
Vision-Based Concrete-Crack Detection on Railway Sleepers Using Dense U-Net Model


Abstract
:1. Introduction
- Collecting railway sleeper images and processing them in the form of a dataset.
- Proposing a modified U-net model for the first time to detect cracks on railway sleepers.
- Quantifying the cracks of railway sleepers for knowing the severity of the cracks.
2. Related Work
2.1. Vision Based Crack Detection Methods
2.2. Crack Detection on Railway Sleepers
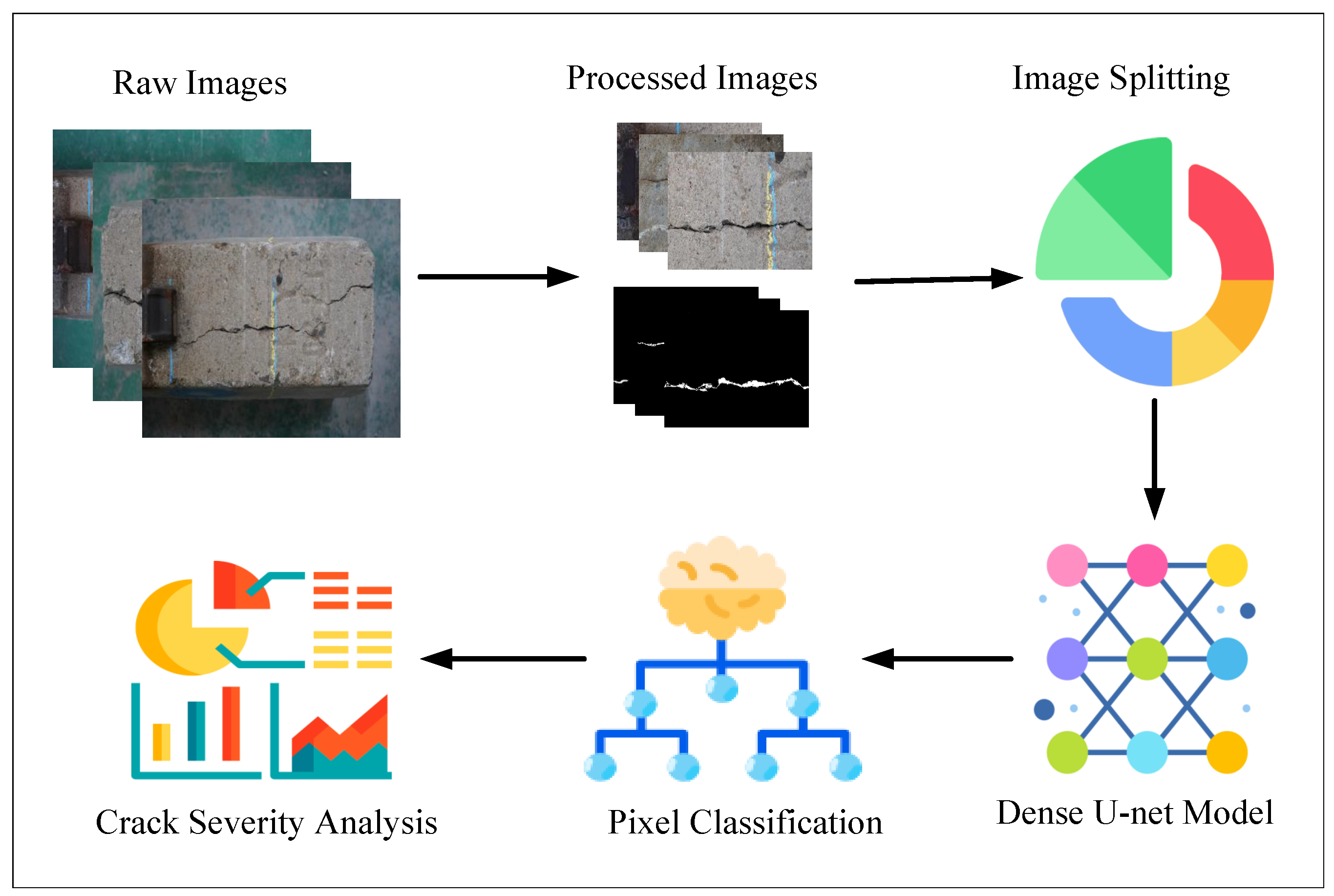
3. Methodology
3.1. Dataset Description
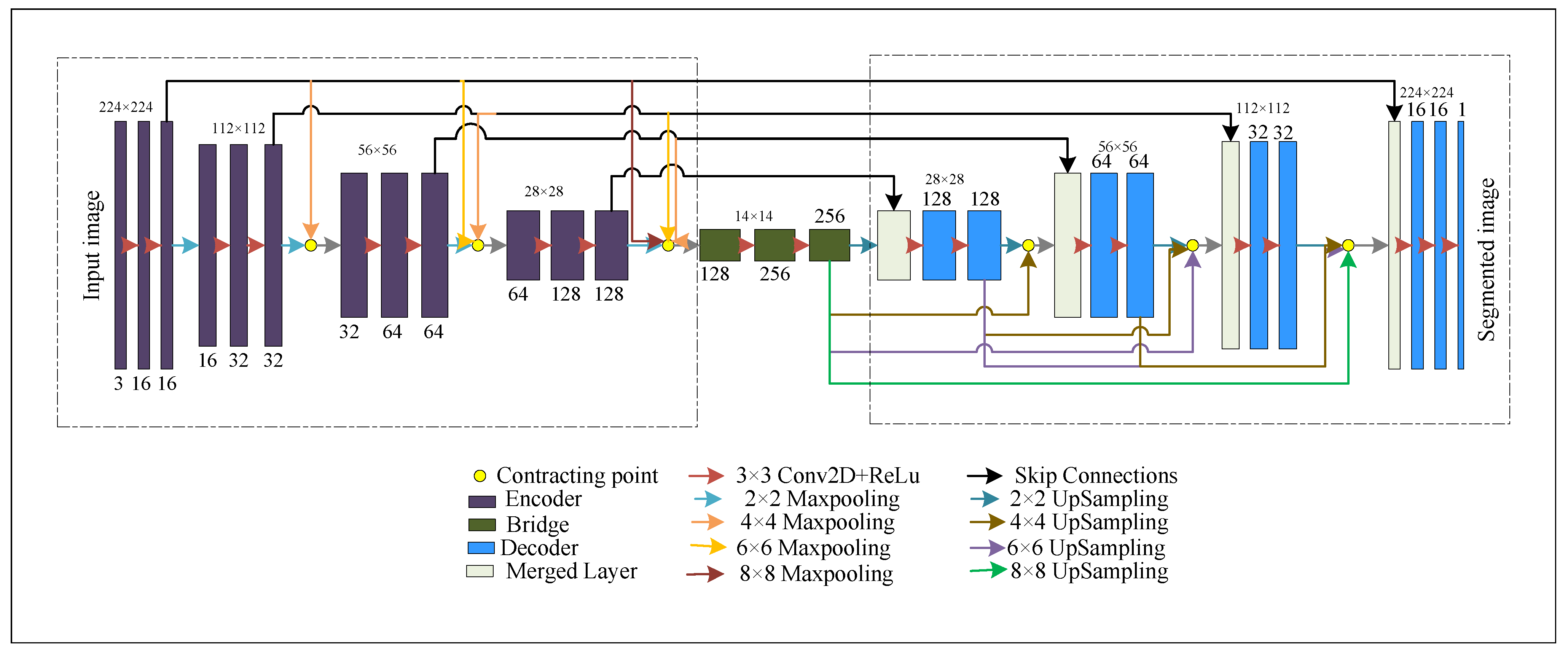
3.2. Model Architecture
3.3. Loss Function and Hyperparameters
3.4. Crack Severity Analysis
3.4.1. Counting the Cracks
3.4.2. Extracting Morphological Features
| Algorithm 1: Algorithm for length and width calculation. |
 |
4. Results and Discussions
4.1. Quantitative Results
4.2. Qualitative Results
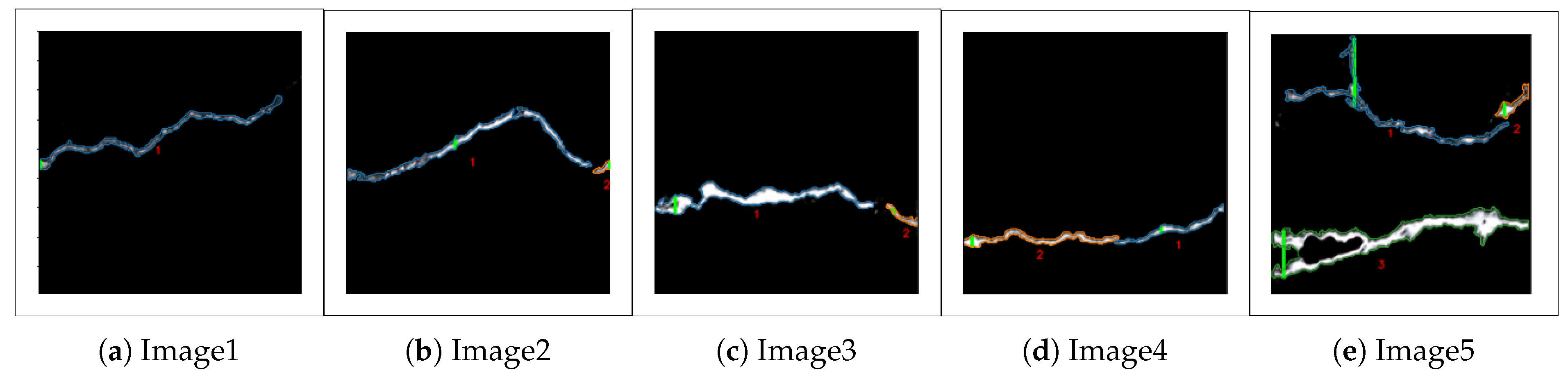
4.3. Crack Measurement Results
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- International Union of Railways—The Worldwide Railway Organisation. UIC. Available online: https://uic.org/ (accessed on 14 December 2023).
- Tang, Y.; Zhang, A.A.; Luo, L.; Wang, G.; Yang, E. Pixel-level pavement crack segmentation with encoder-decoder network. Measurement 2021, 184, 109914. [Google Scholar] [CrossRef]
- Zheng, M.; Lei, Z.; Zhang, K. Intelligent detection of building cracks based on Deep Learning. Image Vis. Comput. 2020, 103, 103987. [Google Scholar] [CrossRef]
- Ren, Y.; Huang, J.; Hong, Z.; Lu, W.; Yin, J.; Zou, L.; Shen, X. Image-based concrete crack detection in tunnels using deep fully convolutional networks. Constr. Build. Mater. 2020, 234, 117367. [Google Scholar] [CrossRef]
- Fu, H.; Meng, D.; Li, W.; Wang, Y. Bridge Crack Semantic segmentation based on improved deeplabv3+. J. Mar. Sci. Eng. 2021, 9, 671. [Google Scholar] [CrossRef]
- Nigam, R.; Singh, S.K. Crack detection in a beam using wavelet transform and photographic measurements. Structures 2020, 25, 436–447. [Google Scholar] [CrossRef]
- Qu, Z.; Chen, Y.-X.; Liu, L.; Xie, Y.; Zhou, Q. The Algorithm of Concrete Surface Crack Detection Based on the Genetic Programming and Percolation Model. IEEE Access 2019, 7, 57592–57603. [Google Scholar] [CrossRef]
- Chen, B.; Zhang, X.; Wang, R.; Li, Z.; Deng, W. Detect concrete cracks based on Otsu algorithm with Differential Image. J. Eng. 2019, 2019, 9088–9091. [Google Scholar] [CrossRef]
- Hou, H.; Lin, W. A new approach for the detection of concrete cracks based on adaptive morphological filtering. In Fuzzy Systems and Data Mining VI; IOS Press: Amsterdam, The Netherlands, 2020. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June September 2014; pp. 1–9. [Google Scholar]
- Zhang, L.; Yang, F.; Zhang, Y.D.; Zhu, Y.J. Road crack detection using deep convolutional neural network. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3708–3712. [Google Scholar] [CrossRef]
- Hoang, N.-D. Detection of surface crack in building structures using image processing technique with an improved Otsu method for image thresholding. Adv. Civ. Eng. 2018, 2018, 3924120. [Google Scholar] [CrossRef]
- Fujita, Y.; Hamamoto, Y. A robust automatic crack detection method from noisy concrete surfaces. Mach. Vis. Appl. 2010, 22, 245–254. [Google Scholar] [CrossRef]
- Hutchinson, T.C.; Chen, Z.Q. Improved image analysis for evaluating concrete damage. J. Comput. Civ. Eng. 2006, 20, 210–216. [Google Scholar] [CrossRef]
- Jahanshahi, M.R.; Masri, S.F.; Padgett, C.W.; Sukhatme, G.S. An innovative methodology for detection and quantification of cracks through incorporation of depth perception. Mach. Vis. Appl. 2011, 24, 227–241. [Google Scholar] [CrossRef]
- Shi, Y.; Cui, L.; Qi, Z.; Meng, F.; Chen, Z. Automatic Road Crack Detection Using Random Structured Forests. IEEE Trans. Intell. Transp. Syst. 2016, 17, 3434–3445. [Google Scholar] [CrossRef]
- Chun, P.; Izumi, S.; Yamane, T. Automatic detection method of cracks from concrete surface imagery using two-step light gradient boosting machine. Comput.-Aided Civ. Infrastruct. Eng. 2020, 36, 61–72. [Google Scholar] [CrossRef]
- Cha, Y.-J.; Choi, W.; Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput.-Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Xu, Y.; Li, S.; Zhang, D.; Jin, Y.; Zhang, F.; Li, N.; Li, H. Identification framework for cracks on a steel structure surface by a restricted boltzmann machines algorithm based on consumer-grade camera images. Struct. Control. Health Monit. 2017, 25, e2075. [Google Scholar] [CrossRef]
- Chen, F.-C.; Jahanshahi, M.R. NB-CNN: Deep Learning-Based Crack Detection Using Convolutional Neural Network and Naïve Bayes Data Fusion. IEEE Trans. Ind. Electron. 2018, 65, 4392–4400. [Google Scholar] [CrossRef]
- Maeda, H.; Sekimoto, Y.; Seto, T.; Kashiyama, T.; Omata, H. Road Damage Detection and Classification Using Deep Neural Networks with Smartphone Images. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 1127–1141. [Google Scholar] [CrossRef]
- Zhang, J.; Cai, Y.Y.; Yang, D.; Yuan, Y.; He, W.Y.; Wang, Y.J. Mobilenetv3-BLS: A broad learning approach for automatic concrete surface crack detection. Constr. Build. Mater. 2023, 392, 131941. [Google Scholar] [CrossRef]
- Nguyen, C.K.; Kawamura, K.; Nakamura, H. Deep learning-based crack detection and classification for Concrete Structures Inspection. In Proceedings of the 17th East Asian-Pacific Conference on Structural Engineering and Construction, Singapore, 27–30 June 2022; Lecture Notes in Civil Engineering. Springer: Singapore, 2023; pp. 710–717. [Google Scholar] [CrossRef]
- Katsigiannis, S.; Seyedzadeh, S.; Agapiou, A.; Ramzan, N. Deep learning for crack detection on masonry façades using limited data and transfer learning. J. Build. Eng. 2023, 76, 107105. [Google Scholar] [CrossRef]
- Deng, J.; Lu, Y.; Lee, V.C.-S. Imaging-based crack detection on concrete surfaces using You Only Look Once network. Struct. Health Monit. 2021, 20, 484–499. [Google Scholar] [CrossRef]
- Huyan, J.; Li, W.; Tighe, S.; Zhai, J.; Xu, Z.; Chen, Y. Detection of sealed and unsealed cracks with complex backgrounds using deep convolutional neural network. Autom. Constr. 2019, 107, 102946. [Google Scholar] [CrossRef]
- Xing, J.; Liu, Y.; Zhang, G.-Z. Improved yolov5-based UAV pavement crack detection. IEEE Sens. J. 2023, 23, 15901–15909. [Google Scholar] [CrossRef]
- Chen, D.-R.; Chiu, W.-M. Deep-learning-based road crack detection frameworks for dashcam-captured images under different illumination conditions. Soft Comput. 2023, 27, 14337–14360. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Yang, X.; Li, H.; Yu, Y.; Luo, X.; Huang, T.; Yang, X. Automatic pixel-level crack detection and measurement using fully convolutional network. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 1090–1109. [Google Scholar] [CrossRef]
- Bang, S.; Park, S.; Kim, H.; Kim, H. Encoder–decoder network for pixel-level road crack detection in black-box images. Comput.-Aided Civ. Infrastruct. Eng. 2019, 34, 713–727. [Google Scholar] [CrossRef]
- Islam, M.M.; Kim, J.-M. Vision-Based Autonomous Crack Detection of Concrete Structures Using a Fully Convolutional Encoder–Decoder Network. Sensors 2019, 19, 4251. [Google Scholar] [CrossRef]
- Liu, Z.; Cao, Y.; Wang, Y.; Wang, W. Computer vision-based concrete crack detection using U-net fully convolutional networks. Autom. Constr. 2019, 104, 129–139. [Google Scholar] [CrossRef]
- Ji, J.; Wu, L.; Chen, Z.; Yu, J.; Lin, P.; Cheng, S. Automated pixel-level surface crack detection using U-Net. In Multi-Disciplinary Trends in Artificial Intelligence; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; pp. 69–78. [Google Scholar]
- Wang, Y.; Ying, J.; Mao, J.; Chen, Y.; Wu, K. Automatic detection method of bridge cracks based on residual network. IOP Conf. Ser. Earth Environ. Sci. 2021, 643, 012045. [Google Scholar] [CrossRef]
- Chen, H.; Lin, H.; Yao, M. Improving the Efficiency of Encoder-Decoder Architecture for Pixel-Level Crack Detection. IEEE Access 2019, 7, 186657–186670. [Google Scholar] [CrossRef]
- Sun, M. Semantic Segmentation Using Modified U-Net Architecture for Crack Detection. Master’s Thesis, South Dakota State University, Brookings, SD, USA, 2020. [Google Scholar]
- Lin, F.; Yang, J.; Shu, J.; Scherer, R.J. Crack Semantic Segmentation using the U-Net with Full Attention Strategy. arXiv 2021, arXiv:2104.14586v1. [Google Scholar]
- Augustauskas, R.; Lipnickas, A. Improved pixel-level pavement-defect segmentation using a Deep Autoencoder. Sensors 2020, 20, 2557. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Ma, R.; Liu, H.; Cheng, G. Real-time high-resolution neural network with semantic guidance for crack segmentation. Autom. Constr. 2023, 156, 105112. [Google Scholar] [CrossRef]
- Wang, W.; Su, C.; Han, G.; Zhang, H. A lightweight crack segmentation network based on knowledge distillation. J. Build. Eng. 2023, 76, 107200. [Google Scholar] [CrossRef]
- Yang, L.; Huang, H.; Kong, S.; Liu, Y.; Yu, H. PAF-NET: A Progressive and adaptive fusion network for Pavement Crack Segmentation. IEEE Trans. Intell. Transp. Syst. 2023, 24, 12686–12700. [Google Scholar] [CrossRef]
- Khan, M.A.-M.; Harseno, R.W.; Kee, S.-H.; Nahid, A.-A. Development of AI- and robotics-assisted automated pavement-crack-evaluation system. Remote Sens. 2023, 15, 3573. [Google Scholar] [CrossRef]
- Saha, S.; Karmakar, S.; Manna, D. Analysis of Railroad Track Crack Detection using Computer Vision. In Proceedings of the 2022 Interdisciplinary Research in Technology and Management (IRTM), Kolkata, India, 24–26 February 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Fan, H.; Wang, Q.; Luo, Y.; Li, B. Abnormal railway fastener detection using minimal significant regions and local binary patterns. J. Opt. Technol. 2019, 86, 799–807. [Google Scholar] [CrossRef]
- Karakose, M.; Yamanand, O.; Murat, K.; Akin, E. A new approach for condition monitoring and detection of rail components and rail track in Railway. Int. J. Comput. Intell. Syst. 2018, 11, 830–845. [Google Scholar] [CrossRef]
- Thendral, R.; Ranjeeth, A. Computer Vision System for Railway Track Crack Detection using Deep Learning Neural Network. In Proceedings of the 2021 3rd International Conference on Signal Processing and Communication (ICPSC), Coimbatore, India, 13–14 May 2021; pp. 193–196. [Google Scholar] [CrossRef]
- Min, Y.; Xiao, B.; Dang, J.; Yue, B.; Cheng, T. Real Time Detection System for Rail Surface Defects Based on Machine Vision. EURASIP J. Image Video Process. 2018, 2018, 3. [Google Scholar] [CrossRef]
- Mohammad, S.P. Machine Vision for Automating Visual Inspection of Wooden Sleepers. Master’s Thesis, DALARNA University, Borlange, Sweden, 2008. [Google Scholar]
- Tabatabaei, S.A.; Delforouzi, A.; Khan, M.H.; Wesener, T.; Grzegorzek, M. Automatic detection of the cracks on the concrete railway sleepers. Int. J. Pattern Recognit. Artif. Intell. 2019, 33, 1955010. [Google Scholar] [CrossRef]
- Kim, M.; Kim, K.; Choi, S. Development of automatic crack identification algorithm for a concrete sleeper using pattern recognition. J. Korean Soc. Railw. 2017, 20, 374–381. [Google Scholar] [CrossRef]
- Wang, G.; Liu, Y.; Xiang, J. A two-stage algorithm of railway sleeper crack detection based on edge detection and CNN. In Proceedings of the 2020 Asia-Pacific International Symposium on Advanced Reliability and Maintenance Modeling (APARM), Vancouver, BC, Canada, 20–23 August 2020. [Google Scholar]
- Xia, B.; Cao, J.; Zhang, X.; Peng, Y. Automatic Concrete Sleeper Crack Detection using a one-stage detector. Int. J. Intell. Robot. Appl. 2020, 4, 319–327. [Google Scholar] [CrossRef]
- Jang, J.; Shin, M.; Lim, S.; Park, J.; Kim, J.; Paik, J. Intelligent image-based railway inspection system using Deep Learning-based object detection and Weber contrast-based image comparison. Sensors 2019, 19, 4738. [Google Scholar] [CrossRef]
- Free Vector Icons and Stickers—Thousands of Resources to Download. Flaticon. Available online: https://www.flaticon.com/ (accessed on 17 November 2021).
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Accuracy (%) | Precision (%) | Recall (%) | F1-Score (%) | IoU (%) | Dice Loss (%) |
|---|---|---|---|---|---|---|
| U-net | 99.10 | 89.43 | 79.93 | 84.41 | 73.03 | 2.96 |
| Dense U-net | 99.17 | 88.53 | 84.63 | 86.56 | 76.31 | 2.93 |
| Image | Cracks | Length | Maximum Width | Area | Total Area | Sum of White Pixels | Density (%) |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 213.47 | 7 | 892.82 | 892.82 | 873 | 1.77 |
| 2 | 1 | 208.24 | 9 | 1227.40 | 1288.82 | 1247 | 2.56 |
| 2 | 17.20 | 6 | 61.41 | ||||
| 3 | 1 | 185.04 | 15 | 1560.91 | 1674.28 | 1645 | 3.33 |
| 2 | 27.51 | 5 | 113.36 | ||||
| 4 | 1 | 96.84 | 5 | 406.74 | 1044.72 | 1000 | 2.08 |
| 2 | 132.00 | 9 | 637.97 | ||||
| 5 | 1 | 194.25 | 60 | 1292.92 | 5960.44 | 5123 | 11.87 |
| 2 | 32.20 | 12 | 254.74 | ||||
| 3 | 224.96 | 40 | 4413.46 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, M.A.-M.; Kee, S.-H.; Nahid, A.-A. Vision-Based Concrete-Crack Detection on Railway Sleepers Using Dense U-Net Model. Algorithms 2023, 16, 568. https://doi.org/10.3390/a16120568
Khan MA-M, Kee S-H, Nahid A-A. Vision-Based Concrete-Crack Detection on Railway Sleepers Using Dense U-Net Model. Algorithms. 2023; 16(12):568. https://doi.org/10.3390/a16120568
Chicago/Turabian StyleKhan, Md. Al-Masrur, Seong-Hoon Kee, and Abdullah-Al Nahid. 2023. "Vision-Based Concrete-Crack Detection on Railway Sleepers Using Dense U-Net Model" Algorithms 16, no. 12: 568. https://doi.org/10.3390/a16120568