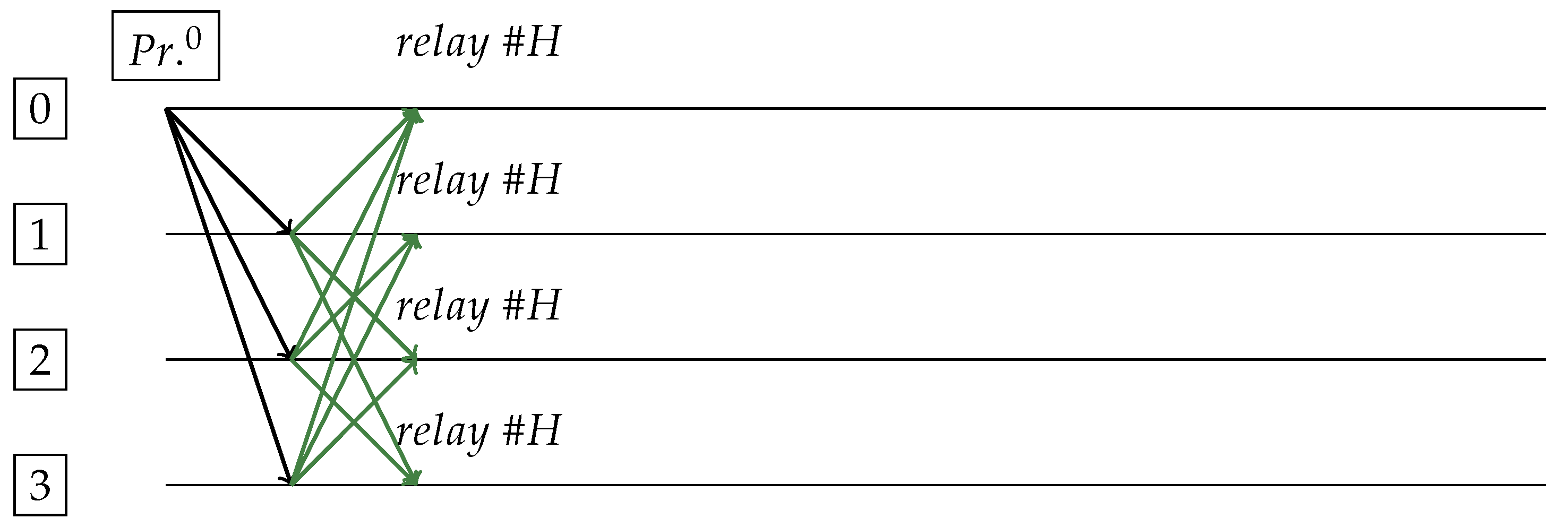
Figure 1.
Perfect case. Request sent and received by Primary (replica 0). Everyone relays block .
Figure 1.
Perfect case. Request sent and received by Primary (replica 0). Everyone relays block .
Figure 2.
Good case (faulty non-primary replica 2). Request sent and received by Primary (replica 0). All except 2 relays block .
Figure 2.
Good case (faulty non-primary replica 2). Request sent and received by Primary (replica 0). All except 2 relays block .
Figure 3.
Primary 0 is dead and no proposal is made. Replicas will change view after timeout (red lines) due to not receiving each other’s responses in time. Replica 1 becomes the new primary () and successfully generates block .
Figure 3.
Primary 0 is dead and no proposal is made. Replicas will change view after timeout (red lines) due to not receiving each other’s responses in time. Replica 1 becomes the new primary () and successfully generates block .
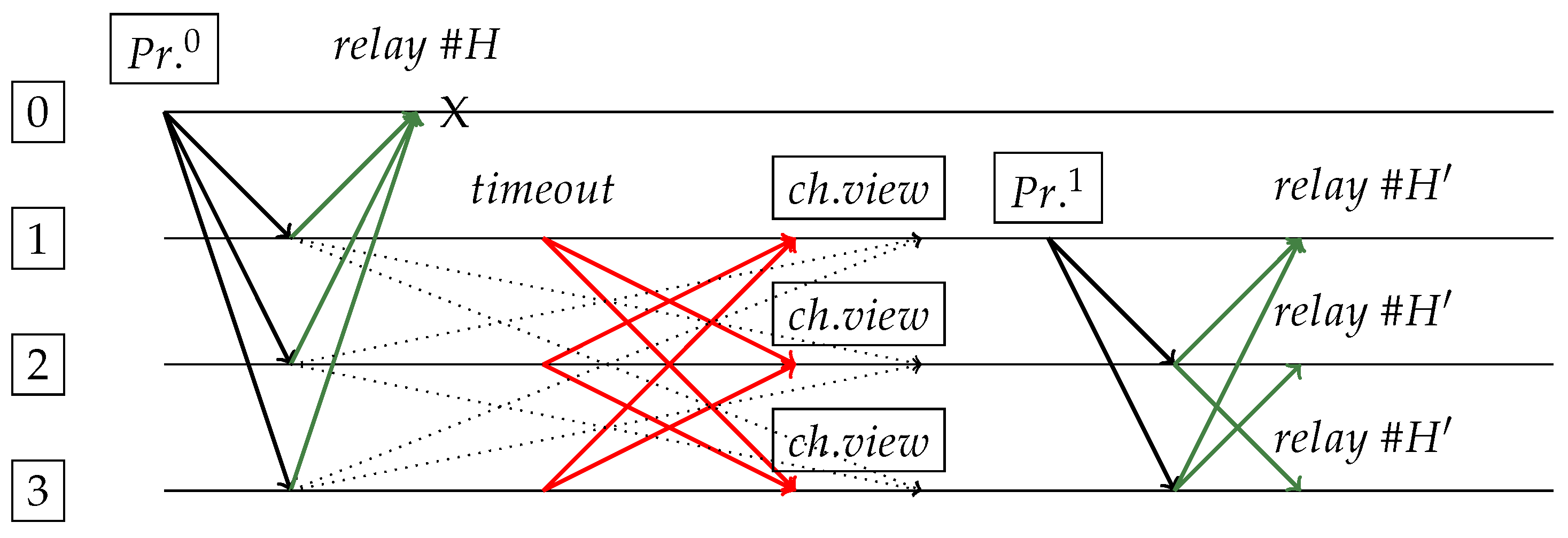
Figure 4.
Request sent and received by replica 0 ( means primary of view 0). Others will not follow it, since they will change view (red lines) due to not receiving each other’s responses (green lines) in time. Replica 1 becomes new primary () and generates “spork” (blocks and are in same height but with different contents). The “X" indicates a complete node crash. Ignored messages are dotted lines (received after a change view has already occurred).
Figure 4.
Request sent and received by replica 0 ( means primary of view 0). Others will not follow it, since they will change view (red lines) due to not receiving each other’s responses (green lines) in time. Replica 1 becomes new primary () and generates “spork” (blocks and are in same height but with different contents). The “X" indicates a complete node crash. Ignored messages are dotted lines (received after a change view has already occurred).
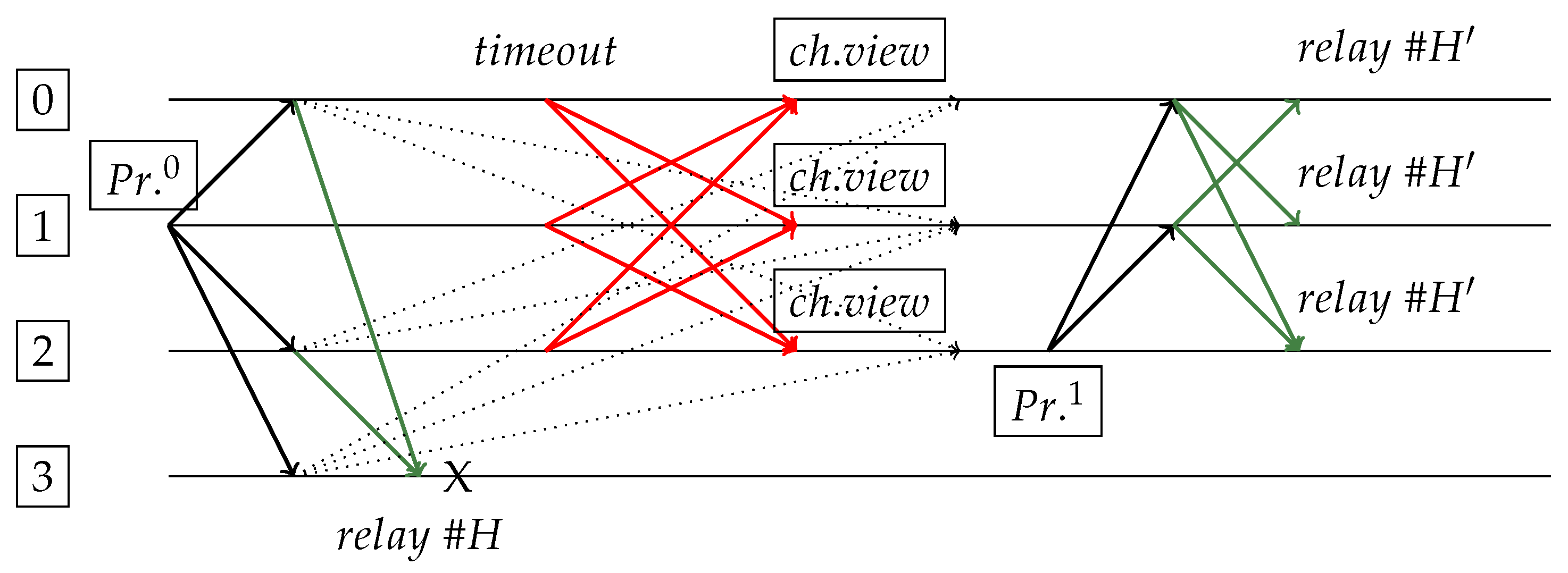
Figure 5.
Request sent by replica 1 and PrepareResponse to replica 3. Primary and others will not follow it, since they will change view due to not receiving each other’s responses. Replica 2 becomes new primary and generates “spork” (blocks and ).
Figure 5.
Request sent by replica 1 and PrepareResponse to replica 3. Primary and others will not follow it, since they will change view due to not receiving each other’s responses. Replica 2 becomes new primary and generates “spork” (blocks and ).
Figure 6.
More “realistic” case analogous to
Figure 4, when Primary proposal is naturally delayed due to a delay on previous Block persistence (event
). Timeouts are set to
time units (in purple), where
v is view number. Please note that most prepare response messages are
ignored after Change View has started, even with a regular and very small delay. Since Primary was already delayed in relation to others, time to respond was actually minimal before a protocol change occurred on replicas 1, 2 and 3.
Figure 6.
More “realistic” case analogous to
Figure 4, when Primary proposal is naturally delayed due to a delay on previous Block persistence (event
). Timeouts are set to
time units (in purple), where
v is view number. Please note that most prepare response messages are
ignored after Change View has started, even with a regular and very small delay. Since Primary was already delayed in relation to others, time to respond was actually minimal before a protocol change occurred on replicas 1, 2 and 3.
Figure 7.
Perfect case. Request sent and received by Primary (replica 0). After responses/proposal, replica is for block . Everyone relays block after commit phase (in blue).
Figure 7.
Perfect case. Request sent and received by Primary (replica 0). After responses/proposal, replica is for block . Everyone relays block after commit phase (in blue).
Figure 8.
Good case (faulty non-primary replica 2). Request sent and received by Primary (replica 0). After responses/proposal, replica is for block . All except 2 relays block after commit phase (in blue).
Figure 8.
Good case (faulty non-primary replica 2). Request sent and received by Primary (replica 0). After responses/proposal, replica is for block . All except 2 relays block after commit phase (in blue).
Figure 9.
Request sent by replica 1 and PrepareResponse to replica 3 that becomes Prepared for . Replica 3 exposes its commit signature, so it will deny any view change message. Others may change view (due to message delays) and replica 2 becomes new primary, generating valid (and unique) block (no spork happens).
Figure 9.
Request sent by replica 1 and PrepareResponse to replica 3 that becomes Prepared for . Replica 3 exposes its commit signature, so it will deny any view change message. Others may change view (due to message delays) and replica 2 becomes new primary, generating valid (and unique) block (no spork happens).
Figure 10.
Request sent by replica 1 and PrepareResponse to replica 2 that becomes Prepared for . Replica 3 is dead. Replicas 0 and 1 want to change view, but are unable due to recovery synchrony condition (where prepared replicas and dead replicas). This prevents nodes from changing view, when next view would be unable to capture necessary signatures to form a block. In this case, system resolves naturally when the minimal number of messages arrive at destination (even with large delays).
Figure 10.
Request sent by replica 1 and PrepareResponse to replica 2 that becomes Prepared for . Replica 3 is dead. Replicas 0 and 1 want to change view, but are unable due to recovery synchrony condition (where prepared replicas and dead replicas). This prevents nodes from changing view, when next view would be unable to capture necessary signatures to form a block. In this case, system resolves naturally when the minimal number of messages arrive at destination (even with large delays).
Figure 11.
Failed attack on dBFT 2.0+, where replica is malicious. Request sent by non-faulty replica (on view 0) makes non-faulty replica commit. Due to delays, no one receives messages from , and malicious pretends that messages were not received (neither the prepare request from , response from , or commit from ). Byzantine requests a change view on timeout, and all nodes do the same (even committed replica ). Please note that ViewChange messages also carry prepares and responses for non-faulty replicas, so necessarily become aware of a valid proposal ( confirmations). This way, new primary cannot maliciously propose a new block , and if it was honest, it would re-propose on view 1. If re-proposed, would again respond to it, including its previous commit (adjusted to view 1). Please note that will never issue a different signature, in any case. Eventually all non-faulty replicas will agree on (even if they need to change view again).
Figure 11.
Failed attack on dBFT 2.0+, where replica is malicious. Request sent by non-faulty replica (on view 0) makes non-faulty replica commit. Due to delays, no one receives messages from , and malicious pretends that messages were not received (neither the prepare request from , response from , or commit from ). Byzantine requests a change view on timeout, and all nodes do the same (even committed replica ). Please note that ViewChange messages also carry prepares and responses for non-faulty replicas, so necessarily become aware of a valid proposal ( confirmations). This way, new primary cannot maliciously propose a new block , and if it was honest, it would re-propose on view 1. If re-proposed, would again respond to it, including its previous commit (adjusted to view 1). Please note that will never issue a different signature, in any case. Eventually all non-faulty replicas will agree on (even if they need to change view again).
![Futureinternet 12 00129 g011]()
Figure 12.
Complex attack on dBFT 2.0+, where replica is malicious. Byzantine helps commit, and then it assumes new proposal . By unfortunate delays, replicas and are unaware of previous proposal from , and delays prevented to participate on next view change, which “elects” byzantine . Although proposal is effectively informed during view change (always at least one non-faulty will inform), there is not enough confirmations of to force malicious primary to keep it (then it starts a new one ). Replica dies after response to (this can also be considered a malicious attack under quota ). As long as delays are large enough, replicas may form a new block .
Figure 12.
Complex attack on dBFT 2.0+, where replica is malicious. Byzantine helps commit, and then it assumes new proposal . By unfortunate delays, replicas and are unaware of previous proposal from , and delays prevented to participate on next view change, which “elects” byzantine . Although proposal is effectively informed during view change (always at least one non-faulty will inform), there is not enough confirmations of to force malicious primary to keep it (then it starts a new one ). Replica dies after response to (this can also be considered a malicious attack under quota ). As long as delays are large enough, replicas may form a new block .
Table 1.
dBFT 3.0-WS2: Good Case for Primary 0. No faulty node. All nodes received confirmations for 0, meaning that at least one non-faulty agrees with replica 0, after responses/proposals. System commits globally at 0.
Table 1.
dBFT 3.0-WS2: Good Case for Primary 0. No faulty node. All nodes received confirmations for 0, meaning that at least one non-faulty agrees with replica 0, after responses/proposals. System commits globally at 0.
| | | | |
|---|
| | | | |
| | | | |
| | | | |
Table 2.
dBFT 3.0-WS2: Good Case for Primary 1. Primary 0 is faulty (or too slow). Replicas agree with primary 1 after responses/proposals for it. System commits globally at 1.
Table 2.
dBFT 3.0-WS2: Good Case for Primary 1. Primary 0 is faulty (or too slow). Replicas agree with primary 1 after responses/proposals for it. System commits globally at 1.
| | - | - | - |
|---|
| | | | |
| | | | |
| | | | |
Table 3.
dBFT 3.0-WS2: Undecided Case 0 (). For subset , no agreement currently exists with zeros (priority) or ones. No faulty node, but requires pending messages to arrive, or network will change view.
Table 3.
dBFT 3.0-WS2: Undecided Case 0 (). For subset , no agreement currently exists with zeros (priority) or ones. No faulty node, but requires pending messages to arrive, or network will change view.
| | | | | | |
|---|
| | | | | | |
| | | | | - | |
| | | | | | |
Table 4.
dBFT 3.0-WS2: Speed-up Case of () with Byzantine node . Node uses speed-up condition to directly commit to 0. A delay of messages could easily generate a need for change views due to the Byzantine attack of .
Table 4.
dBFT 3.0-WS2: Speed-up Case of () with Byzantine node . Node uses speed-up condition to directly commit to 0. A delay of messages could easily generate a need for change views due to the Byzantine attack of .
| | | | | | |
|---|
| | | | | | |
| | | | | - | |
| – | – | | - | - | - |
Table 5.
dBFT 3.0-WS2: Faulty Case with . For subset , no agreement currently exists with zeros (priority) or ones. Replica 2 is faulty, but other replicas cannot know if it will recover to resolve commit, so system will change view due to an undecided situation.
Table 5.
dBFT 3.0-WS2: Faulty Case with . For subset , no agreement currently exists with zeros (priority) or ones. Replica 2 is faulty, but other replicas cannot know if it will recover to resolve commit, so system will change view due to an undecided situation.
| | | | |
|---|
| | | | |
| - | - | - | - |
| | | | |
Table 6.
Comparison for existing dBFT variants
Table 6.
Comparison for existing dBFT variants
| dBFT Comparison |
|---|
| Name | Phases | Issues Faced | Worst Case | Detailed Explanation |
|---|
| dBFT 1.0 | 2 phases | Signature leaks happen at PrepareRequest and PrepareResponse phases, allowing multiple valid (signed) blocks at same height (spork) | sporks | A non-faulty primary node is tricked by delays, relaying a first block .
After that, replicas change view, and a faulty primary assumes.
It waits until near expiration of timeout, and “unlucky” delays trick other nodes again.
This can be repeated f times (by changing f views), and sporking replicas. |
| dBFT 2.0 | 3 phases | No signature leakage due to unique commits, but commits may be different at each view. Recovery mechanism is necessary to put node in correct state after crashing. Possible locking on different commit/views need to be avoided using synchrony conditions. | 0 sporks | Some non-faulty replica can achieve a valid commit state (with responses), thus exposing its signature when others decide to change view (afterwards). Replicas can enter in a locked state situation, where successive change views commit them differently, one by one. A synchrony condition is used , where is known committed replicas, and is expected failed nodes (no communication for some time). This is used to prevent change views when a node knows consensus will be impossible in upper views. |
Table 7.
Comparison for the dBFT variants proposed in this study
Table 7.
Comparison for the dBFT variants proposed in this study
| dBFT Proposals |
|---|
| Name | Phases | Issues Faced | Worst Case | Detailed Explanation |
|---|
| dBFT 2.0+ | 3 phases | Challenges with persistent faulty nodes (one block-time is lost during every round). | 0 sporks | Message proofs during change view resolve the synchronous condition from dBFT 2.0, for extreme scenarios where nodes are constantly failing, and delays are isolating committed nodes. |
| dBFT 3.0-WS2 (or dBFT 3.0) | 3–4 phases | Multiple proposals in the first view may impair liveness. Impossible conflicts may require a new consensus after change view, but only 12% of time with constantly faulty f (and extreme delays in network). | 0 sporks | Liveness can be impaired when the networks is split with PrepareRequest from the priority primary and some from the backup primary. Change view resolves the case and can also optionally brings the consensus towards a single primary operation mode for views greater than 0. |
| dBFT 3.0-WS2+ (or dBFT 3.0+) | 3–4 phases | Change views will occur if there are two persistent faulty priority and backup primaries. There are still undecided situations in which change views are required. | 0 sporks | Preparations proofs are carried along with Pre-Commit, thus, change views consistently keep decisions reached in previous views (similarly as in dBFT 2.0+). |

 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}