

Improved Gradient Descent Iterations for Solving Systems of Nonlinear Equations
 ,
,  ,
,  ,
,
Abstract
:1. Introduction, Preliminaries, and Motivation
1.1. Overview of Methods for Solving SNE
1.2. Motivation
1.2.1. Improved Gradient Descent Methods as Motivation
1.2.2. Discretization of Gradient Neural Networks (GNN) as Motivation
- Step1GNN.
- Define underlying error matrix by the interchange of the unknown matrix in the actual problem by the unknown time-varying matrix , which will be approximated over time . The scalar objective of a GNN is just the Frobenius norm of :
- Step2GNN.
- Compute the gradient of the objective .
- Step3GNN.
- Apply the dynamic GNN evolution, which relates the time derivative and direction opposite to the gradient of :
2. Multiple Step-Size Methods for Solving SNE
2.1. IGDN Methods for Solving SNE
2.2. A Class of Accelerated Double Direction (ADDN) Methods
| Algorithm 2 The iterations based on (37), (38). |
|
2.3. A Class of Accelerated Double Step Size (ADSSN) Methods
2.4. Simplified ADSSN
| Algorithm 4 The ADSSN iteration based on (46) and (48). |
3. Convergence Analysis
- The level set defined in (49) is bounded below.
- Lipschitz continuity holds for the vector function F, i.e., for all and .
- The Jacobian is bounded.
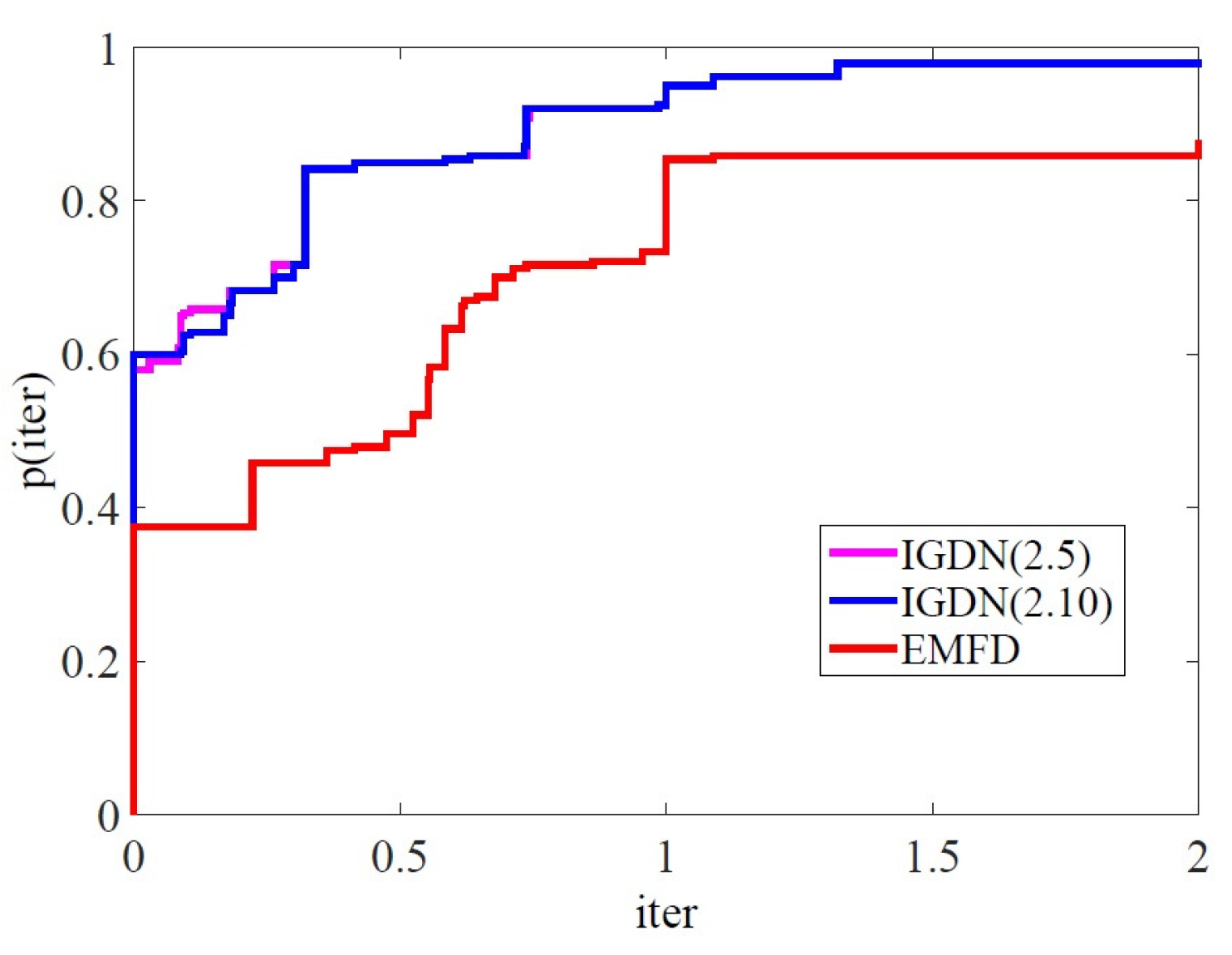
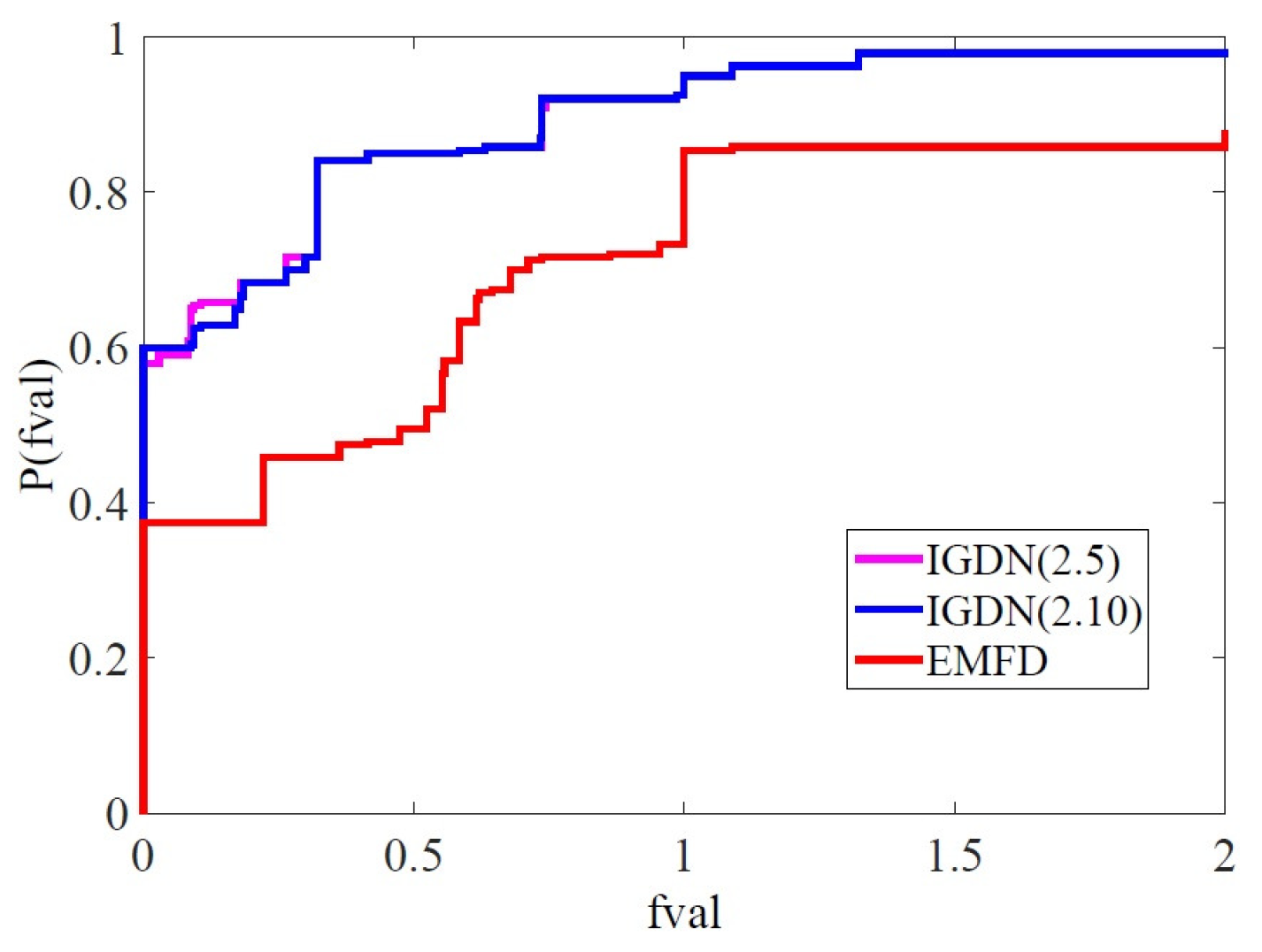
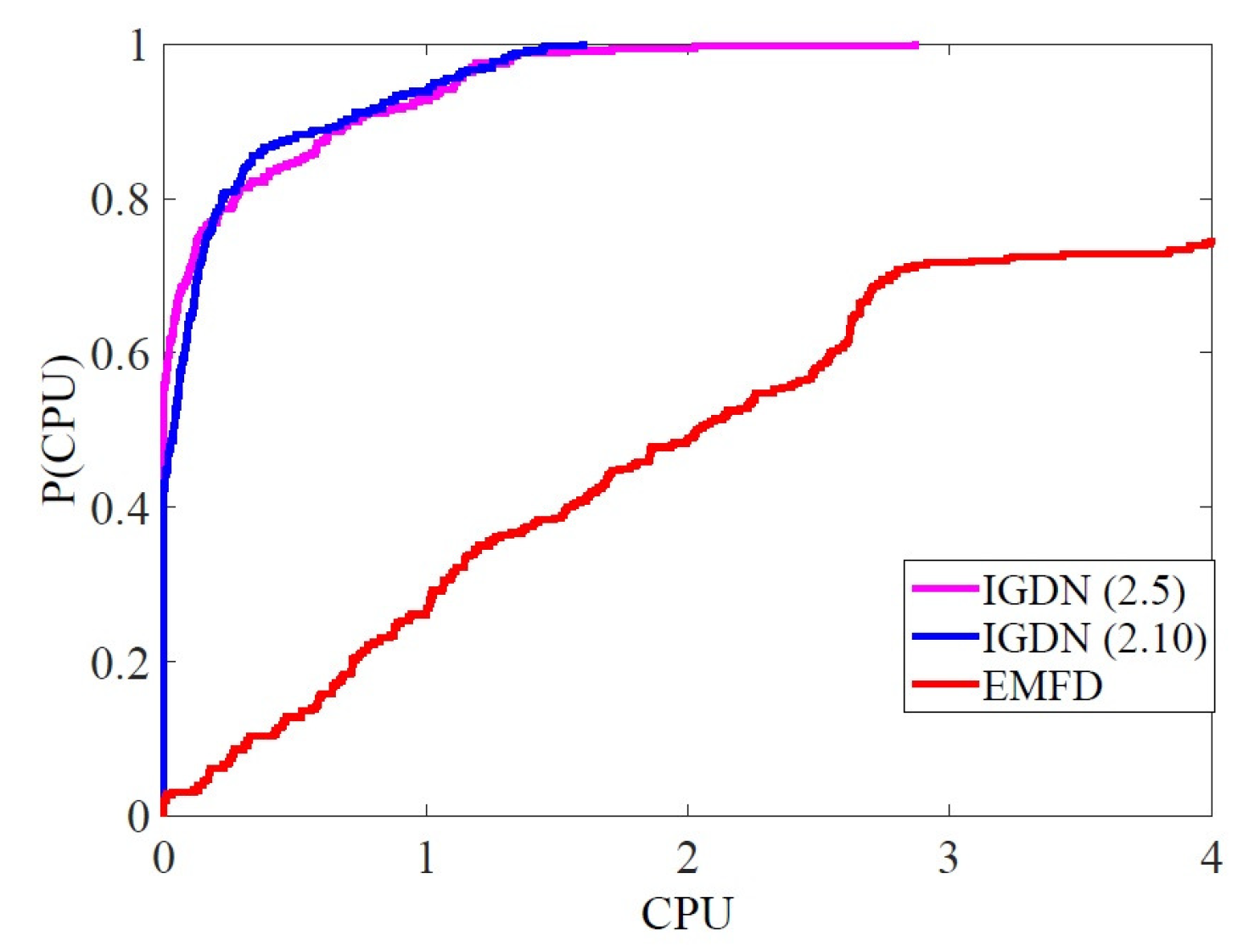
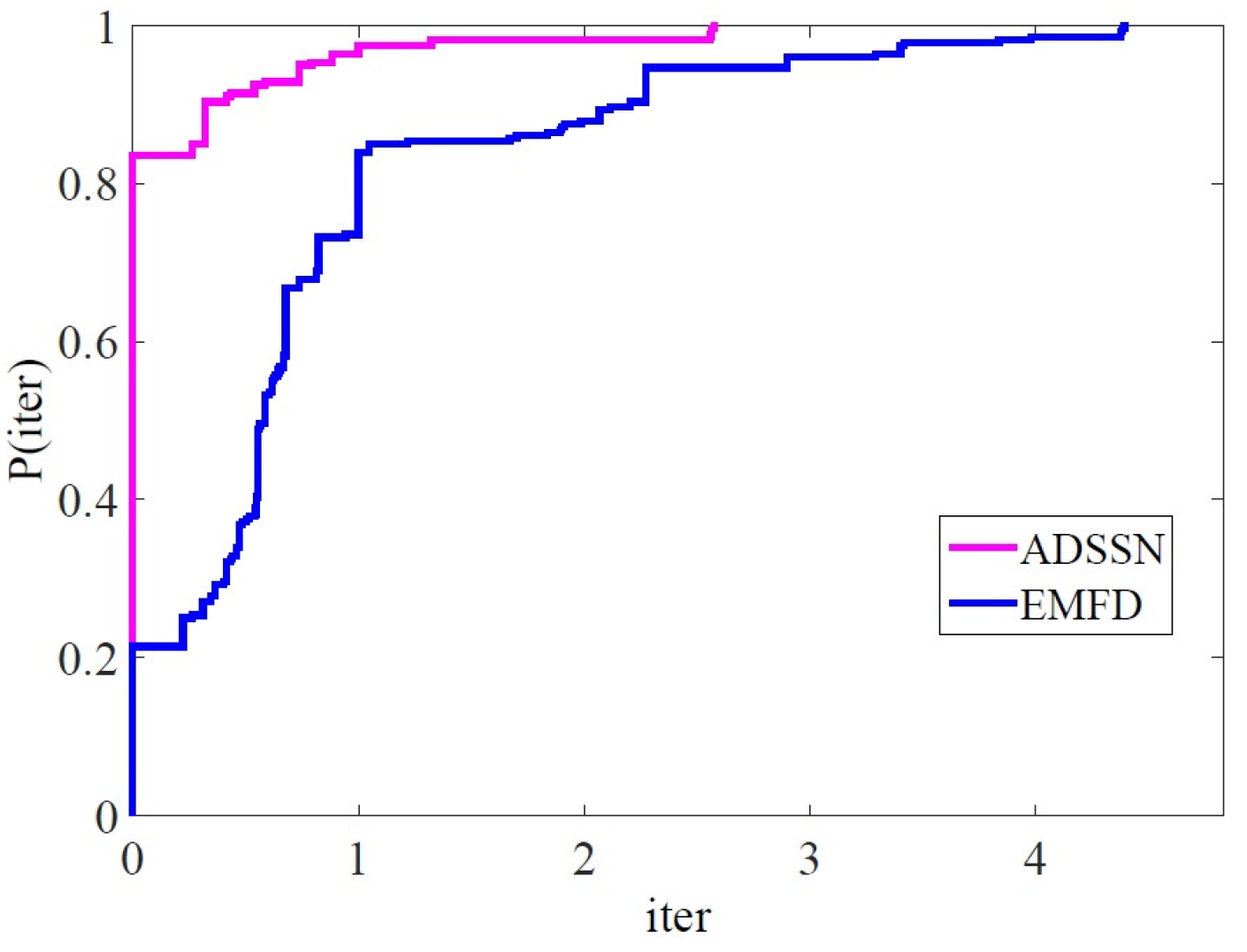
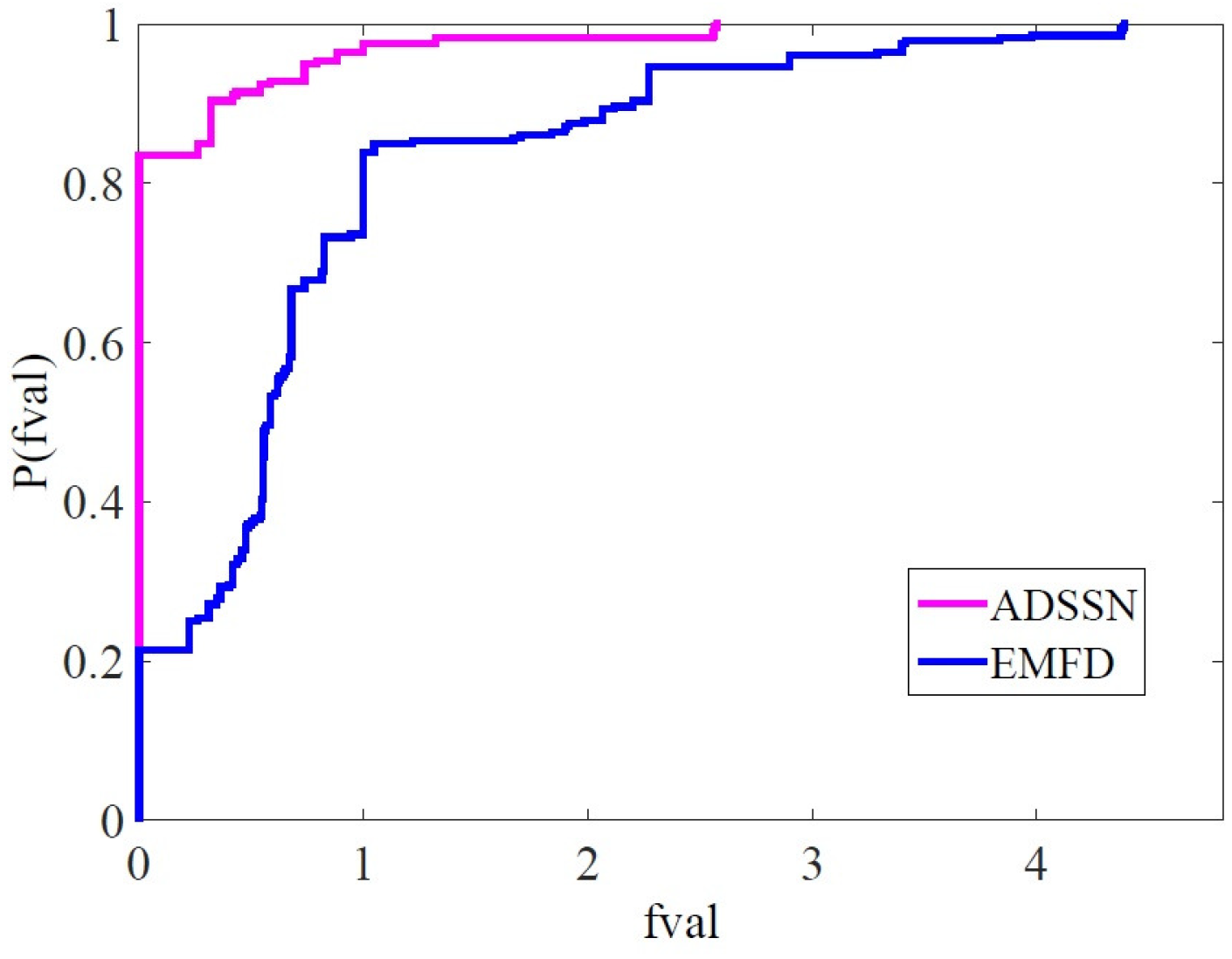
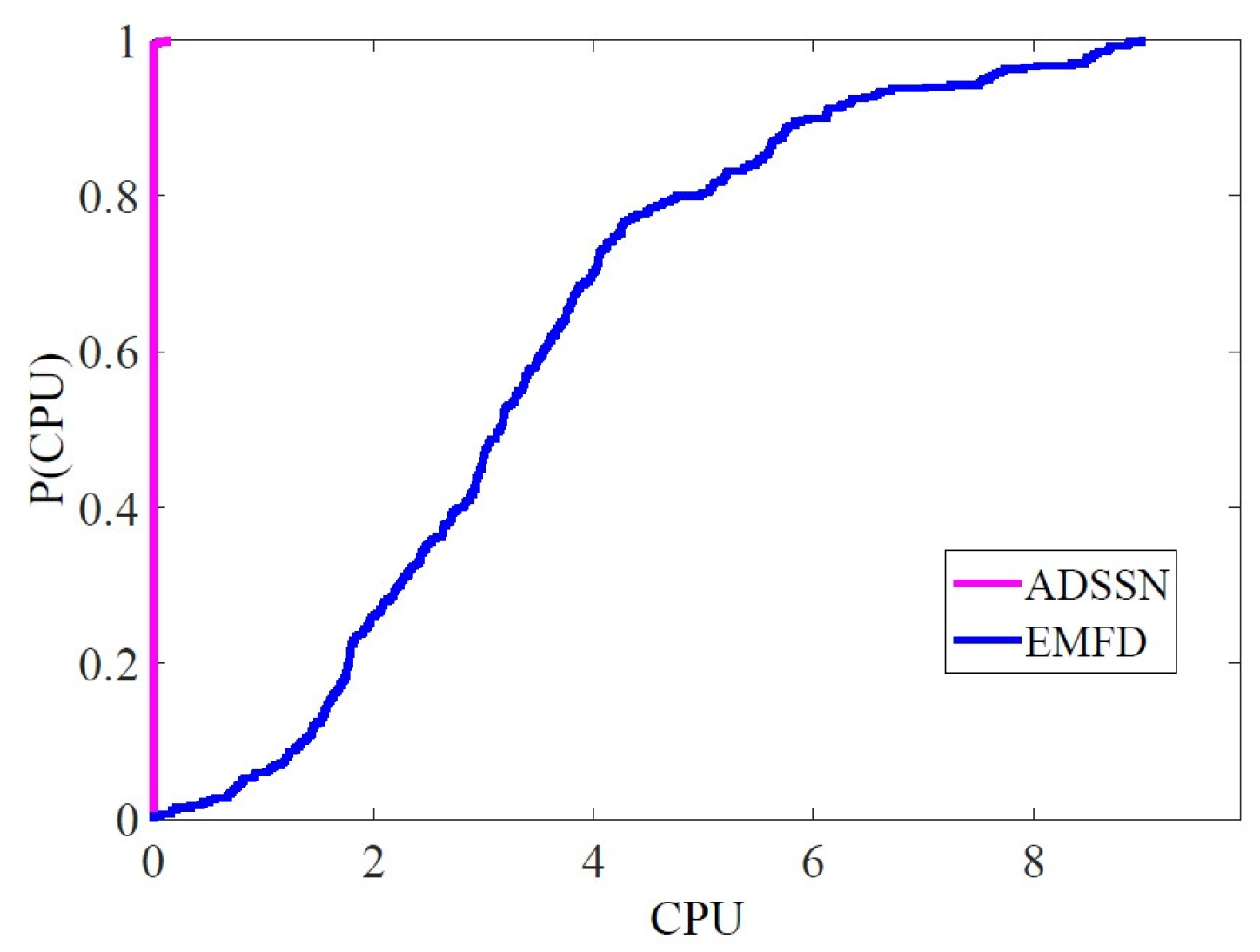
4. Numerical Experience
- algorithms are defined using , , , , and
- method is defined using , , , , and .
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yuan, G.; Lu, X. A new backtracking inexact BFGS method for symmetric nonlinear equations. Comput. Math. Appl. 2008, 55, 116–129. [Google Scholar] [CrossRef] [Green Version]
- Abubakar, A.B.; Kumam, P. An improved three–term derivative–free method for solving nonlinear equations. Comput. Appl. Math. 2018, 37, 6760–6773. [Google Scholar] [CrossRef]
- Cheng, W. A PRP type method for systems of monotone equations. Math. Comput. Model. 2009, 50, 15–20. [Google Scholar] [CrossRef]
- Hu, Y.; Wei, Z. Wei–Yao–Liu conjugate gradient projection algorithm for nonlinear monotone equations with convex constraints. Int. J. Comput. Math. 2015, 92, 2261–2272. [Google Scholar] [CrossRef]
- La Cruz, W. A projected derivative–free algorithm for nonlinear equations with convex constraints. Optim. Methods Softw. 2014, 29, 24–41. [Google Scholar] [CrossRef]
- La Cruz, W. A spectral algorithm for large–scale systems of nonlinear monotone equations. Numer. Algorithms 2017, 76, 1109–1130. [Google Scholar] [CrossRef]
- Papp, Z.; Rapajić, S. FR type methods for systems of large–scale nonlinear monotone equations. Appl. Math. Comput. 2015, 269, 816–823. [Google Scholar] [CrossRef]
- Halilu, A.S.; Waziri, M.Y. En enhanced matrix-free method via double steplength approach for solving systems of nonlinear equations. Int. J. Appl. Math. Res. 2017, 6, 147–156. [Google Scholar] [CrossRef] [Green Version]
- Halilu, A.S.; Waziri, M.Y. A transformed double steplength method for solving large-scale systems of nonlinear equations. J. Numer. Math. Stochastics 2017, 9, 20–32. [Google Scholar]
- Waziri, M.Y.; Muhammad, H.U.; Halilu, A.S.; Ahmed, K. Modified matrix-free methods for solving system of nonlinear equations. Optimization 2021, 70, 2321–2340. [Google Scholar] [CrossRef]
- Osinuga, I.A.; Dauda, M.K. Quadrature based Broyden-like method for systems of nonlinear equations. Stat. Optim. Inf. Comput. 2018, 6, 130–138. [Google Scholar] [CrossRef]
- Muhammad, K.; Mamat, M.; Waziri, M.Y. A Broyden’s-like method for solving systems of nonlinear equations. World Appl. Sci. J. 2013, 21, 168–173. [Google Scholar]
- Ullah, N.; Sabi’u, J.; Shah, A. A derivative–free scaling memoryless Broyden–Fletcher–Goldfarb–Shanno method for solving a system of monotone nonlinear equations. Numer. Linear Algebra Appl. 2021, 28, e2374. [Google Scholar] [CrossRef]
- Abubakar, A.B.; Kumam, P. A descent Dai–Liao conjugate gradient method for nonlinear equations. Numer. Algorithms 2019, 81, 197–210. [Google Scholar] [CrossRef]
- Aji, S.; Kumam, P.; Awwal, A.M.; Yahaya, M.M.; Kumam, W. Two Hybrid Spectral Methods With Inertial Effect for Solving System of Nonlinear Monotone Equations With Application in Robotics. IEEE Access 2021, 9, 30918–30928. [Google Scholar] [CrossRef]
- Dauda, M.K.; Usman, S.; Ubale, H.; Mamat, M. An alternative modified conjugate gradient coefficient for solving nonlinear system of equations. Open J. Sci. Technol. 2019, 2, 5–8. [Google Scholar] [CrossRef]
- Zheng, L.; Yang, L.; Liang, Y. A conjugate gradient projection method for solving equations with convex constraints. J. Comput. Appl. Math. 2020, 375, 112781. [Google Scholar] [CrossRef]
- Waziri, M.Y.; Aisha, H.A. A diagonal quasi-Newton method for system of nonlinear equations. Appl. Math. Comput. Sci. 2014, 6, 21–30. [Google Scholar]
- Waziri, M.Y.; Leong, W.J.; Hassan, M.A.; Monsi, M. Jacobian computation-free Newton’s method for systems of nonlinear equations. J. Numer. Math. Stochastics 2010, 2, 54–63. [Google Scholar]
- Waziri, M.Y.; Majid, Z.A. An improved diagonal Jacobian approximation via a new quasi-Cauchy condition for solving large-scale systems of nonlinear equations. J. Appl. Math. 2013, 2013, 875935. [Google Scholar] [CrossRef] [Green Version]
- Abdullah, H.; Waziri, M.Y.; Yusuf, S.O. A double direction conjugate gradient method for solving large-scale system of nonlinear equations. J. Math. Comput. Sci. 2017, 7, 606–624. [Google Scholar]
- Yan, Q.-R.; Peng, X.-Z.; Li, D.-H. A globally convergent derivative-free method for solving large-scale nonlinear monotone equations. J. Comput. Appl. Math. 2010, 234, 649–657. [Google Scholar] [CrossRef] [Green Version]
- Leong, W.J.; Hassan, M.A.; Yusuf, M.W. A matrix-free quasi-Newton method for solving large-scale nonlinear systems. Comput. Math. Appl. 2011, 62, 2354–2363. [Google Scholar] [CrossRef] [Green Version]
- Waziri, M.Y.; Leong, W.J.; Mamat, M. A two-step matrix-free secant method for solving large-scale systems of nonlinear equations. J. Appl. Math. 2012, 2012, 348654. [Google Scholar] [CrossRef] [Green Version]
- Waziri, M.Y.; Leong, W.J.; Hassan, M.A.; Monsi, M. A new Newton’s Method with diagonal Jacobian approximation for systems of nonlinear equations. J. Math. Stat. 2010, 6, 246–252. [Google Scholar] [CrossRef]
- Waziri, M.Y.; Leong, W.J.; Mamat, M.; Moyi, A.U. Two-step derivative-free diagonally Newton’s method for large-scale nonlinear equations. World Appl. Sci. J. 2013, 21, 86–94. [Google Scholar]
- Yakubu, U.A.; Mamat, M.; Mohamad, M.A.; Rivaie, M.; Sabi’u, J. A recent modification on Dai–Liao conjugate gradient method for solving symmetric nonlinear equations. Far East J. Math. Sci. 2018, 103, 1961–1974. [Google Scholar] [CrossRef]
- Uba, L.Y.; Waziri, M.Y. Three-step derivative-free diagonal updating method for solving large-scale systems of nonlinear equations. J. Numer. Math. Stochastics 2014, 6, 73–83. [Google Scholar]
- Zhou, Y.; Wu, Y.; Li, X. A New Hybrid PRPFR Conjugate Gradient Method for Solving Nonlinear Monotone Equations and Image Restoration Problems. Math. Probl. Eng. 2020, 2020, 6391321. [Google Scholar] [CrossRef]
- Waziri, M.Y.; Leong, W.J.; Mamat, M. An efficient solver for systems of nonlinear equations with singular Jacobian via diagonal updating. Appl. Math. Sci. 2010, 4, 3403–3412. [Google Scholar]
- Waziri, M.Y.; Leong, W.J.; Hassan, M.A. Diagonal Broyden-like method for large-scale systems of nonlinear equations. Malays. J. Math. Sci. 2012, 6, 59–73. [Google Scholar]
- Abubakar, A.B.; Sabi’u, J.; Kumam, P.; Shah, A. Solving nonlinear monotone operator equations via modified SR1 update. J. Appl. Math. Comput. 2021, 67, 343–373. [Google Scholar] [CrossRef]
- Grosan, C.; Abraham, A. A new approach for solving nonlinear equations systems. IEEE Trans. Syst. Man Cybern. 2008, 38, 698–714. [Google Scholar] [CrossRef]
- Dehghan, M.; Hajarian, M. New iterative method for solving nonlinear equations with fourth-order convergence. Int. J. Comput. Math. 2010, 87, 834–839. [Google Scholar] [CrossRef]
- Dehghan, M.; Hajarian, M. Fourth-order variants of Newton’s method without second derivatives for solving nonlinear equations. Eng. Comput. 2012, 29, 356–365. [Google Scholar] [CrossRef]
- Kaltenbacher, B.; Neubauer, A.; Scherzer, O. Iterative Regularization Methods for Nonlinear III—Posed Problems; De Gruyter: Berlin, Germany; New York, NY, USA, 2008. [Google Scholar]
- Wang, Y.; Yuan, Y. Convergence and regularity of trust region methods for nonlinear ill-posed problems. Inverse Probl. 2005, 21, 821–838. [Google Scholar] [CrossRef] [Green Version]
- Dehghan, M.; Hajarian, M. Some derivative free quadratic and cubic convergence iterative formulas for solving nonlinear equations. Comput. Appl. Math. 2010, 29, 19–30. [Google Scholar] [CrossRef]
- Dehghan, M.; Hajarian, M. On some cubic convergence iterative formulae without derivatives for solving nonlinear equations. Int. J. Numer. Methods Biomed. Eng. 2011, 27, 722–731. [Google Scholar] [CrossRef]
- Dehghan, M.; Shirilord, A. Accelerated double-step scale splitting iteration method for solving a class of complex symmetric linear systems. Numer. Algorithms 2020, 83, 281–304. [Google Scholar] [CrossRef]
- Dehghan, M.; Shirilord, A. A generalized modified Hermitian and skew-Hermitian splitting (GMHSS) method for solving complex Sylvester matrix equation. Appl. Math. Comput. 2019, 348, 632–651. [Google Scholar] [CrossRef]
- Bellavia, S.; Gurioli, G.; Morini, B.; Toint, P.L. Trust-region algorithms: Probabilistic complexity and intrinsic noise with applications to subsampling techniques. EURO J. Comput. Optim. 2022, 10, 100043. [Google Scholar] [CrossRef]
- Bellavia, S.; Krejić, N.; Morini, B.; Rebegoldi, S. A stochastic first-order trust-region method with inexact restoration for finite-sum minimization. Comput. Optim. Appl. 2023, 84, 53–84. [Google Scholar] [CrossRef]
- Bellavia, S.; Krejić, N.; Morini, B. Inexact restoration with subsampled trust-region methods for finite-sum minimization. Comput. Optim. Appl. 2020, 76, 701–736. [Google Scholar] [CrossRef]
- Eshaghnezhad, M.; Effati, S.; Mansoori, A. A Neurodynamic Model to Solve Nonlinear Pseudo-Monotone Projection Equation and Its Applications. IEEE Trans. Cybern. 2017, 47, 3050–3062. [Google Scholar] [CrossRef]
- Meintjes, K.; Morgan, A.P. A methodology for solving chemical equilibrium systems. Appl. Math. Comput. 1987, 22, 333–361. [Google Scholar] [CrossRef]
- Crisci, S.; Piana, M.; Ruggiero, V.; Scussolini, M. A regularized affine–acaling trust–region method for parametric imaging of dynamic PET data. SIAM J. Imaging Sci. 2021, 14, 418–439. [Google Scholar] [CrossRef]
- Bonettini, S.; Zanella, R.; Zanni, L. A scaled gradient projection method for constrained image deblurring. Inverse Probl. 2009, 25, 015002. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.K.; Du, X.L. A gradient projection method for the sparse signal reconstruction in compressive sensing. Appl. Anal. 2018, 97, 2122–2131. [Google Scholar] [CrossRef]
- Liu, J.K.; Li, S.J. A projection method for convex constrained monotone nonlinear equations with applications. Comput. Math. Appl. 2015, 70, 2442–2453. [Google Scholar] [CrossRef]
- Xiao, Y.; Zhu, H. A conjugate gradient method to solve convex constrained monotone equations with applications in compressive sensing. J. Math. Anal. Appl. 2013, 405, 310–319. [Google Scholar] [CrossRef]
- Awwal, A.M.; Wang, L.; Kumam, P.; Mohammad, H.; Watthayu, W. A Projection Hestenes–Stiefel Method with Spectral Parameter for Nonlinear Monotone Equations and Signal Processing. Math. Comput. Appl. 2020, 25, 27. [Google Scholar] [CrossRef]
- Fukushima, M. Equivalent differentiable optimization problems and descent methods for asymmetric variational inequality problems. Math. Program. 1992, 53, 99–110. [Google Scholar] [CrossRef]
- Qian, G.; Han, D.; Xu, L.; Yang, H. Solving nonadditive traffic assignment problems: A self-adaptive projection–auxiliary problem method for variational inequalities. J. Ind. Manag. Optim. 2013, 9, 255–274. [Google Scholar] [CrossRef]
- Ghaddar, B.; Marecek, J.; Mevissen, M. Optimal power flow as a polynomial optimization problem. IEEE Trans. Power Syst. 2016, 31, 539–546. [Google Scholar] [CrossRef] [Green Version]
- Ivanov, B.; Stanimirović, P.S.; Milovanović, G.V.; Djordjević, S.; Brajević, I. Accelerated multiple step-size methods for solving unconstrained optimization problems. Optim. Methods Softw. 2021, 36, 998–1029. [Google Scholar] [CrossRef]
- Andrei, N. An acceleration of gradient descent algorithm with backtracking for unconstrained optimization. Numer. Algorithms 2006, 42, 63–73. [Google Scholar] [CrossRef]
- Stanimirović, P.S.; Miladinović, M.B. Accelerated gradient descent methods with line search. Numer. Algorithms 2010, 54, 503–520. [Google Scholar] [CrossRef]
- Sun, W.; Yuan, Y.-X. Optimization Theory and Methods: Nonlinear Programming; Springer: New York, NY, USA, 2006. [Google Scholar]
- Petrović, M.J. An Accelerated Double Step Size model in unconstrained optimization. Appl. Math. Comput. 2015, 250, 309–319. [Google Scholar] [CrossRef]
- Petrović, M.J.; Stanimirović, P.S. Accelerated Double Direction method for solving unconstrained optimization problems. Math. Probl. Eng. 2014, 2014, 965104. [Google Scholar] [CrossRef]
- Stanimirović, P.S.; Milovanović, G.V.; Petrović, M.J.; Kontrec, N. A Transformation of accelerated double step size method for unconstrained optimization. Math. Probl. Eng. 2015, 2015, 283679. [Google Scholar] [CrossRef] [Green Version]
- Nocedal, J.; Wright, S.J. Numerical Optimization; Springer: New York, NY, USA, 1999. [Google Scholar]
- Barzilai, J.; Borwein, J.M. Two-point step size gradient method. IMA J. Numer. Anal. 1988, 8, 141–148. [Google Scholar] [CrossRef]
- Dai, Y.H. Alternate step gradient method. Optimization 2003, 52, 395–415. [Google Scholar] [CrossRef]
- Dai, Y.H.; Fletcher, R. On the asymptotic behaviour of some new gradient methods. Math. Program. 2005, 103, 541–559. [Google Scholar] [CrossRef]
- Dai, Y.H.; Liao, L.Z. R-linear convergence of the Barzilai and Borwein gradient method. IMA J. Numer. Anal. 2002, 22, 1–10. [Google Scholar] [CrossRef]
- Dai, Y.H.; Yuan, J.Y.; Yuan, Y. Modified two-point step-size gradient methods for unconstrained optimization. Comput. Optim. Appl. 2002, 22, 103–109. [Google Scholar] [CrossRef]
- Dai, Y.H.; Yuan, Y. Alternate minimization gradient method. IMA J. Numer. Anal. 2003, 23, 377–393. [Google Scholar] [CrossRef]
- Dai, Y.H.; Yuan, Y. Analysis of monotone gradient methods. J. Ind. Manag. Optim. 2005, 1, 181–192. [Google Scholar] [CrossRef]
- Dai, Y.H.; Zhang, H. Adaptive two-point step size gradient algorithm. Numer. Algorithms 2001, 27, 377–385. [Google Scholar] [CrossRef]
- Raydan, M. On the Barzilai and Borwein choice of steplength for the gradient method. IMA J. Numer. Anal. 1993, 13, 321–326. [Google Scholar] [CrossRef]
- Raydan, M. The Barzilai and Borwein gradient method for the large scale unconstrained minimization problem. SIAM J. Optim. 1997, 7, 26–33. [Google Scholar] [CrossRef]
- Vrahatis, M.N.; Androulakis, G.S.; Lambrinos, J.N.; Magoulas, G.D. A class of gradient unconstrained minimization algorithms with adaptive step-size. J. Comput. Appl. Math. 2000, 114, 367–386. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Y. A new step size for the steepest descent method. J. Comput. Math. 2006, 24, 149–156. [Google Scholar]
- Frassoldati, G.; Zanni, L.; Zanghirati, G. New adaptive step size selections in gradient methods. J. Ind. Manag. Optim. 2008, 4, 299–312. [Google Scholar] [CrossRef]
- Serafino, D.; Ruggiero, V.; Toraldo, G.; Zanni, L. On the steplength selection in gradient methods for unconstrained optimization. Appl. Math. Comput. 2018, 318, 176–195. [Google Scholar] [CrossRef] [Green Version]
- Crisci, S.; Porta, F.; Ruggiero, V.; Zanni, L. Spectral properties of Barzilai–Borwein rules in solving singly linearly constrained optimization problems subject to lower and upper bounds. SIAM J. Optim. 2020, 30, 1300–1326. [Google Scholar] [CrossRef]
- Crisci, S.; Porta, F.; Ruggiero, V.; Zanni, L. Hybrid limited memory gradient projection methods for box–constrained optimization problems. Comput. Optim. Appl. 2023, 84, 151–189. [Google Scholar] [CrossRef]
- Miladinović, M.; Stanimirović, P.S.; Miljković, S. Scalar Correction method for solving large scale unconstrained minimization problems. J. Optim. Theory Appl. 2011, 151, 304–320. [Google Scholar] [CrossRef]
- Raydan, M.; Svaiter, B.F. Relaxed steepest descent and Cauchy-Barzilai-Borwein method. Comput. Optim. Appl. 2002, 21, 155–167. [Google Scholar] [CrossRef]
- Djordjević, S.S. Two modifications of the method of the multiplicative parameters in descent gradient methods. Appl. Math. Comput. 2012, 218, 8672–8683. [Google Scholar]
- Zhang, Y.; Yi, C. Zhang Neural Networks and Neural-Dynamic Method; Nova Science Publishers, Inc.: New York, NY, USA, 2011. [Google Scholar]
- Zhang, Y.; Ma, W.; Cai, B. From Zhang neural network to Newton iteration for matrix inversion. IEEE Trans. Circuits Syst. I Regul. Pap. 2009, 56, 1405–1415. [Google Scholar] [CrossRef]
- Djuranovic-Miličić, N.I.; Gardašević-Filipović, M. A multi-step curve search algorithm in nonlinear optimization - nondifferentiable case. Facta Univ. Ser. Math. Inform. 2010, 25, 11–24. [Google Scholar]
- Zhou, W.J.; Li, D.H. A globally convergent BFGS method for nonlinear monotone equations without any merit functions. Math. Comput. 2008, 77, 2231–2240. [Google Scholar] [CrossRef]
- La Cruz, W.; Martínez, J.; Raydan, M. Spectral residual method without gradient information for solving large-scale nonlinear systems of equations. Math. Comput. 2006, 75, 1429–1448. [Google Scholar] [CrossRef] [Green Version]
- Dolan, E.; Moré, J. Benchmarking optimization software with performance profiles. Math. Program. 2002, 91, 201–213. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | (29) | (34) | (29) = (34) | (29) = (34) = | Total | |
|---|---|---|---|---|---|---|
| iter | 52 | 32 | 181 | 23 | 72 | 265 |
| fval | 52 | 33 | 180 | 24 | 71 | 265 |
| CPU (sec) | 214 | 141 | 0 | 0 | 5 | 355 |
| Methods | ADSSN | EMFD | ADSSN = EMFD |
|---|---|---|---|
| iter | 282 | 55 | 23 |
| fval | 281 | 56 | 23 |
| CPU (sec) | 359 | 1 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stanimirović, P.S.; Shaini, B.I.; Sabi’u, J.; Shah, A.; Petrović, M.J.; Ivanov, B.; Cao, X.; Stupina, A.; Li, S. Improved Gradient Descent Iterations for Solving Systems of Nonlinear Equations. Algorithms 2023, 16, 64. https://doi.org/10.3390/a16020064
Stanimirović PS, Shaini BI, Sabi’u J, Shah A, Petrović MJ, Ivanov B, Cao X, Stupina A, Li S. Improved Gradient Descent Iterations for Solving Systems of Nonlinear Equations. Algorithms. 2023; 16(2):64. https://doi.org/10.3390/a16020064
Chicago/Turabian StyleStanimirović, Predrag S., Bilall I. Shaini, Jamilu Sabi’u, Abdullah Shah, Milena J. Petrović, Branislav Ivanov, Xinwei Cao, Alena Stupina, and Shuai Li. 2023. "Improved Gradient Descent Iterations for Solving Systems of Nonlinear Equations" Algorithms 16, no. 2: 64. https://doi.org/10.3390/a16020064