Improving Forensic Triage Efficiency through Cyber Threat Intelligence

 ,
,
Abstract
:1. Introduction
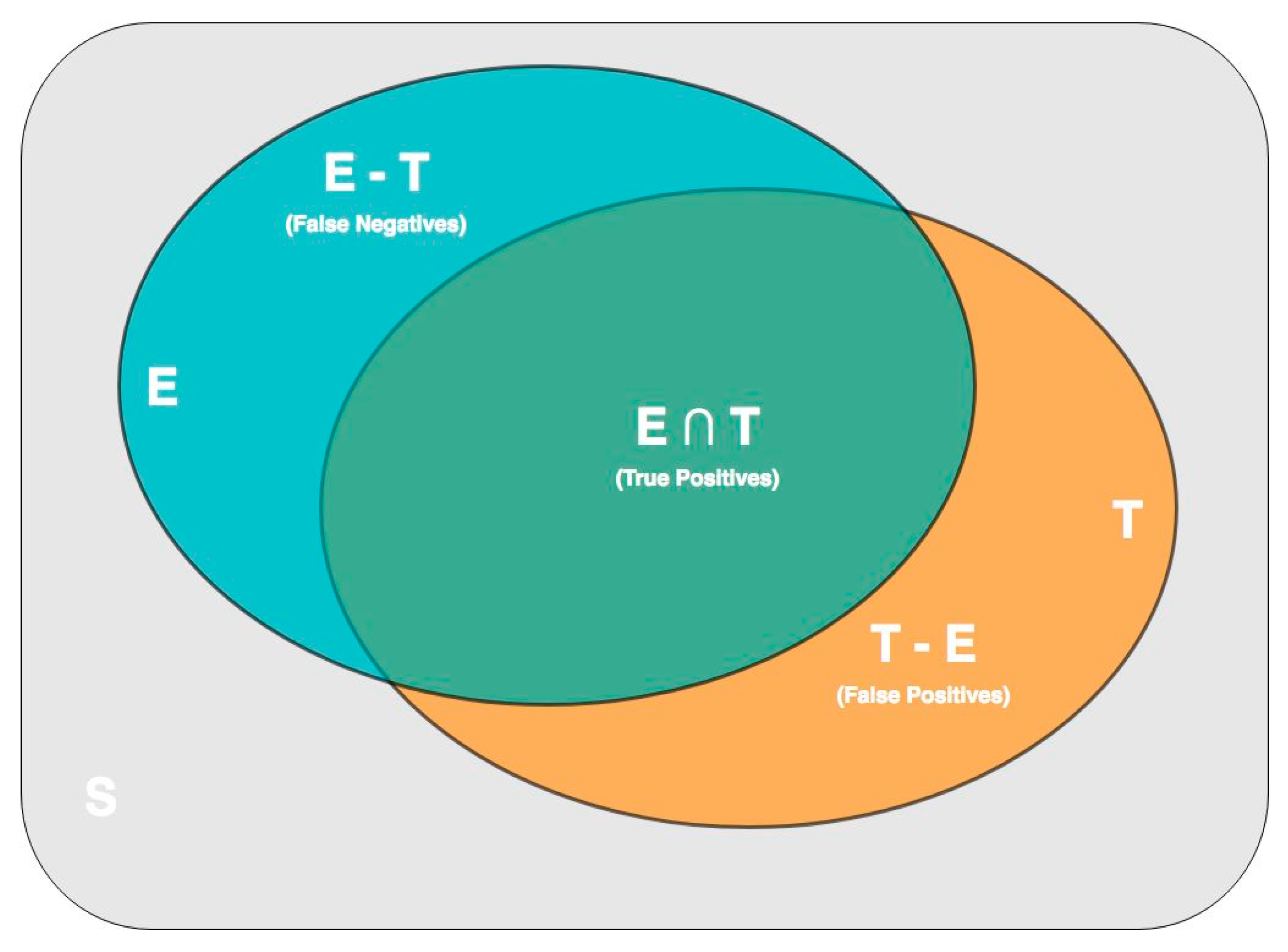
- A subset of digital evidence items identified by triage (true positives or “hits”)
- A subset of items not relevant to the case, but included in the triage subset (false positives)
- A subset of items relevant to the case, but not identified by the triage (false negatives or “misses”).
2. Related Work
2.1. Digital Forensic Readiness
2.2. Digital Forensic Readiness Models
2.3. Digital Forensic Readiness Operations
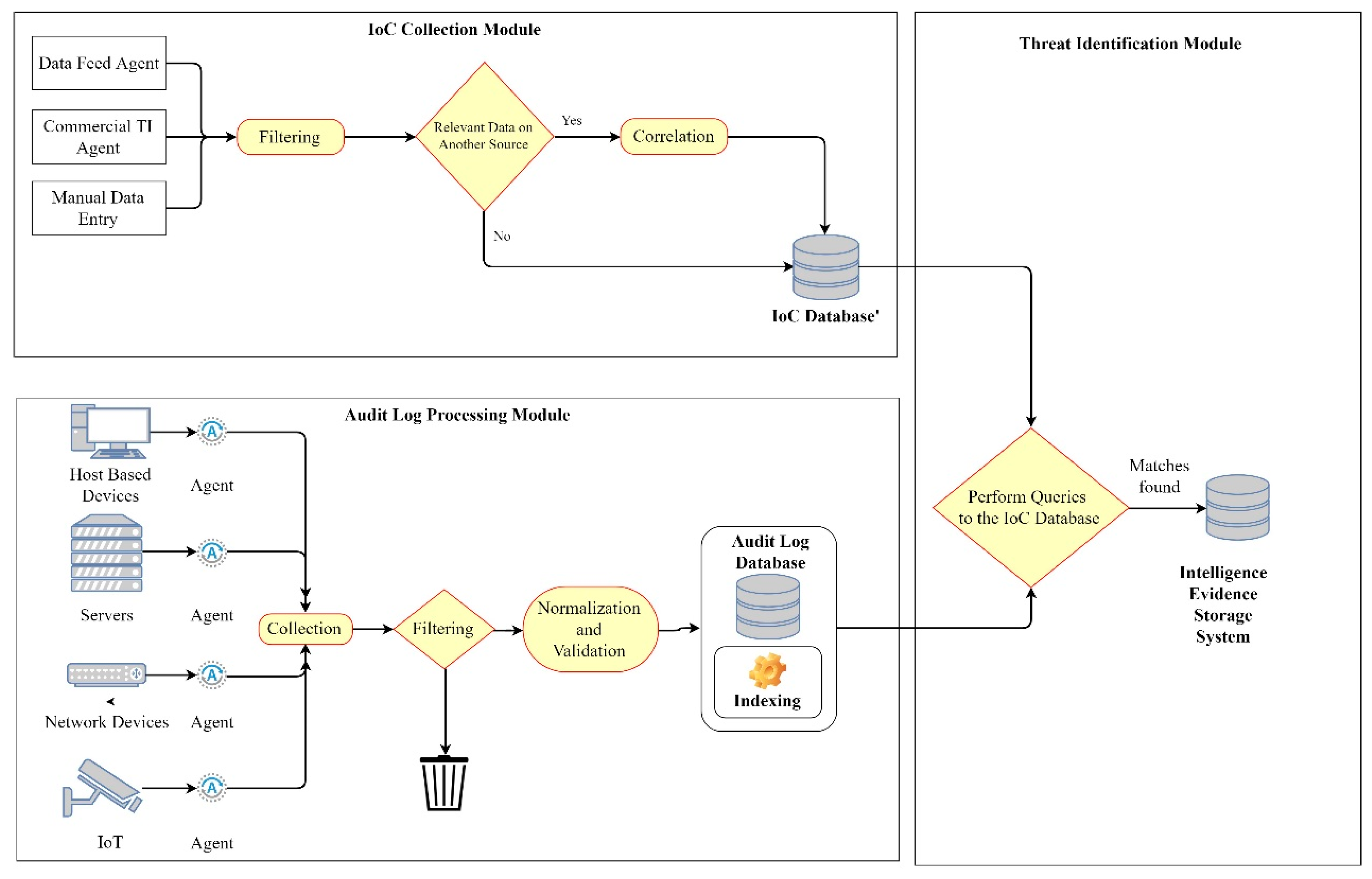
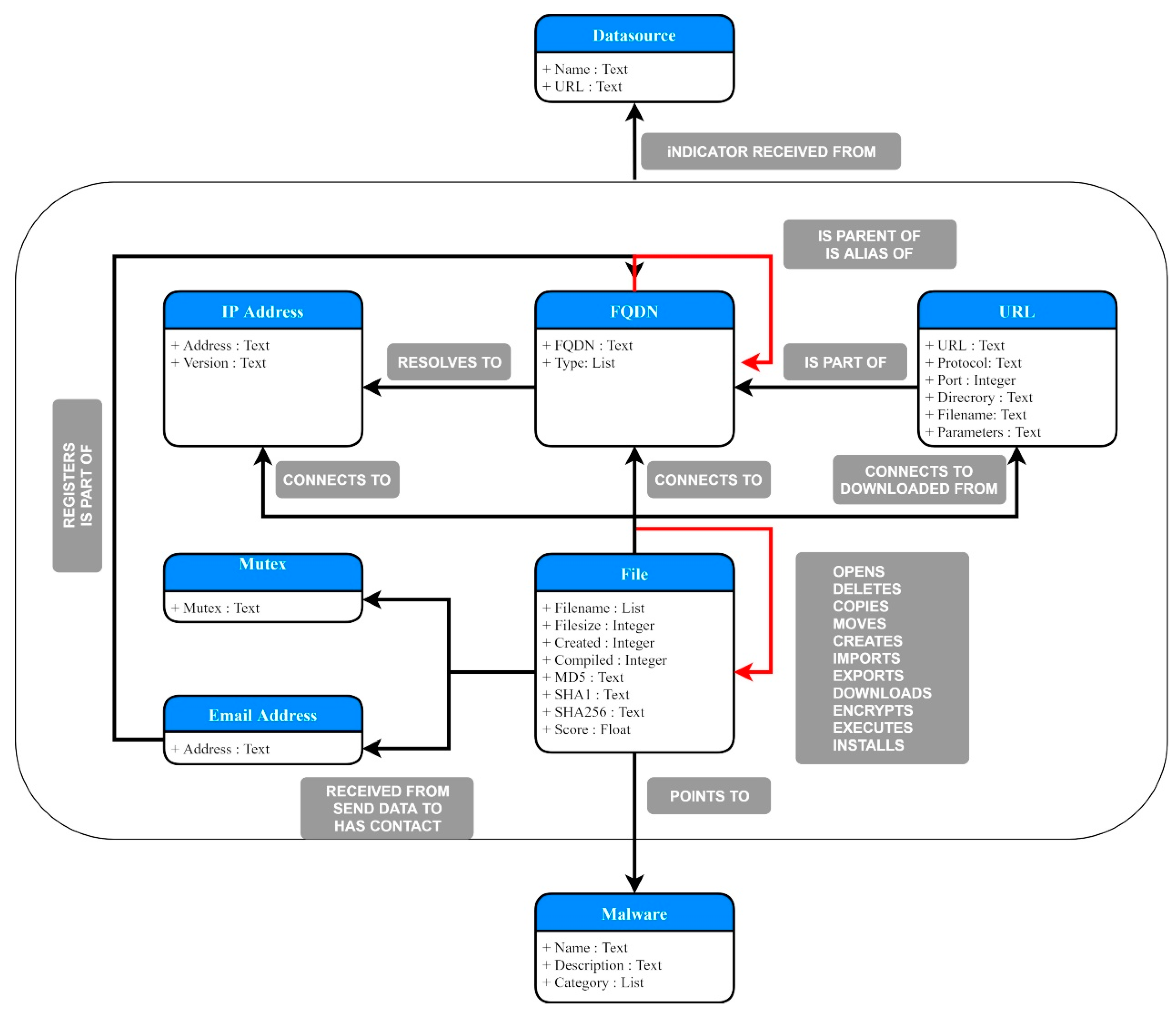
3. The Threat Intelligence Informed Digital Forensic Readiness Reference Model
3.1. The IoC Collection Module
3.2. The Audit Log Processing Module
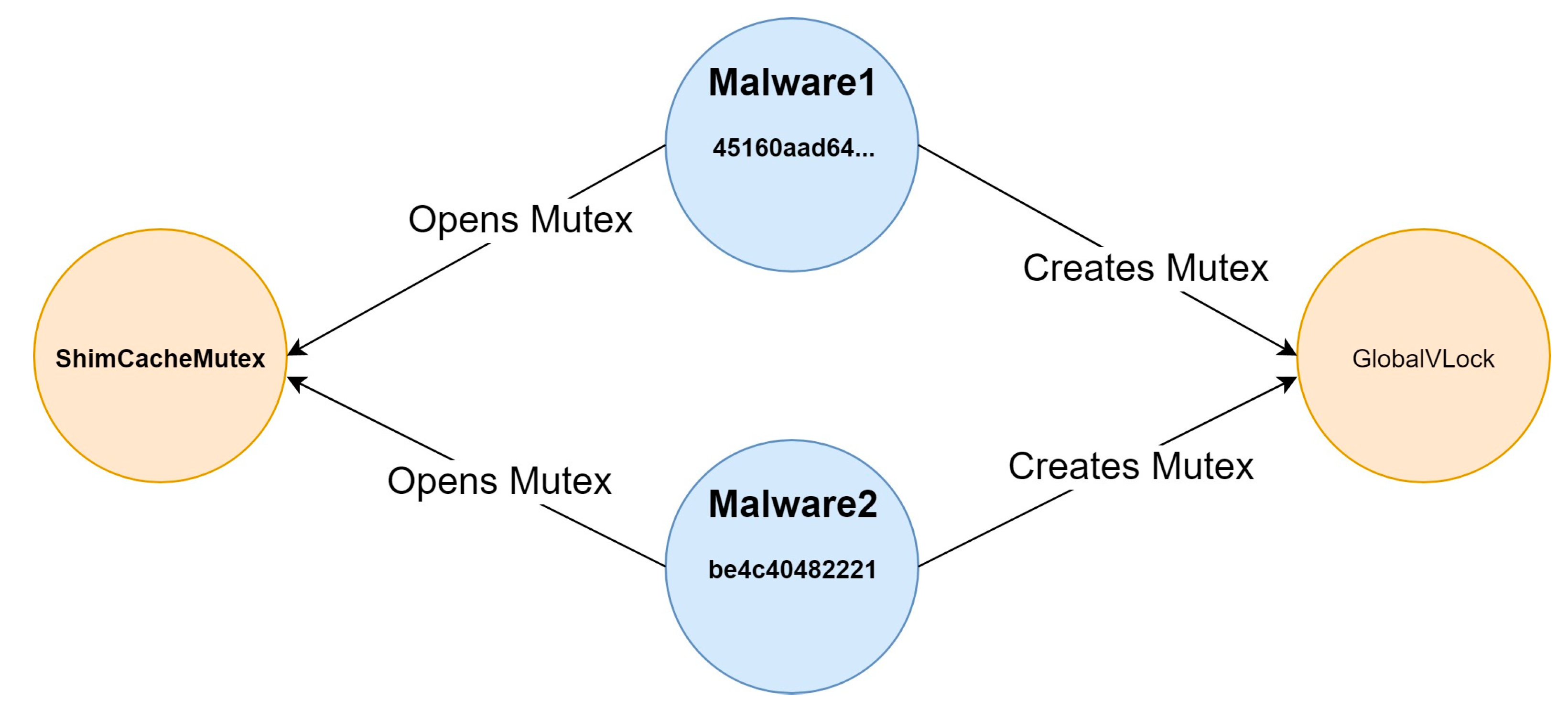
3.3. The Threat Identification Module
4. Evaluation
4.1. Testbed Setup
4.2. IoC Collection Module Operation
4.3. Audit Log Processing Module Operation
4.4. Threat Identification Module Operation
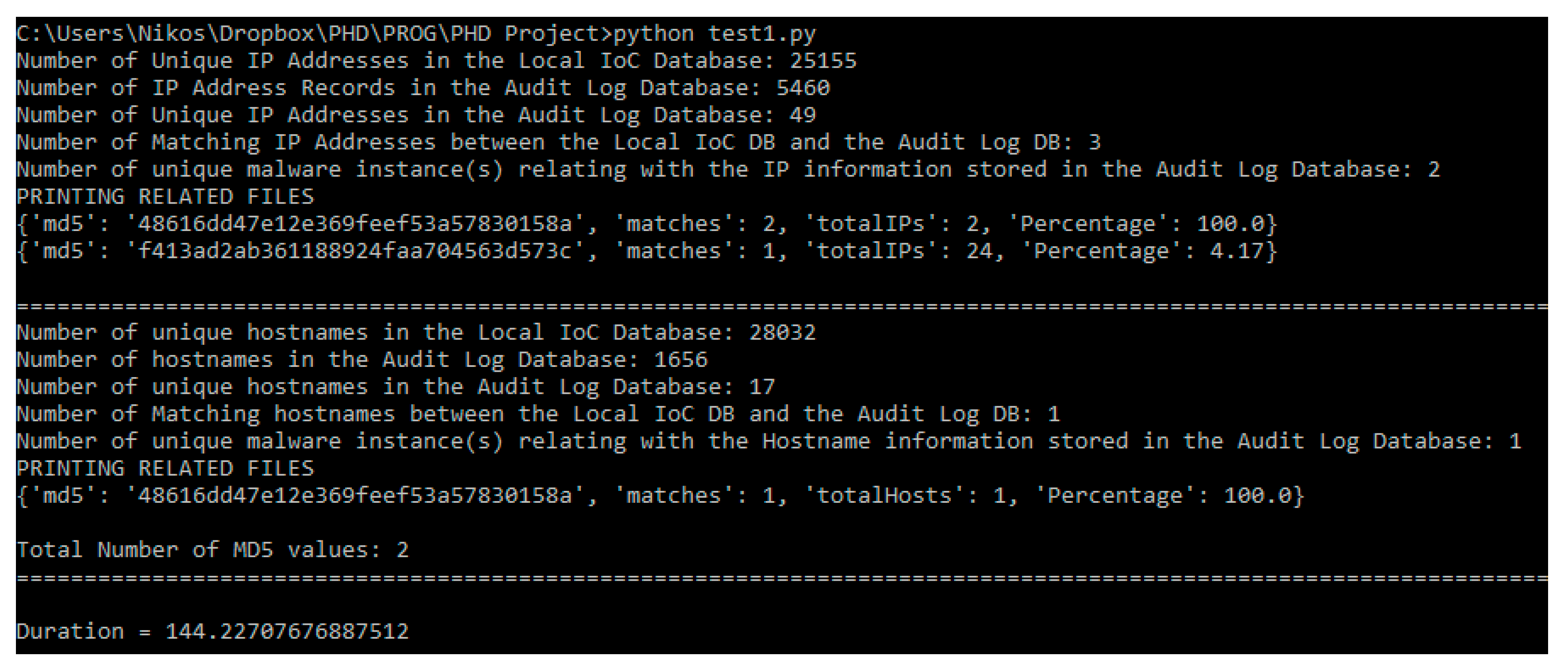
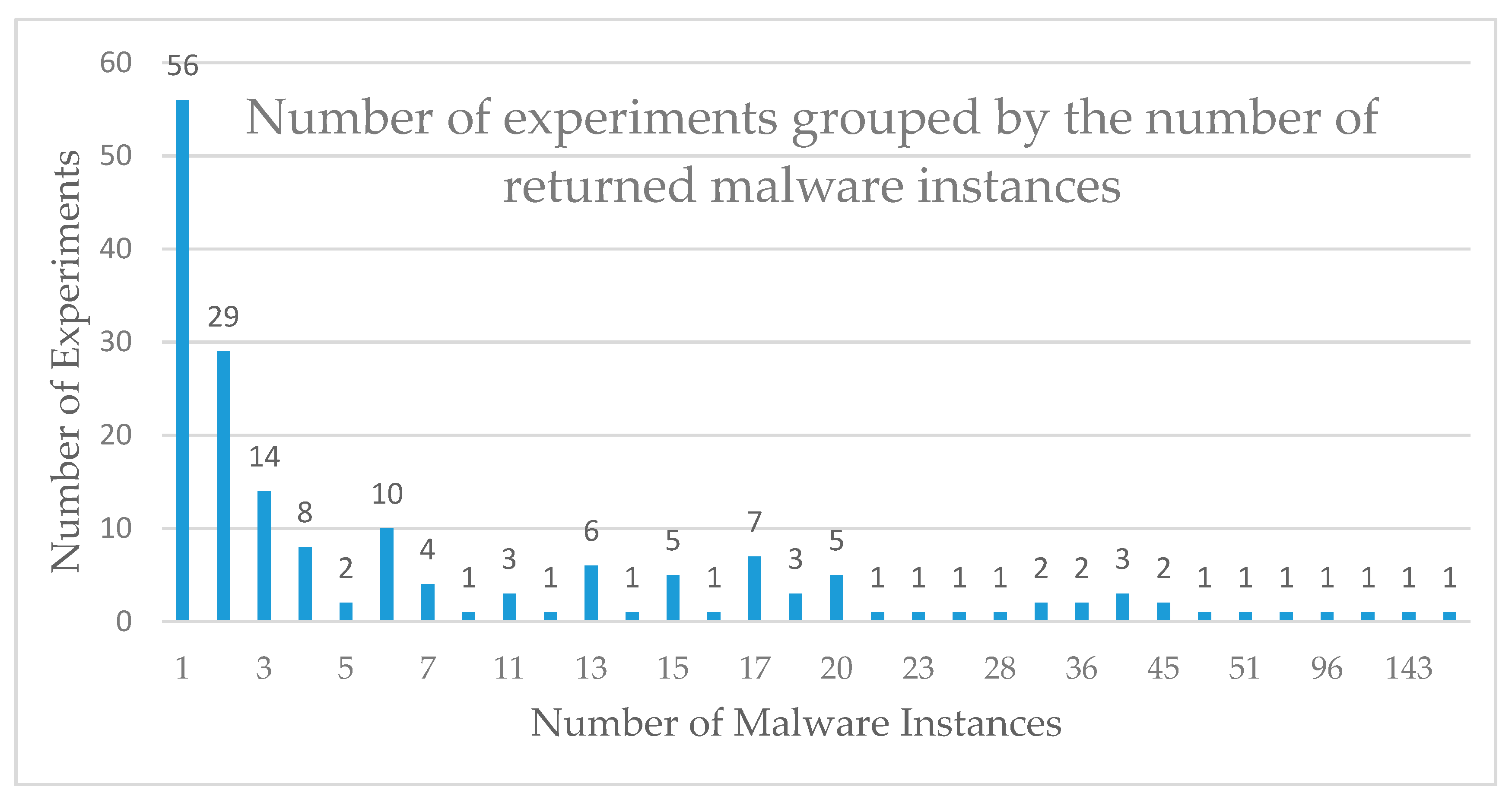
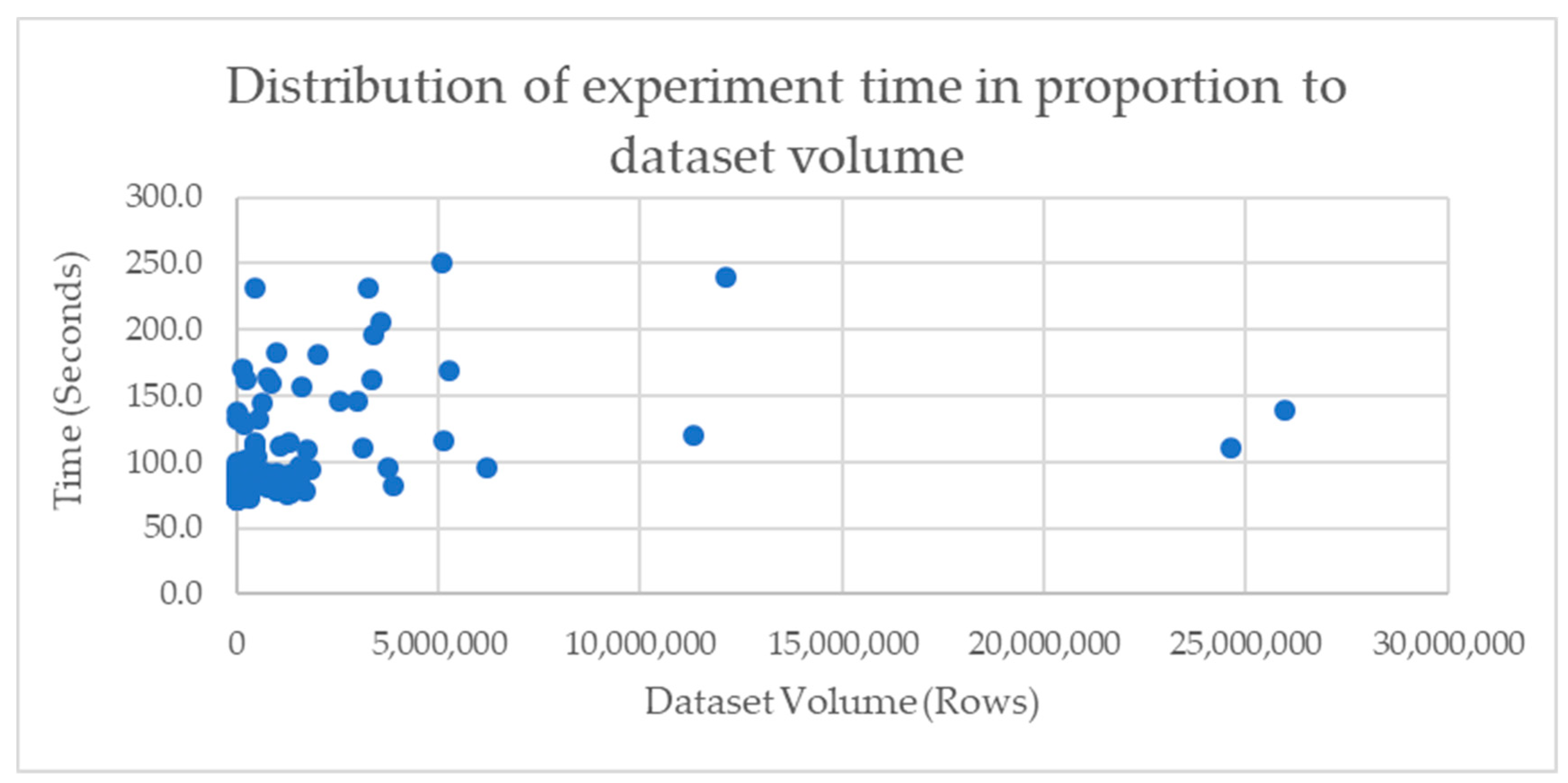
5. Results
- TIPs did not report any malicious network IoCs in 10 of these 29 experiments.
- The TIM did not return any results (no hash value) in 12 of these 29 experiments.
- The TIM returned false results (different malware hash value) in seven of these 29 experiments.
6. Discussion
- Decrease the volume of information an analyst needs to examine
- Minimise the time of a forensic investigation
- Limit the cost of forensic analysis
- Determine the root cause of an incident in a timely manner and with high precision
- Identify relevant threats that may have affected the security posture of an organization.
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Tounsi, W.; Rais, H. A survey on technical threat intelligence in the age of sophisticated cyber attacks. Comput. Secur. 2018, 72, 212–233. [Google Scholar] [CrossRef]
- Serketzis, N.; Katos, V.; Ilioudis, C.; Baltatzis, D.; Pangalos, G.J. Actionable threat intelligence for digital forensics readiness. Inf. Comput. Secur. 2019, 27, 273–291. [Google Scholar] [CrossRef] [Green Version]
- Serketzis, N.; Katos, V.; Ilioudis, C.; Baltatzis, D.; Pangalos, G.J. A Socio-Technical Perspective on Threat Intelligence Informed Digital Forensic Readiness. Int. J. Syst. Soc. 2017, 4, 57–68. [Google Scholar] [CrossRef]
- Bilge, L.; Dumitras, T. Before we knew it: An empirical study of zero-day attacks in the real world. In Proceedings of the 2012 ACM conference on Computer and communications security, Raleigh, NC, USA, 16–18 October 2012. [Google Scholar]
- Mandiant. M-Trends Report; Mandiant: Alexandria, VA, USA, 2018. [Google Scholar]
- Lillis, D.; Becker, B.A.; Sullivan, T.O.; O’Sullivan, T.; Scanlon, M. Current Challenges and Future Research Areas for Digital Forensic Investigation. In Proceedings of the 11th ADFSL Conference on Security and Law (CDFSL 2016), Digital Forensics, Daytona Beach, FL, USA, 13 April 2016. [Google Scholar]
- Tan, J. Forensic Readiness; Cambridge, MA, USA, 2001. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.644.9645&rep=rep1&type=pdf (accessed on 23 July 2019).
- Pangalos, G.; Ilioudis, C.; Pagkalos, I. The Importance of Corporate Forensic Readiness in the Information Security Framework. 2010 19th IEEE Int. Workshops Enabling Technol. Infrastruct. Collab. Enterp. 2010, 12–16. [Google Scholar] [CrossRef]
- International Organization for Standardization. ISO/IEC 27043: Information Technology, Security Techniques, Incident Investigation Principles and Processes; International Organization for Standardization: Geneva, Switzerland, 2015. [Google Scholar]
- Taylor, C.; Endicott-Popovsky, B.; Frincke, D.A. Specifying digital forensics: A forensics policy approach. Digit. Investig. 2007, 4, 101–104. [Google Scholar] [CrossRef]
- Grance, T.; Hash, J.; Stevens, M. Security Considerations in the Information System Development Life Cycle. Nist Spec. Publ. 2004, 800, 1. [Google Scholar]
- Grobler, C.P.; Louwrens, C.P.; Von Solms, S.H. A framework to guide the implementation of proactive digital forensics in organizations. In Proceedings of the ARES 2010-5th International Conference on Availability, Reliability, and Security, Krakow, Poland, 15–18 February 2010; pp. 677–682. [Google Scholar]
- Elyas, M.; Ahmad, A.; Maynard, S.B.; Lonie, A. Digital forensic readiness: Expert perspectives on a theoretical framework. Comput. Secur. 2015, 52, 70–89. [Google Scholar] [CrossRef]
- Al-Mahrouqi, A.; Abdalla, S.; Kechadi, T. Network Forensics Readiness and Security Awareness Framework. Available online: https://researchrepository.ucd.ie/bitstream/10197/6498/1/insight_publication.pdf (accessed on 23 July 2019).
- Kebande, V.R.; Karie, N.M.; Venter, H.S. A generic Digital Forensic Readiness model for BYOD using honeypot technology. In Proceedings of the 2016 IST-Africa Week, Durban, South Africa, 11–13 May 2016. [Google Scholar]
- Kebande, V.R.; Venter, H.S. A Cloud Forensic Readiness Model Using a Botnet as a Service. Int. Conf. Digit. Secur. Forensics 2014, 23–32. Available online: https://www.researchgate.net/profile/Natalie_Walker4/publication/263617788_Proceedings_of_the_International_Conference_on_Digital_Security_and_Forensics_DigitalSec2014/links/0f31753b5cd085c06a000000/Proceedings-of-the-International-Conference-on-Digital-Security-and-Forensics-DigitalSec2014.pdf#page=25 (accessed on 23 July 2019).
- Kebande, V.R.; Venter, H.S. Obfuscating a Cloud-Based Botnet Towards Digital Forensic Readiness. In Proceedings of the 10th International Conference on Cyber Warfare and Security ICCWS 2015, Kruger National Park, South Africa, 24–25 March 2015. [Google Scholar]
- Kebande, V.; Ntsamo, H.S.; Venter, H.S.S. Towards a prototype for Achieving Digital Forensic Readiness in the Cloud using a Distributed NMB Solution. In Proceedings of the European Conference on Cyber Warfare and Security, Munich, Germany, 7–8 November 2016; pp. 369–379. [Google Scholar]
- Rowlingson, R. A Ten Step Process for Forensic Readiness. Int. J. Digit. Evid. 2004, 2, 1–28. [Google Scholar]
- Grobler, C.P.; Louwrens, C.P. Digital Forensic Readiness as a Component of Information Security Best Practice. In IFIP International Information Security Conference; Springer: Boston, MA, USA, 2007. [Google Scholar]
- Valjarevic, A.; Venter, H. Towards a Digital Forensic Readiness Framework for Public Key Infrastructure systems. In Proceedings of the 2011 Information Security for South Africa, Johannesburg, South Africa, 15–17 August 2011. [Google Scholar]
- Valjarevic, A.; Venter, H. Implementation guidelines for a harmonised digital forensic investigation readiness process model. In Proceedings of the 2013 Information Security for South Africa, Johannesburg, South Africa, 14–16 August 2013. [Google Scholar]
- Elyas, M.; Maynard, S.B.; Ahmad, A.; Lonie, A. Towards A Systemic Framework for Digital Forensic Readiness. J. Comput. Inf. Syst. 2014, 54, 97–105. [Google Scholar] [CrossRef]
- Jusas, V.; Birvinskas, D.; Gahramanov, E. Methods and Tools of Digital Triage in Forensic Context: Survey and Future Directions. Symmetry 2017, 9, 49. [Google Scholar] [CrossRef]
- Miller, J. Graph Database Applications and Concepts with Neo4j. Proc. 2013 South. Assoc. 2013, 141–147. Available online: https://pdfs.semanticscholar.org/322a/6e1f464330751dea2eb6beecac24466322ad.pdf (accessed on 23 July 2019).
- Bellis, E. The Problem with Your Threat Intelligence 2015. Available online: http://pages.kennasecurity.com/rs/958-PRK-049/images/Kenna_WP_TheProblemwithYourThreatIntelligence.pdf (accessed on 23 July 2019).
- Neo4j.Neo4j Graph Platform. 2019. Available online: https://neo4j.com/ (accessed on 11 January 2019).
- Elastic. Elastic Stack Suite. 2018. Available online: https://www.elastic.co/products (accessed on 2 December 2018).
- Vicknair, C.; Macias, M.; Zhao, Z.; Nan, X. A Comparison of a Graph Database and a Relational Database: A Data Provenance Perspective. Available online: https://john.cs.olemiss.edu/~ychen/publications/conference/vicknair_acmse10.pdf (accessed on 23 July 2019).
- Kalyani, D.; Mehta, D.D. Paper on Searching and Indexing Using Elasticsearch. Int. J. Eng. Comput. Sci. 2017, 6, 21824–21829. [Google Scholar] [CrossRef]
- AlienVault. ‘AlienVault-Open Threat Exchange. 2018. Available online: https://otx.alienvault.com/dashboard/new (accessed on 2 December 2019).
- Stratpsphere Lab. Datasets Overview—Stratosphere IPS. Available online: https://www.stratosphereips.org/datasets-overview/ (accessed on 4 December 2018).
- VirusTotal. VirusTotal Malware Analysis Platform. 2018. Available online: https://www.virustotal.com/ (accessed on 2 December 2018).
- Crowdstrike. Hybrid Analysis-Free Automated Analysis Service’, 2018. Available online: https://www.hybrid-analysis.com (accessed on 2 December 2018).
- ThreatConnect. ThreatConnect Enterprise Threat Intelligence Platform. 2011. Available online: https://threatconnect.com (accessed on 11 January 2019).
- Garcia, S. Modelling the Network Behaviour of Malware to Block Malicious Patterns. The Stratosphere Project: A Behavioural Ips. Available online: https://www.virusbulletin.com/uploads/pdf/conference/vb2015/Garcia-VB2015.pdf (accessed on 23 July 2019).
- Stratosphere Lab. Stratosphere Datasets. 2015. Available online: https://www.stratosphereips.org/ (accessed on 10 August 2018).
- Małowidzki, M.; Berezi, P.; Mazur, M. Network Intrusion Detection: Half a Kingdom for a Good Dataset. ECCWS 2017 PDF. In Proceedings of the 16th European Conference on Cyber Warfare and Security, Dublin, Ireland, 29–30 June 2017. [Google Scholar]
- The Zeek Project. Bro Network Intrusion Detection System. 2018. Available online: https://docs.zeek.org/en/latest/intro/index.html (accessed on 3 January 2019).
- Mehra, P. A brief study and comparison of Snort and Bro Open Source Network Intrusion Detection Systems. Int. J. Adv. Res. Comput. Commun. Eng. 2012, 1, 383–386. [Google Scholar]
- Volonino, L. Electronic Evidence and Computer Forensics. Commun. Assoc. Inf. Syst. 2003, 12, 1–24. [Google Scholar] [CrossRef]
- Friedberg, I.; Skopik, F.; Settanni, G.; Fiedler, R. Combating advanced persistent threats: From network event correlation to incident detection. Comput. Secur. 2015, 48, 35–57. [Google Scholar] [CrossRef]
- Reddy, K.; Venter, H.S.; Olivier, M.S. Using time-driven activity-based costing to manage digital forensic readiness in large organisations. Inf. Syst. Front. 2012, 14, 1061–1077. [Google Scholar] [CrossRef]
- Roberts, K.; Anderson, S.R. Time-Driven Activity-Based Costing: A Simpler and More Powerful Path to Higher Profits; Harvard Business Review Press: Brighton, MA, USA, 2007. [Google Scholar]
- Lockheed Martin. The Cyber Kill Chain. Available online: https://www.lockheedmartin.com/en-us/capabilities/cyber/cyber-kill-chain.html (accessed on 10 February 2019).
- Bianco, D. The Pyramid of Pain. 2013. Available online: http://detect-respond.blogspot.gr/2013/03/the-pyramid-of-pain.html (accessed on 26 September 2017).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
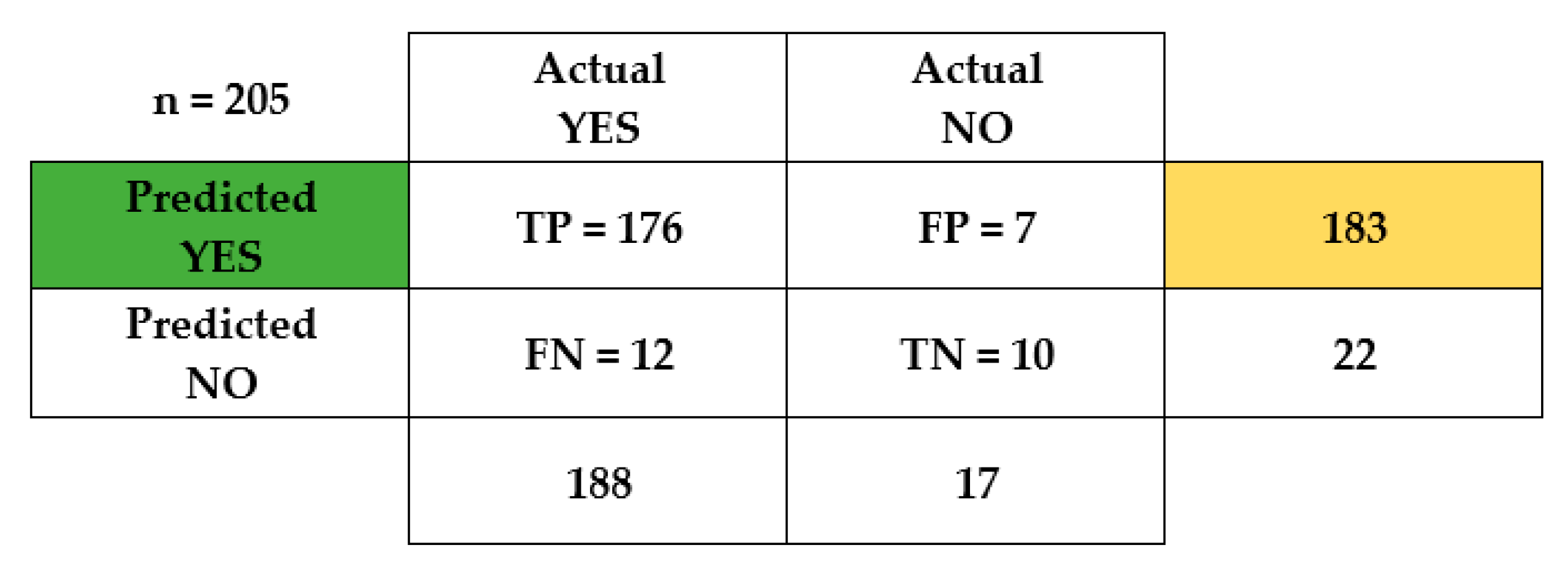
| Malware Instances Identified | Malware Instances Not Identified | |
|---|---|---|
| Number of Experiments | 176 | 29 |
| Percentage Rates | 85.85% | 14.15% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Serketzis, N.; Katos, V.; Ilioudis, C.; Baltatzis, D.; Pangalos, G. Improving Forensic Triage Efficiency through Cyber Threat Intelligence. Future Internet 2019, 11, 162. https://doi.org/10.3390/fi11070162
Serketzis N, Katos V, Ilioudis C, Baltatzis D, Pangalos G. Improving Forensic Triage Efficiency through Cyber Threat Intelligence. Future Internet. 2019; 11(7):162. https://doi.org/10.3390/fi11070162
Chicago/Turabian StyleSerketzis, Nikolaos, Vasilios Katos, Christos Ilioudis, Dimitrios Baltatzis, and Georgios Pangalos. 2019. "Improving Forensic Triage Efficiency through Cyber Threat Intelligence" Future Internet 11, no. 7: 162. https://doi.org/10.3390/fi11070162