

A Comparison of Different Topic Modeling Methods through a Real Case Study of Italian Customer Care

Abstract
:1. Introduction
1.1. Literature Review
1.2. Motivation Example
2. Topic Modeling
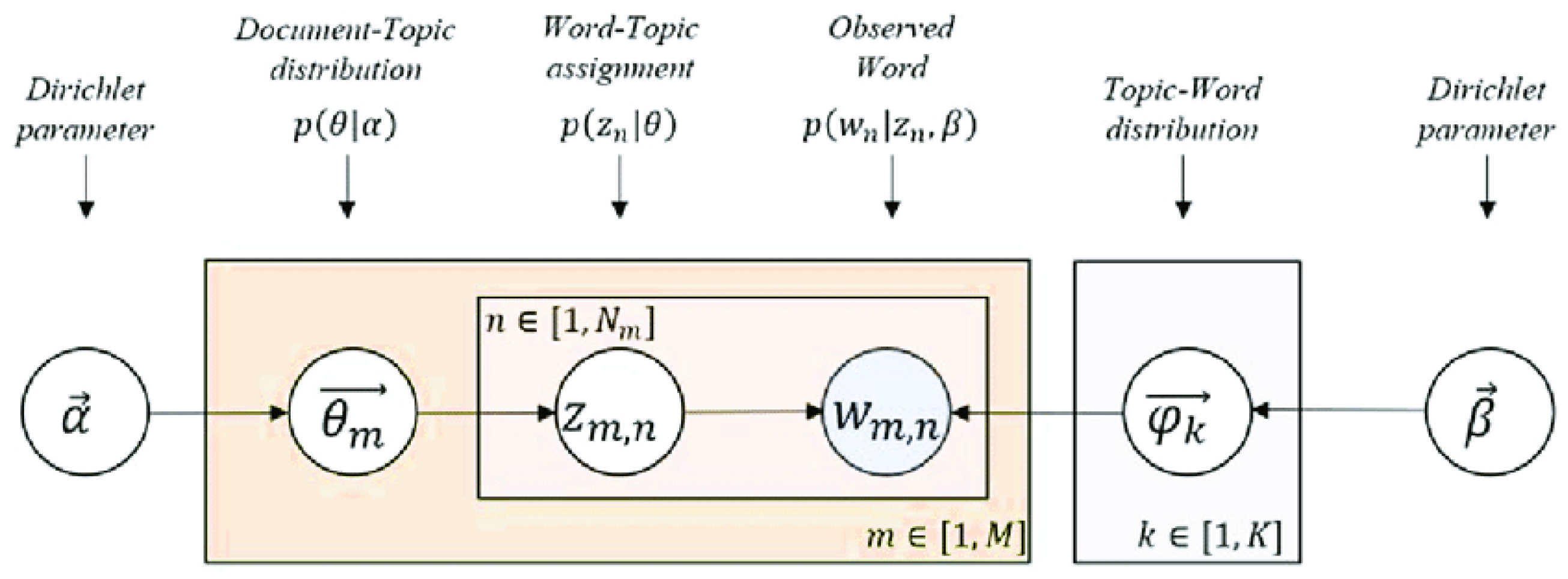
2.1. Latent Dirichlet Allocation (LDA)
- Retrospective topic detection: the algorithm identifies the topics featured in a set of “never seen before” data; after processing them, it groups them into homogeneous clusters.
- Online new topic detection: the algorithm processes and establishes whether textual data deal with new topics or belongs to the existing clusters.
2.2. Non-Negative Matrix Factorization (NMF)
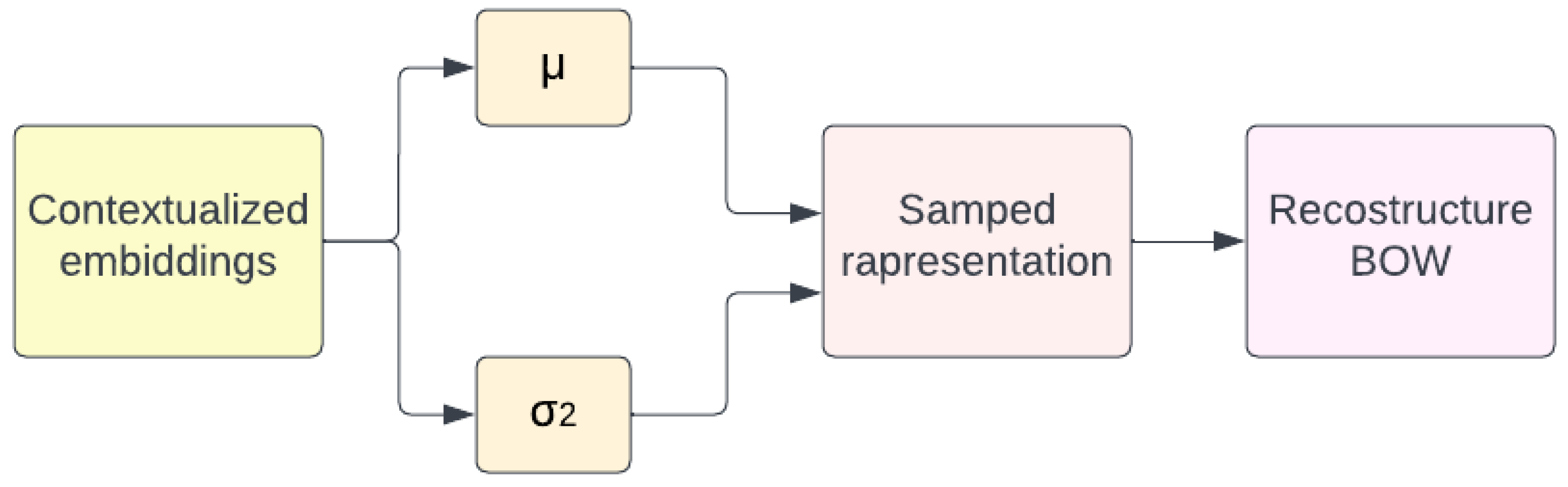
2.3. Neural-ProdLDA
2.4. Contextualized Topic Models (CTM)
2.5. Evaluation Metrics
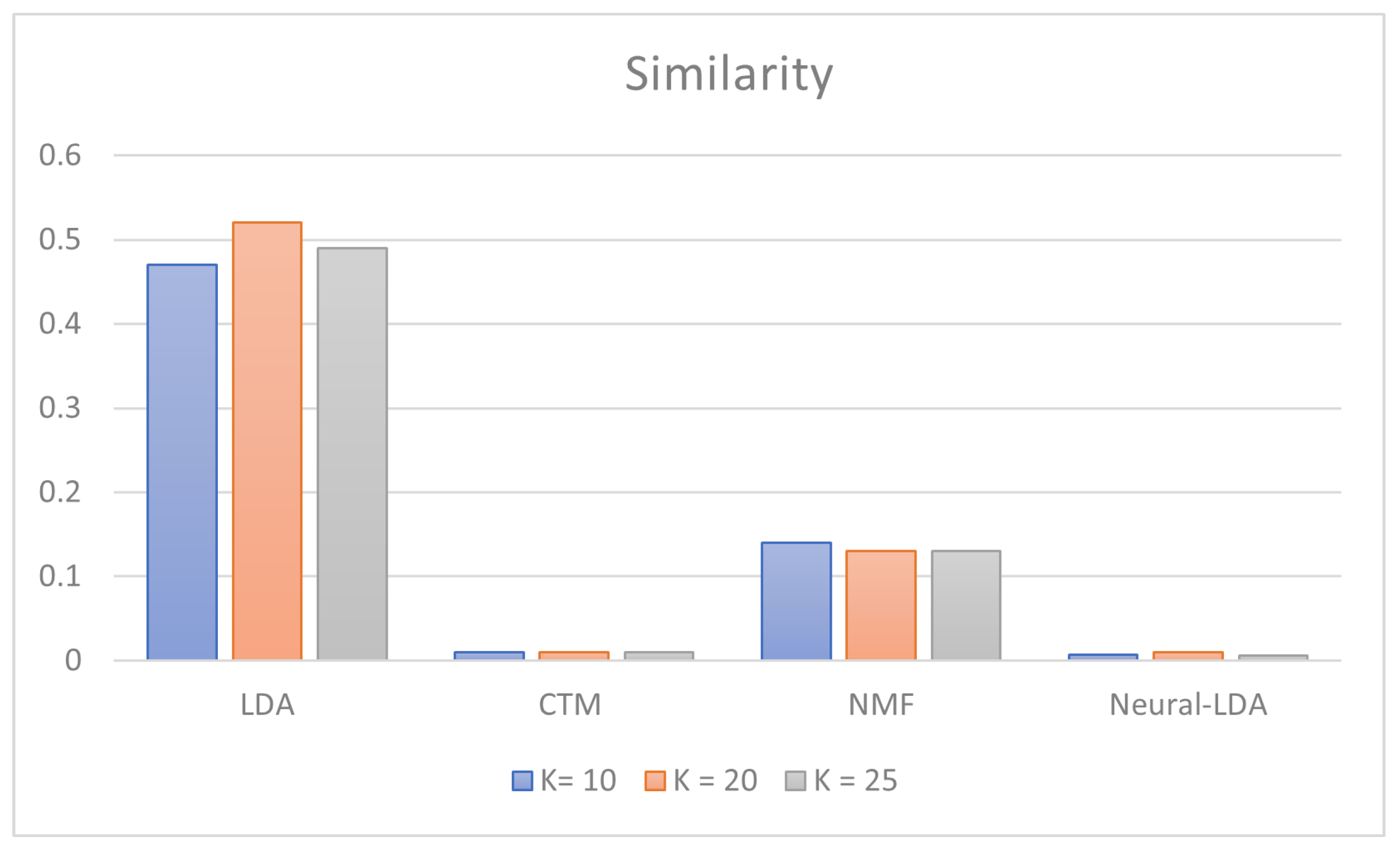
- Similarity metrics, based on Ranked-Biased Overlap (RBO) measure [6]. By using this metric, the top words of each topic are compared by a similarity score, which ranges from 0 to 1. RBO is equal to 1 when all the top words of a topic are equal and in the same order, and vice versa. RBO is equal to 0 when the top words of the various topics are completely different from each other.
- Diversity metric [5]: this metric assigns a value based on how much the top-k words of the various topics differ from each other. It is based on the Inverse Ranked-Biased Overlap measure.
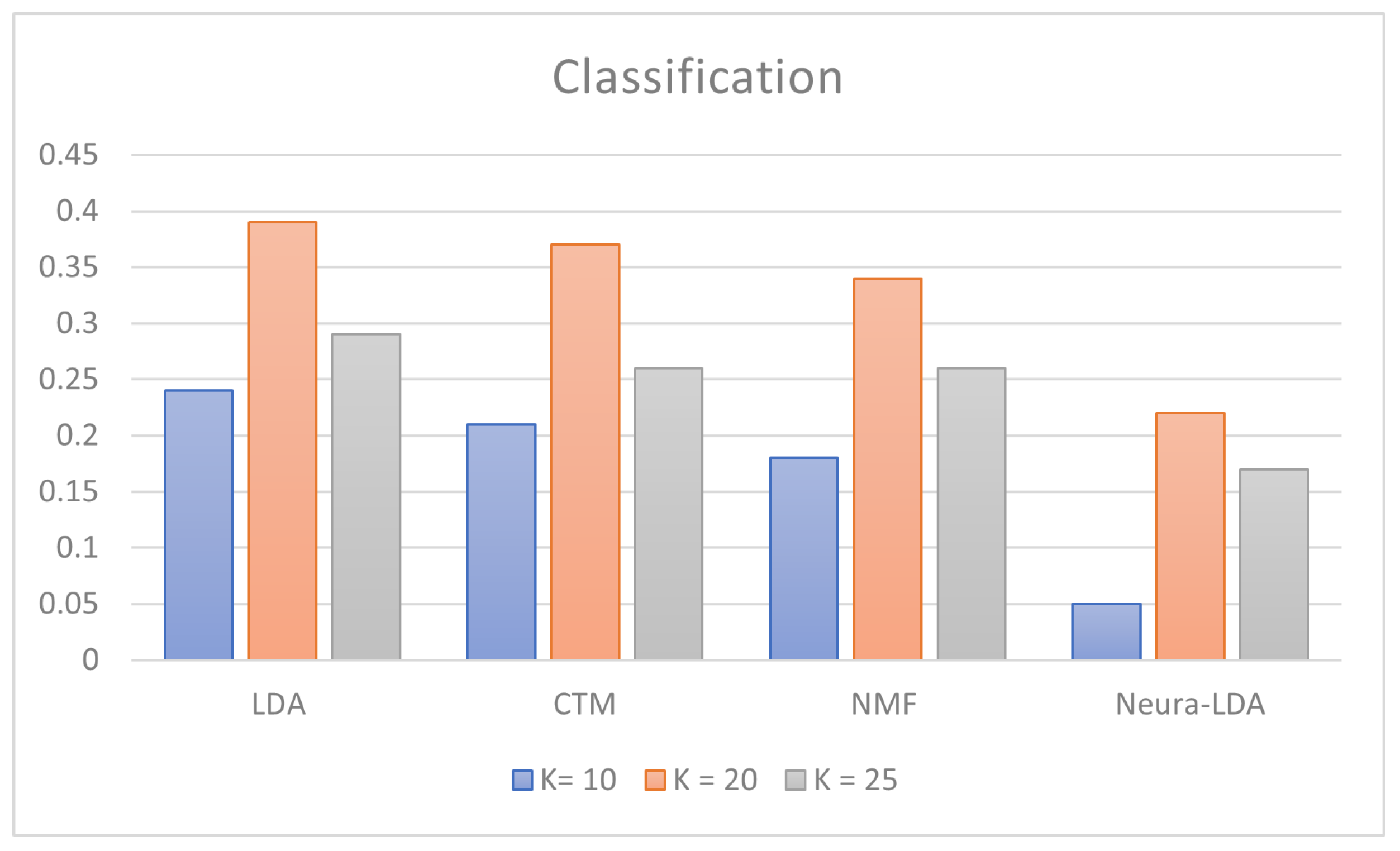
- Classification score [31]: to examine the classification accuracy within the training data, we randomly divided the training set into five equal partitions and performed five-fold cross-validation.
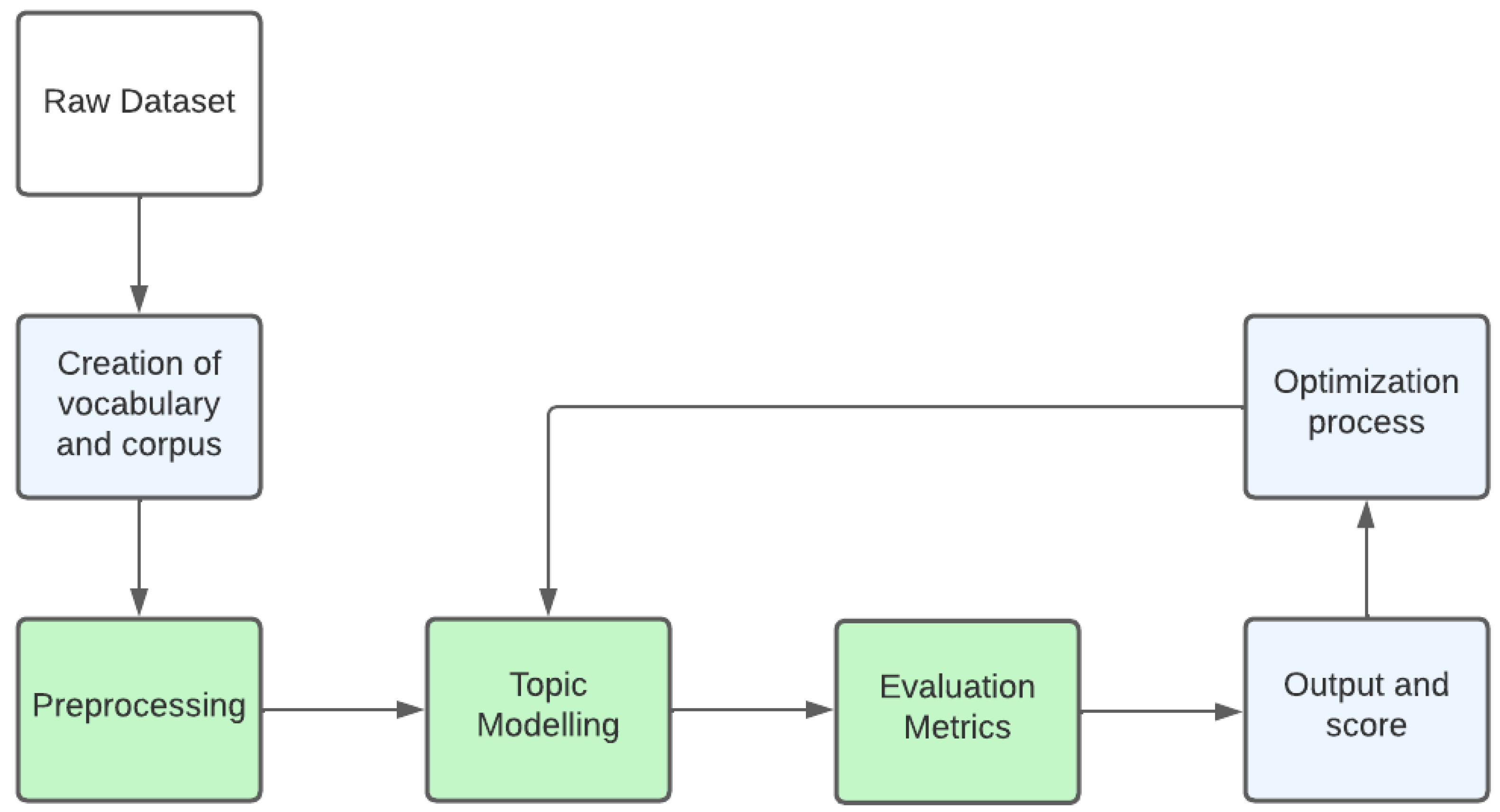
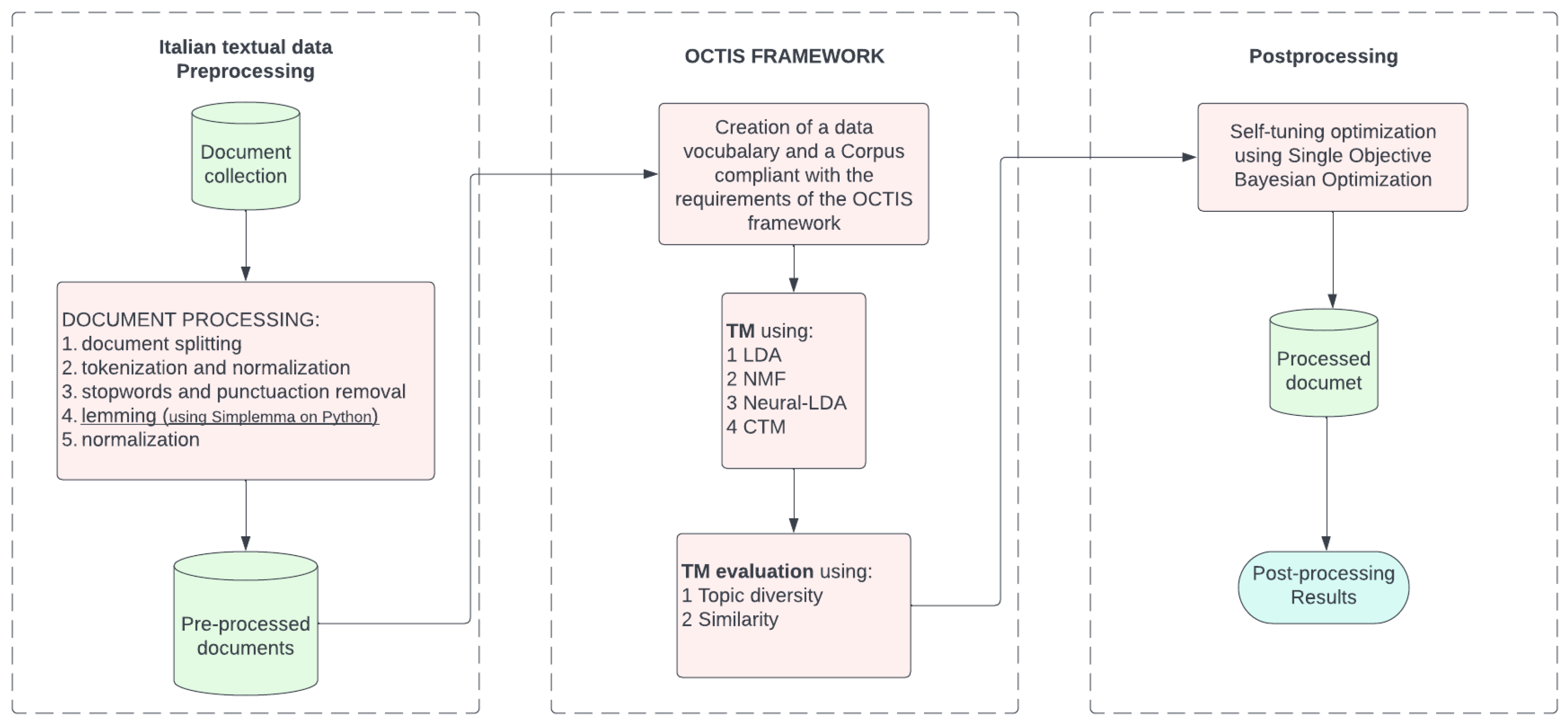
3. Data Pre-Processing
- Tokenization: a process of breaking down captured text data into words, called tokens. One of the most used tools in computer science to perform tokenization is the python library Natural Language Toolkit (NLTK).
- Lowercasing: the process of converting each word to its lowercase (WORD → word).
- Stopwords and punctuation removal: the phase in which the stopwords, i.e., meaningless terms such as articles and propositions, and punctuation are removed. In this way, it is possible to lighten the dataset from all those superfluous elements to evaluate the topics.
- Stemming: truncation of words at the root, omitting endings that indicate, for example, gender, number; alterations for nouns and adjectives; or mood, tense, or person for verbs. This makes sense if the root of the word is sufficiently representative of the meaning without the risk of ambiguity.
- Lemming: reduction of the word to a more canonical form—to be used as an alternative to stemming when you want to achieve maximum convergence of words—towards a common lemma that can grasp its meaning. Lemmatization operates at a considerably higher level of complexity than stemming. This phase turns out to be one of the most complex to implement for the Italian language, as there is no Python library capable of performing a correct lemmatization for the natural Italian language.
“sollecitato” → “sollecit”
“sollecito”, “sollecitare” → “sollecit”
“sollecitato” → “sollecita”
4. Case Study
4.1. Italian Pre-Processing
| Algorithm 1. Pre-processing |
|
4.2. Models and Methods Implementation
- vocabulary: a .txt file where each line represents a word of the vocabulary.
- corpus: a .tsv file (tab-separated) that contains up to three columns, i.e., the document, the partition, and the label associated with the document (optional).
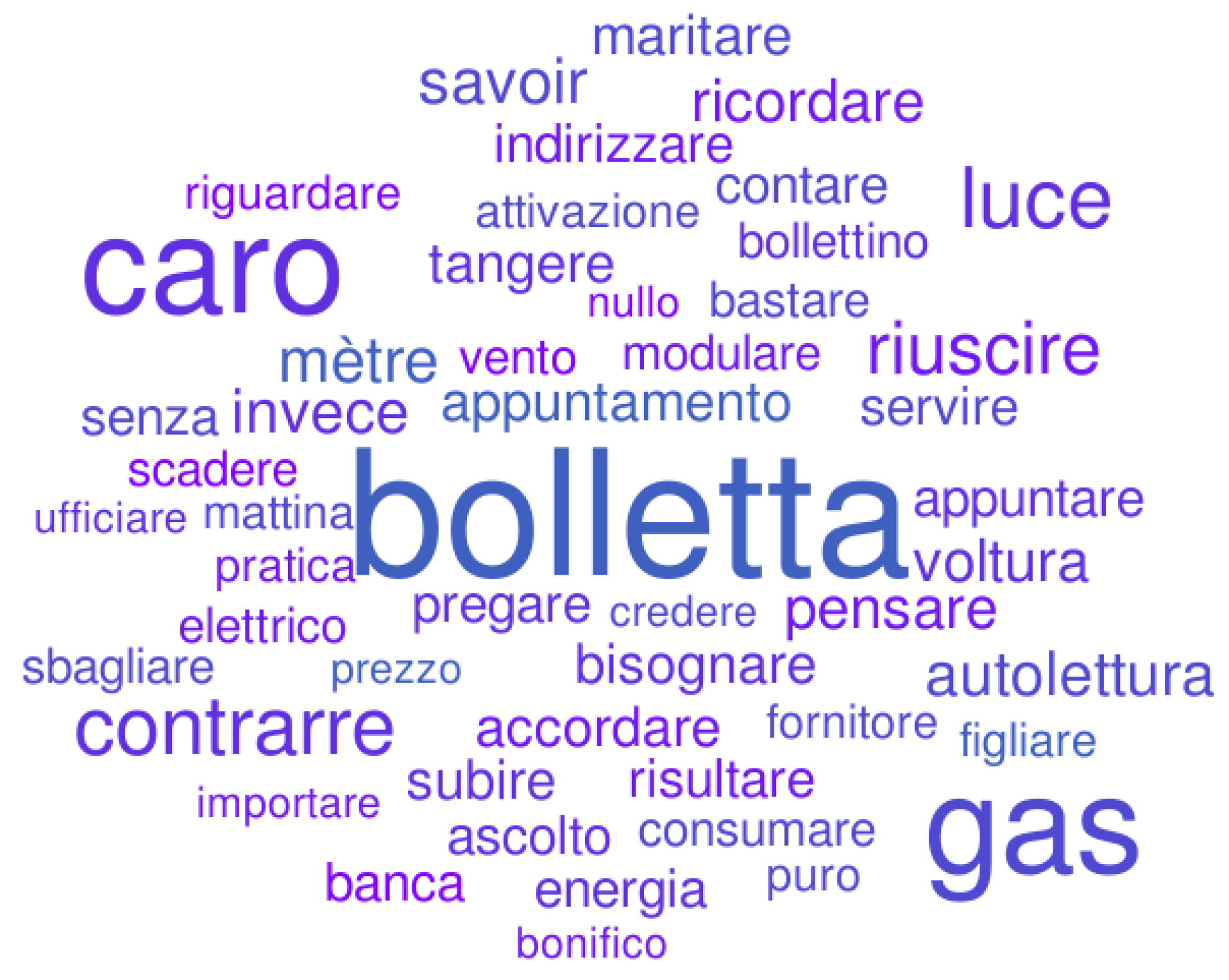
- Top k-words topic words: i.e., the identification of the most representative words for each of the topics discovered.
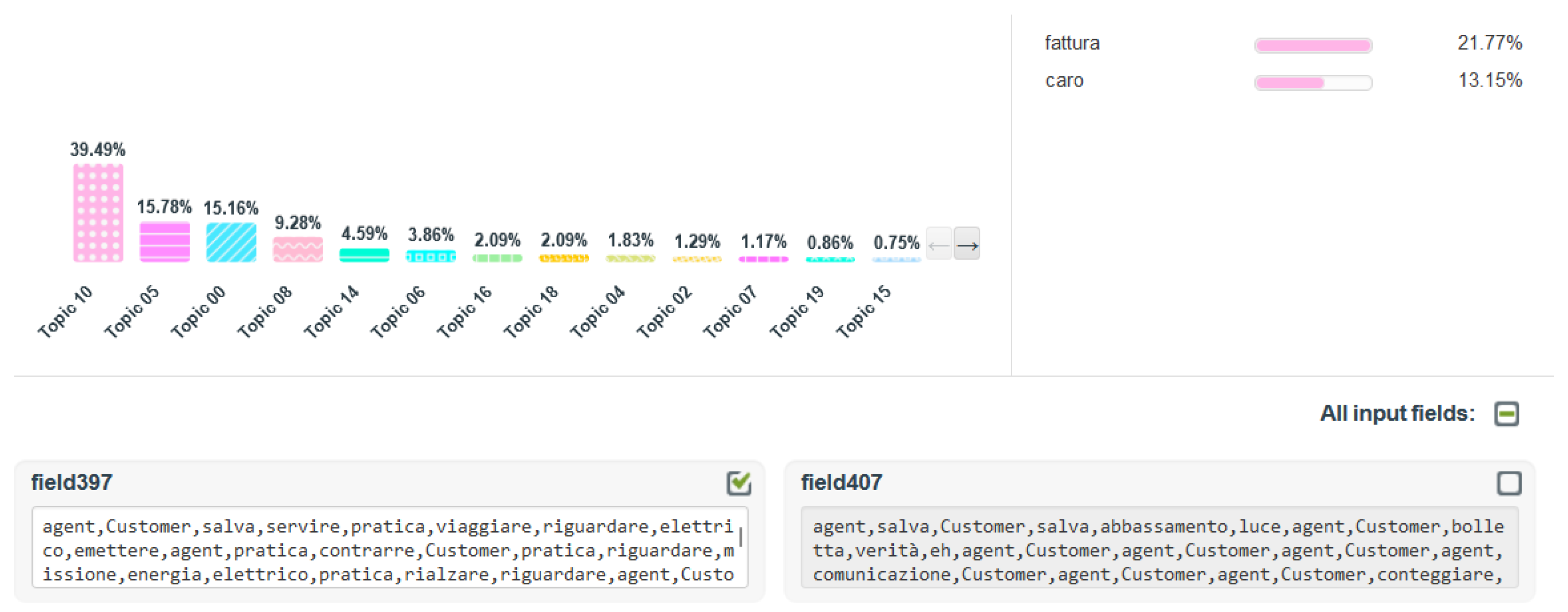
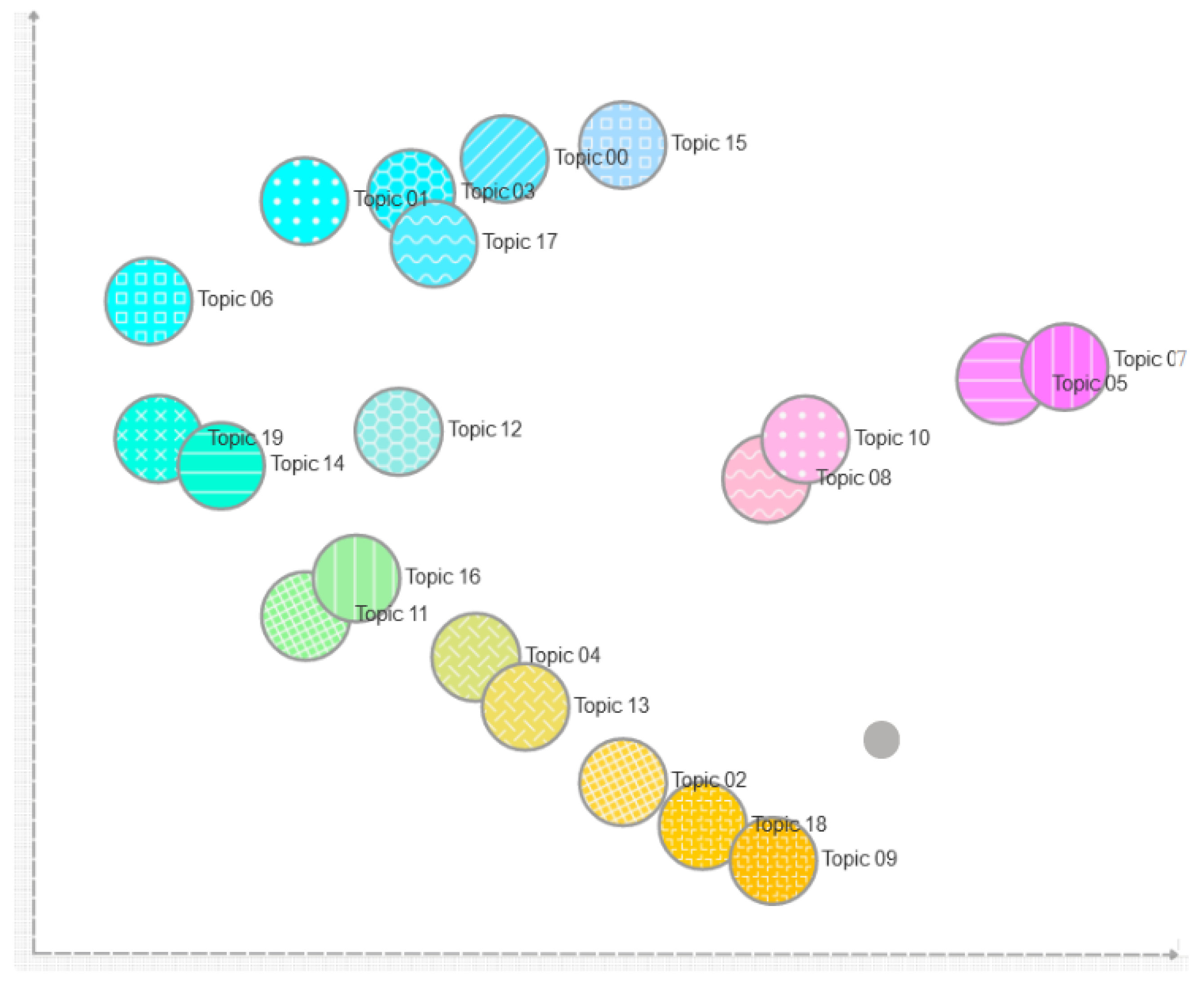
- Topic document distributions: the possibility that every real Italian conversation, extrapolated from the dataset, belongs to a specific topic among those identified.
4.3. Post-Processing and Results Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Lee, D.; Seung, H.S. Algorithms for Non-negative Matrix Factorization. In Proceedings of the Advances in Neural Information Processing Systems; Leen, T., Dietterich, T., Tresp, V., Eds.; MIT Press: Cambridge, MA, USA, 2000; Volume 13. [Google Scholar]
- Srivastava, A.; Sutton, C. Autoencoding Variational Inference For Topic Models. arXiv 2017, arXiv:1703.01488. [Google Scholar]
- Bianchi, F.; Terragni, S.; Hovy, D.; Nozza, D.; Fersini, E. Cross-lingual Contextualized Topic Models with Zero-shot Learning. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Online, 19–23 April 2021. [Google Scholar]
- Dieng, A.B.; Ruiz, F.J.; Blei, D.M. The dynamic embedded topic model. arXiv 2019, arXiv:1907.05545. [Google Scholar]
- Webber, W.; Moffat, A.; Zobel, J. A similarity measure for indefinite rankings. ACM Trans. Inf. Syst. (TOIS) 2010, 28, 1–38. [Google Scholar] [CrossRef]
- Papadia, G.; Pacella, M.; Giliberti, V. Topic Modeling for Automatic Analysis of Natural Language: A Case Study in an Italian Customer Support Center. Algorithms 2022, 15, 204. [Google Scholar] [CrossRef]
- Churchill, R.; Singh, L. The evolution of topic modeling. ACM Comput. Surv. 2022, 54, 1–35. [Google Scholar] [CrossRef]
- Nigam, K.; McCallum, A.K.; Thrun, S.; Mitchell, T. Text classification from labeled and unlabeled documents using EM. Mach. Learn. 2000, 39, 103–134. [Google Scholar] [CrossRef]
- Blei, D.; Lafferty, J. Correlated topic models. In Proceedings of the NIPS’06, Vancouver, BC, Canada, 4–7 December 2006; Volume 18, p. 147. [Google Scholar]
- Dieng, A.B.; Ruiz, F.J.; Blei, D.M. Topic modeling in embedding spaces. Trans. Assoc. Comput. Linguist. 2020, 8, 439–453. [Google Scholar] [CrossRef]
- Bianchi, F.; Terragni, S.; Hovy, D. Pre-training is a hot topic: Contextualized document embeddings improve topic coherence. arXiv 2020, arXiv:2004.03974. [Google Scholar]
- Lau, J.H.; Newman, D.; Baldwin, T. Machine reading tea leaves: Automatically evaluating topic coherence and topic model quality. In Proceedings of the EACL’14, Gothenburg, Sweden, 26–30 April 2014; pp. 530–539. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Xia, L.; Luo, D.; Zhang, C.; Wu, Z. A survey of topic models in text classification. In Proceedings of the 2019 2nd International Conference on Artificial Intelligence and Big Data (ICAIBD), Chengdu, China, 25–28 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 244–250. [Google Scholar]
- Likhitha, S.; Harish, B.; Kumar, H.K. A detailed survey on topic modeling for document and short text data. Int. J. Comput. Appl. 2019, 178, 1–9. [Google Scholar] [CrossRef]
- Abdelrazek, A.; Eid, Y.; Gawish, E.; Medhat, W.; Hassan, A. Topic modeling algorithms and applications: A survey. Inf. Syst. 2022, 112, 102131. [Google Scholar] [CrossRef]
- Liu, Z.; Ng, A.; Lee, S.; Aw, A.T.; Chen, N.F. Topic-aware pointer-generator networks for summarizing spoken conversations. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 814–821. [Google Scholar]
- Tur, G.; De Mori, R. Spoken Language Understanding: Systems for Extracting Semantic Information from Speech; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Jelodar, H.; Wang, Y.; Yuan, C.; Feng, X.; Jiang, X.; Li, Y.; Zhao, L. Latent Dirichlet Allocation (LDA) and Topic modeling: Models, applications, a survey. Multimed. Tools Appl. 2019, 78, 15169–15211. [Google Scholar] [CrossRef]
- Hazen, T.J. Chapter 12: Topic identification. In Spoken Language Understanding: Systems for Extracting Semantic Information from Speech; John Wiley & Sons: Hoboken, NJ, USA, 2011; Volume 12, pp. 319–356. [Google Scholar]
- Zhao, G.; Zhao, J.; Li, Y.; Alt, C.; Schwarzenberg, R.; Hennig, L.; Schaffer, S.; Schmeier, S.; Hu, C.; Xu, F. MOLI: Smart conversation agent for mobile customer service. Information 2019, 10, 63. [Google Scholar] [CrossRef]
- Pota, M.; Ventura, M.; Catelli, R.; Esposito, M. An effective BERT-based pipeline for Twitter sentiment analysis: A case study in Italian. Sensors 2020, 21, 133. [Google Scholar] [CrossRef] [PubMed]
- Agostino, D.; Brambilla, M.; Pavanetto, S.; Riva, P. The contribution of online reviews for quality evaluation of cultural tourism offers: The experience of Italian museums. Sustainability 2021, 13, 13340. [Google Scholar] [CrossRef]
- Aria, M.; Cuccurullo, C.; D’Aniello, L.; Misuraca, M.; Spano, M. Thematic analysis as a new culturomic tool: The social media coverage on COVID-19 pandemic in Italy. Sustainability 2022, 14, 3643. [Google Scholar] [CrossRef]
- Murdock, J.; Allen, C. Visualization Techniques for Topic Model Checking. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; Volume 29. [Google Scholar]
- Maier, D.; Waldherr, A.; Miltner, P.; Wiedemann, G.; Niekler, A.; Keinert, A.; Pfetsch, B.; Heyer, G.; Reber, U.; Häussler, T.; et al. Applying LDA topic modeling in communication research: Toward a valid and reliable methodology. Commun. Methods Meas. 2018, 12, 93–118. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Terragni, S.; Fersini, E.; Galuzzi, B.G.; Tropeano, P.; Candelieri, A. Octis: Comparing and optimizing topic models is simple! In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations, Online, 19–23 April 2021; pp. 263–270. [Google Scholar]
- Röder, M.; Both, A.; Hinneburg, A. Exploring the space of topic coherence measures. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, Shanghai, China, 2–6 February 2015; pp. 399–408. [Google Scholar]
- Phan, X.H.; Nguyen, L.M.; Horiguchi, S. Learning to classify short and sparse text & web with hidden topics from large-scale data collections. In Proceedings of the 17th International Conference on World Wide Web, Beijing, China, 21–25 April 2008; pp. 91–100. [Google Scholar]
- Simplemma: A Simple Multilingual Lemmatizer for Python [Computer Software]. Available online: https://github.com/adbar/simplemma (accessed on 11 December 2022).
- Barbaresi, A.; Hein, K. Data-driven identification of German phrasal compounds. In Proceedings of the International Conference on Text, Speech, and Dialogue, Prague, Czech Republic, 27–31 August 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 192–200. [Google Scholar]
- Barbaresi, A. An unsupervised morphological criterion for discriminating similar languages. In Proceedings of the 3rd Workshop on NLP for Similar Languages, Varieties and Dialects (VarDial 2016), Osaka, Japan, 12 December 2016; pp. 212–220. [Google Scholar]
- Barbaresi, A. Bootstrapped OCR error detection for a less-resourced language variant. In Proceedings of the 13th Conference on Natural Language Processing (KONVENS 2016), Bochum, Germany, 19–21 September 2016; pp. 21–26. [Google Scholar]
- Guo, L.; Li, S.; Lu, R.; Yin, L.; Gorson-Deruel, A.; King, L. The research topic landscape in the literature of social class and inequality. PLoS ONE 2018, 13, e0199510. [Google Scholar] [CrossRef] [PubMed] [Green Version]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LDA 1: fax bonifico emettere bolletta fattura |
| LDA 2: fax bonifico bolletta gas tariffa |
| LDA 3: tariffa IBAN bolletta energia attivazione |
| LDA 4: fax bolletta gas luce autolettura |
| LDA 5: interesse bonifico ultimare presidente saldo |
| CTM 1: interesse attaccare presidente saldo creare |
| CTM 2: sbloccare chilowatt voir pratica aggiuntivo |
| CTM 3: gas vento tariffa modulare conguaglio |
| CTM 4: contare dettare bolletta pregare attaccare riallacciare |
| CTM 5: elettronico acqua nota addebito insistere |
| NMF 1: voltura pratica bonifico attivazione saldo |
| NMF 2: banca autolettura energia bolletta tariffa |
| NMF 3: bolletta energia luce autolettura attivazione |
| NMF 4: bolletta savoir profilo modulo pagare |
| NMF 5: ricordo bolletta mattina indirizzo documento |
| Neural-LDA 1: ultimare ufficacia disdetta identità prezzo |
| Neural-LDA 2: nota riscaldamento documentazione disdire pervenire |
| Neural-LDA 3: fax luce bonifico salva pensa |
| Neural-LDA 4: detta dice emette sbaglio pagare |
| Neural-LDA 5: metano interesse papà caldaia avviso |
| LDA 1: prezzo bonifico gas proporre conto |
| LDA 2: fax bolletta gas fattura bonifico |
| LDA 3: bolletta fax bonifico fattura luce |
| LDA 4: fax gas bolletta bonifico IBAN |
| LDA 5: fax bonifico bolletta voltura energia |
| CTM 1: alza comunicazione conguaglio caldaia mangia |
| CTM 2 fax allacciare preferire bonifico cordoglio |
| CTM 3: eventuale approva bonifico accredito inverno |
| CTM 4: raccomandata fatturare stipendio sbaglio plastica |
| CTM 5: biro biologo disc meccanismo residenza |
| NMF 1: bonifico gas scusa fattura IBAN |
| NMF 2: fax riallaccio fermo combinazione luce |
| NMF 3: fax gas bolletta ascolto savoir |
| NMF 4: bolletta puro bonifico luce rimborso |
| NMF 5: dettare fattura fax risulta bolletta |
| Neural-LDA 1: scuola contratto rotto spelling mora |
| Neural-LDA 2: appuntamento attivazione mattina ufficiare energia |
| Neural-LDA 3: comunicazione acqua lavoro inizia documenta |
| Neural-LDA 4: fornitore conto interesse gas IBAN |
| Neural-LDA 5: nullo fossa metano indirizzo ascolta |
| LDA 1: fax dettare fattura bolletta luce |
| LDA 2: bolletta emettere contrarre fax gas |
| LDA 3: fattura fax bollettino autolettura ringrazia |
| LDA 4: bolletta emettere dettare fax gas |
| LDA 5: fax emettere bolletta gas IBAN |
| CTM 1: registra consumo randomica rateizzazione gas |
| CTM 2: raccomandata tangere ascolto fattura luce |
| CTM 3: nostro raccomandata disdire prevede fax |
| CTM 4: patente salute Vodafone giornale bolletta |
| CTM 5: luce fax giornale bolletta gas |
| NMF 1: voltura accorda fattura contare bollettino |
| NMF 2: ricorda dettare voltura fax costo |
| NMF 3: servire indirizzo fax attivazione scadenza |
| NMF 4: dettare gas fax appuntamento mètre |
| NMF 5: autolettura gas energia consumare fattura |
| Neural-LDA 1: intestatario tesare IBAN occorre traduzione |
| Neural-LDA 2: affatto perfetta battere contante Romagna supporto |
| Neural-LDA 3: fax tangere consumo autolettura emettere |
| Neural-LDA 4: quarantott affatto risorsa contante IBAN |
| Neural-LDA 5: accordare funzionare facile risorsa consegna |
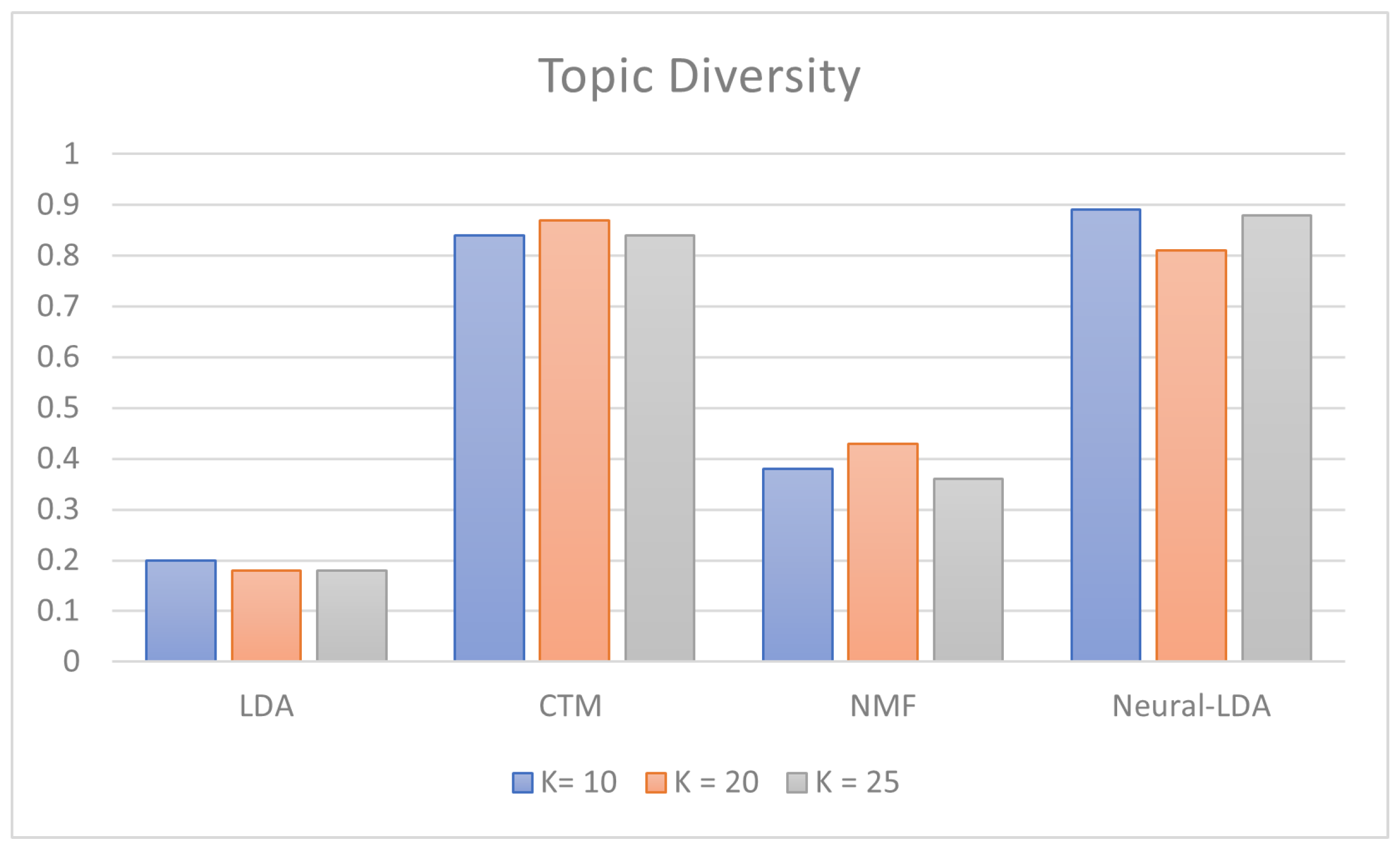
| k = 10 | k = 20 | k = 25 | |
|---|---|---|---|
| LDA | 0.2 | 0.185 | 0.188 |
| CTM | 0.84 | 0.875 | 0.84 |
| NMF | 0.38 | 0.435 | 0.364 |
| Neural-LDA | 0.895 | 0.81 | 0.884 |
| k = 10 | k = 20 | k = 25 | |
|---|---|---|---|
| LDA | 0.47 | 0.52 | 0.494 |
| CTM | 0.012 | 0.01 | 0.010 |
| NMF | 0.146 | 0.14 | 0.130 |
| Neural-LDA | 0.007 | 0.017 | 0.006 |
| k = 10 | k = 20 | k = 25 | |
|---|---|---|---|
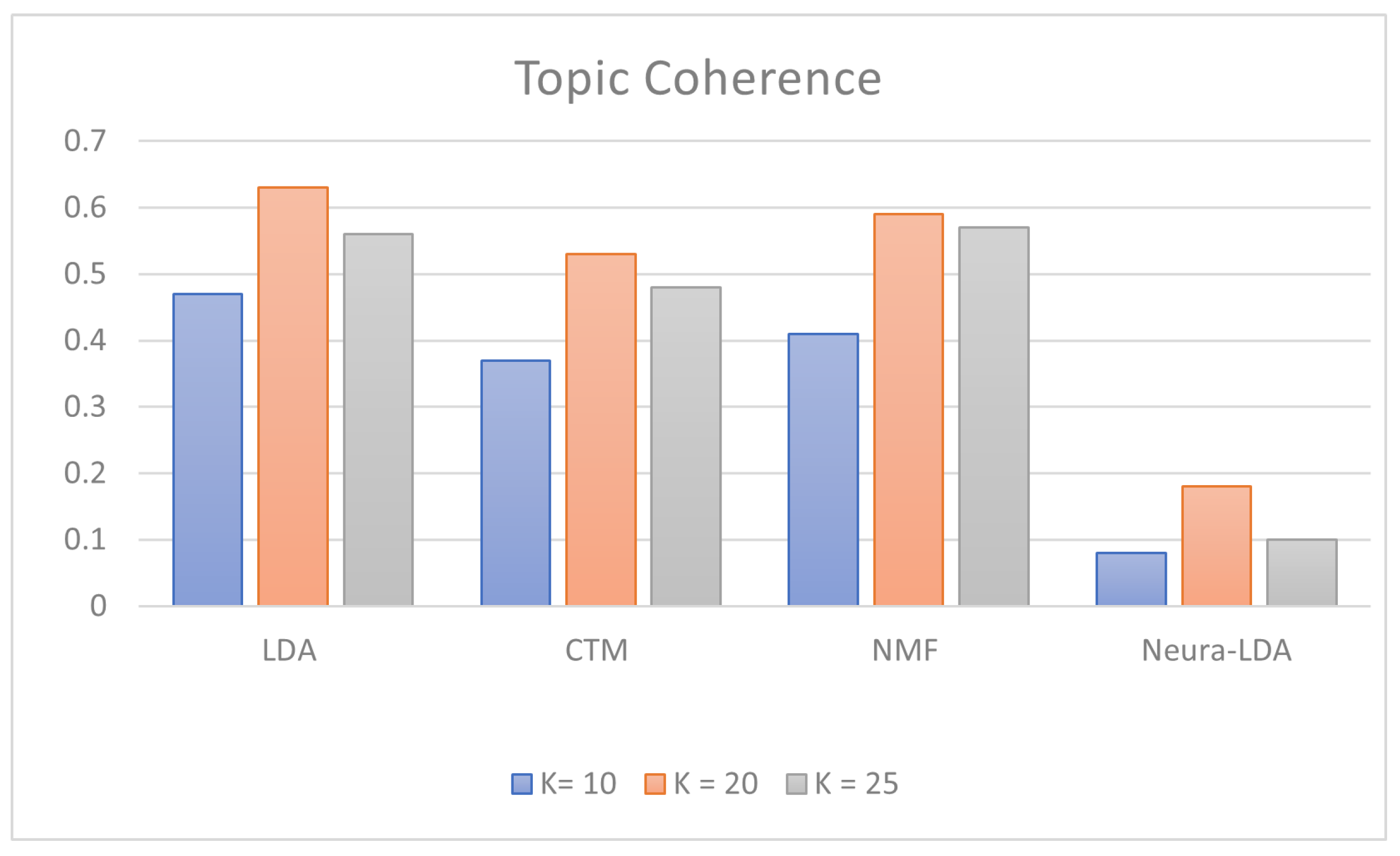
| LDA | 0.47 | 0.63 | 0.56 |
| CTM | 0.37 | 0.53 | 0.48 |
| NMF | 0.41 | 0.59 | 0.57 |
| Neural-LDA | 0.08 | 0.18 | 0.10 |
| k = 10 | k = 20 | k = 25 | |
|---|---|---|---|
| LDA | 0.24 | 0.39 | 0.29 |
| CTM | 0.21 | 0.37 | 0.26 |
| NMF | 0.18 | 0.34 | 0.26 |
| Neural-LDA | 0.05 | 0.22 | 0.17 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Papadia, G.; Pacella, M.; Perrone, M.; Giliberti, V. A Comparison of Different Topic Modeling Methods through a Real Case Study of Italian Customer Care. Algorithms 2023, 16, 94. https://doi.org/10.3390/a16020094
Papadia G, Pacella M, Perrone M, Giliberti V. A Comparison of Different Topic Modeling Methods through a Real Case Study of Italian Customer Care. Algorithms. 2023; 16(2):94. https://doi.org/10.3390/a16020094
Chicago/Turabian StylePapadia, Gabriele, Massimo Pacella, Massimiliano Perrone, and Vincenzo Giliberti. 2023. "A Comparison of Different Topic Modeling Methods through a Real Case Study of Italian Customer Care" Algorithms 16, no. 2: 94. https://doi.org/10.3390/a16020094