
Assessing Algorithms Used for Constructing Confidence Ellipses in Multidimensional Scaling Solutions


Abstract
:1. Introduction
2. Theoretical Background
2.1. Methods for Creating Confidence Ellipses in MDS Plots
- Pseudo-confidence ellipses (PCE). This method has been proposed by De Leeuw [5] and creates pseudo-confidence ellipses around MDS points based on an implementation of the Hessian of the stress loss function. However, the area of the pseudo-confidence ellipses depends upon the value of a parameter ε, which shows that the stress value at the perturbation region should be at most 100 ε% larger than the local minimum of the stress loss function. Thus, in fact, the calculation of confidence ellipses assumes an arbitrary choice of the value of parameter ε.
- Jackknife method (JACmds). This has been developed by De Leeuw and Meulman [6], who proposed a leave-one-out method that can be used both in metric and nonmetric MDS. The jackknife MDS plot is a graph with stars, where the centers of the stars are the jackknife centroids and the rays are the jackknife solutions. In the present study, we have added a convex hull to the points of each star, and we have calculated their areas.
- Bootstrapping of the MDS residuals (BOOTres). This method is described in the manual of the MultBiplotR package of R in the details of the BootstrapDistance function [7]. It is based on the study carried out by Ringrose [8], Efron and Tibshirani [9], and Milan and Whittaker [10] and uses random sampling or permutations of MDS residuals to obtain the bootstrap replications that are used to create bootstrap confidence ellipses.
- Overlapping MDS maps (MAPSov). This is one of the most interesting methods whose origin can be found in the study carried out by Meulman and Heiser [11]; Heiser and Meulman [12]; and Weinberg, Carroll, and Cohen [13], whereas its current version is due to Jacoby and Armstrong [14]. The steps used in MAPSov to construct confidence ellipses in a MDS plot are the following: Based on the original dataset, a great number of datasets of artificial distances are generated using simulations or resampling techniques. For each artificial dataset of pairwise distances, the MDS map, that is, the first two MDS dimensions, is computed. The MDS maps are scaled, reflected, rotated, translated, and finally superimposed. From the superimposed data, confidence ellipses are constructed.
2.2. Cluster Probabilities
2.3. Distance Measures and MDS Techniques
3. Implementation and Software
3.1. Implementation of the Stability Measures
3.2. Implementation of HCA to Estimate Cluster Probabilities
3.3. Implementation of Distances and MDS Methods
3.4. Software
- Input the initial dataset consisting of g samples of Ni observations each and r continuous or binary variables.
- Compute all pairwise Euclidean or Mahalanobis-type distances between sample centroids. The mean measure of divergence can also be used.
- Create simulated distances based on the initial dataset and the selected distance measure using the Monte-Carlo method or bootstrapping.
- For each generated dataset of pairwise distances, compute the first two MDS dimensions.
- Use Ordinary Procrustes Analysis to scale, reflect, rotate, translate, and superimpose the MDS solutions created in step 4.
- Construct confidence ellipses from the superimposed data and display them as a MDS map.
- In the MDS map, randomly select a point from each ellipse and calculate all pairwise Euclidean distances among these points.
- Repeat step 7 multiple times, generating a large dataset of Euclidean distances.
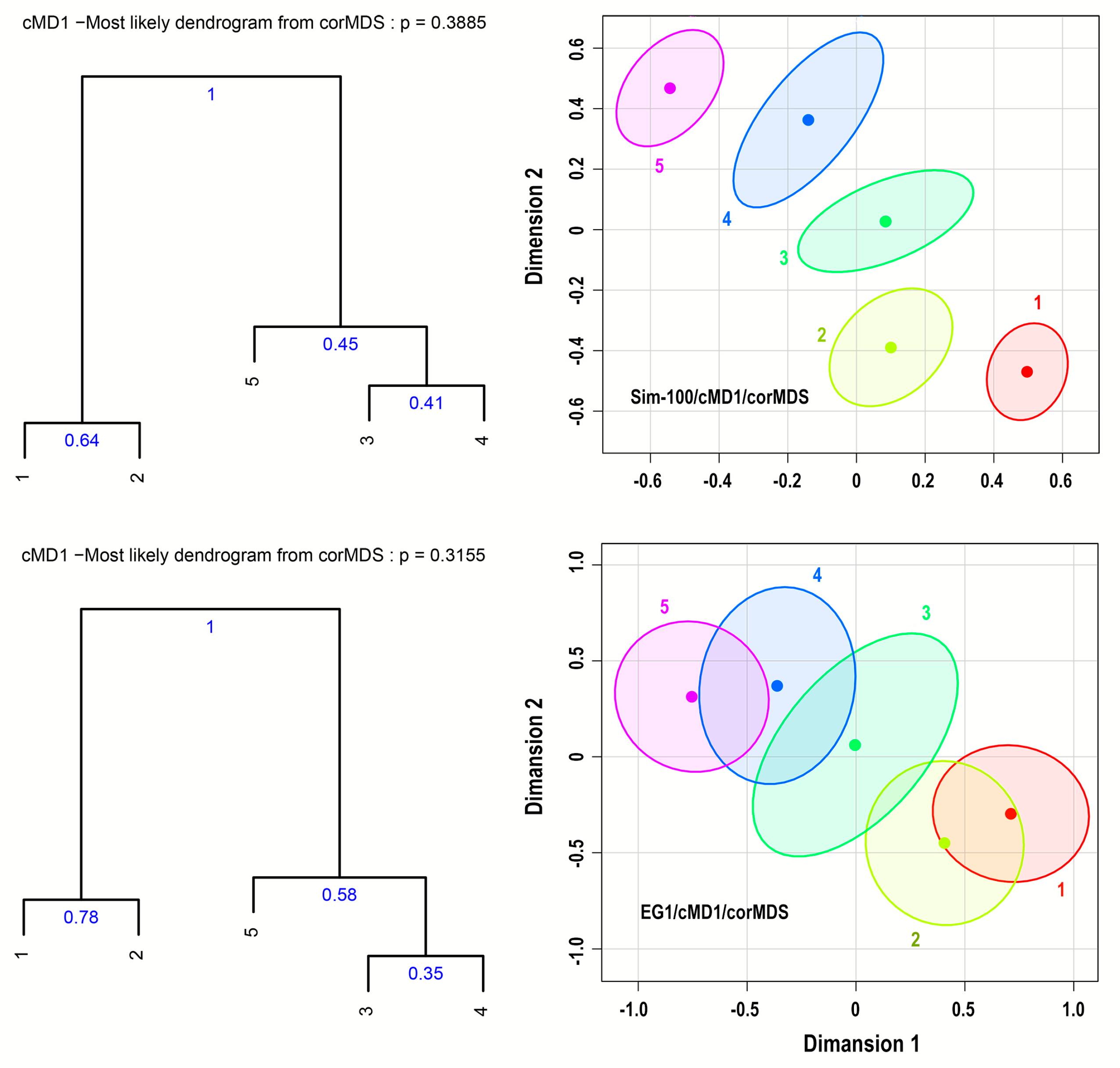
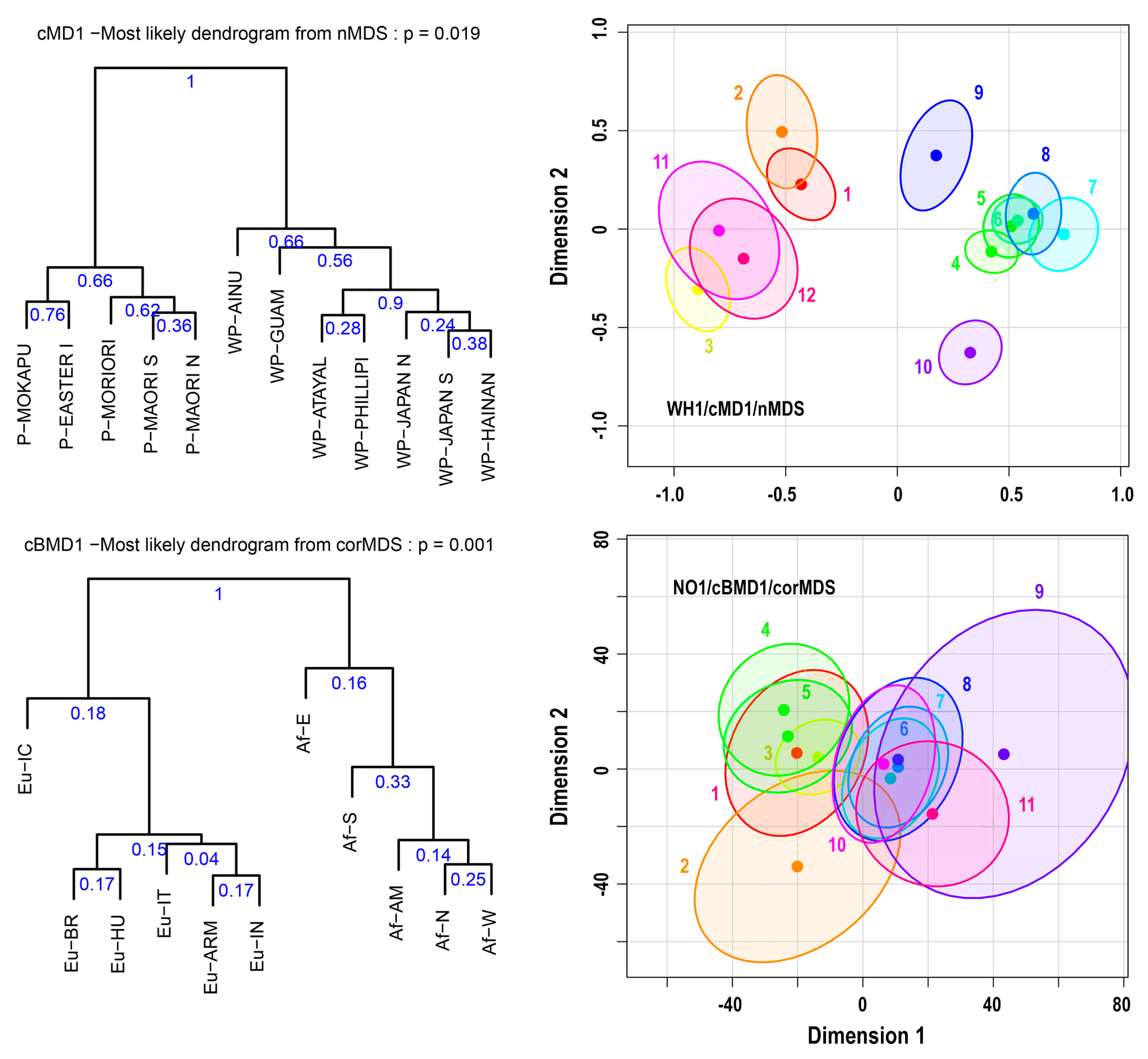
- Estimate all dendrograms of the Euclidean distances of step 8 and determine the most probable dendrogram.
- Count the number of times that each pattern in the most probable dendrogram appears in the dendrograms of the Euclidean distances and use it to estimate the probability of the formation of this pattern. This procedure is also used to estimate cluster probabilities for all pairwise clusters.
- The most probable dendrogram related to the confidence ellipses is displayed along with the probabilities of its patterns.
4. Materials
5. Results and Discussion
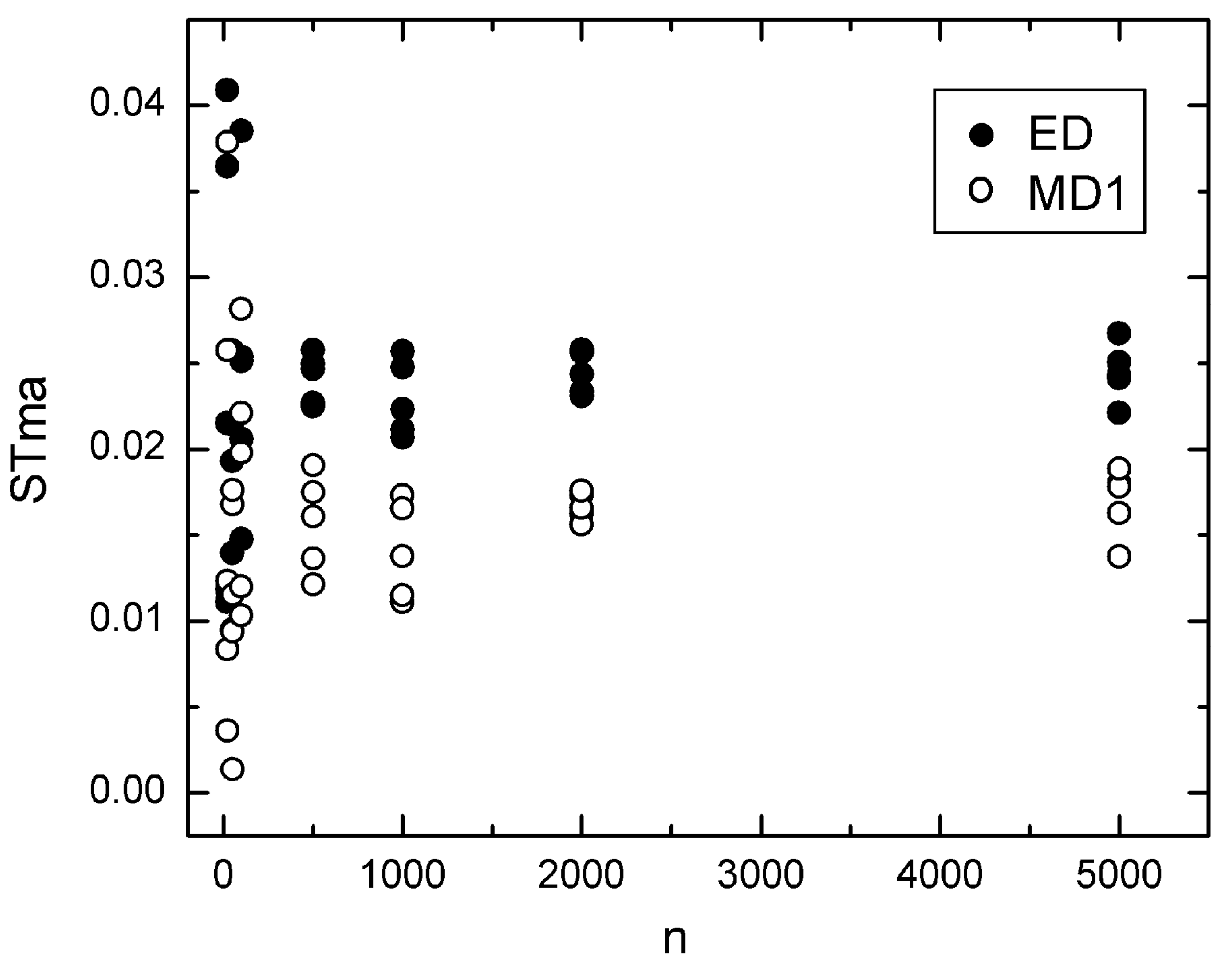
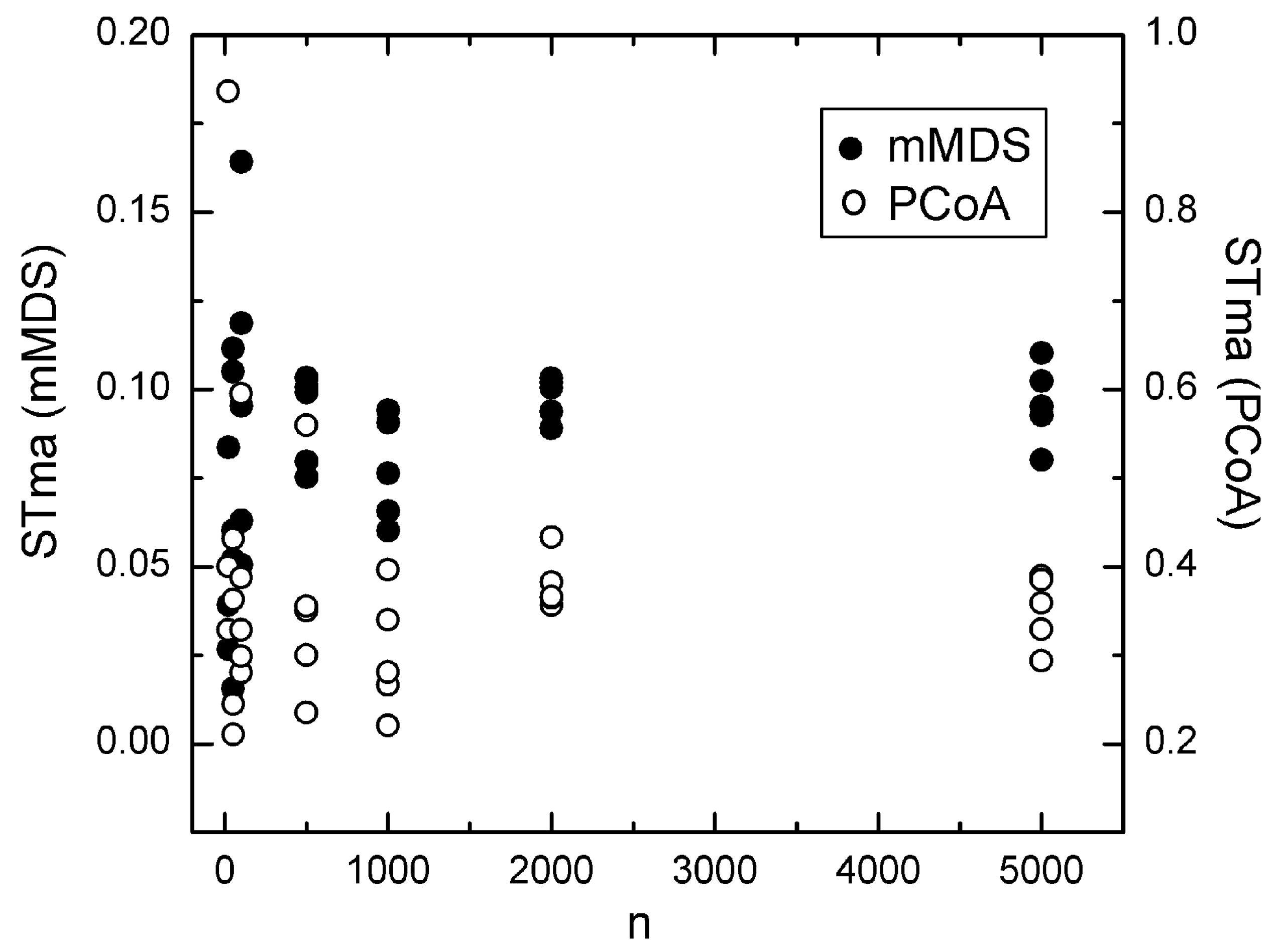
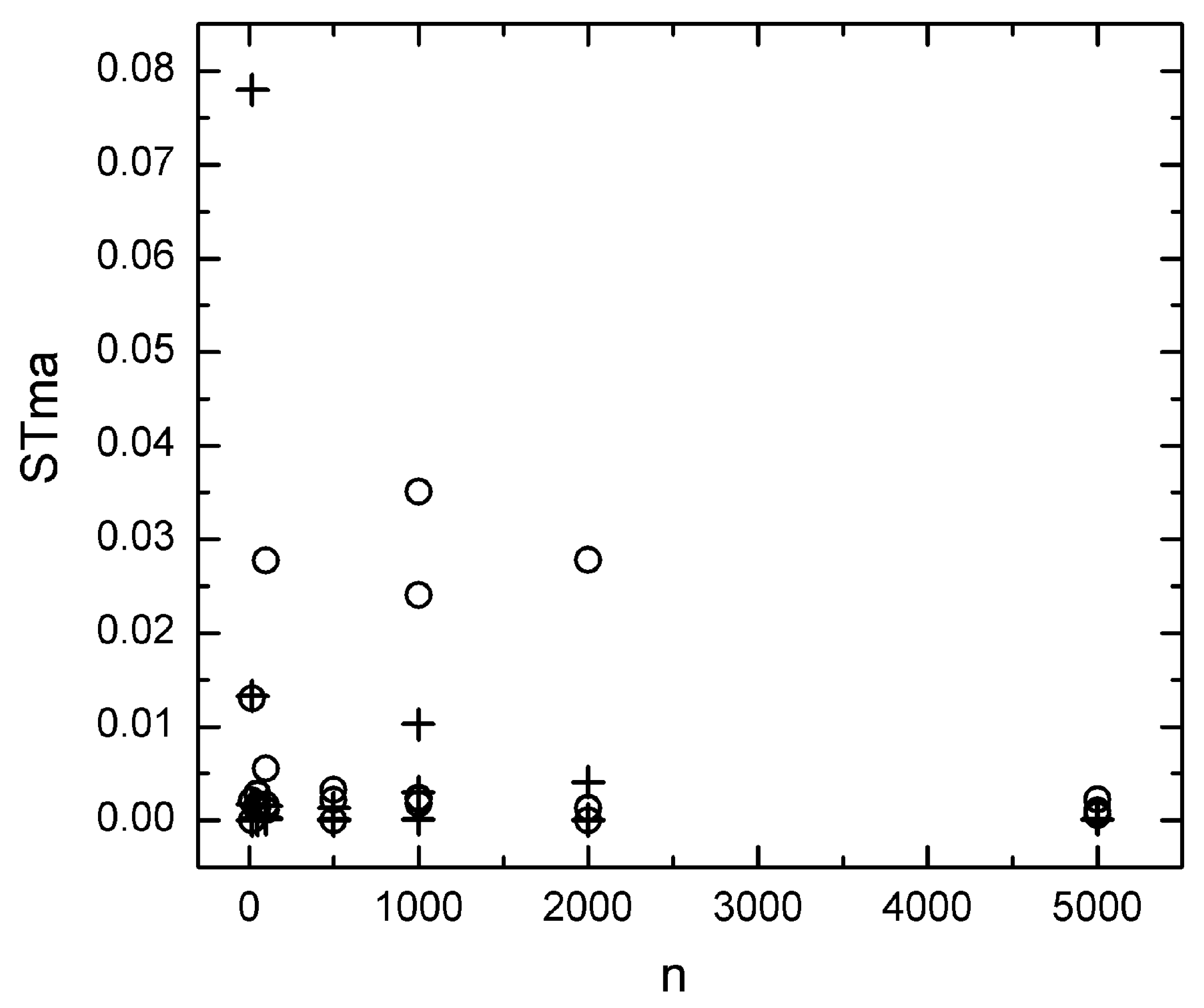
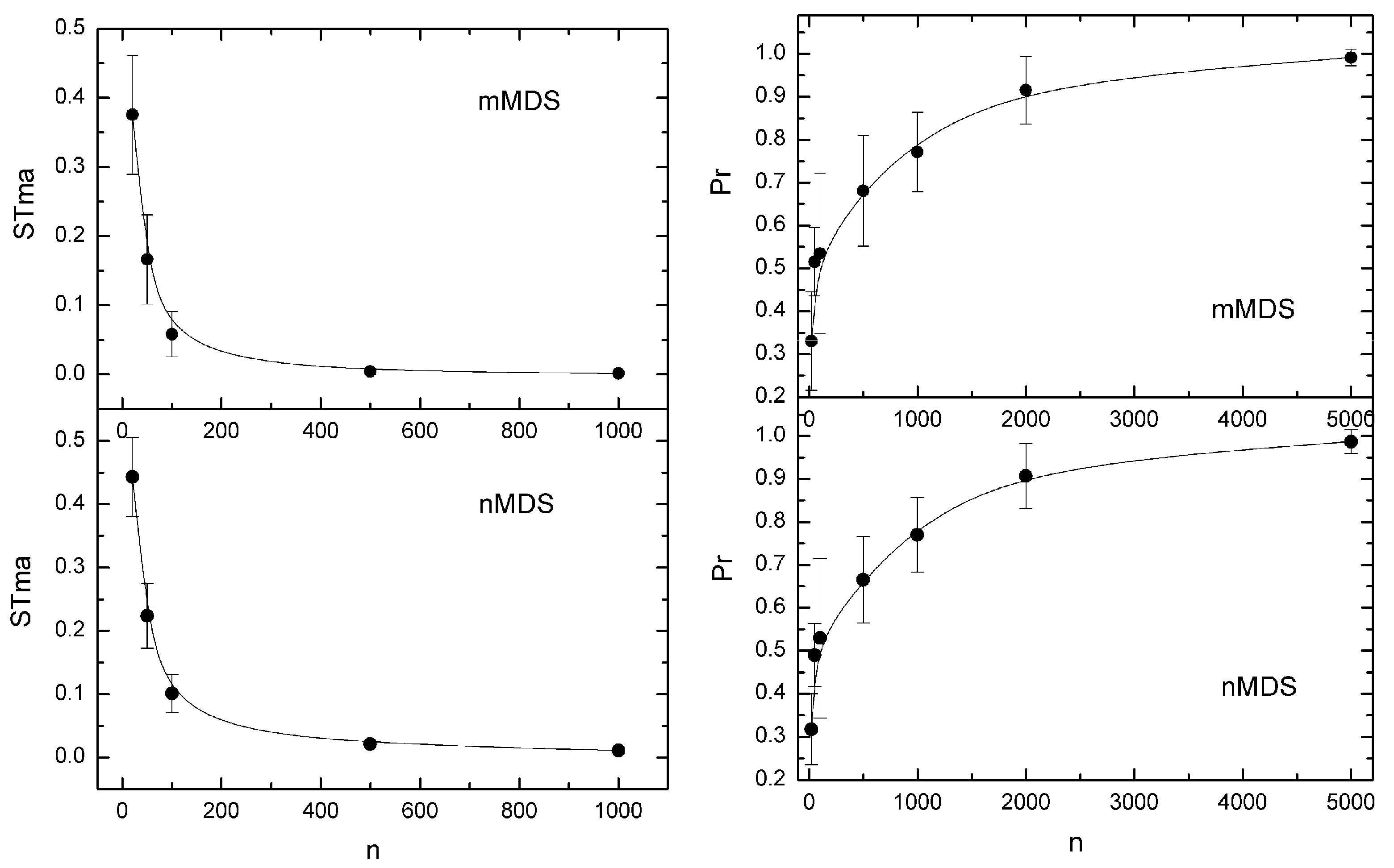
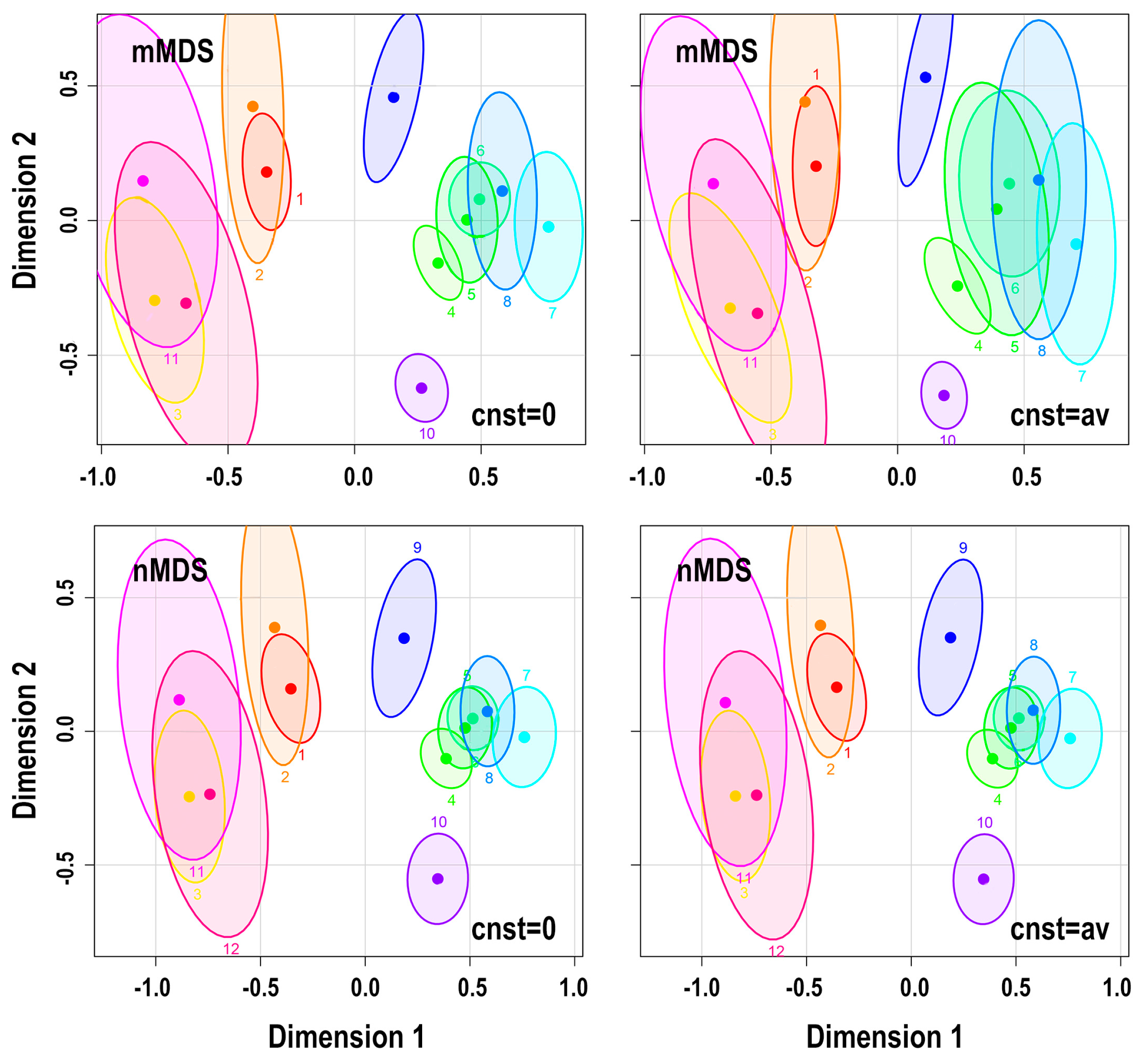
5.1. Effect of Sample Size
5.2. Effect of Adding a Constant
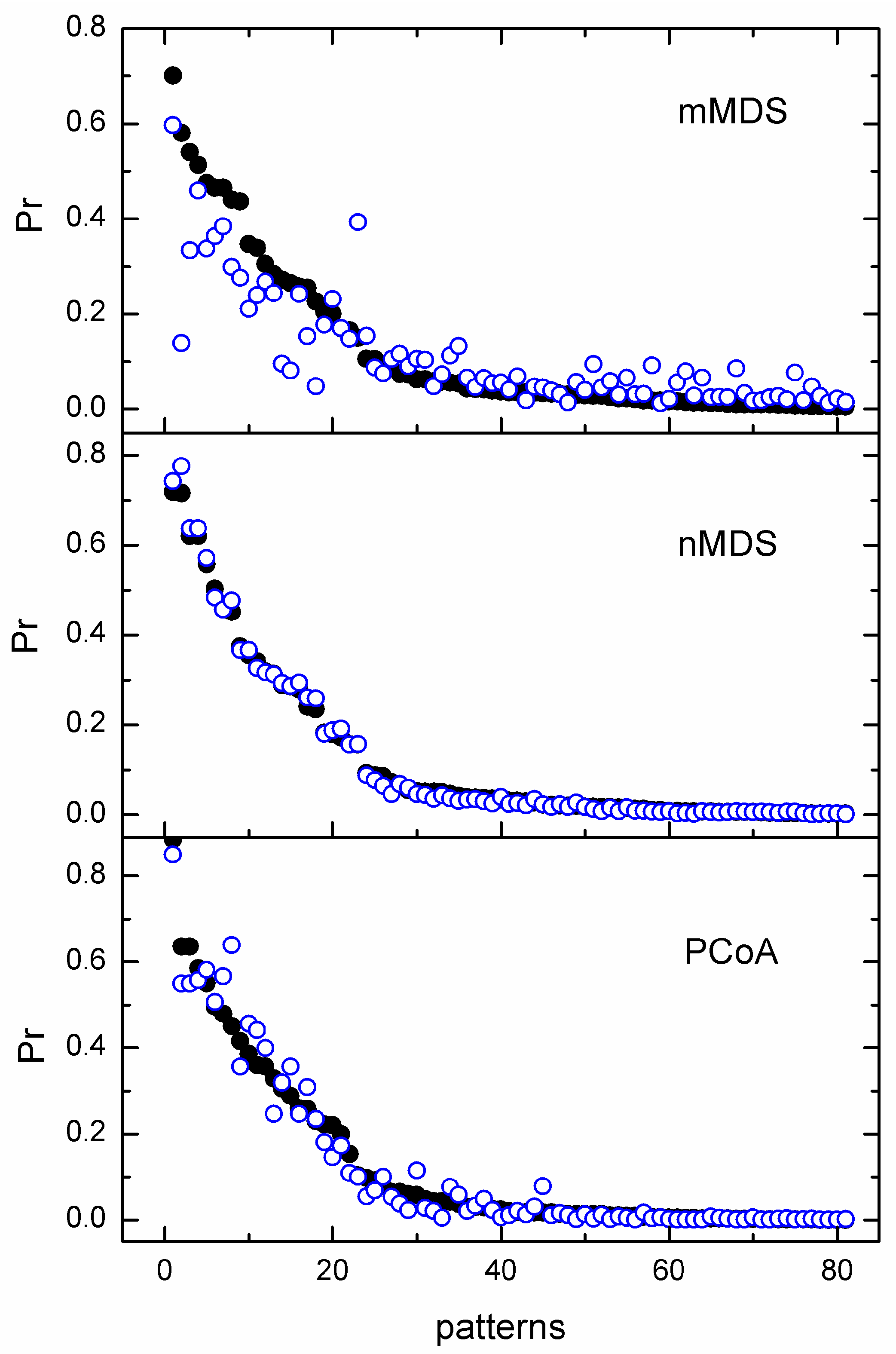
5.3. Confidence Regions and Cluster Probabilities
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Borg, I.; Groenen, P. Modern Multidimensional Scaling: Theory and Applications, 2nd ed.; Springer: New York, NY, USA, 2005. [Google Scholar]
- Cox, T.F.; Cox, M.A.A. Multidimensional Scaling, 2nd ed.; Chapman and Hall: New York, NY, USA, 2001. [Google Scholar]
- Johnson, R.A.; Wichern, D.W. Applied Multivariate Statistical Analysis, 4th ed.; Prentice-Hall: Upper Saddle River, NJ, USA, 1998. [Google Scholar]
- Mair, P.; Groenen, P.J.F.; De Leeuw, J. More on Multidimensional Scaling and Unfolding in R: Smacof Version 2. J. Stat. Softw. 2022, 102, 1–47. [Google Scholar] [CrossRef]
- De Leeuw, J. Pseudo Confidence Regions for MDS. 2019. Available online: https://rpubs.com/deleeuw/292595 (accessed on 15 October 2023).
- De Leeuw, J.; Meulman, J. A special Jackknife for Multidimensional Scaling. J. Classif. 1986, 3, 97–112. [Google Scholar] [CrossRef]
- Vicente-Villardon, J.L. Package ‘MultBiplotR’, Multivariate Analysis Using Biplots in R Version 1.3.30. 2021. Available online: https://cran.r-project.org/web/packages/MultBiplotR/MultBiplotR.pdf (accessed on 21 November 2023).
- Ringrose, T.J. Bootstrapping and correspondence analysis in archaeology. J. Archaeol. Sci. 1992, 19, 615–629. [Google Scholar] [CrossRef]
- Efron, B.; Tibshirani, R.J. An Introduction to the Bootstrap; Chapman and Hall: New York, NY, USA, 1993. [Google Scholar]
- Milan, L.; Whittaker, J. Application of the parametric bootstrap to models that incorporate a singular value decomposition. Appl. Stat. 1995, 44, 31–49. [Google Scholar] [CrossRef]
- Meulman, J.; Heiser, W.J. The Display of Bootstrap Solutions in MDS. Technical Report; Bell Laboratories: Murray Hill, NJ, USA, 1983. [Google Scholar]
- Heiser, W.J.; Meulman, J. Constrained Multidimensional Scaling, including confirmation. Appl. Psych. Meas. 1983, 7, 381–404. [Google Scholar] [CrossRef]
- Weinberg, S.L.; Carroll, J.D.; Cohen, H.S. Confidence regions for INDSCAL using the Jackknife and Bootstrap techniques. Psychometrika 1984, 49, 475–491. [Google Scholar] [CrossRef]
- Jacoby, W.G.; Armstrong, D.A. Bootstrap confidence regions for Multidimensional Scaling solutions. Am. J. Polit. Sci. 2014, 58, 264–278. [Google Scholar] [CrossRef]
- Nikita, E.; Nikitas, P. Simulation methods for squared Euclidean and Mahalanobis type distances for multivariate data and their application in assessing the uncertainty in hierarchical clustering. J. Stat. Comput. Sim. 2022, 92, 2403–2424. [Google Scholar] [CrossRef]
- Suzuki, R.; Shimodora, H. Pvclust: An R package for assessing the uncertainty in hierarchical clustering. Bioinformatics 2006, 22, 1540–1542. [Google Scholar] [CrossRef] [PubMed]
- Konigsberg, L.W. Analysis of prehistoric biological variation under a model of isolation by geographic and temporal distance. Hum. Biol. 1990, 62, 49–70. [Google Scholar] [PubMed]
- Mahalanobis, P.C. On tests and measures of gronp divergence. J. Asiat. Soc. Bengal 1930, 26, 541–588. [Google Scholar]
- Mardia, K.V.; Kent, J.T.; Bibby, J.M. Multivariate Analysis; Academic Press: San Diego, CA, USA, 1995. [Google Scholar]
- McLachlan, G.J. Mahalanobis distance. Resonance 1999, 4, 20–26. [Google Scholar] [CrossRef]
- Nikita, E. A critical review of the Mean Measure of Divergence and Mahalanobis Distances using artificial data and new approaches to estimate biodistances from non-metric traits. Am. J. Phys. Anthropol. 2015, 157, 284–294. [Google Scholar] [CrossRef] [PubMed]
- Gower, J.C. Some distance properties of latent root and vector methods used in multivariate analysis. Biometrika 1966, 53, 325–338. [Google Scholar] [CrossRef]
- Dryden, I.L.; Mardia, K.V. Statistical Shape Analysis; Wiley: Chichester, UK, 1998. [Google Scholar]
- Gower, J.C. Generalized Procrustes analysis. Psychometrika 1975, 40, 33–50. [Google Scholar] [CrossRef]
- Harris, E.F.; Sjøvold, T. Calculation of Smith’s mean measure of divergence for inter-group comparisons using nonmetric data. Dent. Anthropol. 2004, 17, 83–93. [Google Scholar] [CrossRef]
- Ossenberg, N.S.; Dodo, Y.; Maeda, T.; Kawakubo, Y. Ethnogenesis and craniofacial change in Japan from the perspective of nonmetric traits. Anthropol. Sci. 2006, 114, 99–115. [Google Scholar] [CrossRef]
- Thomson, A.; Randall-Maciver, R. Ancient Races of the Thebaid; Oxford University Press: Oxford, UK, 1905. [Google Scholar]
- Egyptian Skulls. Available online: https://www3.nd.edu/~busiforc/handouts/Data%20and%20Stories/regression/egyptian%20skull%20development/EgyptianSkulls.html (accessed on 21 November 2023).
- Howells, W.W. Cranial Variation in Man: A Study by Multivariate Analysis of Patterns of Difference among Recent Human Populations; Harvard University Press: Cambridge, MA, USA, 1973. [Google Scholar]
- Howells, W.W. Skull Shapes and the Map: Craniometric Analyses in the Dispersion of Modern Homo; Harvard University Press: Cambridge, MA, USA, 1989. [Google Scholar]
- Howells, W.W. Who’s Who in Skulls: Ethnic Identification of Crania from Measurements; Harvard University Press: Cambridge, MA, USA, 1995. [Google Scholar]
- Howells, W.W. Howells’ craniometric data on the Internet. Am. J. Phys. Anthropol. 1996, 101, 441–442. [Google Scholar] [CrossRef] [PubMed]
- The William W. Howells Craniometric Data Set. Available online: https://web.utk.edu/~auerbach/HOWL.htm (accessed on 21 November 2023).
- Ossenberg, N.S. Cranial nonmetric trait database on the internet. Am. J. Phys. Anthropol. 2013, 152, 551–553. [Google Scholar] [CrossRef] [PubMed]
- Cranial Nonmetric Trait Database, 2013. Available online: https://borealisdata.ca/dataset.xhtml?persistentId=hdl:10864/TTVHX (accessed on 21 November 2023).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| EG1 | EG1 | EG1 | EG2 | EG2 | EG2 | WH1 | WH1 | WH1 | ||
|---|---|---|---|---|---|---|---|---|---|---|
| MDS | Stability | MD1-m | MD1-av | cMD1 | MD1-m | MD1-av | cMD1 | MD1-m | MD1-av | cMD1 |
| mMDS | STvr | 0.65 | 7.41 | 0.05 | 0.2 | 5.85 | 0.46 | 2.07 | 5.82 | 1.12 |
| mMDS | STov | 2.17 | 6.42 | 1.34 | 5.25 | 9.25 | 5.31 | 0.28 | 1.06 | 0.08 |
| mMDS | STma | 28.6 | 61.5 | 21.3 | 0.67 | 5.08 | 3.34 | 12.8 | 35.6 | 14.7 |
| nMDS | STvr | 0.52 | 4.67 | 0.14 | 0.02 | 1.04 | 0.09 | 0.01 | 0.05 | 0.01 |
| nMDS | STov | 1.02 | 3.80 | 0.88 | 2.46 | 6.96 | 2.03 | 0.02 | 0.01 | 0 |
| nMDS | STma | 8.53 | 23.9 | 4.84 | 0.18 | 8.02 | 0.07 | 0.34 | 1.00 | 0.28 |
| PCoA | STvr | 0.05 | 2.85 | 0.16 | 0.47 | 0.54 | 0.39 | 0.06 | 0.37 | 0.03 |
| PCoA | STov | 0.70 | 1.74 | 0.36 | 2.22 | 6.28 | 1.86 | 0.24 | 0.62 | 0.2 |
| PCoA | STma | 5.18 | 18.85 | 2.11 | 0.75 | 10.62 | 0.55 | 4.68 | 10.92 | 5.42 |
| MDS | Stability | ED-m | ED-av | cED | ED-m | ED-av | cED | ED-m | ED-av | cED |
| mMDS | STvr | 0.19 | 5.13 | 0.08 | 0.32 | 7.03 | 0.22 | 0.41 | 4.21 | 0.19 |
| mMDS | STov | 1.97 | 6.78 | 1.27 | 7.28 | 13.53 | 6.05 | 0.2 | 0.57 | 0.22 |
| mMDS | STma | 33.8 | 102.4 | 23.0 | 4.28 | 6.78 | 7.33 | 9.7 | 43.9 | 7.98 |
| nMDS | STvr | 0.22 | 3.3 | 0.02 | 0.61 | 0.31 | 0.11 | 0.02 | 0.05 | 0.04 |
| nMDS | STov | 1.3 | 4.11 | 0.99 | 4.38 | 13.5 | 2.61 | 0.04 | 0.16 | 0.03 |
| nMDS | STma | 10.14 | 39.5 | 5.32 | 0.45 | 6.21 | 1.89 | 0.94 | 3.74 | 2.08 |
| PCoA | STvr | 0.19 | 1.95 | 0.1 | 0.83 | 1.05 | 0.2 | 0.07 | 0.08 | 0.1 |
| PCoA | STov | 0.98 | 2.85 | 0.5 | 4.1 | 10.77 | 2.47 | 0.07 | 0.26 | 0.12 |
| PCoA | STma | 6.03 | 31.36 | 2.59 | 0.3 | 8.35 | 2.58 | 3.91 | 17.1 | 3.61 |
| MDS | Stability | MMD | UMD | BMD1-m | BMD1-av | cBMD1 |
|---|---|---|---|---|---|---|
| mMDS | STvr | 3.04 | 2.64 | 5.87 | 11.6 | 4.89 |
| mMDS | STov | 0.97 | 1.12 | 2.98 | 6.70 | 0.60 |
| mMDS | STma | 0.41 | 1.0 | 6.03 | 8.48 | 2.65 |
| nMDS | STvr | 0.01 | 0.01 | 0.65 | 1.25 | 0.46 |
| nMDS | STov | 0.11 | 0.08 | 0.61 | 0.94 | 0.42 |
| nMDS | STma | 0.27 | 0.18 | 1.31 | 2.27 | 0.62 |
| PCoA | STvr | 0.23 | 0.21 | 1.41 | 3.07 | 0.28 |
| PCoA | STov | 0.55 | 0.65 | 0.06 | 0.78 | 0.34 |
| PCoA | STma | 0.8 | 0.67 | 1.06 | 1.83 | 0.54 |
| WH1 | WH1 | WH1 | NO1 | NO1 | NO1 | |
|---|---|---|---|---|---|---|
| MDS | MD1-m | MD1-av | cMD1 | MMD | UMD | cBMD1 |
| mMDS | 0.9811 | 0.9037 | 0.9826 | 0.9966 | 0.9965 | 0.9951 |
| nMDS | 0.9989 | 0.9989 | 0.9992 | 0.9985 | 0.9970 | 0.9964 |
| PCoA | 0.9971 | 0.9847 | 0.9964 | 0.9975 | 0.9972 | 0.9968 |
| MDS | ED-m | ED-av | cED | BMD1-m | BMD1-av | |
| mMDS | 0.9968 | 0.9266 | 0.9984 | 0.9868 | 0.9648 | |
| nMDS | 0.9998 | 0.9995 | 0.9998 | 0.9972 | 0.9970 | |
| PCoA | 0.9992 | 0.9715 | 0.9997 | 0.9952 | 0.9892 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nikitas, P.; Nikita, E. Assessing Algorithms Used for Constructing Confidence Ellipses in Multidimensional Scaling Solutions. Algorithms 2023, 16, 535. https://doi.org/10.3390/a16120535
Nikitas P, Nikita E. Assessing Algorithms Used for Constructing Confidence Ellipses in Multidimensional Scaling Solutions. Algorithms. 2023; 16(12):535. https://doi.org/10.3390/a16120535
Chicago/Turabian StyleNikitas, Panos, and Efthymia Nikita. 2023. "Assessing Algorithms Used for Constructing Confidence Ellipses in Multidimensional Scaling Solutions" Algorithms 16, no. 12: 535. https://doi.org/10.3390/a16120535