
A Lightweight Graph Neural Network Algorithm for Action Recognition Based on Self-Distillation

Abstract
:1. Introduction
2. Previous Works
2.1. GNNs
2.2. Model Compression
3. Algorithm
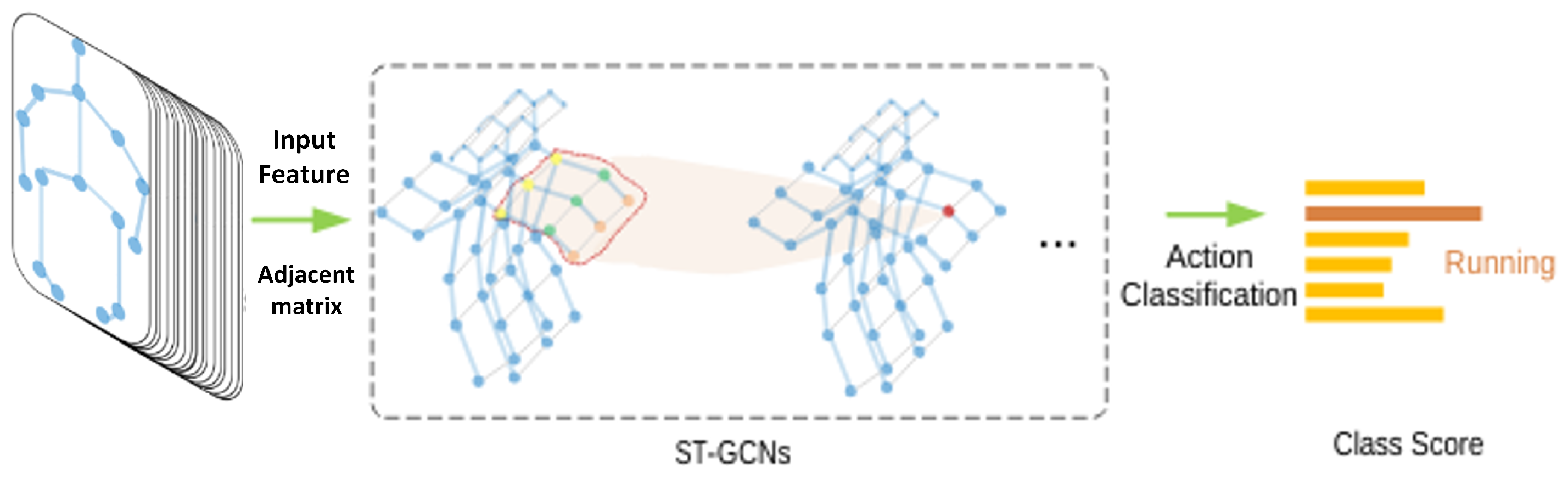
3.1. Problem Definition
3.2. Input Features
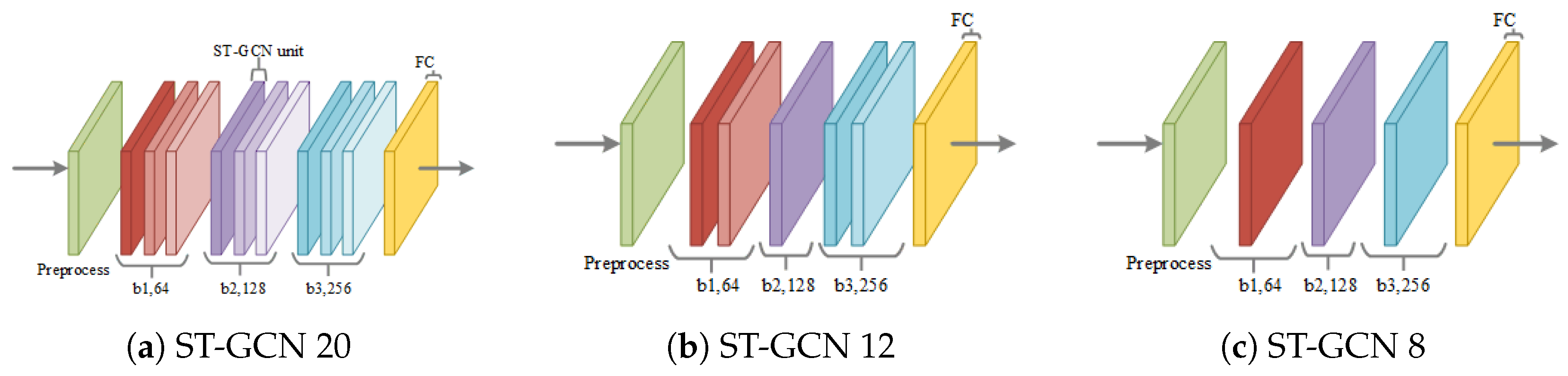
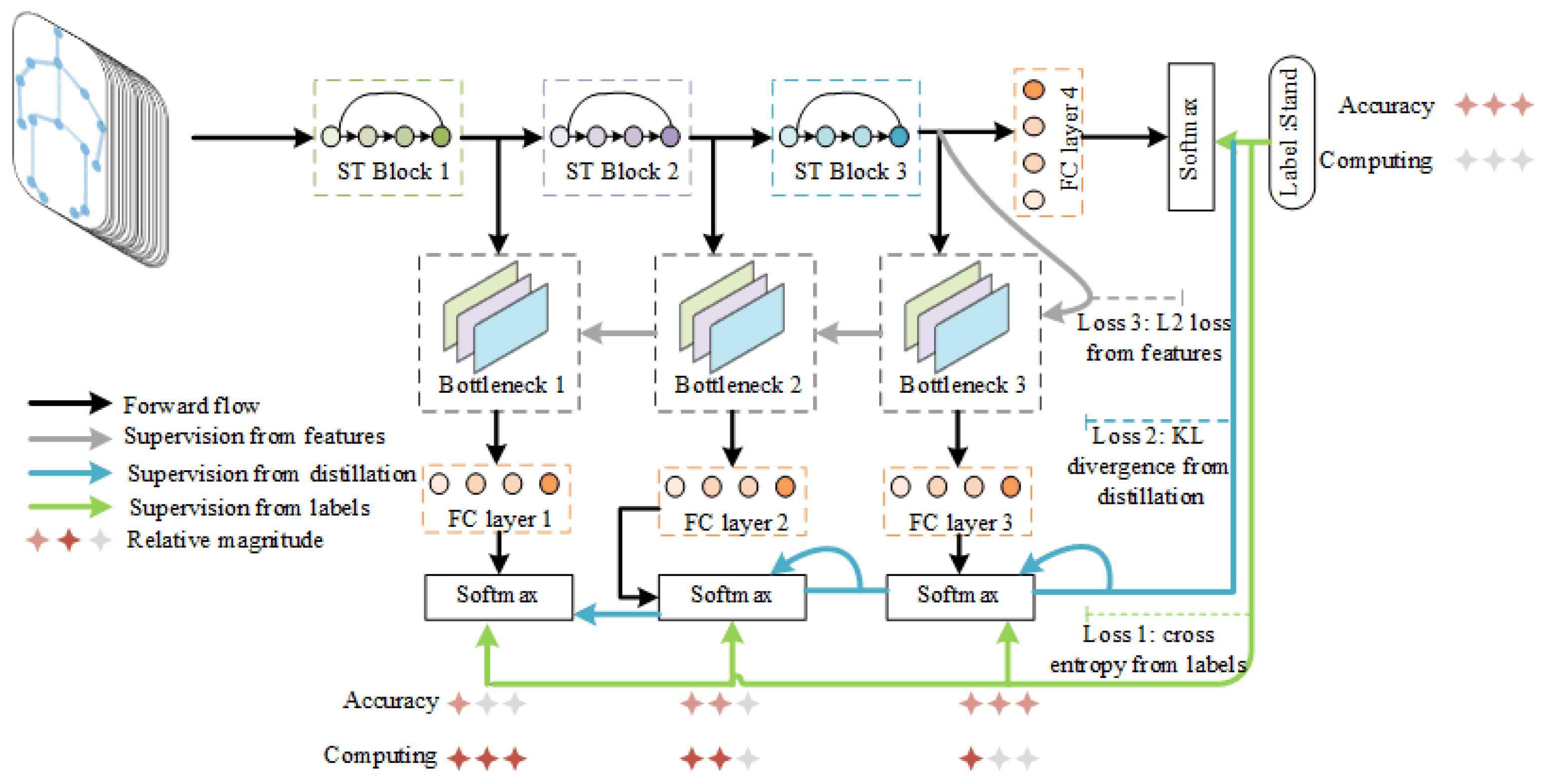
3.3. ST-GCN Compression Based on Self-Distillation
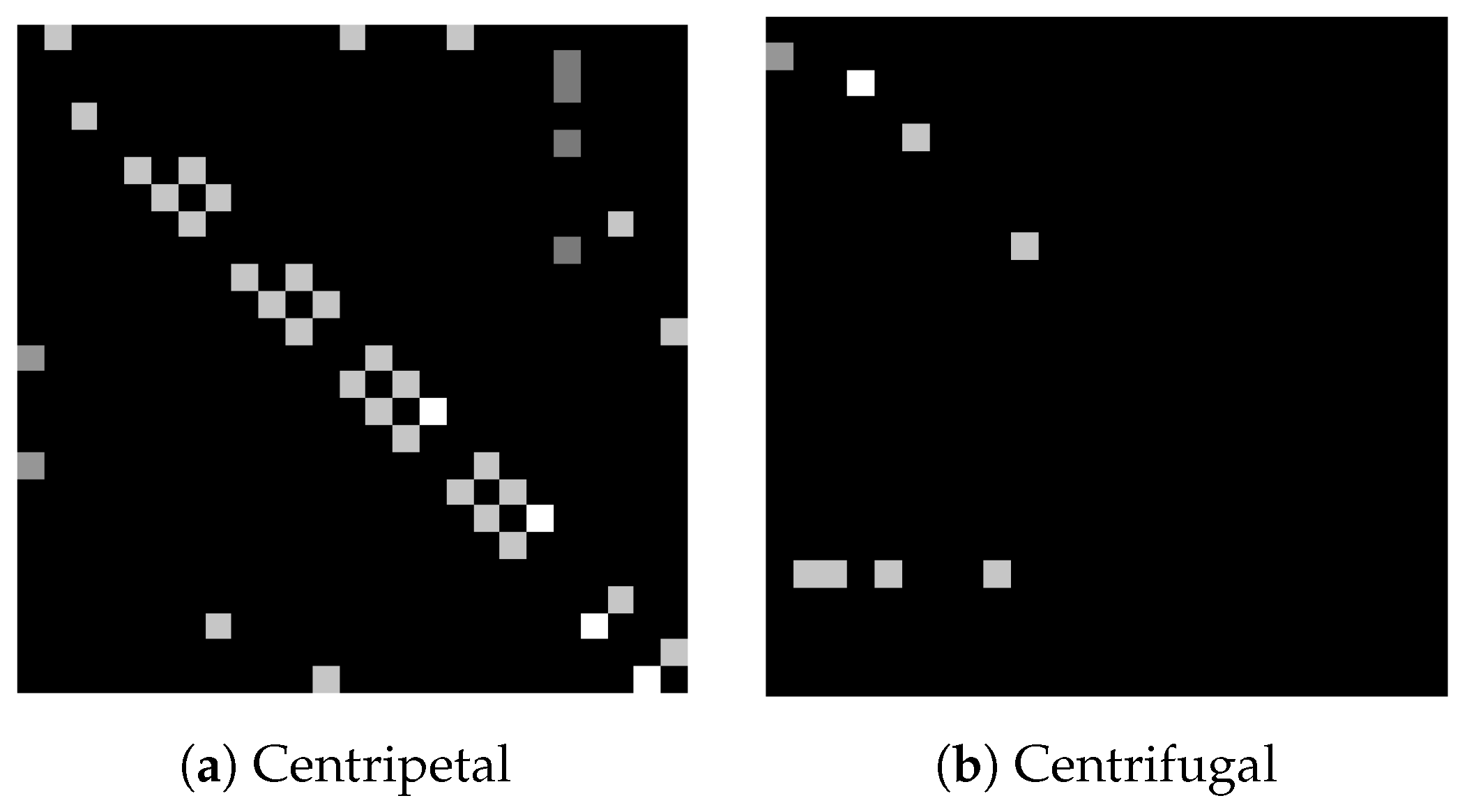
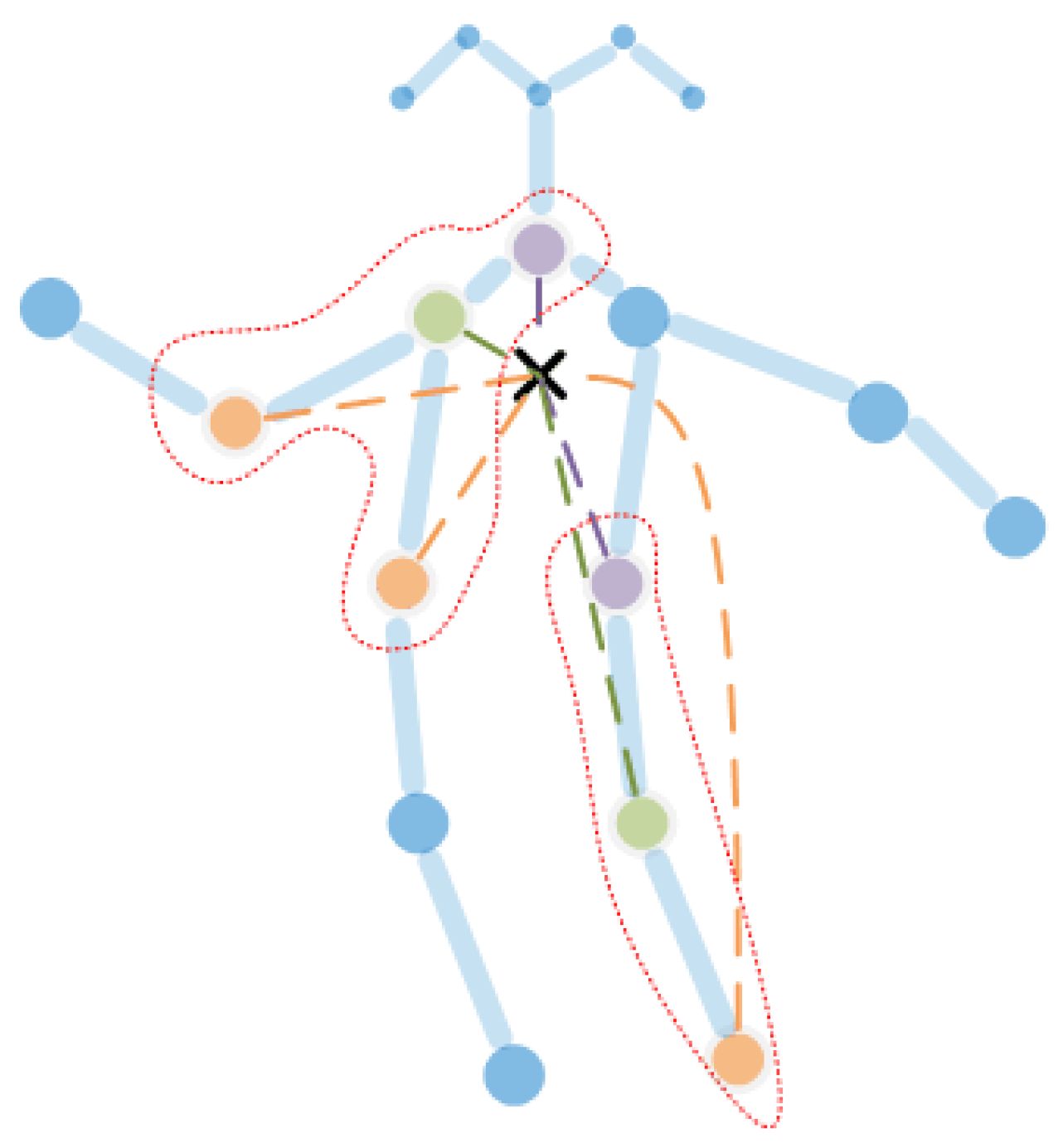
3.3.1. ST-GCN Blocks
3.3.2. Self-Distillation Compression
4. Experiments and Discussion
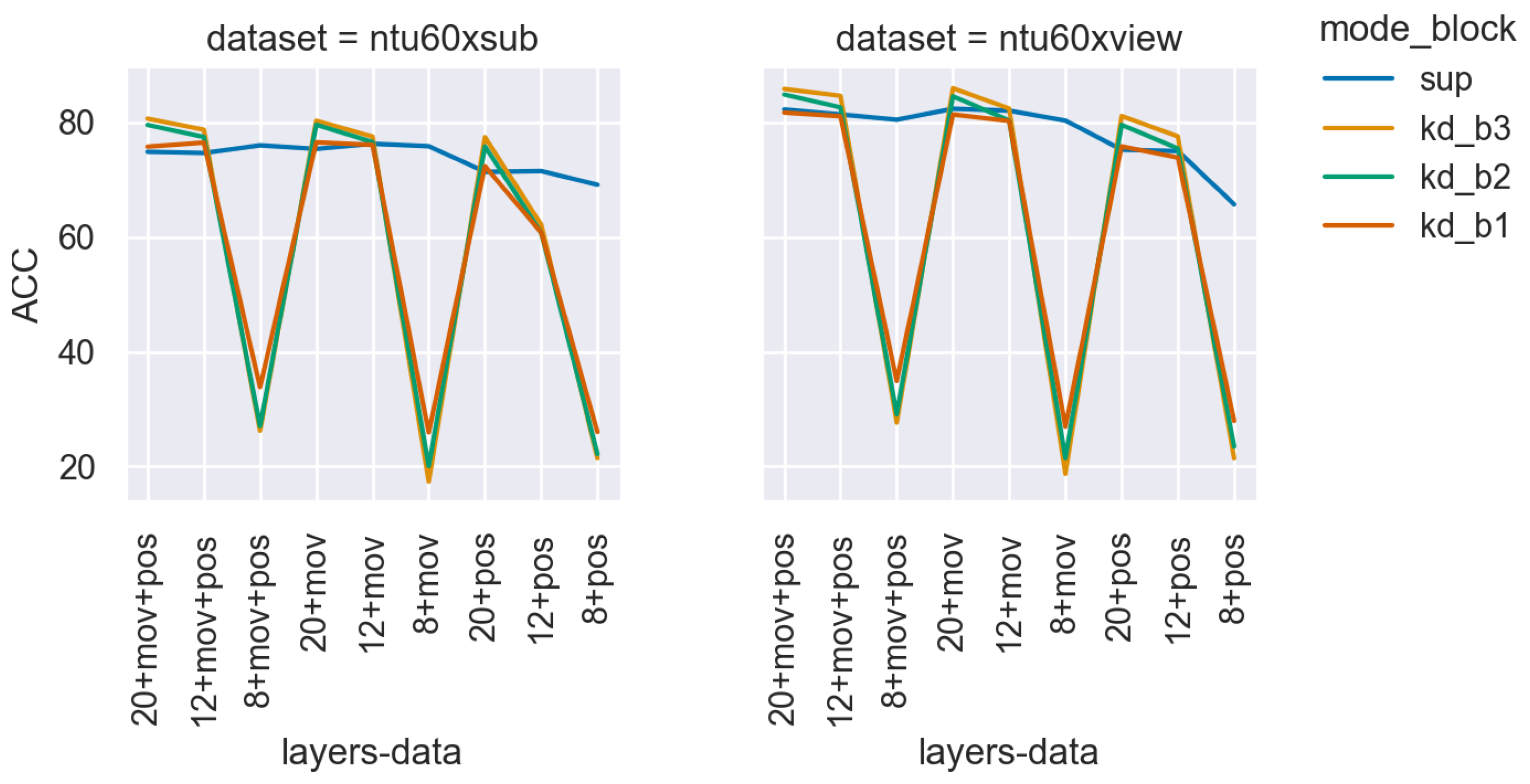
4.1. Accuracy
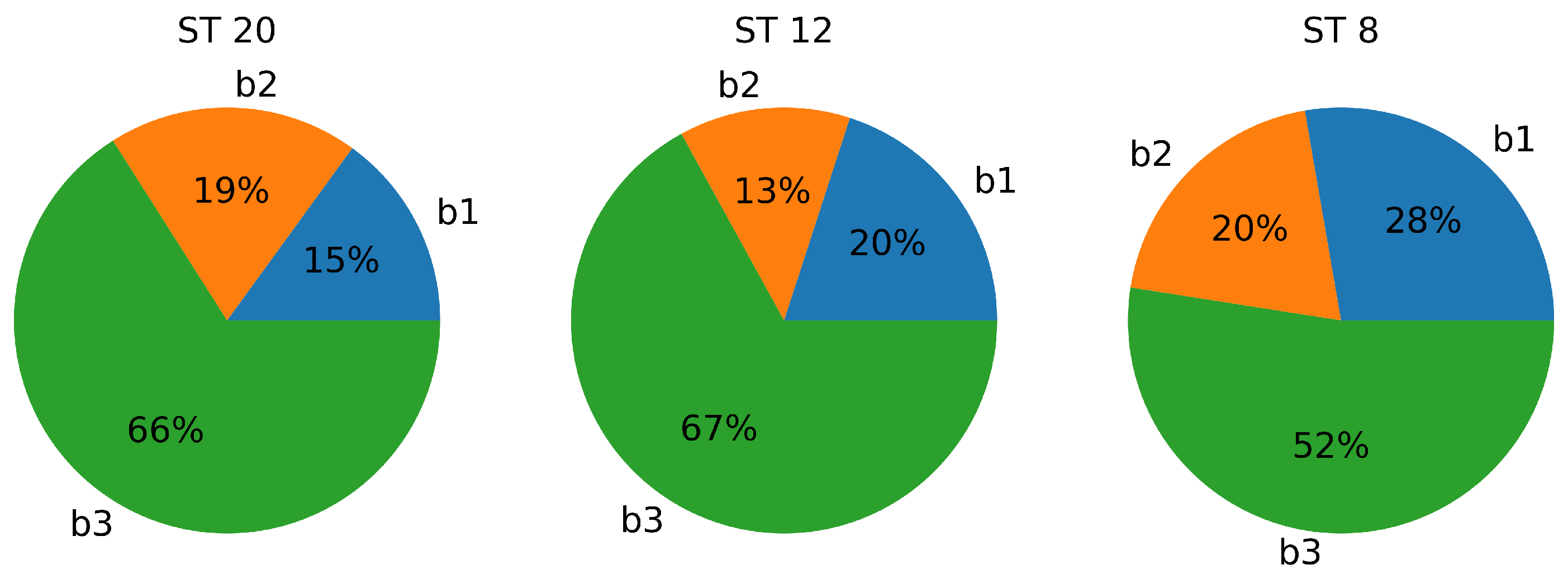
4.2. Compression
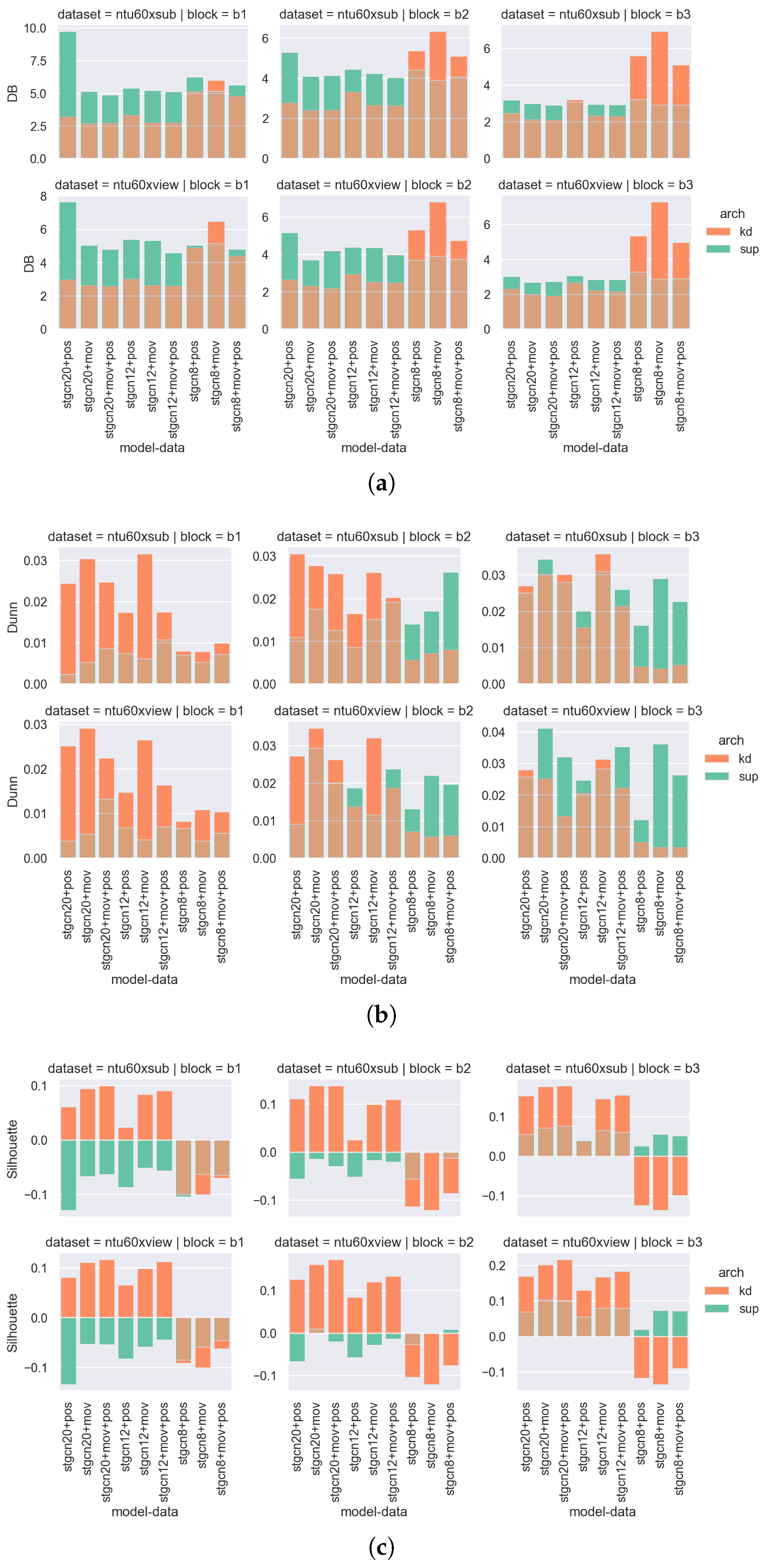
4.3. Denser Representations
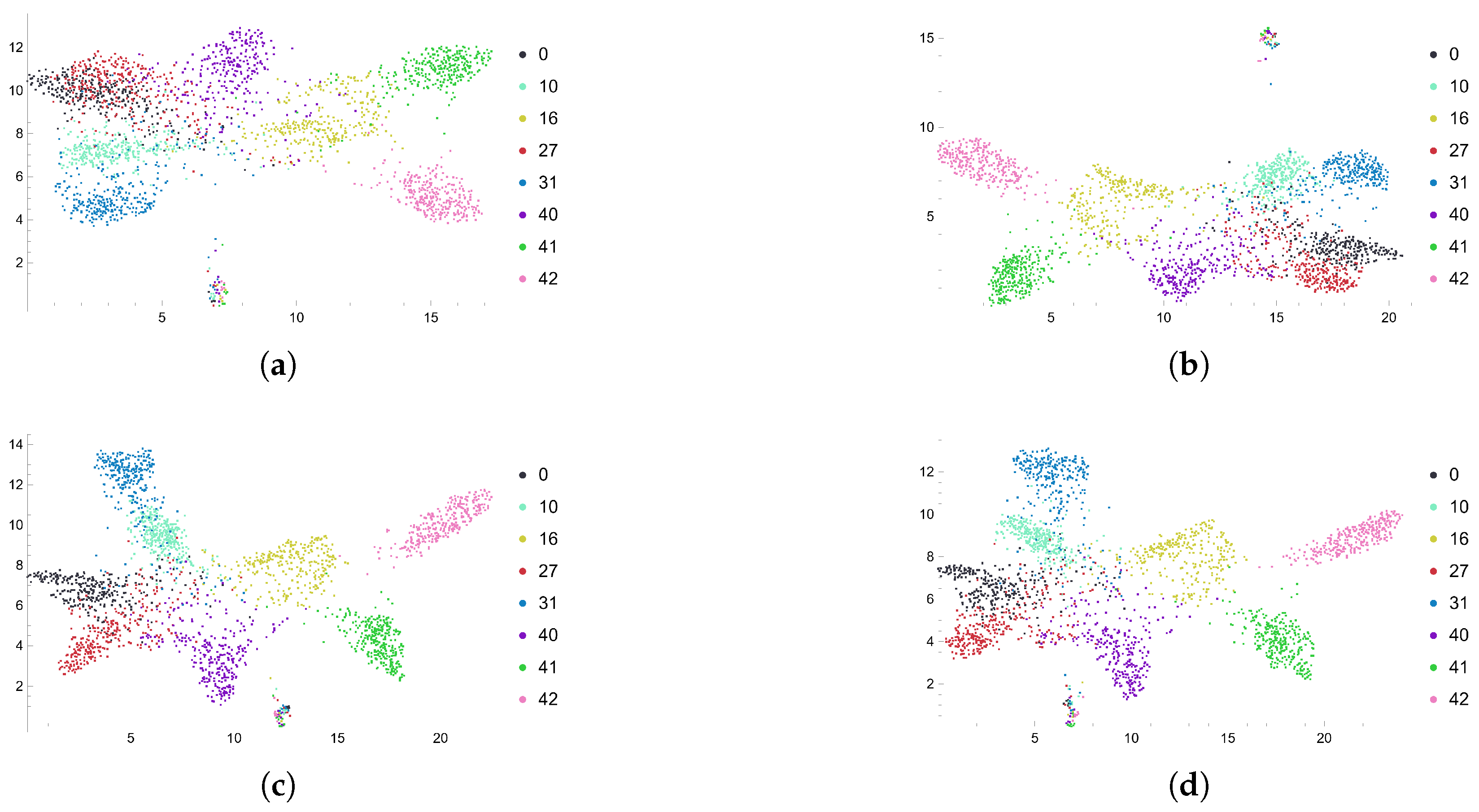
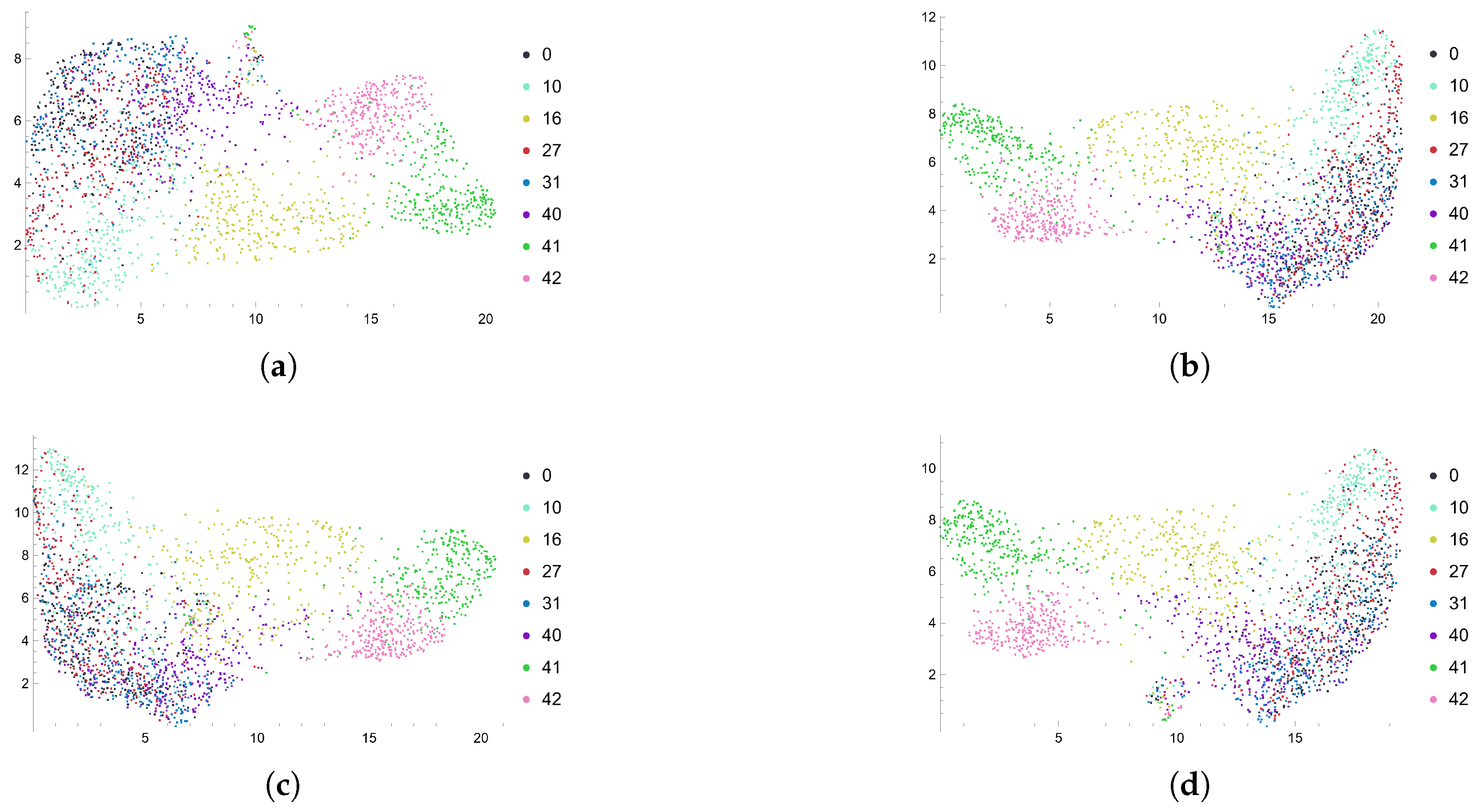
- Davies–Bouldin [20]: The good clusters should have low intra-cluster distance and high inter-cluster distance, and therefore a small Davies–Bouldin index. The metric is defined aswhere K is the number of clusters, is the centroid for the i-th cluster, is the average intra-class distance and is the distance between centroids . It assumes a spherical shape with similar sizes and densities for each cluster.
- Dunn index [21,22]: The clusters with a higher Dunn Index are more desirable. The formula iswhere is the inter-class distance between cluster and the distance between centroids and is the maximum distance between points in cluster . One issue for the Dunn Index is that if only one cluster is extremely stretched, while the other clusters are tightly packed, the Dunn index will be low because of the max in the denominator.
- Silhouette coefficients [23]: The clusters with a high silhouette value are considered well clustered. The silhouette coefficients ranges in . Its formula iswhere and . denote the number of points inside the clusters .
4.3.1. Geometric Shapes of Feature Representations
4.3.2. Self-Distillation vs. Supervision
4.3.3. Each Block’s Feature Representation
5. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| GNNs | Graph Neural Networks |
| HAR | Human Action Recognition |
| BYOT | Be Your Own Teacher |
References
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12026–12035. [Google Scholar]
- Cheng, Y.; Wang, D.; Zhou, P.; Zhang, T. A Survey of Model Compression and Acceleration for Deep Neural Networks. arXiv 2020, arXiv:1710.09282. [Google Scholar]
- Zhang, L.; Song, J.; Gao, A.; Chen, J.; Bao, C.; Ma, K. Be Your Own Teacher: Improve the Performance of Convolutional Neural Networks via Self Distillation. arXiv 2019, arXiv:1905.08094. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Veličković, P. Everything is connected: Graph neural networks. Curr. Opin. Struct. Biol. 2023, 79, 102538. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Xu, H.; Wang, X.; Xu, X.; Wang, Z. A Graph Neural Network and Pointer Network-Based Approach for QoS-Aware Service Composition. IEEE Trans. Serv. Comput. 2023, 16, 1589–1603. [Google Scholar] [CrossRef]
- Zhang, Y.; Hu, Y.; Han, N.; Yang, A.; Liu, X.; Cai, H. A survey of drug-target interaction and affinity prediction methods via graph neural networks. Comput. Biol. Med. 2023, 163, 107136. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Q.; Feng, X. Utilizing citation network structure to predict paper citation counts: A Deep learning approach. J. Inf. 2022, 16, 101235. [Google Scholar] [CrossRef]
- Bukumira, M.; Antonijevic, M.; Jovanovic, D.; Zivkovic, M.; Mladenovic, D.; Kunjadic, G. Carrot grading system using computer vision feature parameters and a cascaded graph convolutional neural network. J. Electron. Imaging 2022, 31, 061815. [Google Scholar] [CrossRef]
- Hameed, M.S.A.; Schwung, A. Graph neural networks-based scheduler for production planning problems using reinforcement learning. J. Manuf. Syst. 2023, 69, 91–102. [Google Scholar] [CrossRef]
- Hamilton, W.L. Graph representation learning. Synth. Lect. Artifical Intell. Mach. Learn. 2020, 14, 1–159. [Google Scholar]
- Bruna, J.; Zaremba, W.; Szlam, A.; LeCun, Y. Spectral networks and locally connected networks on graphs. arXiv 2013, arXiv:1312.6203. [Google Scholar]
- Gori, M.; Monfardini, G.; Scarselli, F. A new model for learning in graph domains. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 2, pp. 729–734. [Google Scholar]
- Feng, M.; Meunier, J. Skeleton Graph-Neural-Network-Based Human Action Recognition: A Survey. Sensors 2022, 22, 2091. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Li, H.; Meng, L. Model Compression for Deep Neural Networks: A Survey. Computers 2023, 12, 60. [Google Scholar] [CrossRef]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge distillation: A survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. Ntu rgb+ d: A large scale dataset for 3d human activity analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar]
- Stanton, S.; Izmailov, P.; Kirichenko, P.; Alemi, A.A.; Wilson, A.G. Does knowledge distillation really work? Adv. Neural Inf. Process. Syst. 2021, 34, 6906–6919. [Google Scholar]
- Davies, D.L.; Bouldin, D.W. A Cluster Separation Measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, PAMI-1, 224–227. [Google Scholar] [CrossRef]
- Dunn, J.C. A Fuzzy Relative of the ISODATA Process and Its Use in Detecting Compact Well-Separated Clusters. J. Cybern. 1973, 3, 32–57. [Google Scholar] [CrossRef]
- Dunn†, J.C. Well-Separated Clusters and Optimal Fuzzy Partitions. J. Cybern. 1974, 4, 95–104. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Jolliffe, I.T.; Cadima, J. Principal component analysis: A review and recent developments. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2016, 374, 20150202. [Google Scholar] [CrossRef]
- Hinton, G.E.; Roweis, S. Stochastic neighbor embedding. Adv. Neural Inf. Process. Syst. 2002, 15, 833–840. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Preparata, F.P.; Shamos, M.I. Computational Geometry: An Introduction; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The kinetics human action video dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | ST 20 | ST 12 | ST 8 | Sup. ST 20 | Sup. ST 12 | Sup. ST 8 |
|---|---|---|---|---|---|---|
| pos | 81.37 | 77.49 | 21.46 | 75.19 | 74.97 | 79.47 |
| mov | 85.91 | 82.34 | 18.75 | 82.32 | 81.99 | 80.28 |
| mov + pos | 85.79 | 84.63 | 27.84 | 82.19 | 81.34 | 80.34 |
| Model | ST 20 | ST 12 | ST 8 | Sup. ST 20 | Sup. ST 12 | Sup. ST 8 |
|---|---|---|---|---|---|---|
| pos | 77.36 | 62.14 | 21.46 | 71.34 | 71.48 | 69.09 |
| mov | 80.25 | 77.47 | 17.41 | 75.35 | 76.25 | 75.81 |
| mov + pos | 80.61 | 78.67 | 26.29 | 74.83 | 74.63 | 75.96 |
| Block | ST 20 | ST 12 | ST 8 |
|---|---|---|---|
| block 1 | 2.33× | 3.43× | 4.60× |
| block 2 | 1.42× | 2.36× | 2.90× |
| block 3 | 1.00× | 1.54× | 2.03× |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, M.; Meunier, J. A Lightweight Graph Neural Network Algorithm for Action Recognition Based on Self-Distillation. Algorithms 2023, 16, 552. https://doi.org/10.3390/a16120552
Feng M, Meunier J. A Lightweight Graph Neural Network Algorithm for Action Recognition Based on Self-Distillation. Algorithms. 2023; 16(12):552. https://doi.org/10.3390/a16120552
Chicago/Turabian StyleFeng, Miao, and Jean Meunier. 2023. "A Lightweight Graph Neural Network Algorithm for Action Recognition Based on Self-Distillation" Algorithms 16, no. 12: 552. https://doi.org/10.3390/a16120552