Chinese Text Classification Model Based on Deep Learning


Abstract
:1. Introduction
2. Related Work
3. Hybrid Deep-Learning Model
3.1. Input Layer
3.1.1. Remove The Stop Words
3.1.2. Segmentation
- -
- Achieve efficient word graph scanning based on a prefix dictionary structure [16]. Build a directed acyclic graph (DAG) for all possible word combinations.
- -
- Use dynamic programming to find the most probable combination based on the word frequency.
- -
- For unknown words, an HMM-based model [17] is used with the Viterbi algorithm.
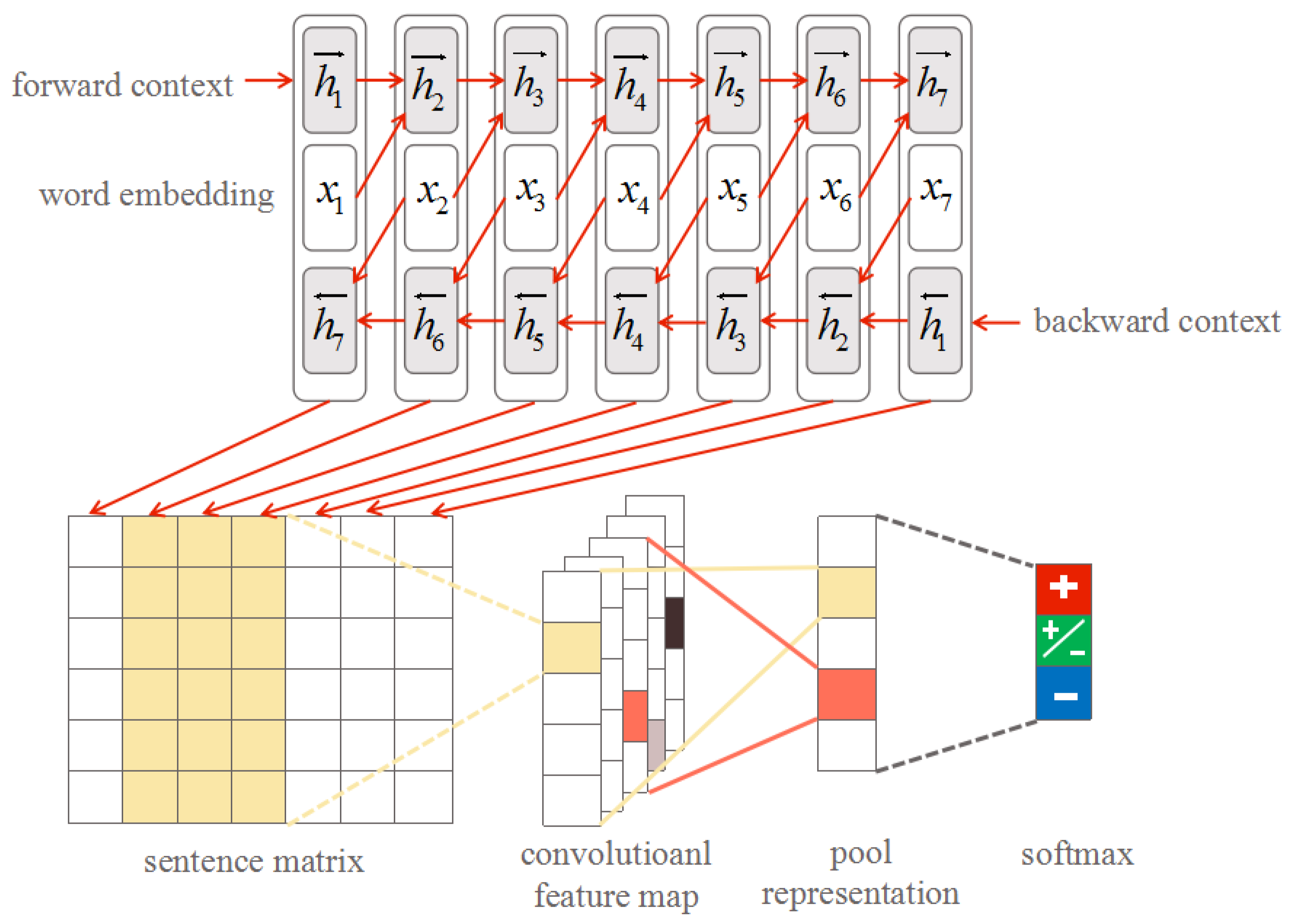
3.2. BLSTM Layer
3.3. Convolutional Neural Networks Layer
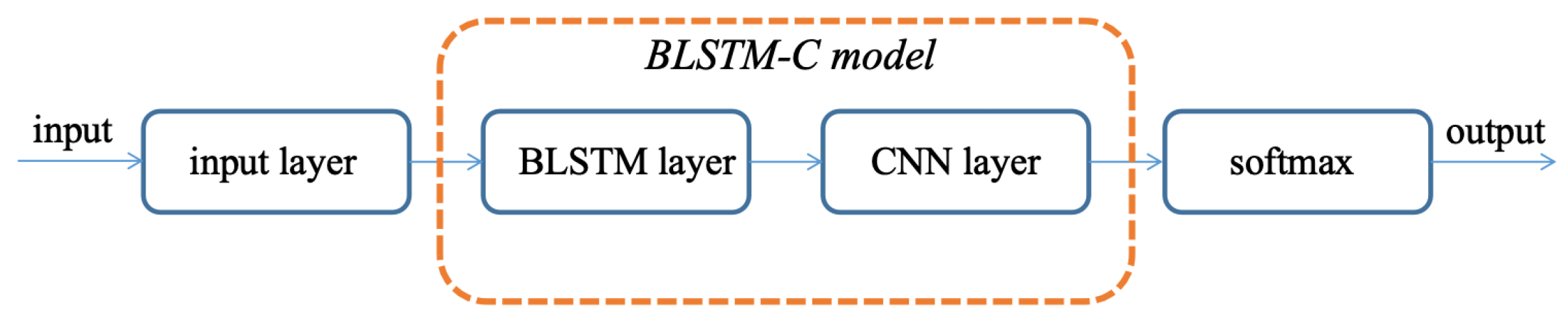
3.4. Proposed BLSTM-C Model
4. Experiment
4.1. Datasets
4.2. Word Vector Initialization and Padding
4.3. Hyper-Parameter Setting
5. Results
5.1. Overall Performance
5.2. Comparison between English and Chinese
5.3. Performance Analysis
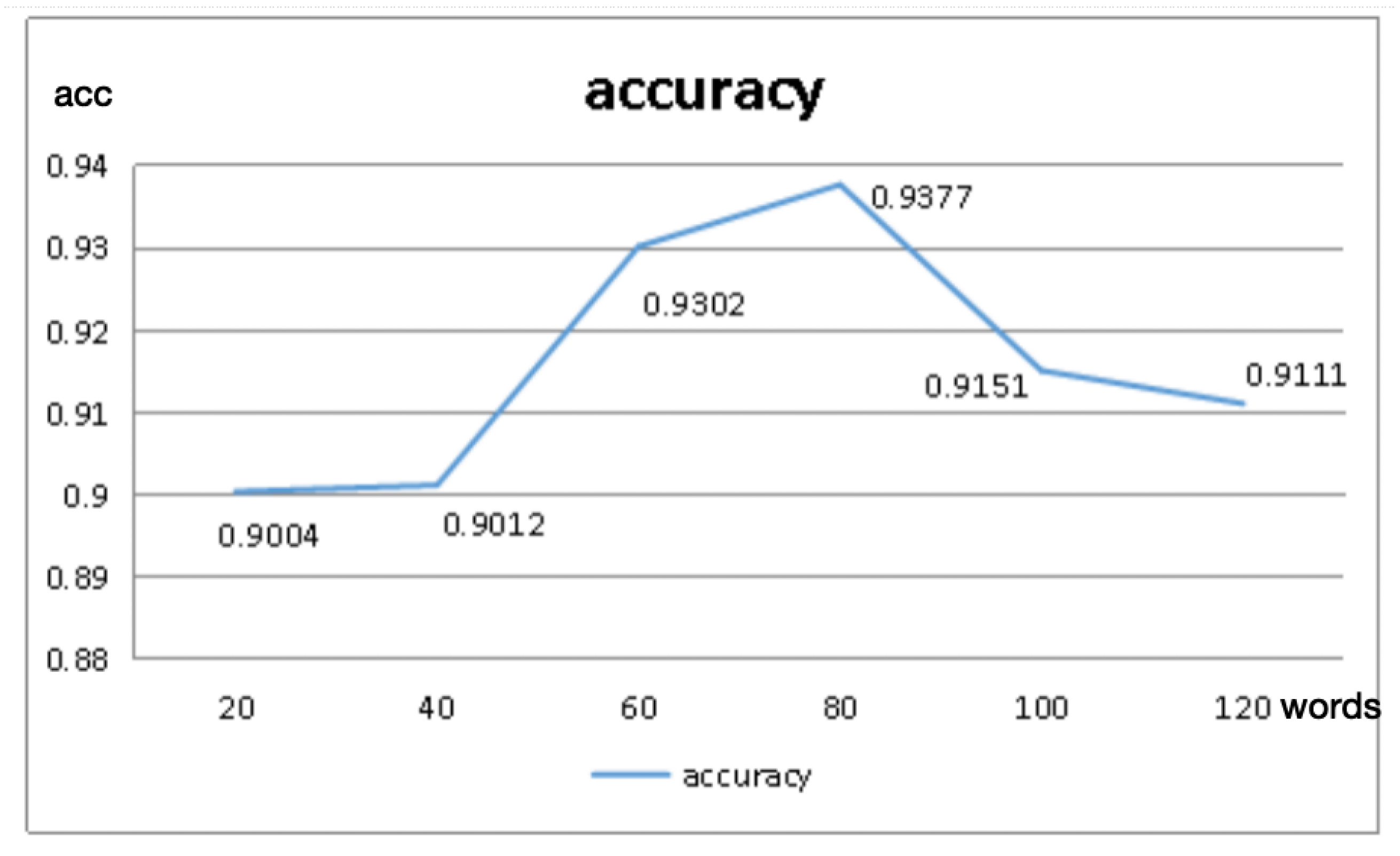
- The length of theIn the initialization and padding of word vectors, the parameter, maxlen, was set up to determine the length of the words that are chosen to represent the article. As for SST-1 and SST-2 datasets, the average length of articles are 18, and the length is so short that it is difficult to obtain the different influences of the article length. Therefore, the THUCNews dataset is selected for an experiment to find out the effect of article length. Figure 4 shows that different lengths of the articles result in different performance.The best result, 93.77%, occurs when 80 words are employed to represent the article, which is also deemed as the closest length to the average article length of the dataset. Once the maxlen is far greater than the average length of the articles, then the accuracy will decrease greatly because many more zero vectors will exist in the vectors of the article.
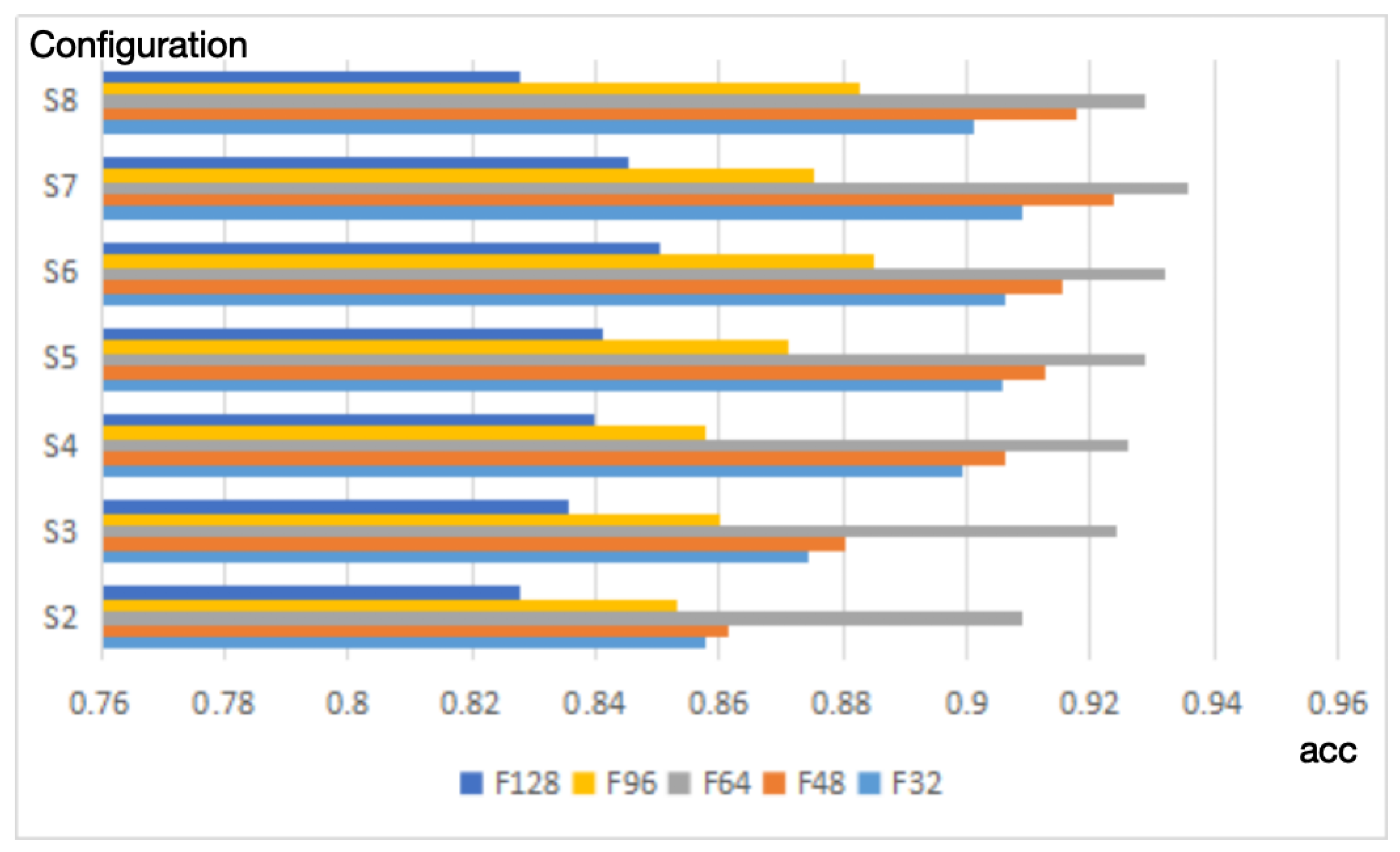
- The size of Convolutional FilterIn Figure 5, different convolution filter configurations are adopted to present the prediction accuracy on the question classification. As for the horizontal axis, the number indicates convolutional kernel size, and bar charts of five different colors on each filter size represent different dimensions of the convolution output. For example, “S8” means that the size of the kernel is 8 while “F128” denotes that the dimension of the convolution output is 128. It is quite obvious that the dimension of 64 outperforms the other dimensions and the best result, the accuracy of 93.55%, occurs when the window size is 7.
6. Conclusions
Funding
Conflicts of Interest
References
- Wang, S.; Manning, C.D. Aselines and bigrams: Simple, good sentiment and topic classification. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, Jeju Island, Korea, 8–14 July 2012; Volume 2, pp. 90–94. [Google Scholar]
- Socher, R.; Perelygin, A.; Wu, J.Y.; Chuang, J.; Manning, C.D.; Ng, A.Y.; Potts, C. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; Merrienboer, B.V.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using rnn encoder-decoder for statistical machine translation. arXiv, 2014; arXiv:1406.1078. [Google Scholar]
- Krizhevsky, A.I.S.A.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A convolutional neural network for modelling sentences. arXiv, 2014; arXiv:1404.2188. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; Volume 2, pp. 3111–3119. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the 31st International Conference on Machine Learning (ICML-14), Beijing, China, 21–26 June 2014; pp. 1188–1196. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv, 2014; arXiv:1408.5882. [Google Scholar]
- Conneau, A.; Schwenk, H.; Barrault, L.; Lecun, Y. Very deep convolutional networks for text classification. arXiv, 2017; arXiv:1606.01781. [Google Scholar]
- Tai, K.S.; Socher, R.; Manning, C.D. Improved semantic representations from tree-structured long short-term memory networks. arXiv, 2015; arXiv:1503.00075. [Google Scholar]
- Zhou, P.; Shi, W.; Tian, J.; Qi, Z.; Li, B.; Hao, H.; Xu, B. Attention-based bidirectional long short-term memory networks for relation classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; p. 207. [Google Scholar]
- Zhang, H.-P.; Yu, H.-K.; Xiong, D.-Y.; Liu, Q. Hhmm-based chinese lexical analyzer ictclas. In Proceedings of the Second SIGHAN Workshop on Chinese Language Processing, SIGHAN ’03, Sapporo, Japan, 11–12 July 2003; pp. 184–187. [Google Scholar]
- Zhou, C.; Sun, C.; Liu, Z.; Lau, F. A c-lstm neural network for text classification. arXiv, 2015; arXiv:1511.08630. [Google Scholar]
- Zhu, Z.; Yin, H.; Chai, Y.; Li, Y.; Qi, G. A novel multi-modality image fusion method based on image decomposition and sparse representation. Inf. Sci. 2018, 432, 516–529. [Google Scholar] [CrossRef]
- Lee, K.-F.; Hon, H.-W. Speaker-independent phone recognition using hidden Markov models. IEEE Trans. Acoust. Speech Signal Process. 1989, 37, 1641–1648. [Google Scholar] [CrossRef] [Green Version]
- Socher, R.; Huval, B.; Manning, C.D.; Ng, A.Y. Semantic compositionality through recursive matrixvector spaces. In Proceedings of the Empirical Methods on Natural Language Processing, Jeju Island, Korea, 12–14 July 2012; pp. 1201–1211. [Google Scholar]
- Irsoy, O.; Cardie, C. Deep recursive neural networks for compositionality in language. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2096–2104. [Google Scholar]
- Lei, T.; Barzilay, R.; Jaakkola, T. Molding cnns for text: Non-linear, nonconsecutive convolutions. arXiv, 2015; arXiv:1508.04112. [Google Scholar]
- Zhu, X.; Sobhani, P.; Guo, H. Long short-term memory over recursive structures. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1604–1612. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | SST-1 (%) | SST-1 (%) | THUCNews (%) | Reported in |
|---|---|---|---|---|
| SVM | 40.7 | 79.4 | 77.5 | Socher et al. (2013b) [2] |
| NBoW | 42.4 | 80.5 | 75.5 | Le and Mikolov (2014) [8] |
| Paragraph Vector | 48.7 | 48.7 | 48.7 | Le and Mikolov (2014) [8] |
| DCNN | 48.5 | 86.8 | - | Kalchbrenner et al. (2014) [6] |
| CNN-non-static | 48.0 | 87.2 | - | Kim (2014) [10] |
| Modeling-CNN | 51.2 | 88.6 | - | Lei et al. (2015) [20] |
| CNN-multichannel | 47.4 | 88.1 | - | Kim (2014) [10] |
| RCNN | 47.21 | - | - | Lai et al. (2015) [20] |
| S-LSTM | - | 81.9 | - | Zhu et al. (2015) [21] |
| BLSTM | 49.1 | 87.5 | - | Tai et al. (2015) [12] |
| Tree-LSTM | 51.0 | 87.5 | - | Tai et al. (2015) [12] |
| MV-RNN | 44.4 | 82.9 | - | Socher et al. (2012) [18] |
| RNTN | 45.7 | 85.4 | - | Socher et al. (2013b) [2] |
| DRNN | 49.8 | 86.6 | - | Irsoy and Cardie (2014) [19] |
| LSTM | 47.1 | 87.0 | 83.4 | Our implementation |
| B-LSTM | 47.3 | 88.1 | 86.5 | Our implementation |
| CNN | 46.5 | 85.5 | 82.5 | Our implementation |
| BLSTM-C | 50.2 | 89.5 | 90.8 | Our implementation |
| Tech | Sports | Politics | Entertainment | Business | |
|---|---|---|---|---|---|
| Tech | 145 | 2 | 1 | 46 | 13 |
| Sports | 0 | 264 | 0 | 0 | 0 |
| Politics | 1 | 6 | 178 | 2 | 7 |
| Entertainment | 2 | 0 | 0 | 180 | 0 |
| Business | 2 | 1 | 6 | 3 | 254 |
| Accuracy | 91.73% |
| Tech | Sports | Politics | Entertainment | Business | |
|---|---|---|---|---|---|
| Tech | 187 | 0 | 0 | 9 | 11 |
| Sports | 1 | 261 | 0 | 1 | 1 |
| Politics | 2 | 1 | 179 | 0 | 12 |
| Entertainment | 4 | 0 | 2 | 175 | 1 |
| Business | 5 | 0 | 7 | 0 | 254 |
| Accuracy | 94.88% |
| Tech | Sports | Politics | Entertainment | Business | |
|---|---|---|---|---|---|
| Tech | 163 | 3 | 4 | 27 | 10 |
| Sports | 3 | 250 | 7 | 1 | 3 |
| Politics | 3 | 2 | 178 | 1 | 10 |
| Entertainment | 1 | 7 | 0 | 173 | 1 |
| Business | 6 | 2 | 6 | 2 | 250 |
| Accuracy | 91.11% |
| Tech | Sports | Politics | Entertainment | Business | |
|---|---|---|---|---|---|
| Tech | 200 | 0 | 0 | 5 | 2 |
| Sports | 1 | 258 | 0 | 5 | 0 |
| Politics | 2 | 1 | 184 | 1 | 6 |
| Entertainment | 3 | 5 | 0 | 172 | 2 |
| Business | 3 | 1 | 4 | 1 | 257 |
| Accuracy | 96.23% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Wang, X.; Xu, P. Chinese Text Classification Model Based on Deep Learning. Future Internet 2018, 10, 113. https://doi.org/10.3390/fi10110113
Li Y, Wang X, Xu P. Chinese Text Classification Model Based on Deep Learning. Future Internet. 2018; 10(11):113. https://doi.org/10.3390/fi10110113
Chicago/Turabian StyleLi, Yue, Xutao Wang, and Pengjian Xu. 2018. "Chinese Text Classification Model Based on Deep Learning" Future Internet 10, no. 11: 113. https://doi.org/10.3390/fi10110113