
Graph Representation-Based Deep Multi-View Semantic Similarity Learning Model for Recommendation


Abstract
:1. Introduction
- To overcome the challenges of cold start, we propose a novel GraphSAGE based collaborative filtering recommendation method, called GraphSAGE-CF. This paper tries to integrate GraphSAGE with a collaborative filtering technique for recommendation systems;
- A GraphSAGE based user embedding method is developed to learn low dimensional feature representation of global and local structures of users in social networks. Then, the implicit trust relationship between users can be measured;
- We conduct comprehensive experiments on four commonly used benchmark datasets. The experimental results demonstrate that our method outperforms the state-of-the-art.
2. Related Work
2.1. Collaborative Filtering
2.2. Graph Embedding
2.2.1. Matrix Decomposition-Based Graph Embedding Method
2.2.2. Graph Embedding Method Based on Random Wandering
2.2.3. Deep Learning Based Graph Embedding Method
3. Problem Definition
3.1. Recommend Formal Description of the Problem
3.2. User-Based Collaborative Filtering Recommendation Algorithm
4. Collaborative Filtering Algorithm Based on Graph Embedding Model
4.1. GraphSAGE
Select Aggregator
4.2. Collaborative Filtering Algorithm Based on Graph Embedding Model
5. Experiment
5.1. Dataset
5.2. Evaluation Metric
5.3. Settings
- Baseline1 uses the average of all scored items scored by the current active users as the predicted scores of the target items by the current active users;
- Baseline2 The user-based collaborative filtering algorithm finds users with similar interests to the current active users based on their historical ratings, and then uses the weight of similar users’ ratings on target items to predict the average of the current active users’ ratings on target items;
- PMF [40] was proposed by Mnih and Salakhutdinov, which can be considered a probabilistic extension of the SVD model. PMF learns the implicit feature vector of users and items from the user-item rating matrix and uses the inner product of the implicit feature vector of users and items to predict the missing items in the user-item rating matrix;
- TrustSVD [25] proposes an advanced SVD++ algorithm. Based on the original SVD++, it takes both explicit trust relationship and rating information of users into model construction;
- DeepCoNN [41] proposes a parallel framework by jointly using the users’ feedbacks, two parallel neural networks are used to deal with users’ and items’ information synchronously.
5.4. Performance Comparison
- PMF consistently outperforms Baseline1 and Baseline2. Because Baseline1 only uses the average of all scored items scored by the active users as the predicted scores of the target items, Baseline2 uses the weight of similar users’ ratings on target items to predict the average of the active users’ ratings; At the same time, PMF learns the implicit feature vector of users and items from the user–item rating matrix and uses the inner product of the implicit feature vector of users and items;
- TrustSVD obtains a much better performance than PMF. Both methods take the SVD algorithm into model construction. However, TrustSVD uses an advanced SVD++ algorithm and takes direct trust relationship and rating information into the model construction;
- DeepCoNN performances are better than TrustSVD, PMF, Baseline1, and Baseline2. The reason is that DeepCoNN is based on two parallel neural networks, which further indicate the power of neural network models in social recommendations;
- Our proposed technique, GraphSAGE-CF, outperforms all the baseline methods. Compared with the above methods, our model learns low dimensional feature representation of the global and local structures of users in social networks to assist the rating prediction.
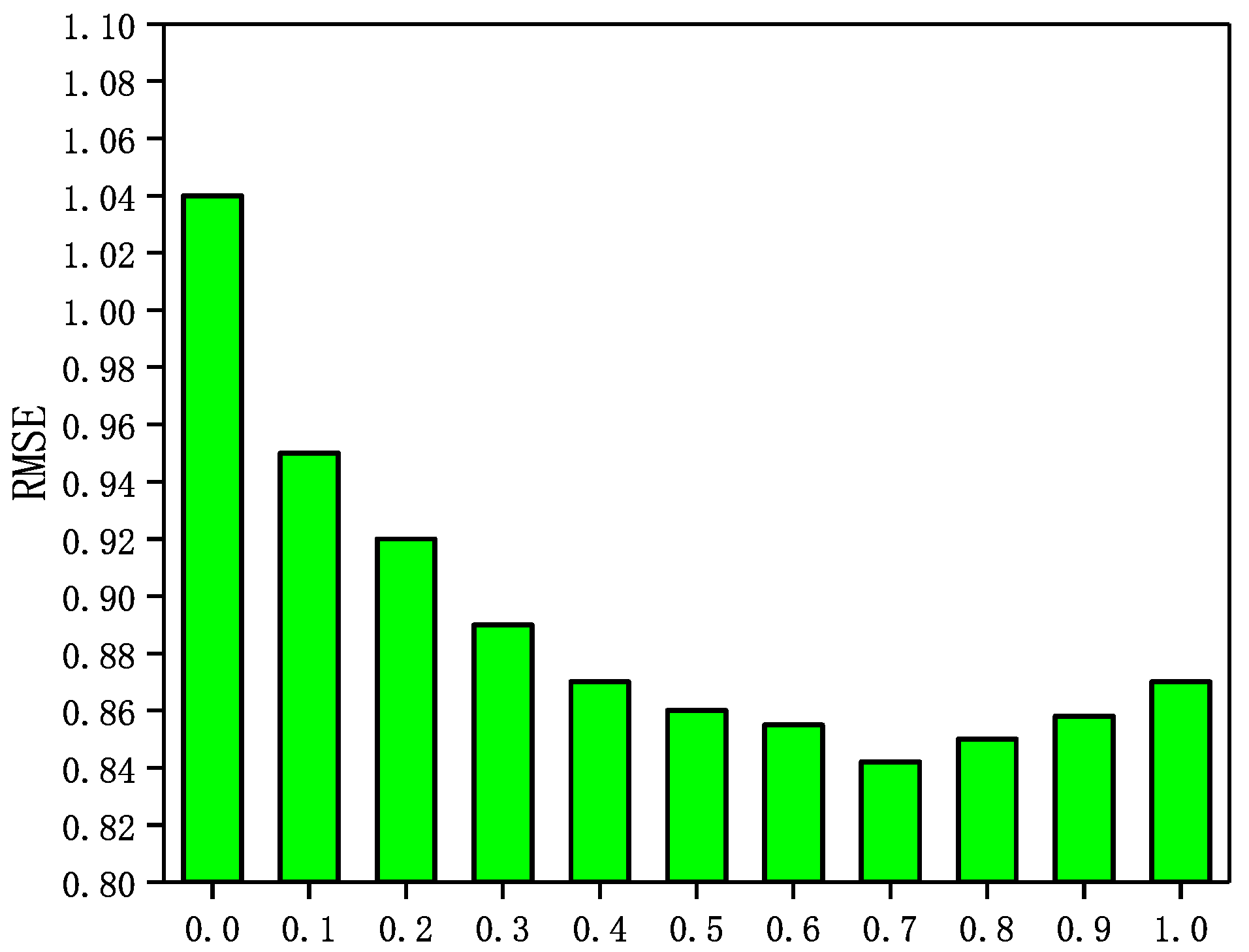
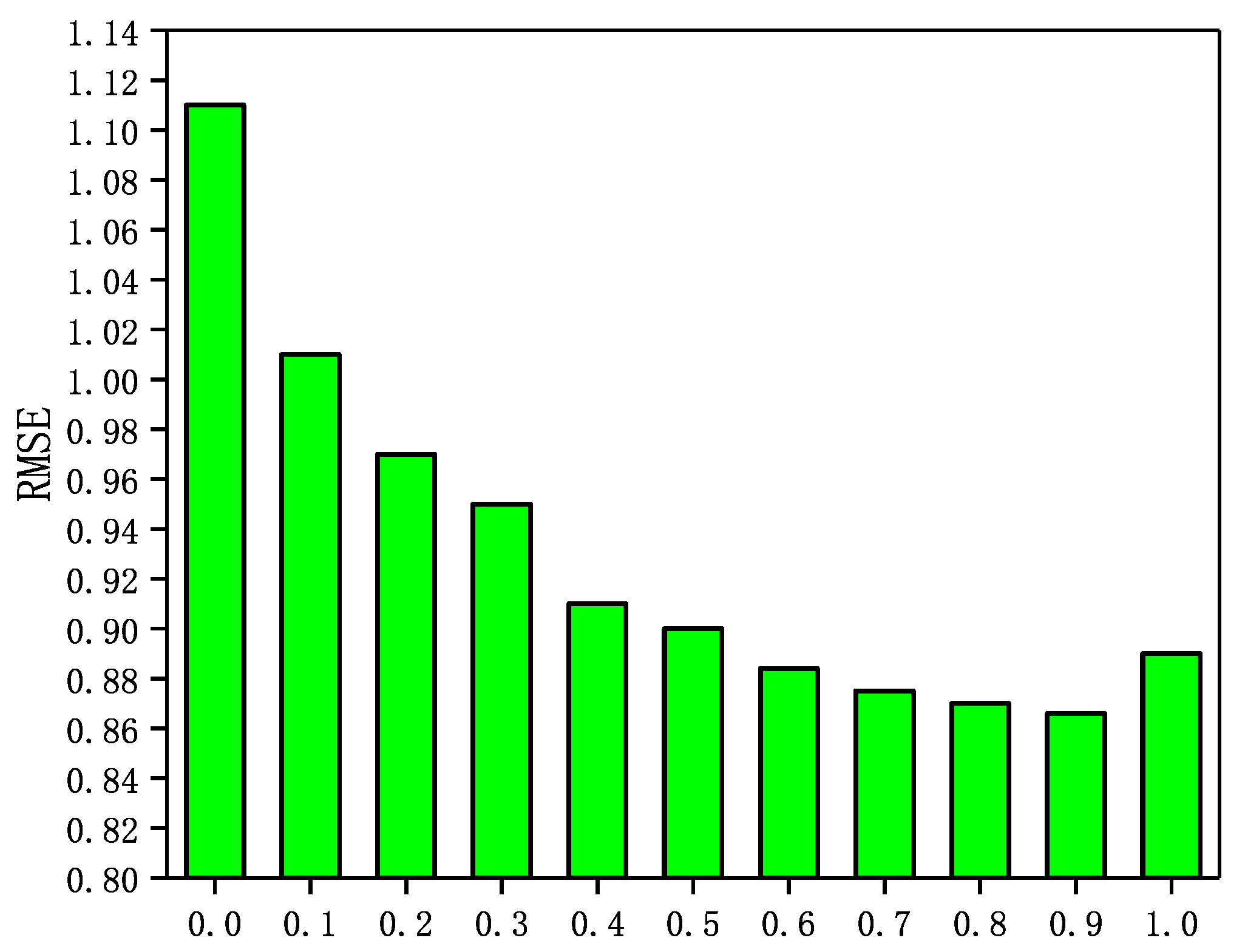
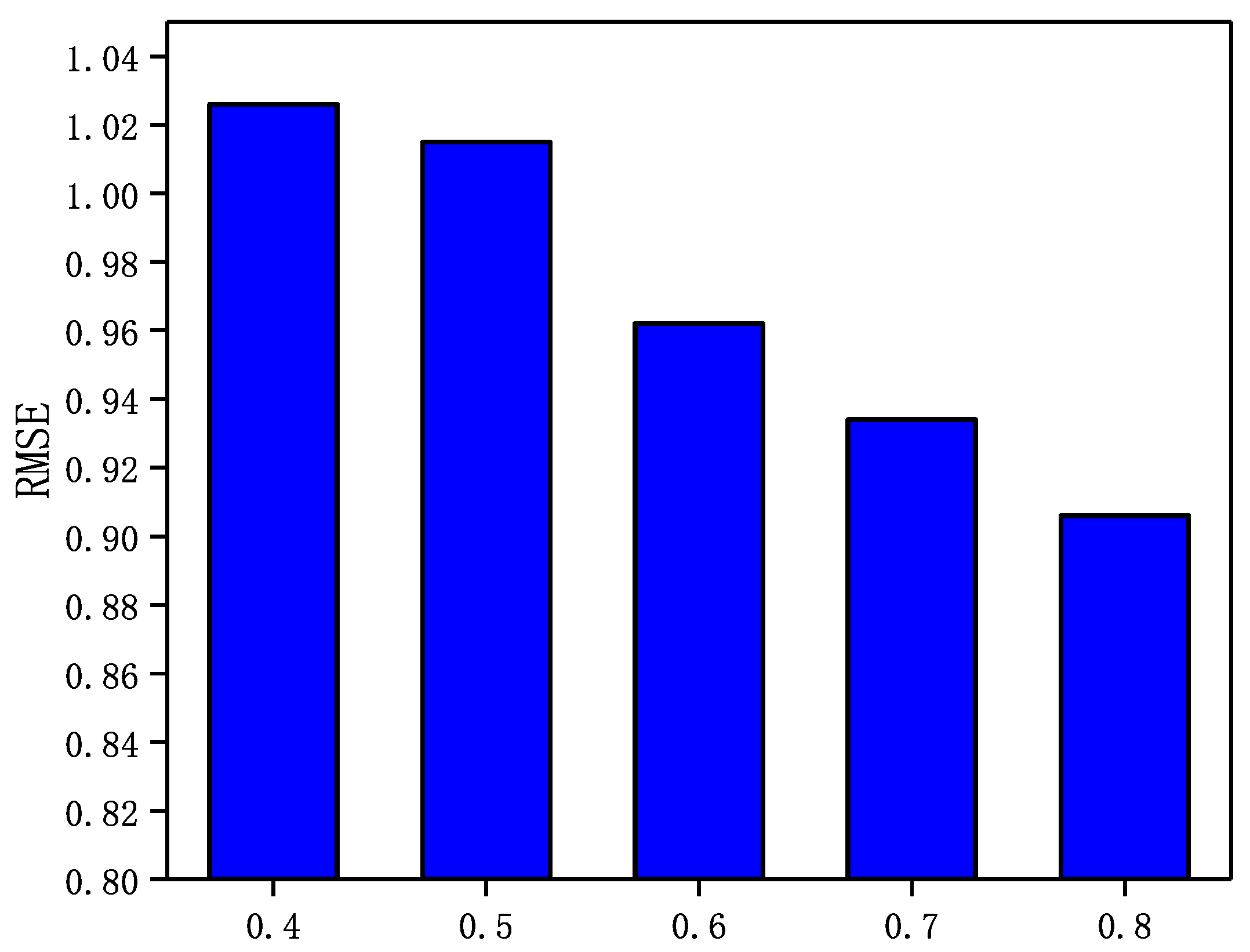
5.5. Influence of Parameter
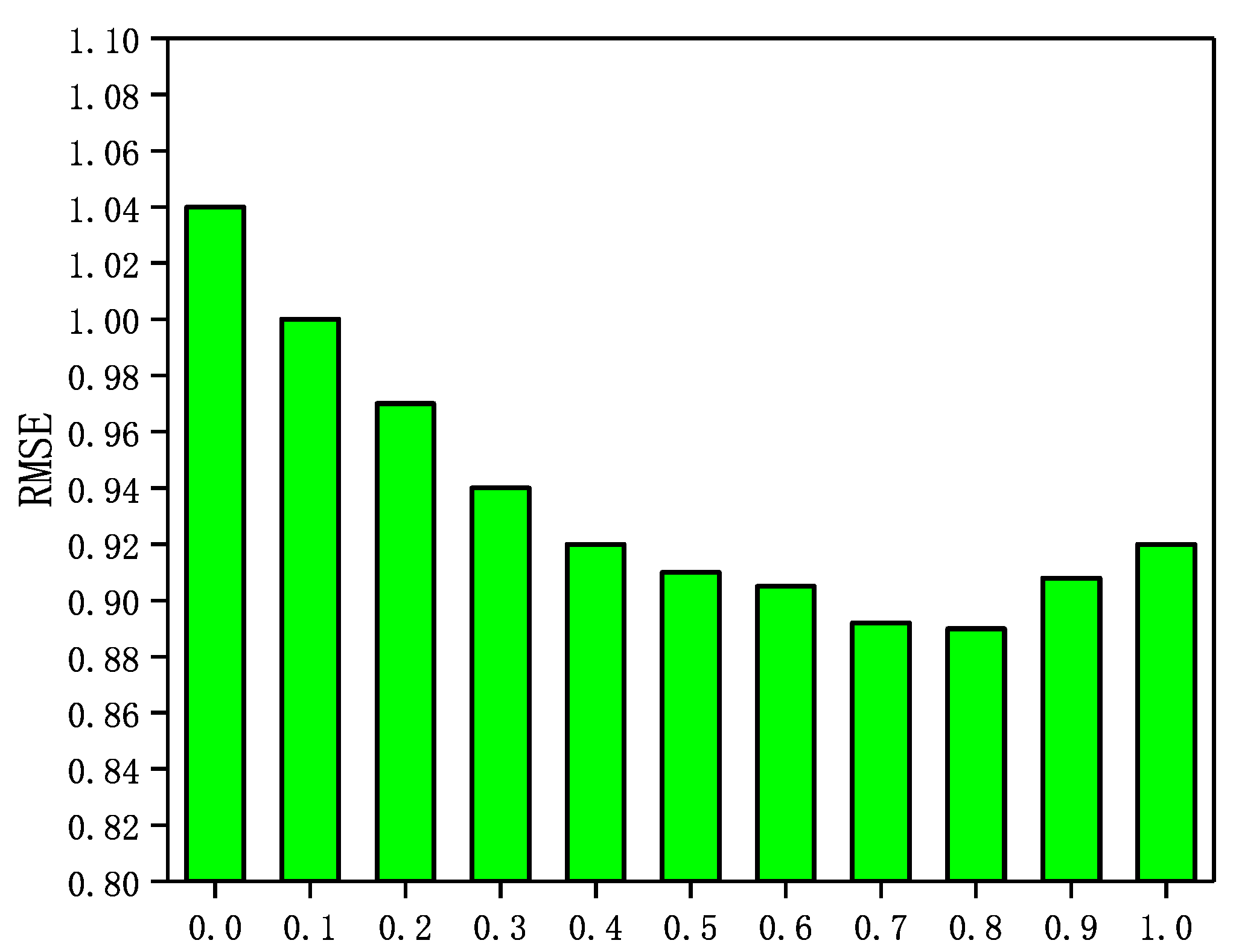
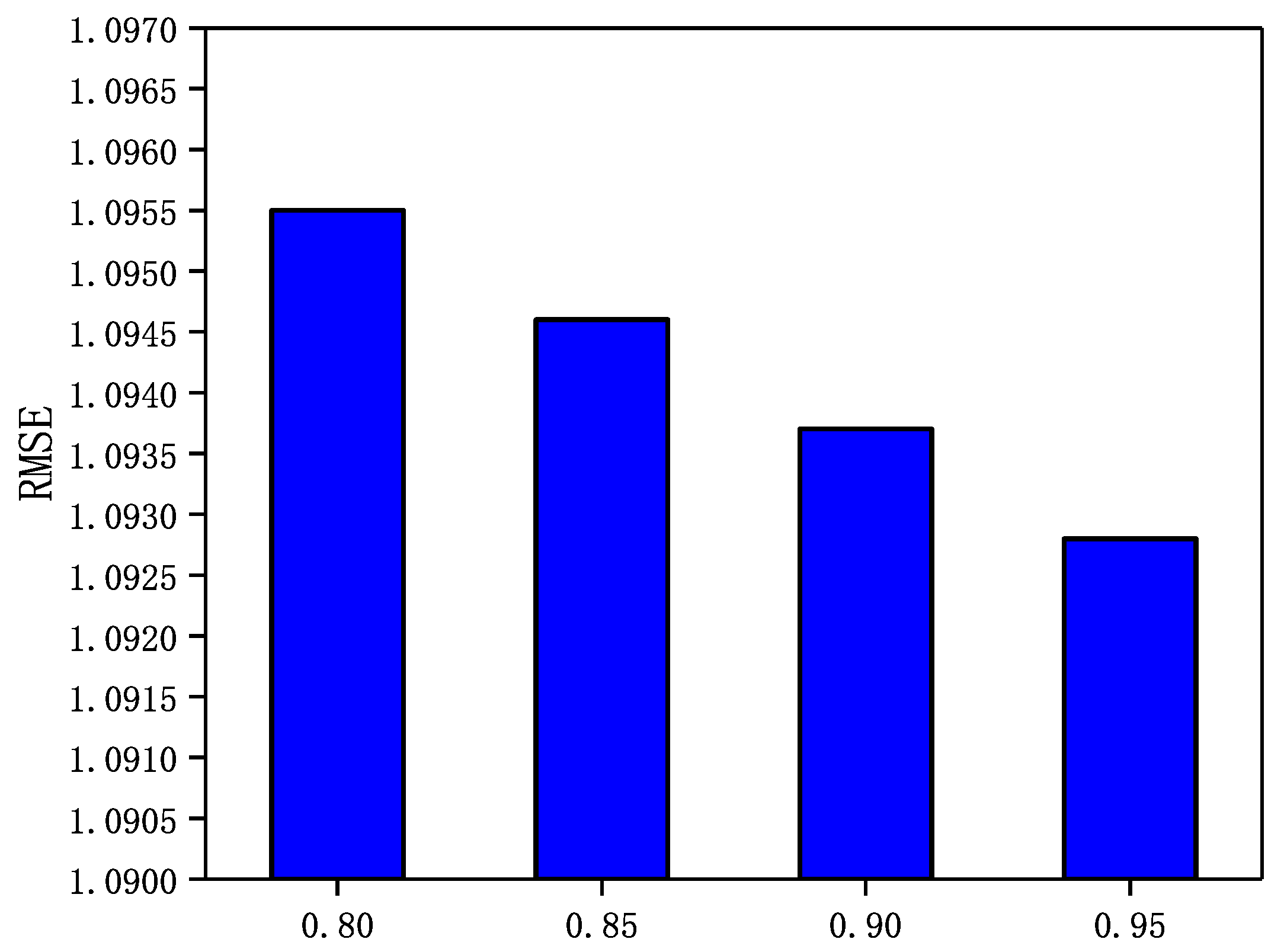
5.6. Influence of Parameter
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| u | user |
| i | item |
| Scoring data of user u | |
| user u’s rating of item j | |
| prediction score of user u for item j | |
| the average rating of user u for all rated items | |
| the average rating of user v for all rated items | |
| D | the set of users most similar to user |
| L | the set of users that user u trusts the most |
| the k-th layer vector representation of the target node | |
| , | Weight parameter |
| SIM(u,v) | the user trust derived from the social network structure |
| The embedding of user u | |
| The embedding of user v |
References
- Zhang, C.; Wang, Y.; Zhu, L.; Song, J.; Yin, H. Multi-graph heterogeneous interaction fusion for social recommendation. Acm Trans. Inf. Syst. (TOIS) 2021, 40, 1–26. [Google Scholar] [CrossRef]
- Wang, Y. Survey on deep multi-modal data analytics: Collaboration, rivalry, and fusion. Acm Trans. Multimed. Comput. Commun. Appl. (TOMM) 2021, 17, 1–25. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, W.; Wu, L.; Lin, X.; Fang, M.; Pan, S. Iterative views agreement: An iterative low-rank based structured optimization method to multi-view spectral clustering. arXiv 2016, arXiv:1608.05560. [Google Scholar]
- Wu, L.; Wang, Y.; Gao, J.; Wang, M.; Zha, Z.-J.; Tao, D. Deep coattention-based comparator for relative representation learning in person re-identification. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 722–735. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Wang, Y.; Ren, P.; Wang, M.; de Rijke, M. Bayesian feature interaction selection for factorization machines. Artif. Intell. 2022, 302, 103589. [Google Scholar] [CrossRef]
- Zhang, C.; Song, J.; Zhu, X.; Zhu, L.; Zhang, S. Hcmsl: Hybrid cross-modal similarity learning for cross-modal retrieval. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2021, 17, 1–22. [Google Scholar] [CrossRef]
- Zhu, L.; Song, J.; Zhu, X.; Zhang, C.; Zhang, S.; Yuan, X. Adversarial learning-based semantic correlation representation for cross-modal retrieval. IEEE Multimed. 2020, 27, 9–90. [Google Scholar] [CrossRef]
- Zhu, L.; Zhang, C.; Song, J.; Liu, L.; Zhang, S.; Li, Y. Multi-graph based hierarchical semantic fusion for cross-modal representation. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Zhu, L.; Song, J.; Yang, Z.; Huang, W.; Zhang, C.; Yu, W. DAP2CMH: Deep adversarial privacy-preserving cross-modal hashing. Neural Process. Lett. 2021, 1–21. [Google Scholar] [CrossRef]
- Zhang, C.; Xie, F.; Yu, H.; Zhang, J.; Zhu, L.; Li, Y. PPIS-JOIN: A novel privacy-preserving image similarity join method. Neural Process. Lett. 2021, 1–19. [Google Scholar] [CrossRef]
- Goldberg, D.; Nichols, D.; Oki, B.M.; Terry, D. Using collaborative filtering to weave an information tapestry. Commun. ACM 1992, 35, 61–70. [Google Scholar] [CrossRef]
- Qian, B.; Wang, Y.; Hong, R.; Wang, M.; Shao, L. Diversifying inference path selection: Moving-mobile-network for landmark recognition. IEEE Trans. Image Process. 2021, 30, 4894–4904. [Google Scholar] [CrossRef] [PubMed]
- Albadvi, A.; Shahbazi, M. A hybrid recommendation technique based on product category attributes. Expert Syst. Appl. 2009, 36, 11480–11488. [Google Scholar] [CrossRef]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th International Conference on World Wide Web, Hong Kong, China, 1–5 May 2001; pp. 285–295. [Google Scholar]
- Ambulgekar, H.; Pathak, M.K.; Kokare, M. A survey on collaborative filtering: Tasks, approaches and applications. In Proceedings of the International Ethical Hacking Conference 2018, Kolkata, India, 2018; Springer: Berlin, Germany, 2019; pp. 289–300. [Google Scholar]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Wang, G.; Liu, H. Survey of personalized recommendation system. Comput. Eng. Appl. 2012, 48, 66–76. [Google Scholar]
- Shi, Y.; Larson, M.; Hanjalic, A. Collaborative filtering beyond the user-item matrix: A survey of the state of the art and future challenges. ACM Comput. Surv. (CSUR) 2014, 47, 1–45. [Google Scholar] [CrossRef]
- Ma, H.; Yang, H.; Lyu, M.R.; King, I. Sorec: Social recommendation using probabilistic matrix factorization. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, CIKM 2008, Napa Valley, CA, USA, 26–30 October 2008. [Google Scholar]
- Yang, B.; Lei, Y.; Liu, D.; Liu, J. Social collaborative filtering by trust. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013. [Google Scholar]
- Ma, H.; King, I.; Lyu, M.R. Learning to recommend with social trust ensemble. In Proceedings of the 32nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2009, Boston, MA, USA, 19–23 July 2009. [Google Scholar]
- Jamali, M.; Ester, M. A matrix factorization technique with trust propagation for recommendation in social networks. In Proceedings of the ACM Conference on Recommender Systems, Barcelona, Spain, 26–30 September 2010. [Google Scholar]
- Ma, H.; Zhou, D.; Liu, C.; Lyu, M.R.; King, I. Recommender systems with social regularization. In Proceedings of the Forth International Conference on Web Search and Web Data Mining, WSDM 2011, Hong Kong, China, 9–12 February 2011. [Google Scholar]
- Koren, Y. Factorization meets the neighborhood: A multifaceted collaborative filtering model. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008. [Google Scholar]
- Guo, G.; Zhang, J.; Yorke-Smith, N. Trustsvd: Collaborative filtering with both the explicit and implicit influence of user trust and of item ratings. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Belkin, M.; Niyogi, P. Laplacian eigenmaps and spectral techniques for embedding and clustering. Adv. Neural Inf. Process. Syst. 2001, 14, 585–591. [Google Scholar]
- Tenenbaum, J.B.; Silva, V.D.; Langford, J.C. A global geometric framework for nonlinear dimensionality reduction. Science 2000, 290, 2319–2323. [Google Scholar] [CrossRef] [PubMed]
- Roweis, S.T.; Saul, L.K. Nonlinear dimensionality reduction by locally linear embedding. Science 2000, 290, 2323–2326. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Luo, D.; Ding, C.H.; Nie, F.; Huang, H. Cauchy graph embedding. In Proceedings of the ICML, Bellevue, WA, USA, 28 June–2 July 2011. [Google Scholar]
- Cao, S.; Lu, W.; Xu, Q. Grarep: Learning graph representations with global structural information. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 19–23 October 2015; pp. 891–900. [Google Scholar]
- Ou, M.; Cui, P.; Pei, J.; Zhang, Z.; Zhu, W. Asymmetric transitivity preserving graph embedding. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1105–1114. [Google Scholar]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Dong, Y.; Chawla, N.V.; Swami, A. metapath2vec: Scalable representation learning for heterogeneous networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 135–144. [Google Scholar]
- Wang, D.; Cui, P.; Zhu, W. Structural deep network embedding. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1225–1234. [Google Scholar]
- Cao, S.; Lu, W.; Xu, Q. Deep neural networks for learning graph representations. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 16, pp. 1145–1152. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1024–1034. [Google Scholar]
- Goyal, P.; Ferrara, E. Graph embedding techniques, applications, and performance: A survey. Knowl. Based Syst. 2017, 151, 78–94. [Google Scholar] [CrossRef] [Green Version]
- Balasubramanian, M. The isomap algorithm and topological stability. Science 2002, 295, 7. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Salakhutdinov, R.; Mnih, A. Probabilistic matrix factorization. In Advances in Neural Information Processing Systems 20, Proceedings of the Twenty-First Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; Platt, J.C., Koller, D., Singer, Y., Roweis, S.T., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2007; pp. 1257–1264. [Google Scholar]
- Zheng, L.; Noroozi, V.; Yu, P.S. Joint deep modeling of users and items using reviews for recommendation. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, WSDM 2017, Cambridge, UK, 6–10 February 2017. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Property | NC | WI | Epinions | LastFM |
|---|---|---|---|---|
| # Users | 22,737 | 8386 | 18,088 | 1874 |
| # Items | 12,502 | 4593 | 261,649 | 2828 |
| # Ratings | 225,580 | 80,643 | 764,352 | 71,411 |
| Density of relations | 0.0793% | 0.2093% | 0.0161% | 2.0286% |
| # social relations | 111,394 | 34,099 | 355,813 | 25,174 |
| Competitor | RMSE | MAE |
|---|---|---|
| Baseline1 | 1.432 | 1.142 |
| Baseline2 | 1.311 | 1.034 |
| PMF | 1.201 | 0.903 |
| TrustSVD | 1.135 | 0.867 |
| DeepCoNN | 1.113 | 0.859 |
| GraphSAGE-CF | 1.091 | 0.841 |
| Competitor | RMSE | MAE |
|---|---|---|
| Baseline1 | 1.143 | 0.879 |
| Baseline2 | 1.037 | 0.794 |
| PMF | 0.923 | 0.723 |
| TrustSVD | 0.887 | 0.685 |
| DeepCoNN | 0.863 | 0.674 |
| GraphSAGE-CF | 0.842 | 0.668 |
| Competitor | RMSE | MAE |
|---|---|---|
| Baseline1 | 1.478 | 1.208 |
| Baseline2 | 1.403 | 1.124 |
| PMF | 0.923 | 1.062 |
| TrustSVD | 1.174 | 0.904 |
| DeepCoNN | 1.133 | 0.886 |
| GraphSAGE-CF | 1.093 | 0.867 |
| Competitor | RMSE | MAE |
|---|---|---|
| Baseline1 | 1.298 | 1.035 |
| Baseline2 | 1.207 | 0.947 |
| PMF | 0.923 | 0.898 |
| TrustSVD | 0.957 | 0.758 |
| DeepCoNN | 0.928 | 0.726 |
| GraphSAGE-CF | 0.891 | 0.714 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, J.; Song, J.; Yuan, X.; He, X.; Zhu, X. Graph Representation-Based Deep Multi-View Semantic Similarity Learning Model for Recommendation. Future Internet 2022, 14, 32. https://doi.org/10.3390/fi14020032
Song J, Song J, Yuan X, He X, Zhu X. Graph Representation-Based Deep Multi-View Semantic Similarity Learning Model for Recommendation. Future Internet. 2022; 14(2):32. https://doi.org/10.3390/fi14020032
Chicago/Turabian StyleSong, Jiagang, Jiayu Song, Xinpan Yuan, Xiao He, and Xinghui Zhu. 2022. "Graph Representation-Based Deep Multi-View Semantic Similarity Learning Model for Recommendation" Future Internet 14, no. 2: 32. https://doi.org/10.3390/fi14020032