1. Introduction
Data often has a higher-order structure, and leveraging this structure can significantly improve the results of the problem at hand. However, many machine learning methods do not naturally extend to tensors in a way that account for this tensorial structure. In the case of classification problems, for example, there has been tremendous interest in extending linear discriminant analysis (LDA) to the tensorial setting. LDA is a classical and versatile method for classification, but is typically not well suited for data in matrix or in tensor forms (higher-order matrices). These types of data, with a higher order structure, are very common nowadays and there has been a lot of interest in developing machine learning methods that can leverage this structure. Natural examples of data in matrix form are black-and-white images and multi-lead electrocardiogram (ECG) readings. Similarly, color images, videos, and data in matrix forms that vary with time are examples of third order tensors. Classifying matrix data with LDA (or other vector-based classical machine learning algorithms) requires the data to be vectorized first; this often leads to large vectors, but—perhaps more importantly—also causes the loss of important information such as spatial locality. Furthermore, vectorization ignores the multilinear structure of the data. For example, a matrix of rank one depends on fewer parameters than a full-rank matrix. On top of that, matrices from different classes might have different ranks, so using the multilinear structure might help in the classification task. These considerations apply even more strongly to higher-order data, and tensor techniques have been successfully applied in a variety of classification settings such as images (see [
1]), electroencephalogram (EEG) data (see [
2,
3]), and ECG signals (see [
4,
5]); for a recent survey of applications to clinical informatics, see [
6]. On the other hand, tensors of order 3 or more enjoy many good properties (e.g., unique decompositions), so that sometimes it is in fact advantageous to reshape data given in form of vectors or matrices into data of higher order [
7].
For these reasons, there has been intensive work in recent years on extending LDA to multilinear discriminant analysis (MDA) to leverage the multilinear structure of the data. Using the Fisher criterion for LDA, given data points
belonging to two classes
of size
, one seeks the optimal projection to a hyperplane that maximizes distances between different classes (measured by the between-class scatter matrix) and minimizes distances within the same class (measured by the within-class scatter matrix). If
are the means for each class and
is the overall mean, one can define the scatter matrix for class
i as the covariance matrix for that class,
the within class scatter matrix as
, and the between class scatter matrix as
The hyperplane
to project onto is then obtained by maximizing
In an attempt to extend Fisher’s approach, most MDA methods seek to project tensor data to a lower dimensional vector or tensor space by similarly maximizing distances between classes while simultaneously minimizing distances within the same class. Early work [
8,
9,
10] considered the case of matrix data. After that, many methods have been proposed for tensorial data, usually introducing between-class and within-class scatter matrices for each mode. Different methods consider various functions to optimize (like the scatter-ratio criterion or the scatter-difference criterion from Fisher discriminant analysis), and propose different algorithms to optimize them. Discriminant analysis with tensor representation (DATER) [
11], generalized eigenvalue discriminant analysis with tensor representation (DATEReig) [
12] and constrained multilinear discriminant analysis (CMDA) [
1] seek to maximize the scatter-ratio criterion iteratively by alternating through each mode; direct general tensor discriminant analysis (DGTDA) [
1] seeks to maximize the scatter difference directly. The methods proposed in [
3], such as manifold Tucker discriminant analysis (ManTDA) and manifold PARAFAC discriminant analysis (ManPDA), seek to optimize simultaneously, in all modes, the projection matrices over a product of Stiefel manifolds with respect to the scatter-ratio criterion or its simplified trace ratio objective.
However, the optimization problems considered so far are ill-behaved in general due to the existence of local optima. Because of this, several iterations with different random initializations are sometimes necessary to try to avoid such local optima. However, this adds to the computational cost of the method, while still having no guarantee the computed solution is a global optimum. Furthermore, the performance of these methods drastically depends on the choice of the dimensions of the space to project onto. For example, a tensor of size can be projected onto a tensor of size with . This amounts to, in principle, 1000 possibilities. In practice, one usually chooses all dimensions to be equal, but if the size of tensor varies greatly from one mode to the other, this option is not viable. Therefore these methods include the additional cost of determining the best dimensions to project onto. We will see that our proposed method does not share these issues, since instead of projecting onto a lower dimensional subspace we look for a change of coordinates in the given space.
In this paper, we take a radically different approach: Kempf–Ness multilinear discriminant analysis (KNMDA). Starting from the interpretation of classic LDA as a nearest Mahalanobis distance classifier, we reformulate LDA by means of invariant theory, which allows us to extend it naturally to structured data in the form of a well-behaved optimization problem. In fact, our framework allows us to also reformulate quadratic discriminant analysis (QDA) by means of invariant theory, and to extend QDA to tensorial data for the first time.
Invariant theory, originating in 19th century and modernized by David Hilbert, can be applied to many areas of computer science, such as coding theory [
13] and computer vision [
14,
15]. Some newer applications more relevant to this study are those related to scaling algorithms [
16], matrix and tensor completion [
17], and maximum likelihood estimation [
18]. In invariant theory, one studies the linear action of groups on vector spaces and polynomials that are invariant under these group symmetries.
A major tool of invariant theory is the Kempf–Ness theorem [
19]. Roughly speaking, the theorem states that if an orbit has a point that is closest to the origin, then this point is essentially unique. This translates to a certain optimization problem having a unique optimal solution. This result of Kempf–Ness theory provides a natural extension of LDA to the higher order setting.
LDA is related to the Mahalanobis distance: it can be interpreted as a k-means algorithm, where we classify a data point based on the smallest distance from the mean of the training data of each class, and the distance is given by the Mahalanobis one. In turn, the Mahalanobis distance of a point x from the mean of the training data can be thought of as Euclidean distance after a suitable change of coordinates, namely , where is the sample covariance matrix across the entire training dataset. Therefore, we can interpret LDA as a k-means algorithm in a suitable coordinate system. By allowing different sample covariance matrices for each class—i.e., different sets of coordinates for each class—we can similarly interpret QDA in this framework. If is a matrix (or tensor), applying a change of coordinates after vectorization might radically alter the structure of . This can be especially nefarious when the data is sparse, e.g., it has low rank or few non-zero entries. To solve this issue, we can apply a different change of coordinates in each mode of , i.e., multiply by an invertible matrix in each mode. This strategy would preserve the rank. To further preserve the structure of the data, one might want to consider coordinate changes that preserve volumes; therefore we will consider invertible matrices with the determinant 1. The restriction to matrices with determinant 1 does not have a large impact on the method, as it amounts to rescaling an invertible matrix to make its determinant equal to 1. The question now is how to appropriately choose such a change of coordinates. The Kempf–Ness theory gives us a choice of coordinates by solving a well-behaved optimization problem which reduces to Mahalanobis distance in the case of vectorial data.
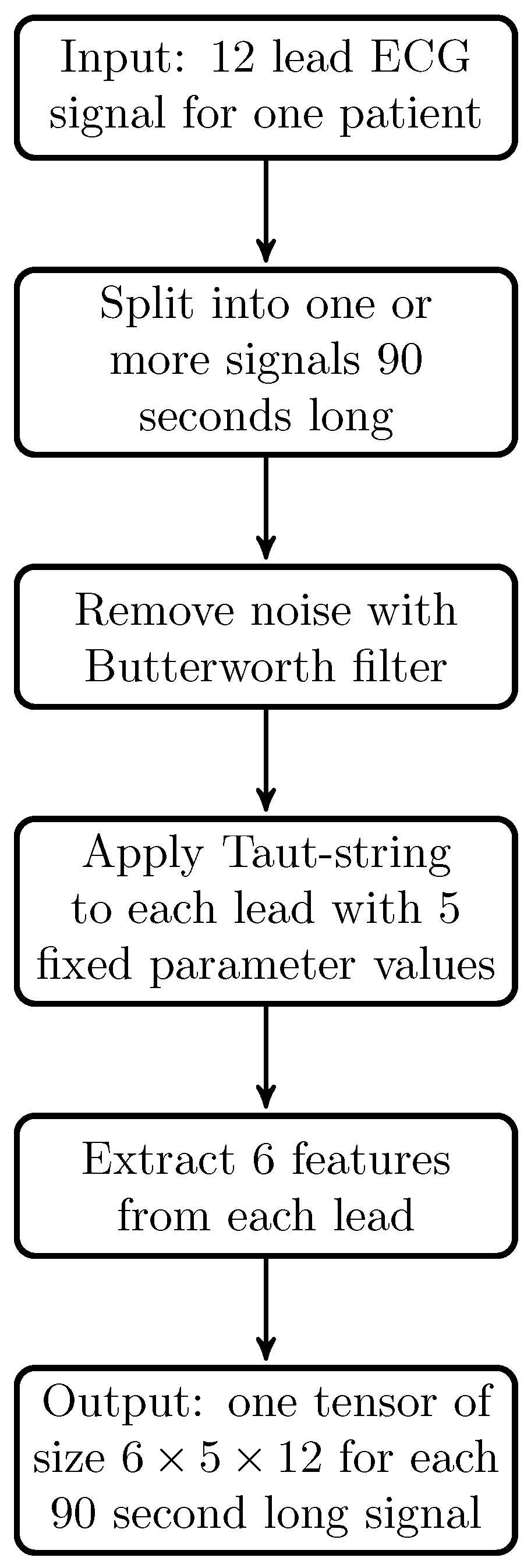
The proposed method was tested on synthetic data of several types, some of which have already appeared in the literature [
3,
20]. The results demonstrate that there are classes of data on which the proposed method achieves significantly better results than other existing methods. The method was also employed to classify tensors extracted from ECG signals. The analysis of ECG recordings with tensor-based approaches has proven to be very fruitful in a variety of settings, such as the detection and localization of myocardial infarction, irregular heartbeat classification, ECG data compression, detection and quantification of T-wave alternans, and analysis of changes in heartbeat morphology (see [
4] for an overview). In our experiments, we consider third-order tensors extracted from multi-lead ECG signals from the publicly available PhysioNet PTB dataset [
21]. There are several ways of constructing tensors from ECG data; here we follow the approach of [
22] by extracting features from taut-string approximations of the signals. In [
22], feature vectors were extracted from ECG signals via taut string as well as other methods, and then classification was performed with standard machine learning techniques, among which linear support vector machine (SVM) performed best. We found that the same applies to our experiments, which is why in the comparisons we also include the results of an SVM classifier on the vectorized tensors. We believe that the method by which we construct third-order tensors via taut string from multi-lead ECG signals (which we have not found anywhere else) is also a potentially interesting new way of extracting tensors from signals.
2. Notation and Background Material
A tensor is a multi-way extension of a matrix whose entries depend on 3 or more indices. For example, entries of a 3-way tensor (or tensor with 3 modes)
depend on 3 indices,
, where
,
, and
. We will limit our exposition to the case of three-way tensors, but everything extends in the obvious way to four or more modes (as well as to matrices, with only two modes). We refer the reader to [
23,
24] for an extensive overview of tensors and their applications.
Working with tensors, it is often convenient to break them up into vectors and matrices. Given a tensor , fixing two of the indices, we obtain fibers (which are vectors) of the tensor in a given mode; fixing one of the indices, we obtain slices (which are matrices) of the tensor in a given mode. One can flatten (or matricize) a three-way tensor in three different ways, by juxtaposing slices in the chosen mode; will denote the mode-n flattening of . For example, the mode-1 flattening of is a matrix of size , which can be thought of as arranging mode-1 fibers as columns of an matrix.
We will be interested in two types of products. The -mode matrix-tensor product is a way of multiplying an matrix A by a tensor , and consists of multiplying each mode-i fiber of by A. Equivalently, this amounts to multiplying A by the mode-i flattening . This product is denoted , and its result is another tensor, although of different size: for example, is a tensor in . Another product we are interested in is the outer product of vectors: if are vectors of lengths , their outer product (or tensor product) is a 3-way tensor with entries defined as . A tensor of the form is said to have rank 1.
A fundamental tool in studying matrices is the singular value decomposition (SVD). This decomposition does not generalize to tensors completely (we cannot retain both a diagonal core and orthogonal side matrices) but it generalizes in two main ways: the danonical polyadic (CP) decomposition and the Tucker decomposition (as well as many variants of these).
A CP decomposition of a tensor
is a generalization of SVD that keeps a diagonal core, and amounts to writing the tensor as a minimum-length sum of tensors of rank 1:
Such a minimum
r is called the rank of the tensor (which is a generalization of the rank of a matrix) and it is unfortunately NP-hard to compute [
25,
26,
27]. This decomposition is often unique (up to permuting the indices and rescaling the vectors), and therefore the vectors
contain useful features to further study the tensor
, even though in practice, one only computes an approximation of this decomposition. The matrices
,
, and
are often called factor matrices of
.
Another generalization of the SVD of a matrix is the higher-order singular value decomposition (HOSVD), which preserves the orthogonality of the factor matrices but does not have a diagonal core:
with
orthogonal. The dimensions of the core
can be chosen to be smaller than those of
, making this decomposition useful for dimension reduction (among other things).
The main result from invariant theory we will use is the Kempf–Ness theorem [
19]. Over the real numbers, it first appeared in ([
28], Theorem 4.3). We will describe the general setup of [
28], which is technical, but note that it applies to some concrete situations of interest. Let
(resp.
) be the group of invertible
matrices with real (resp. complex) entries. Suppose that
is a reductive, Zariski closed subgroup of
that is closed under complex conjugation. Let
be a subgroup that contains the connected component of the identity in
. The orbit
of a vector
with respect to
G is defined as the set of vectors
as
g varies in the group
G. Finally, define
, where
is the group of orthogonal
matrices. This setup applies to the following situations that are of interest to us:
, the group of matrices with determinant 1 and , the special orthogonal group acting on in the usual way;
The group of diagonal matrices of determinant 1 with positive diagonal entries, and is the trivial group;
The group acting on the space of tensors of size and , where ;
The same as the previous example, but where G and K acts on m-tuples of tensors, or equivalently, on tensors (and ).
We can now state the real Kempf–Ness theorem:
Theorem 1 (Kempf–Ness). Suppose that be as in the setup above, and is nonzero. The Euclidean norm function has a critical point on the orbit if and only if the orbit is closed. If a critical point exists, then it is an absolute minimum and the set of critical points is unique up to the action of K, i.e., the set of critical points is a unique K-orbit.
3. Algorithm
Before we apply Kempf–Ness theory for tensor classification, let us discuss an easier situation where we are not using any tensor structure. We consider a sequence of vectors
and the action of a subgroup
by multiplication. We combine the vectors into a matrix
. We will see that in the case of centered vector data, simultaneously minimizing the norm of all vectors with respect to the
-action coincides with considering the Mahalanobis distance (up to a constant). The proof of the next Proposition can be found in
Appendix A.
Proposition 1 (Critical points for
-action).
Let of rank n, with . Suppose that is a (truncated) singular value decomposition with and S a diagonal matrix whose diagonal entries are the singular values . Let be the geometric mean. If and , then is a critical point for the norm function, and therefore an absolute minimum point. If the mean of the vectors
is zero and
, then we have
where
is the covariance matrix. Therefore, we have
The Mahalanobis distance between two vectors
x and
y is
so that (up to a scalar)
A gives us the Mahalanobis distance
. Multiplying with
A can be thought of as a normalization, so that the covariance matrix of
is the identity, up to a scalar.
If
X has a rank less than
n, we can first “regularize”
X by replacing it with
for some chosen
to ensure that the rank is
n, and then apply the previous proposition. One can think of
as a regularization parameter that can be used even if the rank of the matrix is already
n. Experimental results (as described in
Section 4) suggest, on the other hand, that the results are often not affected by the choice of
.
QDA is an algorithm for binary classification of vector data that uses the Mahalanobis distance as follows. Suppose that there are two classes. In the training data, we have vectors that belong to the first class and training data that belong to the second class. Let and be the means of the x’s and the y’s, respectively. Let and be the covariance matrices of the x’s and y’s. To classify a given vector z, we compare the -Mahalanobis distance of z to with the -Mahalanobis distance of z to . Our goal is to generalize this approach to tensor data, and replace the Mahalanobis distance with a distance that respects the tensor structure.
Instead of the action of
, we can also consider the action of
, the group of diagonal matrices with positive diagonal entries and determinant 1. We have the following result, the proof of which can be found in
Appendix A.
Proposition 2 (Critical points for
-action).
Suppose that has no zero rows. Let be the Euclidean lengths of the rows of X, and let be the geometric mean. If then is a critical point for the norm function, and therefore an absolute minimum point. Suppose that the means of the rows of are zero. Thus, all features of the vector data have mean 0. Multiplying with A has the effect that all the features (rows) are normalized to have the same standard deviation.
If X has a zero row, we can first “regularize” X by replacing it with for some chosen , where is a row vector with n entries equal to 1.
Instead of vector data, we will now consider tensor data. The techniques using Kempf–Ness theory are valid for tensors of any order, but we will work with 3-way tensors. Suppose that
are tensors. We could normalize the data with an arbitrary change of coordinates in
, where
, but this could change the tensor structure of the tensor data. For example, the tensor rank is not preserved under arbitrary coordinate changes in
. Instead, we will consider the action of the a group
on
where for each
i,
is equal to
or
. An element
in the group acts on a tensor
by multiplying
A,
B and
C with
in the first, second and third mode, respectively:
for
G and
fixed, the
-orbit
of
is the set of tensors of the form
as
A,
B and
C vary.
Consider the binary classification problem with training data given by three-way tensors of size in class 1, and of the same size in class 2. Given a new test tensor from one of the two classes above, our goal is to identify the class to which it belongs. Though we have restricted our discussion to a binary classification problem for simplicity, our algorithm extends naturally to cases with more than two classes.
Working with Theorem 1, it can be hard in general to check the existence of a critical point, or to find one if it exists. The optimization problem we wish to solve is to find matrices
such that
is minimal for the first class (where
is the mean of the tensors in the first class), and similarly matrices
for the second class. This optimization problem can be formulated in terms of Kempf–Ness theory. Denote by
the four-way tensor obtained by concatenating along the fourth mode all (centered) tensors
, and denote by
the group acting as
on the first 3 modes, and trivially (via the identity matrix) on the fourth mode. This optimization problem can then be equivalently stated as finding the minimum of the norm over the orbit
. By Theorem 1 (or, more precisely, its version for fourth order tensors) it then follows that if there is a critical point, our problem has a unique minimum. In general, we will not be able to determine whether a critical point exists, but experimentally it will turn out to be the case if we adopt a suitable regularization technique.
While the above optimization problem is difficult to solve in general, it has an explicit solution in the case of vectors , and in this case we would recover the covariance matrix for each class. In this sense, the optimization problem we suggest can perhaps be also thought of as an extension of QDA to higher order data. Our method to estimate a solution is an alternating algorithm that iteratively keeps two of the three matrices fixed, and computes the third one. To deal with several tensors at once, we iteratively concatenate their flattenings along each of the modes.
We can now describe the algorithm we use on each class to obtain a new set of coordinates. Let
be the four-way tensor obtained by concatenating along the fourth mode all (centered) tensors
in class 1, and consider its matricizations
,
, and
along the first, second, and third mode, respectively. Once a group
G has been chosen (i.e., which group action to use in each mode), the problem to be solved is
The challenge to solving the above problem is that the previous propositions do not readily extend to a method of minimizing in more than one mode simultaneously. On the other hand, we know how to minimize the norm in a given mode exactly. For this reason, we adopt an alternating algorithm, which keeps two of the matrices
A,
B and
C fixed at each step, and minimizes the norm with respect to the third one. If
B and
C are fixed and we call
the tensor obtained from
after multiplying by
B snd
C in the second and third mode, respectively, the problem
is equivalent to
which can be solved using either Proposition 1 or Proposition 2 (depending on which group we chose to act on the first mode).
Similarly,
are equivalent to
where we defined
and
.
We keep iterating until each minimization reduces the norm beyond a given tolerance level, or a maximum chosen number of iterations is reached. As we will see in the experiments, this choice does not typically affect the outcome of the classification. Algorithm 1 describes this process.
Figure 1 is a schematic graphical representation of Algorithm 1 in the case of matrix data (instead of third order tensors) for drawing ease. While we are not guaranteed the existence of a minimum, by Theorem 1 we know that if it exists, it is unique. Experimentally, it turns out that if we apply regularization at each iterative step, a minimum will exist in most cases.
| Algorithm 1 New sets of coordinates. |
Input: (Centered) Training data from one class. Output: Change of coordinates . |
We can think of the group action via (
) as a change of coordinates for centered tensors in a given class. Therefore to classify a new tensor
we apply a
k-means algorithm, computing the distances
and
from the means of the two classes in the new coordinates. The process is described in Algorithm 2, which is our KNMDA algorithm.
Figure 2 is a schematic graphical representation of Algorithm 2 in the case of matrix data (instead of third-order tensors) for drawing ease.
| Algorithm 2 Classification via KNMDA. |
Data: Training data , from two classes. Input: Tensor to classify. Output: Class to which belongs. |
One could also use this algorithm to obtain two similarity scores
and
, between 0 and 1, that represent how close
is to each class, by defining
To make an overall summary, given a training set of tensors (of any order), for each class we find the average tensor and center the data in that class. We then apply the Kempf–Ness Theorem to find optimal coordinates for a given class. Given a new tensor to be classified, we compute a distance from each class by subtracting the class average and applying the class change of coordinates. The smallest distance will identify the class to which the tensor is assigned.
5. Discussion
Our proposed method depends on the choice of group action, the regularization parameter , and the maximum number of iterations.
In all the experiments we performed, our method seems to be mostly affected by the choice of group action (as we would expect). This might suggest a cross-validation approach to choose the best group action for a given dataset. On the other end, on the synthetic data—perhaps due to their symmetry—
consistently achieved the best results. In the case of ECG tensors from the PTB dataset,
Table 9 reports average AUCs for each possible group action:
is still best or close to being best. Therefore, it seems that in practice choosing
action in each mode is always a safe choice, and results in a less costly model. On the other hand, it is possible that for tensors whose dimensions vary greatly from one mode to another, and for which each mode has a significantly different nature, another group action would perform much better. In that case, we would still be limited to eight choices (for third-order tensors). In any case, varying the regularization parameter
or the maximum number of iterations typically results in negligible variations in performance.
Table 10 and
Table 11 report variations in AUC for the ECG tensors from the PTB dataset.
We note that other MDA methods would require us to test, in principle,
dimensions; significantly more than the 8 possible combinations of groups for KNMDA (and similarly for higher order tensors). Additionally, another known issue of correctly choosing the reduced dimensions is that the performance is not monotonic as dimensionality increases (as shown in [
11]). This costly step of finding best dimensions to project onto is not necessary in KNMDA, since it looks for an optimal change of coordinates instead of an optimal projection.
On the other hand, one potential downside of the fact that KNMDA does not project the data onto a smaller dimensional space is that the most costly operations involve the computation of inverse matrices of dimensions
,
, and
, which could be computationally heavier. However, in our experiments on relatively small tensors it is significantly faster than any other tensor method we tested. This is shown in
Table 12, reporting average times in seconds for training and testing several methods over HOSVD-based data; training times are averages over 40 samples and testing times are averages over 100 samples. One limitation of KNMDA is that it might not be suited for tensors of very large dimension: in this scenario, a standard tensor dimensionality reduction preprocessing step would be useful.
Furthermore, most MDA methods require random initialization, which means they can provide different results for each run on the same dataset, and incur the additional cost of trying out different initializations for each run. KNMDA’s results on the contrary are completely determined by the input and do not change with different runs of the algorithm. This fact and the previous discussion make a case for the stability of the proposed method.
Based on the experiments on synthetic data, we can see that generating data with both fundamental tensorial decompositions (CP and HOSVD), KNMDA outperforms the other methods we compared it with. In cases where KNMDA is comparable to one or more other methods, it will still often outperform it as the amount of noise is increased. Another impressive feature of KNMDA is that its performance is consistent over tensors of very different natures. For example, linear SVM performs better than all other MDA methods over CP-based data, but it is close to random guessing on HOSVD-based data. This latter type of data is where MDA methods seem strongest, with manifold-based techniques performing better than the other MDA methods, concordant with the results from [
3]. However, KNMDA performs better than both tensor-based methods and linear SVM on both of these datasets. Finally, in the case of sparsity patterns, KNMDA achieves a perfect classification already at a level of noise at which other methods are unable to distinguish between classes.
We can notice a similar behavior in the case of tensors extracted from ECG, even though the performances of all methods are now closer to each other. Adding noise, KNMDA retains the best performance with the lowest standard deviation. It might seem surprising that linear SVM achieves better results than other MDA methods, but this is consistent with other papers that effectively used linear SVM for this type of data, as already discussed.

 ,
, 





{kind=link}
{kind=link}
{kind=link}