1. Introduction
In today’s digital age, online media has become integral to our lives. With the increasing accessibility and diversity of online interaction and information-sharing platforms, text, photos, and multimedia content can reach larger audiences faster than ever before [
1]. According to the American Press Institute, a significant percentage of individuals, 59% of those aged 18 to 34 and 56% of those aged 35 to 49, rely on digital media for news updates and access to the latest information [
2]. However, this heavy dependance on online media for news consumption establishes inherent risks. It exposes individuals to the danger of encountering misleading, manipulative, or even violence-inciting fake news [
3].
Consuming news through social media has become gradually common [
4]. Social networks have become popular as platforms for news utilization due to their diverse multimedia formats, affordability, and ability to facilitate rapid news broadcasting [
5]. However, fake news producers often develop these very features, rapidly spreading false information [
6]. Consequently, the wide usage of social media has led to the broader dissemination of misinformation, making news consumed from online feeds unreliable [
7]. The spreading of fake information can severely impact society. For instance, the circulation of fake news can manipulate the results of significant public events [
8]. During the 2016 United States presidential election, the impact of fake news on shaping public opinion was evident [
9]. False stories circulated widely on social media platforms, leading to a significant influence on people’s perceptions. Examples include claims such as Pope Francis endorsing Donald Trump for president and Hillary Clinton’s alleged participation in a child trafficking ring. These fabricated stories not only contributed to political polarization but also misled voters, potentially influencing the election’s outcome [
10].
Additionally, children’s exposure to fake news poses a critical concern, as they are more sensitive to believing fake information than adults [
11]. Children are still developing critical thinking skills, so they require assistance distinguishing between reliable and unreliable information. Moreover, fake news can propagate negativity among people when consumed by young users [
12]. Recent research has shown that users between 18 and 28 are the most active on social media [
13]. Consequently, the early identification of fake news on social media has gained popularity and garnered significant attention.
Several fake news detection methods, including conventional machine learning (ML) and deep learning (DL) models, have been developed [
14]. In traditional approaches, features from the news must be extracted before they are classified. Conversely, DL models can automatically extract significant features from text or images in the news [
15]. Due to the time-consuming process of manual feature extraction, DL approaches are often preferred over traditional approaches [
16]. Ensemble methods are widely used to merge multiple models into a composite model that achieves better performance than individual models. The accuracy and diversity of each model significantly impacts the effectiveness of an ensemble model. In general, the utilization of ML and DL models to detect fake news stems from their limitations in comprehending and interpreting the intricacies of human language [
17].
The alignment prediction of headline and article body pairs was conducted using the term frequency-inverse document frequency (TF-IDF) and a deep neural network [
18]. Although this approach shows promise in detecting fake news, distinguishing between real news and articles that employ humor or satire may face challenges, as they often rely on linguistic subtleties and context-specific meanings. To address this issue, ref. [
8] introduced an ensemble-based ML technique incorporating a deep neural network model for classifying fake news. However, many existing methods, including [
19], rely on a single prototype embedding model. Such models often overlook polysemous terms, which pose multiple interpretations or meanings depending on the context [
15]. The lack of multiple prototype embeddings for each can result in difficulties in accurately processing and understanding polysemous sentences [
16]. The primary goal of this study was to identify the most effective approach for accurately classifying false information. The driving force behind this endeavor is the need to combat the widespread dissemination of misleading information and to maintain international peace by identifying and rectifying incorrect information. The major contributions of this research are as follows:
We propose a comprehensive fake news detection classifier for news article, considering the platform’s unique characteristics and challenges.
We conduct experiments and analyze multiple ML and DL techniques to evaluate their performance on the fake news dataset, aiming to address the problem effectively.
Exploring various deep features, such as TF-IDF, n-gram, Word2Vec, and global vectors for word representation (GloVe), to find the optimal combination that enhances the detection process and improves classifier accuracy.
Comparing diverse ML and DL techniques provides insights into their strengths and weaknesses for fake news detection, aiding researchers in making informed decisions about their applications.
The remainder of the study is organized as follows.
Section 2 discusses recent research studies relevant to fake news detection methods.
Section 3 presents the proposed research methodology, deep features, diverse ML and DL methods, and their architecture to resolve the challenges of fake news detection.
Section 4 presents a detailed empirical analysis of the model with comprehensive analysis. Finally, in
Section 5, conclusions, implications, and future work are discussed.
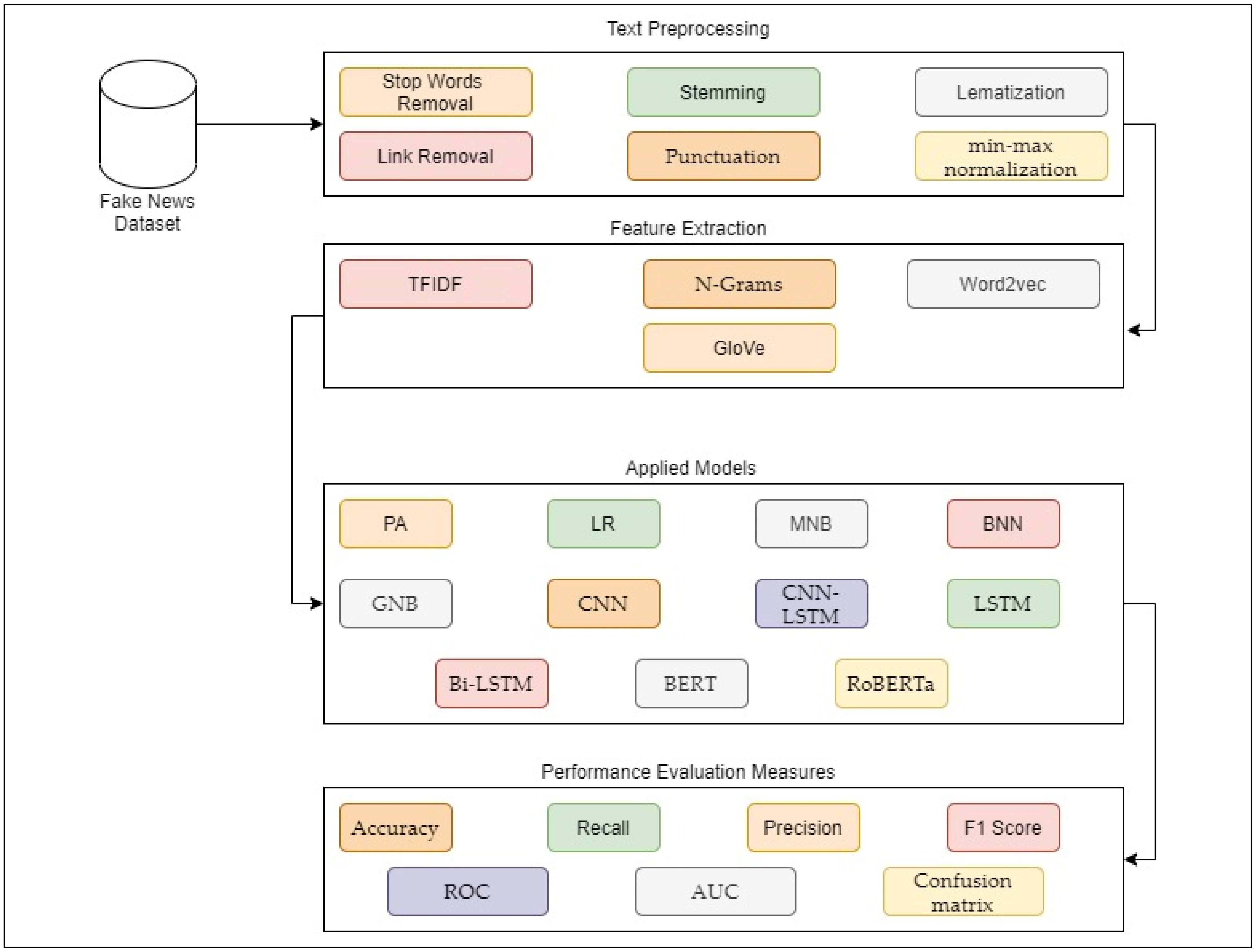
3. Proposed Methodology
This study proposes a hybrid ensemble method and a DL model to classify news articles as ham or spam. The purpose of the model is to assess and monitor the impact of this content. For this study Kaggle fake news dataset has been used. The extracted dataset was initially raw and contained ambiguities, noise, and optional information. Following the data collection stage, the datasets underwent a series of preparation stages, including removing links, stop words, punctuation, tokenizing, lemmatizing, and stemming the data. After removing any stop words, min-max normalization was performed on the dataset. The textual aspects were collected from the news data on top of the retrieved features. These ensemble methods consist of different ML-based algorithms, such as PA, LR, multinomial naïve Bayes (MNB), Bernoulli NB (NN), Gaussian NB (GNN), and LSTM, BERT and RoBERTa. Next, we split the dataset into two sets: training and testing. The PA, LR, MNB, Bernoulli NN, Gaussian NN ML models, and DL-based LSTM models were used to estimate whether the news was ham or spam. The results were assessed using accuracy, precision, recall, and F1 scores as the performance metrics, and the ML and DL models were compared. The collected data were then evaluated considering previously established methods for classifying news as ham or spam. The proposed methodology is shown in
Figure 1.
3.1. Data Acquisition and Pre-Processing
A reliable and labeled dataset is crucial to developing an effective fake news classifier. In this study, we utilized the “Fake News” dataset (
https://www.kaggle.com/c/fake-news/data accessed on 15 September 2023), which comprises a collection of news articles labeled as either “reliable” (real news) or “unreliable” (fake news). The dataset contains 87,500 articles, distributed into 70,000 and 17,500 classes for reliable and unreliable data, respectively. The dataset provides essential features, such as the article title, text content, publication date, source, and author, enabling us to leverage multiple aspects for classification. The dataset comprises a diverse range of news articles obtained from various sources. Several pre-processing steps were applied to prepare the data for training the fake news classifier. These steps aimed to clean and transform the raw text data into a format suitable for ML algorithms.
The utilization of specific pre-processing techniques in this study is motivated by established best practices and prior research in the NLP and fake news detection. The application of these pre-processing techniques is crucial in our pursuit of developing an effective fake news classifier. In the era of information overload and the rapid dissemination of news through digital platforms, the quality of the data we feed into our models is paramount. By carefully preparing and cleaning the text data, we aim to reduce noise, extract meaningful information, and enhance the discriminative power of our classifier. These techniques are not merely procedural but are essential for uncovering the underlying patterns and distinguishing characteristics that differentiate fake news from real news. The following pre-processing techniques were employed:
Stop Word Removal: Stop word removal is a crucial step in fake news detection, eliminating common, insignificant words like “the” and “is” to focus on meaningful content. This process reduces noise, improves efficiency, and helps identify relevant keywords and phrases.
Word Tokenization: Word tokenization involves splitting the text into individual words or tokens. We utilized a tokenization algorithm to break down the text content of each article into a sequence of tokens, facilitating further analysis at the word level.
URL Removal: Many news articles contain URLs or web links that may not contribute to the classification task. Therefore, we removed the URLs from the text data to focus solely on the textual content of the articles.
Stemming: Stemming is a technique that reduces words to their base or root form, removing suffixes or prefixes. This process helps reduce the feature space’s dimensionality and captures the words’ core meaning. We applied a stemming algorithm to transform words into their base form, thus aiding the classification process.
By implementing these pre-processing steps, we aimed to enhance the quality and relevance of the text data, thus improving the performance of the fake news classifier. The pre-processed dataset was then ready for the subsequent feature engineering, model training, and evaluation stages.
3.2. Feature Extraction
Handling a large dataset with many variables can be computationally intensive and challenging. Feature extraction, a dimensionality reduction technique, breaks down large amounts of raw data into more manageable groups. Feature extraction refers to methods for selecting and/or combining variables into features, significantly reducing the amount of data that must be processed while accurately describing the initial dataset.
3.2.1. TF-IDF
After the pre-processing phase, the
TF-IDF algorithm extracted textual features from the dataset. This algorithm computes the frequency of a word with its sentimental meaning. The algorithm calculates the frequency of terms in a document and multiplies them by the inverse frequency of words that appear regularly in several texts. The frequency of documents in a corpus is then calculated by the
TF-IDF algorithm [
28] using the following mathematical formulation shown in Equation (1):
where
TF(
w, d) represents the term frequency of word w in document d, and
IDF(
w, D) represents the inverse document frequency of the word w in the set of documents
D.
3.2.2. N-Grams
The n-gram method is frequently employed in statistical NLP. N-grams are continuous sequences of n-words from a given text. In this research study, we employ different word sequence models. These include unigrams (1-g), bigrams (2-g), trigrams (3-g), and so on, depending on the word length of the text. In the case of word sequences, consider the example sentence, “He went to the zoo”. The trigrams for this sentence can be formed as follows:
“# He went” (adding a blank space # before the first word)
“He went to”
“went to the”
“to the zoo”
“the zoo #” (adding a blank space # after the last word).
# represents a blank space denoting the sentence’s beginning and end.
3.2.3. Word2Vec
Word2Vec is a technique for encoding semantic information from text documents into vector form. Using extensive English text corpora, we trained a skip-gram model for the English language, resulting in 300-dimensional word vectors. Word2Vec analyses the semantic perspective of the content using a three-layered deep NN, which then groups words with similar contexts.
3.2.4. GloVe
The GloVe paradigm uses word co-occurrence in a matrix to produce word embeddings. A significant corpus of words was created, and each word was individually examined. GloVe constructs a large co-occurrence matrix that captures the frequency of words appearing together in the text. The algorithm then learns lower-dimensional embeddings by factorizing this matrix while preserving these co-occurrence patterns. A GloVe model with 200 dimensions was trained using text corpora in English to represent words comprehensively [
39].
3.3. Ensemble ML Algorithms
ML algorithms, which are built on the fundamental principles of artificial intelligence (AI), can learn from input data, continually improve their performance, and generate predictions based on newly acquired knowledge. ML models can be applied individually or in combination with other ML techniques to achieve better results. This is achieved through ensemble methods, which combine multiple models to reduce prediction errors by adding bias values to the model and decreasing the prediction dispersion and variance. This study used ensemble ML algorithms to determine whether a news article was fake or genuine.
3.3.1. Passive Aggressive Classifier
The passive-aggressive classifier (PAC) is an online learning algorithm that belongs to large-margin classifiers. This algorithm is well-suited for handling extensive datasets and adapts in response to each new instance it encounters. As an online learning algorithm, the PAC updates its weights based on new input. A key feature of the PAC is its regularization parameter, C, which allows for a trade-off between the margin’s size (space between the classes) and the number of misclassifications. At each iteration, the PAC looks at a new instance, determines whether it was correctly classified, and adjusts its weights accordingly. If the instance was correctly classified, the weights do not change. If the instance was incorrectly classified, the PAC updates its weights based on the misclassified instance to better classify subsequent instances. The amount to which the PAC adjusts its weight depends on the regularization parameter C and the degree of confidence in classifying that instance. Higher values of C lead to aggressive weight updates, while lower values result in conservative updates.
3.3.2. Logistic Regression
LR has a rich history of application in the biological and social sciences, particularly with categorical dependent variables. The importance of LR can be observed in tasks such as categorizing spam emails. Because linear regression requires a threshold to be set for classification and cannot efficiently handle categorization tasks, misclassification may lead to serious consequences. Logistic regression offers a better way to address this limitation. LR is preferable to linear regression for categorical classification because it ensures that the predicted values fall within a range of 0 to 1. This formulation allows LR to produce probability estimates and reliable categorical predictions. The mathematical equation of the LR algorithm is shown in Equation (2):
where the variables
x,
y,
b0, and
b1 represent the coefficient of a single input value, the predicted output, the bias or intercept term, and the corresponding input value, respectively.
3.3.3. Multinomial Naïve Bayes Algorithm
Popular Bayesian learning methods, such as the MNB algorithm, are widely used in NLP tasks. This algorithm makes informed predictions about classifying text data, such as emails or news articles, using the guiding principles of the Bayesian theorem. The method computes the probability of each potential class for a given sample and selects the class with the highest probability. A significant feature of the NB classifier is the assumption that the features are independent. This means that the presence or absence of other features does not influence the presence or absence of a particular feature. Due to this independence assumption, the algorithm can effectively combine different approaches and successfully classify a variety of features from the dataset. The mathematical equation of the MNB algorithm, based on the Bayesian theorem, is shown in Equation (3):
3.3.4. Bernoulli Naïve Bayes
The Bernoulli NB algorithm is a member of the naïve Bayesian family of algorithms. It is considered a compact model that takes only binary values. The most straightforward illustration is checking whether each word is present in a text. When counting word frequencies is unimportant, the Bernoulli NB algorithm can yield more accurate results.
Simply put, we need to summarize all the binary features indicating whether a word is included in a text. These features are used instead of counting the number of times a word appears in a document. The mathematical equation of the Bernoulli NB algorithm is shown in Equation (4):
3.3.5. Gaussian Naïve Bayes
The Gaussian NB algorithm is a probabilistic classification method that uses strong independence assumptions to apply the Bayesian theorem. This algorithm assumes that the presence or absence of one feature value does not affect the presence or absence of another in the context of categorization (although this differs from independence in probability theory). Despite their naïve independence assumption, naïve Bayes classifiers are well-known in ML for their expressiveness, scalability, and respectable accuracy. However, as the training set’s size grows, NB classifiers’ effectiveness may deteriorate. Various factors influence their performance. NB classifiers have the advantage of not requiring parameter tuning, scaling well with larger training datasets, and effectively handling continuous features. These advantages contribute to their effectiveness.
In the Gaussian NB algorithm (Equation (5)), certain assumptions are made, such as the independence of variance with respect to Y (denoted as
σi), the independence of variance with respect to
xi (denoted as
σk), or both (denoted as
σ):
These assumptions play a crucial role in formulating the Gaussian NB algorithm.
3.4. DL Models
DL models, however, are a subset of ML models specifically designed to mimic the workings of the human brain’s NNs. DL models, particularly artificial neural networks, consist of multiple layers of interconnected nodes (neurons) that learn representations of input data at different levels of abstraction. These models can automatically learn complex features and hierarchies from raw data without the need for manual feature engineering. In the context of fake news detection, DL models, such as LSTM, CNNs, and different combinations of LSTM and CNNs, can process and analyze textual information to make predictions about the authenticity of news articles.
3.4.1. Long Short-Term Memory
LSTM is a recurrent neural network (RNN) frequently used in problems in which predictions are made sequentially. The usefulness of RNNs is limited by long-term dependency issues caused by vanishing gradient concerns due to their operation—information persistence. LSTM comprises input, output, forget gates, and hidden states that keep track of historical and current data timestamps. The input gate accepts new data and assesses their importance. The output gate produces a result based on the learned information, while the forget gate helps separate old knowledge from current information in the model.
3.4.2. Convolutional Neural Networks
CNNs are prominent DL methods that excel at analyzing and classifying images. They can automatically learn unique features and patterns by optimizing learnable weights and biases [
40]. CNNs have the advantage of requiring less pre-processing than other classification techniques, which is one of their benefits. CNNs can independently identify and enhance the filters and attributes necessary for accurate classification during training. Simpler approaches, however, often require manual filter construction.
3.4.3. CNN-LSTM
The CNN-LSTM model, which combines the LSTM and CNN layers, enables sequence prediction and feature extraction from input data. These models are frequently used for tasks such as predicting visual time series and generating textual descriptions from collections of images. They benefit from various applications, including activity recognition, image and video annotation, and image tagging. By combining the strengths of the CNN and LSTM models, the CNN-LSTM architecture can handle complex tasks that require spatial and temporal understanding.
3.4.4. BERT
BERT represents a cutting-edge advancement in NLP and has demonstrated exceptional performance across a spectrum of language understanding tasks, including text classification. The foundational architecture of BERT is rooted in the Transformer model, which effectively processes input sequences of varying lengths. This architecture comprises a stack of transformer encoder layers, each consisting of two integral sub-layers: a multi-head self-attention mechanism and a position-wise feedforward neural network. These components synergistically enable BERT to capture context-rich information from both directions, fostering a bidirectional understanding of text. Furthermore, BERT undergoes unsupervised pre-training on a substantial text corpus, where it hones its ability to predict missing words within sentences and discern the sequential coherence of sentences in the original text [
41].
3.4.5. RoBERTa
RoBERTa, short for “A Robustly Optimized BERT Pretraining Approach”, is a BERT variant meticulously crafted to enhance the pre-training phase for improved language comprehension. While, like BERT, RoBERTa undergoes pre-training on an extensive text corpus, it distinguishes itself by implementing refinements in this process. These include employing larger batch sizes and extending the training duration for more epochs, thereby exposing the model to a more diverse array of textual data and variations. During pre-training, RoBERTa adheres to the Masked Language Model task, wherein it randomly masks words within sentences and trains the model to predict these masked terms based on contextual cues, thereby facilitating the acquisition of intricate contextual representations. Furthermore, RoBERTa integrates data augmentation techniques such as sentence order shuffling and additional sentence span randomization within input documents. This strategic augmentation fosters superior generalization capabilities by exposing the model to a broader spectrum of sentence arrangements.
3.5. Performance Evaluation Measures
In this study, we applied widely used evaluation measures such as accuracy, Precision, recall, F1-score, AUC, ROC, and confusion matrix to perform empirical analysis. These measures are discussed in detail in the following sections.
3.5.1. Accuracy
Accuracy is an essential metric for evaluating classification models. It measures the proportion of correct predictions made by the model. The formal definition of accuracy is shown in Equation (6):
3.5.2. Precision
Precision is crucial for evaluating a model’s ability to produce precise predictions. It rates how well the model performs in making accurate predictions. The mathematical definition of Precision is shown in Equation (7):
3.5.3. Recall
Recall measures the percentage of accurate positive predictions compared to all potential positive predictions. It assesses a model’s capacity to locate and consider all pertinent positive examples. The mathematical definition of recall is shown in Equation (8):
3.5.4. F1 Score
The
F1 score combines recall and Precision using the harmonic mean. The
F1 scoring formula is represented by Equation (9):
3.5.5. Receiver Operating Characteristic Curve
The receiver operating characteristic (ROC) curve depicts the performance of a classification model at various thresholds. It displays the true positive rate (
TPR) and the false positive rate (
FPR). The ROC curve illustrates the trade-off between these rates for various classification thresholds. Equations (10) and (11) represent the
TPR and the
FPR, respectively:
3.5.6. Area under the Curve
The area under the curve (AUC) summarizes the performance across all available classification criteria. The AUC is the probability that the model will value a randomly chosen positive example more highly than a randomly picked negative example.
3.5.7. Confusion Matrix
A confusion matrix is a performance metric for a classification problem that uses ML and produces a possible output of two or more classes. It provides a clear and detailed representation of a model’s performance by comparing its predicted results against a given dataset’s actual ground truth labels. The matrix is typically a square table with rows and columns corresponding to the true classes and the predicted classes, respectively. The mathematical formula of the confusion matrix is shown in
Table 3.
4. Discussion
In this section, we present the results of the experiments using the proposed model. The model incorporates various evolutionary algorithms trained and tested with ML and DL models.
4.1. Data Visualization
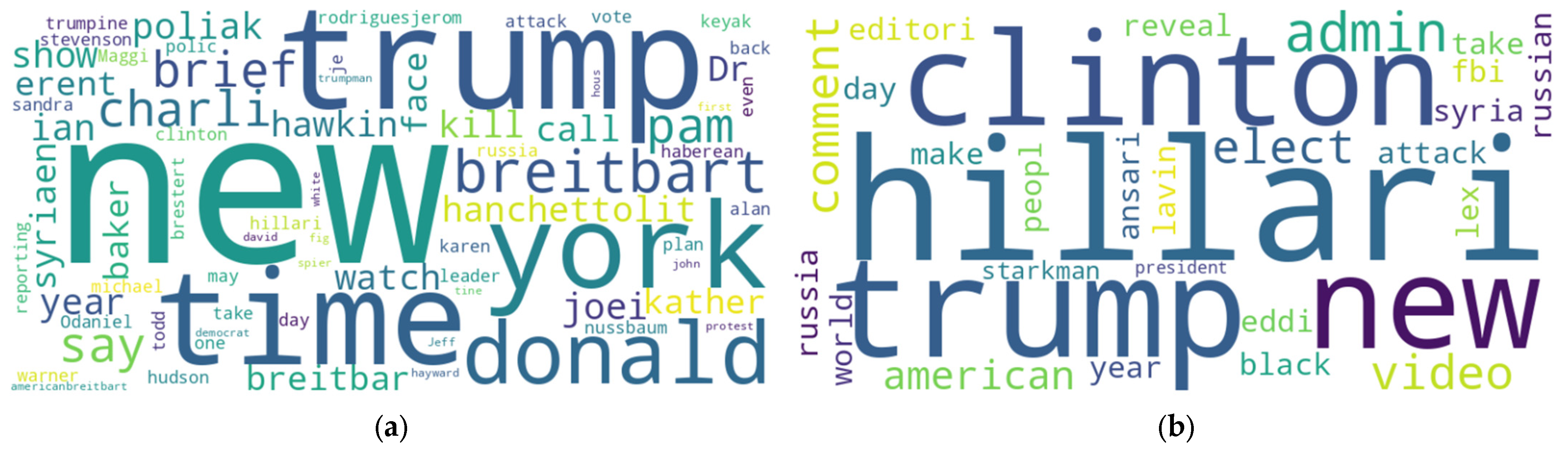
As previously mentioned, the data for these experiments were gathered from Kaggle.com. The dataset underwent several pre-processing steps, such as lowercase conversion, tokenization, lemmatization, stop word removal, link removal, and stemming. During pre-processing, news articles were processed using various NLP techniques to tokenize the text into words instead of sentences. Word clouds for fake and real news are presented in
Figure 2.
Once the mathematical and statistical computations are complete, the news data variables are translated into graphical representations, using graphs and charts to effectively illustrate their trends and patterns. Information about stock data variables, including the types and whether there are any null values within them, is shown in
Table 4. The final dataset contains variable columns, such as ID, title, author, and text.
Missing data are values or information for some variables that are absent in the dataset. Many ML techniques struggle to perform accurately when values are missing. However, algorithms such as NB and K-nearest neighbors can handle data with missing values. By appropriately addressing missing values, we can prevent the creation of biased ML models that yield inaccurate results. Inaccurate statistical analyses may arise from missing data, making removing empty entries from the corpus essential.
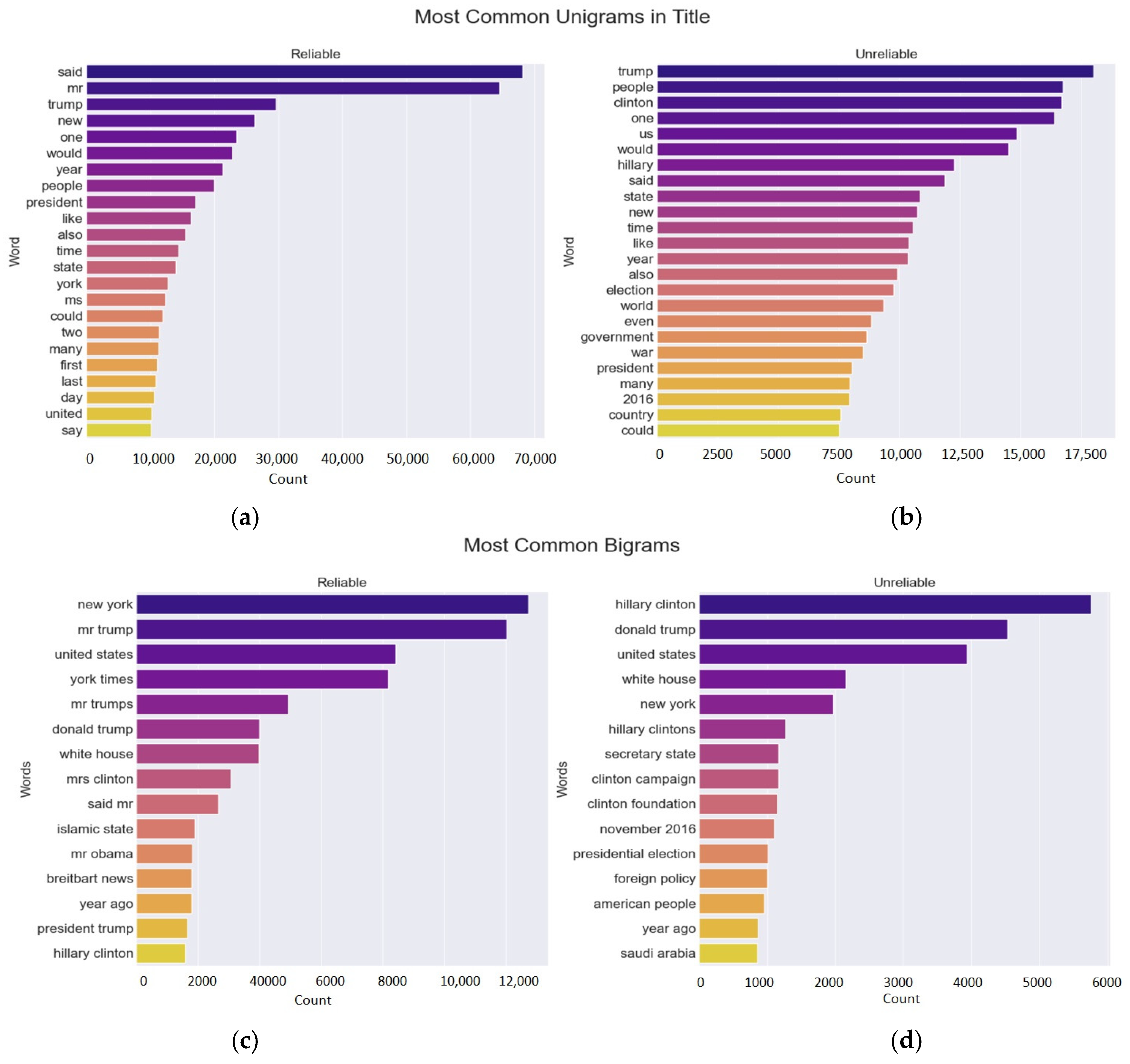
Figure 3a illustrates the top 20 unigrams in the uncleaned corpus. According to this figure, the most frequent words in the uncleaned corpus are primarily stop words. Classification can be performed effectively only after these stop words are removed from the corpus.
Figure 3b displays the top 20 unigrams from the cleaned corpus, allowing us to analyze the most common unigrams after the cleaning process.
Figure 3c presents the top 20 bigrams of the uncleaned corpus, while
Figure 3d shows the top 20 bigrams of the cleaned corpus. Furthermore,
Figure 3 illustrates the distribution of n-gram frequencies, with darker colors representing higher frequencies and lighter colors indicating less frequent n-grams.
4.2. Experimentation with the Ensemble Method
During the initial stage of dataset pre-processing, the text is converted to lowercase, tokenized, and lemmatized. Additionally, stop words and links are removed, and words are stemmed. This process yields a pre-processed dataset with 59,589 features, which serves as input for TF-IDF feature extraction. The selected features are then utilised to train four distinct machine learning classifiers (PA, LR, MNB, Bernoulli NB, and Gaussian NB), along with a deep learning-based LSTM, for the purpose of classifying the text into “ham” or “spam” categories. The model’s performance is evaluated using various metrics, such as accuracy, precision, recall, ROC, AUC, and F1 score, to gain insights into the effectiveness and efficiency of the classification process.
4.2.1. Ensemble ML Algorithms
The computed results of ML algorithms using TF-IDF, and n-grams are shown in
Table 5. The results show that LR outperforms the other algorithms, achieving 90.06% accuracy with TF-IDF and 60.74% accuracy with the n-gram. In addition, DT attains 65.93% accuracy using TF-IDF and 62.59% accuracy using n-grams. The ROC curve is shown for text-based features, such as TF-IDF and N-gram, where LR demonstrates better results than the other algorithms.
4.2.2. DL Algorithm Results
Table 5 presents the computed results of the DL algorithms using TF-IDF. According to the results, it can be observed that the RoBERTa transformers-based model achieved the highest overall performance, with impressive scores across all metrics, ranging from 95.12.75% to 96.10%. The BERT and Bi-LSTM models also demonstrated strong performance, consistently scoring above 90% across all metrics. On the other hand, the LSTM, CNN, and CNN-LSTM models achieved slightly lower scores but still showed reasonable accuracy and Precision in identifying fake news.
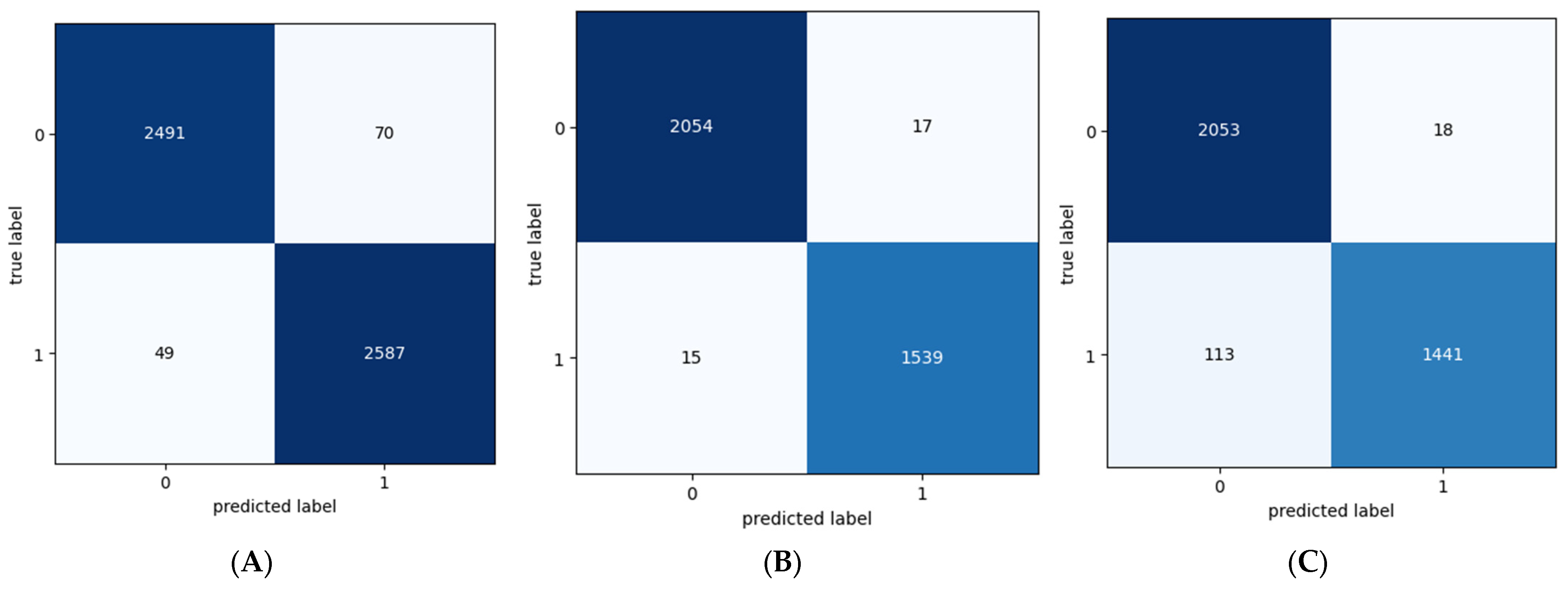
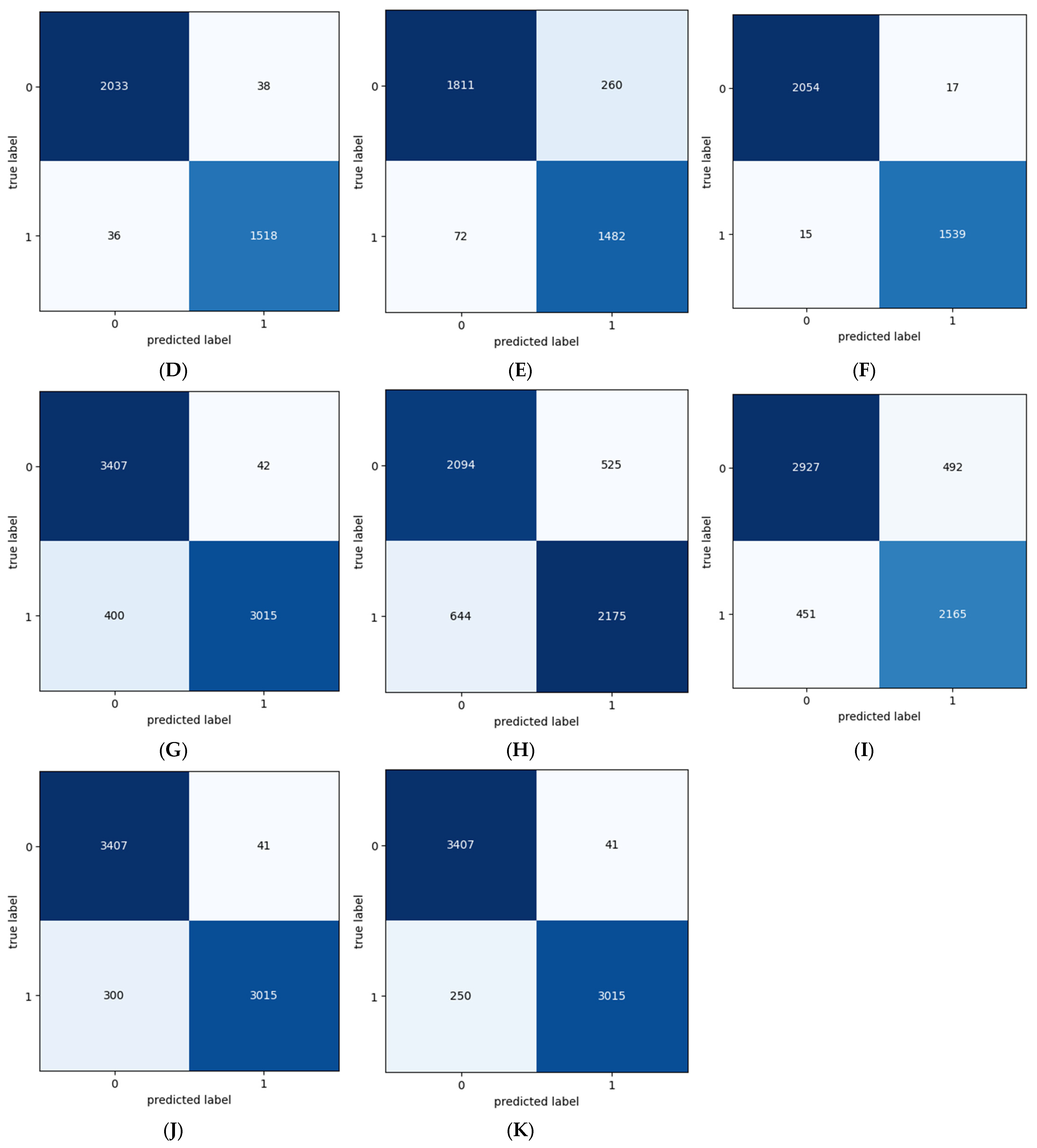
Figure 4 shows the confusion matrix of the PA, LR, MNB, BNN, GNN, LSTM, BI-LSTM, BERT, RoBERTa, CNN, and CNN-LSTM models.
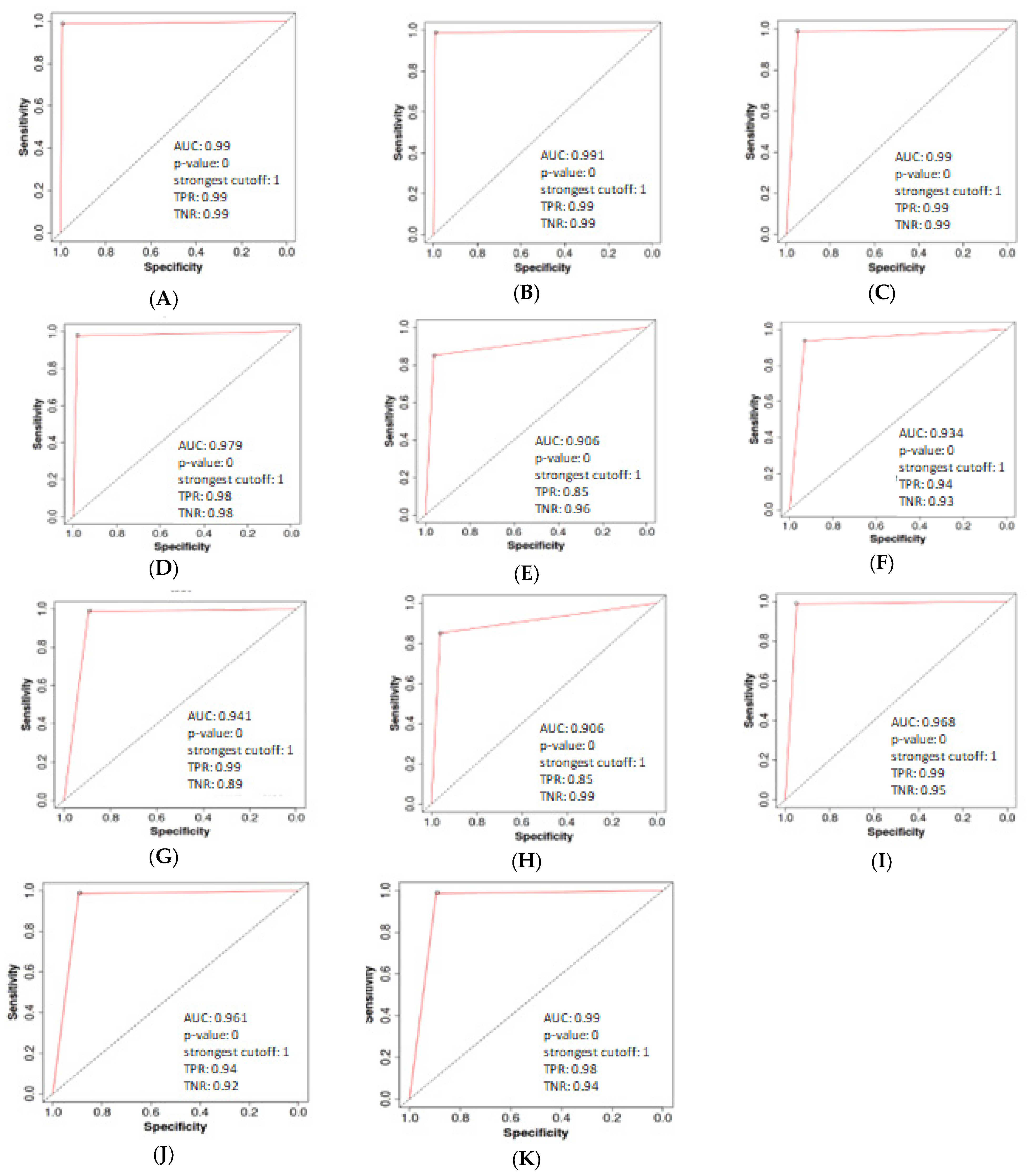
Figure 5 shows the ROC curve of the PA, LR, MNB, BNN, GNN, LSTM, BI-LSTM, CNN, and CNN-LSTM models.
Table 6 shows the AUC of the PA, LR, MNB, BNN, GNN, LSTM, BI-LSTM, BERT, RoBERTa, CNN, and CNN-LSTM models. Among the traditional machine learning models, Passive Aggressive and LR exhibit remarkable performance, achieving high AUC values of 0.99 and displaying equally impressive TPR and TNR scores of 0.99. MNB and BNB also demonstrate favorable results, achieving competitive AUC values of 0.968 and 0.979, respectively, and maintaining high TPR and TNR percentages. On the other hand, GNB exhibits a slightly lower AUC value of 0.906, indicating a comparatively less robust performance. Though it maintains a good TNR of 0.96, its TPR score is relatively lower at 0.85.
Regarding the deep learning models, the RoBERTa model achieves the highest AUC score of 0.967, showcasing an exceptional performance in fake news detection, along with a near-perfect TPR of 0.98. However, its TNR of 0.94 indicates a slightly higher false positive rate. Both BERT and Bi-LSTM models display commendable performance, with AUC values of 0.951 and 0.941, respectively. The LSTM model shows a balanced TPR and TNR of 0.94 and 0.93, while the CNN model achieves a good TNR of 0.97, though with a slightly lower TPR of 0.84.
Table 7 presents the comparison of the proposed model against the conventional ML and DL methods. Compared to other models, the proposed methodology stands out, with RoBERTa achieving an accuracy of 96.10% and PA achieving an even higher accuracy of 97.71%. These results demonstrate the promising performance of the proposed RoBERTa and PA models in detecting fake news, showcasing their potential for effective and reliable classification.
5. Conclusions
Fake news classification is a dynamic and continuously evolving research area. In this study, we propose a novel model for classifying fake news using “Fake News” dataset obtained from the Kaggle’s platform. We applied several pre-processing steps to prepare the dataset, including punctuation and link removal, tokenization, and lemmatization. Combining the datasets established the relationship between genuine and fake news. Feature extraction was carried out using TF-IDF on the data, and these extracted features were then utilized in multiple ML models, such as PA, LR, MNB, GNB, and BNB, as well as DL models like CNN, LSTM, and BI-LSTM, to classify fake news. We utilized various evaluation metrics to assess the models’ performance, including accuracy, precision, recall, F1 score, AUC, ROC, and confusion matrix. Among the models tested, LR emerged as the top performer, achieving the highest accuracy, and showcasing its effectiveness in fake news classification. This research contribution lies in presenting a superior-performing LR model compared to existing studies in the field. For future work, we aim to explore the impact of incorporating temporal information from tweets and utilizing more advanced deep learning architectures may further improve the model’s performance.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}