
Key Points’ Location in Infrared Images of the Human Body Based on Mscf-ResNet


Abstract
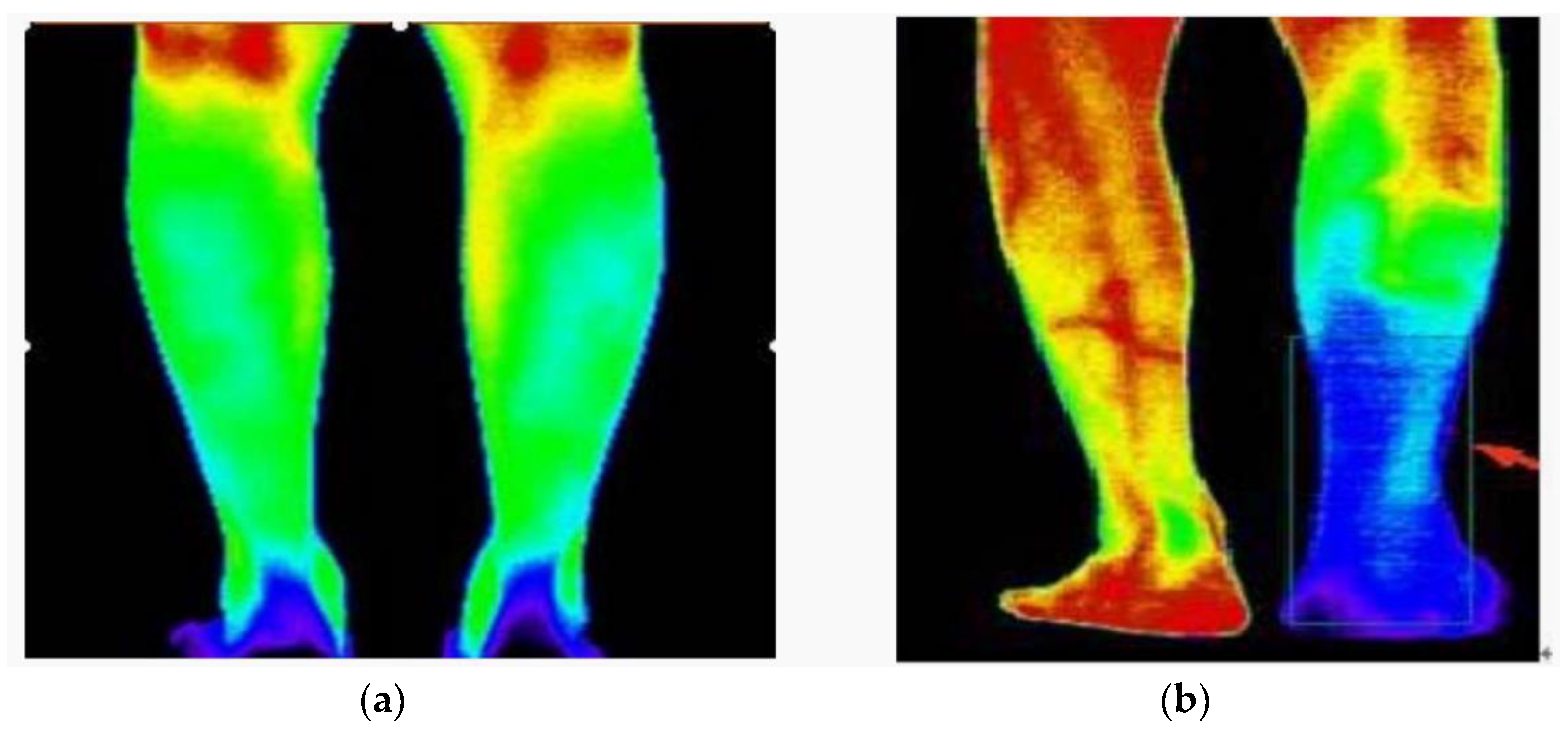
:1. Introduction
2. Related Work
2.1. Conventional CNN Models
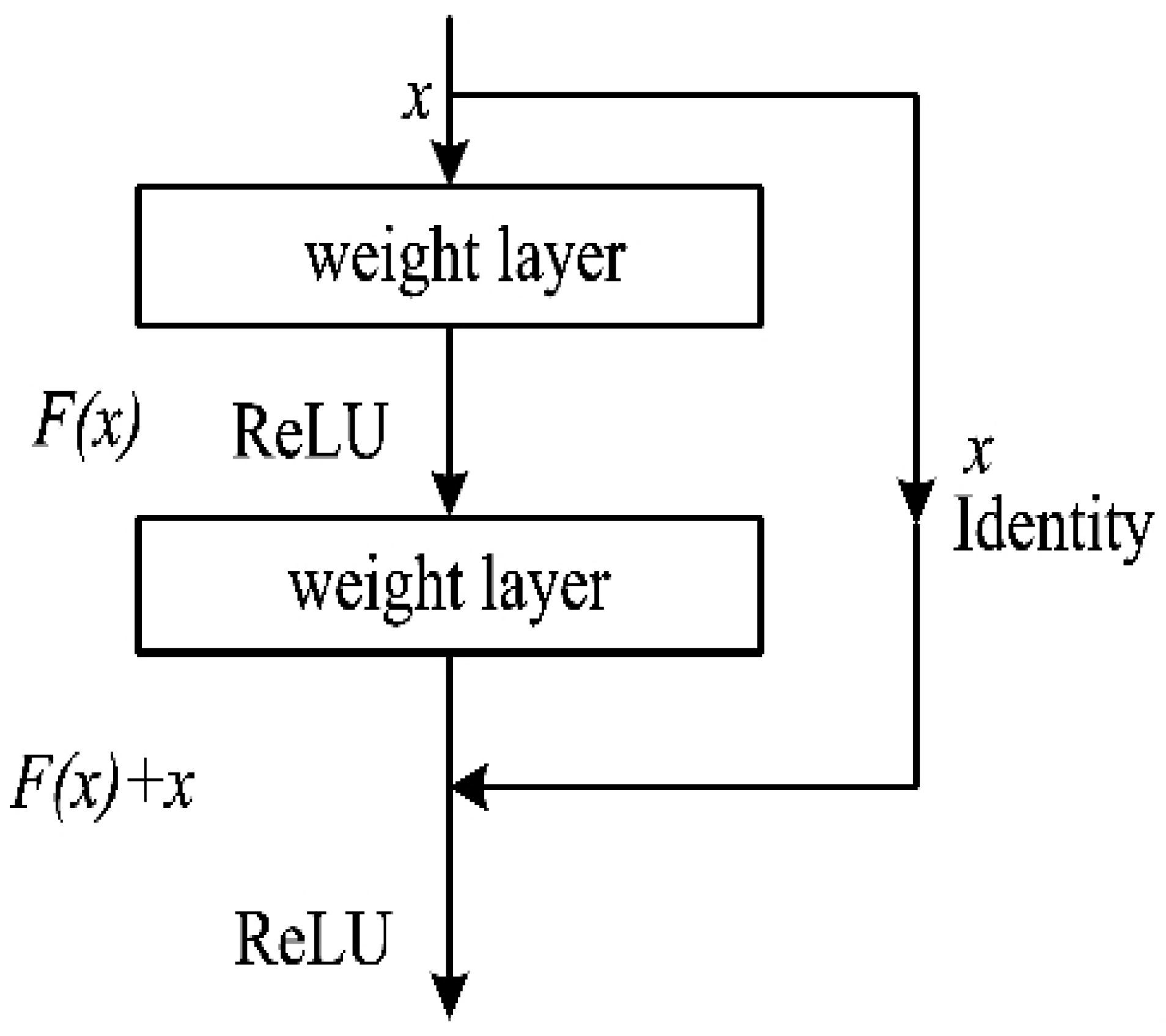
2.2. Residual Learning
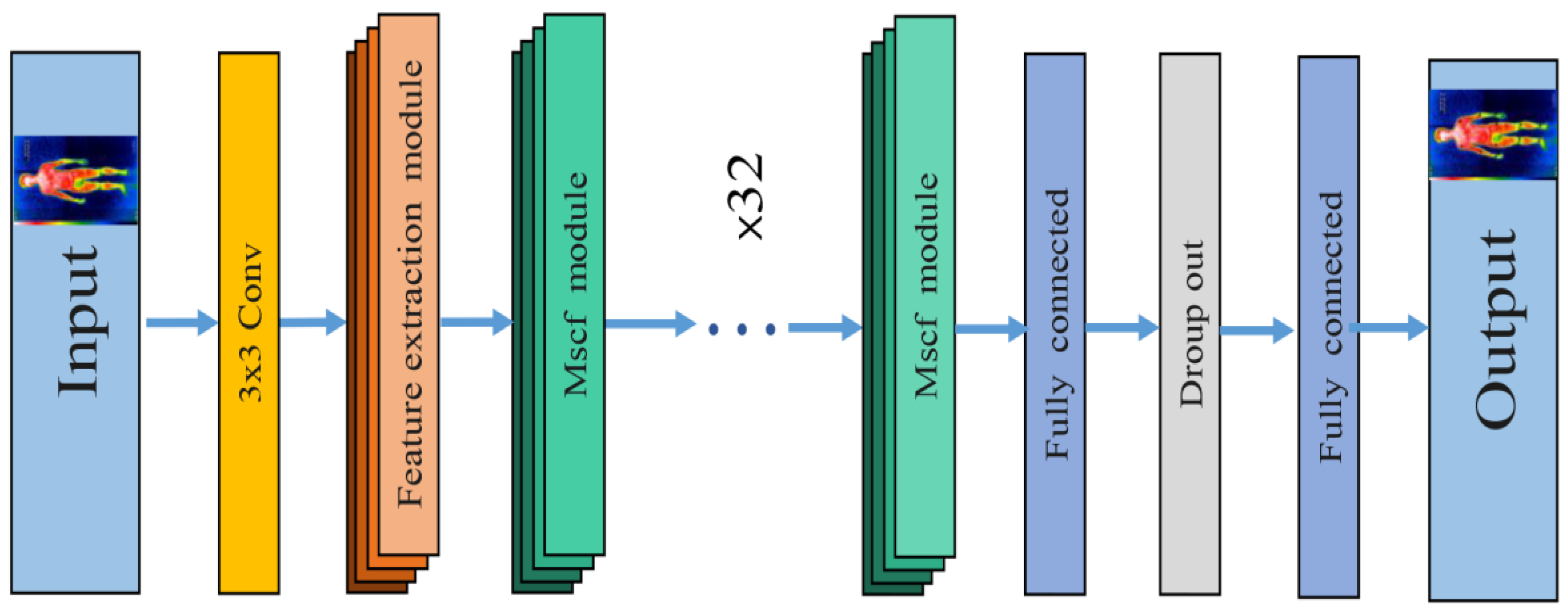
3. The Key Point Location Model for Human Infrared Images
3.1. Feature Extraction Module
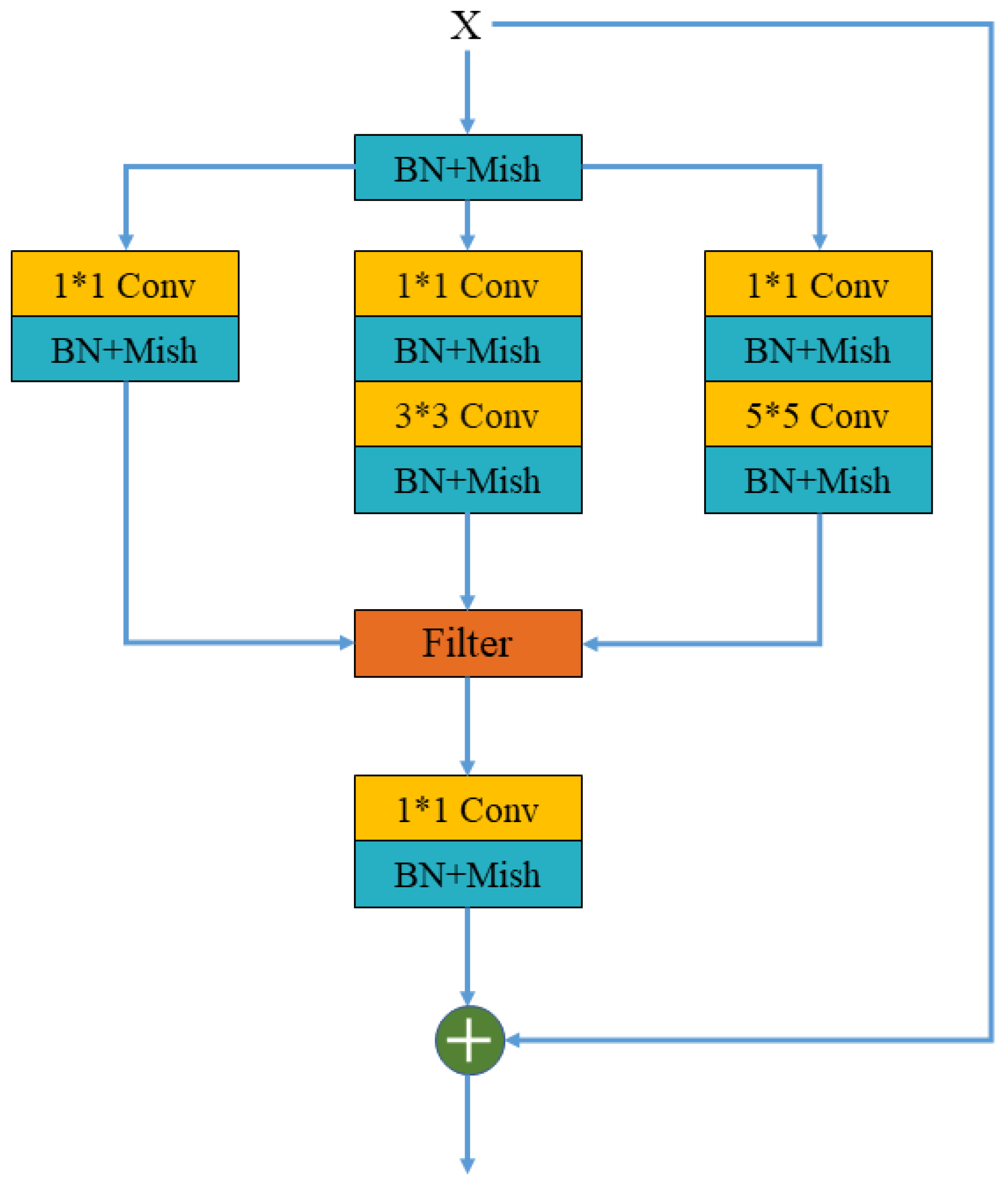
3.2. Mscf Module
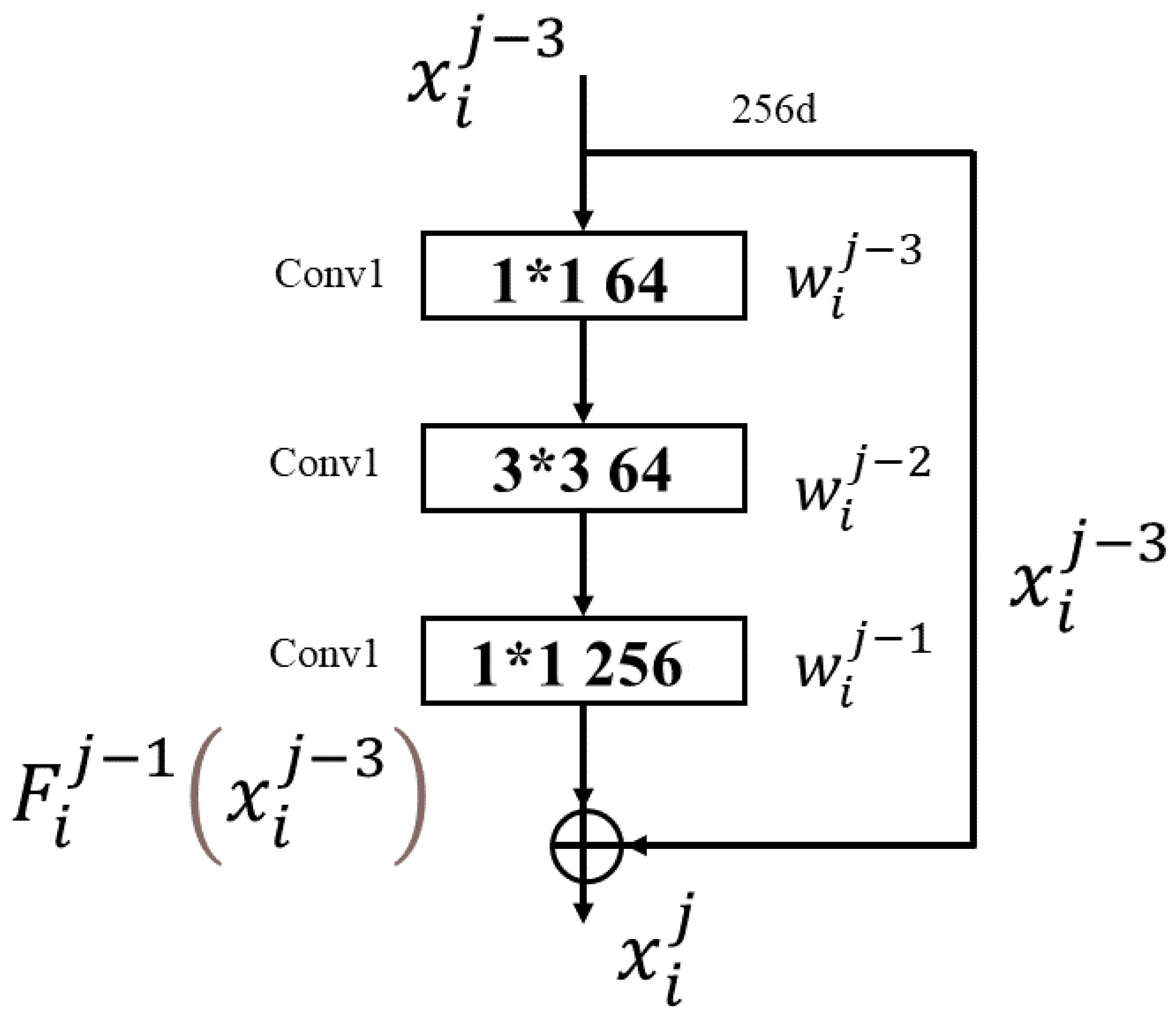
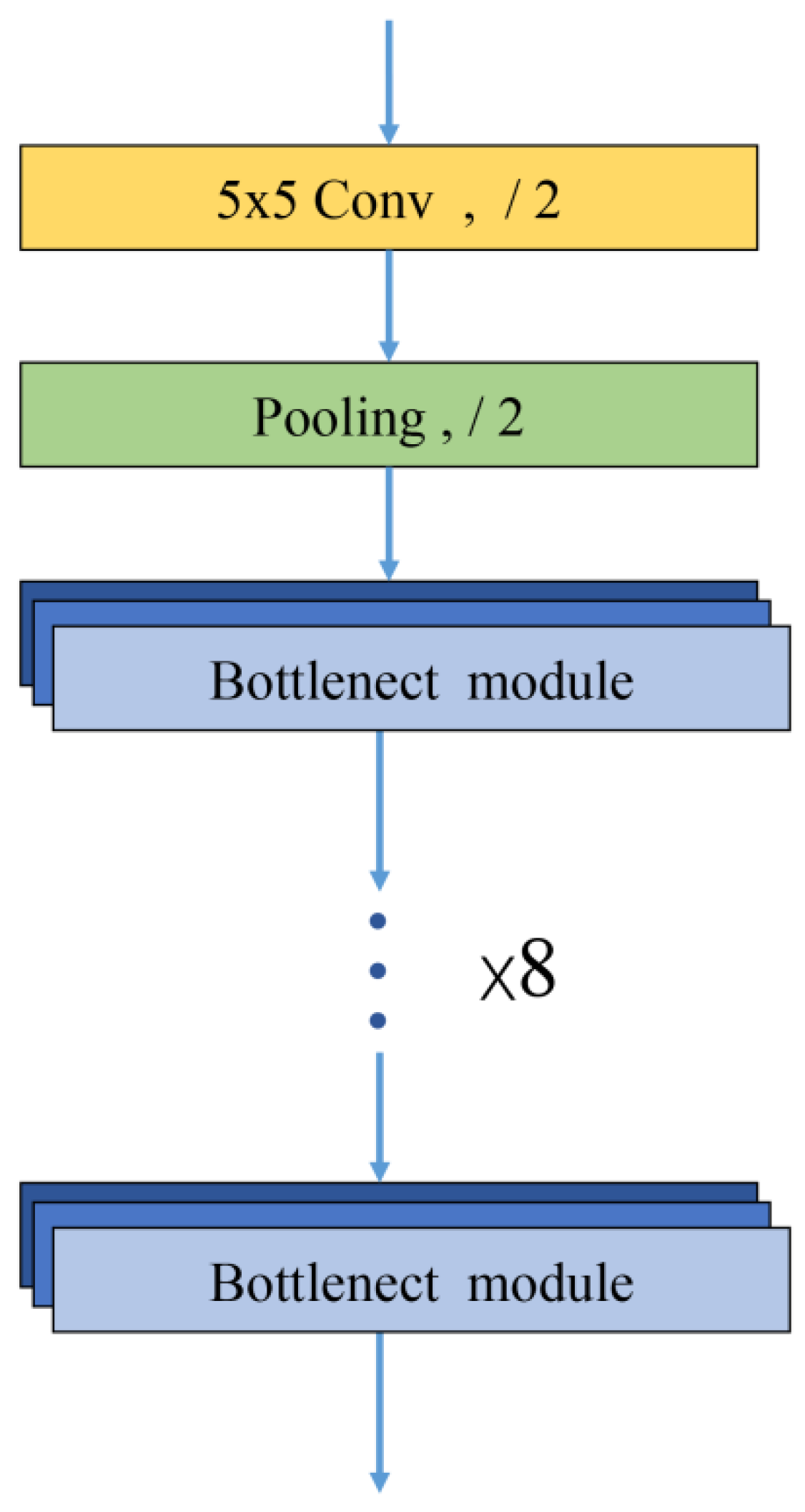
3.3. Mscf-ResNet Module
4. Experiment and Analysis
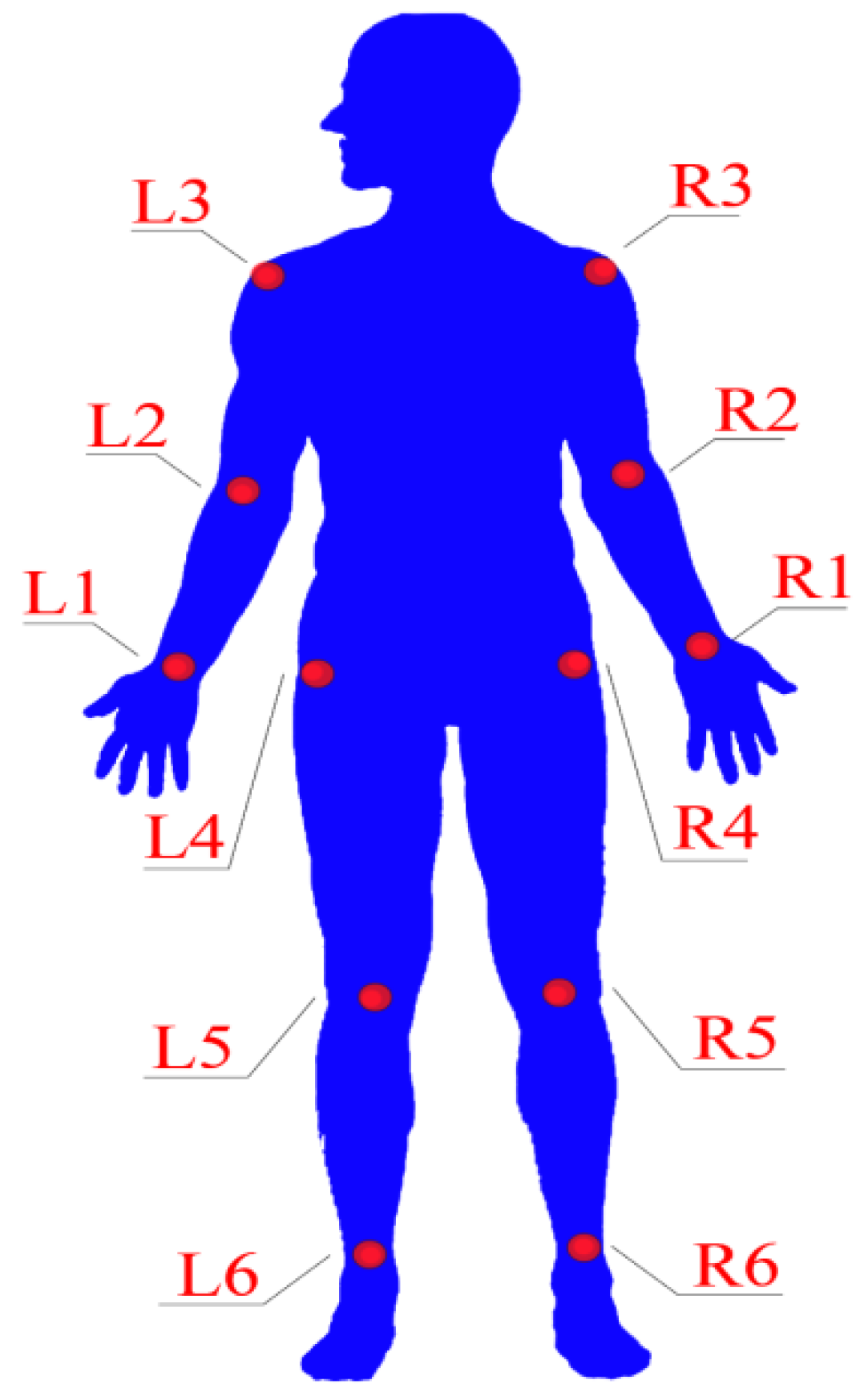
4.1. Data and Operating Environment
4.2. Experimental Evaluation
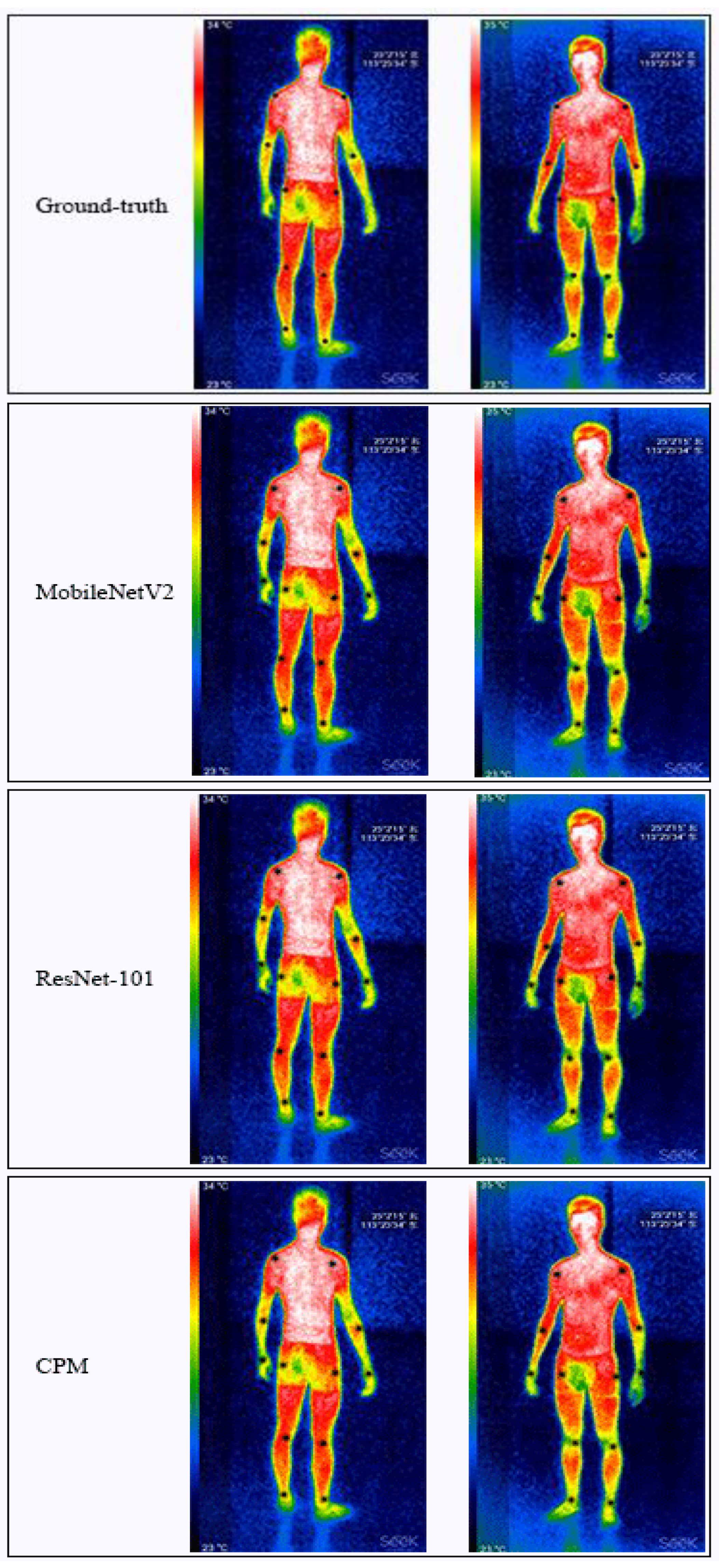
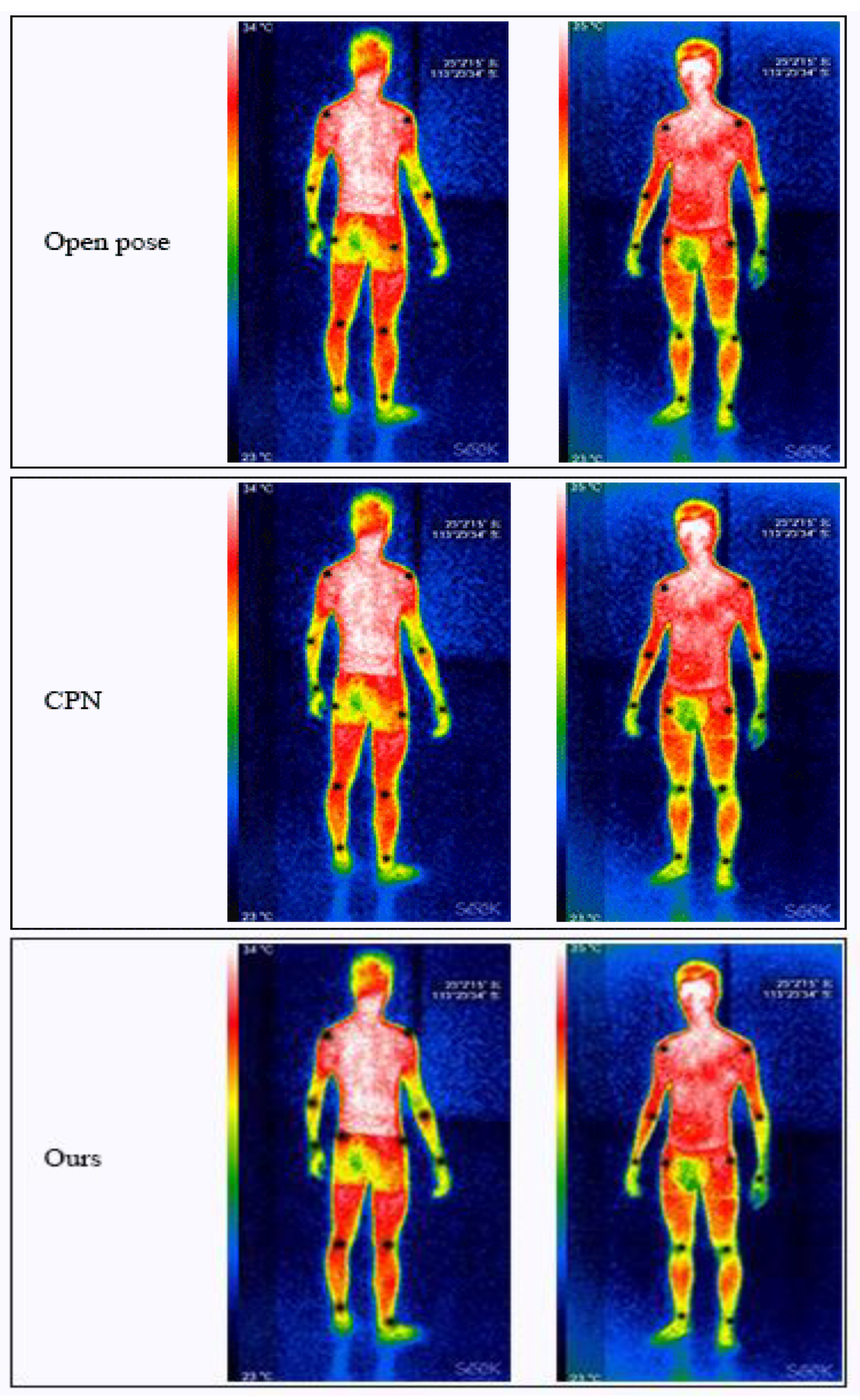
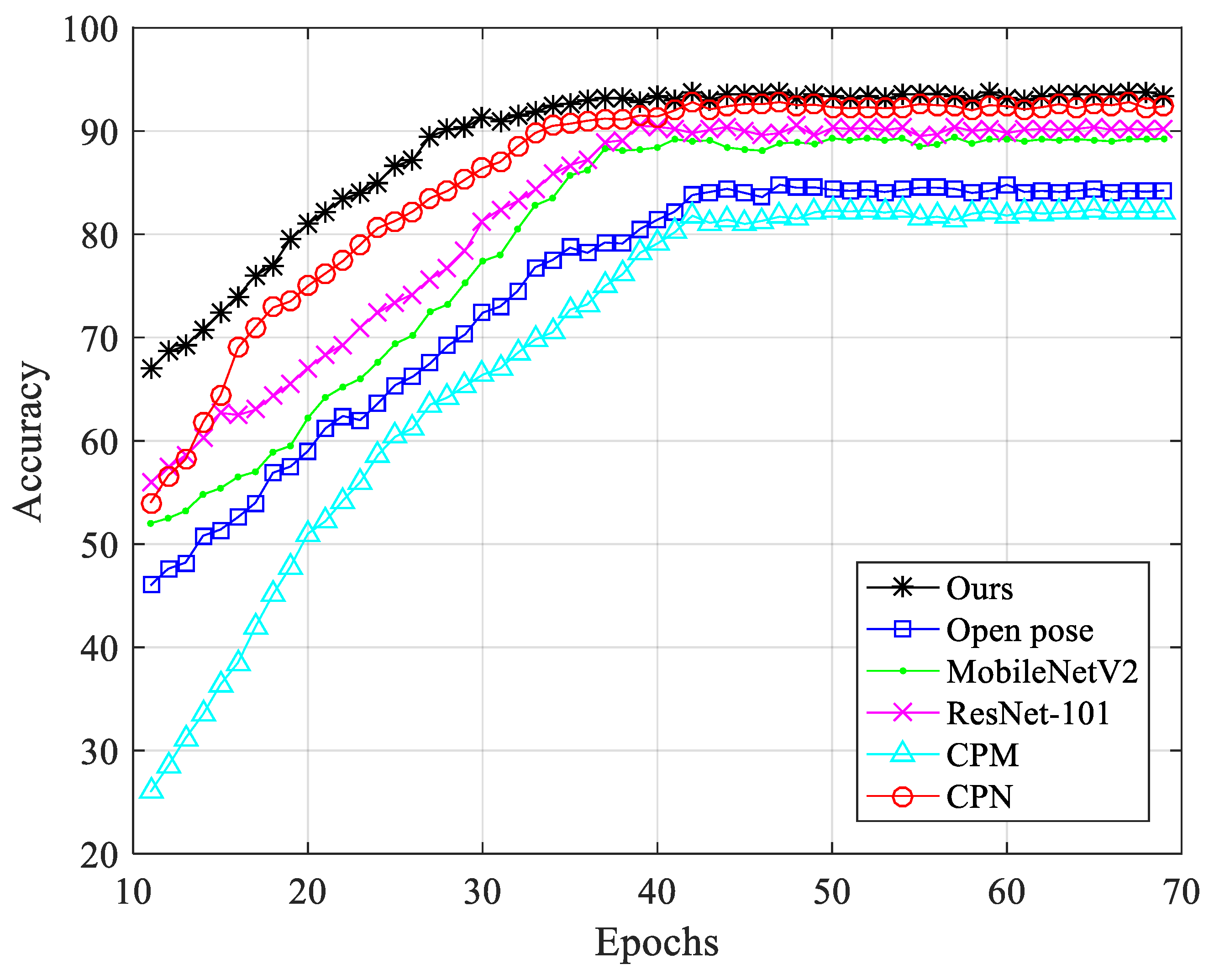
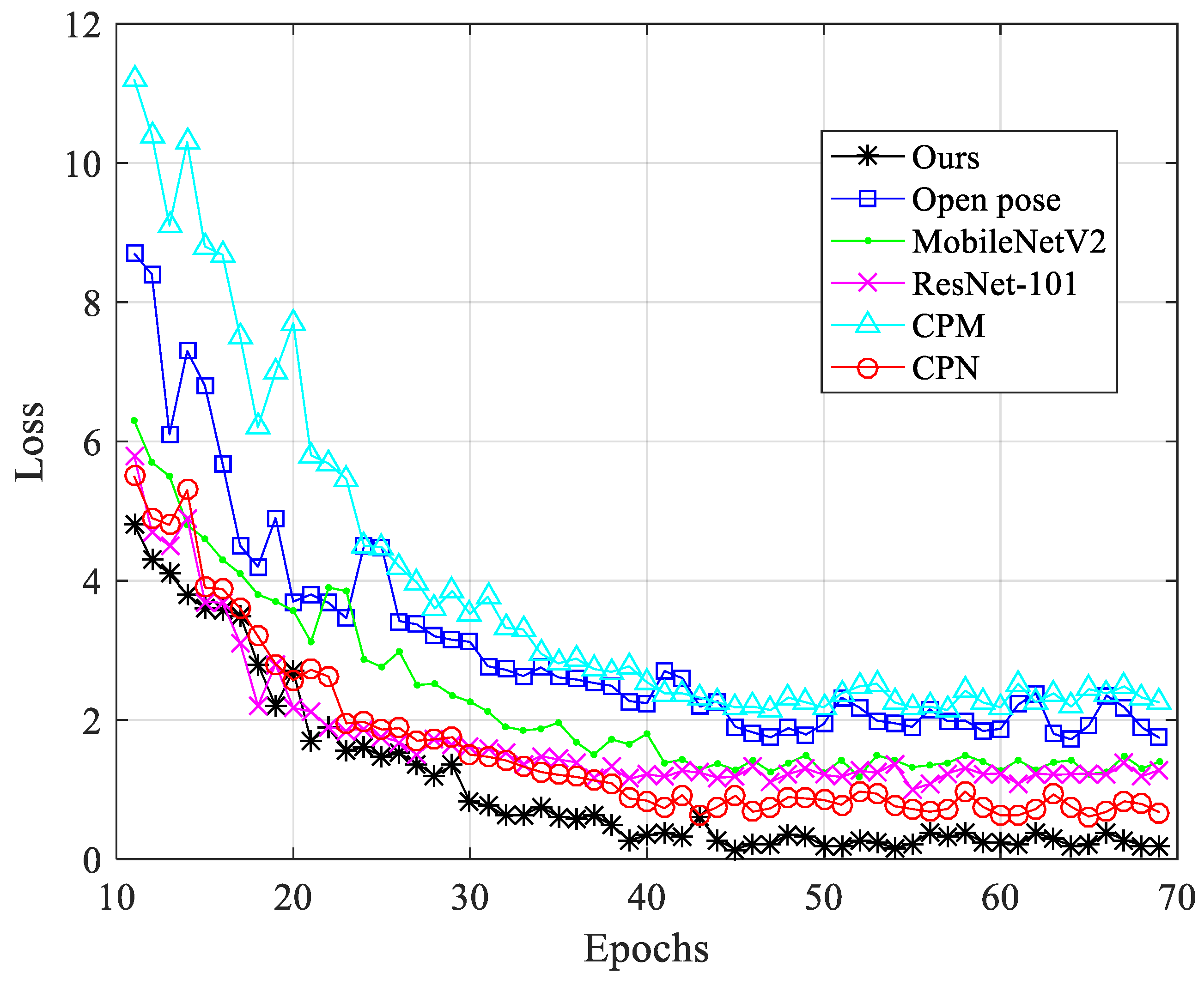
4.3. Experimental Results and Analysis
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, X.-D.; Huang, Y.; Zhang, P.Q.; Song, B.A.; Dai, S.X.; Tie-Feng, X.U.; Nie, Q.H. Infrared imaging system and applications. Laser Infrared 2014, 44, 3. [Google Scholar]
- Resendiz-Ochoa, E.; Osornio-Rios, R.A.; Benitez-Rangel, J.P.; Romero-Troncoso, R.D.J.; Morales-Hernandez, L.A. Induction motor failure analysis: An automatic methodology based on infrared imaging. IEEE Access 2018, 6, 76993–77003. [Google Scholar] [CrossRef]
- Saif, M.; Kwanten, W.J.; Carr, J.A.; Chen, I.X.; Posada, J.M.; Srivastava, A.; Bawendi, M.G. Non-invasive monitoring of chronic liver disease via near-infrared and shortwave-infrared imaging of endogenous lipofuscin. Nat. Biomed. Eng. 2020, 4, 801–813. [Google Scholar] [CrossRef] [PubMed]
- Babaeian, E.; Sadeghi, M.; Gohardoust, M.R.; Arthur, E.; Effati, M.; Jones, S.B.; Tuller, M. The feasibility of shortwave infrared imaging and inverse numerical modeling for rapid estimation of soil hydraulic properties. Vadose Zone J. 2021, 20, e20089. [Google Scholar] [CrossRef]
- Hixson, J.G.; Teaney, B.P.; Graybeal, J.J.; Nehmetallah, G. Analysis and modeling of observer performance while using an infrared imaging system. Opt. Eng. 2020, 59, 033106. [Google Scholar] [CrossRef]
- Qinyuan, Q.; Zhangqing, C. Application of thermal infrared technology in traditional Chinese medicine diagnosis. World Sci. Technol. Mod. Tradit. Chin. Med. Mater. Med. 2011, 13, 1027–1031. [Google Scholar]
- Selvarani, A.; Suresh, G. Infrared thermal imaging for diabetes detection and measurement. J. Med. Syst. 2019, 43, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Zou, T.; Chen, G.; Li, Z.; He, W.; Qu, S.; Gu, S.; Knoll, A. KAM-Net: Keypoint-Aware and Keypoint-Matching Network for Vehicle Detection from 2D Point Cloud. IEEE Trans. Artif. Intell. 2021. [Google Scholar] [CrossRef]
- He, Y.; Sun, W.; Huang, H.; Liu, J.; Fan, H.; Sun, J. Pvn3d: A deep point-wise 3d keypoints voting network for 6dof pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11632–11641. [Google Scholar]
- Wang, Y.; Mori, G. Multiple tree models for occlusion and spatial constraints in human pose estimation. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2008; pp. 710–724. [Google Scholar]
- Wang, F.; Li, Y. Beyond physical connections: Tree models in human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 596–603. [Google Scholar]
- Dantone, M.; Gall, J.; Leistner, C.; Van Gool, L. Human pose estimation using body parts dependent joint regressors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3041–3048. [Google Scholar]
- Sun, M.; Kohli, P.; Shotton, J. Conditional regression forests for human pose estimation. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3394–3401. [Google Scholar]
- Kiefel, M.; Gehler, P.V. Human pose estimation with fields of parts. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014; pp. 331–346. [Google Scholar]
- Hara, K.; Chellappa, R. Computationally efficient regression on a dependency graph for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3390–3397. [Google Scholar]
- Toshev, A.; Szegedy, C.D. Human Pose Estimation via Deep Neural Networks’; CVPR: Columbus, OH, USA, 2014; pp. 1653–1660. [Google Scholar]
- Tompson, J.J.; Jain, A.; LeCun, Y.; Bregler, C. Joint training of a convolutional network and a graphical model for human pose estimation. Adv. Neural Inf. Process. Syst. 2014, 27, 1799–1807. [Google Scholar]
- Pfister, T.; Charles, J.; Zisserman, A. Flowing convnets for human pose estimation in videos. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1913–1921. [Google Scholar]
- Wei, S.-E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional pose machines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4724–4732. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 483–499. [Google Scholar]
- Yang, W.; Li, S.; Ouyang, W.; Li, H.; Wang, X. Learning feature pyramids for human pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1281–1290. [Google Scholar]
- Carreira, J.; Agrawal, P.; Fragkiadaki, K.; Malik, J. Human pose estimation with iterative error feedback. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4733–4742. [Google Scholar]
- Lifshitz, I.; Fetaya, E.; Ullman, S. Human pose estimation using deep consensus voting. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 246–260. [Google Scholar]
- Pishchulin, L.; Insafutdinov, E.; Tang, S.; Andres, B.; Andriluka, M.; Gehler, P.V.; Schiele, B. Deepcut: Joint subset partition and labeling for multi person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4929–4937. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Insafutdinov, E.; Pishchulin, L.; Andres, B.; Andriluka, M.; Schiele, B. Deepercut: A deeper, stronger, and faster multi-person pose estimation model. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 34–50. [Google Scholar]
- Xia, F.; Wang, P.; Chen, X.; Yuille, A.L. Joint multi-person pose estimation and semantic part segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6769–6778. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.-E.; Sheikh, Y. Realtime multi-person 2d pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Papandreou, G.; Zhu, T.; Kanazawa, N.; Toshev, A.; Tompson, J.; Bregler, C.; Murphy, K. Towards accurate multi-person pose estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4903–4911. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded pyramid network for multi-person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7103–7112. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Oquab, M.; Bottou, L.; Laptev, I.; Sivic, J. Learning and transferring mid-level image representations using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1717–1724. [Google Scholar]
- Rojas, R. The backpropagation algorithm. In Neural Networks; Springer: Berlin/Heidelberg, Germany, 1996; pp. 149–182. [Google Scholar]
- Hawkins, D.M. The problem of overfitting. J. Chem. Inf. Comput. Sci. 2004, 44, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Murray, N.; Perronnin, F. Generalized max pooling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2473–2480. [Google Scholar]
- Wu, X.; Irie, G.; Hiramatsu, K.; Kashino, K. Weighted generalized mean pooling for deep image retrieval. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 495–499. [Google Scholar]
- Sainath, T.N.; Vinyals, O.; Senior, A.; Sak, H. Convolutional, long short-term memory, fully connected deep neural networks. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 4580–4584. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yan, C.; Wang, Y. A Novel Multi-User Face Detection under Infrared Illumination by Real Adaboost. In Proceedings of the 2009 International Conference on Computational Intelligence and Software Engineering, Wuhan, China, 11–13 December 2009; pp. 1–6. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International Conference on Machine Learning; PMLR: Lille, France, 2015; pp. 448–456. [Google Scholar]
- Mish, M.D. A self regularized non-monotonic neural activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MobileNetV2 | ResNet-101 | CPM | Open Pose | CPN | Ours | |
|---|---|---|---|---|---|---|
| Key point L1 (%) | 88.6 | 89.2 | 82.2 | 84.6 | 91.2 | 93.6 |
| Key point L2 (%) | 89.5 | 90.3 | 82.8 | 85.3 | 92.6 | 94.2 |
| Key point L3 (%) | 89.6 | 89.6 | 81.3 | 82.6 | 92.4 | 94.1 |
| Key point L4 (%) | 88.6 | 89.3 | 81.6 | 83.6 | 91.2 | 93.6 |
| Key point L5 (%) | 88.9 | 88.6 | 82.4 | 83.4 | 90.6 | 93.5 |
| Key point L6 (%) | 87.2 | 89.6 | 81.8 | 84.6 | 91.7 | 92.8 |
| Key point R1 (%) | 88.6 | 90.5 | 81.3 | 85.1 | 91.6 | 93.8 |
| Key point R2 (%) | 89.4 | 90.6 | 82.6 | 85.2 | 92.1 | 94.6 |
| Key point R3 (%) | 87.6 | 89.6 | 81.6 | 84.3 | 91.2 | 93.7 |
| Key point R4 (%) | 87.9 | 88.7 | 82.2 | 83.5 | 90.6 | 92.5 |
| Key point R5 (%) | 88.6 | 88.9 | 82.4 | 82.6 | 90.8 | 93.4 |
| Key point R6 (%) | 89.0 | 89.3 | 81.9 | 84.8 | 91.6 | 93.6 |
| Average | 88.6 | 89.5 | 82.0 | 84.1 | 91.5 | 93.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ge, S.; Rum, S.N.M. Key Points’ Location in Infrared Images of the Human Body Based on Mscf-ResNet. Future Internet 2022, 14, 15. https://doi.org/10.3390/fi14010015
Ge S, Rum SNM. Key Points’ Location in Infrared Images of the Human Body Based on Mscf-ResNet. Future Internet. 2022; 14(1):15. https://doi.org/10.3390/fi14010015
Chicago/Turabian StyleGe, Shengguo, and Siti Nurulain Mohd Rum. 2022. "Key Points’ Location in Infrared Images of the Human Body Based on Mscf-ResNet" Future Internet 14, no. 1: 15. https://doi.org/10.3390/fi14010015