Revisiting the High-Performance Reconfigurable Computing for Future Datacenters


Abstract
:1. Introduction
2. Revisiting the Nomenclature
3. Revisiting the Network on Chip Evaluation Tools
4. Revisiting the FPGA Virtualization
4.1. Resource Level Virtualization
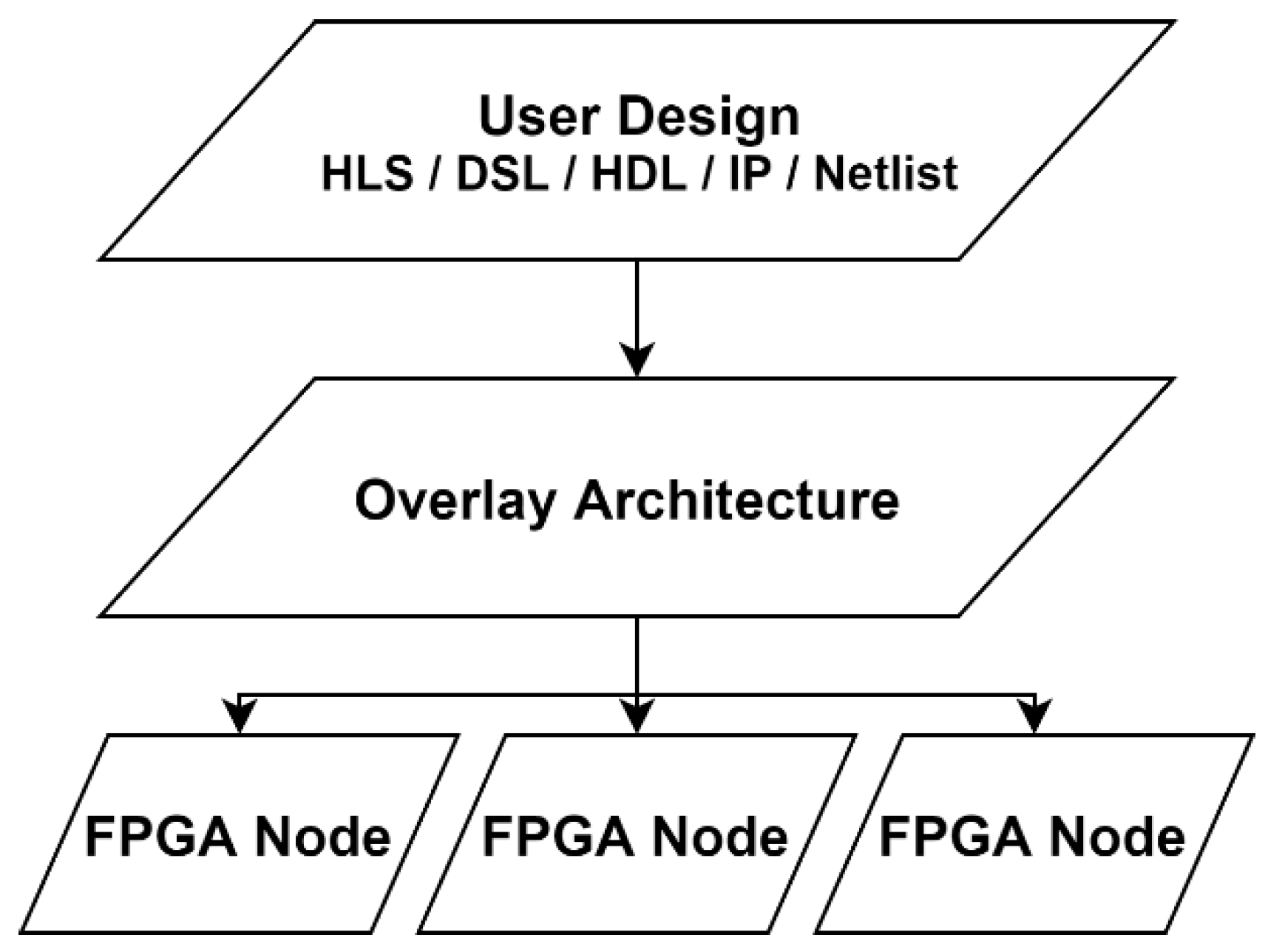
4.1.1. Overlays
4.1.2. Input Output (I/O) Virtualization
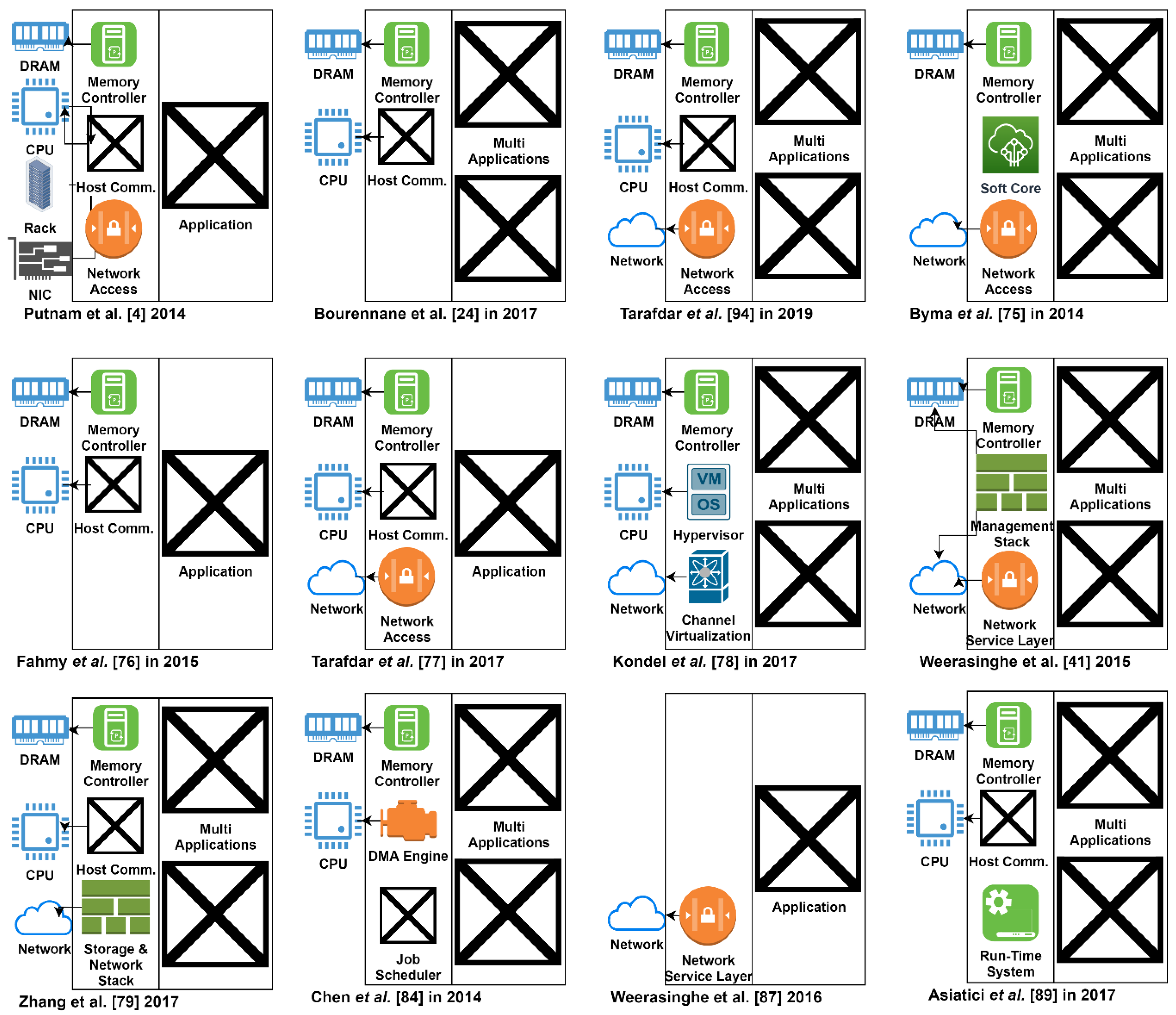
4.2. Node Level Virtualization
4.2.1. Virtual Machine Monitors (VMMs)
4.2.2. Shells
4.2.3. Scheduling
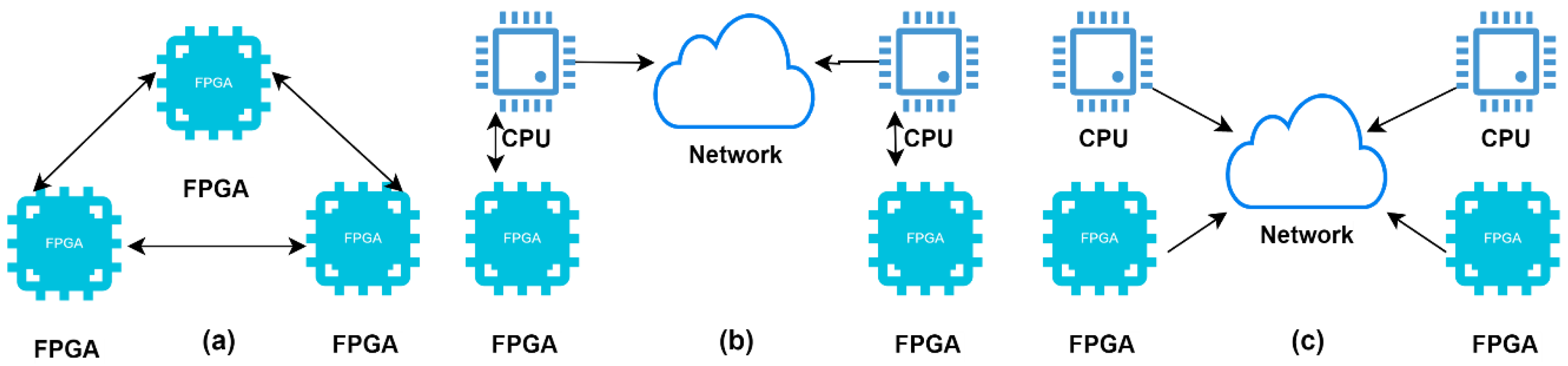
4.3. Multi-Node Level Virtualization
4.3.1. Custom Clusters
4.3.2. Frameworks
4.3.3. Cloud Services
4.4. Execution Model based Distribution
5. Open Problems and Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Escobar, F.A.; Chang, X.; Valderrama, C. Suitability analysis of FPGAs for heterogeneous platforms in HPC. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 600–612. [Google Scholar] [CrossRef]
- De Bernardinisa, L.P.; Pinelloa, C.; Sgroia, A.L. Platform-based design for embedded systems. In Embedded Systems Handbook, 1st ed.; CRC Press: San Francisco, CA, USA, 2005. [Google Scholar]
- Inta, R.; Bowman, D.J.; Scott, S.M. The chimera: An off-theshelf CPU/GPGPU/FPGA hybrid computing platform. Int. J. Reconfigurable Comput. 2012, 2012, 241439. [Google Scholar] [CrossRef] [PubMed]
- Putnam, A.; Caulfield, A.M.; Chung, E.S.; Chiou, D.; Constantinides, K.; Demme, J.; Esmaeilzadeh, H.; Fowers, J.; Gopal, G.P.; Gray, J.; et al. A reconfigurable fabric for accelerating large-scale datacenter services. In Proceedings of the 2014 ACM/IEEE 41st International Symposium on Computer Architecture (ISCA), Minneapolis, MN, USA, 14–18 June 2014. [Google Scholar]
- Plessl, C.; Platzner, M. Virtualization of hardware-introduction and survey. In ERSA; CSREA Press: Las Vegas, NV, USA, 2004. [Google Scholar]
- Vaishnav, A.; Pham, K.D.; Koch, D. A survey on FPGA virtualization. In Proceedings of the 2018 28th International Conference on Field Programmable Logic and Applications (FPL), Dublin, Ireland, 27–31 August 2018. [Google Scholar]
- Göhringer, D.; Hübner, M.; Hugot-Derville, L.; Becker, J. Message passing interface support for the runtime adaptive multi-processor system-on-Chip RAMPSoC. In Proceedings of the 2010 International Conference on Embedded Computer Systems: Architectures, Modeling and Simulation, Samos, Greece, 19–22 July 2010; pp. 357–364. [Google Scholar]
- Shen, X.; Wang, X.; Zhu, Y.; Huang, T.; Kong, X. Implementing dynamic web page interactions with a Java processor core on FPGA. In Proceedings of the Engineering and Industries (ICEI), 2nd International Conference on IEEE, Jeju, Korea, 29 November–1 December 2011. [Google Scholar]
- Farooq, U.; Parveza, H.; Mehrez, H.; Marrakchi, Z. A new heterogeneous tree-based application specific FPGA and its comparison with mesh-based application specific FPGA. Microprocess. Microsyst. 2012, 36, 588–605. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, Y.; Ha, Y.; Felipe, M.R.; Ren, S.; Aung, K.M.M. sAES: A high throughput and low latency secure cloud storage with pipelined DMA based PCIe interface. In Proceedings of the 2013 International Conference on Field-Programmable Technology (FPT), Kyoto, Japan, 9–11 December 2013; pp. 374–377. [Google Scholar]
- Xu, L.; Shi, W.; Suh, T. PFC: Privacy preserving FPGA cloud—A case study of mapreduce. In Proceedings of the IEEE International Conference on Cloud Computing, Anchorage, AK, USA, 27 June–2 July 2014; pp. 280–287. [Google Scholar]
- Yang, H.; Yan, X. Memory coherency based CPU-Cache-FPGA acceleration architecture for cloud computing. In Proceedings of the Information Science and Control Engineering (ICISCE), 2nd International Conference, Shanghai, China, 24–26 April 2015; pp. 304–307. [Google Scholar]
- Kidane, H.L.; Bourennane, E.B.; Ochoa-Ruiz, G. Noc based virtualized accelerators for cloud computing. In Proceedings of the IEEE 2016, 10th International Symposium on Embedded Multicore/Many-core Systems-on-Chip (MCSOC), Lyon, France, 21–23 September 2016; pp. 133–137. [Google Scholar]
- Will, M.A.; Ko, R.K. Secure FPGA as a service—Towards secure data processing by physicalizing the cloud. In Proceedings of the IEEE Trustcom/BigDataSE/ICESS 2017, Sydney, NSW, Australia, 1–4 August 2017; pp. 449–455. [Google Scholar]
- Yazar, A.; Erol, A.; Schmidt, E.G. ACCLOUD (Accelerated CLOUD): A novel FPGA-Accelerated cloud architecture. In Proceedings of the 26th Signal Processing and Communications Applications (SIU), Izmir, Turkey, 2–5 May 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Mbongue, J.; Hategekimana, F.; Tchuinkou Kwadjo, D.; Andrews, D.; Bobda, C. FPGAVirt: A Novel Virtualization Framework for FPGAs in the Cloud. In Proceedings of the IEEE 11th International Conference on Cloud Computing, San Francisco, CA, USA, 2–7 July 2018. [Google Scholar]
- Al-Aghbari, A.A.; Elrabaa, M.E.S. Cloud-based FPGA custom computing machines for streaming applications. IEEE Access 2019, 7, 38009–38019. [Google Scholar] [CrossRef]
- Skhiri, R.; Fresse, V.; Jamont, J.P.; Suffran, B.; Malek, J. From FPGA to support cloud to cloud of FPGA: State of the art. Int. J. Reconfigurable Comput. 2019, 2019, 8085461. [Google Scholar] [CrossRef]
- Bittner, R.; Ruf, E.; Forin, A. Direct GPU/FPGA communication via PCI express. Cluster Comput. 2013, 17, 339–348. [Google Scholar] [CrossRef]
- Mueller, R.; Teubner, J.; Alonso, G. Streams on wires: A query compiler for FPGAS. Proc. VLDB Endow. 2009, 2, 229–240. [Google Scholar] [CrossRef] [Green Version]
- Dally, W.J.; Towles, B. Route packets, not wires: On-chip interconnection networks. In Proceedings of the Design Automation Conference, Las Vegas, NV, USA, 18–22 June 2001; pp. 684–689. [Google Scholar]
- Yazdanshenas, S.; Betz, V. Interconnect solutions for virtualized field-programmable gate arrays. IEEE Access 2018, 6, 10497–10507. [Google Scholar] [CrossRef]
- de Lima, O.A.; Costa, W.N.; Fresse, V.; Rousseau, F. A survey of NoC evaluation platforms on FPGAs. In Proceedings of the International Conference on Field-Programmable Technology (FPT), Xi’an, China, 7–9 December 2016. [Google Scholar]
- Kidane, H.L.; Bourennane, E.B.; Ochoa-Ruiz, G. Run-time scalable noc for fpga based virtualized ips. In Proceedings of the IEEE 11th International Symposium on Embedded Multicore/Many-core Systems-on-Chip (MCSoC), Seoul, Korea, 18–20 September 2017; pp. 91–97. [Google Scholar]
- Kidane, H.L.; Bourennane, E.B. MARTE and IP-XACT based approach for run-time scalable NoC. In Proceedings of the IEEE 12th International Symposium on Embedded Multicore/Many-Core Systems-on-Chip (MCSoC), Hanoi, Vietnam, 12–14 September 2018; pp. 162–167. [Google Scholar]
- Liu, Y.; Liu, P.; Jiang, Y.; Yang, M.; Wu, K.; Wang, W.; Yao, Q. Building a multi-FPGA-based emulation framework to support networks-on-chip design and verification. Int. J. Electron. 2010, 97, 1241–1262. [Google Scholar] [CrossRef]
- Krishnaiah, G.; Silpa, B.V.; Panda, P.R.; Kumar, A. Fastfwd: An efficient hardware acceleration technique for trace-driven network-on-chip simulation. In Proceedings of the eighth IEEE/ACM/IFIP International Conference on Hardware/Software Codesign and System Synthesis, Scottsdale, AZ, USA, 24–29 October 2010; ACM: New York, NY, USA, 2010; pp. 247–256. [Google Scholar]
- Wang, C.; Hu, W.H.; Lee, S.E.; Bagherzadeh, N. Area and power-efficient innovative network on-chip architecture. In Proceedings of the 2010 18th Euromicro Conference on Parallel, Distributed and Network-Based Processing (PDP), Pisa, Italy, 17–19 February 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 533–539. [Google Scholar]
- Lotlikar, S.; Pai, V.; Gratz, P. AcENoCs: A configurable HW/SW platform for FPGA accelerated NoC emulation. In Proceedings of the 24th Internatioal Conference on VLSI Design (VLSI Design), Chennai, India, 2–7 January 2011; pp. 147–152. [Google Scholar]
- Papamichael, M.K. Fast scalable FPGA-based network-on-chip simulation models. In Proceedings of the 2011 9th IEEE/ACM Internatioal Conference on Formal Methods and Models for Codesign (MEMOCODE), Cambridge, UK, 11–13 July 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 77–82. [Google Scholar]
- Papamichael, M.K.; Hoe, J.C.; Mutlu, O. Fist: A fast, lightweight, FPGA-friendly packet latency estimator for noc modeling in full-system simulations. In Proceedings of the 2011 Fifth IEEE/ACM International Symposium on Networks on Chip (NoCS), Pittsburgh, PA, USA, 1–4 May 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 137–144. [Google Scholar]
- Ku, W.-C.; Chen, T.-F. Accelerating manycore simulation by efficient noc interconnection partition on FPGA simulation platform. In Proceedings of the 2011 International Symposium on VLSI Design, Automation and Test (VLSI-DAT), Hsinchu, Taiwan, 25–28 April 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1–4. [Google Scholar]
- Pellauer, M.; Adler, M.; Kinsy, M.; Parashar, A.; Emer, J. Hasim: FPGA-based high-detail multicore simulation using time-division multiplexing. In Proceedings of the 2011 IEEE 17th International Symposium on High Performance Computer Architecture (HPCA), San Antonio, TX, USA, 12–16 February 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 406–417. [Google Scholar]
- Tan, J.; Fresse, V.; Rousseau, F. Generation of emulation platforms for NoC exploration on FPGA. In Proceedings of the 22nd IEEE International Symposium on Rapid System Prototyping (RSP), Karlsruhe, Germany, 24–27 May 2011; pp. 186–192. [Google Scholar]
- Heck, G.; Guazzelli, R.; Moraes, F.; Calazans, N.; Soares, R. HardNoC: A platform to validate networks on chip through FPGA prototyping. In Proceedings of the VIII Southern Conference on Programmable Logic (SPL), Bento Goncalves, Spain, 20–23 March 2012; pp. 1–6. [Google Scholar]
- Fresse, V.; Ge, Z.; Tan, J.; Rousseau, F. Case study: Deployment of the 2d noc on 3d for the generation of large emulation platforms. In Proceedings of the 2012 23rd IEEE International Symposium on Rapid System Prototyping (RSP), Tampere, Finland, 11–12 October 2012; pp. 23–29. [Google Scholar]
- van Chu, T.; Sato, S.; Kise, K. Knocemu: High speed fpga emulator for kilo-node scale nocs. Embedded Multicore/Manycore SoCs (MCSoc). In Proceedings of the 2014 IEEE 8th International Symposium on Embedded Multicore/Manycore SoCs, Aizu-Wakamatsu, Japan, 23–25 September 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 215–222. [Google Scholar]
- de Lima, O.A.; Fresse, V.; Rousseau, F. Evaluation of snmp-like protocol to manage a NOC emulation platform. In Proceedings of the 2014 International Conference on Field-Programmable Technology (FPT), Shanghai, China, 10–12 December2014; pp. 199–206. [Google Scholar]
- Kang, J.M.; Bannazadeh, H.; Leon-Garcia, A. Savi testbed: Control and management of converged virtual ict resources. In Proceedings of the IFIP/IEEE International Symposium on Integrated Network Management, Ghent, Belgium, 27–31 May 2013. [Google Scholar]
- Amazon Web Services EC2. FPGA Hardware and Software Development Kit. Available online: https://github.com/aws/aws-fpga (accessed on 2 December 2019).
- Weerasinghe, J.; Abel, F.; Hagleitner, C.; Herkersdorf, A. Enabling FPGAs in hyperscale data centers. In Proceedings of the 15th IEEE UIC-ATC-ScalCom, Beijing, China, 10–14 August 2015. [Google Scholar]
- Alveo Nimbix Cloud. Available online: https://www.nimbix.net/alveotrial (accessed on 23 March 2020).
- Voss, N.; Quintana, P.; Mencer, O.; Luk, W.; Gaydadjiev, G. Memory mapping for multi-die FPGAs. In Proceedings of the IEEE 27th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), San Diego, CA, USA, 28 April–1 May 2019. [Google Scholar]
- Voss, N.; Girdlestone, S.; Becker, T.; Mencer, O.; Luk, W.; Gaydadjiev, G. Low area overhead custom buffering for FFT. In Proceedings of the International Conference on ReConFigurable Computing and FPGAs (ReConFig), Cancun, Mexico, 9–11 December 2019. [Google Scholar]
- Li, X.; Maskell, D.L. Time-multiplexed FPGA overlay architectures: A survey. ACM Trans. Des. Autom. Electron. Syst. 2019, 24, 54. [Google Scholar] [CrossRef] [Green Version]
- Jain, A.K. Architecture Centric Coarse-Grained FPGA Overlays. Ph.D. Thesis, Nanyang Technological University, Singapore, 2017. [Google Scholar]
- Cheah, H.Y.; Fahmy, S.A.; Maskell, D.L. iDEA: A DSP block-based FPGA Soft Processor. In Proceedings of the 2012 International Conference on Field-Programmable Technology (FPT), Seoul, Korea, 10–12 December 2012. [Google Scholar]
- Xilinx MicroBlaze Soft Processor Core. Available online: https://www.xilinx.com/products/design-tools/microblaze.html (accessed on 3 December 2019).
- Altera Nios II Processor. Available online: https://www.altera.com/products/processors/overview.html (accessed on 4 December 2019).
- Severance, A.; Lemieux, G.G.F. Embedded supercomputing in FPGAs with the VectorBlox MXP matrix processor. In Proceedings of the International Conference on Hardware/Software Codesign and System Synthesis, Montreal, QC, Canada, 29 September–4 October 2013. [Google Scholar]
- Severance, A.; Lemieux, G. VENICE: A compact vector processor for FPGA Applications. In Proceedings of the 2011 IEEE Hot Chips 23 Symposium (HCS), Stanford, CA, USA, 17–19 August 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1–5. [Google Scholar]
- Chou, C.H.; Severance, A.; Brant, A.D.; Liu, Z.; Sant, S.; Lemieux, G.G. VEGAS: Soft vector processor with scratchpad memory. In Proceedings of the 19th ACM/SIGDA international symposium on Field programmable gate arrays 2011, Monterey, CA, USA, 27 February–1 March 2011. [Google Scholar]
- Yiannacouras, P.; Steffan, J.G.; Rose, J. VESPA: Portable, scalable, and flexible FPGA-based vector processors. In Proceedings of the 2008 international conference on Compilers, architectures and synthesis for embedded systems, Atlanta, GA, USA, 19–24 October 2008. [Google Scholar]
- Yu, J.; Lemieux, G.; Eagleston, C. Vector Processing as a Soft-core CPU Accelerator. In Proceedings of the 16th International ACM/SIGDA Symposium on Field Programmable Gate Arrays, Monterey, CA, USA, 24–26 February 2008. [Google Scholar]
- Cong, J.; Huang, H.; Ma, C.; Xiao, B.; Zhou, P. A fully pipelined and dynamically composable architecture of CGRA. In Proceedings of the 2014 IEEE 22nd Annual International Symposium on Field-Programmable Custom Computing Machines, Boston, MA, USA, 11–13 May 2014. [Google Scholar]
- Shukla, S.; Bergmann, N.W.; Becker, J. QUKU: A FPGA based flexible coarse grain architecture design paradigm using process networks. In Proceedings of the 2007 IEEE International Parallel and Distributed Processing Symposium, Rome, Italy, 26–30 March 2007. [Google Scholar]
- Landy, A.; Stitt, G. A low-overhead interconnect architecture for virtual reconfigurable fabrics. In Proceedings of the 2012 International Conference on Compilers, Architectures and Synthesis for Embedded Systems, Tampere, Finland, 7–12 October 2012. [Google Scholar]
- Coole, J.; Stitt, G. Fast, flexible high-level synthesis from OpenCL using reconfiguration contexts. IEEE Micro 2014, 34, 42–53. [Google Scholar] [CrossRef]
- Govindaraju, V.; Ho, C.H.; Nowatzki, T.; Chhugani, J.; Satish, N.; Sankaralingam, K.; Kim, C. DySER: Unifying functionality and parallelism specialization for energy-efficient computing. IEEE Micro 2012, 32, 38–51. [Google Scholar] [CrossRef] [Green Version]
- So, H.K.-H.; Liu, C. FPGA Overlays. In FPGAs for Software Programmers; Springer: Cham, Germany, 2016. [Google Scholar]
- Brant, A.D. Coarse and Fine Grain Programmable Overlay Architectures for FPGAs. MSc Thesis, University of British Columbia, Vancouver, BC, Canada, 2012. [Google Scholar]
- Rashid, R.; Steffan, J.G.; Betz, V. Comparing performance, productivity and scalability of the TILT overlay processor to OpenCL HLS. In Proceedings of the 2014 International Conference on Field-Programmable Technology (FPT), Shanghai, China, 10–12 December 2014. [Google Scholar]
- Paul, K.; Dash, C.; Moghaddam, M.S. reMORPH: A runtime reconfigurable architecture. In Proceedings of the 2012 15th Euromicro Conference on Digital System Design, Cesme, Izmir, Turkey, 5–8 September 2012. [Google Scholar]
- Kapre, N.; Mehta, N.; Delorimier, M.; Rubin, R.; Barnor, H.; Wilson, M.J.; Wrighton, M.; DeHon, A. Packet switched vs. time multiplexed FPGA overlay networks. In Proceedings of the 2006 14th Annual IEEE Symposium on Field-Programmable Custom Computing Machines, Napa, CA, USA, 24–26 April 2006. [Google Scholar]
- Papamichael, M.K.; Hoe, J.C. CONNECT: Re-examining conventional wisdom for designing nocs in the context of FPGAs. In Proceedings of the ACM/SIGDA International Symposium on Field Programmable Gate Arrays 2012, Monterey, CA, USA, 22–24 February 2012. [Google Scholar]
- Huan, Y.; DeHon, A. FPGA optimized packet-switched NoC using split and merge primitives. In Proceedings of the 2012 International Conference on Field-Programmable Technology, Seoul, Korea, 10–12 December 2012. [Google Scholar]
- Kapre, N.; Gray, J. Hoplite: Building austere overlay NoCs for FPGAs. In Proceedings of the 2015 25th International Conference on Field Programmable Logic and Applications (FPL), London, UK, 2–4 September 2015. [Google Scholar]
- Brant, A.; Lemieux, G.G.F. ZUMA: An open FPGA overlay architecture. In Proceedings of the 2012 IEEE 20th international symposium on field-programmable custom computing machines, Toronto, ON, Canada, 29 April–1 May 2012. [Google Scholar]
- Ferreira, R.; Vendramini, J.G.; Mucida, L.; Pereira, M.M.; Carro, L. An FPGA-based heterogeneous coarse-grained dynamically reconfigurable architecture. In Proceedings of the 14th International Conference on Compilers, Architectures and Synthesis for Embedded Systems, Taipei, Taiwan, 9–14 October 2011. [Google Scholar]
- Kinsy, M.A.; Pellauer, M.; Devadas, S. Heracles: Fully synthesizable parameterized mips based multicore system. In Proceedings of the 21st International Conference on Field Programmable Logic and Applications, Chania, Greece, 5–7 September 2011. [Google Scholar]
- Liu, C.; Yu, C.L.; So, H.K. A soft coarse-grained reconfigurable array based high-level synthesis methodology: Promoting design productivity and exploring extreme FPGA frequency. In Proceedings of the IEEE 21st Annual International Symposium on Field-Programmable Custom Computing Machines, Seattle, WA, USA, 28–30 April 2013. [Google Scholar]
- Gray, J. GRVI-phalanx: A massively parallel RISC-V FPGA accelerator. In Proceedings of the IEEE 24th Annual International Symposium on Field-Programmable Custom Computing Machines, Washington, DC, USA, 1–3 May 2016. [Google Scholar]
- Li, X.; Jain, A.; Maskell, D.; Fahmy, S.A. An area-efficient FPGA overlay using DSP block based time-multiplexed functional units. In Proceedings of the 2nd International Workshop on Overlay Architectures for FPGAs, Monterey, CA, USA, 21–23 February 2016. [Google Scholar]
- Kumar, H.B.C.; Ravi, P.; Modi, G.; Kapre, N. 120-core microAptiv MIPS overlay for the Terasic DE5-NET FPGA board. In Proceedings of the ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2017. [Google Scholar]
- Byma, S.; Steffan, J.G.; Bannazadeh, H.; Garcia, A.L.; Chow, P. FPGAs in the cloud: Booting virtualized hardware accelerators with OpenStack. In Proceedings of the 2014 IEEE 22nd Annual International Symposium on Field-Programmable Custom Computing Machines, Boston, MA, USA, 11–13 May 2014. [Google Scholar]
- Fahmy, S.A.; Vipin, K.; Shreejith, S. Virtualized FPGA accelerators for efficient cloud computing. In Proceedings of the 2015 IEEE 7th International Conference on Cloud Computing Technology and Science (CloudCom), Vancouver, BC, Canada, 30 November–3 December 2015. [Google Scholar]
- Tarafdar, N.; Lin, T.; Fukuda, E.; Bannazadeh, H.; Leon-Garcia, A.; Chow, P. Enabling flexible network FPGA clusters in a heterogeneous cloud data center. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (FPGA ’17), Monterey, CA, USA, 22–24 February 2017; ACM: New York, NY, USA, 2017. [Google Scholar]
- Knodel, O.; Genssler, P.R.; Spallek, R.G. Virtualizing reconfigurable hardware to provide scalability in cloud architectures. In Proceedings of the Tenth International Conference on Advances in Circuits, Electronics and Micro-electronics (CENICS 2017), Rome, Italy, 10–14 September 2017; IARIA: Wilmington, DE, USA, 2017. [Google Scholar]
- Zhang, J.; Xiong, Y.; Xu, N.; Shu, R.; Li, B.; Cheng, P.; Chen, G.; Moscibroda, T. The feniks FPGA operating system for cloud computing. In Proceedings of the 8th Asia-Pacific Workshop on Systems, Mumbai, India, 2 September 2017. [Google Scholar]
- Abbani, N.; Ali, A.; Doa’A, A.O.; Jomaa, M.; Sharafeddine, M.; Artail, H.; Akkary, H.; Saghir, M.A.; Awad, M.; Hajj, H. A distributed reconfigurable active SSD platform for data intensive applications. In Proceedings of the 2011 IEEE International Conference on High Performance Computing and Communications, Banff, AB, Canada, 2–4 September 2011. [Google Scholar]
- Wang, W. pvFPGA: Accessing an FPGA-based hardware accelerator in a paravirtualized environment. In Proceedings of the 2013 International Conference on Hardware/Software Codesign and System Synthesis (CODES+ ISSS), Montreal, QC, Canada, 29 September–4 October 2013; IEEE: Piscataway, NJ, USA, 2013. [Google Scholar]
- Xia, T.; Prévotet, J.C.; Nouvel, F. Hypervisor mechanisms to manage FPGA reconfigurable accelerators. In Proceedings of the 2016 International Conference on Field-Programmable Technology (FPT), Xi’an, China, 7–9 December 2016. [Google Scholar]
- Jain, A.K.; Pham, K.D.; Cui, J.; Fahmy, S.A.; Maskell, D.L. Virtualized execution and management of hardware tasks on a hybrid ARM-FPGA platform. J. Signal Process. Syst. 2014, 77, 61–76. [Google Scholar] [CrossRef]
- Chen, F.; Shan, Y.; Zhang, Y.; Wang, Y.; Franke, H.; Chang, X.; Wang, K. Enabling FPGAs in the cloud. In Proceedings of the 11th ACM Conference on Computing Frontiers, Cagliari, Italy, 20–22 May 2014. [Google Scholar]
- Bobda, C.; Majer, A.; Ahmadinia, A.; Haller, T.; Linarth, A.; Teich, J. The erlangen slot machine: Increasing flexibility in FPGA-based reconfigurable platforms. In Proceedings of the 2005 IEEE International Conference on Field-Programmable Technology, Singapore, 11–14 December 2005. [Google Scholar]
- Zhao, Q. Enabling FPGA-as-a-service in the cloud with hCODE platform. IEICE Trans. Inf. Syst. 2018, 101, 335–343. [Google Scholar] [CrossRef] [Green Version]
- Weerasinghe, J.; Polig, R.; Abel, F.; Hagleitner, C. Network-attached FPGAs for data center applications. In Proceedings of the 2016 International Conference on Field-Programmable Technology (FPT), Xi’an, China, 7–9 December 2016. [Google Scholar]
- Tarafdar, N.; Eskandari, N.; Lin, T.; Chow, P. Designing for FPGAs in the Cloud. IEEE Des. Test 2017, 35, 23–29. [Google Scholar] [CrossRef]
- Asiatici, M.; George, N.; Vipin, K.; Fahmy, S.A.; Ienne, P. Virtualized execution runtime for FPGA accelerators in the cloud. IEEE Access 2017, 5, 1900–1910. [Google Scholar] [CrossRef]
- Pahl, C. Containerization and the PaaS cloud. IEEE Cloud Comput. 2015, 2, 24–31. [Google Scholar] [CrossRef]
- Kirchgessner, R.; Stitt, G.; George, A.; Lam, H. VirtualRC: A virtual FPGA platform for applications and tools portability. In Proceedings of the ACM/SIGDA International Symposium on Field Programmable Gate Arrays (FPGA’12), ACM, Monterey, CA, USA, 22–24 February 2012; pp. 205–208. [Google Scholar]
- Asghari, M.; Rajabzadeh, A.; Dashtbani, M. HFIaaS: A proposed FPGA infrastructure as a service framework using high-level synthesis. In Proceedings of the 6th International Conference on Computer and Knowledge Engineering (ICCKE), Mashhad, Iran, 20–21 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 72–77. [Google Scholar]
- Najem, M.; Bollengier, T.; le Lann, J.C.; Lagadec, L. Extended overlay architectures for heterogeneous FPGA cluster management. J. Syst. Archit. 2017, 78, 1–14. [Google Scholar] [CrossRef]
- Eskandari, N.; Tarafdar, N.; Ly-Ma, D.; Chow, P. A modular heterogeneous stack for deploying FPGAs and CPUs in the data center. In Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Seaside, CA, USA, 24–26 February 2019; ACM: New York, NY, USA, 2019. [Google Scholar]
- Vaishnav, A.; Pham, K.D.; Manev, K.; Koch, D. The FOS (FPGA Operating System) Demo. In Proceedings of the 29th International Conference on Field Programmable Logic and Application (FPL), Barcelona, Spain, 8–12 September 2019. [Google Scholar]
- Intel OPAE. Available online: http://01.org/OPAE (accessed on 24 March 2020).
- Yazdanshenas, S.; Betz, V. Quantifying and mitigating the costs of FPGA virtualization. In Proceedings of the 27th International Conference on Field Programmable Logic and Applications (FPL), Ghent, Belgium, 4–8 September 2017. [Google Scholar]
- Happe, M.; Traber, A.; Keller, A. Preemptive hardware multitasking in ReconOS. In Applied Reconfigurable Computing; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Rupnow, K.; Fu, W.; Compton, K. Block, drop or roll(back): Alternative preemption methods for RH multi-tasking. In Proceedings of the 17th IEEE Symposium on Field Programmable Custom Computing Machines, Napa, CA, USA, 5–7 April 2009. [Google Scholar]
- Bourge, A.; Muller, O.; Rousseau, F. Generating efficient context-switch capable circuits through autonomous design flow. ACM TRETS 2016, 10, 1–23. [Google Scholar] [CrossRef] [Green Version]
- Lubbers, E.; Platzner, M. ReconOS: An RTOS supporting hard-and software threads. In Proceedings of the 2007 International Conference on Field Programmable Logic and Applications, Amsterdam, Netherlands, 27–29 August 2007. [Google Scholar]
- Peck, W.; Anderson, E.; Agron, J.; Stevens, J.; Baijot, F.; Andrews, D. Hthreads: A computational model for reconfigurable devices. In Proceedings of the 2006 International Conference on Field Programmable Logic and Applications, Madrid, Spain, 28–30 August 2006. [Google Scholar]
- Shan, Y.; Wang, B.; Yan, J.; Wang, Y.; Xu, N.; Yang, H. FPMR: MapReduce framework on FPGA. In Proceedings of the 18th annual ACM/SIGDA international symposium on Field programmable gate arrays 2010, Monterey, CA, USA, 21–23 February 2010. [Google Scholar]
- Chen, Y.T.; Cong, J.; Fang, Z.; Lei, J.; Wei, P. When spark meets FPGAs: A case study for next generation DNA sequencing acceleration. In Proceedings of the 24th FCCM, Washington, DC, USA, 1–3 May 2016. [Google Scholar]
- Mavridis, S.; Pavlidakis, M.; Stamoulias, I.; Kozanitis, C.; Chrysos, N.; Kachris, C.; Soudris, D.; Bilas, A. VineTalk: Simplifying software access and sharing of FPGAs in datacenters. In Proceedings of the 27th International Conference on Field Programmable Logic and Applications (FPL), Ghent, Belgium, 4–8 September 2017. [Google Scholar]
- Eguro, K. SIRC: An extensible reconfigurable computing communication API. In Proceedings of the 18th IEEE Annual International Symposium on Field-Programmable Custom Computing Machines, FCCM, Charlotte, NC, USA, 2–4 May 2010. [Google Scholar]
- Intel FPGA. SDK for OpenCL. Programming Guide. UG-OCL002. 2016. Available online: https://www.intel.com/content/dam/www/programmable/us/en/pdfs/literature/hb/opencl-sdk/archives/ug-aocl-programming-guide-16.1.pdf (accessed on 23 March 2020).
- Segal, O.; Colangelo, P.; Nasiri, N.; Qian, Z.; Margala, M. SparkCL: A unified programming framework for accelerators on heterogeneous clusters. arXiv 2015, arXiv:1505.01120. [Google Scholar]
- Kulp, J.; Siegel, S.; Miller, J. Open Component Portability Infrastructure (OPENCPI); Technial Report; Mercury Federal Systems Inc.: Arlington, VA, USA, 2013. [Google Scholar]
- Intel HLS Compiler: Fast Design, Coding and Hardware. Available online: https://www.intel.com/content/www/us/en/software/programmable/quartus-prime/hls-compiler.html (accessed on 24 March 2020).
- Vivado High-Level Synthesis: Accelerates IP Creation by Enabling C, C++ and System C Specifications. Available online: https://www.xilinx.com/products/design-tools/vivado/integration/esl-design.html (accessed on 24 March 2020).
- Open Spatial Programming Language (OpenSPL), Maxeler Technologies. Available online: https://www.maxeler.com/openspl-announced/ (accessed on 24 March 2020).
- Pell, O.; Mencer, O.; Tsoi, K.H.; Luk, W. Maximum performance computing with dataflow engines. In Computing in Science & Engineering; IEEE: Piscataway, NJ, USA, 2012; pp. 98–103. [Google Scholar]
- Fleming, K.; Adler, M. The LEAP FPGA Operating System. In FPGAs for Software Programmers; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Vesper, M.; Koch, D.; Vipin, K.; Fahmy, S.A. JetStream: An open-source high-performance PCI express 3 streaming library for FPGA-to-Host and FPGA-to-FPGA communication. In Proceedings of the 2016 26th international conference on field programmable logic and applications (FPL), Lausanne, Switzerland, 29 August–2 September 2016. [Google Scholar]
- Jacobsen, M.; Richmond, D.; Hogains, M.; Kastner, R. RIFFA 2.1: A reusable integration framework for FPGA accelerators. ACM TRETS 2015, 8, 1–23. [Google Scholar] [CrossRef]
- Yoshimi, M.; Nishikawa, Y.; Miki, M.; Hiroyasu, T.; Amano, H.; Mencer, O. A performance evaluation of CUBE: One Dimensional 512 FPGA cluster. In Proceedings of the International Symposium on Applied Reconfigurable Computing, ARC 2010, Bangkok, Thailand, 17–19 March 2010; Springer: Heidelberg, Germany, 2010. [Google Scholar]
- Wang, Z.; Zhang, S.; He, B.; Zhang, W. Melia: A MapReduce framework on OpenCL-Based FPGAs. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 3547–3560. [Google Scholar] [CrossRef]
- Yeung, J.H.C. Map-reduce as a programming model for custom computing machines. In Proceedings of the 2008 16th International Symposium on Field-Programmable Custom Computing Machines, Palo Alto, CA, USA, 14–15 April 2008. [Google Scholar]
- Tsoi, K.H.; Luk, W. Axel: A Heterogeneous Cluster with FPGAs and GPUs. In Proceedings of the 18th Annual ACM/SIGDA International Symposium on Field Programmable Gate Arrays 2010, Monterey, CA, USA, 21–23 February 2010. [Google Scholar]
- Iordache, A.; Pierre, G.; Sanders, P.; de FCoutinho, J.G.; Stillwell, M. High performance in the cloud with FPGA groups. In Proceedings of the 9th International Conference on Utility and Cloud Computing, Shanghai, China, 6–9 December 2016. [Google Scholar]
- Huang, M. Programming and runtime support to blaze FPGA accelerator deployment at datacenter scale. In Proceedings of the Seventh ACM Symposium on Cloud Computing, SoCC ’16, Santa Clara, CA, USA, 5–7 October 2016. [Google Scholar]
- Theodoropoulos, D.; Alachiotis, N.; Pnevmatikatos, D. Multi-FPGA evaluation platform for disaggregated computing. In Proceedings of the 2017 IEEE 25th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Napa, CA, USA, 30 April–2 May 2017. [Google Scholar]
- Ouyang, J.; Lin, S.; Qi, W.; Wang, Y.; Yu, B.; Jiang, S. SDA: Software-defined accelerator for large-scale DNN systems. In Proceedings of the IEEE Hot Chips 26 Symposium (HCS), Cupertino, CA, USA, 10–12 August 2014. [Google Scholar]
- El-Araby, E.; Gonzalez, I.; El-Ghazawi, T. Virtualizing and sharing reconfigurable resources in high-performance reconfigurable computing systems. In Proceedings of the 2008 Second International Workshop on High-Performance Reconfigurable Computing Technology and Applications, Austin, TX, USA, 17 November 2008. [Google Scholar]
- Zheng, Z.; Wang, T.; Weng, J.; Mumtaz, S.; Bashir, A.K.; Hussain, C.S. Differentially private high-dimensional data publication in internet of things. IEEE Internet Things J. 2019. [Google Scholar] [CrossRef]
- Bashir, A.K.; Ohsita, Y.; Murata, M. A distributed virtual data center network architecture for the future internet. IEICE Tech. Rep. (IN2014–165) 2015, 114, 261–266. [Google Scholar]
- Bashir, A.K.; Ohsita, Y.; Murata, M. Abstraction layer based virtual data center architecture for network function chaining. In Proceedings of the International Conference on Distributed Computing Systems Workshops (ICDCSW)—ICDCS, Nara, Japan, 27–30 June 2016. [Google Scholar]
- Bashir, A.K.; Ohsita, Y.; Murata, M. Abstraction layer based distributed architecture for virtualized data centers. In Proceedings of the Cloud Computing 2015: 6th International Conference on Cloud Computing, Grids, and Virtualization, Nice, France, 22–27 March 2015; pp. 46–51. [Google Scholar]
- Flynn, M.J. Flynn’s taxonomy. Encycl. Parallel Comput. 2011, 689–697. [Google Scholar] [CrossRef]
- Caldeira, P.; Penha, J.C.; Bragança, L.; Ferreira, R.; Nacif, J.A.; Ferreira, R.; Pereira, F.M. From Java to FPGA: An experience with the intel HARP system. In Proceedings of the 30th International Symposium on Computer Architecture and High Performance Computing (SBAC-PAD), Lyon, France, 24–27 September 2018. [Google Scholar]
- Feng, L.; Zhao, J.; Liang, T.; Sinha, S.; Zhang, W. LAMA: Link-Aware Hybrid Management for Memory Accesses in Emerging CPU-FPGA Platforms. In Proceedings of the 56th ACM/IEEE Design Automation Conference, Las Vegas, NV, USA, 2–6 June 2019. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Non-Standard Term(s) in Published Literature |
|---|---|
| 2010 | RAMPSoC in [7] |
| 2011 | Lightweight IP (LwIP) in [8] |
| 2012 | ASIF (Application Specific FPGA) in [9] |
| 2013 | sAES (FPGA based data protection system) in [10] |
| 2014 | PFC (FPGA cloud for privacy preserving computation in [11] |
| 2015 | CPU-Cache-FPGA in [12] |
| 2016 | HwAcc (Hardware accelerators), RIPaaS and RRaaS in [13] |
| 2017 | FPGA as a Service (FaaS) and Secure FaaS in [14] |
| 2018 | ACCLOUD (Accelerated CLOUD) in [15], FPGAVirt in [16] |
| 2019 | vFPGA-based CCMs (Custom Computing Machines) in [17] |
| Year | Network Type | Traffic Type | No. of Routers | Target FPGA | Freq. (M.Hz.) | Work |
|---|---|---|---|---|---|---|
| 2010 | Multiple FPGA | Real: App. Cores | 16 | Virtex 5 × 5 | - | [26] |
| 2010 | Direct Mapping | Real: Traces based | 64 | Virtex 2 | 45 | [27] |
| 2010 | Fast Prototyping | Synthetic | 49 | Virtex 6 | 50 | [28] |
| 2011 | Direct Mapping | Real: Traces based | 25 | Virtex 5 | - | [29] |
| 2011 | Virtualization | Real: Traces based | 256 | Virtex 6 | 152 | [30] |
| 2011 | Fast Prototyping | Synthetic | 576 | Virtex 6 | 300 | [31] |
| 2011 | Virtualization | Real: App. Cores | 64 | Virtex 2 | - | [32] |
| 2011 | Virtualization | Real: App. Cores | 16 | Virtex 5 | 3, 15 | [33] |
| 2011 | Direct Mapping | Synthetic | 36 | Virtex 5 | - | [34] |
| 2012 | Direct Mapping | Real: App. Cores | 9 | Virtex 5 | - | [35] |
| 2013 | Multiple FPGA | Synthetic | 18 | Virtex 5 × 2 | - | [36] |
| 2014 | Virtualization | Synthetic | 1024 | Virtex 7 | 42 | [37] |
| 2015 | Direct Mapping | Synthetic | 64 | Virtex 6 | 50 | [38] |
| 2016 | Direct Mapping | Synthetic | 16 | Virtex 6 | 250 | [13] |
| 2017 | Direct Mapping | Synthetic | 16 | Virtex 6 | 250 | [24] |
| 2018 | Direct Mapping | Synthetic | 16 | Virtex 6 | 250 | [25] |
| Abstract Classification | Sub-Class | Work Examples References |
|---|---|---|
| Resource Level | Overlays | [45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74] |
| Input Output (I/O) Virtualization | [4,75,76,77,78,79,80] | |
| Node Level | Virtual Machine Monitors | [81,82,83,84] |
| Shells | [4,41,75,76,77,78,85,86,87,88,89,90,91,92,93,94,95,96,97] | |
| Scheduling | [82,89,98,99,100,101,102,103,104,105,106,107,108,109,110,111,112] | |
| Multi Node Level | Custom Clusters | [113,114,115,116,117] |
| Frameworks | [77,103,118,119,120,121,122,123] | |
| Cloud Services | [4,40,124,125,126,127,128,129,130] |
| Author(s) [Ref.] Year | Language | Board | Frequency | Granularity | Size |
|---|---|---|---|---|---|
| Ferreira et al. [69] 2011 | VHDL | Virtex 6 | 100 MHz | 8 / 32 / 64 bits | 30 |
| Kinsy et al. [70] 2011 | Verilog | Virtex 5 | 155 MHz | 32 bits | 4 × 4 |
| Brant [61] 2012 | Verilog | Stratix III | 150 MHz | 32 bits | 2 × 2 |
| Paul et al. [63] 2012 | - | Virtex 6 | 400 MHz | 32 bits | 40 |
| Liu et al. [71] 2013 | HLS Method | Zynq 7000 | 250 MHz | 32 bits | 2 × 2 |
| Gray [72] 2016* | RISC V ISA | UltraScale | 375 MHz | 32 bits | 10 × 5 × 8 |
| Li et al. [73] 2016 | HLS Method | Zynq 7000 | 286 MHz | 32 bits | 8 |
| Kumar et al. [74] 2017 | C | Stratix V | 94 MHz | 32 bits | 60 × 2 |
| Works | Hardware Characteristics | Virtualization Characteristics | ||||||
|---|---|---|---|---|---|---|---|---|
| Authors, Reference, Year | Target FPGA Board(s) | FPGA Utilization | DDR Size (GB) | Partial Reconfiguration | Multitenancy | Scalability | Adoptability | Time to Market |
| Kirchgessner et al. [91] 2012 | StratixIII, Virtex6, Nallatech H101 | 1% Area Overhead | - | No | No | Low | High | High |
| Byma et al. [75] 2014 | Virtex5 | 74% BRAM | 0.128 | Yes | Yes | Med | Med | Med |
| Chen et al. [84] 2014 | Kintex7 | 51% Logic | 1.866 | Yes | Yes | Med | Med | High |
| Putnam et al. [4] 2014 | Virtex6, Stratix V | 76% All | 8 | Yes | No | High | High | Low |
| Fahmy et al. [76] 2015 | Virtex7 | 7% All | 8 | Yes | No | Low | Low | Med |
| Weerasinghe et al. [41] 2015 | Zynq7100 | 33% Logic | - | No | Yes | High | Med | Med |
| Asghari et al. [92] 2016 | Virtex7 | - | - | No | Yes | Med | Med | Low |
| Bourennane et al. [13] 2016 | Virtex6 | 11% LUTs | - | Yes | No | Med | Low | Low |
| Weerasinghe et al. [87] 2016 | Virtex7 | 32% BRAM | 8 | Yes | No | High | Med | Med |
| Asiatici et al. [89] 2017 | Virtex7 | 5% Area Overhead | 8 | Yes | Yes | Med | Low | Med |
| Kondel et al. [78] 2017 | Virtex7 | 42% Logic | Virtualized | Yes | Yes | High | High | Med |
| Najem et al. [93] 2017 | Artix7, CycloneV | 30% FFs, 55% FFs | On Board | Yes | No | Low | Med | Med |
| Tarafdar et al. [77] 2017 | Virtex7 | 20% BRAM | 8 | Yes | No | High | Med | High |
| Zhang et al. [79] 2017 | StratixV | 13% Logic | - | Yes | Yes | High | High | High |
| Bourennane et al. [25] 2018 | Virtex6 | 3% LUTs | - | Yes | Yes | Med | Med | Med |
| Yazdanshenas et al. [22] 2018 | Arria10 | 2% Logic | 8 | Yes | Yes | Med | High | Med |
| Tarafdar et al. [94] 2019 | Kintex UltraScale | 15–20% LUTs | - | No | Yes | High | Med | High |
| Vaishnav et al. [95] 2019 | Zynq UltraScale+ Ultra96 | 12% LUTs 25% LUTs | 2 | Yes | Yes | High | High | High |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ijaz, Q.; Bourennane, E.-B.; Bashir, A.K.; Asghar, H. Revisiting the High-Performance Reconfigurable Computing for Future Datacenters. Future Internet 2020, 12, 64. https://doi.org/10.3390/fi12040064
Ijaz Q, Bourennane E-B, Bashir AK, Asghar H. Revisiting the High-Performance Reconfigurable Computing for Future Datacenters. Future Internet. 2020; 12(4):64. https://doi.org/10.3390/fi12040064
Chicago/Turabian StyleIjaz, Qaiser, El-Bay Bourennane, Ali Kashif Bashir, and Hira Asghar. 2020. "Revisiting the High-Performance Reconfigurable Computing for Future Datacenters" Future Internet 12, no. 4: 64. https://doi.org/10.3390/fi12040064