

A Biased-Randomized Discrete Event Algorithm to Improve the Productivity of Automated Storage and Retrieval Systems in the Steel Industry


Abstract
:1. Introduction
2. Related Work
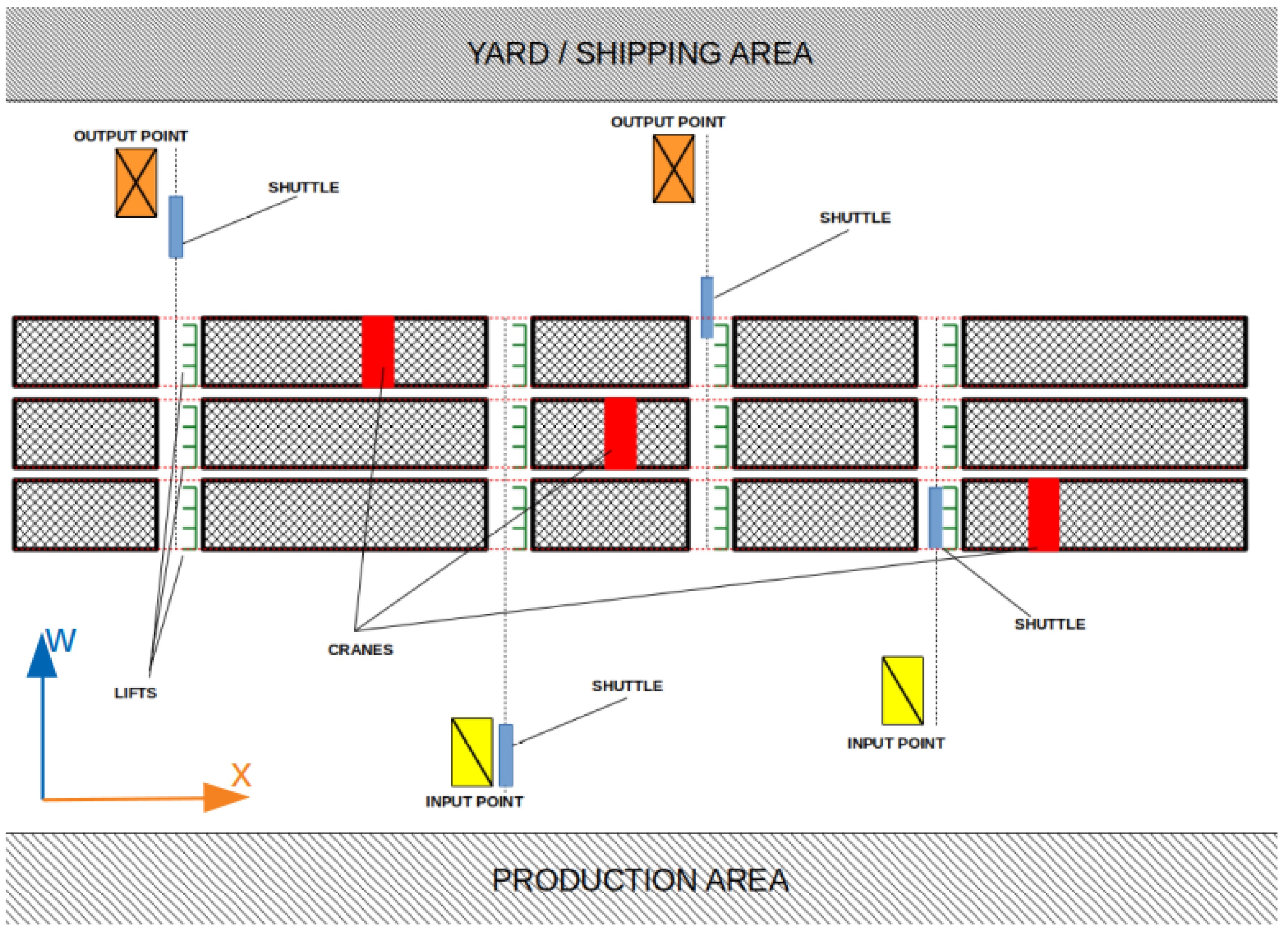
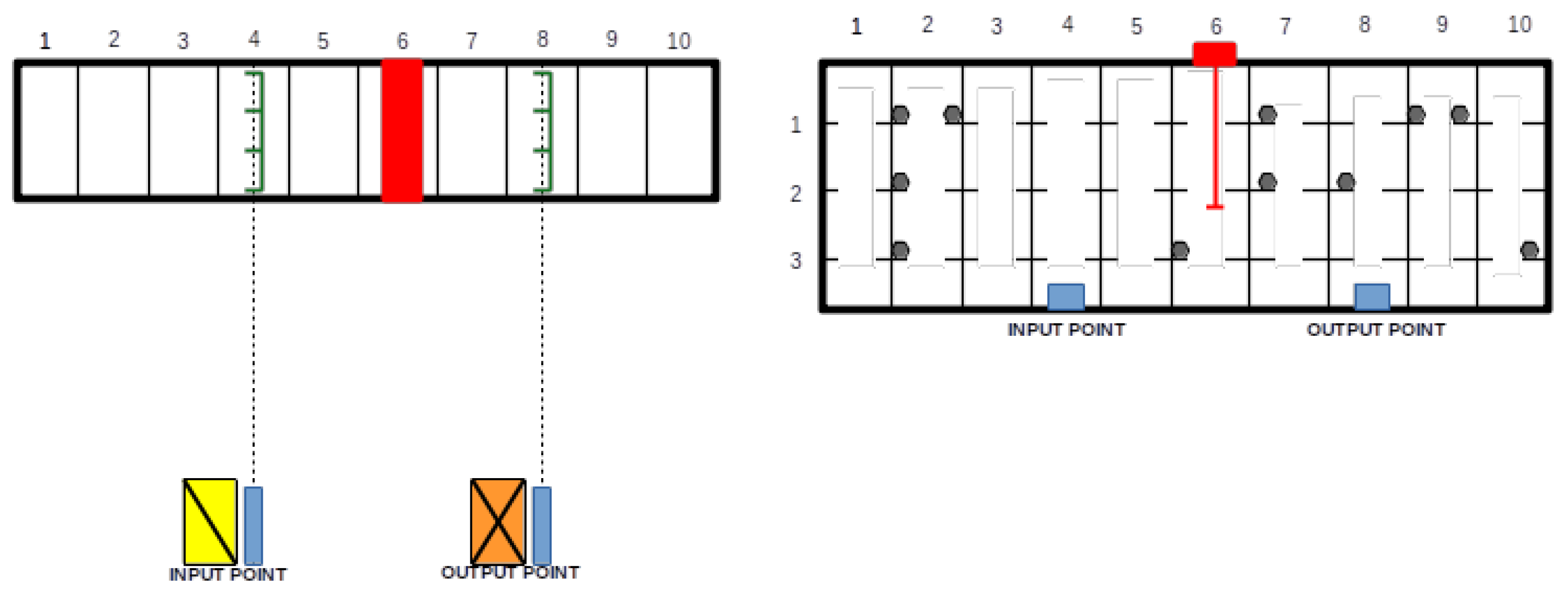
3. Modeling an Automated Warehouse in the Steel Sector
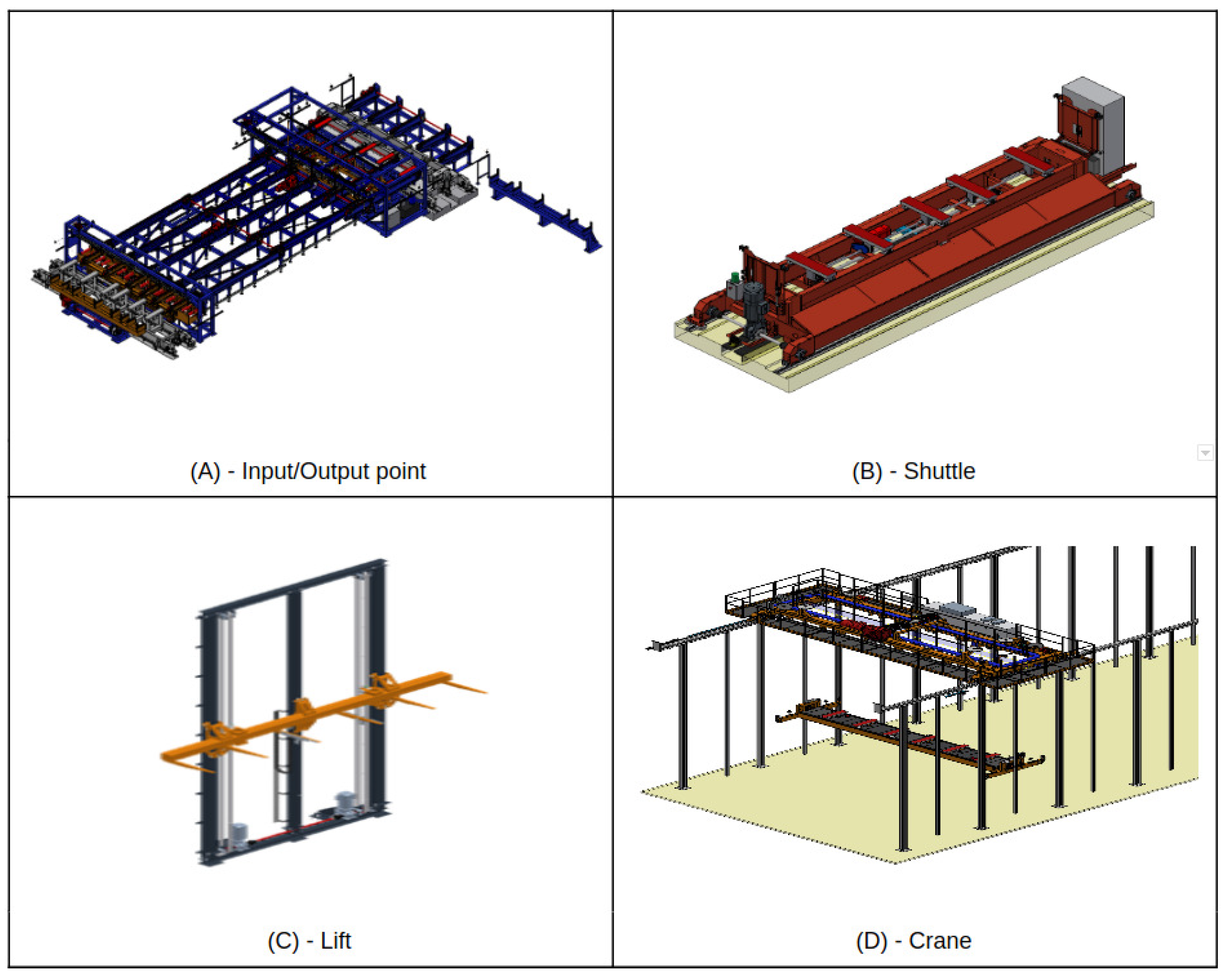
- I/O points: Chain conveyors serve as buffers between the system and external processes, such as truck loading or production lines. Input points, equipped with sensors for bundle alignment and weight control, are also depicted in Figure 4A.
- Shuttles: Vehicles handle horizontal movements, transporting bundles between I/O points and racks. They can transport one or two bundles, depending on single-depth or double-deep storage, as illustrated in Figure 4B.
- Lifts: Responsible for vertical movements and transporting bundles between shuttles and the top of racks or cranes. Figure 4C showcases an example of these lifts.
- Cranes: Essential for storage and retrieval operations, moving bundles between lifts and shelves or vice versa. Each rack houses one crane capable of three-axis movements, as detailed in Figure 4D.
4. Detailed Problem Description
4.1. Main Assumptions and Stock-Keeping Units Description
4.2. Customers’ Orders and Storage Requests
4.3. Mathematical Formalization and Scope of the Algorithm
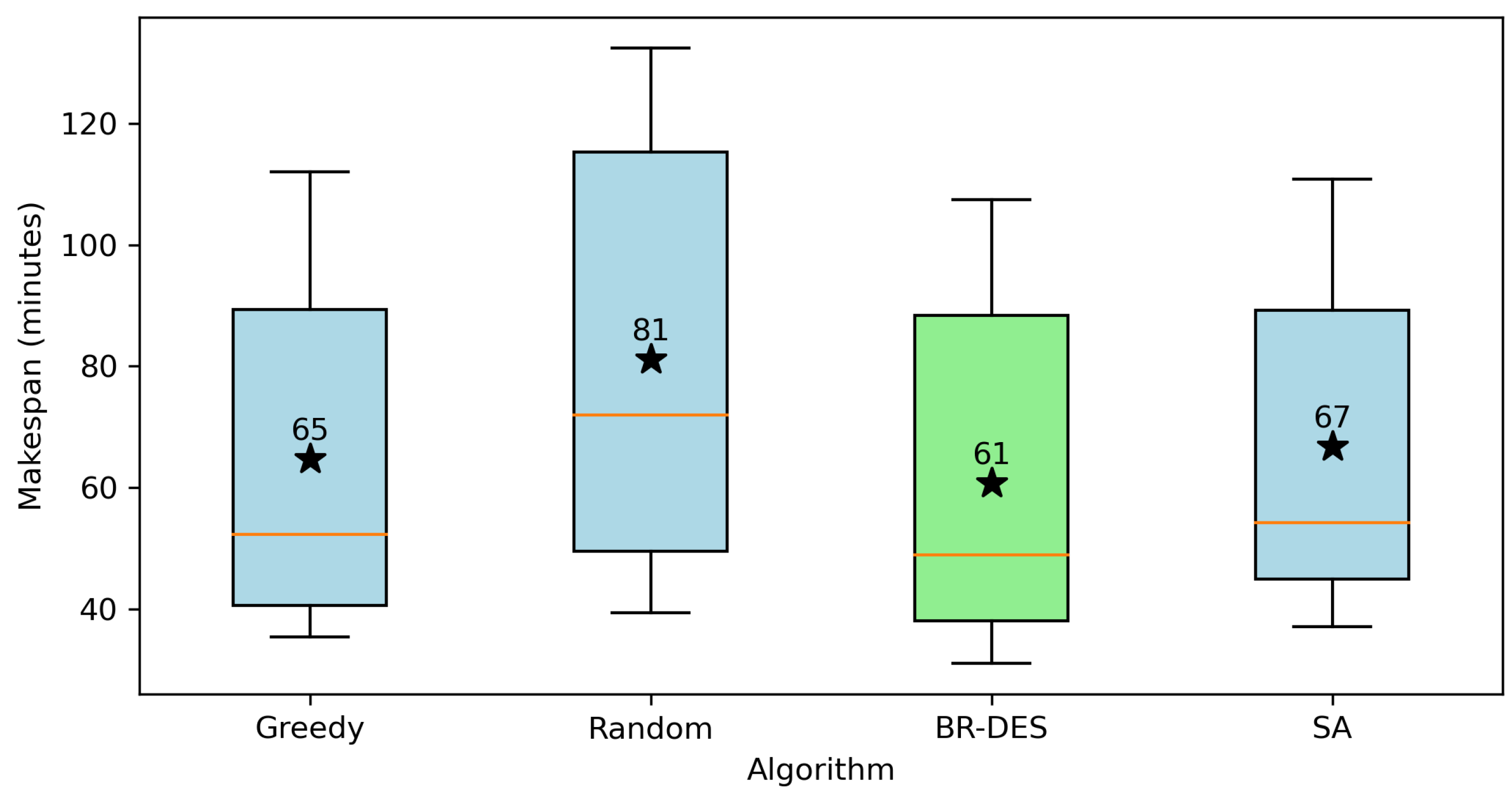
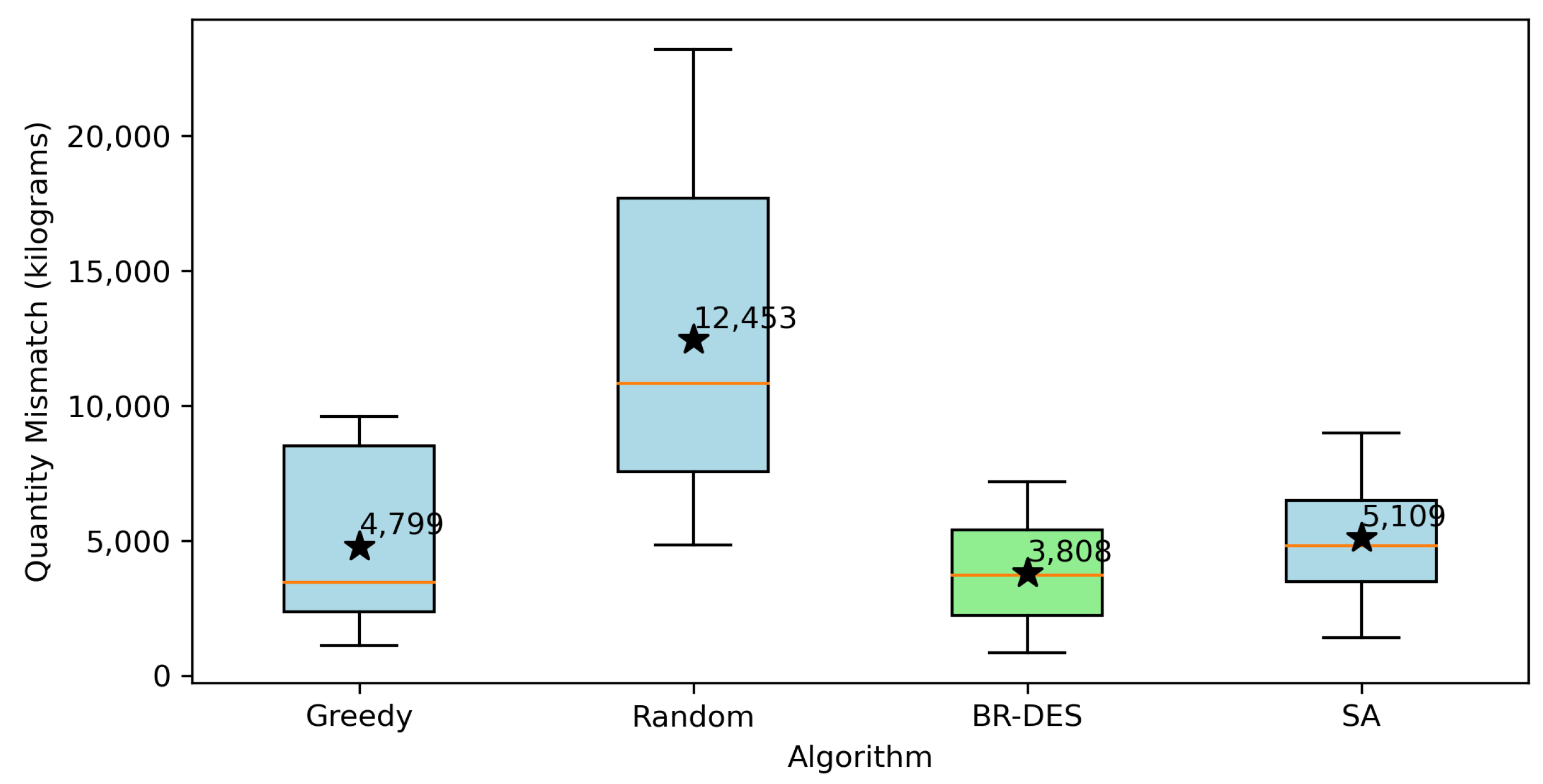
5. Evaluation of the Solutions
- , , and represent the crane, shuttle, and lift necessary for operation j, dependent on its associated operation and the bundle it involves.
- denotes the most recent operation involving machines r, s, and l. Similarly, signifies the most recent operation involving only r, while indicates the most recent operation involving crane r and shuttle s.
- represents the moment when operation j becomes available for machine m.
- signifies the start time when machine m initiates work on operation j.
- indicates the completion time when machine m finishes work on operation j.
- and denote the first and second positions that crane must visit to execute operation j. If j is an input operation, represents the interchange point between lift and crane , while denotes the storage location. Conversely, for an output operation, corresponds to the storage location, while indicates the interchange point between lift and crane .
- .
- .
- .
- .
- .
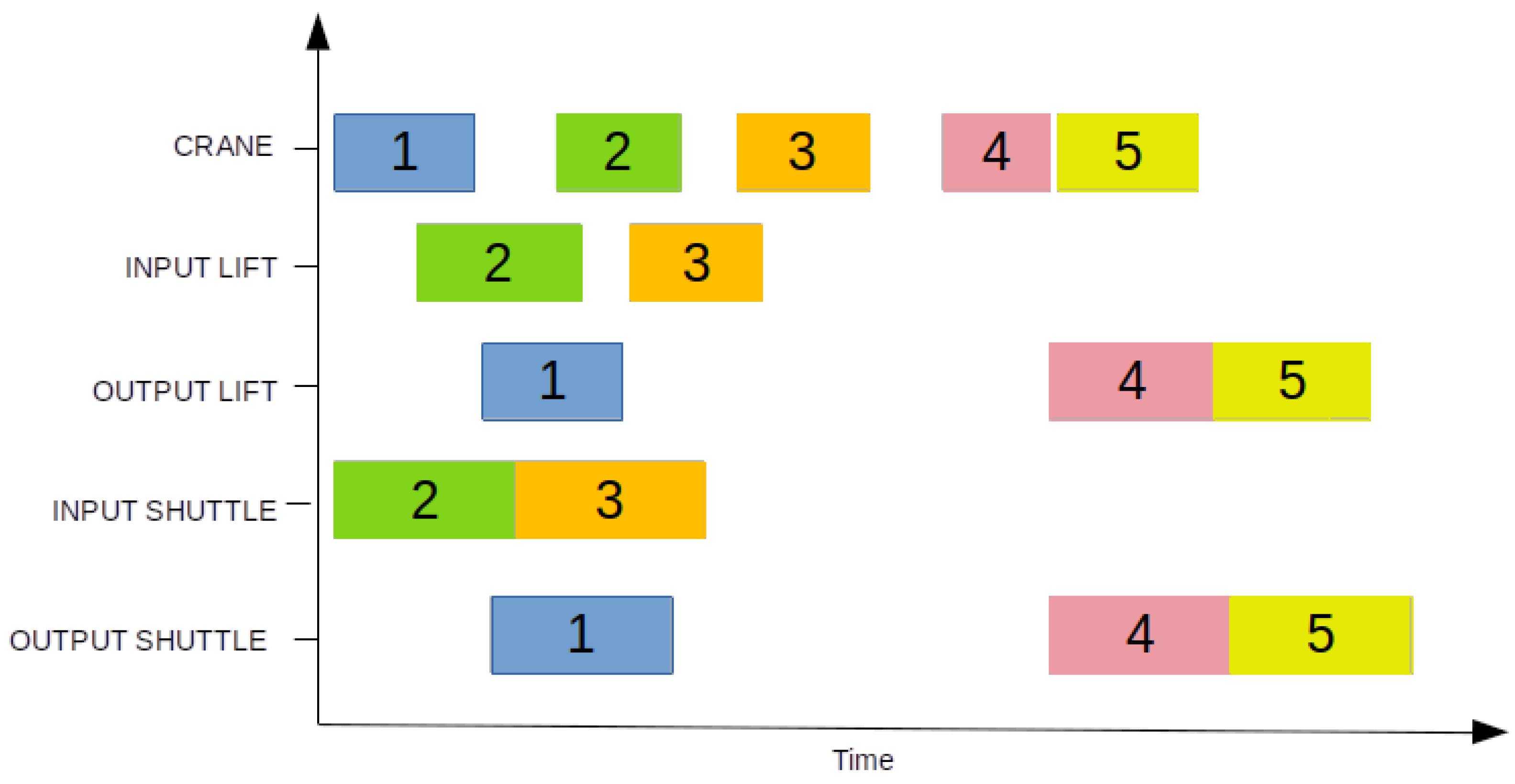
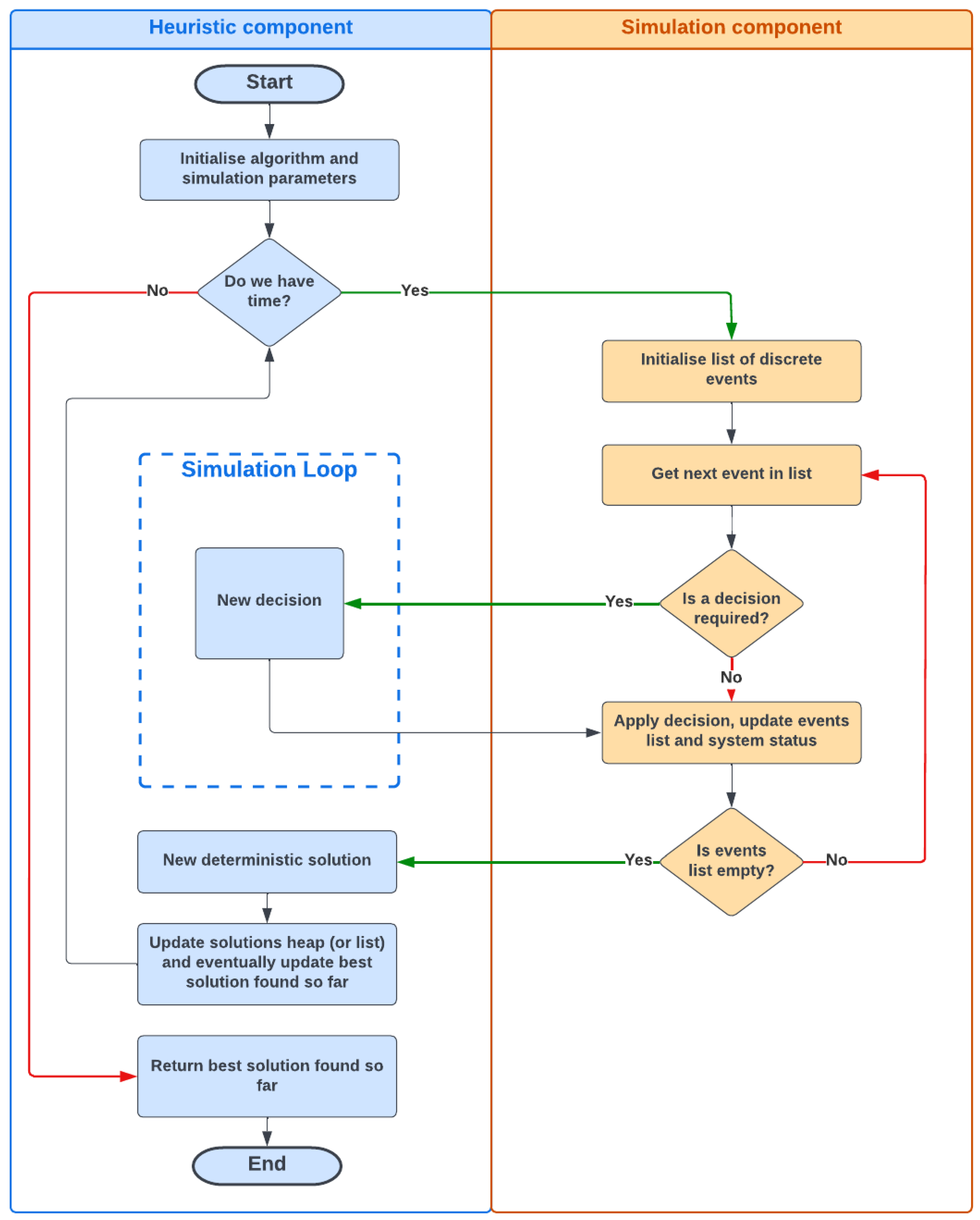
6. The Proposed Simulation Optimization Algorithm
6.1. Biased-Randomized Heuristics
6.2. Adding Discrete Event Simulation Principles to BR
| Algorithm 1 Pseudo-code of the proposed BR-DES algorithm. | |
| input: requests, racks, beta | |
| ▹ init final solution | |
| while length(requests) > 0 do | |
| ▹ init solution to current request | |
| if type() == Input then | |
| else if type() == Output then | |
| end if | |
| if isFeasible() then | |
| ▹ request postponed | |
| else | |
| end if | |
| end while | |
| return | |
| Algorithm 2 Pseudo-code for input processing | |
| input: , , , | |
| copy | ▹ list of racks to consider |
| ▹ solution to the current request | |
| whileanddo | |
| sort | ▹ sort racks prioritizing the busiest |
| ones | |
| findBR | ▹ select a rack by using BR |
| feasiblePlaces | ▹ feasible storage locations |
| if then | |
| randomUniformChoice | ▹ pick a random storage location |
| new | |
| scheduleOperation | ▹ schedule the new operation to carry out |
| else | ▹ if rack has no feasible solution, remove it |
| remove | |
| end if | |
| end while | |
| return | |
| Algorithm 3 Pseudo-code for output processing. | |
| input: , , , | |
| copy | ▹ save the state of the solution |
| ▹ solution to the current request | |
| copy | ▹ list of racks to consider |
| ▹ total weight of retrieved bundles | |
| ▹ total quality of retrieved bundles | |
| ▹ number of retrieved bundles | |
| while and do | |
| sort | ▹ sort racks prioritizing the busiest |
| ones | |
| findBR | ▹ select a rack by using BR |
| feasibleBundles | ▹ feasible bundles in rack |
| if then | |
| sort | ▹ sort bundles by weight |
| sort | ▹ sort bundles by quality |
| findBR | ▹ select a bundle by using BR |
| ▹ update weight | |
| ▹ update quality | |
| ▹ update number of retrieved bundles | |
| new | ▹ instantiate a retrieve |
| scheduleOperation | ▹ schedule a retrieval operation |
| add | |
| copy | ▹ restore the set of possible racks |
| else | |
| remove | |
| end if | |
| end while | |
7. Computational Experiments
8. Conclusions and Future Perspectives
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, G.; Lai, K. Combining path relinking and genetic algorithms for the multiple-level warehouse layout problem. Eur. J. Oper. Res. 2006, 169, 413–425. [Google Scholar] [CrossRef]
- Roodbergen, K.J.; Vis, I.F. A survey of literature on automated storage and retrieval systems. Eur. J. Oper. Res. 2009, 194, 343–362. [Google Scholar] [CrossRef]
- Chen, L.; Langevin, A.; Riopel, D. The storage location assignment and interleaving problem in an automated storage/retrieval system with shared storage. Int. J. Prod. Res. 2010, 48, 991–1011. [Google Scholar] [CrossRef]
- Foley, R.D.; Hackman, S.T.; Park, B.C. Back-of-the-envelope miniload throughput bounds and approximations. IIE Trans. 2004, 36, 279–285. [Google Scholar] [CrossRef]
- Kosanić, N.Ž.; Milojević, G.Z.; Zrnić, N. A survey of literature on shuttle based storage and retrieval systems. FME Trans. 2018, 46, 400–409. [Google Scholar] [CrossRef]
- Bertolini, M.; Esposito, G.; Mezzogori, D.; Neroni, M. Optimizing retrieving performance of an automated warehouse for unconventional stock keeping units. Procedia Manuf. 2019, 39, 1681–1690. [Google Scholar] [CrossRef]
- Dominguez, O.; Juan, A.A.; Faulin, J. A biased-randomized algorithm for the two-dimensional vehicle routing problem with and without item rotations. Int. Trans. Oper. Res. 2014, 21, 375–398. [Google Scholar] [CrossRef]
- Bertolini, M.; Neroni, M.; Uckelmann, D. A survey of literature on automated storage and retrieval systems from 2009 to 2019. Int. J. Logist. Syst. Manag. 2023, 44, 514–552. [Google Scholar] [CrossRef]
- Liu, S.; Wang, Q.; Sun, J. Integrated optimization of storage allocations in automated storage and retrieval system of bearings. In Proceedings of the 25th Chinese Control and Decision Conference, Guiyang, China, 25–27 May 2013; pp. 4267–4271. [Google Scholar]
- Wang, W.; Tang, X.; Shao, Z. Study on energy consumption and cable force optimization of cable-driven parallel mechanism in automated storage/retrieval system. In Proceedings of the Second International Conference on Soft Computing and Machine Intelligence, Dubai, United Arab Emirates, 23–25 November 2016; pp. 144–150. [Google Scholar]
- Lerher, T.; Sraml, M.; Potr, I. Simulation analysis of mini-load multi-shuttle automated storage and retrieval systems. Int. J. Simul. Model. 2015, 14, 48–59. [Google Scholar] [CrossRef]
- Ekren, B.Y.; Heragu, S.S.; Krishnamurthy, A.; Malmborg, C.J. Matrix-geometric solution for semi-open queuing network model of autonomous vehicle storage and retrieval system. Comput. Ind. Eng. 2014, 68, 78–86. [Google Scholar] [CrossRef]
- Liu, T.; Gong, Y.; De Koster, R.B. Travel time models for split-platform automated storage and retrieval systems. Int. J. Prod. Econ. 2018, 197, 197–214. [Google Scholar] [CrossRef]
- Zou, B.; Xu, X.; Gong, Y.; De Koster, R. Modeling parallel movement of lifts and vehicles in tier-captive vehicle-based warehousing systems. Eur. J. Oper. Res. 2016, 254, 51–67. [Google Scholar] [CrossRef]
- Ekren, B.; Heragu, S. A New Technology for Unit-Load Automated Storage System: Autonomous Vehicle Storage and Retrieval System; Springer: London, UK, 2012; pp. 285–339. [Google Scholar]
- Roy, D.; Krishnamurthy, A.; Heragu, S.S.; Malmborg, C.J. Performance analysis and design trade-offs in warehouses with autonomous vehicle technology. IIE Trans. 2012, 44, 1045–1060. [Google Scholar] [CrossRef]
- Liu, T.; Xu, X.; Qin, H.; Lim, A. Travel time analysis of the dual command cycle in the split-platform AS/RS with I/O dwell point policy. Flex. Serv. Manuf. J. 2016, 28, 442–460. [Google Scholar] [CrossRef]
- Hu, Y.H.; Huang, S.Y.; Chen, C.; Hsu, W.J.; Toh, A.C.; Loh, C.K.; Song, T. Travel time analysis of a new automated storage and retrieval system. Comput. Oper. Res. 2005, 32, 1515–1544. [Google Scholar] [CrossRef]
- Cai, X.; Heragu, S.S.; Liu, Y. Modeling and evaluating the AVS/RS with tier-to-tier vehicles using a semi-open queueing network. IIE Trans. 2014, 46, 905–927. [Google Scholar] [CrossRef]
- Carlo, H.J.; Vis, I.F.A. Sequencing dynamic storage systems with multiple lifts and shuttles. Int. J. Prod. Econ. 2012, 140, 844–853. [Google Scholar] [CrossRef]
- Zammori, F.; Neroni, M.; Mezzogori, D. Cycle time calculation of shuttle-lift-crane automated storage and retrieval system. IISE Trans. 2021, 54, 40–59. [Google Scholar] [CrossRef]
- Arnau, Q.; Barrena, E.; Panadero, J.; de la Torre, R.; Juan, A.A. A biased-randomized discrete-event heuristic for coordinated multi-vehicle container transport across interconnected networks. Eur. J. Oper. Res. 2022, 302, 348–362. [Google Scholar] [CrossRef]
- Arcus, A.L. A computer method of sequencing operations for assembly lines. Int. J. Prod. Res. 1965, 4, 259–277. [Google Scholar] [CrossRef]
- Tonge, F.M. Assembly line balancing using probabilistic combinations of heuristics. Manag. Sci. 1965, 11, 727–735. [Google Scholar] [CrossRef]
- Glover, F. Tabu search—Part I. ORSA J. Comput. 1989, 1, 190–206. [Google Scholar] [CrossRef]
- Glover, F. Tabu search—Part II. ORSA J. Comput. 1990, 2, 4–32. [Google Scholar] [CrossRef]
- Dorigo, M.; Gambardella, L.M. Ant colony system: A cooperative learning approach to the traveling salesman problem. IEEE Trans. Evol. Comput. 1997, 1, 53–66. [Google Scholar] [CrossRef]
- Hatami, S.; Calvet, L.; Fernandez-Viagas, V.; Framinan, J.M.; Juan, A.A. A simheuristic algorithm to set up starting times in the stochastic parallel flowshop problem. Simul. Model. Pract. Theory 2018, 86, 55–71. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Operations | ||||
|---|---|---|---|---|
| Operation 1 | Operation 2 | Operation 3 | Operation 4 | Operation 5 |
| Request k | Type | I/O Point | Bundle Type | Request k | Type | I/O Point | Bundle Type |
|---|---|---|---|---|---|---|---|
| 1 | IN | 1 | A | 2 | IN | 2 | B |
| 2 | IN | 2 | B | 4 | OUT | 3 | B |
| 3 | IN | 1 | C | 5 | OUT | 3 | A |
| 4 | OUT | 3 | B | 1 | IN | 1 | A |
| 5 | OUT | 3 | A | 3 | IN | 1 | C |
| 6 | IN | 2 | C | 6 | IN | 2 | C |
| Type | Bay | Desired Quality | Desired Quantity | Length (in Shelves) |
|---|---|---|---|---|
| 0 | 1 | 9 | 900 | 5 |
| 0 | 0 | 4 | 1200 | 4 |
| 0 | 1 | 8 | 800 | 5 |
| 0 | 0 | 1 | 800 | 6 |
| 0 | 1 | 7 | 900 | 6 |
| 0 | 1 | 5 | 1200 | 5 |
| 0 | 0 | 2 | 1000 | 5 |
| 0 | 1 | 9 | 1000 | 4 |
| 0 | 0 | 7 | 1100 | 6 |
| 1 | 2 | 9 | 3056 | 4 |
| 1 | 2 | 10 | 766 | 3 |
| 1 | 3 | 4 | 3719 | 3 |
| 1 | 3 | 10 | 6682 | 4 |
| 1 | 2 | 6 | 6788 | 6 |
| 1 | 3 | 2 | 8165 | 6 |
| 1 | 2 | 10 | 4257 | 6 |
| 1 | 2 | 4 | 9901 | 5 |
| 1 | 2 | 10 | 1449 | 3 |
| 1 | 2 | 7 | 6592 | 4 |
| 1 | 2 | 10 | 7505 | 4 |
| 1 | 3 | 5 | 6394 | 3 |
| 1 | 3 | 5 | 1922 | 6 |
| 1 | 3 | 9 | 6943 | 5 |
| 1 | 3 | 6 | 1615 | 3 |
| 1 | 2 | 3 | 2567 | 4 |
| 1 | 3 | 5 | 1268 | 4 |
| 1 | 2 | 6 | 6621 | 5 |
| 1 | 3 | 2 | 8400 | 5 |
| 1 | 2 | 7 | 9665 | 6 |
| 1 | 3 | 4 | 8262 | 3 |
| Instance | Number of Requests | Greedy | Random (Beta = 0.3) | BR-DES | SA | |||
|---|---|---|---|---|---|---|---|---|
| Avg. | St.Dev. | Avg. | St.Dev. | Avg. | St.Dev. | |||
| 1 | 30 (9 in/21 out) | 37.24 | 48.36 | 2.29 | 32.04 | 0.15 | 43.22 | 4.52 |
| 2 | 30 (12 in/18 out) | 35.34 | 39.41 | 0.48 | 31.03 | 0.32 | 37.12 | 3.28 |
| 3 | 30 (12 in/18 out) | 40.53 | 49.47 | 4.87 | 38.02 | 0.18 | 44.97 | 0.01 |
| 4 | 60 (9 in/51 out) | 55.46 | 71.95 | 3.76 | 51.19 | 0.89 | 59.03 | 0.74 |
| 5 | 60 (12 in/48 out) | 52.20 | 69.00 | 5.82 | 44.63 | 2.08 | 54.25 | 2.17 |
| 6 | 60 (26 in/34 out) | 52.24 | 72.04 | 0.93 | 48.93 | 0.55 | 52.10 | 1.75 |
| 7 | 90 (42 in/48 out) | 112 | 132.43 | - | 105.02 | 3.9 | 110.84 | 10.23 |
| 8 | 90 (28 in/62 out) | 89.29 | 115.24 | 4.18 | 88.32 | 1.52 | 89.20 | 3.33 |
| 9 | 90 (35 in/55 out) | 108.36 | 132.14 | 4.70 | 107.50 | 1.84 | 110.34 | 2.21 |
| 10 | 150 (38 in/112 out) | - | - | - | 230.96 | 100.23 | 257.12 | 23.04 |
| 11 | 150 (73 in/77 out) | - | 255.67 | - | 227.94 | 7.90 | 241.23 | 0.34 |
| 12 | 150 (59 in/91 out) | - | - | - | 195.89 | 6.64 | 201.32 | 6.43 |
| Instance | Number of Requests | Greedy | Random (Beta = 0.3) | BR-DES | SA | |||
|---|---|---|---|---|---|---|---|---|
| Avg. | St.Dev. | Avg. | St.Dev. | Avg. | St.Dev. | |||
| 1 | 30 (9 in/21 out) | 0.001 | 0.001 | 0 | 1.002 | 0.002 | 5.234 | 0.122 |
| 2 | 30 (12 in/18 out) | 0.001 | 0.001 | 0 | 1.034 | 0.004 | 8.032 | 0.392 |
| 3 | 30 (12 in/18 out) | 0.001 | 0.002 | 0 | 1.009 | 0 | 6.003 | 3.211 |
| 4 | 60 (9 in/51 out) | 0.001 | 0.001 | 0 | 1.023 | 0.002 | 6.023 | 0.045 |
| 5 | 60 (12 in/48 out) | 0.001 | 0.003 | 0 | 1.206 | 0.034 | 5.998 | 1.520 |
| 6 | 60 (26 in/34 out) | 0.001 | 0.003 | 0 | 1.115 | 0.078 | 5.104 | 2.174 |
| 7 | 90 (42 in/48 out) | 0.002 | 0.005 | 0 | 1.904 | 0.022 | 19.047 | 2.348 |
| 8 | 90 (28 in/62 out) | 0.001 | 0.019 | 0 | 1.821 | 0.103 | 18.222 | 2.011 |
| 9 | 90 (35 in/55 out) | 0.003 | 0.004 | 0 | 2.338 | 0.088 | 22.304 | 8.327 |
| 10 | 150 (38 in/112 out) | - | - | - | 2.904 | 0.155 | 35.120 | 2.664 |
| 11 | 150 (73 in/77 out) | - | 0.027 | - | 3.011 | 0.095 | 33.979 | 2.884 |
| 12 | 150 (59 in/91 out) | - | - | - | 2.992 | 0.121 | 34.014 | 6.092 |
| Instance | Greedy | Random (Beta = 0.3) | BR-DES | SA | ||||
|---|---|---|---|---|---|---|---|---|
| Quantity Mismatch | Quality Mismatch | Quantity Mismatch | Quality Mismatch | Quantity Mismatch | Quality Mismatch | Quantity Mismatch | Quality Mismatch | |
| 1 | 2373 | 3.70 | 9219 | 16.40 | 1326 | 9.59 | 2881 | 40.21 |
| 2 | 1890 | 8.42 | 6084 | 36.89 | 860 | 14.91 | 1421 | 28.91 |
| 3 | 1134 | 14.19 | 7470 | 16.72 | 931 | 21.95 | 1721 | 22.21 |
| 4 | 3468 | 16.94 | 23,205 | 112.86 | 3809 | 67.58 | 5580 | 93.21 |
| 5 | 8880 | 15.78 | 12,432 | 56.66 | 3143 | 12.28 | 5772 | 88.28 |
| 6 | 2418 | 29.62 | 7832 | 84.69 | 2539 | 50.36 | 4103 | 18.22 |
| 7 | 4896 | 38.63 | 19,296 | 13.96 | 4752 | 20.17 | 5193 | 33.22 |
| 8 | 9610 | 15.42 | 21,204 | 55.61 | 3640 | 41.71 | 3698 | 17.03 |
| 9 | 8525 | 13.27 | 4850 | 146.91 | 5225 | 42.46 | 4433 | 31.99 |
| 10 | - | - | - | - | 6272 | 19.15 | 9003 | 198.02 |
| 11 | - | - | 12,936 | 15.44 | 6006 | 14.14 | 8633 | 92.26 |
| 12 | - | - | - | - | 7189 | 120.45 | 8874 | 6.31 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Neroni, M.; Bertolini, M.; Juan, A.A. A Biased-Randomized Discrete Event Algorithm to Improve the Productivity of Automated Storage and Retrieval Systems in the Steel Industry. Algorithms 2024, 17, 46. https://doi.org/10.3390/a17010046
Neroni M, Bertolini M, Juan AA. A Biased-Randomized Discrete Event Algorithm to Improve the Productivity of Automated Storage and Retrieval Systems in the Steel Industry. Algorithms. 2024; 17(1):46. https://doi.org/10.3390/a17010046
Chicago/Turabian StyleNeroni, Mattia, Massimo Bertolini, and Angel A. Juan. 2024. "A Biased-Randomized Discrete Event Algorithm to Improve the Productivity of Automated Storage and Retrieval Systems in the Steel Industry" Algorithms 17, no. 1: 46. https://doi.org/10.3390/a17010046