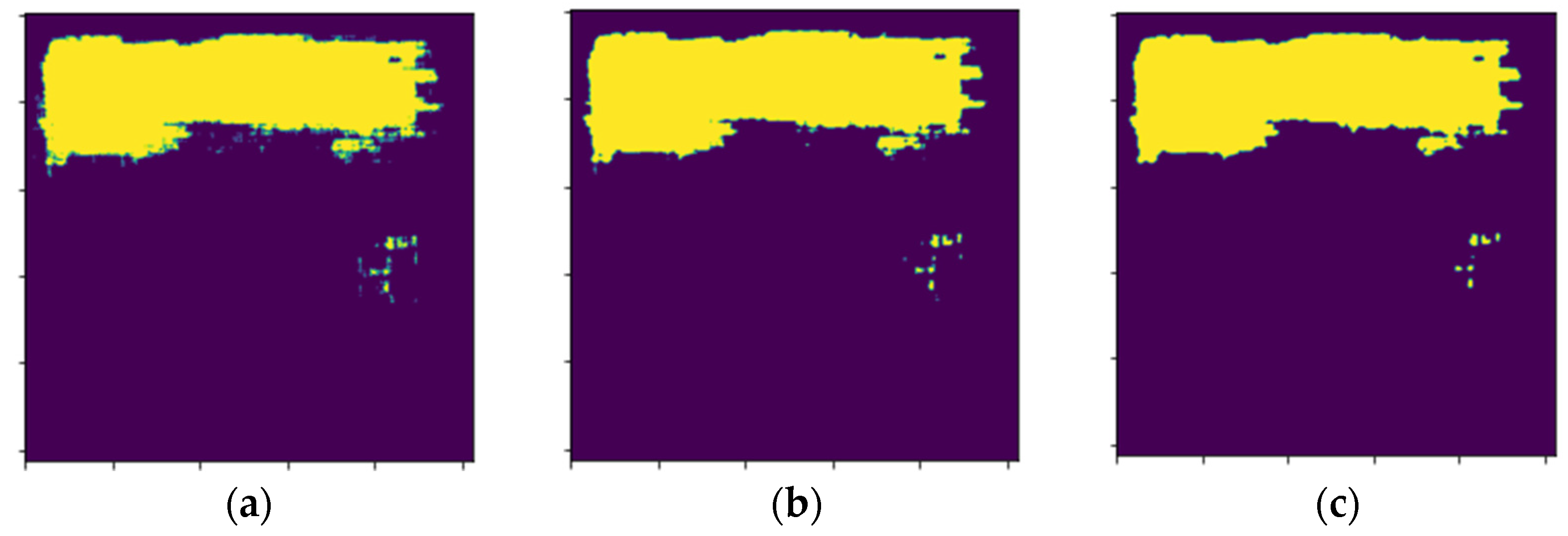
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- The consumer act of the Philippines. Available online: https://www.officialgazette.gov.ph/1992/04/13/republic-act-no-7394-s-1992/ (accessed on 11 March 2022).
- Administration Code of the Russian Federation. Available online: http://pravo.gov.ru/proxy/ips/?docbody&nd=102074277 (accessed on 11 March 2022).
- Consumer Rights Protection Law of the People’s Republic of China. Available online: http://www.npc.gov.cn/zgrdw/englishnpc/Law/2007-12/12/content_1383812.htm (accessed on 11 March 2022).
- Hassanat, A.B. Two-point-based binary search trees for accelerating big data classification using KNN. PLoS ONE 2018, 13, e0207772. [Google Scholar] [CrossRef] [Green Version]
- Mnasri, S.; Nasri, N.; van den Bossche, A.; Thierry, V.A.L. 3D indoor redeployment in IoT collection networks: A real prototyping using a hybrid PI-NSGA-III-VF. In Proceedings of the 2018 14th International Wireless Communications & Mobile Computing Conference (IWCMC), Limassol, Cyprus, 25–29 June 2018; pp. 780–785. [Google Scholar]
- Rakhmanenko, I.A.; Shelupanov, A.A.; Kostyuchenko, E.Y. Automatic text-independent speaker verification using convolutional deep belief network. Comput. Opt. 2020, 44, 596–605. [Google Scholar] [CrossRef]
- Kostyuchenko, E.; Novokhrestova, D.; Pekarskikh, S.; Shelupanov, A.; Nemirovich-Danchenko, M.; Choynzonov, E.; Balatskaya, L. Assessment of Syllable Intelligibility Based on Convolutional Neural Networks for Speech Rehabilitation after Speech Organs Surgical Interventions. In Proceedings of the International Conference on Speech and Computer, Istanbul, Turkey, 20–25 August 2019; Springer: Cham, Switzerland, 2019; pp. 359–369. [Google Scholar]
- Kurtukova, A.; Romanov, A.; Shelupanov, A. Source Code Authorship Identification Using Deep Neural Networks. Symmetry 2020, 12, 2044. [Google Scholar] [CrossRef]
- Haurum, J.B.; Bahnsen, C.H.; Pedersen, M.; Moeslund, T.B. Water level estimation in sewer pipes using deep convolutional neural networks. Water 2020, 12, 3412. [Google Scholar] [CrossRef]
- Kweik, O.M.A.; Hamid, M.A.A.; Sheqlieh, S.O.; Abu-Nasser, B.S.; Abu-Naser, S.S. Artificial Neural Network for Lung Cancer Detection. Int. J. Acad. Eng. Res. 2020, 4, 1–7. [Google Scholar]
- Harz, H.H.; Rafi, A.O.; Hijazi, M.O.; Abu-Naser, S.S. Artificial Neural Network for Predicting Diabetes Using JNN. Int. J. Acad. Eng. Res. 2020, 4, 14–22. [Google Scholar]
- Hussin, M.N.A.; Ahmad, A.H.; Razak, M.A. Price tag recognition using hsv color space. J. Telecommun. Electron. Comput. Eng. JTEC 2017, 9, 77–84. [Google Scholar]
- Kovtunenko, A.; Yakovleva, O.; Liubchenko, V.; Yanholenko, O. Research of the joint use of mathematical morphology and convolutional neural networks for the solution of the price tag recognition problem. Bull. Natl. Tech. Univ. KhPI Ser. Syst. Anal. Control Inf. Technol. 2020, 1, 24–31. [Google Scholar] [CrossRef]
- Mou, Y.-Q.; Fan, B.-J.; Sun, C.; Yan, R.; Guo, Y.-S. Towards accurate price tag recognition algorithm with multi-task RNN. Acta Autom. Sin. 2020, 48, 608–614. [Google Scholar]
- Klippa Price Tag Scanning, OCR & Data Capturing. Available online: https://www.klippa.com/en/ocr/financial-documents/price-tags/ (accessed on 20 December 2021).
- Neti Price Tag Recognition: A Smartphone Instead of a PDT. Available online: https://ml.i-neti.com/portfolio-item/raspoznavanie-tsennikov-zamenite-tsd-na-smartfon/ (accessed on 20 December 2021).
- Weng, Y.; Zhou, T.; Li, Y.; Qiu, X. Nas-unet: Neural architecture search for medical image segmentation. IEEE Access 2019, 7, 44247–44257. [Google Scholar] [CrossRef]
- Pravitasari, A.A.; Iriawan, N.; Almuhayar, M.; Azmi, T.; Fithriasari, K.; Purnami, S.W.; Ferriastuti, W. UNet-VGG16 with transfer learning for MRI-based brain tumor segmentation. Telkomnika 2020, 18, 1310–1318. [Google Scholar] [CrossRef]
- Seidaliyeva, U.; Akhmetov, D.; Ilipbayeva, L.; Matson, E.T. Real-Time and accurate drone detection in a video with a static background. Sensors 2020, 20, 3856. [Google Scholar] [CrossRef] [PubMed]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ferguson, M.; Ak, R.; Lee, Y.T.T.; Law, K.H. Automatic localization of casting defects with convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Big Data, Boston, MA, USA, 11–14 December 2017; pp. 1726–1735. [Google Scholar]
- Abdurahman, F.; Fante, K.A.; Aliy, M. Malaria parasite detection in thick blood smear microscopic images using modified YOLOV3 and YOLOV4 models. BMC Bioinform. 2021, 22, 112. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13029–13038. [Google Scholar]
- Pyzbar. Available online: https://github.com/NaturalHistoryMuseum/pyzbar (accessed on 20 December 2021).
- De Myttenaere, A.; Golden, B.; Le Grand, B.; Rossi, F. Mean absolute percentage error for regression models. Neurocomputing 2016, 192, 38–48. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Yang, J. Research on Scene Text Recognition Algorithm Basedon Improved CRNN. In Proceedings of the 2020 4th International Conference on Digital Signal Processing, Chengdu, China, 19–21 June 2020; pp. 107–111. [Google Scholar]
- Zacharias, E.; Teuchler, M.; Bernier, B. Image Processing Based Scene-Text Detection and Recognition with Tesseract. arXiv 2020, arXiv:2004.08079. [Google Scholar]
- Veeranampalayam Sivakumar, A.N.; Li, J.; Scott, S.; Psota, E.; JJhala, A.; Luck, J.D.; Shi, Y. Comparison of object detection and patch-based classification deep learning models on mid-to late-season weed detection in UAV imagery. Remote Sens. 2020, 12, 2136. [Google Scholar] [CrossRef]
- Magalhães, S.A.; Castro, L.; Moreira, G.; Dos Santos, F.N.; Cunha, M.; Dias, J.; Moreira, A.P. Evaluating the single-shot multibox detector and YOLO deep learning models for the detection of tomatoes in a greenhouse. Sensors 2021, 21, 3569. [Google Scholar] [CrossRef]
- da Silva, D.Q.; Dos Santos, F.N.; Sousa, A.J.; Filipe, V. Visible and Thermal Image-Based Trunk Detection with Deep Learning for Forestry Mobile Robotics. J. Imaging 2021, 7, 176. [Google Scholar] [CrossRef]
- Guo, C.; Lv, X.L.; Zhang, Y.; Zhang, M.L. Improved YOLOv4-tiny network for real-time electronic component detection. Sci. Rep. 2021, 11, 22744. [Google Scholar] [CrossRef]
- Ayoub, N.; Schneider-Kamp, P. Real-time on-board deep learning fault detection for autonomous uav inspections. Electronics 2021, 10, 1091. [Google Scholar] [CrossRef]
- Tan, L.; Huangfu, T.; Wu, L.; Chen, W. Comparison of YOLO v3, Faster R-CNN, and SSD for Real-Time Pill Identification. BMC Med. Inform. Decis. Mak. 2021, 21, 324. [Google Scholar] [CrossRef] [PubMed]
- Ramil Brick, E.; Caballero Alonso, V.; O’Brien, C.; Tong, S.; Tavernier, E.; Parekh, A.; Addlesee, A.; Lemon, O. Am I Allergic to This? Assisting Sight Impaired People in the Kitchen. In Proceedings of the 2021 International Conference on Multimodal Interaction, New York, NY, USA, 18–22 October 2021; pp. 92–102. [Google Scholar]
- EasyOCR. Available online: https://www.jaided.ai/easyocr/ (accessed on 20 December 2021).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | UNet | MobileNetV2 | VGG16 | YOLOv4-Tiny | |
|---|---|---|---|---|---|
| Cross validation accuracy | Train | 90.64% | 82.79% | 89.16% | 98.24% |
| Validation | 92.12% | 78.56% | 83.72% | 96.92% | |
| F1 score | Train | 0.36 | 0.34 | 0.65 | 0.62 |
| Validation | 0.38 | 0.32 | 0.58 | 0.61 | |
| Time per epoch | Full dataset | 16.74 s | 8.97 s | 11.95 s | 2.74 s |
| Description | Rub | Kop | Rub_Card | Kop_Card | Barcode | Total Accuracy | |
|---|---|---|---|---|---|---|---|
| Accuracy | 93.34% | 100% | 90% | 100% | 100% | 88% | 95.22% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Laptev, P.; Litovkin, S.; Davydenko, S.; Konev, A.; Kostyuchenko, E.; Shelupanov, A. Neural Network-Based Price Tag Data Analysis. Future Internet 2022, 14, 88. https://doi.org/10.3390/fi14030088
Laptev P, Litovkin S, Davydenko S, Konev A, Kostyuchenko E, Shelupanov A. Neural Network-Based Price Tag Data Analysis. Future Internet. 2022; 14(3):88. https://doi.org/10.3390/fi14030088
Chicago/Turabian StyleLaptev, Pavel, Sergey Litovkin, Sergey Davydenko, Anton Konev, Evgeny Kostyuchenko, and Alexander Shelupanov. 2022. "Neural Network-Based Price Tag Data Analysis" Future Internet 14, no. 3: 88. https://doi.org/10.3390/fi14030088