

Computing the Gromov-Wasserstein Distance between Two Surface Meshes Using Optimal Transport

Abstract
:1. Introduction
2. The Discrete Gromov-Wasserstein Problem
| Algorithm 1 An iterative solver for the regularized GW problem. |
|
- (i)
- Solving the regularized OT problem in step 2 is difficult when (a necessary condition to get to the real GW distance).
- (ii)
- Algorithm 1 is basically a fixed point method for which there is no guarantee of convergence. This is discussed in detail in Ref. [22].
- (iii)
- There is no easy option within Algorithm 1 to compute a scaling factor between distances within and distances within . Those distances may have different scales, however, which can significantly impact the numerical stability of the algorithm.
3. A Statistical Physics Approach to Solving the Gromov-Wasserstein Problem
4. Implementation
- (i)
- Faster computation of the “cost matrix” .Recall that in the SPA system of equations, the cost matrix C is defined as:with a total time complexity of to compute the whole matrix. In the special case , the absolute value is not necessary and the equation can be rewritten in matrix form aswhere is a vector of ones of dimension N and ⊙ is the Hadamard product. The time complexity of computing C using this equation of , a significant improvement compared to the general case when and are large. This property was already proposed as “Proposition 1” by Peyré et al. [22].
- (ii)
- Computing the scaling factor. In the general case, given the matrix D, solving Equation (27) for the scaling factor s amounts to finding the zeros of a polynomial function of degree , with possibly real roots (see Equation (27)). In the specific case , however, there is a unique solution to this problem, defined as
| Algorithm 2 FreeGW: a temperature dependent framework for computing the Gromov Wasserstein Distance between two weighted set of points belonging to two different metric spaces. |
|
5. Computational Experiments
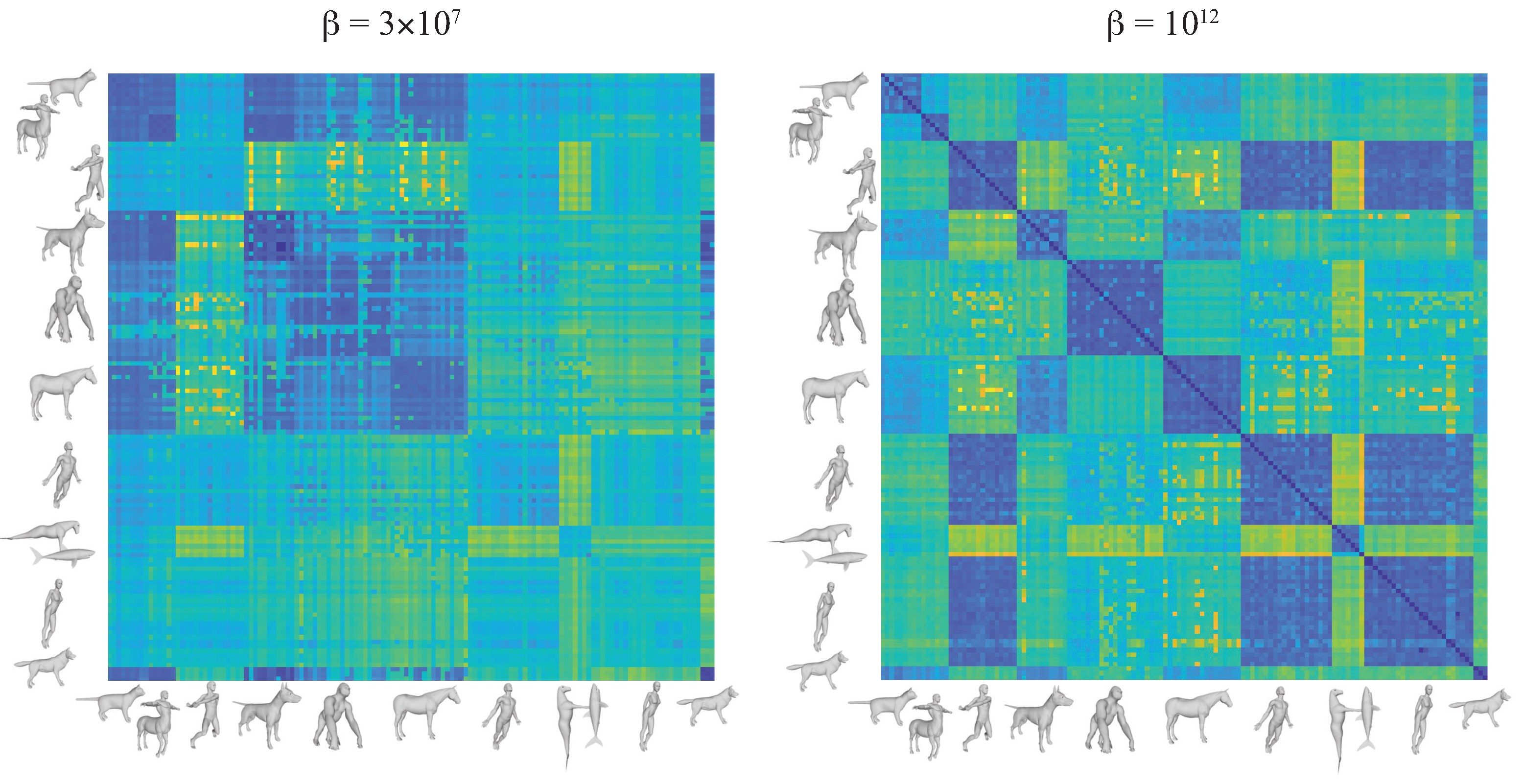
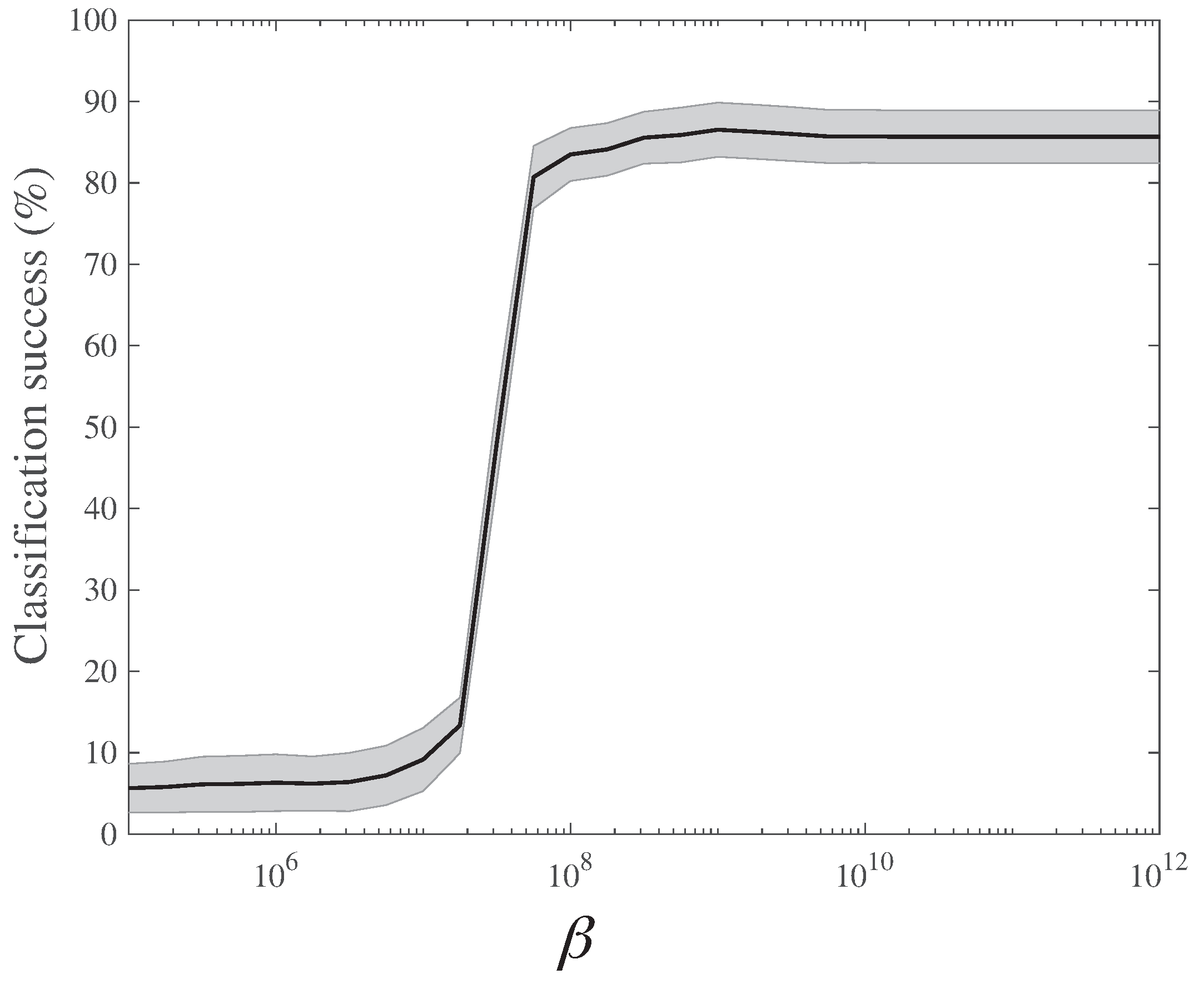
5.1. Shape Similarity: Synthetic Data from TOSCA
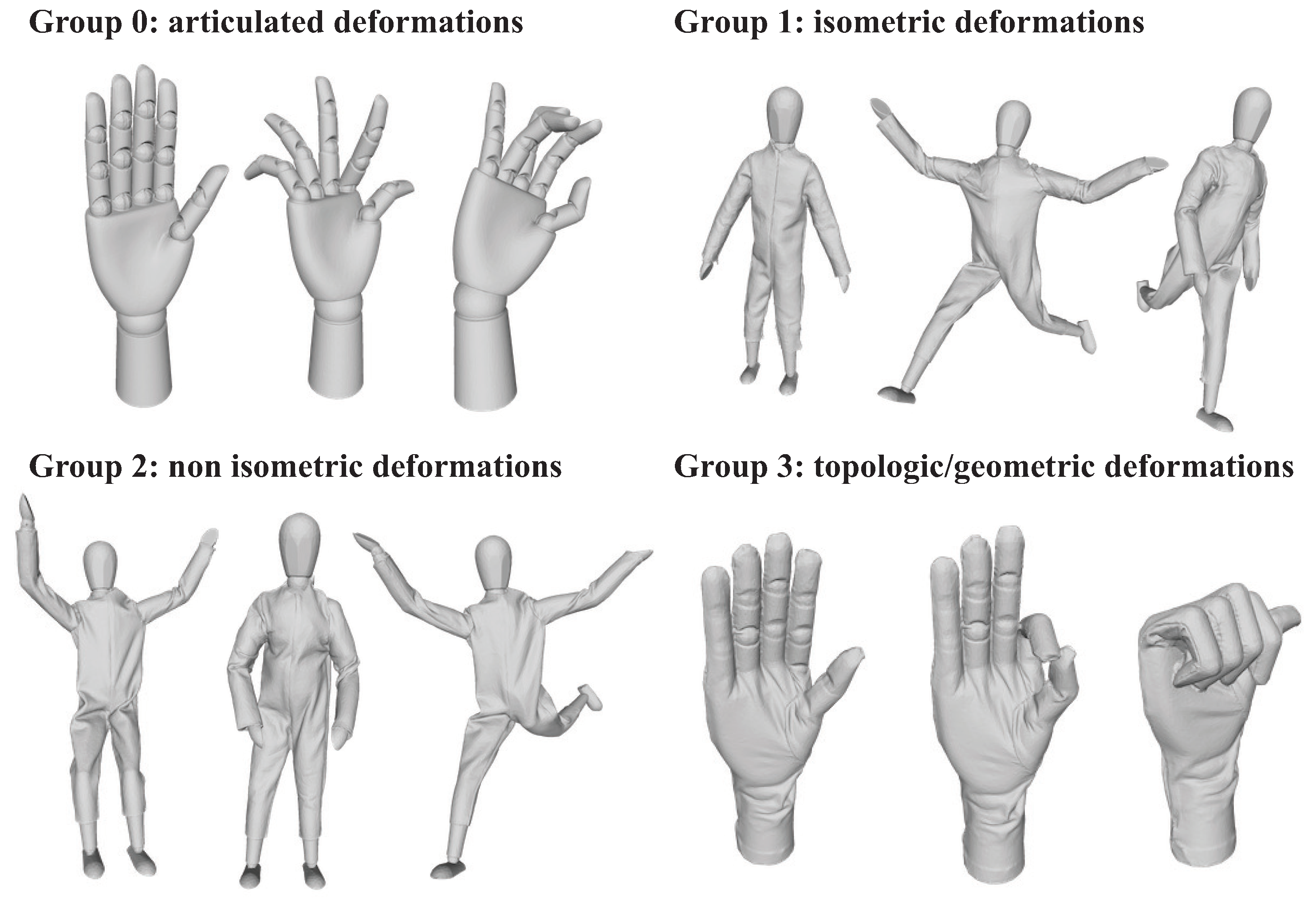
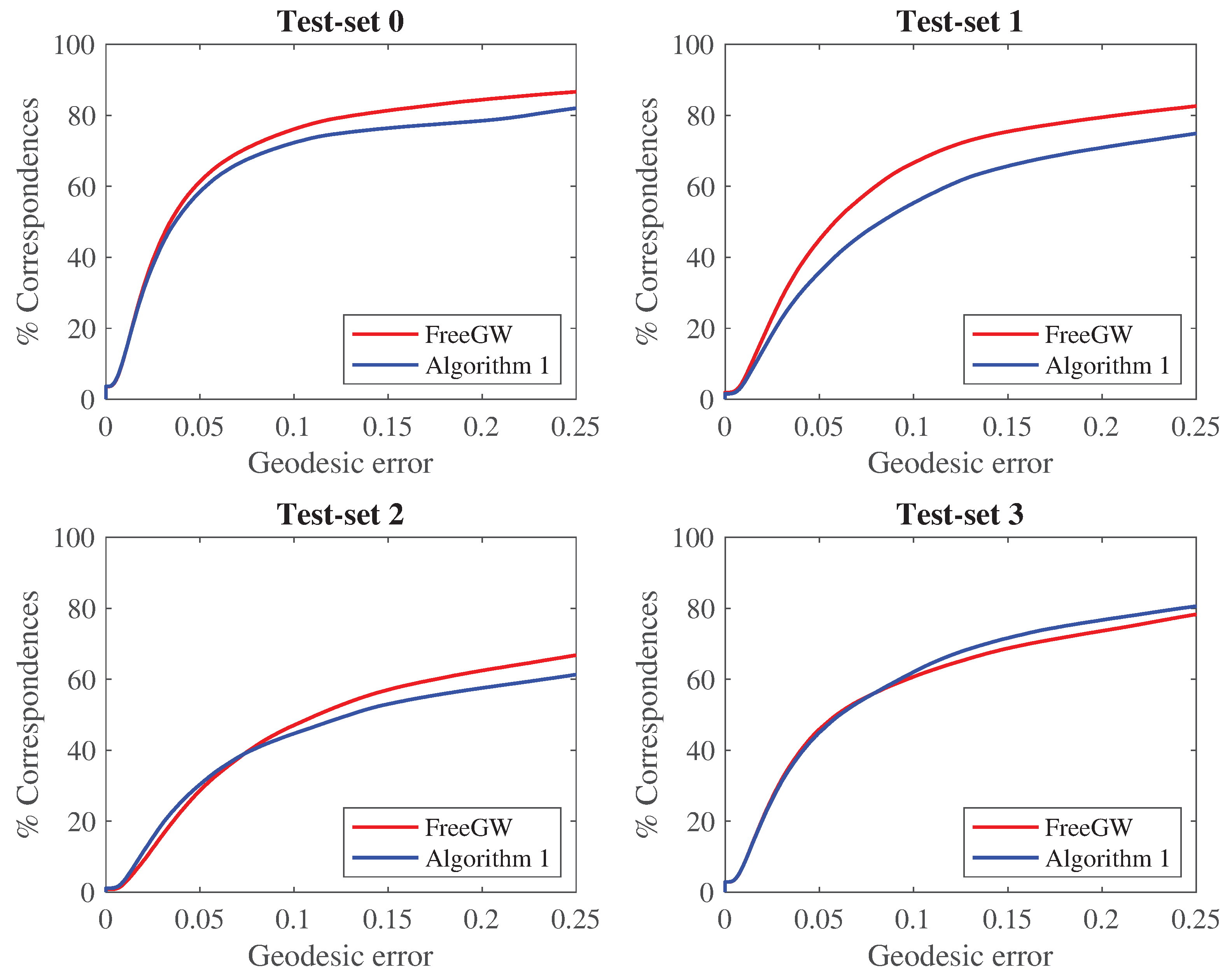
5.2. Shape Correspondence: Synthetic Data from SHREC19
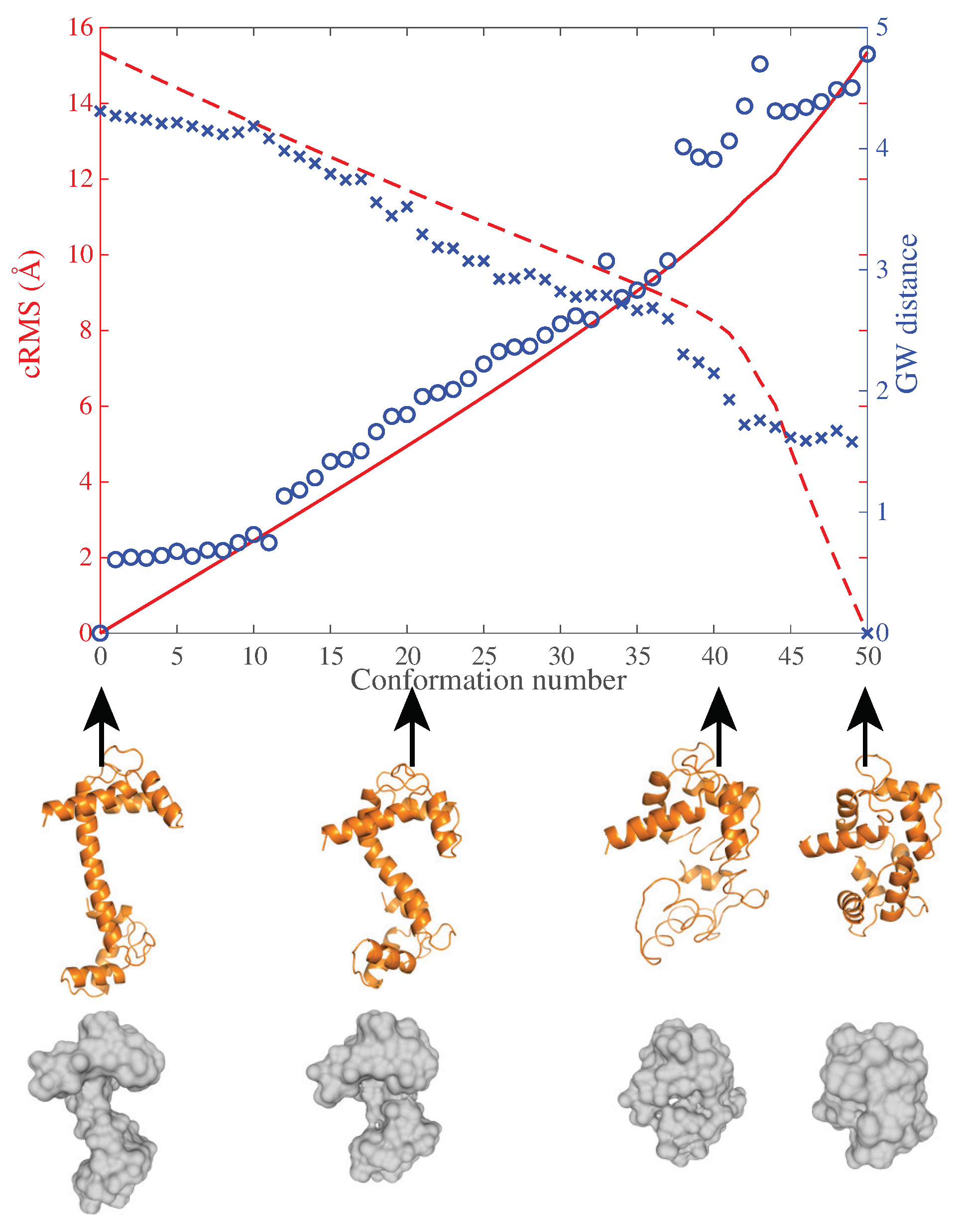
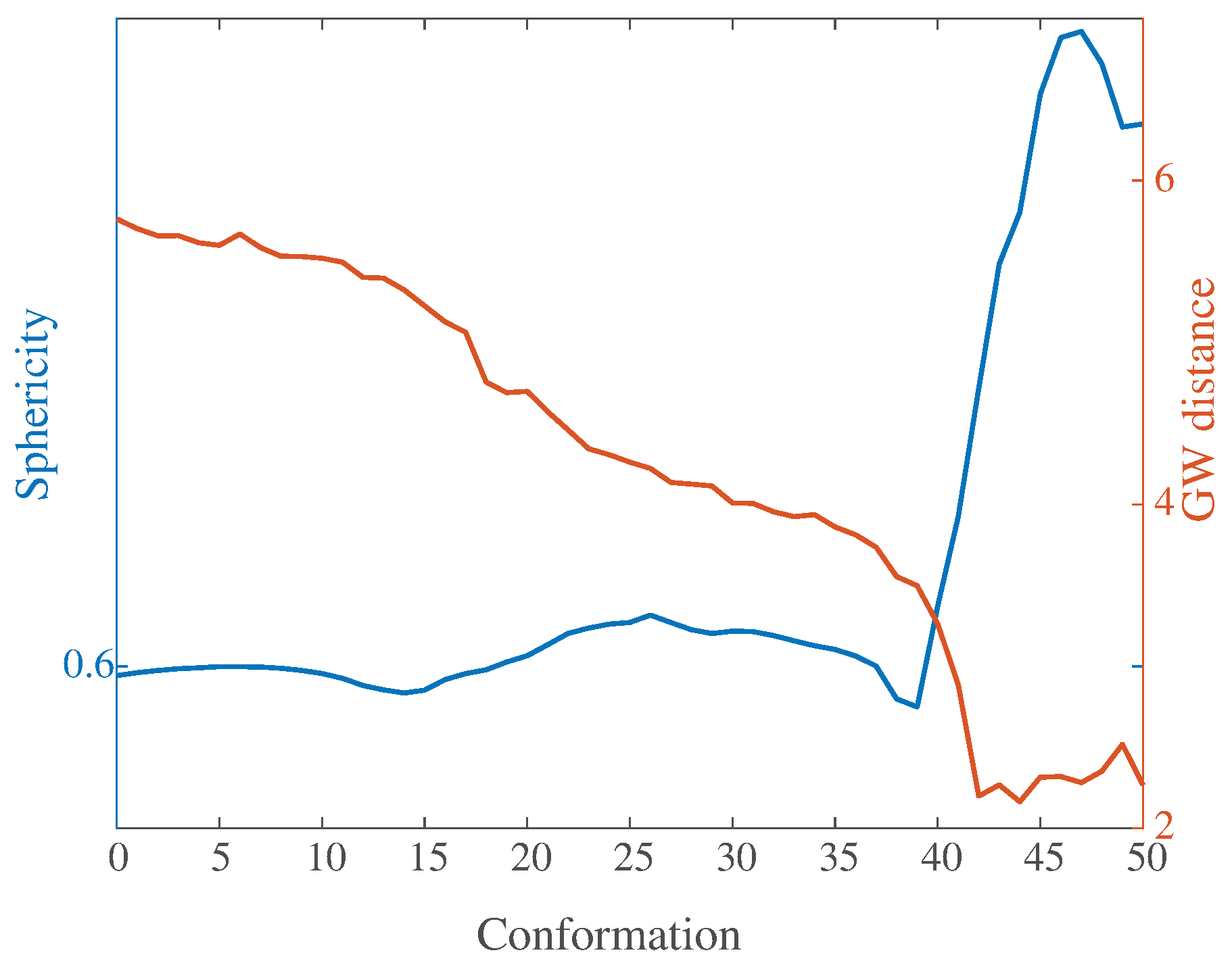
5.3. Shape Similarity: Morphodynamics of Protein Structure Surfaces
5.4. How Round Is Calmodulin?
- (i)
- The sphericity S of a surface F quantifies how well it encloses volume. It is expressed as the surface area of an equivalent sphere (i.e., with the same volume V as the volume enclosed by F) divided by the surface area A of F:The sphericity is at most one, and equals one only for the round sphere,
- (ii)
- The GW distance between the surface of the protein and the surface of a round sphere.
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Proof of Property 1: Monotonicity of the Free Energy and Average Energy
Appendix B. Proof of Proposition 2: Retrieving the Transport Plan from the SPA Solutions
Appendix C. Proof of Proposition 3: Monotonicity and Limits of F MF (β) and U MF (β)
Appendix C.1. Monotonicity of the Free Energy
Appendix C.2. Monotonicity of the Energy
References
- Monge, G. Mémoire sur la theorie des deblais et des remblais. Hist. l’Acad. R. Sci. Mem. Math. Phys. Tires Regist. Cette Acad. 1781, 1784, 666–704. [Google Scholar]
- Léonard, C. A survey of the Schrödinger problem and some of its connections with optimal transport. Discret. Contin. Dyn. Syst. Ser. A 2014, 34, 1533–1574. [Google Scholar] [CrossRef]
- Kantorovich, L. On the transfer of masses. Dokl. Acad. Nauk. USSR 1942, 37, 7–8. [Google Scholar]
- Villani, C. Optimal Transport: Old and New; Grundlehren der Mathematischen Wissenschaften; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Peyré, G.; Cuturi, M. Computational Optimal Transport. arXiv 2018, arXiv:1803.00567. [Google Scholar]
- Villani, C. Topics in Optimal Transportation; Graduate Studies in Mathematics; American Mathematical Society: Providence, RI, USA, 2003. [Google Scholar]
- Mémoli, F. On the use of Gromov-Hausdorff Distances for Shape Comparison. In Proceedings of the Eurographics Symposium on Point-Based Graphics, Prague, Czech Republic, 2–3 September 2007; pp. 81–90. [Google Scholar]
- Mémoli, F. Gromov-Wasserstein distances and the metric approach to object matching. Found. Comput. Math. 2011, 11, 417–487. [Google Scholar] [CrossRef]
- Boyer, D.; Lipman, Y.; StClair, E.; Puente, J.; Patel, B.; Funkhouser, T.; Jernvall, J.; Daubechies, I. Algorithms to automatically quantify the geometric similarity of anatomical surface. Proc. Natl. Acad. Sci. USA 2011, 108, 18221–18226. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alvarez-Melis, D.; Jaakkola, T.S. Gromov-Wasserstein alignment of word embedding spaces. arXiv 2018, arXiv:1809.00013. [Google Scholar]
- Yan, Y.; Li, W.; Wu, H.; Min, H.; Tan, M.; Wu, Q. Semi-Supervised Optimal Transport for Heterogeneous Domain Adaptation. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018; Volume 7, pp. 2969–2975. [Google Scholar]
- Ezuz, D.; Solomon, J.; Kim, V.G.; Ben-Chen, M. GWCNN: A metric alignment layer for deep shape analysis. In Proceedings of the Computer Graphics Forum, Lyon, France, 24–28 April; 2017; Volume 36, pp. 49–57. [Google Scholar]
- Nguyen, D.H.; Tsuda, K. On a linear fused Gromov-Wasserstein distance for graph structured data. Pattern Recognit. 2023, 138, 109351. [Google Scholar] [CrossRef]
- Titouan, V.; Courty, N.; Tavenard, R.; Flamary, R. Optimal transport for structured data with application on graphs. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6275–6284. [Google Scholar]
- Zheng, L.; Xiao, Y.; Niu, L. A brief survey on Computational Gromov-Wasserstein distance. Procedia Comput. Sci. 2022, 199, 697–702. [Google Scholar] [CrossRef]
- Chowdhury, S.; Needham, T. Generalized spectral clustering via Gromov-Wasserstein learning. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Virtual, 13–15 April 2021; pp. 712–720. [Google Scholar]
- Bunne, C.; Alvarez-Melis, D.; Krause, A.; Jegelka, S. Learning generative models across incomparable spaces. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 851–861. [Google Scholar]
- Cuturi, M. Sinkhorn Distances: Lightspeed Computation of Optimal Transport. In Advances in Neural Information Processing Systems 26; Burges, C.J.C., Bottou, L., Welling, M., Ghahramani, Z., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2013; pp. 2292–2300. [Google Scholar]
- Deming, W.E.; Stephan, F.F. On a least squares adjustment of a sampled frequency table when the expected marginal totals are known. Ann. Math. Stat. 1940, 11, 427–444. [Google Scholar] [CrossRef]
- Sinkhorn, R. A relationship between arbitrary positive matrices and doubly stochastic matrices. Ann. Math. Stat. 1964, 35, 876–879. [Google Scholar] [CrossRef]
- Sinkhorn, R.; Knopp, P. Concerning nonnegative matrices and doubly stochastic matrices. Pacific J. Math. 1967, 21, 343–348. [Google Scholar] [CrossRef] [Green Version]
- Peyré, G.; Cuturi, M.; Solomon, J. Gromov-Wasserstein Averaging of Kernel and Distance Matrices. In Proceedings of the Proceeding ICML’16, New York, NY, USA, 19–24 June 2016; pp. 2664–2672. [Google Scholar]
- Koehl, P.; Delarue, M.; Orland, H. A statistical physics formulation of the optimal transport problem. Phys. Rev. Lett. 2019, 123, 040603. [Google Scholar] [CrossRef] [PubMed]
- Koehl, P.; Delarue, M.; Orland, H. Finite temperature optimal transport. Phys. Rev. E 2019, 100, 013310. [Google Scholar] [CrossRef] [PubMed]
- Koehl, P.; Orland, H. Fast computation of exact solutions of generic and degenerate assignment problems. Phys. Rev. E 2021, 103, 042101. [Google Scholar] [CrossRef]
- Koehl, P.; Delarue, M.; Orland, H. Physics approach to the variable-mass optimal-transport problem. Phys. Rev. E 2021, 103, 012113. [Google Scholar] [CrossRef]
- Gould, N.I.; Toint, P.L. A quadratic programming bibliography. Numer. Anal. Group Intern. Rep. 2000, 1, 32. [Google Scholar]
- Wright, S. Continuous optimization (nonlinear and linear programming). In The Princeton Companion to Applied Mathematics; Higham, N., Dennis, M., Glendinning, P., Martin, P., Sentosa, F., Tanner, J., Eds.; Princeton University Press: Princeton, NJ, USA, 2015; pp. 281–293. [Google Scholar]
- Pardalos, P.; Vavasis, S. Quadratic programming with one negative eigenvalue is (strongly) NP-hard. J. Glob. Optim. 1991, 1, 15–22. [Google Scholar] [CrossRef]
- Nocedal, J.; Wright, S.J. Quadratic programming. Numer. Optim. 2006, 448–492. [Google Scholar]
- Benamou, J.; Carlier, G.; Cuturi, M.; Nenna, L.; Peyré, G. Iterative Bregman Projections for Regularized Transportation Problems. SIAM J. Sci. Comput. 2015, 37, A1111–A1138. [Google Scholar] [CrossRef] [Green Version]
- Genevay, A.; Cuturi, M.; Peyré, G.; Bach, F. Stochastic Optimization for Large-scale Optimal Transport. In Advances in Neural Information Processing Systems 29; Curran Associates, Inc.: Red Hook, NY, USA, 2016; pp. 3440–3448. [Google Scholar]
- Schmitzer, B. Stabilized Sparse Scaling Algorithms for Entropy Regularized Transport Problems. arXiv 2016, arXiv:1610.06519. [Google Scholar] [CrossRef] [Green Version]
- Dvurechensky, P.; Gasnikov, A.; Kroshnin, A. Computational Optimal Transport: Complexity by Accelerated Gradient Descent Is Better Than by Sinkhorn’s Algorithm. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 1367–1376. [Google Scholar]
- Chizat, L.; Peyré, G.; Schmitzer, B.; Vialard, F.X. Scaling Algorithms for Unbalanced Transport Problems. Math. Comp. 2018, 87, 2563–2609. [Google Scholar] [CrossRef]
- Bronstein, A.; Bronstein, M.; Kimmel, R. Efficient computation of isometry-invariant distances between surfaces. SIAM J. Sci. Comput. 2006, 28, 1812–1836. [Google Scholar] [CrossRef] [Green Version]
- Bronstein, A.; Bronstein, M.; Kimmel, R. Calculus of non-rigid surfaces for geometry and texture manipulation. IEEE Trans. Vis. Comput. Graph 2007, 13, 902–913. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mitchell, J.; Mount, D.; Papadimitriou, C. The discrete geodesic problem. SIAM J. Comput. 1987, 16, 647–668. [Google Scholar] [CrossRef]
- Dyke, R.M.; Stride, C.; Lai, Y.K.; Rosin, P.L.; Aubry, M.; Boyarski, A.; Bronstein, A.M.; Bronstein, M.M.; Cremers, D.; Fisher, M.; et al. Shape Correspondence with Isometric and Non-Isometric Deformations. In Proceedings of the Eurographics Workshop on 3D Object Retrieval; Biasotti, S., Lavoué, G., Veltkamp, R., Eds.; The Eurographics Association: Eindhoven, The Netherlands, 2019. [Google Scholar]
- Li, K.; Yang, J.; Lai, Y.K.; Guo, D. Robust non-rigid registration with reweighted position and transformation sparsity. IEEE Trans. Visual. Comput. Graphics 2018, 25, 2255–2269. [Google Scholar] [CrossRef] [Green Version]
- Dyke, R.; Lai, Y.K.; Rosin, P.; Tam, G. Non-rigid registration under anisotropic deformations. Comput. Aided Geom. Des. 2019, 71, 142–156. [Google Scholar] [CrossRef]
- Vestner, M.; Lähner, Z.; Boyarski, A.; Litany, O.; Slossberg, R.; Remez, T.; Rodolà, E.; Bronstein, A.; Bronstein, M.; Kimmel, R.; et al. Efficient deformable shape correspondence via kernel matching. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 517–526. [Google Scholar]
- Sahillioğlu, Y. A genetic isometric shape correspondence algorithm with adaptive sampling. ACM Trans. Graph. (ToG) 2018, 37, 1–14. [Google Scholar] [CrossRef]
- Franklin, J.; Koehl, P.; Doniach, S.; Delarue, M. MinActionPath: Maximum likelihood trajectory for large-scale structural transitions in a coarse-grained locally harmonic energy landscape. Nucl. Acids. Res. 2007, 35, W477–W482. [Google Scholar] [CrossRef] [Green Version]
- Chou, J.; Li, S.; Klee, C.; Bax, A. Solution structure of Ca(2+)-calmodulin reveals flexible hand-like properties of its domains. Nat. Struct. Biol. 2001, 8, 990–997. [Google Scholar] [CrossRef]
- Berman, H.; Westbrook, J.; Feng, Z.; Gilliland, G.; Bhat, T.; Weissig, H.; Shindyalov, I.; Bourne, P. The Protein Data Bank. Nucleic Acids Res. 2000, 28, 235–242. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kabsch, W. A solution for the best rotation to relate two sets of vectors. Acta Crystallogr. 1976, 32, 922–923. [Google Scholar] [CrossRef]
- Coutsias, E.; Seok, C.; Dill, K. Using quaternions to calculate RMSD. J. Comput. Sci. 2004, 25, 1849–1857. [Google Scholar] [CrossRef] [PubMed]
- Edelsbrunner, H. Deformable Smooth Surface Design. Discret. Comput. Geom. 1999, 21, 87–115. [Google Scholar] [CrossRef] [Green Version]
- Cheng, H.; Shi, X. Guaranteed Quality Triangulation of Molecular Skin Surfaces. In Proceedings of the IEEE Visualization, Austin, TX, USA, 10–15 October 2004; pp. 481–488. [Google Scholar]
- Cheng, H.; Shi, X. Quality Mesh Generation for Molecular Skin Surfaces Using Restricted Union of Balls. In Proceedings of the IEEE Visualization, Minneapolis, MN, USA, 23–28 October 2005; pp. 399–405. [Google Scholar]
- Semeshko, A. Suite of Functions to Perform Uniform Sampling of a Sphere. GitHub. Available online: https://github.com/AntonSemechko/S2-Sampling-Toolbox (accessed on 2 January 2023).
- Barber, C.B.; Dobkin, D.; Huhdanpaa, H. The Quickhull Algorithm for Convex Hulls. ACM Trans. Math. Softw. 1996, 22, 469–483. [Google Scholar] [CrossRef] [Green Version]
- Abdul-Hassan, N.Y.; Ali, A.H.; Park, C. A new fifth-order iterative method free from second derivative for solving nonlinear equations. J. Appl. Math. Comput. 2021, 68, 2877–2886. [Google Scholar] [CrossRef]
- Séjourné, T.; Peyré, G.; Vialard, F.X. Unbalanced Optimal Transport, from theory to numerics. arXiv 2022, arXiv:2211.08775. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method a | Test-Set 0 | Test-Set 1 | Test-Set 2 | Test-Set 3 | All Test Sets |
|---|---|---|---|---|---|
| RPTS [40] | 0.920 b | 0.926 | 0.824 | 0.929 | 0.899 |
| NRP [41] | 0.878 | 0.899 | 0.801 | 0.858 | 0.862 |
| WRAP | 0.853 | 0.920 | 0.772 | 0.870 | 0.856 |
| KM [42] | 0.760 | 0.865 | 0.757 | 0.799 | 0.804 |
| FreeGW d | 0.706 | 0.879 | 0.550 | 0.320 | 0.588 |
| Algo1 e | 0.666 | 0.846 | 0.490 | 0.338 | 0.548 |
| GISC [43] | 0.565 | 0.659 | 0.674 | NA c | NA c |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koehl, P.; Delarue, M.; Orland, H. Computing the Gromov-Wasserstein Distance between Two Surface Meshes Using Optimal Transport. Algorithms 2023, 16, 131. https://doi.org/10.3390/a16030131
Koehl P, Delarue M, Orland H. Computing the Gromov-Wasserstein Distance between Two Surface Meshes Using Optimal Transport. Algorithms. 2023; 16(3):131. https://doi.org/10.3390/a16030131
Chicago/Turabian StyleKoehl, Patrice, Marc Delarue, and Henri Orland. 2023. "Computing the Gromov-Wasserstein Distance between Two Surface Meshes Using Optimal Transport" Algorithms 16, no. 3: 131. https://doi.org/10.3390/a16030131