
Models versus Datasets: Reducing Bias through Building a Comprehensive IDS Benchmark


Abstract
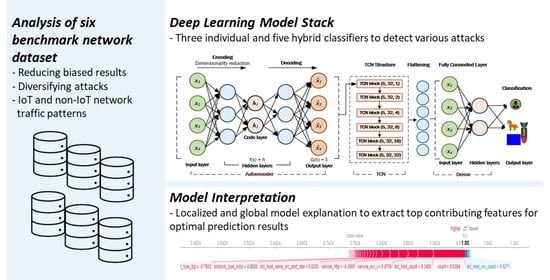
:
1. Introduction
2. Literature Review
2.1. Related Work
2.2. Benchmark Datasets
2.3. Dataset Quality and Reliability Issues
2.4. Deep Learning Classifiers for Sequential Data
2.5. Feature Importance
2.5.1. Local Interpretable Model-Agnostic Explanation (LIME)
2.5.2. SHapley Additive Explanation (SHAP)
3. Proposed Framework
4. Experiments, Results, and Analysis
4.1. Individual Prediction Interpretation—Localized Explanation
4.2. Model Interpretation—Global Explanation
4.3. Top Contributing Features
5. Models versus Datasets, a Comparison Study
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Anthi, E.; Williams, L.; Słowińska, M.; Theodorakopoulos, G.; Burnap, P. A supervised intrusion detection system for smart home IoT devices. IEEE Internet Things J. 2019, 6, 9042–9053. [Google Scholar] [CrossRef]
- Agazzi, A.E. Smart home, security concerns of IoT. arXiv 2020, arXiv:2007.02628. [Google Scholar]
- Karie, N.M.; Sahri, N.M.; Haskell-Dowland, P. IoT threat detection advances, challenges and future directions. In Proceedings of the 2020 Workshop on Emerging Technologies for Security in IoT (ETSecIoT), Sydney, Australia, 21–21 April 2020; pp. 22–29. [Google Scholar] [CrossRef]
- Khan, A.Y.; Latif, R.; Latif, S.; Tahir, S.; Batool, G.; Saba, T. Malicious insider attack detection in IoTs using data analytics. IEEE Access 2020, 8, 11743–11753. [Google Scholar] [CrossRef]
- Soe, Y.N.; Santosa, P.I.; Hartanto, R. DDoS Attack Detection Based on Simple ANN with SMOTE for IoT Environment. In Proceedings of the 2019 Fourth International Conference on Informatics and Computing (ICIC), Semarang, Indonesia, 16–17 October 2019; pp. 1–5. [Google Scholar] [CrossRef]
- GarcIa-Teodoro, P.; DIaz-Verdejo, J.; MaciA-FernAndez, G.; VAzquez, E. Anomaly-based network intrusion detection: Techniques, systems and challenges. Comput. Secur. 2009, 28, 18–28. [Google Scholar] [CrossRef]
- Zong, Y.; Huang, G. A feature dimension reduction technology for predicting DDoS intrusion behavior in multimedia internet of things. In Multimedia Tools and Applications; Dordrecht; Springer Nature B.V.: Dordrecht, The Netherlands, 2019; pp. 1–14. [Google Scholar] [CrossRef]
- Dushimimana, A.; Tao, T.; Kindong, R.; Nishyirimbere, A. Bi-directional recurrent neural network for intrusion detection system (IDS) in the internet of things (IoT). Int. J. Adv. Eng. Res. Sci. 2020, 7, 524–539. [Google Scholar] [CrossRef]
- Das, S.; Venugopal, D.; Shiva, S.; Sheldon, F.T. Empirical Evaluation of the Ensemble Framework for Feature Selection in DDoS Attack. In Proceedings of the 2020 7th IEEE International Conference on Cyber Security and Cloud Computing (CSCloud)/2020 6th IEEE International Conference on Edge Computing and Scalable Cloud (EdgeCom), New York, NY, USA, 1–3 August 2020; pp. 56–61. [Google Scholar] [CrossRef]
- Ma, L.; Chai, Y.; Cui, L.; Ma, D.; Fu, Y.; Xiao, A. A Deep Learning-Based DDoS Detection Framework for Internet of Things. In Proceedings of the ICC 2020–2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Das, S.; Mahfouz, A.M.; Venugopal, D.; Shiva, S. DDoS intrusion detection through machine learning ensemble. In Proceedings of the 2019 IEEE 19th International Conference on Software Quality, Reliability and Security Companion (QRS-C), Sofia, Bulgaria, 22–26 July 2019; IEEE: Sofia, Bulgaria, 2019; pp. 471–477. [Google Scholar] [CrossRef]
- Chaabouni, N.; Mosbah, M.; Zemmari, A.; Sauvignac, C.; Faruki, P. Network Intrusion Detection for IoT Security Based on Learning Techniques. IEEE Commun. Surv. Tutor. 2019, 21, 2671–2701. [Google Scholar] [CrossRef]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Feng, Z.; Xu, C.; Tao, D. Self-supervised representation learning from multi-domain data. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV) 2019, Seoul, Korea, 27 October–2 November 2019. [Google Scholar] [CrossRef]
- Kelly, C.; Pitropakis, N.; McKeown, S.; Lambrinoudakis, C. Testing and hardening IoT devices against the Mirai botnet. In Proceedings of the 2020 International Conference on Cyber Security and Protection of Digital Services (Cyber Security), Dublin, Ireland, 15–19 June 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Singh, D.; Mishra, M.K.; Lamba, A. Security Issues in Different Layers of IoT and Their Possible Mitigation. 2020. Available online: http://www.ijstr.org/final-print/apr2020/Security-Issues-In-Different-Layers-Of-Iot-And-Their-Possible-Mitigation.pdf (accessed on 5 September 2020).
- Otoum, Y.; Liu, D.; Nayak, A. DL-IDS: A Deep Learning–Based Intrusion Detection Framework for Securing IoT. Available online: https://www.researchgate.net/profile/Yazan-Otoum/publication/337641081_DL-IDS_a_deep_learning-based_intrusion_detection_framework_for_securing_IoT/links/5f5a67c9299bf1d43cf97509/DL-IDS-a-deep-learning-based-intrusion-detection-framework-for-securing-IoT.pdf (accessed on 5 September 2020).
- Shorey, T.; Subbaiah, D.; Goyal, A.; Sakxena, A.; Mishra, A.K. Performance comparison and analysis of slowloris, goldenEye and xerxes DDoS attack Tools. In Proceedings of the 2018 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Bangalore, India, 19–22 September 2018; pp. 318–322. [Google Scholar] [CrossRef]
- Fadele, A.; Othman, M.; Hashem, I.; Yaqoob, I.; Imran, M.; Shoaib, M. A novel countermeasure technique for reactive jamming attack in internet of things. Multimed. Tools Appl. 2019, 78, 29899–29920. [Google Scholar] [CrossRef]
- Ankit Thakkar, R.L. A Review of the Advancement in Intrusion Detection Datasets. Procedia Comput. Sci. 2020, 167, 636–645. [Google Scholar] [CrossRef]
- Kim, B.; Khanna, R.; Koyejo, O. Examples Are not enough, Learn to Criticize! Criticism for Interpretability. In Proceedings of the NIPS’16, Barcelona, Spain, 5–10 December 2016; Curran Associates Inc.: Red Hook, NY, USA, 2016; pp. 2288–2296. [Google Scholar]
- Binbusayyis, A.; Vaiyapuri, T. Identifying and benchmarking key features for cyber intrusion detection: An ensemble approach. IEEE Access 2019, 7, 106495–106513. [Google Scholar] [CrossRef]
- Wang, M.; Zheng, K.; Yang, Y.; Wang, X. An Explainable Machine Learning Framework for Intrusion Detection Systems. IEEE Access 2020, 8, 73127–73141. [Google Scholar] [CrossRef]
- Hu, Z.; Ma, X.; Liu, Z.; Hovy, E.; Xing, E. Harnessing Deep Neural Networks with Logic Rules. arXiv 2020, arXiv:1603.06318. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps. arXiv 2014, arXiv:1312.6034. [Google Scholar]
- Zhou, B.; Sun, Y.; Bau, D.; Torralba, A. Interpretable Basis Decomposition for Visual Explanation; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; pp. 122–138. [Google Scholar] [CrossRef] [Green Version]
- Shi, S.; Zhang, X.; Fan, W. A Modified Perturbed Sampling Method for Local Interpretable Model-agnostic Explanation. arXiv 2020, arXiv:2002.07434. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Model-Agnostic Interpretability of Machine Learning. arXiv 2016, arXiv:1606.05386. [Google Scholar]
- Alvarez-Melis, D.; Jaakkola, T.S. On the Robustness of Interpretability Methods. arXiv 2018, arXiv:1806.08049. [Google Scholar]
- Magesh, P.R.; Myloth, R.D.; Tom, R.J. An Explainable Machine Learning Model for Early Detection of Parkinson’s Disease using LIME on DaTscan Imagery. arXiv 2020, arXiv:2008.00238. [Google Scholar] [CrossRef]
- Mane, S.; Rao, D. Explaining Network Intrusion Detection System Using Explainable AI Framework. arXiv 2021, arXiv:2103.07110. [Google Scholar]
- Siddique, K.; Akhtar, Z.; Aslam Khan, F.; Kim, Y. KDD Cup 99 Data Sets: A Perspective on the Role of Data Sets in Network Intrusion Detection Research. Computer 2019, 52, 41–51. [Google Scholar] [CrossRef]
- Marino, D.L.; Wickramasinghe, C.S.; Manic, M. An Adversarial Approach for Explainable AI in Intrusion Detection Systems. arXiv 2018, arXiv:1811.11705. [Google Scholar]
- Ahmad, R.; Alsmadi, I.; Alhamdani, W.; Tawalbeh, L. Towards building data analytics benchmarks for IoT intrusion detection. Clust. Comput. 2021, 1–17. [Google Scholar] [CrossRef]
- Koroniotis, N.; Moustafa, N.; Sitnikova, E.; Turnbull, B. Towards the development of realistic botnet dataset in the internet of things for network forensic analytics: Bot-IoT dataset. arXiv 2018, arXiv:1811.00701. [Google Scholar] [CrossRef] [Green Version]
- Meidan, Y.; Bohadana, M.; Mathov, Y.; Mirsky, Y.; Breitenbacher, D.; Shabtai, A.; Elovici, Y. N-BaIoT: Network-based detection of IoT botnet attacks using deep autoencoders. IEEE Pervasive Comput. 2018, 17, 12–22. [Google Scholar] [CrossRef] [Green Version]
- Alsamiri, J.; Alsubhi, K. Internet of things cyber attacks detection using machine learning. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 627–634. [Google Scholar] [CrossRef] [Green Version]
- Kurniabudi, K.; Stiawan, D.; Dr, D.; Idris, M.; Bamhdi, A.; Budiarto, R. CICIDS-2017 dataset feature analysis with information gain for anomaly detection. IEEE Access 2020, 8, 132911–132921. [Google Scholar] [CrossRef]
- Sharafaldin, I.; Habibi Lashkari, A.; Ghorbani, A.A. Toward generating a new Intrusion detection dataset and intrusion traffic characterization. In Proceedings of the 4th International Conference on Information Systems Security and Privacy, Funchal, Portugal, 22–24 January 2018; SCITEPRESS—Science and Technology Publications: Funchal, Portugal, 2018; pp. 108–116. [Google Scholar] [CrossRef]
- Mera, C.; Branch, J.W. A Survey on Class Imbalance Learning on Automatic Visual Inspection. IEEE Lat. Am. Trans. 2014, 12, 657–667. [Google Scholar] [CrossRef]
- Wang, S.; Minku, L.L.; Yao, X. A Systematic Study of Online Class Imbalance Learning With Concept Drift. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 4802–4821. [Google Scholar] [CrossRef] [PubMed]
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, Australia, 10–12 November 2015. [Google Scholar] [CrossRef]
- Yavanoglu, O.; Aydos, M. A Review on Cyber Security Datasets for Machine Learning Algorithms. Available online: https://www.researchgate.net/profile/Murat-Aydos-2/publication/321906131_A_Review_on_Cyber_Security_Datasets_for_Machine_Learning_Algorithms/links/5a3a6ece458515889d2dded5/A-Review-on-Cyber-Security-Datasets-for-Machine-Learning-Algorithms.pdf (accessed on 5 September 2020).
- Divekar, A.; Parekh, M.; Savla, V.; Mishra, R.; Shirole, M. Benchmarking datasets for Anomaly-based Network Intrusion Detection: KDD CUP 99 alternatives. Version: 1. arXiv 2018, arXiv:1811.05372. [Google Scholar] [CrossRef] [Green Version]
- Koroniotis, N.; Moustafa, N.; Sitnikova, E.; Turnbull, B. Towards the development of realistic botnet dataset in the Internet of Things for network forensic analytics: Bot-IoT dataset. Future Gener. Comput. Syst. 2019, 100, 779–796. [Google Scholar] [CrossRef] [Green Version]
- Ingre, B.; Yadav, A. Performance Analysis of NSL-KDD Dataset Using ANN. Available online: https://www.researchgate.net/profile/Anamika-Yadav-5/publication/309698316_Performance_analysis_of_NSL-KDD_dataset_using_ANN/links/5959eceeaca272c78abf14bc/Performance-analysis-of-NSL-KDD-dataset-using-ANN.pdf (accessed on 5 September 2020).
- McHugh, J. Testing Intrusion detection systems: A critique of the 1998 and 1999 DARPA intrusion detection system evaluations as performed by Lincoln Laboratory. ACM Trans. Inf. Syst. Secur. 2000, 3, 262–294. [Google Scholar] [CrossRef]
- Haihua, C.; Ngan, T.; Anand, T.; Jay, B.; Junhua, D. Data Curation and Quality Assurance for Machine Learning-based Cyber Intrusion Detection. arXiv 2021, arXiv:2105.10041v1. [Google Scholar]
- Nithya, S.; Shivani, K.; Hannah, H.; Diana, A.; Praveen, P. Everyone Wants to Do the Model Work, Not the Data Work: Data Cascades in High-Stakes AI. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Online Virtual Conference, 8–13 May 2021. [Google Scholar]
- Eitel, L.; Giri, T. Statistical machine learning for network intrusion detection: A data quality perspective. Int. J. Serv. Sci. 2018, 1, 179–195. [Google Scholar] [CrossRef]
- Nagisetty, A.; Gupta, G.P. Framework for detection of malicious activities in IoT networks using keras deep learning library. In Proceedings of the 2019 3rd International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 27–29 March 2019; pp. 633–637. [Google Scholar] [CrossRef]
- Lai, Y.; Zhou, K.; Lin, S.; Lo, N. Flow-based Anomaly Detection Using Multilayer Perceptron in Software Defined Networks. In Proceedings of the 2019 42nd International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 20–24 May 2019; pp. 1154–1158. [Google Scholar] [CrossRef]
- Liu, J.; Liu, S.; Zhang, S. Detection of IoT Botnet Based on Deep Learning. In Proceedings of the 2019 Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 8381–8385. [Google Scholar] [CrossRef]
- Mergendahl, S.; Li, J. Rapid: Robust and adaptive detection of distributed denial-of-service traffic from the internet of things. In Proceedings of the 2020 IEEE Conference on Communications and Network Security (CNS), Avignon, France, 29 June–1 July 2020; pp. 1–9. [Google Scholar] [CrossRef]
- Moussa, M.M.; Alazzawi, L. Cyber attacks detection based on deep learning for cloud-dew computing in automotive IoT applications. In Proceedings of the 2020 IEEE International Conference on Smart Cloud (SmartCloud), Washington, DC, USA, 6–8 November 2020; pp. 55–61. [Google Scholar] [CrossRef]
- Ahmad, R.; Alsmadi, I. Machine learning approaches to IoT security: A systematic literature review. Internet Things 2021, 14, 100365. [Google Scholar] [CrossRef]
- Liang, X.; Znati, T. A Long Short-Term Memory Enabled Framework for DDoS Detection. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Fu, N.; Kamili, N.; Huang, Y.; Shi, J. A novel deep intrusion detection model based on a convolutional neural network. Aust. J. Intell. Inf. Process. Syst. 2019, 15, 52–59. [Google Scholar]
- Chang, S.; Zhang, Y.; Han, W.; Yu, M.; Guo, X.; Tan, W.; Cui, X.; Witbrock, M.; Hasegawa-Johnson, M.; Huang, T.S. Dilated Recurrent Neural Networks. arXiv 2017, arXiv:1710.02224. [Google Scholar]
- Rezaei, S.; Liu, X. Deep learning for encrypted traffic classification: An overview. IEEE Commun. Mag. 2019, 57, 76–81. [Google Scholar] [CrossRef] [Green Version]
- Hayashi, T.; Watanabe, S.; Toda, T.; Hori, T.; Roux, J.L.; Takeda, K. Bidirectional LSTM-HMM Hybrid System for Polyphonic Sound Event Detection. Available online: http://dcase.community/documents/challenge2016/technical_reports/DCASE2016_Hayashi_2006.pdf (accessed on 16 April 2021).
- Cui, Z.; Ke, R.; Pu, Z.; Wang, Y. Deep bidirectional and unidirectional LSTM recurrent neural network for network-wide traffic speed prediction. arXiv 2019, arXiv:1801.02143. [Google Scholar]
- Hwang, R.H.; Peng, M.C.; Huang, C.W.; Lin, P.C.; Nguyen, V.L. An Unsupervised Deep Learning Model for Early Network Traffic Anomaly Detection. IEEE Access 2020, 8, 30387–30399. [Google Scholar] [CrossRef]
- Mohammadi, M.; Al-Fuqaha, A.; Sorour, S.; Guizani, M. Deep learning for IoT big data and streaming analytics: A survey. IEEE Commun. Surv. Tutor. 2018, 20, 2923–2960. [Google Scholar] [CrossRef] [Green Version]
- Derhab, A.; Aldweesh, A.; Emam, A.Z.; Khan, F.A. Intrusion detection system for internet of things based on temporal convolution neural network and efficient feature engineering. Wirel. Commun. Mob. Comput. 2020, 2020, 6689134. [Google Scholar] [CrossRef]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional sequence to sequence learning. arXiv 2017, arXiv:1705.03122. [Google Scholar]
- Veena, K. A Survey on Network Intrusion Detection. Int. J. Sci. Res. Sci. Eng. Technol. 2018, 4, 595–613. [Google Scholar] [CrossRef]
- Nguyen, H.; Franke, K.; Petrovic, S. Feature Extraction Methods for Intrusion Detection Systems. Available online: https://www.researchgate.net/profile/Hai-Nguyen-122/publication/231175349_Feature_Extraction_Methods_for_Intrusion_Detection_Systems/links/09e41512b872eebc5d000000/Feature-Extraction-Methods-for-Intrusion-Detection-Systems.pdf (accessed on 5 September 2021).
- Xue, B.; Fu, W.; Zhang, M. Multi-Objective Feature Selection in Classification: A Differential Evolution Approach; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2014; pp. 516–528. [Google Scholar] [CrossRef]
- Roopak, M.; Tian, G.Y.; Chambers, J. Deep Learning Models for Cyber Security in IoT Networks. In Proceedings of the 2019 IEEE 9th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 7–9 January 2019; pp. 0452–0457. [Google Scholar] [CrossRef]
- Roopak, M.; Tian, G.Y.; Chambers, J. An Intrusion Detection System Against DDoS Attacks in IoT Networks. In Proceedings of the 2020 10th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 6–8 January 2020; pp. 0562–0567. [Google Scholar] [CrossRef]
- Miller, T. Explanation in Artificial Intelligence: Insights from the Social Sciences. arXiv 2018, arXiv:1706.07269. [Google Scholar] [CrossRef]
- Das, A.; Rad, P. Opportunities and Challenges in Explainable Artificial Intelligence (XAI): A Survey. Version: 2. arXiv 2020, arXiv:2006.11371. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. arXiv 2016, arXiv:1602.04938. [Google Scholar]
- Lundberg, S.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Pal, N.; Ghosh, P.; Karsai, G. DeepECO: Applying Deep Learning for Occupancy Detection from Energy Consumption Data. In Proceedings of the 2019 18th IEEE International Conference On Machine Learning and Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; pp. 1938–1943. [Google Scholar] [CrossRef]
- SHAP API Reference. 2021. Available online: https://shap.readthedocs.io/en/latest/api.html (accessed on 8 May 2021).
- Naveed, K.; Wu, H. Poster: A Semi-Supervised Framework to Detect Botnets in IoT Devices. In Proceedings of the 2020 IFIP Networking Conference (Networking), Paris, France, 22–26 June 2020; pp. 649–651. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Omar, E.; Mohammed, A.; Bahari, B.; Basem, A. Flow-Based IDS for ICMPv6-Based DDoS Attacks Detection. Arab. J. Sci. Eng. 2018, 43, 12. [Google Scholar] [CrossRef]
- Wojtowytsch, W. Can Shallow Neural Networks Beat the Curse of Dimensionality? A mean field training perspective. arXiv 2021, arXiv:2005.10815. [Google Scholar] [CrossRef]
- Xiaoxin, H.; Fuzhao, X.; Xiaozhe, R.; Yang, Y. Large-Scale Deep Learning Optimizations: A Comprehensive Survey. arXiv 2021, arXiv:2111.00856. [Google Scholar]
- Eduardo, P.; Pedro, B.; Rodrigo, B. Can we trust deep learning models diagnosis? The impact of domain shift in chest radiograph classification. arXiv 2020, arXiv:1909.01940. [Google Scholar]
- Haipeng, C.; Fuhai, X.; Dihong, W.; Lingxiang, Z.; Ao, P. Assessing impacts of data volume and data set balance in using deep learning approach to human activity recognition. In Proceedings of the 2017 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Kansas City, MO, USA, 13–16 November 2017; pp. 1160–1165. [Google Scholar] [CrossRef]
- Susilo, B.; Sari, R.F. Intrusion detection in IoT networks using deep learning algorithm. Information 2020, 11, 279. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Attacks Captured | Total Features | Total Benign Records | Total Malicious Records | Description |
|---|---|---|---|---|---|
| Bot-IoT | DoS, DDoS, Reconnaissance, Theft | 45 | 477 | 3,668,045 | The dataset consists of both legitimate and simulated IoT traffic and various attack types. It provides full packet capture information with corresponding labels [35]. The dataset is highly imbalanced, with very few benign and a large volume of malicious records. The full dataset consists of 73,360,900 rows and has a size of over 69 GB. UNSW provides a scaled-down 5 percent dataset to make data handling easy. |
| N-BaIoT | Gafgyt combo, Gafgyt junk, Gafgyt scan, Gafgyt TCP, Gafgyt UDP, Mirai ack, Mirai scan, Mirai syn, Mirai UDP, and mirai_udpplain | 115 | 555,932 | 6,506,676 | The dataset consists of real IoT network traffic collected from 9 commercial IoT devices. Dataset is infected with two famous and harmful IoT botnets Mirai and BASHLITE (also known as Gafgyt) [36]. Dataset is unbalanced, with benign records much smaller than malicious records [37]. |
| CICIDS-2017 | DoS Hulk, PortScan, DDoS, DoS GoldenEye, FTP-Patator, SSH-Patator, DoS slowloris, DoS Slowhttptest, Bot, Web Attack Brute, Force, Web Attack XSS, Infiltration, Web Attack SQL Injection, Heartbleed | 85 | 2,271,320 | 556,556 | This dataset consists of complex features that were not available in previous datasets, such as NSL-KDD, KDDCUP 99 [38]. Dataset does not provide IoT-specific traffic [12]. The dataset contains some of the recent large-scale attacks such as DDoS and bot [39]. The dataset consists of 83 features and captures 14 attacks. The dataset is highly imbalanced [40] and is prone to generate biased results towards the majority classes with poor generalization [41] |
| UNSW-NB15 | Generic, Exploits, Fuzzers, DoS, Reconnaissance, Analysis, Backdoor, Shellcode, Worms | 49 | 2,218,764 | 321,283 | Dataset is designed based on a synthetic environment for generating attack activities [42]. The dataset is not IoT specific and generated by collecting the real benign network traffic and synthetically generated attacks. It contains approximately one hour of anonymized traffic traces from a DDoS attack in 2007 [43]. The overall classification accuracy has a mitigating effect on this dataset; it is due to the greater number of classes (10 in NB15 vs. 5 in KDD) and a higher Null Error Rate (55.06% in NB15 vs. 26.1% in KDD) [44] |
| NSL-KDD | DoS, Probe, R2L, U2R | 43 | 77,054 | 71,463 | Dataset is an extension of the dataset “KDDCUP 99”. It is not IoT specific, contains no duplicate records, and lacks in modern large-scale attacks [5,12,45]. The training dataset provides 22 attack types, and the test dataset provides 37 attack types, which are categorized into four attack classes [46]. |
| KDD CUP 99 | Dos, Probe, R2L, U2R | 41 | 1,033,372 | 4,176,086 | Dataset is not specific to the IoT environment. Lacks the latest attack data and contains unbalanced labels [5,12,13]. Excessive duplication in records leads to skewed label distribution, and the classifier generates biased results towards most occurring records and cannot thoroughly learn the least occurring records [47] |
| Trainable | Training | Model | |||
|---|---|---|---|---|---|
| Classifier | Dataset | Parameters | Time | Size | Accuracy |
| MLP | Bot-IoT | 32,581 | 7 min | 434 KB | 100.00% |
| CICIDS2017 | 38,255 | 5 min | 500 KB | 99.90% | |
| NSL-KDD (*a) | 43,205 | 1 min | 193 KB | 78.20% | |
| NSL-KDD (*b) | 43,205 | 0.5 min | 560 KB | 98.90% | |
| UNSW_NB15 (*a) | 52,890 | 0.5 min | 673 KB | 38.90% | |
| UNSW_NB15 (*c) | 53,786 | 5 min | 684 KB | 97.80% | |
| N-BaIoT | 42,411 | 2 min | 550 KB | 90.80% | |
| KDD CUP 99 | 42,693 | 1 min | 553 KB | 99.90% | |
| CNN | Bot-IoT | 12,901 | 11 min | 198 KB | 100.00% |
| CICIDS2017 | 18,495 | 9 min | 264 KB | 100.00% | |
| NSL-KDD (*a) | 23,525 | 1 min | 322 KB | 80.10% | |
| NSL-KDD (*b) | 23,525 | 1 min | 322 KB | 98.60% | |
| UNSW_NB15 (*a) | 33,170 | 1 min | 436 KB | 37.30% | |
| UNSW_NB15 (*c) | 34,066 | 15 min | 447 KB | 97.70% | |
| N-BaIoT | 22,683 | 5 min | 313 KB | 90.90% | |
| KDD CUP 99 | 23,013 | 2 min | 316 KB | 99.90% | |
| LSTM | Bot-IoT | 3,100,261 | 162 min | 36 MB | 100.00% |
| CICIDS2017 | 3,188,495 | 248 min | 37 MB | 100.00% | |
| NSL-KDD (*a) | 3,270,245 | 23 min | 38 MB | 73.60% | |
| NSL-KDD (*b) | 3,270,245 | 20 min | 38 MB | 98.70% | |
| UNSW_NB15 (*a) | 3,423,930 | 23 min | 39 MB | 51.50% | |
| UNSW_NB15 (*c) | 3,438,266 | 532 min | 39 MB | 98.00% | |
| N-BaIoT | 3,256,011 | 121 min | 37 MB | 90.80% | |
| KDD CUP 99 | 3,262,053 | 61 min | 37 KB | 99.90% |
| Classifier | Dataset | Trainable Params | Epoch | Batch Size | Training Time | Model Size | Accuracy |
|---|---|---|---|---|---|---|---|
| Autoencoder + TCN | Bot-IoT | 87,483 | 20 | 256 | 70 min | 1 MB | 100% |
| CICIDS2017 | 140,315 | 10 | 512 | 24 min | 2 MB | 99.99% | |
| NSL-KDD (*a) | 173,505 | 100 | 256 | 25 min | 2 MB | 75.6% | |
| NSL-KDD (*b) | 173,505 | 100 | 256 | 15 min | 2 MB | 99% | |
| UNSW_NB15 (*a) | 339,626 | 100 | 32 | 53 min | 2 MB | 75.7% | |
| UNSW_NB15 (*c) | 348,858 | 50 | 256 | 208 min | 3 MB | 97.9% | |
| N-BaIoT | 167,073 | 20 | 128 | 39 min | 2 MB | 90.7% | |
| KDD CUP 99 | 169,473 | 10 | 32 | 22 min | 2 MB | 99.9% | |
| Autoencoder + LSTM | Bot-IoT | 3,104,180 | 5 | 512 | 35 min | 36 MB | 100% |
| CICIDS2017 | 3,204,681 | 5 | 512 | 40 min | 37 MB | 99.4% | |
| NSL-KDD (*a) | 3,291,591 | 100 | 256 | 90 min | 38 MB | 79% | |
| NSL-KDD (*b) | 3,291,591 | 20 | 32 | 68 min | 38 MB | 98.9% | |
| UNSW_NB15 (*a) | 3,454,951 | 50 | 32 | 193 min | 40 MB | 42.3% | |
| UNSW_NB15 (*c) | 3,511,558 | 15 | 512 | 216 min | 40 MB | 97.9% | |
| N-BaIoT | 3,276,174 | 10 | 256 | 42 min | 38 MB | 80.5% | |
| KDD CUP 99 | 3,282,603 | 10 | 128 | 30 min | 38 MB | 99.9% | |
| Autoencoder + BRNN | Bot-IoT | 2,329,268 | 5 | 512 | 121 min | 27 MB | 100% |
| CICIDS2017 | 2,517,833 | 5 | 512 | 181 min | 29 MB | 99.4% | |
| NSL-KDD (*a) | 2,686,663 | 50 | 256 | 350 min | 31 MB | 73.6% | |
| NSL-KDD (*b) | 2,686,663 | 20 | 256 | 121 min | 31 MB | 51.9% | |
| UNSW_NB15 (*a) | 3,044,095 | 50 | 256 | 375 min | 35 MB | 31.9% | |
| UNSW_NB15 (*c) | 3,074,566 | 5 | 512 | 272 min | 35 MB | 95.7% | |
| N-BaIoT | 2,656,910 | 5 | 256 | 181 min | 31 MB | 23.3% | |
| KDD CUP 99 | 2,669,483 | 10 | 128 | 228 min | 31 MB | 79.2% | |
| Autoencoder + BLSTM | Bot-IoT | 8,825,780 | 5 | 512 | 56 min | 101 MB | 100% |
| CICIDS2017 | 9,014,345 | 5 | 512 | 88 min | 103 MB | 99.9% | |
| NSL-KDD (*a) | 9,183,175 | 100 | 256 | 300 min | 105 MB | 76% | |
| NSL-KDD (*b) | 9,183,175 | 20 | 32 | 145 min | 105 MB | 98.7% | |
| UNSW_NB15 (*a) | 9,540,607 | 50 | 256 | 156 min | 109 MB | 38.1% | |
| UNSW_NB15 (*c) | 9,571,078 | 5 | 512 | 300 min | 110 MB | 97.7% | |
| N-BaIoT | 9,153,422 | 10 | 256 | 162 min | 105 MB | 90.8% | |
| KDD CUP 99 | 9,165,995 | 10 | 128 | 105 min | 105 MB | 99.5% | |
| CNN + LSTM | Bot-IoT | 3,115,925 | 20 | 256 | 126 min | 36 MB | 100% |
| CICIDS2017 | 3,204,159 | 20 | 256 | 190 min | 37 MB | 100% | |
| NSL-KDD (*a) | 3,285,909 | 20 | 256 | 18 min | 38 MB | 73.4% | |
| NSL-KDD (*b) | 3,285,909 | 20 | 256 | 20 min | 38 MB | 98.9% | |
| UNSW_NB15 (*a) | 3,439,594 | 20 | 256 | 25 min | 39 MB | 52.7% | |
| UNSW_NB15 (*c) | 3,453,930 | 20 | 256 | 550 min | 39 MB | 97.7% | |
| N-BaIoT | 3,271,675 | 20 | 256 | 125 min | 38 MB | 90.9% | |
| KDD CUP 99 | 3,277,717 | 20 | 256 | 62 min | 38 MB | 99.9% |
| Dataset | Feature Name |
|---|---|
| BoT_IoT | mean, min, N_IN_Conn_P_DstIP, N_IN_Conn_P_SrcIP, Pkts_P_State_P_Protocol_P_DestIP, proto_number, seq, state_number, stddev, stime, TnP_Per_Dport, dur, TnP_PDstIP |
| CICIDS2017 | ACK Flag Count, Destination I.P., Fwd Packet Length Max, Init_Win_bytes_forward, Min Packet Length, Source I.P., Source Port |
| NSL-KDD (*a) | count, dst_host_count, dst_host_rerror_rate, dst_host_same_src_port_rate, dst_host_same_srv_rate, dst_host_serror_rate, dst_host_srv_count, service_http, dst_host_srv_serror_rate, flag_S0, logged_in, same_srv_rate, srv_rerror_rate |
| NSL-KDD (*b) | count, dst_host_count, dst_host_rerror_rate, dst_host_same_src_port_rate, dst_host_same_srv_rate, dst_host_serror_rate, dst_host_srv_count, same_srv_rate, service_http, srv_serror_rate, logged_in |
| UNSW_NB15 (*a) | ct_dst_src_ltm, ct_srv_dst, ct_srv_src, ct_state_ttl, dmean, dttl, service_dns, service_-, sttl |
| UNSW_NB15 (*c) | ct_dst_sport_ltm, ct_dst_src_ltm, ct_src_dport_ltm, ct_srv_dst, ct_state_ttl, dmeansz, dttl, service_dns, service_-, sttl, swin |
| N-BaIoT | MI_dir_L0.1_weight |
| KDD CUP 99 | count, dst_host_count, logged_in, protocol_type_icmp, dst_host_same_src_port_rate, dst_host_srv_count, service_ecr_i, same_srv_rate, service_http |
| Dataset | Feature Name |
|---|---|
| BoT_IoT | flgs_number, ltime, max, sum, Pkts_P_State_P_Protocol_P_SrcIP, TnP_PerProto, TnP_PSrcIP |
| CICIDS2017 | Protocol, Average Packet Size, Destination Port, PSH Flag Count, Fwd IAT Std |
| NSL-KDD (*a) | dst_host_diff_srv_rate, dst_host_srv_rerror_rate, rerror_rate. service_private |
| NSL-KDD (*b) | diff_srv_rate, dst_host_diff_srv_rate, dst_host_srv_serror_rate, serror_rate, flag_SF, rerror_rate |
| UNSW_NB15 (*a) | id, smean, ct_src_dport_ltm, ct_src_ltm, proto_tcp |
| UNSW_NB15 (*c) | ct_srv_src, smeansz, proto_tcp, proto_udp |
| N-BaIoT | MI_dir_L1_variance, H_L0.01_weight, H_L0.1_variance, H_L1_weight, H_L0.1_weight, H_L0.01_variance, H_L1_variance, MI_dir_L0.1_variance, MI_dir_L0.01_weight, MI_dir_L1_weight |
| KDD CUP 99 | dst_host_diff_srv_rate, dst_host_same_srv_rate, protocol_type_udp, serror_rate, dst_host_serror_rate, dst_host_srv_serror_ra, protocol_type_tcp, srv_count |
| Dataset | Feature Name |
|---|---|
| BoT_IoT | sport, TnBPSrcIP, dport, drate, pkts |
| CICIDS2017 | Packet Length Variance, Down/Up Ratio, Fwd IAT Max, Packet Length Std, Flow IAT Std, Avg Bwd Segment Size, Bwd IAT Total, Bwd Packet Length Max, Bwd Packet Length Mean, Bwd Packet Length Min, Bwd Packet Length Std, FIN Flag Count, Flow Duration, Flow IAT Max, Flow Packets/s, Fwd IAT Total, Fwd Packet Length Mean, Fwd Packet Length Min, Fwd Packet Length Std, Idle Max, Idle Mean, Idle Min, Max Packet Length, Packet Length Mean |
| NSL-KDD (*a) | serror_rate, srv_serror_rate, diff_srv_rate, fla_REJ, flag_SF, protocol_type_tcp, protocol_type_udp, service_telnet, srv_count |
| NSL-KDD (*b) | dst_host_srv_rerror_rate, fla_REJ, flag_S0, hot, protocol_type_icmp, protocol_type_tcp, protocol_type_udp, service_domain_u, service_ecr_i, service_private, srv_count, srv_diff_host_rate, srv_rerror_rate |
| UNSW_NB15 (*a) | ackdat, ct_dst_ltm, ct_dst_sport_ltm, ct_flw_http_mthd, djit, dload, dur, dwin, proto_udp, proto_unas, rate, service_http, sjit, sload, state_CON, state_FIN, state_INT, swin, trans_depth |
| UNSW_NB15 (*c) | ackdat, ct_dst_ltm, ct_src_ltm, djit, dload, dtcpb, dwin, ltime, proto_leaf-2, proto_unas, sjit, sload, sloss, spkts, state_CON, state_FIN, state_INT, stcpb, stime |
| N-BaIoT | H_L0.01_mean, H_L0.1_mean, H_L1_mean, H_L3_mean, H_L3_variance, H_L3_weight, H_L5_weight, HH_jit_L0.01_mean, HH_jit_L0.01_weight, HH_jit_L0.1_mean, HH_jit_L0.1_weight, HH_jit_L1_mean, HH_jit_L1_weight, HH_jit_L3_mean, HH_jit_L5_mean, HH_L0.01_magnitude, HH_L0.01_mean, HH_L0.01_weight, HH_L0.1_mean, HH_L0.1_weight, HH_L1_magnitude, HH_L1_weight, HH_L3_mean, HH_L5_magnitude, HH_L5_mean, HH_L5_weight, HpHp_L0.01_mean, HpHp_L0.1_magnitude, HpHp_L0.1_mean, HpHp_L1_magnitude, HpHp_L1_mean, HpHp_L3_magnitude, HpHp_L5_magnitude, HpHp_L5_mean, MI_dir_L0.01_mean, MI_dir_L0.01_variance, MI_dir_L0.1_mean, MI_dir_L1_mean, MI_dir_L3_weight, MI_dir_L5_variance, MI_dir_L5_weight |
| KDD CUP 99 | srv_serror_rate, dst_host_rerror_rate, flag_SF, diff_srv_rate, service_domain_u, service_other, service_smtp, flag_S0, hot, service_ftp_data, dst_bytes, dst_host_srv_diff_host_rate, duration, flag_REJ, rerror_rate, service_private |
| Other Researcher’s Model and Accuracy | |||||||
|---|---|---|---|---|---|---|---|
| Ref. | Dataset | Model | Accuracy | ||||
| [10] | NSL-KDD | CNN | 92.99% | ||||
| [70] | CICIDS2017 | MLP | 86.34% | ||||
| CNN | 95.14% | ||||||
| LSTM | 96.24% | ||||||
| CNN + LSTM | 97.16% | ||||||
| [71] | CICIDS2017 | CNN + LSTM | 99.03% | ||||
| [58] | NSL-KDD | TCN | 90.50% | ||||
| [51] | UNSW-NB15 | DNN | 99.24% | ||||
| MLP | 98.96% | ||||||
| [53] | N-BaIoT | CNN | 99.57% | ||||
| MLP | 96.13% | ||||||
| [85] | BoT-IoT | CNN | 90.76% | ||||
| MLP | 54.43% | ||||||
| [8] | KDD CUP 1999 | BRNN | 99.04% | ||||
| Accuracy of Our Models | |||||||
| MLP | CNN | LSTM | AE + TCN | AE + LSTM | AE + BRNN | AE + BLSTM | CNN + LSTM |
| 98.90% | 98.60% | 98.70% | 99.00% | 98.90% | 51.90% | 98.70% | 98.90% |
| 99.90% | 100.00% | 100.00% | 99.99% | 99.40% | 99.40% | 99.90% | 100.00% |
| 99.90% | 100.00% | 100.00% | 99.99% | 99.40% | 99.40% | 99.90% | 100.00% |
| 98.90% | 98.60% | 98.70% | 99.00% | 98.90% | 51.90% | 98.70% | 98.90% |
| 97.80% | 97.70% | 98.00% | 97.90% | 97.90% | 95.70% | 97.70% | 97.70% |
| 90.80% | 90.90% | 90.80% | 90.70% | 80.50% | 23.30% | 90.80% | 90.90% |
| 100.00% | 100.00% | 100.00% | 100.00% | 100.00% | 100.00% | 100.00% | 100.00% |
| 99.90% | 99.90% | 99.90% | 99.90% | 99.90% | 79.20% | 99.50% | 99.90% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmad, R.; Alsmadi, I.; Alhamdani, W.; Tawalbeh, L. Models versus Datasets: Reducing Bias through Building a Comprehensive IDS Benchmark. Future Internet 2021, 13, 318. https://doi.org/10.3390/fi13120318
Ahmad R, Alsmadi I, Alhamdani W, Tawalbeh L. Models versus Datasets: Reducing Bias through Building a Comprehensive IDS Benchmark. Future Internet. 2021; 13(12):318. https://doi.org/10.3390/fi13120318
Chicago/Turabian StyleAhmad, Rasheed, Izzat Alsmadi, Wasim Alhamdani, and Lo’ai Tawalbeh. 2021. "Models versus Datasets: Reducing Bias through Building a Comprehensive IDS Benchmark" Future Internet 13, no. 12: 318. https://doi.org/10.3390/fi13120318