1. Introduction
Due to the advancement of technology, a massive amount of data is generated on various offline/online platforms. Data analysis and Big Data are at the forefront of business and science today. These data are collected from online transactions, emails, images, videos, audio files, log files, posts, health records, social networking interactions, scientific data, sensors, and mobile phones. However, this Big Data is stored in different data islands that grow immensely and are challenging to capture, store, organize, analyze, and visualize. The challenges that big data carry include understanding the data, poor data quality, data scaling, incorrect integration, considerable costs, real-time data issues, and data verification. A substantial amount of this unstructured generated data consists of images and videos, e.g., on Google Images and surveillance cameras. Moreover, the emergence of social media has resulted in countless daily images uploaded by users on numerous online platforms, such as Instagram and Facebook [
1]. Therefore, managing, curating, processing, and analyzing this vast amount of data is of significant importance. To be more specific, data analysis can help businesses better understand their customers, increase sales, improve customer targeting, diminish costs, and solve problems more effectively. It is used to evaluate data with statistical tools to discover useful information. Therefore, analyzing data is crucial in many organizations, businesses, and research studies, as well as academia.
Images are one of the essential categories among the vast available data. There are various means of processing and analyzing image data by assigning keywords, detecting objects, annotating, captioning, or creating a textual description. Thus, there has been an explosion of interest in this area, which is used in various applications such as image annotation, object detection, and image captioning. Various traditional computer vision approaches have been proposed for solving these tasks; however, they have limited capabilities. It is necessary to choose which features are important in each given image in traditional methods (feature selection step). The traditional approaches use well-established computer vision (CV) techniques such as feature descriptors (e.g., SIFT [
2], SURF [
3], BRIEF [
4]), and after that, a feature extraction step is carried out. The features in an image are small areas of interest that are descriptive or informative. Several computer vision algorithms may be involved in this step, such as edge detection, corner detection, or threshold segmentation.
In recent years, machine learning (ML) and deep learning (DL) have been recognized as highly effective means for advancing technology and have pushed the limits of what is possible in the domain of image processing and artificial intelligence (AI) in general. As a result, ML and DL are increasingly applied to machine vision applications. Furthermore, multiple problems in vision tasks (e.g., object detection, image annotation, and multilabel image classification) have leveraged these learning techniques to interpret an image to figure out what is occurring. Recent DL-based approaches have demonstrated promising results in vision tasks, and the introduction of convolutional networks has set off a technological revolution in “image understanding”.
In the last decade, we have witnessed a significant advancement in the field of image processing, analytics, and understanding. We can discover patterns in raw image data using data analytics techniques and gain valuable insights. However, these techniques have limitations, such as hidden bias and complexity, which affects the decision process. On the other hand, they do not provide sufficient techniques for discovering, linking, and understanding image data. Transforming the data extracted from images into commonly understood and subjective descriptions to make subsequent decisions according to the various interpretations of the image data is challenging. The current techniques in image processing are incapable of deriving an understanding from various perspectives, and image data analytics is often insufficient. Narratives are effective means of conveying the underlying information in an image and gaining a rich understanding of it. We can effortlessly distinguish between a story and a narrative by shuffling the order of events and generating a new narrative of the same story every time we change the event order. Stories, which are various combinations of narratives, are subjective and assist in understanding images based on an analyst’s view. Storytelling with image data and image processing are not the same but are deeply intertwined, since storytelling is integral to analytics. Storytelling with image data is a broad and complicated task; its intention is to collect images most representative of an event. Then, after steps such as curation, enrichment, extraction, summarization, labeling, and narrative construction, a textual story is generated based on the incidents in the images.
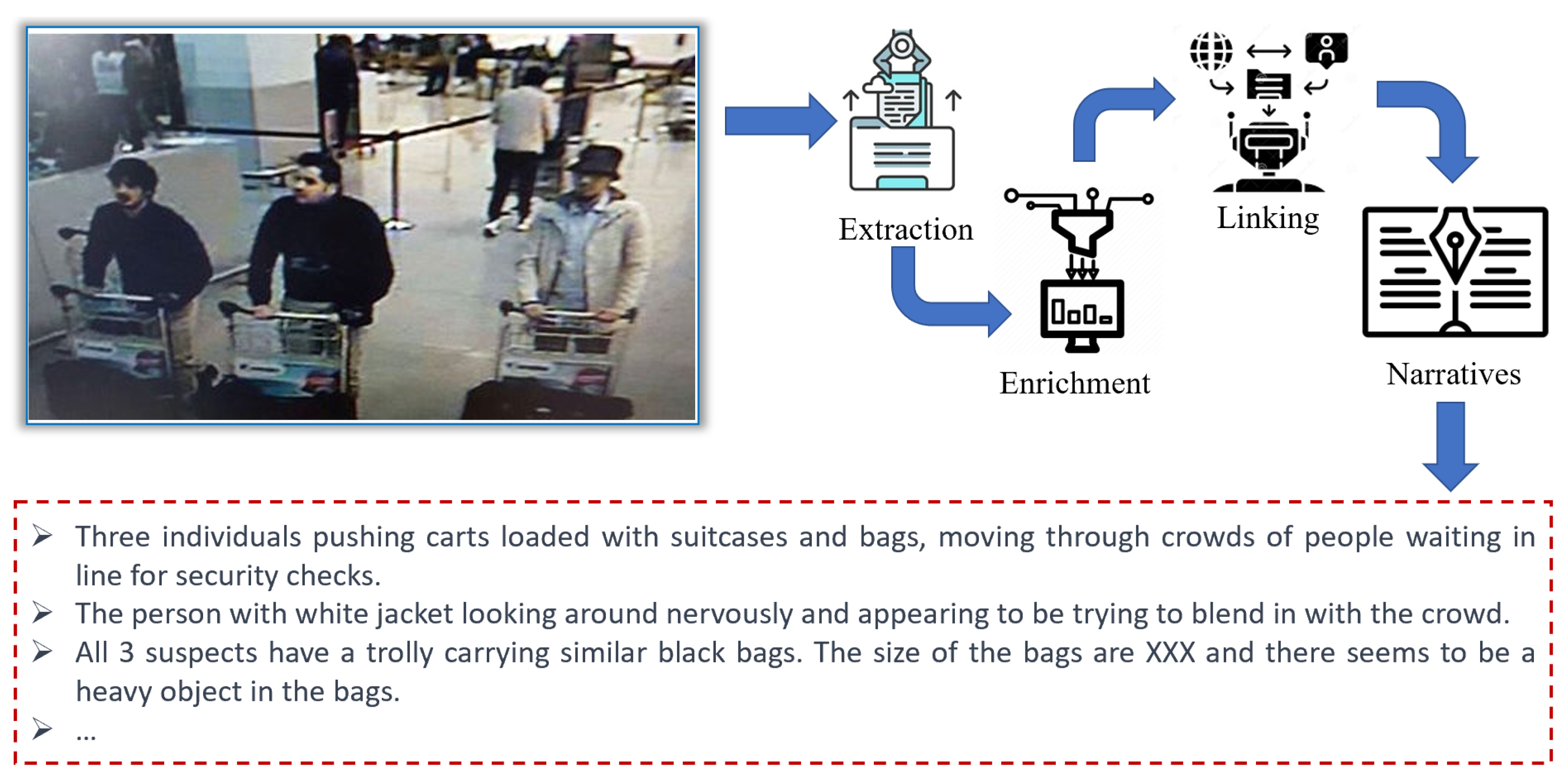
Storytelling with image data can play a crucial role in preventing tragedies such as the 2016 Brussels airport bombings (
https://en.wikipedia.org/wiki/2016_Brussels_bombings, accessed on 1 December 2022) by using image analysis technology to detect and automatically predict suspicious activities and unattended packages. By extracting information from images and enriching it with external knowledge sources, AI systems can generate detailed narratives that provide context and guidance for security personnel. This enables them to respond quickly and effectively to potential threats, potentially preventing harm to innocent civilians.
Figure 1 presents an exemplary end-to-end storytelling scenario that highlights the potential of utilizing image data obtained from cameras installed in airports to gain a better understanding of events and activities. In the background, an AI system equipped with image analysis technology constantly scans security camera footage for potential threats. In an image of an airport, various objects can be extracted to detect suspicious activities, these include the following:
Unattended bags or packages: these can be detected by analyzing the shape, size, and position of bags and packages in an image.
People loitering or moving in a suspicious manner: this can be detected by analyzing the movements and patterns of people in the image.
Individuals wearing bulky or concealed clothing: this can be detected by analyzing the size and shape of individuals in the image.
Suspicious behavior: this can be detected by analyzing the posture and gestures of individuals in the image.
Abandoned vehicles or other objects: these can be detected by analyzing the position and size of vehicles and other objects in the image.
By extracting information about these objects, an AI system can identify potential threats and generate a detailed story that provides context and guidance for security personnel. By enriching these data and linking information items to external knowledge sources, such as social and historical police data, the AI system can generate a detailed story that provides context for the situation. The system can highlight potential warning signs, identify potential threats, and provide guidance on how to respond.
Accordingly, storytelling with image data is capable of capturing and representing temporal/sequential order of key events [
5]. Moreover, a story can be told at multiple levels, i.e., a very abstract story versus a detailed story, to support the subjective nature of storytelling with data. To the best of our knowledge, no system can interactively generate different narratives from the timeline of events/activities that happened since the crime incident up to the present time.
Storytelling with image data can be identified as an analytics approach to turning insights into actions. Despite the early adoption, storytelling systems are still in the early stages of development, with many unsolved theoretical and technical challenges stemming from the lack of a formal framework for story modeling and creation from data identifying the notion of story schema, story instance, story element, and narrative. Most related works [
6,
7] in storytelling presented interactive visualizations to convey data-driven discoveries in a captivating and intuitive way. However, storytelling with image data is much more than sophisticated ways of presenting data visually. Organizing image data, contextualizing it, enhancing the discovery of related events and entities in the image, and presenting it interactively to end-users are the main challenges in storytelling with image data. However, more importantly, there is a need to evaluate the quality of the constructed stories and narratives, which is still a big challenge. We further discuss the current methods for assessing the quality of generated stories in
Section 8; however, we leave it as future work since there is a huge knowledge gap in this part and it is still an active research field.
In this survey, we focus on the research problem of “understanding the image data” in general and, more particularly, analyzing the state of the art in the curation, summarization, and presentation of large amounts of image data in a succinct and consumable manner to end-users. We argue that stories are able to combine data with narratives to reduce the ambiguity of data, connect data with the context, and describe a specific interpretation. We aim to advance the scientific understanding of storytelling with image data in general, and image data curation, event/entity extraction and discovery, narrative formation (e.g., event stream processing), Knowledge Bases [
8], Knowledge Lakes [
9], and Knowledge Graphs [
10,
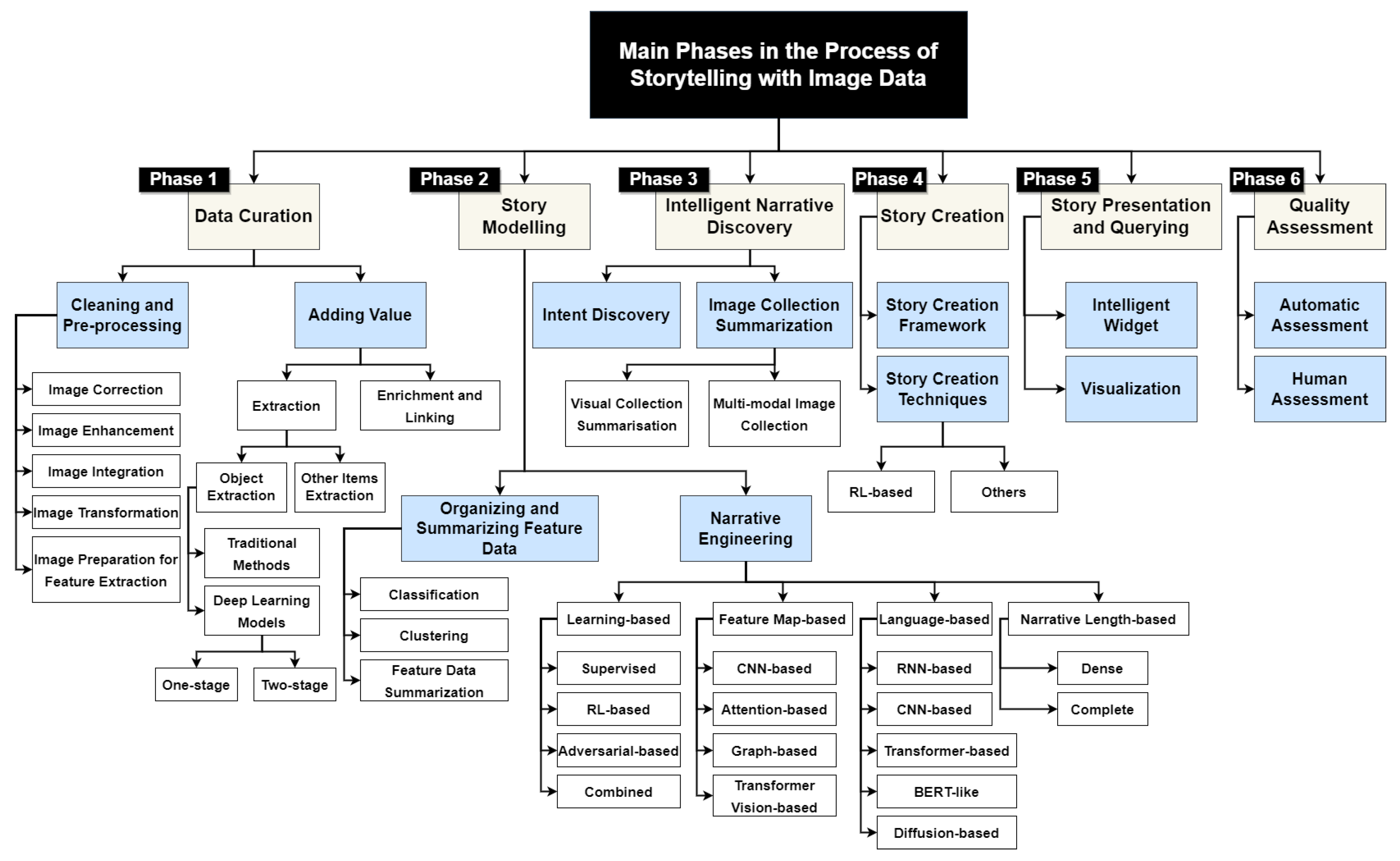
11] in particular. We provide a systematic review and comparative analysis of methods and tools to identify, evaluate, and interpret relevant research in the field of storytelling with image data. This paper introduces storytelling as a process that facilitates understanding image data. This process uses several phases, from cleaning and cleansing, followed by curation and adding value. Several approaches in this paper focus on preparing an image for data analytics and turning a raw image into contextualized knowledge, which is very critical for the process of storytelling with image data. Therefore, we decided to conduct a comprehensive review of the existing work in image processing, cleaning, and curation, preparing the understanding of the importance of these phases in the storytelling process. These phases and steps of storytelling with image data are highlighted in
Figure 2.
The method used to select the literature for this survey is described in
Section 2. Storytelling with image data is decomposed into five tasks. Data curation is the first task toward story generation with image data, which is discussed in
Section 3.1. Then, in
Section 4, we investigate the story modeling process. Intelligent narrative discovery is further studied in
Section 5. Story creation and intelligent widgets for narrative discovery are discussed in
Section 6 and
Section 7.
Section 8 explains the quality assessment step. Finally, in
Section 9, we conclude our study and provide the future works that we have in mind. The taxonomy of storytelling with image data is demonstrated in
Figure 2.
2. Literature Selection
2.1. Background and Motivation
This work is a systematic literature review (SLR) on storytelling with image data based on the standard guidelines for performing SLR in software engineering [
12]. The most crucial aspect of any SLR is identifying the research questions (RQs).
Table 1 demonstrates the list of research questions (RQs), the discussion, and the main motivation that we focus on to identify state-of-the-art storytelling methods with image data, which is discussed in detail in
Section 2.2. Moreover,
Figure 3a shows a word cloud representation of research questions and their corresponding main motivations, with more frequent words in larger font sizes. Word clouds, in general, are visual representations of textual data. They highlight the most prominent or frequent words and ignore the most common words in the language. These figures pinpoint the most important keywords in our search keywords and question–motivation pairs for storytelling with the image data field. Finally, the detailed classification of different categories with their subcategories, references, time period, and the number of references in each subcategory is mentioned in
Table 2 in this survey.
2.2. Research Questions
The use of image data in storytelling has gained significant attention in recent years as an effective way for businesses to communicate their messages to their audience. Storytelling with image data can help brands stand out from the competition and increase customer engagement by creating an emotional connection with their target audience. However, there are several research questions that remain unanswered regarding the use of image data in storytelling. In this section, we explore the main motivations behind these research questions and summarize the findings that they offer to the field of visual storytelling. By understanding the motivations behind these research questions and their contributions to the field, we can gain insights into the best practices for using image data in storytelling and the potential benefits for businesses.
Table 1 illustrates the research questions (RQs) examined in this survey.
The main motivation behind this research question is to explore the use of image data as a means of storytelling and understanding visual content. In today’s world, we are bombarded with vast amounts of visual data, and it is becoming increasingly important to understand how we can effectively use these data to communicate ideas and convey messages. The research question aims to identify and analyze the methods and techniques used in storytelling with image data and explore how these methods can be used to enhance our understanding of visual content.
The findings of this research question will offer insights into how images can be effectively used as a medium for storytelling and how they can be used to convey complex information in a way that is easy to understand and engaging for the audience. The research question will offer a summary of the key techniques and strategies used in storytelling with image data, including data visualization, image classification, and image recognition. It will also provide insights into how these techniques can be used to improve our understanding of images, including their context, content, and meaning.
The main motivation behind this research question is to identify and understand the unique approaches and techniques used in storytelling with image data compared with image/video captioning methods. While both methods involve using images and videos to convey information, the way they approach storytelling can be quite different. The research question aims to analyze the differences between storytelling with image data and image/video captioning methods, including the use of context, narrative structure, and audience engagement. It will explore how storytelling with image data is focused on creating a narrative that engages and resonates with the audience, whereas image/video captioning methods are often more focused on providing a concise and accurate description of the visual content.
The findings of this research question will offer insights into the unique strategies and techniques used in storytelling with image data, including the use of data visualization, creative design, and visual storytelling. It will also provide a better understanding of how these methods can be used to create more engaging and impactful visual content.
The main motivation behind this research question is to investigate the effectiveness of using multiple images to tell a story as opposed to using a single image. The question arises from the need to understand how different visual storytelling techniques can be utilized to create more impactful and engaging narratives. The research question aims to analyze the differences between using a set of related images and a single image to tell a story, including the ways in which they convey information, create meaning, and engage the audience. It will explore the various factors that contribute to the effectiveness of using multiple images, such as context, sequence, and visual coherence.
The findings of this research question will offer insights into the unique strategies and techniques used in storytelling with a set of related images, including the use of visual hierarchy, narrative structure, and visual metaphors. It will also provide a better understanding of how these methods can be used to create more engaging and impactful visual content.
The main motivation behind this research question is to identify the technical difficulties that arise when utilizing image data for storytelling purposes. This research question is crucial because, while there are numerous techniques available for analyzing and understanding image data, there are significant challenges that remain to be addressed in utilizing image data for storytelling purposes. Some of the technical challenges that may be addressed by this research question include issues related to image recognition, feature extraction, data preprocessing, and scalability. Additionally, the research may delve into challenges related to representing the narrative structure and visual language of the story in a coherent and meaningful way.
The findings of this research question may offer insights into the limitations and challenges of utilizing image data for storytelling and provide potential solutions to these issues. By understanding these challenges, we may be able to improve the effectiveness and efficiency of storytelling with image data and enhance our ability to communicate complex concepts and narratives.
The main motivation behind this research question is to identify and understand the different approaches and methods that have been used to create compelling stories using image data. This research question is important because there are various ways to approach storytelling with image data, and by examining the different techniques that have been employed, we can gain insights into the strengths and limitations of each approach.
The findings of this research question may offer a comprehensive overview of the techniques that have been used for storytelling with image data. This can include methods such as visual narratives, data-driven narratives, photo essays, and multimedia storytelling. By analyzing these different approaches, we can gain insights into their unique features, advantages, and challenges. Additionally, this research may highlight emerging techniques and trends in storytelling with image data, providing new avenues for exploration and innovation in this field.
The main motivation behind this research question is to explore the potential benefits of using image data in storytelling for businesses. With the increasing availability of visual data, businesses have the opportunity to communicate their brand messages in more engaging and impactful ways through the use of images. By answering this research question, we can gain insights into the various applications of storytelling with image data, such as creating marketing campaigns, visualizing data, and enhancing customer experiences. Additionally, we can explore how businesses can leverage these applications to create value for their brand, increase customer engagement, and drive revenue growth. Some potential findings that could arise from this research question include the following:
Image data can be used to create compelling marketing campaigns that are more engaging than traditional text-based approaches.
Visualizations of data through image data can provide businesses with valuable insights and help them make data-driven decisions.
The use of image data can enhance the customer experience by creating more immersive and interactive experiences.
Storytelling with image data can help businesses to differentiate their brand and stand out in a crowded marketplace.
The adoption of image data in storytelling can lead to improved brand perception, increased customer loyalty, and ultimately, increased revenue growth.
The main motivation behind this research question is to provide a framework for evaluating the effectiveness of visual storytelling. While there is a growing interest in the use of visual storytelling, there is a lack of guidance on how to measure the quality of the stories being created. By answering this research question, we can gain insights into the key elements that contribute to the quality of visual stories, such as the clarity of the message, the coherence of the narrative, the use of visual elements to support the story, and the emotional impact of the story. Additionally, we can explore how to measure these elements to assess the overall quality of the story. Some potential findings that could arise from this research question include the following:
The identification of key elements that contribute to the quality of visual stories, such as the use of clear and concise messaging, the use of compelling visual elements, and the emotional impact of the story.
The development of a framework for evaluating the quality of visual stories, including the creation of metrics to assess the effectiveness of the story in achieving its intended goals.
The importance of considering the target audience when assessing the quality of visual stories, as different audiences may have different preferences and expectations.
The need to balance the creative and technical aspects of visual storytelling when assessing quality, as both elements are important in creating effective stories.
The potential for using technology, such as eye-tracking or emotional recognition software, to measure the impact of visual storytelling on the viewer.
2.3. Literature Selection
We broke down our research questions into individual facets and conducted an extensive literature search on electronic sources such as Google Scholar (
https://scholar.google.com, accessed on 1 December 2022) and arXiv (
https://arxiv.org/, accessed on 1 December 2022) based on sophisticated search queries and keywords. We did our best to have an unbiased search strategy. The following search string uses AND and OR operators to represent our “storytelling with image data” generic search query:
([“Image” AND “Captioning”] OR [“Image” AND “Caption” AND “Generation”]) AND ([“Visual” AND “Question” AND “Answering”] OR [“VQA”]) AND ([“Visual” AND “Question” AND “Generation”] OR [“VQG”]) AND (“Visual” AND “Dialog”) AND ([“Visual” AND “Storytelling”] OR [“Storytelling” AND “Image” AND “Data”] OR [“Multi-Image” AND “Story” AND “Generation”]).
We included all possible search strings related to each part and did our best to make sure no potential study is missed in our results. Moreover, the word cloud representation for the search keywords is demonstrated in
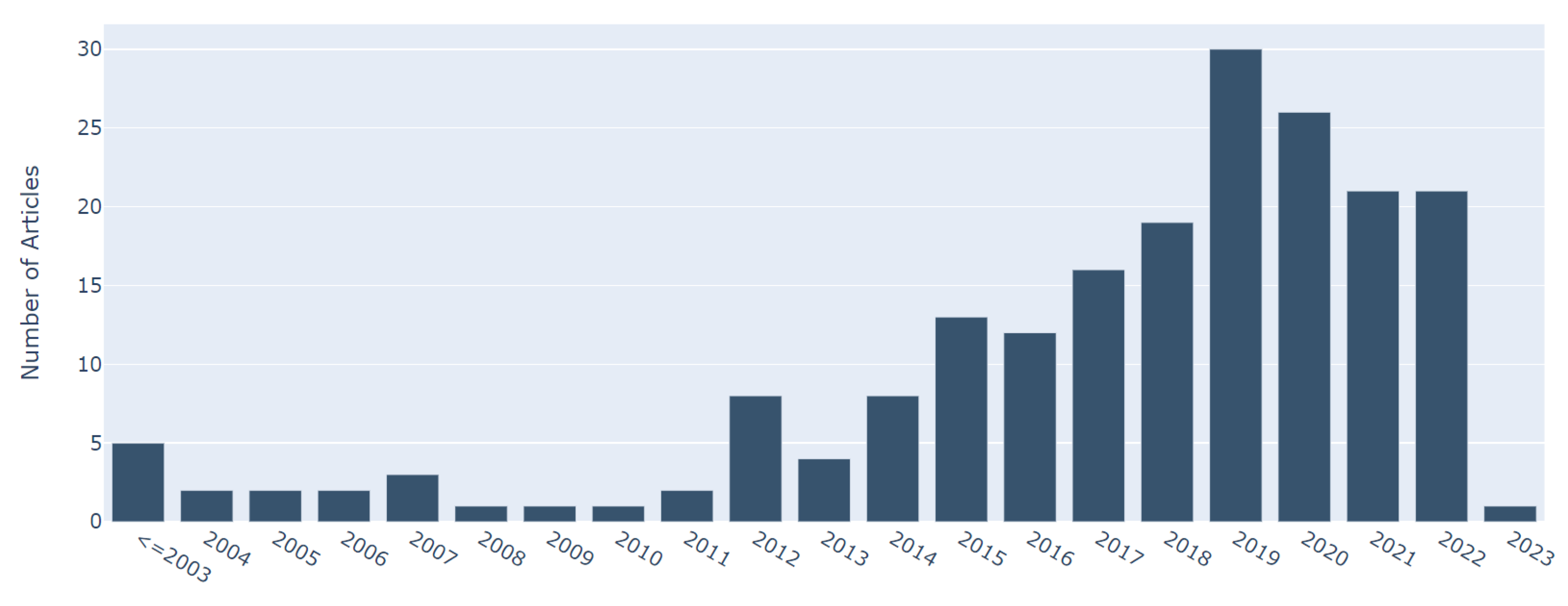
Figure 3b. In addition, we included articles published since 1980, and the yearwise distribution of the selected articles after the paper quality assessment phase is represented in
Figure 4. These selected articles were included in our study if they met the inclusion criteria explained in the following.
English language studies.
Articles dated between 1980 and 2022.
Articles related to at least one aspect of our research questions.
Reference list from relevant studies and review articles.
On the other hand, we excluded some articles based on our exclusion criteria, which include the following items:
Informal literature surveys (no defined research questions, no search process, no defined data extraction or data analysis process).
Articles that are not published (except for preprints and arXiv).
Non-English articles.
Studies not related to at least one aspect of our research questions.
Ultimately, the quality of the selected studies is assessed based on the following list:
Frequency of citations.
Are the study’s research challenges/contributions/experiments clearly explained?
Is there a clear statement of the objectives of the research?
Are the experiments realized to evaluate the ideas presented in the study?
4. Task 2. Story Modeling
Data curation is the preprocessing, organization, enrichment, and integration of data collected from various sources. In previous sections, we discussed data curation approaches for image data in detail. To aggregate this huge amount of curated feature data, we can shift away from the common feature data and move to a better organization of data in the form of Knowledge Graphs, a collection of interlinked descriptions of concepts, entities, relationships, and events. Knowledge Graphs put the data into context via linking, as well as semantic metadata, created by subject-matter experts.
We present the Story Model, which transforms the raw image data into contextualized knowledge. Then, it automatically discovers and links the events and entities of interest from the contextualized data to create a Knowledge Graph. Ultimately, it summarizes the Knowledge Graph and facilitates intelligent narrative discovery. It is a primary step before modeling and representing the story based on the data. As a semantic network, this Story Model represents a network of real-world entities, i.e., objects, events, or concepts. It is a reusable data layer for answering complex queries across data silos.
Images require summarization, representation, understanding, and analysis from various perspectives. Summarization is the presentation of a summary of generated data in an informative manner. The image features are considered the cornerstone of image summarization, and the most crucial issue is what features are to be considered in the summarization process. On the other hand, narratives are perhaps the most efficacious way to understand these images. Narratives are a choice of which events/entities to relate to and in what order each narrative can be constructed based on a specific path in the data Knowledge Graph in the Story Model. However, narratives are subjective and depend on the analyst’s perspective. Therefore, analyzing image data narratives using models is indispensable to understanding how analysts reason about images. Therefore, various aspects of the narrative, such as its structure, time, purpose, and listener’s role, should be considered to accomplish this. A story based on multiple images is a unique combination of a set of narratives. Storytelling with image data deals with presenting large amounts of data in a straightforward manner to end-users. Storytelling best represents image data since it captures and represents temporal/sequential relationships between key events. There are multiple levels to a story, i.e., an abstract story might differ from a detailed story. In this section, we first focus on organizing and summarizing feature data to create narratives and the final story. Then, we focus on narrative engineering from the summarized data and categorize it from different perspectives.
4.1. Organizing and Summarizing Feature Data
In previous sections, we discussed how different features have been extracted, collected, summarized, and curated from raw data. In this section, we discuss organizing and summarizing feature data to be prepared for narrative engineering. Here, we examine classification, clustering, and summarization techniques to organize the feature data.
4.1.1. Classification
Multiple features are extracted from images, and images are enriched with metadata extracted from different sources. These metadata belong to various categories and classes. For example, some are words of places and some are human names; some are separate objects and items in the image. These metadata must be classified into various categories to organize our final feature data. Several existing classification methods are suitable for different data types; in this article, some of the most useful ones are described [
66].
Decision Tree. Decision trees are one of the classification methods that classify the data based on several conditions, each including one or more features of the data. It is a tree model, in that each node contains a condition that divides the training data into two or more parts, and the number of leaf nodes will determine the number of classes.
Probabilistic Methods. A model created using probabilistic classifiers estimates the probability of the relation between the feature and its class. Naive Bayes and Logistic Regression are two popular probabilistic classifiers.
Support Vector Machines. Support Vector Machines classify the data into two classes and are suitable for binary classification tasks. In the feature space for the data, this method tries to fit a hyperplane that separates the two data classes, so that the hyperplane has the maximum margin with the data of both categories.
Neural Networks. Neural networks are also one type of classifier. Different architectures of neural networks with different output and input layers could be used based on the type of data and the number of classes to nonlinearly classify the data into different categories.
4.1.2. Clustering
Sometimes the metadata we use do not belong to specific categories; however, different metadata groups have similar features and could be clustered into a single group. Several existing clustering methods fit different data types. In this section, some of the most useful ones are described [
67].
Representative-Based Methods. These methods are the most straightforward clustering techniques, since they use the similarity or distance of the data points in the feature space. In these methods, candidates are chosen among either the data points or a function of the data points, such as mean or median, to be the center of the clusters. The most popular techniques in this category are K-Means, K-Median, and K-Medoids.
Hierarchical Clustering Methods. Hierarchical clustering methods cluster the data on different levels. In the hierarchical clustering approach, a tree-shaped clustering is produced so that each tree level demonstrates one option for clustering with a specific number of clusters. e.g., the first node of the tree represents all data points in one cluster, and the leaf nodes represent clustering with C clusters, in which C is the number of data points. This approach is advantageous when we need different insights from the clustering and we could obtain those insights by looking at each tree level. Bottom-Up (Agglomerative) and Top-Down (Divisive) are two types of hierarchical clustering approaches.
Probabilistic Methods. In the probabilistic approaches, for each data point, C likelihoods will be calculated, in which C is equal to or less than the number of the clusters. In these approaches, each data point could belong to multiple clusters but with different probabilities. This method is called soft clustering.
Density-Based Methods. The problem with distance-based and probabilistic clustering is that the shapes of the clusters are always defined based on the model we are using, e.g., the K-means technique’s cluster shape is always spherical. However, sometimes the clusters of our data points have multiple odd shapes, and the clusters are too close to each other. In this scenario, none of the above functions can correctly cluster them. Density-based clustering solves this problem by identifying fine-grained dense regions.
4.1.3. Feature Data Summarization
The features extracted in the previous sections are of different types, such as images, text, words, items, and keywords, and they also have a large volume. Using data summarization is of the utmost importance to effectively analyze such extensive data. There are several summarization techniques for each of the data types. In the storytelling use case, we are dealing with unstructured data as our features. Hence, in this part, we introduce some popular summarization techniques for unstructured data. Different classification and clustering methods discussed in the previous part could also be used to summarize the feature data. e.g., Decision trees, Hidden Markov Model (HMM), Artificial Neural Networks (ANN), and similarity-measure-based models. For text summarization, topic modeling, and natural language processing (NLP), summarization techniques are also widely used. For item and keyword summarization, techniques such as removing irrelevant and less effective items and keywords, frequent itemset selection, and sampling could be used [
68].
4.2. Narrative Engineering
Narrative construction develops descriptive text for images using computer vision and natural language processing. However, over and above that, an accurate image and language understanding should be paired syntactically and semantically. There have been various approaches to tackling the task of “Image Narrative Generation” [
100,
140]. In this section, we first define the concept of a narrative, then investigate its generation process from different perspectives. Narrative construction can be studied and categorized into learning-based, feature-map-based, language-based, and narrative length-based methods.
Definition1. A narrative N is a specific subgraph, path, or walk in a Story Model starting from a random node i and ending in another random node j while traversing the Knowledge Graph G with a sequence of vertices in-between them. Graph G is the Knowledge Graph containing the contextualized data information, extracted concepts, objects, topics, captions, metadata, and rules from the image data.
Learning-Based Methods. Narrative construction has utilized a variety of learning-based approaches. We classify them into three main categories. A supervised learning method, which is the first category, refers to training the model under the supervision of a teacher. Labels are used to supervise the learning process. In the second category, reinforcement learning (RL) aims to maximize the long-term reward of agents by taking the optimal action (through trial and error) in a particular state. Finally, a generative adversarial network (GAN) trains a generative model by defining the problem as a supervised learning problem consisting of two submodels: a generator and a discriminator. The generator generates fake new samples and the discriminator tries to ascertain whether the input samples are real or fake. Finally, a zero-sum adversarial game is used to train these two models together until the discriminator is fooled half the time.
Supervised Learning Methods. Multimodal Recurrent Neural Network (m-RNN) architecture has been proposed in [
69] to handle these two tasks: (1) image-to-sentence description generation and (2) image and sentence retrieval. Additionally, this architecture is trained by utilizing a log-likelihood cost function. The model parameters are learned by differentiating from the cost function given the input and the backpropagation algorithm. Karlpathy et al. [
70] introduce a multimodal RNN architecture that learns to generate narratives for image regions based on inferred alignments (multimodal embeddings of convolutions over images and bi-RNNs over sentences). They map every image and sentence into a shared space of h-dimensional vectors. The supervision is carried out at the entire image and sentence level, so they formulate an image–sentence score based on the individual region scores. Vinyals et al. [
71] present an end-to-end solution to the caption generation problem, which is fully trainable by employing stochastic gradient descent, and the loss is the sum of each step’s negative log-likelihood of the correct word.
Reinforcement Learning (RL). SCST [
72] is a reinforcement learning (RL) optimization technique that normalizes rewards by exploiting the output of its test-time inference algorithm. This approach baselines the REINFORCE approach more efficaciously, leading to better results with nondifferentiable evaluation metrics. Ren et al. [
73] take a collaborative approach and propose a decision-making framework. They use a policy and value network to predict the word for each step of narrative generation. Specifically, an actor–critic RL algorithm is introduced to learn these two networks. Gordon et al. [
74] introduce the Interactive Question Answering (IQA) task (answering questions that demand the agent’s interaction with a dynamic environment) and propose the Hierarchical Interactive Memory Network (HIMN). HIMN is factorized into a Planner, a set of controllers, and a semantic spatial memory. The Planner, formulated as an RL problem, invokes the controllers to explore the environment and answer the question in the IQA task.
Generative Adversarial Networks (GANs). Patro et al. [
75] present a Correlated Collaborative Model (CCM) that guarantees the coherence of the generated textual explanations and answers. CCM collaborates with the answer and explanation features and employs generative adversarial strategies for training. In addition, the results are robust to noise in images and text (even if the model is not trained for noise-based attacks).
Combined Methods (RL + GAN). To generate more human-like answers to questions, Wu et al. [
76] combine RL with GANs and introduce a novel framework. This framework updates the generator by employing the reward of the generator policy at each training step. After sampling data from the dialog history (a sequence of textual data), maximum likelihood estimation (MLE) is used to update the generator. Chen et al. [
77] introduce a conditional generative adversarial captioning technique to extend RL-based architectures. Furthermore, CNN- and RNN-based architectures are presented for the discriminator module. The discriminator judges whether a human described the resulting caption or if it is machine-generated.
Feature-Map-Based Methods. One of the critical challenges in narrative construction based on an image is extracting visual features which best represent the image content. Therefore, we categorize these methods into three main groups based on various strategies proposed for extracting visual features: CNN-based, attention-based, graph-based, and vision-transformer-based methods, which are discussed in detail in the following paragraphs.
CNN-Based Methods. Vinyals et al. [
71] employ a vision CNN model to extract image features, since CNNs can embed images in fixed-length vectors. They utilize the result feature vector of GoogleNet [
141] for the visual feature extraction step. Moreover, Karpathy et al. [
70] used the visual features extracted from AlexNet [
142]. Many studies employ the CNN modules to extract features such as [
72,
143,
144].
Attention-Based Methods. Simple CNN-based methods have the main advantage of being compact and straightforward. At the same time, the extreme compactness and lack of granularity are crucial issues that need to be addressed. An attention module handles this issue by computing attention weights and attending to specific parts of the visual features. Many approaches fit into attention-based methods that can be divided into three main categories: grid-based, region-based, and self-attention. In the following items, these three categories are further discussed.
- –
Grid-Based Attention Methods. A significant proportion of image captioning methods use the attention mechanism to make captioning more flexible and provide better granularity. Xu et al. [
78] introduced an attention-based image captioning model inspired by a recent study in machine translation [
79] and object detection [
80,
81]. The authors proposed two attention-based image caption generators: a “soft” deterministic attention mechanism and a “hard” stochastic attention mechanism. An adaptive encoder–decoder model [
82] also automatically determines when to rely on the language model and when to look at the image (the spatial CNN features at each of the k grid locations of the image).
- –
Region-Based Attention Methods. Anderson et al. [
83] employ a novel bottom-up and top-down attention module (based on Faster R-CNN [
49] and task-specific context). First, the bottom-up visual attention module extracts salient regions of an image and represents them using convolutional feature vectors. Then, the top-down module estimates the distribution of attention over image regions (specifies weights of the features). As a result, a weighted average of all image features is the final attended feature vector. The Look-Back and Predict-Forward (LBPF) approach [
84] presents two main modules: Look-Back (LB) module and Predict-Forward (PF) module. As the input of the attention module, the LB module concatenates the previous attention vector and the current hidden state. In contrast, the PF module sequentially predicts the two following hidden states based on the current hidden state. For constructing high-quality image captions, the Reflective Decoding Network (RDN) [
85] improves the capability of the standard caption generator to handle long sequential modeling by examining the caption’s word consistency. Li et al. [
145] also addresses both the tasks of VQA and VQG using the attention mechanism after extracting the visual features from the input image.
- –
Self-Attention Methods. Despite the widespread use of attention mechanisms in image captioning, we still do not know how closely related attended vectors and given attention queries are. Therefore, Huang et al. [
86] proposed the “Attention on Attention” (AoA) module, which specifies the attention results and queries relevancy. Applying AoA to both the encoder and decoder in this research, the authors introduced AoANet for image captioning. Guo et al. [
87] first proposed a normalized self-attention (NSA), which indicated that conducting this normalization on the hidden activations inside self-attention is advantageous. Then, a geometric-aware self-attention (GSA) module was proposed to compute the objects’ geometric bias to assist with image comprehension. Furthermore, the self-attention module in the encoder facilitated the EnTangled Attention (ETA) model [
88] to examine the detected entities’ relationships.
Graph-Based Methods. This image encoder incorporates two kinds of visual relationships (semantic and spatial object relationships) in the proposed GCN-LSTM framework [
89], which attempts to explore the relations between objects. Based on these visual relationships, they developed graphs over the detected objects in an image and used GCNs proposed in [
146]. The Scene Graph Auto-Encoder (SGAE) [
90] embeds inductive bias into a dictionary unsupervised. Subsequently, it is shared as a re-encoder for text generation, enhancing the encoder–decoder performance. For captioning, Yao et al. [
91] utilize the hierarchical structure in images at the instance, region, and whole image level. This hierarchical structure is analyzed with a tree-structured LSTM model, and each instance-, region-, and image-level feature is improved. Image encoding is also based on a hierarchical scene parsing architecture.
Vision-Transformer-Based Methods. In this category, the methods [
147,
148,
149] study the importance of spatial dimension conversion and its effectiveness on Vision Transformer (ViT) [
150]. These methods are considered a better-performing detector-free image captioning model.
Language-Based Methods. Story generation is a cross between computer vision and natural language processing. Researchers use various methods to encode or decode textual data. We categorize these approaches into four groups: RNN-based, CNN-based, Transformer-based, BERT-like, and Diffusion-based methods.
RNN-Based Methods. RNNs are a class of artificial neural networks that are derived from feedforward neural networks. RNNs can process variable-length sequences of inputs using their internal state (memory) and are used to handle text data generation due to the sequential structure of the language. Recurrent methods can be divided into three primary types: single-layer, stacked-layer, and attention-based approaches.
- –
Single-Layer Approaches. Vinyals et al. [
71,
151] propose a simple single-layer LSTM-based [
152] captioning system. Specifically, a convolutional neural Network is employed as an image encoder, followed by LSTM Recurrent Neural Networks as decoders to generate the output sequence. The authors conceptualize image captioning in a way that predicts the probability of a given sentence based on the input image.
- –
Stacked-Layers Approaches. LRCN model [
153] processes the visual input with CNN modules, whose outputs are fed into a stack of recurrent sequence models (two-layer LSTMs) to generate a variable-length sentence description for an input image. Donahue et al. input the image and context word features to the recurrent model at each step instead of feeding visual features to the system solely at the initial phase.
- –
Attention-Based Approaches. This work [
83] introduces top-down and bottom-up attention to salient objects and other image regions. According to this work, based on Faster R-CNN [
49], the bottom-up mechanism proposes image regions with a feature vector associated with them (each represented by a pooled convolutional feature vector). In contrast, the top-down mechanism uses task-specific context to predict an attention distribution over the image regions and determine feature weights.
CNN-Based Methods. LSTM modules overlook a sentence’s underlying hierarchy. Moreover, a memory cell’s long-term dependencies also demand notable storage, which leads to the introduction of CNNs as language models. Unlike LSTMs, CNNs are faster and can learn the internal structure of sentences. The language CNN model introduced in [
154] is able to capture long-range dependencies in sequences. It examines the hierarchical and temporal data sequentially for image captioning. An image captioning method using convolutional LSTM units is proposed in [
92] to resolve this issue that arises from LSTM units’ complexity and sequential nature. It uses convolutional machine translation models combined with an attention mechanism to utilize spatial image features. The authors of this work provide valuable insights, such as CNNs produce more entropy, do not suffer from vanishing gradients, and are more accurate. The CNN + CNN framework [
93], another fast and competitive model with LSTM-based language models, investigated how the kernel width and layer depth of the language CNN impact image captioning. In a meaningful way, according to the authors, the model can visualize learned attention maps and discover the concepts by paying attention to the related areas in images.
Transformer-Based Methods. The majority of conventional captioning systems use an encoder–decoder framework. First, an input image is encoded into a representation of information within the image and then decoded into an image description. However, these practical and state-of-the-art methods overlook the spatial relationships among the detected objects. The Object Relation Transformer [
94] integrates object spatial relationship modeling into image captioning. The Dual-Level Collaborative Transformer (DLCT) [
95] leverages region and grid features to enhance image captioning. Moreover, the locality-constrained cross-attention (LCCA) module designed in this work addresses the problem of semantic noise produced when two sources of features are directly fused. To guide the alignment of two sources of features, LCCA constructs a geometric alignment graph.
BERT-Like Paradigm Methods. Instead of constructing the narrative of an image using the encoder–decoder framework, some approaches have attempted to tackle this task by following the structure of BERT [
155]. This category of methods, such as the Vision-Language Pretraining (VLP) model [
96], which can be fine-tuned for image-to-text generation and understanding tasks, directly connect the visual and textual inputs.
Diffusion-Based Methods. In image captioning, the text tokens are decoded one at a time using an auto-regressive method. Non-autoregressive methods, such as diffusion-based captioning models [
156,
157,
158], emit all words simultaneously, enabling bidirectional textual message exchange, in contrast to autoregressive methods that generate sentences word-by-word.
Narrative Length-Based Methods. Most methods generate narratives for the complete scene in the query image. On the other hand, another category for narrative construction, called dense captioning, generates narratives for each scene region. These two various approaches are discussed in detail in the following paragraphs.
7. Task 5: Story Presentation and Querying
7.1. Intelligent Widget for Narrative Discovery
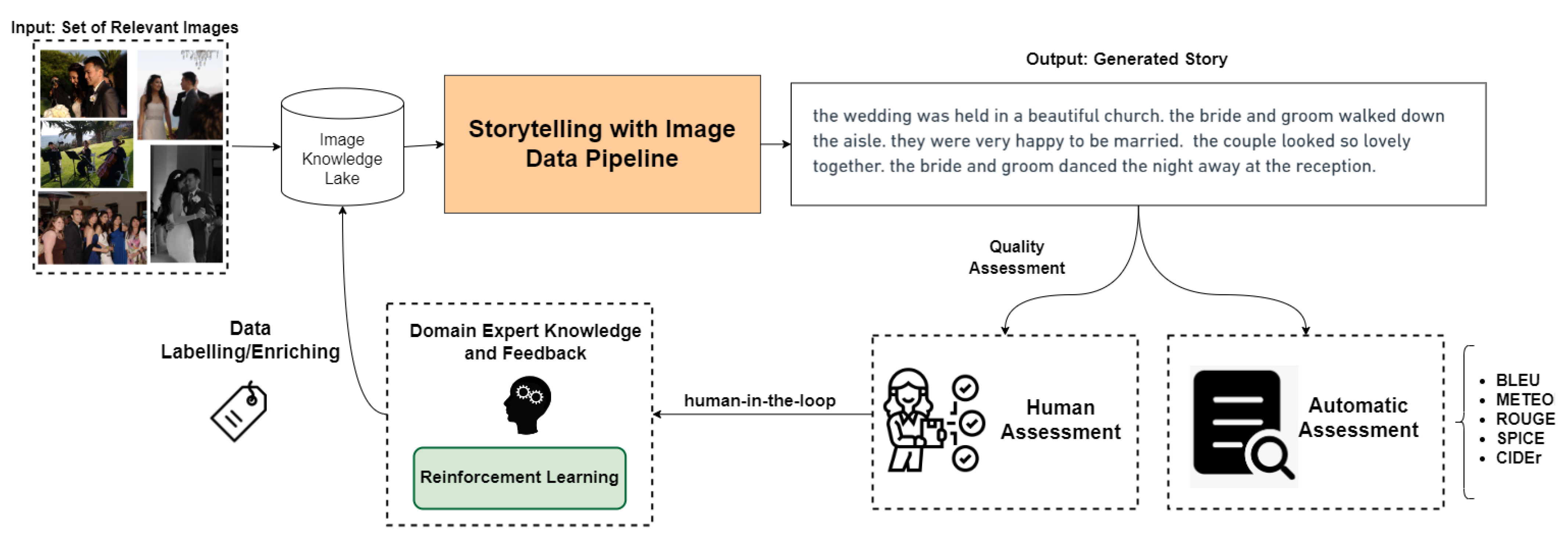
In the past decades, numerous images have been uploaded to online platforms containing hidden, interesting information that should be discovered. However, the uploaded raw data do not deliver any insights. Accordingly, these raw data should be curated and transformed into knowledge. Data analytics helps understand the data; however, it is insufficient, and a solution to accomplish such knowledge could be storytelling with image data.
Personalized storytelling demands human–computer interaction, since direct interaction with the end-users is indispensable. Story creation has complicated challenges; however, representing the generated story to end-users is another issue that needs careful attention. Creating graphical representations of data is known as data visualization. Visualization techniques translate information into a visual context, such as a map or graph, so the human brain can comprehend and extract hidden insights. For example, large datasets can be visualized to identify patterns, trends, and outliers. Therefore, an interactive visualization module, a dashboard, is the most proper environment for engaging users and being able to recommend various data based on the user’s needs. Regardless, storytelling with image data is more than simply visualizing data. Instead, this process transforms raw image data into insightful narratives by highlighting valuable information and proving key points. Together, storytelling and visualization make a powerful combination. An intelligent widget allows for presenting a contextual and visual component alongside content in a platform, supplying the end-users with a visual fragment of the most relevant and representative data. It also enables user interaction and uses domain knowledge and expertise to achieve a subjective demand. Visualization objectives, benefits, and challenges are discussed in the following.
Visualization Objectives. Data visualization serves a straightforward objective. It is to comprehend the data and use them for the end-user benefit. However, since data are complex, they attain more value when visualized. Therefore, visualization is crucial for communicating data findings, identifying patterns, and interacting with data.
Visualization Benefits. In addition to providing a better understanding of the data, data visualization facilitates sharing information with some audiences, helps accurately analyze data, and uncovers relationships between events and entities.
Visualization Challenges. Visualization delivers estimation, not accuracy. It may not be objective, may have improper design issues, and the core messages may be skipped.
7.2. Visualization Techniques
Data visualization involves various strategies, so knowing which ones to utilize and when is essential. We can point out bar charts, line charts, pie charts, histograms, radial maps, box plots, and violin plots as some of the essential data visualization techniques.
Static Data Visualization. There is no interaction capability in static data visualization, and the information does not change over time. Because static visualizations cannot be adjusted, such as through filtering and zooming, it is vital to consider what data are displayed. Knaflic et al. [
123] mainly focuses on static data visualization.
Interactive Data Visualization. Users can better identify patterns and discover new relationships within their data by allowing direct interaction. Data visualization assists in transforming raw data into valuable insights. Using interactive visualization, the end-user experience is also collected, which assists the customer journey/experience process. As an interactive data visualization approach, we can point to the storytelling engine in iStory presented in [
6].
Adaptive Data Visualization. This visualization improves visualization by incorporating adaptations, i.e., changing the visualization based on various end-user features, either explicitly provided or inferred from the traces of the user’s actions. For example, Toker et al. [
124] proves that specific user characteristics significantly affect task efficiency, user preference, and ease of use.
9. Conclusions, Discussion, and Future Directions
The field of storytelling with image data is a relatively new area of research that has not been well-established despite recent accomplishments in storytelling in general. To address this, a systematic review and a comparative analysis of methods and tools were conducted to identify, evaluate, and interpret relevant research in this field. The state of the art in the curation, summarization, and presentation of large amounts of image data in a succinct and consumable manner to end-users was analyzed, and a taxonomy was introduced to identify important tasks in constructing narratives and stories from image data.
The proposed taxonomy consists of several phases, including data curation (from preprocessing to extraction, enrichment, linking, and adding value), story modeling, intelligent narrative discovery, story creation, and story presentation and querying. It is argued that storytelling is distinct from simple data visualization techniques or image data analytics, since it enables the discovery and understanding of hidden, complex, and valuable data insights. The paper also discussed the evaluation measures for assessing the quality of the generated story, which are crucial for ensuring that the story is both informative and relevant to the end-user. In summary, this paper lays the foundation for further research in the field of storytelling with image data by providing a framework for identifying important tasks and evaluation measures.
9.1. Discussion
The proposed approach of storytelling with image data has several advantages. First, this framework can help address the challenges in understanding and analyzing large amounts of image data, which are often scattered across different sources and data islands. By curating and summarizing these data in a digestible manner, storytelling with image data can help users gain a better understanding of the insights and relationships locked within the data. Moreover, the use of storytelling as a metaphor can make the data more accessible to a wider range of users who may not have the technical skills to understand complex data analysis techniques.
However, this approach also faces several challenges. One of the major obstacles is the lack of effective methods for labeling, captioning, and extracting information from images. As a result, it can be difficult to ensure the accuracy and relevance of the data presented in the stories. Another challenge is the potential for bias and subjectivity in the narratives presented in the stories. Depending on the storyteller’s perspective, the story may focus on certain details and overlook others, potentially leading to incomplete or misleading interpretations of the data. Additionally, the sheer volume of image data available poses a significant challenge for data processing and storage, making it necessary to develop scalable and efficient methods for analyzing and presenting these data in a meaningful way.
In particular, while the storytelling with image data approach has great potential for improving data comprehension and analysis, it also faces several challenges. Addressing these challenges will require ongoing research and development of new methods for image data labeling, extraction, and analysis, as well as careful consideration of the potential for bias and subjectivity in the narratives presented in the stories. With continued innovation and collaboration, storytelling with image data has the potential to revolutionize the way we analyze and understand large amounts of unstructured data in the digital age.
9.2. Future Directions
The field of storytelling with image data is a rapidly evolving research area, with ongoing efforts to improve the techniques and metrics used to assess the generated story. Despite recent advances, there are still significant knowledge gaps and limitations in the state-of-the-art methods. Recent research in text generation has focused on open-ended domains, such as stories, but evaluating the quality of the generated text remains a complex challenge. Current evaluation methods often rely on human judgments of the quality of narratives, which can be unreliable if not properly conducted. Improving the quality assessment of storytelling with image data is essential and requires further investigation. Additionally, benchmark datasets in different domains of storytelling with image data need to be properly labeled to facilitate research and development in this field.
In future work, we aim to use the knowledge gained from this survey to present an Open Story Model that will transform raw image data into contextualized data and knowledge. The model will automatically discover and connect events and entities from the contextualized data to construct a Knowledge Graph. This graph will be summarized and used to facilitate intelligent narrative discovery, enabling image data stories to combine with narratives to reduce ambiguity and connect image data with context. The model will also support interactive visualization on top of the data summaries to help analysts construct their own stories based on their points of view and subjective goals.
There are several other potential areas for future research and development in the field of storytelling with image data. Some potential avenues of exploration include the following: (i) Developing more advanced metrics for evaluating image data stories, such as those that take into account sentence structure and topic coherence. These metrics could help improve the quality assessment of image data stories and provide insights into specific errors made by the model. (ii) Exploring new approaches for generating image data stories that are more creative and engaging. For example, researchers could explore the use of generative adversarial networks (GANs) to create more visually appealing and realistic image data stories. (iii) Investigating the use of multimodal data sources to enhance the quality of image data stories. For example, combining image data with text, audio, or video data could help to provide a more complete and engaging story. (iv) Developing new interactive tools and platforms for creating and sharing image data stories. These tools could be designed to make it easier for users to explore and interact with image data stories and to share their own stories with others. (v) Applying image data storytelling techniques to new domains and applications. For example, researchers could explore the use of image data stories in education, healthcare, or social media, where they could be used to communicate complex information in a more engaging and accessible way.
Overall, the field of storytelling with image data is still in its early stages, and there is a wealth of potential areas for future research and development. As researchers continue to explore these areas, we can expect to see significant advances in the techniques and tools used to create and evaluate image data stories, with far-reaching implications for a wide range of applications.



 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}