1. Introduction
Pharmacokinetic studies in healthy volunteers commonly collect multiple observations in each subject. These datasets often arise from Phase I clinical trials and have been traditionally analyzed by noncompartmental methods or by modeling via the standard two-stage approach. Patient datasets often contain complex dosage regimens and only a few (or one) observation(s) per patient. To analyze such sparse datasets, e.g., in pediatric or critically ill patients, population modeling is required, since noncompartmental analysis and the standard two-stage approach are not applicable [
1,
2]. Population modeling has been shown to estimate PK parameters without bias and with good precision for such sparse datasets [
3]. Parametric population modeling algorithms are commonly used and assume typically either normal or log-normal distributions for the between subject variability of PK parameters. While this assumption is made for virtually every parametric population PK model, it is difficult to prove, especially for datasets with a small number of subjects. Nonparametric population modeling can describe a multivariate distribution of PK parameters without assuming any shape of the PK parameter distribution. This is a key advantage of the nonparametric approach that is based on the exact log-likelihood. The present work comprehensively describes the foundation of this nonparametric estimation algorithm for the first time. This algorithm has been used in hundreds of peer-reviewed papers.
Pharmacometric observations can be described statistically by a mixture model. In this case, the probability of random variable arguments (the PK population model) of the pharmacokinetic compartmental model are described by a mixing distribution. The problem of estimating the mixing distribution from a set of pharmacometric observations can be stated as follows. Let
be a sequence of independent but not necessarily identically distributed random vectors constructed from one or more observations from each of
N subjects in the population. Let
be a sequence of independent and identically distributed random vectors that represent unknown parameter values of
N subjects. The
belong to a compact subset
of Euclidean space with common but unknown distribution
F. In other words,
F is a distribution of the parameters in the population model.
represents the parameter space, and the dimension of this space is the number of parameters in the population model. The
are not observed. It is assumed that the conditional densities
are known, for
.
represents the model of observations
given parameter values
including uncertainties of the measurement protocol. The mixing distribution of
with respect to
F is given by
. Because of independence of the
, the mixing distribution of the
with respect to
F is given by
The mixing distribution problem is to maximize the likelihood function with respect to all probability distributions F on .
Remark 1. The distribution that maximizes is a consistent estimator of the true mixing distribution; which means that will converge to the true distribution if the number of subjects is large. This was proved originally by Kiefer and Wolfowitz in 1956 [4]. The consistency of is especially important for our application to population pharmacokinetics where is used as a prior distribution for Bayesian dosage regimen design [5]. The algorithm described in this paper differs from most other published methods in a number of ways. Our algorithm allows for high dimensional parameter space
. Most published methods require the dimension of
to be small and many require the dimension of
to be 1, i.e., these methods required the number of parameters in the population model to be small. We have treated examples where the dimension of
is as high as 29, see
Section 3.
Most published algorithms require the
to be identically distributed and assume that the population model
is rather simple, such as
is a multivariate normal density with mean vector
and covariance matrix
. Even if
is unknown and has to be estimated, the structure of this model is straightforward. However, the estimation of
has to be done carefully to avoid singularities, see Wang and Wang [
6]. As will be described in
Section 3, we allow
to be calculated from a system of nonlinear ordinary differential–algebraic equations.
We now describe the details of our algorithm. It was proved by Lindsay [
7] and Mallet [
8], under simple hypotheses on the population model
, that the global maximizer
of
could be represented by a discrete distribution with support on at most
N points, i.e., a distribution with nonzero probability located on at most
N points.
Remark 2. One way to motivate this result by Lindsay and Mallet is as follows: Suppose by some lucky chance, we knew the exact parameters for each subject. How can we package this into a distribution? Answer: The “empirical distribution” of the exact parameters. That is the discrete distribution supported at the N exact parameters with equal weights. It turns out in this case that this empirical distribution is also the nonparametric maximum likelihood (NPML) distribution of the parameters. What is remarkable is that if we only have noisy measurements of the N subjects only indirectly related to the subject parameters, the structure of the NPML is the same. A discrete distribution supported at N points. Of course, in this real case, the position and weights of the N support points are unknown. Finding these positions and weights is the subject of this paper.
This result leads immediately to a finite dimensional optimization problem for
, namely to maximize the likelihood function
with respect to the support points
and weights
such that
for
,
and
.
In our algorithm
is maximized, so that
and the maximization problem becomes
such that
,
,
and
.
Although the maximization problem in Equation (
4) is finite dimensional, it is still high-dimensional. The dimension of the maximization problem in Equation (
4) is
.
The optimization problem in Equation (
4) is naturally divided into two problems:
Problem 1. Given a set of support points , find the optimal weights .
Problem 2. Given the solution to Problem 1, find a better set of support points.
Problems 1 and 2 are solved cyclically until convergence, i.e., no significant improvement in .
Problem 1 is a convex programming problem. In our algorithm, we solve this problem by the primal-dual interior-point (PDIP) method. This type of method is standard in convex optimization theory (see Boyd and Vandenberghe [
9]). However, the exact implementation for a specific problem varies from problem to problem. The exact details of our implementation are described in the Appendix. See also Bell [
10], Baek [
11] and Yamada et al. [
12]. Our PDIP implementation is fast and can easily handle thousands of variables.
Finding a better set of support points in Problem 2 is a more difficult problem. This location problem is a nonconvex global optimization problem with many local extrema and whose dimension is potentially
. The details of our algorithm, called the adaptive grid (AG) method, will be described in
Section 2.3 and in Algorithm 1.
| Algorithm 1 Nonparametric adaptive grid (NPAG) algorithm. Input: , and are the lists of lower and upper bounds, respectively, of ; is the minimum distance allowable between points in the estimated . see Section 2.7. Output: |
| 1: | procedureNPAG(, ) | ▹ Estimate given |
| 2: | Initialization: , , , , , , , , , | |
| 3: | while or do | |
| 4: | Calculate | ▹ matrix |
| 5: | | ▹ Appendix A |
| 6: | if then | |
| 7: | | |
| 8: | | |
| 9: | return | |
| 10: | end if | |
| 11: | | |
| 12: | | ▹ Algorithm 3 |
| 13: | | ▹ |
| 14: | | |
| 15: | if then | |
| 16: | | |
| 17: | | |
| 18: | return | |
| 19: | end if | |
| 20: | if and then | |
| 21: | | ▹ Adjust precision |
| 22: | end if | |
| 23: | if then | ▹ check EXIT conditions |
| 24: | | |
| 25: | if then | |
| 26: | | |
| 27: | | |
| 28: | return | |
| 29: | else | |
| 30: | ; | ▹ Reset Algorithm |
| 31: | end if | |
| 32: | end if | |
| 33: | | ▹ Algorithm 2 |
| 34: | | |
| 35: | end while | |
| 36: | end procedure | |
Roughly speaking, Problems 1 and 2 are solved as follows. An initial large grid of possible support points is defined in the hypercube . Problem 1 is solved on this large grid. After PDIP, most of the original grid points are removed due to near-zero weights, leaving a smaller high-probability grid. Problem 1 is then solved on this smaller grid. Then, the adaptive grid method for Problem 2 takes place. For each remaining grid point, up to new (daughter) support points are added. A daughter point outside the search space or too close to a parent point is discarded. The new grid contains the current high-probability points plus the added daughter points. The algorithm is then ready for Problem 1 again. By construction, each iteration increases the value of . This process continues until the function does not significantly change.
1.1. Comparable Methods
Because of space limitations, in this section, we only discuss NPML methods that optimize Equation (
4), methods that treat multivariate distributions, and methods which allow general conditional probabilities
. As explained in this paper, any such NPML algorithm has to address two problems: locations of support points and weights of support points. NPAG does locations by an adaptive grid method and weights by the primal-dual interior-point (PDIP) method. The algorithms discussed in this seection are summarized in
Table 1.
The original methods of Lindsay [
7] and Mallett [
8] were based on algorithms of optimal design in the style of Fedorov [
13]. In Schumitzky [
14], an algorithm was proposed which did both locations and weights by the expectation maximization algorithm (EM). It was stable but also slow.
In Lesperance and Kalbfleisch [
15], a new method was introduced which did weights by the dual method described in Section 5 of Lindsay [
7] and locations by what they called the intra-simplex direction method (ISDM). Even though the Lesperance and Kalbfleisch paper was restricted to univariate distributions, the ISDM method has been generalized to the multivariate case. To briefly describe ISDM, let
be the directional derivative of
in the direction of the Dirac distribution
supported at
. (This function is defined in
Section 4 below). ISDM is an iterative algorithm. At stage
k, let
be the current estimate
. Then, find all the local maxima of
. These local maxima are added to the current set of support points and a new
is calculated. If there are no new local maxima, then the algorithm is done.
In Pilla, Bartolucci, and Lindsay [
16], another new method was developed where the locations were found by an initial fine grid. However, the weights were found by a dual version of the PDIP method.
In Savic, Kjellsson, and Karlsson [
17], a nonparametric method (NONMEM-NP) was added to the popular NONMEM
® program. NONMEM-NP is a hybrid parametric–nonparametric approach The locations of support points were found by a parametric maximum likelihood algorithm. Then, the weights were found by maximizing Equation (4) relative to the newly found support points. NONMEM-NP can handle high-dimensional and complex multivariate distributions. An extension to NONMEM-NP was developed in Savic and Karlsson [
18] where additional support points are added to the original set. A comparison between NONMEM-NP and NPAG is discussed in Leary [
19].
In Wang and Wang [
6], a new algorithm was developed for multivariate distributions. The locations were found by a combination of EM and a variant of ISDM. The weights were found by a family of quadratic programs. In [
6], examples are performed for 8- and 13-dimensional mutivariate mixing distributions.
Table 1.
Table of NPML Methods.
Table 1.
Table of NPML Methods.
| Author(s)/Reference/Date | Problem 1 Method | Problem 2 Method |
|---|
| Lindsay [7] (1983) | Convex Geometry | VDM |
| Mallet [8] (1986) | Optimal Design | VDM |
| Lesparance and Kalbfleisch [15] (1992) | Semi-Infinite Programming | ISDM |
| Savic, Kjellsson and Karlsson [17] (2009) | Parametric NONMEM | None |
| Pilla, Bartolucci and Lindsay [16] (2006) | Dual of PDIP | Adaptive Grid |
| Schumitzky [14] (1991) | EM | EM |
| X. Wang and Y. Wang [6] (2015) | Quadratic Programming | ISDM |
| NPAG [20] (2001) | PDIP | Adaptive Grid |
Note: The quadratic programming algorithm (QP) of Wang and Wang [
6] has an attractive feature. For a prescribed set of support points, QP finds the zero probabilities exactly. Thus, QP avoids the grid condensation step where support points from PDIP with sufficiently low probabilities are deleted. However, QP and PDIP are based on different numerical methods and a comparison of the efficiency of both algorithms has not been determined.
We finally mention that the NPML problem is a special case of a finite mixture model problem with unknown supports and weights. For a discussion of this approach, see Tatarinova and Schumitzky [
21].
The algorithms which have shown by published examples to handle the highest dimensional multivariate problems are NONMEM-NP, Wang and Wang [
6], and NPAG.
1.2. Benders Decomposition
For any set of grid points
in
, let
be the corresponding set of optimal weights given by the PDIP method. Then, the function
depends only on
and can be maximized directly. For optimization methods, this technique is called Benders decomposition. The NPAG algorithm maximizes
by an adaptive search method. In a method proposed by James Burke,
is maximized by a Newton-type method. Since the function
) is not necessarily differentiable, a relaxed Newton method must be used similar to what is described in the Appendix for the primal-dual algorithm. For details of Benders decomposition as applied to our problem, see Bell [
10], Baek [
11] and Jordan-Squire [
22].
Founded on this prior work, the present study aimed to comprehensively describe, for the first time, the nonparametric adaptive grid algorithm (NPAG). This approach uses the exact log-likelihood to solve population modeling problems and does not make any assumptions about the shape of the PK parameter distributions. We illustrated the features and capabilities of this algorithm using a population PK modeling example. This algorithm presents the computational foundation of several hundred peer-reviewed papers, to date, and is ideally suited to optimize individual patient dosage regimens. The output of the NPAG algorithm becomes the input of the BestDose™ patient dosing software which is used at the bedside in real-time [
23].
2. Materials and Methods
2.1. Pmetrics
The simulations and NPAG optimizations in this paper can be duplicated in R, using programs in the Pmetrics package [
24]. R and Pmetrics are free software. R is available from many download sites. Pmetrics is available from lapk.org. NPAG is run using the NPrun() command in Pmetrics. Sample datasets and compartmental models are also available at lapk.org.
2.2. NPAG Subprograms
NPAG is a Fortran program consisting of a number of subroutines as described below. The main program performs the adaptive grid (AG) method (consisting of expansion and compression algorithms) and calls the primal-dual interior-point (PDIP) subprogram. The PDIP algorithm solves the maximization problem of Equation (
4) for a fixed grid and is described precisely in the Appendix.
2.3. NPAG Implementation (NPAG—Algorithm 1)
For the purpose of this discussion, we can think of PDIP as a function
from
into the set
=
defined as follows: If
then
maximizes Equation (
4) relative to the fixed set of grid points
. In this case, we write
G =
and
=
.
In NPAG, there are two types of grids: expanded and condensed. The expanded grids are the initial grid and the grids after grid expansion (Algorithm 2). The condensed grids are generated by grid condensation (Algorithm 3). Each cycle of NPAG begins with an expanded grid. The likelihood calculation is done on the condensed grids.
Now for the adaptive grid method. Assume that
is a bounded
Q-dimensional hyper-rectangle. Initially, we let
be the set of
M Faure grid points in
(see [
25,
26,
27]). Alternatively, we could initially let
be generated by a uniform distribution on
or by a prior run of the program.
Remark. The Faure grid points for a hyper-rectangle
are a low-discrepancy set which in some sense optimally and uniformly covers
. In our implementation of NPAG, the Faure point sets come in discrete sizes which nest with each other. (Allowable number of points equals 2129, 5003, 10,007, 20,011, 40,009, 80,021, and multiples of 80,021.) This nesting property is useful for checking the optimality of
(see
Section 4). We have found that replacing the initial Faure set with a set generated by a uniform distribution on
increases the time to convergence but results in the same optimal distribution.
Now set
=
. Our approach is to generate a sequence of solutions
to Equation (
4) of increasingly greater likelihood, where unless otherwise specified,
refers to the condensed grid at the
cycle of the algorithm. If
has log-likelihood negligibly different than
, then
is considered the optimal solution to Equation (
4) and is relabeled
. If not, then the process continues using the
as the new seed. This loop is repeated until
is found.
The stopping conditions for NPAG are defined precisely in Algorithm 1. If the stopping conditions are not met prior to a set maximum number of iterations, the program will exit after writing the last calculated
into a file.
| Algorithm 2 EXPAND. Input: = , , , , , . Output: =, where . Note: In this algorithm, = is a matrix, with |
| functionExpand(, , , , ) | |
| 2: | Initialize: , Identity matrix, |
| for do | ▹ |
| 4: | for do | ▹ |
| | |
| 6: | if then | ▹ Check upper boundary |
| | |
| 8: | | |
| end if | |
| 10: | for do | |
| | ▹ x ./y done |
| component-wise | |
| 12: | | |
| end for | |
| 14: | if then | ▹ Check distance to new support point |
| | |
| 16: | end if | |
| if then | ▹ Check lower boundary |
| 18: | | |
| | |
| 20: | end if | |
| for do | |
| 22: | | ▹ x./y done |
| component-wise | |
| | |
| 24: | end for | |
| if then | ▹ Check distance to new support point |
| 26: | | |
| end if | |
| 28: | end for | |
| end for | |
| 30: | | |
| end function | |
| Algorithm 3 Condense algorithm. Input: , Output: Note: is considered a subset of |
| functionCondense() | |
| ind = find ( ) | ▹ Inequality and max are performed component-wise |
| | |
| return | |
| end function | |
2.4. Grid Expansion (EXPAND—Algorithm 2)
The crux of the adaptive grid method is how to go from to or, more generally, from to . The details of doing this are now explained roughly below and precisely in Algorithm 1.
Let Q be the dimension of . Suppose at stage n we have a grid of high-probability support points . We then add daughter points for each support point . The daughter points are the vertices of a small hyper-rectangle centered at each with size proportional to the original size of the hyper-rectangle defining . The size of this small hyper rectangle decreases as the accuracy of the estimates increases. (See Algorithm 2).
Let = . Then the PDIP subprogram is applied to resulting in the new solution set = (see Algorithm 1). The solution set is now ready for grid condensation.
2.5. Grid Condensation (CONDENSE—Algorithm 3)
The above solution set
may have many support points with low probability. We remove all support points which have corresponding probability less than
, where
is the vector of current probabilities and the default for
is
. (Note that the remaining probabilities are not normalized at this point.) The probabilities of the remaining support points are normalized by a second call to the PDIP subprogram. This second call to PDIP is fast. The likelihood associated with these remaining support points and normalized probabilities is then used to update the program control parameters and check for convergence (Algorithm 1 and
Section 2.7). If convergence is attained, then the output of this second call to PDIP provides the support points and probabilities of the final solution. If convergence is not attained, then the remaining support points are sent to the grid expansion subprogram (Algorithm 2), initializing the next cycle.
At the end of the program, the output of this second call to PDIP provides the location and weights of the final solution.
2.6. PDIP Subprogram—See Appendix A
The PDIP subprogram finds the optimal solution to Equation (
4) with respect to
for fixed
. PDIP employs a primal-dual interior-point method that uses a relaxed Newton method to solve the corresponding Karush–Kuhn–Tucker equations. (See Equations (14)–(17) of
Appendix A).
For any
=(
) and any
=(
, the input to the PDIP subprogram is the
matrix
. The output consists of the optimal weights
and the corresponding log-likelihood
. An in-depth description of the PDIP algorithm and its implementation is presented in
Appendix A. See also [
10,
11,
12].
2.7. NPAG Stopping Conditions
As explained above, a potential solution to is not accepted as a global optimum until successive sequences of produce final distributions evaluating to sufficiently close log-likelihood. The various upper and lower bounds for NPAG control and stopping conditions are defined below and are used in Algorithms 1–3.
- ΔL
Primary upper bound on the allowable difference between two successive estimated log-likelihoods; the default initialization is .
- ΔF
Secondary upper bound on the allowable difference between two successive estimated log-likelihoods of potential ; the default initialization is .
- Δe
Sets an upper bound on the accuracy variable of Algorithm 1. The default initialization for is . The default initialization for is and is stepped down until and define the two stopping conditions for Algorithm 1.
- ΔD
Sets a lower bound on how close two support points can get; the default initialization is .
- Δλ
Sets a lower bound factor on the probabilities of the weights ; the default initialization is .
2.8. Calculation of
Given observations
,
and grid points
,
, the PDIP subprogram only depends on the
matrix
. NPAG can be used for any problem once this matrix is defined. However, the default setting of NPAG is for the problem of population pharmacokinetics. For a good background of population pharmacokinetics, see Davidian and Giltinan [
28,
29].
In population pharmacokinetics, generally
is a matrix of vector observations for the
ith subject. Since NPAG allows multiple outputs, each
is itself a
q-dimensional vector
=
. The observations
, are then typically given by a regression equation of the form:
In the above Equation (5), is a known nonlinear function depending on the model structure, the dosage regimen, the sampling schedule, all covariates and of course the subject-specific parameter vector . Except for simple models, requires the solution of (possibly nonlinear) ordinary differential equations.
In the current implementation of NPAG, it is assumed that the
are independent. Then
where
and
=
. For the purposes of matrix multiplication in Equation (6),we think of
and
as
q-dimensional row vectors.
To complete the description of Equation (6) we need to model the standard deviation terms
of the assay noise. In our implementation of NPAG, four different models are allowed. Let
and set
The parameter
in Equation (8) is a variance factor. Artificially increasing the variance during the first several cycles of NPAG increases the likelihood for each
, allowing the algorithm to use these cycles to find a better initial state from which to begin optimization. NPAG also has an option to “optimize”
. This changes NPAG from a nonparametric method to a “semiparametric” method and will not be discussed here. The interested reader can consult [
12].
Next, if
in Equation (7), then
can become small for certain values of
that in early iterations can be far from optimal. This, in turn, causes numerical problems as the likelihood is infinite if
. One way to avoid this problem is to take
. Another way would be to assume that
is known and is given by
That is, to approximate
by using a polynomial of the observed values rather than model predicted values. In our experience with NPAG, the approximation of Equation (9) is useful for ensuring computational stability (especially during the early cycles of the algorithm). However, from a theoretical perspective, this change violates the conditions of maximum likelihood and will not be discussed here. Again, the interested reader can consult [
12].
2.9. Convergence
For a given initial grid , the NPAG algorithm is only guaranteed to find a local maximum of . More precisely, if is the final grid of NPAG starting from , then is a global maximum on but the support points may be only a local maximum.
Global convergence of a nonparameteric maximum likelihood method for estimation of a multivariate mixing distribution is difficult. For one-dimensional distributions the problem is straightforward. The idea of proof goes back to at least Fedorov [
13] in 1972, which involves the use of directional derivatives.
Let F be any distribution on . Then, the directional derivative of in the direction of the Dirac distribution supported at is defined by
= [
,
, where
. Let
be the current NPML estimate at iteration
k. The Fedorov method involves maximizing
for
, at every iteration. Then, the point at which the maximum occurs is added in an optimal way to
to give
. Under the assumptions of regularity, Fedorov shows that
converges to
, see Fedorov [
13], (Theorem 2.5.3). Many improvements to this method have been made. In Lesperance and Kalbfleisch [
15] and Wang and Wang [
6], instead of just adding the point at which
occurs, all the points where local maxima occur are added in an optimal way. Again, under the assumptions of regularity, convergence as above is proved. In one dimension, these methods are efficient. In higher dimensions, these methods are not computationally practical.
We now suggest a method to check whether the final distribution of NPAG is globally optimal and, if not optimal, how close it is to the optimal. It also involves the use of the directional derivative
, but only at the last iteration of NPAG. Now define
Note that the
in the above expression is only over
and not over
. It is proved in Lindsay [
7] that
is a global maximum of
, i.e.,
=
, if and only if
. Even if
, it is useful to make this computation as it is also proved in Lindsay [
7] that
, so this last expression gives an estimate of the accuracy of the final NPAG result.
Now, even though we said above it is not practical to calculate at every iteration of an algorithm, we are just suggesting to make this calculation at the end of the algorithm. This calculation can be performed by a deterministic or stochastic optimization algorithm.
3. Examples
First of all, the NPAG program has been used successfully in high-dimensional and very complex pharmacokinetic–pharmacodynamic models. In Ramos-Martin et al. [
30], the NPAG program was used for a population model of the pharmacodynamics of vancomycin for coagulase-negative staphylococci (CoNS) infection in neonates. Vancomycin is an antibiotic used to treat a number of serious bacterial infections. CoNS are the most commonly isolated pathogens in the neonatal intensive care unit. This model had 7 nonlinear differential equations and 11 random parameters. The population was a combination of 300 experimental and animal subjects. In Drusano et al. [
31], the NPAG program was used for a population model of two drugs for the treatment of tuberculosis. This model had 5 nonlinear differential equations, 3 nonlinear algebraic equations, 1671 observations from 6 outputs and 29 random parameters. In the algebraic equations, the state variables were only defined implicitly and had to be solved for by an iterative method.
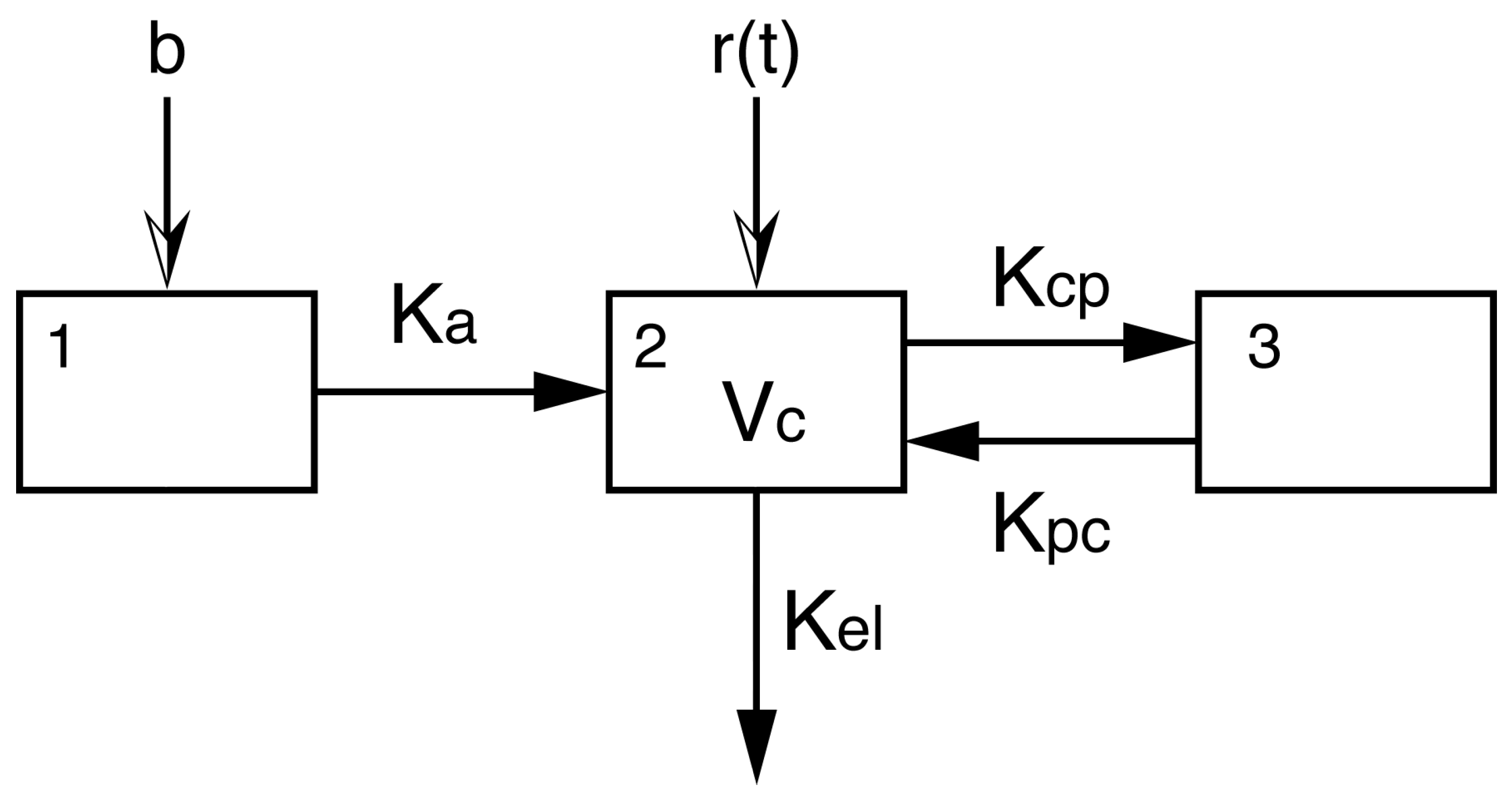
The above two examples are too complex to use for simulation purposes. Consequently, we present here a simpler model which has an analytic solution and which can be checked by other algorithms. Nevertheless, the estimation of parameters in this model is not trivial. We consider a three-compartment PK model with a continuous IV infusion into the central compartment and a bolus input into the absorption compartment. The individual subject model is described by the following differential equations:
and output equation
The inputs are a bolus
mg at
Hr and a continuous infusion
Hr
, for
Hr. This model has 5 random parameters (
V,
,
,
,
). A diagram of this model is given in
Figure A1. It is known that this model is structurally identifiable, see Godfrey [
32]. However, we have found that for a continuous IV infusion, the parameters
and
can be difficult to estimate in a noisy environment.
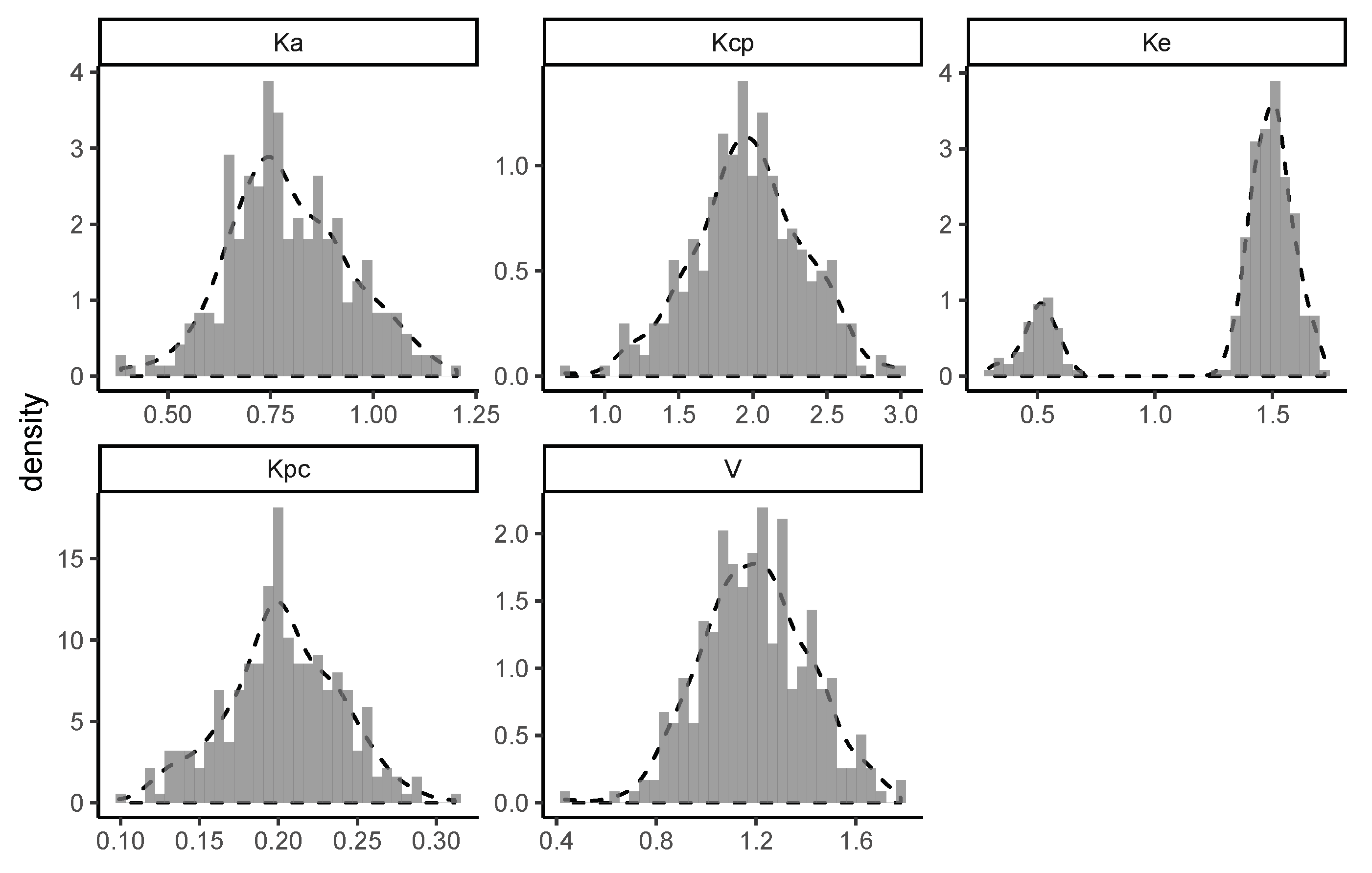
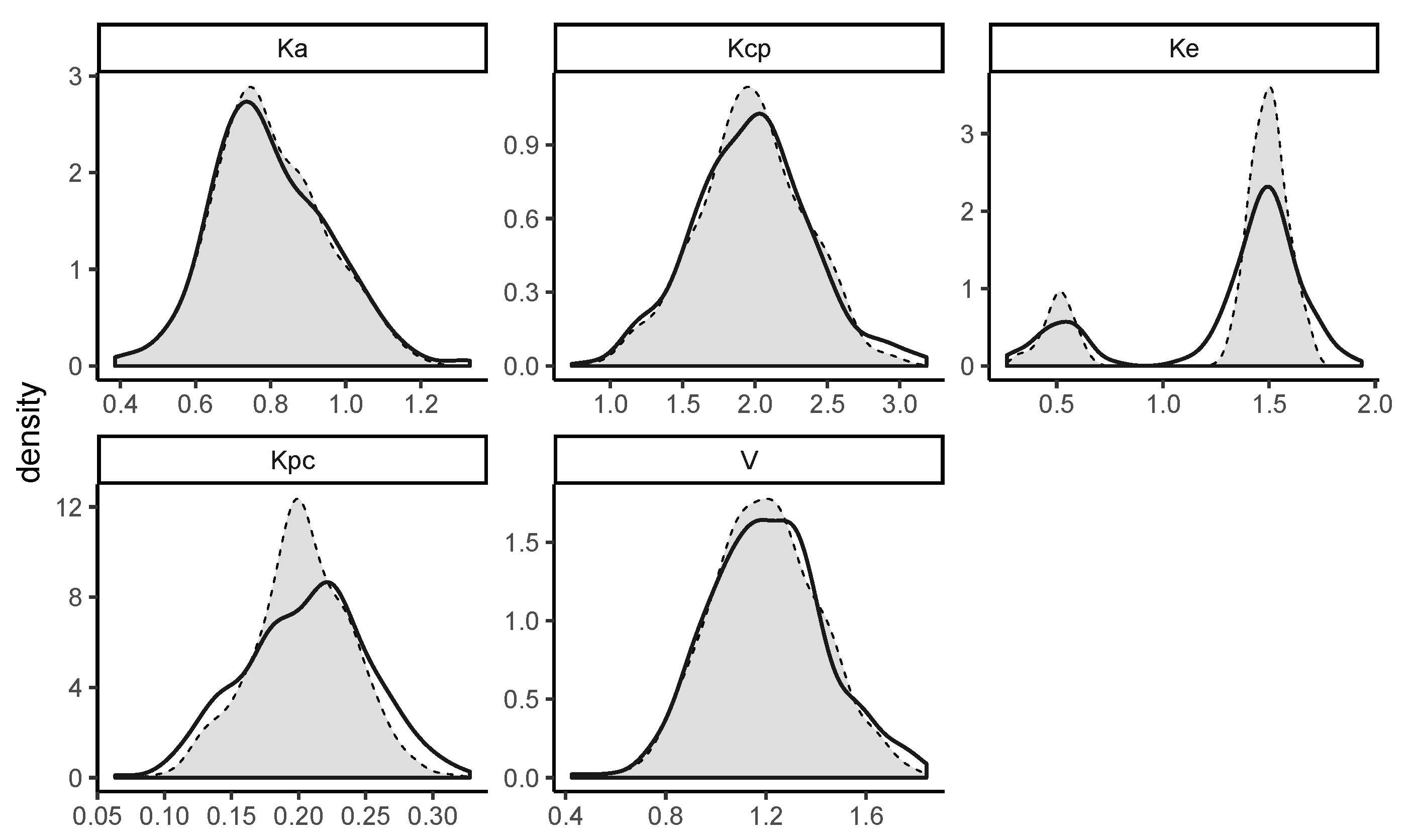
The details of the simulation are as follows. There were 300 simulated subjects. The random variables were independently simulated from normal distributions with means respectively equal to and standard deviations equal to 25% coefficient of variation.
The random variable was independently simulated from a bimodal mixture of two normal distributions with means respectively equal to and , with standard deviations equal to coefficient of variation, and with weights equal to and . This distribution would apply to an elimination rate constant with a bimodal distribution where of the subjects have a mean of , and only have a mean of . The power of the nonparametric method allows the detection of the group.
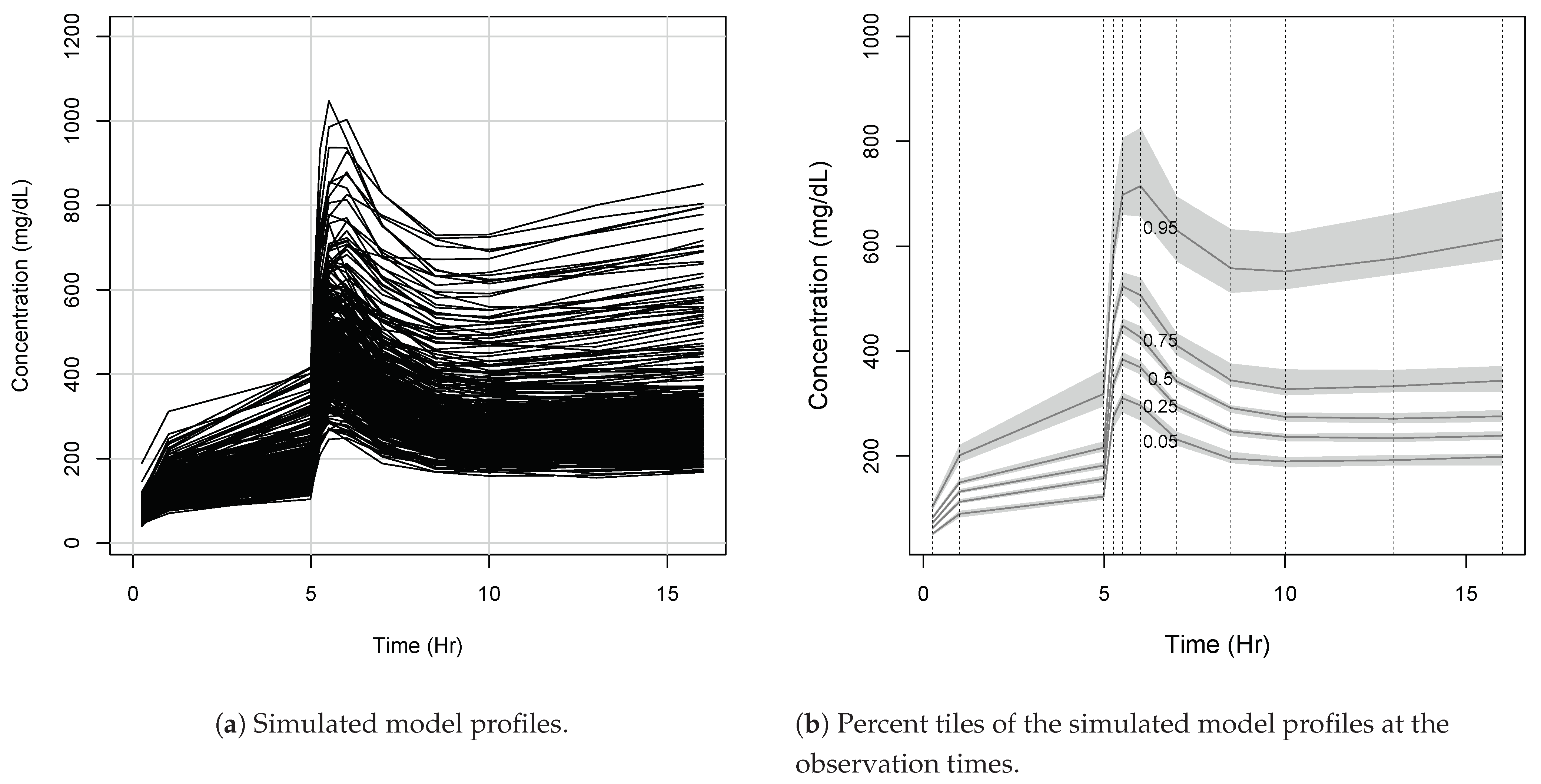
Eleven observations were taken at times .
These sampling times were chosen in an ad hoc fashion and are not to be considered optimal. In
Figure A2, we show the profiles of the 300 noisy model outputs
. These profiles are plotted as piecewise linear functions with nodes at the observation times.
The initial Faure set had
support points dispersed in the volume
The assay error (Equation (
8)) is not always known. An approximate assay error polynomial can be inferred from literature and Pmetrics includes a routine to estimate the assay error polynomial from the data. Another approach to analyzing data with unknown measurement error is to run successive NPAG optimizations using decreasing error magnitude for each new run. An advantage of this approach is that model development is faster. The first cycle of NPAG, which begins with a relatively large measurement error, can be initialized using a relatively small number of support points. Each NPAG solution is used as a prior to skip the first (and most computationally burdensome) step in the next NPAG run. We demonstrate this approach can converge to the correct solution on this simulated data.
Convergence for this problem was accomplished after applying NPAG four times. For the first application, . The output distribution of this first application was used as a prior to start NPAG again, this time with . The output of this second application was used as a prior to start a third NPAG run, this time with . Finally, the output density of this third run was used as a prior to run NPAG a fourth time, this time with , the same as for the simulation. The step down in assumed observation error happened at convergence for each previous error levels: at cycles 4513, 5972, and 6791. Final convergence happened at cycle 8012. There are 284 support points in the final density.
The simulated and estimated marginal distributions are shown in
Figure A3 and
Figure A4. It is seen that the estimated marginal distributions are similar to the simulated histograms. In particular, the bimodal shape of
was uncovered. Similarity is tested using the
R routine
mtsknn.eq(..., k = 3), which returns a
.
mtsknn.eq applies a
K—nearest neighbors approach to estimate the probability that two non-parametric distributions arise from the same distribution.
NPAG is designed to estimate the whole joint distribution of the parameters. As mentioned earlier, the estimate
is especially important for our application to population pharmacokinetics where
is used as a prior distribution for Bayesian dosage regimen design. However,
is a consistent estimator of the true mixing distribution and consequently, the moments of
should be consitent estimators of the true moments. Means and variances of parameter estimates for
can be easily obtained by integrating the corresponding marginal distributions. So as a check of this fact, in
Table A1, the comparisons of estimated versus simulated means and variances are shown. Again, results are quite accurate (see
Table A1 and
Table A2).
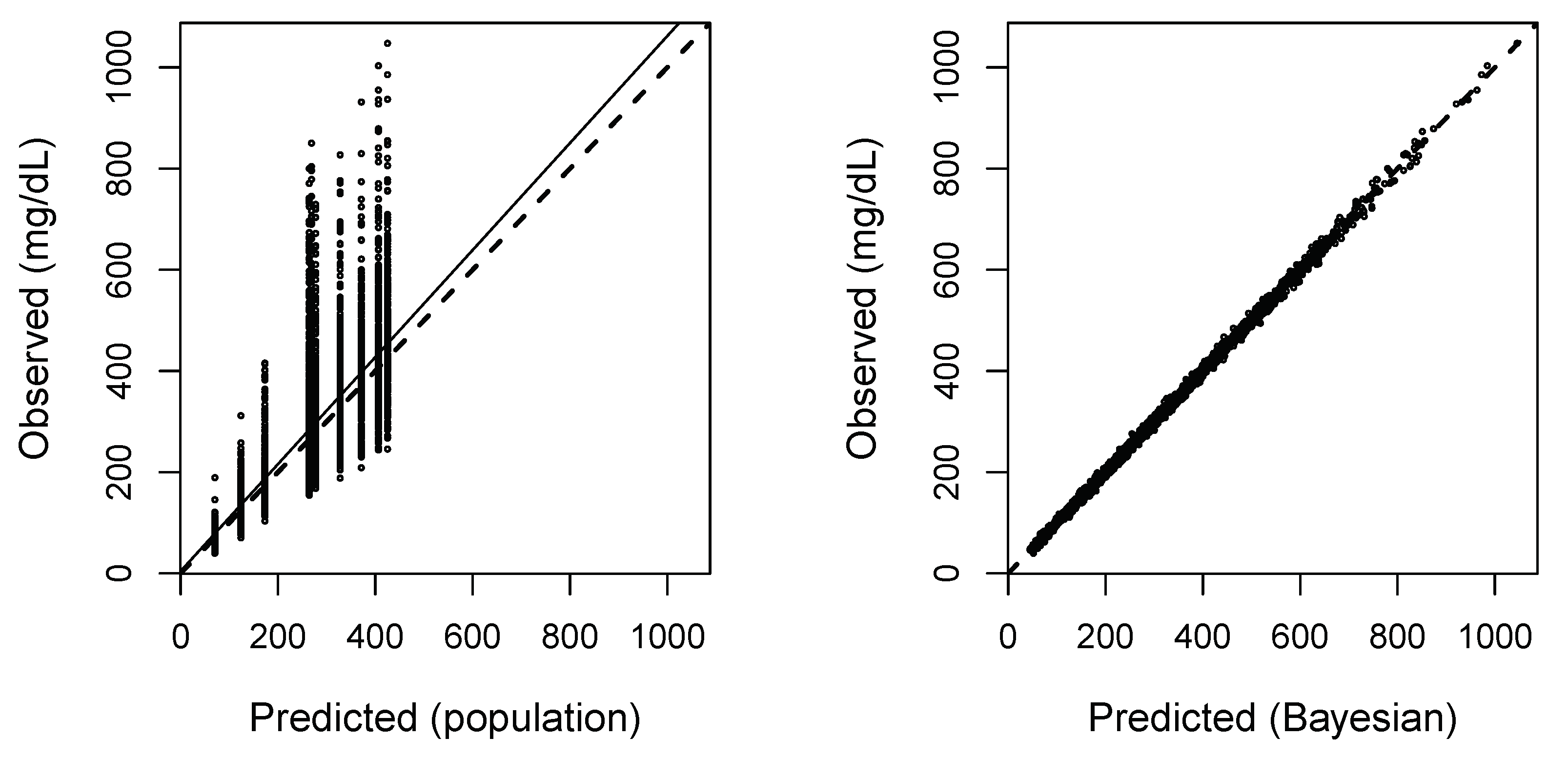
Finally, in
Figure A5 we include a graph of Predicted versus Observed values which shows the all around good fit of the data. The predicted (right panel: Predicted Bayesian) values are gotten as follows: For each subject, the Bayesian mean estimate of the parameters are found using the final NPAG distribution as a prior and that subject’s observations. Then, based on these parameter means, the subject’s concentration profile is calculated. The predicted (left panel: Predicted Population) is the weighted average of the evaluation of all support points for subject model.

 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




